Cross-Modal Learning Based on Semantic Correlation and Multi-Task Learning for Text-Video Retrieval

Abstract
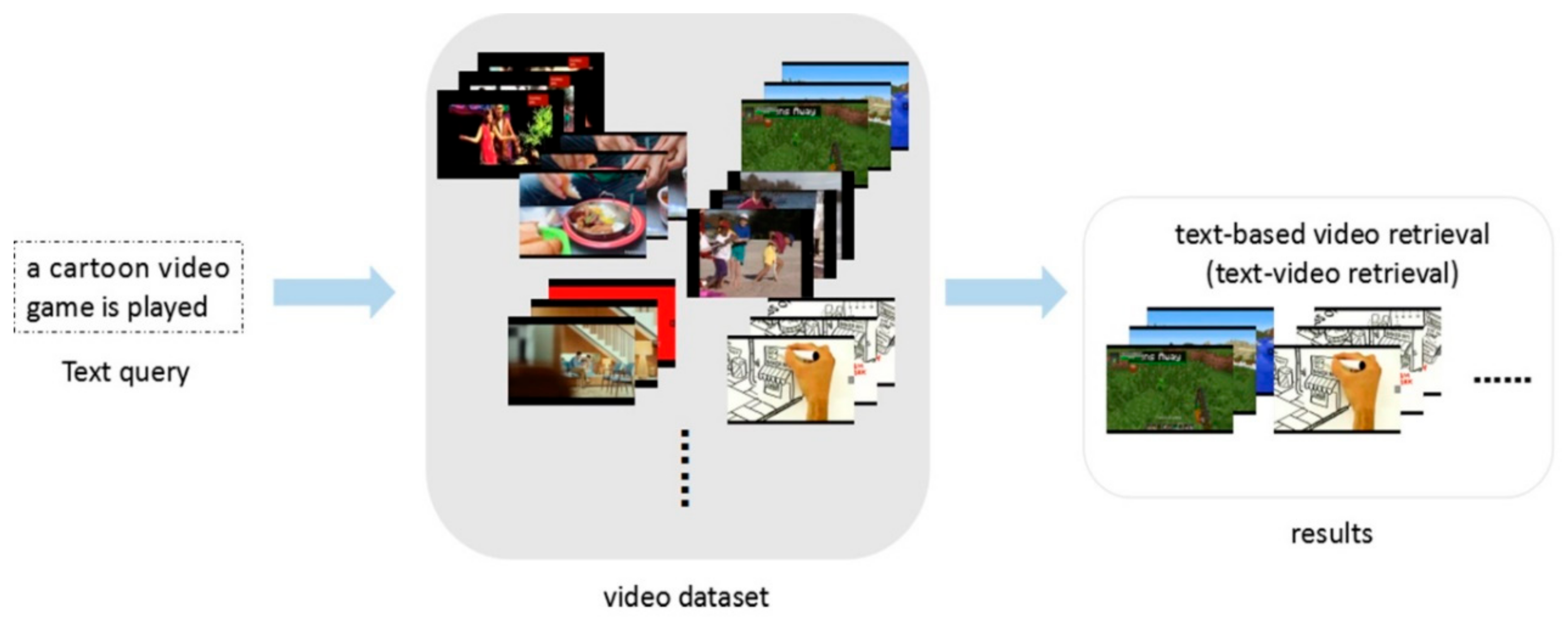
1. Introduction
- We propose a novel multi-task learning model that combines the original text-video retrieval task and a classification task. By exploiting the classification auxiliary task with semantic alignment consistency and constructing the constraint between text and video modalities, we achieve the semantic association between different modality and improve the retrieval performance through the jointly learning;
- A new loss function that restricts relative distance and absolute distance simultaneously is presented. The new triplet loss based on the hardest negative sample [16] and the absolute distance between different modality of any sample, that is, while correctly distinguishing the positive sample pair from the negative sample pair with the minimum cross-modal distance, we adjust the distance to fully consider the between-class distance of different modes in the common subspace. The experimental results demonstrate our methods achieve competitive performances on two widely adopted datasets;
- In addition, dual multi-level feature representations for text and video are improved in contrast to the reference [10]. Based on our task, the slightly modified SlowFast [17] model is utilized to extract accurate video features in the spatial domain, and the BERT [18] model is used to embed the high-level text semantic embedding in sentences rather in words.
