Abstract
As an emerging edge device aimed at consumers, Unmanned Aerial Vehicles (UAVs) have attracted significant attention in the consumer electronics market, particularly for intelligent imaging applications. However, aerial image detection tasks face two major challenges: first, there are numerous small and overlapping objects that are difficult to identify from an aerial perspective, and second, if the detection frame rate is not high enough, missed detections may occur when the UAV is moving quickly, which can negatively impact the user experience by reducing detection accuracy, increasing the likelihood of collision-avoidance failures, and potentially causing unsafe flight behavior. To address these challenges, this paper proposes a novel YOLO (you only look once) framework, named YOLOFLY, which includes a C4f feature extraction module and a DWcDetect head to make the model lightweight, as well as an MPSA attention mechanism and an ACIoU loss function, aimed at improving detection accuracy and performance for consumer-grade UAVs. Extensive experiments on the public VisDrone2019 dataset demonstrate that YOLOFLY outperforms the latest state-of-the-art model, YOLOv11n, by 3.2% in mAP50-95, reduces detection time by 27.2 ms, decreases the number of parameters by 0.6 M, and cuts floating-point operations by 1.8 B. Finally, testing YOLOFLY in real-world environments also yielded the best results, including a 3.75% reduction in missed detections at high speeds. These findings validate the superiority and effectiveness of YOLOFLY.
1. Introduction
With the rapid development of UAV technology, UAVs equipped with object detection capabilities have penetrated various consumer electronics sectors, including industrial inspections [], aquaculture environmental monitoring [], agricultural crop monitoring [], and civil search and rescue operations in mountainous areas []. Although UAV aerial images generally have high resolution, they still face challenges, such as a large number of small targets, frequent overlapping, and difficulties in achieving real-time monitoring. In recent years, the YOLO series of object detection algorithms [] has gained increasing importance due to their high adaptability, ease of deployment, excellent accuracy, and widespread use in various object detection tasks and industrial applications. However, YOLO algorithms were originally designed for object detection in a wide variety of natural scenes [], such as those found in datasets like MS COCO [] and PASCAL VOC [], and may not directly apply to UAV images. In order to make YOLO better suited for UAV-based object detection, the algorithm’s feature extraction and reasoning processes must be improved to address the fine details of aerial images, target overlapping, and fast-moving scenarios in real-world UAV scenes.
To address this need, this paper proposes YOLOFLY, which introduces a C4f feature extraction module, a DWcDetect (depthwise separable convolution detection) head, an MPSA (multi-level attention) mechanism, and an ACIoU (area-constrained intersection over union) loss function. These components are specifically designed to tackle the challenges of UAV-based object detection. The C4f module uses spatially separable convolutions, significantly reducing computational costs while maintaining strong feature extraction capability, thereby improving model inference speed. DWcDetect is a detection head structure that combines depthwise separable convolutions with standard convolutions, reducing computational complexity to support high-frame-rate real-time detection in fast-moving UAVs. MPSA is a multi-level attention mechanism that effectively enhances the model’s ability to capture the fine details of small and overlapping objects. Finally, the ACIoU loss function incorporates the area ratio concept, overcoming the limitations of traditional IoU metrics in handling area differences between predicted and ground-truth boxes, thereby improving the accuracy of bounding box predictions.
Extensive experiments are conducted on the public VisDrone2019 dataset []. The results show that YOLOFLY outperforms the latest state-of-the-art model, YOLOv11n, achieving a 3.2% improvement in mAP50-95, a 27.2 ms faster detection speed, a 0.6 M reduction in model parameters, and a 1.8 B reduction in floating-point operations. Additionally, experiments in real-world scenarios, such as the tourism areas of southern Yunnan, demonstrate that YOLOFLY reduces the missed detection rate by 3.75% compared to conventional models. These experimental results validate the superiority and effectiveness of YOLOFLY, showing that it achieves a balance of both accuracy and speed in various UAV-based detection environments.
In summary, the main innovations of this paper are as follows:
- The design of the C4f feature extraction module, which uses spatially separable convolution bottleneck blocks to significantly reduce computational costs while maintaining high feature extraction ability, thereby improving inference speed in UAV scenarios.
- The proposal of the DWcDetect head, which replaces some traditional convolutions with depthwise separable convolutions to drastically reduce computational costs and support real-time detection for fast-moving UAVs.
- The introduction of the MPSA multi-level attention mechanism, which enhances the model’s ability to capture fine-grained features and addresses issues with small and overlapping objects.
- The design of the new ACIoU loss function, which considers both aspect ratio and area ratio to overcome the limitations of the traditional IoU metric in handling area discrepancies, leading to improved prediction accuracy.
2. Related Works
Object detection, a critical task in the field of computer vision, has seen significant advancements in recent years []. Current object detection methods primarily focus on two key aspects: accuracy and speed []. Different detection models place varying emphasis on these two factors.
