
A Raspberry Pi Cluster Instrumented for Fine-Grained Power Measurement †

Abstract
:1. Introduction
2. Experimental Section
2.1. Board Comparison
2.1.1. Experimental Setup
2.1.2. Benchmarking Programs
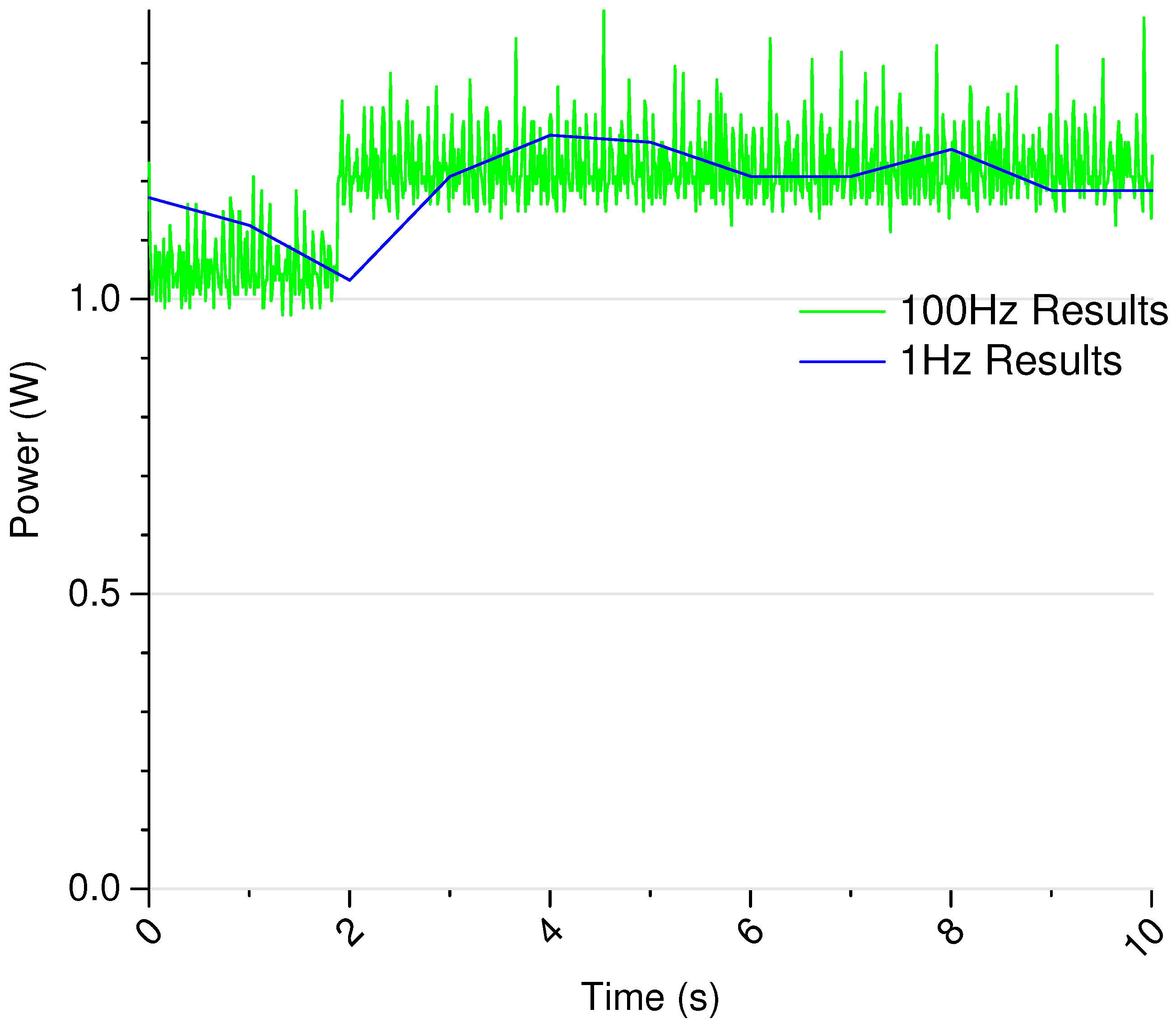
2.1.3. Power Measurement
2.1.4. HPL FLOPS Results
