
Geometry-Aware 3D Hand–Object Pose Estimation Under Occlusion via Hierarchical Feature Decoupling


Abstract
1. Introduction
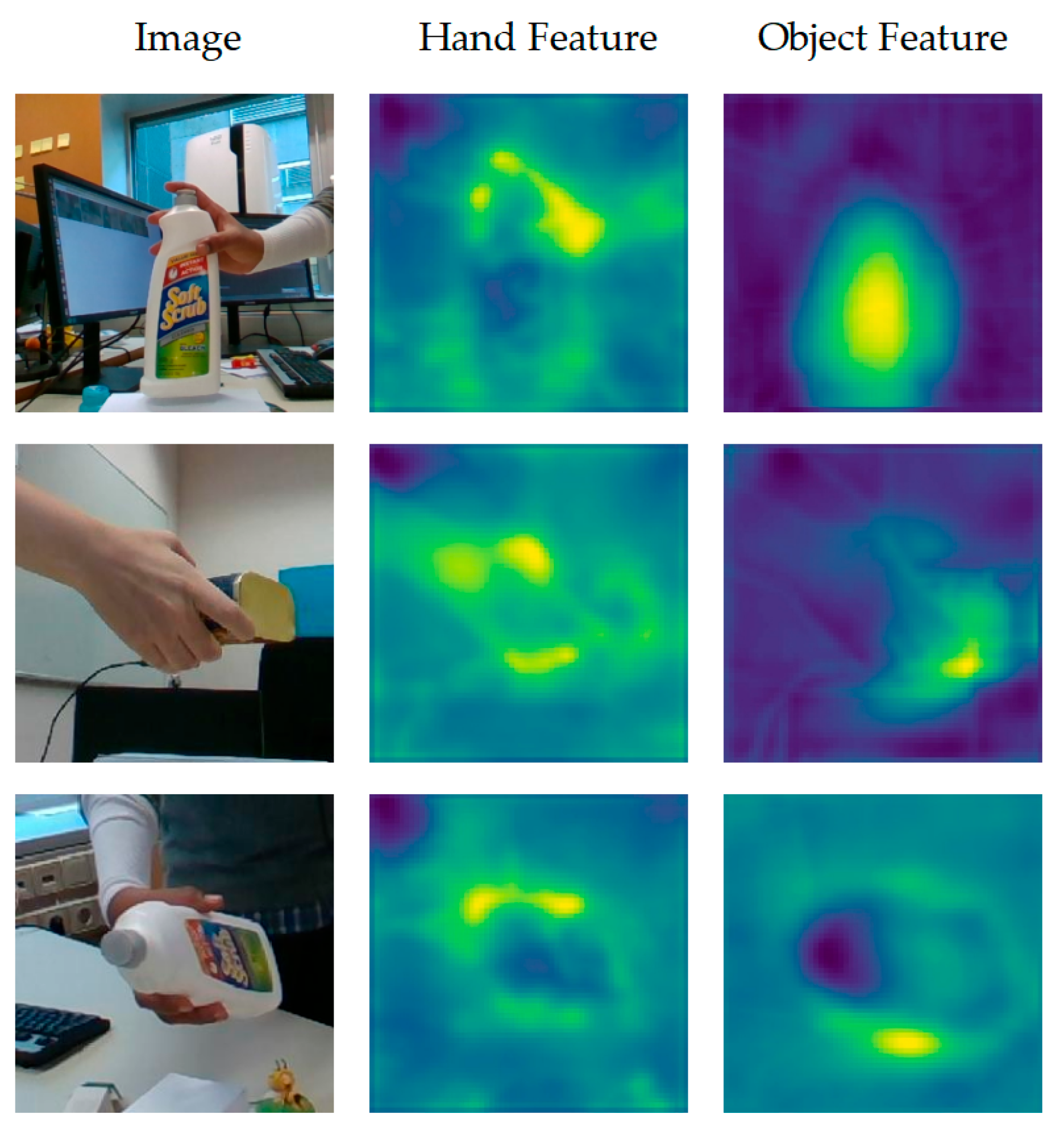
- We propose a novel 3D hand–object pose estimation network that estimates a 3D hand–object pose from a single RGB image. It incorporates a multi-branch feature pyramid, which shares low-level features while dividing high-level features into two branches to extract separate features for the hand and object. While multi-branch networks are widely used in pose estimation, our design explicitly decouples hand and object features based on their physical properties (non-rigid vs. rigid). The shared low-level layers capture interaction contexts, while independent high-level branches refine features tailored to hand articulation and object geometry. This strategy significantly reduces feature contamination under occlusion.
