
Efficient Spiking Neural Network for RGB–Event Fusion-Based Object Detection

 , and
, and
Abstract
1. Introduction
- We propose a novel spiking RGB–event fusion-based detection network, termed SFDNet, which is a fully spiking object detector that achieves robust object detection with remarkably low power consumption;
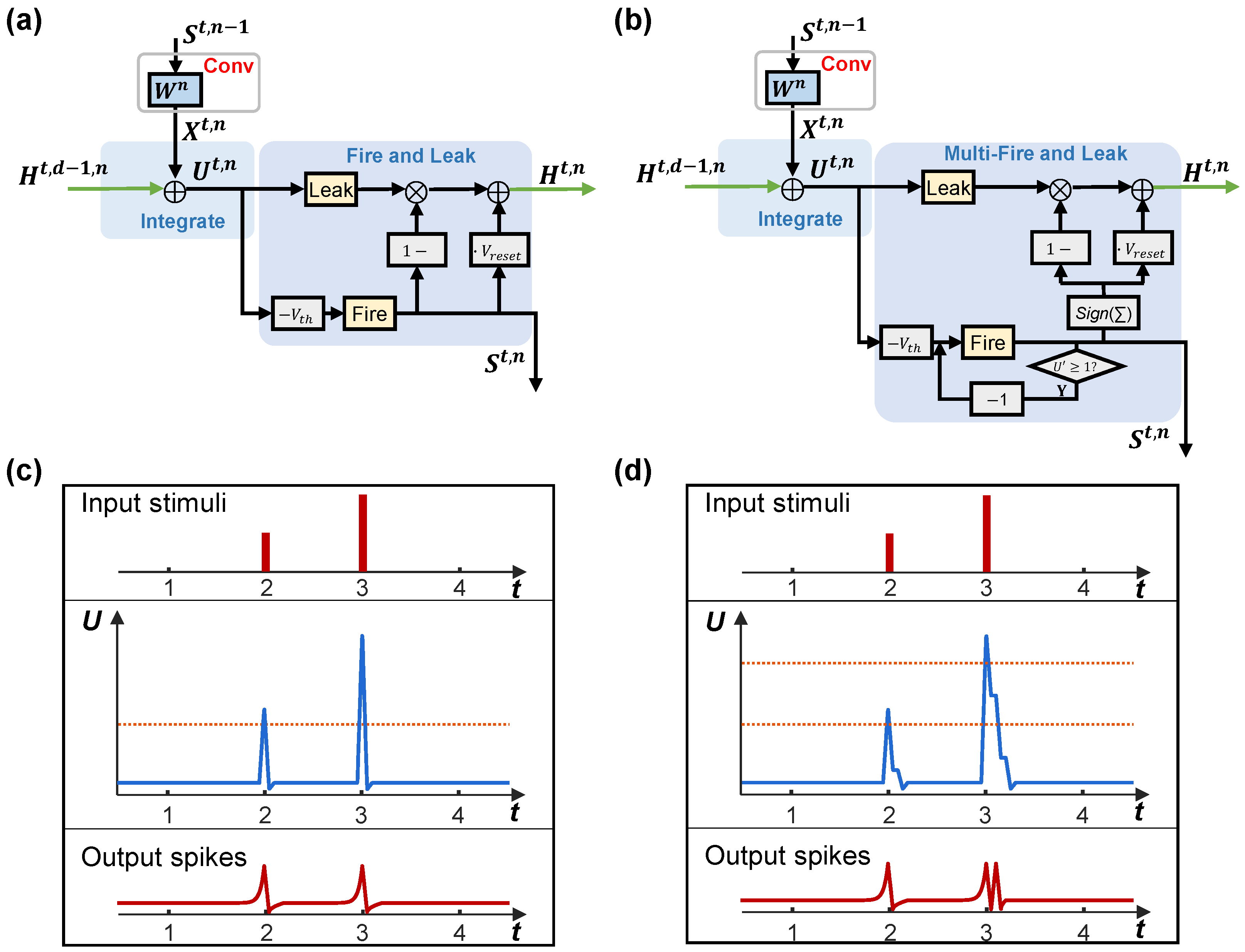
- We introduce the Leaky Integrate-and-Multi-Fire (LIMF) neuron model, which combines soft and hard reset mechanisms to enhance feature representation in SNNs;
- We develop a multi-scale hierarchical spiking residual attention network and a lightweight spiking aggregation module for efficient and effective extraction and fusion of features from both events and RGB frames;
- Extensive experimental results on two public multimodal object detection datasets demonstrate that our SFDNet outperforms state-of-the-art object detectors with significantly lower power consumption.
