1. Introduction
Hearing impairments affect approximately 1.5 billion individuals worldwide, with over 430 million experiencing significant challenges in their daily lives, according to the World Health Organization (WHO). For those with normal hearing, spoken language serves as the primary means of communication. In contrast, sign language is an essential tool for deaf and mute individuals, enabling them to express thoughts, emotions, national identities, and needs through a complex system of gestures, facial expressions, body movements, and specific hand shapes. Sign languages possess unique grammatical structures and sequences that do not exist in spoken languages, making accurate translation a multifaceted and challenging task.
To address these challenges, recent developments in translation theory, particularly multimodal translation theory and semiotics in translation, alongside dynamic equivalence theory, a foundational theory in translation, have become integral to developing effective sign language translation (SLT) systems. Multimodal translation theory emphasizes the need for aligning and integrating visual, auditory, and textual data, which is particularly relevant for sign language translation where gestures and non-verbal cues play a crucial role in conveying meaning [
1,
2,
3]. Additionally, dynamic equivalence theory, articulated by Nida (1964), stresses that the focus of translation should be on conveying meaning in a way that resonates with the target audience, rather than achieving a word-for-word correspondence [
4]. This perspective is vital for SLT, as it ensures that both the literal and contextual meanings of signs, including their emotional and cultural nuances, are accurately captured. Furthermore, the semiotic approach to translation underscores the importance of preserving the symbolic meaning of communication during translation, ensuring that the core meaning, emotions, and context of the source language are maintained [
5,
6]. These principles guide the development of more dynamic and context-aware SLT systems.
Traditional sign language translation (SLT) models have predominantly relied on gloss-based methods [
7,
8,
9], which involve converting visual sign language inputs into gloss sequences—intermediate symbolic representations—before generating corresponding textual translations [
10,
11]. While these gloss-based approaches have established a foundational framework for automated SLT [
12], they come with significant limitations. These methods depend heavily on extensive annotated data, making the annotation process labor-intensive and time-consuming. Moreover, gloss-based models are susceptible to error propagation throughout the translation pipeline, which can degrade the quality and accuracy of the final translations. Additionally, these models often struggle with low-frequency or unseen sign language vocabulary, limiting their practical applicability and scalability in real-world scenarios.
In recent years, open-vocabulary methods have emerged as a pivotal advancement in computer vision and natural language processing. These approaches enable models to recognize and process a broader range of categories beyond predefined vocabularies, enhancing both flexibility and scalability. Leveraging large-scale vision-language (VL) models [
13,
14,
15,
16,
17] like CLIP [
18], open-vocabulary techniques bridge the semantic gap between visual inputs and textual outputs, facilitating zero-shot learning capabilities essential for handling diverse and previously unseen categories. The success of open-vocabulary methods in tasks such as image classification, object detection, and semantic segmentation underscores their potential applicability to SLT. Unlike traditional gloss-based methods, open-vocabulary SLT can dynamically adapt to new and rare sign terms without requiring exhaustive manual annotations, thereby addressing a critical limitation of existing models.
The inherent variability and richness of sign languages make the integration of open-vocabulary methods particularly compelling for SLT. Sign languages are dynamic and context-dependent, with an expansive and continuously evolving lexicon. Open-vocabulary SLT methods offer the potential to overcome the constraints of traditional gloss-based models by enabling translation systems to effectively adapt to new and low-frequency sign terms. This adaptability is crucial for developing robust and inclusive SLT systems capable of catering to the diverse needs of the global deaf community. By incorporating advanced vocabulary embedding techniques and dynamic vocabulary expansion mechanisms, open-vocabulary SLT can recognize and translate new sign language terms without relying on a fixed vocabulary list, thereby enhancing translation accuracy and practicality.
In response to these challenges, we propose the open-vocabulary sign language translation (OVSLT) method. OVSLT is designed to overcome the limitations of traditional gloss-based SLT by integrating open-vocabulary techniques that enable the model to handle a wide range of sign language terms, including those that are infrequent or previously unseen. Our approach leverages advanced feature representation and alignment strategies, such as Grid Feature Grouping and enhanced contrastive learning, to capture the nuanced visual features of sign language gestures and align them with their corresponding textual descriptions. Furthermore, OVSLT incorporates dynamic vocabulary expansion mechanisms that allow the model to adapt to new sign terms seamlessly, ensuring high accuracy and scalability in diverse and real-world applications. The innovations introduced by OVSLT include the incorporation of Grid Feature Grouping for enhanced feature representation, the use of enhanced contrastive learning to improve feature–text alignment, and the implementation of balanced region loss scaling to ensure uniform learning across diverse visual regions. Grid Feature Grouping allows the model to detect and group salient visual features more effectively, facilitating better alignment with textual descriptions. Enhanced contrastive learning refines the discriminative power of feature representations, ensuring that subtle variations in gestures are accurately captured and translated. Balanced region loss scaling addresses the issue of unequal gradient contributions from different regions, promoting balanced feature learning and preventing the dominance of larger regions during training. These components collectively enhance the model’s ability to capture subtle variations in sign language gestures and maintain balanced learning across different regions of the visual input.
The organization of this paper is as follows. The first section introduces the motivation behind the study and outlines the key challenges in open-vocabulary sign language translation. In
Section 2, we review the relevant literature, including the principles of sign language translation (SLT), existing network architectures for SLT, and recent advancements in open-vocabulary SLT.
Section 3 presents the methodology, detailing the components of our proposed framework, including the Caption Generation and Description (CGD) module, Grid Feature Grouping, Vision-Language Model, and Translation Decoder. The methodology is further elaborated through ablation studies in
Section 4, which assess the contribution of each component.
Section 5 provides experimental results and a limitation analysis to highlight the effectiveness and challenges of the proposed approach. Finally, we conclude with a discussion of the model’s contributions and potential future work.
The main contributions of this paper are as follows:
Proposed Open-Vocabulary Sign Language Translation (OVSLT) Framework: We introduce a novel OVSLT method that effectively handles both high-frequency and unseen sign language vocabulary without relying on predefined gloss sequences, thereby overcoming the limitations of traditional gloss-based translation approaches.
Enhanced Caption Generation and Description: We introduce an advanced caption generation module that leverages a GPT model to produce precise and contextually relevant textual descriptions of sign language gestures, and further enhanced with a Negative Retriever and Semantic Retrieval-Augmented Features (SRAF), which enrich the semantic information and significantly improve the discriminative power of the generated captions.
Grid Feature Grouping with Advanced Alignment Techniques: We introduce a Grid Feature Grouping method, augmented with enhanced contrastive learning, feature-discriminative contrastive loss, and balanced region loss scaling. These Advanced Alignment Techniques refine feature representations and ensure robust alignment with textual descriptions.
Superior Performance and Robustness: Through extensive experiments on the PHOENIX-14T and CSL-Daily dataset, OVSLT demonstrates significant improvements in translation accuracy and adaptability. The ablation studies validate the effectiveness of each component, showcasing the framework’s ability to generalize to diverse and novel sign language terms.
2. Related Work
2.1. Principles of Sign Language Translation
Multimodal translation and learning theories tackle the challenge of aligning information across various modalities, such as visual, auditory, and textual inputs. In sign language translation, this involves combining visual features—such as hand gestures, facial expressions, and body movements—with text descriptions to capture both linguistic and non-linguistic meanings. Baltrušaitis et al. (2019) emphasized how multimodal machine learning enhances the understanding of complex data by integrating visual and textual signals [
1]. Similarly, Poria et al. (2015) explored how multimodal learning improves sentiment analysis by processing multiple modalities in tandem [
2]. OVSLT incorporates these principles by employing Grid Feature Grouping and contrastive learning to align visual and textual features, ensuring that translations are both accurate and contextually sensitive.
