

Romanian Style Chinese Modern Poetry Generation with Pre-Trained Model and Direct Preference Optimization

Abstract
1. Introduction
2. Related Work
2.1. Poetry Generation
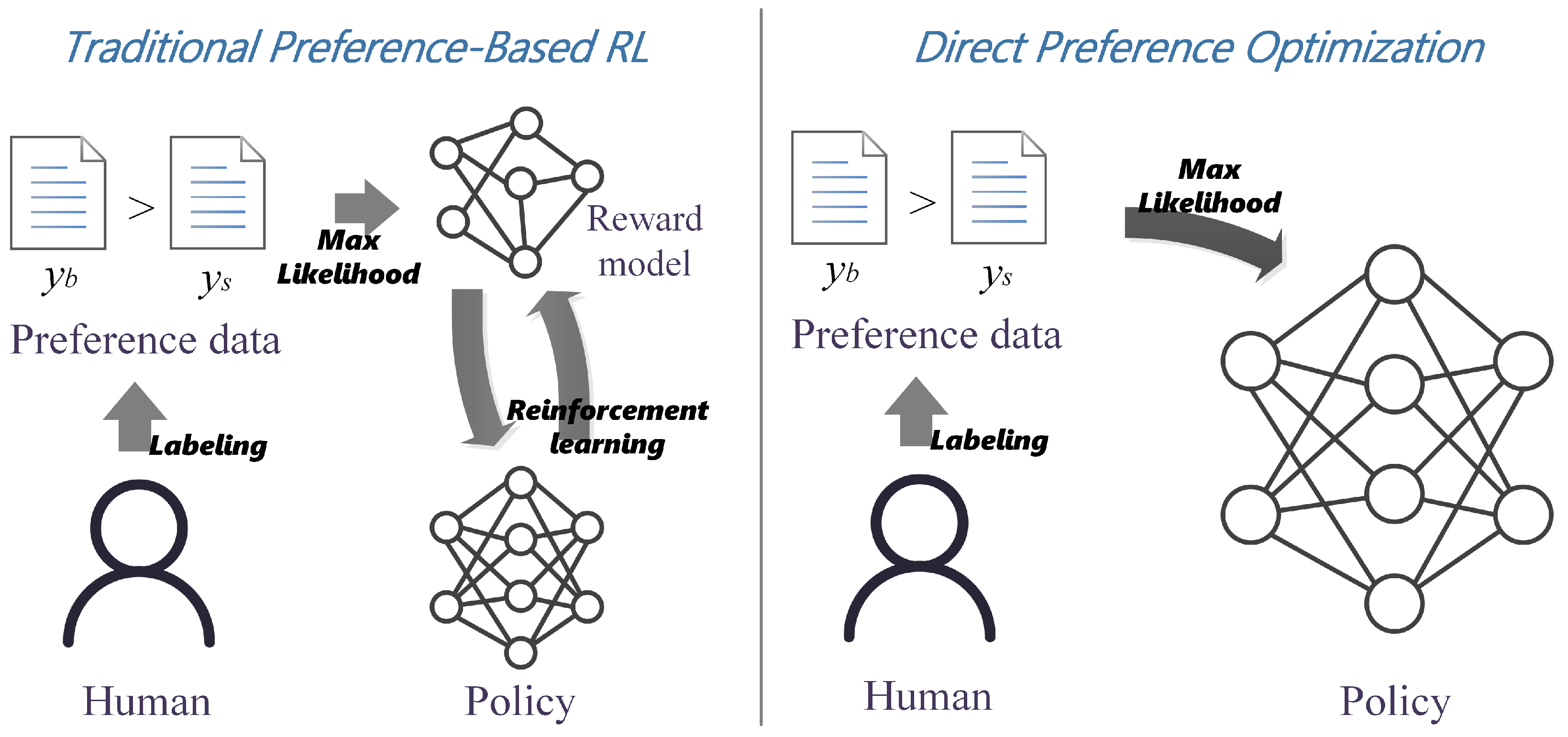
2.2. Direct Preference Optimization
3. Method
3.1. Model Architecture
3.2. Aligning with Human Judgement via Preference Data
3.3. Eliminating the Need for Explicit Reward Models
3.4. Simplifying Policy Optimization Without Reinforcement Learning
3.5. Direct Optimization of Human Preferences
3.6. Gradient-Based Update for Fine-Tuning
4. Experiments
4.1. Datasets
4.2. Collecting Data for Evaluation
- Guidelines: Annotators are requested to select their favorite poem by considering the following criteria: relevance to the theme, coherence of the content, originality, and the use of form, vocabulary, syntax, figurative language, idioms, and cultural references.
