


Benchmarking Hyper-Breakpoints for Efficient Virtual Machine Introspection
 , , , and
, , , and
Abstract
1. Introduction
- We propose and implement a benchmark for x86_64 breakpoint approaches suitable for measuring the execution performance (timing) of VMI-based breakpoint implementations.
- We provide preliminary results of our breakpoint benchmark workloads for the VMI-based breakpoints implemented in SmartVMI.
2. Background
2.1. Breakpoint Basics
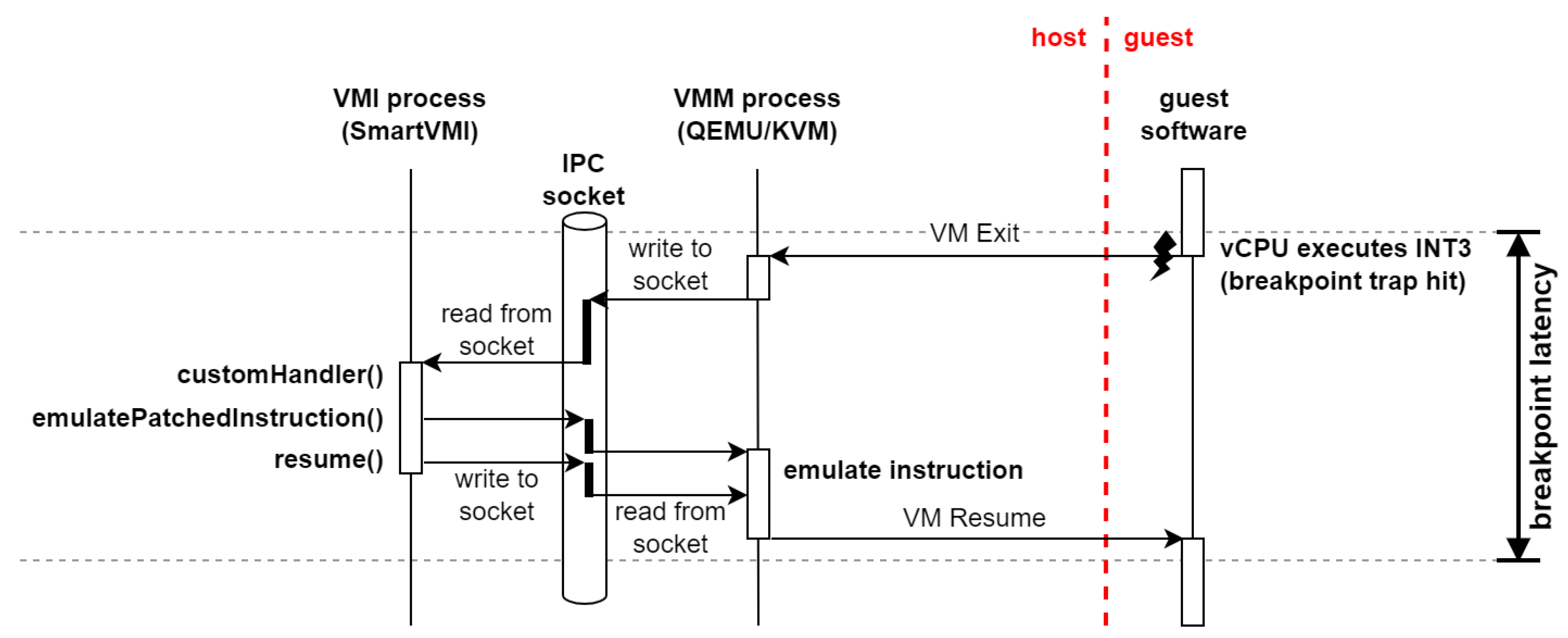
2.2. Breakpoint-Handling Approaches for VMI Debugging
2.3. Breakpoint Invocation Optimization
3. Benchmarking Design
- Is it faster to use instruction emulation or perform EPT switches and single-stepping?
- How expensive is it to handle reads with EPT violations and read emulations?
- What is the performance penalty for the whole system when a VM exit happens on every context switch to manage breakpoint statuses?
