An Efficient Smoke Detection Algorithm Based on Deep Belief Network Classifier Using Energy and Intensity Features





Abstract
:1. Introduction
2. Review of Smoke Features and Classifiers
2.1. Review of Some Smoke Features
2.1.1. Smoke Motion
2.1.2. Smoke Color Feature
2.1.3. Smoke Energy
2.1.4. Smoke Disorder
2.2. Smoke and No-Smoke Classification Regions Methods
3. Proposed Methodology
3.1. Dataset Presentation and Proposed Methodology Description
3.2. Pre-Processing of Smoke Images
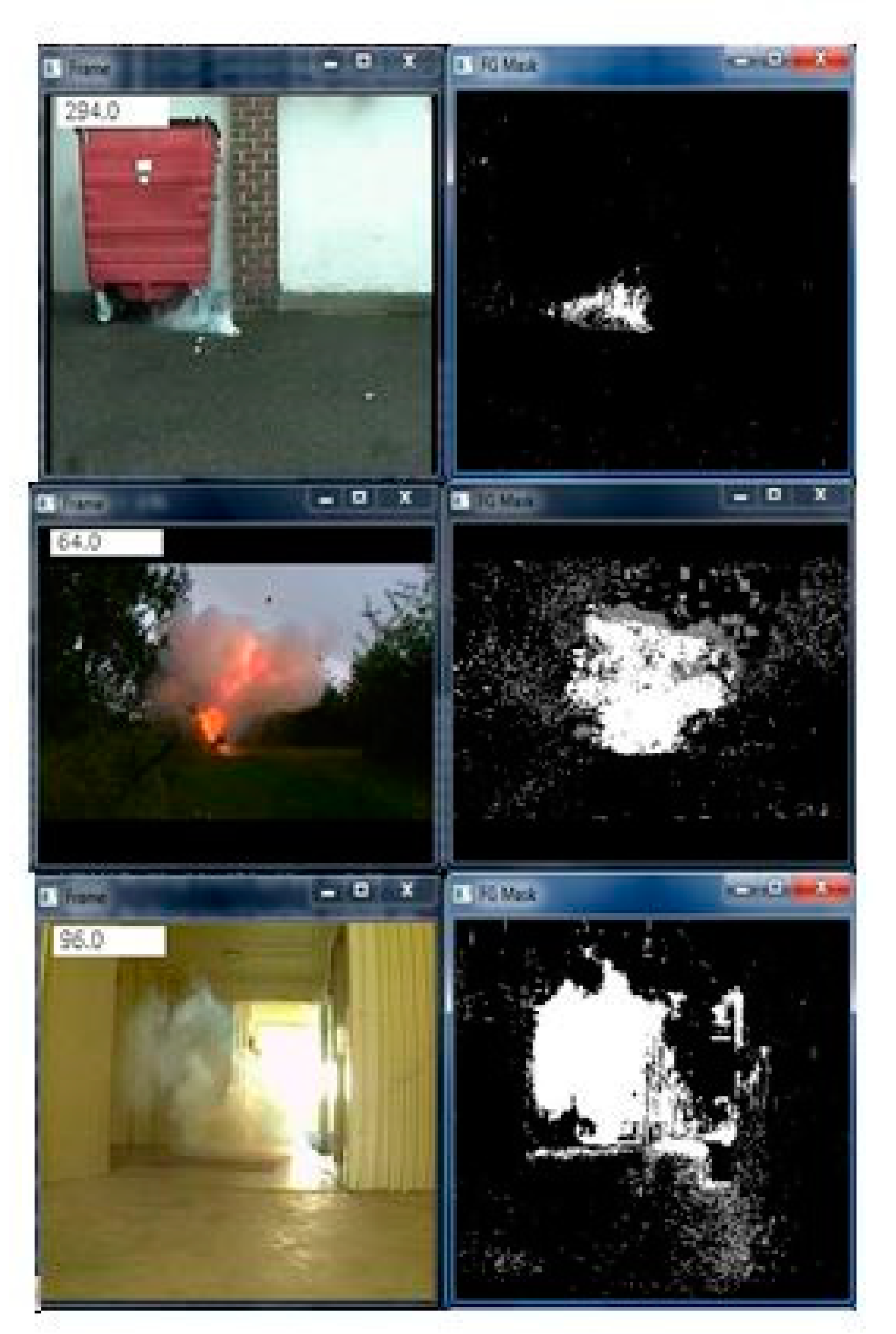
3.3. Localization of Smoke Regions
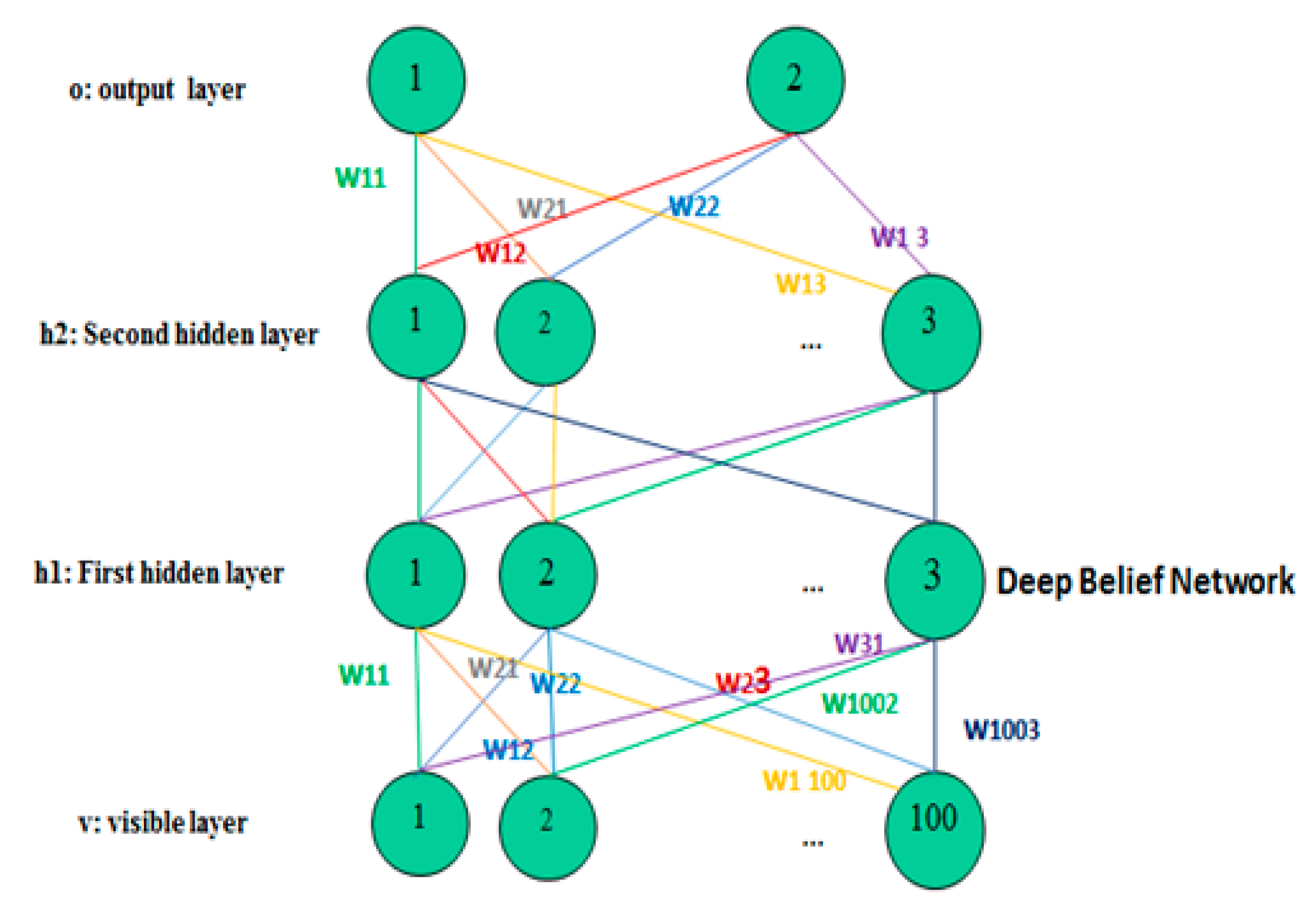
3.4. The Use of the Deep Belief Network
3.4.1. The Pre-Training and Feature Extraction
3.4.2. The Multi-Layer Perceptron
- Train the first layer as an RBM that models the raw input v = h0 as its visible layer.