Object detection models are generally categorized into two main types: two-stage detectors and single-stage detectors, each exhibiting distinct differences in terms of detection accuracy and computational efficiency [,,]. Two-stage detectors decompose the detection process into two phases: the first phase generates a large number of candidate regions with approximate location information, while the second phase classifies and regresses these candidate regions [,]. This staged approach typically enables two-stage models to achieve higher accuracy, particularly in complex scenes and when detecting small objects [,]. Representative two-stage detectors include R-CNN [], Fast R-CNN [], Faster R-CNN [], SPPNet [], Mask R-CNN [], and FPN [], among others. However, these models often suffer from high computational costs and slower inference speeds, limiting their applicability in real-time settings [].
In contrast, single-stage detectors bypass the region proposal generation step, directly performing dense sampling on the entire image and regressing the bounding boxes of objects []. This characteristic allows single-stage detectors to achieve higher computational efficiency and faster inference speeds, making them well suited for real-time detection tasks []. YOLO, a prominent single-stage detector, achieves efficient object detection by directly regressing target bounding boxes []. While YOLO excels in speed, its accuracy tends to lag behind that of two-stage models, particularly in the detection of small objects and the handling of overlapping objects [].
In scenarios requiring real-time responses, such as in UAV applications, the YOLO series has become widely adopted due to its high speed and satisfactory detection performance []. However, challenges remain in improving its accuracy, especially in complex backgrounds and for detecting small objects [].
As research advances, YOLO models have been continually optimized for both speed and accuracy []. Specifically, in contexts such as UAV-based applications in complex environments, various modifications have been proposed to enhance YOLO’s performance, balancing both precision and efficiency. One key area of improvement is the optimization of feature extraction modules, which play a vital role in enhancing both detection accuracy and computational efficiency []. For example, Guo et al. [] introduced a novel backbone network called CSP-DarkNet53, along with lightweight convolutional modules, resulting in improved accuracy and efficiency. This approach is not part of YOLO; it is a separate development of deep learning for object detection. Additionally, to address the challenges of small-object detection, Chen et al. [] incorporated more multi-scale feature extraction layers into the network, enhancing the model’s ability to detect small objects more effectively.
Another critical direction of optimization is the detection head, which has become a focal point for improving both the speed and accuracy of YOLO-based models in recent years []. Traditional detection heads strike a balance between computational load and structural complexity, but they often fail to meet the specific requirements of certain scenarios. For instance, Khaki et al. [] proposed a lightweight detection head based on depthwise separable convolutions to reduce computational complexity while supporting high frame-rate detection. Moreover, the design of detection heads increasingly emphasizes the ability to capture small and overlapping objects, with improvements such as the incorporation of various convolution types or attention mechanisms to enhance object localization and classification performance.
Furthermore, the integration of attention mechanisms has further contributed to improved accuracy []. Many enhanced YOLO models leverage attention mechanisms such as CBAM [], SE [], and EPSA []. These mechanisms direct the network’s focus toward more relevant regions of the image, helping the model better handle complex backgrounds and occlusions, which improves detection performance for small and overlapping objects []. Additionally, optimizing the loss function has proven to be a key factor in boosting detection accuracy []. Traditional loss functions based on the IoU have gradually been replaced with more advanced alternatives, such as the GIoU [], DIoU [], and CIoU []. These newer loss functions not only account for the overlap between predicted and ground-truth bounding boxes but also incorporate constraints on aspect ratio and center point distance, resulting in improved detection accuracy []. To address the area discrepancies between predicted and ground-truth boxes, improved loss functions, such as CDIoU [], have been introduced to further refine the matching between them.
The YOLOFLY framework proposed in this paper aims to enhance the object detection performance of consumer-grade UAVs in complex environments. To achieve this, we have designed several innovative modules, including the C4f feature extraction module, the MPSA attention mechanism, the DWcDetect depthwise separable convolution detection head, and the ACIoU loss function. The overall network architecture is shown in Figure 1.
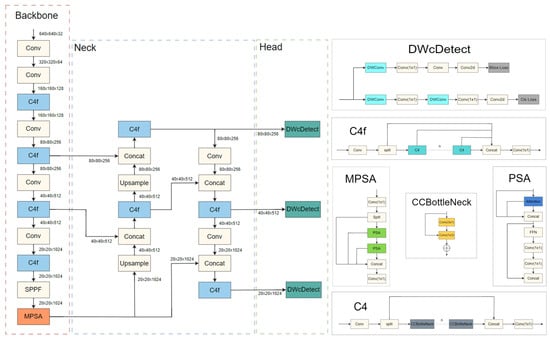
Figure 1.
Components of the YOLOFLY architecture.
3. Method
Detailed descriptions of the modules designed to enhance the object detection performance of consumer-grade UAVs in complex environments are provided below. The explanations of important abbreviations used in this paper are shown in Table 1.

Table 1.
Abbreviations and their fully spelled-out terms.
3.1. C4f
For object detection algorithms, the ability of a model to learn effective target features from the input depends on having an excellent backbone feature extraction module. From YOLOv8 to YOLOv11, the feature extraction module has evolved from C2f [] to C3k2 [], both of which maintain a residual structure. The key difference is that C3k2 incorporates two types of bottleneck blocks, light and heavy, and the specific bottleneck used in feature extraction can be switched. The original intention of C3k2 was to leverage the switching mechanism between the light and heavy bottlenecks to improve the feature extraction capability without significantly increasing computational costs. However, this switching mechanism introduces a new issue: determining when to switch. For different scales and categories of detection targets, the optimal switching point during model training may vary.
