
Designing Spiking Neural Network-Based Reinforcement Learning for 3D Robotic Arm Applications


Abstract
1. Introduction
- The first attempt to mimic human arm movements using SNN-based RL.
- The first implementation of 3D target-reaching tasks using SNN-based TD3.
2. Related Work
3. Materials and Methods
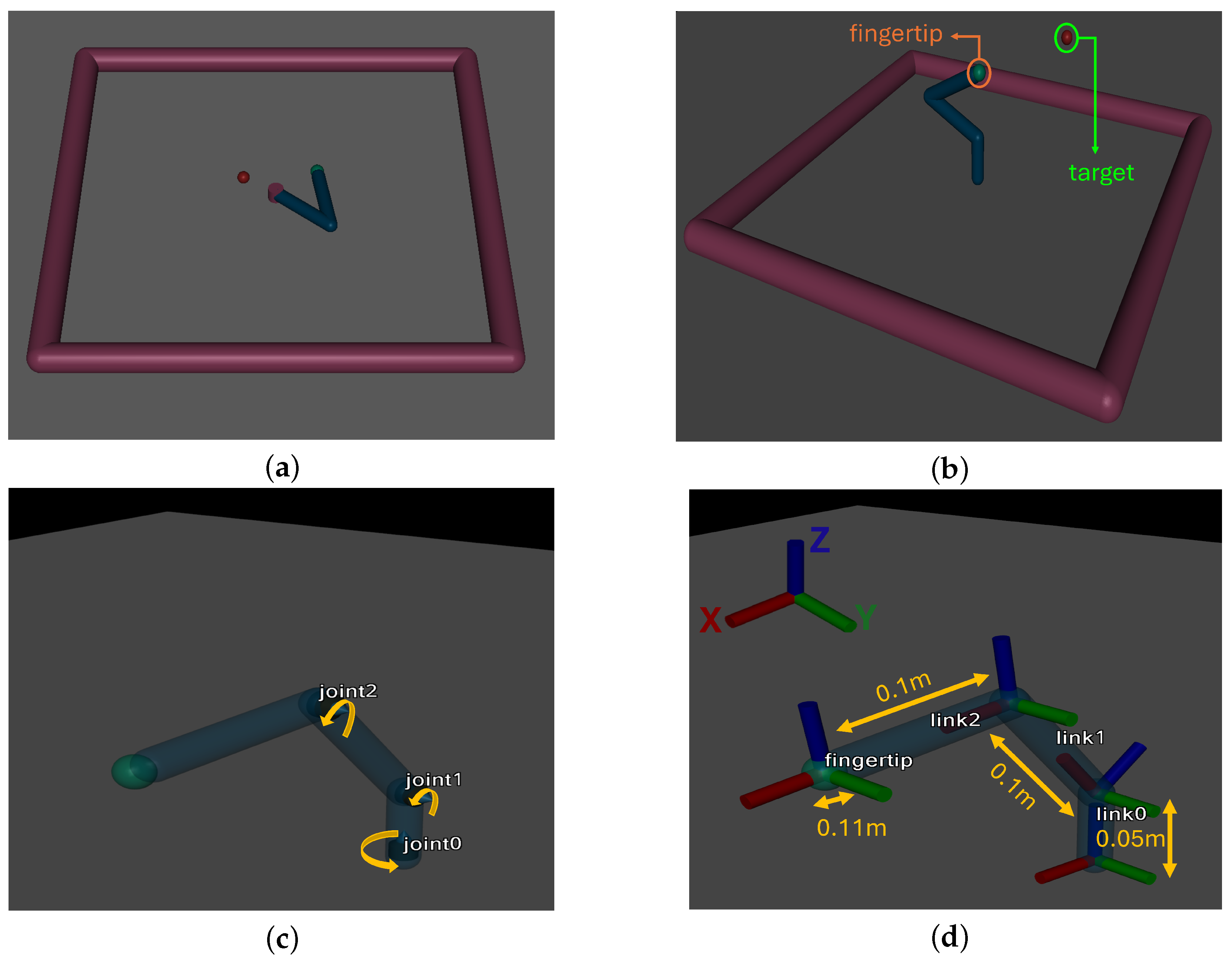
3.1. Robotic Arm Design
- Joint 1: Rotation in the Z-axis (vertical axis).
- Joint 2, 3: Rotation in the Y-axis (horizontal axis).
- A vertical base link of 0.05 m.
- Two horizontal links of 0.1 m in length.
- A fingertip with a diameter of 0.11 m.