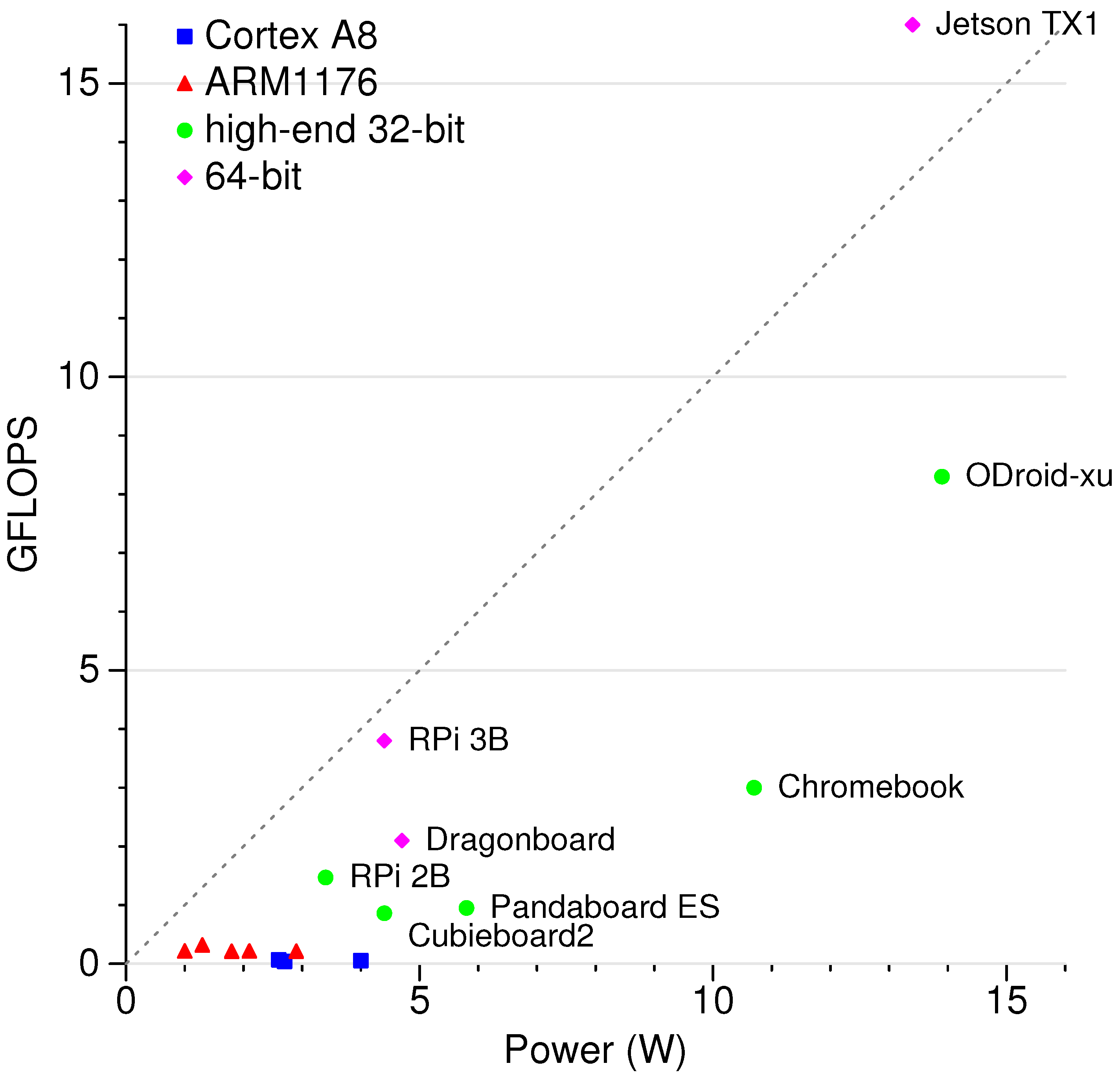
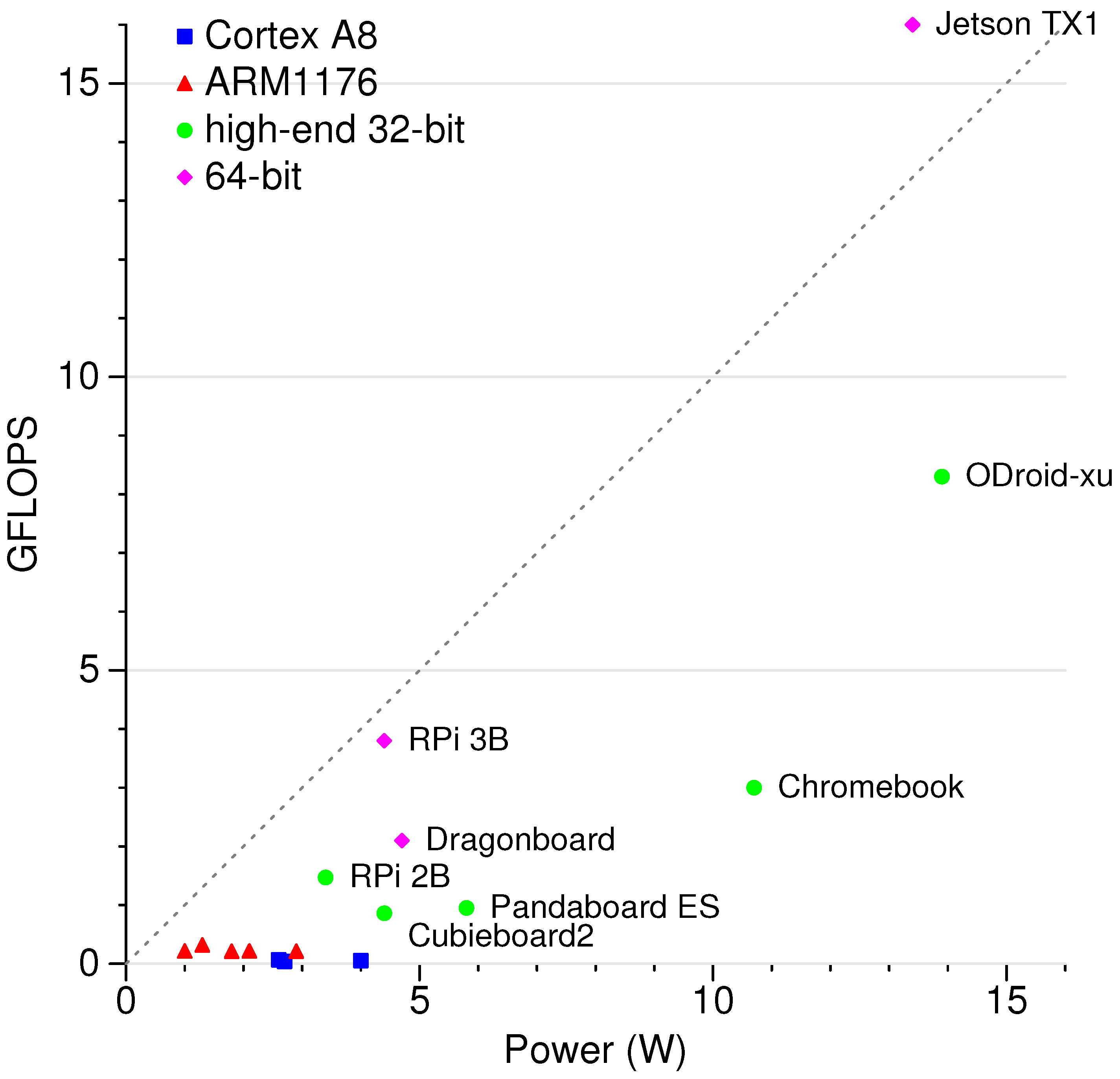
2.1.5. HPL FLOPS per Watt Results
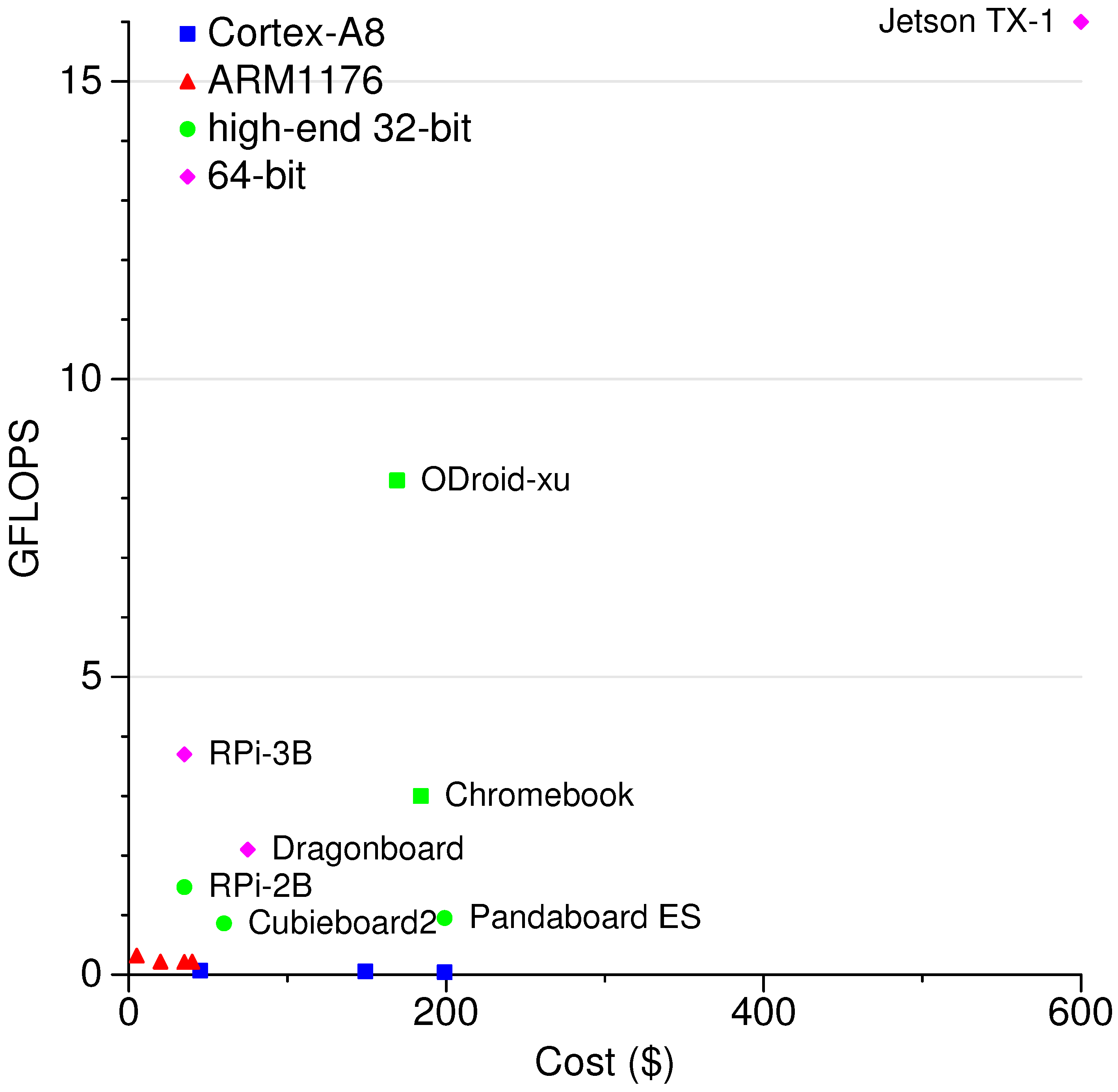
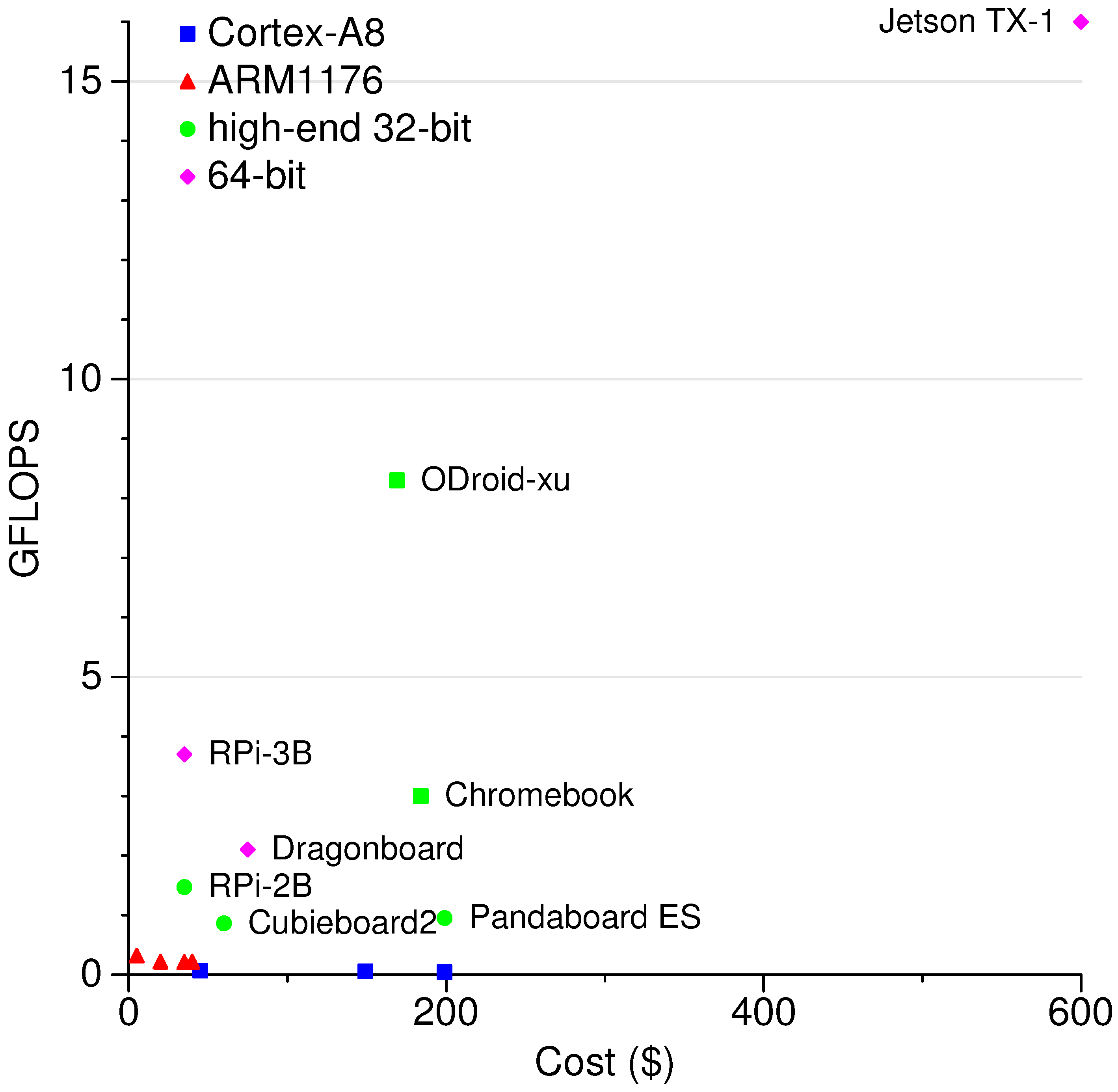
2.1.6. HPL FLOPS per Cost Results
2.1.7. STREAM Results
2.1.8. Summary
