A New Stock Price Forecasting Method Using Active Deep Learning Approach

 ,
,  and
and 
Abstract
1. Introduction
- Study the effects of the additional features (i.e., High, Low, Volume, Open, HiLo, OpSe).
- Detect the effect of the size of the datasets on the prediction accuracy.
- Detect the difference between the deep learning models (i.e., MLP, GRU, LSTM, Bi-LSTM, CNN, and CNN-LSTM).
2. Related Work
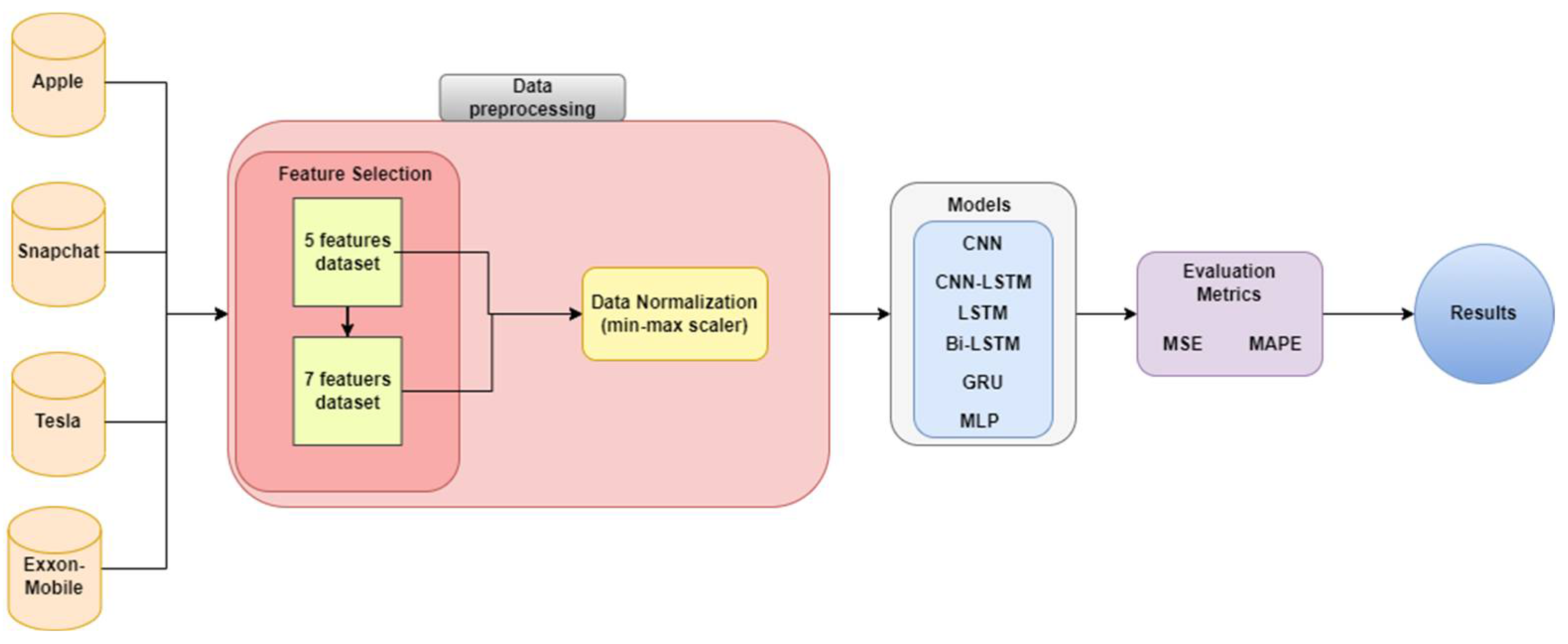
3. Methodology
3.1. Datasets
- -
- x*: is the new value
- -
- x: is the old value
- -
- min: the minimum value
- -
- max: the maximum value
3.2. Used Models
- MLP Model
- CNN Model
- LSTM Model
- Bi-LSTM Model
- GRU Model
- CNN-LSTM Model
3.3. Feature Engineering
- High: represents the highest price of the stock on a particular day.
