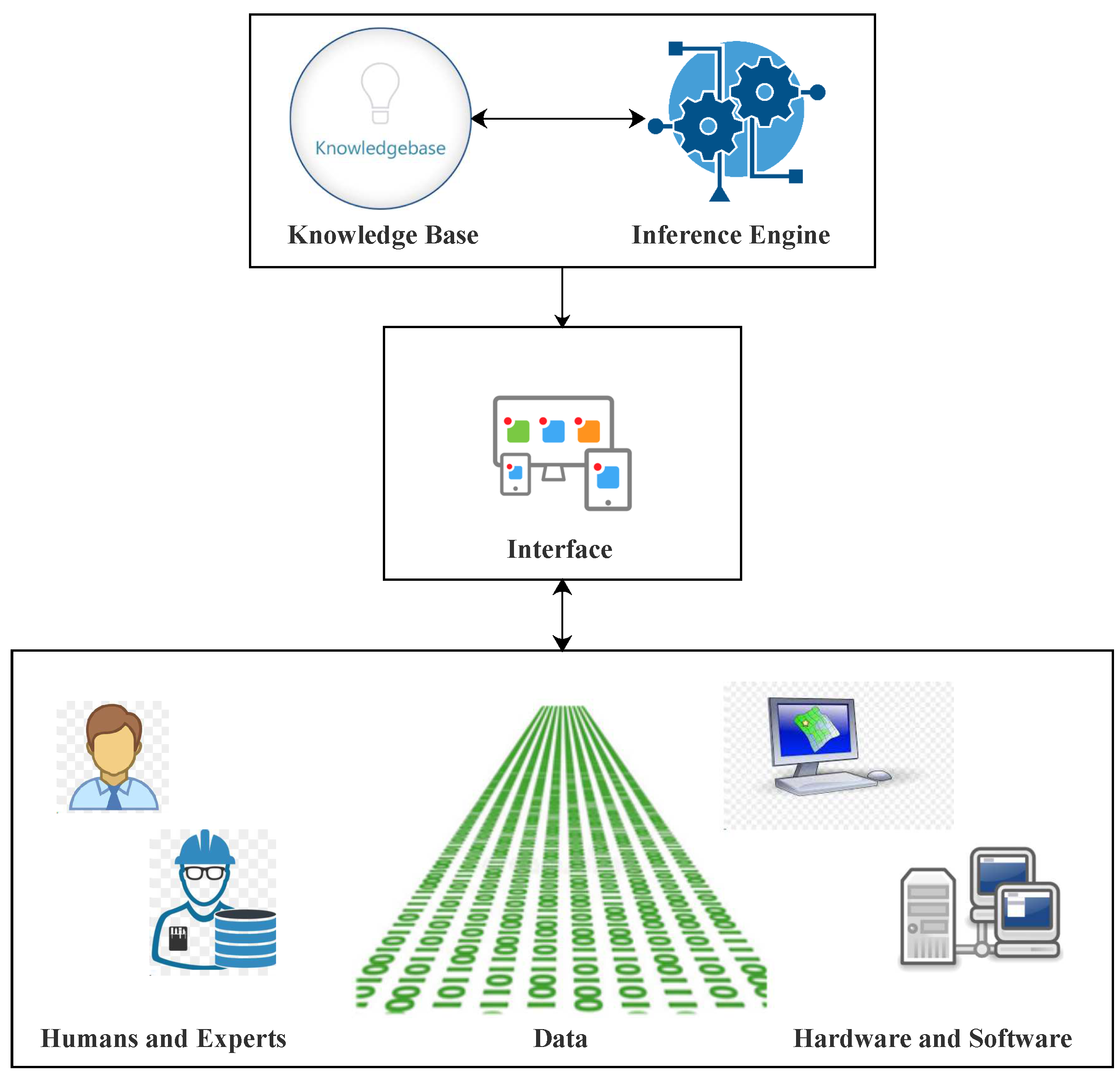
1. Introduction
In the modern day world, smart meters offer two way communication between the users and the utilities. This communication leads towards a prevalent computing environment, which develops large-scale data with high velocity and veracity [
1]. The resultant data also give rise to a time series concept. This phenomenon generally includes power consumption measurements of appliances over a specific time interval [
2]. The techniques of big data are proficient enough to utilize resultant huge volumes data of sequential time series. Moreover, these techniques also assist in data-driven decision making. Besides, this big data can update utilities to learn power consumption patterns of consumers, predicting demand and averting blackouts.
The utilities are keen on finding the optimal ways for cost reduction. Moreover, electricity companies desire to increase their yields by acquainting their consumers with effective programs like Demand Side Management (DSM) and demand response. Currently, marginal success has been observed in achievement of goals for these programs. However, viable results still need to be achieved [
3]. Furthermore, implementation of DSM and demand response is a challenging task for utilities. It is difficult to comprehend and conclude the behavior of every individual consumer. Moreover, it is also challenging to customize strategies that include profit contrary to distress from varying behavior of consumers on the basis of energy-saving policies introduced by utilities. Besides, the association between consumer behavior and the constraints that affect power utilization patterns are non-static, i.e., the activities of consumers keep on changing from time to time [
4].
Usually, the behavior of consumers is reliant on weather and seasons, which has a capricious effect on power utilization decisions. Thus, active participation of consumers in customized power management is crucial for energy saving schemes. The companies should give timely response on power consumption and associated costs [
5]. Consequently, it is challenging to design such models that are proficient enough to evaluate energy time series from smart meters. Also, it is stimulating to train the model that predicts power consumption.
The aforementioned discussion helps to study the influence of consumers’ behavior on power consumption and to forecast the energy utilization patterns. This analysis can assist the utilities to develop power saving strategies. Moreover, the utilities can design programs to stabilize the demand and supply of energy ahead of time. For instance, short term forecast is related to daily and weekly power usage. This type of prediction is best suitable when there is a need to enhance scheduling and distribution. Alternatively, medium term forecasting is related to weekly and monthly forecasting. Besides, long term forecasting is about yearly predictions of energy consumption. Medium and long term predictions are capable of maintaining the equilibrium between the production of smart grid and strategic scheduling [
6]. However, such a task is very challenging as it is significant to mine complex interdependencies between appliance usages where numerous data streams are taking place.
Generally, DRM can be characterized in two extents, which are the utilities and consumers. There has been substantial quantity of work done in power systems to maintain the balance between supply and demand [
7]. However, these studies have laid emphasis on the financial aspects on the planning and production levels. Moreover, these studies are unable to take both consumer and utility as a substantial constituent. Contrariwise, the literature on consumer and utility has presented models to increase user comfort, devoid of taking the cost of power or the profits of the utilities [
8]. This paper takes motivation from this phenomenon. Moreover, this paper observes the increased profits for consumers and utilities.
This paper analyzes the collaborations between several utilities and consumers. Both entities share mutual objectives, i.e., maximization of their payoffs. The utilities can increase their profits by setting a suitable price per unit. Nonetheless, the users select a specified amount of power to purchase from any utility on the basis of announced prices. Furthermore, the purchasing behavior of consumer is dependent on the prices settled by the company. Likewise, the behavior of utilities is reliant for the prices settled by other utilities. Thus, for solving these challenging collaborations between consumers and utilities, this paper employs a game theoretical framework. This paper presents a Stackelberg game plan between consumers and utilities. In this game, the utilities play a non-cooperative game and the users look for their best optimum response.
The systematic and proficient utilization of electrical power is a hot debate topic in today’s world [
9]. The optimal power management and maintaining balance between demand and supply are considered as challenging tasks for modern power systems [
10]. Moreover, the prediction of uncertain production of renewable energy resources [
11] and short-term load forecasting [
12] are measured as significant components of the power grid for optimal power scheduling. Besides, short-term load forecasting has wide applications in the energy market like load scheduling, unit commitment and power production [
13]. It has been observed in the literature that error maximization in short-term load forecasting can result in substantial growth in the utility operating expenses. Thus, enhancing the accuracy of predicted results is a challenging task and vital issue in power management.