To avoid this issue, this paper proposes a new optimization direction for feature extraction—changing the convolutional form in the feature extraction process. Specifically, we introduce C4f, which, like C2f and C3k2, maintains a residual structure but uses spatially separable convolutions (m × 1, 1 × m) in place of traditional convolutions (m × m) in the bottleneck blocks. The feature extraction process of C4f is shown in Figure 2. The input feature map is first split into two parts via a split operation. One part undergoes spatially separable convolution to learn more refined features. The processed feature map is then concatenated with the other part, resulting in the final output feature map. This residual connection enables better gradient propagation during training, preventing vanishing gradients and thus improving the model’s performance.
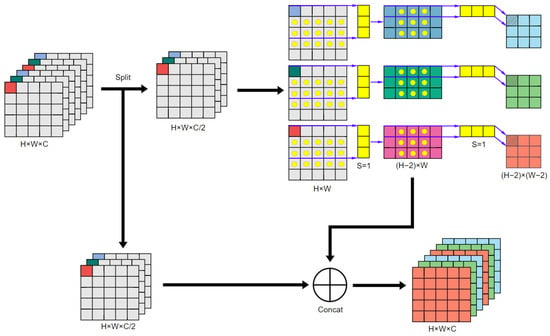
Figure 2.
C4f feature extraction process.
Although spatially separable convolutions significantly reduce computational costs compared to traditional convolutions, they theoretically also reduce the ability to capture fine-grained features. However, in the case of overlapping targets from the UAV perspective, the high redundancy of features in overlapping objects actually reduces the risk of overfitting, making the ability to extract fine-grained features comparable or even improved in some cases. Subsequent experimental results show that the C4f module successfully reduces computational complexity while maintaining nearly the same feature extraction capability, significantly lowering resource consumption during inference. Therefore, C4f is particularly well suited for image processing tasks in resource-constrained UAV scenarios, providing efficient feature extraction for overlapping target detection.
3.2. DWcDetect
In UAV object detection, there are two most important tasks: one is object classification, and the other is predicting bounding boxes. Both of these tasks are ultimately handled by the model’s head. Given this, the second optimization target is the model’s head.
In general object detection models, there is a wide variety of target categories. The most common general detection datasets contain thousands to hundreds of thousands of images, each with dozens to hundreds of labels. Therefore, the heads of general object detection models are designed with the goal of ensuring high detection accuracy. However, in UAV object detection, particularly for consumer-grade detection tasks, the number of labels is usually much smaller. Directly applying the head of a general object detection model is not ideal. Thus, this paper proposes a lightweight modification of the detection head in YOLO. By replacing traditional convolutions with depthwise separable convolutions, we address the issue of excessive computational overhead in the detection head when applying general object detection models to consumer-grade UAV object detection tasks. A comparison between DWcDetect and Detect is shown in Figure 3. The parameter ratio between depthwise separable convolutions and standard convolutions is calculated as shown in Formula (1):
where is the kernel size, M is the number of input channels, and N is the number of output channels. In theory, the computational complexity and the number of parameters are reduced to of the original, assuming the kernel size is typically 3 × 3. Given that the output channels are usually large, this reduction factor can be further approximated, making it roughly .
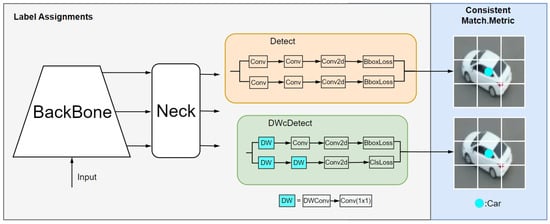
Figure 3.
A comparison between DWcDetect and Detect.
3.3. MPSA
PSA enables a model to focus more on target-relevant regions during feature extraction, improving detection accuracy. It also allows dynamic adjustment of the weights of features at different levels by learning the spatial distribution of the feature map. This enhances the model’s response to important regions (such as small targets or prominent areas in complex backgrounds) while suppressing background noise.
To improve the model’s ability to detect small targets, the MPSA module is introduced. This module incorporates a multi-level attention mechanism that enables the model to more effectively capture key features and suppress irrelevant information, significantly enhancing small-target detection capability. The workflow of the MPSA module is shown in Figure 4. The MPSA module uses multiple stacked PSA blocks, with two PSA blocks implemented in YOLOFLY, allowing the model to focus on key features at finer scales and deeper depths.
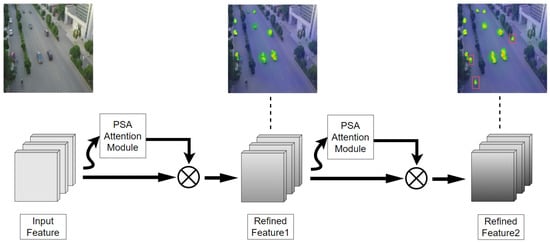
Figure 4.