2.2. Cluster Design
2.2.1. Node Installation and Software
2.2.2. Node Arrangement and Construction
2.2.3. Visualization Displays
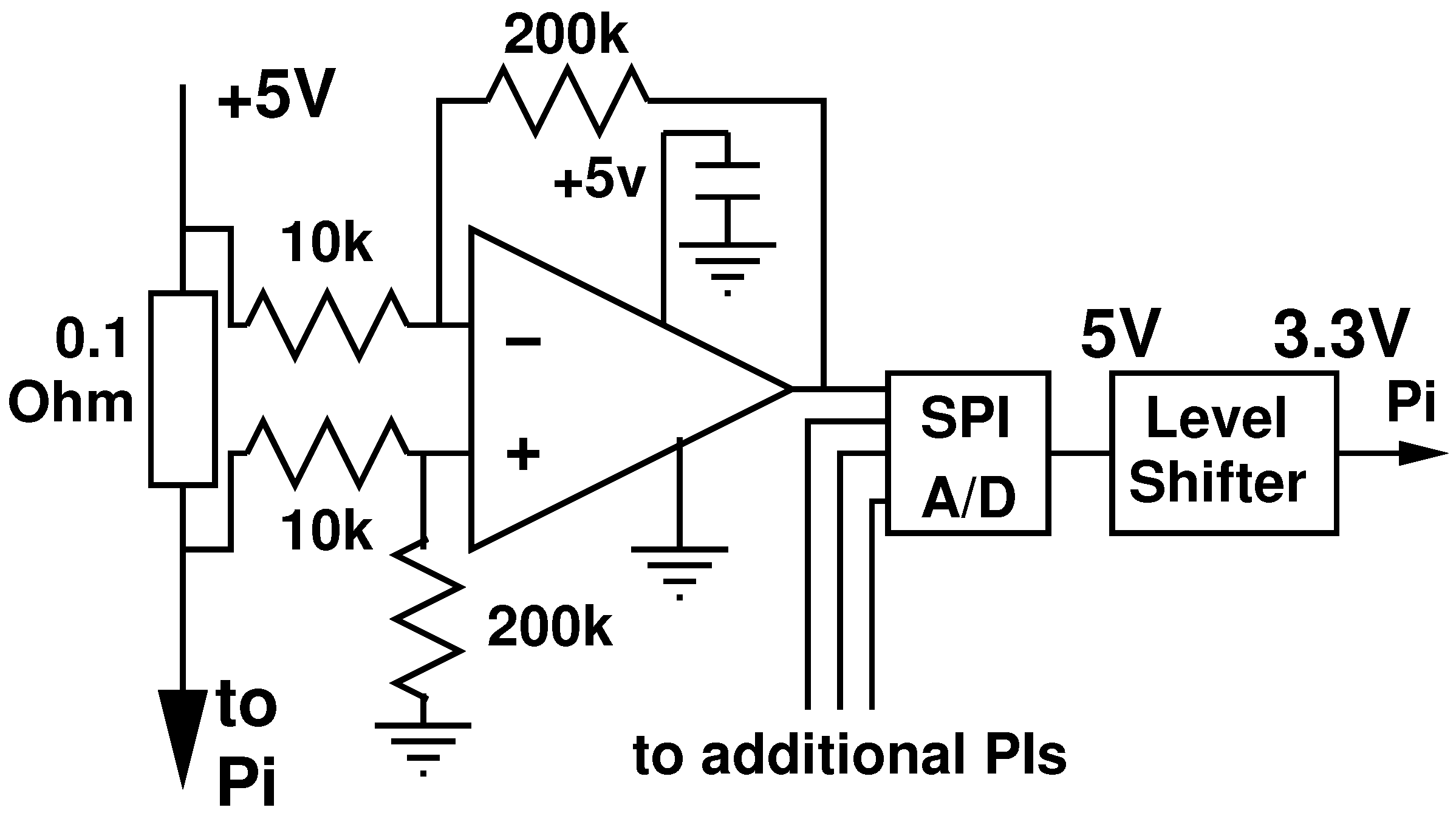
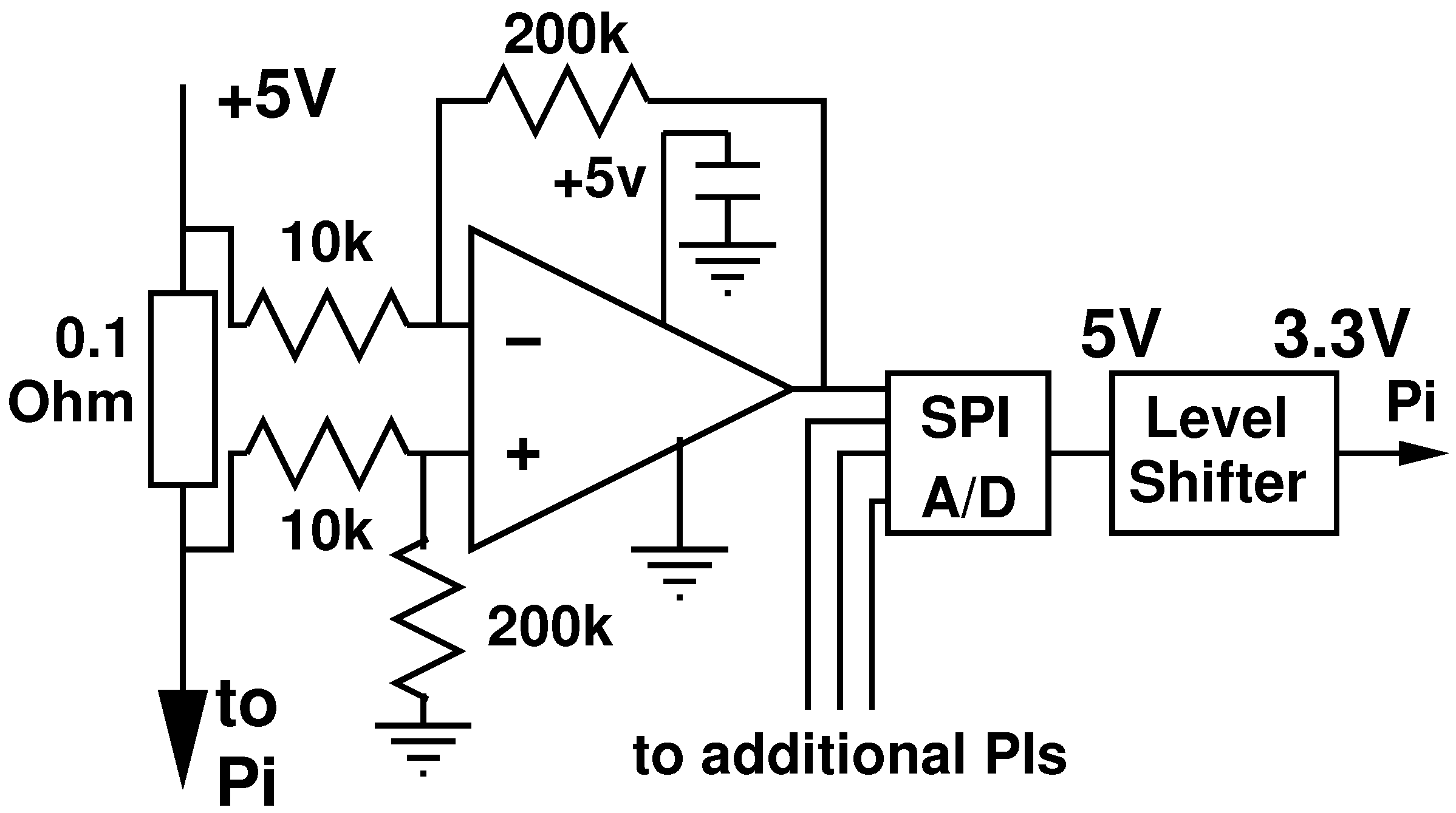
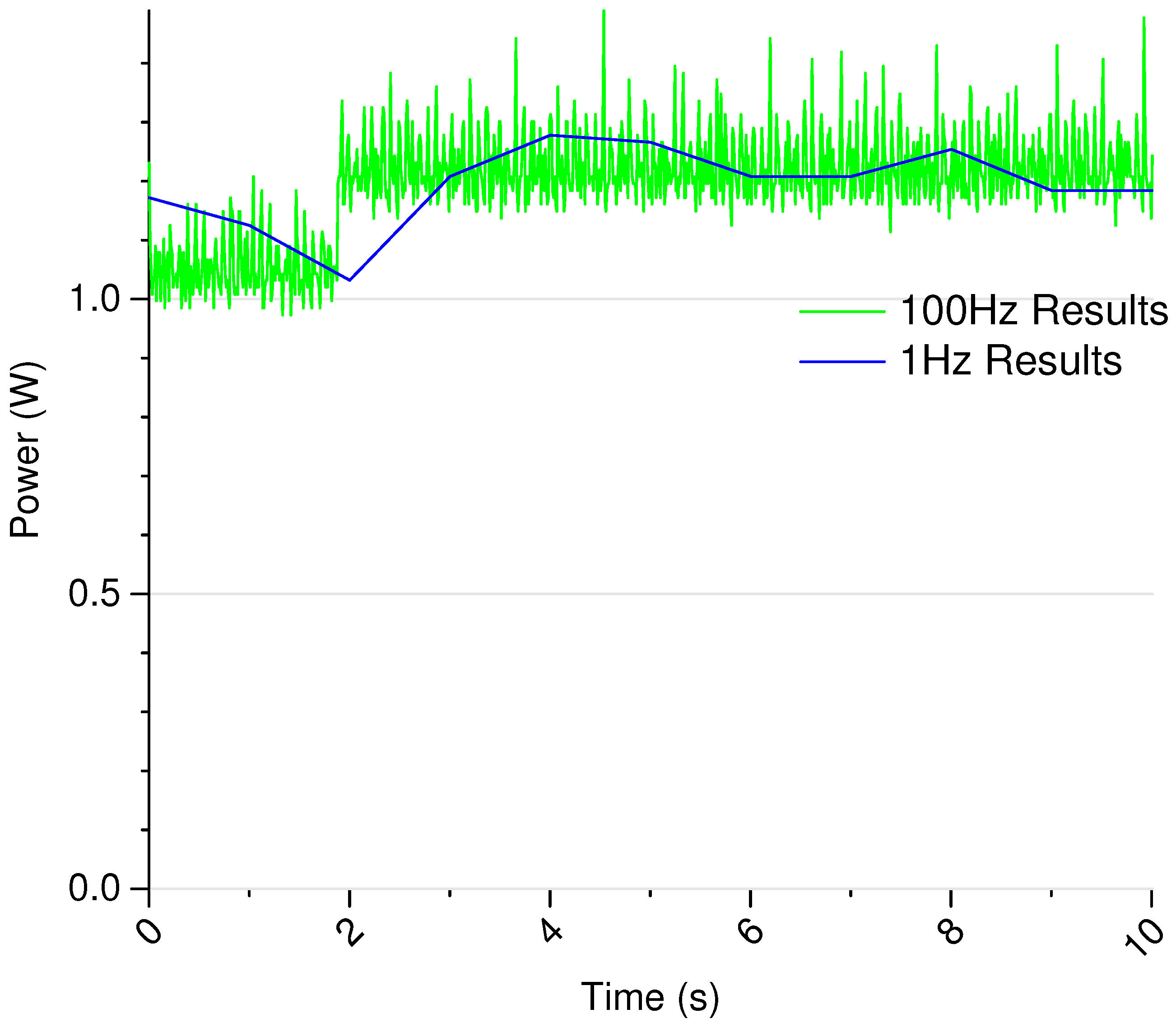
2.2.4. Power Measurement