- Use the first layer to obtain the representation of the input (W(1), h(1)) and use h(1) as the data of the second layer.
- Fix the parameter of the second layer of features and use the samples of h as the data for training the third layer.
- Fine tune all parameters with respect for DBN log-likelihood.
- Fine tune the parameters.
3.4.3. Classification Using Logistic Regression/Adam Optimizer
- a.
- Logistic Regression
- b.
- Adam Optimizer
4. Experimental Results and Discussion
4.1. The Network Parameters Tuning
4.2. The Detection Rate and Loss Analysis
4.3. Training and Validation Using the Proposed Method on the Studied Database
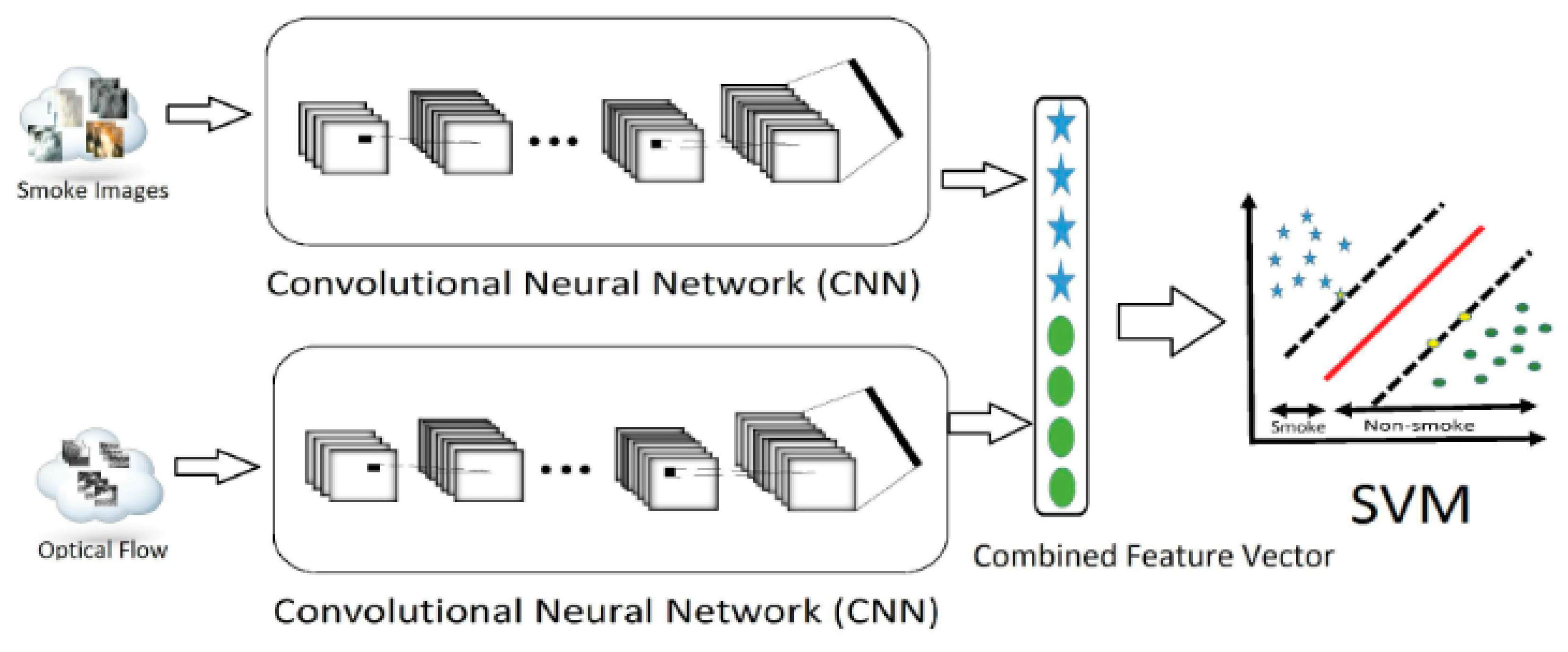
4.4. Comparison of Smoke Detection Results Using Support Vector Machine and Deep CNN
4.5. Robustness of the Proposed Method in the Noisy Case
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Hinton, G.E.; Osindero, S.; Teh, Y.-W. A Fast Learning Algorithm for Deep Belief Nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning for Single Image Super-Resolution: A Brief Review. Int. J. Sci. Nat. 2015, 521, 436–444. [Google Scholar]
- Yang, J.; Yuan, X.; Liao, X.; Llull, P.; Brady, D.J.; Sapiro, G.; Carin, L. Video Compressive Sensing Using Gaussian Mixture Models. IEEE Trans. Image Process. 2014, 23, 4863–4878. [Google Scholar] [CrossRef] [PubMed]
- Viswanath, A.; Behera, R.K.; Senthamilarasu, V.; Kutty, K. Background Modelling from a Moving Camera. Procedia Comput. Sci. 2015, 58, 289–296. [Google Scholar] [CrossRef] [Green Version]
- Huang, M.; Chen, G.; Yang, G.-F.; Cao, R. An Algorithm of the Target Detection and Tracking of the Video. Procedia Eng. 2012, 29, 2567–2571. [Google Scholar] [CrossRef] [Green Version]
- Mahfouf, Z.; Merouani, H.F.; Bouchrika, I.; Harrati, N. Investigating the use of motion-based features from optical flow for gait recognition. Neurocomputing 2018, 283, 140–149. [Google Scholar] [CrossRef]
- Santoyo-Morales, J.E.; Hasimoto-Beltrán, R. Video Background Subtraction in Complex Environments. J. Appl. Res. Technol. 2014, 12, 527–537. [Google Scholar] [CrossRef]
- Demidova, L.; Klyueva, I.; Sokolova, Y.; Stepanov, N.; Tyart, N. Intellectual Approaches to Improvement of the Classification Decisions Quality on the Base of the SVM Classifier. Procedia Comput. Sci. 2017, 103, 222–230. [Google Scholar] [CrossRef]
