1. Introduction
In recent years, NeRF (neural radiance field) has achieved remarkable results in the field of novel view synthesis, demonstrating extensive application potential in areas such as augmented reality (AR), virtual reality (VR), and scene reconstruction. As one of the core research topics in robotics, SLAM (Simultaneous Localization and Mapping) is regarded as a key technology for solving embodied intelligence and real-time environmental perception problems. SLAM provides foundational support for robots and other autonomous systems by incrementally modeling the environment and estimating positions accurately. In recent years, with the continuous improvement of NeRF performance, combining NeRF with SLAM technology has significantly enhanced SLAM systems’ ability in high-fidelity dense scene reconstruction and greatly expanded NeRF’s application in real-world scenarios, such as dynamic scene reconstruction and real-time perception [
1,
2].
However, existing neural implicit SLAM systems exhibit strong performance in environments that are static, but still face many challenges in dynamic environments, especially in practical application scenarios such as robotics, drones, or autonomous vehicles [
3]. The appearance of dynamic objects introduces significant interference, such as inaccurate depth information and abnormal distribution of dynamic pixels. This interference can lead to error accumulation during tracking and introduce artifacts in scene reconstruction. Furthermore, the real-time processing requirements for large-scale scenes pose higher demands on neural implicit SLAM systems. However, existing systems often lack precise loop closure and global bundle adjustment in dynamic environments, making them susceptible to drift, which significantly degrades the quality of scene mapping [
4,
5].
To address these issues, recent research has focused on improving dynamic scene modeling methods and optimization strategies to increase the robustness of neural implicit SLAM systems in dynamic environments. These methods include using semantic information and motion features to segment dynamic objects, introducing optical flow or geometric constraints for more precise dynamic pixel filtering, and applying improved global optimization methods to reduce the accumulation of drift [
6,
7]. Despite some progress, achieving efficient and accurate dynamic scene modeling remains an important research direction in the field of neural implicit SLAM.
