
A Novel Machine Vision-Based Collision Risk Warning Method for Unsignalized Intersections on Arterial Roads


Abstract
:1. Introduction
1.1. Background and Motivation
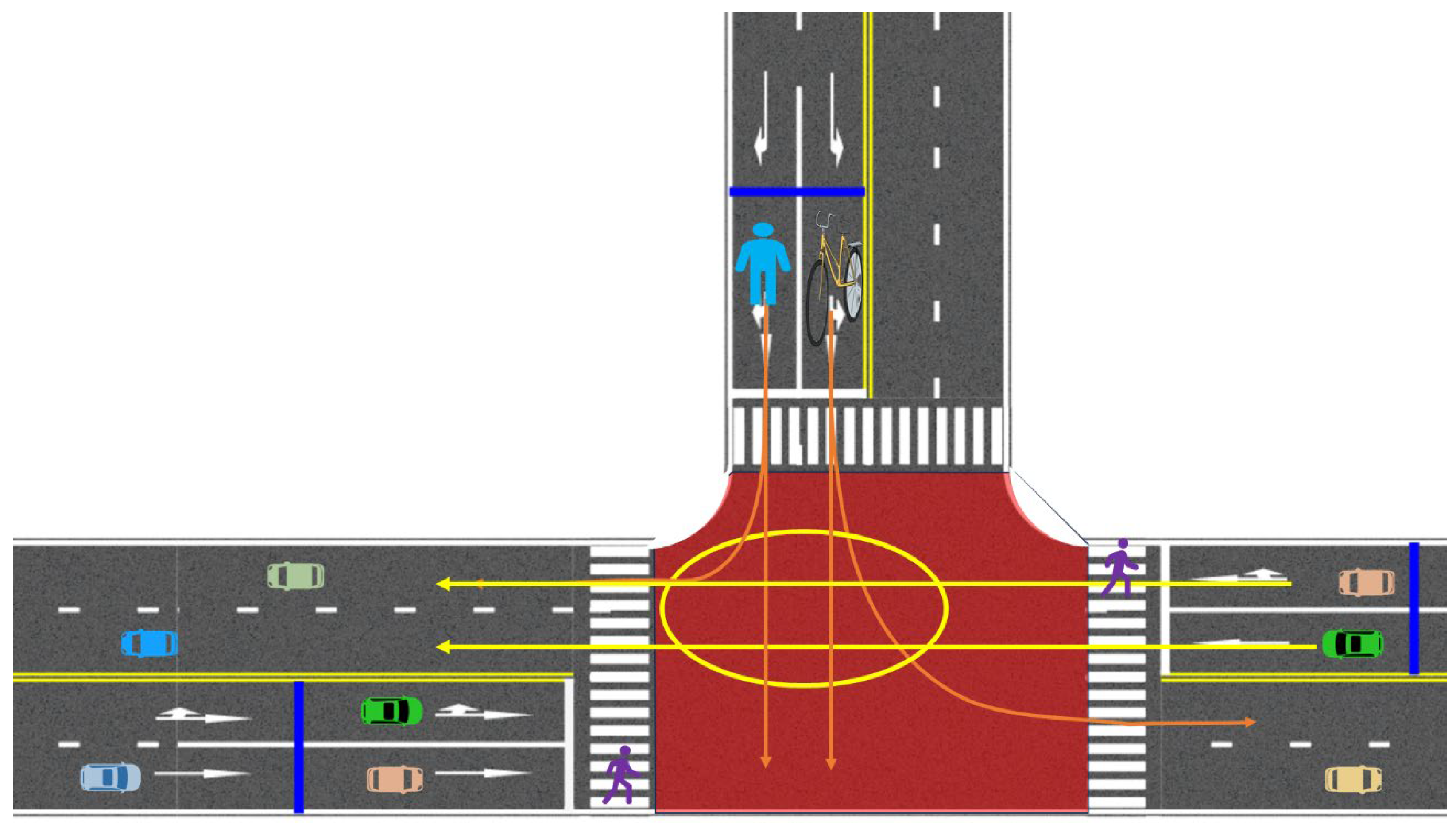
1.2. Problem Statement
- The primary objectives of this research are:
- To develop a real-time collision warning system for unsignalized intersections using YOLOv8 and Deep SORT for object detection and tracking.
- To implement deep learning models for accurate trajectory prediction of road users.
- To evaluate the effectiveness of the proposed system in various traffic scenarios and assess its potential for reducing accident risks.