The workflow of the MPSA module.
After multi-level attention processing, the module integrates features from different layers with weighted fusion, generating a final feature representation that contains multi-scale information. This fusion method enhances semantic information while preserving detailed features, providing high-quality feature inputs for the subsequent detection head. It is worth noting that our experiments show that the increase in computational costs due to MPSA is within an acceptable range, making it suitable for application in UAV aerial imaging scenarios.
3.4. ACIoU
In object detection tasks, the standard IoU loss has limitations and cannot accurately measure both localization and area errors. Although the recently proposed DIoU and CIoU loss functions have made significant improvements in the precision of predicted bounding boxes, they are not perfect. The formula for the CIoU (Complete Intersection over Union) is as follows:
where B is the predicted bounding box, C is the ground-truth bounding box, is the intersection over union between the predicted box B and the ground-truth box C, is the Euclidean distance between the centers of B and C, c is the diagonal length of the smallest enclosing box that contains both B and C, and is a balancing factor, which is calculated as
where v is the aspect ratio term, given by
where and are the width and height of the predicted box B, and and are the width and height of the ground-truth box C.
Consider a simple example, as shown in Figure 5. When the IoU between the predicted box A and the predicted box B relative to the ground-truth box C is zero, the center point distances are equal, the diagonal of the smallest enclosing box is the same, the aspect ratios are identical, and the loss values of the predicted boxes A and B for the IoU, DIoU, and CIoU are all the same. In other words, from these metrics, there is no distinction between the two; however, based on human experience, it is clear that the prediction performance of box A is much better than that of box B. To address this, we propose an improved ACIoU loss function. ACIoU introduces an additional area ratio factor, more comprehensively considering the multiple differences between the predicted box and the ground-truth box, thus providing a more accurate measure of how close the predicted box is to the ground-truth box. The ACIoU (area-constrained intersection over union) loss is defined as:
where and are the areas of the predicted box B and the ground-truth box C, is a hyperparameter that controls the weight of the area ratio term.
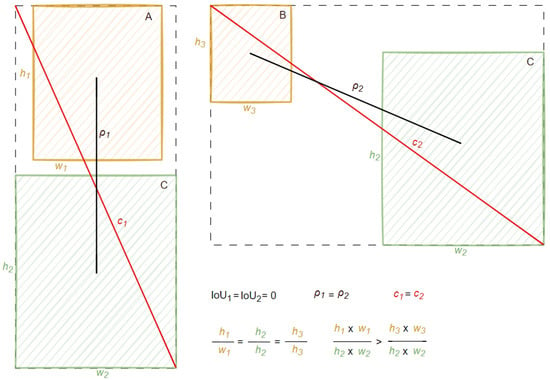
Figure 5.
An additional prediction scenario handled by the ACIoU loss function.
4. Results
4.1. Experimental Environment and Parameter Settings
Model training was performed on a high-performance computing server equipped with an NVIDIA GeForce RTX 3070Ti, using CUDA 12.1 and Python 3.12 environments. The model evaluation was performed using the PyTorch 2.1.0 framework. Model training used the AdamW optimizer, with an initial learning rate of 0.001 and a learning rate decay every 10 epochs (iterations). The weighted sum of the cross-entropy loss and the bounding box regression loss was used as the loss function. An early stopping mechanism was set during training, and training stopped when the validation set loss no longer decreased after more than 20 epochs. The UAV model used in the experiment was the DJI Air 2S., Manufactured by Shenzhen DJI Innovations Technology Co., Ltd., located in Shenzhen, Guangdong Province, China.
We conducted a performance comparison of YOLOFLY with other state-of-the-art object detection models on the VisDrone dataset, particularly focusing on detection accuracy (mAP50-95), detection speed, model parameters, computational complexity, and missed detection rates (MS and MF).
The mAP50-95 is a multi-scale average precision metric used to evaluate the detection accuracy of models in object detection tasks. It is computed across multiple different IoU thresholds and calculates the average precision at these thresholds. mAP50-95 refers to the average precision calculated over the range of the IoU from 50% to 95%. The formula is as follows:
where is the precision calculated at each IoU threshold and i takes integer values from 0 to 9, corresponding to different IoU thresholds.
The inference time per image is the time taken by the model from inputting the image to producing the detection results, measured in milliseconds (ms). The detection speed directly affects the performance of real-time applications.
Params refers to the total number of trainable parameters in the model, measured in millions (M). The number of parameters is an important indicator of a model’s complexity and computational overhead and is typically directly related to the model’s performance, especially in terms of memory usage and inference speed.
FLOPs
refers to the number of floating-point operations and measures the computational load during model inference. The higher the FLOPs, the more complex the model and the greater the computational resources required. The unit is typically expressed in billions of floating-point operations (billion FLOPs, abbreviated as B). For convolutional layers, FLOPs can be calculated using the following formula:
where and are the height and width of the output feature map, is the number of input channels, is the number of output channels, and and are the height and width of the convolutional kernel.