2. Related Work
3. Cross-Modal Learning Based on Semantic Correlation and Multi-Task Learning
3.1. Multi-Level Video Semantic Feature Encoding
3.1.1. Global Encoding
3.1.2. Temporal-Aware Encoding
3.1.3. Temporal-Domain Multi-Scale Encoding
3.2. Multi-Level Text Semantic Feature Encoding
3.3. Cross Modal Multi-Task Learning
3.3.1. Text-Video Similarity Task Loss
3.3.2. Text-Video Semantic Consistency Classification Task Loss
4. Experiments
4.1. Dataset
4.2. Measurements
4.3. Implementation Details
4.4. Experiment Results
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chang, X.; Yang, Y.; Hauptmann, A.; Xing, E.P.; Yu, Y.L. Semantic concept discovery for large-scale zero-shot event detection. In Proceedings of the Twenty-fourth International Joint Conference on Artificial Intelligence (IJCAI’15), Buenos Aires, Argentina, 25–31 July 2015; pp. 2234–2240. [Google Scholar]
- Dalton, J.; Allan, J.; Mirajkar, P. Zero-shot video retrieval using content and concepts. In Proceedings of the 22nd ACM International Conference on Information & Knowledge Management (CIKM’13), San Francisco, CA, USA, 27 October–1 November 2013; pp. 1857–1860. [Google Scholar]
- Habibian, A.; Mensink, T.; Snoek, C.G.M. Composite concept discovery for zero-shot video event detection. In Proceedings of the 4th ACM International Conference on Multimedia Retrieval (ICMR’14), Glasgow, UK, 1–4 April 2014; pp. 17–24. [Google Scholar]
- Markatopoulou, F.; Moumtzidou, A.; Galanopoulos, D.; Mironidis, T.; Kaltsa, V.; Ioannidou, A.; Symeonidis, S.; Avgerinakis, K.; Andreadis, S.; Gialampoukidis, I.; et al. ITICERTH Participation in TRECVID 2016. Available online: https://www-nlpir.nist.gov/projects/tvpubs/tv16.slides/tv16.avs.iti-certh.slides.pdf (accessed on 18 October 2020).
- Jiang, L.; Meng, D.; Mitamura, T.; Hauptmann, A.G. Easy Samples First: Self-paced Reranking for Zero-Example Multimedia Search. In Proceedings of the 22nd ACM International Conference on Multimedia (MM’14), Orlando, FL, USA, 4 November 2014; pp. 547–556. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV’17), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Lu, Y.J.; Zhang, H.; de Boer, M.H.T.; Ngo, C.W. Event detection with zero example: Select the right and suppress the wrong concepts. In Proceedings of the 6th ACM International Conference on Multimedia Retrieval (ICMR’16), New York, NY, USA, 6–9 June 2016. [Google Scholar]
- Tao, Y.; Wang, T.; Machado, D.; Garcia, R.; Tu, Y.; Reyes, M.P.; Chen, Y.; Tian, H.; Shyu, M.L.; Chen, S.C. Florida International University—University of Miami Participation in TRECVID 2019. Available online: https://www-nlpir.nist.gov/projects/tvpubs/tv19.papers/fiu_um.pdf (accessed on 7 March 2020).
- Dong, J.; Li, X.; Xu, C.; Ji, S.; He, Y.; Yang, G.; Wang, X. Dual encoding for zero-example video retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9346–9355. [Google Scholar]
- Liu, Y.; Albanie, S.; Nagrani, A.; Zisserman, A. Use what you have: Video retrieval using representations from collaborative experts. In Proceedings of the 30th British Machine Vision Conference (BMVC’19), Cardiff, Wales, UK, 9–12 September 2019. [Google Scholar]
- Mithun, N.C.; Li, J.; Metze, F.; Roy-Chowdhury, A.K. Learning joint embedding with multimodal cues for cross-modal video-text retrieval. In Proceedings of the 2018 ACM on International Conference on Multimedia Retrieval (ICMR’18), Yokohama, Japan, 11–14 June 2018; pp. 19–27. [Google Scholar]
- Xu, R.; Xiong, C.; Chen, W.; Corso, J.J. Jointly modeling deep video and compositional text to bridge vision and language in a unified framework. In Proceedings of the 29th AAAI Conference on Artificial Intelligence (AAAI’15), Austin, TX, USA, 25–29 January 2015. [Google Scholar]
- Dong, J.; Li, X.; Snoek, C.G.M. Predicting Visual Features from Text for Image and Video Caption Retrieval. IEEE Trans. Multimed. 2018, 20, 3377–3388. [Google Scholar] [CrossRef]
- Yu, Y.; Ko, H.; Choi, J.; Kim, G. End-to-End Concept Word Detection for Video Captioning, Retrieval, and Question Answering. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3261–3269. [Google Scholar]
- Faghri, F.; Fleet, D.J.; Kiros, J.R.; Fidler, S. VSE++: Improved Visual-Semantic Embeddings. In Proceedings of the 29th British Machine Vision Conference (BMVC’18), Newcastle upon Tyne, UK, 3–6 September 2018. [Google Scholar]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. SlowFast Networks for Video Recognition. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6201–6210. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- TRECVid AVS Task. Available online: https://www-nlpir.nist.gov/projects/tv2016/tv2016.html (accessed on 6 March 2020).