- Low: represents the lowest price of the stock on a particular day.
- Open: represents the price at the opening stock exchange on a particular day.
- Volume: represents the total number of shares or contracts exchanged between buyers and sellers.
4. Results
5. Discussion
6. Conclusions
6.1. Implication
6.2. Limits and Future Reserch Topic
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Al-qaness, M.A.; Ewees, A.A.; Fan, H.; Abualigah, L.; Abd Elaziz, M. Boosted ANFIS model using augmented marine predator algorithm with mutation operators for wind power forecasting. Appl. Energy 2022, 314, 118851. [Google Scholar] [CrossRef]
- Mehr, A.D.; Ghiasi, A.R.; Yaseen, Z.M.; Sorman, A.U.; Abualigah, L. A novel intelligent deep learning predictive model for meteorological drought forecasting. J. Ambient Intell. Humaniz. Comput. 2022, 1–15. [Google Scholar] [CrossRef]
- Mexmonov, S. Stages of Development of the Stock Market of Uzbekistan. Арxив нayчныx иccлeдoвaний 2020, 24, 6661–6668. [Google Scholar]
- Nti, I.K.; Adekoya, A.F.; Weyori, B.A. A systematic review of fundamental and technical analysis of stock market predictions. Artif. Intell. Rev. 2019, 53, 3007–3057. [Google Scholar] [CrossRef]
- Sengupta, A.; Sena, V. Impact of open innovation on industries and firms—A dynamic complex systems view. Technol. Forecast. Soc. Chang. 2020, 159, 120199. [Google Scholar] [CrossRef]
- Terwiesch, C.; Xu, Y. Innovation Contests, Open Innovation, and Multiagent Problem Solving. Manag. Sci. 2008, 54, 1529–1543. [Google Scholar] [CrossRef]
- Blohm, I.; Riedl, C.; Leimeister, J.M.; Krcmar, H. Idea evaluation mechanisms for collective intelligence in open innovation communities: Do traders outperform raters? In Proceedings of the 32nd International Conference on Information Systems, Cavtat, Croatia, 21–24 June 2010.
- Del Giudice, M.; Carayannis, E.G.; Palacios-Marqués, D.; Soto-Acosta, P.; Meissner, D. The human dimension of open innovation. Manag. Decis. 2018, 56, 1159–1166. [Google Scholar] [CrossRef]
- Daradkeh, M. The Influence of Sentiment Orientation in Open Innovation Communities: Empirical Evidence from a Business Analytics Community. J. Inf. Knowl. Manag. 2021, 20, 2150031. [Google Scholar] [CrossRef]
- Kao, L.-J.; Chiu, C.-C.; Lu, C.-J.; Yang, J.-L. Integration of nonlinear independent component analysis and support vector regression for stock price forecasting. Neurocomputing 2013, 99, 534–542. [Google Scholar] [CrossRef]
- Ezugwu, A.E.; Ikotun, A.M.; Oyelade, O.O.; Abualigah, L.; Agushaka, J.O.; Eke, C.I.; Akinyelu, A.A. A comprehensive survey of clustering algorithms: State-of-the-art machine learning applications, taxonomy, challenges, and future research prospects. Eng. Appl. Artif. Intell. 2022, 110, 104743. [Google Scholar] [CrossRef]
- Wang, Y.; Guo, Y. Forecasting method of stock market volatility in time series data based on mixed model of ARIMA and XGBoost. China Commun. 2020, 17, 205–221. [Google Scholar] [CrossRef]
- Mosteanu, N.; Faccia, A. Fintech Frontiers in Quantum Computing, Fractals, and Blockchain Distributed Ledger: Paradigm Shifts and Open Innovation. J. Open Innov. Technol. Mark. Complex. 2021, 7, 19. [Google Scholar] [CrossRef]
- Guo, Y.; Zheng, G. How do firms upgrade capabilities for systemic catch-up in the open innovation context? A multiple-case study of three leading home appliance companies in China. Technol. Forecast. Soc. Chang. 2019, 144, 36–48. [Google Scholar] [CrossRef]
- Yun, J.J.; Won, D.; Park, K. Entrepreneurial cyclical dynamics of open innovation. J. Evol. Econ. 2018, 28, 1151–1174. [Google Scholar] [CrossRef]
- Shabanov, V.; Vasilchenko, M.; Derunova, E.; Potapov, A. Formation of an Export-Oriented Agricultural Economy and Regional Open Innovations. J. Open Innov. Technol. Mark. Complex. 2021, 7, 32. [Google Scholar] [CrossRef]