For fully connected layers, the FLOPs can be calculated as
where and are the number of input and output nodes, respectively.
The missed detection rate measures the proportion of targets that the model fails to detect. A low missed detection rate indicates better performance of the model in high-dynamic environments. In the experiments presented in this paper, two cases are considered: slow motion (MS) and fast motion (MF). Specifically, slow motion is defined as 5 m/s, and fast motion is defined as 19 m/s.
By comparing YOLOFLY with other models, such as Faster R-CNN, SSD, RetinaNet, CenterNet, CornerNet, and various YOLO models (e.g., YOLOv5n, YOLOv8n, YOLOv8m, YOLOv9m, YOLOv10m, YOLOv11n, etc.), the results in Table 2 clearly demonstrate YOLOFLY’s advantages in multiple performance metrics, particularly in the missed detection rate and real-time detection speed.
Table 2.
Performance comparison of different object detection models on the VisDrone test set.
In terms of detection accuracy, heavyweight YOLO models, such as YOLOv8m, YOLOv9m, YOLOv10m, and YOLOv11m, generally outperformed other models. For example, YOLOv11m achieved an mAP50-95 of 28.06%, significantly higher than YOLOFLY’s 24.72%, showing the advantages of these models in fine-grained feature extraction. However, these models exhibited slower detection speeds, leading to poorer performance in terms of the missed detection rate. Specifically, YOLOv8m exhibited a missed detection rate for slow motion (MS) of 0.58% and a missed detection rate for fast motion (MF) of 27.26%, whereas YOLOv11m’s MS rate was 0.12%, but its MF rate was 14.07%. These data indicate that although heavyweight models provide higher detection accuracy in static scenes, their missed detection rate increases significantly when targets move quickly, especially in high-dynamic environments (such as UAV-captured scenes), leading to a substantial drop in detection performance. This is mainly due to the more complex structures of heavyweight models, which result in longer inference times and affect their responsiveness in fast-moving scenarios. The detection results of YOLOFLY on VisDrone are shown in Figure 6, whereas the detection results of YOLOv11n on VisDrone are shown in Figure 7.

Figure 6.
The detection results of YOLOFLY on VisDrone.

Figure 7.
The detection results of YOLOv11n on VisDrone.
In contrast, YOLOFLY performed exceptionally well in terms of the missed detection rate, particularly with a fast-motion (MF) missed detection rate of 0.96%, much lower than the heavyweight models. For example, YOLOv8m’s MF rate was 27.26%, whereas YOLOFLY’s was significantly lower. Even under slow-motion conditions, YOLOFLY maintained an extremely low missed detection rate, with an MS rate of 0%, further demonstrating its superior real-time detection capability.
4.2. Ablation Experiment
The ablation study explored the contribution of each module to the overall performance of the model by gradually removing or replacing certain components. To better understand the role of each module proposed in this paper, we designed an ablation experiment to analyze the impact of each individual module and the combination of modules on the overall model performance. The ablation study included the following model configurations:
- YOLOv11n: Baseline model without any added modules.
- YOLOC: Only the C4f module was added.
- YOLOD: Only the DWcDetect module was added.
- YOLOM: Only the MPSA module was added.
- YOLOA: Only the ACIoU loss function was added.
- YOLOCD: The C4f and DWcDetect modules were added.
- YOLOCM: The C4f and MPSA modules were added.
- YOLOCA: The C4f module and the ACIoU loss function were added.
- YOLODM: The DWcDetect and MPSA modules were added.
- YOLODA: The DWcDetect module and the ACIoU loss function were added.
- YOLOMA: The MPSA module and the ACIoU loss function were added.
- YOLOCDM: The C4f, DWcDetect, and MPSA modules were added.
- YOLOCDA: The C4f module, the DWcDetect module, and the ACIoU loss function were added.
- YOLODMA: The DWcDetect module, the MPSA module, and the ACIoU loss function were added.
- YOLOFLY: All modules (the C4f, DWcDetect, and MPSA modules, as well as the ACIoU loss function) were combined.
In Table 3, we present the results of the performance comparison of models with various combinations of modules on the VisDrone test set. The ablation study clearly shows the impact of adding different modules on model performance. In terms of detection speed, the C4f and DWcDetect modules demonstrated significant advantages. For example, YOLOC (with only C4f added) achieved a detection speed of 46.2 ms, representing an improvement of 9.9 ms over the baseline model YOLOv11n (56.1 ms). Similarly, YOLOD (with only DWcDetect added) achieved a 43.8 ms detection speed, representing an improvement of 12.3 ms over the baseline. Although the combination of the C4f and DWcDetect modules in YOLOCD exhibited a slight decrease in precision (mAP50-95: 21.51%), it achieved a detection speed of 27.6 ms, representing an improvement of 28.5 ms over YOLOv11n, greatly optimizing inference efficiency.
Table 3.
Performance comparison of models with various combinations of modules.