- Le, D.D.; Phan, S.; Nguyen, V.T.; Renoust, B.; Nguyen, T.A.; Hoang, V.N.; Ngo, T.D.; Tran, M.T.; Watanabe, Y.; Klinkigt, M.; et al. NII-HITACHI-UIT at TRECVID 2016. Available online: https://www-nlpir.nist.gov/projects/tvpubs/tv16.papers/nii-hitachi-uit.pdf (accessed on 13 November 2020).
- Nguyen, P.A.; Li, Q.; Cheng, Z.Q.; Lu, Y.J.; Zhang, H.; Wu, X.; Ngo, C.W. VIREO @ TRECVID 2017: Video-to-Text, Ad-hoc Video Search and Video Hyperlinking. Available online: https://www-nlpir.nist.gov/projects/tvpubs/tv17.papers/vireo.pdf (accessed on 5 December 2020).
- Ueki, K.; Hirakawa, K.; Kikuchi, K.; Ogawa, T.; Kobayashi, T. Waseda_Meisei at TRECVID 2017: Ad-hoc video search. Available online: https://www-nlpir.nist.gov/projects/tvpubs/tv17.papers/waseda_meisei.pdf (accessed on 13 November 2020).
- Nguyen, P.A.; Wu, J.; Ngo, C.W.; Danny, F.; Huet, B. VIREO-EURECOM @ TRECVID 2019: Ad-hoc Video Search (AVS). Available online: https://www-nlpir.nist.gov/projects/tvpubs/tv19.papers/eurecom.pdf (accessed on 7 March 2020).
- Habibian, A.; Mensink, T.; Snoek, G.C.M. Video2vec Embeddings Recognize Events When Examples Are Scarce. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2089–2103. [Google Scholar] [CrossRef] [PubMed]
- Yu, Y.; Kim, J.; Kim, G. A joint sequence fusion model for video question answering and retrieval. In Proceedings of the 15th European Conference on Computer Vision (ECCV’18), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Li, X.; Dong, J.; Xu, C.; Wang, X.; Yang, G. Renmin University of China and Zhejiang Gongshang University at TRECVID 2018: Deep Cross-Modal Embeddings for Video-Text Retrieval. Available online: https://www-nlpir.nist.gov/projects/tvpubs/tv18.papers/rucmm.pdf (accessed on 13 November 2020).
- Hernandez, R.; Perez-Martin, J.; Bravo, N.; Barrios, J.M.; Bustos, B. IMFD_IMPRESEE at TRECVID 2019: Ad-Hoc Video Search and Video to Text. Available online: https://www-nlpir.nist.gov/projects/tvpubs/tv19.papers/imfd_impresee.pdf (accessed on 7 March 2020).
- Wu, X.; Chen, D.; He, Y.; Xue, H.; Song, M.; Mao, F. Hybrid Sequence Encoder for Text Based Video Retrieval. Available online: https://www-nlpir.nist.gov/projects/tvpubs/tv19.papers/atl.pdf (accessed on 7 March 2020).
- Gong, Y.; Wang, L.; Guo, R.; Lazebnik, S. Multi-scale Orderless Pooling of Deep Convolutional Activation Features. In Proceedings of the 13th European Conference on Computer Vision (ECCV’14), Zurich, Switzerland, 6–12 September 2014; pp. 392–407. [Google Scholar]
- Schuster, M.; Paliwal, K.K. Bidirectional Recurrent Neural Networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Cho, K.; Van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. In Proceedings of the 19th Conference on Empirical Methods in Natural Language (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 19th Conference on Empirical Methods in Natural Language (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. In Proceedings of the 2013 International Conference on Learning Representations (ICLR), Scottsdale, AZ, USA, 2–4 May 2013. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global Vectors for Word Representation. In Proceedings of the Conference on Empirical Methods in Natural Language Proceeding (EMNLP’14), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Chen, D.L.; Dolan, W.B.; Yao, T. Collecting highly parallel data for paraphrase evaluation. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics (ACL’11), Portland, OR, USA, 19 June 2011; pp. 190–200. [Google Scholar]
- Xu, J.; Mei, T.; Yao, T.; Rui, Y. MSR-VTT: A large video description dataset for bridging video and language. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 5288–5296. [Google Scholar]
- Kiros, R.; Salakhutdinov, R.; Zemel, R.S. Unifying Visual-Semantic Embeddings with Multimodal Neural Language Models. arXiv 2014, arXiv:1411.2539. [Google Scholar]
- BERT Word Embeddings Tutorial. Available online: https://mccormickml.com/2019/05/14/BERT-word-embeddings-tutorial/ (accessed on 4 December 2020).
