PPK-Means: Achieving Privacy-Preserving Clustering Over Encrypted Multi-Dimensional Cloud Data


Abstract
:1. Introduction
1.1. Motivation
1.2. Contributions
- (1)
- We propose an encrypted cloud-based data mining system model. In our model, the cloud server can perform privacy-preserving clustering and decision over encrypted outsourced data on behalf of users.
- (2)
- Considering the clustering problem, we propose a privacy-preserving k-means clustering framework based on our proposed system model. In terms of different attack models, three concrete privacy-preserving k-means clustering schemes are constructed, PPK-means_1, PPK-means_2, and PPK-means_3, all of which allow the cloud server alone handle multi-dimension data efficiently in a privacy-preserving manner.
- (3)
- We provide detailed security analysis for our designs to demonstrate the privacy preservation guarantee against different threat models. Extensive experimental evaluations in simulation data-sets and real-life data-sets demonstrate our scheme is secure, correct, and practical.
2. Related Work
3. Scenario
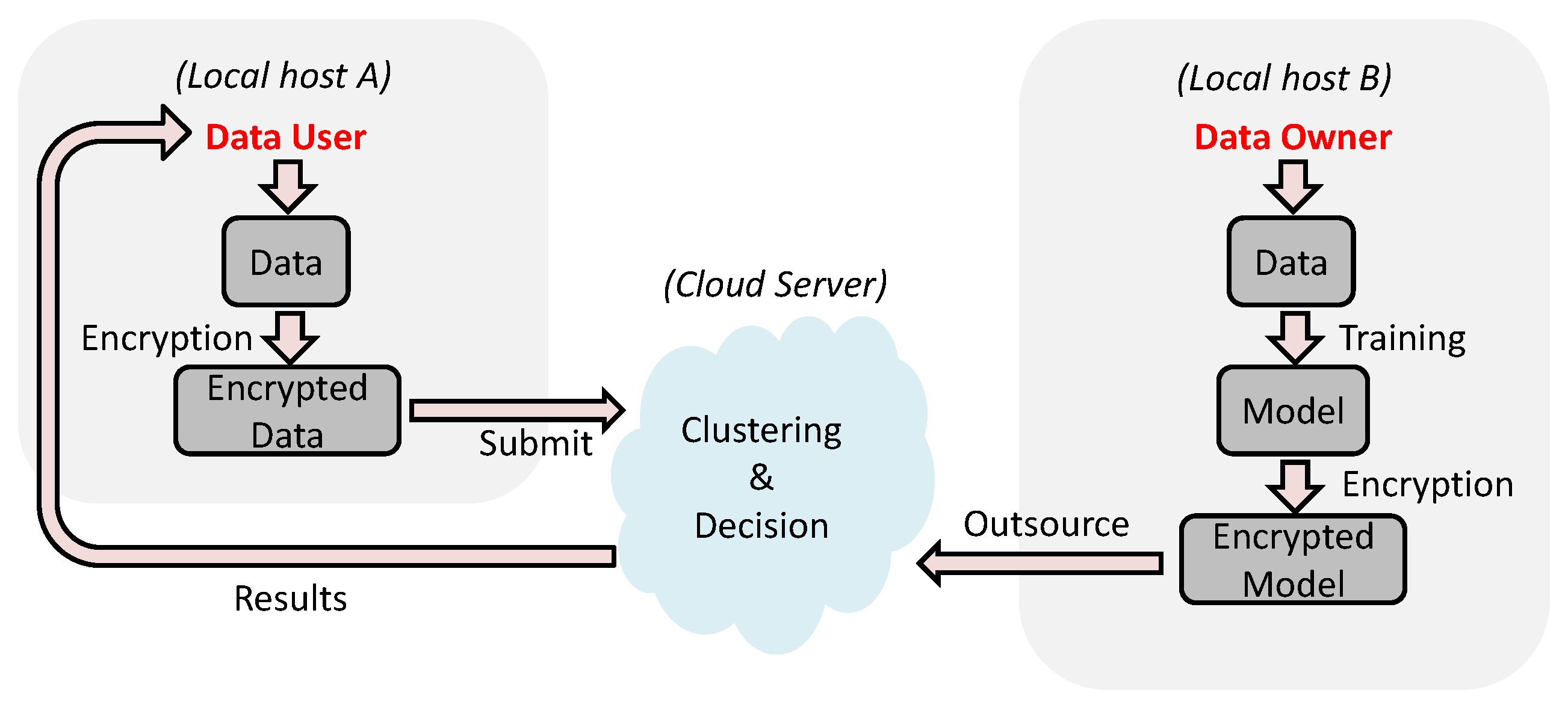
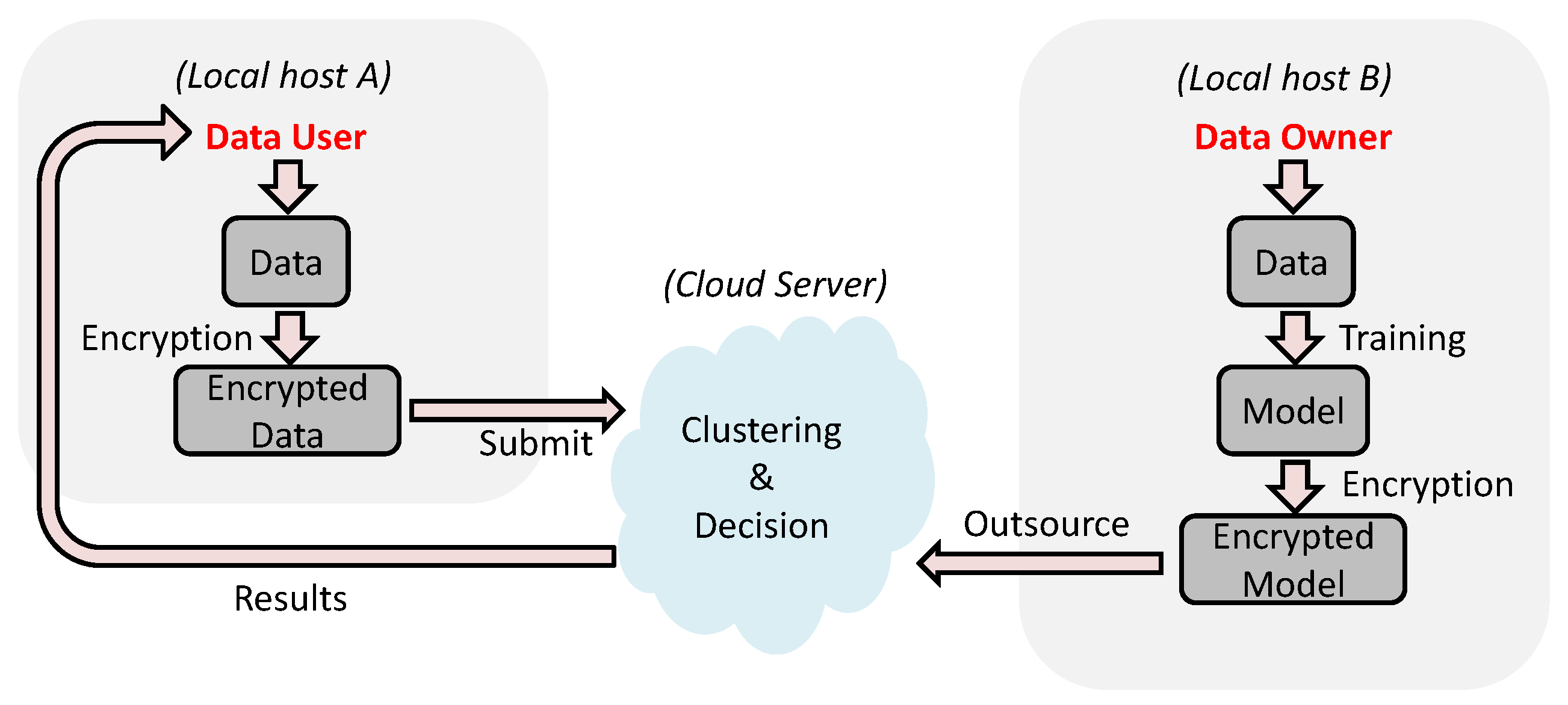
3.1. System Model
3.2. Threat Model
- Known Ciphertext Model: In this model, except for the encrypted trained model and the encrypted data user’s data, the cloud server can know nothing else.
