A Multimodal User Interface for an Assistive Robotic Shopping Cart

 ,
,  ,
,  and
and 
Abstract
1. Introduction
2. Related Work
2.1. Carts that Follow the Customers
2.2. Mobile Phone-Based Customer-Robot Interaction
2.3. Robotic Cart for Elderly and People with Special Needs
2.4. People with Visual Impairments
2.5. The Next Group Includes Robotic Platforms, the Key Feature of Which Is Remote Control and Remote Shopping
2.6. Issues Can Arise When Multiple Robots Are Functioning in the Shopping Room at Once
3. AMIR Robot Architecture
- Dimensions—60 × 60 × 135 cm
- Carrying capacity—20 kg
- Power supply unit—LiPo 44000 mAh 14.8V
- Omni-wheels (10 cm in diameter)
- 2 lidars with 360° sweep
- 16 obstacle sensors
- Computing unit with Nvidia Jetson TX2/Xavier.
4. AMIR’s Human-Machine Interaction Interface
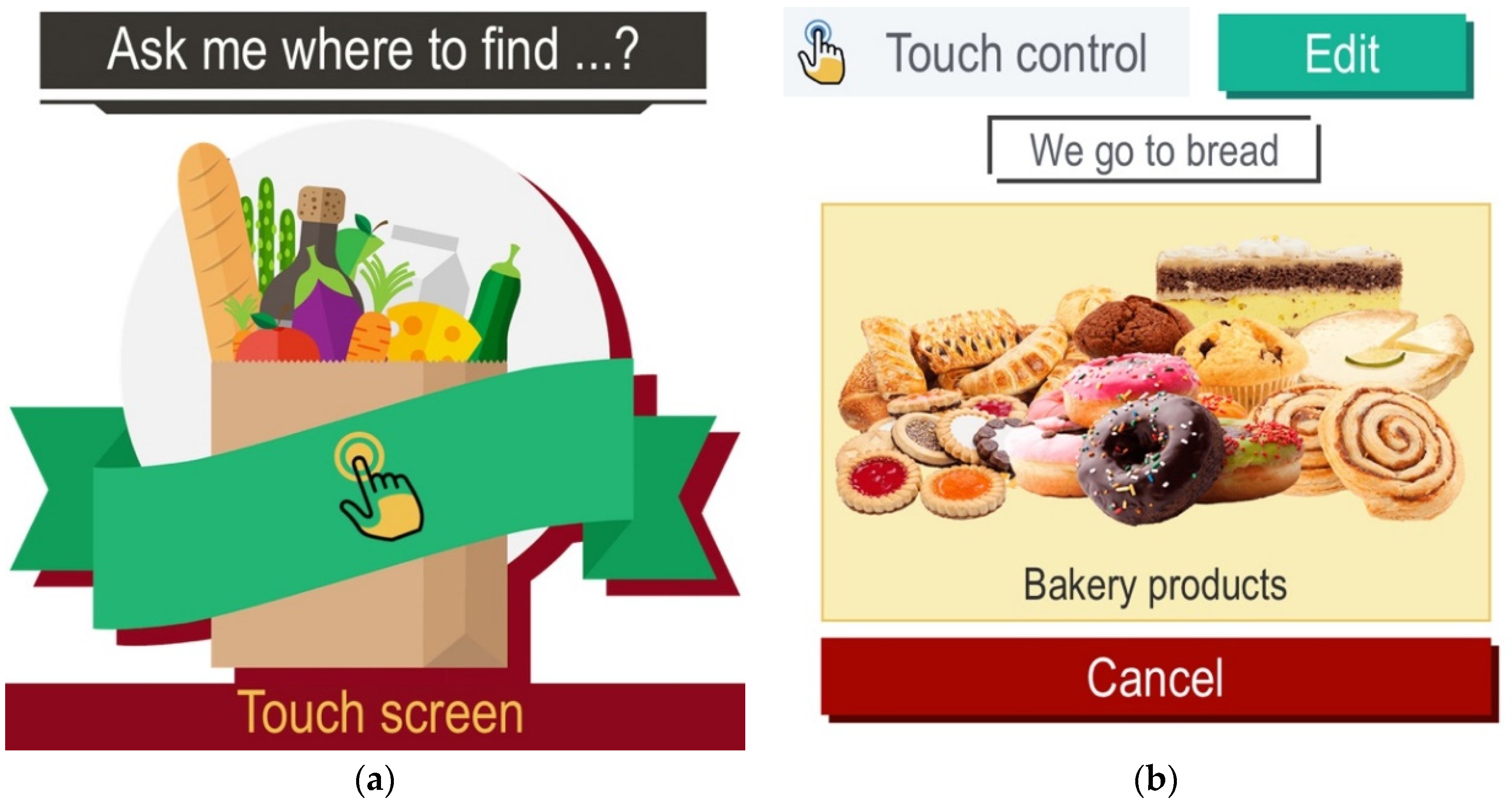
4.1. Touch Graphical Interface
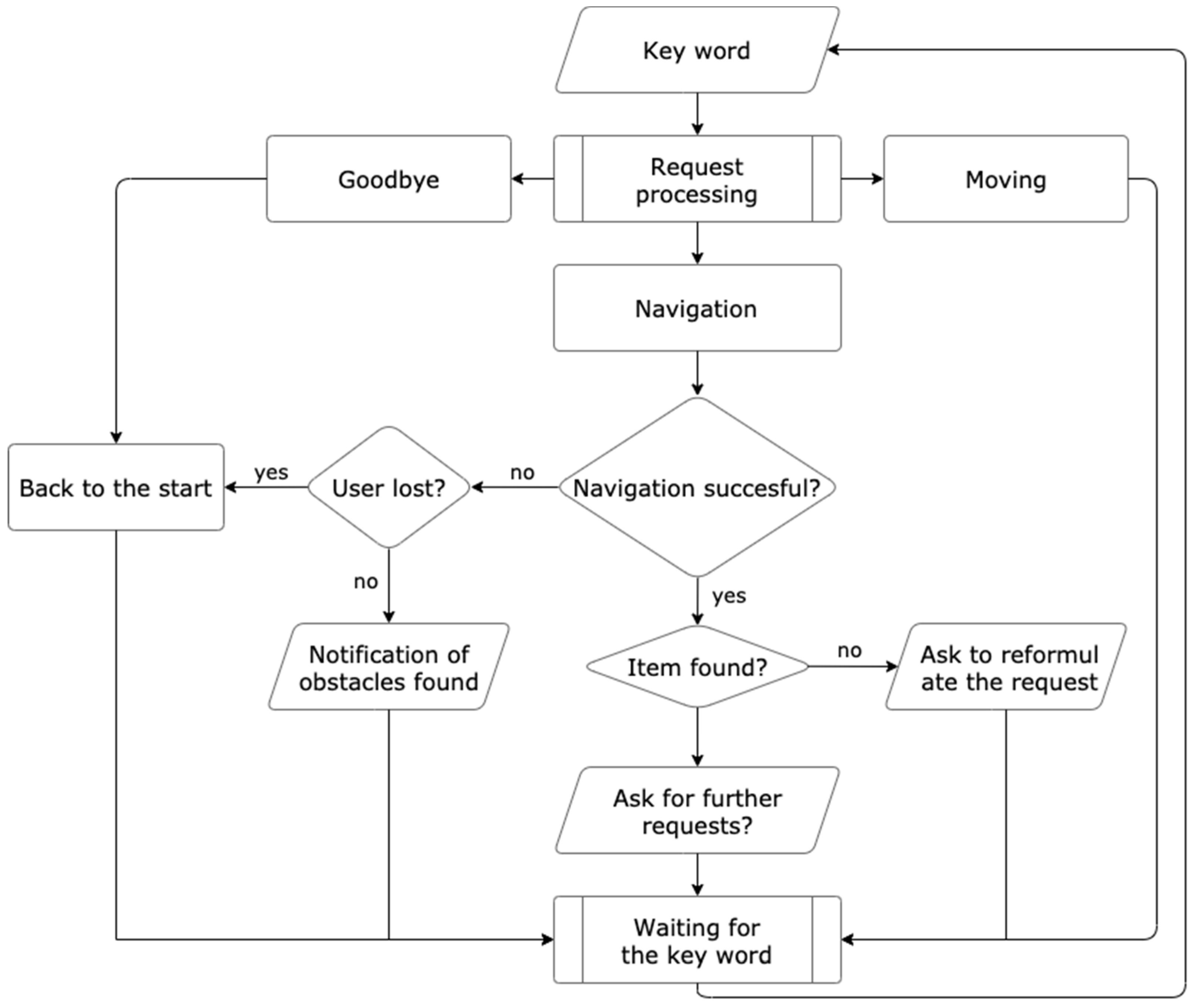
4.2. Voice Interface
4.3. Gesture Interface (Details of Gesture Recognition System Were Previously Published. This Section of the Present Paper Is a Summary of This Work, Briefing the Reader on Key Aspects of It)
4.3.1. Sign Language Synthesis
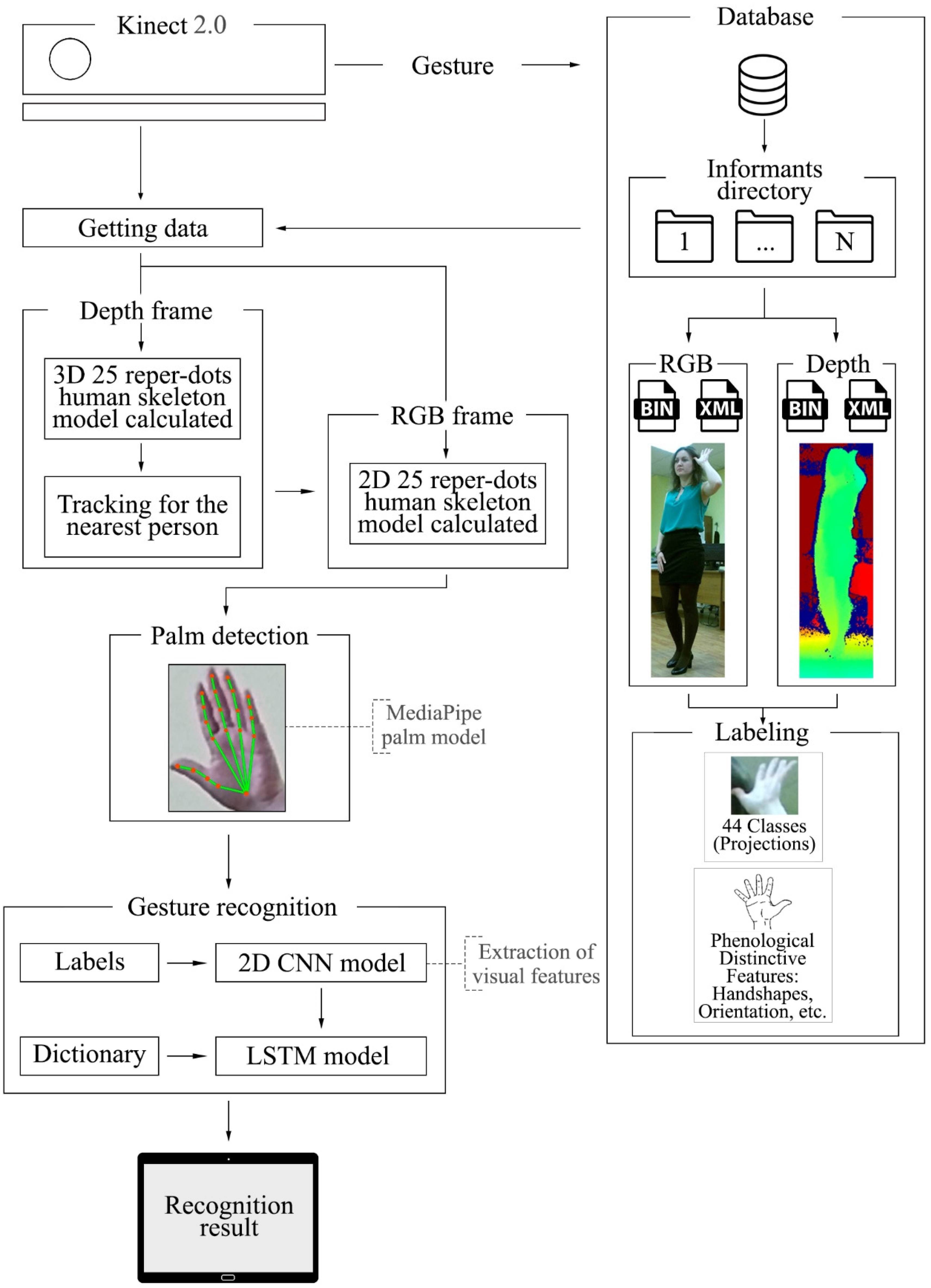
4.3.2. Sign Language Recognition
5. Preliminary Experiments and Results
5.1. Database Annotation
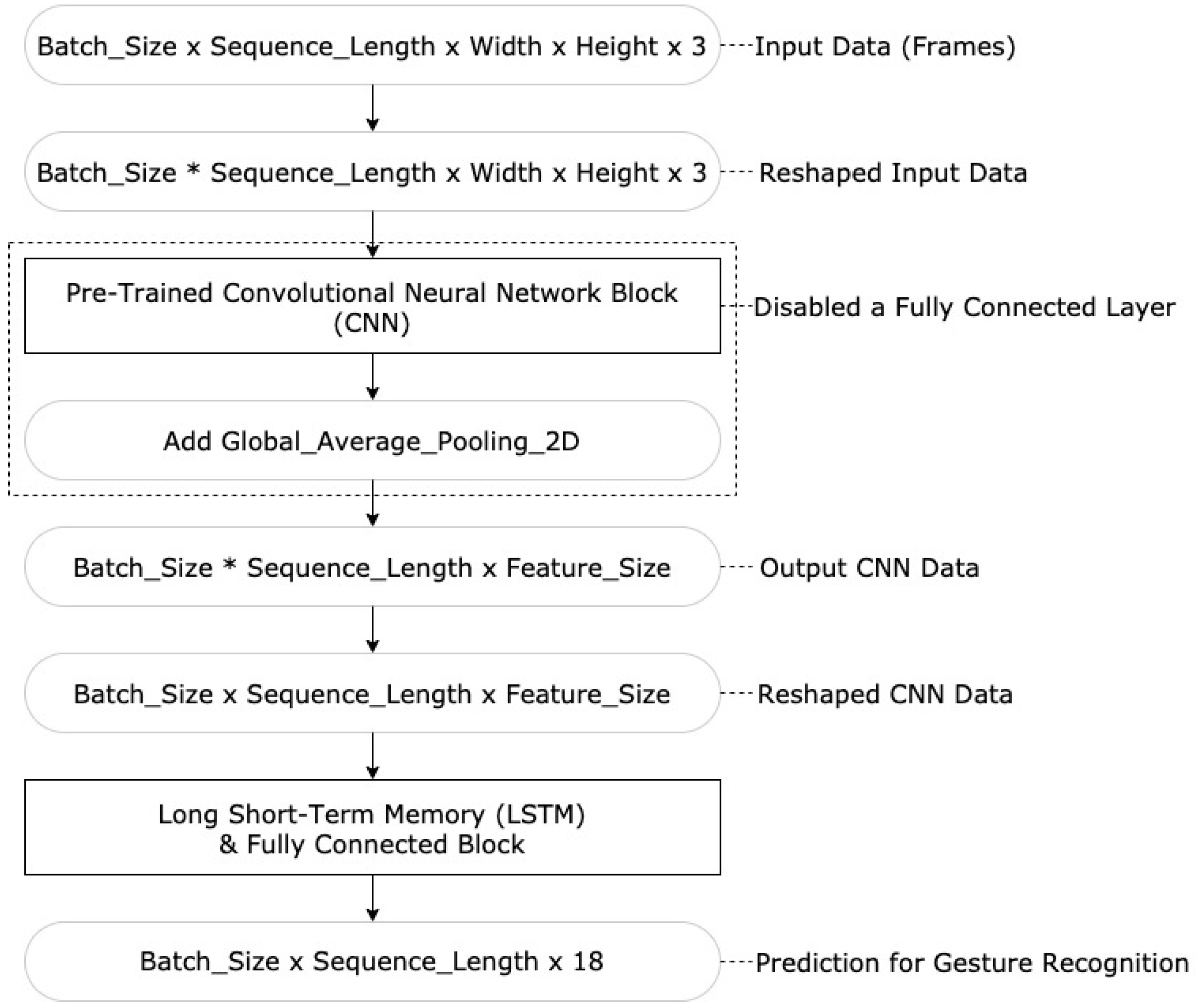
5.2. Gesture Recognition Experiments
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wada, K.; Shibata, T. Living with seal robots—Its sociopsychological and physiological influences on the elderly at a care house. IEEE Trans. Robot. 2007, 23, 972–980. [Google Scholar] [CrossRef]
- Wada, K.; Shibata, T.; Musha, T.; Kimura, S. Robot therapy for elders affected by dementia. IEEE Eng. Med. Biol. Mag. 2008, 27, 53–60. [Google Scholar] [CrossRef]
- Wada, K.; Shibata, T. Social and physiological influences of robot therapy in a care house. Interact. Stud. 2008, 9, 258–276. [Google Scholar] [CrossRef]
