1. Introduction
The face is an invaluable characteristic for human identity, and has been studied in diverse areas of computer graphics and computer vision. Some researchers in the field of non-photorealistic rendering (NPR) have considered various types of artistic styles of human face. A cartoon face is an instance of these artistic representations, which is stylish, simple and usually humorous. Thanks to rapid developments in computer graphics, realistic human-like characters are becoming more widespread in digital world. The phenomenon of uncanny valley reveals that moving towards absolute human-like character surprisingly changes the viewer’s feeling of it to a less life-like character [
1]. Hanson [
2] indicates the effect of cartoon-like style on reduction of uncanniness. On the other hand, rendering a high quality realistic character with complex texture map demands costly computation tasks. Over the recent years, cartoon face generation has become particularly interesting research topic due to the advantageous features of privacy, simplicity, funniness and their dominant digital applications such as in video games, virtual entertainment, social networks and mobile applications.
However, drawing cartoon faces is difficult for ordinary users. Hence, cartoon face producers attempt to imitate the artistic style using automatic or semi-automatic approaches. Generally, there are two prominent factors to consider in producing a cartoon face: likeness and aesthetic. Likeness can be addressed using facial feature extraction methods, and the artistic side is tackled by applying predesigned templates, learning the artistic style and NPR techniques. The system proposed by Koshimizu et al. [
3], PICASSO, and the one developed by [
4] generate stiff facial sketches according to the facial feature points using image processing techniques. Microsoft introduced a cartoon system, MSN cartoon, which requires user interactions to choose the desired cartoon style, adjust the form and attach some add-ons. PicToon [
5] is an automatic portrait generator based on a statistical model. Using training examples it captures an artistic style, and a non-parametric sampling approach is applied to render the vector-based facial sketch. In [
6], an active shape model (ASM)-based facial feature extraction and an interactive template-based cartoon texture mapping is proposed.
Recent cartoon producers [
7,
8,
9] are mostly based on fitting active models, commonly ASM [
10] and active appearance model (AAM) [
11], at the global level for face alignment and locating facial feature points. Although we make use of a similar model fitting approach, our system optimizes the contours at component level. Liu et al. [
8] classified current approaches for cartoon depiction to contour and component representation. In their cartoon face producer, NatureFace, a component-based approach for modeling face and cartoon is integrated. A similar component-based method is used by Chen et al. [
12] and Zhang et al. [
13]. However, unlike our system, their cartoon matching is based on an imaged-based comparison approach such as k-nearest neighbor. In some recent works such as [
9,
14], to preserve the shape structure, the facial outline is drawn directly using feature points of the face component, and the remaining components are composed using template matching. Meng et al. [