- Known Background Model: In this model, the cloud server bears more knowledge than what can be accessed in the known ciphertext model, by which it can obtain useful information by analysing ciphertext. For example, the cloud server may know a few plaintexts and the corresponding ciphertexts, which can be used to recover the whole plaintexts from the ciphertext space.
3.3. Basic Techniques
3.3.1. k-means
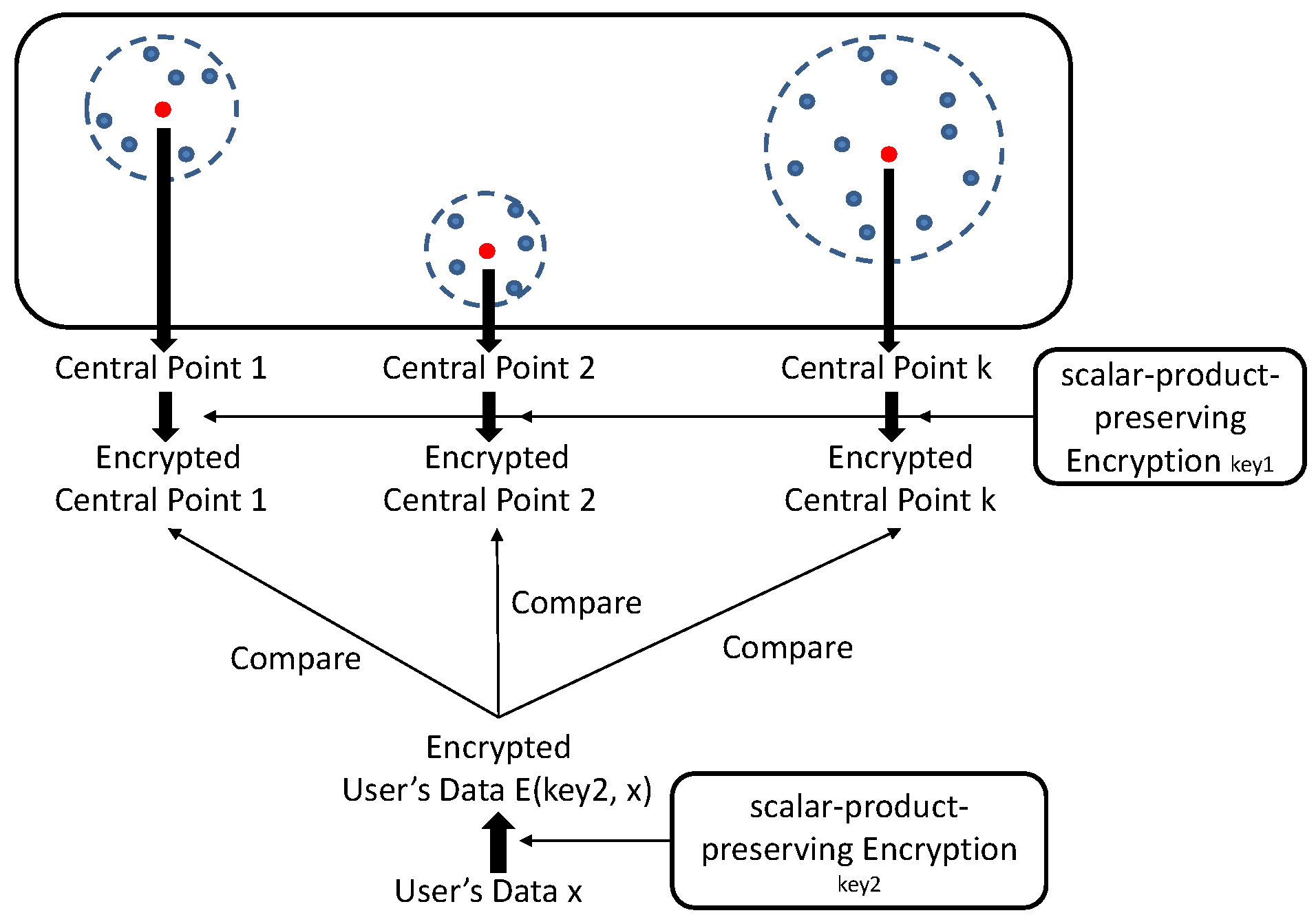
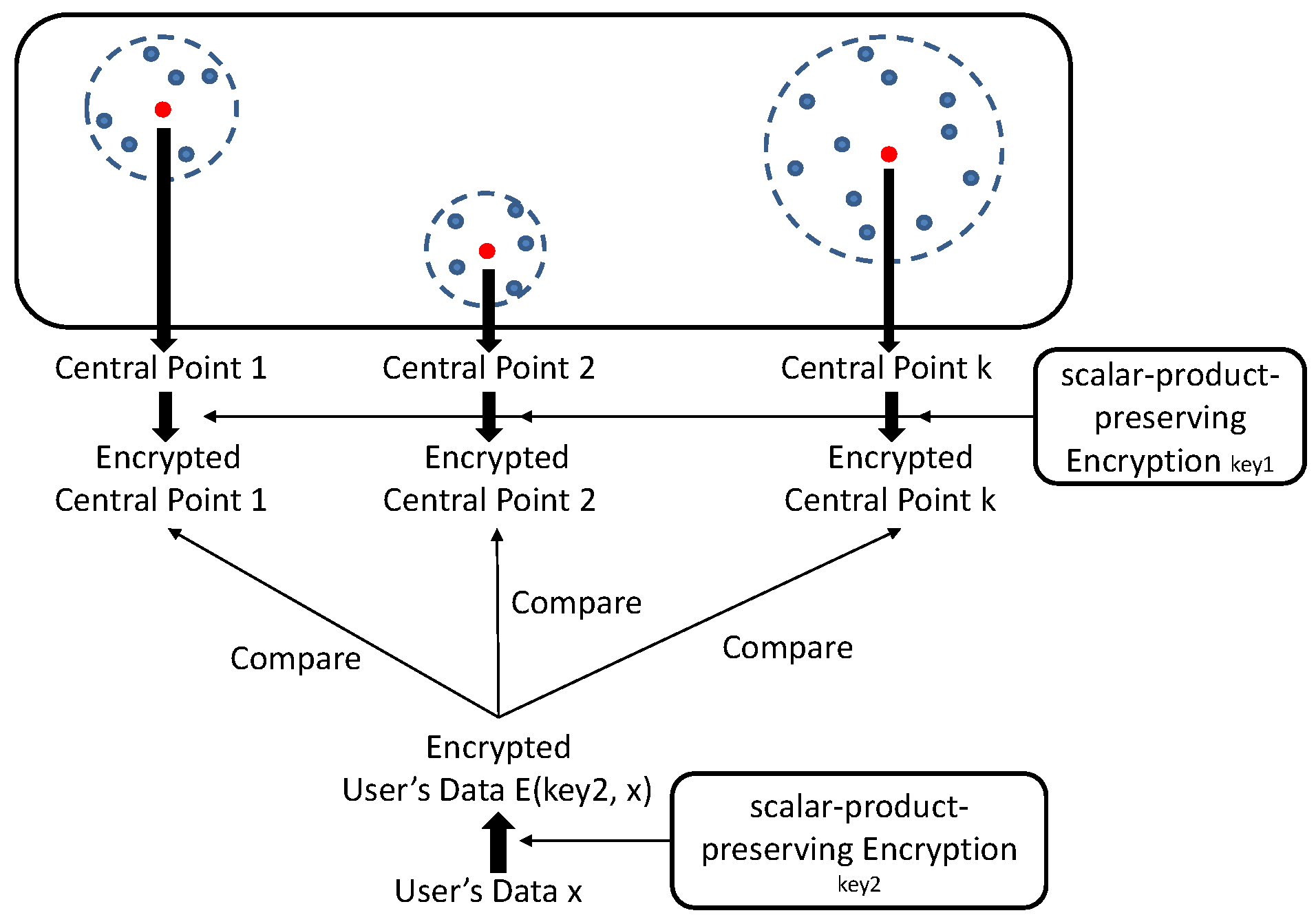
3.3.2. Scalar-Product-Preserving Encryption
3.4. The Basic Design
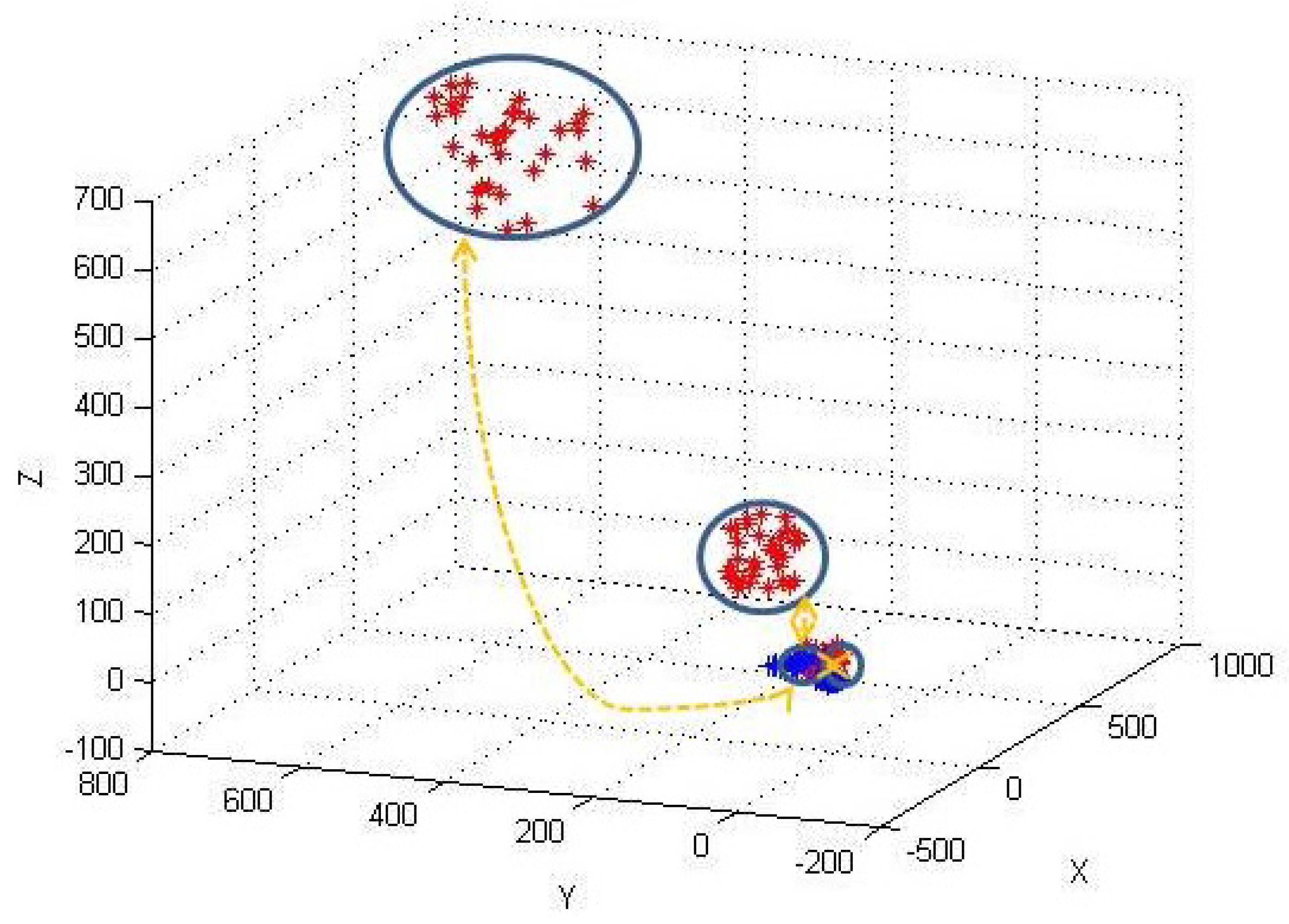
3.4.1. Work Flow
3.4.2. Framework
- Setup: In the initialization, the system generates a symmetric key , which is shared between the data owner and the data user.
- ModelEnc: The data owner takes the trained model P with k central points and the symmetric key as input, the algorithm outputs the encrypted trained model .
- DataEnc The data user takes a D-dimensional data vector and the symmetric key as input, the algorithm outputs the encrypted data vector .
- Decision The cloud server takes the encrypted model and the encrypted data vector , the algorithm outputs a label for x, which means which central point x is clustered into.
