
Research on Textile Tiny Defective Targets Detection Method Based on YOLO-GCW


Abstract
1. Introduction
- (1)
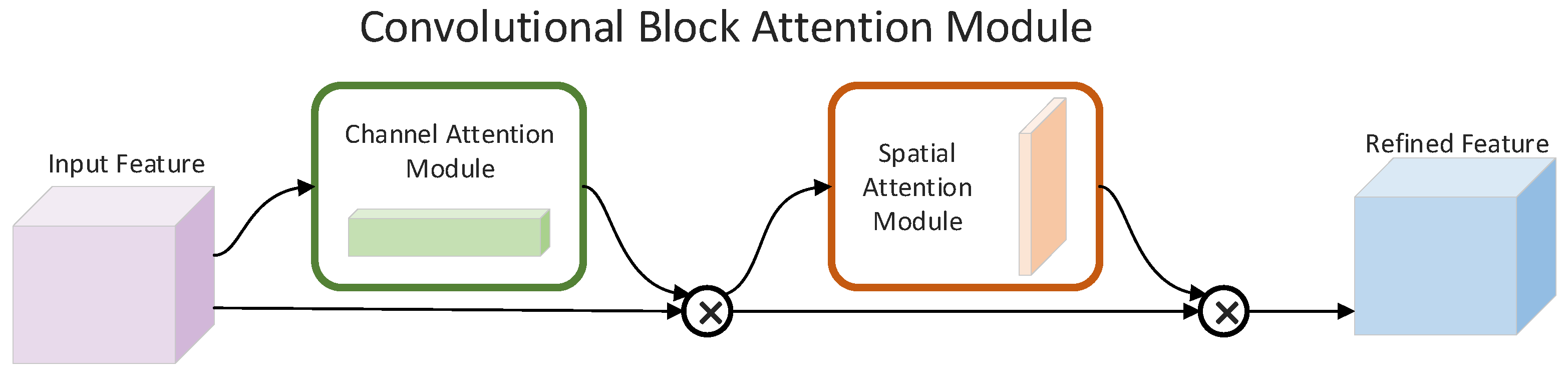
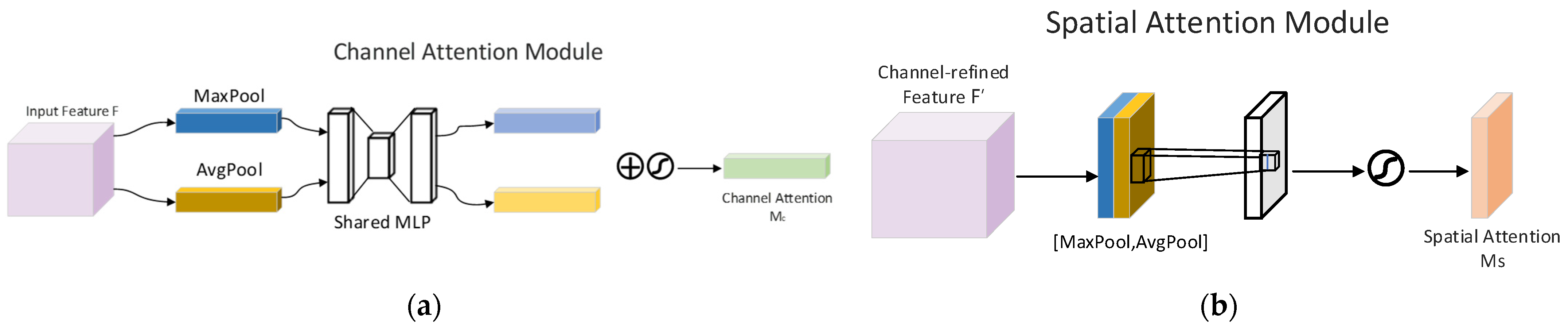
- This paper incorporated the CBAM attention mechanism module to lead the model to focus on the spatial localization characteristics of textile defects, which could effectively solve the problem of tiny defect detection.
- (2)
- The WIoU loss function was adopted to quantify the matching degree between the predicted border of the model and the real target border in a more accurate way to enhance the model’s accuracy in detecting tiny textile defective targets.