2. Related Works
2.1. RGB–Event Fusion for Object Detection
2.2. Spiking Neural Networks for Object Detection
3. Methods
3.1. Network Input
3.2. Network Architecture
3.2.1. Dual-Pathway Feature Extraction
3.2.2. Spiking Aggregation Module
3.2.3. Spiking Detection Head
3.3. Spiking Neuron Model
4. Results
4.1. Experiment Settings
4.2. Performance Evaluation in Various Scenarios
4.3. Comparison with State-of-the-Art Methods
4.4. Ablation Studies
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sun, K.; Wu, W.; Liu, T.; Yang, S.; Wang, Q.; Zhou, Q.; Ye, Z.; Qian, C. FAB: A robust facial landmark detection framework for motion-blurred videos. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5462–5471. [Google Scholar]
- Sayed, M.; Brostow, G. Improved handling of motion blur in online object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1706–1716. [Google Scholar]
- Hu, Y.; Delbruck, T.; Liu, S.C. Learning to exploit multiple vision modalities by using grafted networks. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 85–101. [Google Scholar]
- Zhang, J.; Newman, J.P.; Wang, X.; Thakur, C.S.; Rattray, J.; Etienne-Cummings, R.; Wilson, M.A. A closed-loop, all-electronic pixel-wise adaptive imaging system for high dynamic range videography. IEEE Trans. Circuits Syst. I Regul. Pap. 2020, 67, 1803–1814. [Google Scholar] [CrossRef] [PubMed]
- Brandli, C.; Berner, R.; Yang, M.; Liu, S.C.; Delbruck, T. A 240 × 180 130 db 3 μs latency global shutter spatiotemporal vision sensor. IEEE J. Solid-State Circuits 2014, 49, 2333–2341. [Google Scholar] [CrossRef]
- Moeys, D.P.; Corradi, F.; Li, C.; Bamford, S.A.; Longinotti, L.; Voigt, F.F.; Berry, S.; Taverni, G.; Helmchen, F.; Delbruck, T. A sensitive dynamic and active pixel vision sensor for color or neural imaging applications. IEEE Trans. Biomed. Circuits Syst. 2017, 12, 123–136. [Google Scholar] [CrossRef] [PubMed]
- Lichtsteiner, P.; Posch, C.; Delbruck, T. A 128 ×128 120 dB 15μs latency asynchronous temporal contrast vision sensor. IEEE J. Solid-State Circuits 2008, 43, 566–576. [Google Scholar] [CrossRef]
- Finateu, T.; Niwa, A.; Matolin, D.; Tsuchimoto, K.; Mascheroni, A.; Reynaud, E.; Mostafalu, P.; Brady, F.; Chotard, L.; LeGoff, F.; et al. A 1280× 720 back-illuminated stacked temporal contrast event-based vision sensor with 4.86 μm pixels, 1.066 GEPS readout, programmable event-rate controller and compressive data-formatting pipeline. In Proceedings of the 2020 IEEE International Solid-State Circuits Conference-(ISSCC), San Francisco, CA, USA, 16–20 February 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 112–114. [Google Scholar]
- Fan, L.; Li, Y.; Shen, H.; Li, J.; Hu, D. From Dense to Sparse: Low-Latency and Speed-Robust Event-Based Object Detection. IEEE Trans. Intell. Veh. 2024. [Google Scholar] [CrossRef]
- Gallego, G.; Delbrück, T.; Orchard, G.; Bartolozzi, C.; Taba, B.; Censi, A.; Leutenegger, S.; Davison, A.J.; Conradt, J.; Daniilidis, K.; et al. Event-based vision: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 154–180. [Google Scholar] [CrossRef]