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Chen, S.; Zhao, Y.; Jin, Q.; Wu, Q. Fine-Grained Video-Text Retrieval with Hierarchical Graph Reasoning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 10635–10644. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Baseline | Our Works | Results | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Dual Encoding | Semantic Similarity | Multi-Task 4 | R@1(%) | R@5(%) | R@10(%) | Med r | mAP | |||
| loss3 | ||||||||||
| 1 | √ | 12.7 | 34.5 | 46.4 | 13.0 | 0.234 | ||||
| 2 | √ | √ | 13.7 | 34.8 | 47.0 | 12.0 | 0.242 | |||
| 3 | √ | √ | √ | 14.7 | 39.3 | 52.4 | 9.0 | 0.268 | ||
| 4 | √ | √ | √ | √ | 15.3 | 39.5 | 52.7 | 9.0 | 0.272 | |
| 5 | √ | √ | √ | √ | √ | 15.6 | 39.9 | 53.3 | 9.0 | 0.276 |
| Methods | R@1(%) | R@5(%) | R@10(%) | Med r | mAP |
|---|---|---|---|---|---|
| W2VV [14] | / | / | / | / | 0.100 |
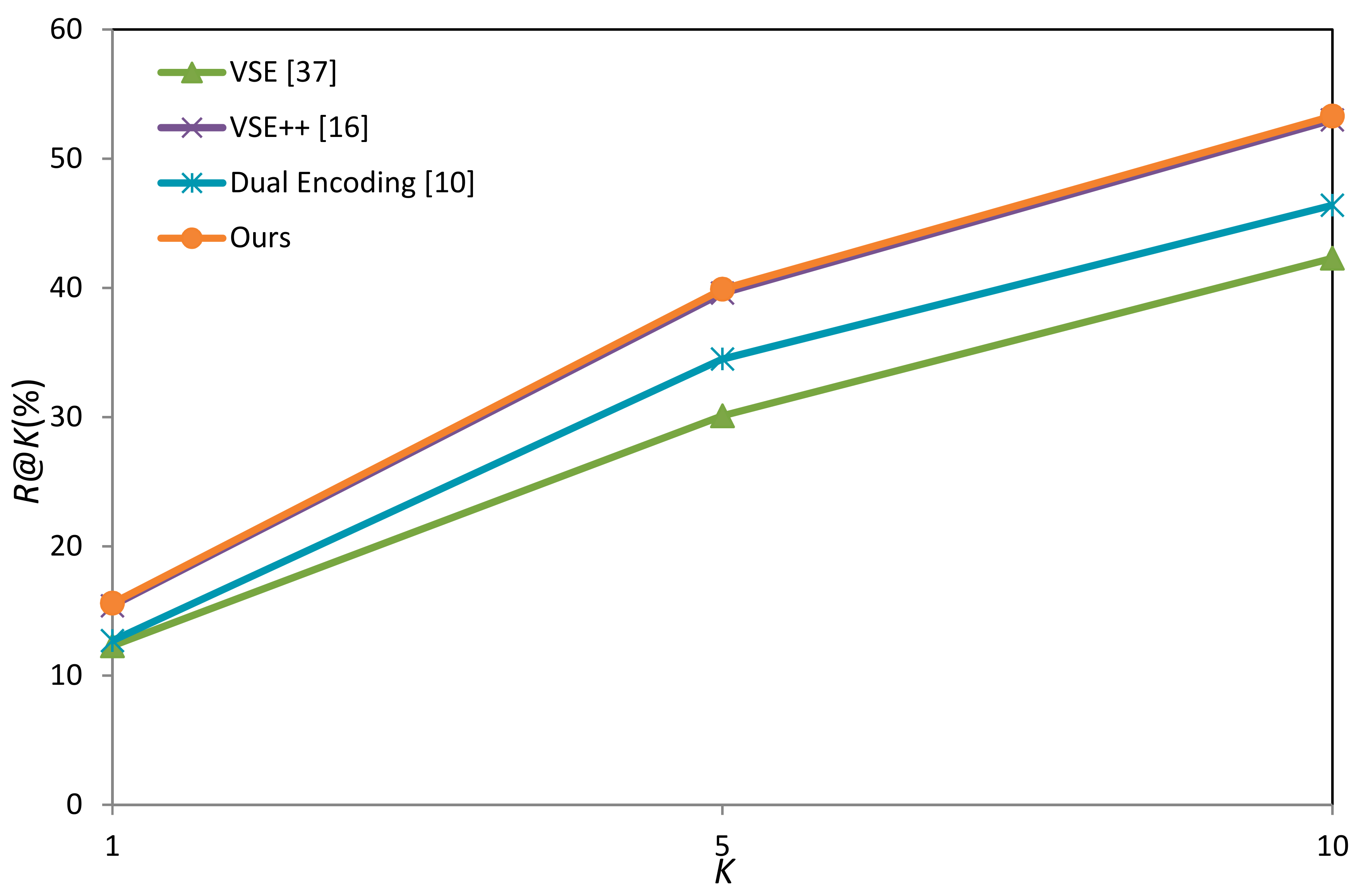
| VSE [37] | 12.3 | 30.1 | 42.3 | 14.0 | / |
| VSE++ [16] | 15.4 | 39.6 | 53.0 | 9.0 | 0.218 |
| Dual Encoding [10] | 12.7 | 34.5 | 46.4 | 13.0 | 0.234 |
| Ours 1 | 15.6 | 39.9 | 53.3 | 9.0 | 0.276 |
| Index | Baseline | Our Works | Results | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Dual Encoding | Semantic Similarity | Multi-Task 4 | R@1(%) | R@5(%) | R@10(%) | Med r | mAP | |||
| loss3 | ||||||||||
| 1 | √ | 8.0 | 22.9 | 32.6 | 32.0 | 0.159 | ||||
| 2 | √ | √ | 8.6 | 24.3 | 34.2 | 27.0 | 0.169 | |||
| 3 | √ | √ | √ | 8.7 | 24.8 | 34.9 | 26.0 | 0.172 | ||