- (3)
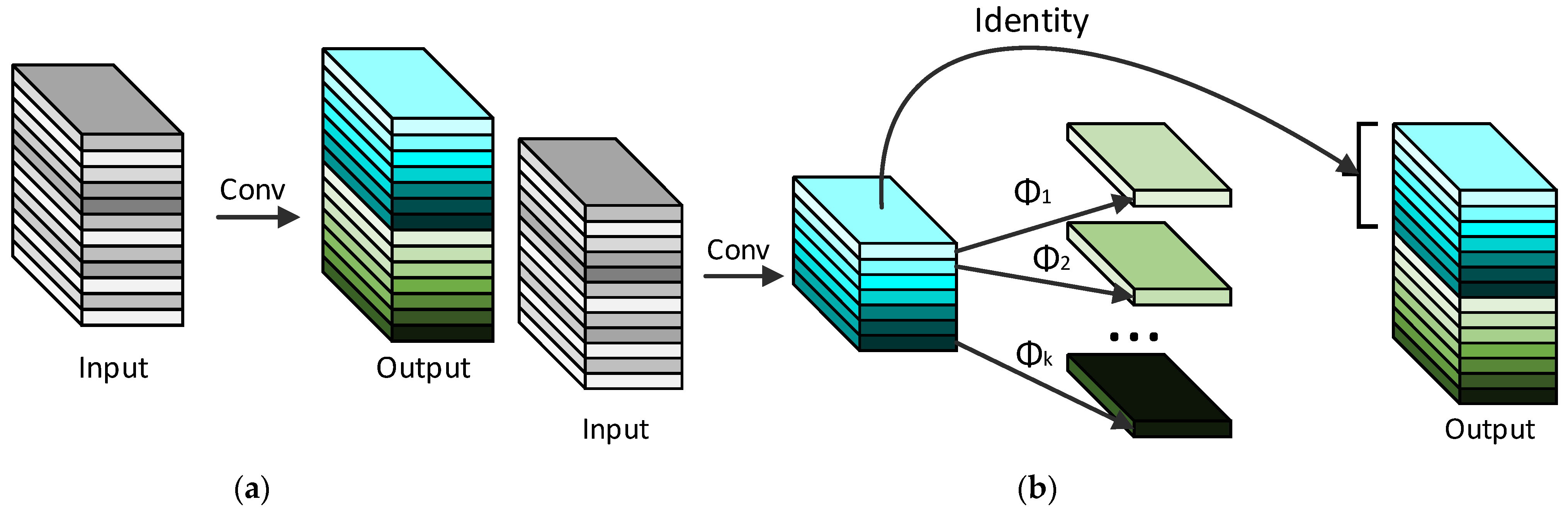
- The Ghost convolutional structure was utilized to replace the traditional convolutional operation to compress the model parameter scale and promote the real-time response detection speed of the model, enabling convenient, lightweight deployment on embedded and edge devices.
2. Related Work
3. Proposed Method
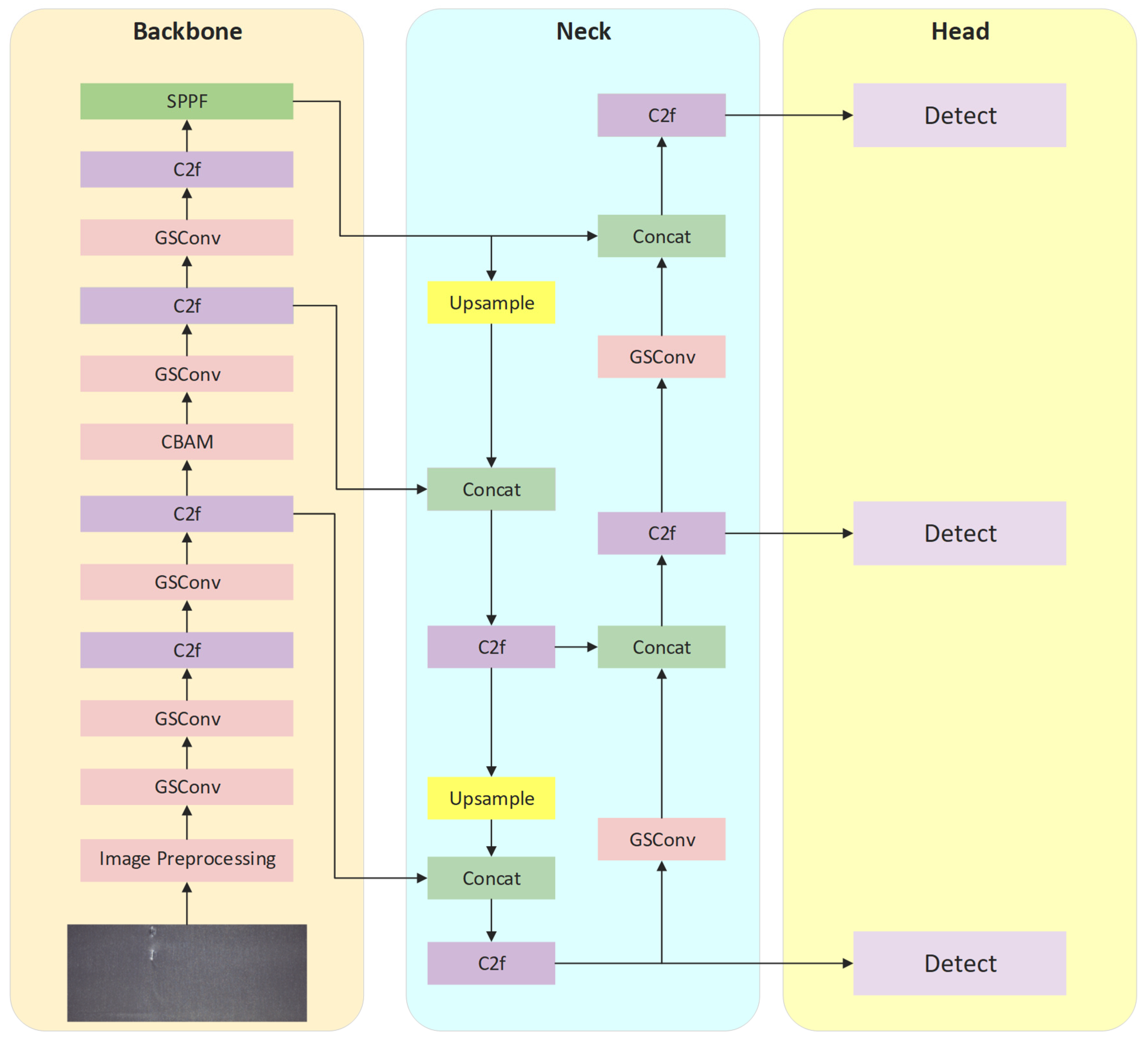
3.1. Textile Defect Detection Framework Based on YOLO-GCW
3.2. Convolutional Block Attention Module
3.3. Loss Function
3.4. Ghost Convolution
4. Experiment Results and Analysis
4.1. Dataset and Experimental Environment
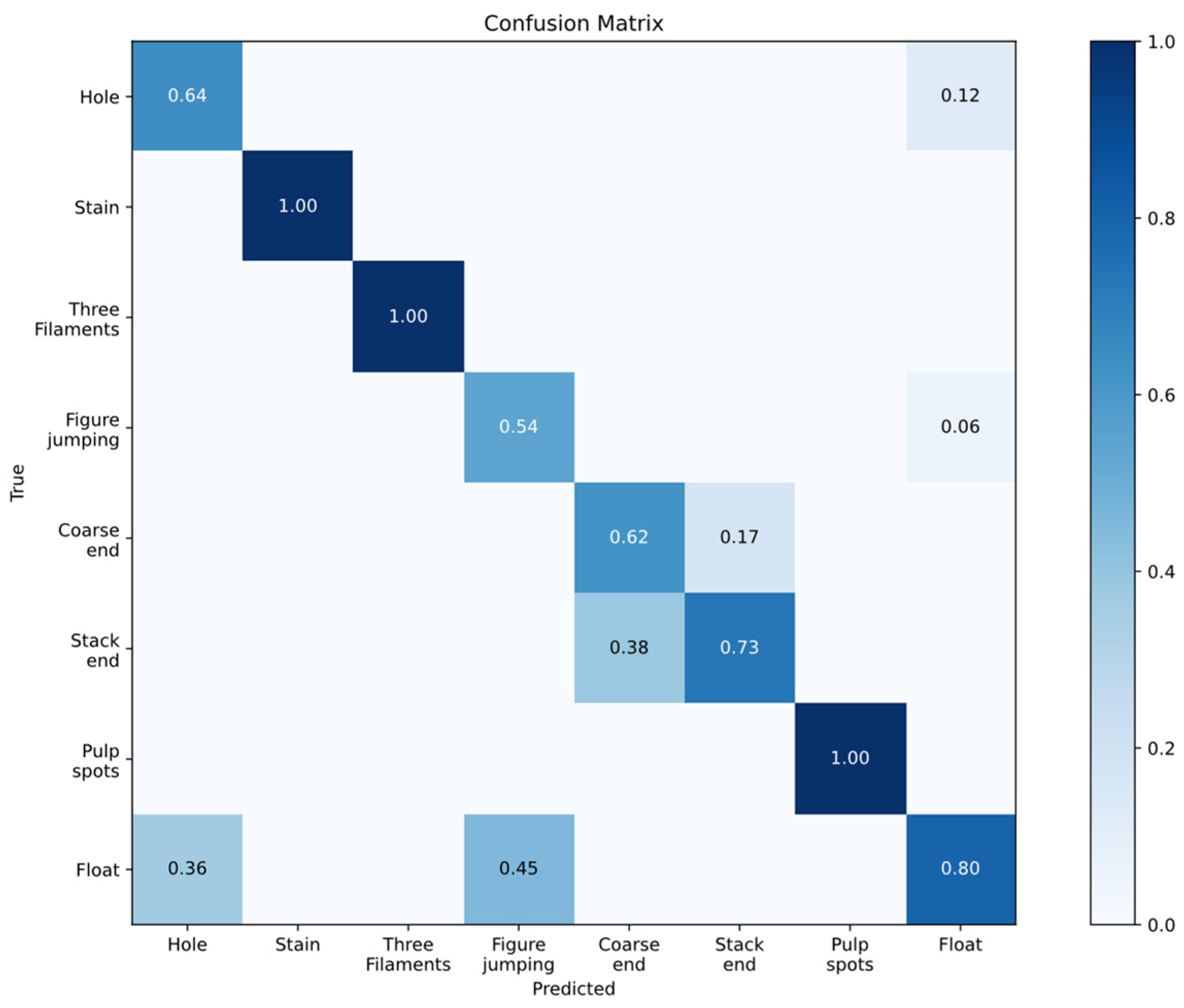
4.2. Evaluation Metrics
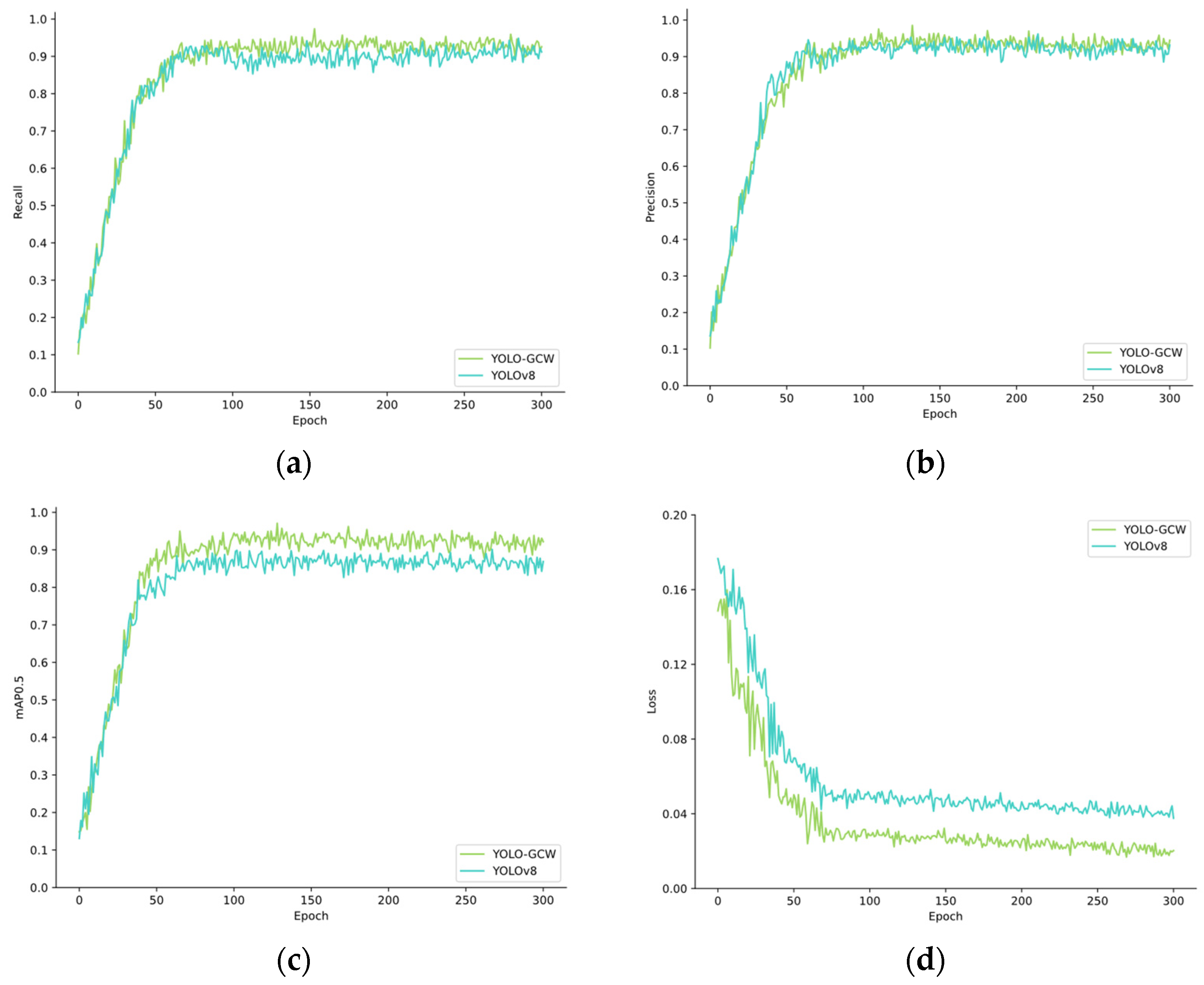
4.3. Comparative Experiments
4.4. Ablation Experiments
5. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wanjin, W.U.; Canfei, H.E. China’s textile export trade network expansion. World Reg. Stud. 2022, 31, 12–28. [Google Scholar]
- Kumar, A. Computer-Vision-Based Fabric Defect Detection: A Survey. IEEE Trans. Ind. Electron. 2008, 55, 348–363. [Google Scholar] [CrossRef]
- Ha, Y.S.; Oh, M.; Pham, M.V.; Lee, J.S.; Kim, Y.T. Enhancements in Image Quality and Block Detection Performance for Reinforced Soil-Retaining Walls under Various Illuminance Conditions. Adv. Eng. Softw. 2024, 195, 103713. [Google Scholar] [CrossRef]