2.2.5. Temperature Measurement
3. Results
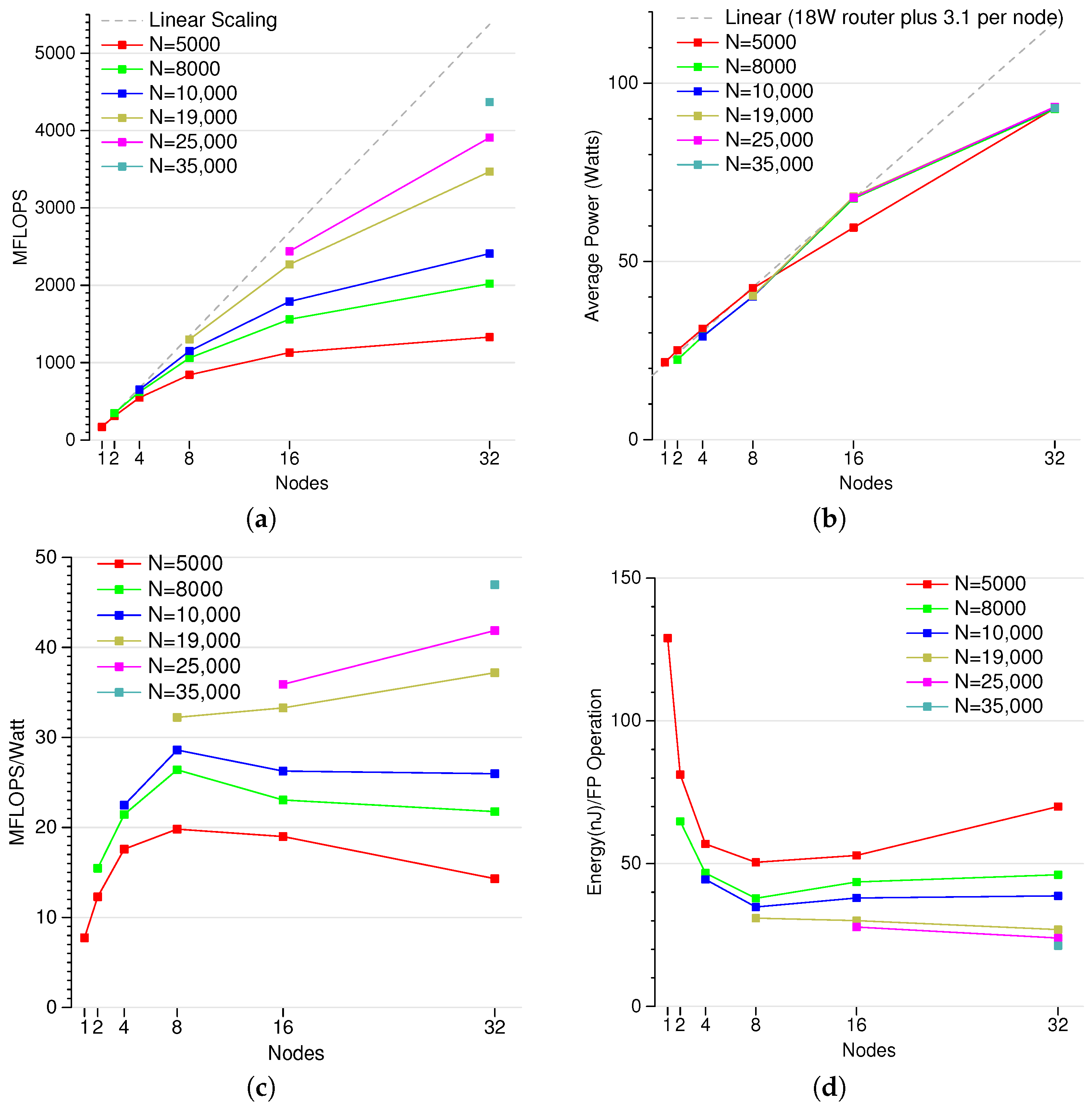
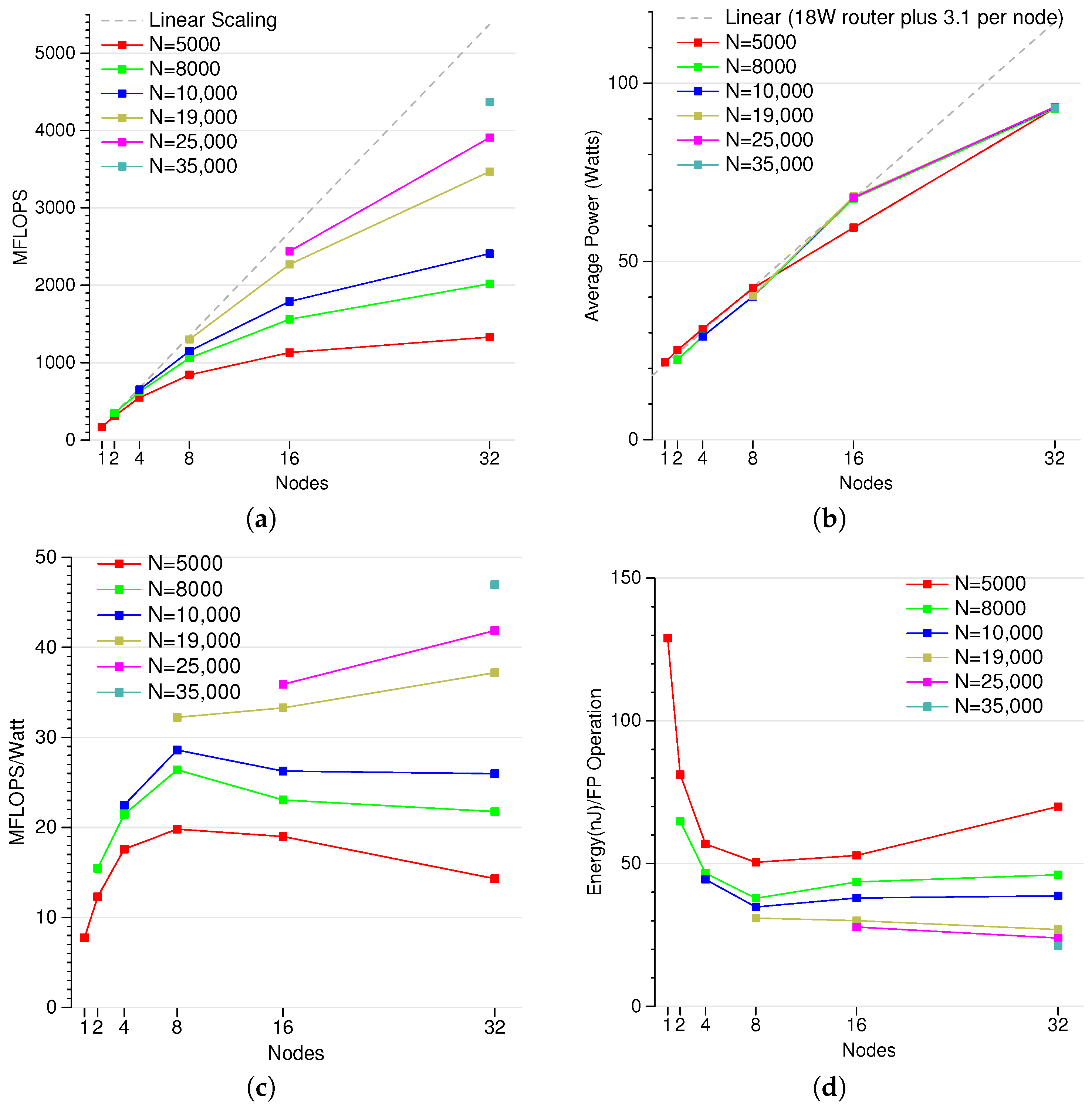
3.1. Peak FLOPS Results
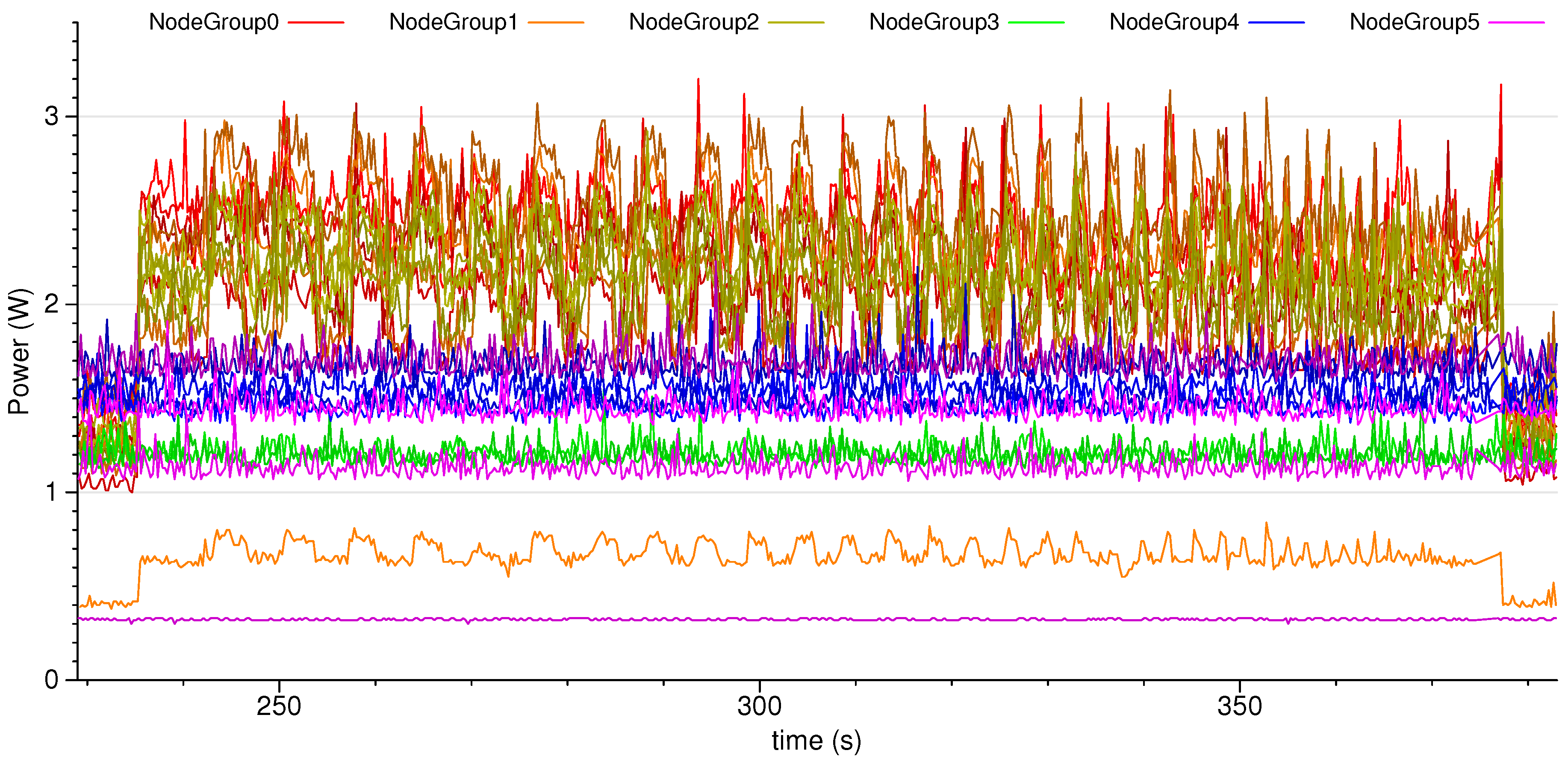
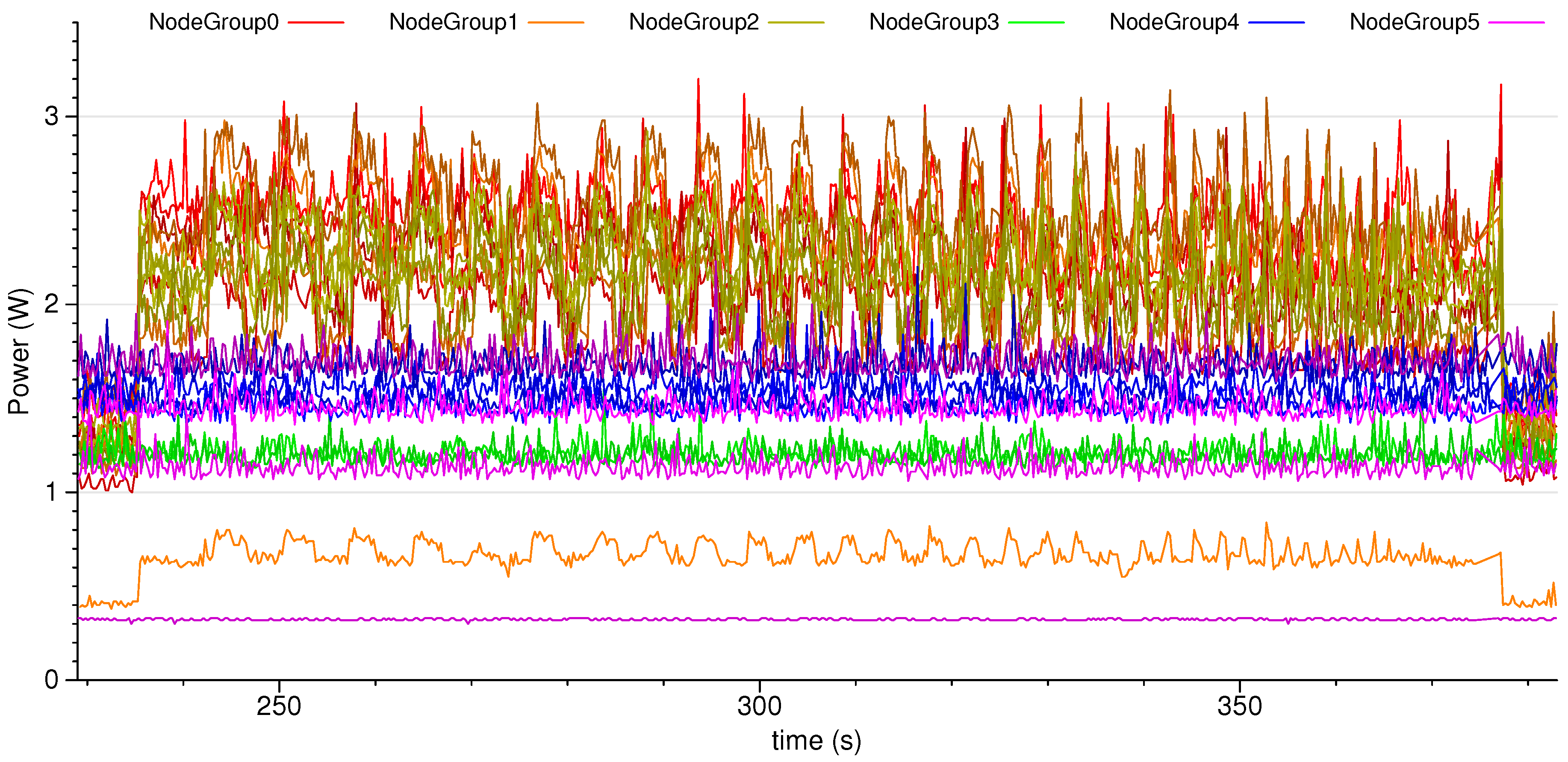
3.2. Cluster Scaling
3.3. Summary
4. Discussion
4.1. Related Work
4.1.1. Cluster Power Measurement
4.1.2. ARM HPC Performance Comparisons
4.1.3. ARM Cluster Building
4.1.4. Raspberry Pi Clusters
4.1.5. Summary
4.2. Future Work
- Expand the size: We have parts to expand to 48 nodes. This can be done without requiring a larger network switch.