- Hsu, C.-W.; Lin, C.-J. A comparison of methods for multiclass support vector machines. IEEE Trans. Neural Netw. 2002, 13, 415–425. [Google Scholar]
- Bicegoa, M.; Mário, V.M.; Figueiredo, A.T. Similarity-based classification of sequences using hidden Markov models. Pattern Recognit. 2004, 37, 2281–2291. [Google Scholar] [CrossRef]
- DeNoyer, L.; Gallinari, P. Bayesian network model for semi-structured document classification. Inf. Process. Manag. 2004, 40, 807–827. [Google Scholar] [CrossRef]
- Kaabi, R.; Frizzi, S.; Bouchouicha, M.; Fnaich, F.; Moreau, E. Video Smoke Detection Review. In Proceedings of the 2017 International Conference on Smart, Monitored and Controlled Cities (SM2C), Sfax, Tunisia, 17–19 February 2017. [Google Scholar]
- Zhao, Y.; Li, Q.; Gu, Z. Early smoke detection of forest fire video using CS Adaboost algorithm. Int. J. Light Electron. Opt. 2015, 126, 2121–2124. [Google Scholar] [CrossRef]
- Xiong, Z.; Caballero, R.; Wang, H.; Finn, A.M.; Lelic, M.A.; Peng, P.-Y. Video-Based Smoke Detection: Possibilities, Techniques, and Challenges; IFPA Fire Suppression & Detection Research & Applications: East Hartford, CT, USA, 2007; pp. 1–7. [Google Scholar]
- Toreyin, B.U.; Dedeoglu, Y.; Cetin, A.E. Contour Based Smoke Detection in Video Using Wavelets. In Proceedings of the 14th European Signal Processing Conference (EUSIPCO 2006), Florence, Italy, 4–8 September 2006; pp. 1–5. [Google Scholar]
- Ghazali, K.H.; Mansor, M.F.; Mustafa, M.M.; Hussain, A. Feature Extraction Technique using Discrete Wavelet Transform for Image Classification. In Proceedings of the 2007 5th Student Conference on Research and Development, Selangor, Malaysia, 11–12 December 2007; pp. 1–4. [Google Scholar]
- Calderara, S.; Piccinini, P.; Cucchiara, R. Smoke Detection in Video Surveillance: A MoG Model in the Wavelet Domain. In Computer Vision Systems; Springer Science and Business Media: Berlin/Heidelberg, Germany, 2008; Volume 5008, pp. 119–128. [Google Scholar]
- Wang, Y. Smoke Recognition Based on Machine Vision. In Proceedings of the 2016 International Symposium on Computer, Consumer and Control (IS3C), Xi’an, China, 4–6 July 2016; Volume 283, pp. 668–671. [Google Scholar]