- Hilmola, O.P.; Torkkeli, M.; Viskari, S. Riding the economic long wave: Why are the open innovation index and the performance of leading manufacturing industries intervened? Int. J. Technol. Intell. Plan. 2007, 3, 174. [Google Scholar] [CrossRef]
- Du, J.; Leten, B.; Vanhaverbeke, W. Managing open innovation projects with science-based and market-based partners. Res. Policy 2014, 43, 828–840. [Google Scholar] [CrossRef]
- Bahadur, S.G.C. Stock market and economic development: A causality test. J. Nepal. Bus. Stud. 2006, 3, 36–44. [Google Scholar]
- Bharathi, S.; Geetha, A.; Sathiynarayanan, R. Sentiment Analysis of Twitter and RSS News Feeds and Its Impact on Stock Market Prediction. Int. J. Intell. Eng. Syst. 2017, 10, 68–77. [Google Scholar] [CrossRef]
- Sharma, A.; Bhuriya, D.; Singh, U. Survey of stock market prediction using machine learning approach. In Proceedings of the 2017 International Conference of Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 20–22 April 2017; pp. 506–509. [Google Scholar]
- Nassar, L.; Okwuchi, I.E.; Saad, M.; Karray, F.; Ponnambalam, K. Deep learning based approach for fresh produce market price prediction. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar]
- Bathla, G. Stock Price prediction using LSTM and SVR. In Proceedings of the 2020 Sixth International Conference on Parallel, Distributed and Grid Computing (PDGC), Waknaghat, India, 6–8 November 2020; pp. 211–214. [Google Scholar] [CrossRef]
- Kara, Y.; Boyacioglu, M.A.; Baykan, Ö.K. Predicting direction of stock price index movement using artificial neural networks and support vector machines: The sample of the Istanbul Stock Exchange. Expert Syst. Appl. 2011, 38, 5311–5319. [Google Scholar] [CrossRef]
- Abualigah, L.; Diabat, A. Improved multi-core arithmetic optimization algorithm-based ensemble mutation for multidisciplinary applications. J. Intell. Manuf. 2022, 1–42. [Google Scholar] [CrossRef]
- Alkhatib, K.; Almahmood, M.; Elayan, O.; Abualigah, L. Regional analytics and forecasting for most affected stock markets: The case of GCC stock markets during COVID-19 pandemic. Int. J. Syst. Assur. Eng. Manag. 2021, 1–11. [Google Scholar] [CrossRef]
- Zeng, Z.; Khushi, M. Wavelet denoising and attention-based RNN-ARIMA model to predict forex price. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar]
- Pang, X.; Zhou, Y.; Wang, P.; Lin, W.; Chang, V. An innovative neural network approach for stock market prediction. J. Supercomput. 2018, 76, 2098–2118. [Google Scholar] [CrossRef]
- Shahi, T.B.; Sitaula, C.; Neupane, A.; Guo, W. Fruit classification using attention-based MobileNetV2 for industrial applications. PLoS ONE 2022, 17, e0264586. [Google Scholar] [CrossRef] [PubMed]
- Sitaula, C.; Shahi, T.B.; Aryal, S.; Marzbanrad, F. Fusion of multi-scale bag of deep visual words features of chest X-ray images to detect COVID-19 infection. Sci. Rep. 2021, 11, 1–12. [Google Scholar] [CrossRef]
- Chen, Y.; Wu, J.; Bu, H. Stock market embedding and prediction: A deep learning method. In Proceedings of the 2018 15th International Conference on Service Systems and Service Management (ICSSSM), Hangzhou, China, 21–22 July 2018; pp. 1–6. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Elman, J.L. Finding structure in time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386–408. [Google Scholar] [CrossRef]
- Atlas, L.; Homma, T.; Marks, R. An artificial neural network for spatio-temporal bipolar patterns: Application to phoneme classification. In Neural Information Processing Systems; American Institute of Physics: Maryland, MD, USA, 1987; pp. 31–40. [Google Scholar]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Processing 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Kim, S.; Kim, H. A new metric of absolute percentage error for intermittent demand forecasts. Int. J. Forecast. 2016, 32, 669–679. [Google Scholar] [CrossRef]