- Upgrade the cluster to use Raspberry Pi Model 3B nodes: The 3B has the same footprint as the 2B, so this would require minimal changes. This would improve the performance of the cluster by at least a factor of two, if not more. The main worry is the possible need for heat sinks and extra cooling as the 3B systems are known to have problems under extreme loads (i.e., while running Linpack).
- Enable distributed hardware performance counter support: The tools we have currently can gather power measurements cluster-wide. It would be useful to gather hardware performance counter measures (such as cycles, cache misses, etc.) at the same time.
- Harness the GPUs. Table A2 shows the GPU capabilities available on the various boards. The Raspberry Pi has a potential 24 GFLOPS available perf node, which is over an order of magnitude more than found on the CPU. Grasso et al. [40] use OpenCL on a Cortex A15 board with a Mali GPU and find that they can get 8.7-times better performance than the CPU with 1/3 the energy. If similar work could be done to obtain GPGPU support on the Raspberry Pi, our cluster could obtain a huge performance boost.
- Perform power and performance optimization: We now have the capability to do detailed performance and power optimizations on an ARM cluster. We need to develop new tools and methodologies to take advantage of this.
4.3. Conclusions
Author Contributions
Conflicts of Interest
Appendix A. Detailed System Information

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| System | Family | Type | Process | CPU Design | BrPred | Network |
|---|---|---|---|---|---|---|
| RPi Zero | ARM1176 | Broadcom 2835 | 40 nm | InOrder 1-issue | YES | n/a |
| RPi Model A+ | ARM1176 | Broadcom 2835 | 40 nm | InOrder 1-issue | YES | n/a |
| RPi Compute Module | ARM1176 | Broadcom 2835 | 40 nm | InOrder 1-issue | YES | n/a |
| RPi Model B | ARM1176 | Broadcom 2835 | 40 nm | InOrder 1-issue | YES | 100 USB |
| RPi Model B+ | ARM1176 | Broadcom 2835 | 40 nm | InOrder 1-issue | YES | 100 USB |
| Gumstix Overo | Cortex A8 | TI OMAP3530 | 65 nm | InOrder 2-issue | YES | 100 |
| Beagleboard-xm | Cortex A8 | TI DM3730 | 45 nm | InOrder 2-issue | YES | 100 |
| Beaglebone Black | Cortex A8 | TI AM3358/9 | 45 nm | InOrder 2-issue | YES | 100 |
| Pandaboard ES | Cortex A9 | TI OMAP4460 | 45 nm | OutOfOrder | YES | 100 |
| Trimslice | Cortex A9 | NVIDIA Tegra2 | 40 nm | OutOfOrder | YES | 1000 |
| RPi Model 2-B | Cortex A7 | Broadcom 2836 | 40 nm | InOrder | YES | 100 USB |
| Cubieboard2 | Cortex A7 | AllWinner A20 | 40 nm | InOrder Partl-2-Issue | YES | 100 |
| Chromebook | Cortex A15 | Exynos 5 Dual | 32 nm | OutOfOrder | YES | Wireless |
| ODROID-xU | Cortex A7 | Exynos 5 Octa | 28 nm | InOrder | YES | 100 |
| Cortex A15 | OutOfOrder | |||||
| RPi Model 3-B | Cortex A53 | Broadcom 2837 | 40 nm | InOrder 2-issue | YES | 100 USB |
| Dragonboard | Cortex A53 | Snapdragon 410c | 28 nm | InOrder 2-issue | YES | n/a |
| Jetson-TX1 | Cortex A53 | Tegra X1 | 20 nm | InOrder 2-issue | YES | 1000 |
| Cortex A57 | OutOfOrder |
| System | FPSupport | NEON | GPU | DSP/Offload Engine |
|---|---|---|---|---|
| RPi Zero | VFPv2 | no | VideoCore IV (24 GFLOPS) | DSP |
| RPi Model A+ | VFPv2 | no | VideoCore IV (24 GFLOPS) | DSP |
| RPi Compute Node | VFPv2 | no | VideoCore IV (24 GFLOPS) | DSP |
| RPi Model B | VFPv2 | no | VideoCore IV (24 GFLOPS) | DSP |
| RPi Model B+ | VFPv2 | no | VideoCore IV (24 GFLOPS) | DSP |
| Gumstix Overo | VFPv3 (lite) | YES | PowerVR SGX530 (1.6 GFLOPS) | n/a |
| Beagleboard-xm | VFPv3 (lite) | YES | PowerVR SGX530 (1.6 GFLOPS) | TMS320C64x+ |
| Beaglebone Black | VFPv3 (lite) | YES | PowerVR SGX530 (1.6 GFLOPS) | n/a |
| Pandaboard ES | VFPv3 | YES | PowerVR SGX540 (3.2 GFLOPS) | IVA3 HW Accel |
| 2 × Cortex-M3 Codec | ||||
| Trimslice | VFPv3, VFPv3d16 | no | 8-core GeForce ULP GPU | n/a |
| RPi Model 2-B | VFPv4 | YES | VideoCore IV (24 GFLOPS) | DSP |
| Cubieboard2 | VFPv4 | YES | Mali-400MP2 (10 GFLOPS) | n/a |
| Chromebook | VFPv4 | YES | Mali-T604MP4 (68 GFLOPS) | Image Processor |
| ODROID-xU | VFPv4 | YES | PowerVR SGX544MP3 (21 GFLOPS) | n/a |
| RPi Model 3-B | VFPv4 | YES | VideoCore IV (24 GFLOPS) | DSP |
| Dragonboard | VFPv4 | YES | Qualcomm Adreno 306 | Hexagon QDSP6 |
| Jetson TX-1 | VFPv4 | YES | NVIDIA GM20B Maxwell (1 TFLOP) | n/a |
| System | RAM | L1-I Cache | L1-D Cache | L2 Cache | Prefetch |
|---|---|---|---|---|---|
| RPi Zero | 512 MB LPDDR2 | 16 k,4-way, 32 B | 16 k,4-way, 32 B | 128 k * | no |
| RPi Model A+ | 256 MB LPDDR2 | 16 k, 4-way, 32 B | 16 k, 4-way, 32 B | 128 k * | no |
| RPi Compute Module | 512 MB LPDDR2 | 16 k, 4-way, 32 B | 16 k, 4-way, 32 B | 128 k * | no |
| RPi Model B | 512 MB LPDDR2 | 16 k, 4-way, 32 B | 16 k, 4-way, 32 B | 128 k * | no |
| RPi Model B+ | 512 MB LPDDR2 | 16 k, 4-way, 32 B | 16 k, 4-way, 32 B | 128 k * | no |
| Gumstix Overo | 256 MB DDR | 16 k, 4-way | 16 k, 4-way | 256 k | no |
| Beagleboard-xm | 512 MB DDR2 | 32 k, 4-way, 64 B | 32 k, 4-way, 64 B | 256 k, 64 B | no |
| Beaglebone Black | 512 MB DDR3 | 32 k, 4-way, 64 B | 42 k, 4-way, 64 B | 256 k, 64 B | no |
| Pandaboard ES | 1 GB LPDDR2 Dual | 32 k, 4-way,32B | 32 k, 4-way,32B | 1 MB (external) | yes |
| Trimslice | 1 GB LPDDR2 Single | 32 k | 32 k | 1 MB | yes |
| RPi Model 2B | 1 GB LPDDR2 | 32 k | 32 k | 512 k | yes |
| Cubieboard2 | 1 GB DDR3 | 32 k | 32 k | 256 k shared | yes |
| Chromebook | 2 GB LPDDR3, Dual | 32 k | 32 k | 1 M | yes |
| ODROID-xU | 2 GB LPDDR3 | 32 k | 32 k | 512 k/2 MB | yes |
| Dual 800 MHz | |||||
| RPi Model 3B | 1 GB LPDDR2 | 16 k | 16 k | 512 k | yes |
| Dragonboard | 1 GB LPDDR3 | unknown | unknown | unknown | yes |
| 533 MHz | yes | ||||
| Jetson TX-1 | 4 GB LPDDR4 | 48 kB, 3-way, | 32 kB, 2-way | 2 MB/512 kB | yes |
Appendix B. Materials and Methods
References
- Gara, A.; Blumrich, M.; Chen, D.; Chiu, G.T.; Coteus, P.; Giampapa, M.; Haring, R.A.; Heidelberger, P.; Hoenicke, D.; Kopcsay, G.; et al. Overview of the Blue Gene/L system architecture. IBM J. Res. Dev. 2005, 49, 195–212. [Google Scholar] [CrossRef]
- IBM Blue Gene Team. Overview of the IBM Blue Gene/P project. IBM J. Res. Dev. 2008, 52, 199–220. [Google Scholar]
- Haring, R.; Ohmacht, M.; Fox, T.; Gschwind, M.; Boyle, P.; Chist, N.; Kim, C.; Satterfield, D.; Sugavanam, K.; Coteus, P.; et al. The IBM Blue Gene/Q Compute Chip. IEEE Micro 2012, 22, 48–60. [Google Scholar] [CrossRef]
- Top 500 Supercomputing Sites. Available online: http://www.top500.org/ (accessed on 30 April 2016).