- Bemelmans, R.; Gelderblom, G.J.; Jonker, P.; Witte, L. The potential of socially assistive robotics in care for elderly, a systematic review. Hum. Robot Pers. Relatsh. 2011, 59, 83–89. [Google Scholar]
- Bemelmans, R.; Gelderblom, G.J.; Jonker, P.; Witte, L. Socially assistive robots in elderly care: A systematic review into effects and effectiveness. J. Am. Med Dir. Assoc. 2012, 13, 114–120. [Google Scholar] [CrossRef] [PubMed]
- Maldonado-Bascon, S.; Iglesias-Iglesias, C.; Martín-Martín, P.; Lafuente-Arroyo, S. Fallen people detection capabilities using assistive robot. Electronics 2019, 8, 915. [Google Scholar] [CrossRef]
- Lotfi, A.; Langensiepen, C.; Yahaya, S.W. Socially Assistive Robotics: Robot Exercise Trainer for Older Adults. Technologies 2018, 6, 32. [Google Scholar] [CrossRef]
- Piezzo, C.; Suzuki, K. Feasibility Study of a Socially Assistive Humanoid Robot for Guiding Elderly Individuals during Walking. Future Internet 2017, 9, 30. [Google Scholar] [CrossRef]
- Sumiya, T.; Matsubara, Y.; Nakano, M.; Sugaya, M. A mobile robot for fall detection for elderly-care. Procedia Comput. Sci. 2015, 60, 870–880. [Google Scholar] [CrossRef]
- Antonopoulos, C.P.; Kelverkloglou, P.; Voros, N.; Fotiou, I. Developing Autonomous Cart Equipment and Associated Services for Supporting People with Moving Disabilities in Supermarkets: The EQUAL Approach. In Proceedings of the Project Track of IISA 2019, Patras, Greece, 15–17 July 2019; pp. 20–24. [Google Scholar]
- Broekens, J.; Heerink, M.; Rosendal, H. Assistive social robots in elderly care: A review. Gerontechnology 2009, 8, 94–103. [Google Scholar] [CrossRef]
- Feil-Seifer, D.; Mataric, M.J. Defining socially assistive robotics. In Proceedings of the IEEE 9th International Conference on Rehabilitation Robotics, Chicago, IL, USA, 28 June–1 July 2005. [Google Scholar]
