1. Introduction
Online reviews have received considerable attention for impacting consumers’ purchasing behaviors. To make a purchase decision online, consumers often face difficulty relying solely on seller-provided information. Consequently, they turn to online reviews from other consumers for more detailed product information [
1]. Recently, there has been growing interest in examining how online reviews affect sales [
2]. For example, Wang et al. [
3] investigated how online reviews affect the offline sales of high-involvement products. Liu et al. [
4] studied how the dispersion of online reviews influences consumers’ purchasing decisions. However, in real-world scenarios, consumers typically assess several related products during a single shopping experience. This process, known as “market basket selection” [
5], is a key factor influencing sales.
Our research primarily focuses on competing products. The term “spillover” was used by Borah et al. to describe the phenomenon in which negative evaluations of one product spill over into negative evaluations of another product [
6]. When searching for a product online, consumers consider not only the reviews of the focal product (the one they intend to purchase) but also the reviews of their competitors [
7]. Kwark et al. [
7] explored how the online review ratings of related products can influence consumers’ purchase decisions of focal products through the spillover effect. Deng et al. [
8] developed a fixed effect model to investigate the spillover effects of online review ratings. There is currently a lack of research on the effects of the more detailed content (such as sentiment polarity) of other competing products on the purchase of focal products.
In online reviews, consumers’ expressions of product attributes often contain valuable opinion and sentiment information, which is important for companies to improve product quality and provide potential consumers with the required information [
9,
10]. With the expansion of online product categories, some platforms (e.g., JD.com) encourage consumers to evaluate the usage of products in various aspects. By analyzing different sentiment dimensions in online reviews, it is possible to reveal consumers’ perceptions of specific product attributes (e.g., quality, appearance, etc.), thereby reducing the uncertainty of product information [
11]. However, consumers may have differing opinions about product attributes when writing online reviews. When multiple online reviews present conflicting evaluations of the same product, online review dissimilarity arises, meaning that the same attribute may be positively evaluated in one online review and negatively evaluated in another [
12]. Therefore, it is imperative to explore the unique effects of positive and negative sentiment.
In addition, it is crucial to understand how contextual factors moderate the spillover effects of online reviews for competing products. Contextual factors refer to the associations between individual pieces of information within an information set, such as review dissimilarity. Online review dissimilarity refers to contradictions that emerge either within individual reviews or across multiple reviews along various dimensions [
13]. While prior research has discussed the empirical evidence of the moderating role of contextual factors in online review ratings, differences in online review content have been neglected [
12]. In a single online review, dissimilarity often manifests as two-sidedness, where both the advantages and disadvantages of a product are presented [
12]. Compared to a single-sided online review, two-sided online reviews offer a broader range of perspectives, helping consumers assess more fully whether a product meets their needs [
14]. For example, in online reviews of headphones, some consumers might describe the headphones as lightweight, while others might find them bulky. Although consumers may be more inclined to accept two-sided online reviews, we still have limited knowledge of how they respond to inconsistencies across multiple online reviews [
13]. In addition, prospect theory posits that evaluators respond to positive and adverse information in distinct ways [
15]. Therefore, considering the direction of online review dissimilarity helps identify consumers’ heterogeneous perceptions of review content.
This study aims to address the research question: How do the sentiment polarities of attributes and the dissimilarity online review dissimilarity of competing products influence the sales of the focal products?
To answer this question, we first employ a semi-supervised deep learning model to predict the sentiment polarity in online reviews. Then, we construct a spillover effect regression model and examine online review dissimilarity across three dimensions: online review rating–sentiment dissimilarity, which reflects the discrepancy between review ratings and textual sentiment within individual reviews; cross-online review dissimilarity, which manifests as significant variations in content characteristics across different reviews for the same product; product brand dissimilarity mainly investigates the comparative differences between the online reviews of competing brands and the focal product. The findings indicate that sentiment attributes in competing products’ online reviews generate distinct spillover effects: positive attribute sentiment has a negative spillover effect on focal product sales, while negative attribute sentiment produces a positive spillover effect. Particularly, when competing products exhibit significant differences in online reviews, positive online reviews promote focal product sales, while negative online reviews tend to suppress focal product sales. Furthermore, the spillover effects of online reviews are more pronounced between products of the same brands compared to those of different brands. The contributions of this study are as follows:
Sentiment Analysis: We propose a semi-supervised deep learning approach for capturing attribute-specific sentiment polarity in online reviews. The approach can identify and quantify fine-grained sentiment features in online reviews, thereby revealing their impact on product sales.
Cross-dissimilarity: We develop a conceptual framework of online review dissimilarity across three dimensions. Unlike previous research focusing on brand effects [
16], we propose and analyze how online review dissimilarity across same-brand and different-brand products influences focal product sales.