15] employs a dynamic thresholding scheme at component level to generate paper-cut portraits using predefined paper-cut templates. Ding and Martinez [
16] train local classifiers for some facial components with large number of examples. In our proposed cartoon system, contour modification has been investigated for more components to retain the individualism of features and improve the template selection stage. Furthermore, cartoon results are evaluated in a subjective manner based on similarity of the cartoon face to the real face, which is a missing part in all previous research.
The rest of the paper is organized as follows. The description of our cartoon system is covered in
Section 2. The proposed facial feature locating method is described in
Section 2.1.
Section 2.2 is dedicated to the cartoon sample collection and the consequent parameterization. In
Section 2.3, processes required for cartoon rendering is presented. In
Section 3, the final results are shown and our experiments are described in detail. Finally, in
Section 4, we sum up our work, outline the benefits and limitations of the proposed system, and consider some future research topics.
2. Materials and Methods
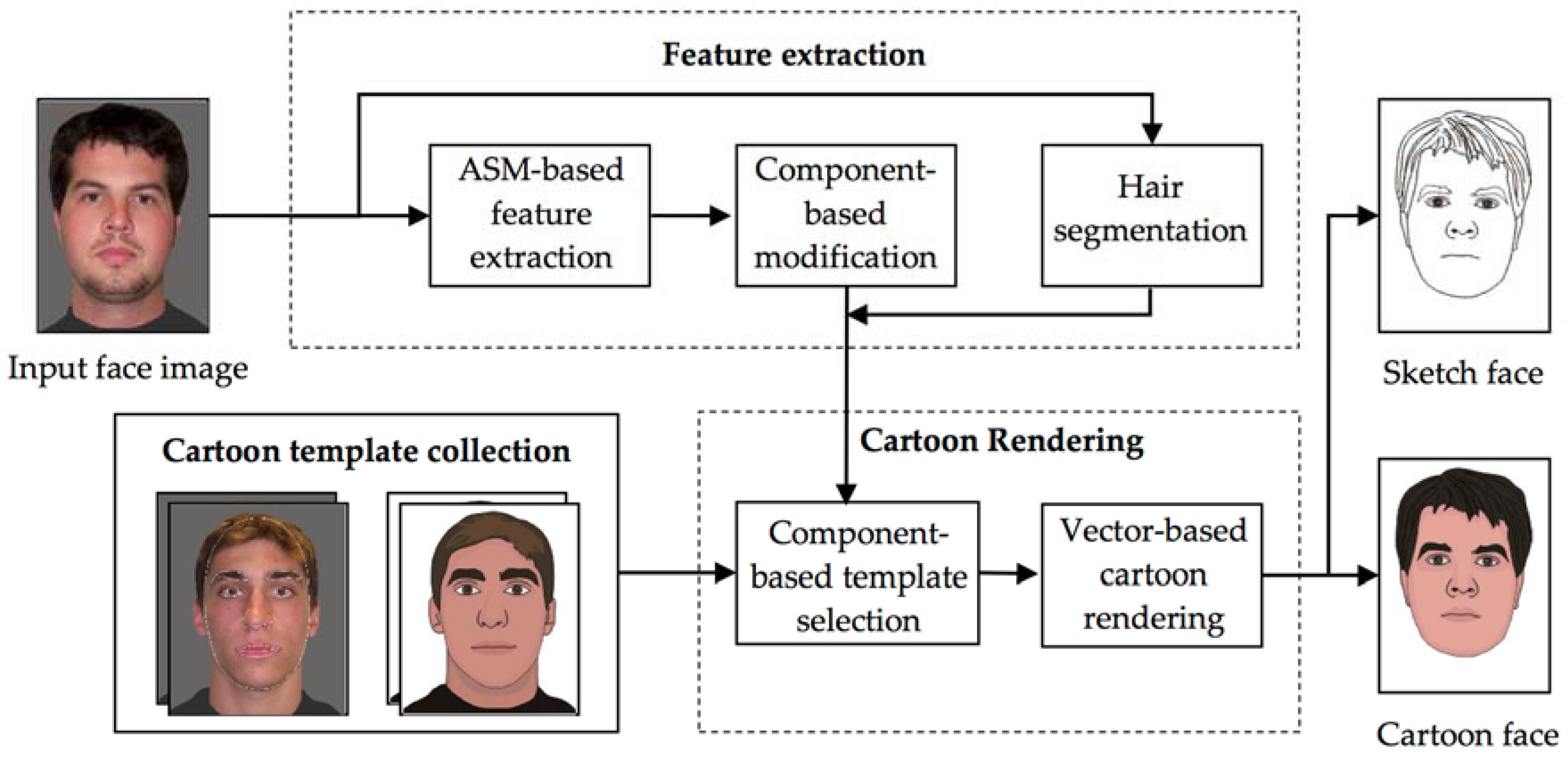
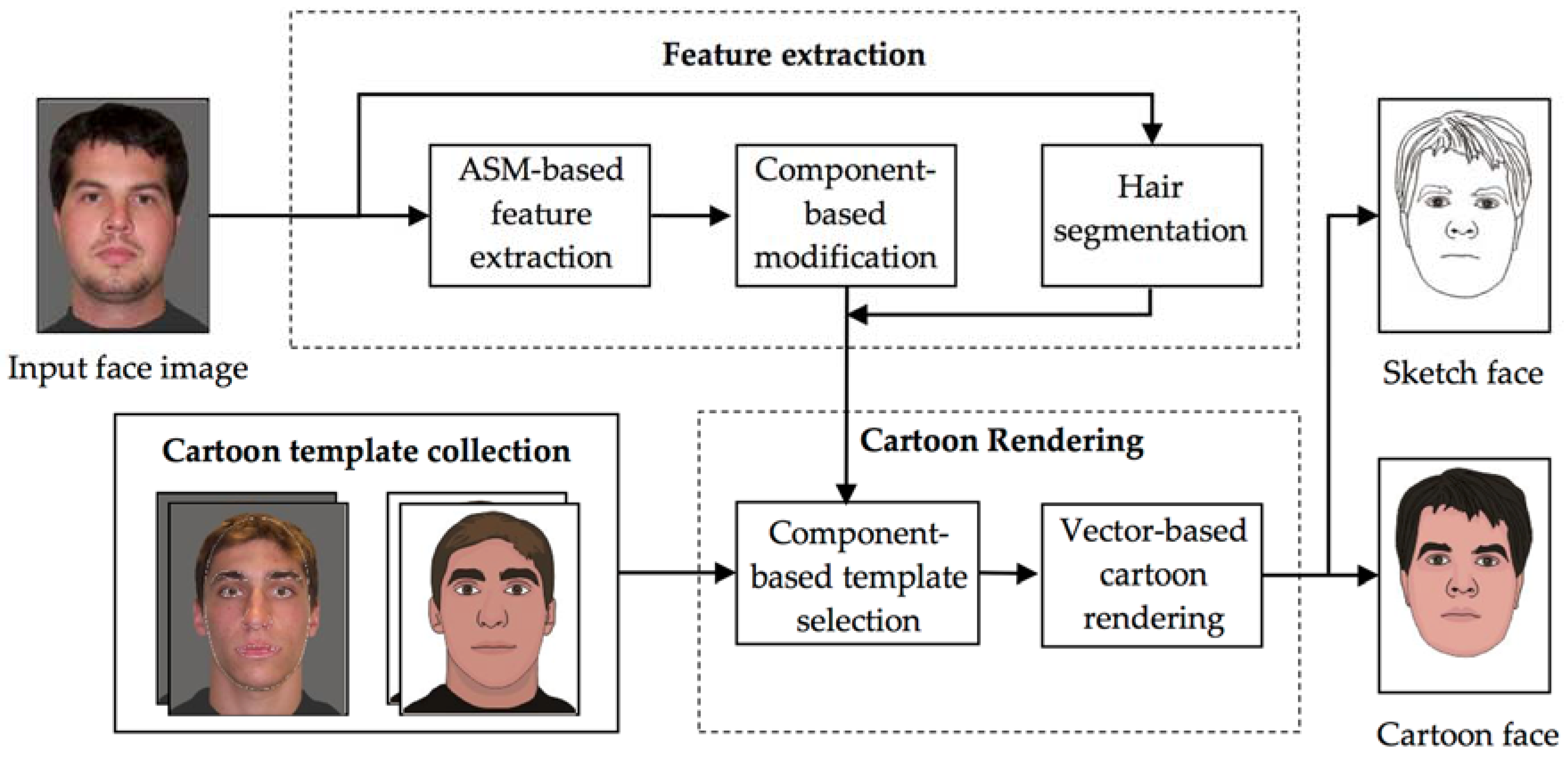
The architecture of our cartoon face producer is shown in
Figure 1. The proposed system can generate a cartoon face and a sketch representation from a given frontal face photograph using automatic techniques. The system incorporates three major components: cartoon template collection, feature extraction and cartoon rendering.
In the feature extraction stage, first, an extended ASM is employed to capture the initial locations and contours of the facial components. Contours of the components are optimized to better fit the input face. The hair region is segmented separately, as model fitting cannot address hair extraction properly [
7].
Cartoon sample collection is an offline step, in which a number of different face images are painted by cartoonists and further decomposed into components. The same component-based feature extraction, except for the hair, has been applied to all the sample images in order to extract contours of their components. Using these original contours and those of the cartoons, we can match located components of the input face image to the fitting cartoon templates.
Finally, using the spatial information of extracted components from the input face, selected components are composited and deformed to match the input face. The output can either be rendered as a sketch or a cartoon face. Cartoon representation features such as shadows, highlights and supplementary curves for each component are captured from the corresponding template. Sketch output lacks cartoon features and is just composited with contours and supplementary curves of matched cartoon components. The matching system is based solely on the comparison of contours between extracted components and template components. Supplementary curves of facial components are ignored in template selection phase. However, in cartoon rendering, they are copied from the matched template to enrich the cartoon or sketch output.
