Abstract
In this paper, we propose a novel integrated model architecture, called a level-of-detail (LoD)-aware convolutional vision transformer network (LCvT). It is designed to enhance digital twin (DT) synchronization by effectively integrating LoD awareness in DTs through hierarchical image classification. LCvT employs a vision transformer (ViT)-based backbone coupled with dedicated branch networks for each LoD. This integration of ViT and branch networks ensures that key features are accurately detected and tailored to the specific objectives of each detail level while also efficiently extracting common features across all levels. Furthermore, LCvT leverages a coarse-to-fine inference strategy and incorporates an early exit mechanism for each LoD, which significantly reduces computational overhead without compromising accuracy. This design enables a single model to dynamically adapt to varying LoD requirements in real-time, offering substantial improvements in inference time and resource efficiency compared to deploying separate models for each level. Through extensive experiments on benchmark datasets, we demonstrate that LCvT outperforms existing methods in accuracy and efficiency across all LoDs, especially in DT synchronization scenarios where LoD requirements fluctuate dynamically.
1. Introduction
A digital twin (DT) is a virtual representation of a real-world physical object that is continuously updated to reflect its counterpart for various purposes, including real-time monitoring and simulation [1,2]. The utilization of DTs brings significant advantages such as time and cost savings, improved decision-making, and enhanced performance in managing complex physical systems [3,4]. Recently, there has been growing interest in enhancing DT performance through considering level-of-detail (LoD), implying an approach that optimizes DT tasks by processing only the necessary degree of detail required for specific applications [5].
LoD-aware DT synchronization addresses a primary challenge in replicating complex physical objects within the virtual world based on data collected from Internet-of-things (IoT) devices like cameras or sensors on edges [6,7,8]. Accurate DT synchronization requires transforming raw sensor data into metadata for real-time replication, ensuring that the digital model faithfully represents the physical object. By incorporating LoD, DT systems can hierarchically classify and process features, with lower LoD capturing basic attributes and higher LoD providing detailed features [9,10]. This tailored approach not only enhances accuracy but also improves resource efficiency in DT-related tasks such as simulation and visualization by dedicating computational power to the most relevant LoDs for each task.
Despite the growing importance of DT systems, existing deep learning approaches still face notable limitations [11]. In particular, from the perspective of LoD-aware DT synchronization, convolutional neural network (CNN)-based models are effective at extracting localized features to identify physical objects, but they struggle to capture global context. Conversely, transformer-based models provide richer representations but incur high computational costs. Hybrid and hierarchical architectures attempt to combine these strengths; however, they often lack explicit mechanisms for LoD-awareness or the ability to adapt to dynamic LoD requirements. In addition, conventional inference pipelines often perform redundant computations and depend on separate models for each LoD, which limits efficiency and real-time applicability. The following subsection provides a detailed review of the related literature and identifies key research motivations.
1.1. Literature Review
Recently, deep neural networks (DNNs) have played a significant role in DT synchronization, especially for image-based data processing [4,5], for converting raw data collected from IoT sensors. CNNs in particular, such as ResNet [12], have been the dominant models due to their strength in capturing spatial features through localized receptive fields. These approaches provide strong performance in extracting low-level visual attributes, but they are limited in capturing long-range dependencies.
In contrast, vision transformers (ViTs) leverage self-attention mechanisms to model global contextual information effectively [13]. Therefore, ViTs are well-suited for handling the hierarchical features of complex physical objects in DT synchronization. This capability makes ViTs a promising approach for further enhancing DT synchronization. Hybrid models, such as the convolutional vision transformer (CvT) [14] and attention branch network [15], attempt to combine the benefits of both approaches by combining global attention with local feature extraction to achieve higher accuracy. These models improve accuracy and contextual understanding, but they are computationally expensive to be applied in real-time DT environments.
As one of the ways to reduce computational costs and accelerate inference speed, early exit mechanisms have been widely adopted in DNN architectures [16,17]. In a typical DNN model, inference is performed by sequentially processing each layer of the model. Early exit mechanisms leverage this sequential structure by inserting exit points between selected consecutive layers. At each exit point, an inference is generated using the intermediate features, and its credibility is evaluated. If the inference meets a predefined confidence threshold, the inference process terminates, thereby bypassing the remaining layers of the model; otherwise, computation proceeds to the next exit point. This strategy significantly reduces the computational burden and overall execution time by allowing inference to conclude early when sufficient confidence is achieved [16,18].