5. Results and Evaluation
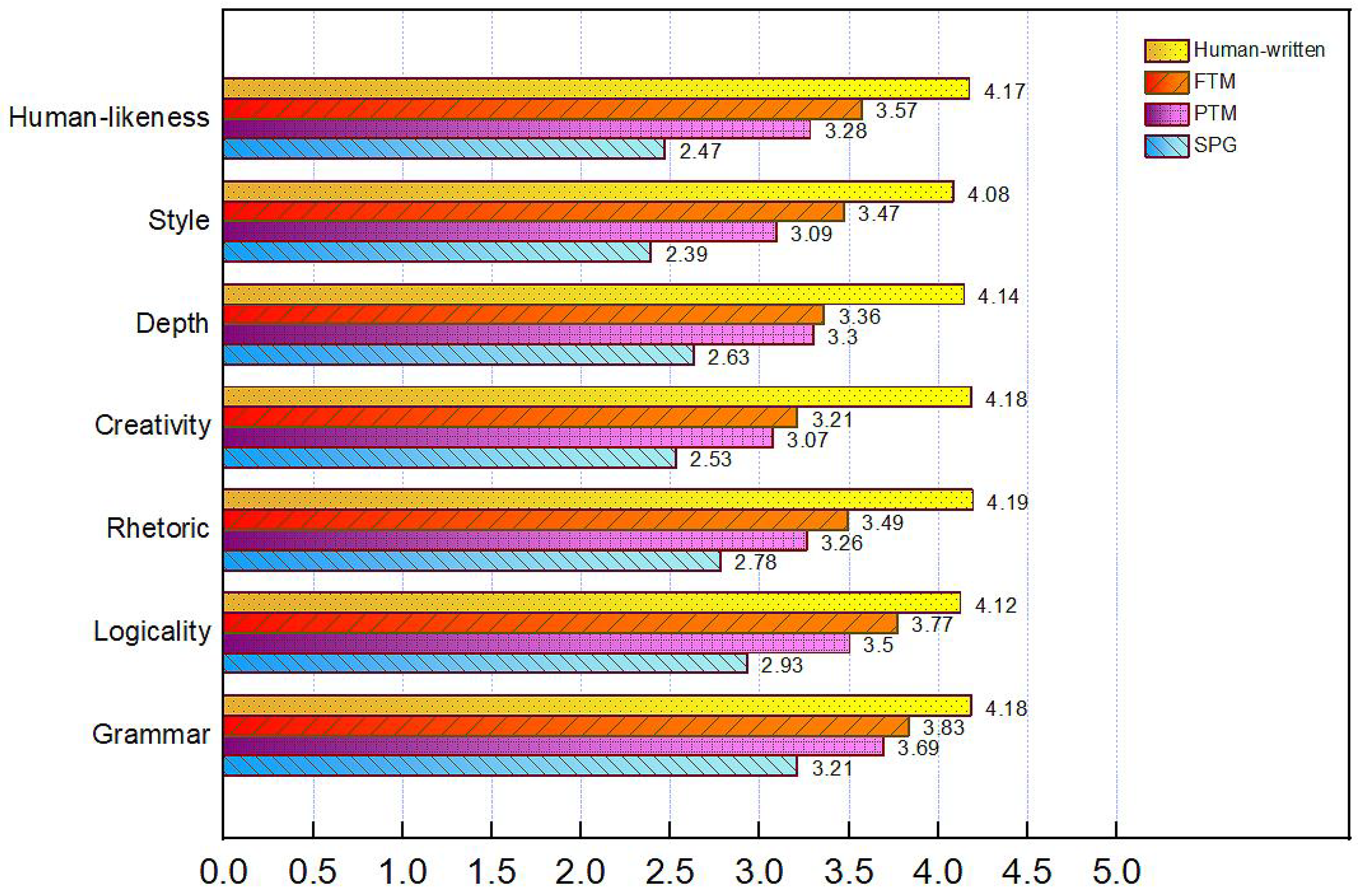
5.1. Human Evaluation
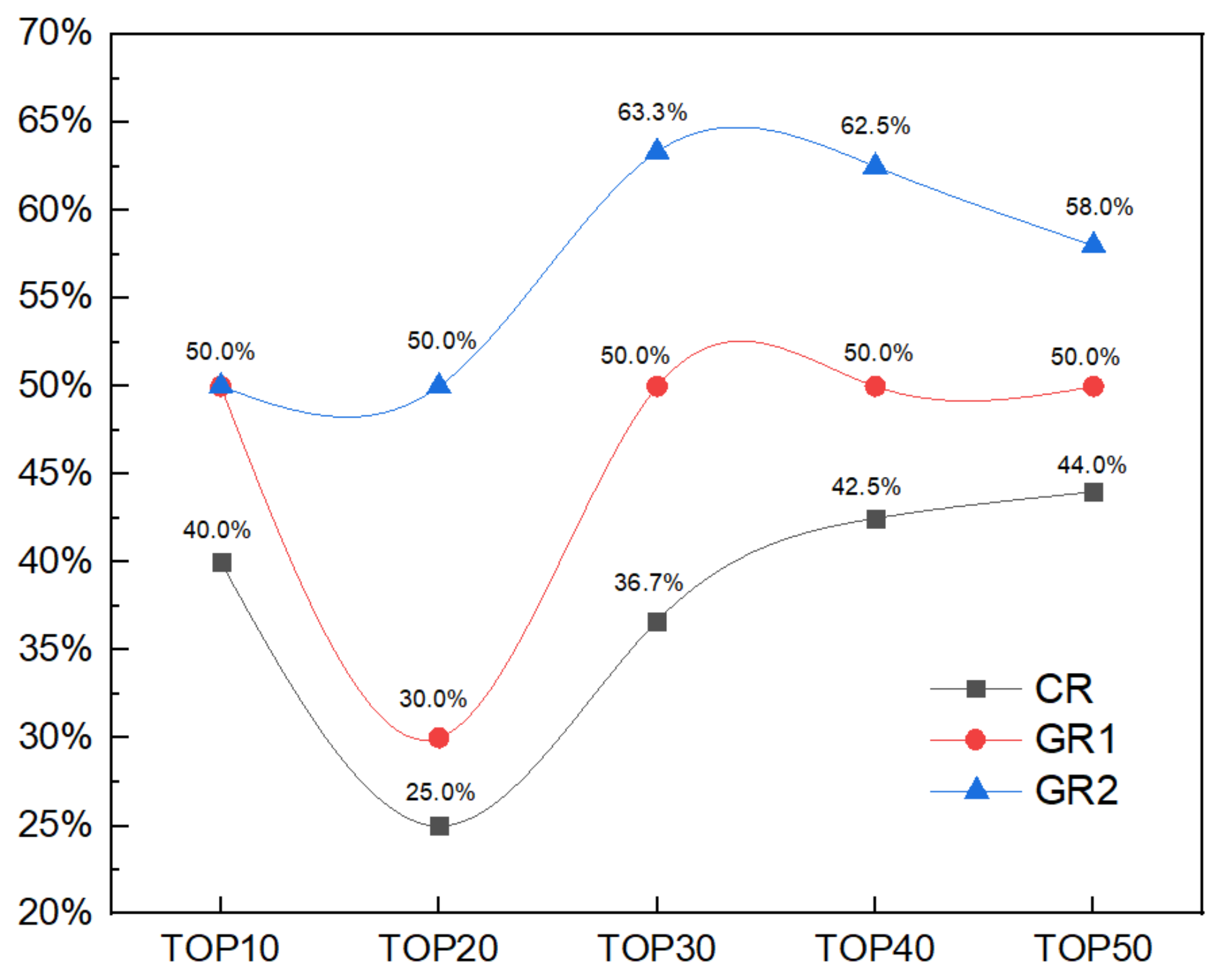
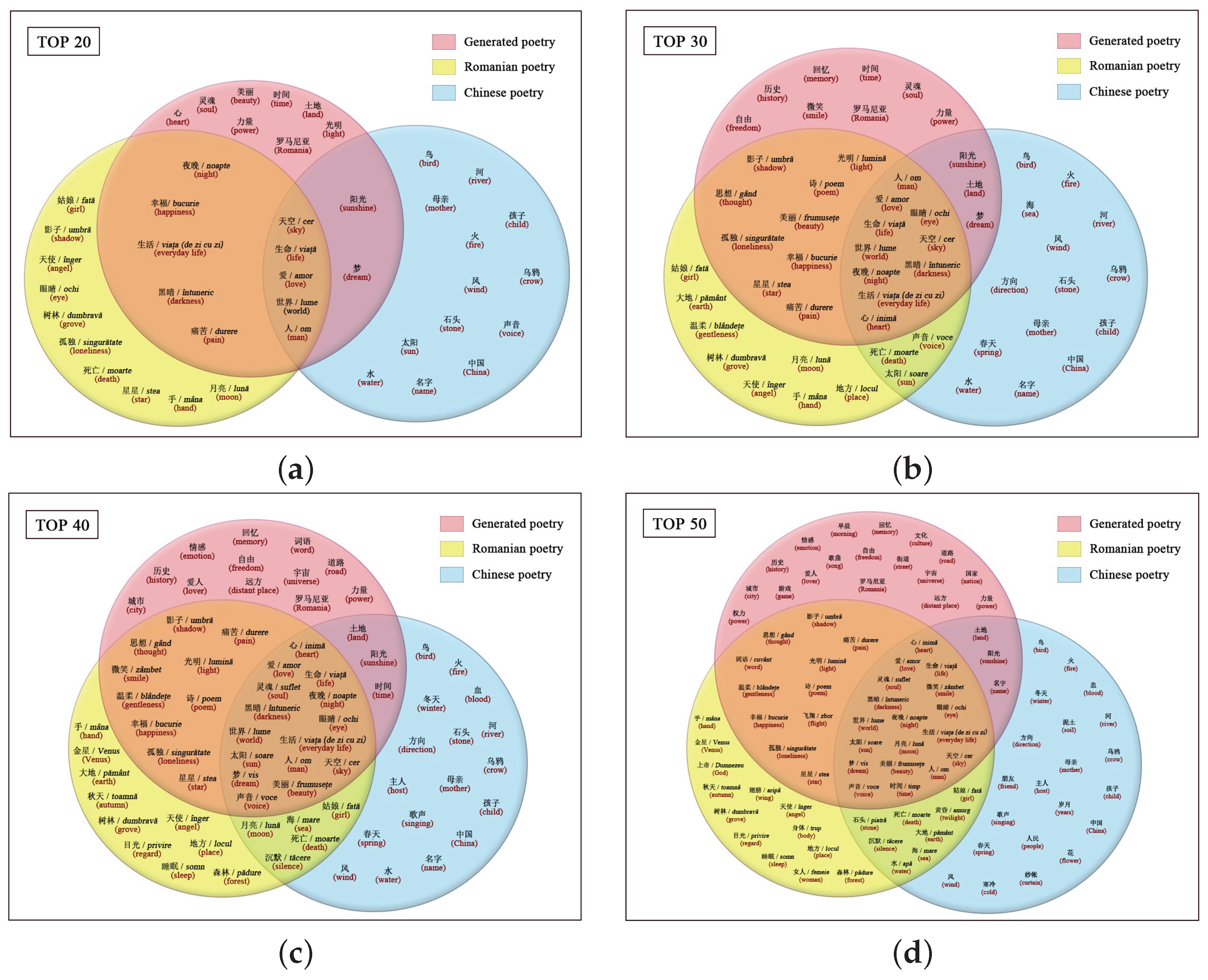
5.2. Imagery Evaluation
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gervas, P. WASP: Evaluation of different strategies for the automatic generation of Spanish verse. In Proceedings of the AISB00 Symposium on Creative & Cultural Aspects of AI, Birminham, UK, 17–20 April 2000; pp. 93–100. [Google Scholar]
- Oliveira, H.G. PoeTryMe: A versatile platform for poetry generation. In Proceedings of the Computational Creativity, Concept Invention, and General Intelligence (C3GI), Montpellier, France, 27 August 2012; pp. 21–26. [Google Scholar]
- Jiang, L.; Zhou, M. Generating Chinese couplets using a statistical MT approach. In Proceedings of the 22nd International Conference on Computational Linguistics, Manchester, UK, 18–22 August 2008; pp. 377–384. [Google Scholar]
- He, J.; Zhou, M.; Jiang, L. Generating Chinese classical poems with statistical machine translation models. In Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012; Volume 26, pp. 1650–1656. [Google Scholar]
- Wang, L.; Yu, Y.; Zhang, Y. Custom Generation of Poetry Based on Seq2Seq Model. J. Front. Comput. Sci. Technol. 2020, 14, 1028–1035. [Google Scholar]
- Hopkins, J.; Kiela, D. Automatically generating rhythmic verse with neural networks. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 168–178. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A robustly optimized BERT pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Hämäläinen, M.; Alnajjar, K.; Poibeau, T. Modern French poetry generation with RoBERTa and GPT-2. In Proceedings of the 13th International Conference on Computational Creativity (ICCC), Bolzano, Italy, 27 June–1 July 2022; pp. 12–16. [Google Scholar]
- Nehal, E.; Mervat, A.; Maryam, E.; Mohamed, A. Generating Classical Arabic Poetry using Pre-trained Models. In Proceedings of the Seventh Arabic Natural Language Processing Workshop (WANLP), Abu Dhabi, United Arab Emirates, 8 December 2022; pp. 53–62. [Google Scholar]