- Ryumin, D.; Kagirov, I.; Železný, M. Gesture-Based Intelligent User Interface for Control of an Assistive Mobile Information Robot. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2020; Volume 12336 LNAI, pp. 126–134. [Google Scholar]
- Ryumin, D.; Kagirov, I.; Ivanko, D.; Axyonov, A.; Karpov, A. Automatic detection and recognition of 3D manual gestures for human-machine interaction. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2019, XLII-2/W12, 179–183. [Google Scholar] [CrossRef]
- Matsuhira, N.; Ozaki, F.; Tokura, S.; Sonoura, T.; Tasaki, T.; Ogawa, H.; Sano, M.; Numata, A.; Hashimoto, N.; Komoriya, K. Development of robotic transportation system-Shopping support system collaborating with environmental cameras and mobile robots. In Proceedings of the 41st International Symposium on robotics and 6th German Conference on Robotics (ROBOTIK 2010), Munich, Germany, 7–9 June 2010; pp. 1–6. [Google Scholar]
- Chiang, H.; Chen, Y.; Wu, C.; Kau, L. Shopping assistance and information providing integrated in a robotic shopping cart. In Proceedings of the 2017 IEEE International Conference on Consumer Electronics (ICCE-TW), Taipei, Taiwan, 12–14 June 2017; pp. 267–268. [Google Scholar]
- Raulcezar, A.; Linhares, B.A.; Souza, J.R. Autonomous Shopping Cart: A New Concept of Service Robot for Assisting Customers. In 2018 Latin American Robotic Symposium, 2018 Brazilian Symposium on Robotics (SBR) and 2018 Workshop on Robotics in Education (WRE); IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Whitley, D. A genetic algorithm tutorial. Stat. Comput. 1994, 4, 65–85. [Google Scholar] [CrossRef]
- Davendra, D. (Ed.) Traveling Salesman Problem: Theory and Applications; InTech: Munich, Germany, 2010; Available online: https://www.intechopen.com/books/traveling-salesman-problem-theory-and-applications (accessed on 10 September 2020).