- Watanabe, C.; Shin, J.; Heikkinen, J.; Tarasyev, A. Optimal dynamics of functionality development in open innovation. IFAC Proc. Vol. 2009, 42, 173–178. [Google Scholar] [CrossRef]
- Jeong, H.; Shin, K.; Kim, E.; Kim, S. Does Open Innovation Enhance a Large Firm’s Financial Sustainability? A Case of the Korean Food Industry. J. Open Innov. Technol. Mark. Complex. 2020, 6, 101. [Google Scholar] [CrossRef]
- Le, T.; Hoque, A.; Hassan, K. An Open Innovation Intraday Implied Volatility for Pricing Australian Dollar Options. J. Open Innov. Technol. Mark. Complex. 2021, 7, 23. [Google Scholar] [CrossRef]
- Wu, B.; Gong, C. Impact of open innovation communities on enterprise innovation performance: A system dynamics perspective. Sustainability 2019, 11, 4794. [Google Scholar] [CrossRef]
- Arias-Pérez, J.; Coronado-Medina, A.; Perdomo-Charry, G. Big data analytics capability as a mediator in the impact of open innovation on firm performance. J. Strategy Manag. 2021, 15, 1–15. [Google Scholar] [CrossRef]
- Zhang, K.; Zhong, G.; Dong, J.; Wang, S.; Wang, Y. Stock Market Prediction Based on Generative Adversarial Network. Procedia Comput. Sci. 2019, 147, 400–406. [Google Scholar] [CrossRef]
- Chesbrough, H.W. Open Innovation: The New Imperative for Creating and Profiting from Technology; Harvard Business Press: Boston, MA, USA, 2003. [Google Scholar]
- Moretti, F.; Biancardi, D. Inbound open innovation and firm performance. J. Innov. Knowl. 2020, 5, 1–19. [Google Scholar] [CrossRef]
- Kiran, G.M. Stock Price prediction with LSTM Based Deep Learning Techniques. Int. J. Adv. Sci. Innov. 2021, 2, 18–21. [Google Scholar]
- Bhatti, S.H.; Santoro, G.; Sarwar, A.; Pellicelli, A.C. Internal and external antecedents of open innovation adoption in IT organisations: Insights from an emerging market. J. Knowl. Manag. 2021, 25, 1726–1744. [Google Scholar] [CrossRef]
- Yang, C.H.; Shyu, J.Z. A symbiosis dynamic analysis for collaborative R&D in open innovation. Int. J. Comput. Sci. Eng. 2010, 5, 74. [Google Scholar]
- Patil, P.; Wu CS, M.; Potika, K.; Orang, M. Stock market prediction using ensemble of graph theory, machine learning and deep learning models. In Proceedings of the 3rd International Conference on Software Engineering and Information Management, Sydney, Australia, 12–15 January 2020; pp. 85–92. [Google Scholar]
- Rana, M.; Uddin, M.M.; Hoque, M.M. Effects of activation functions and optimizers on stock price prediction using LSTM recurrent networks. In Proceedings of the 2019 3rd International Conference on Computer Science and Artificial Intelligence, Normal, IL, USA, 6–8 December 2019; pp. 354–358. [Google Scholar]
- Di Persio, L.; Honchar, O. Recurrent neural networks approach to the financial forecast of Google assets. Int. J. Math. Comput. Simul. 2017, 11, 7–13. [Google Scholar]
- Roondiwala, M.; Patel, H.; Varma, S. Predicting stock prices using LSTM. Int. J. Sci. Res. 2017, 6, 1754–1756. [Google Scholar]
- Hiransha, M.; Gopalakrishnan, E.A.; Menon, V.K.; Soman, K.P. NSE stock market prediction using deep-learning models. Procedia Comput. Sci. 2018, 132, 1351–1362. [Google Scholar]
- Wen, M.; Li, P.; Zhang, L.; Chen, Y. Stock Market Trend Prediction Using High-Order Information of Time Series. IEEE Access 2019, 7, 28299–28308. [Google Scholar] [CrossRef]
- Selvin, S.; Vinayakumar, R.; Gopalakrishnan, E.A.; Menon, V.K.; Soman, K.P. Stock price prediction using LSTM, RNN and CNN-sliding window model. In Proceedings of the 2017 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Udupi, India, 13–16 September 2017; pp. 1643–1647. [Google Scholar]
- Agrawal, M.; Shukla, P.; Rgpv, B. Deep Long Short Term Memory Model for Stock Price Prediction using Technical Indicators. Available online: https://www.researchgate.net/publication/337800379_Deep_Long_Short_Term_Memory_Model_for_Stock_Price_Prediction_using_Technical_Indicators (accessed on 22 April 2022).