Dynamic equivalence theory, introduced by Nida (1964), asserts that translation’s primary goal is to convey meaning, rather than adhering to a literal word-for-word translation, ensuring the message resonates with the target audience [
4]. This theory is especially relevant to sign language translation (SLT), where visual and non-verbal elements, such as facial expressions and body language, carry significant emotional and contextual weight. OVSLT adopts this perspective by prioritizing meaning over form. The model integrates dynamic vocabulary extension mechanisms, such as Semantic Retrieval-Augmented Features, enabling it to capture not only the literal meaning of gestures but also their emotional and cultural contexts. This ensures that the subtle nuances behind gestures are faithfully communicated in the target language, in line with the principles of dynamic equivalence.
A semiotic approach to translation, as proposed by Eco (1976), underscores the importance of preserving the core symbolic content—meaning, emotion, and context—during the translation process [
5]. In the context of SLT, non-verbal signs like gestures and facial expressions are essential in conveying these meanings. Jakobson (1959) further highlighted the significance of preserving the integrity of symbols across languages, emphasizing that translation should maintain the meaning and message of the source language [
6]. OVSLT aligns with this theory by using Grid Feature Grouping and contrastive learning to extract and align visual features with textual descriptions. This process ensures that the visual symbols—such as hand gestures, facial expressions, and body movements—are preserved and accurately mapped to their corresponding semantic meanings. Additionally, the model leverages semantic enhancement features, including negative retrieval and semantic search, to ensure that not only the literal meaning but also the contextual, emotional, and cultural nuances of the source language are retained in the translation. This approach guarantees that the symbolic richness of sign language is faithfully conveyed in the target language, in accordance with the principles of semiotics in translation.
In summary, the integration of multimodal translation theory, dynamic equivalence theory, and semiotics in translation provides a solid theoretical foundation for the OVSLT model. By aligning visual and textual features, focusing on meaning over form, and ensuring the conservation of symbolic content, OVSLT delivers a more accurate, expressive, and context-aware approach to sign language translation. These theoretical approaches not only guide the development of a system that translates sign language but also ensure that its cultural and emotional depth is preserved throughout the translation process.
2.2. Network Architectures for Sign Language Translation
Early approaches to sign language translation (SLT) typically separated the tasks of recognition and translation into distinct stages, with the performance of subsequent tasks heavily dependent on the accuracy of the preceding stage, particularly the word error rate (WER) [
19].
Convolutional Neural Networks (CNNs) were widely used to extract visual features, while Long Short-Term Memory (LSTM) networks translated these features into textual representations. For instance, FCN [
9] was one of the first to explore 1D CNNs for SLR, utilizing temporal convolutions to capture sequential hand movements. However, its application did not extend to SLT, limiting its utility in end-to-end translation tasks. Wei et al. [
20] introduced a multiscale strategy with R-CNN to learn high-dimensional feature representations for sign videos, while Koller et al. [
21] incorporated CNNs into an iterative framework to enhance weak supervision and frame-level accuracy.
Despite the success of CNN-based methods like ResNet-152 [
22] in modeling local features in dynamic video sequences, they struggled to capture long-range dependencies over extended sequences. This limitation often resulted in fragmented or contextually shallow translations, as the models failed to maintain coherence over longer sign sequences. Additionally, 3D CNNs [
23], while effective in modeling spatiotemporal features, remained computationally expensive and impractical for real-time applications. Recurrent methods such as CNN-LSTM-HMM [
24] attempted to refine recognition but often fell short in multistream processing and failed to fully leverage the potential of convolutional layers, highlighting the limitations of traditional approaches compared to newer transformer-based models.
Transformers have become increasingly dominant in SLR and SLT tasks due to their ability to capture long-range dependencies and model global sequence information. The introduction of transformer architectures marked a significant advancement in SLR, with the Sign Language Transformer (SL-Transformer) [
25] establishing a strong baseline by employing a joint-train protocol with gloss supervision, thereby greatly improving translation performance. This approach was further refined by Tunga et al. [
26], who combined Graph Convolutional Networks (GCNs) with Transformers to better model spatial and temporal dependencies in sign videos. Variants such as STMC-Transformer [
27] aggregated spatial and temporal channels to enhance glossary representation and translation accuracy, though these methods often required model ensembles to achieve reported performance levels.
Additionally, studies by Varol et al. [
28] and Yin et al. [
29] leveraged Transformers for both recognition and translation, benefiting from their ability to model global sequence dynamics. However, while Transformers excelled in capturing complex relationships, they often struggled with sparse annotations and noisy data, necessitating high-quality, large-scale datasets for effective training. The use of additional resources like Kinetic400 [
30], along with pretrained language models such as mBART [
31] and mBERT [
32], further boosted performance but highlighted challenges related to scaling laws and transfer learning.
Recent keypoint-based optimization techniques have also enhanced model performance by explicitly capturing dynamic gesture features. For example, Hu et al. [
33] proposed CorrNet, which models key motion trajectories through correlation maps between frames, while Guo et al. [
34] introduced a dual-path network to capture both local and global temporal contexts. These advancements have significantly improved the accuracy of both recognition and translation in sign language tasks, although they rely on accurate keypoint detection, which is challenging to achieve in real-world scenarios due to varying video quality, occlusion, and lighting conditions. Inaccurate keypoint localization can lead to errors in gesture recognition and translation, underscoring the ongoing need for more robust and adaptable models.
2.3. Open-Vocabulary Sign Language Translation
Sign language translation (SLT) has advanced with the introduction of large language models (LLMs), shifting from gloss-based methods to more sophisticated, gloss-free approaches that offer deeper insights into natural language use through advanced video-to-text modeling. GFSLT-VLP [
35] leverages CLIP to bridge the semantic gap between visual sign language inputs and textual outputs, improving the model’s ability to learn joint visual-textual representations. However, its reliance on CLIP limits its adaptability to sign language variations not well-represented in CLIP’s training data. Similarly, Sign2GPT [
36] integrates a pretrained GPT model with a LoRA adapter but suffers from inaccuracies introduced by pseudo glosses. SignLLM [
37], which utilizes VQ-Sign and CRA modules, also converts video inputs into discrete tokens but risks oversimplifying sign language’s visual nuances, compromising translation fidelity.
These models, while advanced, struggle with several key limitations. Many fail to adequately capture the temporal dynamics inherent in sign language, leading to fragmented translations. Moreover, using intermediate representations like pseudo glosses can result in the loss of important visual information, reducing the overall translation quality.
Recent advancements in 2D open-vocabulary tasks such as image classification and object detection have made significant strides, with models like CLIP [
18] enabling zero-shot learning for novel categories. In segmentation, approaches like MaskCLIP [
38] and OpenSeg [
39] have refined alignment between text and image regions, enhancing the ability to segment new categories. Similarly, zero-shot object detection methods [
40,
41] and recent innovations like ZegFormer [
42] and GroupViT [
43] have shown the potential of VL models in achieving robust performance in open-vocabulary tasks by leveraging advanced feature extraction and alignment strategies.
Overall, despite significant advancements in transformer-based and CLIP-based methods for sign language translation (SLT), existing models often struggle with key challenges such as sparse annotations, noisy data, and the inability to handle unseen sign language gestures. These limitations are exacerbated by the reliance on fixed vocabularies or glosses, which constrain the model’s ability to adapt to the dynamic nature of sign language communication. While transformers excel at capturing long-range dependencies, they are typically bound by gloss-based vocabularies and require high-quality, large-scale datasets for effective training. Similarly, CLIP-based models, although effective for cross-modal alignment, fail to address variations in sign language that are not well-represented in their training data.