- Su, H.; Zhang, Y.; Li, J.; Hu, J. The shopping assistant robot design based on ROS and deep learning. In Proceedings of the 2nd International Conf. Cloud Computing and Internet of Things, Dalian, China, 22–23 October 2016; pp. 173–176. [Google Scholar]
- Kobayashi, Y.; Yamazaki, S.; Takahashi, H.; Fukuda, H.; Kuno, Y. Robotic shopping trolley for supporting the elderly. In Proceedings of the AHFE 2018 International Conference on Human Factors and Ergonomics in Healthcare and Medical Devices, Loews Sapphire Falls Resort at Universal Studios, Orlando, FL, USA, 21–25 July 2018; pp. 344–353. [Google Scholar]
- Garcia-Arroyo, M.; Marin-Urias, L.F.; Marin-Hernandez, A.; Hoyos-Rivera, G.D.J. Design, integration, and test of a shopping assistance robot system. In Proceedings of the 7th Annual ACM/IEEE International Conference on Human-Robot Interaction, Boston, MA, USA, 5–8 March 2012; pp. 135–136. [Google Scholar]
- Marin-Hernandez, A.; de Jesus Hoyos-Rivera, G.; Garcia-Arroyo, M.; Marin-Urias, L.F. Conception and implementation of a supermarket shopping assistant system. In Proceedings of the 11th Mexican International Conference on Artificial Intelligence, San Luis Potosi, Mexico, 27 October–4 November 2012; pp. 26–31. [Google Scholar]
- Sales, J.; Marti, J.V.; Marín, R.; Cervera, E.; Sanz, P.J. CompaRob: The shopping cart assistance robot. Int. J. Distrib. Sens. Netw. 2016, 12, 16. [Google Scholar] [CrossRef]
- Ikeda, H.; Kawabe, T.; Wada, R.; Sato, K. Step-Climbing Tactics Using a Mobile Robot Pushing a Hand Cart. Appl. Sci. 2018, 8, 2114. [Google Scholar] [CrossRef]
- Elgendy, M.; Sik-Lanyi, C.; Kelemen, A. Making Shopping Easy for People with Visual Impairment Using Mobile Assistive Technologies. Appl. Sci. 2019, 9, 1061. [Google Scholar] [CrossRef]
- Andò, B.; Baglio, S.; Marletta, V.; Crispino, R.; Pistorio, A. A Measurement Strategy to Assess the Optimal Design of an RFID-Based Navigation Aid. IEEE Trans. Instrum. Meas. 2019, 68, 2356–2362. [Google Scholar] [CrossRef]