Spillover effect: We investigate the moderating effects of online review dissimilarity from the perspective of competing products, uncovering the differential spillover mechanisms of online review content across positive and negative contexts.
The structure of this paper is as follows:
Section 2 reviews the literature on the spillover effect of online reviews and online review dissimilarity. The hypotheses are detailed in
Section 3. In
Section 4, we present a sentiment analysis and an econometric model method.
Section 5 provides the sentiment analysis and empirical results.
Section 6 summarizes the research, and discusses the results, implications, and limitations.
4. Methodology
First, we conducted a pre-experiment to gain a deeper understanding of consumer preferences and selection behaviors when browsing products. Next, we analyzed products and selected competing products. Then, we developed a sentiment analysis model based on the several key product attributes consumers focus on within the JD.com online review, aiming to capture the sentiment polarities expressed in the online reviews. Finally, drawing on the sentiment analysis results, online review rating-sentiment dissimilarity, cross-online review dissimilarity, and product brand dissimilarity, we developed a regression model to investigate the specific impact of online reviews for both the focal product and its competing products on the focal product’s sales.
4.1. Focal and Competing Product Selection
We conducted a detailed survey on consumer preferences for browsing and purchasing related products during online shopping via the Credano.com platform. To ensure the completeness and reliability of the data, a total of 188 valid questionnaires were obtained after excluding incomplete and missing responses. By collecting and analyzing this data, we were able to gain deeper insights into consumer habits and preferences when browsing products, particularly regarding which information sources and tools consumers tend to rely on when faced with a diverse range of product choices. In the first stage of the study, participants were asked to select three products of interest, with potential purchase intent, from a list of 20 different electronic products. These electronic products were selected from JD’s Gold List and included categories, such as USB drives, headphones, and keyboards, each with distinct attribute features. In addition to product selection, participants were also asked to provide information about their primary methods of browsing related products. The preliminary test indicates that “headphones” were the most selected product among participants, accounting for 20.5% of the total choices. Additionally, consumers used several different methods when browsing related products: 35.5% search for information directly through product searches, 39.4% rely on product ranking lists, 23.7% depend on platform-recommended products, and only 1.4% use recommendations from bloggers, friends, or social media. These results provide an important foundation for subsequent model design and consumer behavior research.
Consumers frequently come across similar products during their online shopping experiences [
58]. Therefore, during the purchasing process, consumers pay attention to online reviews of the target (focal) product and take into account the online reviews of other similar (related) products [
7]. Based on this, it is necessary to conduct a reasonable selection and analysis of similar products to accurately explore how the spillover effect of online reviews influences consumer purchasing behavior. Based on the survey results, we selected headphone product datasets from three sources to form an initial competing product set
, including direct product search (first ten pages), product rankings, and platform-recommended products (recommended products on each product detail page). First, we crawled each product’s title and description information, use the TF-IDF to extract keywords, and manually reviewed them to determine the key product attributes. Next, we chose a focal product and calculated the attribute overlap degree between other products and the focal product. According to the overlap values, we selected the top
products with the highest overlap to constitute the competing product set for the focal product. The formula is as follows:
where
is the attribute overlap degree between focal product
and the other product, and
is the number of attributes of a product that are the same as the focal product.
represents the number of specific attributes involved in products. Thus, we have a set of competing products for each product.
4.2. Sentiment Analysis
In this section, we provide a detailed discussion on constructing an aspect-level sentiment analysis model. Compared to overall sentiment analysis, aspect-level sentiment analysis offers finer granularity, focusing primarily on identifying the sentiment polarity associated with different attributes or aspects within the text [
59]. For example, the sentence “Although the sound quality is excellent, the battery life is disappointing” involves two distinct attributes: “sound quality” and “battery life.” These two attributes exhibit positive and negative sentiment polarities, respectively. Thus, conducting an overall sentiment analysis of the sentence would fail to accurately capture the complexity of the sentiment expressed, as the sentiment polarities of the different attributes diverge.
