
Research on Morphological Detection of FR I and FR II Radio Galaxies Based on Improved YOLOv5


Abstract
:1. Introduction
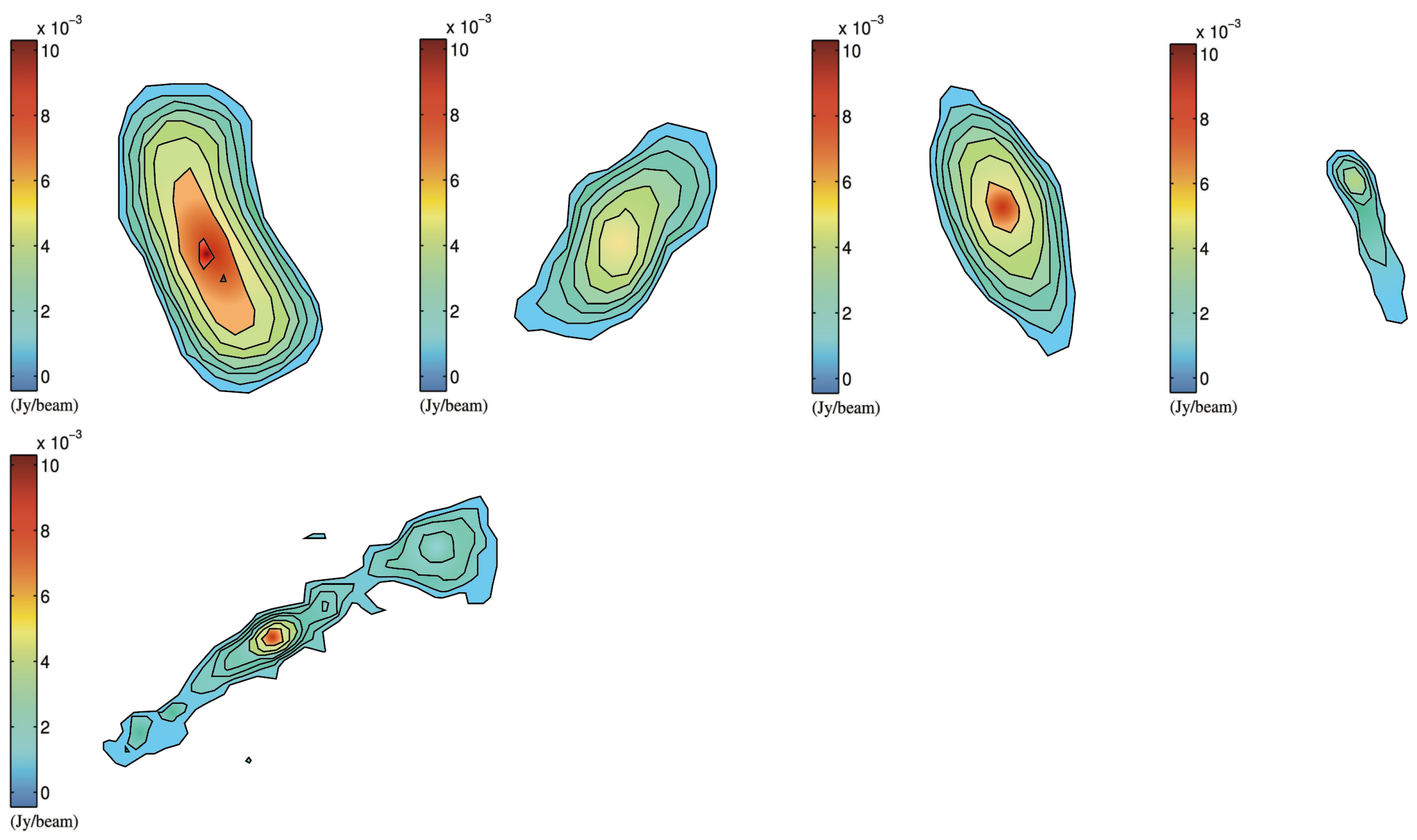
