Channel and Spatial Attention Regression Network for Cup-to-Disc Ratio Estimation



Abstract
1. Introduction
- We propose an end-to-end channel and spatial attention regression deep learning network for predicting CDR, which jointly learns the self-attention module and the regression module.
- Proposed channel attention block can select relatively important feature maps in channel dimension, shifting the emphasis on the feature map that is closely related to the optic disc and cup region, and proposed spatial attention block can capture the relationship of the intra-feature map to improve the discriminative ability of feature representation at pixel level.
- We design a segmentation-auxiliary task to help the regression task focus on the optic disc and cup region instead of non-optic disc and cup region.
2. Related Work
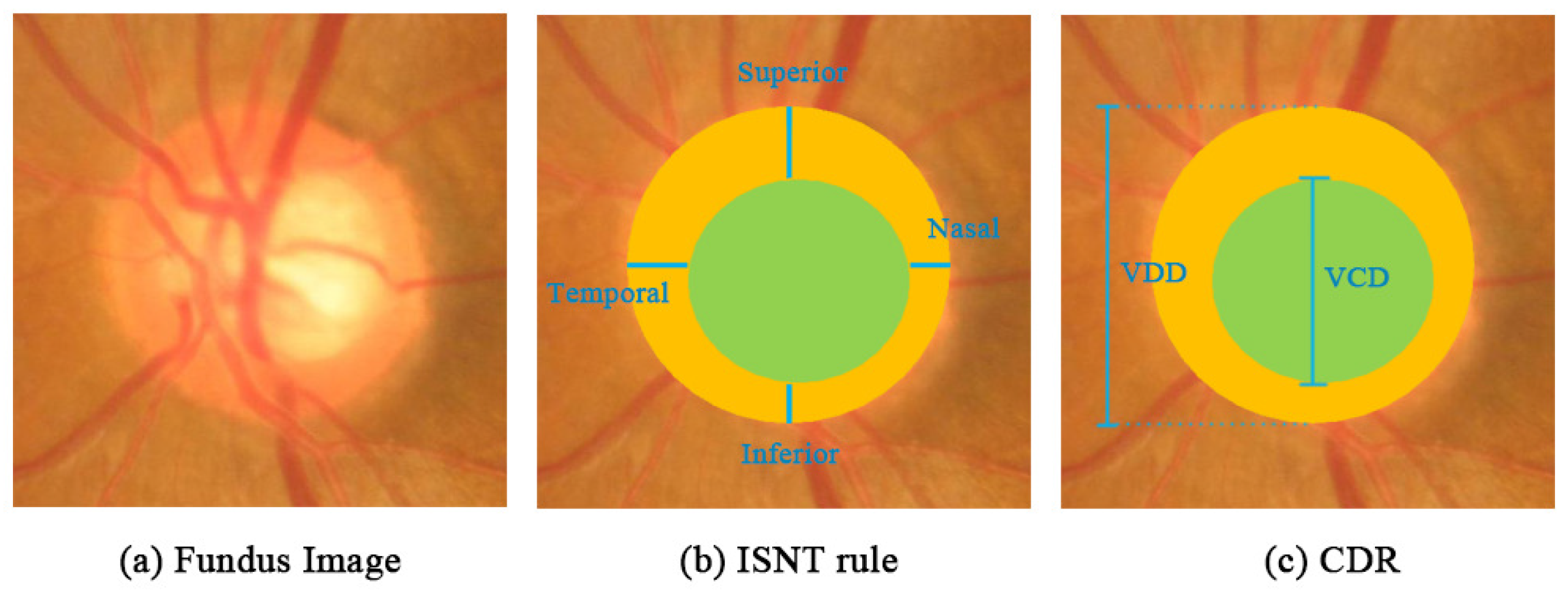
2.1. Existing Two Methods of the Calculation of CDR
- Segmentation methods. Most researchers focus their efforts on the segmentation methods, part of which tend to focus on OD and OC segmentation independently. For the perspective of only OD’s segmentation, hand-crafted features are inevitably required, such as image gradient information extracted by active contour model [24], the local texture features [25], the disparity features extracted from the stereo image [26], and a novel polar transform method [27]. OC segmentation is also highly dependent on hand-crafted visual features. However, because the OD and OC have a certain structural similarity and positional correlation, joint OD and OC segmentation approaches obtain better performance [28,29]. Zheng et al. [28] joint the OD and OC segmentation leveraging a graph-cut mechanism. A superpixel-level classifier [29] is utilized to provide robustness for segmenting OD and OC. Recently, deep learning techniques have an excellent performance in computer vision, which are also widely used to joint OD and OC segmentation. Sevastopolsky et al. [30] design a modification of the U-net convolutional neural network (CNN), but it still operates in two stages. Futhermore, based on U-net, Qin et al. [31] combine deformable convolution and create a novel architecture for segmentation of OD and OC. Subsequently, the residual network (ResNet) is introduced, and whether generative adversarial networks (GAN) is helpful for OD and OC segmentation is discussed in [32]. M-net [12] develops the one stage multi-scale mechanism and adopts polar transformation to shift the fundus images to the polar coordinate system. However, finding the center point of OD is inevitably required, and the workload is increased to some extent. Unsupervised domain adaptation for joint OD and OC segmentation over different retinal fundus image datasets is exploited in [33]. The work in [34] deals with the OD and OC by combining the GAN. The segmentation problem is addressed as an object problem [35].
- Direct estimation methods. Direct methods usually deduce the CDR numbers directly without segmented OD and OC. The existing method using machine learning has two stages: unsupervised feature representation with CNN and CDR number regression by random forest regressor separately [36].