The proximity of choosing a similar day to the target day is very crucial for selecting the similar day along with temperature, according to previous studies. In this regard, this paper proposes a different priority indexing technique for selection of similar days by analyzing the date proximity and temperature similarity. Moreover, the date proximity used in this paper is the total number and nature of days between selected and similar days. In contrast, the historic power load data is categorized according to nature of days in demand prediction. Furthermore, this paper also presents four different day types and two data-sets are presented for utilization of historical power load data. In addition, the proposed knowledge based short-term load forecasting method employs monthly and weekly data for two different data-sets. The best optimum results for short-term load forecasting will be achieved by grouping of prediction results obtained from these two data-sets.
The consideration of exceptional temperature for any region is ineffectual because of variations in temperatures in a vast topographical zone. A vast topographical zone is separated into three climate types in [
14]. Moreover, the temperature of three cities is labeled as cold, moderate, and warm. The biased integration of these temperatures is presented as the temperature of the huge region. The temperature is taken in [
15] and the whole system is distributed in different regions. Besides, the short-term load has been forecasted by some regression techniques. However, the precedence of choosing similar days is also unnoticed in previous studies.
This paper divides the entire system in nine regions. Moreover, the climatic conditions of only one city is chosen from every region. The knowledge based short-term load forecasting is employed to every region after the consideration of temperature. In addition, the predicted power load of the entire system is the aggregate of predicted load of particular regions. The impact of temperature is believed to be much more efficient and result improving when the system is divided.
The proposed system model is employed in Pakistan’s National Power Network (PNPN), which is taken as a sample system in this paper. In the proposed system model, Affinity Propagation (AP) [
16], and Binary Firefly Algorithm (BFFA) are used as hybrid model. The proposed system model shows a significant decrease in MAPE in comparison with other traditional knowledge based methods. This paper uses algorithms of Deep Belief Network (DBN) and Fuzzy Local Linear Model Tree (F-LOLIMOT) for comparison purposes. The experimental results specifies that the proposed model requires minimum time for computation when associated with DBN and F-LOLIMOT.
The major research contributions of this paper include the proposition of the priority index for selection of similar days by means of temperature of specified regions and date proximity. Moreover, the historic power load is separated in two different data-sets in the paper. Subsequently, the data-sets predict the short-term load and then the final outcome is supposed to be more precise. The final outcomes are achieved by the summation of predicted results from two data-sets. Furthermore, the paper makes the impact of temperature effective by dividing the system in different regions.
The remaining paper is organized in following manner: Section II presents the previous work done, Section III provides a brief discussion of a Stackelberg game and demonstrates the distinctiveness and existence of the Stackelberg Equilibrium. Moreover, Section IV discusses the categorization of knowledge based short-term load forecasting and Section V employs the proposed method on different topographical regions. Moreover, results and their discussion are presented in Section VI and Section VII concludes the paper.
2. Related Work
The challenges addressed in Section I are also discussed in the literature through methodologies of big-data. A brief discussion of behavioral power consumption data to acquire better energy competence are presented in [
6]. Likewise, the influence of developmental fluctuations for energy savings was observed by [
17]. The study also discussed the contribution of consumers to collaborate with the utilities and better energy savings were highlighted.
The literature has proposed many novel methods for short-term load forecasting like fuzzy [
18], exponential smoothing [
19], regression based [
20], neural networks [
21], and others. Moreover, every proposed model has incorporated some techniques. For example, regression based processes are usually comprised of Autoregressive Integrated Moving Average (ARIMA) [
22], Auto-Regressive Moving Average (ARMA) [
23], Support Vector Regression (SVR) [
24], and Auto-Regressive Moving Average with Exogenous variable (ARMAX) [
25]. Nevertheless, it is essential for aforementioned techniques to learn the process by bulks of preceding data for tuning of various parameters. Furthermore, the complexities of these techniques, minimum time of computation and memory essentials of knowledge based model, can initiate a different perspective to knowledge based short-term load forecasting.
In literature, there are some works cited in knowledge based systems that employ a similar day method [
26,
27,
28]. Although, there is a lot of room for enhancement in this scenario which can be studied. The authors in [
29] proposed a knowledge based system for short-term load demand forecasting. However, the paper overlooked the consequences of temperature. The change in temperature can cause fluctuations in the load demand. Consequently, the effect of temperature must be included in the short-term load forecasting. The different eight day categories are enumerated in [
30].
Moreover, average stabilized loads of historic data for every day has been evaluated by means of least and maximum load per hour. Furthermore, the least and maximum load for 11 days was forecasted by means of regression techniques. The Mean Absolute Percentage Error (MAPE) of Irish electrical power system attained was 2.52%. Moreover, the temperature was also incorporated in this study and was associated with 3.86% by the statistical technique in [
31].
The authors in [
32] calculated the weighted mean load of every hour for three preceding and similar days for short-term load forecasting. Moreover, the impact of temperature on prediction of short-term load is also considered by means of exponential association between power demand and temperature. Likewise, the mean prediction error for a daily peak load of France was attained 2.74% in [
32]. Besides, the consequences of temperature, wind pressure and humidity, was scrutinized in [
33]. The MAPE calculated in this study was 1.43%. The study in [
23] was almost equivalent to the proposed model presented in [
22]. Moreover, the MAPE achieved in this study was between 1.23% to 3.35% in seven different states of America [
34].
The mean prediction error for daily peak load in [
24] was achieved 4.65% for weekdays and 7.08% for weekends of three different states of Turkey [
35]. This mean prediction error was achieved after smoothing the temperature discrepancies throughout the day. The precedence of similar days is overlooked in previous studies. It is obvious that there are numerous days which are advantageous for the knowledge based forecasting of load. Nevertheless, the best suitable preference of these same days has a substantial effect on forecasting results.
The consequences of temperature are neglected in [
36] in terms of priority index. Moreover, in [
37] a priority index for medium term load prediction was presented. The proposed model was based on the similarity of temperature for the selected day. The mean error achieved in [
37] for Western States of America was 3.25% for summer season. Besides, few values of error were attained that were more than 6%. Though, the temperature was the only parameter, which was assessed in this study and the proximity of chosen day to similar day was ignored. It is a well-known fact that same days do not have alike temperature. Moreover, the similar days must be near to the target days in order to avert the selection of similar days with similar temperature and different power load.
The work presented in [
38] used the Bayesian network to forecast activities of different residents by a particular appliance. However, the model was not efficient enough to be functional towards real world circumstances. The authors in [
39] and [
40] discussed a multi-label and time sequence based classifier model for a decision tree taking appliance association as a correlation. The basic purpose of their model was to predict the power consumption of the appliance. Though, the authors merely observed the past 24 h frame for future forecasting.
The work in [
41] presented the association rule mining method to classify the interdependence between power consumption and appliance usage to help power saving, anomaly detection, and demand response. Nevertheless, this work lacked the proper rule mining process and appliance-appliance association.
At present, Artificial Neural Network (ANN) and SVM are considered to work efficiently for non-linear time series sequences. Karatasou et al. [
42] demonstrated the practical implementation of ANN in forecasting power expenditure of a building accompanied by statistical study. In [
43,
44], a model is presented which hybrids the Support Vector Regression (SVR) and Immune Algorithm (IA) to estimate local yearly report and power load in Taiwan.
Zhao et al. [
45] presented a framework, which employed SVM to predict residential power utilization in the humid area. Moreover, the study took meteorological conditions of that particular area. Besides, Xuemei et al. [
46] suggested Least Square Support Vector Machine (LS-SVM) for chilling load prediction [
47] for a residential zone in Singapore. The forecasting was done by hourly weather information.
Wang et al. [
48] discussed that the SVM based models have proven to be efficient as compared to ANN and ARIMA configurations. They employed Differential Evolution (DE) and SVM to predict the configurations for yearly energy consumption. Conversely, the development of SVM model is influenced by the category and constraints of the kernel function. Generally, it is discussed in literature that the tuning constraints of SVM is a challenging task [
49]. In addition, a number of models are presented in literature to tune the parameters of SVM by techniques of machine learning and artificial intelligence.
