1. Introduction
In the coming years, fifth-generation (5G) networks may face a drawback in meeting the desired quality of service (QoS) for vehicle-to-everything (V2X) communications, for example, due to limitations in resources, enormous traffic volume, and advanced digital devices and applications. In contrast, cutting-edge technologies are required to meet V2X QoS in terms of power consumption, latency-sensitive applications, achievable data rates, etc. [
1]. Sixth-generation (6G) communication networks are expected to support intelligent transportation systems (ITSs) by meeting the broad-range requirements of V2X communications [
2]. As shown in
Figure 1, V2X communications include vehicle-to-network (V2N), vehicle-to-infrastructure (V2I), vehicle-to-vehicle (V2V), and vehicle-to-pedestrian (V2P) communications, including communications with vulnerable road users (VRUs) [
3]. An example of a V2I link is a vehicle-to-roadside unit (RSU), where the RSU is a device that facilitates communications between vehicles and the transportation infrastructure in ITSs.
Sixth-generation V2X communications require ultra-high data rates (in Gbps) and reliability (99.999%), extremely low latencies (1 millisecond), high mobility, and ubiquitous connectivity. To fulfill these requirements, technological advancements are needed, including artificial intelligence (AI) and machine learning (ML) techniques, intelligent edge, terahertz communications, lower wavelengths, and higher frequencies [
4]. The open radio access network (Open RAN) is a promising architecture to enhance and optimize the implementation of future 6G V2X networks. The open RAN deployment is based on disaggregated, virtualized, and software-based units, connected by open interfaces between multiple vendors [
5]. The next-generation Node-B (gNB) functionality in Open RAN is disaggregated into a central unit (CU), a distributed unit (DU), and a radio unit (RU), connected via open interfaces to intelligent controllers that manage the network at near-real-time (10 milliseconds to 1 s) and non-real-time (longer than 1 s) time scales [
6].
The deployment of multi-access edge computing (MAEC) at the Open RAN edge and close to the V2X user equipment (UE), that is, the vehicle, provides network capabilities for end users that deploy computing and storage services with minimal latency and reduced energy consumption [
7]. Due to constrained MAEC servers, such as RSUs, resource management is considered one of the key challenges that play a role in addressing the energy-efficient and ultra-low latency requirements of 6G V2X applications [
8]. Traditional optimization takes a long convergence time to optimize the energy consumption because of the extensive searching when the action space is huge. An ML approach is considered a promising technique for resource management optimization due to its ability to map any input to the required output and make a suboptimal decision without waiting for the optimal one [
9].
Classical ML techniques include supervised and unsupervised learning. Supervised learning requires a well-labeled data set to train its model, while in unsupervised learning, there is no such requirement to label the data. An alternative technique is reinforcement learning (RL), where agents can learn the best strategy by interacting with the environment based on its feedback represented as an immediate reward [
10]. Deep reinforcement learning (DRL) is favored for V2X communication tasks in complex scenarios due to its efficacy in rapid decision making, overcoming the difficulties associated with labeled data in dynamic environments [
9].
To satisfy the aforementioned challenges, appropriate assignments must be performed between vehicles and RSUs, taking into consideration the management of signal-to-noise-to-interference ratio (SINR) and intercell interference (ICI). Furthermore, to optimize resource allocation and save energy, RSUs can be turned on or off depending on the traffic demand of the vehicles [
11]. The CU control plane of the RSU should take decisions quickly, in the order of seconds, to determine the appropriate assignments and activation, which lead to minimizing the energy consumption while satisfying the QoS requirements in terms of ultra-low latency and available radio resource, i.e., resource blocks (RBs).
To this end, in this study, we investigate the problem of how to allocate the resources efficiently in MAEC to optimize resource management and save energy while meeting the QoS requirements for 6G V2X Open RAN. In particular, given the number of RSUs with available RBs and the number of vehicles with required RBs for sending tasks, we need to find an optimal vehicle-to-RSU association and a state of each RSU to minimize the number of active RSUs and energy consumption while satisfying the constraints on the number of required RBs, data rates, allowed latency, and available resources.