- Shahi, T.B.; Shrestha, A.; Neupane, A.; Guo, W. Stock Price Forecasting with Deep Learning: A Comparative Study. Mathematics 2020, 8, 1441. [Google Scholar] [CrossRef]
- Pun, T.B.; Shahi, T.B. Nepal stock exchange prediction using support vector regression and neural networks. In Proceedings of the 2018 Second International Conference on Advances in Electronics, Computers and Communications (ICAECC), Bangalore, India, 9–10 February 2018; pp. 1–6. [Google Scholar]
- Zhang, R.; Yuan, Z.; Shao, X. A new combined CNN-RNN model for sector stock price analysis. In Proceedings of the 2018 IEEE 42nd Annual Computer Software and Applications Conference (COMPSAC), Tokyo, Japan, 23–27 July 2018; pp. 546–551. [Google Scholar]
- Chandar, S.K.; Sumathi, M.; Sivanandam, S.N. Prediction of Stock Market Price using Hybrid of Wavelet Transform and Artificial Neural Network. Indian J. Sci. Technol. 2016, 9, 1–5. [Google Scholar] [CrossRef]
- McNally, S.; Roche, J.; Caton, S. Predicting the price of bitcoin using machine learning. In Proceedings of the 2018 26th euromicro international conference on parallel, distributed and network-based processing (PDP), Cambridge, UK, 21–23 March 2018; pp. 339–343. [Google Scholar]
- Chung, H.; Shin, K.-S. Genetic algorithm-optimized multi-channel convolutional neural network for stock market prediction. Neural Comput. Appl. 2019, 32, 7897–7914. [Google Scholar] [CrossRef]
- Rezaei, H.; Faaljou, H.; Mansourfar, G. Stock price prediction using deep learning and frequency decomposition. Expert Syst. Appl. 2021, 169, 114332. [Google Scholar] [CrossRef]
- Xu, Y.; Chhim, L.; Zheng, B.; Nojima, Y. Stacked deep learning structure with bidirectional long-short term memory for stock market prediction. In International Conference on Neural Computing for Advanced Applications; Springer: Singapore, 2020; pp. 447–460. [Google Scholar]
- Lu, W.; Li, J.; Wang, J.; Qin, L. A CNN-BiLSTM-AM method for stock price prediction. Neural Comput. Appl. 2021, 33, 4741–4753. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, L.; Yang, F.; Di, W.; Chang, Q. Advantages of direct input-to-output connections in neural networks: The Elman network for stock index forecasting. Inf. Sci. 2020, 547, 1066–1079. [Google Scholar] [CrossRef]
- Wu, J.M.; Li, Z.; Srivastava, G.; Tasi, M.; Lin, J.C. A graph-based convolutional neural network stock price prediction with leading indicators. Software: Pract. Exp. 2020, 51, 628–644. [Google Scholar] [CrossRef]
- Dutta, A.; Kumar, S.; Basu, M. A Gated Recurrent Unit Approach to Bitcoin Price Prediction. J. Risk Financial Manag. 2020, 13, 23. [Google Scholar] [CrossRef]
- Qiu, J.; Wang, B.; Zhou, C. Forecasting stock prices with long-short term memory neural network based on attention mechanism. PLoS ONE 2020, 15, e0227222. [Google Scholar] [CrossRef]
