1. Introduction
Recent advancements in deep learning have revolutionized wireless communication, and the concept of semantic communication has gained increasing attention as a fundamental shift from Shannon’s [
1] bit-accurate transmission to meaning-aware information exchange. This evolution aligns with the growing demands of IoT ecosystems, where heterogeneous devices—from industrial sensors to voice-enabled edge nodes—require adaptive communication frameworks that balance efficiency, intelligibility, and interoperability. Unlike conventional approaches, which primarily aim to recover transmitted symbols, semantic communication systems prioritize the preservation of meaning and intelligibility. To this end, modern communication networks evolve toward 6G and beyond, and new paradigms that prioritize semantic meaning over exact bit recovery have emerged. This shift is particularly important for bandwidth-limited and noisy environments, where the reconstruction of the underlying semantic content can prove to be more beneficial than the sole recovery of the symbols. Such environments are ubiquitous in IoT applications, ranging from smart factories with high electromagnetic interference to urban deployments with dense wireless traffic.
The transition from technical-level communication (Level A) to semantic-level communication (Level B) was first theorized by Weaver [
2], who proposed that communication systems should not only transmit symbols accurately but also preserve their intended meaning. Several studies have attempted to formalize semantic information theory, laying the groundwork for modern AI-driven communication paradigms. Bao et al. [
3] extend Shannon’s classic information theory (CIT) [
1] to incorporate semantic-level communication that goes beyond bit-accurate transmission to meaning-aware transmission. They introduce a model-theoretic approach to semantic data compression and reliable transmission. Niu & Zhang [
4] formalize semantic information processing by defining entropy, compression, and transmission limits. Shao et al. [
5] propose a structured approach to defining semantic information, semantic noise, and the fundamental limits of semantic coding.
It appears that recent advances have shown the significance of deep learning (DL) and the impacts of physical-layer (PHY) communications. These perspectives lead to end-to-end learned transmission models, adaptive modulation techniques, and AI-driven semantic communication. Different from conventional rule-based systems, deep learning facilitates global optimization across transmitter, channel, and receiver components, thereby paving the way for semantic-aware communication models. O’Shea & Hoydis [
6] introduced the concept of autoencoder-based communication, where a transmitter, channel, and receiver are jointly optimized as a deep neural network. Their work shows that deep learning can substitute traditional encoding, modulation, and decoding blocks, which offers improved performance under complex channel conditions. Qin et al. [
7] investigated the potential of deep neural networks (DNNs) to enhance modulation, signal compression, and detection processes.
Early works such as DeepSC have demonstrated the potential of end-to-end deep learning-based semantic communication models [
8]. They have proposed a system that is capable of jointly performing semantic channel coding for text transmission using neural networks (NNs). Furthermore, DeepSC-S extends semantic communication to speech signals [
9]. The utilization of semantic speech information has been shown to facilitate more efficient transmission compared to conventional systems. Specifically, the NN-based joint design of speech coding and channel coding has been developed to facilitate the learning and extraction of essential speech information. L-DeepSC [
10] has been introduced as a lightweight alternative to DeepSC, with the objective of reducing computational complexity for Internet of Things (IoT) applications. This objective is pursued by employing model compression techniques such as quantization and model pruning. Tong et al. [
11] investigated Federated Learning (FL) for Audio Semantic Communication (ASC), introducing a wav2vec-based autoencoder that extracts semantic speech features for transmission over wireless networks. Although there exist remarkable studies in this context, these models often assume fully neural transceivers, making them impractical for real-world integration with existing wireless infrastructure. They lack structured feature discretization and remain heavily dependent on black-box AI models. Numerous studies suggest the concept of analog modulation which involves the transmission of continuous signals without discretization into constellation symbols, allowing for the representation of any value. However, this ideal assumption regarding modulation poses significant challenges in practical implementation due to limitations inherent in hardware components, such as power amplifiers.
With regard to digital semantic communications, Huang et al. [
12] introduced D
2-JSCC, a digital deep joint source–channel coding (JSCC) framework for semantic communication by utilizing deep source coding to extract and encode semantic features before transmission and employing adaptive density models to jointly optimize digital source and channel coding for image-based transmission. Bo et al. [
13] proposed a Joint Coding–Modulation (JCM) framework based on Variational Autoencoders (VAEs) to facilitate digital semantic communication by using the Gumbel Softmax method [
14] to create a differentiable constellation of symbols for image semantic communications. Yu et al. [
15] introduced HybridBSC, a hybrid bit and semantic communication system that enables the co-existence of semantic information and bit information within the same transmission framework for image transmission. Alongside these works, there are numerous surveys and tutorials designed to give a broad overview of semantic communications [
16,
17,
18,
19,
20]. While the field is still evolving, existing studies predominantly focus on image- or text-based communication.