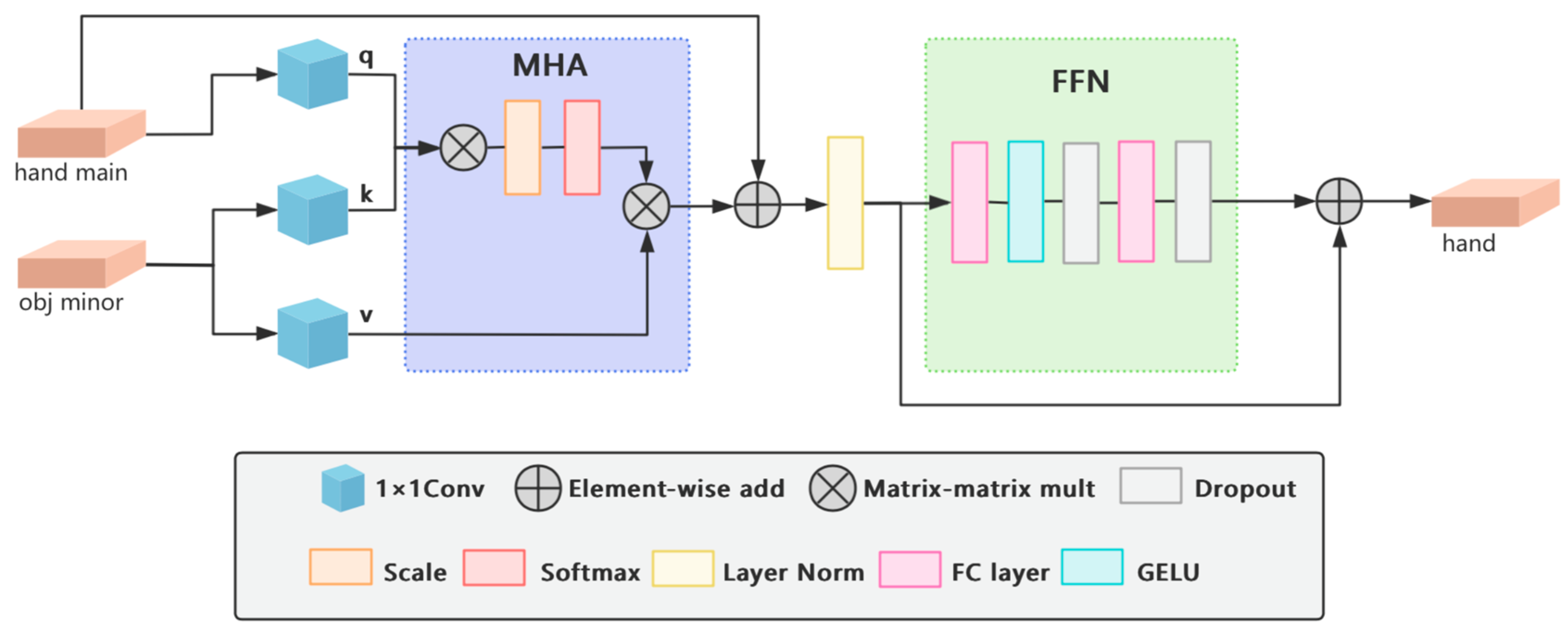
- Because existing attention mechanisms lack geometric constraints for occlusion reasoning, we designed a Hand–Object Cross-Attention Transformer (HOCAT) module, which uniquely integrates the object’s geometric stability as a priori: the rigid object features (key/value) guide the reconstruction of occluded hand regions (query), ensuring physically plausible predictions. This module effectively integrates minor object features into the primary hand features, enhancing the hand features and improving the model’s adaptability to complex occlusion scenarios, as well as its overall task performance.