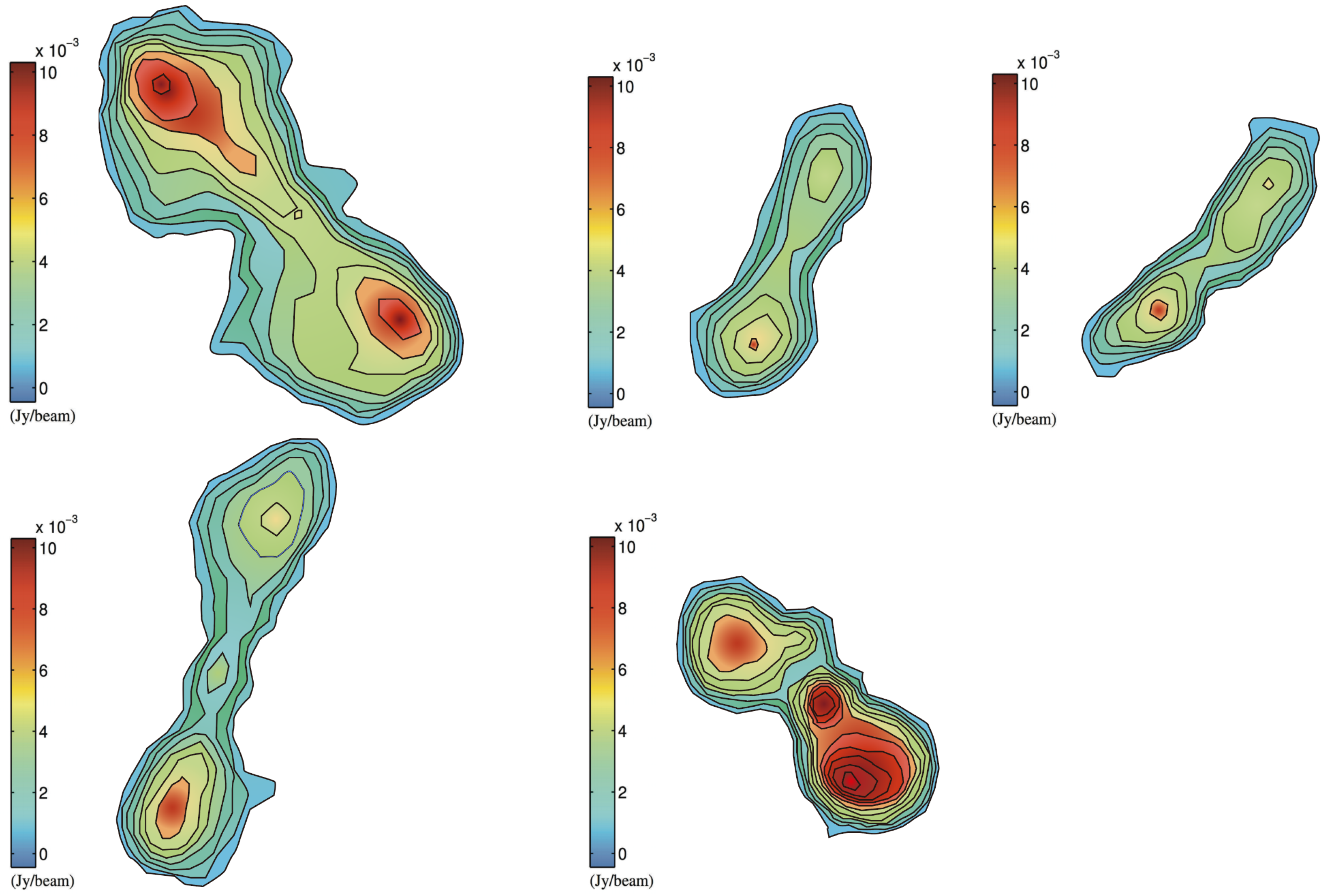
2. Radio Galaxy Catalog
3. Image Preprocessing and Data Augmentation
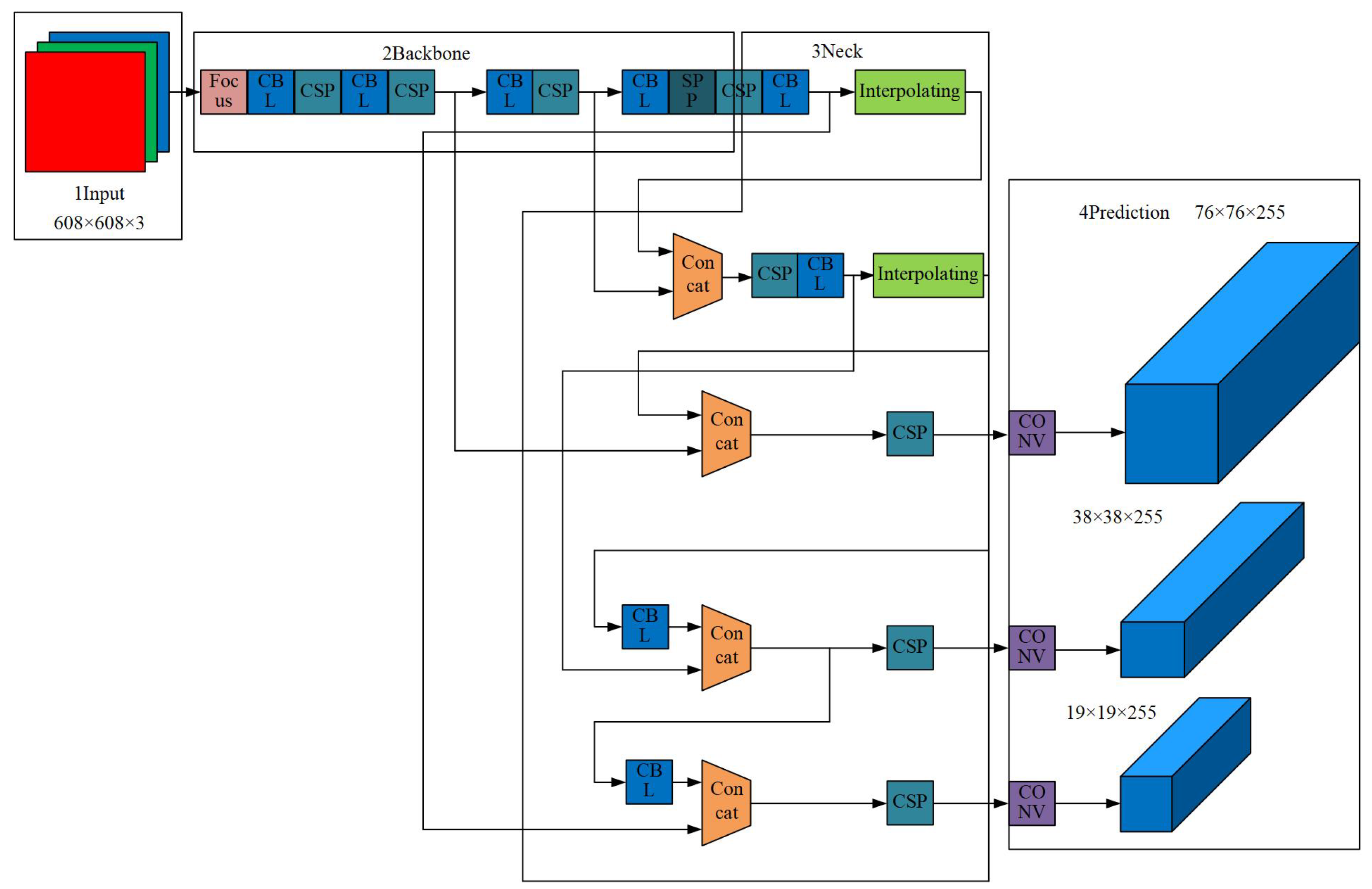