- Rafailov, R.; Sharma, A.; Mitchell, E.; Manning, C.D.; Ermon, S.; Finn, C. Direct preference optimization: Your language model is secretly a reward model. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]
- Shihadeh, J.; Ackerman, M. EMILY: An Emily Dickinson machine. In Proceedings of the 11th International Conference on Computational Creativity (ICCC’20), Coimbra, Portugal, 7–11 September 2020; pp. 243–246. [Google Scholar]
- Ghazvininejad, M.; Shi, X.; Choi, Y.; Knight, K. Generating topical poetry. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 1183–1191. [Google Scholar]
- Li, J.; Song, Y.; Zhang, H.; Chen, D.; Shi, S.; Zhao, D.; Yan, R. Generating classical Chinese poems via conditional variational autoencoder and adversarial training. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP), Brussels, Belgium, 31 October–4 November 2018; pp. 3890–3900. [Google Scholar]
- Gao, T.; Xiong, P.; Shen, J. A new automatic Chinese poetry generation model based on neural network. In Proceedings of the 2020 IEEE World Congress on Services (SERVICES), Beijing, China, 18–23 October 2020; pp. 41–44. [Google Scholar]
- Zhang, X.; Lapata, M. Chinese poetry generation with recurrent neural networks. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 670–680. [Google Scholar]
- Zhang, H.; Zhang, Z. Automatic generation method of ancient poetry based on LSTM. In Proceedings of the 2020 15th IEEE Conference on Industrial Electronics and Applications (ICIEA), Kristiansand, Norway, 9–13 November 2020; pp. 95–99. [Google Scholar]
- Liu, Z.; Fu, Z.; Cao, J.; De Melo, G.; Tam, Y.C.; Niu, C.; Zhou, J. Rhetorically controlled encoder-decoder for modern Chinese poetry generation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1992–2001. [Google Scholar]
- Hirata, K.; Yokoyama, S.; Yamashita, T.; Kawamura, H. Implementation of autoregressive language models for generation of seasonal fixed-form Haiku in Japanese. IIAI Lett. Inform. Interdiscip. Res. 2023, 3, LIIR075. [Google Scholar] [CrossRef]
- Shao, G.; Kobayashi, Y.; Kishigami, J. Traditional Japanese Haiku generator using RNN language model. In Proceedings of the 2018 IEEE 7th Global Conference on Consumer Electronics (GCCE), Nara, Japan, 9–12 October 2018; pp. 263–264. [Google Scholar]