3.4.3. Algorithm Overview
| Algorithm 1 PPK-Means Algorithm |
|
4. PPK-Means Construction
4.1. PPK-Means_1
4.2. PPK-Means_2
4.3. PPK-Means_3
5. Privacy Analysis
5.1. PPK-Means_1
5.2. PPK-Means_2
5.3. PPK-Means_3
6. Scheme Evaluation
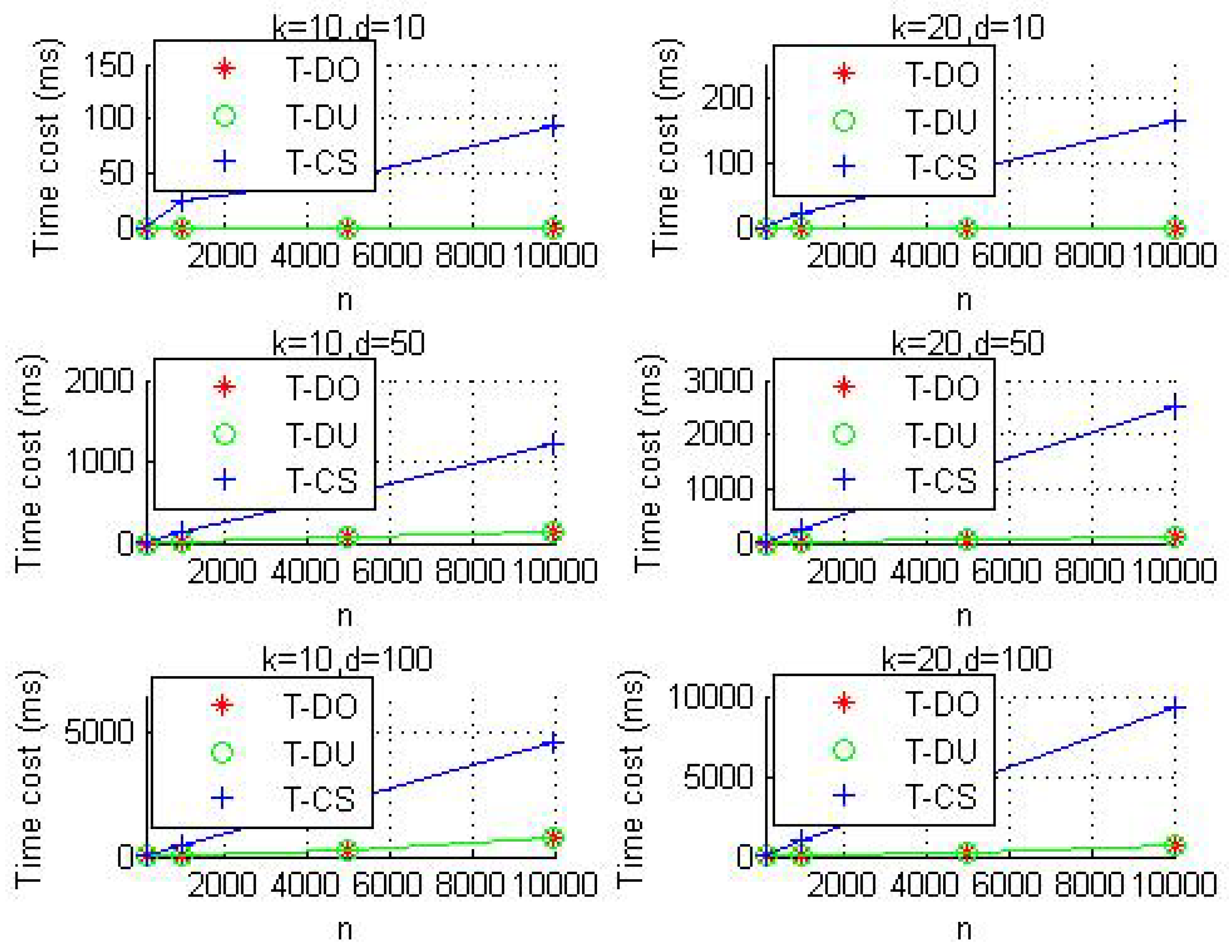
6.1. Time Complexity Analysis
6.2. Experimental Evaluation
6.2.1. Setup
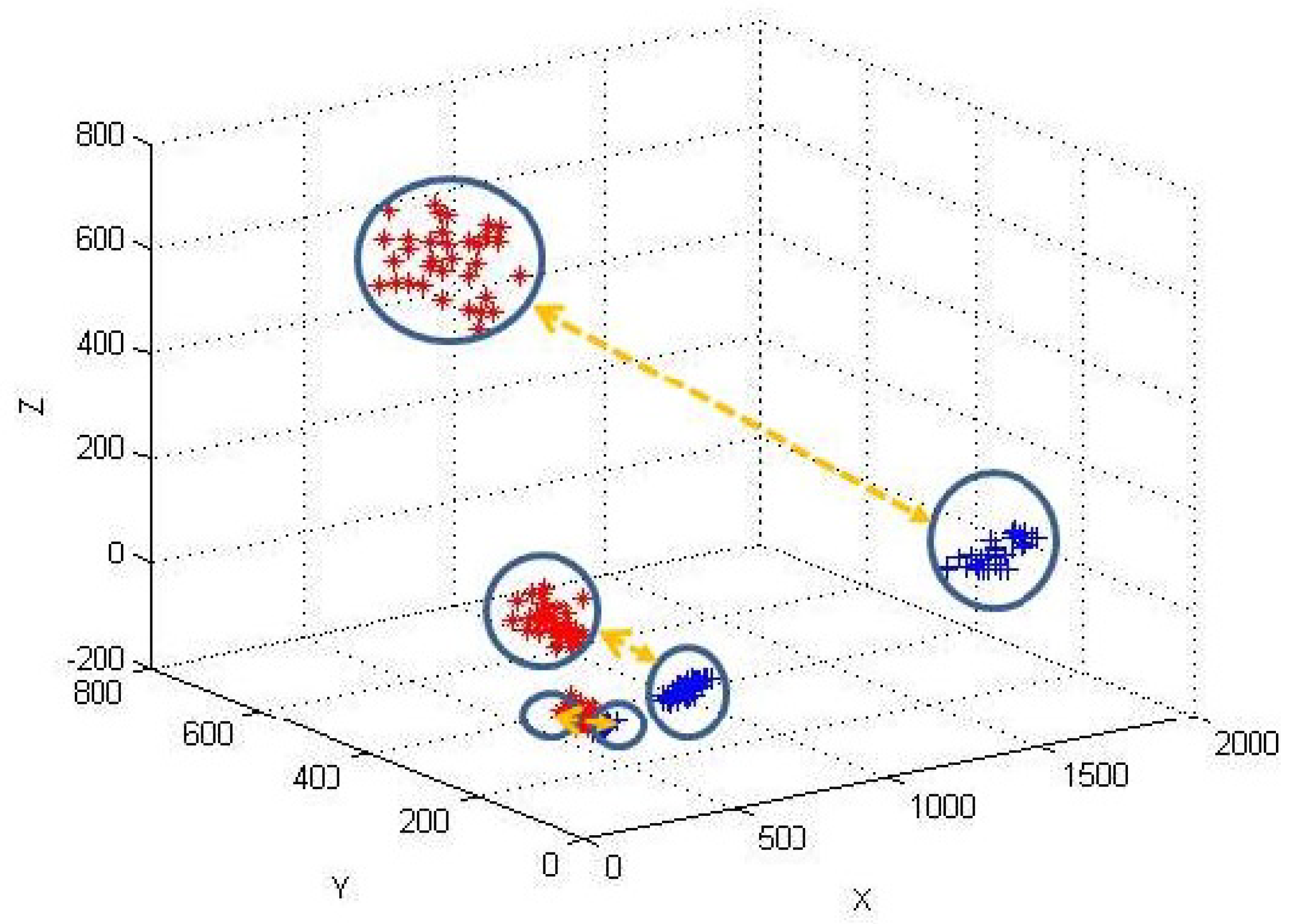
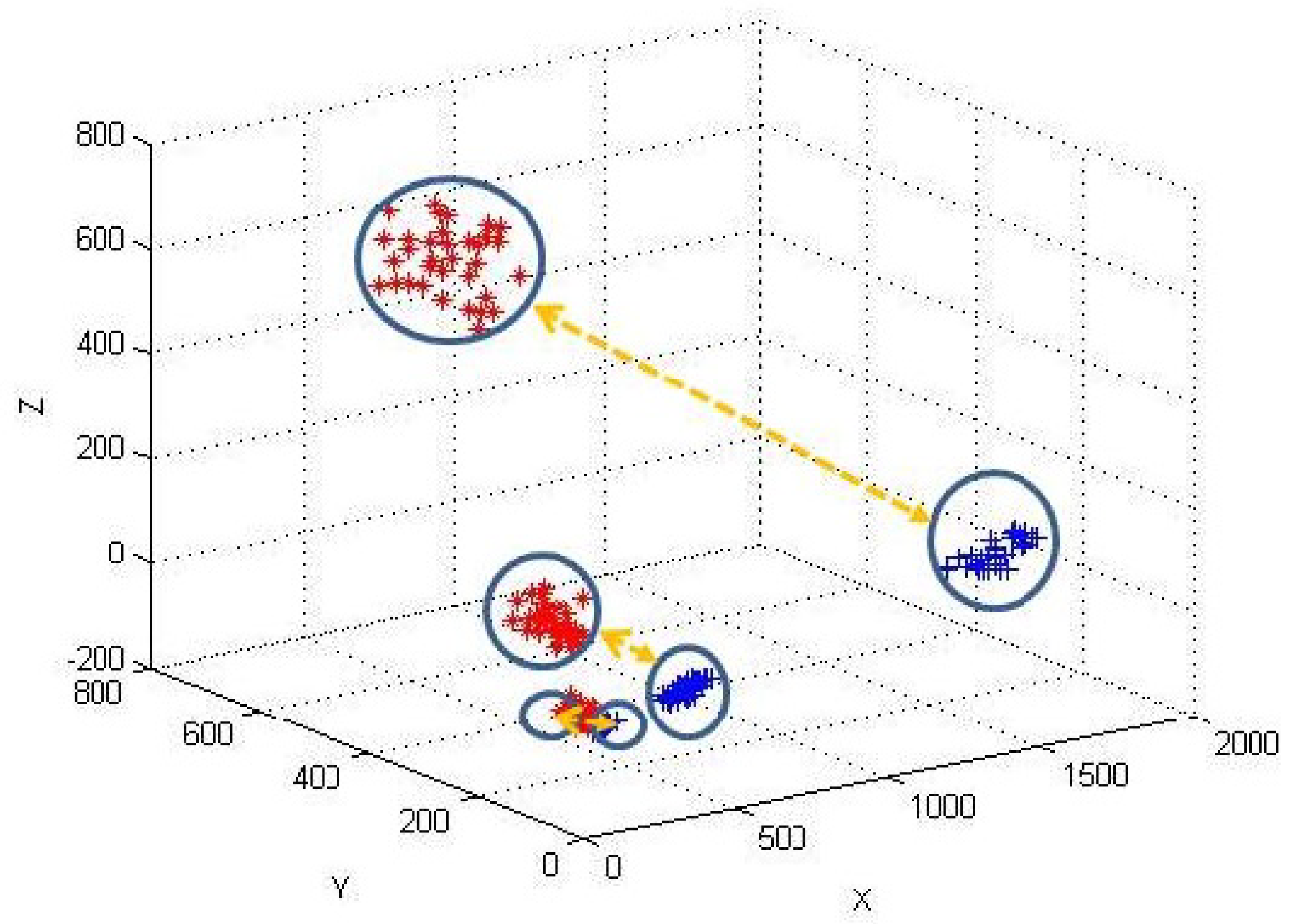
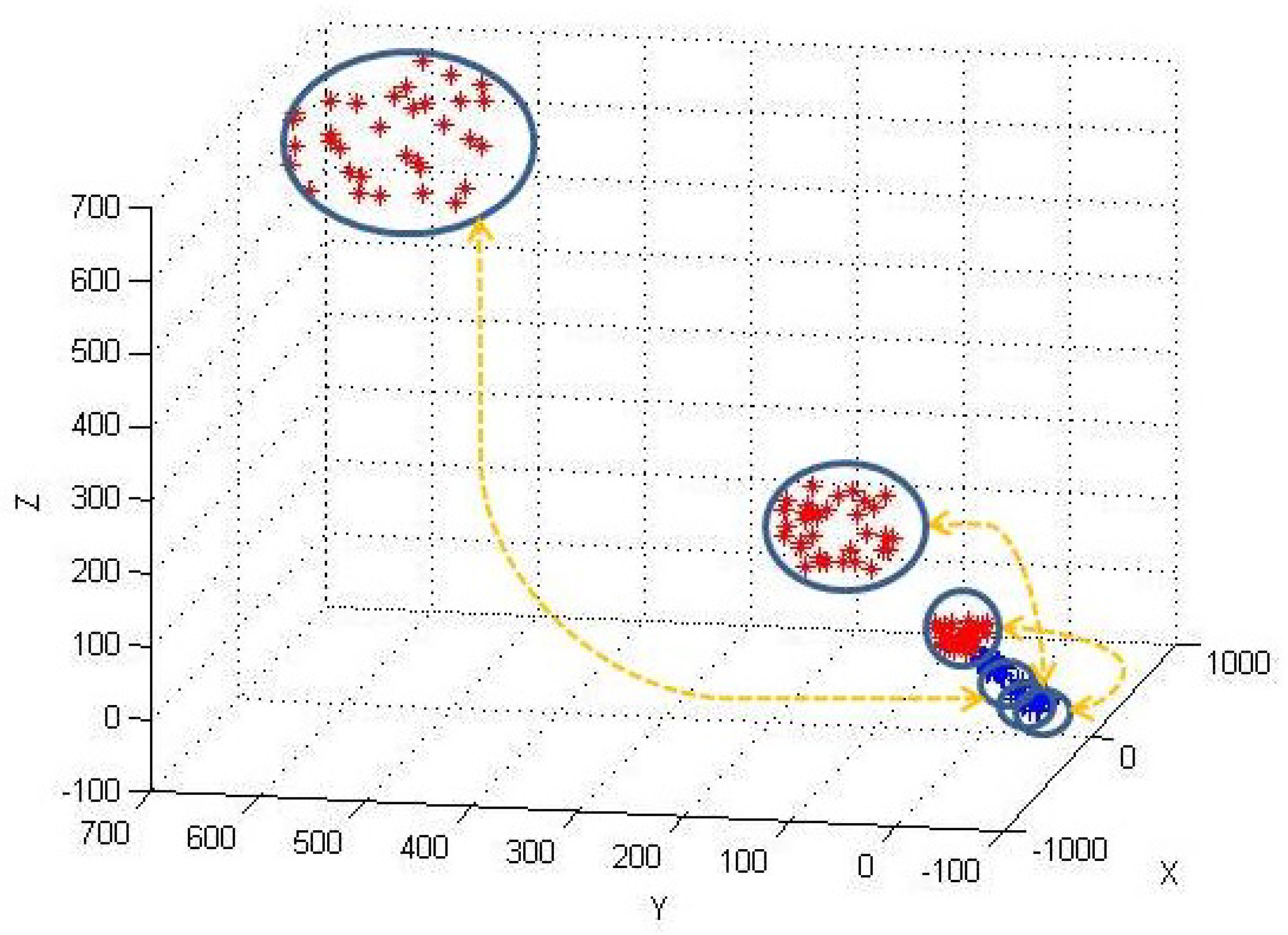
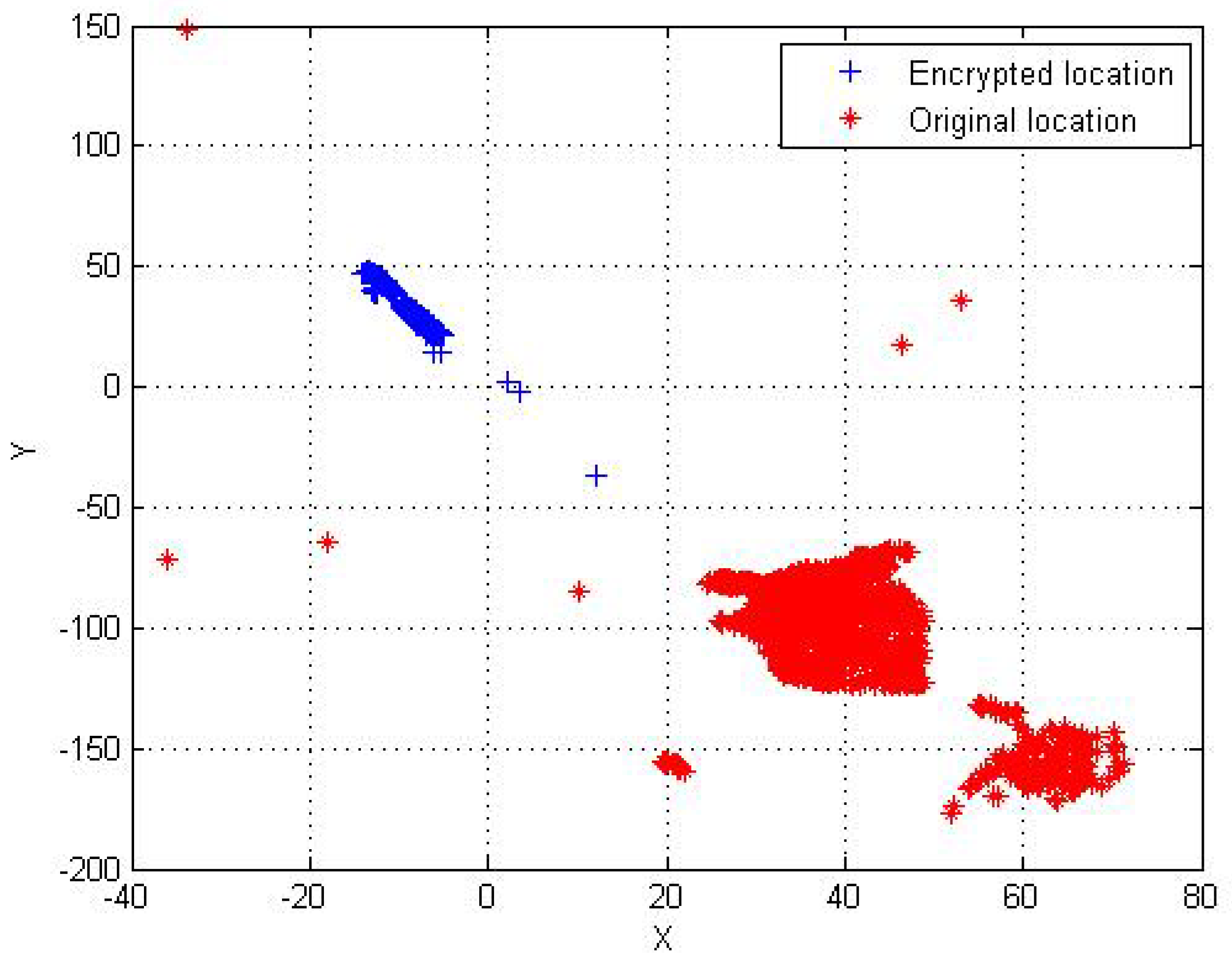
6.2.2. Evaluation with Simulation data-set
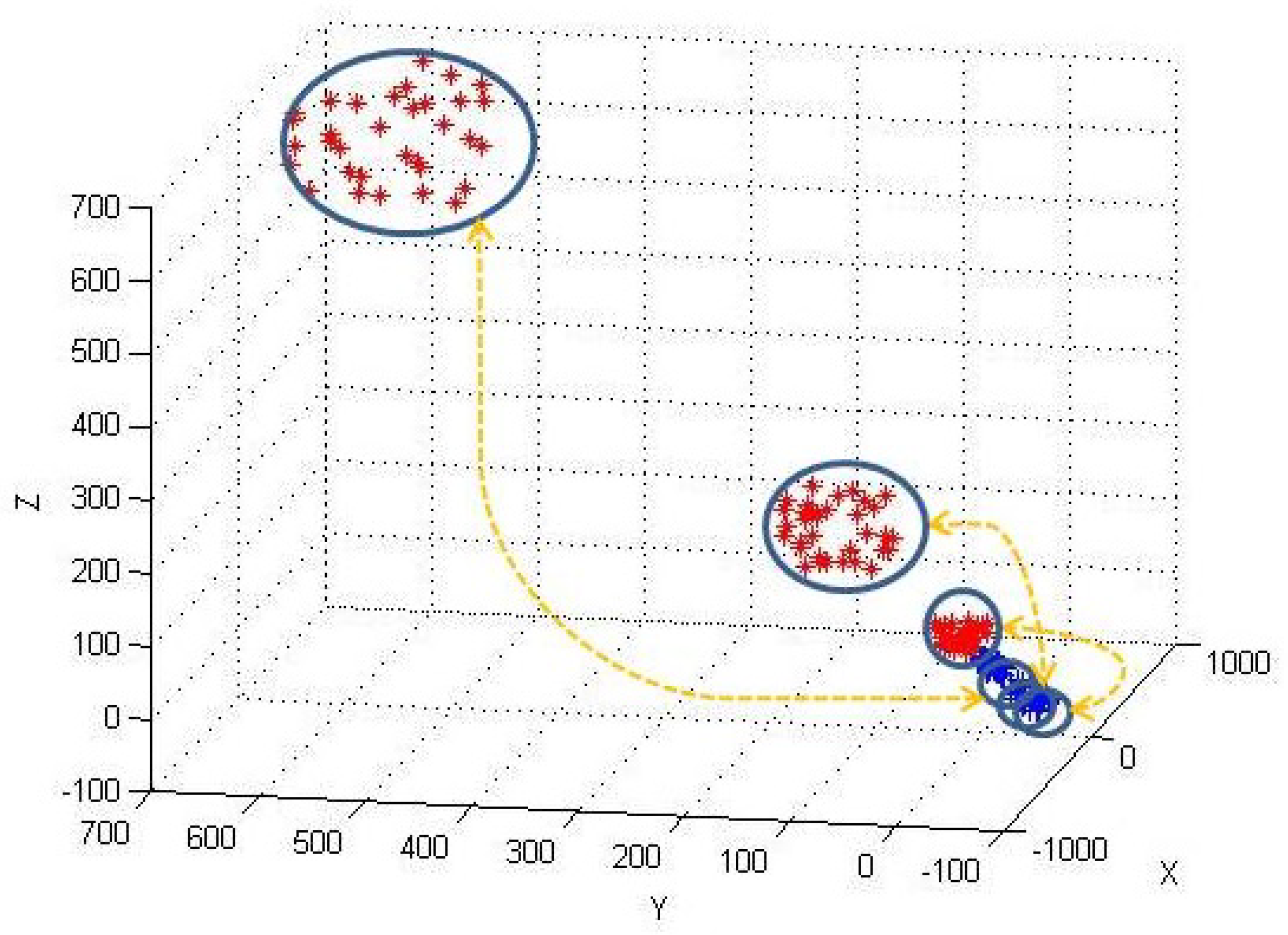
6.2.3. Evaluation with Real-Life data-set
7. Limitation and Conclusions
7.1. Limitation
7.2. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ren, K.; Wang, C.; Wang, Q. Security Challenges for the Public Cloud. IEEE Internet Comput. 2012, 16, 69–73. [Google Scholar] [CrossRef]
- Kamara, S.; Lauter, K. Cryptographic Cloud Storage; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Graepel, T.; Lauter, K.; Naehrig, M. ML Confidential: Machine Learning on Encrypted Data; Springer: Berlin/Heidelberg, Germany, 2012; pp. 1–21. [Google Scholar]
- Nikolaenko, V.; Weinsberg, U.; Ioannidis, S.; Joye, M.; Boneh, D.; Taft, N. Privacy-preserving ridge regression on hundreds of millions of records. In Proceedings of the 2013 IEEE Symposium on Security and Privacy, Berkeley, CA, USA, 19–22 May 2013; pp. 334–348. [Google Scholar]
- Hu, S.; Wang, Q.; Wang, J.; Chow, S.S.M.; Zou, Q. Securing Fast Learning! Ridge Regression over Encrypted Big Data. In Proceedings of the 2016 IEEE Trustcom/BigDataSE/ISPA, Tianjin, China, 23–26 August 2016; pp. 19–26. [Google Scholar]
- Bost, R.; Popa, R.A.; Tu, S.; Goldwasser, S. Machine Learning Classification over Encrypted Data. In Proceedings of the Network and Distributed System Security Symposium, San Diego, CA, USA, 23–26 February 2014. [Google Scholar]
- Samanthula, B.K.; Elmehdwi, Y.; Jiang, W. K-Nearest Neighbor Classification over Semantically Secure Encrypted Relational Data. IEEE Trans. Knowl. Data Eng. 2015, 27, 1261–1273. [Google Scholar] [CrossRef]