- Yuan, F. A fast accumulative motion orientation model based on integral image for video smoke detection. Pattern Recognit. Lett. 2008, 29, 925–932. [Google Scholar] [CrossRef]
- Favorskaya, M.N.; Pyataeva, A.; Popov, A. Spatio-temporal Smoke Clustering in Outdoor Scenes Based on Boosted Random Forests. Procedia Comput. Sci. 2016, 96, 762–771. [Google Scholar] [CrossRef] [Green Version]
- Xu, G.; Zhang, Y.; Zhang, Q.; Lin, G.; Wang, Z.; Jia, Y.; Wang, J. Video smoke detection based on deep saliency network. Fire Saf. J. 2019, 105, 277–285. [Google Scholar] [CrossRef] [Green Version]
- Gu, K.; Xia, Z.; Qiao, J.; Lin, W. Deep Dual-Channel Neural Network for Image-Based Smoke Detection. IEEE Trans. Multimed. 2020, 22, 311–323. [Google Scholar] [CrossRef]
- Lee, B.; Han, D. Real-Time Fire Detection Using Camera Sequence Image in Tunnel Environment. In Lecture Notes in Computer Science; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 2007; Volume 4681, pp. 1209–1220. [Google Scholar]
- Mishina, Y.; Tsuchiya, M.; Fujiyoshi, H. Boosted Random Forest. In Proceedings of the International Conference on Computer Vision Theory and Applications, Liston, Portugal, 5–8 January 2014; pp. 594–598. [Google Scholar]
- Kaabi, R.; Sayadi, M.; Bouchouicha, M.; Fnaiech, F.; Moreau, É.; Ginoux, J.M. Early smoke detection of forest wildfire video using deep belief network. In Proceedings of the 2018 4th International Conference on Advanced Technologies for Signal and Image Processing (ATSIP), Sousse, Tunisia, 21–24 March 2018; pp. 1–6. [Google Scholar]
- Yin, Z.; Wan, B.; Yuan, F.; Xia, X.; Shi, J. A Deep Normalization and Convolutional Neural Network for Image Smoke Detection. IEEE Access 2017, 5, 18429–18438. [Google Scholar] [CrossRef]
- Hu, Y.; Lu, X. Real-time video fire smoke detection by utilizing spatial-temporal ConvNet features. Multimed. Tools Appl. 2018, 77, 29283–29301. [Google Scholar] [CrossRef]
- Pundir, A.S.; Raman, B. Dual Deep Learning Model for Image Based Smoke Detection. Fire Technol. 2019, 55, 2419–2442. [Google Scholar] [CrossRef]
- Cetin, A.E.; on behalf of the Bilkent SPG Signal Processing Group. Computer Vision Based Fire Detection Software. Available online: http://signal.ee.bilkent.edu.tr/VisiFire/index.html (accessed on 10 May 2020).