- Talafha, S.; Rekabdar, B. Arabic poem generation with hierarchical recurrent attentional network. In Proceedings of the 2019 IEEE 13th International Conference on Semantic Computing (ICSC), Newport Beach, CA, USA, 30 January–1 February 2019; pp. 316–323. [Google Scholar]
- Gonçalo Oliveira, H.; Hervás, R.; Díaz, A.; Gervás, P. Adapting a generic platform for poetry generation to produce Spanish poems. In Proceedings of the 5th International Conference on Computational Creativity (ICCC), Ljubljana, Slovenia, 9–13 June 2014; pp. 63–71. [Google Scholar]
- Gonçalo Oliveira, H.G.; Cardoso, A. Poetry generation with PoeTryMe. In Computational Creativity Research: Towards Creative Machines; Besold, T., Schorlemmer, M., Smaill, A., Eds.; Atlantis Press: Amsterdam, The Netherlands, 2015; Volume 7, pp. 243–266. [Google Scholar]
- Hämäläinen, M.; Alnajjar, K. Let’s FACE it. Finnish poetry generation with aesthetics and framing. arXiv 2019, arXiv:1910.13946. [Google Scholar]
- Toivanen, J.M.; Toivonen, H.; Valitutti, A.; Gross, O. Corpus-based generation of content and form in poetry. In Proceedings of the 3rd International Conference on Computational Creativity (ICCC), Dublin, Ireland, 30 May–1 June 2012; pp. 211–215. [Google Scholar]
- Das, A.; Gambäck, B. Poetic Machine: Computational creativity for automatic poetry generation in Bengali. In Proceedings of the International Conference on Innovative Computing and Cloud Computing, Guilin, China, 19–21 October 2014; pp. 230–238. [Google Scholar]
- Ahmad, S.; Joglekar, P. Urdu and Hindi poetry generation using neural networks. In Data Management, Analytics and Innovation, Proceedings of the ICDMAI 2022, Kolkata, India, 17–19 January 2025; Goswami, S., Barara, I.S., Goje, A., Mohan, C., Bruckstein, A.M., Eds.; Lecture Notes on Data Engineering and Communications Technologies Series; Springer: Singapore, 2023; Volume 137. [Google Scholar]
- Zhang, L.; Zhang, R.; Mao, X.; Chang, Y. QiuNiu: A Chinese lyrics generation system with passage-level input. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics System Demonstrations, Dublin, Ireland, 22–27 May 2022; pp. 76–82. [Google Scholar]