2.2. Existing Attention Model
3. Methodology
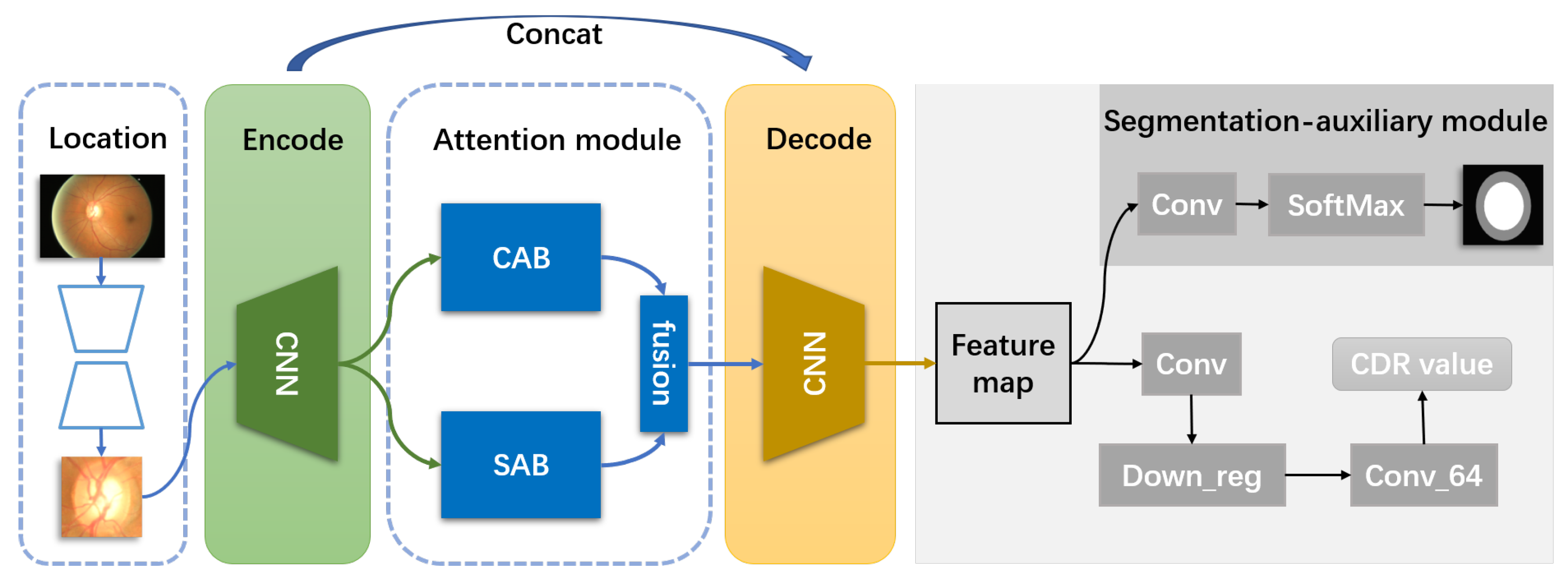
3.1. Overview
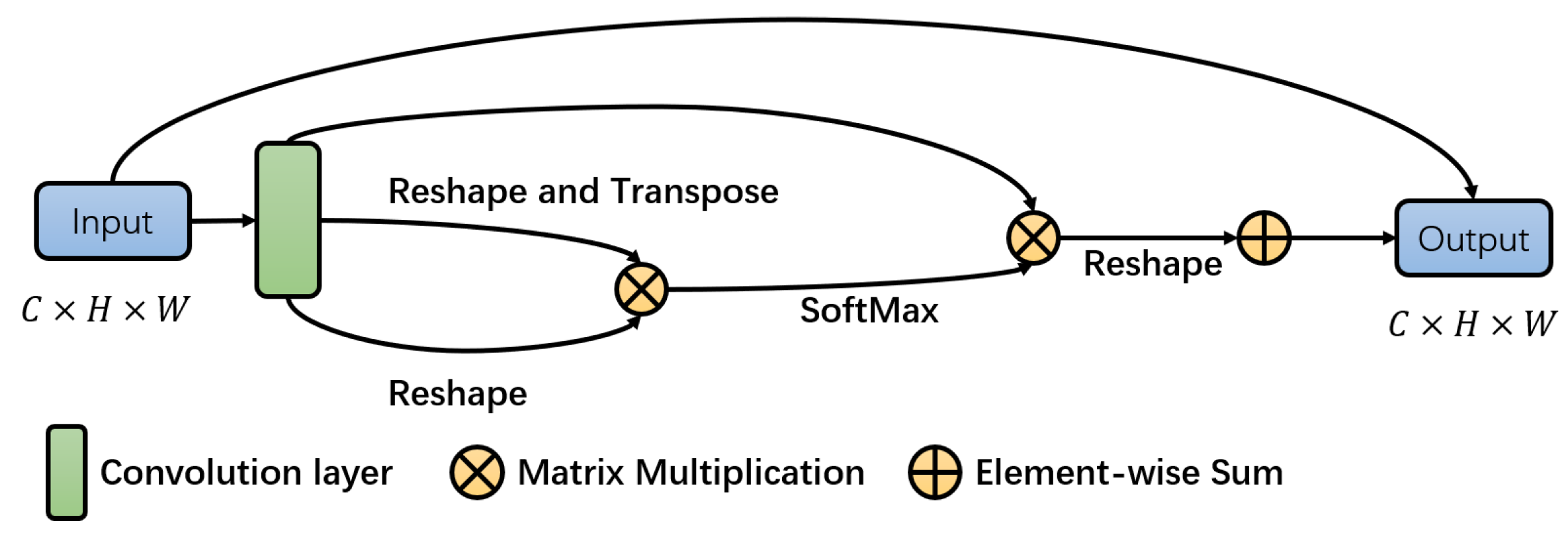
3.2. The Spatial Attention Block
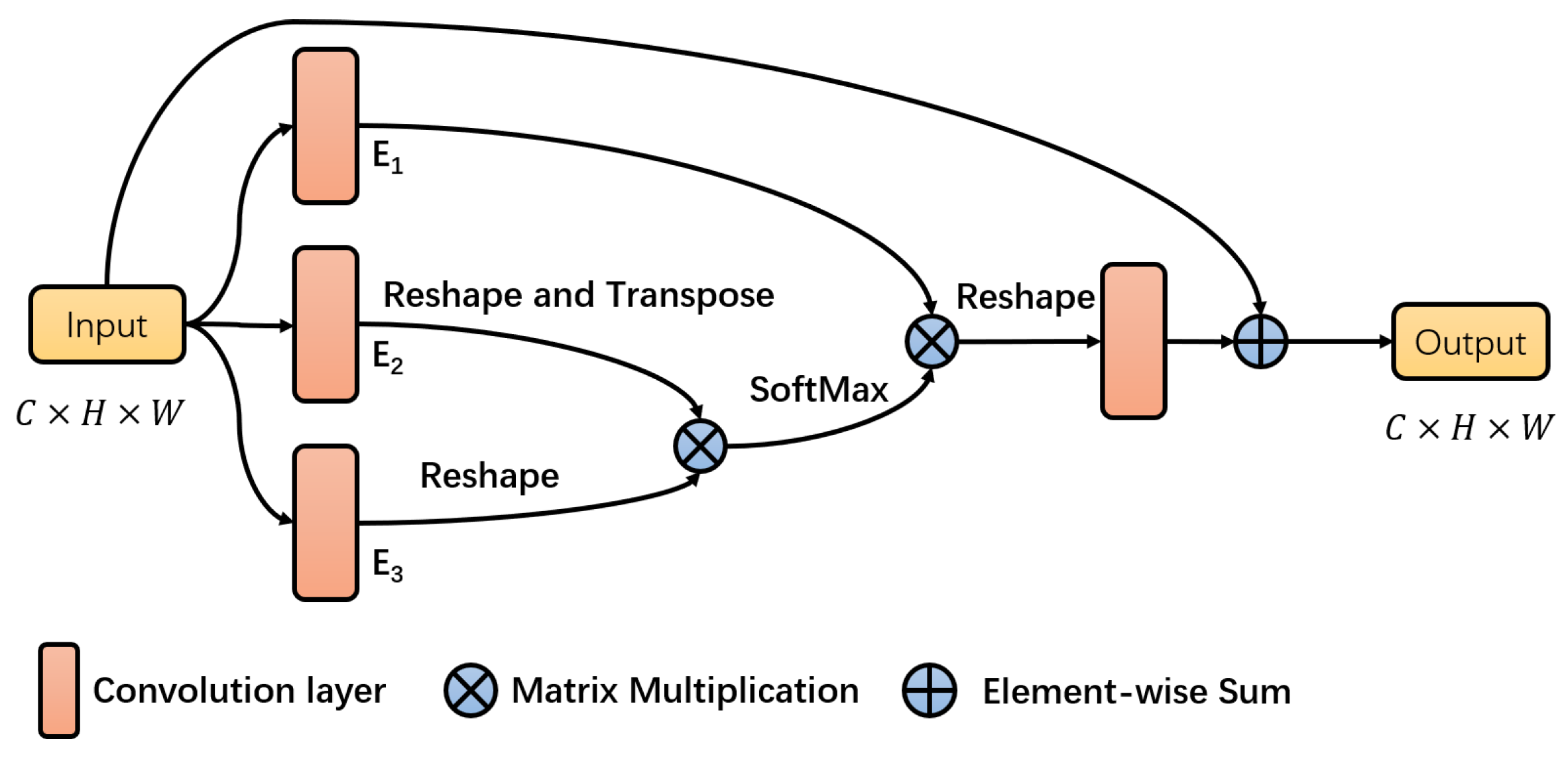
3.3. The Channel Attention Block
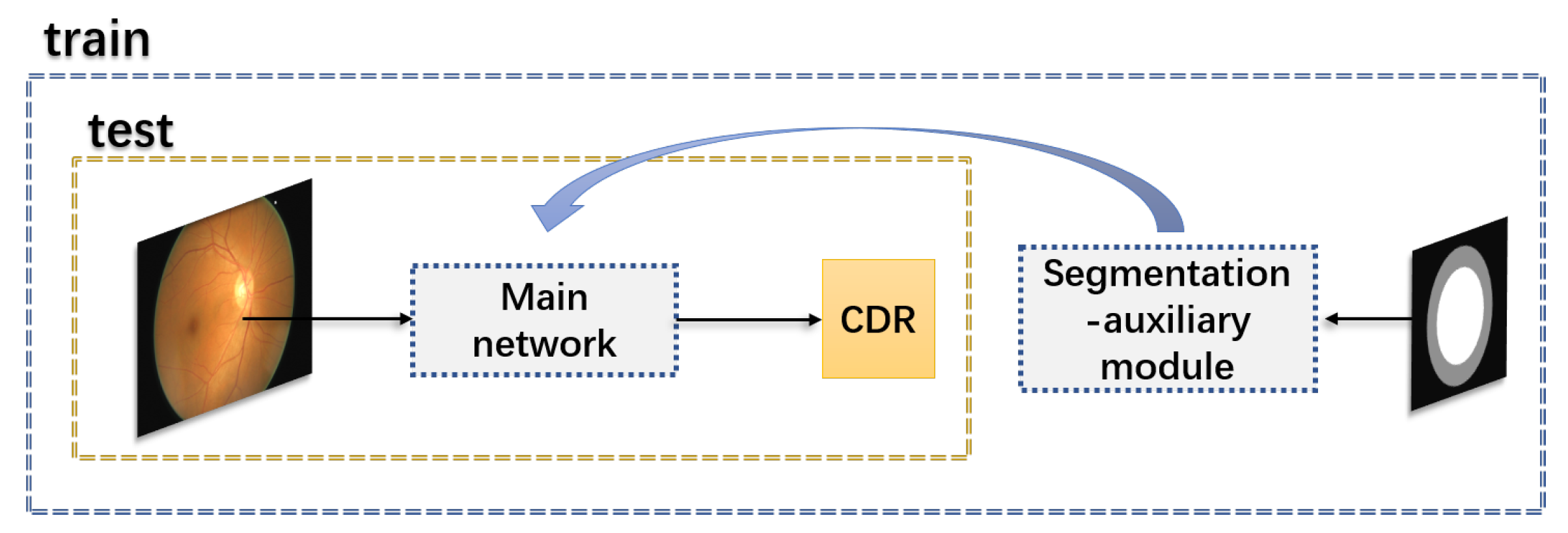
3.4. The Segmentation-Auxiliary Module
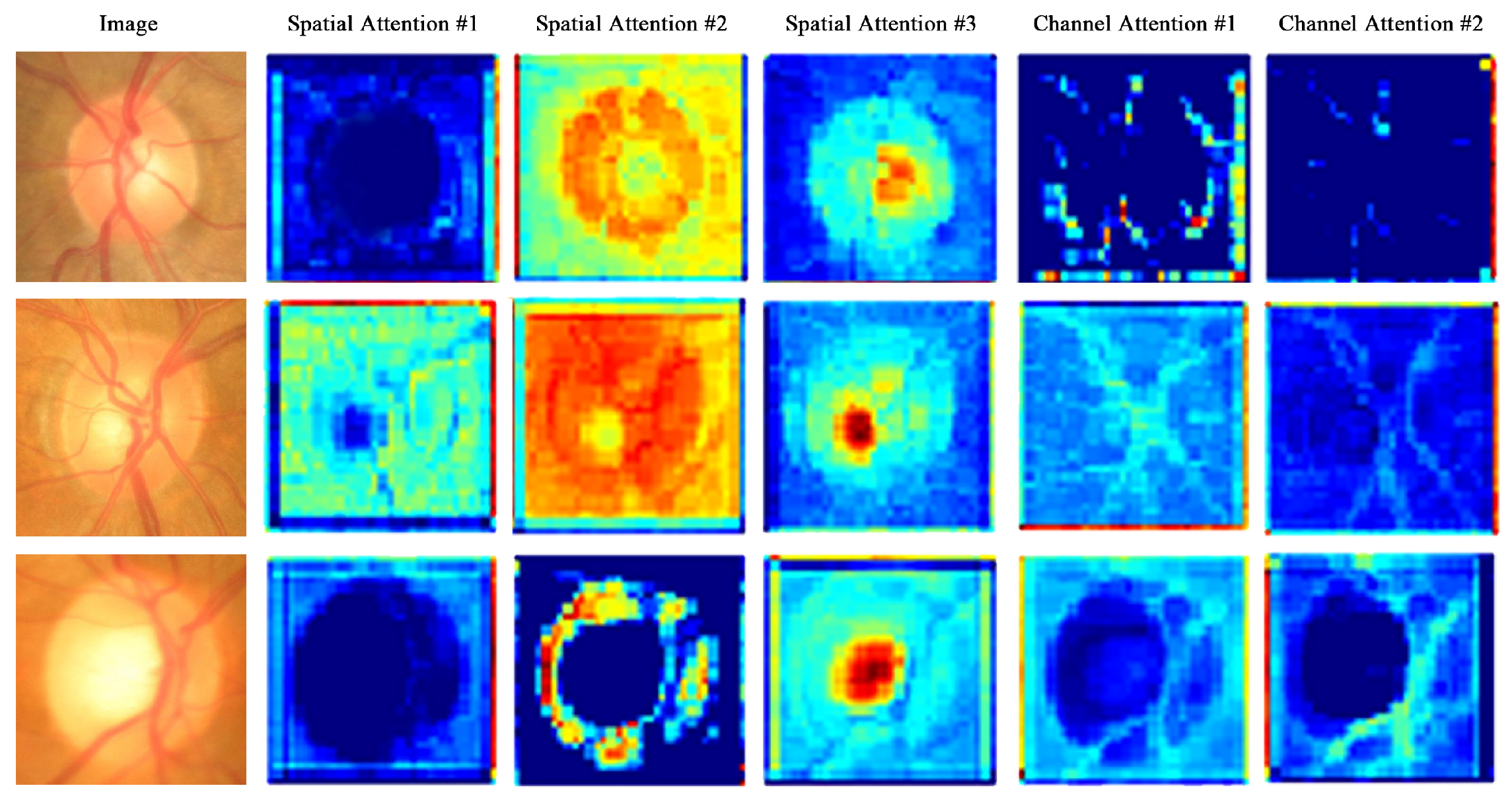
- Direct regression deep learning network is more like a black box, and we cannot understand which features are well mapped in the regression. Meanwhile, it is tough to select features that could represent the boundary of the optic cup and disc. The addition of the segmentation-auxiliary module makes the features about OD and OC have a specific prominent enhancement in the feature selection of the regression map. The experimental results prove that our conclusion is correct.
- The addition of the segmentation auxiliary module can improve the degree of network convergence.
3.5. Training Loss
4. Experiments and Analysis
4.1. Datasets and Configurations
4.2. Evaluation Criteria
4.2.1. Absolute CDR Error
4.2.2. Pearson’s Correlation Coefficient
4.2.3. Screening for Glaucoma
4.3. Performance Improvement with Two Attention Blocks
4.3.1. Ablation Study
4.3.2. Attention Map Visualization
4.4. Benefit of Joint Learning Framework
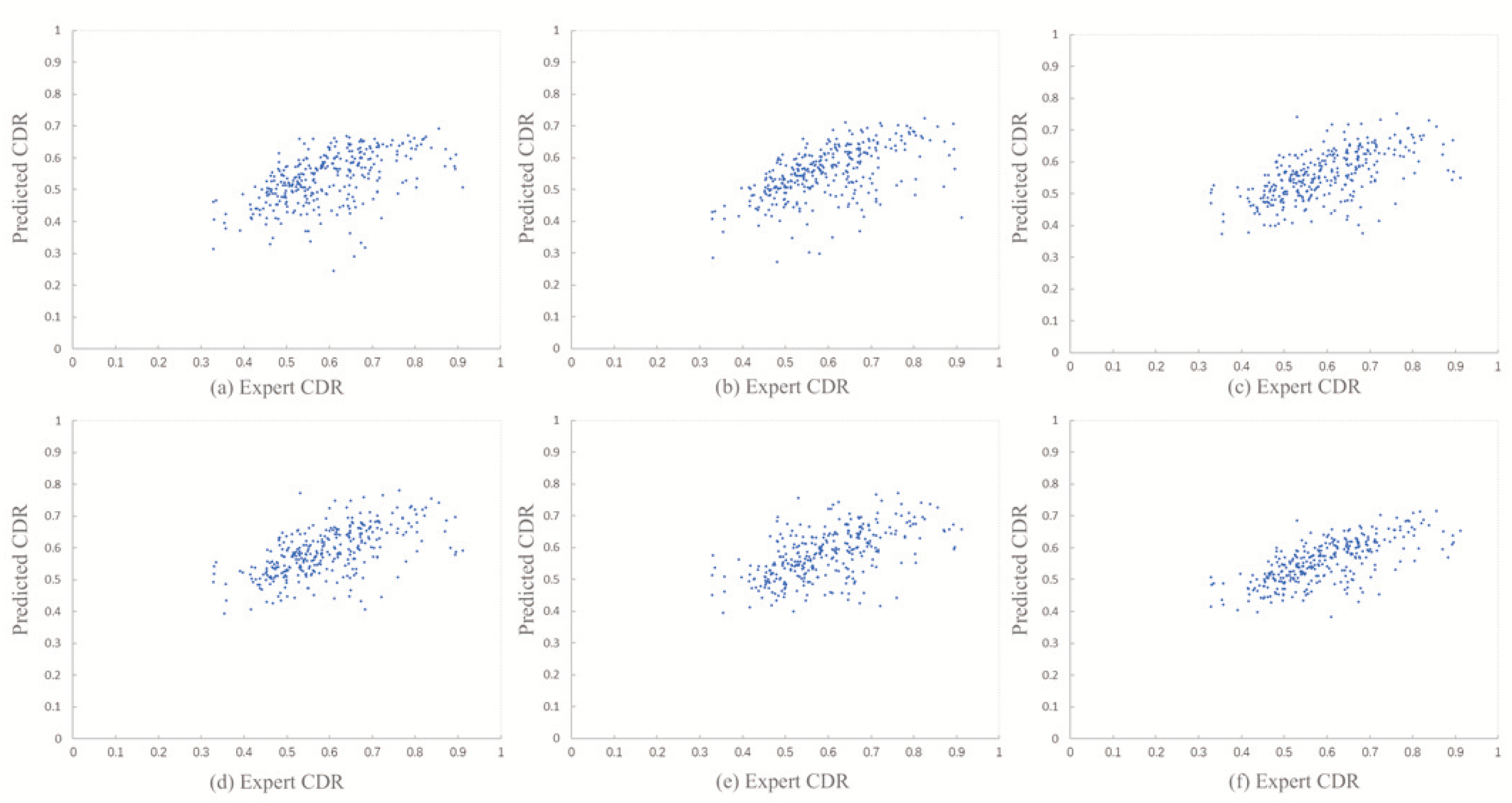
4.4.1. Absolute CDR Error
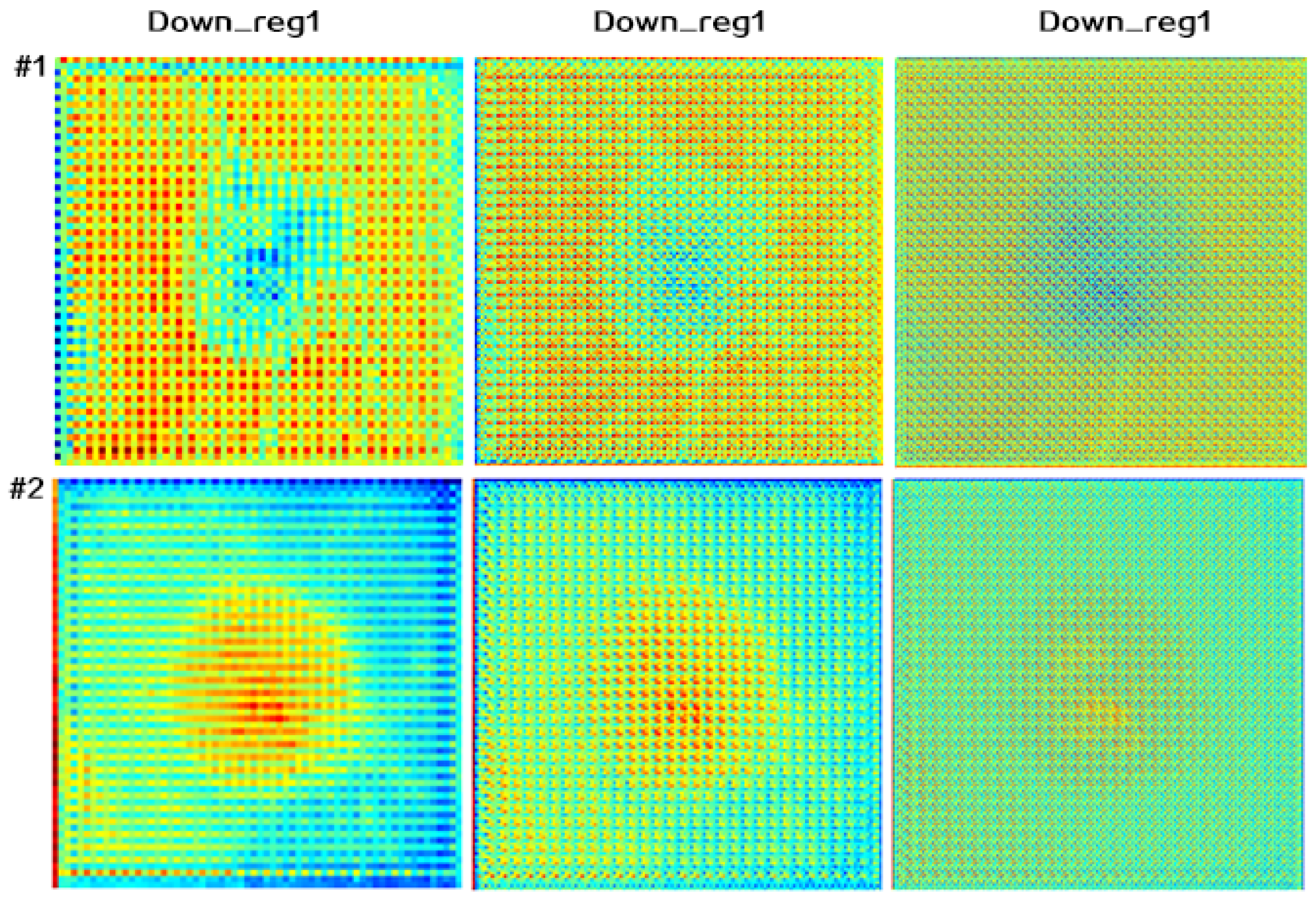
4.4.2. Attention Map Visualization
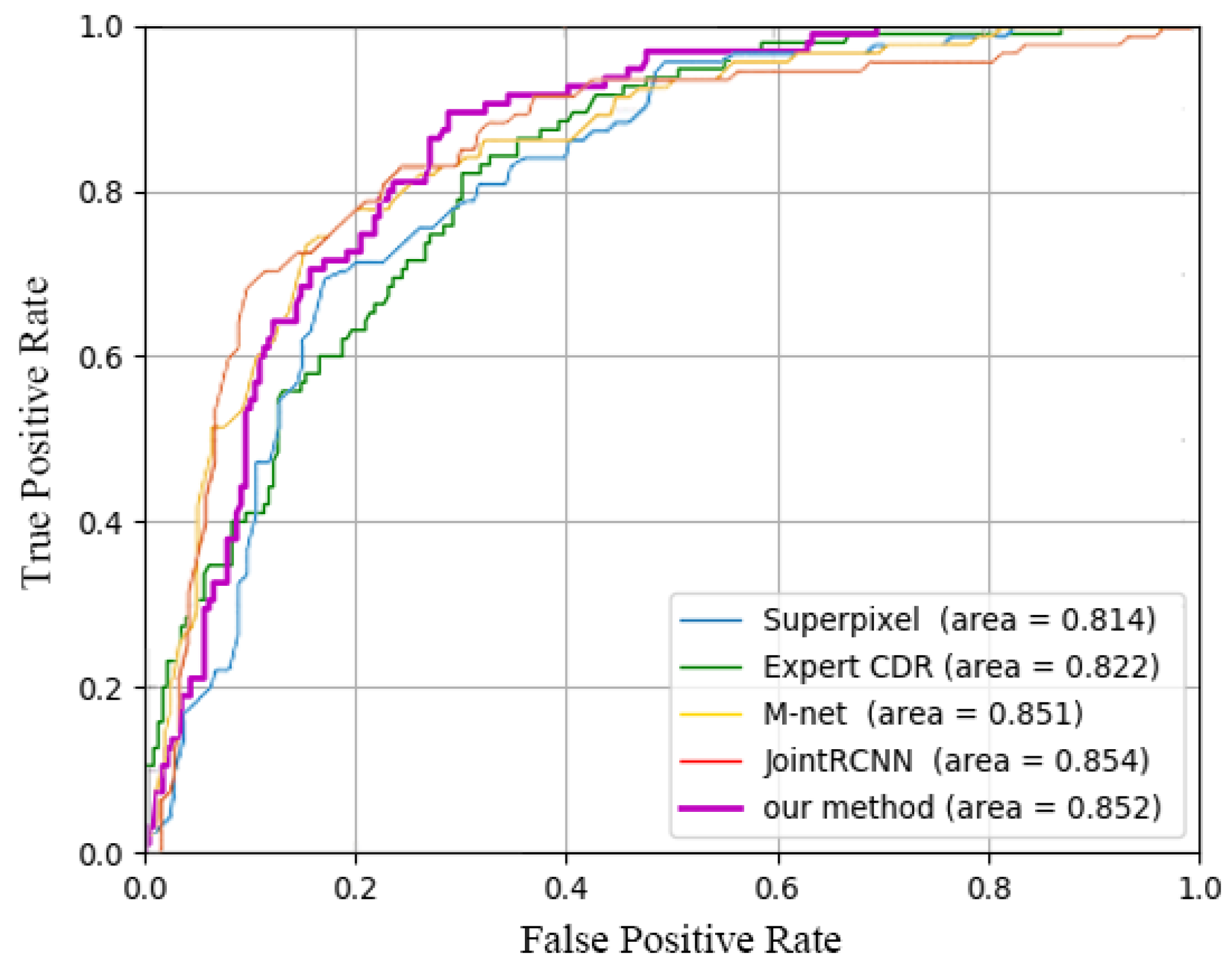
4.5. Comparison with Exist Methods
4.6. Discuss
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Almazroa, A.; Burman, R.; Raahemifar, K.; Lakshminarayanan, V. Optic disc and optic cup segmentation methodologies for glaucoma image detection: A survey. J. Ophthalmol. 2015, 2015, 180972. [Google Scholar] [CrossRef] [PubMed]