In [19], a transformer-based architecture called CF-ViT is proposed, which employs a coarse-to-fine inference strategy combined with an early exit mechanism. Specifically, CF-ViT first generates a prediction from coarse features; if the prediction confidence is insufficient, it refines image regions to extract finer features for subsequent prediction. This approach enhances inference efficiency without compromising accuracy. However, CF-ViT still lacks explicit mechanisms for LoD-awareness or adaptive inference strategies.
As a potential model for LoD-aware classification, a hierarchical deep CNN (HD-CNN) is proposed, which incorporates a two-level category hierarchy into CNNs [20]. However, HD-CNN introduces additional complexity due to its multiple subnetworks, and it did not provide unified control over dynamic computation across multi-LoD prediction. Similarly, in [21], a branch CNN (B-CNN) is proposed to predict hierarchical levels using branch networks built upon a CNN backbone. B-CNN captures hierarchical relationships by combining backbone networks with branch structures, but it still relies on multiple outputs and cannot perform dynamic prediction within a single model. Consequently, existing hierarchical classification methods often lack the adaptability to the dynamically changing LoD requirements in DT tasks.
Beyond model architecture design, recent studies have explored auxiliary techniques to improve the robustness and reliability of DNN models in industrial systems, including DT systems. For example, in [22], a lite automatic data augmentation framework, ALADA, is proposed to improve the generalizability of DNN models in industrial applications. One way to directly consider the reliability of DNN models in industrial systems is to quantify their predictive uncertainties, as discussed in [23]. In addition, in [24], it is demonstrated that continual learning for intelligent industrial systems is an effective method for providing robust long-term adaptability in industrial operations. However, while these methods enhance general robustness, they are not directly aligned with LoD-aware DT synchronization.
1.2. Research Motivation
Despite these advancements from the above literature, most existing DNN models do not explicitly consider how to address dynamic LoD-awareness in DT systems, a critical feature for real-time DT applications. Effective LoD-awareness in DT synchronization ensures that DTs describe their physical counterparts with precision tailored to task-specific requirements [25,26]. By processing only the necessary level of detail, LoD-aware DT synchronization improves both performance and resource efficiency. This approach naturally drives the hierarchical classification of physical object features, ensuring that DT synchronization aligns with the precise level of detail needed.
In light of this, we identify several key challenges for LoD-aware classification. First, most existing architectures are not explicitly designed to capture hierarchical, LoD-specific features, which limits their adaptability across different LoDs. Second, conventional inference pipelines incur redundant computation since full processing is carried out even when coarse-level classification would suffice. Third, existing approaches do not consider end-to-end LoD-awareness, implying the need for separate models for each LoD. This increases both training and inference costs, hindering real-time deployment in dynamic DT environments.
To address these issues, a novel approach is needed that carefully incorporates attention mechanisms from transformers into branch network architectures, with each branch addressing a specific LoD. Furthermore, adopting early exit strategies for each branch network accelerates inference at the corresponding LoD. This integration improves the performance of both backbone and branch networks, thereby enabling more accurate and efficient LoD-aware DT synchronization across a wide range of applications. These considerations directly motivate the design of this work.
1.3. Our Contributions
In this paper, we propose a novel integrated model architecture, called LoD-aware convolutional vision transformer networks (LCvT), to effectively perform LoD-aware DT synchronization (i.e., LoD-aware classification problem) for DT-related tasks. As existing CNN- or transformer-based models are not explicitly designed for hierarchical, LoD-specific feature extraction, they often suffer from redundant computation and require separate models for each LoD, limiting their adaptability in dynamic DT environments. To address these challenges, LCvT integrates a CvT-based backbone with LoD-specific ViT branch networks, incorporating a coarse-to-fine inference strategy and early exit mechanisms. This unified architecture design allows a single model to dynamically adapt across varying LoDs while maintaining both accuracy and efficiency. The contributions of this paper are summarized as follows:
- We propose a unified architecture that integrates a CvT backbone with multiple LoD-specific ViT branch networks. This design enables the model to detect key features tailored to each LoD using the corresponding ViT-based branch network, as well as to extract collective features across all LoDs using a CvT-based backbone.