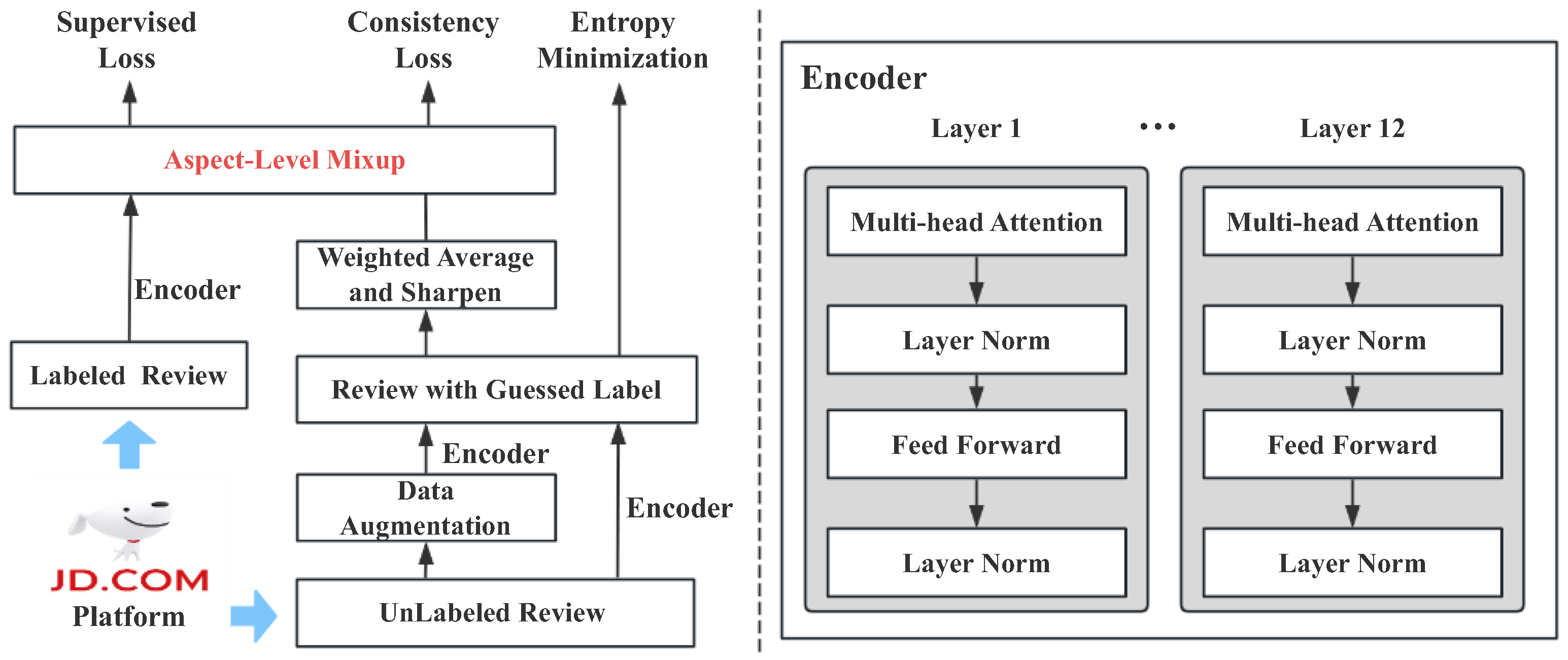
Manually labeled data are typically costly and time-consuming, especially in tasks, such as sentiment analysis, where the labeling process requires substantial human intervention. When label data are insufficient, supervised learning methods often exhibit a decline in performance and may lead to model overfitting. To address this issue, we adopted a semi-supervised deep learning approach, leveraging a small amount of manually labeled data to iteratively predict pseudo-labels for the unlabeled data. This process expands the labeled dataset, enhancing the model’s prediction accuracy [
60]. As shown in
Figure 2, given limited labelled reviews
with corresponding label
under each aspect and a substantial amount of unlabeled reviews
, we initially estimated low-entropy labels for the unlabeled data. Then, based on these guessed labels, we mixed the labeled and unlabeled data to create an infinite number of augmented data samples for model training.
4.2.1. Manually Labeled Data
We first manually labeled the product attribute categories mentioned in consumer reviews. To help potential consumers quickly understand the product experience conveyed in online reviews, the JD.com platform extracted frequently mentioned product attributes from many online reviews and displayed an overview of these attributes in the online review section. Based on this, we categorized the attributes of headphones into “workmanship, sound quality, comfort, battery life” and further explored the sentiment polarities related to these attributes.
Figure 3 illustrates a specific example of the labeling process, where 1 represents positive sentiment, 3 represents neutral, 2 represents negative, and 0 indicates that the attribute is not mentioned. To enhance the validity of the labeled data, we performed preliminary data cleaning on the collected online review data. Additionally, the labeling process was independently conducted by two individuals with extensive online shopping experience, and only online reviews where both annotators agreed were included in the final training dataset.
We evaluated the model’s performance on 127,022 unlabeled data points with labeled data sizes of 6000 and 12,000. For the labeled dataset, we split the data into training, validation, and test sets following an 8:1:1 ratio. The training set consists of 4800 (or 9600) samples, while both the validation and test sets include 600 (or 1200) samples each. It is important to note that the fine-grained attribute sentiment classification in this study is a multi-label classification task, where the model must assess the sentiment polarities for four attributes (4 × 4 = 16 categories). Given the complexity added by the large number of categories, we trained a separate model for each attribute.