- Hagiwara, Y.; Koh, J.E.W.; Tan, J.H.; Bhandary, S.V.; Laude, A.; Ciaccio, E.J.; Tong, L.; Acharya, U.R. Computer-aided diagnosis of glaucoma using fundus images: A review. Comput. Methods Programs Biomed. 2018, 165, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Pathan, S.; Kumar, P.; Pai, R.M. Segmentation Techniques for Computer-Aided Diagnosis of Glaucoma: A Review. In Advances in Machine Learning and Data Science (NIPS); Springer: Singapore, 2018; pp. 163–173. [Google Scholar]
- Lian, J.; Hou, S.; Sui, X.; Xu, F.; Zheng, Y. Deblurring retinal optical coherence tomography via a convolutional neural network with anisotropic and double convolution layer. Comput. Vis. IET 2018, 12, 900–907. [Google Scholar] [CrossRef]
- Thakur, N.; Juneja, M. Survey on segmentation and classification approaches of optic cup and optic disc for diagnosis of glaucoma. Biomed. Signal Process. Control 2018, 42, 162–189. [Google Scholar] [CrossRef]
- Fumero, F.; Sigut, J.; Alayón, S.; González-Hernández, M.; González de la Rosa, M. Interactive Tool and Database for Optic Disc and Cup Segmentation of Stereo and Monocular Retinal Fundus Images; Vaclav Skala-UNION Agency: Plzen, Czech Republic, 2015. [Google Scholar]
- Guo, J.; Azzopardi, G.; Shi, C.; Jansonius, N.M.; Petkov, N. Automatic determination of vertical cup-to-disc ratio in retinal fundus images for glaucoma screening. IEEE Access 2019, 7, 8527–8541. [Google Scholar] [CrossRef]
- Wang, Q.; Zheng, Y.; Yang, G.; Jin, W.; Chen, X.; Yin, Y. Multi-Scale Rotation-Invariant Convolutional Neural Networks for Lung Texture Classification. IEEE J. Biomed. Health Inform. 2017, 21, 184–195. [Google Scholar]
- Liang, D.; Yang, F.; Wang, X.; Ju, X. Multi-Sample Inference Network. IET Comput. Vis. 2019, 36, 605–613. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Fu, H.; Cheng, J.; Xu, Y.; Wong, D.W.K.; Liu, J.; Cao, X. Joint optic disc and cup segmentation based on multi-label deep network and polar transformation. IEEE Trans. Med. Imaging 2018, 37, 1597–1605. [Google Scholar] [CrossRef]