3.1. Workloads
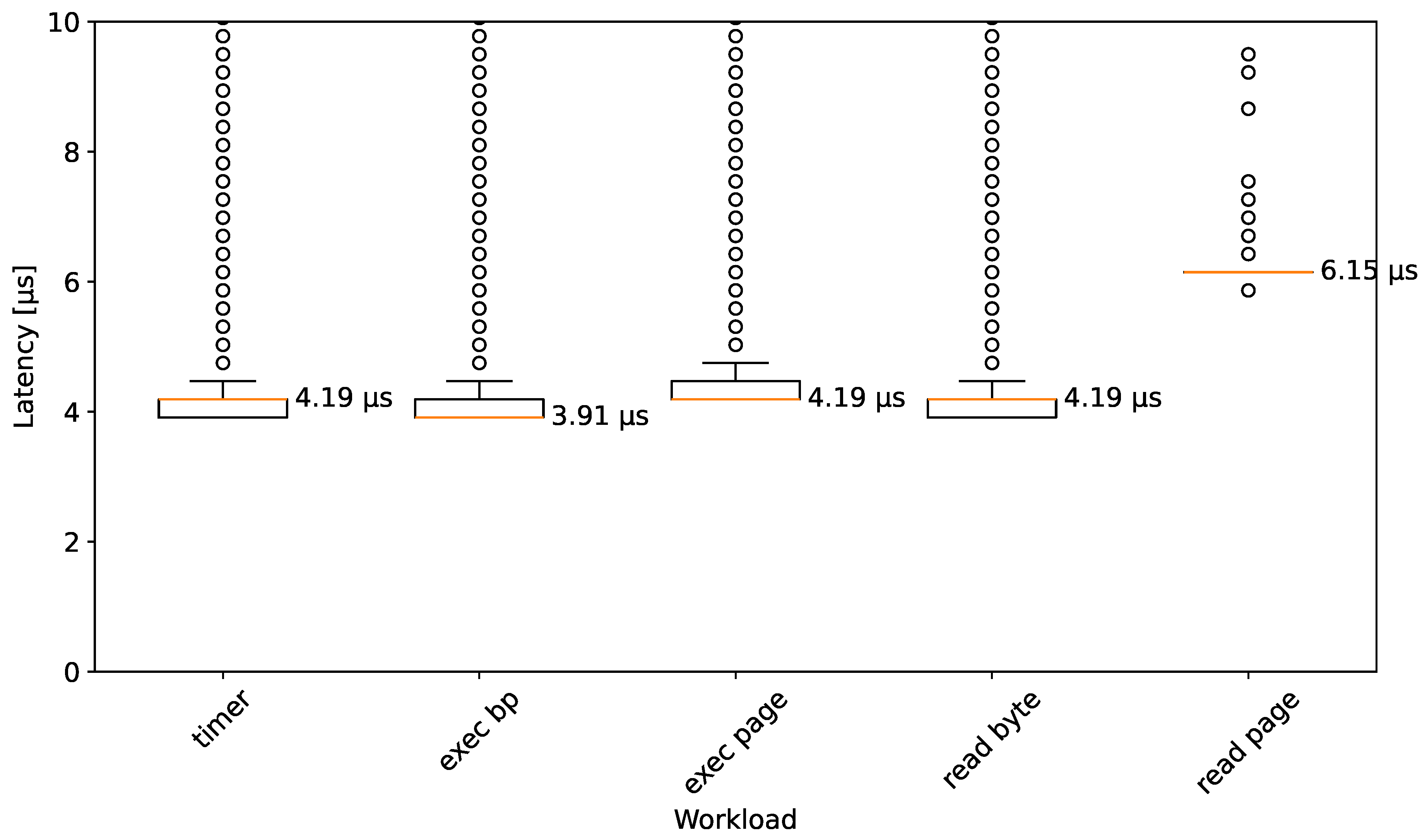
- WL1: Breakpoint execution. This workload is supposed to measure how long it takes the VMI infrastructure to handle a breakpoint. There are a multitude of factors that comprise this latency: VM exits, processing in the hypervisor, communication between the hypervisor and VMI application, processing in the VMI application, and VM entries.
- WL2: Breakpoint execution + additional instructions. Most of the approaches introduced do not add latency to the execution of an instruction where no breakpoint is placed. However, altp2m effectively also breakpoints all other instructions that are on the same page as the target instruction. The previous workload does not reflect that, so this one is supposed to measure the latency of executing the breakpoint as well as additional instructions that are located on the same page.