- Hrasko, R.; Pacheco, A.G.C.; Krohling, R.A. Time Series Prediction Using Restricted Boltzmann Machines and Backpropagation. Procedia Comput. Sci. 2015, 55, 990–999. [Google Scholar] [CrossRef] [Green Version]
- Zhang, N.; Ding, S.; Zhang, J.; Xue, Y. An overview on Restricted Boltzmann Machines. Neurocomputing 2018, 275, 1186–1199. [Google Scholar] [CrossRef]
- Efron, B. The efficiency of logistic regression compared to Normal Discriminant Analysis. J. Am. Stat. Assoc. 1975, 70, 892–898. [Google Scholar] [CrossRef]
- Maruta, H.; Nakamura, A.; Kurokawa, F. A novel smoke detection method using support vector machine. In TENCON 2010–2010 IEEE Region 10 Conference; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2010; Volume 431, pp. 210–215. [Google Scholar]
- Carreira-Perpinan, M.A.; Hinton, G.E. On contrastive divergence learning. In Proceedings of the Artificial Intelligence and Statistics (AISTATS), Bridgetown, Barbados, 6–8 January 2005; pp. 1–8. [Google Scholar]
- Hinton, G.E. Training Products of Experts by Minimizing Contrastive Divergence. Neural Comput. 2002, 14, 1771–1800. [Google Scholar] [CrossRef] [PubMed]
- Chou, P.-H. A Gibbs sampling approach to the estimation of linear regression models under daily price limits. Pac.-Basin Financ. J. 1997, 5, 39–62. [Google Scholar] [CrossRef]
- Chang, T.-C.; Chao, R.-J. Application of back-propagation networks in debris flow prediction. Eng. Geol. 2006, 85, 270–280. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Zou, F.; Shen, L.; Jie, Z.; Zhang, W.; Liu, W. A Sufficient Condition for Convergences of Adam and RMSProp. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 11119–11127. [Google Scholar]
- Basu, A.; De, S.; Mukherjee, A.; Ullah, E. Convergence guarantees for RMSProp and ADAM in non-convex optimization and their comparison to Nesterov acceleration on autoencoders. arXiv 2018, arXiv:1807.06766. [Google Scholar]
- Horn, B.K.; Schunck, B.G. Determining optical flow. Artif. Intell. 1981, 17, 185–203. [Google Scholar] [CrossRef] [Green Version]
- Neelakantan, A.; Vilnis, L.; Le, Q.V.; Sutskever, I.; Kaiser, L.; Kurach, K.; Martens, J. Adding Gradient Noise Improves Learning for Very Deep Networks. arXiv 2015, arXiv:1511.06807. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Color Feature | Moving Object | Energy/Flicker Analysis | Disorder Analysis | Smoke Flutter | Classification (SVM, KNN, HMM…) |
|---|---|---|---|---|---|---|
| Toreyin [15] (2006) | YUV | ✖ | ✖ | ✖ | - | ✖ |
| Xiong [14] (2007) | - | ✖ | ✖ | ✖ | - | - |
| Zhao [13] (2015) | RGB | ✖ | ✖ | - | ✖ | ✖ |
| Yuanbin [19] (2016) | - | ✖ | - | - | - | ✖ |
| Yini [26] (2017) | RGB | ✖ | - | - | - | DNCNN |
| Hu [27] (2018) | RGB | ✖ | - | - | - | CNN |
| Pundir [28] (2019) | RGB | ✖ | - | - | - | Deep CNN |
| Proposed method | RGB | ✖ | ✖ | - | - | DBN |
| Hyper Parameter | Designation |
|---|---|
| vi = {1, 2, …,100} | Value of node i in the visible layer |
| hj = {1, 2, 3} | Value of node j in the hidden layer |
| b = {b1, b2, b3, …, b100} c = {c1, c2, c3} | bi, cj: bias associated with the ith visible node and jth hidden node, respectively. |