4.2.2. Unlabeled Data Label Guessing
For unlabeled online reviews
, we generated
augmentations for each review text, namely
. In practice, we proposed four ways to generate the augmentations, namely, by dropping a fraction of words, replacing some words, changing the order of words as well as translating original review texts, and then translating them back. Then, we generate the guessed label for these generated augmentations. In specific, we utilized a 12-layer BERT-base [
61] as our encoder model to predict the labels under each aspect. The guessed label for the unlabeled data was obtained by taking the weighted average of the predicted results, ensuring that the model produces consistent labels across the different augmentations, which can be defined as follows:
where
is the label prediction model, and
and
are the learnable weights controlling the contributions of different quality of augmentations to the guessed label. We further utilized a sharpening function with a temperature parameter
to prevent the generated labels from being too uniform, which can be expressed as follows:
where
is the
1-norm function and the generated label becomes a one-hot vector when
. In this manner, we can obtain the guessed labels
for the unlabeled online reviews and augmented review text
with their guessed label
. Note that we considered two scenarios for generating guessed labels for the unlabeled data. In the first scenario, we predicted the sentiment for all aspects simultaneously, treating the prediction problem as a multi-label classification with a total of
categories, where
and
represent the number of aspects and the number of classes per aspect, respectively. In the second scenario, we simplified the task by decomposing the categories and training a separate model for each aspect, treating each model as a multi-class classification problem with
classes.
4.2.3. Aspect-Level Label Mixup
Given the limited labeled online reviews under each aspect and the guessed labels for unlabeled online reviews, we interpolated them in their hidden space and the corresponding aspect labels to create an infinite amount of new augmented data samples. In this way, our Mixup strategy leverages information from unlabeled online reviews while learning from labeled review texts, which facilitates mining implicit relations between sentences, prompting models to maintain linearity between training examples, and many previous studies have also demonstrated its effectiveness [
62]. In practice, we found
layers provided the most representational power, with each layer capturing distinct types of information, spanning from syntactic details to aspect-level semantic nuances in text. Thus, we chose layer
from
as our mixing layer and two samples from the merged dataset
, namely
and
. We first computed the hidden representation
at the
-th layer, calculated as follows:
where
denotes the
-th layer of the encoder network. The linear interpolations can be defined as follows:
where
is the mix parameter.
4.2.4. Semi-Supervised Mixup Training
In training, we utilize the kL-divergence as the training loss of the two samples:
Since are randomly sampled from , the interpolated review texts can be defined from different categories: Mixup among labeled data, Mixup between labeled and unlabeled data, and Mixup of unlabeled data. Thus, the loss can be divided into two types based on the interpolated reviews:
- (1)
Supervised loss. When two samples are both from the labeled data, namely , the training loss degenerates as a supervision loss.
- (2)
Consistency loss. When two samples are from unlabeled or augmentation data, namely , the KL-divergence can be seen as a consistency loss to enforce the model to predict the same labels with the original data sample.
Meanwhile, we also define the entropy of the predicted labels on unlabeled data as a self-training loss and minimize this loss to encourage the model to produce confident labels, defined as follows:
where
is the
2-norm function,
is the margin hyper-parameter. The overall objective function can be,
With the trained semi-supervised sentiment classification model, we can obtain the aspect-level sentiment of the online reviews. Algorithm 1 provides an overview of the sentiment analysis algorithm, as summarized in the flow table below.
| Algorithm 1 Online review aspect-level sentiment analysis process |
1: Input: Online review set , Aspect-level sentiment label
2: for do
3: Unlabeled review text augmentation to obtain
4: Predict labels for and add it to
5: Predict labels for , calculate and add it to
6: Minimize entropy on labels to obtain
7: end for
8: Mix labeled and unlabeled set together
9: for and do
10: Encode two samples to obtain hidden representation at the -th layer,
11: Mixup training process to obtain
12: end for
13: Minimize the objective function to train the model
14: Output: Aspect-level sentiment scores |
4.3. Variable Measurement
4.3.1. Online Review Dissimilarity Analysis
Rating-sentiment Dissimilarity. The rating-sentiment dissimilarity is calculated using the following equation [
13]:
where
and
represents the
of sentiment and the rating of the
online review, respectively.
Cross-online Review Dissimilarity. When online reviews show significant differences in evaluating the same attribute, it creates uncertainty and complexity in consumer decision-making. The cross-online review dissimilarity is calculated as follows:
where
,
are the mean percentages of positive, negative, and unmentioned attributes, respectively, in all online reviews at time
.
Product Brand Dissimilarity. We incorporated brand dimension dissimilarity measures to analyze the effects of attribute sentiment expressions emanating from intra-brand and inter-brand competing products:
where
is the mean number of product attributes exhibiting sentiment polarity (positive or negative) expressions in consumer-generated online reviews, specifically for competing products within the same brand portfolio as the focal product.
is the mean number of product attributes exhibiting sentiment polarity (positive or negative) expressions in consumer-generated online reviews, specifically for competing products within a different brand portfolio as the focal product. The total number of competing products
for focal product
is the sum of the same-brand competitors
and different-brand competitors
, expressed as
.