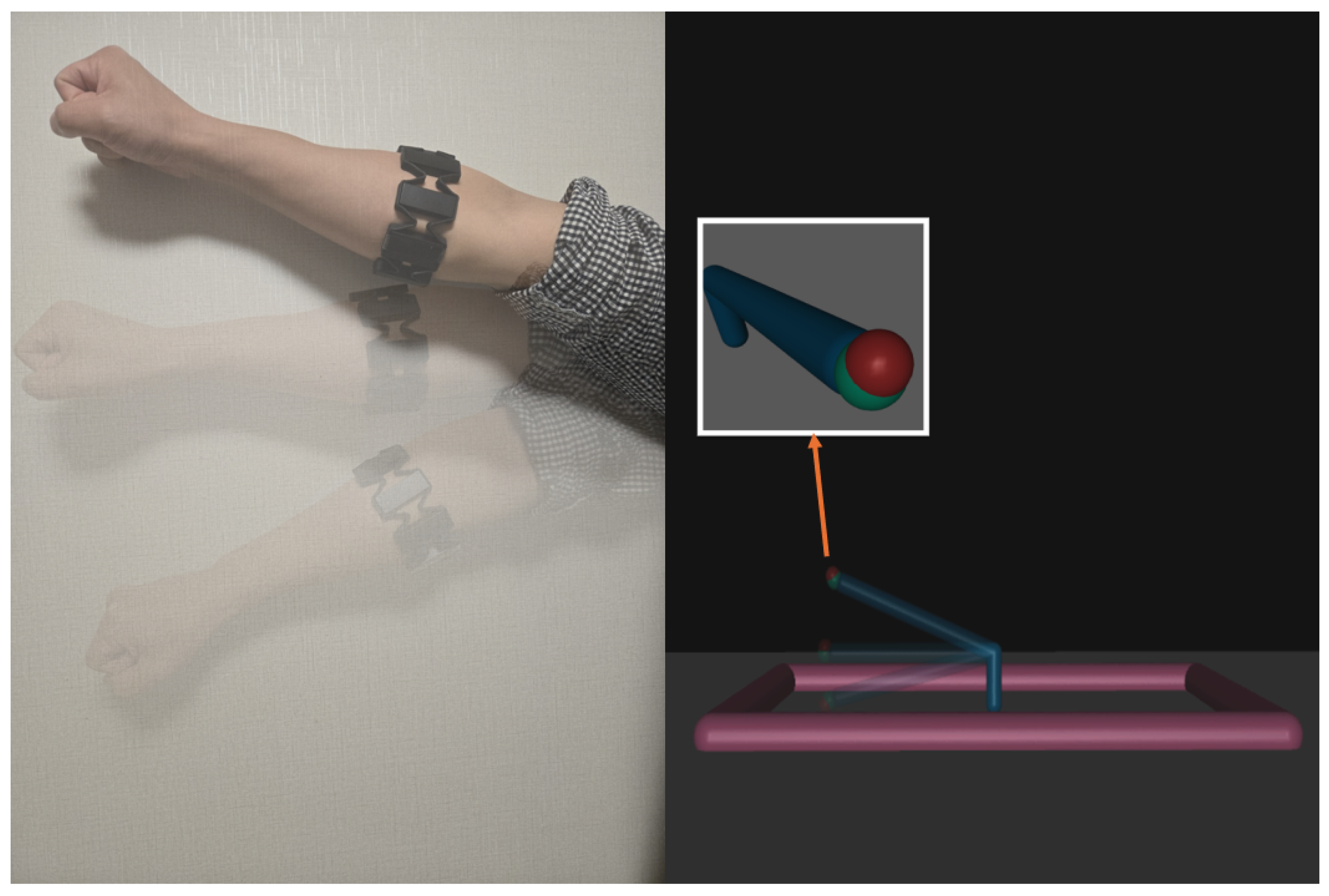
3.2. Simulation Environment
- DoF Expansion: The arm was redesigned for 3D movements adding an additional degree of freedom.
- Target Positioning: The target points are randomly generated within the workspace using spherical coordinates and are positioned to remain within the robot arm’s maximum reach.
- Reward System: Distance-based rewards are refined to vary based on the distance to the target, with additional weighted adjustments applied upon reaching the target depending on collision status and proximity.
- Collision Logic: Collisions between the ground and the robot arm’s links, as well as between the links themselves, are detected and penalized accordingly.