- WL3: Reading the breakpoint. Using EPT permissions to control read accesses to breakpoint locations causes overhead for similar reasons to the breakpoint executions. This workload is designed to quantify this latency by reading from the exact memory location where a breakpoint is placed.
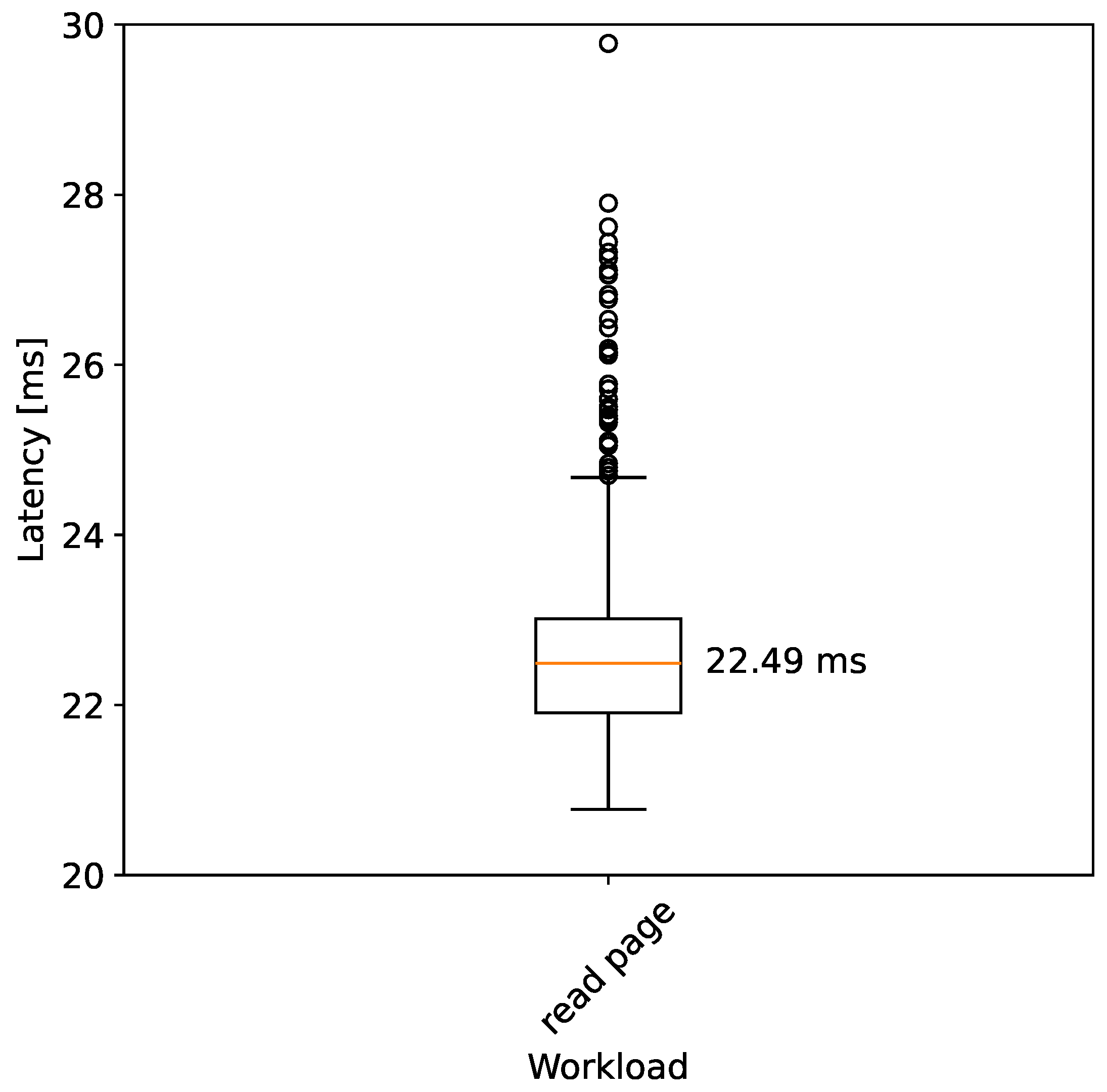
- WL4: Reading a page with breakpoint. EPT read control has page-granularity, so all mentioned approaches behave the same independently of whether exactly the breakpoint or any address on the same page has been read. Thus, the results should show the same trend as the previous workload. The purpose of this approach is mainly to mimic the behavior of Microsoft’s PatchGuard.