- Vaidya, J.; Clifton, C. Privacy-preserving k-means clustering over vertically partitioned data. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 24–27 August 2003; pp. 206–215. [Google Scholar]
- Jagannathan, G.; Wright, R.N. Privacy-preserving distributed k-means clustering over arbitrarily partitioned data. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 21–24 August 2005; pp. 593–599. [Google Scholar]
- Beye, M.; Erkin, Z.; Lagendijk, R.L. Efficient privacy preserving K-means clustering in a three-party setting. In Proceedings of the IEEE International Workshop on Information Forensics and Security, Iguacu Falls, Brazil, 29 November–2 December 2011; pp. 1–6. [Google Scholar]
- Gheid, Z.; Challal, Y. Efficient and Privacy-Preserving k-Means Clustering for Big Data Mining. In Proceedings of the IEEE Trustcom/BigdataSE/ISPA, Tianjin, China, 23–26 August 2017; pp. 791–798. [Google Scholar]
- Dwork, C. Differential privacy: A survey of results. In Proceedings of the International Conference on Theory and Applications of MODELS of Computation, Xi’an, China, 25–29 April 2008; pp. 1–19. [Google Scholar]
- Yan, S.; Pan, S.; Zhao, Y.; Zhu, W.T. Towards Privacy-Preserving data mining in Online Social Networks: Distance-Grained and Item-Grained Differential Privacy. In Proceedings of the Australasian Conference on Information Security and Privacy, Melbourne, Australia, 4–6 July 2016; pp. 141–157. [Google Scholar]
- Xiong, X.; Chen, F.; Huang, P.; Tian, M.; Hu, X.; Chen, B.; Qin, J. Frequent Itemsets Mining with Differential Privacy over Large-scale Data. IEEE Access 2018, 6, 28877–28889. [Google Scholar] [CrossRef]
- Yun, Y.E.; Shi, C.C.; Yong, Y.U.; Meng-Di, H.; Lin, W.M.; Peng, G. Privacy-Preserving Distributed Naive Bayes data mining. J. Appl. Sci. 2018, 35, 1–10. [Google Scholar]