Ogliari et al. [
50] proposed a hybrid model using Neural Network and Genetical Swarm Optimization for energy prediction. The authors in [
51] combined SVM with algorithms of Simulated Snnealing to predict yearly load. On the subject of optimization techniques, Jaya Algorithm has achieved attention in the last few years as a metaheuristic computing technique. The authors in [
52] and [
53] observed that Jaya Algorithm outperforms other optimization techniques. Moreover, Jaya Algorithm has also been employed for various real work applications.
There is a variety of literature available on the topic of game theory and DRM. In [
54], the authors have discussed power utilization and forecasting as a non-cooperative game plan. This basic aim was to maximize the cost functions. Likewise, the authors in [
55] have proposed a distributed set-up. In this set-up, the cost function is demonstrated by its dependence on inclusive load. The consumers adjusted their behavior for power consumption on the basis of cost function introduced by the utility. The authors in [
56] presented a theoretical framework for mutual optimization of investment and functioning of a smart grid. Moreover, the aspects of power storing, renewable energy integration, and demand response were taken into consideration. The paper signified the sharing of portfolio decisions, day-ahead pricing, and scheduling. They also presented the benefits of integrated renewable energy and demand response in terms of minimizing the sharing cost.
A robust optimization has been discussed in [
57] in order to increase the utility of the end-user by hourly prediction. The study presented in [
58] laid emphasis on the knowledge and interest of users to be aware of the announced electricity prices. The study proposed a technique to cope with preferences of the consumers to increase power competence and consumer satisfaction. Moreover, a dynamic cost price has been introduced to motivate users for attaining a cumulative load [
59]. Also, this load was handled by different utilities and DRM was scrutinized for bi-directional communication between consumers in the micro-grid. The authors in [
60] and [
61] discussed the dynamic pricing in detail for smart energy model of a smart grid. The discussed model was dependent on renewable energy sources, which were further integrated with intelligent control that processed information from a smart metering devices.
The studies discussed above are inadequate to meet the needs, i.e., the electricity firms considered utility companies as a single firm. This study differs in this context as this incorporates numerous utilities and consumers. Moreover, the basic aim of both entities is to increase their profits (remunerations) by game theoretic approach. Besides, there is a broad literature and findings available on the Stackelberg game on the topics of profits maximization, congestion control, and interactive communication [
62,
63].
3. Game Theoretical Problem Formulation
This study takes
n consumers and
utility companies in consideration. Besides, the energy sources of the utilities include non-renewable and renewable resources. In literature, it is observed that power generators, which are centered on the energy of fossils utilize a definite amount of energy. Moreover, the energy of fossils is also supposed to be harmful for the environment. Contrarily, renewable energy sources are considered environmentally friendly. However, renewable resources have inherent natural stochastic behavior, which makes it difficult to predict and control. The studies show that uncertainties are common with renewable resources. Furthermore, Markov chain (discrete time) has been extensively employed in literature for the generation of power from renewable resources [
64].
This study takes residential type consumers into account. In addition, all users have dissimilar requirements for power consumption. The study also distinguishes the users based on their financial plans; i.e., purchasing power of electrical energy. Likewise, this study proposes a utility function for every consumer. The function shows an increment using the total expanse of power that any consumer is able to utilize. Moreover, this paper integrates cost parameters for every consumer.
The and n have established a two way communication using the advanced metering infrastructure for pricing swapping and information sharing. Conversely, can also communicate with one another. The n collect the value (cost) facts from the . In return, the then provide their services to n.
Power initiation, dissemination, and expenditure can be divided in three ways [
65]: Power generators,
, and
n. This paper emphasizes the communication between
n and
. Moreover, this paper assumes that
show a fluctuating behavior at the business level. Inspired from the game theory models, the
can play a vital part in an economical marketplace. No participant is capable enough to affect the market price of electricity through his particular activities. Thus, the market price is such constraint over which
have no control. Moreover, the
need to increase their production up to the point where the minimal cost is equivalent to the cost of the market. This phenomenon occurs once the total contributors increase and no contributor is authorized to govern an enormous power generation quantity. Nonetheless, this study proposes a predetermined figure of
(contributors). This scenario depicts that every utility will announce its own price according to its generation capacity.
Table 1 shows the list of symbols used.
3.1. Analysis of User and Utility Company
The cost for every consumer shows fluctuation when there are various utility firms having diverse electricity costs. Moreover, the setting of cost is highly reliant on the rates of other
. In this regard, game theory offers an ordinary pattern to represent the activities of
n and
. Consequently, the
settle the cost for each unit of energy and then publicize this to consumers. The users then respond back to the cost by demanding an optimal amount of power from the
. In this case,
play first. The consumers then decide on the basis of announced prices. Moreover, both events are in sequence. The events are that the utilities play primarily and at that time the consumers decide their verdict based on the cost. Hence, this paper models the communication between the
and
n by a Stackelberg game [
66]. The proposed game model takes the
as influential (leaders) and users as followers. Moreover, the proposed model also considers the events as a multiple leaders and followers game.
3.1.1. Analysis of User Side
Assume that
is the request of consumer
from a utility
. Hence, the value of a consumer
,
can be expressed as:
Here
and
are constants. Also, the
ln function is extensively employed in literature for user making decisions [
67]. The valuable function used for consumer
in Equation (
1) is interrelated to the function
.
The consumer will recompense -∞ when the valuable function is used regarding , such that, = 0. When and are equivalent to 0, then benefit of regarding begin to be finite. Generally, the representative cost of = 1.
Suppose
is the per unit cost given by any utility company
and
0 is the total expenditure of any consumer
. Each
has given a distinct price rates of electrical energy [
,
,……,
] when
. Subsequently, the
computes the best demand response through resolving best optimum solution (
) given in Equation (
2).
where
,
is a convex optimization problem. Therefore, the obtained solution is distinctive and optimal.
This paper considers the scrutiny accompanied by
consumers and three
s. Thus, they seek for best optimum solution in this scenario for a specified
can be expressed as follows:
where
and
.
The paper employs Lagrange multipliers (
) for the respective
and setting of parameters as discussed above. Thus, the Equation (
4) can be rewritten as:
The values of the Lagrange multipliers are used as strategies for finding the local maximal and minimal of the function subjected to inequality constraint. Thus, it improves the performance of Equation (
5).
Moreover, setting
and
generates Equation (
6) to 0. Whereas,
, and
.
The first order optimality condition for linear, best optimum solution and maximization problem is by setting
. Here,
). All of the
n are interconnected by
. Also,
shows that,
Next, this paper has considered four of the cases, which the can avail.
Case 1
If
and
are greater than 0, then
. So, Equations (
8) and (
9) are generalized as:
where
and
. Now, using Equation (
6) in Equation (
10),
Thus, Equation (
11) becomes Equation (
12) after simplification.
Here value of varies; i.e., 1, 2, or 3.
Case 2
If
and
are equivalent to 0, then
. As discussed above that
corresponds to 0. This paper derives Equation (
13) by considering the cost of the first utility.
This paper further expands Equation (
6) to include extra parameter and ease simplification. Thus, Equation (
14) is derived.
As
and
, which refers to the point that
. Now, evaluating this in Equation (
13),
Equation (
15) is now equivalent to
. Moreover, Equation (
15) can also be presented as:
where
.
Case 3
If
is equivalent to 0 and
, then the identical scrutiny can be valuated as specified in Case 2. This paper considered the cost of the second utility; thus, the demand of users with respect to the second utility is given in Equation (
17).
Subsequently, Equation (
17) is now equivalent to
.
Case 4
If and both are equivalent to 0, then , and are real and positive values. It is noted that Case 4 is assumed as best case which rarely occurs only when or else .