- Mary, V.S.; Rajsingh, E.B.; Naik, G.R. Retinal fundus image analysis for diagnosis of glaucoma: A comprehensive survey. IEEE Access 2016, 4, 4327–4354. [Google Scholar] [CrossRef]
- Zheng, Y.; Zhang, S.; Huang, J.; Cai, W. Guest Editorial: Special issue on advances in computing techniques for big medical image data. Neurocomputing 2016, 100, S0925231216313704. [Google Scholar] [CrossRef]
- Sui, X.; Zheng, Y.; Wei, B.; Bi, H.; Wu, J.; Pan, X.; Yin, Y.; Zhang, S. Choroid segmentation from Optical Coherence Tomography with graph edge weights learned from deep convolutional neural networks. Neurocomputing 2017, 237, 332–341. [Google Scholar] [CrossRef]
- Hou, S.; Zhou, S.; Liu, W.; Zheng, Y. Classifying advertising video by topicalizing high-level semantic concepts. Multimed. Tools Appl. 2018, 77, 25475–25511. [Google Scholar] [CrossRef]
- Jiang, Y.; Zheng, Y.; Hou, S.; Chang, Y.; James, G. Multimodal Image Alignment via Linear Mapping between Feature Modalities. J. Healthc. Eng. 2017, 2017, 8625951. [Google Scholar] [CrossRef]
- Deng, X.; Zheng, Y.; Xu, Y.; Xi, X.; Li, N.; Yin, Y. Graph cut based automatic aorta segmentation with an adaptive smoothness constraint in 3D abdominal CT images. Neurocomputing 2018, 310, 46–58. [Google Scholar] [CrossRef]
- Khalil, T.; Akram, M.U.; Raja, H.; Jameel, A.; Basit, I. Detection of glaucoma using cup to disc ratio from spectral domain optical coherence tomography images. IEEE Access 2018, 6, 4560–4576. [Google Scholar] [CrossRef]
- Lee, K.; Niemeijer, M.; Garvin, M.K.; Kwon, Y.H.; Sonka, M.; Abramoff, M.D. Segmentation of the optic disc in 3-D OCT scans of the optic nerve head. IEEE Trans. Med. Imaging 2009, 29, 159–168. [Google Scholar]