In contrast to frameworks such as D
2-JSCC, which focuses on image-based semantic communications through deep source–channel coding, our work introduces structured feature discretization, allowing it to be integrated with traditional digital telecommunication frameworks. Moreover, while HybridBSC incorporates semantic- and bit-based transmission, a crucial limitation of HybridBSC is the lack of an explicit bit allocation for hybrid bit–semantic transmission. Without a defined bit burden framework, the system’s efficiency and adaptability to varying channel conditions remain vague. In addition, its main focus is on image transmission. Speech signals are required to preserve perceptual quality rather than solely minimize pixel distortion. Yan & Li [
21] present a transmission technique for transmitting digital signals by utilizing images as carrier signals. Although this study addresses digital signal transmission within a semantic communication framework, its methodology fundamentally differs from ours in both encoding strategy and transmission approach. These situations leave semantic-aware digital speech transmission underexplored.
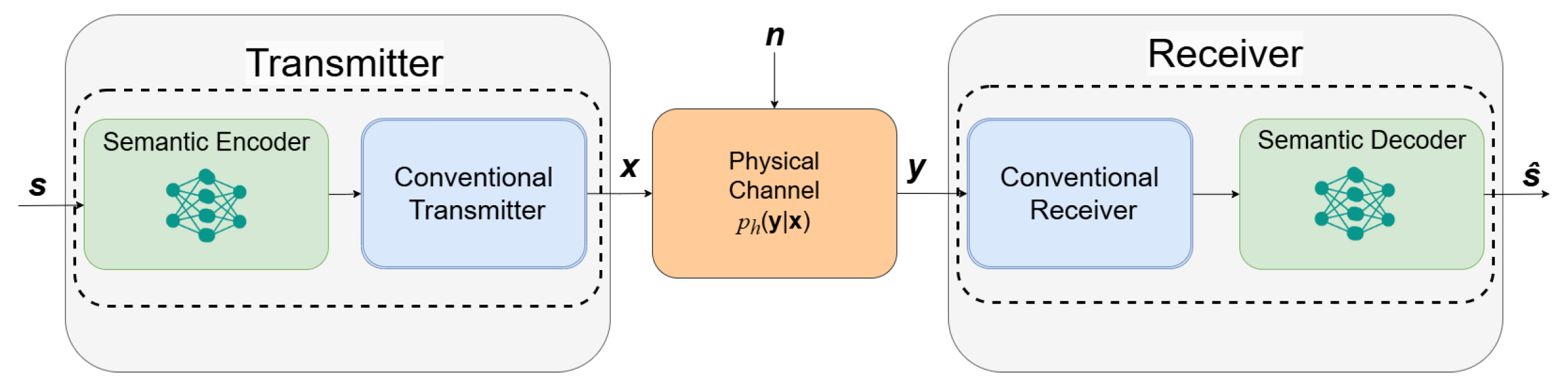
To address these gaps, this paper proposes a semantic-aware digital speech communication system that serves as an intermediate transition between conventional and fully end-to-end semantic communication models. Unlike purely deep learning-based systems, our model is capable of the following:
Extracts structured semantic representations of speech while ensuring compatibility with conventional digital transmission techniques.
Discretizes feature tensors before transmission, initiating a pathway for integration with existing bit-based communication systems.
Mirrors the transmitter architecture at the receiver side, reconstructing speech with high perceptual quality while maintaining structured signal integrity.
Our system is designed to function under practical wireless conditions, incorporating stochastic channel models (Additive White Gaussian Noise: AWGN, Rayleigh, Rician multipath fading) while ensuring robust speech transmission across varying signal-to-noise (SNR) levels. Performance is evaluated using the Signal-to-Distortion Ratio (SDR), Perceptual Evaluation of Speech Quality (PESQ), and Short-Time Objective Intelligibility (STOI) to comprehensively assess both signal fidelity and intelligibility. By integrating semantic-aware encoding within a structured digital transmission framework, our system remains applicable to existing telecommunication infrastructures while demonstrating the potential of deep learning-based feature representation and reconstruction. This hybrid approach enables gradual adoption in practical deployments, making it more accessible for real-world applications, such as low-bandwidth speech communication, robust voice transmission over wireless networks, and AI-assisted speech processing for edge computing devices.
This study provides a scalable and interpretable approach to integrating semantic-aware speech processing into digital communication frameworks, bridging the gap between conventional wireless systems and emerging AI-driven transmission paradigms. Our core novelty lies in the pragmatic fusion of deep learning-driven semantic speech understanding with established digital communication principles. By moving beyond purely end-to-end neural models, we introduce a structured discretization process that allows semantic features to be transmitted as digital signals, initiating a pathway for integration with existing wireless infrastructure. Specifically, by focusing on speech, we address the critical need for perceptual quality preservation in voice communications—a requirement that differentiates it significantly from image- and text-centric semantic models. It serves as a transitional framework between conventional source–channel coding techniques and end-to-end deep learning-based semantic communication models. Instead of replacing existing paradigms outright, our work demonstrates how semantic processing can be incrementally introduced into current speech communication systems, ensuring practical viability. By seamlessly integrating semantic-aware speech processing into IoT ecosystems, our framework elevates voice-driven interactions in critical domains such as industrial automation, healthcare monitoring, and smart city infrastructure. Designed for practical deployment, the system operates harmoniously with existing edge networks, avoiding costly hardware upgrades while delivering reliable performance in resource-limited environments—an essential feature for scalable IoT solutions. The rest of this paper is organized as follows:
Section 2 describes the system model,
Section 3 details the experimental setup and implementation,
Section 4 presents the results and performance analysis, and
Section 5 concludes the study with key findings and future research directions.