- Extensive experiments demonstrate that our framework achieves superior performance compared to state-of-the-art 3D hand–object pose estimation methods on datasets of hand–object interactions with significant hand occlusions. On the HO3D V2 dataset, the PAMPJPE reaches 9.1 mm, the PAMPVPE is 9.0 mm, and the F-score reaches 95.8%.
2. Related Work
2.1. Unified Frameworks for Rigid Body, Hand, and Hand Pose Estimation
2.2. Occlusion Challenges and Hand–Object Interaction Modeling
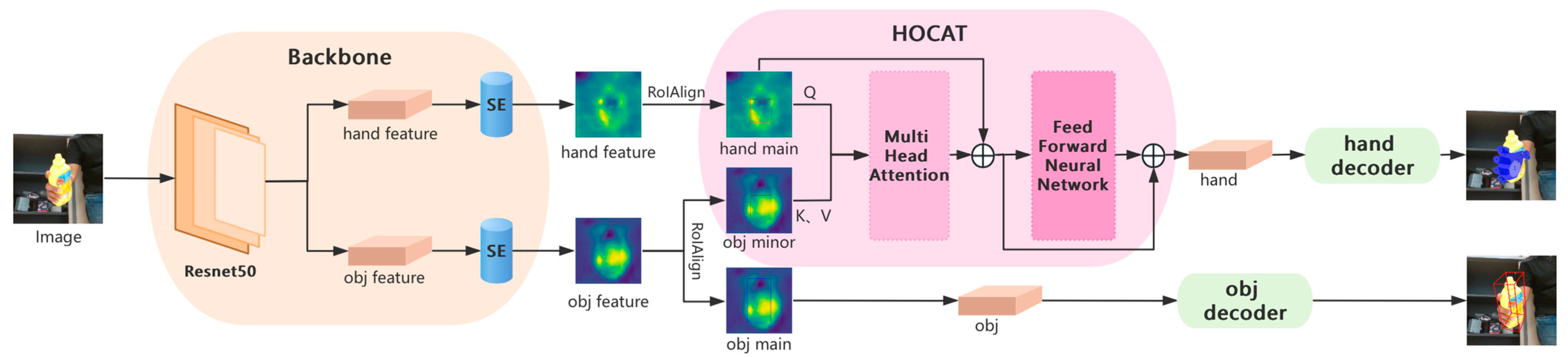
3. Methods
3.1. Backbone
3.2. Hand–Object Cross-Attention Transformer Module
3.3. Regressor
3.4. Loss Function
4. Experiments and Results