- Liu, N.; Han, W.; Liu, G.; Peng, D.; Zhang, R.; Wang, X.; Ruan, H. ChipSong: A controllable lyric generation system for Chinese popular song. In Proceedings of the First Workshop on Intelligent and Interactive Writing Assistants (In2Writing 2022), Dublin, Ireland, 26 May 2022; pp. 85–95. [Google Scholar]
- Zhang, R.; Mao, X.; Li, L.; Jiang, L.; Chen, L.; Hu, Z.; Xi, Y.; Fan, C.; Huang, M. Youling: An AI-assisted lyrics creation system. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Online, 16–20 November 2020; pp. 85–91. [Google Scholar]
- Ziegler, D.M.; Stiennon, N.; Wu, J.; Brown, T.B.; Radford, A.; Amodei, D.; Christiano, P.; Irving, G. Fine-tuning language models from human preferences. arXiv 2019, arXiv:1909.08593. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Stiennon, N.; Ouyang, L.; Wu, J.; Ziegler, D.; Lowe, R.; Voss, C.; Radford, A.; Amodei, D.; Christiano, P.F. Learning to summarize with human feedback. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020; Volume 33, pp. 3008–3021. [Google Scholar]
- Bai, Y.; Jones, A.; Ndousse, K.; Askell, A.; Chen, A.; DasSarma, N.; Drain, D.; Fort, S.; Ganguli, D.; Henighan, T.; et al. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv 2022, arXiv:2204.05862. [Google Scholar]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training language models to follow instructions with human feedback. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; Volume 35, pp. 27730–27744. [Google Scholar]
- Bradley, R.A.; Terry, M.E. Rank analysis of incomplete block designs: I. The method of paired comparisons. Biometrika 1952, 39, 324–345. [Google Scholar] [CrossRef]
- Wu, J.; Ouyang, L.; Ziegler, D.M.; Stiennon, N.; Lowe, R.; Leike, J.; Christiano, P. Recursively summarizing books with human feedback. arXiv 2021, arXiv:2109.10862. [Google Scholar]
- Joachims, T. Optimizing search engines using clickthrough data. In Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Edmonton, AB, Canada, 23–26 July 2002. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L. BPR: Bayesian personalized ranking from implicit feedback. arXiv 2012, arXiv:1205.2618. [Google Scholar]