To address these gaps, we propose the Open-Vocabulary Sign Language Translation (OVSLT) method, which enables translation systems to handle a wider and more diverse set of gestures without depending on predefined vocabularies. By integrating dynamic vocabulary embedding and an open-vocabulary approach, OVSLT allows the model to adapt to unseen gestures and contextual variations. This approach moves beyond the constraints of gloss-based systems, enabling the model to generalize across different sign languages and effectively capture the complex temporal dynamics and visual nuances inherent in sign language.
3. Method
3.1. Overall
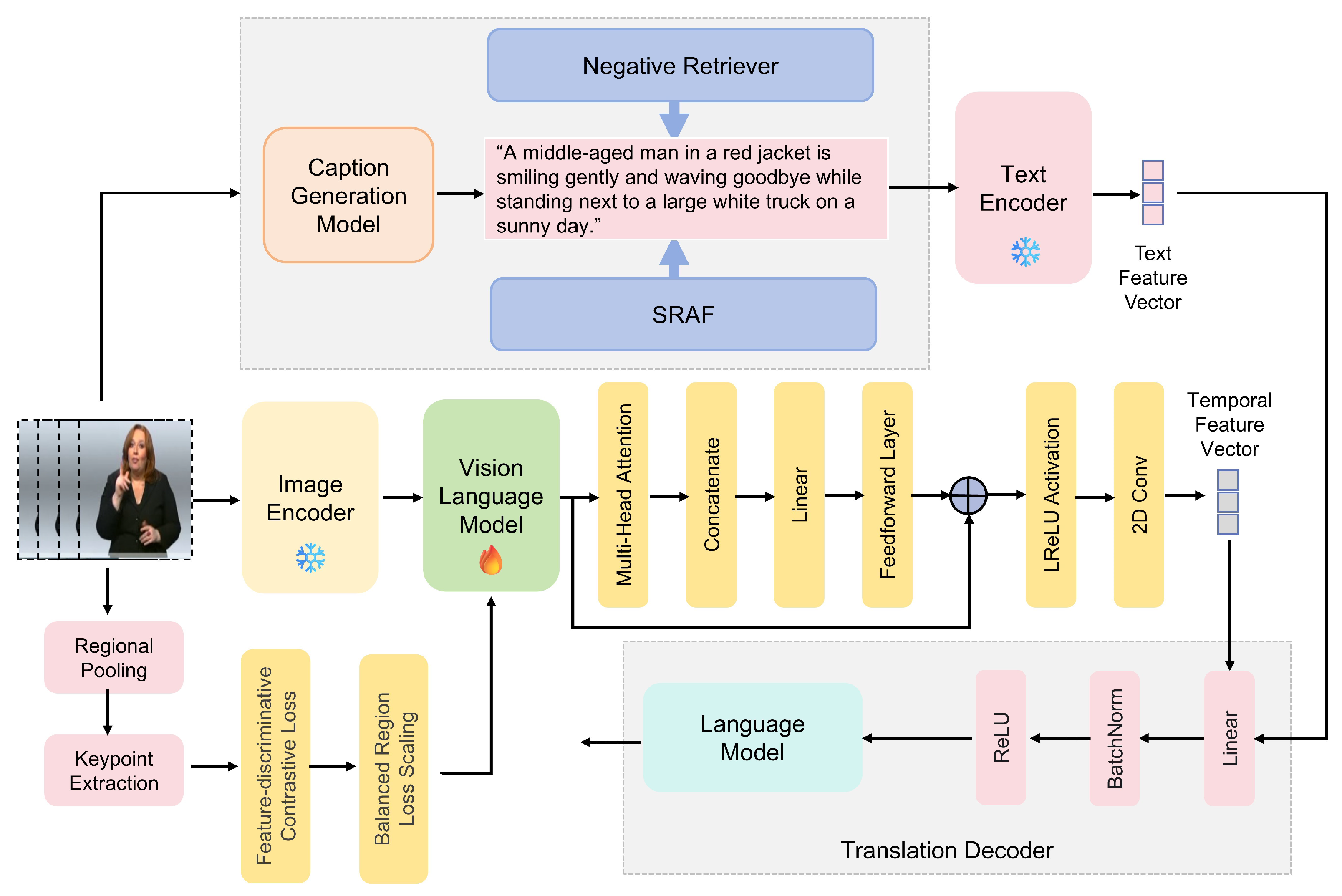
In this study, we propose a comprehensive framework for open-vocabulary sign language translation, which integrates advanced techniques from the vision and language domains to address the inherent challenges of sign language interpretation. The methodology is designed to generate accurate textual descriptions of sign gestures and translate them into natural language, ensuring both semantic richness and contextual relevance.
The proposed framework consists of several interconnected components, each playing a crucial role in the end-to-end translation process. These components are detailed in subsections focused on the following: Caption Generation and Description (CGD), Grid Feature Grouping, Vision-Language Model, Translation Decoder, and loss function.
At the core of the system is the Caption Generation and Description (CGD) module, which uses the GPT model to produce detailed, domain-specific textual descriptions of sign language gestures. This step ensures that the generated captions capture the nuanced movements and expressions characteristic of sign language, providing a solid foundation for subsequent processing. The CGD module is explained in more detail in
Section 3.2.
To enhance the discriminative power of the captions and improve the alignment between visual and textual data, we introduce the Negative Retriever and Semantic Retrieval-Augmented Features (SRAF). The Negative Retriever selects challenging negative samples from a large vocabulary, facilitating the model’s ability to distinguish between similar sign gestures. Concurrently, the SRAF component enriches the visual features with semantic information derived from concept descriptions generated by a large language model (LLM). This bridging of visual and textual semantics is discussed further in
Section 3.3, where we detail the Grid Feature Grouping method for extracting and organizing key visual features from sign language images. This method, which includes edge detection, region pooling, and clustering, is crucial for gesture recognition and feature–text alignment.
Following caption generation, the Vision-Language Model serves as the central hub for aligning visual and textual features within a shared embedding space. By leveraging an Enhanced Multihead Transformer (EMHT), the model captures both spatial and temporal dependencies inherent in sign language gestures. This step ensures deep and nuanced understanding of gesture dynamics, which is critical for accurate translation.
Section 3.4 provides more details on the Vision-Language Model and its role in ensuring robust feature alignment.
Finally, the Translation Decoder translates the multimodal features into coherent and contextually appropriate natural language sentences. Using a fine-tuned mBART model, the decoder ensures fluent and semantically accurate translations, effectively bridging the communication gap between sign language users and natural language speakers. This process is outlined in
Section 3.5, where we discuss the role of the decoder in generating precise translations.
The entire framework is trained using a composite loss function, combining contrastive loss for feature alignment and cross-entropy loss for translation accuracy. This holistic approach, discussed in
Section 3.6, ensures that the model not only aligns visual and textual data effectively but also generates high-quality translations that are both precise and natural.
Figure 1 provides an overview of the proposed methodology, illustrating the flow of data through each component and highlighting the interactions that facilitate accurate sign language translation.
This integrated approach leverages the strengths of both vision and language models, addressing the complexities of sign language translation by ensuring that each component contributes to a unified and effective translation pipeline. By combining advanced feature extraction, semantic enrichment, and robust alignment techniques, the proposed methodology sets a new standard for open-vocabulary sign language translation.
3.2. Caption Generation and Description
In open-vocabulary sign language recognition, generating accurate and contextually appropriate descriptions for sign gestures presents a challenge. Existing models often fail to fully capture the nuances of sign language due to its unique visual and contextual nature [
44,
45,
46,
47,
48]. To address this, we use the GPT model to generate textual descriptions of sign language gestures, ensuring accuracy and domain-specific relevance.