- Houssein, E.H.; Dirar, M.; Abualigah, L.; Mohamed, W.M. An efficient equilibrium optimizer with support vector regression for stock market prediction. Neural Comput. Appl. 2021, 34, 3165–3200. [Google Scholar] [CrossRef]
- Al Bashabsheh, E.; Alasal, S.A. ES-JUST at SemEval-2021 Task 7: Detecting and Rating Humor and Offensive Text Using Deep Learning. In Proceedings of the 15th International Workshop on Semantic Evaluation (SemEval-2021), Online, 5–6 August 2021; pp. 1102–1107. [Google Scholar]
- Jia, H. Investigation into the effectiveness of long short term memory networks for stock price prediction. arXiv 2016, arXiv:1603.07893. [Google Scholar]
- Qin, L.; Yu, N.; Zhao, D. Applying the convolutional neural network deep learning technology to behavioural recognition in intelligent video. Tehnički vjesnik 2018, 25, 528–535. [Google Scholar]
- Hao, Y.; Gao, Q. Predicting the Trend of Stock Market Index Using the Hybrid Neural Network Based on Multiple Time Scale Feature Learning. Appl. Sci. 2020, 10, 3961. [Google Scholar] [CrossRef]
- Kamalov, F. Forecasting significant stock price changes using neural networks. Neural Comput. Appl. 2020, 32, 17655–17667. [Google Scholar] [CrossRef]
- Livieris, I.E.; Pintelas, E.; Pintelas, P. A CNN–LSTM model for gold price time-series forecasting. Neural Comput. Appl. 2020, 32, 17351–17360. [Google Scholar] [CrossRef]
- Clevert, D.A.; Unterthiner, T.; Hochreiter, S. Fast and accurate deep network learning by exponential linear units (elus). arXiv 2015, arXiv:1511.07289. [Google Scholar]
- Cococcioni, M.; Rossi, F.; Ruffaldi, E.; Saponara, S. A novel posit-based fast approximation of elu activation function for deep neural networks. In Proceedings of the 2020 IEEE International Conference on Smart Computing (SMARTCOMP), Bologna, Italy, 14–17 September 2020; pp. 244–246. [Google Scholar]
- Armano, G.; Marchesi, M.; Murru, A. A hybrid genetic-neural architecture for stock indexes forecasting. Inf. Sci. 2005, 170, 3–33. [Google Scholar] [CrossRef]
- Zhong, X.; Enke, D. Predicting the daily return direction of the stock market using hybrid machine learning algorithms. Financ. Innov. 2019, 5, 1–20. [Google Scholar] [CrossRef]
- Hu, Z.; Zhao, Y.; Khushi, M. A Survey of Forex and Stock Price Prediction Using Deep Learning. Appl. Syst. Innov. 2021, 4, 9. [Google Scholar] [CrossRef]
- Dang, H.; Mei, B. Stock Movement Prediction Using Price Factor and Deep Learning. Int. J. Comput. Inf. Eng. 2022, 16, 73–76. [Google Scholar]
- Borodin, A.; Mityushina, I.; Streltsova, E.; Kulikov, A.; Yakovenko, I.; Namitulina, A. Mathematical Modeling for Financial Analysis of an Enterprise: Motivating of Not Open Innovation. J. Open Innov. Technol. Mark. Complex. 2021, 7, 79. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Method | Contribution | Measures | Year |
|---|---|---|---|---|