This paper has satisfied the power and cost parameters as equalities in Case 1, 2, and 3. However, this scenario cannot be mapped on Case 4. This study further assumes that there are
n consumers in total and
utilities that satisfies the equality conditions in previous cases for a given set of
. So, Equations (
12), (
16), and (
17) can be combined in the above discussed scenario as:
In Equation (
18),
and
. As
. So,
3.1.2. Analysis of Utility Companies
This study assumes that
(
) depicts the available electrical energy of
. The aim of every
is to vend the energy to gain maximum profit. For instance, if there is only one
then this firm will settle the price range according to its ease as there is no competition involved. However, this study takes two basic strategies that decide the cost range of any
. Firstly, it can be the economical conditions of average consumers and secondly, it could be an aspect of competitiveness among
. Furthermore, the
also take part in choosing the best optimum cost (
game) with another. Additionally, this study expresses the maximum profit
of any
as:
Here,
is cost of
apart from
. Thus, the best optimum solution for any
can be related in terms of
and can be expressed as:
where
and
. The maximum profit of any
is fluctuating in relation to energy for a constant
. According to Equation (
20), this phenomenon leads to parameters of equality. Every
proffers to vend all its energy to consumers. This paper assumes
to resolve
by:
The best optimal solution for the
furthers presents
, which is equivalent to 0.
where
and
. Moreover, the conditions used in Equations (21) and (22) express
equations. Now, solving these three
, this study sets
and
. Furthermore,
can be evaluated by means of
. Consequently, employing Equation (
18) for
,
Now, using the current value of
this study observes that,
It can also be deduced from Equation (
23) that
. Also,
and
. It refers to the phenomenon that there is no essential need to play any game when
. Therefore, the study merely focuses on the circumstances when
. To handle the discussed scenario, Equation (
23) can now be computed as:
, and
. From the above equations, it can be concluded that
is an invertible matrix. However, it could be expressed as:
This paper considers some cases to achieve closed-form solution of .
Case 1
All the
have equivalent amount of energy available and capacity to produce, then
. Utilizing Equation (
26),
Also,
. Then the Equation (
27) is used in Equation (
19), so that the total demand to any
from
is given as:
Here, Equation (30) indicates that . This phenomenon indicates that now all s produce equivalent amount of power. Moreover, they have settled some pricing scheme that users have to follow.
Case 2
Contrary to Case 1, this case considers that capacity of power generation is different for all
s. The
in Equation (
26) has some unique aspects, which relates that a real valued matrix
is only considered diagonal as shown in Equation (
31),
where,
. According to [
68], a taut diagonal matrix is always non-singular and
is positive. It is observed that
is taut and diagonal matrix as
. Consequently,
. Thus,
is invertible.
Theorem 1. The distinctive solution achieved from is positive.
Proof of Theorem 1. The solution of
is deduced by
Since
is invertible; thus,
is positive if its eigenvalues are non zeros and show a symmetry property. Also, the solution presented in Equation (
32) depicts that
. □
Theorem 2. The cost function discussed in Equation (27) is a best optimum solution for raising profits. Proof of Theorem 2. Let the solution gained from Equation (
27) be
for any
. Moreover, this paper assumes that
has increased the cost from
to
, while
have same cost of power generation. From Equation 19, suppose that any consumer
n demands power
from any
then the constraint in Equation (
33) is satisfied.
Now suppose that
and
fulfil the requirements of Equation (
33). In this regard, the necessities of consumers will show deviating behavior from
to
as:
The differentiation among the necessities of any
n from the firm
will now be expressed as:
From Equation (
35), it is obvious that
. Hence, the consumers are not capable of demanding the total power generated by any
, i.e., the consumer will then demand for lesser energy as required. Moreover, the profit and cost of
will increase on the basis of consumer total power demand. Thus, Equation (
36) provides the balanced equation of demand and supply.
It is observed that in Equation (
36),
. Thus, the profit gaining of
leads towards the loss and it is concluded that the price function presented in Equation (
27) is the best optimum function as it will result in financial advantage.
On the subject of range of , . As a matter of fact, is owing to the cost functions that is generated by . Moreover, any is not capable to lessen the price lower than . Nonetheless, is the maximum range. According to , the government has to settle the cost, which consumers have to follow. □
3.2. Proposed Stackelberg Game Modeling
All the
s partake to play the non-cooperative game with one another in order to settle the price that will be further used by consumers. This is a critical point where Nash Equilibrium is required. In a Stackelberg game, the equilibrium strategy for the followers is defined as any strategy that is compromised of the best response. The response is optimal as compared to the strategy that is adopted or announced by the leaders [
69].
This study assumes that
is the game-plan rectified for any
and
is the scheme planned for
. Subsequently, the game-plan for
will be
and for
will be
. Thus,
is proposed Stackelberg equilibrium for any
if,
Here,
is the game plan of all consumers
n. Moreover,
and
are best feedback of all consumers, i.e.,
. The best feedback of any consumer
for any particular (
is:
Here, . Thus, is supposed to be best optimum scheme for . Besides, and is a Stackelberg equilibrium achieved for the game concerning the and n.
3.3. Distinctiveness of Stackelberg Equilibrium
The has an exclusive maximum range (as discussed above) for . Whenever the cost planning game is played between the companies with a distinctive Nash Equilibrium, then the Stackelberg game plan holds a special equilibrium.
Theorem 3. An exclusive Nash equilibrium occurs in the cost selection game plan between . Likewise, a distinctive Stackelberg equilibrium subsists as well.
Proof of Theorem 3. There is equilibrium if is a real value and . Moreover, is constant in . On the topic of cost choosing of all in Stackelberg game, . Here, . Moreover, . Therefore, the game plan is real value and . □
Furthermore,
is constant in
as discussed in Equation (
20). Subsequently, the
according to
is,
3.4. Distributed Algorithm
The users are now proficient enough to compute their optimum demands on the basis of the cost function provided by the utility companies as discussed in the preceding section. However, the different utilities show the significant response to policies announced by other companies. Moreover, it is essential to calculate the price per unit. For this purpose, should know the production capacity of other utilities. Contrary to this, this paper proposes a distributed algorithm that further proves the Stackelberg equilibrium of the game. The equilibrium is established in such a way that utilities are not able to identify the constraints of each other.
The establishes a subjective cost and then conduct their cost statistics to the users. This communication is done efficiently by setting an interactive environment for utilities and consumers. As a consequence, the consumers choose specific amount of electricity they need to purchase from .
All the
acquire these demanding conditions from consumers. At that moment,
will analyze the contrast among the available electrical energy and the entire energy needed by consumers from the company. The
will upgrade its price per unit with the help of Equation (
40).
In Equation (
40),
is the repetition number and
is the rate modification constraint of
. Whenever a
updates its cost function, it sends this information to
. Furthermore, the
update the demands and send this information back to
. Subsequently, the
s will also update their cost functions sequentially. Thus, the procedure lasts until the cost function shows convergence. Algorithm 1 supposes that
specifies the first consumer.
Theorem 4. Given that andAlgorithm 1 meets the best optimum solution for all and n
as the particular game plans are upgraded in a specified order. Proof of Theorem 4. The feedback of a consumer as specified in Equation (
18) is best optimum solution for a particular
.
Whenever, the cost per unit shows a converging behavior then the demand of every consumer will coincides towards an established set. Therefore, it is necessary to discuss the converging behavior of cost in order to demonstrate the changing performance of Algorithm 1.
Algorithm 1 will only show the diverging behavior whenever the
will be negative in Equation (
41).
| Algorithm 1: Distributed Algorithm |
 |
In Equation (
40), if
then the significant constraint for
for not gaining a negative amount is
. Furthermore, the condition that is discussed above can be revised as
. □
Equation (
40) suggests that the cost
amplifies only if
gives positive results and vice versa. However, in Equation (
40), when
the price value is not changed. This particular condition is the established stage to which Algorithm 1 shows converging behavior. This stage is the Nash Equilibrium of the game plan (Stackelberg game between
n and
). Afterwards, the
will not show any fluctuating behavior.