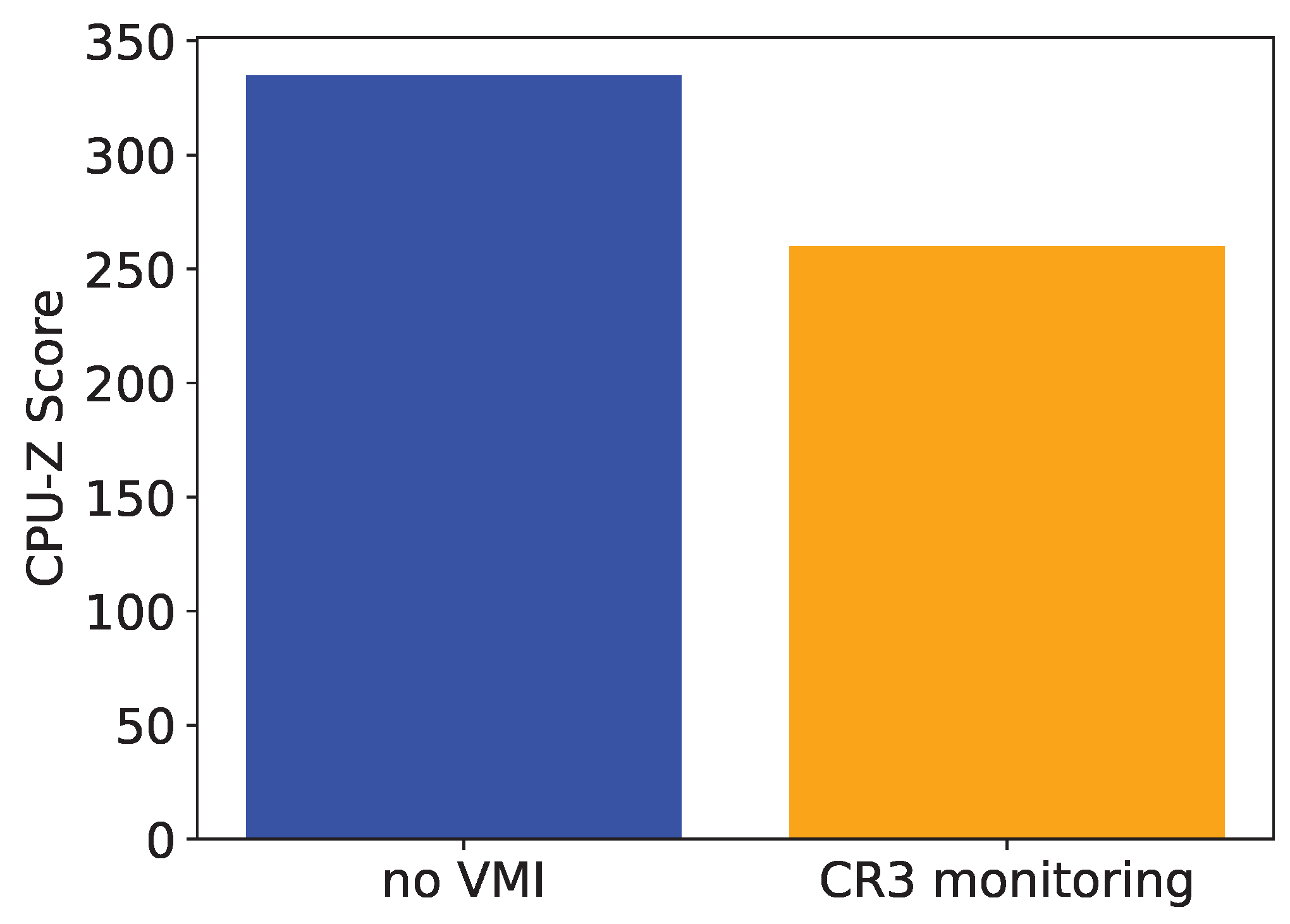
- WL5: CPU workload with and without CR3 monitoring. The final workload is not concerned with breakpoints themselves. To implement process-specific breakpoints, context switches have to be detected and handled by intercepting at every CR3 register write. Given a CPU performance benchmark, it should be run with and without VMI monitoring CR3 writes. The difference in performance is the minimal cost of processing context switches with VMI. It is important to note that the chosen benchmark most likely has an impact on the measurable overhead. Performing only calculations will not cause any additional context switches, while repeatedly invoking system calls, e.g., to write to a file, inevitably triggers context switches.