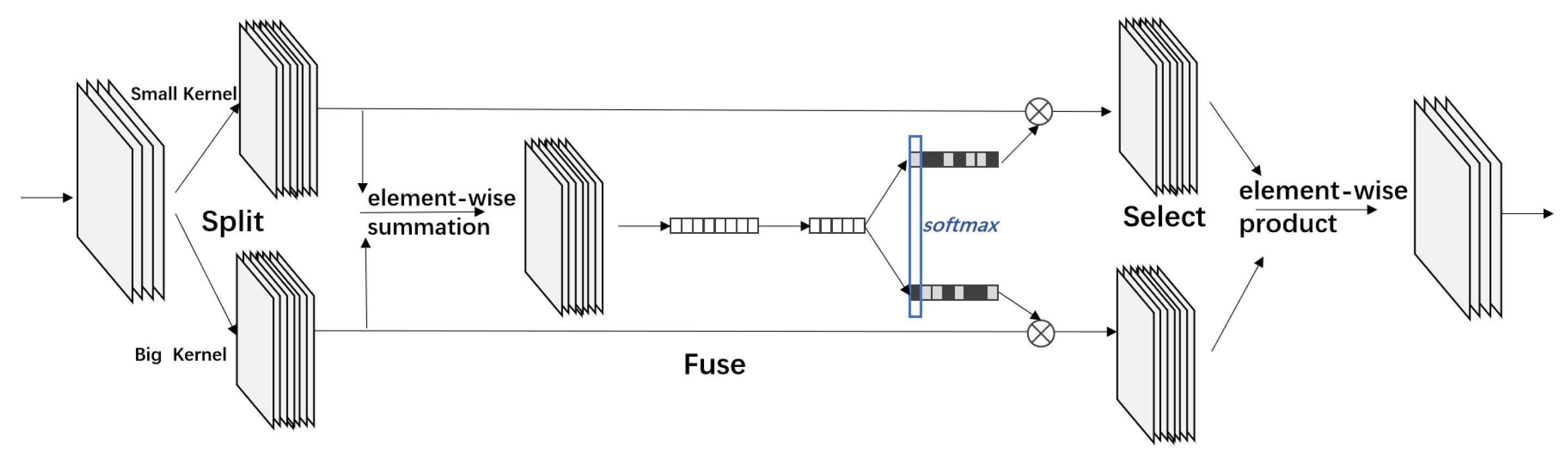
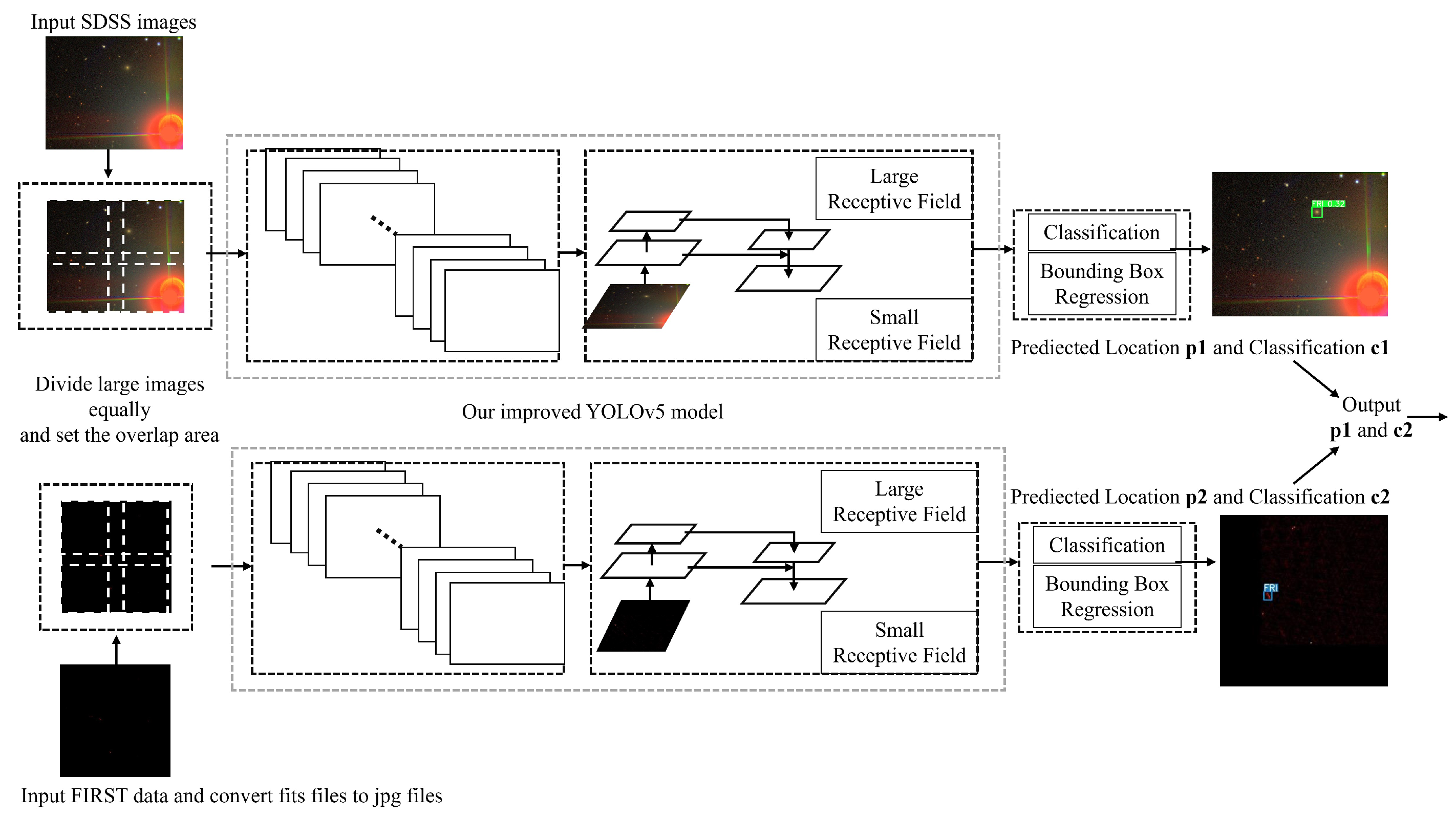
4. Object Detection
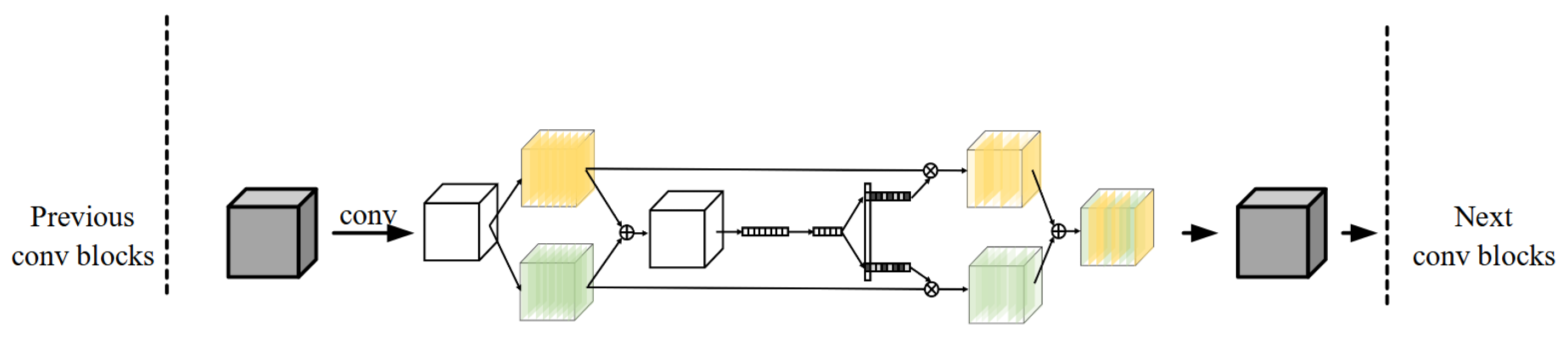