| The weight between the visible units i and hidden units j | |
| the covariance for the ith distribution | |
| batch | 64 |
| Size of hidden layer | 2 |
| True Positive Frames | True Negative Frames | Accuracy% | Precision% | Recall% | F1 Score | Time Processing | IoU | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Total Number of Frames | M1 | M2 | M1 | M2 | M1 | M2 | M1 | M2 | M1 | M2 | M1 | M2 | M2 | M2 | |
| Test 1 | 275 | 210 | 225 | 14 | 23 | 82 | 90 | 89 | 94 | 88 | 93 | 0.88 | 0.93 | 0.6 | 0.85 |
| Test 2 | 483 | 439 | 457 | 15 | 7 | 94 | 96 | 95 | 99 | 94 | 96 | 0.94 | 0.97 | 0.68 | 0.92 |
| Test 3 | 123 | 104 | 109 | 6 | 3 | 89 | 91 | 94 | 97 | 93 | 94 | 0.93 | 0.95 | 0.43 | 0.87 |
| Test 4 | 888 | 784 | 829 | 32 | 5 | 92 | 94 | 96 | 98 | 92 | 96 | 0.94 | 0.97 | 0.82 | 0.91 |
| Test 5 | 808 | 731 | 762 | 20 | 14 | 93 | 96 | 96 | 99 | 95 | 96 | 0.95 | 0.97 | 0.76 | 0.94 |
| Test 6 | 466 | 408 | 435 | 12 | 8 | 90 | 95 | 95 | 99 | 93 | 95.5 | 0.94 | 0.97 | 0.65 | 0.93 |
| Test 7 | 626 | 536 | 560 | 27 | 10 | 90 | 91 | 90 | 92 | 98 | 99 | 0.93 | 0.95 | 0.71 | 0.88 |
| Test 8 | 214 | 160 | 174 | 30 | 19 | 89 | 90 | 90 | 91.5 | 95 | 97 | 0.92 | 0.94 | 0.44 | 0.87 |
| Test 9 | 507 | 400 | 430 | 36 | 21 | 86 | 90 | 88 | 91 | 95 | 96 | 0.91 | 0.93 | 0.68 | 0.89 |
| Test 10 | 304 | 0 | 0 | 291 | 298 | 95 | 98 | 0 | 0 | 0 | 0 | - | - | 0.48 | - |
| Test 11 | 109 | 0 | 0 | 102 | 104 | 93 | 95 | 0 | 0 | 0 | 0 | - | - | 0.31 | - |
| Test 12 | 84 | 0 | 0 | 79 | 81 | 94 | 96 | 0 | 0 | 0 | 0 | - | - | 0.29 | - |
| SNR | Accuracy |
|---|---|
| 1 dB | 87.5% |
| 5 dB | 93% |
| 20 dB | 94.5% |
| Condition | Classifier | Accuracy | F1 Score | Precision | Recall | Time of Training Process (s) |
|---|---|---|---|---|---|---|
| Without Noise | SVM | 0.93 | 0.95 | 1 | 0.91 | 135 |
| Deep CNN | 0.97 | 0.98 | 1 | 0.96 | 100 | |
| Proposed DBN | 0.96 | 0.97 | 1 | 0.95 | 60 | |
| With Gaussian Noise SNR 5 dB | SVM | 0.91 | 0.95 | 0.91 | 1 | 168 |
| Deep CNN | 0.95 | 0.97 | 0.94 | 1 | 115 | |
| Proposed DBN | 0.93 | 0.96 | 0.92 | 1 | 84 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kaabi, R.; Bouchouicha, M.; Mouelhi, A.; Sayadi, M.; Moreau, E. An Efficient Smoke Detection Algorithm Based on Deep Belief Network Classifier Using Energy and Intensity Features. Electronics 2020, 9, 1390. https://doi.org/10.3390/electronics9091390
Kaabi R, Bouchouicha M, Mouelhi A, Sayadi M, Moreau E. An Efficient Smoke Detection Algorithm Based on Deep Belief Network Classifier Using Energy and Intensity Features. Electronics. 2020; 9(9):1390. https://doi.org/10.3390/electronics9091390
Chicago/Turabian StyleKaabi, Rabeb, Moez Bouchouicha, Aymen Mouelhi, Mounir Sayadi, and Eric Moreau. 2020. "An Efficient Smoke Detection Algorithm Based on Deep Belief Network Classifier Using Energy and Intensity Features" Electronics 9, no. 9: 1390. https://doi.org/10.3390/electronics9091390
APA StyleKaabi, R., Bouchouicha, M., Mouelhi, A., Sayadi, M., & Moreau, E. (2020). An Efficient Smoke Detection Algorithm Based on Deep Belief Network Classifier Using Energy and Intensity Features. Electronics, 9(9), 1390. https://doi.org/10.3390/electronics9091390