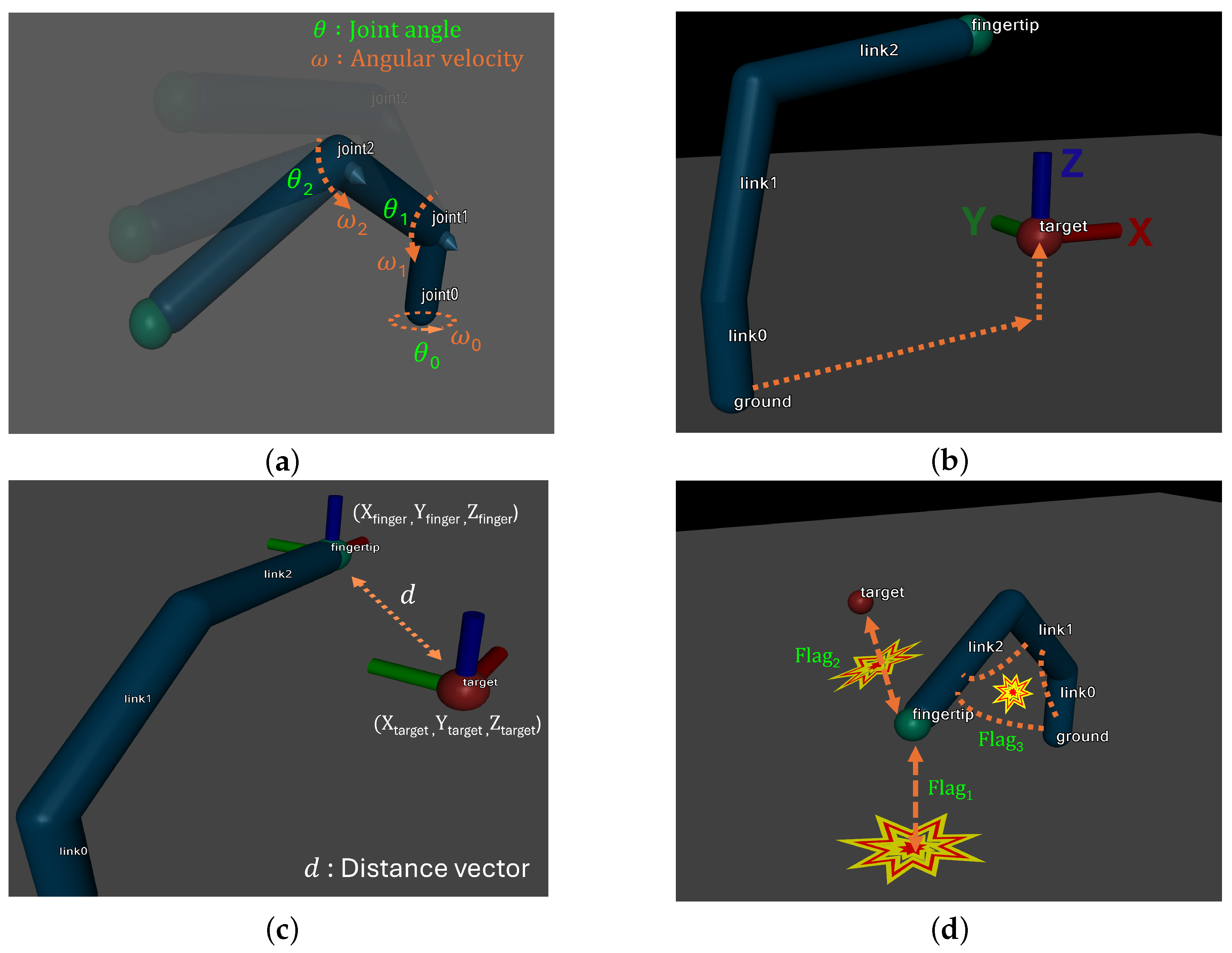
- Cosine and sine of joint angles.
- Joint angular velocities.
- Target’s x, y, and z coordinates.
- Distance vector between the fingertip and the target.
- Flag indicating collision with the ground.
- Flag indicating collision between links.
- Flag indicating whether the goal has been reached.
3.3. Reward Function Design for Target Reaching
- Ignoring collisions: The existing reward function does not account for collisions between the robot and other objects in the environment (e.g., the ground or its own links), which might undermine the robot’s stability in realistic scenarios.
- Lack of clarity in goal achievement: The reward function lacks clear criteria for determining whether the goal has been successfully reached, leading to potential instability in learning even after the goal is achieved.
- Collision Reward: To detect and address collisions, the system identifies collision states within the environment and applies penalties or rewards accordingly. Penalties are imposed when the robot collides with the ground or when self-collisions occur between links, thereby reinforcing the stability of the robot’s movements.
- Target-reaching Reward: Rewards are assigned proportionally based on the distance to the target, with higher rewards provided for closer proximity. After reaching the target, additional rewards or penalties are applied depending on the presence or absence of collisions, ensuring the robot maintains a stable state after achieving the goal.