2.1. Feature Extraction
To address the shape-preserving necessity of cartoon face generation, most of the present systems employed either AAM [
5,
7,
9,
17] or a variation of ASM [
6,
15,
18,
19]. Generally, ASM shows better robustness to different conditions, as it searches through local regions oppose to the AAM, which uses models of holistic appearance.
An ASM-based facial feature extraction fails to capture the accurate contours required for artistic representation of all facial parts. It is well suited to be fitted at global level, as there is a trained constraint, which keeps the proportion of the facial components in ASM. Besides, the number of landmarks is not sufficient for some components. Thus, a local modification is proposed to enhance the quality of feature extraction by fine-tuning the contours of the captured components. Unlike current cartoon systems, which ask users to choose from hair templates [
8] or determine the color distribution of the hair region using two brushes provided for the users [
5], an automatic method for hair extraction is investigated to remove the requirement for user interaction and to enrich the appearance of the cartoon face by adding a cartoon-like hair. Since hair extraction is not a main focus in our proposed system, we consider a simple hair segmentation approach with some predefined conditions such as uniform background.
2.1.1. An Extended Active Shape Model
We utilize a modified ASM system named STASM, which is introduced by Milborrow et al. [
20]. They proposed 2D profile areas around the landmarks. This modification is also considered by [
14,
21] to boost the accuracy of the ASM. For the early initialization of the ASM, a global face detector is employed by STASM to specify the initial search area. Starting from the mean shape adjusted by size and position to the detected face in the input image, STASM searches for the landmarks. As basic ASM can suffer from sensitivity to local extremum, good initial approximation improves the searching result. Gao et al. [
14], locate irises and use them to calculate a rough starting approximation. However, STASM [
20], which is employed in our system, uses the result of 1D profile ASM as a starting position for the searching with 2D profiles.
This global ASM-based feature locating, like STASM, cannot guarantee the accurate contour of all facial components at the same time. Hence, we extend the feature extraction stage with some optimization at component level using current shapes and spatial parameters of the facial elements that are discussed in the next section.
2.1.2. Component-Based Modification
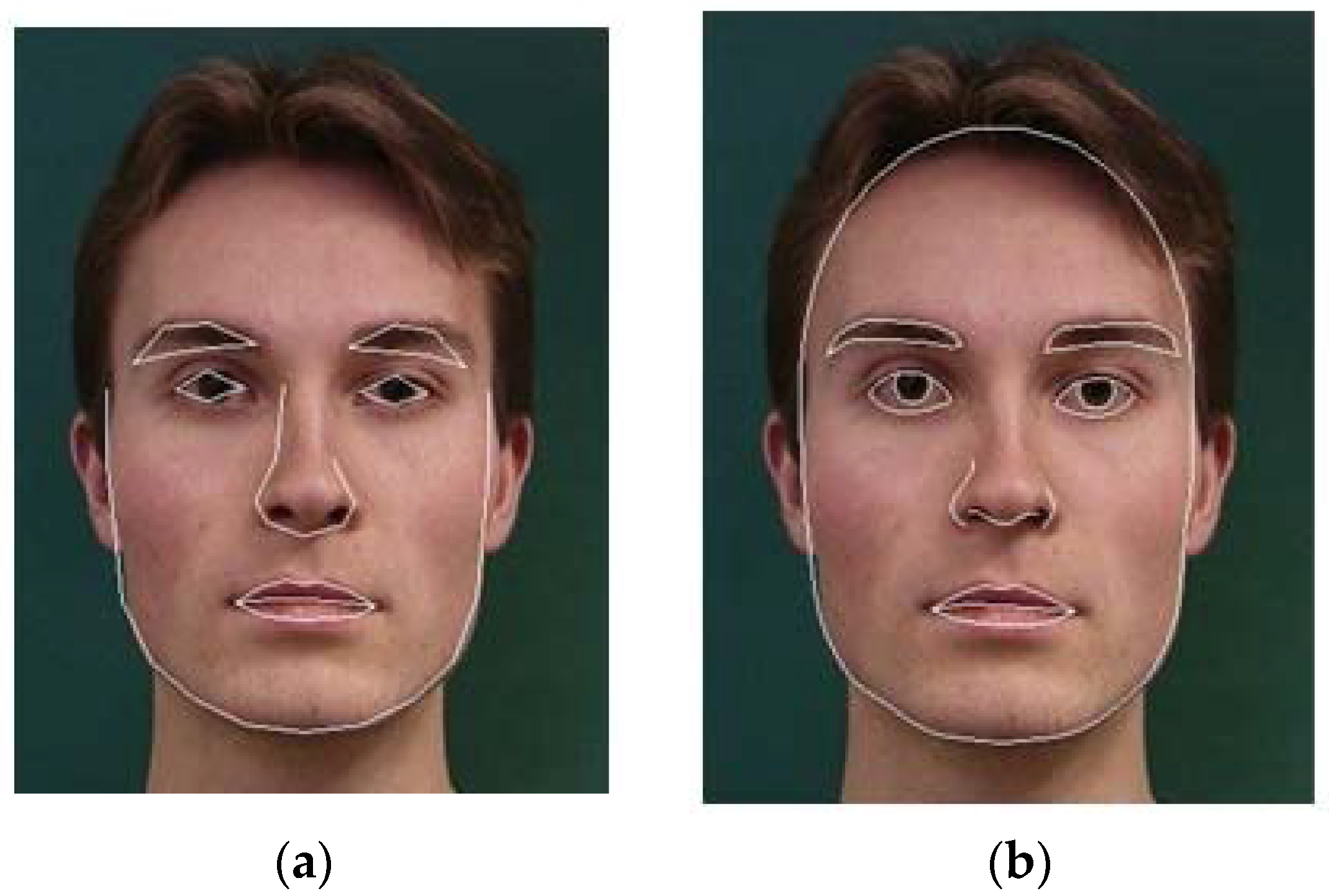
As shown in
Figure 2a,b, the facial contours are better fitted using our local modification technique. ASM, generally, captures contours for face, nose and lips parts more robustly than those for eyes and eyebrows. On the other hand, to keep the originality of appearance in cartoon level, we need to extract these features more precisely. Therefore, eyes and eyebrows are relocated specifically based on their starting regions. Additionally, Hermit interpolation and Bezier curve fitting are applied for the remaining components to satisfy the continuity and shape-preserving of the overall output.