1.3. Organization of the Paper
2. Literature Review
2.1. Traffic Accident Prevention Systems
2.2. Object Detection and Tracking Technologies
2.3. Trajectory Prediction Methods
3. Methodology
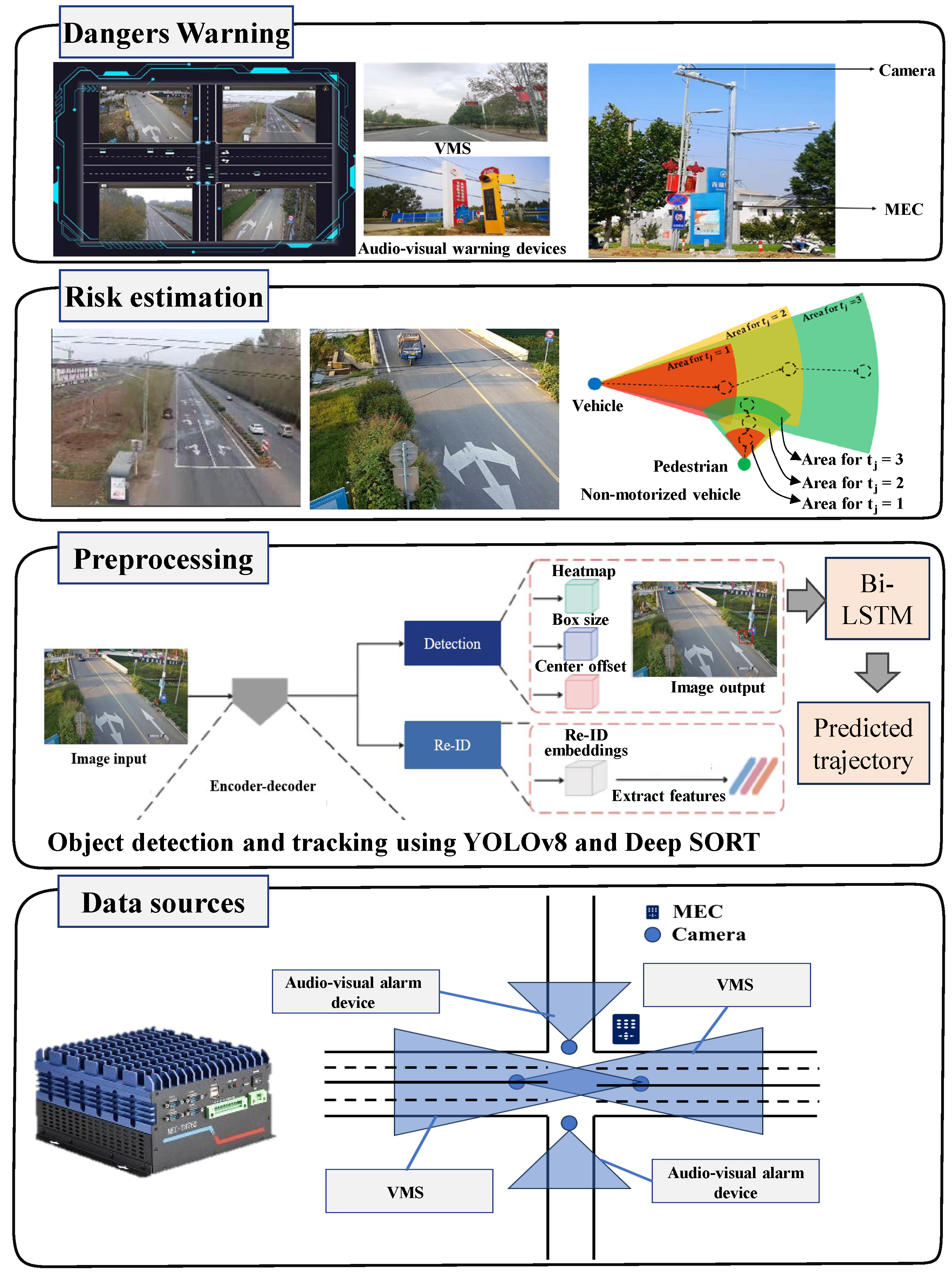
3.1. System Architecture
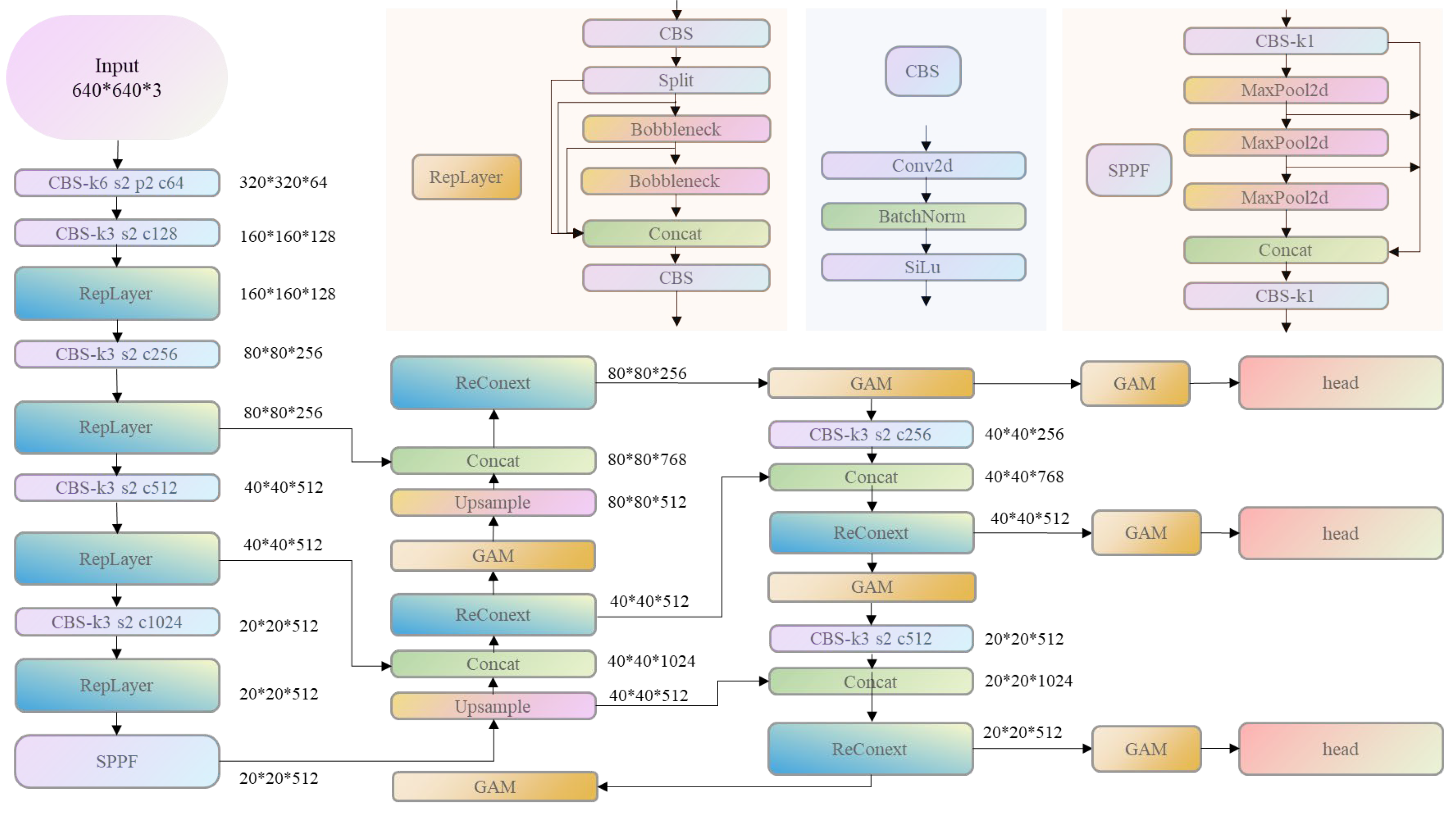
3.2. Object Detection
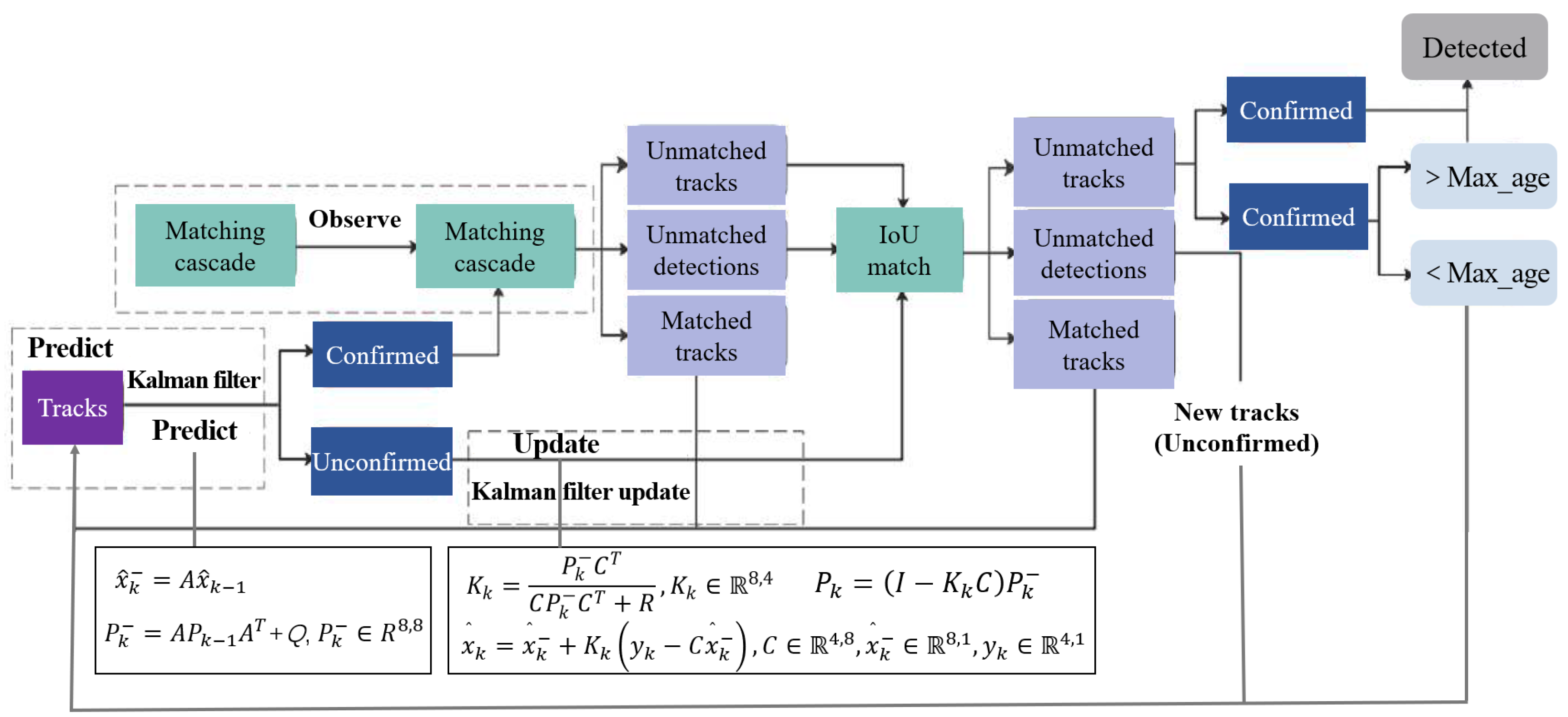
3.3. Object Tracking
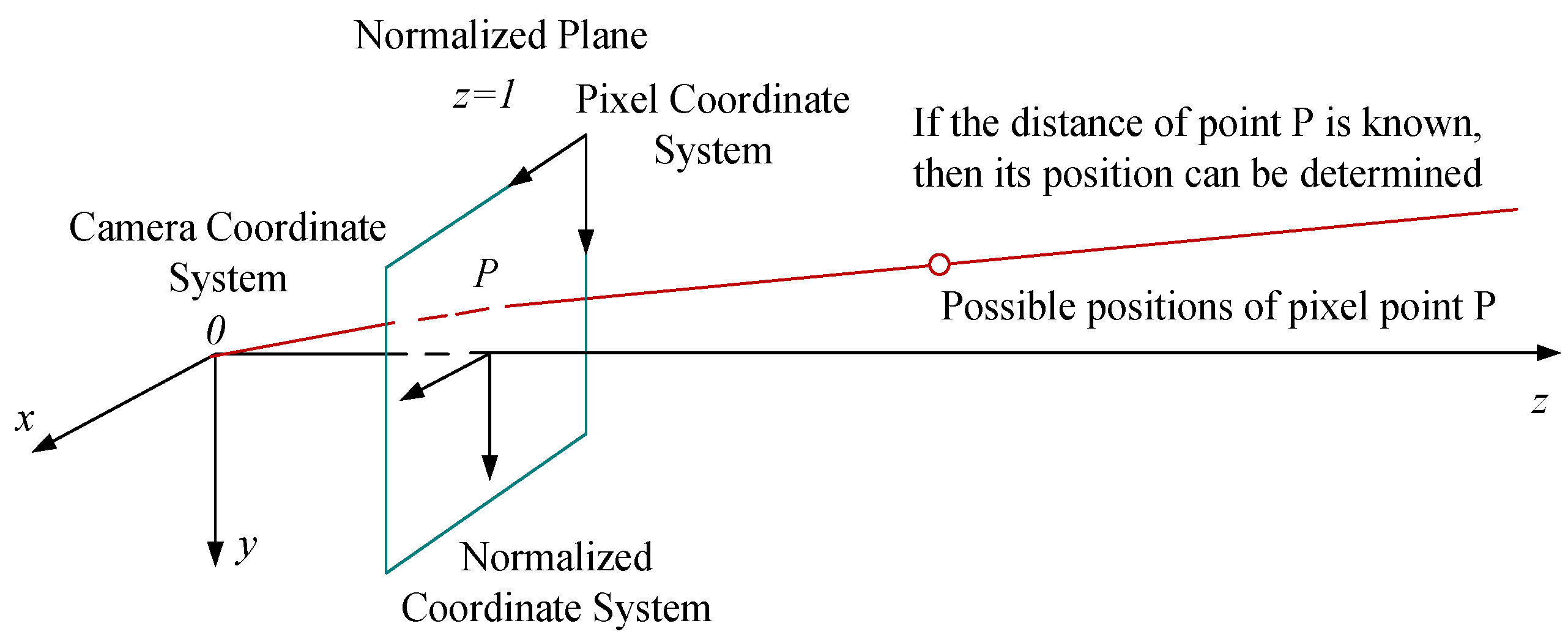
3.4. Vehicle Speed Measurement Model
3.4.1. Model Assumptions
3.4.2. Model Design and Implementation
3.4.3. Vehicle Speed Measurement
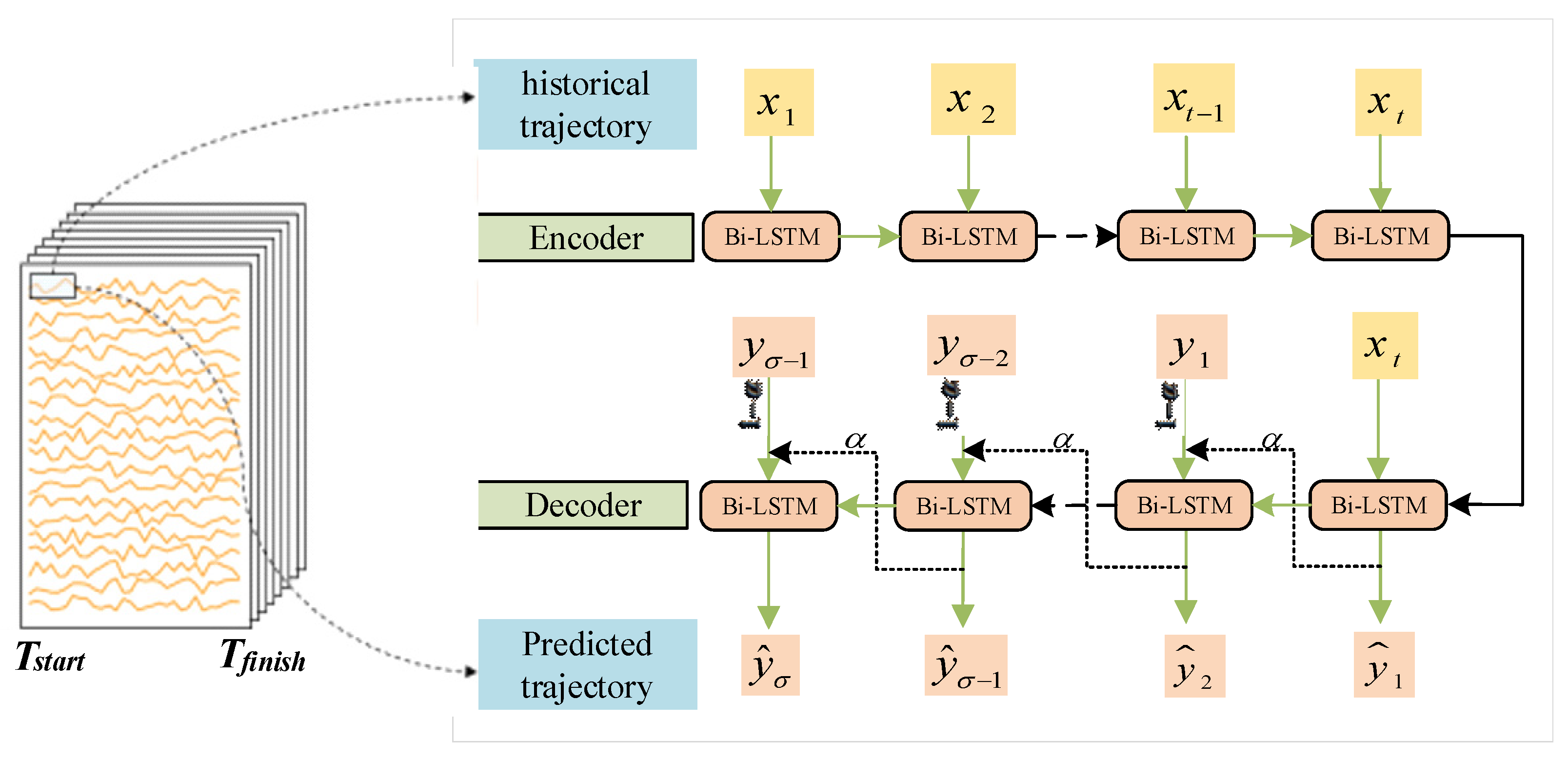
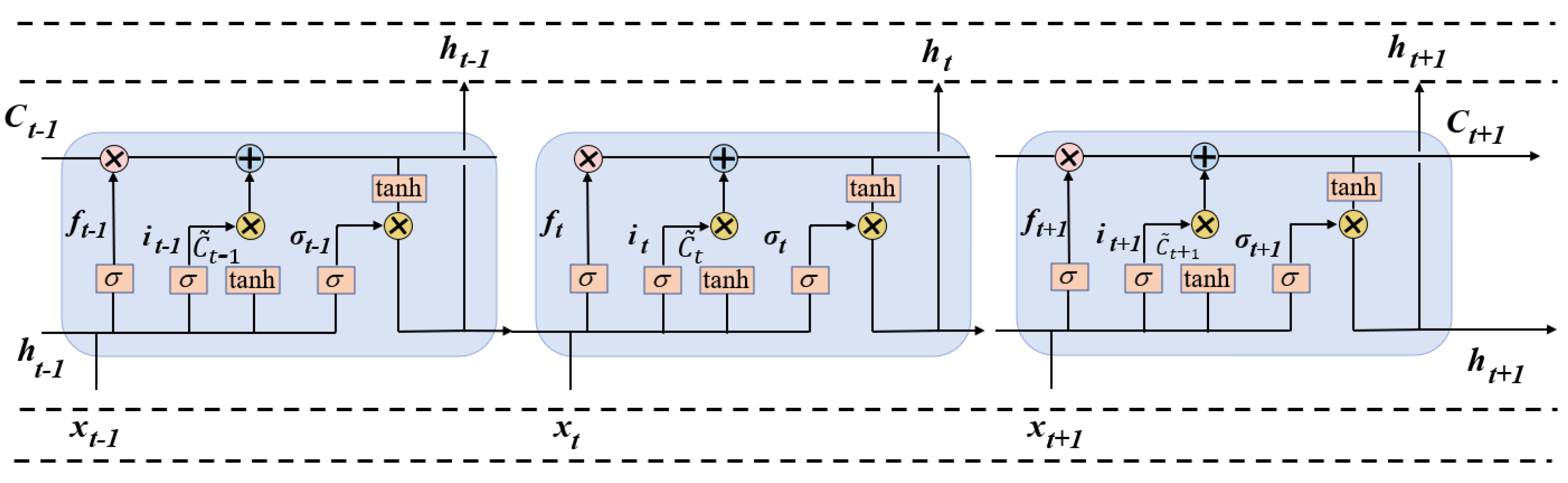
3.5. Trajectory Prediction
- (1)
- Forget Gate
- (2)
- Input Gate
- (3)
- Output Gate
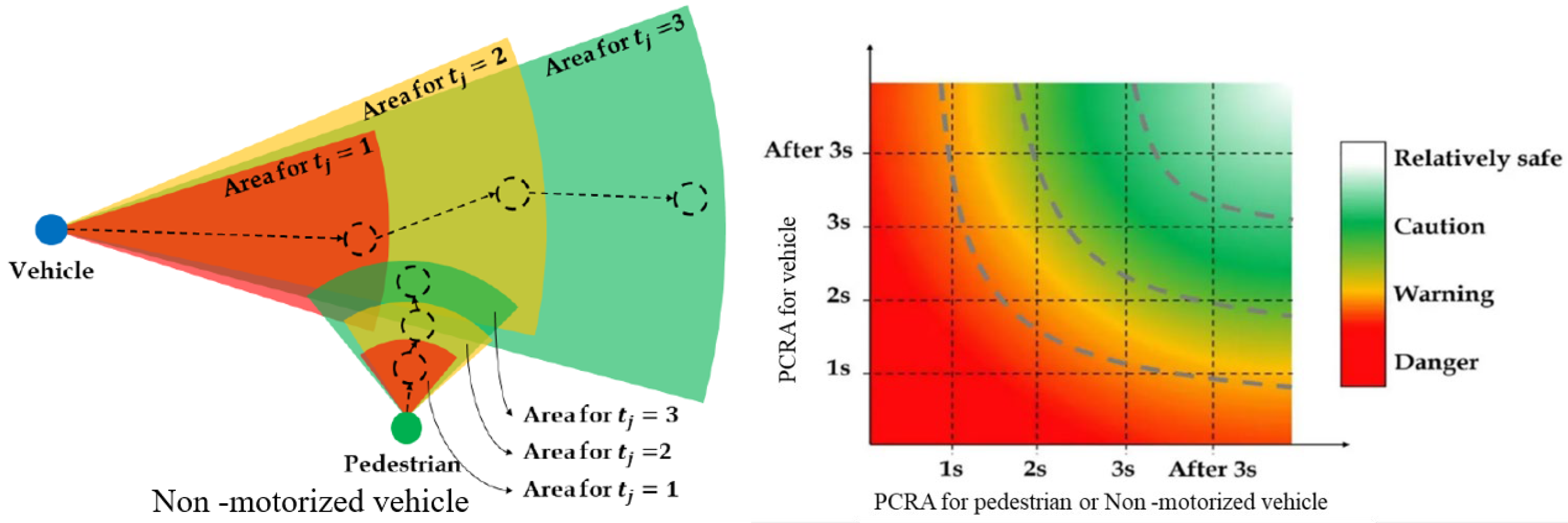
3.6. Collision Risk Estimation
4. Experimental Analysis
4.1. Experimental Setup and Model Training
4.1.1. Dataset Annotation
4.1.2. Dataset Training
4.2. Selection of Evaluation Metrics
5. Results and Discussion
5.1. Detection and Tracking Performance