5. Application of Proposed Method on Vast Topographical Zone
This paper employs the knowledge based short-term load forecasting model on a vast topographical region. Moreover, this paper has selected regions of Pakistan for implementation of the proposed model. Pakistan has four seasons and different climates with significant discrepancies throughout the year. PNPN is a huge topographical system, which is distributed in nine regions that are equivalent to regional electric utilities. The primary objective of PNPN in this study is to forecast the demand load for every region. In addition,
Figure 3 presents the different colored portions along with the mean of regions having high temperature throughout the year.
A city is selected from every region that is supposed to be the representative of the region. Moreover, a city also specifies the temperature of that particular region. There is no restriction on any system to distribute into specified number of regions. However, the system can be divided according to the requirement of the system and fluctuating behavior of weather.
Figure 4 depicts the changing behavior of temperature for Lahore city as a sample.
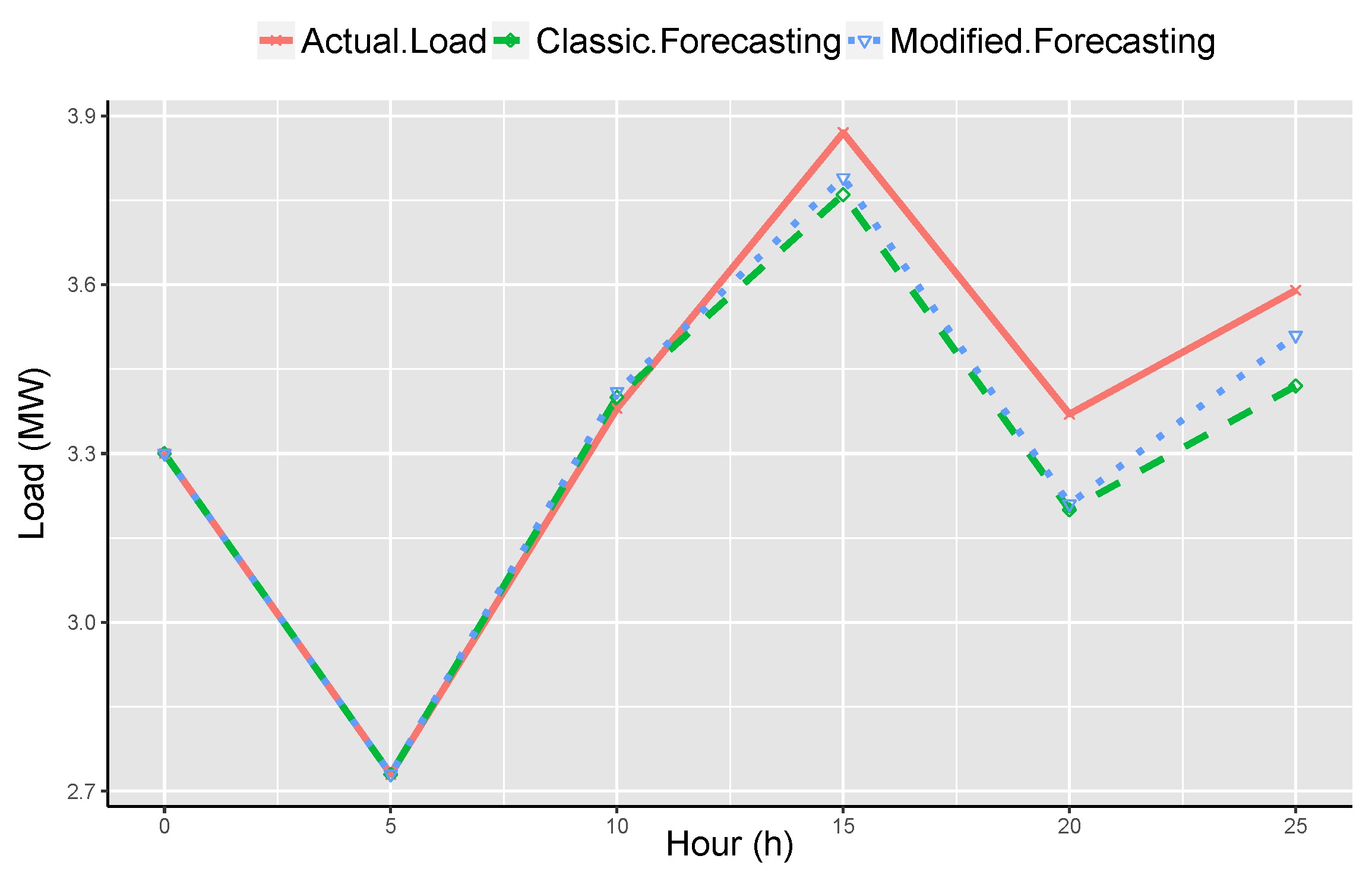
The investigation of PNPN demands more scrutiny of Pakistan’s user consumption behavioral analytics. Monday is the first working day of the week while Sunday is the last one. Moreover, the seven days of the week are categorized into four types in Pakistan. The first category of the day is Monday, which is the first working day in Pakistan. Monday has different power demand provisions, especially in early morning (peak-hours). Furthermore, the days from Tuesday to Friday that are also considered week-days in Pakistan, show the same load curve. The difference between Monday and other days of the week is illustrated in
Figure 5.
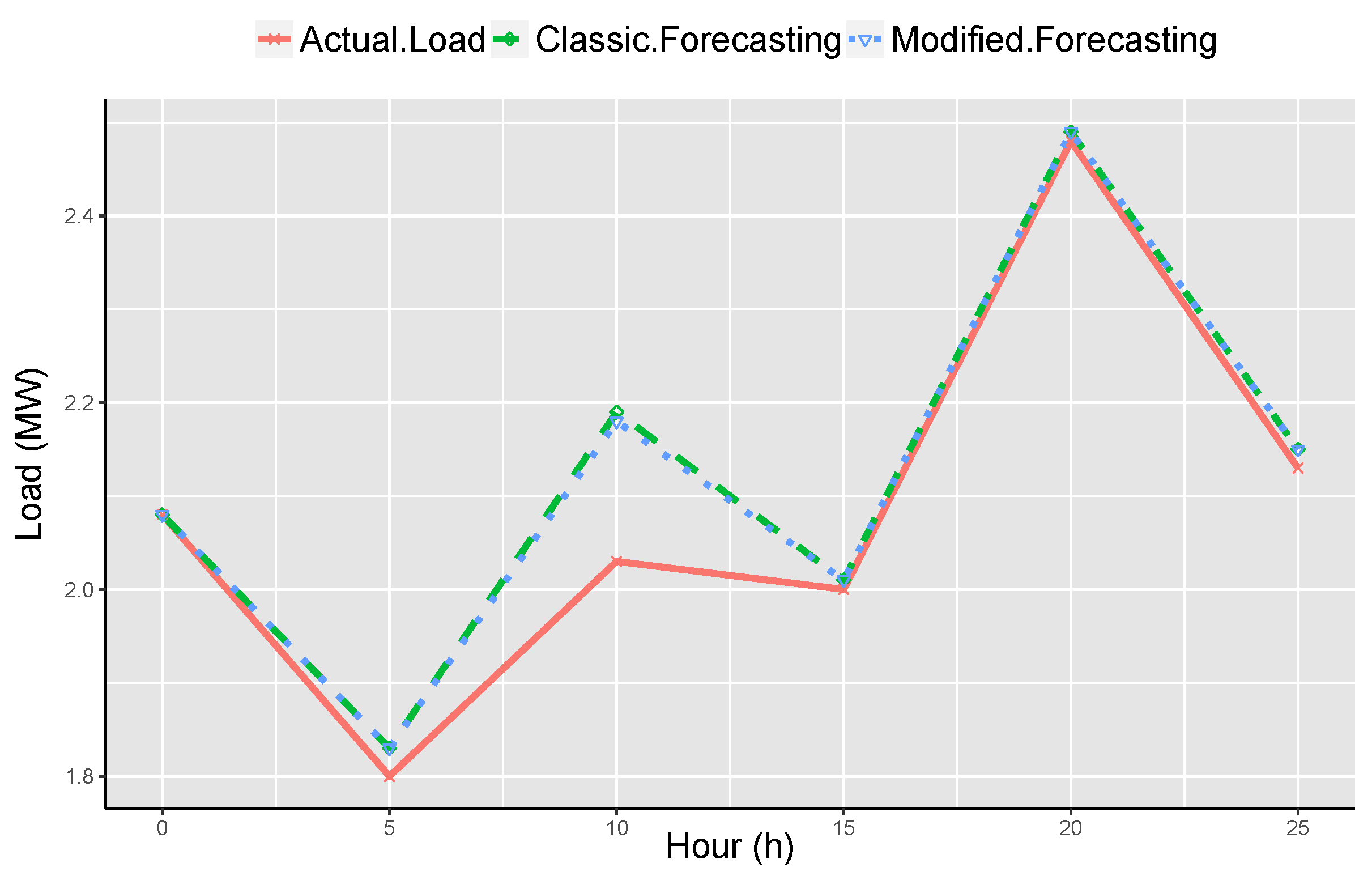
Subsequently, another category of day is Friday and Saturday. In this category of days, the operational hours of most workplaces and factories show a fluctuating behavior in contradiction to other week-days. Moreover, Sunday is supposed to be the rest day in Pakistan and is the last category of day. The load curve and load demand depict an entire variating behavior from other categories of day.