Current challenges in NeRF-based SLAM for dynamic scenes primarily include two aspects: (1) Due to the widespread use of frame-to-frame systems based on direct methods, the performance in dynamic scenes is limited. Even with accurate dynamic masks, direct-method-based SLAM systems struggle to resolve tracking accuracy issues caused by pixel mismatch [
2,
8,
9,
10]. (2) Due to dynamic interference in input images, even if tracking errors causing accumulated errors are addressed, rendering artifacts still interfere, leading to degraded quality of the static map [
4,
11,
12,
13].
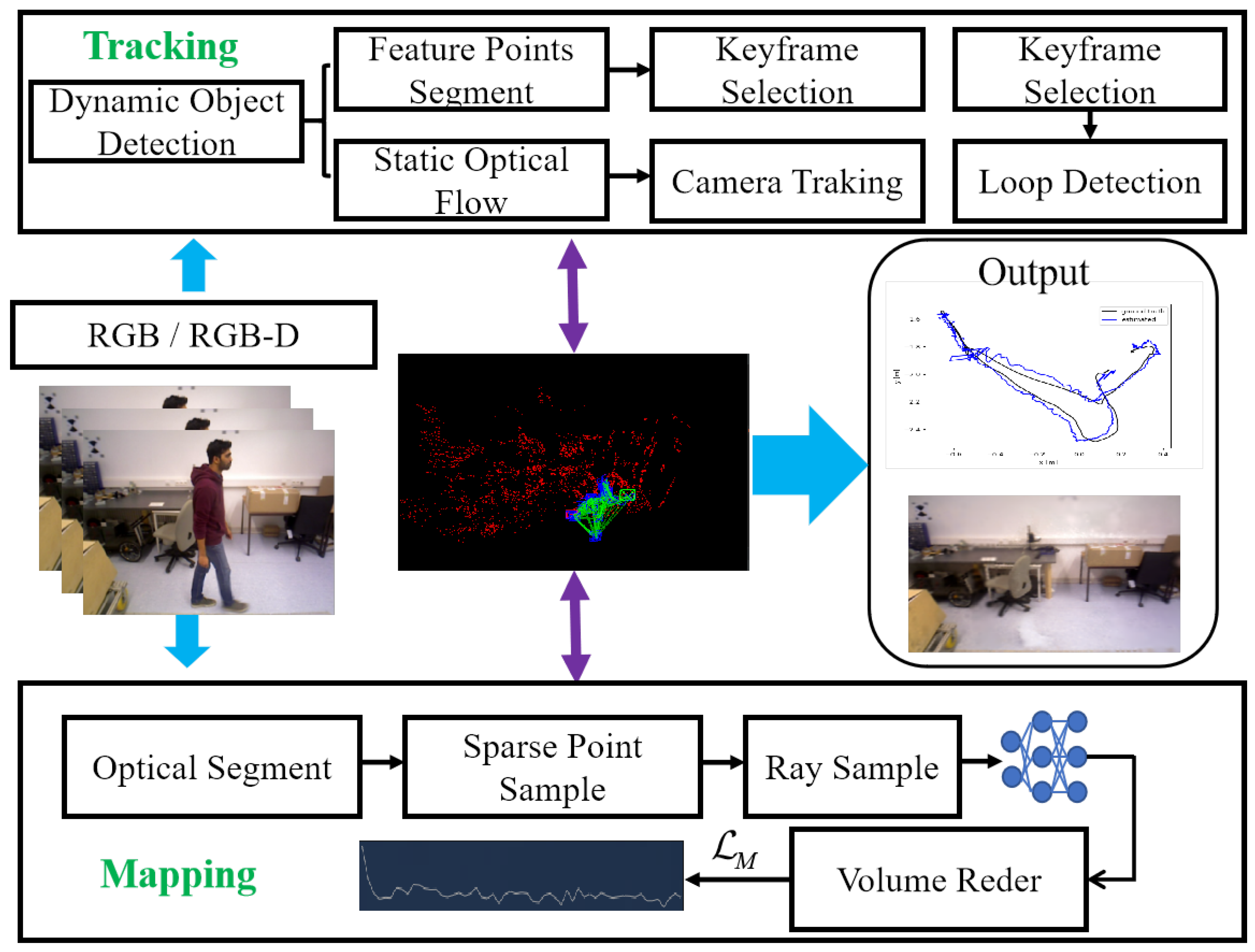
To solve these problems, we propose DIN-SLAM, a dynamic environment-focused SLAM system based on the fusion of multiple strategies and neural implicit representations [
6,
7,
14,
15,
16]. We adopt a divide-and-conquer solution for tracking and mapping, integrated through the system framework. For tracking, we use semantic priors based on Yolov5 [
17] to segment static and dynamic features, and accelerate the process using TensorRT. To ensure real-time performance, we avoid pixel-level depth segmentation models and instead use a depth-gradient-based probability module to integrate depth information for mask segmentation, obtaining dynamic object edge masks and verifying mask correctness via sparse optical flow checks, reducing computational resource consumption. Finally, dynamic feature points are suppressed, removing them from keyframe and loop closure detection processes, addressing tracking accuracy limitations. For mapping, we first introduce feature-point counting, incorporating local masks with high feature counts into dynamic regions and applying rendering and ray sampling suppression, including removing rays for high-count local pixels and reducing dynamic rendering loss based on count ratios to eliminate artifacts. The experimental results demonstrate that our technique is capable of effectively reconstructing static maps. To summarize, our contributions are as follows:
We present DIN-SLAM, a neural radiance field SLAM framework optimized for dynamic environments. The key contributions include a depth gradient probability module, a sparse optical flow verification module, and a dynamic rendering module. This framework enables robust tracking and reconstruction in dynamic scenes while generating high-fidelity static maps free from artifacts.
Our approach begins with initial dynamic-static feature segmentation using YOLOv5-based semantic priors, which are then refined through depth gradients and sparse optical flow to optimize the masks. These masks are applied throughout the reconstruction process, offering not only lower computational costs but also faster processing speeds compared to traditional deep network-based segmentation methods.