- Gehrig, M.; Scaramuzza, D. Recurrent vision transformers for object detection with event cameras. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 13884–13893. [Google Scholar]
- Li, J.; Dong, S.; Yu, Z.; Tian, Y.; Huang, T. Event-Based Vision Enhanced: A Joint Detection Framework in Autonomous Driving. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo, Shanghai, China, 8–12 July 2019; pp. 1396–1401. [Google Scholar] [CrossRef]
- Jiang, Z.; Xia, P.; Huang, K.; Stechele, W.; Chen, G.; Bing, Z.; Knoll, A. Mixed frame-/event-driven fast pedestrian detection. In Proceedings of the International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 8332–8338. [Google Scholar]
- Li, D.; Li, J.; Tian, Y. SODFormer: Streaming Object Detection with Transformer Using Events and Frames. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 14020–14037. [Google Scholar] [CrossRef]
- Tomy, A.; Paigwar, A.; Mann, K.S.; Renzaglia, A.; Laugier, C. Fusing event-based and rgb camera for robust object detection in adverse conditions. In Proceedings of the International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 933–939. [Google Scholar]
- Cao, H.; Zhang, Z.; Xia, Y.; Li, X.; Xia, J.; Chen, G.; Knoll, A. Embracing events and frames with hierarchical feature refinement network for object detection. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Cham, Switzerland, 2024; pp. 161–177. [Google Scholar]
- Zhou, Z.; Wu, Z.; Boutteau, R.; Yang, F.; Demonceaux, C.; Ginhac, D. RGB-event fusion for moving object detection in autonomous driving. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 7808–7815. [Google Scholar]
- Zhang, H.; Wang, X.; Xu, C.; Wang, X.; Xu, F.; Yu, H.; Yu, L.; Yang, W. Frequency-Adaptive Low-Latency Object Detection Using Events and Frames. arXiv 2024, arXiv:2412.04149. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020; pp. 1–16. [Google Scholar]
- Wang, T.; Yuan, L.; Chen, Y.; Feng, J.; Yan, S. PnP-DETR: Towards efficient visual analysis with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 4661–4670. [Google Scholar]
- Perot, E.; De Tournemire, P.; Nitti, D.; Masci, J.; Sironi, A. Learning to detect objects with a 1 megapixel event camera. Adv. Neural Inf. Process. Syst. 2020, 33, 16639–16652. [Google Scholar]
- Lu, Y.; Lu, C.; Tang, C.K. Online video object detection using association LSTM. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2344–2352. [Google Scholar]
- Su, Q.; Chou, Y.; Hu, Y.; Li, J.; Mei, S.; Zhang, Z.; Li, G. Deep directly-trained spiking neural networks for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 6555–6565. [Google Scholar]
- Kim, S.; Park, S.; Na, B.; Yoon, S. Spiking-YOLO: Spiking neural network for energy-efficient object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 11270–11277. [Google Scholar]
- Luo, X.; Yao, M.; Chou, Y.; Xu, B.; Li, G. Integer-valued training and spike-driven inference spiking neural network for high-performance and energy-efficient object detection. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 October 2025; pp. 253–272. [Google Scholar]