- Kesh, S. Shopping by Blind People: Detection of Interactions in Ambient Assisted Living Environments using RFID. Int. J. Wirel. Commun. Netw. Technol. 2017, 6, 7–11. [Google Scholar]
- Kulyukin, V.; Gharpure, C.; Nicholson, J. Robocart: Toward robot-assisted navigation of grocery stores by the visually impaired. In Proceedings of the International Conference on Intelligent Robots and Systems (IROS-2005), Edmonton, AB, Canada, 2–6 August 2005; pp. 2845–2850. [Google Scholar]
- Kuipers, B. The spatial semantic hierarchy. Artif. Intell. 2000, 119, 191–233. [Google Scholar] [CrossRef]
- Azenkot, S.; Zhao, Y. Designing smartglasses applications for people with low vision. ACM SIGACCESS Access. Comput. 2017, 119, 19–24. [Google Scholar] [CrossRef]
- López-de-Ipiña, D.; Lorido, T.; López, U. Indoor navigation and product recognition for blind people assisted shopping. In Proceedings of the International Workshop on Ambient Assisted Living (IWAAL), Torremolinos-Málaga, Spain, 8–10 June 2011; pp. 33–40. [Google Scholar]
- Tomizawa, T.; Ohya, A.; Yuta, S. Remote shopping robot system: Development of a hand mechanism for grasping fresh foods in a supermarket. In Proceedings of the Intelligent Robots and Systems (IROS-2006), Bejing, China, 3–8 November 2006; pp. 4953–4958. [Google Scholar]
- Tomizawa, T.; Ohba, K.; Ohya, A.; Yuta, S. Remote food shopping robot system in a supermarket-realization of the shopping task from remote places. In Proceedings of the International Conference on Mechatronics and Automation (ICMA-2007), Harbin, Heilongjiang, China, 5–8 August 2007; pp. 1771–1776. [Google Scholar]
- Wang, Y.C.; Yang, C.C. 3S-trolley: A lightweight, interactive sensor-based trolley for smart shopping in supermarkets. IEEE Sens. J. 2016, 16, 6774–6781. [Google Scholar] [CrossRef]
- Hart, P.E.; Nilsson, N.J.; Raphael, B. A Formal Basis for the Heuristic Determination of Minimum Cost Paths. IEEE Trans. Syst. Sci. Cybern. 1968, 4, 100–107. [Google Scholar] [CrossRef]