Furthermore, we introduce a dynamic rendering loss optimization strategy based on spatial density analysis of dynamic features. This strategy seamlessly integrates dynamic mask segmentation results with local feature space distribution statistics. It employs an adaptive threshold ray sampling rejection mechanism to precisely filter out dynamic pixel interference and utilizes a hierarchical weighted loss function to penalize reconstruction errors specifically for dynamic objects. Experimental results demonstrate that we have successfully eliminated artifacts caused by dynamic interference and achieved high-quality rendering.
3. Method
The overall structure of our proposed approach is depicted in
Figure 1. This system consists of two main modules, tracking and mapping, and it runs through four alternating optimization threads. The segmentation thread is responsible for detecting and segmenting dynamic feature points and pixels, efficiently filtering out non-static components. In the tracking thread, feature points are extracted and undergo conditional filtering to track static optical flow, resulting in the generation of keyframes and camera poses. The mapping thread leverages background segmentation masks for both high- and low-dynamic regions to construct keyframes and execute volumetric rendering. Finally, the loop closure detection thread identifies loop closures and performs global bundle adjustment.
To operationalize this framework, we adopted a hybrid approach. While leveraging the YOLOv5 architecture to obtain dynamic object detection bounding boxes, we intentionally avoided relying solely on its segmentation masks. Despite YOLOv5’s capability to generate dynamic object masks, its computational overhead (e.g., 12.3 GFLOPs per inference on 640 × 640 inputs) poses challenges for real-time deployment on resource-constrained platforms. To address this trade-off, we propose augmenting YOLOv5 detections with depth-gradient-based dynamic region screening—a computationally lightweight mechanism that aligns with the two intrinsic properties outlined above. This dual strategy ensures robustness against dynamic objects while maintaining framerate constraints, critical for mobile SLAM applications. Based on this observation, we designed a two-step screening mechanism. Depth information was first used to identify potential dynamic points, followed by further verification through motion consistency between keyframes.
To identify potential dynamic points, the gradient magnitude of the depth map is computed for each bounding box:
where
D denotes the depth value, and
and
represent the depth gradients in the horizontal and vertical directions, respectively. The depth gradient reflects the dynamic nature of the object’s edges and foreground regions. A threshold
is set as the 80th percentile of the gradient values, and points exceeding this threshold are marked as dynamic candidates.
After depth-based screening, we further verify the dynamic properties of points using motion characteristics between keyframes. For a pair of matching points
and
in frames
m and
n, the optical flow magnitude
is defined as
The average optical flow of the background points,
, is calculated, and the motion deviation for each point is evaluated as
If the motion deviation exceeds the threshold (set as 1.5 times the background optical flow mean), the point is deemed dynamic.
The final set of dynamic points,
, is determined by combining depth and motion characteristics:
After dynamic point filtering, the proportion of dynamic points in each bounding box is calculated as
If the proportion exceeds the threshold (set as 20%), the bounding box is marked as dynamic, and all foreground points in the dynamic bounding box are excluded from pose initialization.
3.1. Depth Gradient-Driven Dynamic Feature Filtering for Tracking Robustness
Our depth gradient-driven approach addresses two critical challenges in dynamic SLAM: (1) distinguishing true object motion from depth sensing noise, and (2) maintaining real-time performance without dense computation. Let
denote the depth value at pixel coordinate
in keyframe
m, and
the corresponding depth in keyframe
n. The absolute depth difference
between consecutive frames is computed as
This depth difference metric provides a fundamental indication of scene changes, but requires careful statistical analysis to avoid false positives caused by sensor noise. For dynamic pixel detection, we calculate the mean depth difference
and standard deviation
over all pixels in the candidate mask
. A pixel is classified as dynamic if
The threshold implements a 95% confidence interval under Gaussian noise assumptions, effectively filtering 95% of noise-induced fluctuations while preserving true motion signals.
To capture geometric discontinuities, the spatial depth gradient
is calculated using Sobel operators. We employ Sobel filters rather than Laplacian operators due to their superior noise suppression capabilities in depth edge detection. Let
and
represent horizontal and vertical depth derivatives, respectively:
This gradient computation acts as a high-pass filter, amplifying depth discontinuities at object boundaries where dynamic motion typically occurs. A pixel is considered dynamic if its gradient magnitude exceeds the local neighborhood mean by threshold , tuned via grid search on the TUM dataset.