- Wu, M.; Leng, T.; de Sisternes, L.; Rubin, D.L.; Chen, Q. Automated segmentation of optic disc in SD-OCT images and cup-to-disc ratios quantification by patch searching-based neural canal opening detection. Opt. Express. 2015, 23, 31216–31229. [Google Scholar] [CrossRef] [PubMed]
- Fu, H.; Xu, D.; Lin, S.; Wong, D.W.K.; Liu, J. Automatic optic disc detection in oct slices via low-rank reconstruction. IEEE Trans. Biomed. Eng. 2014, 62, 1151–1158. [Google Scholar] [CrossRef]
- Fu, H.; Xu, Y.; Lin, S.; Zhang, X.; Wong, D.W.K.; Liu, J.; Frangi, A.F.; Baskaran, M.; Aung, T. Segmentation and quantification for angle-closure glaucoma assessment in anterior segment OCT. IEEE Trans. Med. Imaging 2017, 36, 1930–1938. [Google Scholar] [CrossRef]
- Lowell, J.; Hunter, A.; Steel, D.; Basu, A.; Ryder, R.; Fletcher, E.; Kennedy, L. Optic nerve head segmentation. IEEE Trans. Med. Imaging 2004, 23, 256–264. [Google Scholar] [CrossRef]
- Joshi, G.D.; Sivaswamy, J.; Krishnadas, S. Optic disk and cup segmentation from monocular color retinal images for glaucoma assessment. IEEE Trans. Med. Imaging 2011, 30, 1192–1205. [Google Scholar] [CrossRef] [PubMed]
- Abramoff, M.D.; Alward, W.L.; Greenlee, E.C.; Shuba, L.; Kim, C.Y.; Fingert, J.H.; Kwon, Y.H. Automated segmentation of the optic disc from stereo color photographs using physiologically plausible features. Investig. Ophthalmol. Vis. Sci. 2007, 48, 1665–1673. [Google Scholar] [CrossRef] [PubMed]
- Zahoor, M.N.; Fraz, M.M. Fast optic disc segmentation in retina using polar transform. IEEE Access 2017, 5, 12293–12300. [Google Scholar]
- Zheng, Y.; Stambolian, D.; O’Brien, J.; Gee, J.C. Optic disc and cup segmentation from color fundus photograph using graph cut with priors. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Nagoya, Japan, 22–26 September 2013; pp. 75–82. [Google Scholar]