- Peters, J.; Schaal, S. Reinforcement learning by reward-weighted regression for operational space control. In Proceedings of the 24th International Conference on Machine Learning, Corvalis, OR, USA, 20–24 June 2007. [Google Scholar]
- Korbak, T.; Elsahar, H.; Kruszewski, G.; Dymetman, M. On reinforcement learning and distribution matching for fine-tuning language models with no catastrophic forgetting. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; Volume 35, pp. 16203–16220. [Google Scholar]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Lucian, B.; Maria, B.; Stefan, A.D.; Nina, C.; Petre, S.; Nichita, S.; Marin, S.; Gheorghe, G.; Cezar, B.; Dan, L.; et al. Anthology of Contemporary Romanian Lyric Poetry; Gao, X., Translator; Flower City Press: Guangzhou, China, 2018. [Google Scholar]
- Mihai, E. Mihai Eminescu, Poezii; Ding, C., Constantin, L., Eds.; Ge, B., Xu, W., Li, N., Feng, Z., Translator; Foreign Language Teaching and Research Press: Beijing, China, 2018. [Google Scholar]
- Yang, C.; Sun, M.; Yi, X.; Li, W. Stylistic Chinese Poetry Generation via Unsupervised Style Disentanglement. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3960–3969. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Types of Poetry | Quantity | Percentage |
|---|---|---|---|
| Modern Chinese versions of the works of Romanian poets (79,000 Chinese characters, 328 poems) | Lyric Poetry | 65 | 19.8% |
| Love Poetry | 104 | 31.7% | |
| Narrative Poetry | 39 | 11.9% | |
| Philosophical Poetry | 33 | 10.1% | |
| Pastoral Poetry | 46 | 14.0% | |
| Satirical Poetry | 15 | 4.6% | |
| Mourning Poetry | 26 | 7.9% |
| Model | Generated Verses | Generated Verses in English |
|---|---|---|
| Original Pre-trained Model | 所以我会继续前行, 为我的梦想和理想而战, 不被困难和阻碍打败, 向世界展示像我这样的人存在。 | So I will keep going, Fight for my dreams and ideals, I will not be defeated by difficulties and obstacles, Show the world that people like me exist. |
| 我喜欢看雨落在 松树叶上, 感觉自己就像是唯一的存在, 在这个广阔的世界里。 | I like to watch the rain fall On the pine leaves, Feel like I am the only being, In this vast world. | |
| 我记得以前的日子, 我的心跳得更快, 太阳在天空的一角升起, 照耀着绿色的田野和鲜花。 | I remember the old days, My heart used to beat faster, The sun rises in the corner of the sky, Shining on the green fields and flowers. | |