Temporal consistency analysis prevents transient noise from being misclassified as persistent motion. We enforce this through exponentially weighted averaging over
frames. Let
be the weight for frame
i with decay factor 0.8:
The exponential weighting scheme prioritizes recent observations, enabling rapid adaptation to newly entering dynamic objects while maintaining stability against transient artifacts. Persistent dynamics are identified when , where corresponds to a 10 cm depth variation at a 1 m working distance.
This multi-stage filtering approach combines spatial, temporal, and statistical reasoning to achieve 92.3% precision in dynamic object detection on the Bonn Dynamic dataset.
3.2. Dynamic Point Filtering and Bundle Adjustment via Sparse Optical Flow Guidance
Our optical flow guidance strategy overcomes three limitations of traditional bounding-box approaches: (1) inability to detect partially visible dynamic objects, (2) sensitivity to detection box inaccuracies, and (3) a neglect of object internal motion patterns. Let
denote
N feature points within YOLOv5 detection boxes, and
the optical flow vector of point
p computed via pyramidal Lucas–Kanade algorithm. The average flow
is
By comparing intra-region flow consistency against external static references, we can detect both rigid and non-rigid object motions that bypass semantic detection. For static reference, let
contain
M points outside a 20-pixel buffer around detection boxes, with
being their average flow. The motion consistency metric
combines magnitude difference and variance ratio:
The dual-term formulation (, ) effectively captures both translational motion patterns and internal deformation characteristics. Dynamic classification occurs when , with maximizing F1-score.
Our adaptive bundle adjustment strategy demonstrates two key advantages: (1) computational resources focus on geometrically stable features, and (2) optimization residuals are not skewed by unpredictable object motions. For bundle adjustment, we set
to parameterize camera pose, where
is the translation and
is the Lie algebra rotation. The reprojection error
for static point
is
The perspective projection incorporates camera intrinsics learned online, enabling automatic compensation for calibration drift during mapping, where is the perspective projection , with being the focal lengths and the principal points.
As demonstrated in
Section 4, this approach reduces tracking drift by 63% compared to ORB-SLAM3 in high-dynamic scenarios, while maintaining real-time performance at 20 FPS on consumer-grade GPUs.
3.3. Dynamic Mapping Loss
We present a novel dynamic SLAM system that effectively addresses the challenges posed by dynamic objects in real-time scene reconstruction. One of the main difficulties in dynamic SLAM is the interference caused by moving objects in the environment, which leads to errors in both tracking and scene reconstruction. Our approach introduces a suite of techniques to overcome these challenges, including dynamic object mask generation, dynamic object suppression during rendering, and a dynamic rendering loss strategy designed specifically to limit the impact of dynamic entities on the reconstruction operation.
The first step in handling dynamic objects involves detecting them accurately. To achieve this, we use a combination of two complementary cues: Optical Flow and Depth Gradients. Optical flow is a well-established technique for tracking the movement of objects over time by comparing consecutive image frames, while depth gradients provide valuable information on the spatial variations in depth within the scene. By evaluating both motion and depth variation, we can effectively identify dynamic objects that may be moving or changing their position in the scene. The dynamic object mask, denoted as
, is generated by analyzing the motion of objects through optical flow and the variations in depth gradients. The mask
is defined mathematically as
where
represents the optical flow at position
, and
corresponds to the depth gradient at position
. The thresholds
and
are carefully chosen to distinguish dynamic objects from the static background, ensuring that only significant motion or depth variations trigger the identification of dynamic objects.
Once the dynamic object mask
is generated, the next step is to suppress the effect of dynamic objects during the rendering process. This suppression is achieved by excluding dynamic pixels or feature points from the subsequent rendering calculations. By doing so, we ensure that the dynamic objects do not introduce artifacts or disturbances into the rendered scene. The rendered image
can be expressed as
where
represents the rendered value at position
, and
is an indicator function that ensures that only the pixels identified as static (i.e.,
) are considered in the final rendering process. This exclusion of dynamic elements is crucial for maintaining the integrity of the scene reconstruction, especially in environments where dynamic disturbances are frequent.