4.1. Implementation Details
4.2. Datasets and Evaluation Metrics
4.3. Experimental Results and Analysis
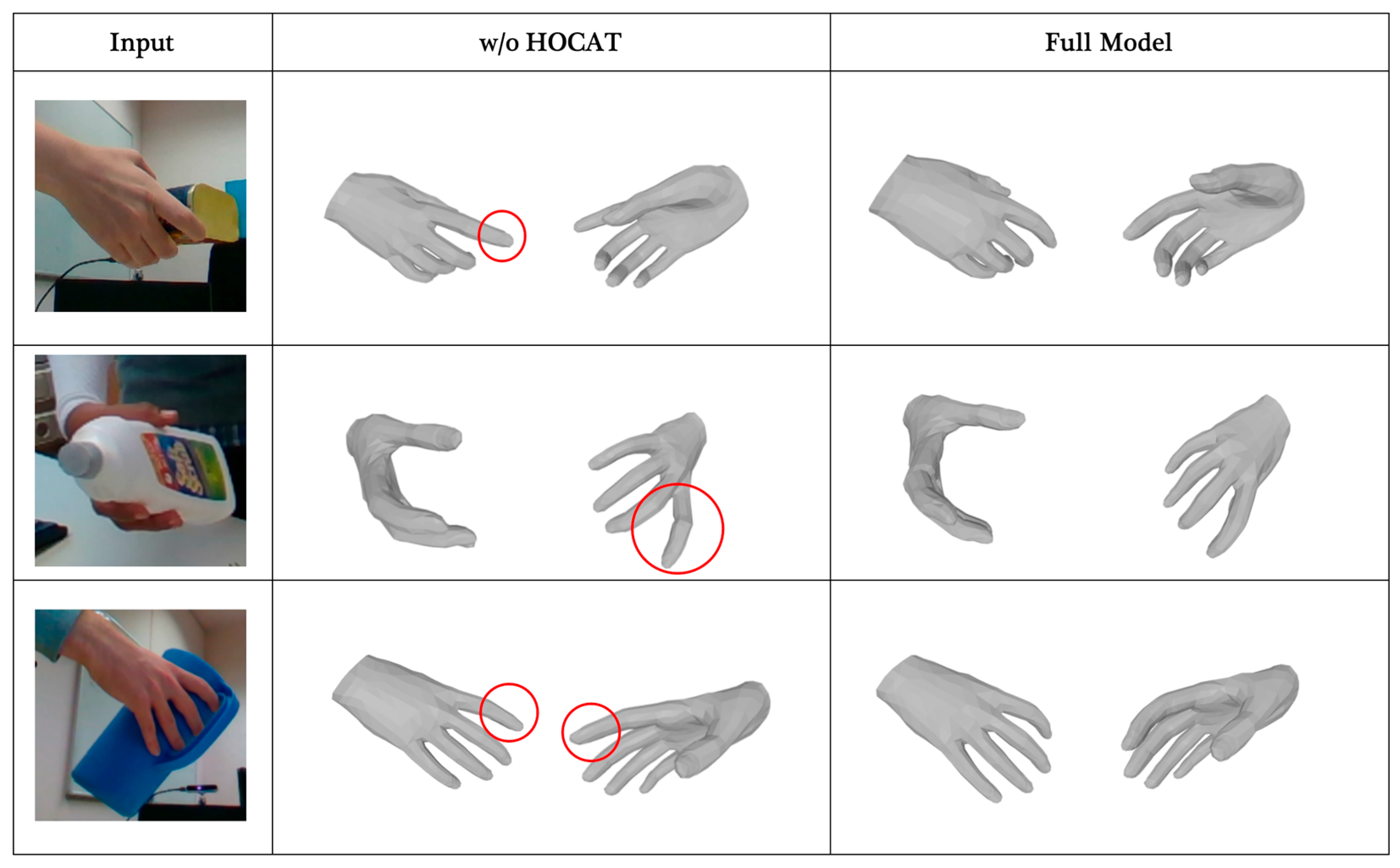
4.4. Ablation Study
4.5. Qualitative Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Huerst, W.; Van Wezel, C. Gesture-based interaction via finger tracking for mobile augmented reality. Multimed. Tools Appl. 2013, 62, 233–258. [Google Scholar] [CrossRef]
- Piumsomboon, T.; Clark, A.; Billinghurst, M.; Cockburn, A.J.A. User-Defined Gestures for Augmented Reality. In CHI’13 Extended Abstracts on Human Factors in Computing Systems; 2013; Available online: https://dl.acm.org/doi/10.1145/2468356.2468527 (accessed on 3 March 2025).