- Yao, M.; Hu, J.; Hu, T.; Xu, Y.; Zhou, Z.; Tian, Y.; XU, B.; Li, G. Spike-driven Transformer V2: Meta Spiking Neural Network Architecture Inspiring the Design of Next-generation Neuromorphic Chips. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Zhang, H.; Li, Y.; He, B.; Fan, X.; Wang, Y.; Zhang, Y. Direct training high-performance spiking neural networks for object recognition and detection. Front. Neurosci. 2023, 17, 1229951. [Google Scholar] [CrossRef] [PubMed]
- Lien, H.H.; Chang, T.S. Sparse compressed spiking neural network accelerator for object detection. IEEE Trans. Circuits Syst. I Regul. Pap. 2022, 69, 2060–2069. [Google Scholar] [CrossRef]
- Chitta, K.; Prakash, A.; Jaeger, B.; Yu, Z.; Renz, K.; Geiger, A. Transfuser: Imitation with transformer-based sensor fusion for autonomous driving. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 12878–12895. [Google Scholar] [CrossRef] [PubMed]
- Tulyakov, S.; Gehrig, D.; Georgoulis, S.; Erbach, J.; Gehrig, M.; Li, Y.; Scaramuzza, D. Time lens: Event-based video frame interpolation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16155–16164. [Google Scholar]
- Duan, P.; Wang, Z.; Shi, B.; Cossairt, O.; Huang, T.; Katsaggelos, A. Guided event filtering: Synergy between intensity images and neuromorphic events for high performance imaging. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 8261–8275. [Google Scholar] [CrossRef]
- Zhang, J.; Yang, X.; Fu, Y.; Wei, X.; Yin, B.; Dong, B. Object tracking by jointly exploiting frame and event domain. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 13043–13052. [Google Scholar]
- Gehrig, D.; Rüegg, M.; Gehrig, M.; Hidalgo-Carrió, J.; Scaramuzza, D. Combining events and frames using recurrent asynchronous multimodal networks for monocular depth prediction. IEEE Robot. Automat. Lett. 2021, 6, 2822–2829. [Google Scholar] [CrossRef]
- Zuo, Y.F.; Yang, J.; Chen, J.; Wang, X.; Wang, Y.; Kneip, L. DEVO: Depth-event camera visual odometry in challenging conditions. In Proceedings of the International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 2179–2185. [Google Scholar]
- Gao, L.; Liang, Y.; Yang, J.; Wu, S.; Wang, C.; Chen, J.; Kneip, L. VECtor: A Versatile event-centric benchmark for multi-sensor SLAM. IEEE Robot. Automat. Lett. 2022, 7, 8217–8224. [Google Scholar] [CrossRef]
- Kim, S.; Park, S.; Na, B.; Kim, J.; Yoon, S. Towards fast and accurate object detection in bio-inspired spiking neural networks through Bayesian optimization. IEEE Access 2020, 9, 2633–2643. [Google Scholar] [CrossRef]
- Yuan, M.; Zhang, C.; Wang, Z.; Liu, H.; Pan, G.; Tang, H. Trainable Spiking-YOLO for low-latency and high-performance object detection. Neural Netw. 2024, 172, 106092. [Google Scholar] [CrossRef]
- Li, Y.; He, X.; Dong, Y.; Kong, Q.; Zeng, Y. Spike calibration: Fast and accurate conversion of spiking neural network for object detection and segmentation. arXiv 2022, arXiv:2207.02702. [Google Scholar]
- Chen, N.F. Pseudo-labels for supervised learning on dynamic vision sensor data, applied to object detection under ego-motion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 644–653. [Google Scholar]