Other Improvements
Because of the impact of the hair, feature points of the upper face contour are omitted in facial feature locating methods. We calculate the approximate full contour of the face by adding a cubic Bezier curve at the upper part of the face component according to the starting and ending points of the ASM face landmarks. The completing part of face contour is proportional to the ratio of the face, which is calculated using ASM-based contour of the face. The complete contour of the face is beneficial for template matching process.
With overall analysis of the cartoon samples painted by our cartoonist, we considered three major curves for the representation of the nose. Therefore, using the ASM landmarks for the nose, three cubic Bezier curves are calculated to represent the shape of nose.
The shape of the lips, chiefly, is more sensitive to the emotion of a character, especially in cartoon representation. Predesigned cartoons of the lips can be used for diverse faces without major negative impact in likeness. Hence, we leave the contour of the lips untouched.
2.1.3. Hair Segmentation
Due to the wide range of variation in hair structure, model-based approaches are not successful in hair extraction. Moreover, presence of strong shadows and highlights in the hair region is a key problem for edge detection methods. In our proposed approach, the hair component is extracted using HSV color segmentation. HSV color space separates components for color, hue, and illumination (value) compared to RGB color space [
27]. Hence, this color space is better for hair segmentation.
The initial region of the hair is extracted after skin detection and background segmentation. Using the extracted facial components and sampling color from the skin area, we can do a color segmentation to extract the skin region. With the same approach, we can separate the background. Considering
Figure 3a, the initial region of the hair,
Figure 3b is extracted after excluding skin and background. Now, an early color of hair is calculated from the region. With this early color of hair, regions extracted by HSV color segmentation are shown in
Figure 3c. As can be seen in
Figure 3d, binary morphology is employed to output a continuous hair region. The general location of the hair is taken into account to ignore other isolated areas. In the case of complex texture, we can utilize graph cut [
28] technique for segmentation. Meng et al. [
15] and Min et al. [
7] used similar approaches for hair segmentation.
2.2. Cartoon Template Collection
The crucial issue of a templates-based approach in cartoon generation systems is cartoon collection, since it is very time-consuming and demands careful attention. As our template selection approach is based on feature points matching rather than pixel-based comparison, we used a well-known vector drawing software, Adobe Illustrator, to collect hand-drawn cartoon faces. In another part of our cartoon template collection, we extract facial components of the training set to be used further in the template matching section. The whole process of this phase is done offline.
2.2.1. Hand-Drawn Cartoon Faces
We asked a cartoonist to illustrate cartoon faces for different face images in predefined layers specified for each component. This components are hair, left eyebrow, right eyebrow, left eye, right eye, nose, lips, left and right ears, neck and shirt. For the matching process, we need a rendering contour for each facial component of the cartoons, so our artist illustrated a contour for each of the mentioned components. Moreover, the cartoon medium requires some specific features such as shadows, highlights and some sketches around each facial part. For example, unlike current cartoon systems, our cartoon faces have eyelashes for females. These features are drawn in sub-layers of the components. When a cartoon component from the template collection is selected, its cartoon properties such as shadows and additional curves are composited as well.
Shapes and curves are represented by different paths which contain anchor points with their two control points. This representation allows us to construct sequences of cubic Bezier curves for the contours. The whole properties of the components are collected automatically, i.e., spatial properties and rendering rules. The proposed approach is especially effective and convenient when we want to change the artistic style. Compared to the cartoon collection system proposed by [
8], our approach is simple and also it can be done using many available software.
2.2.2. Component Extraction of the Sample Faces
As hand-drawn cartoon faces can differ from the corresponding real faces, direct comparison between cartoon components in the template set and the extracted components of the input face, cannot guarantee a proper selection of cartoon templates. Hence, we need to do one more comparison in the template selection procedure: a comparison between the extracted components of the input face and the extracted components of the template faces. More information about this matching procedure can be found in
Section 2.3.1.
In this offline phase, facial components of the training images are extracted using our proposed feature extraction method. These components involve eyes, eyebrows, nose, mouth, and face contour. The matching procedure of the hair component is based on direct comparison between the extracted hair of the input face and the cartoon templates of the hair in the template collection.
Finally, in our cartoon template collection, there are some pairs of facial components in which we collected the original and its corresponding cartoon component, so each type of cartoon template can be compared and selected independently.
2.3. Cartoon Rendering
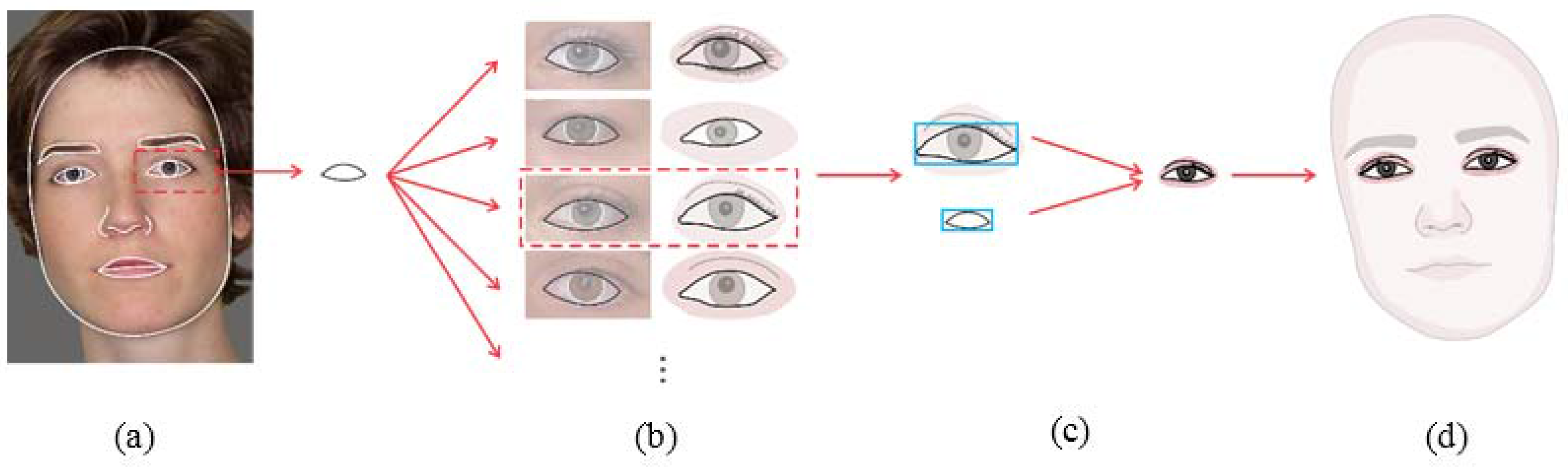
Although the shape of the extracted facial components is sufficient to preserve the likeness, they cannot bring the aesthetic aspect of the cartoon faces and we need to make use of suitable cartoon shapes for each component. For example,
Figure 4 illustrates the general process for the cartoon rendering of eyes.