4. Experimental Results
4.1. Experimental Settings
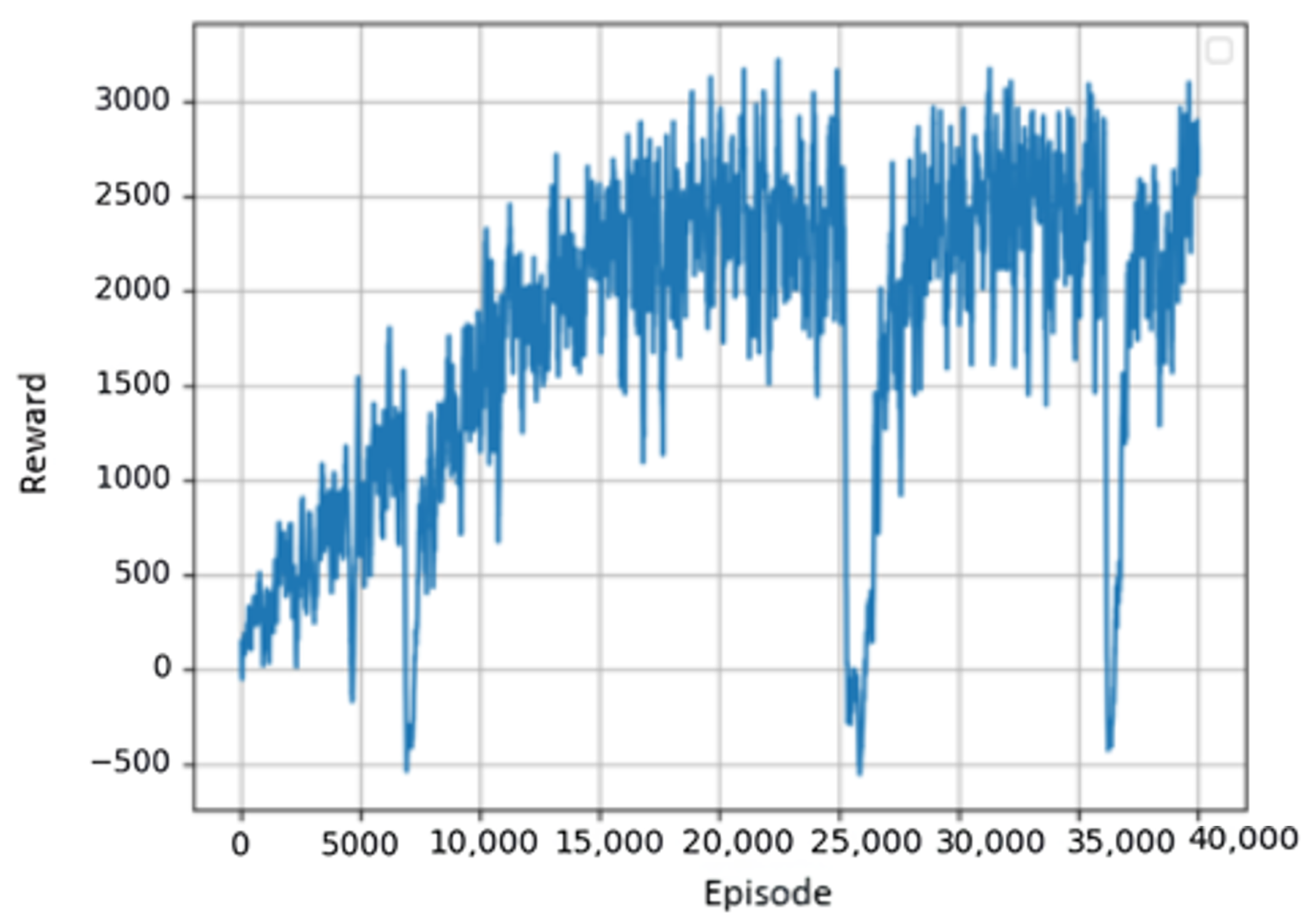
4.2. Training and Testing Results for the Target-Reaching Task
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Akanyeti, O.; Nehmzow, U.; Billings, S.A. Robot training using system identification. Robot. Auton. Syst. 2008, 56, 1027–1041. [Google Scholar] [CrossRef]
- Mompó Alepuz, A.; Papageorgiou, D.; Tolu, S. Brain-inspired biomimetic robot control: A review. Front. Neurorobot. 2024, 18, 1395617. [Google Scholar] [CrossRef] [PubMed]
- Gulletta, G.; Erlhagen, W.; Bicho, E. Human-like arm motion generation: A review. Robotics 2020, 9, 102. [Google Scholar] [CrossRef]
- Shim, S.; Kim, J.Y.; Hwang, S.W.; Oh, J.M.; Kim, B.K.; Park, J.H.; Hyun, D.J.; Lee, H. A comprehensive review of cyber-physical system (CPS)-based approaches to robot services. IEIE Trans. Smart Process. Comput. 2024, 13, 69–80. [Google Scholar] [CrossRef]
- Kim, S.; Kim, C.; Park, J.H. Human-like arm motion generation for humanoid robots using motion capture database. In Proceedings of the 2006 IEEE/RSJ International Conference on Intelligent Robots and Systems, Beijing, China, 9–15 October 2006; pp. 3486–3491. [Google Scholar]
- Lee, K.; Shin, U.; Lee, B.U. Learning to Control Camera Exposure via Reinforcement Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 2975–2983. [Google Scholar]
- Schabron, B.; Reust, A.; Desai, J.; Yihun, Y. Integration of forearm sEMG signals with IMU sensors for trajectory planning and control of assistive robotic arm. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 5274–5277. [Google Scholar]
- Ghadge, K.; More, S.; Gaikwad, P.; Chillal, S. Robotic arm for pick and place application. Int. J. Mech. Eng. Technol. 2018, 9, 125–133. [Google Scholar]
- Shih, C.L.; Lee, Y. A simple robotic eye-in-hand camera positioning and alignment control method based on parallelogram features. Robotics 2018, 7, 31. [Google Scholar] [CrossRef]
- Marwan, Q.M.; Chua, S.C.; Kwek, L.C. Comprehensive review on reaching and grasping of objects in robotics. Robotica 2021, 39, 1849–1882. [Google Scholar] [CrossRef]
- Kucuk, S.; Bingul, Z. Robot Kinematics: Forward and Inverse Kinematics; INTECH Open Access Publisher: London, UK, 2006. [Google Scholar]
- Slim, M.; Rokbani, N.; Neji, B.; Terres, M.A.; Beyrouthy, T. Inverse kinematic solver based on bat algorithm for robotic arm path planning. Robotics 2023, 12, 38. [Google Scholar] [CrossRef]
- Csiszar, A.; Eilers, J.; Verl, A. On solving the inverse kinematics problem using neural networks. In Proceedings of the 2017 24th International Conference on Mechatronics and Machine Vision in Practice (M2VIP), Auckland, New Zealand, 21–23 November 2017; pp. 1–6. [Google Scholar]
- Bensadoun, R.; Gur, S.; Blau, N.; Wolf, L. Neural inverse kinematic. In Proceedings of the International Conference on Machine Learning, PMLR, Baltimore, MD, USA, 17–23 July 2022; pp. 1787–1797. [Google Scholar]
- De Momi, E.; Kranendonk, L.; Valenti, M.; Enayati, N.; Ferrigno, G. A neural network-based approach for trajectory planning in robot—Human handover tasks. Front. Robot. AI 2016, 3, 34. [Google Scholar] [CrossRef]
- Gu, S.; Holly, E.; Lillicrap, T.P.; Levine, S. Deep reinforcement learning for robotic manipulation. arXiv 2016, arXiv:1610.00633. [Google Scholar]