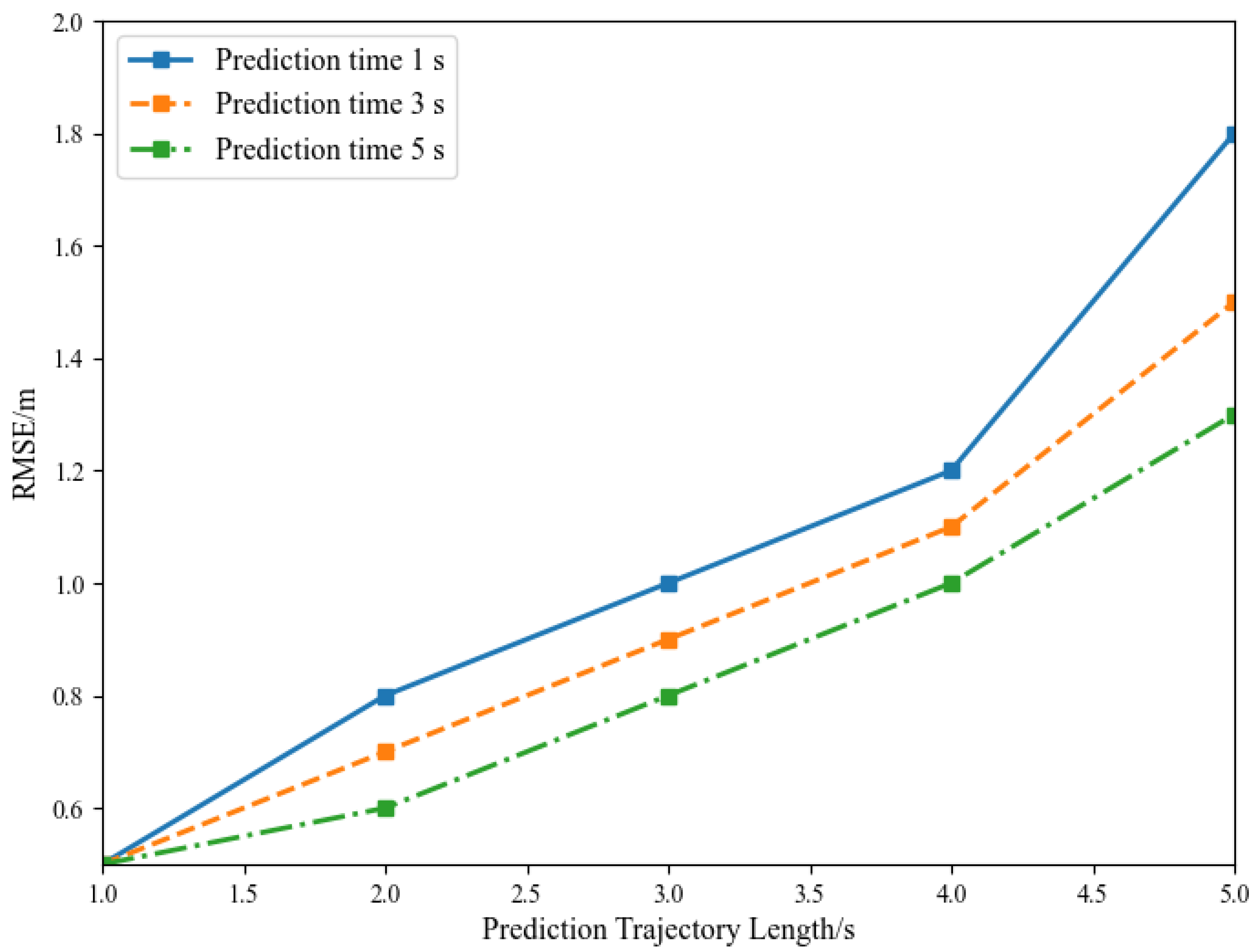
5.2. Trajectory Prediction Accuracy
5.3. System Performance
5.4. System Limitations
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fernando, D.M.; Tennakoon, S.U.; Samaranayake, A.N.; Wickramasinghe, M. Characteristics of Road Traffic Accident Casualties Admitted to a Tertiary Care Hospital in Sri Lanka. Forensic Sci. Med. Pathol. 2017, 13, 44–51. [Google Scholar] [CrossRef] [PubMed]
- Peličić, D.; Ristić, B.; Radević, S. Epidemiology of Traffic Traumatism. Sanamed 2024, 19, 233–238. [Google Scholar] [CrossRef]
- Yang, P.; Yang, R.; Luo, Y.; Zhang, Y.; Hu, M. Hospitalization Costs of Road Traffic Injuries in Hunan, China: A Quantile Regression Analysis. Accid. Anal. Prev. 2024, 194, 107368. [Google Scholar] [CrossRef] [PubMed]
- Song, L.; (David) Fan, W. Exploring Truck Driver-Injury Severity at Intersections Considering Heterogeneity in Latent Classes: A Case Study of North Carolina. Int. J. Transp. Sci. Technol. 2021, 10, 110–120. [Google Scholar] [CrossRef]