Each gesture
is first represented as visual features extracted from sign language images or videos. These features capture important aspects like hand shape, movement, and facial expression. Along with visual features, contextual information—such as the intended meaning or cultural context—is integrated to enhance the description. The combined visual and contextual features
are fed into GPT, which generates the corresponding textual description
. This process is mathematically expressed as:
For example, the gesture for “goodbye” could be described as: “A sign language user waves both hands from the front outward to the sides with palms facing outward, accompanied by a relaxed facial expression”. These descriptions provide rich semantic information for downstream Vision-Language Models.
To further enhance the quality and discriminative power of the generated captions, we introduce two key components: the Negative Retriever and Semantic Retrieval-Augmented Features (SRAF).
The Negative Retriever selects hard negative and easy negative samples from a large vocabulary V.
Hard negatives are words that are semantically distant from the true label , meaning they have low semantic similarity. These samples are challenging for the model to distinguish from the true label, thus improving its discriminative capabilities. Easy negatives are words that are semantically close to the true label, meaning they have high semantic similarity. These samples help the model learn to differentiate between closely related gestures.
The selection of negative samples is based on a semantic similarity metric, which we compute using pre-trained word embeddings (e.g., BERT). Specifically, the similarity between the true label
and a candidate word
w from vocabulary
V is measured using cosine similarity:
where
denotes the word embedding function. Hard negatives are selected as the words with the lowest similarity scores, while easy negatives are selected as those with higher similarity scores but still distinct from the true label. The retrieval process is formulated as:
where
represents the set of negative samples,
is the true text description, and
V is the large vocabulary from which negatives are retrieved.
The SRAF process leverages a large language model (LLM) to generate textual descriptions for each sign language category, such as “Smile easily and wave goodbye”, “wave your hands out”, or “Wave your hands outward from your chest”. These descriptions capture the nuances of the gestures, and once generated, they are embedded into a semantic space using either the same LLM or a separate embedding model. This embedding step enhances the semantic richness of the visual feature representations, enabling better alignment between the visual gestures and their corresponding textual descriptions.
The SRAF process can be expressed as:
where
represents the retrieval-augmented visual features and
generates the concept descriptions.
By integrating the Negative Retriever and SRAF, we refine the caption generation process to ensure that textual descriptions are not only accurate and relevant but also semantically enriched. The Negative Retriever enhances the model’s discriminative capabilities by providing challenging negative samples, while SRAF augments the visual features with rich semantic information derived from concept descriptions. The final augmented visual features are obtained by concatenating the SRAF features
with the original image features
extracted from the image encoder and Grid Feature Grouping module:
where
represents the final augmented visual features,
represents the retrieval-augmented visual features, and
represents the original image features.
This dual enhancement significantly improves the model’s performance in aligning sign language gestures with their corresponding textual descriptions. The Negative Retriever ensures that the model is exposed to a diverse range of negative samples, while SRAF enriches the visual features with semantic context, leading to more accurate and discriminative caption generation.
To effectively utilize the generated textual descriptions, we employ a text encoder based on the BERT (Bidirectional Encoder Representations from Transformers) model. The BERT model captures rich contextual information and generates high-quality text feature representations by pre-training on large-scale text corpora. To adapt BERT to the specific requirements of sign language recognition, we fine-tuned it using a dataset of sign language gesture descriptions.
The fine-tuning process adjusts the pre-trained BERT weights to better capture the unique linguistic patterns and semantic relationships present in sign language descriptions. As a result, the fine-tuned BERT model generates text feature representations that align more closely with the visual features of sign language gestures, enhancing the overall translation accuracy and robustness of the framework.
The text features generated by the fine-tuned BERT model are integrated with the image features obtained from the image encoder and Grid Feature Grouping module. By mapping both sets of features into the same embedding space, the Vision-Language Model can effectively compute alignment scores and perform contrastive learning to optimize the association between sign language gestures and their textual descriptions. This integration is pivotal for achieving high-performance open-vocabulary sign language translation, as it ensures that the model comprehensively understands and translates a diverse range of sign language gestures into accurate textual representations.
3.3. Grid Feature Grouping
To enhance feature representation and facilitate effective alignment with textual descriptions, we employ a Grid Feature Grouping method tailored for open-vocabulary sign language translation. This approach begins with detecting significant edge information in sign language images using edge detection algorithms such as the Canny edge detector. Following contour detection, the edge-detected images are divided into multiple regions where pooling operations aggregate spatial information. Subsequently, the K-Means clustering algorithm is applied to group pooled features, extracting salient key points critical for recognizing diverse sign language gestures. This method improves the quality of feature representations and optimizes the model’s efficiency in aligning visual data with text queries.
To further strengthen the alignment between grid features and textual descriptions, we introduce enhanced contrastive learning for feature–text alignment. This enhancement aims to improve the discriminative power of the extracted features and ensure robust alignment with text descriptions specific to sign language translation. We adopt a CLIP-style contrastive loss to align the pooled grid features with their corresponding text descriptions, pulling paired grid and language features closer while pushing away unmatched ones. The contrastive loss is formulated as:
where
is the average-pooled region feature,
Pool(P,
) is a custom pooling operation to gather features over the grid regions,
concatenates all caption embeddings in a scene,
z and
s measure the similarity and the score probability between a grid region and all captions,
is the sigmoid function, and
is the one-hot label highlighting the position paired with
.
Recognizing that CLIP-style contrastive loss focuses on global image-level features and may neglect point-wise discriminative features essential for dense prediction tasks in sign language translation, we propose a feature-discriminative contrastive loss (
). Instead of aggregating grid features into an averaged region-level feature,
directly computes the similarity between point-wise embeddings and caption embeddings:
where
z and
s indicate the similarity and probability matrix between point-wise features and all caption embeddings. This approach allows each grid point to adapt its optimization direction based on its own embeddings, thereby enhancing the discriminative capability of the features.
To ensure balanced gradient contributions across regions of varying sizes, we introduce a balanced region loss scaling factor. This scaling mitigates the implicit bias towards larger regions that could arise due to pooling operations, promoting uniform feature learning across all regions. The balanced region scaled loss
is defined as:
where
is the balanced region scaling factor,
is the number of text-query pairs per scene, and
represents the cardinality of region
.
Integrating enhanced contrastive learning for feature–text alignment into our Grid Feature Grouping method significantly enhances representation learning. The feature-discriminative contrastive loss ensures that each grid point captures unique semantic information without interference from unrelated points, which is crucial for accurately recognizing diverse sign language gestures. Additionally, the balanced region loss scaling ensures that all regions contribute equally to the learning process, preventing the dominance of larger regions and promoting balanced feature representation.
This enhanced Grid Feature Grouping approach allows our model to effectively capture and represent the critical aspects of sign language gestures, facilitating more accurate and contextually relevant alignment with textual descriptions. Consequently, this leads to improved semantic understanding and translation capabilities in open-vocabulary sign language translation systems.
3.4. Vision-Language Model
The Vision-Language Model (VL Model) is the core component of our framework, responsible for aligning sign language image features with text features to facilitate efficient loss calculation and optimization in subsequent translation tasks. By aligning these features, the VL Model enhances the model’s ability to understand and generate accurate textual descriptions of sign language gestures.
After processing through the image encoder and Grid Feature Grouping, we obtain the feature representation of the sign language image. Simultaneously, text encoders, such as the fine-tuned BERT model, generate corresponding text features from the textual descriptions of the gestures. To achieve feature alignment, we map both the image features and text features into the same embedding space, ensuring that they share a similar representation in this unified space.
This alignment process involves projecting the high-dimensional image features and text features into a common latent space where semantically related image–text pairs are positioned closely together, while unrelated pairs are distanced apart. The mapping functions for the image features and text features are learned jointly during training, allowing the model to effectively capture the intricate relationships between visual sign language gestures and their corresponding textual meanings.