Figure 4a illustrates the result of the component extraction phase. As shown in
Figure 4b, in this phase corresponding cartoon components for the extracted eye are chosen from the pre-designed cartoon templates. Then, as shown in
Figure 4c,d, the selected cartoon component is deformed according to the input face and further rendered based on the rendering rules of the component.
2.3.1. Component-Based Template Selection
To match a proper cartoon template to each extracted component we need to measure a shape distance for each instance in the template collection set. Current cartoon systems use a fixed number of corresponding feature points in sample cartoon faces and the input face image. This means that specified number of corresponding points, which are extracted using ASM, should exist in both cartoon and input face.
However, as we applied a modification stage and extracted a more accurate contour for the components, there is no correspondence for the feature points and the number of feature points are not constant, so the components should be compared based on their contours. In the template collection phase, each component is represented as a sequence of Bezier curves. The same approach is applied to every component of the input face image after the extraction process. We employ Hausdorff distance as a shape distance measure since it requires neither one-to-one correspondence of feature points nor the same number of points in each point set [
29]. The conventional Hausdorff distance is shown in Equation (2).
Point sets and belong to the components a and b. Points i and j are instances of point sets and, respectively. Consider as a distance between two points, for example, Euclidian distance.
This distance is very sensitive to noise. Sim et al. [
30] proposed a robust Hausdorff distance measure suitable for object matching in noisy images. However, our feature extraction uses ASM and also further local modification to extract continuous contours for each component (
Figure 2b). Hence, the extracted components have less noises than images and the Hausdorff distance proposed by Sim et al. is not suitable for our purpose. We can make the Hausdorff distance more robust for our component matching using averaging the minimum distances for all points, despite the simple maximization over the minimum distances in the conventional one:
Moreover, Hausdorff distance is neither scale nor rotation and translation invariant. Before shape matching step, all templates should be normalized, i.e., rotated, scaled and translated if needed.
The amount of rotation is calculated by the angle of the line linking the two eyes that were extracted earlier.
When components are extracted, each component is compared with its corresponding templates in training set. As shown in
Figure 4b, there are two comparisons for each instance in the template collection set: comparison with the cartoon component and comparison with the original component. The final distance of a component in input face from its correspondence in an instance of the template set is calculated using Equation (3). Let
be a facial component in input face image. Let
and
be the original component and the cartoon component in sample i of the template set, respectively.
where
is the final distance of component A from its corresponding component
in the template set.
is the Hausdorff distance of component A from component
and
is the Hausdorff distance of component A from component
We assign weights for both cartoon shape and the extracted shape of samples. The weights
and
are determined experimentally with respect to each component.
Finally, the template giving the smallest error value is selected and further deformed and fitted to the input face according to result of feature extraction phase.
Due to the wide range of hair structure, we use shape context [
31] for hair matching. After the contour of the hair component is extracted, we can select the closest hair component in our template collection using shape context distance. A thin plate spline model is used to warp the contours of the matched hair template to the contour of the extracted hair of input face image. A similar approach for hair matching has been used by Min et al. [
7].
2.3.2. Vector-Based Cartoon Representation
Matched cartoon components should be adjusted to the input face and arranged together to have the final cartoon face rendered. Location, size and rotation of the original components are available using the information gained from the feature extraction stage. Additionally, rendering rules such as geometrical shape, supplementary curves and shadow regions of the final components are obtained by cartoon templates. For example, cartoon eye component is matched based on its contour, but the shadow region supplemented in the matched cartoon template is further added to the final cartoon face output (
Figure 4c). Adjustment of color is done by searching through a color table which maps skin color ranges to some constant skin colors used in cartoon templates.
After normalization of the cartoon templates and the original components based on the rotation of the input face, cartoon templates are resized by their width and height considering the width and height of the corresponding original components (
Figure 4c). Deformed cartoon templates are placed according to the spatial information of the components (
Figure 4d). Components are accompanied by their add-ons such as neck and collar for face contour component and eyelash for eye component. These add-ons are deformed and rendered based on the basic shape of their components.
In our cartoon system, shapes are represented by Bezier curves. These shapes are rendered layer by layer with their color and stroke information. The final cartoon face can be generated in vector graphics, which is a suitable format for animation. Furthermore, cartoons are in vector format, the benefit of which is that they are pretty easy to modify in the shape, so exaggerations can be easily applied to create caricature like images that are out of scope of this paper.
3. Results
To prepare cartoon templates and evaluate the results of our system, our experiment is conducted based on frontal faces of different genders, ages and races. 30 images are collected from dataset of adult facial stimuli [
32] and 30 images are obtained from an AR dataset [
33] and IMM dataset [
34]. Although we collect cartoon templates of all 60 face images, we consider 30 images as our training set and the rest for the test phase. Here are conditions considered in our cartoon collection set:
Faces are frontal with no significant pose variance.
Face images are with neutral expression.
Training images are 640 × 480.
Cartoon faces are drawn in a specific artistic style in Adobe Illustrator with open layers.
Each pair of cartoon and original faces match perfectly.
Some of the cartoon faces generated using our approach are shown in
Figure 5. Regarding the cartoon hair in
Figure 5, it should be noted that cartoon hair rendering is a separate part of our system, and because of the wide range of hair styles, we incorporated all hand-drawn hair for hair cartoon selection. Since the matched hair templates already have the correct shape then the TPS warp for hair adjustment is essentially the identity mapping, which is why the artist-generated hair is identical to the automatically generated hair.
To verify our system, we conducted two user studies and asked 94 participants of different genders and ages with various backgrounds to answer the questions. The parameters are considered constant among the evaluation process.
In one experiment, our aim is to verify the diversity of the cartoon faces generated by our system. To evaluate this, we consider 12 questions in which a real face image is depicted along with five cartoon faces. These cartoon faces are generated by five different faces using our proposed system and only one cartoon face belongs to the real face image in each question.