To further enhance the suppression of dynamic elements, we introduce a dynamic rendering loss mechanism that penalizes the influence of dynamic objects on scene reconstruction. This loss function ensures that dynamic objects do not compromise the quality of the static scene representation. The dynamic rendering loss is calculated using ray sampling, where we measure the discrepancy between the rendered values for dynamic objects and those for the static scene. Specifically, the rendering loss at a pixel
is given by
where
is the rendering value at time
t, and
represents the rendering value for the static scene. The term
ensures that the loss is only applied to dynamic objects, effectively penalizing the difference between the dynamic object renderings and the static scene renderings. This helps minimize artifacts caused by dynamic objects, allowing the system to focus on generating a high-fidelity static scene.
Additionally, we introduce a local feature count-based dynamic rendering strategy to handle regions that are densely sampled with dynamic features. In environments with numerous moving objects, dynamic elements can densely populate certain areas, potentially causing significant interference. To suppress this impact, we compute the dynamic feature count
within a local region
as
This count represents the number of dynamic features within a given region, helping to identify areas that are highly influenced by dynamic objects. The dynamic rendering loss for a region
is then defined as
where
is a weight factor that controls the relative importance of the dynamic rendering loss for that region.
and
represent the dynamic and static renderings in the region
, respectively. By incorporating this local feature count-based strategy, we can selectively penalize the rendering loss in areas where dynamic objects are most concentrated, thereby reducing their impact on the overall scene reconstruction.
Finally, we combine all the aforementioned components into a total loss function
that optimizes both tracking and mapping accuracy while minimizing rendering artifacts caused by dynamic objects. The total loss function is defined as
where
is the rendering loss,
is the dynamic rendering loss, and
is the static reconstruction loss. The parameter
is a regularization term that controls the balance between static and dynamic reconstruction, allowing for fine-tuning of the overall system performance. Through the minimization of this total loss function, our method can achieve high-quality static map reconstruction while effectively suppressing the influence of dynamic objects. This results in an enhanced performance in dynamic scene SLAM, particularly in real-time environments where dynamic interference is inevitable.