The main contributions of this work are summarized as follows:
We formulate the resource allocation problem as an integer linear programming (ILP) optimization problem to minimize energy consumption and the number of active RSUs by determining the best vehicle-to-RSU association and whether to turn the RSU on or off.
We reduce the number of RSUs that are active and minimize energy consumption while satisfying the constraints on the number of RBs, data rates, SINR, and latency.
We use a CPLEX implementation [
12] to find the optimal solutions to our optimization problem and evaluate our proposed model.
We transform the aforementioned problem into an equivalent DRL environment and subsequently propose a proximal policy optimization (PPO) algorithm to solve it.
We perform a comprehensive comparison between optimal and approximate solutions to assess the effectiveness of the DRL environment and the performance of our proposed model.
We examine the performance of our proposed model in 6G V2X Open RANs for different scenarios with various vehicle densities and RSUs.
The remainder of this paper is organized as follows:
Section 2 reviews previous works on energy efficiency for MAEC networks.
Section 3 describes the system model and the formulation of the optimization problem, including the DRL environment and the proposed PPO algorithm.
Section 4 presents the performance of the model and the numerical results.
Section 5 concludes the article and points out future work.
3. System Model and Problem Formulation
This section describes the architecture of the 6G V2X Open RAN, communication and computation models, problem formulation, and the DRL allocation framework.
Table 2 summarizes the mathematical notation used in this paper.
3.1. Network Model
We consider a 6G V2X Open RAN computing infrastructure consisting of sets of vehicles and RSUs that provides new radio communication capabilities to the vehicles. RSUs are densely deployed closer to vehicles and provide computing and communication capabilities to end users. In our model of the system under study, as shown in
Figure 2, vehicles need to upload their tasks to the RSUs for processing. In particular, we investigate a scenario consisting of a set of RSUs (
) and a set of vehicles (
). Each RSU
n has a number of RBs available per time slot, indicated by
. Each vehicle
v, if it is associated with RSU
n, will require several RBs per time interval to send the sensing data, indicated by
. The required number of RBs depends on the SINR values and the uplink data rates.
3.2. Communication Model
Given the number of RSUs with available uplink RBs and the number of vehicles with RBs required to send data to RSUs, we need to decide whether to turn the RSU on or off and determine the optimal associations of vehicles with RSUs. Our goal aims at reducing the number of turned-on RSUs depending on the required tasks and subject to the uplink bandwidth constraints exemplified by ICI and SINR.
SINR can be expressed as the signal power divided by the noise power plus the interference power of other signals in the network. SINR can be calculated from the transmission power of the vehicle and the interference power level of other interferer RSUs in the network. SINR values for uplink transmission can be obtained as
where
is the transmission power of the vehicle
v;
is the distance between the vehicle
v and the center of the RSU
n;
is the attenuation factor, that is, the path loss, calculated from the COST 231–Hata Model [
40];
is the power spectral density of a white noise source; and
is the aggregated uplink ICI.
Assuming that the network model is fully loaded with traffic, omnidirectional antennas are used, and the regular coverage pattern occurs, we could approximate the uplink ICI from the RSU
n with a log-normal distribution by analytically determining the statistical parameters [
41]. Therefore, the aggregated uplink ICI,
, is approximated with another log-normal distribution and calculated according to
where
is the mean value of the uplink ICI of the interfering RSU
i, and for each RSU, only a single interference source is considered since only one vehicle is scheduled per RB.
is computed as (in this paper, we focus on the optimization problem rather than on the interference and SINR; for further details, we refer the reader to [
41])
where
C is the coverage of the RSU in kilometers,
is the distance between the vehicle and the interferer RSU in kilometers,
is the distance from the transmitter to the receiver in kilometers,
is the angle of the vehicle to the directed line connecting the target RSU to the interferer RSU, and
denotes the Euclidean distance between the target RSU and the interferer RSU [
41].