In terms of precision improvement, adding the MPSA and ACIoU modules significantly boosted model performance. YOLOM (with only the MPSA module added) achieved an mAP of 22.49%, representing a 0.97% increase over YOLOv11n (21.52%), which shows that the MPSA module enhanced feature extraction capabilities and small-object detection performance. Further, YOLOMA (with both the MPSA module and the ACIoU loss added) performed even better, achieving an mAP50-95 of 24.64%, a 3.12% increase, with only a slight increase in detection time. However, the improvement in accuracy confirms the key role of the ACIoU loss in improving bounding box regression accuracy.
In terms of module combinations, the combination of the C4f and MPSA modules in YOLOCM resulted in performance improvements. YOLOCM achieved an mAP50-95 of 22.56%, representing a 1.04% improvement over YOLOv11n, with a detection speed of 50.7 ms, which was faster than YOLOv11n’s 56.1 ms. This demonstrates that although the C4f and MPSA modules individually improved speed and accuracy, their combination further optimized overall model performance, especially in handling multi-scale targets and complex scenes.
Most notably, the YOLOFLY model, which combines all four innovative modules (C4f, DWcDetect, MPSA, and ACIoU), achieved the best balance of performance. YOLOFLY achieved an mAP50-95 of 24.72%, representing a 3.2% improvement over YOLOv11n, while the detection speed significantly improved to 28.9 ms, 27.2 ms faster than YOLOv11n’s 56.1 ms. This balance between accuracy and speed makes YOLOFLY highly advantageous for real-time UAV target detection, especially in complex environments, where it not only enhances detection accuracy but also ensures low latency.
In conclusion, an analysis of the data in Table 3 leads to the following conclusions:
- The C4f and DWcDetect modules effectively improve detection speed, particularly in the YOLOCD model, where detection speed significantly increases.
- The MPSA and ACIoU modules play a crucial role in enhancing detection precision, especially in small-object detection and bounding box regression accuracy.
- The comprehensive optimization of the YOLOFLY model significantly improves detection accuracy while maintaining excellent detection speed, demonstrating an outstanding balance of performance and making it suitable for applications requiring both real-time processing and high accuracy.
4.3. Real-World Experiment
To evaluate the performance of YOLOFLY in practical applications, we conducted a real-time UAV target detection experiment in the tourism areas of southern Yunnan. We compared YOLOFLY with other advanced object detection models to assess its performance in dynamic environments. In the experiment, we used images with a 1080 × 1080-pixel resolution and measured the detection accuracy, detection speed, and missed detection rate of each model under real-world conditions.
In real-world scenarios, YOLOFLY significantly outperformed other models, achieving an mAP50-95 score of 78.16%. The results are shown in Table 4. This score far exceeded that of YOLOv8n (57.68%), YOLOv9t (61.84%), YOLOv10n (65.83%), and YOLOv11n (67.52%), demonstrating YOLOFLY’s superior detection accuracy in complex environments. This indicates that YOLOFLY has undergone significant optimization in feature extraction and multi-scale object detection, allowing it to detect targets more accurately in highly dynamic environments.
Table 4.
Performance comparison of different object detection models in a real-world scenario.
In terms of detection speed, YOLOFLY achieved an inference time of 20.2 ms, much lower than that of YOLOv8n (65.8 ms), YOLOv9t (53.8 ms), YOLOv10n (40.9 ms), and YOLOv11n (34.6 ms). The significant improvement in inference speed makes YOLOFLY highly suitable for real-time object detection tasks, especially in applications requiring high real-time performance, such as UAV target detection. Its excellent inference speed and efficiency make it an ideal choice for real-time detection systems in dynamic environments.
The missed detection rate is a key indicator of a model’s performance in high-speed, dynamic environments. For slow-moving (MS) targets, YOLOFLY achieved a missed detection rate of 0%, indicating almost no missed detections and demonstrating its stable performance in static or low-speed scenarios. For fast-moving (MF) targets, YOLOFLY’s missed detection rate was 0.96%, much lower than that of YOLOv8n (8.36%), YOLOv9t (8.02%), YOLOv10n (5.29%), and YOLOv11n (4.71%). This shows that YOLOFLY exhibits exceptional stability in detecting fast-moving targets, significantly reducing the missed detection rate, especially in the case of fast-moving targets detected by UAVs.
In addition, we performed a comparison of the real-time detection results between YOLOFLY and YOLOv11n, as shown in Figure 8. As can be seen, from time t1 to t2 and finally to t3, YOLOFLY completed detection on three video frames ((a), (b), and (c)), yielding a rich set of detection results. However, YOLOv11n only completed detection on frames (a) and (c), missing frame (b), which resulted in significant missed detections.

Figure 8.
Detection results of YOLOFLY in a real-world scenario.
In conclusion, YOLOFLY, with its outstanding detection accuracy, extremely fast inference speed, and excellent missed detection control, performs exceptionally well in complex, dynamic real-world environments, making it an ideal choice for real-time object detection systems.
5. Conclusions
This paper presents YOLOFLY, an efficient and lightweight model designed specifically for object detection tasks in UAV-captured images. YOLOFLY effectively addresses performance bottlenecks associated with small-target detection and complex backgrounds. By introducing the C4f feature extraction module, the DWcDetect depthwise separable convolution detection head, the MPSA attention module, and the ACIoU loss function, the model achieves comprehensive optimization in feature extraction, detection head design, attention mechanisms, and loss calculation. These improvements enable YOLOFLY to significantly enhance its ability to detect small targets and handle complex backgrounds while reducing computational overhead.