- Maqueda, A.I.; Loquercio, A.; Gallego, G.; García, N.; Scaramuzza, D. Event-based vision meets deep learning on steering prediction for self-driving cars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 5419–5427. [Google Scholar]
- Sironi, A.; Brambilla, M.; Bourdis, N.; Lagorce, X.; Benosman, R. HATS: Histograms of averaged time surfaces for robust event-based object classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 1731–1740. [Google Scholar]
- Zhu, A.Z.; Yuan, L.; Chaney, K.; Daniilidis, K. Unsupervised event-based learning of optical flow, depth, and egomotion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 989–997. [Google Scholar]
- Hu, Y.; Deng, L.; Wu, Y.; Yao, M.; Li, G. Advancing spiking neural networks toward deep residual learning. IEEE Trans. Neural Netw. Learn. Syst. 2024, 36, 2353–2367. [Google Scholar] [CrossRef]
- Yao, M.; Zhao, G.; Zhang, H.; Hu, Y.; Deng, L.; Tian, Y.; Xu, B.; Li, G. Attention spiking neural networks. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 9393–9410. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Maass, W. Networks of spiking neurons: The third generation of neural network models. Neural Netw. 1997, 10, 1659–1671. [Google Scholar] [CrossRef]
- Gerstner, W.; Kistler, W.M.; Naud, R.; Paninski, L. Neuronal Dynamics: From Single Neurons to Networks and Models of Cognition; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Gehrig, D.; Scaramuzza, D. Low-latency automotive vision with event cameras. Nature 2024, 629, 1034–1040. [Google Scholar] [CrossRef]
- Yin, B.; Corradi, F.; Bohté, S.M. Accurate and efficient time-domain classification with adaptive spiking recurrent neural networks. Nat. Mach. Intell. 2021, 3, 905–913. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 740–755. [Google Scholar]
- Li, J.; Li, J.; Zhu, L.; Xiang, X.; Huang, T.; Tian, Y. Asynchronous spatio-temporal memory network for continuous event-based object detection. IEEE Trans. Image Process 2022, 31, 2975–2987. [Google Scholar] [CrossRef]
- Liu, B.; Xu, C.; Yang, W.; Yu, H.; Yu, L. Motion robust high-speed light-weighted object detection with event camera. IEEE Trans. Instru. Meas. 2023, 72, 1–13. [Google Scholar] [CrossRef]
- Zubić, N.; Gehrig, M.; Scaramuzza, D. State Space Models for Event Cameras. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024. [Google Scholar]
- Tu, Z.; Talebi, H.; Zhang, H.; Yang, F.; Milanfar, P.; Bovik, A.; Li, Y. Maxvit: Multi-axis vision transformer. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 459–479. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenario | Modality | AP50 | mAP | mAP50 | ||
|---|---|---|---|---|---|---|
| Car | Pedestrian | Two-Wheeler | ||||
| Normal | Events | 54.4 | 29.4 | 52.8 | 21.1 | 45.5 |
| Frames | 82.8 | 48.3 | 67.3 | 35.0 | 66.1 | |
| Frames + Events | 83.0 | 49.5 | 69.9 | 35.8 | 67.5 | |
| Motion blur | Events | 44.5 | 13.6 | 49.0 | 16.3 | 35.7 |
| Frames | 69.4 | 35.3 | 46.9 | 25.8 | 50.5 | |
| Frames + Events | 71.3 | 34.6 | 52.6 | 27.0 | 52.8 | |
| Low-light | Events | 54.6 | 1.8 | 53.2 | 15.0 | 36.5 |