Figure 6 shows the fluctuating behavior of load curve for a successive week.
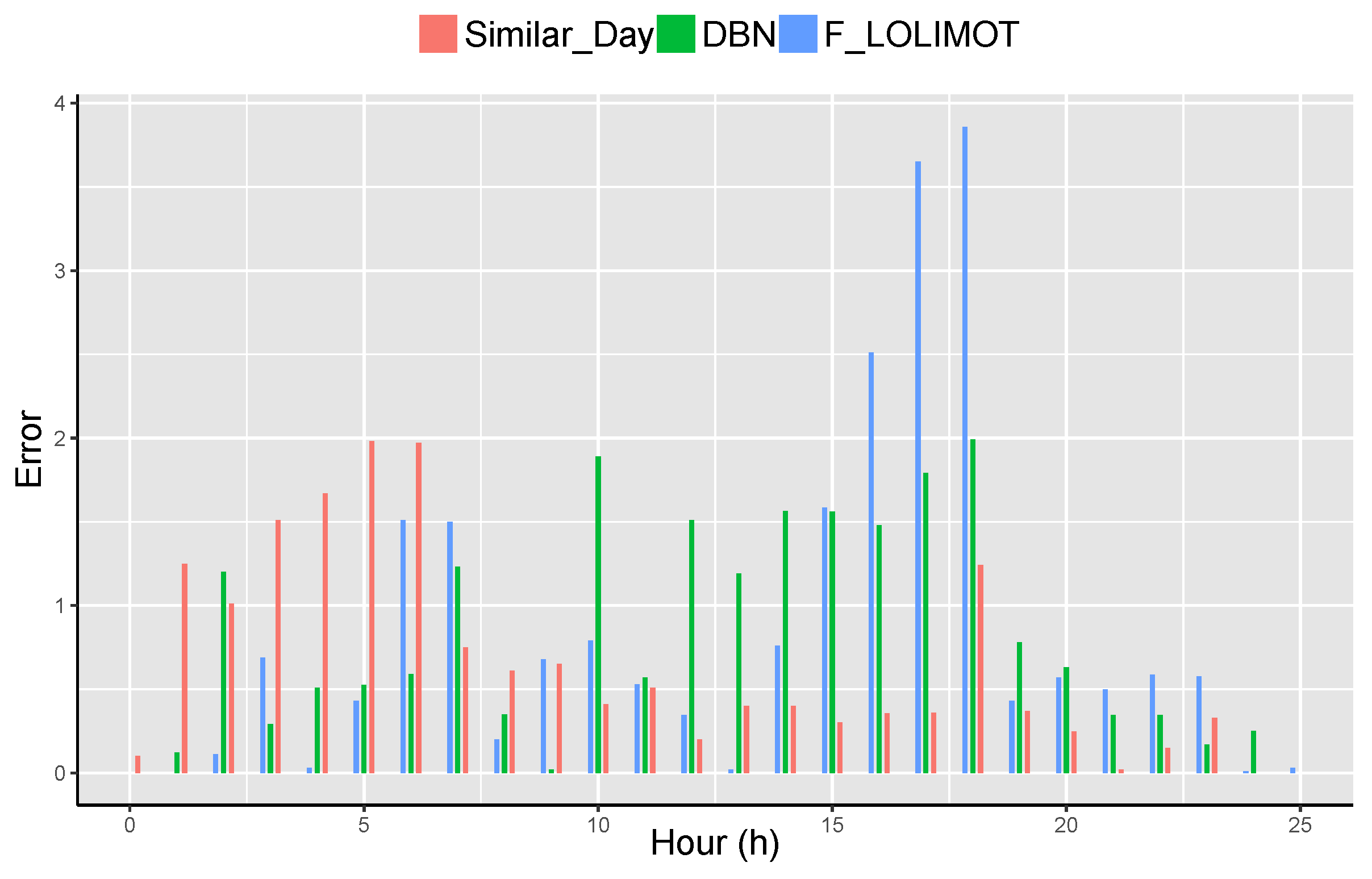
The paper scrutinizes hourly load for nine regions of PNPN. In this regard, the data form the duration of June 2015 to May 2017 is used as historic data for short-term load forecasting. Besides, the paper predicts the load demand for the duration of June 2017 to May 2018. A city is chosen from every region as a representative of that particular region. It is observed in the literature that there is no concept of splitting the data-set into training and test data in knowledge based systems. Moreover, the knowledge based systems use the entire historic data for choosing the best optimum results and similar days as discussed in Section II. However, the data-sets are divided into training and test data in DBN and F-LOLIMOT. This paper labels 77% of the data as training data and the remaining 23% of the data as test data.
This paper performs sensitivity analysis on the PNPN and concludes that the optimal values achieved for , , and are 8, 0.4, and 0.6, respectively. The sensitivity analysis is performed by means of historic data for the duration of June 2015 to May 2018 in order to get the best optimum parameter values. Moreover, the data for the duration of June 2017 to May 2018 is not utilized to get the best optimum parameter values. The load demand for the specified time period of previous data like from the duration of June 2016 to May 2017 is supposed to be the vital goal of prediction by the load information and earlier than that period. This helps in selecting the best optimum parameter values. The best optimal value is achieved when it has least prediction error for the specified period as discussed above. The value of is changing from 0 to 1. Therefore, it is now obvious that the value of will be calculated by .
In addition, the best optimum values of
and
are evaluated by the scrutiny of the historic data. Besides, data for the duration of June 2017 to May 2018 is not used in this analysis as this data is for prediction purposes. Likewise, the value of
is also attained from this method. This constraint shows a fluctuating behavior to achieve the least predicting error for a particular time spell.
Table 2 presents the prediction error for every execution. In this table, the values of
and
show a variance between 0 and 1. Nonetheless, the value of
lies between 5 and 15. The best optimum values for
,
and
are 8, 0.4, and 0.6, respectively.
This paper further assumes that the proposed methodology employs the similar day load demand data in the preceding years for the distinct days like public and religious holidays. This is done because there is an inadequacy in the historic data. Therefore, the technique of priority index is not applicable for distinct days. Consequently, it is one of the major reasons to observe the effect of temperature in the priority index for normal days instead of distinct days.
The paper only lays emphasis on the short-term forecasting for normal days. Moreover, the distinct days are overlooked from record for selection of similar day. Besides, the paper explains the knowledge based short-term forecasting for Tuesday, 28 June 2016.
At first, the days having a similar category of day are chosen on the basis of categorization of target day. In this scenario, Tuesday is included in the second category of day classification as discussed above. Moreover, all the days between Tuesday to Friday are selected. However, all the distinct days is overlooked for analytical purposes. Subsequently, these days are distributed in two data-sets, as discussed in Section II.