3. Results
We investigate the performance of our model compared to conventional communication systems for speech signals. The systems are tested under AWGN, Rician, and Rayleigh fading channels, with the assumption of perfect channel state information (CSI) at the receiver. These channel conditions are selected to represent a range of real-world wireless transmission scenarios, from ideal Gaussian noise environments to multipath-dominated fading conditions. The experiments utilize the Edinburgh DataShare dataset [
25], which provides diverse speech recordings suitable for robust performance evaluation.
3.1. Dataset and Preprocessing
The dataset consists of a training set of 10,000 .wav files, a validation set of 800 files, and a test set of 50 files. The speech signals are originally sampled at 48 kHz, and in this study, they are downsampled to 8 kHz to match practical bandwidth constraints in wireless communication, as speech intelligibility is largely contained within the 4 kHz frequency range.
Before transmission, all speech samples undergo amplitude normalization to mitigate level variations across recordings to achieve a consistent dynamic range. The selection of dataset emphasizes phonetic and acoustic diversity to evaluate the system’s generalization ability across different speaker profiles and speech characteristics.
For evaluation, each test speech sample undergoes five independent transmission iterations, each initialized with a different random seed. By doing so, we introduce a controlled randomness in the transmission process which ensures robustness against initialization biases. Additionally, performance is assessed across SNR levels and fading channels for simulating real-world wireless conditions.
To ensure a fair comparison between semantic-aware transmission and conventional digital speech communication, we enforce a bit allocation constraint based on conventional PCM encoding. In traditional digital speech transmission, an audio signal is represented by its sampling rate and bit depth, which determine the total number of bits required for transmission. For a speech signal of
s, sampled at 8 kHz with a 16-bit resolution, the total bit allocation is given by the following:
Numerically, in our case, this becomes the following:
This bit allocation serves as a reference for conventional communication, where each sample is explicitly quantized into a 16-bit PCM format for digital transmission. To maintain a fair and analytically rigorous comparison, we impose the same bit burden constraint on our proposed model. Specifically, the output of the semantic compressor, after flattening and discretization, is mapped into 16-bit integers to match the bit depth of conventional PCM encoding. This ensures that the overall number of bits used for semantic-aware transmission aligns with conventional digital transmission, enabling an equitable performance evaluation. Furthermore, this structured feature discretization prevents uncontrolled increases in transmission overhead while preserving semantic integrity.
By enforcing this constraint, we confirm that our semantic-aware model aligns with the same bit-rate requirements as conventional methods, allowing for a meaningful comparison in terms of transmission efficiency, perceptual quality, and robustness to channel impairments.
3.2. Implementation Details
The proposed semantic-aware transmission system is implemented using TensorFlow 2.10.0 and trained on an NVIDIA RTX 2080 Ti GPU. The training configuration is as follows:
Batch size: 64
Loss/cost function: MSE
Optimization: RMSProp
Learning rate: 0.0005
Training epochs: 750
Fading model: Rayleigh
Training SNR: 8 dB
The semantic encoder consists of following components as shown in
Table 1:
A semantic feature extraction network, comprising two 2D CNN layers followed by five Squeeze-and-Excitation Residual Network (SE-ResNet) blocks, which extract meaningful speech representations.
A semantic compression module, consisting of two 2D CNN layers, which efficiently reduces redundant information before encoding.
A quantization module, which maps the compressed semantic representations to a finite set of discrete values before modulation.
We use SE-ResNet blocks as they are commonly implemented in semantic speech encoding in the literature [
26]. Thanks to their attention-based and excitation mechanism, SE blocks adaptively facilitate feature extraction with essential speech information. The selection of hyperparameters, including the training SNR of 8 dB and the number of filters, was based on empirical tuning in place of an exhaustive grid search. This work mainly aims to demonstrate a proof of concept, and these hyperparameters were chosen as reasonable settings rather than globally optimized values. Future work could further refine these choices using hyperparameter search methods.
In the semantic compression module, the first 2D CNN layer employs a ReLU activation function, while the second layer does not incorporate any activation function. At the receiver, a symmetric architecture is employed for semantic decoding, where the semantic expander reconstructs feature dimensions before the semantic interpreter synthesizes the speech waveform. The first 2D transposed CNN layer in the semantic expander operates without an activation function, whereas the second layer applies the ReLU activation function. Through our empirical analyses, this configuration resulted in the lowest reconstruction error. The last layer of the semantic compressor is designed without an activation function to ensure semantic information remains within an appropriate range [
11,
27]. Notably, we determined that omitting activation functions in specific layers led to the best performance in our case. In particular, the second layer of the semantic compressor and the first layer of the semantic expander achieved the best results without activation functions. Additionally, the output of the semantic interpreter showed improved performance when no activation function was applied. The training phase of the proposed system differs from conventional communication models as it does not involve explicit channel encoding, modulation, or decoding operations. These traditional signal processing components are inherently non-differentiable, which makes them unsuitable for the backpropagation-based optimization commonly used in deep learning models [
13]. The conventional transmission system follows a standard digital communication approach, as summarized in
Table 2.