- D’Souza, A.; Vijayakumar, S.; Schaal, S. Learning inverse kinematics. In Proceedings of the 2001 IEEE/RSJ International Conference on Intelligent Robots and Systems. Expanding the Societal Role of Robotics in the the Next Millennium (Cat. No. 01CH37180), Maui, HI, USA, 29 October–3 November 2001; Volume 1, pp. 298–303. [Google Scholar]
- Zhao, C.; Wei, Y.; Xiao, J.; Sun, Y.; Zhang, D.; Guo, Q.; Yang, J. Inverse kinematics solution and control method of 6-degree-of-freedom manipulator based on deep reinforcement learning. Sci. Rep. 2024, 14, 12467. [Google Scholar] [CrossRef] [PubMed]
- Zhong, J.; Wang, T.; Cheng, L. Collision-free path planning for welding manipulator via hybrid algorithm of deep reinforcement learning and inverse kinematics. Complex Intell. Syst. 2022, 8, 1899–1912. [Google Scholar] [CrossRef]
- Yu, S.; Tan, G. Inverse Kinematics of a 7-Degree-of-Freedom Robotic Arm Based on Deep Reinforcement Learning and Damped Least Squares. IEEE Access 2024, 13, 4857–4868. [Google Scholar] [CrossRef]
- Lin, G.; Huang, P.; Wang, M.; Xu, Y.; Zhang, R.; Zhu, L. An inverse kinematics solution for a series-parallel hybrid banana-harvesting robot based on deep reinforcement learning. Agronomy 2022, 12, 2157. [Google Scholar] [CrossRef]
- Yoon, Y.K.; Park, K.H.; Shim, D.W.; Han, S.H.; Lee, J.W.; Jung, M. Robotic-assisted foot and ankle surgery: A review of the present status and the future. Biomed. Eng. Lett. 2023, 13, 571–577. [Google Scholar] [CrossRef]
- Lee, Y.-S. Approach to smart mobility intelligent traffic signal system based on distributed deep reinforcement learning. IEIE Trans. Smart Process. Comput. 2024, 13, 89–95. [Google Scholar] [CrossRef]
- Mohammed, M.Q.; Chung, K.L.; Chyi, C.S. Review of deep reinforcement learning-based object grasping: Techniques, open challenges, and recommendations. IEEE Access 2020, 8, 178450–178481. [Google Scholar] [CrossRef]
- Liu, Y.C.; Huang, C.Y. DDPG-based adaptive robust tracking control for aerial manipulators with decoupling approach. IEEE Trans. Cybern. 2021, 52, 8258–8271. [Google Scholar] [CrossRef]
- Dong, Y.; Zou, X. Mobile robot path planning based on improved DDPG reinforcement learning algorithm. In Proceedings of the 2020 IEEE 11th International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 16–18 October 2020; pp. 52–56. [Google Scholar]
- Gong, H.; Wang, P.; Ni, C.; Cheng, N. Efficient path planning for mobile robot based on deep deterministic policy gradient. Sensors 2022, 22, 3579. [Google Scholar] [CrossRef]
- Naya, K.; Kutsuzawa, K.; Owaki, D.; Hayashibe, M. Spiking neural network discovers energy-efficient hexapod motion in deep reinforcement learning. IEEE Access 2021, 9, 150345–150354. [Google Scholar] [CrossRef]
- Tang, G.; Kumar, N.; Michmizos, K.P. Reinforcement co-learning of deep and spiking neural networks for energy-efficient mapless navigation with neuromorphic hardware. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October–24 January 2020; pp. 6090–6097. [Google Scholar]
- Tang, G.; Kumar, N.; Yoo, R.; Michmizos, K. Deep reinforcement learning with population-coded spiking neural network for continuous control. In Proceedings of the Conference on Robot Learning, PMLR, London, UK, 8–11 November 2021; pp. 2016–2029. [Google Scholar]
- Tavanaei, A.; Ghodrati, M.; Kheradpisheh, S.R.; Masquelier, T.; Maida, A. Deep learning in spiking neural networks. Neural Netw. 2019, 111, 47–63. [Google Scholar] [CrossRef] [PubMed]
- Tang, G.; Shah, A.; Michmizos, K.P. Spiking neural network on neuromorphic hardware for energy-efficient unidimensional slam. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 4176–4181. [Google Scholar]