- For each ViT-based branch network, we adopt the coarse-to-fine inference strategy for effectively detecting key features of the corresponding LoD. This refines informative image patches and processes them at a finer granularity. An early exit mechanism in the coarse-to-fine structure significantly reduces not only the computational burden but also the inference time at each LoD if the intermediate inference is accurate enough.
- From the perspective of LoD-aware DT synchronization, LCvT enables a single model to address end-to-end hierarchical classification across different LoDs, overcoming the need for independent models for each LoD.
- Through experiments with real datasets, we demonstrate that LCvT effectively learns key features across varying LoDs and consistently outperforms existing baseline models. Moreover, LCvT achieves a shorter inference time than using independent models for each LoD, especially in real-world scenarios where LoDs dynamically change.
1.4. Paper Structure
The rest of this paper is organized as follows: Section 2 describes the LoD-aware classification problem. Then, Section 3 provides the architecture, components, and training method of LCvT. Section 4 discusses the role of LCvT in the context of LoD-awareness in DT systems. In Section 5, the experimental results on benchmark datasets are provided. Finally, the paper concludes in Section 6.
2. LoD-Aware Classification Problem
In this section, we define an LoD-aware classification problem tailored for effective LoD-aware DT synchronization. Typically, LoD-aware DTs inherently exhibit a hierarchical structure, where higher LoD levels require more precise details and lower-level details, are inherently part of higher levels. In this light, the problem is formulated as a hierarchical classification task, where the objective is to identify the classes for all LoD levels, from the lowest up to a specified target LoD level. Once the LoD-aware classification is completed for the desired LoD level, the resulting labels can directly inform and drive the corresponding DT synchronization process.
To formally describe the LoD-aware classification problem, we first introduce an LoD label tree that organizes hierarchical classes for each LoD level. We denote the index of LoD levels by , where L represents the total number of LoD levels. The set of classes associated with LoD level l is denoted by , where is the number of classes associated with LoD level l. Importantly, the LoD label tree should be constructed in a broad-to-detailed manner (i.e., progressing from general to specific) so as to represent the hierarchical structure inherent in LoDs.
Figure 1 illustrates an example of an LoD label tree for LoD-aware classification. At LoD level 1, the classification distinguishes between basic object types, such as cars and trucks. At LoD level 2, the car category is further divided into manufacturer, such as BMW, Benz, and Audi, while the truck category is further divided into MAN and Volvo. At LoD level 3, classification becomes even more granular by identifying specific models.
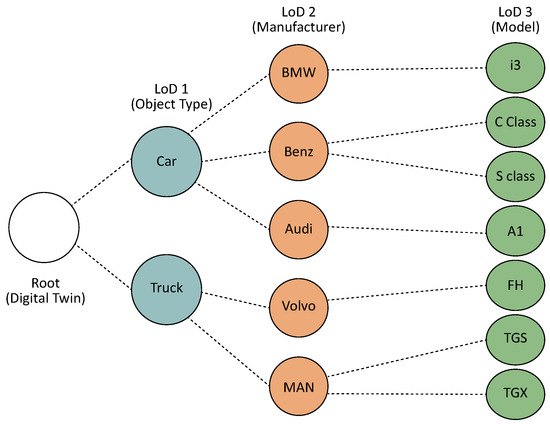
Figure 1.
The example of an LoD label tree.
The LoD-aware classification problem for a given target LoD level involves determining the appropriate classes for an input image from the lowest level to the target level of a hierarchical LoD label tree. We formulate the LoD-aware classification problem as finding an LoD-aware classifier that outputs a predicted label for a given input and LoD level l. With this formulation, once the label at LoD level l is predicted, the corresponding labels for lower LoD levels (from 1 to ) can be naturally determined based on the label tree without any additional classification procedure. This formulation efficiently handles LoD awareness by avoiding the need for repetitive multi-stage classification.