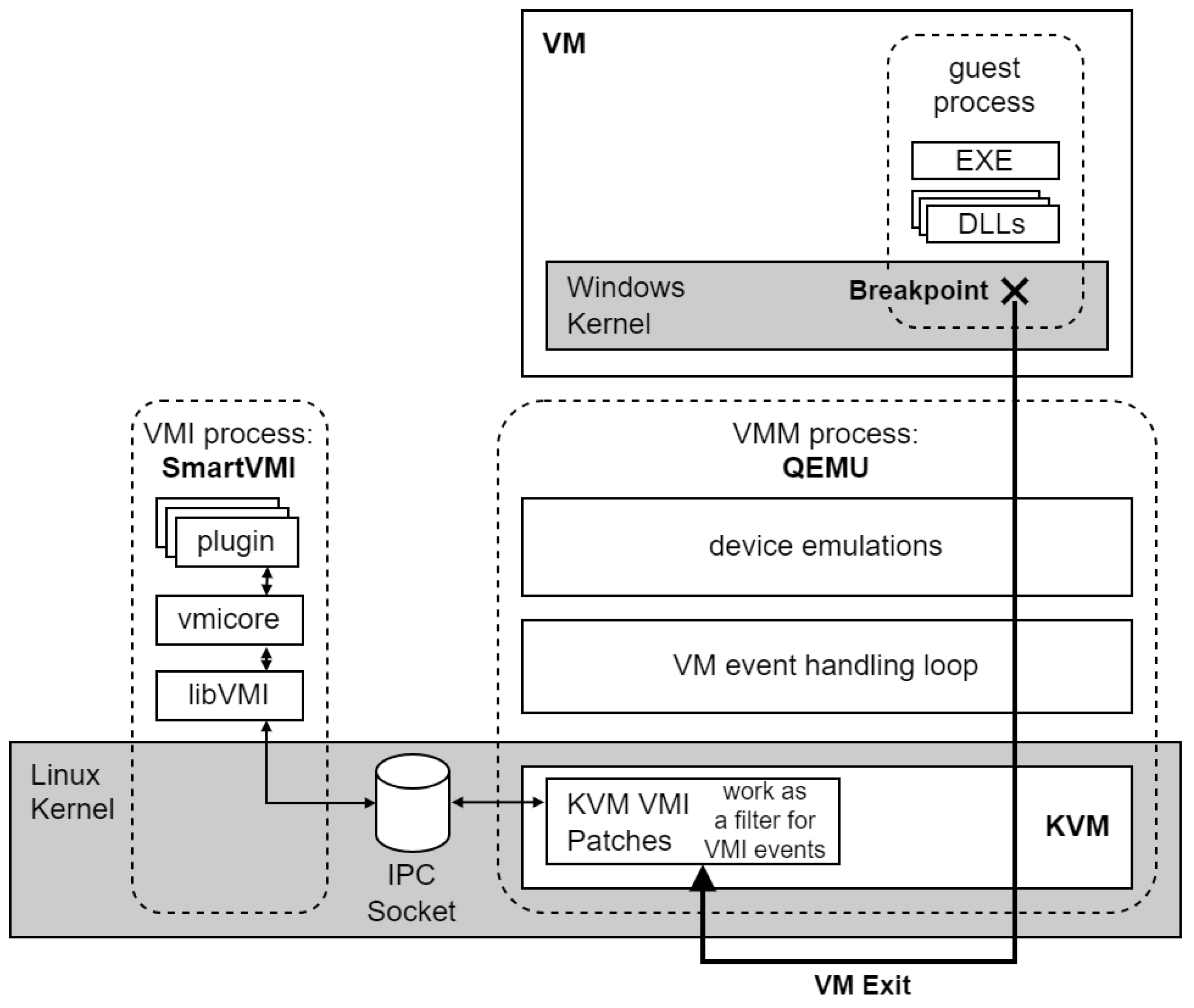
3.2. Implementation Considerations
3.3. The Bpbench Benchmarking Application
4. Initial Measurement Results
4.1. VMI Setup
4.2. Breakpoint Execution and Reading
4.3. CR3 Write Monitoring
5. Related Work
6. Conclusions
6.1. Summary and Discussion
6.2. Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Garfinkel, T.; Rosenblum, M. A virtual machine introspection based architecture for intrusion detection. In Proceedings of the Internet Society’s 2003 Symposium on Network and Distributed System Security, San Diega, CA, USA, 27–31 January 2003; Volume 3, pp. 191–206. [Google Scholar]
- wook Baek, H.; Srivastava, A.; Van der Merwe, J. CloudVMI: Virtual Machine Introspection as a Cloud Service. In Proceedings of the 2014 IEEE International Conference on Cloud Engineering, Boston, MA, USA, 11–14 March 2014; pp. 153–158. [Google Scholar] [CrossRef]
- Jiang, X.; Wang, X.; Xu, D. Stealthy malware detection through VMM-based ‘out-of-the-box’semantic view. In Proceedings of the 14th ACM Conference on Computer and Communications Security, Alexandria, VA, USA, 2 November–31 October 2007; Volume 10, pp. 128–138. [Google Scholar] [CrossRef]
- Dinaburg, A.; Royal, P.; Sharif, M.; Lee, W. Ether: Malware analysis via hardware virtualization extensions. In Proceedings of the 15th ACM Conference on Computer and Communications Security, Alexandria, VA, USA, 27–31 October 2008; pp. 51–62. [Google Scholar] [CrossRef]
- Willems, C.; Hund, R.; Holz, T. Cxpinspector: Hypervisor-Based, Hardware-Assisted System Monitoring; Technical Report; Ruhr-Universität Bochum: Bochum, Germany, 2013. [Google Scholar]
- Dolan-Gavitt, B.; Leek, T.; Zhivich, M.; Giffin, J.; Lee, W. Virtuoso: Narrowing the Semantic Gap in Virtual Machine Introspection. In Proceedings of the 2011 IEEE Symposium on Security and Privacy, Oakland, CA, USA, 22–25 May 2011; pp. 297–312. [Google Scholar] [CrossRef]