After calculating the SINR values for each vehicle, we need to calculate the RB data rate according to the SINR value, channel quality indicator (CQI) index and efficiency from the mapping table that determines various CQI indices based on different modulation orders, SINR ranges, and efficiencies [
42]. We use this mapping to obtain the number of necessary RBs. For the sake of simplicity, we consider both vehicles and RSUs forming the network working in single-input-single-output (SISO) mode [
42]. The CQI index is calculated in the vehicle and reported to the RSU. We use the CQI to determine the efficiency and calculate the data rate of an RB. An RB per time slot of 0.25 milliseconds consists of 12 subcarriers of 60 kHz wide in frequency, and each subcarrier consists of 14 symbols. Accordingly, the data rate of an RB (bits/milliseconds) is calculated as
After calculating the data rates of the RBs, we can determine the number of RBs (
) requested by each vehicle to execute its uplink task.
depends on the uplink and RB’s data rates, i.e.,
and
. We use the following formula:
3.3. Computation Model
In our model, the tasks of the vehicles are offloaded to RSUs equipped with computational capabilities to process traffic volumes. The computation task is related to both energy consumption (in joules) and processing (in seconds). There are three stages to accomplish task computation: (i) task uploading, (ii) task computing, and (iii) task downloading. Depending on the computation and communication demands, the vehicles will experience latencies influenced by the computing and communication capacities of the RSUs. The uplink and downlink bandwidths influence the communication latency. We neglect the downloading latency due to the small size of the computed tasks and the high data rates of the RSUs. The task of vehicle
v is represented by the communication demand
(in bits) and the computation demand
(in CPU cycles per bit). We denote the task offloading time by
, which includes the uploading time
and the processing time
. We calculate
as
where
and
is the communication capacity (throughput or data transmission rate from vehicle
v to RSU
n in bits per second).
is calculated from the SINR mapping table for the throughput of 5G New Radio (NR) with a bandwidth of 100 MHz and a subcarrier spacing of 60 kHz [
43].
is the computing power assigned from RSU
n to vehicle
v in CPU cycles per second (computation capacity). The energy consumption of the computation task
includes the consumptions resulting from offloading and execution. We denote the transmission energy consumption with
and the processing energy consumption with
. We can calculate
as
where
and
is the transmit power of vehicles v. is the energy coefficient associated with the chip architecture of the RSU server (effective capacitance coefficient for each CPU cycle of the RSU).
3.4. Optimization Model
Considering
N RSUs with a number of available uplink RBs (namely,
) and
V vehicles with a number of required RBs per time slot for sending the sensing data from vehicle
v to the RSU
n (namely,
), we need to determine
, which denotes whether the vehicle
v is associated with RSU
n or not;
, which indicates whether to turn the RSU
n on or off; and
, which determines whether a vehicle is not allocated. The whole optimization problem minimizes the number of active RSUs and the energy consumption while satisfying the constraints on maximum allowed latency and the available resources. We formulate it as follows:
Our objective (
12) is to jointly minimize the weighted sum of active RSUs and overall energy consumption. The above-mentioned objective function is subject to the following requirements: constraint (
13) ensures that the number of required RBs per time slot to uplink data from vehicle
v to the RSU
n should not exceed the number of available uplink RBs at the RSU
n, constraint (
14) indicates that vehicle
v can be assigned to RSU
n if the predicted SINR is larger than the assumed threshold
H, constraint (
15) guarantees that the computational capacity assigned from RSU
n to vehicle
v should not exceed the maximum available computational capacity of RSU
n, constraint (
16) ensures that the task offloading time from vehicle
v to RSU
n should not exceed the maximum allowed latency for vehicle
v, constraint (
17) states that each allocated vehicle
v should be associated with one and only one RSU, constraint (
18) ensures that vehicle
v can be connected to RSU
n only if RSU
n is turned on, and constraint (
19) indicates the lower and the upper bounds of the binary decision variables.