We compare our proposed digital semantic-aware system against the conventional approach as shown in
Table 2. It is important to note that the conventional system under discussion is maintained in its current form within the proposed new system.
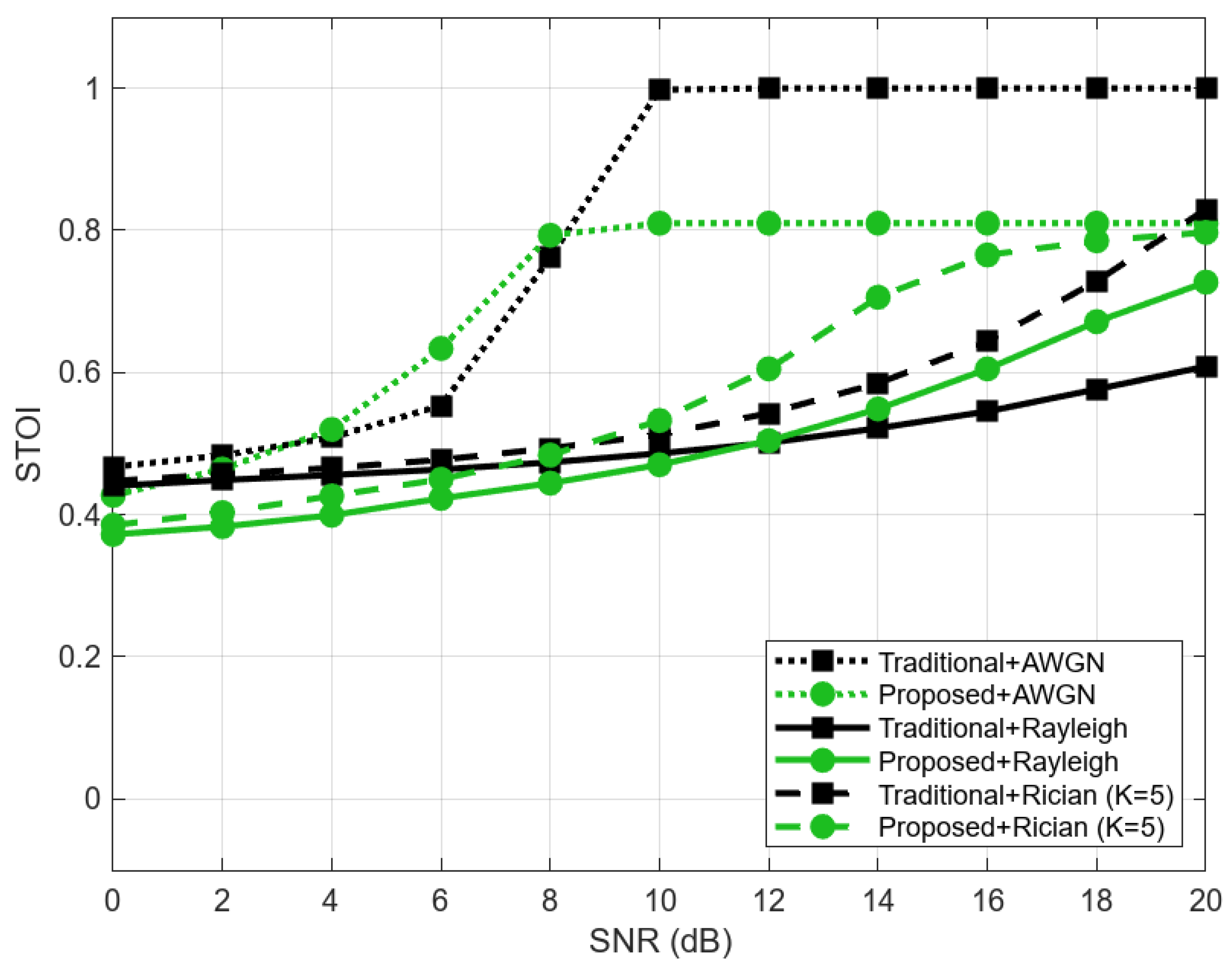
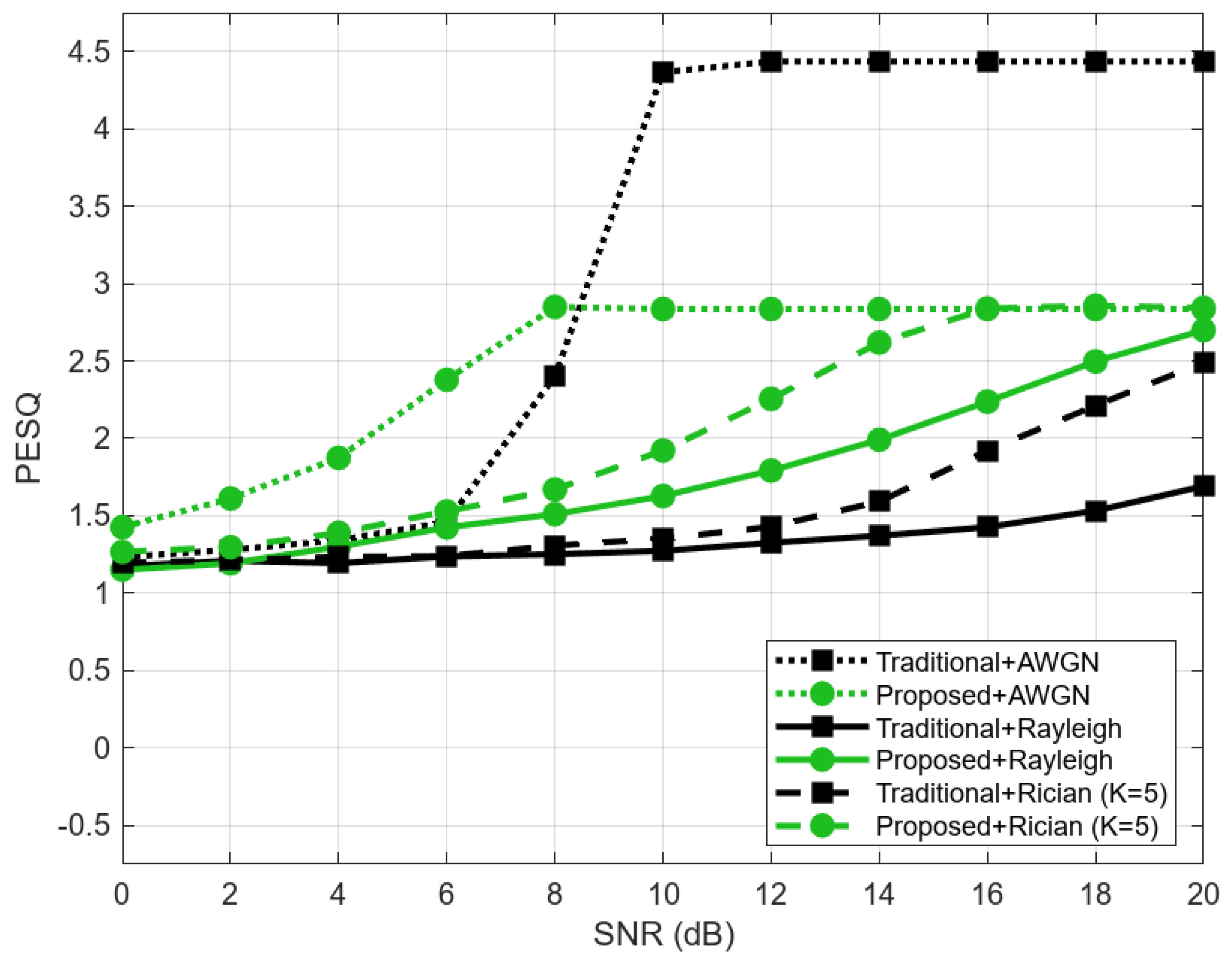
To objectively assess the accuracy of reconstructed speech signals, we analyze SDR, PESQ, and STOI at various SNR levels, which measure how well the system preserves both the structure of the signal and its perceptual quality under different channel conditions. The following figures illustrate the performance evaluation in AWGN, Rayleigh, and Rician (K = 5) channels, using SDR, STOI, and PESQ metrics.
Figure 3 shows the SDR comparison, indicating that the proposed system is better equipped to handle multipath fading, leading to improved signal clarity and lower distortion in Rayleigh and Rician channels.
Figure 4 illustrates the STOI results, showing that the proposed system achieves slightly higher intelligibility scores in fading environments compared to the traditional system. However, under AWGN, the conventional method remains better.
Figure 5 presents the PESQ scores, demonstrating that while traditional methods perform well under AWGN, the proposed system provides better perceptual quality under severe channel impairments.