- Chen, P.; Chen, Y.; Yang, D.; Wu, F.; Li, Q.; Xia, Q.; Tan, Y. I2UV-HandNet: Image-to-UV Prediction Network for Accurate and High-fidelity 3D Hand Mesh Modeling. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2021, Montreal, QC, Canada, 17 October 2021. [Google Scholar]
- Zhang, B.; Wang, Y.; Deng, X.; Zhang, Y.; Tan, P.; Ma, C.; Wang, H. Interacting Two-Hand 3D Pose and Shape Reconstruction From Single Color Image. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 17 October 2021. [Google Scholar]
- Sridhar, S.; Feit, A.M.; Theobalt, C.; Oulasvirta, A. Investigating the Dexterity of Multi-Finger Input for Mid-Air Text Entry. In Proceedings of the ACM Conference on Human Factors in Computing Systems, Seoul, Republic of Korea, 18–23 April 2015. [Google Scholar]
- Chen, Y.; Tu, Z.; Kang, D.; Chen, R.; Yuan, J. Joint Hand-Object 3D Reconstruction from a Single Image with Cross-Branch Feature Fusion. IEEE Trans. Image Process. 2021, 30, 4008–4021. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Jiang, H.; Xu, J.; Liu, S.; Wang, X. Semi-Supervised 3D Hand-Object Poses Estimation with Interactions in Time. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, QC, Canada, 17 October 2021. [Google Scholar]
- Tse, T.H.E.; Kim, K.I.; Leonardis, A.; Chang, H.J. Collaborative Learning for Hand and Object Reconstruction with Attention-guided Graph Convolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 24 June 2022. [Google Scholar]
- Hampali, S.; Sarkar, S.D.; Rad, M.; Lepetit, V. Keypoint Transformer: Solving Joint Identification in Challenging Hands and Object Interactions for Accurate 3D Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 24 June 2022. [Google Scholar]
- Hasson, Y.; Tekin, B.; Bogo, F.; Laptev, I.; Pollefeys, M.; Schmid, C. Leveraging Photometric Consistency Over Time for Sparsely Supervised Hand-Object Reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 19 June 2020. [Google Scholar]
- Huang, L.; Tan, J.; Liu, J.; Yuan, J. Hand-Transformer: Non-Autoregressive Structured Modeling for 3D Hand Pose Estimation; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Hampali, S.; Rad, M.; Oberweger, M.; Lepetit, V.J.I. HOnnotate: A Method for 3D Annotation of Hand and Object Poses. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 19 June 2020. [Google Scholar]
- Chao, Y.W.; Yang, W.; Xiang, Y.; Molchanov, P.; Fox, D. DexYCB: A Benchmark for Capturing Hand Grasping of Objects. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 17 October 2021. [Google Scholar]
- Ballan, L.; Taneja, A.; Gall, J.; Gool, L.V.; Pollefeys, M.J.S. Motion Capture of Hands in Action Using Discriminative Salient Points. In Proceedings of the Computer Vision–ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012. [Google Scholar]
- Oikonomidis, I.; Kyriazis, N.; Argyros, A.A. Full DOF tracking of a hand interacting with an object by modeling occlusions and physical constraints. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2088–2095. [Google Scholar]
- Hasson, Y.; Varol, G.; Tzionas, D.; Kalevatykh, I.; Black, M.J.; Laptev, I.; Schmid, C. Learning Joint Reconstruction of Hands and Manipulated Objects. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 19 June 2020. [Google Scholar]
- Karunratanakul, K.; Yang, J.; Zhang, Y.; Black, M.; Tang, S. Grasping Field: Learning Implicit Representations for Human Grasps. In Proceedings of the 2020 International Conference on 3D Vision (3DV), Fukuoka, Japan, 25–28 November 2020. [Google Scholar]