- Wang, X.; Yan, B.; Pan, R.; Zhou, J. Real-time textile fabric flaw inspection system using grouped sparse dictionary. J. Real Time Image Process. 2023, 20, 67. [Google Scholar] [CrossRef]
- Xiang, Z.; Shen, Y.; Ma, M.; Qian, M. HookNet: Efficient Multiscale Context Aggregation for High-Accuracy Detection of Fabric Defects. IEEE Trans. Instrum. Meas. 2023, 72, 5016311. [Google Scholar] [CrossRef]
- Jeyaraj, P.R.; Nadar, E.R.S. Effective textile quality processing and an accurate inspection system using the advanced deep learning technique. Text. Res. J. 2020, 90, 971–980. [Google Scholar] [CrossRef]
- Wei, B.; Xu, B.; Hao, K.; Gao, L. Textile defect detection using multilevel and attentional deep learning network (MLMA-Net). Text. Res. J. 2022, 92, 3462–3477. [Google Scholar] [CrossRef]
- Tao, C.; Duan, Y.; Hong, X. Discrimination of fabric frictional sounds based on Haar features. Text. Res. J. 2019, 89, 2067–2074. [Google Scholar] [CrossRef]
- Wei, Y.; Tian, Q.; Guo, J.; Huang, W.; Cao, J. Multi-vehicle detection algorithm through combining Harr and HOG features. Math. Comput. Simul. 2019, 155, 130–145. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Sermanet, P. OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- Gulshan, V.; Peng, L.; Coram, M.; Stumpe, M.C.; Wu, D.; Narayanaswamy, A.; Venugopalan, S.; Widner, K.; Madams, T.; Cuadros, J.; et al. Development and Validation of a Deep Learning Algorithm for Detection of Diabetic Retinopathy in Retinal Fundus Photographs. JAMA 2016, 316, 2402–2410. [Google Scholar] [CrossRef] [PubMed]
- Terven, J.; Córdova-Esparza, D.M.; Romero-González, J.A. A Comprehensive Review of YOLO: From YOLOv1 to YOLOv8 and Beyond. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Wagner, T.; Merino, F.; Stabrin, M.; Moriya, T.; Antoni, C.; Apelbaum, A.; Hagel, P.; Sitsel, O.; Raisch, T.; Prumbaum, D.; et al. SPHIRE-crYOLO is a fast and accurate fully automated particle picker for cryo-EM. Commun. Biol. 2019, 2, 218. [Google Scholar] [CrossRef]
- Nogueira, R.G.; Jadhav, A.P.; Haussen, D.C.; Bonafe, A.; Budzik, R.F.; Bhuva, P.; Yavagal, D.R.; Ribo, M.; Cognard, C.; Hanel, R.A.; et al. Thrombectomy 6 to 24 hours after stroke with a mismatch between deficit and infarct. N. Engl. J. Med. 2018, 378, 11–21. [Google Scholar] [CrossRef]
- Ozturk, T.; Talo, M.; Yildirim, E.A.; Baloglu, U.B.; Yildirim, O.; Acharya, U.R. Automated detection of COVID-19 cases using deep neural networks with X-ray images. Comput. Biol. Med. 2020, 121, 103792. [Google Scholar] [CrossRef]