- Jain, B.; Baig, M.B.; Zhang, D.; Porter, D.E.; Sion, R. SoK: Introspections on Trust and the Semantic Gap. In Proceedings of the 2014 IEEE Symposium on Security and Privacy, Berkeley, CA, USA, 18–21 May 2014; pp. 605–620, ISSN 2375-1207. [Google Scholar] [CrossRef]
- Dangl, T.; Taubmann, B.; Reiser, H.P. RapidVMI: Fast and multi-core aware active virtual machine introspection. In Proceedings of the Proceedings of the 16th International Conference on Availability, Reliability and Security, Vienna, Austria, 17–20 August 2021; ARES’21. pp. 1–10. [Google Scholar] [CrossRef]
- Lengyel, T.K.; Maresca, S.; Payne, B.D.; Webster, G.D.; Vogl, S.; Kiayias, A. Scalability, fidelity and stealth in the DRAKVUF dynamic malware analysis system. In Proceedings of the 30th Annual Computer Security Applications Conference, New Orleans, LA, USA, 8–12 December 2014; ACSAC ’14. pp. 386–395. [Google Scholar] [CrossRef]
- Tarral, M. LibVMI: Simplified Virtual Machine Introspection. 2007. Available online: https://github.com/libvmi/libvmi (accessed on 15 January 2025).
- Eikenberg, D. SmartVMI. 2021. Available online: https://github.com/GDATASoftwareAG/smartvmi (accessed on 15 January 2025).
- Reiser, H.P.; Eikenberg, D. SmartVMI—Virtual Machine Introspection (VMI) for Memory Forensics and Machine-Learning. 2021. Available online: http://www.smartvmi.org/ (accessed on 15 January 2025).
- Lengyel, T. DRAKVUF Black-Box Binary Analysis. 2014. Available online: https://github.com/tklengyel/drakvuf (accessed on 19 December 2024).
- Lengyel, T.K. Stealthy Monitoring with xen altp2m. 2016. Available online: https://xenproject.org/blog/stealthy-monitoring-with-xen-altp2m/ (accessed on 17 December 2024).
- Roccia, T. Evolution of Malware Sandbox Evasion Tactics—A Retrospective Study. 2019. Available online: https://www.mcafee.com/blogs/other-blogs/mcafee-labs/evolution-of-malware-sandbox-evasion-tactics-a-retrospective-study/ (accessed on 17 December 2024).