| 我渴望自由, 如同鸟儿飞翔, 却又被命运所束缚, 无法挣脱这束缚。 | I yearn for freedom, Flying like a bird, But I am bound by fate, Unable to break free from this shackle. | |
| 现在,当我看着高高挂在天空中的月亮, 星星似乎在向我微笑, 我感到我已经找到了我所寻求的, 我的生命有一个神圣的意义。 | Now, when I look at the moon high in the sky, The stars seem to be smiling at me, I feel I have found what I am looking for, My life has a sacred meaning. | |
| Fine-tuned Pre-trained Model | 在蒂米什瓦拉的街道上, 你是我见过最美的风景, 你的名字如同古老的城堡, 在我心中徜徉。 | On the streets of Timisoara, Thou art the most beautiful scenery I have ever seen, Thy name, like an ancient castle, Roams in my heart. |
| 他颤抖着手,拿着一本旧笔记本, 里面写着匆忙而又被擦掉的诗句, 他总是说自己是诗人,虽然 没有人读他那沉重而冰冷的诗歌。 | He trembled as he held an old notebook, Inside were hastily written and erased verses, He always claimed to be a poet, even though No one read his heavy and icy poems. | |
| 闭着疼痛的眼睛, 感受时间像一条河流流逝, 在黑暗而沉重的夜晚里, 被遗忘的回忆再次重生。 | With my eyes closed in pain, I feel time flowing like a river, In the dark and heavy night, Forgotten memories are reborn again. | |
| 在早晨的阳光中, 阳台上的花儿在微风中摇曳, 叶子上的露珠闪耀着光芒, 如同千万颗钻石在跳跃。 | In the morning sunshine, The flowers on the balcony sway in the breeze, Dewdrops on the leaves sparkling, Just like millions of diamonds dancing. | |
| 我们站在时间的边缘, 寻找意义, 但也许生命只是一场游戏, 而我们只是舞台上的演员。 | We stand on the edge of time, Looking for meaning, But maybe life is just a game, And we are just actors on the stage. |
| Grammar | Evaluation content | Fluency and grammatical correctness of the poetry. |
| Evaluation criteria | 5 Excellent; 4 Good; 3 Average; 2 Below Average; 1 Poor. | |
| Logicality | Evaluation content | Clarity of thinking, contextual coherence, lack of inconsistency. |
| Evaluation criteria | 5 Excellent; 4 Good; 3 Average; 2 Below Average; 1 Poor. | |
| Rhetoric | Evaluation content | Language richness and rhetorical appropriateness. |
| Evaluation criteria | 5 Excellent; 4 Good; 3 Average; 2 Below Average; 1 Poor. | |
| Creativity | Evaluation content | Uniqueness of expression, novelty of imagery, no clichés. |
| Evaluation criteria | 5 Excellent; 4 Good; 3 Average; 2 Below Average; 1 Poor. | |