- Tian, Y.; Yang, G.; Wang, Z.; Wang, H.; Li, E.; Liang, Z. Apple detection during different growth stages in orchards using the improved YOLO-V3 model. Comput. Electron. Agric. 2019, 157, 417–426. [Google Scholar] [CrossRef]
- Li, Y.; Song, L.; Cai, Y.; Fang, Z.; Tang, M. Research on fabric surface defect detection algorithm based on improved Yolo_v4. Sci. Rep. 2024, 14, 5537. [Google Scholar] [CrossRef]
- Li, X.; Zhu, Y. A real-time and accurate convolutional neural network for fabric defect detection. Complex Intell. Syst. 2024, 10, 3371–3387. [Google Scholar] [CrossRef]
- Yang, L.; Fan, J.; Huo, B.; Li, E.; Liu, Y. A nondestructive automatic defect detection method with pixelwise segmentation. Knowl.-Based Syst. 2022, 242, 108338. [Google Scholar] [CrossRef]
- Luo, X.; Ni, Q.; Tao, R.; Shi, Y. A Lightweight Detector Based on Attention Mechanism for Fabric Defect Detection. IEEE Access 2023, 11, 33554–33569. [Google Scholar] [CrossRef]
- Zhao, C.; Shu, X.; Yan, X.; Zuo, X.; Zhu, F. RDD-YOLO: A modified YOLO for detection of steel surface defects. Meas. J. Int. Meas. Confed. 2023, 214, 112776. [Google Scholar] [CrossRef]
- Luo, X.; Cheng, Z.; Ni, Q.; Tao, R.; Shi, Y. Defect detection algorithm for fabric based on deformable convolutional network. Text. Res. J. 2022, 93, 2342–2345. [Google Scholar] [CrossRef]
- Di, L.; Deng, S.; Liang, J.; Liu, H. Context receptive field and adaptive feature fusion for fabric defect detection. Soft Comput. 2022, 27, 13421–13434. [Google Scholar] [CrossRef]