- Cheng, J.; Liu, J.; Xu, Y.; Yin, F.; Wong, D.W.K.; Tan, N.M.; Tao, D.; Cheng, C.Y.; Aung, T.; Wong, T.Y. Superpixel classification based optic disc and optic cup segmentation for glaucoma screening. IEEE Trans. Med. Imaging 2013, 32, 1019–1032. [Google Scholar] [CrossRef] [PubMed]
- Sevastopolsky, A. Optic disc and cup segmentation methods for glaucoma detection with modification of U-Net convolutional neural network. Pattern Recognit. Image Anal. 2017, 27, 618–624. [Google Scholar] [CrossRef]
- Qin, Y.; Hawbani, A. A Novel Segmentation Method for Optic Disc and Optic Cup Based on Deformable U-net. In Proceedings of the International Conference on Artificial Intelligence and Big Data, ICAIBD, Chengdu, China, 25–28 May 2019; pp. 394–399. [Google Scholar]
- Shankaranarayana, S.M.; Ram, K.; Mitra, K.; Sivaprakasam, M. Joint optic disc and cup segmentation using fully convolutional and adversarial networks. In Fetal, Infant and Ophthalmic Medical Image Analysis; Springer: Cham, Switzerland, 2017; pp. 168–176. [Google Scholar]
- Wang, S.; Yu, L.; Yang, X.; Fu, C.W.; Heng, P.A. Patch-based output space adversarial learning for joint optic disc and cup segmentation. IEEE Trans. Med. Imaging 2019, 38, 2485–2495. [Google Scholar] [CrossRef]
- Jiang, Y.; Tan, N.; Peng, T. Optic Disc and Cup Segmentation Based on Deep Convolutional Generative Adversarial Networks. IEEE Access 2019, 7, 64483–64493. [Google Scholar]
- Jiang, Y.; Duan, L.; Cheng, J.; Gu, Z.; Xia, H.; Fu, H.; Li, C.; Liu, J. JointRCNN: A Region-based Convolutional Neural Network for Optic Disc and Cup Segmentation. IEEE Trans. Biomed. Eng. 2019, 67, 335–343. [Google Scholar]
- Zhao, R.; Chen, X.; Xiyao, L.; Zailiang, C.; Guo, F.; Li, S. Direct cup-to-disc ratio estimation for glaucoma screening via semi-supervised learning. IEEE J. Biomed. Health Inform. 2019, 24, 1104–1113. [Google Scholar] [CrossRef]