The alignment is optimized using a contrastive loss function, which encourages the model to minimize the distance between paired image and text features while maximizing the distance between non-paired features. This contrastive learning approach ensures that the model can accurately associate sign language gestures with their appropriate textual descriptions, thereby improving the overall translation performance.
To further enhance the capabilities of the Vision-Language Model, we integrate an Enhanced Multihead Transformer (EMHT). This improved transformer module is designed to learn the spatiotemporal feature sequences inherent in sign language gestures. By capturing both spatial and temporal dependencies, the EMHT facilitates a more comprehensive understanding of the dynamic movements and contextual nuances present in sign language.
The EMHT operates by processing the aligned feature representations through multiple transformer layers, each consisting of enhanced multihead attention mechanisms that better capture the intricate relationships between different parts of the gesture over time. This allows the model to maintain a coherent representation of the gesture’s flow and structure, leading to more accurate and contextually relevant textual translations.
The inclusion of the EMHT in the VL Model offers several advantages. By modeling the temporal dynamics of sign language gestures, the EMHT ensures that the sequence of movements is accurately captured and represented, thereby enhancing temporal understanding. Additionally, the multihead attention mechanisms within the EMHT facilitate the integration of spatial features from different parts of the gesture, promoting a holistic understanding of each sign. Moreover, the enhanced transformer layers contribute to more robust and discriminative feature representations, reducing ambiguity and improving translation accuracy.
By integrating the Enhanced Multihead Transformer into our Vision-Language Model, we enable a deeper and more nuanced interaction between visual sign language data and textual information. This integration not only enhances the model’s semantic understanding but also facilitates the generation of coherent and contextually relevant translations, thereby advancing the capabilities of open-vocabulary sign language translation systems.
3.5. Translation Decoder
The Translation Decoder serves as the final component of our open-vocabulary sign language translation framework, responsible for generating natural language translations from the integrated multimodal feature representations produced by the Vision-Language Model. To refine these features, they are first passed through a dedicated Sign Embedding module, which consists of a linear layer, Batch Normalization (BN), and a ReLU activation function. The Sign Embedding module enhances the feature representation by stabilizing the training process and introducing non-linearity, capturing the complex dynamics of sign language gestures.
Subsequently, the refined feature vector is fed into the mBART (Multilingual BART) model, a state-of-the-art multilingual sequence-to-sequence language model. mBART was chosen over other multilingual models due to its superior generalization capabilities, particularly when fine-tuned on domain-specific data like paired sign language descriptions and their corresponding natural language translations. This fine-tuning process adjusts the pre-trained mBART weights, enabling the model to capture the semantic and syntactic nuances of sign language, ensuring that the generated translations are both precise and fluent. While models like mBERT and XLM-R are effective for text-to-text tasks, they do not perform as well in sequence-to-sequence generation tasks, especially when handling multimodal inputs. mBART’s ability to seamlessly integrate these inputs and its proven success in multilingual settings make it the optimal choice for our framework, as it supports translations across multiple languages with high accuracy and naturalness.
In the inference stage, a new sign language gesture image is processed by the Image Encoder and Text Encoder to obtain the visual and textual feature vectors. These vectors are then aligned and fused by the Multimodal Feature Integrator, resulting in
, which is subsequently passed through the Sign Embedding module and into mBART for translation:
This seamless integration ensures that the model effectively understands both the static and dynamic aspects of sign language gestures, generating translations that are contextually relevant and linguistically coherent. The incorporation of mBART enhances the framework’s multilingual capabilities, allowing support for translations across various languages with high accuracy and naturalness. Overall, the Translation Decoder plays a pivotal role in bridging the gap between visual sign language data and natural language output, thereby advancing the effectiveness and applicability of open-vocabulary sign language translation systems.
3.6. Loss Function
The training of our open-vocabulary sign language translation model relies on a composite loss function that effectively optimizes both the alignment of multimodal features and the accuracy of the generated translations. This loss function integrates contrastive loss for feature alignment and cross-entropy loss for translation, ensuring that the model learns to associate sign language gestures with their corresponding textual descriptions while generating fluent and accurate natural language translations.
To facilitate the alignment between visual and textual features, we employ a contrastive loss function. This loss encourages the model to minimize the distance between paired image–text feature vectors while maximizing the distance between non-paired vectors. Specifically, we utilize the InfoNCE (Information Noise Contrastive Estimation) loss, which is defined as:
where
N denotes the number of training samples,
and
represent the visual and textual feature vectors for the
i-th sign gesture, respectively, and
denotes the cosine similarity between two feature vectors. The temperature parameter
controls the concentration level of the distribution. By optimizing this loss, the model learns to place semantically related image–text pairs closer in the shared embedding space while distancing unrelated pairs.
For the translation component, we utilize the standard cross-entropy loss to measure the discrepancy between the generated translations and the ground truth natural language sentences. The cross-entropy loss is formulated as:
where
represents the ground truth token at position
t for the
i-th sample,
denotes the predicted probability of the token generated by the mBART model, and
T is the length of the target sentence. Minimizing this loss ensures that the Translation Decoder produces sequences that closely match the reference translations.
The overall loss function used to train the model is a weighted sum of the contrastive loss and the translation loss:
where
and
are hyperparameters that balance the contributions of the contrastive loss and the translation loss, respectively. Typically, these weights are set based on empirical performance on a validation set.
4. Experiments
4.1. Dataset
We conducted experiments on two distinct datasets, PHOENIX-14 and CSL-Daily, to evaluate the performance of our sign language translation system.
PHOENIX-14T: PHOENIX-14T [
24] is a benchmark dataset for German Sign Language (DGS). It comprises 7096 training videos, 519 development videos, and 642 testing videos. These videos are meticulously annotated with 1066 glosses and 2887 German text tokens, providing a robust foundation for training and evaluating translation models in the DGS domain.
CSL-Daily: CSL-Daily [
49] is a comprehensive dataset for Chinese Sign Language (CSL) that contains 20,654 video-gloss-text triplets. The dataset is divided into 18,401 training samples, 1077 development samples, and 1176 testing samples. It features vocabularies of 2000 glosses and 2343 Chinese text tokens, making it an extensive resource for developing and assessing open-vocabulary sign language translation systems in the CSL context.
The differences between German Sign Language and Chinese Sign Language lie primarily in their linguistic structure, vocabulary, and gestural characteristics. German Sign Language closely aligns with spoken German, making it easier to map signs directly to German text. In contrast, Chinese Sign Language has a unique grammar and syntax, with iconic and spatial signs that often represent meanings visually, requiring more complex contextual understanding. Chinese Sign Language also features a larger vocabulary and a more iconic, context-dependent nature, which makes the translation process more challenging compared to German Sign Language, where signs are more standardized. These differences significantly impact the performance of translation models, requiring more adaptation to handle Chinese Sign Language’s gestural and semantic complexities.
4.2. Implementation Details
Evaluation Metrics: In the context of sign language translation (SLT), we employ BLEU and ROUGE as our primary evaluation metrics. BLEU (Bilingual Evaluation Understudy) assesses the quality of translation by measuring the n-gram overlap between the predicted translations and reference texts. It is calculated as follows:
where
is the count of n-grams in the candidate translation,
is the count of n-grams in the reference translation, and
is the precision for n-grams of length
n. The BLEU score ranges from 0 to 1, with higher scores indicating better translation quality.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) focuses on recall and measures the overlap of n-grams between the predicted and reference translations. It is defined as:
where
represents the proportion of n-grams in the reference translation that appear in the candidate translation. Similar to BLEU, ROUGE scores range from 0 to 1, with higher scores indicating greater recall of reference n-grams in the candidate translations.