| Frames | 59.8 | 12.4 | 41.5 | 16.3 | 37.9 | |
| Frames + Events | 62.3 | 12.4 | 58.2 | 19.6 | 44.3 | |
| All | Events | 52.6 | 22.2 | 51.7 | 19.1 | 42.2 |
| Frames | 78.9 | 40.8 | 55.3 | 30.1 | 58.3 | |
| Frames + Events | 79.6 | 42.0 | 60.4 | 31.3 | 60.7 | |
| PKU-DAVIS-SOD [14] | DSEC-Detection [54] | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Modality | Method | Backbone | mAP | mAP50 | Power (mJ) | mAP | AP50 | Power (mJ) | Params (M) |
| Events | ASTMNet [57] | CNN + RNN | - | 29.1 | - | - | - | - | >100 |
| AED [58] | CNN | 23.0 | 45.7 | 27.1 | 43.2 | 15.5 | |||
| VIT-S5 [59] | Transformer + SSM | 23.2 | 46.6 | 23.8 | 38.7 | 18.2 | |||
| RVT [11] | Transformer + RNN | 25.6 | 50.3 | 27.7 | 44.2 | 18.5 | |||
| Frame | YoloX [49] | CNN | 27.4 | 50.9 | - | 38.5 | 57.8 | - | 16.5 |
| MaxVit [60] | Transformer | 26.8 | 50.5 | 32.8 | 51.0 | 15.7 | |||
| Swins [61] | Transformer | 27.7 | 52.3 | 34.1 | 52.0 | 15.8 | |||
| VIT-S5 [59] | Transformer + SSM | 28.2 | 52.2 | 33.2 | 49.6 | 18.1 | |||
| RVT [11] | Transformer + RNN | 27.9 | 53.0 | 39.2 | 61.0 | 18.5 | |||
| DETR [20] | Transformer | 27.5 | 56.2 | 1027.3 | 44.8 | 68.2 | 1028.1 | 41.3 | |
| Fusion | SODFormer [14] | Transformer | 20.7 | 50.4 | 287.5 | - | - | - | 82.5 |
| ReNet [17] | CNN | 28.8 | 54.9 | - | 31.6 | 49.0 | - | 59.8 | |
| FAOD [18] | CNN + RNN | 30.5 | 57.5 | 792.5 | 42.5 | 63.5 | 960.7 | 20.3 | |
| SpikeYOLOX [49] | SNN | 24.0 | 51.4 | 5.1 | 34.8 | 58.8 | 17.4 | 57.4 | |
| SFDNet(ours) | SNN | 31.3 | 60.7 | 8.9 | 51.3 | 73.3 | 31.6 | 58.1 | |
| LIF | LIMF | SA Module | mAP | mAP50 | Power (mJ) | Params (M) |
|---|---|---|---|---|---|---|
| ✓ | 23.8 | 49.7 | 3.3 | 42.2 | ||
| ✓ | ✓ | 24.6 | 51.6 | 5.2 | 58.1 | |
| ✓ | 30.1 | 58.3 | 5.7 | 42.2 | ||
| ✓ | ✓ | 31.3 | 60.7 | 8.9 | 58.1 |
| Method | mAP | mAP50 | mAP75 |
|---|---|---|---|
| Histogram [42] | 30.8 | 59.3 | 27.6 |
| Event images [41] | 30.6 | 59.9 | 27.0 |
| Event temporal images [9] | 31.3 | 60.7 | 27.9 |
| Method | mAP | mAP50 | mAP75 | Params (M) |
|---|---|---|---|---|
| SFDNet (without multi-scale) | 30.7 | 59.7 | 27.3 | 63.7 |
| SFDNet (with multi-scale) | 31.3 (+0.6) | 60.7 (+1.0) | 27.9 (+0.6) | 58.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, L.; Yang, J.; Wang, L.; Zhang, J.; Lian, X.; Shen, H. Efficient Spiking Neural Network for RGB–Event Fusion-Based Object Detection. Electronics 2025, 14, 1105. https://doi.org/10.3390/electronics14061105
Fan L, Yang J, Wang L, Zhang J, Lian X, Shen H. Efficient Spiking Neural Network for RGB–Event Fusion-Based Object Detection. Electronics. 2025; 14(6):1105. https://doi.org/10.3390/electronics14061105
Chicago/Turabian StyleFan, Liangwei, Jingjun Yang, Lei Wang, Jinpu Zhang, Xiangkai Lian, and Hui Shen. 2025. "Efficient Spiking Neural Network for RGB–Event Fusion-Based Object Detection" Electronics 14, no. 6: 1105. https://doi.org/10.3390/electronics14061105
APA StyleFan, L., Yang, J., Wang, L., Zhang, J., Lian, X., & Shen, H. (2025). Efficient Spiking Neural Network for RGB–Event Fusion-Based Object Detection. Electronics, 14(6), 1105. https://doi.org/10.3390/electronics14061105