5. Our Method
6. Experiment and Results
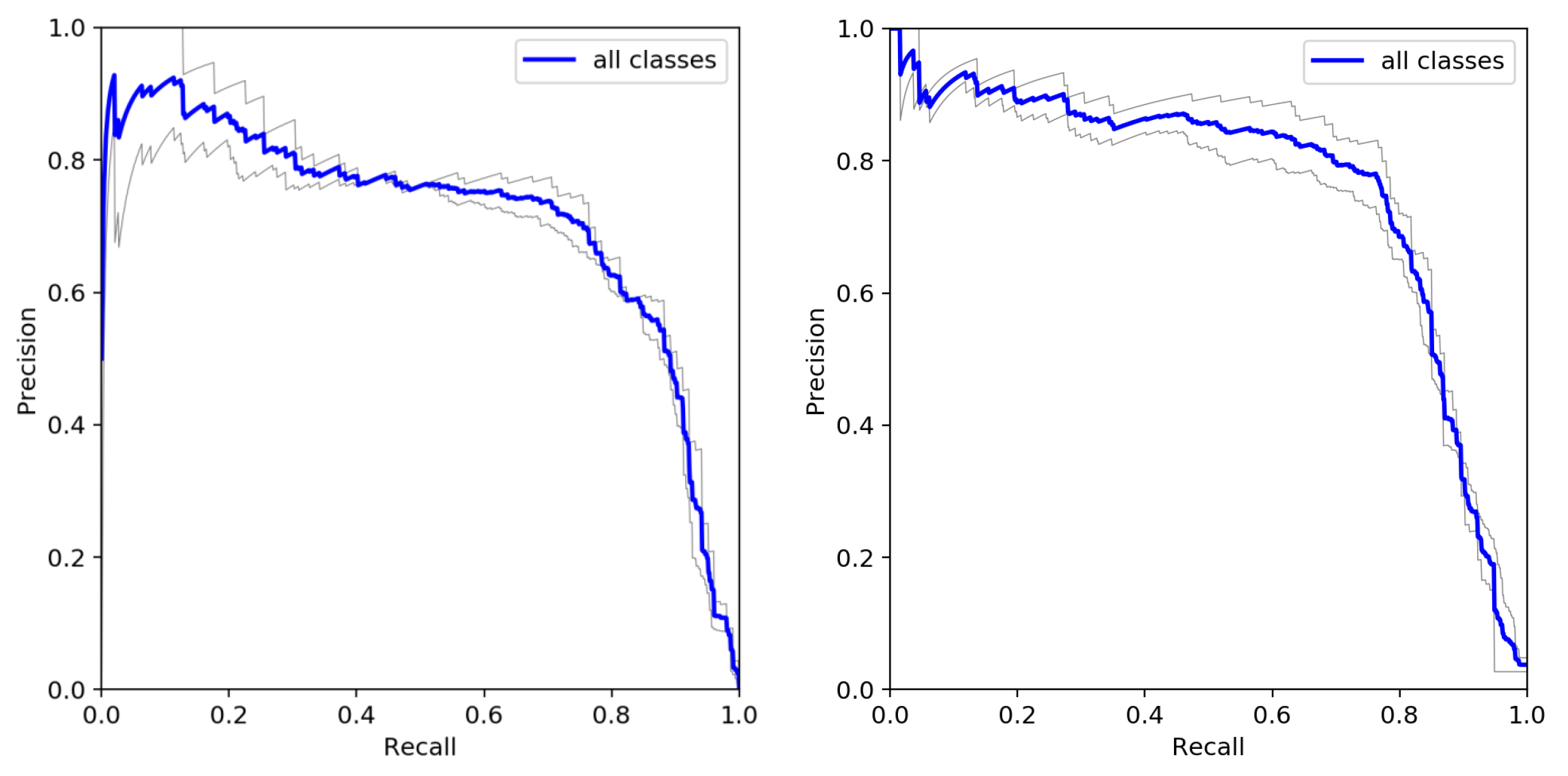
6.1. Metrics and Quantitative Experimental Results
- (i)
- TP means that when we predict the source as FRII and it is FRII in fact. It also satisfies that the IOUs of the prediction box and the ground truth box are greater than 0.5.