These metrics provide a comprehensive evaluation of translation performance, allowing us to assess the accuracy and semantic relevance of the generated textual descriptions of sign language gestures.
Experimental Setup: During training, the model parameters across all modules are jointly optimized using the Adam optimizer with an initial learning rate of 0.001 and a weight decay coefficient of 1 × 10−4. The combined loss function ensures that the model simultaneously learns to align multimodal features and generate accurate translations, leading to a cohesive and high-performing sign language translation system. To prevent overfitting and enhance the generalization capabilities of the model, we incorporate standard regularization techniques such as dropout and weight decay. Specifically, we apply dropout with a rate of 0.3 within the transformer layers and linear transformations. This approach randomly deactivates 30% of the neurons during training, promoting robustness. Additionally, we utilize weight decay with a coefficient of 1 × 10−4, which penalizes large weights in the model and encourages the development of simpler and more generalizable feature representations.
4.3. Experimental Results
SLT Results on CSL-Daily and PHOENIX-14T: We evaluated the performance of our proposed sign language translation system on two prominent datasets, CSL-Daily and PHOENIX-14T, and the comparative results are summarized in
Table 1.
On the PHOENIX-14T dataset, our method achieves a ROUGE score of 50.66% (95% CI: ±0.12%), positioning it competitively among existing approaches. Although state-of-the-art methods such as TwoStream-SLT and IP-SLT obtain higher ROUGE scores of 53.48% and 53.72% respectively, our model demonstrates strong performance across the BLEU metrics. Specifically, our approach achieves a BLEU-1 score of 51.47% (±0.2%), BLEU-2 of 38.37% (±0.11%), BLEU-3 of 30.21% (±0.12%), and BLEU-4 of 24.73% (±0.13%). These results highlight our model’s ability to generate accurate and fluent translations, effectively balancing precision and recall.
For the CSL-Daily dataset, our translation system records a ROUGE score of 50.72% (±0.11%), along with BLEU scores of 51.45% for BLEU-1, 38.39% for BLEU-2, 30.21% for BLEU-3, and 24.73% for BLEU-4, with similar confidence intervals. Although TwoStream-SLT outperforms our method in certain metrics (e.g., a ROUGE score of 55.72% and BLEU scores up to 25.79%), our system exhibits competitive performance overall—particularly excelling in higher-order BLEU scores that reflect its ability to generate more contextually relevant and semantically accurate translations.
Overall, our approach demonstrates robust and consistent performance across both datasets. While certain state-of-the-art methods achieve superior scores in specific metrics, our system offers a balanced performance that underscores its effectiveness in handling diverse sign language translation tasks. The high BLEU scores indicate that our model produces translations that are both precise and fluent, making it a viable option for real-world sign language translation applications. Future work will focus on further enhancing the model’s performance by integrating advanced multimodal fusion techniques and leveraging larger, more diverse training datasets.
Open-Vocabulary SLT Results on CSL-Daily and PHOENIX-14T: To evaluate the effectiveness of our sign language translation system in an open-vocabulary setting, we conducted experiments on the PHOENIX-14T and CSL-Daily datasets, with the results summarized in
Table 2. For open-vocabulary testing, we employed a frequency-based filtering approach using the gloss file to categorize glosses into “seen” and “unseen” classes. The glosses were categorized based on their occurrence frequency within the training data.
In our methodology, high-frequency glosses were selected as “seen” categories, while low-frequency glosses were designated as “unseen”. Specifically, glosses were sorted by frequency, and those that appeared five or more times in the dataset were labeled as high-frequency “seen” glosses. This categorization process mirrors real-world sign language communication, where a small set of high-frequency vocabulary typically covers the majority of daily interactions and essential communication needs. In this context, high-frequency glosses represent common signs used frequently in conversation, such as basic expressions and verbs, which the system must prioritize in order to address the primary communication needs of users. By prioritizing high-frequency glosses for training and optimization, our system can more effectively handle the most commonly used signs, enabling it to generate accurate translations for these key terms. This approach also optimizes resource utilization, as these glosses are supported by more abundant training data, improving the model’s learning efficiency. The extensive data available for high-frequency glosses allows the model to generalize better, enhancing recognition accuracy for signs that are central to communication in sign language.
Moreover, by selecting high-frequency glosses as “seen” categories, we also achieve a more balanced distribution of classes within the training set. This balance addresses the issue of data sparsity, which can occur when certain glosses (often low-frequency ones) are underrepresented in the training data. Without this balance, the model may become biased towards the overrepresented “seen” glosses, failing to generalize effectively to less common signs. By mitigating this bias, we enhance the model’s overall performance, ensuring that it is well-equipped to handle a variety of signs across different contexts. The decision to retain a substantial number of “unseen” glosses is a key strategy in our open-vocabulary setting. By incorporating a diverse set of unseen categories, we encourage the model to develop more generalized feature representations, which is crucial for the open-vocabulary setting. These generalized features allow the model to recognize and translate a broader range of signs that were not part of the training data. In real-world sign language communication, new and novel signs can emerge dynamically, and it is essential for the translation system to adapt and accurately handle such new terms. Retaining a large set of unseen glosses enhances the system’s ability to translate these novel gestures, making it more adaptable to real-world communication and increasing its robustness.
As illustrated in
Table 2, our proposed method consistently outperforms existing open-vocabulary translation approaches across both datasets. On the PHOENIX-14T dataset, our model achieves a ROUGE score of 29.41% (±0.15) and a Test BLEU-4 score of 14.12% (±0.14), surpassing other methods such as TwoStream-SLT and XmDA. Similarly, on the CSL-Daily dataset, our system attains a ROUGE score of 30.61% (±0.11) and a Test BLEU-4 score of 15.65% (±0.14), outperforming state-of-the-art techniques. These results demonstrate the efficacy of our open-vocabulary strategy, which effectively balances resource optimization, category balance, and generalization ability. By focusing on high-frequency glosses and maintaining a diverse set of unseen categories, our model not only delivers superior translation performance but also exhibits robust adaptability in real-world sign language translation applications. Future work will aim to further enhance the model’s performance by integrating more sophisticated multimodal fusion techniques and expanding the training corpus to encompass an even broader spectrum of sign language vocabulary.
4.4. Ablation Study
4.4.1. Ablation Study of Caption Generation and Description
To evaluate the effectiveness of our Caption Generation and Description (CGD) module, we conducted an ablation study on the PHOENIX-14T dataset. The aim was to dissect the contribution of each component—GPT Generation, Negative Retriever, and Semantic Retrieval Augmented Features (SRAF)—to the overall performance of the caption generation process.
Table 3 presents the results of this study, showcasing the impact of each component on the ROUGE scores, which serve as an indicator of the quality and relevance of the generated captions.
Initially, using only the GPT Generation component without the Negative Retriever and SRAF yielded a baseline ROUGE score of 9.2%. The generated prompt, “A person is standing next to a truck”, while accurate, lacks detailed semantic richness and specificity. This indicates that relying solely on GPT for caption generation provides a fundamental descriptive capability but falls short in capturing the nuanced details necessary for high-quality descriptions.
Incorporating the Negative Retriever alongside GPT Generation significantly improved the ROUGE score to 17.1%. The enhanced prompt, “A man wearing a red shirt is standing beside a white truck”, demonstrates increased specificity and contextual relevance. The Negative Retriever effectively distinguishes between relevant and irrelevant glosses by selecting both hard and easy negative samples based on their semantic similarity. This selective retrieval ensures that the model focuses on generating more precise and contextually appropriate descriptions, thereby nearly doubling the ROUGE performance compared to the baseline.