4.3.2. Data
We collected the online review data for products on JD.com, an authoritative e-commerce platform in China. Since JD.com only provides product ranking lists, we used the third-party platform jingcanmou.com to obtain detailed sales data. To ensure the quality of the online reviews, we pre-processed the raw data before building the regression model. The specific pre-processing steps include removing pure symbols and duplicate texts, eliminating invalid characters from online reviews, and excluding products with few online reviews. Following these processing steps, the final dataset comprises 87 products and 127,022 valid online reviews from JD.com, collected between 15 October 2023 and 15 May 2024.
4.3.3. Variables
Dependent variable. This study examined the impact of the online reviews of competing products on the sales of focal products. The dependent variable is the daily sales of the focal product on JD.com.
Independent variables. In terms of independent variables, we applied sentiment analysis to convert the text information from online reviews into the average number of product attributes expressing positive and negative in consumer reviews. To capture the impact of dissimilarity information in online reviews on consumer purchasing decisions, we introduced three variables reflecting online review dissimilarity.
Control variables. Several control variables were considered to account for factors that may influence sales. Specifically, we first took into account the length of the text and the number of online reviews, eliminating certain data, such as cases with excessively long or short texts, and those with a low number of reviews. In addition, based on the aforementioned competing product selection criteria and platform display characteristics, most of the products analyzed in this study are bestsellers, making the impact of publication time negligible. Headphones are commonly used consumer goods, and highly sensitive to price and promotions, so we controlled for these factors.
Table 1 displays the descriptive statistics of the main variables. For example, the mean value of
being 1.306 suggests that most online reviews mention at least one positive sentiment attribute. The mean of
is lower than that of
, reflecting that positive online reviews are more common than negative ones. After that, we performed correlation analysis for each variable. All calculated Variance Inflation Factor (VIF) values are below 3, suggesting no multi-collinearity issues among the variables.
4.4. Empirical Model Specification
4.4.1. Spillover Effect Model
The sentiment expressions of competing products, particularly the positive or negative sentiments surrounding product attributes, may influence consumers’ purchasing decisions regarding the focal product through the dynamic mechanisms of market competition. To more comprehensively capture the spillover effects between different products within the competing environment, we integrated the sentiment variables of competing products’ attributes into the models. Given that consumers typically base their purchase decisions on historical online review data [
10], we incorporated temporal lags for the relevant variables in the following equations:
where
is the sale of product
on day
.
and
indicate the mean number of product attributes in online reviews where consumers express positive and negative sentiments on day
, respectively.
is the mean number of positive sentiment attributes of competing products of the focal product
on day
.
is the mean number of negative sentiment attributes of competing products from the focal product
on day
. For example, an online review analyzed by our sentiment analysis model is represented as the structured string {1, 1, 0, 2}, resulting in
(workmanship and sound quality) and
(battery life). So, the specific sentiment polarity of attributes in online reviews are workmanship-positive, sound quality-positive, comfort-no mention, battery life-negative. In addition, the control variables include
,
. Specifically,
denotes the online selling price of focal products,
is measured by the percentage of promotional effort used to assess the impact of promotions on the focal product within a specific period.
is the intercept term,
captures unobserved individual heterogeneity, and
is the error term.
4.4.2. Moderating Effect Model
- (1)
Rating-sentiment Dissimilarity
We explored the moderating effect of online review dissimilarity from competing products on the focal product’s sales. First, we introduced the variable which measures the dissimilarity of online review ratings and sentiment expressions from competing products; we constructed the model as follows:
where
is the mean dissimilarity of ratings and sentiment from competing products on day
.
is an interactive term for the positive attributes and rating-sentiment dissimilarity, and
is an interactive term for the negative attributes and rating-sentiment dissimilarity.
- (2)
Cross-online Review Dissimilarity
Next, we examined the moderating effect of dissimilarity across several online reviews from competing products by adding interactive terms based on Formulas (13) and (14). These terms are employed to test the moderating effect, and the model is constructed as follows:
where
is the mean cross-online review dissimilarities from competing products on day
.
is an interactive term for the positive attributes and cross-online review dissimilarity, and
is an interactive term for the negative attributes and cross-online review dissimilarity.
- (3)
Product Brand Dissimilarity
To differentiate the spillover effect among competitors under the same and different brand dissimilarities, we added the variables, which are calculated by Formulas (11) and (12). Based on these variables, we then construct the model as follows:
where
is the mean number of positive sentiment attributes in the competing product set from the same brand as the focal product
on day
is the mean number of negative sentiment attributes in the competing product set.
is the mean number of positive sentiment attributes in the competing product set.
is the mean number of negative sentiment attributes in the competing product set.