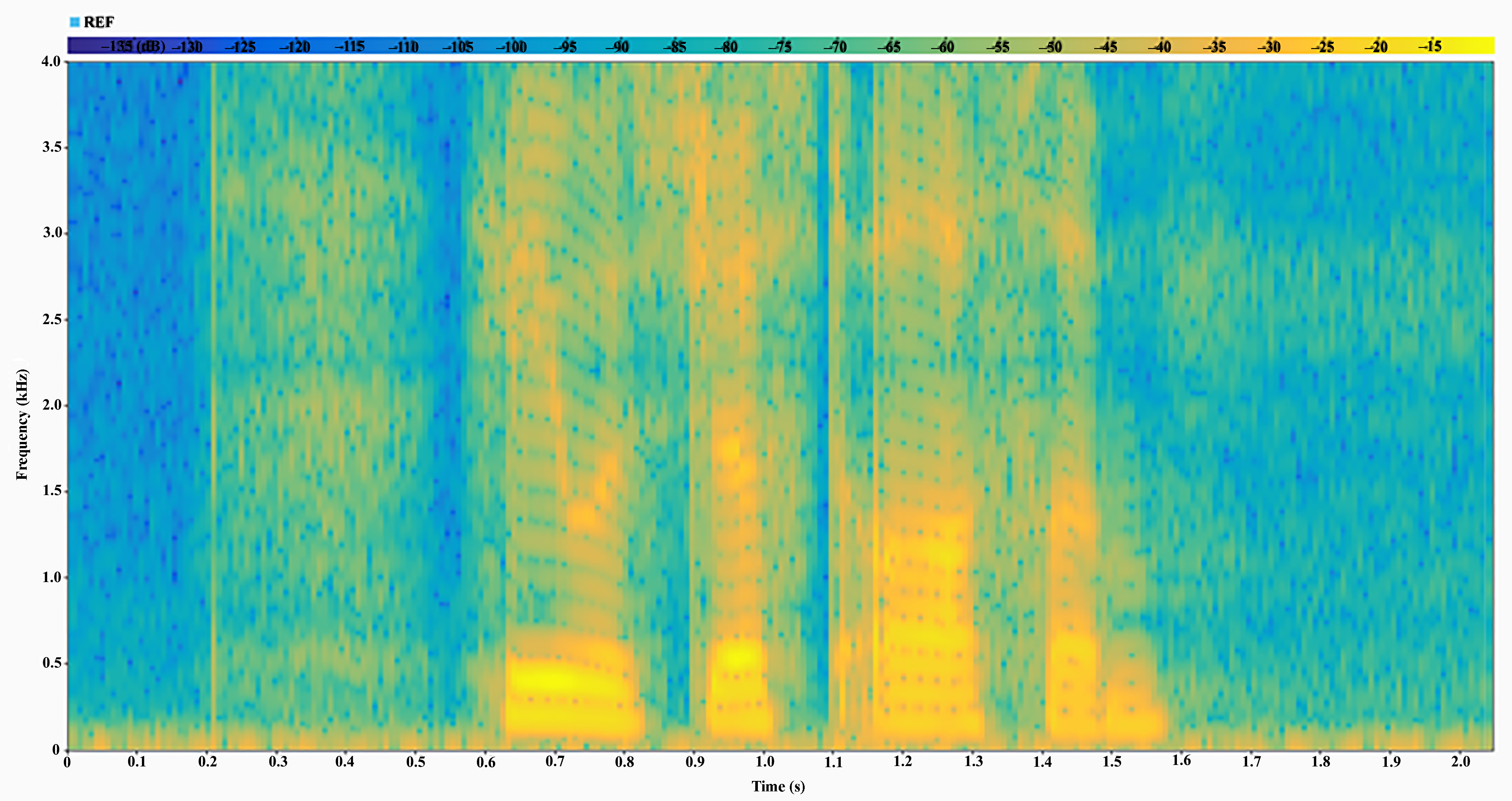
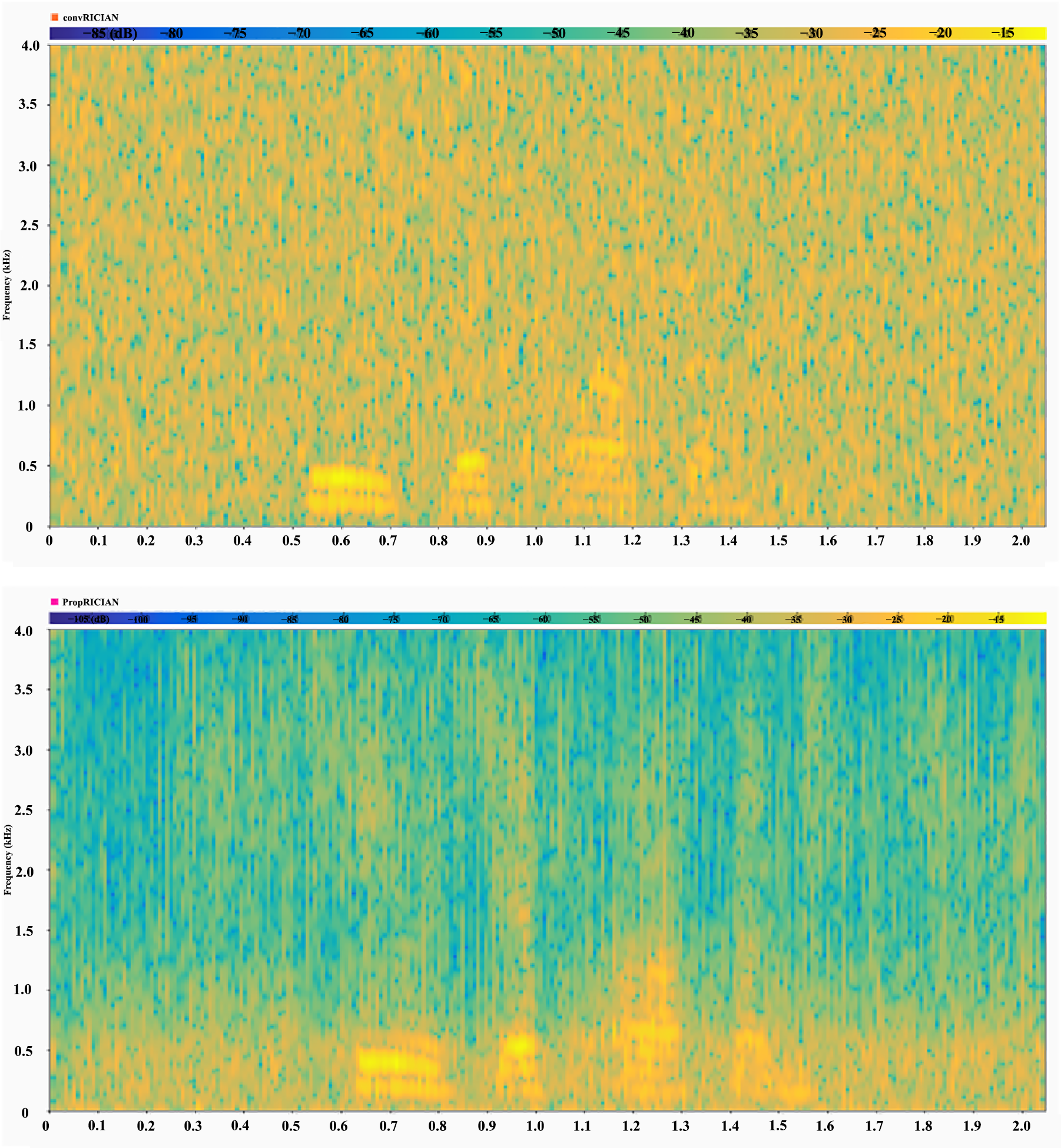
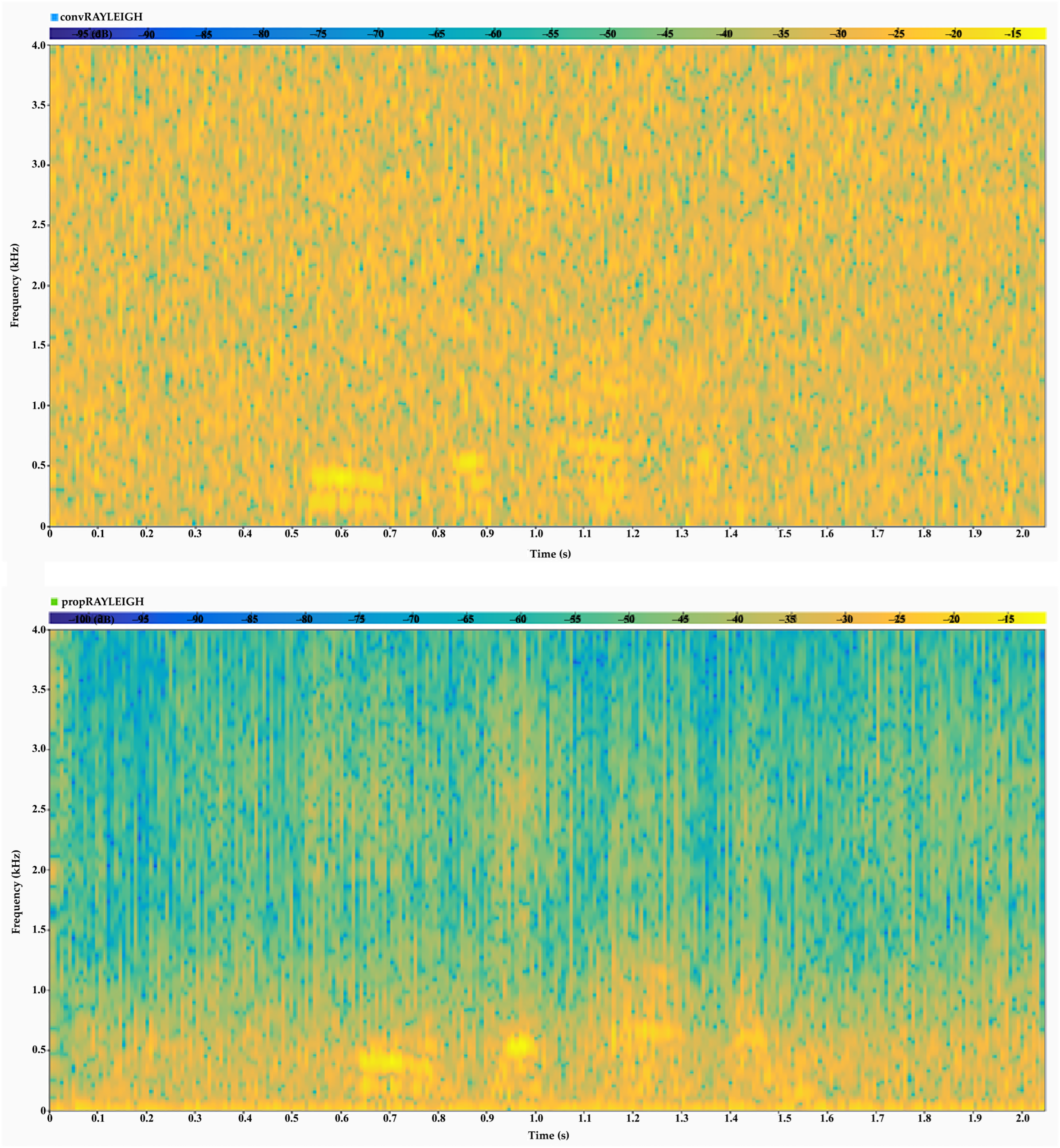
Next, we visually compare the performance of the proposed and conventional models through spectrograms for a sample speech signal.