- Kumar, A.; Pang, G.K. Defect detection in textured materials using Gabor filters. IEEE Trans. Ind. Appl. 2002, 38, 425–440. [Google Scholar] [CrossRef]
- Jing, J.F.; Ma, H.; Zhang, H.H. Automatic fabric defect detection using a deep convolutional neural network. Color. Technol. 2019, 135, 213–223. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision—ECCV 2018: 15th European Conference, Munich, Germany, 8–14 September 2018; Proceedings, Part VII 11211. pp. 3–19. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-Iou Loss: Faster And Better Learning For Bounding Box Regression. In Proceedings of the Thirty-Fourth Aaai Conference on Artificial Intelligence, the Thirty-Second Innovative Applications of Artificial Intelligence Conference and the Tenth Aaai Symposium on Educational Advances in Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More Features from Cheap Operations. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1577–1586. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios. Intell. Syst. Account. Financ. Manag. 2021, 2021, 2778–2788. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 7464–7475. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Computer Vision—ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
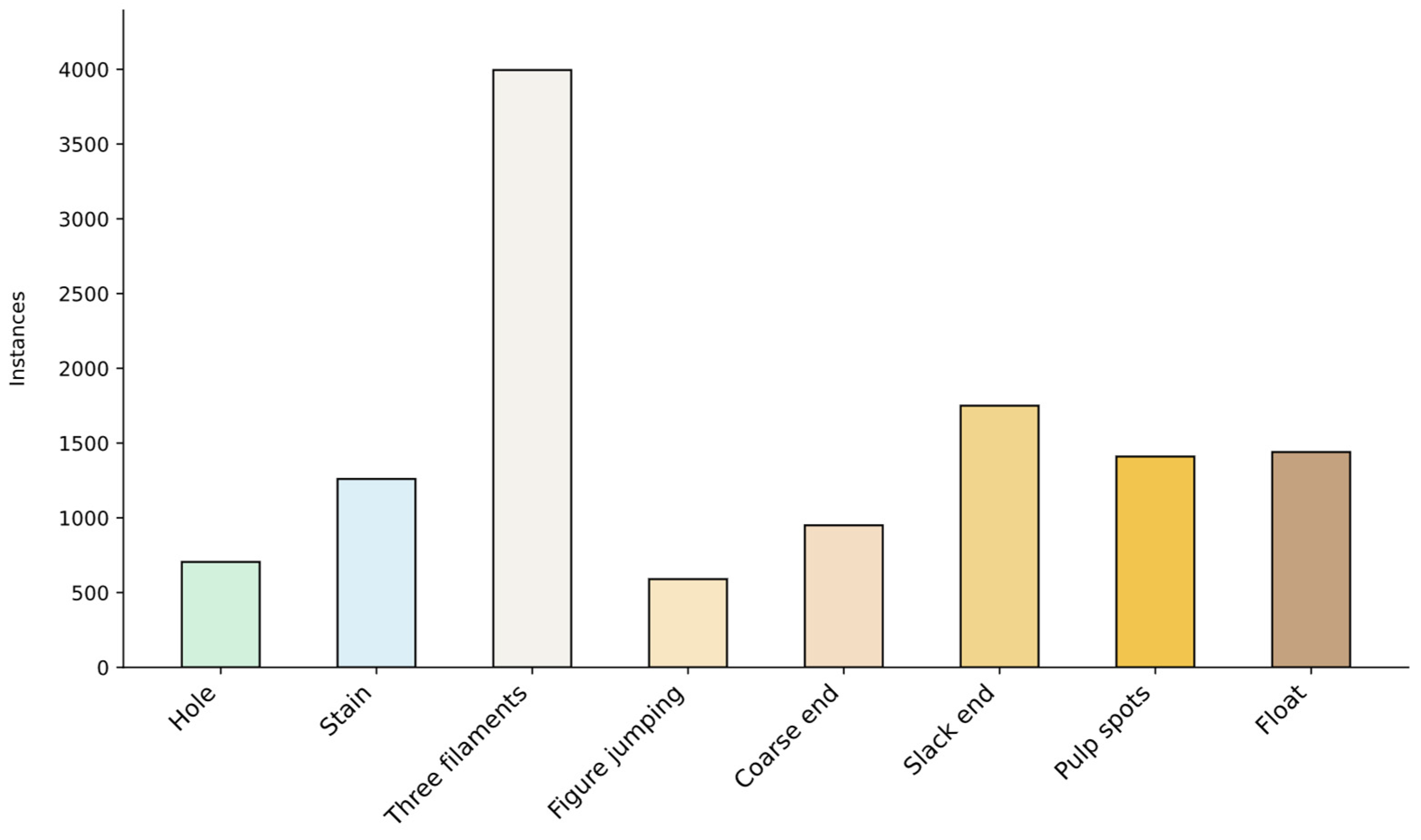
| Number | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| Classifications | Hole | Stain | Three Filaments | Figure jumping | Coarse end | Stack end | Pulp spots | Float |
| Quantities | 876 | 1409 | 4251 | 606 | 973 | 1796 | 1462 | 1454 |
| Model | mAP0.5 | mAP0.5:0.95 | Precision | Recall | FPS | F1 |
|---|---|---|---|---|---|---|
| Fast RCNN | 0.784 | 0.652 | 0.813 | 0.82 | 48.2 | 0.816 |
| SSD | 0.762 | 0.663 | 0.785 | 0.763 | 130.9 | 0.773 |
| YOLOv5 | 0.825 | 0.685 | 0.836 | 0.829 | 92.6 | 0.832 |
| YOLOv7 | 0.858 | 0.704 | 0.862 | 0.845 | 98.2 | 0.853 |
| YOLOv8 | 0.864 | 0.726 | 0.924 | 0.912 | 118.5 | 0.917 |
| PEI-YOLOv5 | 0.883 | 0.758 | 0.928 | 0.916 | 112.4 | 0.918 |
| YOLO-GCW | 0.916 | 0.783 | 0.932 | 0.928 | 132.6 | 0.929 |
| Model | Defect Category | |||
| Hole | Stain | Three Filaments | Figure Jumping | |
| SSD |  |  |  |  |
| Fast RCNN |  |  |  |  |
| YOLOv5 |  |  |  |  |
| YOLOv7 |  |  |  |  |
| YOLOv8 |  |  |  |  |
| YOLO-GCW |  |  |  |  |
| Model | Defect Category | |||
| Coarse End | Slack End | Pulp Spots | Float | |
| SSD |  |  |  |  |
| Fast RCNN |  |  |  |  |
| YOLOv5 |  |  |  |  |
| YOLOv7 |  |  |  |  |
| YOLOv8 |  |  |  |  |
| YOLO-GCW |  |  |  |  |