Further integration of the SRAF component, while excluding the Negative Retriever, resulted in a substantial ROUGE score increase to 26.5%. The generated caption “A person is smiling and waving goodbye next to a truck” highlights the enhanced semantic richness introduced by SRAF. By embedding concept descriptions such as “smiling” and “waving goodbye” into the visual feature representations, SRAF enriches the captions with expressive actions, thereby improving their alignment with the visual context and increasing their descriptive quality.
The most significant improvement was observed when all three components—GPT Generation, Negative Retriever, and SRAF—were employed together, achieving a ROUGE score of 29.6%. The comprehensive prompt “A middle-aged man in a red jacket is smiling gently and waving goodbye while standing next to a large white truck on a sunny day” exemplifies the synergistic effect of combining these components. This configuration leverages GPT’s foundational captioning ability, the Negative Retriever’s capability to filter and select relevant glosses, and SRAF’s enhancement of semantic details. The result is a highly detailed and semantically rich caption that closely mirrors the complexity of the visual scene, as reflected in the highest ROUGE score.
Overall, the ablation study demonstrates that each component of the Caption Generation and Description (CGD) module plays a crucial role in enhancing caption quality. The progressive integration of Negative Retriever and SRAF with GPT Generation leads to significant improvements in both the specificity and semantic richness of the generated captions. These findings underscore the importance of a multifaceted approach in developing robust sign language translation systems, where each component contributes uniquely to the system’s overall performance.
4.4.2. Ablation Study of Grid Feature Grouping
To evaluate the impact of our Grid Feature Grouping module on the overall performance of the sign language translation system, we conducted an ablation study using the PHOENIX-14T dataset. This study systematically examines the contributions of each component within the module: enhanced contrastive learning, feature-discriminative contrastive loss, and balanced region loss scaling. As illustrated in
Table 4, the baseline model, which employs only the fundamental feature grouping approach, achieved a ROUGE score of 10.5%. This baseline establishes the initial capability of the model in generating relevant translations without the advanced enhancements. Introducing enhanced contrastive learning to the baseline resulted in a substantial improvement, increasing the ROUGE score to 15.8%. This enhancement leverages more effective contrastive mechanisms to better differentiate between various visual features, thereby enabling the model to capture more nuanced aspects of sign language gestures. The incorporation of feature-discriminative contrastive loss further elevated the ROUGE score to 21.1%, demonstrating its role in refining the discriminative power of the feature representations. By focusing on distinguishing critical features, this component allows the model to better recognize subtle variations in gestures, leading to more accurate translations. The most significant advancement was observed when balanced region loss scaling was integrated alongside the previous components, pushing the ROUGE score to 29.6%. This final addition ensures that the loss contributions from different regions are balanced, preventing the model from overemphasizing larger regions and promoting uniform feature learning across all areas of the visual input. This balance is crucial for capturing the comprehensive scope of sign language gestures, resulting in more coherent and contextually appropriate translations.
For further context, we also compared the performance of the Grid Feature Grouping approach with traditional feature extraction methods, such as CNN and FPN. The CNN-based model achieved a ROUGE score of 12.5%, while the FPN-based model reached a ROUGE score of 14.1%. As shown in the results, the Grid Feature Grouping approach outperforms both CNN and FPN, with a ROUGE score of 29.6%, highlighting its effectiveness in extracting and aligning visual features with textual descriptions. The progressive enhancements observed with each additional component underscore the importance of the Grid Feature Grouping module in improving the model’s ability to align visual data with textual descriptions.
The substantial increase in ROUGE scores demonstrates the critical role of each component—enhanced contrastive learning, feature-discriminative contrastive loss, and balanced region loss scaling—in developing a robust and high-performing sign language translation system.
4.4.3. Ablation Study of Vision-Language Model and Translation Decoder
To assess the effectiveness of various components within our Vision-Language Model and Translation Decoder for open-vocabulary sign language translation, we conducted an ablation study on the PHOENIX-14T dataset. The objective was to systematically evaluate the contribution of each module to the overall translation performance, as measured by the ROUGE metric.
Table 5 summarizes the results of this study.
Starting with the baseline model, which employs a fundamental approach without any additional enhancements, the system achieved a ROUGE score of 5.0%. This baseline establishes the initial performance level, highlighting the challenges inherent in open-vocabulary sign language translation without specialized feature alignment or advanced decoding strategies. Introducing the Shared Embedding Space to the baseline model led to a significant improvement, increasing the ROUGE score to 9.2%. The Shared Embedding Space facilitates a unified representation of both visual and textual modalities, enabling better alignment and interaction between sign language gestures and their corresponding textual descriptions. This enhancement allows the model to capture semantic similarities more effectively, thereby improving the relevance and accuracy of the translations. Further incorporating the EMHT (Enhanced Multihead Transformer) module resulted in a substantial boost in performance, elevating the ROUGE score to 17.1%. The EMHT module enhances the model’s ability to capture complex dependencies and contextual relationships within the sign language data through advanced transformer architectures. By leveraging multiple attention heads, EMHT enables the model to attend to diverse aspects of the input simultaneously, thereby refining the translation process and producing more coherent and contextually appropriate outputs. Adding the Sign Embedding component to the model, in conjunction with the Shared Embedding Space and EMHT, led to an additional increase in the ROUGE score to 19.3%. The Sign Embedding module enriches the model’s understanding of sign language by providing specialized embeddings that capture the nuances and intricacies of various sign gestures. This focused representation allows the model to better differentiate between similar signs and understand subtle variations, thereby enhancing the precision and clarity of the translations. Finally, integrating the mBART (multilingual BART) decoder into the complete model configuration achieved the highest ROUGE score of 29.6%. The mBART decoder, known for its robust sequence-to-sequence capabilities, significantly improves the generation quality of the translated text by leveraging pre-trained multilingual representations and sophisticated decoding strategies. This advanced decoder facilitates more fluent and accurate translations, effectively bridging the gap between visual sign language inputs and their textual counterparts.
The progressive enhancements observed through the addition of each module—Shared Embedding Space, EMHT, Sign Embedding, and mBART—demonstrate the critical role of each component in advancing the performance of the sign language translation system. The substantial increase in ROUGE scores from 5.0% to 29.6% underscores the importance of integrating specialized embedding spaces, advanced transformer architectures, focused sign representations, and powerful decoding mechanisms. These findings validate the effectiveness of our multi-component approach in developing a robust and high-performing open-vocabulary sign language translation model.
4.4.4. Performance Comparison of Different Components
To evaluate the synergistic effects of various components within our overall framework for open-vocabulary sign language translation, we conducted an ablation study on the PHOENIX-14T dataset.
Table 6 presents the ROUGE scores corresponding to different configurations of our system, highlighting the incremental contributions of each component. Starting with the baseline model, which incorporates only the CGD module, the system achieved a ROUGE score of 9.2%. This baseline establishes the fundamental capability of generating captions based solely on visual inputs without enhanced feature representation or advanced translation mechanisms.
Introducing the Grid Feature Grouping module to the baseline significantly improved the ROUGE score to 17.1%. The Grid Feature Grouping enhances feature representation by detecting and grouping salient visual features, which facilitates better alignment with textual descriptions. This improvement underscores the importance of sophisticated feature extraction in capturing the nuances of sign language gestures, thereby providing a richer foundation for accurate translation.
When the Vision-Language Model component was added to the baseline without the Grid Feature Grouping, the ROUGE score increased to 16.5%. The Vision-Language Model bridges the gap between visual data and textual descriptions by enabling more effective alignment and interaction between sign language gestures and their corresponding textual representations. This enhancement demonstrates the critical role of integrated vision–language interactions in improving translation accuracy.