| [56] | Deep learning architecture-based Long Short-Term Memory (LSTM) | Stock price prediction using LSTM, RNN, and CNN-sliding window model | ARIMA | 2017 |
| [60] | A Deep Wide Neural Network (DWNN) | A new combined CNN-RNN model for sector stock price analysis | Prediction mean squared error | 2018 |
| [44] | Long Short-Term Memory (LSTM) as a generator and Multi-Layer Perceptron (MLP) | A new hybrid machine learning approach for stock market prediction | MAE, RMAE, MAE, AR | 2019 |
| [68] | A new convolutional novel neural network | A graph-based convolutional neural network stock price prediction with leading indicators | Prediction accuracy | 2020 |
| [50] | Support Vector Regression (SVR), Linear Regression (LR), and Long Short-Term Memory (LSTM) | Stock market prediction using an ensemble of graph theory, machine learning and deep learning models | RMAE | 2020 |
| [71] | Support vector regression (SVR) method with equilibrium optimizer (EO) | An efficient equilibrium optimizer with support vector regression for stock market prediction | Mean fitness function (prediction rate) | 2022 |
| Model | MSE (Training) | MAPE (Training) |
|---|---|---|
| MLP | 0.0241 | 1.583 |
| GRU | 0.0265 | 5.3065 |
| LSTM | 0.0105 | 1.29 |
| Bi-LSTM | 0.033 | 4.985 |
| CNN | 0.0396 | 1.993 |
| CNN-LSTM | 0.036 | 2.238 |
| Model | MSE (Training) | MAPE (Training) |
|---|---|---|
| MLP | 0.0188 | 1.582 |
| GRU | 0.0177 | 5.57 |
| LSTM | 0.0019 | 1.08 |
| Bi-LSTM | 0.01 | 4.894 |
| CNN | 0.0301 | 2.228 |
| CNN-LSTM | 0.034 | 2.557 |
| Model | MSE (Training) | MAPE (Training) |
|---|---|---|
| MLP | 0.7101 | 1.809 |
| GRU | 0.4642 | 5.254 |
| LSTM | 0.3695 | 1.672 |
| Bi-LSTM | 0.601 | 3.8 |
| CNN | 0.3157 | 1.576 |
| CNN-LSTM | 0.593 | 2.069 |
| Model | MSE (Training) | MAPE (Training) |
|---|---|---|
| MLP | 0.6071 | 1.86 |
| GRU | 0.1269 | 6.325 |
| LSTM | 0.1099 | 1.765 |
| Bi-LSTM | 0.098 | 5.779 |
| CNN | 0.4015 | 1.791 |
| CNN-LSTM | 0.483 | 1.964 |
| Model | MSE (Training) | MAPE (Training) |
|---|---|---|
| MLP | 0.2348 | 2.184 |
| GRU | 0.145 | 2.62 |
| LSTM | 0.0870 | 1.653 |
| Bi-LSTM | 0.127 | 2.276 |
| CNN | 0.0869 | 1.483 |
| CNN-LSTM | 0.134 | 1.899 |
| Model | MSE (Training) | MAPE (Training) |
|---|---|---|
| MLP | 0.1989 | 1.765 |
| GRU | 0.024 | 1.444 |
| LSTM | 0.0075 | 1.006 |
| Bi-LSTM | 0.021 | 1.363 |
| CNN | 0.0813 | 1.563 |
| CNN-LSTM | 0.126 | 1.926 |
| Model | MSE (Training) | MAPE (Training) |
|---|---|---|
| MLP | 0.479 | 1.422 |
| GRU | 0.325 | 1.15 |
| LSTM | 0.4266 | 1.285 |
| Bi-LSTM | 0.319 | 1.131 |
| CNN | 5.357 | 3.583 |
| CNN-LSTM | 3.186 | 2.823 |
| Model | MSE (Training) | MAPE (Training) |
|---|---|---|
| MLP | 0.43 | 1.377 |
| GRU | 0.304 | 1.012 |
| LSTM | 0.342 | 1.158 |
| Bi-LSTM | 0.266 | 0.99 |
| CNN | 3.188 | 2.985 |
| CNN-LSTM | 3.719 | 2.919 |
| Model | MSE (Validation) | MAPE (Validation) |