- Shao, Y.; Luo, Z.; Wu, H.; Han, X.; Pan, B.; Liu, S.; Claudel, C.G. Evaluation of Two Improved Schemes at Non-Aligned Intersections Affected by a Work Zone with an Entropy Method. Sustainability 2020, 12, 5494. [Google Scholar] [CrossRef]
- Sharafeldin, M.; Farid, A.; Ksaibati, K. Examining the Risk Factors of Rear-End Crashes at Signalized Intersections. J. Transp. Technol. 2022, 12, 635. [Google Scholar] [CrossRef]
- Singh, H.; Kathuria, A. Analyzing Driver Behavior under Naturalistic Driving Conditions: A Review. Accid. Anal. Prev. 2021, 150, 105908. [Google Scholar] [CrossRef]
- Schepers, P.; Hagenzieker, M.; Methorst, R.; van Wee, B.; Wegman, F. A Conceptual Framework for Road Safety and Mobility Applied to Cycling Safety. Accid. Anal. Prev. 2014, 62, 331–340. [Google Scholar] [CrossRef]
- Pawar, D.S.; Patil, G.R. Response of Major Road Drivers to Aggressive Maneuvering of the Minor Road Drivers at Unsignalized Intersections: A Driving Simulator Study. Transp. Res. Part F Traffic Psychol. Behav. 2018, 52, 164–175. [Google Scholar] [CrossRef]