5. Results
In this section, we first provide a detailed presentation of the sentiment analysis results. Following this, we conduct an in-depth discussion of the empirical estimation results. In
Section 5.3, the robustness checks are investigated by introducing additional variables.
5.1. Analysis of Sentiment Model
Classification tasks. Note that aspect-level sentiment classification in our paper can be regarded as a multi-class classification problem for four product attributes (A1, workmanship; A2, sound quality; A3, comfort; A4, battery life). Intuitively, we can convert the problem into sixteen binary classification tasks with each attribute corresponding to four classes (Negative, 0; Neutral, 1; Positive, 2; and Not mentioned, 3). However, we found that decomposing the problem into four binary classification tasks led to better performance. Toward this end, we implement four sentiment classifiers: The 1st/2nd/3rd/4th classifier predicts the attributes A1/A2/A3/A4 to be negative, neutral, positive, and not mentioned.
Classification algorithms. We compare our aspect-level semi-supervised deep learning model with the following baselines: Random Forest (RF), Support Vector Machine (SVM), eXtreme Gradient Boosting (XGBoost), FastText, LSTM + Attention (LSTM with attention mechanism), and Bidirectional Encoder Representations from Transformers (BERT). We turn the hyperparameters of each baseline and our model via cross-validation, and the range of hyperparameters tested in our paper is shown in
Table 2.
Performance evaluation. Due to the large number of hyperparameters to tune, we adopt a cross-validation approach with separate validation and test sets. Specifically, we split the dataset into 80% for training, 10% for validation, and 10% for testing. Various models and hyperparameter combinations are trained on the training set and evaluated on the validation set. The optima model and hyperparameters are selected based on the average accuracy across five experimental runs. We report the average accuracy, precision, recall, and F-1 score results evaluated on the test set.
Sentiment analysis results. In this section, we present the results of aspect-level sentiment analysis. We analyze the model’s performance using four metrics: accuracy, precision, recall, and F1 score. The detailed procedure can be found in
Appendix A.
Table 3 presents the results of attribute-based sentiment classification across 16 classes under two different numbers of data labels. Pretrain BERT and Finetune BERT represent the base pre-trained and fine-tuned BERT classification models, respectively. Experimental results show that the Pretrain BERT model has the lowest accuracy across all evaluation metrics, with accuracy as low as 28.21%. This indicates that the Pretrain BERT model performs poorly in classification without fine-tuning. After fine-tuning, the accuracy of the Finetune BERT model shows a significant improvement, reaching 82.32% (12,000) and 68.30% (6000), respectively. This demonstrates that fine-tuning allows BERT to learn richer features from the data. In addition, the FastText and LSTM + Attention models achieved accuracies of 80.74% (12,000) and 80.01% (12,000), respectively, indicating that the performance of these two models is relatively similar, though neither surpasses the Finetune BERT model. Therefore, the fine-tuned BERT model exhibits the best classification performance in this study.
In addition, we train classification models for four product attributes (A1, work-manship; A2, sound quality; A3, comfort; A4, battery life) and compare the performance of various machine learning and deep learning models. The selected models include commonly used ones, such as Random Forest, SVM, XGBoost, FastText, LSTM + Attention, and BERT. To streamline and emphasize the comparison results, we only present the accuracy of each model (other metrics are similar). As shown in
Table 4, training independent classification models for each attribute significantly improved performance compared to directly performing a 16-class classification task. Furthermore, Random Forest and SVM demonstrate relatively average performance, particularly for the A2 attribute (sound quality), where their accuracy fell below 80%. This indicates that traditional models have limitations in effectively capturing key text features, which leads to a noticeable decline in classification performance. In addition, compared to the Finetuned BERT model, the semi-supervised learning method proposed in this study exhibits superior performance in attribute-based sentiment classification tasks. This method establishes implicit relationships between labeled and unlabeled online review data through consistency regularization, enabling it to achieve better sentiment classification results even with limited labeled data.
5.2. Analysis of Empirical Model
5.2.1. Spillover Effect
We estimate the model using fixed effects and apply robust t-statistics to address potential heteroskedasticity and clustered correlations within the error terms. Online reviews’ positive and negative sentiment polarities have differential impacts on consumer purchasing behavior. As shown in
Table 5, Models 1 and 2 demonstrate the estimated results regarding the sentiment polarity of competing product attributes. The coefficient of
(−0.2173,
p < 0.01) has a significant negative impact on focal products’ sales, while the coefficient of
(0.1579,
p < 0.1) is positive. The findings indicate that positive attribute sentiments in online reviews of competing products have a negative spillover effect on focal product sales, while negative attribute sentiments demonstrate a positive spillover effect. Therefore, the results support Hypothesis 1a and Hypothesis 1b. By observing the coefficient of
, we can see that the spillover effect from negative sentiment attributes of competing products is relatively weaker than positive sentiment attributes. Then, taking Model 6 as an example, we further analyzed the effects of the control variables. The coefficients for price and promotions are both negative and significant. This aligns with the basic principles of market economics: price has a positive effect on product sales, where an increase in price leads to a decrease in sales. Simultaneously, as a market incentive, promotions can effectively boost product sales growth in the short term.