- Kumar, A.; Gupta, A.; Balamurugan, S.; Balaji, S.; Marimuthu, R. Smart shopping cart. In Proceedings of the 2017 International conference on Microelectronic Devices, Circuits and Systems (ICMDCS 2017), VIT University, Vellore, India, 10–12 August 2017; pp. 1–4. [Google Scholar]
- Gangwal, U.; Roy, S.; Bapat, J. Smart shopping cart for automated billing purpose using wireless sensor networks. In Proceedings of the Seventh International Conference on Sensor Technologies and Applications (SENSORCOMM 2013), Barcelona, Spain, 25–31 August 2013; pp. 168–172. [Google Scholar]
- Athauda, T.; Marin, J.C.L.; Lee, J.; Karmakar, N.C. Robust low-cost passive UHF RFID based smart shopping trolley. IEEE J. Radio Freq. Identif. 2018, 2, 134–143. [Google Scholar] [CrossRef]
- Kanda, T.; Shiomi, M.; Miyashita, Z.; Ishiguro, H.; Hagita, N. A communication robot in a shopping mall. IEEE Trans. Robot. 2010, 26, 897–913. [Google Scholar] [CrossRef]
- Kanda, T.; Shiomi, M.; Miyashita, Z.; Ishiguro, H.; Hagita, N. An affective guide robot in a shopping mall. In Proceedings of the 4th ACM/IEEE international conference on Human robot interaction (HRI-09), La Jolla, CA, USA, 11–13 March 2009; pp. 173–180. [Google Scholar]
- Shiomi, M.; Kanda, T.; Glas, D.F.; Satake, S.; Ishiguro, H.; Hagita, N. Field trial of networked social robots in a shopping mall. In Proceedings of the Intelligent Robots and Systems (IROS-2009), Hyatt Regency St. Louis Riverfront, St. Louis, MO, USA, 11–15 October 2009; pp. 2846–2853. [Google Scholar]
- Chen, C.C.; Huang, T.-C.; Park, J.H.; Tseng, H.-H.; Yen, N.Y. A smart assistant toward product-awareness shopping. Pers. Ubiquitous Comput. 2014, 18, 339–349. [Google Scholar] [CrossRef]
- Surdofon: Russian Sign Language On-Line Translation. Available online: https://surdofon.rf (accessed on 14 August 2020).