Experiments show that YOLOFLY outperforms existing mainstream detection algorithms on multiple public datasets, particularly demonstrating higher accuracy and stability in small-target detection and scenarios involving large-scale variations. Additionally, YOLOFLY achieves efficient real-time inference by reducing computational costs without compromising detection performance, making it highly suitable for resource-constrained applications, such as those in UAV environments.
Future work will focus on exploring YOLOFLY’s adaptability in extreme conditions (e.g., low-light environments and adverse weather) and integrating dynamic network designs, as well as more intelligent feature fusion strategies, to expand its application potential in other complex scenarios.
Author Contributions
Conceptualization, P.M.; methodology, P.M.; software, P.M. and H.F.; validation, D.J. and Z.S.; formal analysis, P.M.; investigation, P.M.; resources, D.J.; data curation, P.M.; writing—original draft preparation, P.M.; writing—review and editing, P.M. and H.F.; visualization, Z.S. and N.L.; supervision, P.M. and J.W.; project administration, P.M.; funding acquisition, J.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This paper was funded by the project of the National Key Research and Development Program of the Corps: National Science and Technology Major Project, grant number 2022ZD0115803; Research and Application Demonstration of Information Technology Based on Source-Grid Load Storage and Multi-Energy Complementarity, grant number 2023AB021; the National Key Research and Development Program of the Corps: Key Technology Research and Application for High-Penetration New Energy Grid Dispatch, grant number 2023AB010; the National Key Research and Development Program of the Corps: R&D and Demonstration of the Intelligent Supervision Platform for the Inspection and Testing Institutions of the Corps Based on Big Data and Artificial Intelligence, grant number 2024AB063; and the Young Scientific and Technological Innovation Talents: Key Technological Innovation and Application of Integrated Energy, Intelligent Management and Control, and Precise Low-Carbon Dispatching, grant number 2023TSYCCx0120.
Data Availability Statement
The original contributions presented in the study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Mohsan, S.A.H.; Othman, N.Q.H.; Li, Y.; Alsharif, M.H.; Khan, M.A. Unmanned aerial vehicles (UAVs): Practical aspects, applications, open challenges, security issues, and future trends. Intell. Serv. Robot. 2023, 16, 109–137. [Google Scholar] [CrossRef]
- Eskandari, R.; Mahdianpari, M.; Mohammadimanesh, F.; Salehi, B.; Brisco, B.; Homayouni, S. Meta-analysis of unmanned aerial vehicle (UAV) imagery for agro-environmental monitoring using machine learning and statistical models. Remote Sens. 2020, 12, 3511. [Google Scholar] [CrossRef]
- Yuan, S.; Li, Y.; Bao, F.; Xu, H.; Yang, Y.; Yan, Q.; Zhong, S.; Yin, H.; Xu, J.; Huang, Z.; et al. Marine environmental monitoring with unmanned vehicle platforms: Present applications and future prospects. Sci. Total Environ. 2023, 858, 159741. [Google Scholar] [CrossRef] [PubMed]
- Hu, X.; Assaad, R.H. The use of unmanned ground vehicles and unmanned aerial vehicles in the civil infrastructure sector: Applications, robotic platforms, sensors, and algorithms. Expert Syst. Appl. 2023, 232, 120897. [Google Scholar] [CrossRef]
- Wang, C.; Liang, G. Overview of Research on Object Detection Based on YOLO. In Proceedings of the 4th International Conference on Artificial Intelligence and Computer Engineering, Dalian China, 17–19 November 2023. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014, Proceedings, Part V 13; Springer International Publishing: Cham, Switzerland, 2014. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Zhu, P.; Wen, L.; Du, D.; Bian, X.; Fan, H.; Hu, Q.; Ling, H. Detection and tracking meet drones challenge. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 7380–7399. [Google Scholar] [CrossRef]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef]
- Shi, L.; Zhan, Z.H.; Liang, D. Memory-based ant colony system approach for multi-source data associated dynamic electric vehicle dispatch optimization. IEEE Trans. Intell. Transp. Syst. 2022, 23, 17491–17505. [Google Scholar] [CrossRef]
- Amit, Y.; Felzenszwalb, P.; Girshick, R. Object detection. In Computer Vision: A Reference Guide; Springer International Publishing: Cham, Switzerland, 2021; pp. 875–883. [Google Scholar]
- Wu, X.; Sahoo, D.; Hoi, S.C. Recent advances in deep learning for object detection. Neurocomputing 2020, 396, 39–64. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Wu, P.; Chai, B.; Nie, X.; Yan, L.; Wang, Z.; Zhou, Q.; Wang, B.; Peng, Y.; Li, H. Enhanced object detection: A study on vast vocabulary object detection track for v3det challenge 2024. arXiv 2024, arXiv:2406.09201. [Google Scholar]