- Tekin, B.; Bogo, F.; Pollefeys, M.J.I. H+O: Unified Egocentric Recognition of 3D Hand-Object Poses and Interactions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Romero, J.; Tzionas, D.; Black, M.J. Embodied Hands: Modeling and Capturing Hands and Bodies Together. arXiv 2022, arXiv:2201.02610. [Google Scholar] [CrossRef]
- Boukhayma, A.; Bem, R.D.; Torr, P.H.S. 3D Hand Shape and Pose From Images in the Wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Chen, Y.; Tu, Z.; Kang, D.; Bao, L.; Zhang, Y.; Zhe, X.; Chen, R.; Yuan, J. Model-based 3D Hand Reconstruction via Self-Supervised Learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 17 October 2021. [Google Scholar]
- Baek, S.; Kim, K.I.; Kim, T.K. Pushing the Envelope for RGB-Based Dense 3D Hand Pose Estimation via Neural Rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Moon, G.; Lee, K.M. I2L-MeshNet: Image-to-Lixel Prediction Network for Accurate 3D Human Pose and Mesh Estimation from a Single RGB Image. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Lin, K.; Wang, L.; Liu, Z. End-to-End Human Pose and Mesh Reconstruction with Transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 17 October 2021. [Google Scholar]
- Lin, K.; Wang, L.; Liu, Z. Mesh Graphormer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 17 October 2021. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J.J.I. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42, 386–397. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J.J.S.I.P. Stacked Hourglass Networks for Human Pose Estimation. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Zhang, X.; Li, Q.; Mo, H.; Zhang, W.; Zheng, W. End-to-end Hand Mesh Recovery from a Monocular RGB Image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Paszke, A.; Lerer, A.; Killeen, T.; Antiga, L.; Yang, E.; Tejani, A.; Fang, L.; Gross, S.; Bradbury, J.; Lin, Z. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems 32, Volume 11 of 20: 32nd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, CA, Canada, 8–14 December 2019. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Li, K.; Yang, L.; Zhan, X.; Lv, J.; Xu, W.; Li, J.; Lu, C. ArtiBoost: Boosting Articulated 3D Hand-Object Pose Estimation via Online Exploration and Synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 17 October 2021. [Google Scholar]
- Chen, X.; Liu, Y.; Dong, Y.; Zhang, X.; Ma, C.; Xiong, Y.; Zhang, Y.; Guo, X. MobRecon: Mobile-Friendly Hand Mesh Reconstruction from Monocular Image. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 17 October 2021. [Google Scholar]
- Aboukhadra, A.T.; Malik, J.N.; Elhayek, A.; Robertini, N.; Stricker, D. THOR-Net: End-to-end Graformer-based Realistic Two Hands and Object Reconstruction with Self-supervision. In Proceedings of the IEEE/cvf Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 8 January 2022; pp. 1001–1010. [Google Scholar]
- Fu, Q.; Liu, X.; Xu, R.; Niebles, J.C.; Kitani, K. Deformer: Dynamic Fusion Transformer for Robust Hand Pose Estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 23543–23554. [Google Scholar]
- Qi, H.; Zhao, C.; Salzmann, M.; Mathis, A. HOISDF: Constraining 3D Hand-Object Pose Estimation with Global Signed Distance Fields. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024; pp. 10392–10402. [Google Scholar]