- (ii)
- FP means that when we predict the source as FRII but it is not FRII in fact. It also satisfies that the IOUs of the prediction box and the ground truth box are less than 0.5.
- (iii)
- FN means that when we predict the source as not FRII but it is FRII in fact. It also satisfies that the IOUs of the prediction box and the ground truth box are greater than 0.5.
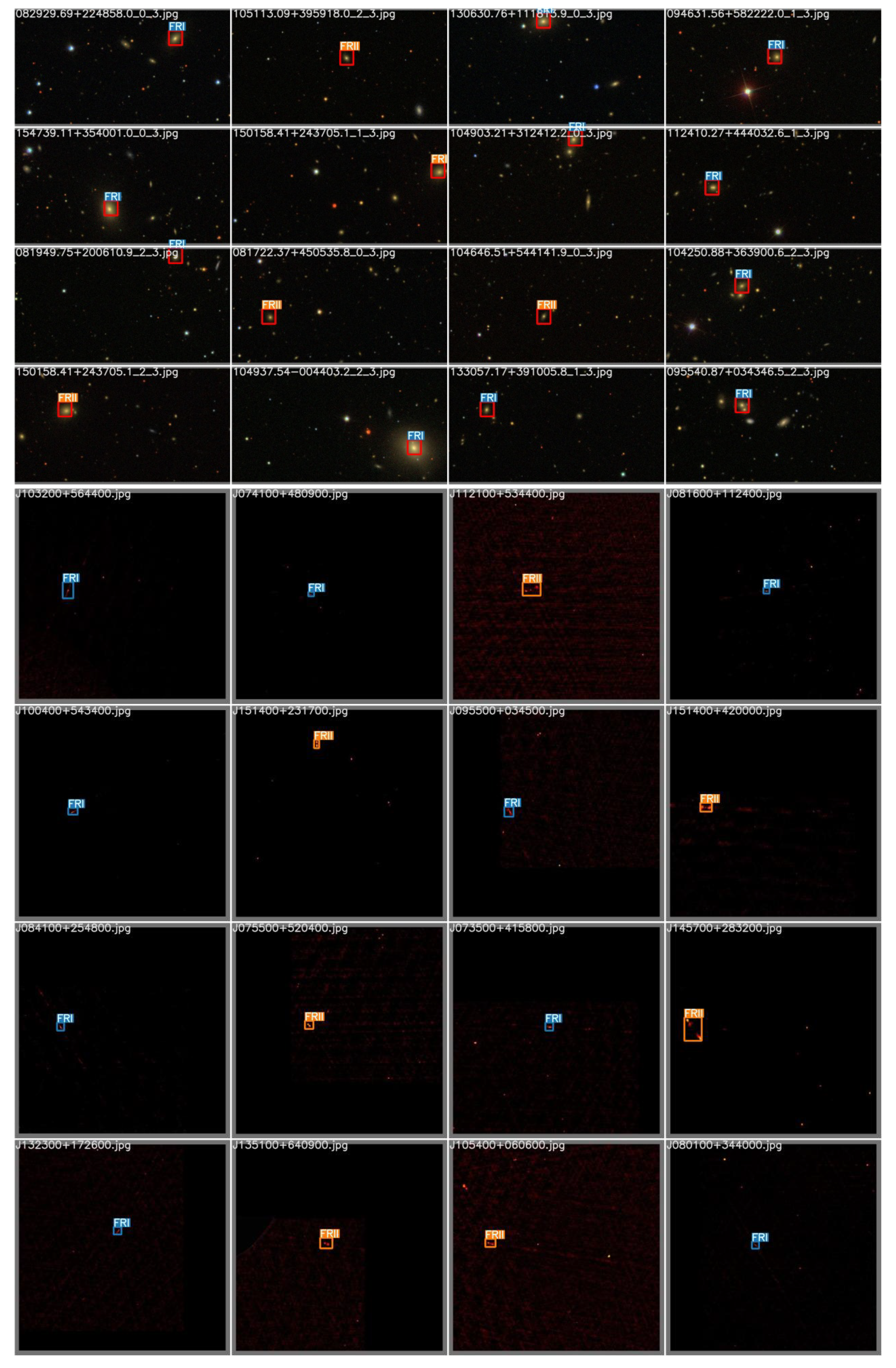
6.2. Results and Effects
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Fanaroff, B.L.; Riley, J.M. The Morphology of Extragalactic Radio Sources of High and Low Luminosity. Mon. Not. R. Astron. Soc. 1974, 167, 31P–36P. [Google Scholar] [CrossRef] [Green Version]
- Alhassan, W.; Taylor, A.R.; Vaccari, M. The FIRST Classifier: Compact and Extended Radio Galaxy Classification using Deep Convolutional Neural Networks. MNRAS 2018, 480, 2085–2093. [Google Scholar] [CrossRef] [Green Version]
- Baldi, R.D.; Capetti, A.; Massaro, F. FRICAT: A FIRST catalog of FR I radio galaxies. Astron. Astrophys. 2017, 598, A49. [Google Scholar]
- Capetti, A.; Massaro, F.; Baldi, R.D. FRIICAT: A FIRST catalog of FR II radio galaxies. Astron. Astrophys. 2017, 601, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Raouf, M.; Shabala, S.S.; Croton, D.J.; Khosroshahi, H.G.; Bernyk, M. The many lives of active galactic nuclei–II: The formation and evolution of radio jets and their impact on galaxy evolution. Mon. Not. R. Astron. Soc. 2017, 471, 658–670. [Google Scholar] [CrossRef] [Green Version]
- Croton, D.J.; Volker, S.; White, S.; De, L.G.; Frenk, C.S.; Gao, L.; Jenkins, A.; Kauffmann, G.; Navarro, J.F.; Yoshida, N. The many lives of active galactic nuclei: Cooling flows, black holes and the luminosities and colours of galaxies. Mon. Not. R. Astron. Soc. 2010, 365, 11–28. [Google Scholar] [CrossRef] [Green Version]
- Khosroshahi, H.G.; Raouf, M.; Miraghaei, H.; Brough, S.; Croton, D.J.; Driver, S.; Graham, A.; Baldry, I.; Brown, M.; Prescott, M. Galaxy And Mass Assembly (GAMA): ‘No Smoking’ zone for giant elliptical galaxies? Astrophys. J. 2017, 842, 81. [Google Scholar] [CrossRef] [Green Version]
- Hocking, A.; Geach, J.E.; Davey, N.; Yi, S. Teaching a machine to see: Unsupervised image segmentation and categorisation using growing neural gas and hierarchical clustering. Physics 2015, 23, 619–620. [Google Scholar]