- Luo, Z.; Shi, H.; Liu, W.; Jin, Y. HMM-Based Traffic Situation Assessment and Prediction Method. In Proceedings of the 20th COTA International Conference of Transportation Professionals, Xi’an, China, 14–16 August 2020. [Google Scholar]
- Cheng, H.T.; Shan, H.; Zhuang, W. Infotainment and Road Safety Service Support in Vehicular Networking: From a Communication Perspective. Mech. Syst. Signal Process. 2011, 25, 2020–2038. [Google Scholar] [CrossRef]
- Khan, M.N.; Das, S. Advancing Traffic Safety through the Safe System Approach: A Systematic Review. Accid. Anal. Prev. 2024, 199, 107518. [Google Scholar] [CrossRef] [PubMed]
- Yuan, T.; Da Rocha Neto, W.; Rothenberg, C.E.; Obraczka, K.; Barakat, C.; Turletti, T. Machine Learning for Next-Generation Intelligent Transportation Systems: A Survey. Trans. Emerg. Telecommun. Technol. 2022, 33, e4427. [Google Scholar] [CrossRef]
- Geng, M.; Cai, Z.; Zhu, Y.; Chen, X.; Lee, D.-H. Multimodal Vehicular Trajectory Prediction with Inverse Reinforcement Learning and Risk Aversion at Urban Unsignalized Intersections. IEEE Trans. Intell. Transp. Syst. 2023, 24, 12227–12240. [Google Scholar] [CrossRef]
- Mihalj, T.; Li, H.; Babić, D.; Lex, C.; Jeudy, M.; Zovak, G.; Babić, D.; Eichberger, A. Road Infrastructure Challenges Faced by Automated Driving: A Review. Appl. Sci. 2022, 12, 3477. [Google Scholar] [CrossRef]
- Nigam, N.; Singh, D.P.; Choudhary, J. A Review of Different Components of the Intelligent Traffic Management System (ITMS). Symmetry 2023, 15, 583. [Google Scholar] [CrossRef]
- Luo, Z.; Bi, Y.; Lei, Q.; Li, Y.; Song, L. Method for Identifying and Alerting to Operational Risks of En-Route Vehicles on Arterial Road. In Proceedings of the Ninth International Conference on Electromechanical Control Technology and Transportation (ICECTT 2024), Guilin, China, 24–26 May 2024. [Google Scholar]
- YOLOv8: Advancements and Innovations in Object Detection|SpringerLink. Available online: https://link.springer.com/chapter/10.1007/978-981-97-1323-3_1 (accessed on 31 October 2024).