- Spurr, A.; Iqbal, U.; Molchanov, P.; Hilliges, O.; Kautz, J. Weakly Supervised 3D Hand Pose Estimation via Biomechanical Constraints. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Xu, H.; Wang, T.; Tang, X.; Fu, C. H2ONet: Hand-Occlusion-and-Orientation-Aware Network for Real-Time 3D Hand Mesh Reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 17048–17058. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | PAMPJPE ↓ | PAMPVPE ↓ | F@5 ↑ | F@15 ↑ | Object |
|---|---|---|---|---|---|
| Hasson et al. [10] | 11.4 | 11.4 | 42.8 | 93.2 | Yes |
| I2L-MeshNet [23] | 11.2 | 13.9 | 40.9 | 93.2 | No |
| Hasson et al. [16] | 11.0 | 11.2 | 46.4 | 93.9 | Yes |
| Hampali et al. [12] | 10.7 | 10.6 | 50.6 | 94.2 | Yes |
| METRO [24] | 10.4 | 11.1 | 48.4 | 94.6 | No |
| Liu et al. [7] | 10.1 | 9.7 | 53.2 | 95.2 | Yes |
| ArtiBoost [35] | 11.4 | 10.9 | 48.8 | 94.4 | Yes |
| KeypointTrans [9] | 10.8 | - | - | - | Yes |
| MobRecon [36] | 9.2 | 9.4 | 53.8 | 95.7 | No |
| THOR-Net [37] | 11.3 | - | - | - | Yes |
| Deformer [38] | 9.4 | 9.1 | 54.6 | 96.3 | No |
| HOISDF [39] | 9.6 | - | - | - | Yes |
| Ours | 9.1 | 9.0 | 56.6 | 95.8 | Yes |
| Methods | Cleanser ↑ | Bottle ↑ | Can ↑ | Average ↑ |
|---|---|---|---|---|
| Liu et al. [7] | 88.1 | 61.9 | 53.0 | 67.7 |
| Ours | 93.4 | 40.6 | 48.5 | 60.8 |
| Methods | MPJPE ↓ | PAMPJPE ↓ | Object |
|---|---|---|---|
| Spurr et al. [40] | 17.3 | 6.83 | No |
| METRO [24] | 15.2 | 6.99 | No |
| Liu et al. [7] | 15.2 | 6.58 | Yes |
| MobRecon [36] | 14.2 | 6.40 | No |
| Xu et al. [41] | 14.0 | 5.70 | No |
| Ours | 13.7 | 5.65 | Yes |
| Methods Metrics in [mm] | ADD-0.1d ↑ | |
|---|---|---|
| Liu et al. [7] | Ours | |
| master chef can | 34.2 | 26.4 |
| cracker box | 56.4 | 73.2 |
| sugar box | 42.4 | 44.8 |
| tomato soup can | 17.1 | 10.3 |
| mustard bottle | 44.3 | 53.6 |
| tuna fish can | 11.9 | 7.4 |
| pudding box | 36.4 | 32.7 |
| gelatin box | 25.6 | 25.6 |
| potted meat can | 21.9 | 23.9 |
| banana | 16.4 | 21.2 |
| pitcher base | 36.9 | 44.1 |
| bleach cleanser | 46.9 | 48.0 |
| bowl | 30.2 | 32.9 |
| mug | 18.5 | 15.1 |
| power drill | 36.6 | 47.8 |
| wood block | 38.5 | 44.0 |
| scissors | 12.9 | 13.2 |
| large marker | 2.8 | 2.5 |
| extra large clamp | 38.9 | 42.0 |
| foam brick | 27.5 | 27.8 |
| average | 29.8 | 31.8 |
| Architectures | PAMPJPE ↓ | PAMPVPE ↓ | F@5 ↑ | F@15 ↑ | Inference Time (s) | FPS | Number of Parameters (MB) |
|---|---|---|---|---|---|---|---|
| Baseline | 11.0 | 10.9 | 48.3 | 93.5 | 0.164 | 6.43 | 118.1 |
| w/o HOCAT | 10.1 | 10.0 | 51.9 | 94.5 | 0.152 | 6.59 | 131.6 |
| Ours | 9.1 | 9.0 | 56.6 | 95.8 | 0.151 | 6.61 | 142.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cai, Y.; Pan, H.; Yang, J.; Liu, Y.; Gao, Q.; Wang, X. Geometry-Aware 3D Hand–Object Pose Estimation Under Occlusion via Hierarchical Feature Decoupling. Electronics 2025, 14, 1029. https://doi.org/10.3390/electronics14051029
Cai Y, Pan H, Yang J, Liu Y, Gao Q, Wang X. Geometry-Aware 3D Hand–Object Pose Estimation Under Occlusion via Hierarchical Feature Decoupling. Electronics. 2025; 14(5):1029. https://doi.org/10.3390/electronics14051029
Chicago/Turabian StyleCai, Yuting, Huimin Pan, Jiayi Yang, Yichen Liu, Quanli Gao, and Xihan Wang. 2025. "Geometry-Aware 3D Hand–Object Pose Estimation Under Occlusion via Hierarchical Feature Decoupling" Electronics 14, no. 5: 1029. https://doi.org/10.3390/electronics14051029
APA StyleCai, Y., Pan, H., Yang, J., Liu, Y., Gao, Q., & Wang, X. (2025). Geometry-Aware 3D Hand–Object Pose Estimation Under Occlusion via Hierarchical Feature Decoupling. Electronics, 14(5), 1029. https://doi.org/10.3390/electronics14051029