The priority index of every region is evaluated by Equation (
45), for all chosen days.
Table 3 presents the priority index of selected days for a sample region Islamabad as an example of 30 June 2015. Moreover, in this scenario the value of
is 0.03 and
is 1.5
. All the values and
Table 3 are associated with the second data-set of Islamabad for the specified date. Every region and every data-set are different from one another.
The priority index and short-term load forecasting of every region is evaluated by Equations (
42) and (
43) as discussed in Section II. In this scenario,
and final best suitable chosen similar days are 25 June 2016, 26 June 2016, 27 June 2016, 4 June 2015, and 7 June 2015 in Islamabad. Moreover,
Table 3 depicts that few same days show less difference in temperature rather than choosing same days. However, they are overlooked in this paper as along with the difference in temperature, the proximity of date has also significant worth. For instance, 10 June 2015 and 11 June 2015 will have less difference in temperature as compared to 15 June 2015. However, such days are neglected because they have maximum values of date proximity. Therefore, this paper can choose a similar day that has maximum difference in temperature in the proposed methodology because of proximities in date. Moreover, this phenomenon can produce more similar load curve shapes. Besides, the same chosen days in Islamabad and other regions can cause a discrepancy in selecting the same days from Islamabad for prediction of 28 June 2016.
The predicted demand load of the entire system is combined load that is obtained from all regions after short-term load forecasting is done for every respective region.
5.1. Deep Belief Network
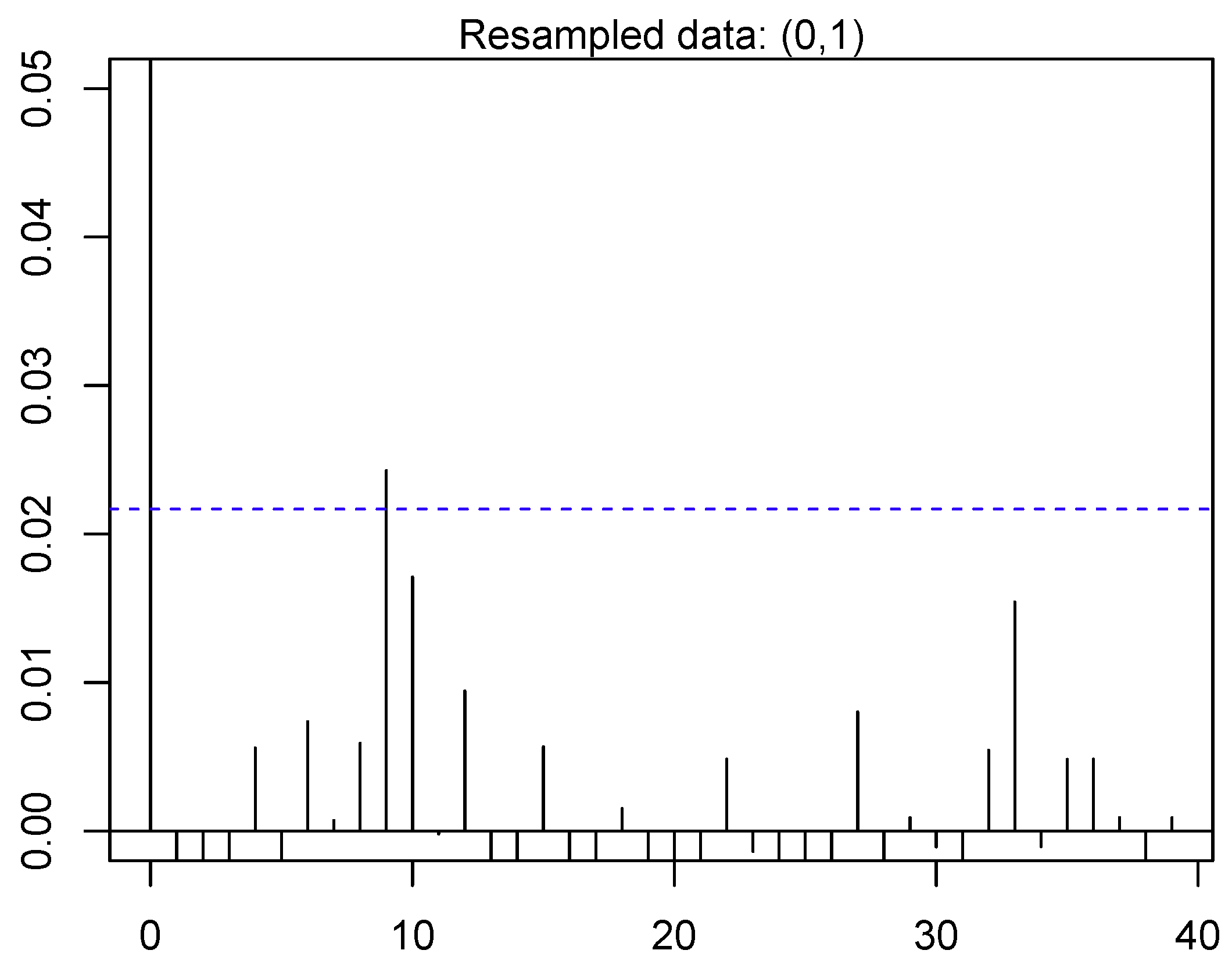
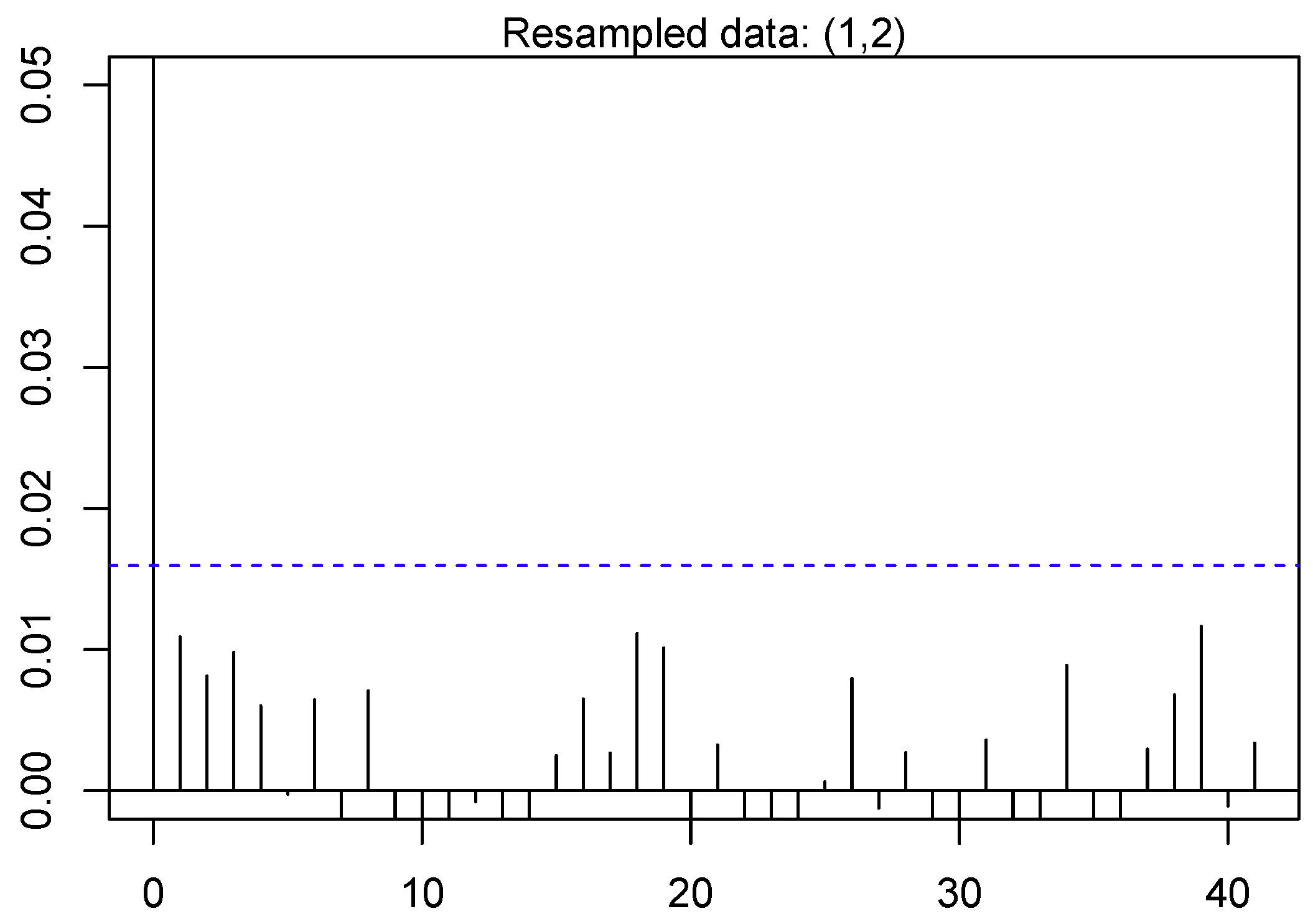
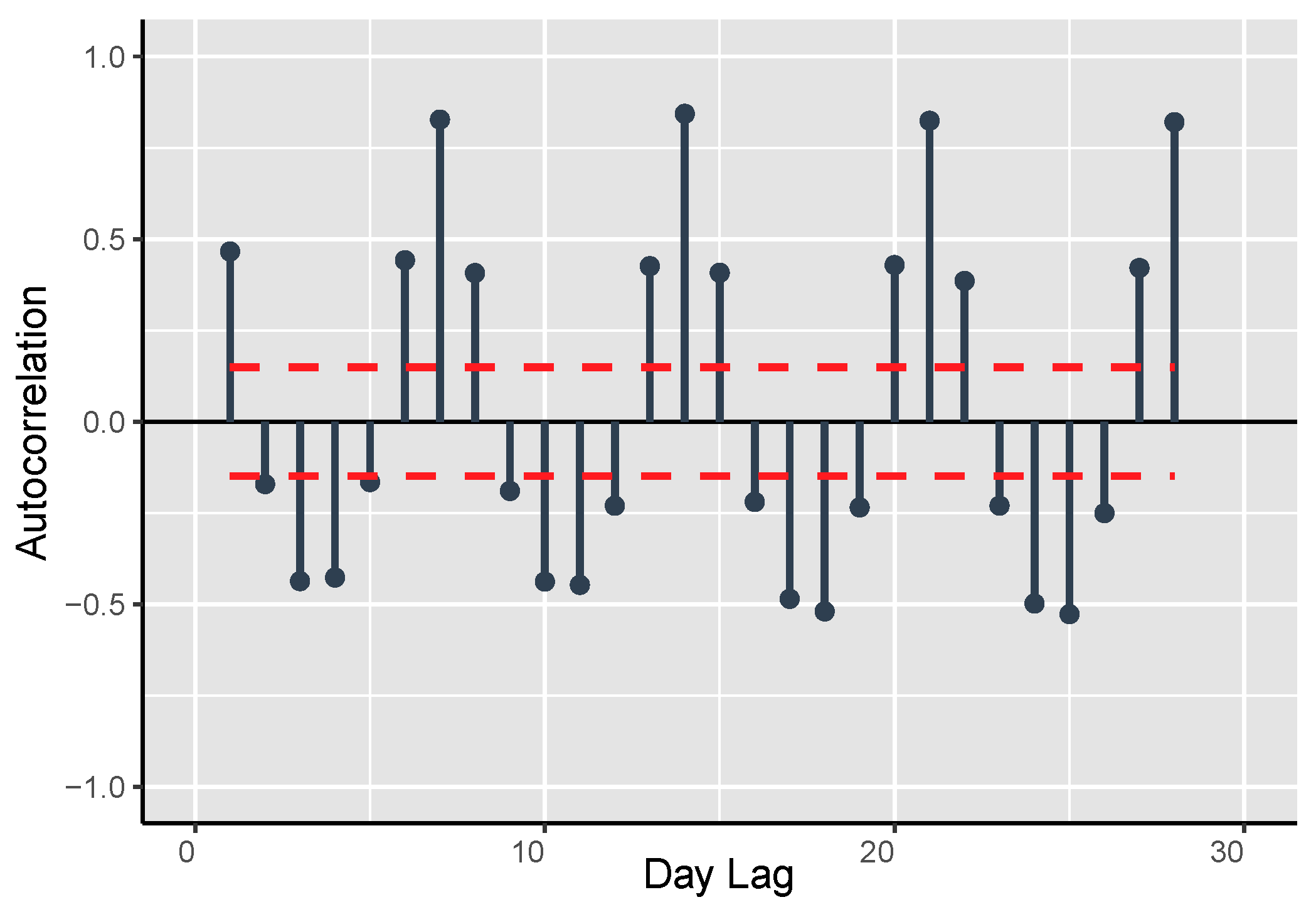
In [
77], the basis of DBN is presented briefly. Moreover, the auto-correlation of load demand data has been depicted in
Figure 7,
Figure 8,
Figure 9 and
Figure 10 for the previous data. It is obvious from the auto-correlation plots that the preceding data is more auto-correlated to experimental data, to some extent. This paper performs Ljung Box [
78] analysis of null supposition to check this assumption more quantitively. The suppositions are as follows:
: The preceding data are disseminated autonomously, i.e., the correlation is 0 in the preceding data from where the sample is chosen. Therefore, any experimental correlations in the preceding data are the resultant from the unpredictability of the test group.
: The preceding data are not disseminated autonomously, i.e., the data show serial correlation.
The auto-correlations tests are performed whose outcomes are shown in