|---|---|---|
| MLP | 9.504 | 3.46 |
| GRU | 19.196 | 4.1615 |
| LSTM | 2.388 | 3.208 |
| Bi-LSTM | 69.915 | 2.875 |
| CNN | 2.281 | 6.744 |
| CNN-LSTM | 3.339 | 8.473 |
| Model | MSE (Validation) | MAPE (Validation) |
|---|---|---|
| MLP | 15.89 | 3.488 |
| GRU | 15.77 | 2.069 |
| LSTM | 3.325 | 1.983 |
| Bi-LSTM | 5.301 | 2.078 |
| CNN | 2.77 | 3.744 |
| CNN-LSTM | 2.494 | 7.624 |
| Model | MSE (Validation) | MAPE (Validation) |
|---|---|---|
| MLP | 39.9 | 2.49 |
| GRU | 19.24 | 2.518 |
| LSTM | 56 | 1.89 |
| Bi-LSTM | 294.95 | 2.037 |
| CNN | 5.475 | 1.46 |
| CNN-LSTM | 3.659 | 1.678 |
| Model | MSE (Validation) | MAPE (Validation) |
|---|---|---|
| MLP | 44.28 | 2.854 |
| GRU | 14.12 | 2.105 |
| LSTM | 47.05 | 2.533 |
| Bi-LSTM | 2.272 | 1.279 |
| CNN | 3.889 | 1.626 |
| CNN-LSTM | 11.261 | 1.765 |
| Model | MSE (Validation) | MAPE (Validation) |
|---|---|---|
| MLP | 37.82 | 5.538 |
| GRU | 12.27 | 1.875 |
| LSTM | 16.23 | 2.054 |
| Bi-LSTM | 4.139 | 3.825 |
| CNN | 5.42 | 3.545 |
| CNN-LSTM | 21.809 | 6.757 |
| Model | MSE (Validation) | MAPE (Validation) |
|---|---|---|
| MLP | 45.11 | 7.409 |
| GRU | 0.904 | 0.612 |
| LSTM | 36.6 | 4.118 |
| Bi-LSTM | 0.997 | 4.523 |
| CNN | 7.839 | 3.219 |
| CNN-LSTM | 18.618 | 6.69 |
| Model | MSE (Validation) | MAPE (Validation) |
|---|---|---|
| MLP | 19.604 | 6.537 |
| GRU | 19.101 | 5.902 |
| LSTM | 27.244 | 7.434 |
| Bi-LSTM | 34.503 | 6.048 |
| CNN | 127.875 | 15.909 |
| CNN-LSTM | 74.338 | 13.814 |
| Model | MSE (Validation) | MAPE (Validation) |
|---|---|---|
| MLP | 18.21 | 5.996 |
| GRU | 19.291 | 5.854 |
| LSTM | 26.56 | 7.672 |
| Bi-LSTM | 19.581 | 6.626 |
| CNN | 72.303 | 13.488 |
| CNN-LSTM | 79.134 | 14.981 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alkhatib, K.; Khazaleh, H.; Alkhazaleh, H.A.; Alsoud, A.R.; Abualigah, L. A New Stock Price Forecasting Method Using Active Deep Learning Approach. J. Open Innov. Technol. Mark. Complex. 2022, 8, 96. https://doi.org/10.3390/joitmc8020096
Alkhatib K, Khazaleh H, Alkhazaleh HA, Alsoud AR, Abualigah L. A New Stock Price Forecasting Method Using Active Deep Learning Approach. Journal of Open Innovation: Technology, Market, and Complexity. 2022; 8(2):96. https://doi.org/10.3390/joitmc8020096
Chicago/Turabian StyleAlkhatib, Khalid, Huthaifa Khazaleh, Hamzah Ali Alkhazaleh, Anas Ratib Alsoud, and Laith Abualigah. 2022. "A New Stock Price Forecasting Method Using Active Deep Learning Approach" Journal of Open Innovation: Technology, Market, and Complexity 8, no. 2: 96. https://doi.org/10.3390/joitmc8020096
APA StyleAlkhatib, K., Khazaleh, H., Alkhazaleh, H. A., Alsoud, A. R., & Abualigah, L. (2022). A New Stock Price Forecasting Method Using Active Deep Learning Approach. Journal of Open Innovation: Technology, Market, and Complexity, 8(2), 96. https://doi.org/10.3390/joitmc8020096