- Falconer, J. Humanoid Robot Demonstrates Sign Language. Available online: https://spectrum.ieee.org/automaton/robotics/humanoids/ntu-taiwan-humanoid-sign-language (accessed on 10 August 2020).
- Kose, H.; Yorganci, R. Tale of a robot: Humanoid robot assisted sign language tutoring. In Proceedings of the 11th IEEE-RAS International Conference on Humanoid Robots, Bled, Slovenia, 26–28 October 2011; pp. 105–111. [Google Scholar]
- Hoshino, K.; Kawabuchi, I. A humanoid robotic hand performing the sign language motions. In Proceedings of the 2003 International Symposium on Micromechatronics and Human Science (MHS-2003), Tsukuba, Japan, 20 October 2003; pp. 89–94. [Google Scholar]
- Koubaa, A. (Ed.) Robot Operating System (ROS): The Complete Reference; Springer: Cham, Switzerland, 2019; Volume 4. [Google Scholar]
- Montemerlo, M.; Thrun, S.; Koller, D.; Wegbreit, B. FastSLAM: A Factored Solution to the Simultaneous Localization and Mapping Problem. In Proceedings of the Eighteenth National Conference on Artificial Intelligence, Edmonton, AB, Canada, 28 July–1 August 2002; pp. 593–598. [Google Scholar]
- Montemerlo, M.; Koller, S.T.D.; Wegbreit, B. FastSLAM 2.0: An improved particle filtering algorithm for simultaneous localization and mapping that provably converges. In Proceedings of the Int. Conf. on Artificial Intelligence (IJCAI-2003), Acapulco, Mexico, 9–15 August 2003; pp. 1151–1156. [Google Scholar]
- Grisetti, G.; Stachniss, C.; Burgard, W. Improved techniques for grid mapping with Rao-Blackwellized particle filters. IEEE Trans. Robot. 2007, 23, 34–46. [Google Scholar] [CrossRef]
- Grisetti, G.; Tipaldi, G.D.; Stachniss, C.; Burgard, W.; Nardi, D. Fast and accurate SLAM with Rao–Blackwellized particle filters. Robot. Auton. Syst. 2007, 55, 30–38. [Google Scholar] [CrossRef]
- Brock, O.; Khatib, O. High-speed navigation using the global dynamic window approach. In Proceedings of the 1999 IEEE international conference on robotics and automation (Cat. No. 99CH36288C), Detroit, MI, USA, 10–15 May 1999; pp. 341–346. [Google Scholar]
- Documentation for Android Developers, SpeechRecognizer. Available online: https://developer.android.com/reference/android/speech/SpeechRecognizer (accessed on 23 July 2020).
- Karger, D.R.; Stein, C. A New Approach to the Minimum Cut Problem. J. ACM 1996, 43, 601–640. [Google Scholar] [CrossRef]
- Kudelic, R. Monte-Carlo randomized algorithm for minimal feedback arc set problem. Appl. Soft Comput. 2016, 41, 235–246. [Google Scholar] [CrossRef]
- Geilman, I.F. Russian Sign Language Dictionary; Prana: St. Petersburg, Russia, 2004. (In Russian) [Google Scholar]
- Kanis, J.; Zahradil, J.; Jurčíček, F.; Müller, L. Czech-sign speech corpus for semantic based machine translation. In Proceedings of the 9th International Conference on Text, Speech and Dialogue (TSD 2006), Brno, Czech Republic, 11–15 September 2006; pp. 613–620. [Google Scholar]
- Aran, O.; Campr, P.; Hrúz, M.; Karpov, A.; Santemiz, P.; Zelezny, M. Sign-language-enabled information kiosk. In Proceedings of the 4th Summer Workshop on Multimodal Interfaces eNTERFACE, Orsay, France, 4–29 August 2008; pp. 24–33. [Google Scholar]
- Jedlička, P.; Krňoul, Z.; Kanis, J.; Železný, M. Sign Language Motion Capture Dataset for Data-driven Synthesis. In Proceedings of the 9th Workshop on the Representation and Processing of Sign Languages: Sign Language Resources in the Service of the Language Community, Technological Challenges and Application Perspectives (LREC-2020), Marceille, France, 11–16 May 2020; pp. 101–106. [Google Scholar]
- Kinect for Windows. Available online: https://docs.microsoft.com/en-us/previous-versions/windows/kinect/dn782037(v=ieb.10) (accessed on 24 July 2020).