- Petitet, A.; Whaley, R.; Dongarra, J.; Cleary, A. HPL—A Portable Implementation of the High-Performance Linpack Benchmark for Distributed-Memory Computers. Available online: http://www.netlib.org/benchmark/hpl/ (accessed on 30 April 2016).
- Gropp, W. MPICH2: A New Start for MPI Implementations. In Recent Advances in Parallel Virtual Machine and Message Passing Interface; Springer: Berlin, Germany, 2002; p. 7. [Google Scholar]
- OpenBLAS An optimized BLAS Library Website. Available online: http://www.openblas.net/ (accessed on 30 April 2016).
- McCalpin, J. STREAM: Sustainable Memory Bandwidth in High Performance Computers. Available online: http://www.cs.virginia.edu/stream/ (accessed on 30 April 2016).
- Electronic Educational Devices. Watts up PRO. Available online: http://www.wattsupmeters.com/ (accessed on 30 April 2016).
- Raspberry Pi Foundation Forums. Pi3 Incorrect Results under Load (Possibly Heat Related). Available online: https://www.raspberrypi.org/forums/viewtopic.php?f=63&t=139712&sid=bfbb48acfb1c4e5607821a44a65e86c5 (accessed on 30 April 2016).
- Jette, M.; Yoo, A.; Grondona, M. SLURM: Simple Linux Utility for Resource Management. In Proceedings of the 9th International Workshop: Job Scheduling Strategies for Parallel Processing (JSSPP 2003), Seattle, WA, USA, 24 June 2003; pp. 44–60.
- Top500. Top 500 Supercomputing Sites. Available online: https://www.top500.org/lists/1993/06/ (accessed on 30 April 2016).
- Ge, R.; Feng, X.; Song, S.; Chang, H.C.; Li, D.; Cameron, K. PowerPack: Energy Profiling and Analysis of High-Performance Systems and Applications. IEEE Trans. Parallel Distrib. Syst. 2010, 21, 658–671. [Google Scholar] [CrossRef]
- Bedard, D.; Fowler, R.; Linn, M.; Porterfield, A. PowerMon 2: Fine-grained, Integrated Power Measurement; Renaissance Computing Institute: Chapel Hill, NC, USA, 2009. [Google Scholar]
- Hackenberg, D.; Ilsche, T.; Schoene, R.; Molka, D.; Schmidt, M.; Nagel, W.E. Power Measurement Techniques on Standard Compute Nodes: A Quantitative Comparison. In Proceedings of the 2013 IEEE International Symposium on Performance Analysis of Systems and Software, Austin, TX, USA, 21–23 April 2013.
- Dongarra, J.; Luszczek, P. Anatomy of a Globally Recursive Embedded LINPACK Benchmark. In Proceedings of the 2012 IEEE Conference on High Performance Extreme Computing Conference, Waltham, MA, USA, 10–12 September 2012.
- Aroca, R.; Gonçalves, L. Towards Green Data Centers: A Comparison of x86 and ARM architectures power efficiency. J. Parallel Distrib. Comput. 2012, 72, 1770–1780. [Google Scholar] [CrossRef]
- Jarus, M.; Varette, S.; Oleksiak, A.; Bouvry, P. Performance Evaluation and Energy Efficiency of High-Density HPC Platforms Based on Intel, AMD and ARM Processors. In Energy Efficiency in Large Scale Distributed Systems; Springer: Berlin, Germany, 2013; pp. 182–200. [Google Scholar]
- Blem, E.; Menon, J.; Sankaralingam, K. Power struggles: Revisiting the RISC vs. CISC debate on contemporary ARM and x86 architectures. In Proceedings of the 2013 IEEE 19th International Symposium on High Performance Computer Architecture, Shenzhen, China, 23–27 February 2013; pp. 1–12.
- Stanley-Marbell, P.; Cabezas, V. Performance, Power, and Thermal Analysis of Low-Power Processors for Scale-Out Systems. In Proceedings of the 2011 IEEE International Symposium on Parallel and Distributed Processing Workshops and PhD Forum (IPDPSW), Anchorage, AK, USA, 16–20 May 2011; pp. 863–870.
- Pinto, V.; Lorenzon, A.; Beck, A.; Maillard, N.; Navaux, P. Energy Efficiency Evaluation of Multi-level Parallelism on Low Power Processors. In Proceedings of the 34th Congresso da Sociedade Brasileira de Computação, Brasilia, Brazil, 28–31 July 2014; pp. 1825–1836.
- Padoin, E.; de Olivera, D.; Velho, P.; Navaux, P. Evaluating Performance and Energy on ARM-based Clusters for High Performance Computing. In Proceedings of 2012 41st International Conference on Parallel Processing Workshops (ICPPW 2012), Pittsburgh, PA, USA, 10–13 September 2012.
- Padoin, E.; de Olivera, D.; Velho, P.; Navaux, P. Evaluating Energy Efficiency and Instantaneous Power on ARM Platforms. In Proceedings of the 10th Workshop on Parallel and Distributed Processing, Porto Alegre, Brazil, 17 August 2012.
- Padoin, E.; de Olivera, D.; Velho, P.; Navaux, P.; Videau, B.; Degomme, A.; Mehaut, J.F. Scalability and Energy Efficiency of HPC Cluster with ARM MPSoC. In Proceedings of the 11th Workshop on Parallel and Distributed Processing, Porto Alegre, Brazil, 16 August 2013.
- Pleiter, D.; Richter, M. Energy Efficient High-Performance Computing using ARM Cortex-A9 cores. In Proceedings of the 2012 IEEE International Conference on Green Computing and Communications, Besançon, France, 20–23 November 2012; pp. 607–610.
- Laurenzano, M.; Tiwari, A.; Jundt, A.; Peraza, J.; Ward, W., Jr.; Campbell, R.; Carrington, L. Characterizing the Performance-Energy Tradeoff of Small ARM Cores in HPC Computation. In Euro-Par 2014 Parallel Processing; Springer: Zurich, Switzerland, 2014; pp. 124–137. [Google Scholar]
- Geveler, M.; Köhler, M.; Saak, J.; Truschkewitz, G.; Benner, P.; Turek, S. Future Data Centers for Energy-Efficient Large Scale Numerical Simulations. In Proceedings of the 7th KoMSO Challenege Workshop: Mathematical Modeling, Simulation and Optimization for Energy Conservation, Heidelberg, Germany, 8–9 October 2015.
- Rajovic, N.; Rico, A.; Vipond, J.; Gelado, I.; Puzovic, N.; Ramirez, A. Experiences with Mobile Processors for Energy Efficient HPC. In Proceedings of the Conference on Design, Automation and Test in Europe, Grenoble, France, 18–22 March 2013.
- Rajovic, N.; Rico, A.; Puzovic, N.; Adeniyi-Jones, C. Tibidabo: Making the case for an ARM-based HPC System. Future Gener. Comput. Syst. 2014, 36, 322–334. [Google Scholar] [CrossRef]
- Göddeke, D.; Komatitsch, D.; Geveler, M.; Ribbrock, D.; Rajovic, N.; Puzovic, N.; Ramirez, A. Energy Efficiency vs. Performance of the Numerical Solution of PDEs: An Application Study on a Low-Power ARM Based Cluster. J. Comput. Phys. 2013, 237, 132–150. [Google Scholar] [CrossRef]
- Sukaridhoto, S.; KHalilullah, A.; Pramadihato, D. Further Investigation of Building and Benchmarking a Low Power Embedded Cluster for Education. In Proceedings of the 4th International Seminar on Applied Technology, Science and Arts, Pusat Robotika, Surabaya, Indonesia, 10 December 2013; pp. 1–8.
- Balakrishnan, N. Building and Benchmarking a Low Power ARM Cluster. Master’s Thesis, University of Edinburgh, Edinburgh, UK, August 2012. [Google Scholar]
- Ou, Z.; Pang, B.; Deng, Y.; Nurminen, J.; Ylä-Jääski, A.; Hui, P. Energy- and Cost-Efficiency Analysis of ARM-Based Clusters. In Proceedings of the 2012 12th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing, Ottawa, ON, Canada, 13–16 May 2012; pp. 115–123.