- Minderer, M.; Gritsenko, A.; Houlsby, N. Scaling Open-Vocabulary Object Detection. arXiv 2023, arXiv:2306.09683. [Google Scholar]
- Zang, Y.; Li, W.; Han, J.; Zhou, K.; Loy, C.C. Contextual object detection with multimodal large language models. Int. J. Comput. Vis. 2024, 133, 825–843. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Girshick, R. Fast r-cnn. arXiv 2015, arXiv:1504.08083. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2017. [Google Scholar]
- Hosain, M.T.; Zaman, A.; Abir, M.R.; Akter, S.; Mursalin, S.; Khan, S.S. Synchronizing Object Detection: Applications, Advancements and Existing Challenges. IEEE Access 2024, 12, 54129–54167. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In European Conference on Computer Vision; Springer International Publishing: Cham, Switzerland, 2020. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully convolutional one-stage object detection. arXiv 2019, arXiv:1904.01355. [Google Scholar]
- Long, X.; Deng, K.; Wang, G.; Zhang, Y.; Dang, Q.; Gao, Y.; Shen, H.; Ren, J.; Han, S.; Ding, E.; et al. PP-YOLO: An effective and efficient implementation of object detector. arXiv 2020, arXiv:2007.12099. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Huang, Y.F.; Liu, T.J.; Liu, K.H. Improved small object detection for road driving based on YOLO-R. In Proceedings of the 2022 IEEE International Conference on Consumer Electronics-Taiwan, Taipei, Taiwan, 6–8 July 2022; IEEE: Piscataway, NJ, USA, 2022. [Google Scholar]
- Gung, J.J.; Lin, C.Y.; Lin, P.F.; Chung, W.K. An incremental meta defect detection system for printed circuit boards. In Proceedings of the 2022 IEEE International Conference on Consumer Electronics-Taiwan, Taipei, Taiwan, 6–8 July 2022; IEEE: Piscataway, NJ, USA, 2022. [Google Scholar]
- Guo, X.; Jiang, F.; Chen, Q.; Wang, Y.; Sha, K.; Chen, J. Deep Learning-Enhanced Environment Perception for Autonomous Driving: MDNet with CSP-DarkNet53. Pattern Recognit. 2024, 160, 111174. [Google Scholar] [CrossRef]
- Chen, W.H.; Hsu, H.J.; Lin, Y.C. Implementation of a real-time uneven pavement detection system on FPGA platforms. In Proceedings of the 2022 IEEE International Conference on Consumer Electronics-Taiwan, Taipei, Taiwan, 6–8 July 2022; IEEE: Piscataway, NJ, USA, 2022. [Google Scholar]
- Rahman, R.; Bin Azad, Z.; Bakhtiar Hasan, M. Densely-populated traffic detection using YOLOv5 and non-maximum suppression ensembling. In Proceedings of the International Conference on Big Data, IoT, and Machine Learning: BIM 2021, Cox’s Bazar, Bangladesh, 23–25 September 2021; Springer: Singapore, 2022. [Google Scholar]
- Khaki, S.; Safaei, N.; Pham, H.; Wang, L. WheatNet: A lightweight convolutional neural network for high-throughput image-based wheat head detection and counting. Neurocomputing 2022, 489, 78–89. [Google Scholar] [CrossRef]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zhang, H.; Zu, K.; Lu, J.; Zou, Y.; Meng, D. EPSANet: An efficient pyramid squeeze attention block on convolutional neural network. In Proceedings of the Asian Conference on Computer Vision, Macau, Chia, 4–8 December 2022. [Google Scholar]
- Junos, M.H.; Mohd Khairuddin, A.S.; Thannirmalai, S.; Dahari, M. Automatic detection of oil palm fruits from UAV images using an improved YOLO model. Vis. Comput. 2022, 38, 2341–2355. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34. [Google Scholar]
- Du, S.; Zhang, B.; Zhang, P.; Xiang, P. An improved bounding box regression loss function based on CIOU loss for multi-scale object detection. In Proceedings of the 2021 IEEE 2nd International Conference on Pattern Recognition and Machine Learning (PRML), Chengdu, China, 16–18 July 2021; IEEE: Piscataway, NJ, USA, 2021. [Google Scholar]
- Huang, P.; Tian, S.; Su, Y.; Tan, W.; Dong, Y.; Xu, W. IA-CIOU: An Improved IOU Bounding Box Loss Function for SAR Ship Target Detection Methods. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 10569–10582. [Google Scholar] [CrossRef]
- Chen, D.; Miao, D. Control distance IoU and control distance IoU loss for better bounding box regression. Pattern Recognit. 2023, 137, 109256. [Google Scholar]
- GitHub-Ultralytics/Ultralytics: YOLOv8 in nn > Modules > Block > c2f. Available online: https://github.com/ultralytics/ultralytics/tree/main (accessed on 24 December 2024).
- GitHub-Ultralytics/Ultralytics: YOLOv11 in nn > Modules > Block > c3k2. Available online: https://github.com/ultralytics/ultralytics/tree/main (accessed on 24 December 2024).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).