- Rahman, M. Beginning Microsoft Kinect for Windows SDK 2.0: Motion and Depth Sensing for Natural User Interfaces; Apress: Berkeley, CA, USA, 2017; pp. 41–76. [Google Scholar]
- Lugaresi, C.; Tang, J.; Nash, H.; McClanahan, C.; Uboweja, E.; Hays, M.; Zhang, F.; Chang, C.L.; Yong, M.G.; Lee, J.; et al. MediaPipe: A Framework for Building Perception Pipelines. arXiv 2019, arXiv:1906.08172. [Google Scholar]
- Kagirov, I.; Ivanko, D.; Ryumin, D.; Axyonov, A.; Karpov, A. TheRuSLan: Database of Russian Sign Language. In Proceedings of the 12th International Conference on Language Resources and Evaluation (LREC-2020), Marceille, France, 11–16 May 2020; pp. 6079–6085. [Google Scholar]
- Russian Sign Language Corpus. Available online: http://rsl.nstu.ru/site/index/language/en (accessed on 7 December 2020).
- Prillwitz, S.; Leven, R.; Zienert, H.; Hanke, T.; Henning, J. HamNoSys; Version 2.0; Hamburg Notation System for Sign Languages; An Introductory Guide; Signum Verlag: Hamburg, Germany, 1989. [Google Scholar]
- Keras Applications. Available online: https://keras.io/api/applications (accessed on 24 July 2020).
- Tan, M.; Le, Q.V. Efficientnet: Rethinking model scaling for convolutional neural networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Command (ID) | Category (Department) |
|---|---|
| yogurt (1), kefir (2), milk (3), butter (4), sour cream (5), cheese (6), cottage cheese (7), eggs (8) | milk products, cheeses, eggs |
| cake (101), cookies (102), bakery products (103) | confectionery |
| chocolate (201), candy (202) | chocolate products |
| long loaf (301), rusks (302), dried bread (303), bread (304) | bakery products |
| water (401), sparkling water (402), kvass (403), juice (404) | drinks |
| tomatoes (501), cabbage (502), cucumbers (503), potatoes (504), onion (505), carrot (506), oranges (507), apples (508), pear (509), lemon (510), bananas (511) | vegetables and fruits |
| Tea (601), coffee (602), pasta (603) | grocery |
| buckwheat grain (701), rice (702), oatmeal (703) | cereals |
| canned food (801) | canned food |
| salt (901), sugar (902), spice (903) | spice |
| sausages (1001), meat (1002) | meat |
| fish (1101), caviar (1102) | fish and seafood |
| sunflower oil (1201), yeast (1202), flour (1203) | vegetable oils sauces and seasonings |
| dumplings (1301), pizza (1302) | frozen semi-finished products |
| ticket window (1401), restroom (1402), output (1403) | departments and locations |
| Input Image Size Width × Height × Channels | Feature Size | Model 2D CNN-LSTM | Accuracy (%) |
|---|---|---|---|
| 299 × 299 × 3 | 2048 | Xception | 80.03 |
| 224 × 224 × 3 | 512 | VGG16 | 72.58 |
| 224 × 224 × 3 | 512 | VGG19 | 73.19 |
| 224 × 224 × 3 | 2048 | ResNet152V2 | 76.11 |
| 299 × 299 × 3 | 2048 | InceptionV3 | 75.92 |
| 299 × 299 × 3 | 1536 | InceptionResNetV2 | 81.44 |
| 224 × 224 × 3 | 1280 | MobileNetV2 | 72.47 |
| 224 × 224 × 3 | 1664 | DenseNet169 | 76.54 |
| 331 × 331 × 3 | 4032 | NASNetLarge | 84.44 |
| 224 × 224 × 3 | 1280 | EfficientNetB0 | 70.32 |
| 528 × 528 × 3 | 2559 | EfficientNetB7 | 87.01 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ryumin, D.; Kagirov, I.; Axyonov, A.; Pavlyuk, N.; Saveliev, A.; Kipyatkova, I.; Zelezny, M.; Mporas, I.; Karpov, A. A Multimodal User Interface for an Assistive Robotic Shopping Cart. Electronics 2020, 9, 2093. https://doi.org/10.3390/electronics9122093
Ryumin D, Kagirov I, Axyonov A, Pavlyuk N, Saveliev A, Kipyatkova I, Zelezny M, Mporas I, Karpov A. A Multimodal User Interface for an Assistive Robotic Shopping Cart. Electronics. 2020; 9(12):2093. https://doi.org/10.3390/electronics9122093
Chicago/Turabian StyleRyumin, Dmitry, Ildar Kagirov, Alexandr Axyonov, Nikita Pavlyuk, Anton Saveliev, Irina Kipyatkova, Milos Zelezny, Iosif Mporas, and Alexey Karpov. 2020. "A Multimodal User Interface for an Assistive Robotic Shopping Cart" Electronics 9, no. 12: 2093. https://doi.org/10.3390/electronics9122093
APA StyleRyumin, D., Kagirov, I., Axyonov, A., Pavlyuk, N., Saveliev, A., Kipyatkova, I., Zelezny, M., Mporas, I., & Karpov, A. (2020). A Multimodal User Interface for an Assistive Robotic Shopping Cart. Electronics, 9(12), 2093. https://doi.org/10.3390/electronics9122093