| ID | YOLOv8 | CBAM | GSConv | WIoU | Precision | Recall | Params | mAP0.5 | mAP0.5:0.95 | FPS | F1 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | √ | 0.924 | 0.912 | 5.2 | 0.864 | 0.726 | 118.5 | 0.917 | |||
| 2 | √ | √ | 0.926 | 0.92 | 6.1 | 0.892 | 0.718 | 115.2 | 0.922 | ||
| 3 | √ | √ | 0.922 | 0.918 | 4.3 | 0.889 | 0.723 | 135.4 | 0.919 | ||
| 4 | √ | √ | √ | 0.928 | 0.925 | 4.4 | 0.905 | 0.745 | 126.7 | 0.926 | |
| 5 | √ | √ | √ | √ | 0.932 | 0.928 | 4.4 | 0.916 | 0.783 | 132.6 | 0.929 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Xiao, Y.; Li, W.; Wang, B.; Wang, G. Research on Textile Tiny Defective Targets Detection Method Based on YOLO-GCW. Electronics 2025, 14, 480. https://doi.org/10.3390/electronics14030480
Chen J, Xiao Y, Li W, Wang B, Wang G. Research on Textile Tiny Defective Targets Detection Method Based on YOLO-GCW. Electronics. 2025; 14(3):480. https://doi.org/10.3390/electronics14030480
Chicago/Turabian StyleChen, Jun, Yuan Xiao, Weiqian Li, Boshi Wang, and Gangfeng Wang. 2025. "Research on Textile Tiny Defective Targets Detection Method Based on YOLO-GCW" Electronics 14, no. 3: 480. https://doi.org/10.3390/electronics14030480
APA StyleChen, J., Xiao, Y., Li, W., Wang, B., & Wang, G. (2025). Research on Textile Tiny Defective Targets Detection Method Based on YOLO-GCW. Electronics, 14(3), 480. https://doi.org/10.3390/electronics14030480