- Gravet, R.; Cabrera-Vives, G.; Pérez-González, P.G.; Kartaltepe, J.S.; Barro, G.; Bernardi, M.; Mei, S.; Shankar, F.; Dimauro, P.; Bell, E.F.; et al. A catalog of visual-like morphologies in the 5 CANDELS fields using deep-learning. Astrophys. J. Suppl. Ser. 2015, 221, 8. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection; IEEE: New York, NY, USA, 2016. [Google Scholar]
- York, D.G.; Adelman, J.; Anderson, J.E., Jr.; Anderson, S.F.; Annis, J.; Bahcall, N.A.; Bakken, J.A.; Barkhouser, R.; Bastian, S.; Berman, E.; et al. The Sloan Digital Sky Survey: Technical Summary. Astron. J. 2000, 120, 1579. [Google Scholar] [CrossRef]
- Library, W.E. The Astronomical Journal; American Institute of Physics: College Park, MD, USA, 1997. [Google Scholar]
- Becker, R.H.; White, R.L.; Helfand, D.J. The FIRST survey: Faint Images of the Radio Sky at Twenty centimeters. Astrophys. J. 1995, 450, 559. [Google Scholar] [CrossRef]
- Aniyan, A.K.; Thorat, K. Classifying Radio Galaxies with the Convolutional Neural Network. Astrophys. J. Suppl. 2017, 230, 20. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Shu, L.; Zhang, Z.; Lei, B. Research on Dense-Yolov5 Algorithm for Infrared Target Detection. Opt. Optoelectron. Technol. 2021, 19, 69–75. [Google Scholar]
- Zhou, X.C.; Gong, J.H.; Yun-Qian, L.I.; Chen, X.J. Research Progress of Malicious Code Detection Technology Based on Deep Learning. Mod. Comput. 2019. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In IEEE Transactions on Pattern Analysis & Machine Intelligence; IEEE: New York, NY, USA, 2017; pp. 2999–3007. [Google Scholar]
- Zhang, H.; Wang, Y.; Dayoub, F.; Sünderhauf, N. VarifocalNet: An IoU-aware Dense Object Detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2020. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective Kernel Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Liu, X.; Wang, Z.; He, Y.; Liu, Q. Research on Small Target Detection Based on Deep Learning. Tactical Missile Technol. 2019. [Google Scholar]
- Ju, M.; Luo, H.; Wang, Z. Improved YOLOv3 Algorithm and Application in Small Target Detection. Acta Opt. 2019, 39, 245–252. [Google Scholar]
- Etten, A.V. You Only Look Twice: Rapid Multi-Scale Object Detection in Satellite Imagery. arXiv 2018, arXiv:1805.09512. [Google Scholar]