- Yamazaki, K.; Vo-Ho, V.K.; Bulsara, D.; Le, N. Spiking neural networks and their applications: A review. Brain Sci. 2022, 12, 863. [Google Scholar] [CrossRef] [PubMed]
- Kim, E.; Kim, Y. Exploring the potential of spiking neural networks in biomedical applications: Advantages, limitations, and future perspectives. Biomed. Eng. Lett. 2024, 14, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Balakrishnan, P.; Baskaran, B.; Vivekanan, S.; Gokul, P. Binarized spiking neural networks optimized with color harmony algorithm for liver cancer classification. IEIE Trans. Smart Process. Comput. 2023, 12, 502–510. [Google Scholar] [CrossRef]
- Oikonomou, K.M.; Kansizoglou, I.; Gasteratos, A. A framework for active vision-based robot planning using spiking neural networks. In Proceedings of the 2022 30th Mediterranean Conference on Control and Automation (MED), Vouliagmeni, Greece, 28 June–1 July 2022; pp. 867–871. [Google Scholar]
- Oikonomou, K.M.; Kansizoglou, I.; Gasteratos, A. A hybrid spiking neural network reinforcement learning agent for energy-efficient object manipulation. Machines 2023, 11, 162. [Google Scholar] [CrossRef]
- Oikonomou, K.M.; Kansizoglou, I.; Gasteratos, A. A hybrid reinforcement learning approach with a spiking actor network for efficient robotic arm target reaching. IEEE Robot. Autom. Lett. 2023, 8, 3007–3014. [Google Scholar] [CrossRef]
- Dankwa, S.; Zheng, W. Twin-delayed ddpg: A deep reinforcement learning technique to model a continuous movement of an intelligent robot agent. In Proceedings of the 3rd International Conference on Vision, Image and Signal Processing, Vancouver, BC, Canada, 26–28 August 2019; pp. 1–5. [Google Scholar]
- Yang, X.; Song, J.; Zhang, X.; Wang, D. Adaptive Spiking TD3+ BC for Offline-to-Online Spiking Reinforcement Learning. In Proceedings of the 2024 International Joint Conference on Neural Networks (IJCNN), Yokohama, Japan, 30 June–5 July 2024; pp. 1–6. [Google Scholar]
- Akl, M.; Ergene, D.; Walter, F.; Knoll, A. Toward robust and scalable deep spiking reinforcement learning. Front. Neurorobot. 2023, 16, 1075647. [Google Scholar] [CrossRef]
- Xie, B.; Zhao, J.; Liu, Y. Human-like motion planning for robotic arm system. In Proceedings of the 2011 15th International Conference on Advanced Robotics (ICAR), Tallinn, Estonia, 20–23 June 2011; pp. 88–93. [Google Scholar]
- Rosado, J.; Silva, F.; Santos, V.; Lu, Z. Reproduction of human arm movements using Kinect-based motion capture data. In Proceedings of the 2013 IEEE International Conference on Robotics and Biomimetics (ROBIO), Shenzhen, China, 12–14 December 2013; pp. 885–890. [Google Scholar]
- Zhao, J.; Xie, B.; Song, C. Generating human-like movements for robotic arms. Mech. Mach. Theory 2014, 81, 107–128. [Google Scholar] [CrossRef]
- Shin, S.Y.; Kim, C. Human-like motion generation and control for humanoid’s dual arm object manipulation. IEEE Trans. Ind. Electron. 2014, 62, 2265–2276. [Google Scholar] [CrossRef]
- Zhao, J.; Monforte, M.; Indiveri, G.; Bartolozzi, C.; Donati, E. Learning inverse kinematics using neural computational primitives on neuromorphic hardware. NPJ Robot. 2023, 1, 1. [Google Scholar] [CrossRef]
- Liu, Z.; Hu, F.; Luo, D.; Wu, X. Learning arm movements of target reaching for humanoid robot. In Proceedings of the 2015 IEEE International Conference on Information and Automation, Lijiang, China, 8–10 August 2015; pp. 707–713. [Google Scholar]