- Wojke, N.; Bewley, A.; Paulus, D. Simple Online and Realtime Tracking with a Deep Association Metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Balasubramani, S.; Aravindhar, D.J.; Renjith, P.N.; Ramesh, K. DDSS: Driver Decision Support System Based on the Driver Behaviour Prediction to Avoid Accidents in Intelligent Transport System. Int. J. Cogn. Comput. Eng. 2024, 5, 1–13. [Google Scholar] [CrossRef]
- Shahid, F.; Zameer, A.; Muneeb, M. Predictions for COVID-19 with Deep Learning Models of LSTM, GRU and Bi-LSTM. Chaos Solitons Fractals 2020, 140, 110212. [Google Scholar] [CrossRef]
- Torbaghan, M.E.; Sasidharan, M.; Reardon, L.; Muchanga-Hvelplund, L.C. Understanding the Potential of Emerging Digital Technologies for Improving Road Safety. Accid. Anal. Prev. 2022, 166, 106543. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, X.; Liang, H.; Liu, Y. A Review of the Self-Adaptive Traffic Signal Control System Based on Future Traffic Environment. J. Adv. Transp. 2018, 2018, 1096123. [Google Scholar] [CrossRef]
- Cicchino, J.B. Effects of Forward Collision Warning and Automatic Emergency Braking on Rear-End Crashes Involving Pickup Trucks. Traffic Inj. Prev. 2023, 24, 293–298. [Google Scholar] [CrossRef]
- Cicchino, J.B. Effectiveness of Forward Collision Warning and Autonomous Emergency Braking Systems in Reducing Front-to-Rear Crash Rates. Accid. Anal. Prev. 2017, 99, 142–152. [Google Scholar] [CrossRef]
- Ismagilova, E.; Hughes, L.; Dwivedi, Y.K.; Raman, K.R. Smart Cities: Advances in Research—An Information Systems Perspective. Int. J. Inf. Manag. 2019, 47, 88–100. [Google Scholar] [CrossRef]
- Zhu, Z.; He, X.; Qi, G.; Li, Y.; Cong, B.; Liu, Y. Brain Tumor Segmentation Based on the Fusion of Deep Semantics and Edge Information in Multimodal MRI. Inf. Fusion 2023, 91, 376–387. [Google Scholar] [CrossRef]
- Liu, Y.; Qi, Z.; Cheng, J.; Chen, X. Rethinking the Effectiveness of Objective Evaluation Metrics in Multi-Focus Image Fusion: A Statistic-Based Approach. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 5806–5819. [Google Scholar] [CrossRef] [PubMed]
- Hussain, M. YOLOv1 to v8: Unveiling Each Variant–A Comprehensive Review of YOLO. IEEE Access 2024, 12, 42816–42833. [Google Scholar] [CrossRef]
- Bakirci, M. Enhancing Vehicle Detection in Intelligent Transportation Systems via Autonomous UAV Platform and YOLOv8 Integration. Appl. Soft Comput. 2024, 164, 112015. [Google Scholar] [CrossRef]
- Wang, H.; Liu, C.; Cai, Y.; Chen, L.; Li, Y. YOLOv8-QSD: An Improved Small Object Detection Algorithm for Autonomous Vehicles Based on YOLOv8. IEEE Trans. Instrum. Meas. 2024, 73, 1–16. [Google Scholar] [CrossRef]
- Bakirci, M. Utilizing YOLOv8 for Enhanced Traffic Monitoring in Intelligent Transportation Systems (ITS) Applications. Digit. Signal Process. 2024, 152, 104594. [Google Scholar] [CrossRef]
- Adžemović, M.; Tadić, P.; Petrović, A.; Nikolić, M. Beyond Kalman Filters: Deep Learning-Based Filters for Improved Object Tracking. arXiv 2024, arXiv:2402.09865. [Google Scholar] [CrossRef]
- Hu, D.; Al Shafian, S. Segmentation and Tracking of Moving Objects on Dynamic Construction Sites. In Proceedings of the Construction Research Congress 2024, Des Moines, IA, USA, 20–23 March 2024. [Google Scholar]
- Zhao, J.; Chen, J. YOLOv8 Detection and Improved BOT-SORT Tracking Algorithm for Iron Ladles. In Proceedings of the 2024 7th International Conference on Image and Graphics Processing, Association for Computing Machinery, New York, NY, USA, 3 May 2024; pp. 409–415. [Google Scholar]
- Mercorelli, P. Denoising and Harmonic Detection Using Nonorthogonal Wavelet Packets in Industrial Applications. Jrl Syst. Sci. Complex. 2007, 20, 325–343. [Google Scholar] [CrossRef]
- He, Y.; Huang, P.; Hong, W.; Luo, Q.; Li, L.; Tsui, K.-L. In-Depth Insights into the Application of Recurrent Neural Networks (RNNs) in Traffic Prediction: A Comprehensive Review. Algorithms 2024, 17, 398. [Google Scholar] [CrossRef]
- Bharilya, V.; Kumar, N. Machine Learning for Autonomous Vehicle’s Trajectory Prediction: A Comprehensive Survey, Challenges, and Future Research Directions. Veh. Commun. 2024, 46, 100733. [Google Scholar] [CrossRef]