In complex real-world V2X environments, rapid solutions are required for the combinatorial optimization model presented in (
12)–(
19). Therefore, approximate solutions are used for real-time allocation. We implement a DRL environment to provide online allocation, where we consider a snapshot of vehicle locations instead of mobility to reduce the complexity of the model. As we focus on uplink in 6G V2X Open RAN, the effect of mobility can be neglected.
3.5. Energy-Efficient Deep Reinforcement Learning Allocation Framework
We formulate the problem of (
12) as an MDP and leverage DRL to solve it. In a DRL-based algorithm, an agent can make decisions in real time by interacting with the environment without the need for prior data sets. The agent reviews and updates its policy using a trial-and-error method. A correct description of the underlying process can be advantageous for a successful implementation of DRL-based algorithms, for example, when considering control strategies in wireless communications [
44] or nonlinear power systems [
45].
A classical MDP is mathematically characterized by the tuple . represents the state space, represents the action space, represents the transition probability from the current state s to the next state , represents the discount factor to achieve trade-off between the current reward and the future reward, and represents the reward function.
We formulate the contexts of a state, an action, and a reward within the framework of V2X with the RSUs network based on the PPO algorithm.
Figure 3 illustrates the structure of the PPO-based allocation, consisting of a V2X environment and an agent. The agent uses system information states
s, such as computation and communication capacity, to determine the optimal allocation decision
a, resulting in a high reward
r (indicative of low energy consumption), thus altering the condition of the system to
. The V2X environment includes the connections to gNB, where the DRL framework is implemented. The DRL framework covers an area composed of several RSUs.
In our 6G V2X Open RAN topology, vehicles are assigned to the infrastructure such as RSUs to process their tasks. The RSUs receive vehicle traffic and decide the amount of resources to be allocated to the vehicle to process its task and minimize energy consumption. The system control plane, which serves as the assignment agent, makes the assignment and allocation decisions. The assignment agent is deployed within an RSU. This learning agent requires environmental information and trains using prior experience to determine the best action. The prior experience has the form of state, action, next-state, and reward . The agent will learn to take the best action during the state of a particular environment.
3.5.1. State
The state represents the status of the current system, which can be determined by monitoring system parameters such as uplink data rates, link capacity, communication capacity, computation capacity, latency, and system energy consumption. The action will transit the state from
s to
with larger or smaller energy consumption. The optimal action minimizes system energy consumption and is positively rewarded. The following states constitute the 6G V2X Open RAN system information: uplink data rate (
), uplink capacity (
), uplink RBs (
), computing resources (
), and tolerable latency (
). The state space of the assignment agent at time
t can be defined as
where
denotes communication resources,
denotes computing resources, and
denotes allowed latency.
3.5.2. Action
The action space represents the allocation status of all vehicles. The action space of the assignment agent at time
t can be expressed as
where
denotes the action of turning on/off the RSU,
denotes the action of associating the vehicle with the RSU, and
denotes the action that determines whether the vehicle is not allocated. The action space is restricted to include only feasible actions, which ensures that constraints (
13)–(
19) are satisfied.