- Mnih, V.; Heess, N.; Graves, A. Recurrent models of visual attention. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2204–2212. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Lu, X.; Chen, Y.; Li, X. Hierarchical recurrent neural hashing for image retrieval with hierarchical convolutional features. IEEE Trans. Image Process. 2017, 27, 106–120. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Du, Y.; Yuan, C.; Li, B.; Zhao, L.; Li, Y.; Hu, W. Interaction-aware spatio-temporal pyramid attention networks for action classification. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 4–8 September 2018; pp. 373–389. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; So Kweon, I. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 4–8 September 2018; pp. 3–19. [Google Scholar]
- Li, L.; Xu, M.; Wang, X.; Jiang, L.; Liu, H. Attention based glaucoma detection: A large-scale database and CNN Model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 10571–10580. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3146–3154. [Google Scholar]
- Kendall, A.; Gal, Y.; Cipolla, R. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7482–7491. [Google Scholar]
- Yin, F.; Liu, J.; Ong, S.H.; Sun, Y.; Wong, D.W.; Tan, N.M.; Cheung, C.; Baskaran, M.; Aung, T.; Wong, T.Y. Model-based optic nerve head segmentation on retinal fundus images. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology, Boston, MA, USA, 30 August–3 September 2011; pp. 2626–2629. [Google Scholar]
- Zhang, Z.; Yin, F.S.; Liu, J.; Wong, W.K.; Tan, N.M.; Lee, B.H.; Cheng, J.; Wong, T.Y. Origa-light: An online retinal fundus image database for glaucoma analysis and research. In Proceedings of the nnual International Conference of the IEEE Engineering in Medicine and Biology, Buenos Aires, Argentina, 31 August–4 September 2010; pp. 3065–3068. [Google Scholar]