Participants choose the most similar cartoon face to the real face in each question based on their point of view. If the diversity of our system is high, users can properly select the right cartoon face. In order to make our verification in this experiment more robust, we omit the hair component for all cartoon faces to evaluate the production diversity even with the lack of hair as a prominent feature in identification. Moreover, we took five cartoon faces to increase the difficulty of the experiment, despite the two cartoon faces used in [
19]. In
Figure 6, the frequency of the number of correct answers among different users is illustrated. Around half of the participants correctly recognized the right cartoon face in more than eight questions (out of 12). On average, each user correctly answered seven questions. This shows that, considering the difficulty of this experiment, in more than half of the questions, the right cartoon face was recognizable and the diversity of our proposed cartoon generator is acceptable.
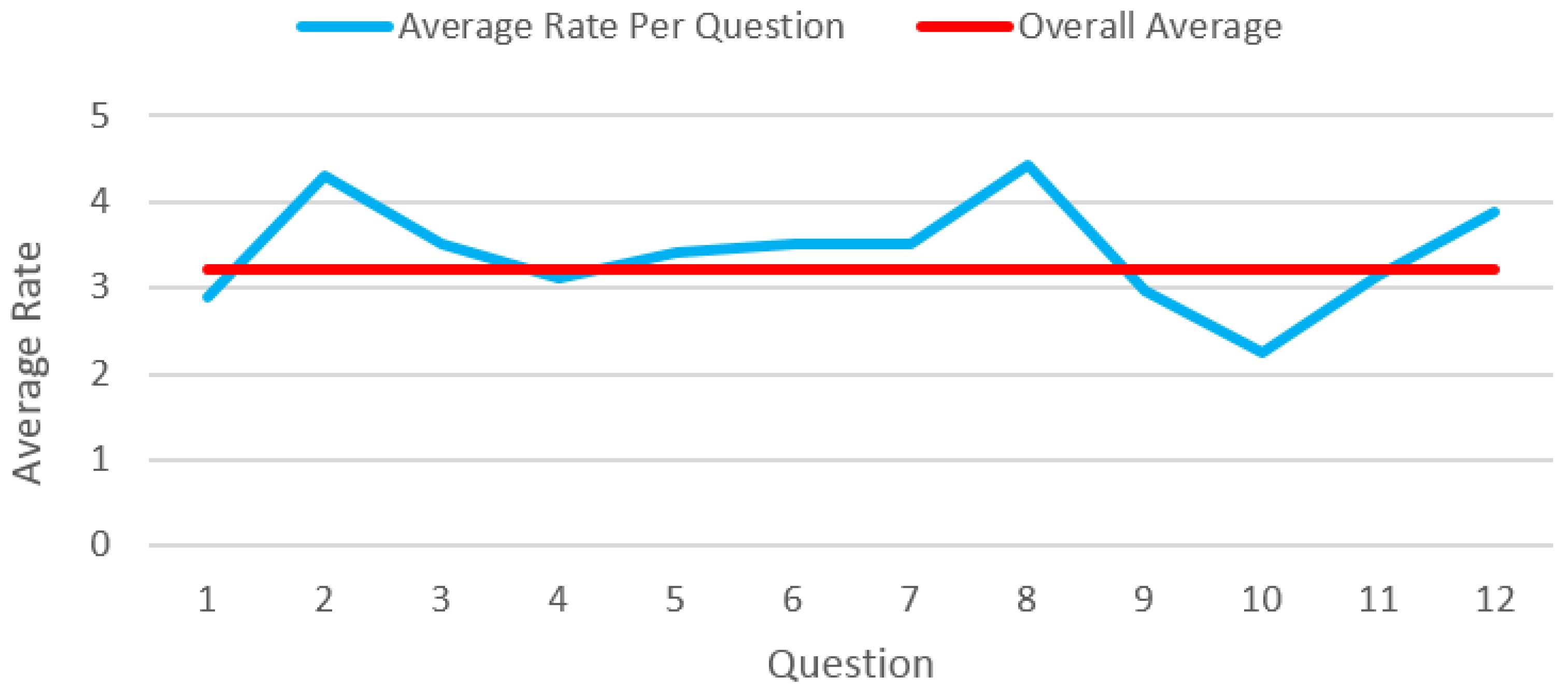
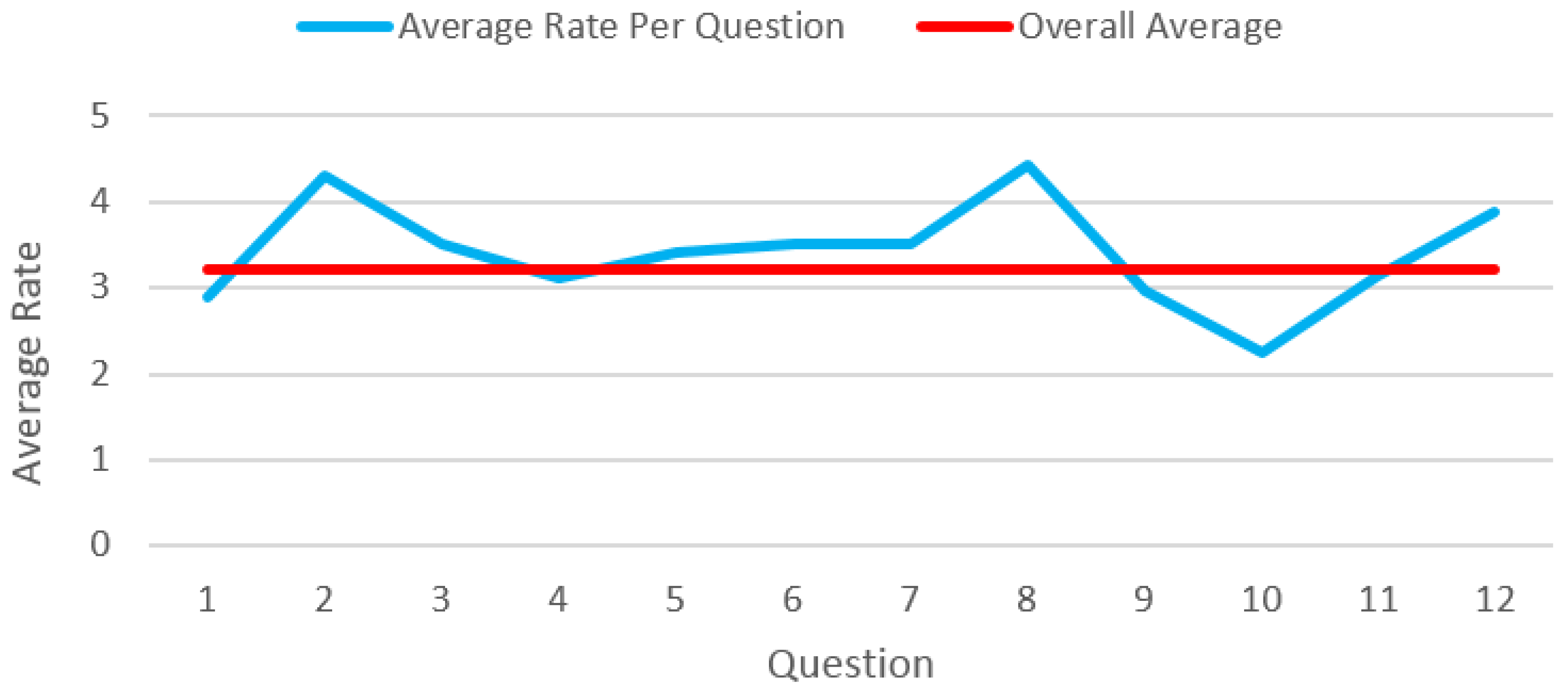
The other experiment aims to assess the likeness of the generated cartoon faces to their corresponding real faces. This test also consists of 12 questions. In each question, a real face image is shown along with its cartoon face produced using our system and involves five answers with values one to five. In each question, a rating of five means the generated cartoon face matches perfectly the real facial image. In this experiment, cartoon faces are depicted completely; all