3.5.3. Reward
The reward function is formed corresponding to the objective in (
12). Since our objective is to minimize energy consumption as much as possible, computational tasks with higher energy consumption in time
t (
) should be assigned a smaller reward value. The objective of DRL is to maximize the reward function for an action made in time
t, which can be expressed as
3.5.4. PPO Algorithm
Our proposed PPO-based algorithm uses an artificial neural network (NN) with an actor-critic framework. The PPO algorithm is selected for its stability and efficiency as a policy-based RL algorithm. The training process of the proposed algorithm is illustrated in Algorithm 1. The critic NN is based on a value function, where the state of the environment changes when the actor NN takes an action
. The critic NN takes the state
as input and returns the state-value function as
where
is the estimator of the policy
and
is the discount factor. The critic NN returns the state-action value as
The advantage function that represents the difference between the current
Q value and the average can be calculated as
The actor network is updated using PPO by the ratio of the new policy and the old policy to ensure stability. The loss function of the actor network can be determined as
where
is a random policy function,
is a penalty coefficient, and
is an estimator of the advantage function at time
t.
| Algorithm 1:Resource Allocation Algorithm Based on PPO |
![Electronics 14 01148 i001]() |
5. Conclusions
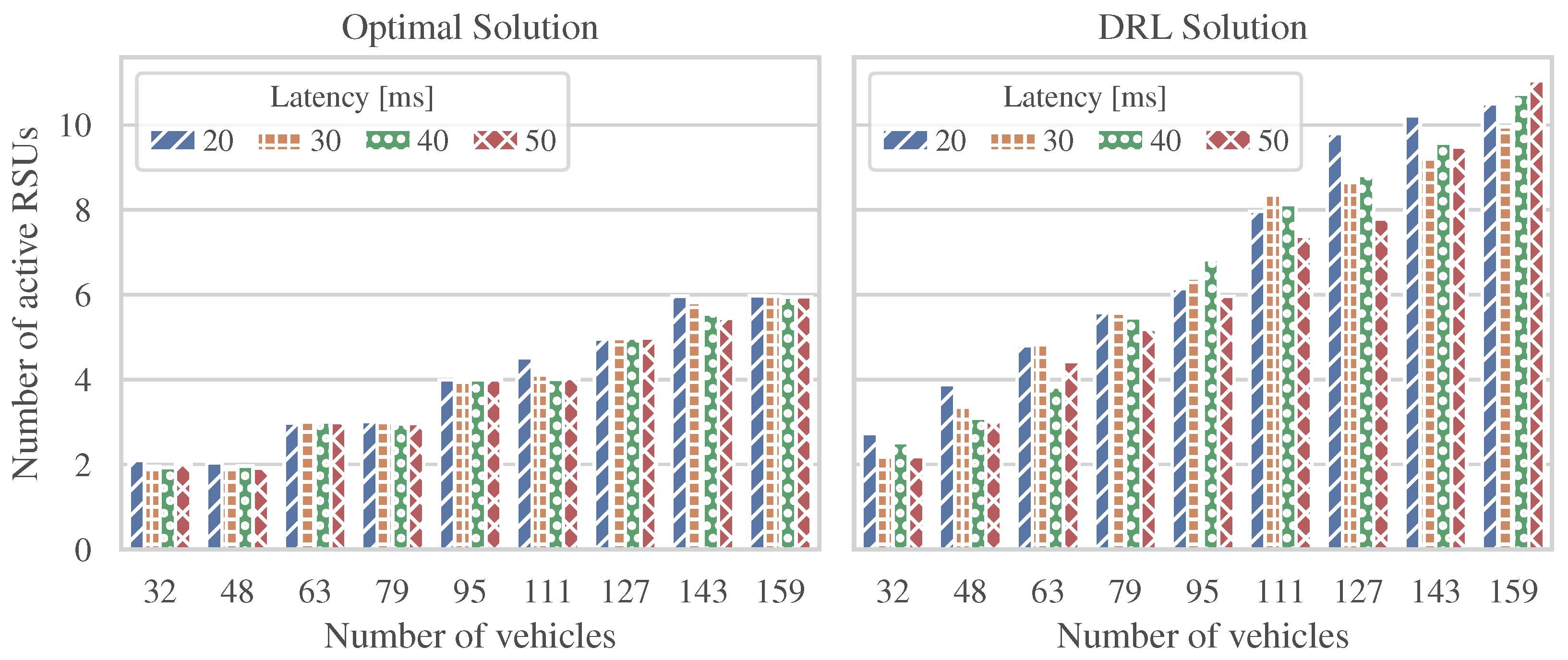
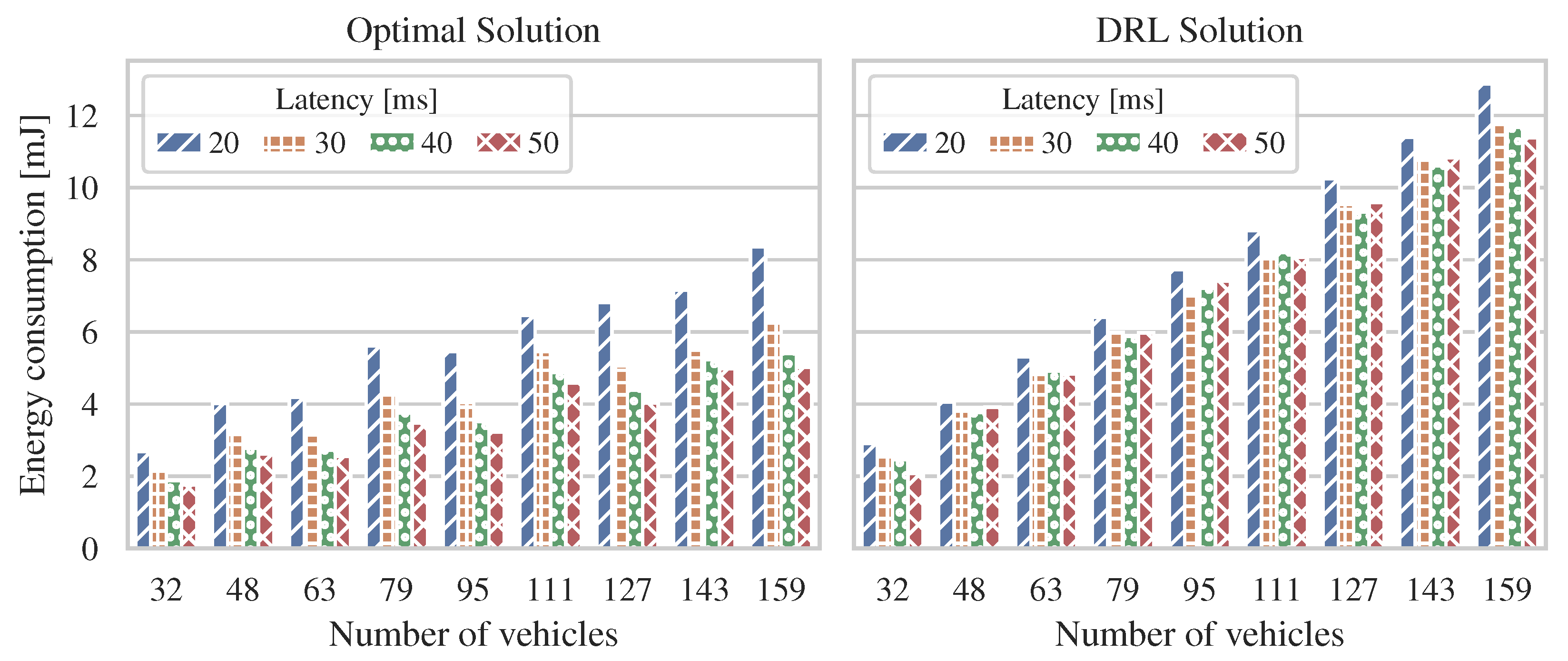
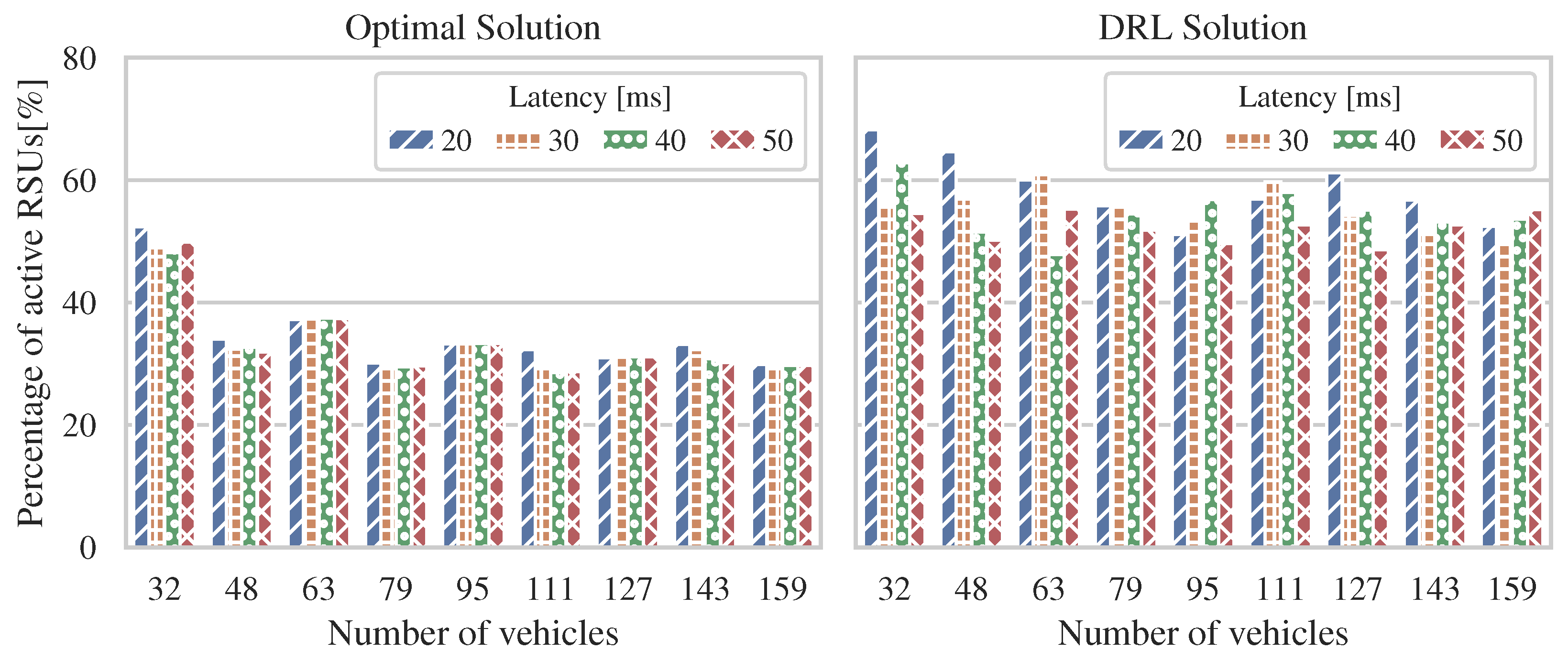
We investigated energy efficiency in 6G V2X communication systems and formulated an ILP-based optimization problem to reduce the energy consumption of the system. We obtained the optimal solutions using the CPLEX solver and implemented a DRL framework using the PPO algorithm. Under various simulated conditions, our research evaluated the DRL-PPO-derived allocation decisions against optimal centralized solutions.