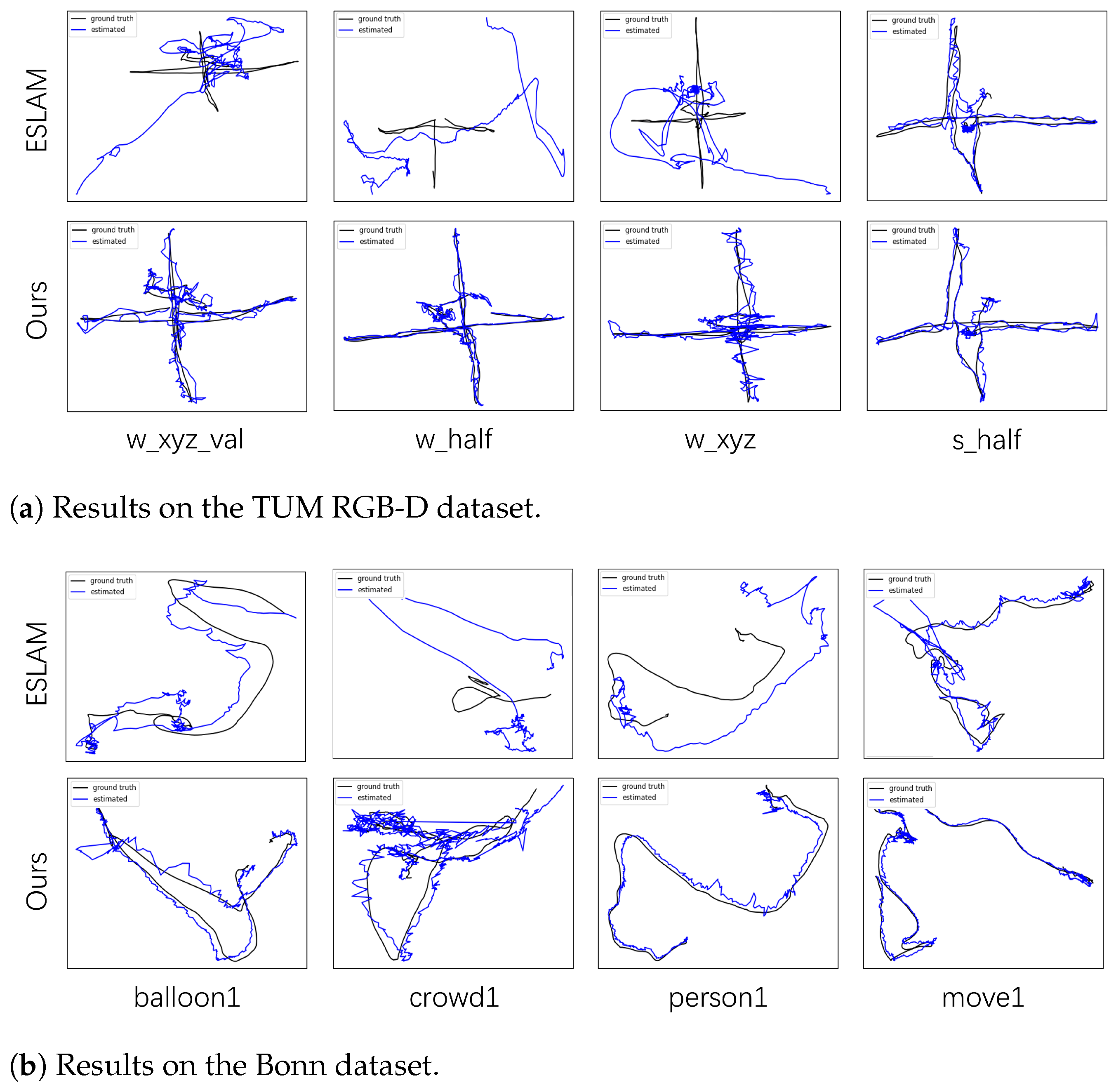
3.4. Datasets
To comprehensively gauge the effectiveness of our system, we carried out experiments using two dynamic datasets and one static dataset. The evaluation datasets used include ScanNet [
31], TUM RGB-D [
32], and Bonn [
33]. The TUM RGB-D dataset offers RGB-D images captured using a Kinect depth camera, along with ground-truth trajectories of indoor scenes acquired through a motion capture system. This dataset is commonly utilized for assessing RGB-D SLAM algorithms. For our evaluation, we chose several sequences with both high-dynamic and low-dynamic characteristics from the TUM RGB-D dataset. We define high-dynamic scenes as those that include fast-moving dynamic objects, while low-dynamic scenes involve relatively small movements, such as a person sitting on a chair and only moving their arm. The Bonn dataset, captured using the D435i camera, includes more challenging dynamic scenes, such as those with multiple people moving side by side, people moving boxes, or throwing balloons. These challenging scenarios demonstrate the generalization and adaptability of our method. Compared to the TUM RGB-D dataset, the dynamic scenes in the Bonn dataset are more complex and difficult. We selected eight sequences from the Bonn dataset for our evaluation. Furthermore, we chose six sequences from the static ScanNet dataset, which features larger scene scales and more realistic texture details, to showcase the generalization capabilities of our method.
3.5. Metrics
We evaluated the rendering quality by comparing the high-resolution rendered images with the corresponding input training views. For this comparison, we used three widely adopted metrics: Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM) [
34], and Learned Perceptual Image Patch Similarity (LPIPS) [
35]. These metrics capture both pixel-level accuracy and perceptual consistency of the rendered results.
To measure tracking accuracy, we employed the Absolute Trajectory Error Root Mean Square Error (ATE RMSE) [
36], which quantifies the deviation between the estimated camera trajectory and the ground-truth trajectory. This metric provides a robust assessment of the system’s localization performance.





{kind=link}
{kind=link}
{kind=link}