cartoon features, including the hair component, are illustrated. In this user study, the cartoon faces are evaluated generally from users’ point of view. As each user has his or her opinion about the ideal level of likeness for a cartoon face, we put two hand-drawn cartoon faces as pivot cases among these 12 questions in order to balance the final ratings. In fact, these two questions are supposed to have the highest level of rating (close to five). In practice, experimental results show that the average ratings of the two standard questions are close to 4.5 (questions 2 and 8 in
Figure 7). Excluding the two pivot cases in this experiment, the average rating of the users is greater than three. It means that the likeness of our generated cartoon faces is acceptable. In
Figure 5, the second cartoon face from the right is assigned the highest rate (around four) among the remaining 10 questions (apart from the two standard cartoon faces).
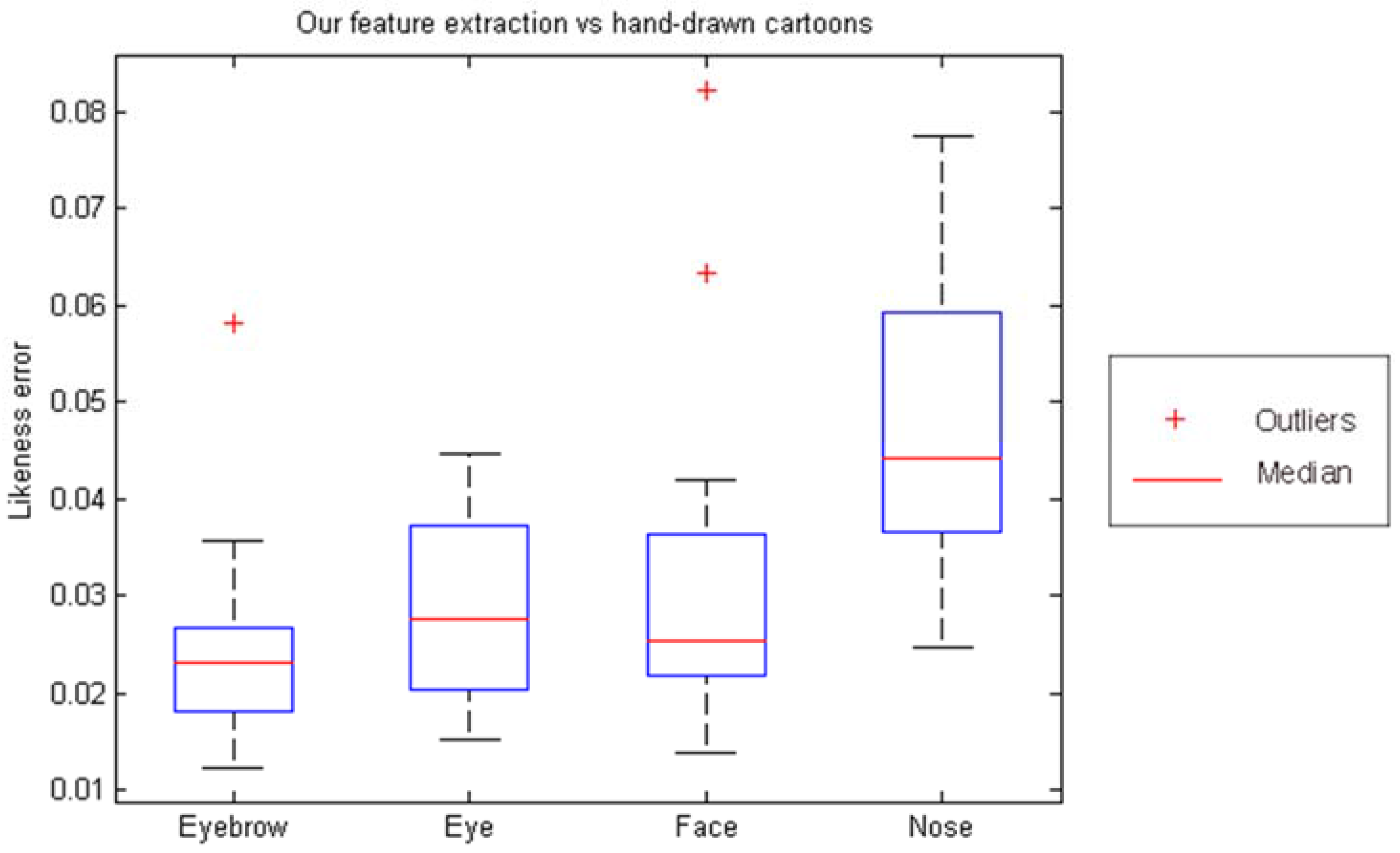
Finally, using Hausdorff distance as a similarity measure, we objectively evaluate the error of extracted components as well as final cartoon components against hand-drawn cartoons. In
Figure 8, the likeness error of lips, eyes, face and nose components are illustrated. We use hand-drawn cartoons to calculate the likeness error for the extracted components using our approach. Thirty hand-drawn cartoon faces are used in this evaluation. It shows the limitation of our system in extracting the nose component. However, other components have lower error, with eyebrows having the least error.