Figure 6 illustrates the spectrograms of the original speech signal, while
Figure 7 and
Figure 8 present the spectogram of reconstructed speech signals under Rician and Rayleigh fading channels for both the proposed and conventional models. These visualizations demonstrate the effectiveness and robustness of our model in preserving spectral features within fading environments, outperforming conventional methods by maintaining critical spectral content.
4. Discussion
The results indicate that under AWGN conditions, the conventional system outperforms the proposed system when the SNR level is higher than 8 dB. However, under fading channels, the proposed semantic-aware system outperforms the conventional approach from low to high-mid SNR regions, demonstrating improved robustness against multipath fading effects. This highlights the ability of semantic-aware transmission to preserve intelligibility and perceptual quality even in highly degraded conditions.
It is important to note that although the proposed system shows improved PESQ and SDR scores in fading scenarios, its STOI performance does not always align with these results. While our system effectively enhances perceptual speech quality compared to the conventional system, as reflected in PESQ and SDR, it potentially introduces subtle distortions in the temporal envelope of the reconstructed speech. These distortions, though not significantly impacting overall perceptual quality, can affect the short-time temporal envelope correlation, which is the core metric assessed by STOI. Specifically, we believe that the semantic decoder, in its effort to generalize and reconstruct speech from compressed semantic features, may smooth out or alter fine-grained temporal details that are critical for STOI. One potential mitigation strategy would be using the hybrid loss function. Incorporating a hybrid loss term that explicitly penalizes temporal envelope distortions during training could help align STOI with PESQ and SDR. This could involve using a time-domain loss function or a STOI-specific loss component.
While we are aware of latency implications, this research places its core focus on the practical applicability of semantic communication. We posit that the semantic computations are executed on a high-performance edge device, mitigating potential latency concerns. Furthermore, the computational efficiency of the proposed model can be significantly enhanced through hardware acceleration, such as Tensor Processing Units (TPUs). Additionally, the application of established model compression techniques, including pruning [
28] and quantization [
29], effectively reduces the computational burden on resource-constrained IoT devices.
These results show the trade-off between bit-level accuracy and semantic reconstruction. While conventional systems excel in ideal conditions, semantic-aware models demonstrate resilience to real-world wireless impairments, making them more suitable for low-SNR and multipath environments.
Complexity Analysis
To provide a quantitative assessment of the computational complexity of Hybrid-DeepSCS, particularly relevant for IoT and edge device applications, we conducted a detailed analysis of the model’s floating-point operations (FLOPs). The following sections present the complexity analysis and FLOP count for each segment of our model. In this study, we analyze the computational cost of our model by estimating the FLOPs for each of its main components. The results are summarized in
Table 3.
From the table, we observe that the semantic interpreter requires the highest computational workload and model size. On the other hand, the semantic compressor has the lowest computational requirement as well as the model size, reflecting its role in reducing data dimensionality before transmission. Future work could explore model compression techniques, such as pruning or quantization, as mentioned earlier, to improve computational efficiency without significant performance loss. Based on the computational power of a given edge device, the latency incurred by the semantic model can be estimated. Specifically, latency can be calculated as the ratio of the FLOP value to the peak floating-point operations per second (FLOPS) capability of the target edge device when the processing unit is operating at maximum utilization [
30]. We denote FLOPs as the number of floating-point operations and FLOPS (note the uppercase ‘S’), as a measure of hardware performance. Mathematically, this can be expressed as follows [
31]:
This approach allows for a device-specific estimation of latency, providing a practical understanding of the system’s performance in resource-constrained environments.
5. Conclusions
In this paper, we present Hybrid-DeepSCS, a novel semantic-aware digital speech communication system that bridges the gap between traditional digital transmission and emerging deep learning-based semantic communication. Our approach integrates a semantic encoder and decoder within a conventional digital transmission chain, enabling the extraction, discretization, and reconstruction of structured semantic features from speech. This hybrid design allows compatibility with existing communication infrastructures while leveraging deep learning for enhanced feature representation and speech reconstruction.
Experimental results demonstrate that Hybrid-DeepSCS significantly improves performance in challenging channel conditions, such as Rayleigh and Rician fading. While conventional systems maintain an advantage in high-SNR AWGN channels, our method offers superior robustness and perceptual quality—measured through PESQ and SDR—under noisy and multipath fading conditions, making it particularly suited for real-world wireless environments. Although STOI performance varies, our findings highlight the trade-off between bit-level accuracy and semantic preservation. Prioritizing semantic content enhances speech intelligibility and resilience, particularly in low-SNR and fading scenarios.
This work marks an important step toward the practical deployment of semantic communication systems, providing a pathway for gradual integration with current technologies. Future research will focus on optimizing semantic encoding and decoding, exploring adaptive modulation strategies, and assessing the impact of different network topologies on overall system performance. Another promising area for future research can be to investigate federated or transfer learning methods to improve the model’s ability to adapt to various speakers and languages. In addition, a further direction is to analyze the system’s performance under extreme bandwidth limitations by testing its effectiveness at ultra-low bit rates. We hope that our work will provide valuable insight for the gradual transition to practical digital semantic communication technologies for future networks.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}