| Depth | Evaluation content | Inspiring and thought-provoking. |
| Evaluation criteria | 5 Excellent; 4 Good; 3 Average; 2 Below Average; 1 Poor. | |
| Style | Evaluation content | Similarity to Romanian poetry style. |
| Evaluation criteria | 5 Very High; 4 High; 3 Average; 2 Below Average; 1 Very Low. | |
| Human- | Evaluation content | Likelihood of the poetry written by human. |
| likeness | Evaluation criteria | 5 Definitely; 4 Very Probably; 3 Probably; 2 Probably Not; 1 Definitely Not. |
| Reliability | Grammar | Logicality | Rhetoric | Creativity | Depth | Style | Human-Likeness |
|---|---|---|---|---|---|---|---|
| Cronbach’s | 0.882 | 0.845 | 0.878 | 0.899 | 0.868 | 0.807 | 0.859 |
| McDonald’s | 0.894 | 0.865 | 0.885 | 0.896 | 0.882 | 0.756 | 0.870 |
| Verses from “Înger şi demon” | Translation in English |
|---|---|
| Ea un înger ce se roagă - El un demon ce visează; | “She” a praying angel—“He” a dreaming demon; |
| Ea o inimă de aur—El un suflet apostat; | “She” a heart of gold—“He” an apostate soul; |
| El, în umbra lui fatală, stă-ndărătnic răzemat— | “He”, in his fatal shadow, stubbornly leans— |
| La picioarele Madonei, tristă, sfântă, Ea veghează. | At the feet of the Madonna, sad, holy, She watches. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zuo, L.; Zhang, D.; Zhao, Y.; Wang, G. Romanian Style Chinese Modern Poetry Generation with Pre-Trained Model and Direct Preference Optimization. Electronics 2025, 14, 294. https://doi.org/10.3390/electronics14020294
Zuo L, Zhang D, Zhao Y, Wang G. Romanian Style Chinese Modern Poetry Generation with Pre-Trained Model and Direct Preference Optimization. Electronics. 2025; 14(2):294. https://doi.org/10.3390/electronics14020294
Chicago/Turabian StyleZuo, Li, Dengke Zhang, Yuhai Zhao, and Guoren Wang. 2025. "Romanian Style Chinese Modern Poetry Generation with Pre-Trained Model and Direct Preference Optimization" Electronics 14, no. 2: 294. https://doi.org/10.3390/electronics14020294
APA StyleZuo, L., Zhang, D., Zhao, Y., & Wang, G. (2025). Romanian Style Chinese Modern Poetry Generation with Pre-Trained Model and Direct Preference Optimization. Electronics, 14(2), 294. https://doi.org/10.3390/electronics14020294