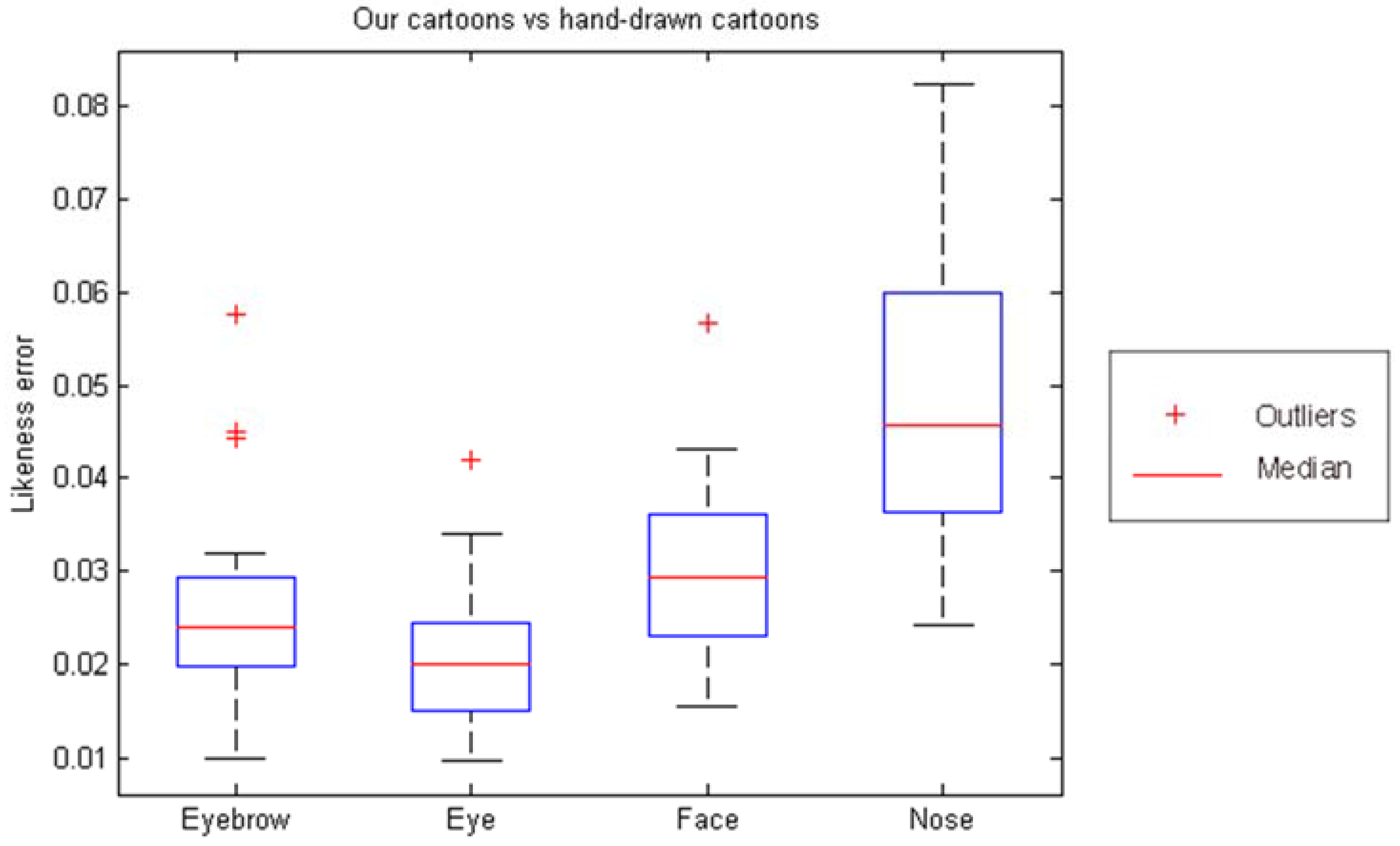
Figure 9 shows the likeness error of the final generated cartoon components against hand-drawn cartoons. A reduction of the likeness error for eye component after template selection is justifiable. As discussed in
Section 2.1.2, the final extracted eye comprises two cubic Bezier curves as illustrated in
Figure 4a. Considering the differences around the eye corners between this contour for eyes and the corresponding hand-drawn ones (
Figure 4b), it is clear that the matched eye templates will result in more similar eyes to hand-drawn eyes. As a result of this, we can see that in
Figure 9, the eyes are improved. No similar situation happens for eyebrows because we do not consider predefined curves for them at the feature extraction stage. With further observation among cartoon faces whose ratings are low, we can admit the limitation of our proposed system in imitating the nose.
4. Discussion
Our proposed system is capable of automatically generating life-like cartoon faces vectorically from an input face image. The system consists of offline and online phases. In the offline stage, hand-drawn cartoon templates are collected and further decomposed into facial components. Components of the original faces in our collection set are extracted as well. We combine global and local approaches for feature extraction. In the online phase, facial components of the input face are extracted using a component-wise approach. The hair component is also extracted automatically. Then, the closest templates of each component are selected and deformed to be fit to the input face. Unlike current cartoon producers, for template matching we employed contour comparison to both cartoon contours and extracted shapes of sample faces.
Further research can be classified into two groups. Group one is related to the process of facial feature extraction and template matching.
Figure 10 shows a failure case with respect to the feature extraction phase where a faulty extraction of face contour in ASM results in inappropriate cartoon face generation. Extraction of high level features such as the upper curve for the eye component and nostrils can be effective in matching procedure. These features lead to the selection of more suitable cartoon templates for facial components of the input face. In another group, future work can bring about better representations of final cartoons. Similar to the approach we conducted for cartoon template collection, we can offer the final cartoon face in Adobe Illustrator layer by layer, so users can modify the final result interactively using powerful graphical tools provided in this software, such as different brushes and filters.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}