5.2.2. Moderating Effect
Our analysis of Models 3 and 4 reveals significant moderating effects of rating-sentiment review dissimilarity. (1.0748, p < 0.01) and (−0.9149, p < 0.01) demonstrate distinct impacts on product sales. When competing products exhibit high online review dissimilarity of rating-sentiment, positive online reviews paradoxically decrease consumer trust in product advantages, ultimately benefiting focal product sales. Conversely, negative online reviews of competing products tend to suppress focal product sales under similar conditions. These findings provide support for Hypotheses 2a and 2b.
Model 5 and Model 6 explore the moderating effect of cross-online review dissimilarity. The results reveal that (2.8349, p < 0.01) is positive and significant, while (−1.8612, p < 0.1) is negative and significant. The interaction between cross-online review dissimilarity and positive (negative) sentiment attributes shows a significant correlation. Specifically, when competing products show significant differences across online reviews, positive online reviews reduce potential consumers’ trust in the corresponding advantages of the product, ultimately promoting focal product sales. In contrast, negative online reviews of competing products tend to suppress focal product sales. Therefore, the results support Hypotheses 3a and Hypothesis 3b.
Next, we present the results of the product brand dissimilarity of competing products from the same or different brands in
Table 6. Model 7 to Model 12 incorporate all explanatory variables of the same or different brands.
(−0.1471,
p < 0.05) and
(−0.1243,
p < 0.05) are negative and significant, whereas coefficients
(0.1242,
p < 0.05) and
(0.1275,
p < 0.05) are positive and significant. Moreover, in comparison with Model 11 and Model 12, the coefficients of
are higher than
, and so are the negative coefficients. The results indicate that the brand of competing products has a significant impact on the focal products’ sales. In addition, the spillover effects of the sentiment attributes in online reviews of competing products (both positive and negative) are significantly higher for same-brand products than for different-brand products, supporting Hypothesis 4a and Hypothesis 4b.
5.3. Robustness Checks
We conduct robustness checks to verify the reliability of our research conclusions. Based on the research by Guo et al. [
16], we add the control variable Brand, which indicates the number of brands present in the competing product set of the focal product. The estimation results in
Table 7 provide additional validation for the robustness of our findings.
6. Discussion and Conclusions
6.1. Main Findings
This study examines the spillover effects of online reviews on focal product sales, with particular emphasis on investigating the moderating roles of online review rating-sentiment dissimilarity, cross-online review dissimilarity, and product brand dissimilarity using semi-supervised sentiment polarity. The research reveals the following key findings:
First, our research reveals that positive attribute sentiment in competing products’ online reviews generates a negative spillover effect on focal product sales, while negative attribute sentiment produces a positive spillover effect. This finding aligns with Kwark et al. [
7], further validating the cross-product spillover effects of online reviews from competing products. Coefficient comparison analysis reveals that the spillover effect of negative sentiment attributes in competing products’ online reviews is relatively weaker compared to positive sentiment attributes. This result resonates with the findings of Luo et al. [
40], indicating that high-quality online reviews not only influence consumers’ choice tendencies but also prompt them to reassess their product preferences. As demonstrated in Sun et al.’s research [
10], given the prevalence of positive online reviews in e-commerce environments, consumers tend to comprehensively evaluate the advantageous features of competing products when confronted with abundant positive feedback.
Second, the analysis demonstrates that the rating-sentiment dissimilarity and cross-online review dissimilarity of competing products moderates spillover effects on the focal product’s sales. When competing products exhibit significant variations in online reviews, positive (negative) online reviews promote (suppress) the sales of the focal product. This is because the discrepancy in evaluations of competing products increases consumers’ information uncertainty, which in turn, affects their judgments of the relative advantages and disadvantages of the products, ultimately influencing their purchase intention towards the focal product. This finding aligns with Yin et al. [
27], who revealed that highly inconsistent online reviews diminish their reference value and significantly influence consumer decision-making. Moreover, cross-online review dissimilarity heightens consumers’ perceived product risk, thus affecting the sales of the product. Notably, the moderating effect of cross-online review dissimilarity is stronger than that of rating-sentiment dissimilarity, suggesting that contradictions in specific review content have a more profound impact on consumer purchase decisions.