Each request for LoD-aware DT synchronization may require a different LoD level, depending on the specific needs of the synchronization requirements, which can be dynamically changed according to DT-related tasks. Consequently, the LoD-aware classification problem requires a hierarchical model architecture that allows a single model to dynamically adapt to and handle different LoD levels. This approach ensures effective and efficient management of LoD-aware DT synchronization.
3. LoD-Aware Convolutional Vision Transformer Network
This section describes an LCvT, designed to effectively address the LoD-aware classification problem by considering key features for each LoD.
3.1. LCvT Architecture
We first present the architecture of LCvT, which consists of a backbone network and LoD-specific branch networks. The backbone network extracts general features from the input data in a manner analogous to typical CNN-based models. Building on these features, the LoD-specific branch networks are designed to isolate and extract key features tailored to each specific LoD level, thereby facilitating precise LoD-aware predictions. Therefore, each LoD-specific branch network corresponds to each LoD for effective LoD awareness. The LCvT architecture is illustrated in Figure 2.
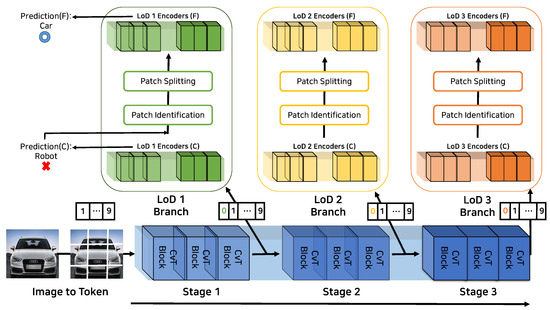
Figure 2.
The architecture of LCvT.
3.1.1. Backbone Network
The backbone network in the LCvT architecture is based on the CvT architecture [14], effectively combining the strengths of both convolutional and self-attention mechanisms. It consists of multiple stages according to the given total LoD levels L, where each stage is linked not only to the next stage but also to a dedicated LoD-specific branch network. For a given prediction request for LoD level l, the backbone network sequentially processes the input data through l stages and then delivers the extracted feature representations (i.e., the tokens in the transformers) to the corresponding branch network for LoD level l. This stage-based design of the backbone architecture is particularly well-suited for addressing LoD-aware classification, where higher LoD levels inherently require abstract and granular feature information to make predictions in more granular details.
In the implementation of the backbone network, each stage involves one or multiple CvT building blocks, each of which consists of a convolutional token embedding and a convolutional transformer block. The CvT building blocks in each stage generate tokens, which will be fed into the next stage or the corresponding branch network according to the given target LoD level.
First, the convolution token embedding plays a role similar to that of convolutional filters in traditional CNNs, using a kernel of size s, a stride of , and padding p. Specifically, it captures local spatial features and patterns by applying convolution operations to image patches. The token embedding produces a token map with a height of and a width of at the l-th stage in the backbone. The height and width of the token map at the l-th stage are derived as and . Then, the token map is subsequently flattened into a shape of and passes through transformer blocks. We here use a convolutional transformer block proposed in [14], which replaces the original position-wise linear projection in typical transformer blocks for the multi-head self-attention (MHSA) with depth-wise separable convolutions. In particular, it provides additional analysis of the local spatial context while achieving efficiency benefits compared with the conventional transformer blocks in [13].
3.1.2. LoD-Specific Branch Network
The LoD-specific branch network for each LoD level is positioned between two corresponding stages of the backbone. Its architecture is primarily based on ViT models [13,19] while incorporating an early exit mechanism [16] to enhance inference efficiency. Each branch network is designed to detect key features at its corresponding LoD level at both broad and detailed granularities. Furthermore, it employs a coarse-to-fine inference strategy using the token map from the backbone, which enables early exiting during the coarse inference procedure when its output meets a predefined confidence threshold.