- Qiu, J.; Yadegari, B.; Johannesmeyer, B.; Debray, S.; Su, X. Identifying and Understanding Self-Checksumming Defenses in Software. In Proceedings of the 5th ACM Conference on Data and Application Security and Privacy, San Antonio, TX, USA, 2–4 March 2015; CODASPY ’15. pp. 207–218. [Google Scholar] [CrossRef]
- Sonawane, S.; Onofri, D. Malware Analysis: GuLoader Dissection Reveals New Anti-Analysis Techniques and Code Injection Redundancy. 2022. Available online: https://www.crowdstrike.com/en-us/blog/guloader-dissection-reveals-new-anti-analysis-techniques-and-code-injection-redundancy/ (accessed on 19 December 2024).
- Blum, D. PatchGuard and Windows security. In Network World Canada; Laurentian Technomedia Inc.: OTTAWA, ON, USA, 2007; Volume 23. [Google Scholar]
- Wahbe, R. Efficient data breakpoints. ACM Sigplan Not. 1992, 27, 200–212. [Google Scholar] [CrossRef]
- Wahbe, R.; Lucco, S.; Graham, S.L. Practical data breakpoints: Design and implementation. In Proceedings of the ACM SIGPLAN 1993 Conference on Programming Language Design and Implementation, Albuquerque, NM, USA, 21–25 June 1993; Volume 28, PLDI93. pp. 1–12. [Google Scholar] [CrossRef]
- Vasudevan, A.; Yerraballi, R. Stealth Breakpoints. In Proceedings of the 21st Annual Computer Security Applications Conference (ACSAC’05), Tucson, AZ, USA, 5–9 December 2005; pp. 381–392. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | BP Trigger | Handling of the Original Instruction | MP-Safe | Stealth |
|---|---|---|---|---|
| User-mode debugging (no VM) | int3 | Replace + single-stepping (TF) | No | None |
| Single-Stepping (SmartVMI) | int3 | Replace + single-stepping (MTF) | No | Trap on read (EPT) + Emul. |
| Instruction Emulation | int3 | Instruction emulation | Yes | Trap on read (EPT) + Emul. |
| altp2m | EPT violation | EPT switch + single-stepping (MTF) | Yes | Invisible by design |
| altp2m with int3 (DRAKVUF) | int3 | EPT switch + single-stepping (MTF) | Yes | Trap on read (EPT) + Emul. |
| bpbench Name | Workload | Measured Actions |
|---|---|---|
| timer | - | none |
| exec bp | WL1 | CALL, breakpoint hit (on RET) |
| exec page | WL2 | CALL, 4095 NOPs, breakpoint hit (on RET) |
| read bp | WL3 | 1-byte read at breakpoint address |
| read page | WL4 | 512 8-byte reads from page with BP, instructions for looping |
| Category | Host | VM |
|---|---|---|
| CPU | Intel Core i5 7300U | 1 vCPU |
| RAM | 2x4 GB DDR4 | 4 GB |
| OS | NixOS 24.05 | Windows 10 Pro 22H2, |
| Kernel version | 5.4.24 1 | Build 19045.2965 |
| Other software | QEMU 4.2.1 1 | bpbench |
| SmartVMI | CPU-Z 2.13.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Beierlieb, L.; Schmitz, A.; Springer, R.; Dietrich, C.; Iffländer, L. Benchmarking Hyper-Breakpoints for Efficient Virtual Machine Introspection. Electronics 2025, 14, 534. https://doi.org/10.3390/electronics14030534
Beierlieb L, Schmitz A, Springer R, Dietrich C, Iffländer L. Benchmarking Hyper-Breakpoints for Efficient Virtual Machine Introspection. Electronics. 2025; 14(3):534. https://doi.org/10.3390/electronics14030534
Chicago/Turabian StyleBeierlieb, Lukas, Alexander Schmitz, Raphael Springer, Christian Dietrich, and Lukas Iffländer. 2025. "Benchmarking Hyper-Breakpoints for Efficient Virtual Machine Introspection" Electronics 14, no. 3: 534. https://doi.org/10.3390/electronics14030534
APA StyleBeierlieb, L., Schmitz, A., Springer, R., Dietrich, C., & Iffländer, L. (2025). Benchmarking Hyper-Breakpoints for Efficient Virtual Machine Introspection. Electronics, 14(3), 534. https://doi.org/10.3390/electronics14030534