Third, the research findings reveal the significant moderating role of product brand dissimilarity in the spillover effect of online review. Specifically, spillover effects of sentiment attributes in online reviews from competing products of the same brands are substantially stronger than those from products of a different brand as the focal product, corroborating Kwark et al.’s findings [
7]. The product brand dissimilarity amplifies the spillover effect of sentiment attributes in the online reviews of competing products. This underscores the important role of brand positioning in shaping consumer evaluation and decision-making processes. When facing cross-brand product choices, consumers exhibit a stronger comparative tendency and are more sensitive to online review information. This has important implications for a company’s brand strategy and online review management.
Table 8 shows the summary of the findings with relevant research. Compared with other studies, this paper comprehensively includes and delves into the various dissimilarities in online reviews from the perspective of spillover effects, particularly focusing on their impact on consumer decision-making and behavior. It offers a more detailed analysis and discussion of these issues. Through the study of these dissimilarities, we gain a better understanding of their role and variation across different contexts.
6.2. Theoretical Implications
This study makes several critical contributions to the literature in the relevant field. First, thoroughly examining the spillover effect of attribute-specific sentiment in online reviews of competing products further enriches research on online reviews and user-generated content. While previous scholars have examined the impact of online review ratings on the sales of competing products [
7], this study is the first to combine sentiment analysis with product attributes, specifically focusing on the spillover effects of online reviews on competing products. Our research offers new evidence, emphasizing the importance of accounting for spillover effects in the analysis of product online reviews within highly competing market environments. This facilitates a deeper understanding of the mechanisms by which spillover effects influence online product sales and extends the theoretical framework surrounding online product marketing strategies.
Second, this study deepens the academic understanding of information inconsistency by thoroughly examining three moderating effects, rating-sentiment dissimilarity, cross-online review dissimilarity, and brand dissimilarity, while emphasizing the crucial role of online review dissimilarity in spillover effects. Our findings reveal that online review dissimilarity produces significant inhibitory effects, enriching and extending existing consumer decision-making theories. Specifically, when reviewers express contradictory opinions about the same product attributes, such dissimilarity diminishes consumers’ confidence in online review information, subsequently affecting their purchase decisions. Based on the analysis of limitations in existing research, this study suggests that future research should adopt a multi-dimensional perspective to measure new influencing factors and explore this phenomenon from a systematic cue theoretical perspective.
Third, this study further investigates how brand dissimilarity (between same-brand and different-brand products) influences spillover effects of online reviews between products. While existing research has demonstrated the significant impact of branding on product sales, studies on brand competition and the spillover effects of online reviews remain relatively scarce. The study finds that the spillover effects between different-brand products are significantly greater than those between same-brand products. This finding expands the literature on brand spillover effects and provides a new theoretical foundation for understanding the differential impact of online reviews on product sales within the same brand and across different brands.
6.3. Managerial Implications
We provide several practical implications regarding online reviews and product sales. Marketers have increasingly come to view online reviews as influential marketing tools. Our research shows that the sentiment polarities of product attributes in online reviews can spill over to other products, and each attribute has a distinct sentiment dimension. Therefore, when formulating marketing strategies, companies must refine their evaluation of different sentiment attributes to capture consumer needs more accurately. Second, the study reveals that the spillover effect between competing products varies significantly between the same brand and different brands. Companies should fully understand the impact of brand perception and more effectively leverage the sentiment polarities of specific attributes in their marketing efforts. Third, when reviewers’ product attribute evaluations significantly differ from other reviewers, providing detailed contextual information and supporting arguments is crucial. Moreover, incorporating warning messages can prevent review dissimilarities caused by user errors, enhance the reference value of online reviews, and effectively mitigate the inhibitory effect of online review dissimilarity on consumers’ purchase intentions. Finally, platforms should optimize the design of online review systems, allowing consumers to provide more detailed feedback on various product attributes, thereby enhancing the diversity of online reviews. Considering that positive online reviews often dominate consumer feedback, platforms can establish an open online review system that enables consumers to interact and verify the authenticity of published online reviews, thus improving their credibility.
6.4. Limitations and Future Work
There are still some areas for improvement in this study. First, the research focuses on a single product category: headphones. Given that the effect of online reviews can vary greatly among different product categories, future research should expand its scope to include a broader range of products, such as smartphones and laptops, to provide more comprehensive marketing insights based on online reviews for businesses. Second, the analysis is limited to online reviews from the JD.com platform. Future research should consider the spillover effects across multiple platforms and examine the combined impact of online reviews from different platforms on product sales. Lastly, online reviews encompass various features (such as reviewer characteristics), which can significantly affect sales. Because of the limitations of data collection techniques, this study cannot perform large-scale data acquisition. In the future, we aim to incorporate more relevant features to establish a more complete model of the impact of online reviews, with a particular focus on exploring spillover effects in greater depth.






{kind=link}
{kind=link}
{kind=link}