Table 4.
The outcomes show that the preceding data is much more auto-correlated as compared to the experimental data. It is often observed in literature that numerous testing process reject the
for the preceding data. However,
is not rejected by experimental data. Therefore, there subsists a spatial correlation in preceding data. Moreover, if sampling techniques are applied on the historic data then this correlation can be disintegrated. The paper also performs sensitivity analysis and the structure of DBN used for this paper includes one hidden layer with five neurons. Moreover, there are 25 neurons are in input layer and 20 neurons in the output layer in the proposed architecture. These neurons generate the prediction of load demand for the target day (24 h). On the topic of architecture of this network, the input layer is comprised of two constraints for mean and maximum temperature for selected day. Moreover, one constraint is for categorization of the forecasted day while the remaining 22 input constraints are associated with the preceding load demand data, which are as follows:
In Equation (
48),
represents the total load demand data,
and
are demand load for
hour (
) preceding to selected day. This paper assumes that
and
represents the
and
-1 hours in Equation (
48). Moreover, there are 20 neurons in the output (
) layer of DBN that signifies the difference of load demand on the hourly basis for preceding and selected days,
The categorization of days in DBN are entirely divergent from knowledge based system. According to Equations (
48) and (
49), Tuesday must be taken apart from days that range from Wednesday to Friday. Therefore, in DBN five categories of days are taken for analysis.
5.2. Fuzzy Local Linear Model Tree Algorithm
The paper employs F-LOLIMOT algorithm for training of the linear fuzzy model. The explanatory analysis of F-LOLIMOT algorithm has been discussed in detail in [
79]. Moreover, the F-LOLIMOT algorithm is capable of predicting the hourly demand load, which is ahead than the current time by means of climatic and load data.
Figure 11 depicts that there are different inputs and outputs of demand load and climatic data. This is done after sensitivity analysis on the system.
Furthermore, the lags of climate are the climatic condition of the preceding week and target day. Likewise, the time lags of each hour load demand (inputs) are actually demand load data of similar hour at preceding 9 and 10 days earlier than selected hour. It is obvious that the initial hour of target day by utilizing preceding and recognized load data the upcoming hourly load is forecasted by preceding data.

 ,
, 



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}