| 4 | √ | √ | √ | √ | 8.9 | 24.9 | 34.9 | 27.0 | 0.173 | |
| 5 | √ | √ | √ | √ | √ | 9.0 | 25.1 | 35.1 | 26.0 | 0.174 |
| Methods | R@1(%) | R@5(%) | R@10(%) | Med r | mAP |
|---|---|---|---|---|---|
| W2VV [14] | 1.8 | 7.0 | 10.9 | 193.0 | 0.052 |
| VSE [37] | 5.0 | 16.4 | 24.6 | 47 | / |
| VSE++ [16] | 5.7 | 17.1 | 24.8 | 65 | / |
| W2VVimrl [10] | 6.1 | 18.7 | 27.5 | 45.0 | 0.131 |
| Mithun et al. [12] | 6.8 | 20.7 | 29.5 | 39.0 | / |
| Dual Encoding [10] | 7.7 | 22.0 | 31.8 | 32.0 | 0.155 |
| HYBRID [28] | 7.8 | 22.5 | 32.0 | 31.0 | 0.158 |
| Ours 1 | 9.0 | 25.1 | 35.3 | 26.0 | 0.175 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, X.; Wang, T.; Wang, S. Cross-Modal Learning Based on Semantic Correlation and Multi-Task Learning for Text-Video Retrieval. Electronics 2020, 9, 2125. https://doi.org/10.3390/electronics9122125
Wu X, Wang T, Wang S. Cross-Modal Learning Based on Semantic Correlation and Multi-Task Learning for Text-Video Retrieval. Electronics. 2020; 9(12):2125. https://doi.org/10.3390/electronics9122125
Chicago/Turabian StyleWu, Xiaoyu, Tiantian Wang, and Shengjin Wang. 2020. "Cross-Modal Learning Based on Semantic Correlation and Multi-Task Learning for Text-Video Retrieval" Electronics 9, no. 12: 2125. https://doi.org/10.3390/electronics9122125
APA StyleWu, X., Wang, T., & Wang, S. (2020). Cross-Modal Learning Based on Semantic Correlation and Multi-Task Learning for Text-Video Retrieval. Electronics, 9(12), 2125. https://doi.org/10.3390/electronics9122125