- Korbmacher, R.; Tordeux, A. Review of Pedestrian Trajectory Prediction Methods: Comparing Deep Learning and Knowledge-Based Approaches. IEEE Trans. Intell. Transp. Syst. 2022, 23, 24126–24144. [Google Scholar] [CrossRef]
- Zhang, C.; Ni, Z.; Berger, C. Spatial-Temporal-Spectral LSTM: A Transferable Model for Pedestrian Trajectory Prediction. IEEE Trans. Intell. Veh. 2024, 9, 2836–2849. [Google Scholar] [CrossRef]
- Pereira, G.A.; Hussain, M. A Review of Transformer-Based Models for Computer Vision Tasks: Capturing Global Context and Spatial Relationships. arXiv 2024, arXiv:2408.15178. [Google Scholar]
- Hussain, A.; Hussain, T.; Ullah, W.; Baik, S.W. Vision Transformer and Deep Sequence Learning for Human Activity Recognition in Surveillance Videos. Comput. Intell. Neurosci. 2022, 2022, 3454167. [Google Scholar] [CrossRef] [PubMed]
- Berhanu, Y.; Alemayehu, E.; Schröder, D. Examining Car Accident Prediction Techniques and Road Traffic Congestion: A Comparative Analysis of Road Safety and Prevention of World Challenges in Low-Income and High-Income Countries. J. Adv. Transp. 2023, 2023, 6643412. [Google Scholar] [CrossRef]
- Formosa, N.; Quddus, M.; Ison, S.; Abdel-Aty, M.; Yuan, J. Predicting Real-Time Traffic Conflicts Using Deep Learning. Accid. Anal. Prev. 2020, 136, 105429. [Google Scholar] [CrossRef]
- Wei, X. Enhancing Road Safety in Internet of Vehicles Using Deep Learning Approach for Real-Time Accident Prediction and Prevention. Int. J. Intell. Netw. 2024, 5, 212–223. [Google Scholar] [CrossRef]
- Hegde, C.; Dash, S.; Agarwal, P. Vehicle Trajectory Prediction Using GAN. In Proceedings of the 2020 Fourth International Conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud) (I-SMAC), Palladam, India, 7–9 October 2020; pp. 502–507. [Google Scholar]
- Pang, Y.; Kashiyama, T.; Yabe, T.; Tsubouchi, K.; Sekimoto, Y. Development of People Mass Movement Simulation Framework Based on Reinforcement Learning. Transp. Res. Part C Emerg. Technol. 2020, 117, 102706. [Google Scholar] [CrossRef]
- Li, C.; Liu, Z.; Lin, S.; Wang, Y.; Zhao, X. Intention-Convolution and Hybrid-Attention Network for Vehicle Trajectory Prediction. Expert Syst. Appl. 2024, 236, 121412. [Google Scholar] [CrossRef]
- Luo, Z.; Bi, Y.; Yang, X.; Li, Y.; Yu, S.; Wu, M.; Ye, Q. Enhanced YOLOv5s + DeepSORT Method for Highway Vehicle Speed Detection and Multi-Sensor Verification. Front. Phys. 2024, 12, 1371320. [Google Scholar] [CrossRef]
- Xing, L.; Liu, W. A Data Fusion Powered Bi-Directional Long Short Term Memory Model for Predicting Multi-Lane Short Term Traffic Flow. IEEE Trans. Intell. Transp. Syst. 2022, 23, 16810–16819. [Google Scholar] [CrossRef]
- Noh, B.; Park, H.; Yeo, H. Analyzing Vehicle–Pedestrian Interactions: Combining Data Cube Structure and Predictive Collision Risk Estimation Model. Accid. Anal. Prev. 2022, 165, 106539. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Fps (frame/s) | p-Value (%) | (%) | mAp50 (%) | mAp50-95 (%) |
|---|---|---|---|---|---|
| YOLOv8n | 256 | 80.2 | 84.6 | 92.5 | 68.3 |
| + RepLayer | 243 | 82.5 | 85.3 | 93.3 | 72.6 |
| + GIoU | 226 | 84.6 | 86.3 | 94.6 | 75.8 |
| + GAM | 182 | 90.6 | 89.3 | 95.6 | 79.8 |
| + ReContext | 165 | 92.3 | 90.7 | 96.7 | 84.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, Z.; Bi, Y.; Ye, Q.; Li, Y.; Wang, S. A Novel Machine Vision-Based Collision Risk Warning Method for Unsignalized Intersections on Arterial Roads. Electronics 2025, 14, 1098. https://doi.org/10.3390/electronics14061098
Luo Z, Bi Y, Ye Q, Li Y, Wang S. A Novel Machine Vision-Based Collision Risk Warning Method for Unsignalized Intersections on Arterial Roads. Electronics. 2025; 14(6):1098. https://doi.org/10.3390/electronics14061098
Chicago/Turabian StyleLuo, Zhongbin, Yanqiu Bi, Qing Ye, Yong Li, and Shaofei Wang. 2025. "A Novel Machine Vision-Based Collision Risk Warning Method for Unsignalized Intersections on Arterial Roads" Electronics 14, no. 6: 1098. https://doi.org/10.3390/electronics14061098
APA StyleLuo, Z., Bi, Y., Ye, Q., Li, Y., & Wang, S. (2025). A Novel Machine Vision-Based Collision Risk Warning Method for Unsignalized Intersections on Arterial Roads. Electronics, 14(6), 1098. https://doi.org/10.3390/electronics14061098