- Nobre, F.; Heckman, C. Learning to calibrate: Reinforcement learning for guided calibration of visual–inertial rigs. Int. J. Robot. Res. 2019, 38, 1388–1402. [Google Scholar] [CrossRef]
- Ahmed, M.H.; Kutsuzawa, K.; Hayashibe, M. Transhumeral arm reaching motion prediction through deep reinforcement learning-based synthetic motion cloning. Biomimetics 2023, 8, 367. [Google Scholar] [CrossRef] [PubMed]
- Bouganis, A.; Shanahan, M. Training a spiking neural network to control a 4-dof robotic arm based on spike timing-dependent plasticity. In Proceedings of the The 2010 International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010; pp. 1–8. [Google Scholar]
- Chen, X.; Zhu, W.; Dai, Y.; Ren, Q. A bio-inspired spiking neural network for control of a 4-dof robotic arm. In Proceedings of the 2020 15th IEEE Conference on Industrial Electronics and Applications (ICIEA), Kristiansand, Norway, 9–13 November 2020; pp. 616–621. [Google Scholar]
- Tieck, J.C.V.; Steffen, L.; Kaiser, J.; Roennau, A.; Dillmann, R. Controlling a robot arm for target reaching without planning using spiking neurons. In Proceedings of the 2018 IEEE 17th International Conference on Cognitive Informatics & Cognitive Computing (ICCI* CC), Berkeley, CA, USA, 16–18 July 2018; pp. 111–116. [Google Scholar]
- Hulea, M.; Uleru, G.I.; Caruntu, C.F. Adaptive SNN for anthropomorphic finger control. Sensors 2021, 21, 2730. [Google Scholar] [CrossRef]
- Volinski, A.; Zaidel, Y.; Shalumov, A.; DeWolf, T.; Supic, L.; Tsur, E.E. Data-driven artificial and spiking neural networks for inverse kinematics in neurorobotics. Patterns 2022, 3, 100391. [Google Scholar] [CrossRef]
- Zahra, O.; Tolu, S.; Navarro-Alarcon, D. Differential mapping spiking neural network for sensor-based robot control. Bioinspir. Biomimetics 2021, 16, 036008. [Google Scholar] [CrossRef]
- Polykretis, I.; Supic, L.; Danielescu, A. Bioinspired smooth neuromorphic control for robotic arms. Neuromorphic Comput. Eng. 2023, 3, 014013. [Google Scholar] [CrossRef]
- Tieck, J.C.V.; Becker, P.; Kaiser, J.; Peric, I.; Akl, M.; Reichard, D.; Roennau, A.; Dillmann, R. Learning target reaching motions with a robotic arm using brain-inspired dopamine modulated STDP. In Proceedings of the 2019 IEEE 18th International Conference on Cognitive Informatics & Cognitive Computing (ICCI* CC), Milan, Italy, 23–25 July 2019; pp. 54–61. [Google Scholar]
- Juarez-Lora, A.; Ponce-Ponce, V.H.; Sossa, H.; Rubio-Espino, E. R-STDP spiking neural network architecture for motion control on a changing friction joint robotic arm. Front. Neurorobot. 2022, 16, 904017. [Google Scholar] [CrossRef]
- Neftci, E.O.; Mostafa, H.; Zenke, F. Surrogate gradient learning in spiking neural networks: Bringing the power of gradient-based optimization to spiking neural networks. IEEE Signal Process. Mag. 2019, 36, 51–63. [Google Scholar] [CrossRef]
- Matheron, G.; Perrin, N.; Sigaud, O. The problem with DDPG: Understanding failures in deterministic environments with sparse rewards. arXiv 2019, arXiv:1911.11679. [Google Scholar]
- Brockman, G. OpenAI Gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- Towers, M.; Kwiatkowski, A.; Terry, J.; Balis, J.U.; De Cola, G.; Deleu, T.; Goulão, M.; Kallinteris, A.; Krimmel, M.; KG, A.; et al. Gymnasium: A standard interface for reinforcement learning environments. arXiv 2024, arXiv:2407.17032. [Google Scholar]
- Zenke, F. SpyTorch (v0.3). 2019. Available online: https://zenodo.org/records/3724018 (accessed on 27 January 2025).