- Fürlinger, K.; Klausecker, C.; Kranzmüller, D. The AppleTV-Cluster: Towards Energy Efficient Parallel Computing on Consumer Electronic Devices. In Proceedings of the First International Conference on Information and Communication on Technology for the Fight against Global Warming, Toulouse, France, 30–31 August 2011.
- Pfalzgraf, A.; Driscoll, J. A Low-Cost Computer Cluster for High-Performance Computing Education. In Proceedings of the 2014 IEEE International Conference on Electro/Information Technology, Milwaukee, WI, USA, 5–7 June 2014; pp. 362–366.
- Kiepert, J. RPiCLUSTER: Creating a Raspberry Pi-Based Beowulf Cluster; Boise State University: Boise, ID, USA, 2013. [Google Scholar]
- Tso, F.; White, D.; Jouet, S.; Singer, J.; Pezaros, D. The Glasgow Raspberry Pi Cloud: A Scale Model for Cloud Computing Infrastructures. In Proceedings of the 2013 IEEE 33rd International Conference on Distributed Computing Systems Workshops (ICDCSW), Philadelphia, PA, USA, 8–11 July 2013; pp. 108–112.
- Cox, S.; Cox, J.; Boardman, R.; Johnston, S.; Scott, M.; O’Brien, N. Irdis-pi: A low-cost, compact demonstration cluster. Clust. Comput. 2013, 17, 349–358. [Google Scholar] [CrossRef]
- Abrahamsson, P.; Helmer, S.; Phaphoom, N.; Nocolodi, L.; Preda, N.; Miori, L.; Angriman, M.; Rikkilä, J.; Wang, X.; Hamily, K.; et al. Affordable and Energy-Efficient Cloud Computing Clusters: The Bolzano Raspberry Pi Cloud Cluster Experiment. In Proceedings of the 2013 IEEE 5th International Conference on Cloud Computing Technology and Science, Bristol, UK, 2–5 December 2013; pp. 170–175.
- Grasso, I.; Radojković, P.; Rajović, N.; Gelado, I.; Ramirez, A. Energy Efficient HPC on Embedded SoCs: Optimization Techniques for Mali GPU. In Proceedings of the 2014 IEEE 28th International Parallel and Distributed Processing Symposium, Phoenix, AZ, USA, 19–23 May 2014; pp. 123–132.


| System | Family | CPU (Central Processing Unit) | Memory | Cost (USD) | ||
|---|---|---|---|---|---|---|
| Raspberry Pi Zero | ARM1176 | 1 | 1 GHz | Broadcom 2835 | 512 MB | $5 |
| Raspberry Pi Model A+ | ARM1176 | 1 | 700 MHz | Broadcom 2835 | 256 MB | $20 |
| Raspberry Pi Compute Module | ARM1176 | 1 | 700 MHz | Broadcom 2835 | 512 MB | $40 |
| Raspberry Pi Model B | ARM1176 | 1 | 700 MHz | Broadcom 2835 | 512 MB | $35 |
| Raspberry Pi Model B+ | ARM1176 | 1 | 700 MHz | Broadcom 2835 | 512 MB | $35 |
| Gumstix Overo | Cortex A8 | 1 | 600 MHz | TI OMAP3530 | 256 MB | $199 |
| Beagleboard-xm | Cortex A8 | 1 | 1 GHz | TI DM3730 | 512 MB | $149 |
| Beaglebone Black | Cortex A8 | 1 | 1 GHz | TI AM3358/9 | 512 MB | $45 |
| Pandaboard ES | Cortex A9 | 2 | 1.2 GHz | TI OMAP4460 | 1 GB | $199 |
| Trimslice | Cortex A9 | 2 | 1 GHz | NVIDIA Tegra2 | 1 GB | $99 |
| Raspberry Pi Model 2-B | Cortex A7 | 4 | 900 MHz | Broadcom 2836 | 1 GB | $35 |
| Cubieboard2 | Cortex A7 | 2 | 912 MHz | AllWinner A20 | 1 GB | $60 |
| Chromebook | Cortex A15 | 2 | 1.7 GHz | Exynos 5 Dual | 2 GB | $184 |
| ODROID-xU | Cortex A15 | 4 | 1.6 GHz | Exynos 5 Octa | 2 GB | $169 |
| Cortex A7 | 4 | 1.2 GHz | ||||
| Raspberry Pi Model 3-B | Cortex A53 | 4 | 1.2 GHz | Broadcom 2837 | 1 GB | $35 |
| Dragonboard | Cortex A53 | 4 | 1.2 GHz | Snapdragon 410 | 1 GB | $75 |
| Jetson TX-1 | Cortex A57 | 4 | 1.9 GHz | Tegra X1 | 4 GB | $600 |
| Cortex A53 | 4 | unknown | ||||
| System | N | GFLOPS | Idle | AvgLoad | GFLOPS | MFLOPS |
|---|---|---|---|---|---|---|
| Power | Power | per Watt | per US$ | |||
| Gumstix Overo | 4000 | 0.041 | 2.0 | 2.7 | 0.015 | 0.20 |
| Beagleboard-xm | 5000 | 0.054 | 3.2 | 4.0 | 0.014 | 0.36 |
| Beaglebone Black | 5000 | 0.068 | 1.9 | 2.6 | 0.026 | 1.51 |
| Raspberry Pi Model B | 5000 | 0.213 | 2.7 | 2.9 | 0.073 | 6.09 |
| Raspberry Pi Model B+ | 5000 | 0.213 | 1.6 | 1.8 | 0.118 | 6.09 |
| Raspberry Pi Compute Module | 6000 | 0.217 | 1.9 | 2.1 | 0.103 | 5.43 |
| Raspberry Pi Model A+ | 4000 | 0.218 | 0.8 | 1.0 | 0.223 | 10.9 |
| Raspberry Pi Zero | 5000 | 0.319 | 0.8 | 1.3 | 0.236 | 63.8 |
| Cubieboard2 | 8000 | 0.861 | 2.2 | 4.4 | 0.194 | 14.4 |
| Pandaboard ES | 4000 | 0.951 | 3.0 | 5.8 | 0.163 | 4.78 |
| Raspberry Pi Model 2B | 10,000 | 1.47 | 1.8 | 3.4 | 0.432 | 42.0 |
| Dragonboard | 8000 | 2.10 | 2.4 | 4.7 | 0.450 | 28.0 |
| Chromebook | 10,000 | 3.0 | 5.9 | 10.7 | 0.277 | 16.3 |
| Raspberry Pi Model 3B | 10,000 | 3.7 * | 1.8 | 4.4 | 0.844 | 106 |
| ODROID-xU | 12,000 | 8.3 | 2.7 | 13.9 | 0.599 | 49.1 |
| Jetson TX-1 | 20,000 | 16.0 | 2.1 | 13.4 | 1.20 | 26.7 |
| pi-cluster | 48,000 | 15.5 | 71.3 | 93.1 | 0.166 | 7.75 |
| 2 core Intel Atom S1260 | 20,000 | 2.6 | 18.6 | 22.1 | 0.149 | 4.33 |
| 16 core AMD Opteron 6376 | 40,000 | 122 | 167 | 262 | 0.466 | 30.5 |
| 16 core Intel Haswell-EP | 80,000 | 428 | 58.7 | 201 | 2.13 | 107 |
| Type | Nodes | Cores | Freq | Memory | Peak | Idle | Busy | GFLOPS |
|---|---|---|---|---|---|---|---|---|
| GFLOPS | Power | Power | per Watt | |||||
| Pi2 Cluster | 24 | 96 | 900 MHz | 24 GB | 15.5 | 71.3 | 93.1 | 0.166 |
| Pi B+ Cluster | 32 | 32 | 700 MHz | 16 GB | 4.37 | 86.8 | 93.0 | 0.047 |
| Pi B+ Overclock | 32 | 32 | 1 GHz | 16 GB | 6.25 | 94.5 | 112.1 | 0.055 |
| AMD Opteron 6376 | 1 | 16 | 2.3 GHz | 16 GB | 122 | 167 | 262 | 0.466 |
| Intel Haswell-EP | 1 | 16 | 2.6 GHz | 80 GB | 428 | 58.7 | 201 | 2.13 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cloutier, M.F.; Paradis, C.; Weaver, V.M. A Raspberry Pi Cluster Instrumented for Fine-Grained Power Measurement. Electronics 2016, 5, 61. https://doi.org/10.3390/electronics5040061
Cloutier MF, Paradis C, Weaver VM. A Raspberry Pi Cluster Instrumented for Fine-Grained Power Measurement. Electronics. 2016; 5(4):61. https://doi.org/10.3390/electronics5040061
Chicago/Turabian StyleCloutier, Michael F., Chad Paradis, and Vincent M. Weaver. 2016. "A Raspberry Pi Cluster Instrumented for Fine-Grained Power Measurement" Electronics 5, no. 4: 61. https://doi.org/10.3390/electronics5040061
APA StyleCloutier, M. F., Paradis, C., & Weaver, V. M. (2016). A Raspberry Pi Cluster Instrumented for Fine-Grained Power Measurement. Electronics, 5(4), 61. https://doi.org/10.3390/electronics5040061