- Everingham, M.; Eslami, S.M.; Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
| 1. | https://www.sdss.org/ (accessed on 10 October 2020). |













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | map@0.5 | map[0.5:0.95] | Precision | Recall |
|---|---|---|---|---|
| Yolov5 | 74.8 | 35.1 | 78.1 | 80.5 |
| Our Model | 82.3 | 39.3 | 82.6 | 84.3 |
| Hyperparameters | Values |
|---|---|
| Batch Size | 16 |
| Dropout Rate | 0.5 |
| Epochs | 400 |
| Course | Ground Truth | Model Prediction | ||||
|---|---|---|---|---|---|---|
| Ra (deg) | Dec (deg) | True Class | Predicted Ra (deg) | Predicted Dec (deg) | Predicted Class | |
 | 119.06145833 | 50.36669444 | FR II | 119.061458 | 50.366694 | FR II |
 | 145.36895833 | 39.69252778 | FR II | 145.368958 | 39.692528 | FR II |
 | 162.80454167 | 39.98833333 | FR II | 162.804542 | 39.988333 | FR II |
 | 181.92404167 | 33.80716666 | FR II | 181.924041 | 33.807166 | FR II |
 | 224.48295833 | 28.49813889 | FR II | 224.482958 | 28.498139 | FR II |
 | 115.37591666 | 48.07438889 | FR I | 115.375917 | 48.074389 | FR I |
 | 124.04991667 | 43.04966667 | FR I | 124.049916 | 43.049667 | FR I |
 | 124.72800000 | 4.05211111 | FR I | 124.728000 | 4.052111 | FR I |
 | 242.10225000 | 37.65530556 | FR I | 242.102250 | 37.655306 | FR I |
 | 247.02729167 | 8.69638889 | FR I | 247.027291 | 8.696389 | FR I |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Wei, J.; Liu, Y.; Li, J.; Zhang, Z.; Chen, J.; Jiang, B. Research on Morphological Detection of FR I and FR II Radio Galaxies Based on Improved YOLOv5. Universe 2021, 7, 211. https://doi.org/10.3390/universe7070211
Wang X, Wei J, Liu Y, Li J, Zhang Z, Chen J, Jiang B. Research on Morphological Detection of FR I and FR II Radio Galaxies Based on Improved YOLOv5. Universe. 2021; 7(7):211. https://doi.org/10.3390/universe7070211
Chicago/Turabian StyleWang, Xingzhu, Jiyu Wei, Yang Liu, Jinhao Li, Zhen Zhang, Jianyu Chen, and Bin Jiang. 2021. "Research on Morphological Detection of FR I and FR II Radio Galaxies Based on Improved YOLOv5" Universe 7, no. 7: 211. https://doi.org/10.3390/universe7070211
APA StyleWang, X., Wei, J., Liu, Y., Li, J., Zhang, Z., Chen, J., & Jiang, B. (2021). Research on Morphological Detection of FR I and FR II Radio Galaxies Based on Improved YOLOv5. Universe, 7(7), 211. https://doi.org/10.3390/universe7070211