- Todorov, E.; Erez, T.; Tassa, Y. Mujoco: A physics engine for model-based control. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 5026–5033. [Google Scholar]
- Pérez-Carrasco, J.A.; Zhao, B.; Serrano, C.; Acha, B.; Serrano-Gotarredona, T.; Chen, S.; Linares-Barranco, B. Mapping from frame-driven to frame-free event-driven vision systems by low-rate rate coding and coincidence processing–application to feedforward ConvNets. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2706–2719. [Google Scholar] [CrossRef] [PubMed]
- Akl, M.; Sandamirskaya, Y.; Ergene, D.; Walter, F.; Knoll, A. Fine-tuning deep reinforcement learning policies with r-stdp for domain adaptation. In Proceedings of the International Conference on Neuromorphic Systems 2022, Knoxville, TN, USA, 27–29 July 2022; pp. 1–8. [Google Scholar]
- Burkitt, A.N. A review of the integrate-and-fire neuron model: I. Homogeneous synaptic input. Biol. Cybern. 2006, 95, 1–19. [Google Scholar] [CrossRef] [PubMed]
- Eschmann, J. Reward function design in reinforcement learning. In Reinforcement Learning Algorithms: Analysis and Applications; Springer: Cham, Switzerland, 2021; pp. 25–33. [Google Scholar]
- Han, R.; Chen, S.; Wang, S.; Zhang, Z.; Gao, R.; Hao, Q.; Pan, J. Reinforcement learned distributed multi-robot navigation with reciprocal velocity obstacle shaped rewards. IEEE Robot. Autom. Lett. 2022, 7, 5896–5903. [Google Scholar] [CrossRef]
- Xie, J.; Shao, Z.; Li, Y.; Guan, Y.; Tan, J. Deep reinforcement learning with optimized reward functions for robotic trajectory planning. IEEE Access 2019, 7, 105669–105679. [Google Scholar] [CrossRef]
- Cahill, A. Catastrophic Forgetting in Reinforcement-Learning Environments. Ph.D. Thesis, University of Otago, Dunedin, New Zealand, 2011. [Google Scholar]
- Muhammad, U.; Sipra, K.A.; Waqas, M.; Tu, S. Applications of myo armband using EMG and IMU signals. In Proceedings of the 2020 3rd International Conference on Mechatronics, Robotics and Automation (ICMRA), Shanghai, China, 16–18 October 2020; pp. 6–11. [Google Scholar]
- Gui, P.; Tang, L.; Mukhopadhyay, S. MEMS based IMU for tilting measurement: Comparison of complementary and kalman filter based data fusion. In Proceedings of the 2015 IEEE 10th Conference on Industrial Electronics and Applications (ICIEA), Auckland, New Zealand, 15–17 June 2015; pp. 2004–2009. [Google Scholar]
- Alatise, M.B.; Hancke, G.P. Pose estimation of a mobile robot based on fusion of IMU data and vision data using an extended Kalman filter. Sensors 2017, 17, 2164. [Google Scholar] [CrossRef]
- El-Gohary, M.; McNames, J. Human joint angle estimation with inertial sensors and validation with a robot arm. IEEE Trans. Biomed. Eng. 2015, 62, 1759–1767. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Success Rate | Execution Time (ms) | |
|---|---|---|
| Training Performance | ||
| Testing Performance |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, Y.; Lee, J.; Sim, D.; Cho, Y.; Park, C. Designing Spiking Neural Network-Based Reinforcement Learning for 3D Robotic Arm Applications. Electronics 2025, 14, 578. https://doi.org/10.3390/electronics14030578
Park Y, Lee J, Sim D, Cho Y, Park C. Designing Spiking Neural Network-Based Reinforcement Learning for 3D Robotic Arm Applications. Electronics. 2025; 14(3):578. https://doi.org/10.3390/electronics14030578
Chicago/Turabian StylePark, Yuntae, Jiwoon Lee, Donggyu Sim, Youngho Cho, and Cheolsoo Park. 2025. "Designing Spiking Neural Network-Based Reinforcement Learning for 3D Robotic Arm Applications" Electronics 14, no. 3: 578. https://doi.org/10.3390/electronics14030578
APA StylePark, Y., Lee, J., Sim, D., Cho, Y., & Park, C. (2025). Designing Spiking Neural Network-Based Reinforcement Learning for 3D Robotic Arm Applications. Electronics, 14(3), 578. https://doi.org/10.3390/electronics14030578