Combining both the Grid Feature Grouping and Vision-Language Model with the CGD module further elevated the ROUGE score to 18.4%. This configuration benefits from the enhanced feature representation provided by Grid Feature Grouping and the improved alignment facilitated by the Vision-Language Model, resulting in more coherent and contextually relevant translations. The combined effect of these components illustrates the complementary nature of advanced feature extraction and vision-language integration in boosting overall system performance.
Finally, incorporating the Translation Decoder module alongside the other components led to the highest ROUGE score of 29.6%. The Translation Decoder leverages sophisticated sequence-to-sequence mechanisms to generate fluent and accurate translations from the aligned visual and textual features. This final component plays a pivotal role in refining the output, ensuring that the translations are not only accurate but also linguistically coherent and contextually appropriate. The substantial increase in ROUGE score from 18.4% to 29.6% highlights the effectiveness of integrating advanced decoding strategies to maximize the performance of the sign language translation system.
Overall, the ablation study demonstrates that each component—Grid Feature Grouping, Vision-Language Model, and Translation Decoder—contributes uniquely and significantly to the performance of the open-vocabulary sign language translation framework. The progressive enhancements in ROUGE scores reflect the critical interplay between sophisticated feature representation, effective vision-language alignment, and advanced decoding mechanisms, validating the comprehensive design of our translation system.
4.5. Visualization
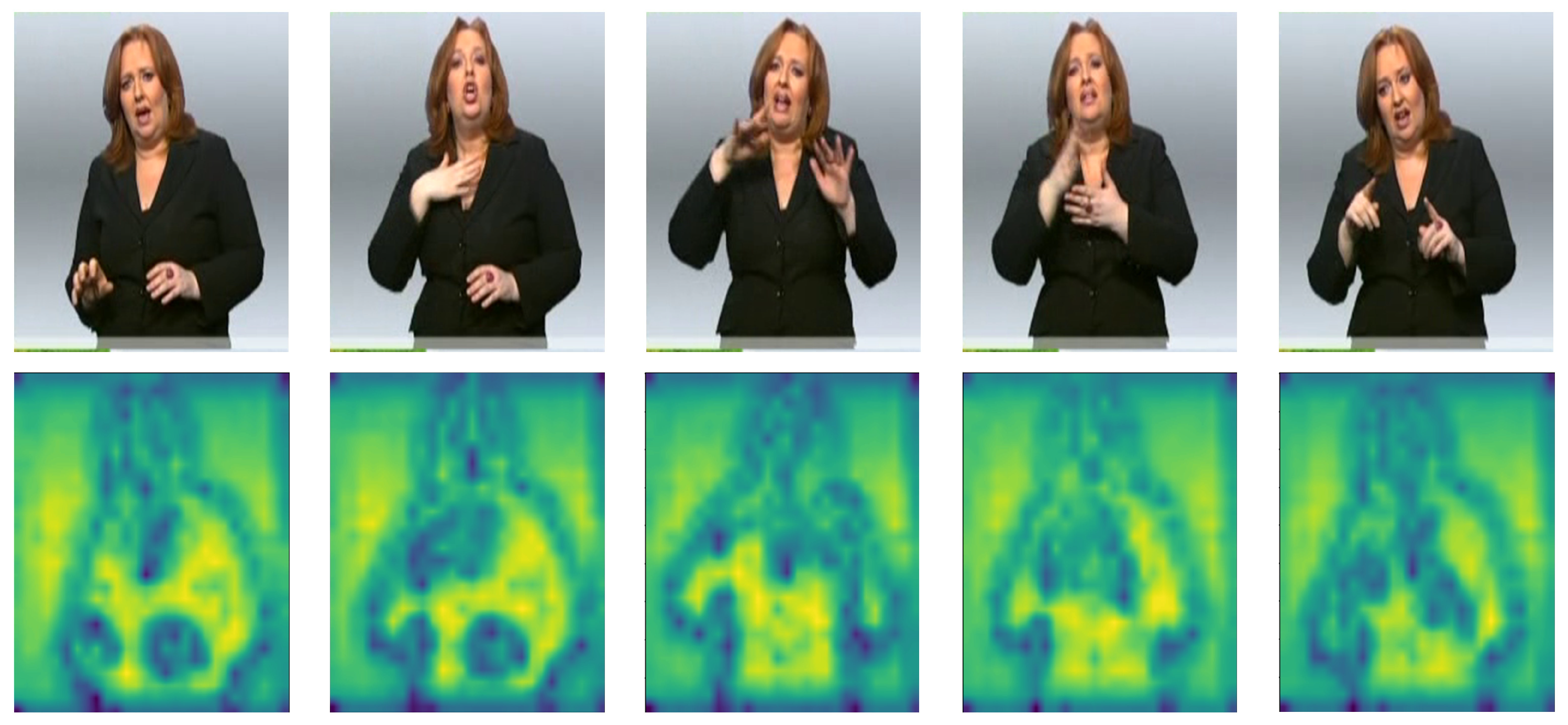
As shown in
Figure 2, to further validate the effectiveness of our proposed method, we provide visualizations of the feature extraction process from the OVSLT model. These visualizations offer insight into how our model processes and interprets sign language gestures at different stages of the feature extraction pipeline. Through these feature visualizations, we provide a deeper understanding of the model’s internal workings, demonstrating its ability to effectively capture and align multimodal information for open-vocabulary sign language translation. The results indicate that our model not only achieves high translation accuracy but also exhibits an intuitive and meaningful interpretation of sign language gestures, reinforcing the effectiveness of our approach.
4.6. Limitation Analysis
While the proposed open-vocabulary sign language translation (OVSLT) framework demonstrates promising results, several limitations should be addressed in future work. Firstly, we have not yet considered the user interface (UI) and user experience (UX), which are critical for ensuring the system’s practical adoption. Future research will focus on designing user-friendly interfaces that facilitate seamless communication. Additionally, the model’s ability to handle regional variations in sign language and its robustness to noise and occlusion, common in real-world scenarios, requires further refinement. The current model is also not optimized for real-time translation, which remains a key challenge for practical deployment. Addressing these aspects will be essential to enhance the framework’s applicability and performance in diverse environments.
5. Conclusions
In this paper, we introduced the open-vocabulary sign language translation (OVSLT) method, a novel approach designed to address the limitations of traditional gloss-based sign language translation (SLT) systems. By leveraging open-vocabulary principles, OVSLT enhances the system’s ability to handle a wide range of sign language terms, including low-frequency and previously unseen signs. Our approach integrates two key modules: the Enhanced Caption Generation and Description (CGD) and Grid Feature Grouping with Advanced Alignment Techniques. The CGD module uses a GPT model, augmented with a Negative Retriever and Semantic Retrieval-Augmented Features (SRAF), to generate precise, contextually relevant textual descriptions of sign gestures. The Grid Feature Grouping module applies advanced techniques such as enhanced contrastive learning, feature-discriminative contrastive loss, and balanced region loss scaling to refine visual feature representations and ensure robust alignment with the generated textual descriptions. Our extensive evaluations on the PHOENIX-14T and CSL-Daily datasets demonstrated that OVSLT achieves ROUGE scores of 29.6% and 30.72%, respectively, outperforming existing baseline models and establishing a new state-of-the-art for sign language translation. These results highlight OVSLT’s ability to effectively generalize across diverse sign language datasets, showcasing its versatility and adaptability to different sign language contexts. Despite these advancements, OVSLT still faces challenges, particularly in translating highly nuanced or culturally specific gestures. Future work will focus on optimizing the model for better efficiency and integrating deeper cultural and contextual understanding to further improve translation quality. Overall, OVSLT marks a significant advancement in the field of sign language translation, offering improved flexibility, scalability, and accuracy. By addressing critical limitations of traditional SLT systems, it paves the way for more inclusive communication technologies, ultimately benefiting the global deaf community and enhancing accessibility.




{kind=link}
{kind=link}