- Wright, R.; Yang, Z. Privacy-preserving Bayesian network structure computation on distributed heterogeneous data. In Proceedings of the International Conference on Knowledge Discovery and data mining (SIGKDD), Seattle, WA, USA, 22–25 August 2004; pp. 713–718. [Google Scholar]
- Vaidya, J.; Kantarcloglu, M.; Clifton, C. Privacy-preserving naive bayes classification. Int. J. Very Large Data Bases 2008, 17, 879–898. [Google Scholar] [CrossRef]
- Du, W.; Han, Y.S.; Chen, S. Privacy-Preserving Multivariate Statistical Analysis: Linear Regression And Classification. In Proceedings of the SIAM International Conference on data mining, Anaheim, CA, USA, 26–28 April 2012; pp. 222–233. [Google Scholar]
- Liu, F.; Ng, W.K.; Zhang, W. Encrypted Gradient Descent Protocol for Outsourced data mining. In Proceedings of the IEEE International Conference on Advanced Information NETWORKING and Applications, Gwangiu, Korea, 24–27 March 2015; pp. 339–346. [Google Scholar]
- Liu, F.; Ng, W.K.; Zhang, W. Encrypted SVM for Outsourced data mining. In Proceedings of the IEEE International Conference on Cloud Computing, New York, NY, USA, 27 June–2 July 2015; pp. 1085–1092. [Google Scholar]
- Sanil, A.P.; Karr, A.F.; Lin, X.; Reiter, J.P. Privacy preserving regression modelling via distributed computation. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 677–682. [Google Scholar]
- Karr, A.F.; Lin, X.; Sanil, A.P.; Reiter, J.P. Secure regression on distributed databases. J. Comput. Graph. Stat. 2005, 14, 263–279. [Google Scholar] [CrossRef]
- De Cock, M.; Nascimento, A.C.; Lin, S.C.N. Fast, Privacy Preserving Linear Regression over Distributed Datasets based on Pre-distributed Data. In Proceedings of the 8th ACM Workshop on Artificial Intelligence and Security, Denver, CO, USA, 16 October 2015; pp. 3–14. [Google Scholar]
- MacQueen, J. Some Methods for classification and Analysis of Multivariate Observations. In Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, CA, USA, 21 June–18 July 1965; pp. 281–297. [Google Scholar]
- Basu, S.; Banerjee, A.; Mooney, R.J. Active Semi-Supervision for Pairwise Constrained Clustering. In Proceedings of the International Conference on Data Mining, Brighton, UK, 1–4 November 2004; pp. 333–344. [Google Scholar]