- Harizman, N.; Oliveira, C.; Chiang, A.; Tello, C.; Marmor, M.; Ritch, R.; Liebmann, J.M. The ISNT rule and differentiation of normal from glaucomatous eyes. Arch. Ophthalmol. 2006, 124, 1579–1583. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | CAB | SAB | SAM | r | MAE | AUC |
|---|---|---|---|---|---|---|
| Baseline model | × | × | × | 0.554 | 0.0823 | 0.806 |
| × | ✓ | × | 0.580 | 0.0739 | 0.795 | |
| ✓ | × | × | 0.610 | 0.0728 | 0.830 | |
| ✓ | ✓ | × | 0.616 | 0.0698 | 0.831 | |
| × | × | ✓ | 0.586 | 0.0722 | 0.824 | |
| ✓ | ✓ | ✓ | 0.694 | 0.0671 | 0.852 |
| Method | MAE | AUC | Coefficient |
|---|---|---|---|
| R-Bend [25] | 0.154 | - | 0.38 |
| ASM [48] | 0.107 | - | - |
| Superpixel [29] | 0.077 | 0.814 | 0.59 |
| Expert CDR estimation | 0 | 0.823 | - |
| Joint U-net + PT | 0.075 | 0.8322 | 0.617 |
| M-net [12] | 0.071 | 0.8508 | 0.671 |
| JointRCNN [35] | 0.068 | 0.8536 | - |
| Baseline+CAB+SAB | 0.070 | 0.8310 | 0.616 |
| Our method | 0.067 | 0.8524 | 0.694 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, S.; Ge, C.; Sui, X.; Zheng, Y.; Jia, W. Channel and Spatial Attention Regression Network for Cup-to-Disc Ratio Estimation. Electronics 2020, 9, 909. https://doi.org/10.3390/electronics9060909
Li S, Ge C, Sui X, Zheng Y, Jia W. Channel and Spatial Attention Regression Network for Cup-to-Disc Ratio Estimation. Electronics. 2020; 9(6):909. https://doi.org/10.3390/electronics9060909
Chicago/Turabian StyleLi, Shuo, Chiru Ge, Xiaodan Sui, Yuanjie Zheng, and Weikuan Jia. 2020. "Channel and Spatial Attention Regression Network for Cup-to-Disc Ratio Estimation" Electronics 9, no. 6: 909. https://doi.org/10.3390/electronics9060909
APA StyleLi, S., Ge, C., Sui, X., Zheng, Y., & Jia, W. (2020). Channel and Spatial Attention Regression Network for Cup-to-Disc Ratio Estimation. Electronics, 9(6), 909. https://doi.org/10.3390/electronics9060909