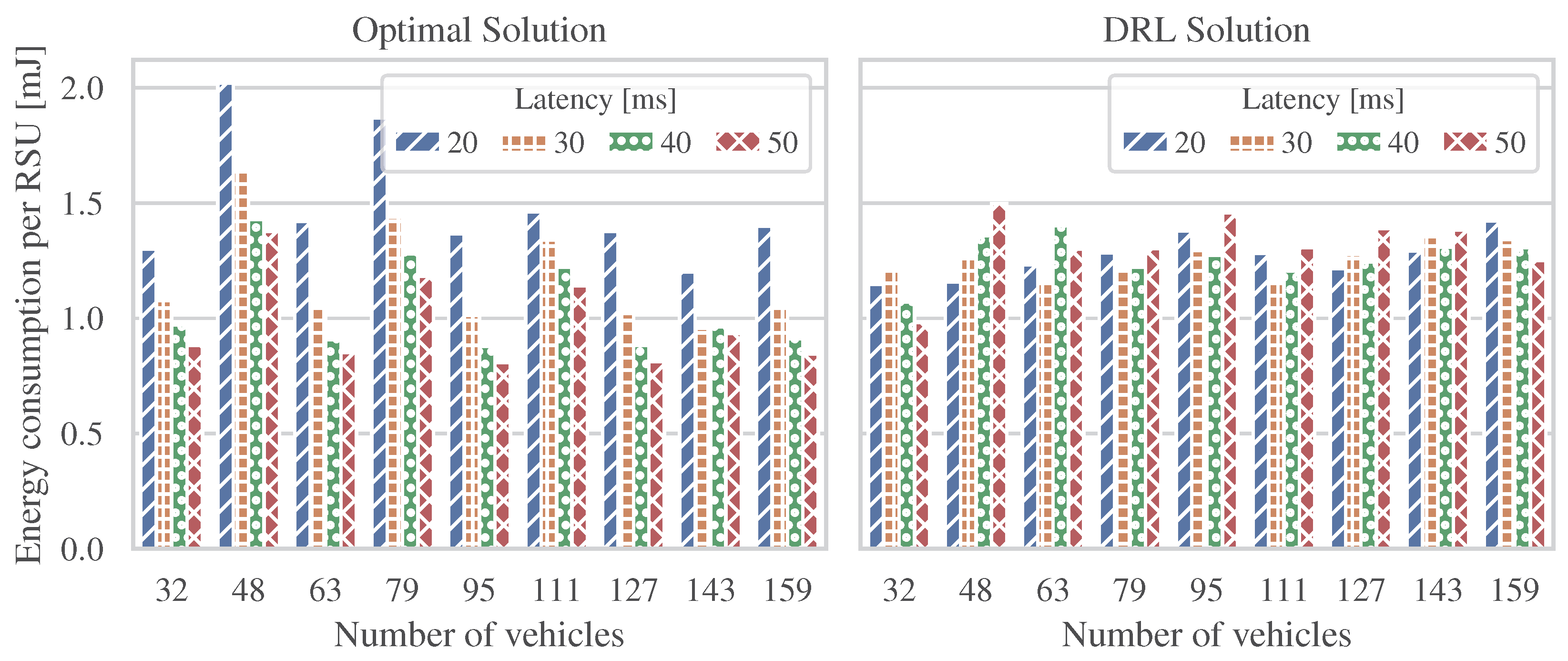
The energy consumption linearly increased with respect to the problem scale in both ILP-based and DRL-based solutions. The proposed DRL approach ran efficiently in the range of scenarios studied and produced dynamic decisions that approximated the optimal ones at acceptable energy consumption levels. An important aspect of the DRL-based solution is that even when different latency levels were studied, the calculated energy consumption per RSU remained stable in different scenarios.
Our numerical results illustrated that the proposed approach is appropriate for energy-saving operation in 6G V2X networks. The system model under study allowed us to minimize the energy consumption while satisfying the allowed latency levels to ensure 6G V2X communications.
For further research and future work, we plan to consider additional constraints (e.g., vehicle mobility), formulate multi-objective optimization models, and investigate the impact of different factors on the performance of the proposed model. We also plan to perform a comparative analysis between our PPO-based algorithm and alternative DRL approaches. In addition, we plan to address security and reliability concerns by validating the proposed model through real testbed experiments to assess its robustness and resilience.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}