- Ahmadyfard, A.; Modares, H. Combining PSO and k-means to enhance data clustering. In Proceedings of the International Symposium on Telecommunications, Tehran, Iran, 27–28 August 2008; pp. 688–691. [Google Scholar]
- K-Means. Available online: https://en.wikipedia.org/wiki/K-means_clustering (accessed on 7 November 2018).
- Wang, C.; Cao, N.; Li, J.; Ren, K.; Lou, W. Secure ranked keyword search over encrypted cloud data. In Proceedings of the 2010 IEEE 30th International Conference on Distributed Computing Systems, Genova, Italy, 21–25 June 2010; pp. 253–262. [Google Scholar]
- Cao, N.; Wang, C.; Li, M.; Ren, K.; Lou, W. Privacy-preserving multi-keyword ranked search over encrypted cloud data. In Proceedings of the IEEE INFOCOM, Shanghai, China, 10–15 April 2011; pp. 829–837. [Google Scholar]
- Li, H.; Yang, Y.; Luan, T.H.; Liang, X.; Zhou, L.; Shen, X. Enabling Fine-grained Multi-keyword Search Supporting Classified Sub-dictionaries over Encrypted Cloud Data. IEEE Trans. Dependable Secur. Comput. 2016, 13, 312–325. [Google Scholar] [CrossRef]
- Yin, H.; Qin, Z.; Ou, L.; Li, K. A query privacy-enhanced and secure search scheme over encrypted data in cloud computing. J. Comput. Syst. Sci. 2017, 90, 14–27. [Google Scholar] [CrossRef]
- Wong, W.; Cheung, D.; Kao, B.; Mamoulis, N. Secure knn computation on encrypted databases. In Proceedings of the ACM International Conference on Management of Data, SIGMOD, Providence, RI, USA, 29 June–2 July 2009; pp. 139–152. [Google Scholar]
- Enabling Personalized Search over Encrypted Outsourced Data with Efficiency Improvement. IEEE Trans. Parallel and Distrib. Syst. 2016, 27, 2546–2559. [CrossRef]
- Kaggle. 2018. Available online: http://www.kaggle.com (accessed on 15 September 2018).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scheme | T-DO | T-DU | T-CS |
|---|---|---|---|
| PPK-means_1 | <1 ms | <1 ms | 53 ms |
| PPK-means_2 | <1 ms | <1 ms | 87 ms |
| PPK-means_3 | <1 ms | <1 ms | 87 ms |
| Group ID | Accuracy | ||
|---|---|---|---|
| PPK-Means_1 | PPK-means_2 | PPK-Means_3 | |
| Group 1. (k = 10, D = 10, n=10,000) | 100% | 100% | 99.96% |
| Group 2. (k = 20, D = 10, n=10,000) | 100% | 100% | 99.96% |
| Group 3. (k = 10, D = 50, n=10,000) | 100% | 100% | 99.98% |
| Group 4. (k = 20, D = 50, n=10,000) | 100% | 100% | 99.98% |
| Group 5. (k = 10, D = 100, n=10,000) | 100% | 100% | 100% |
| Group 6. (k = 20, D = 100, n=10,000) | 100% | 100% | 100% |
| data-set | Number of Records | Number of Dimensions |
|---|---|---|
| heart disease | 383 | 14 |
| cells | 15,608 | 6 |
| airport locations | 1435 | 2 |
| data-set | T-DO | T-DU | T-CS |
|---|---|---|---|
| heart disease | <1 ms | <1 ms | 12 ms |
| cells | <1 ms | <1 ms | 41 ms |
| airport locations | <1 ms | <1 ms | 11 ms |
| data-set | Accuracy | ||
|---|---|---|---|
| PPK-Means_1 | PPK-Means_2 | PPK-Means_3 | |
| heart disease | 100% | 100% | 100% |
| cells | 100% | 100% | 99.97% |
| airport locations | 100% | 100% | 99.86% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, H.; Zhang, J.; Xiong, Y.; Huang, X.; Deng, T. PPK-Means: Achieving Privacy-Preserving Clustering Over Encrypted Multi-Dimensional Cloud Data. Electronics 2018, 7, 310. https://doi.org/10.3390/electronics7110310
Yin H, Zhang J, Xiong Y, Huang X, Deng T. PPK-Means: Achieving Privacy-Preserving Clustering Over Encrypted Multi-Dimensional Cloud Data. Electronics. 2018; 7(11):310. https://doi.org/10.3390/electronics7110310
Chicago/Turabian StyleYin, Hui, Jixin Zhang, Yinqiao Xiong, Xiaofeng Huang, and Tiantian Deng. 2018. "PPK-Means: Achieving Privacy-Preserving Clustering Over Encrypted Multi-Dimensional Cloud Data" Electronics 7, no. 11: 310. https://doi.org/10.3390/electronics7110310
APA StyleYin, H., Zhang, J., Xiong, Y., Huang, X., & Deng, T. (2018). PPK-Means: Achieving Privacy-Preserving Clustering Over Encrypted Multi-Dimensional Cloud Data. Electronics, 7(11), 310. https://doi.org/10.3390/electronics7110310