The LoD-specific branch network for each LoD level operates in four steps: First, during a coarse inference step, the encoders perform a coarse inference. Then, in an early exit decision step, an early exit mechanism evaluates whether the coarse inference result is sufficiently credible to serve as a final output. If so, the inference process is terminated. If not, the network proceeds to a patch-identifying and splitting step, where informative patches are identified from the token map and further divided into fine-grained patches. Finally, during a fine inference step, the encoders perform a fine inference using such fine-grained patches. A detailed description of each step is provided below.
(1) Coarse Inference: The token map delivered from the backbone network to the LoD-specific branch network at LoD level l, denoted as , is denoted by the following:
where is a token of the i-th coarse patch for , is an class token represents the global image information that will be used for prediction, is the number of coarse-grained patches at LoD level l, and is the position embedding added to the coarse-grained patches for retaining positional information [13]. For efficient inference, the LoD-specific branch network first attempts to predict the input’s class simply using the token map without further patch investigation or splitting. Specifically, the token map is processed through encoders for coarse inference, yielding the token map for each m-th encoder. In particular, the output class token sequence of the -th encoder is fed into the coarse classifier to produce the coarse inference (i.e., the probability distribution across classes at LoD level l) given as follows:
Finally, the predicted class of LoD level l in the coarse inference step is given as follows:
(2) Early Exit Decision: To balance inference accuracy and computational efficiency, an early exit mechanism is integrated into the LoD-specific branch networks. After the coarse inference step, the network produces the predicted class based on the coarse token map. In the subsequent early exit decision step, the confidence level of this prediction is evaluated to determine whether it can be accepted as the final output. This mechanism enables early termination of the inference process, reducing the computational cost of further steps without deteriorating inference accuracy.
We first evaluate a confidence score for the prediction obtained in the coarse inference step, denoted by . This score can be derived via various metrics, such as the entropy of the probability distribution [16] and the probability of the predicted class [19]. A confidence threshold is then set to determine early termination of the inference, managing the trade-off between inference accuracy and computational efficiency. If the confidence score meets the threshold (i.e., ), the inference process for LoD level l is terminated, and the predicted class is accepted as the final output. Otherwise, the network determines that the coarse-grained patches are insufficient, and it proceeds with a fine-grained patch investigation in the subsequent step.
(3) Patch-Identifying and Splitting: In this step, the LoD-specific branch network splits the coarse-grained patches obtained in the previous step. Instead of splitting all patches, the network first identifies the informative ones and then further divides them into fine-grained patches. This selective fine-grained patch splitting improves inference accuracy while significantly reducing the computational cost compared to splitting every coarse-grained patch.
To identify the informative patches, the class attention computed in each m-th encoder can be used as an informative score of the patches at the encoder, since it reflects how much interaction there is between the class token and other coarse patch tokens in the m-th encoder [19,27,28]. For reflecting the class attention across different encoders, a global class attention can be derived by combining class attention across all encoders using exponential moving average (EMA) [19] as follows:
where is a smoothing parameter. The EMA is computed for , and then, the class attention average at , will be used as the global class attention.
The coarse-grained patches that will be further split are now chosen using the informative score . In particular, the top- coarse-grained patches are selected, where controls the ratio of informative patches. Each of the chosen patches is then divided into patches (e.g., ), which can provide more fine-grained representations. Then, the number of patches for the fine inference step, , is derived as follows:
where and denote rounding-up and down operators, respectively.
After patch splitting, the input token sequence for the fine inference step is constructed as follows:
where is the positional embedding for the fine-grained patches. In this step, to further enhance model performance, information from the coarse-grained patches can be transferred to the re-split fine-grained patches using the feature reuse method described in [19]. This approach helps preserve the local context of the original coarse-grained patches during the fine-grained splitting process.
(4) Fine Inference: In the fine inference step, the input token is processed through the encoders, and the final encoder yields the output class token sequence for fine inference . Then, the fine inference classifier produces the probability distribution for fine inference across classes, which is given as follows:
The predicted class of LoD level l in the fine inference step is given as follows:
which will be used as the final prediction of the LoD-specific branch network for LoD level l.
3.2. Training of LCvT
To achieve high-accuracy inferences across all LoD levels, we design a loss function for LCvT, , that accounts for the different LoD levels. Specifically, the loss function is defined as a weighted sum of the coarse and fine inference loss functions of the LoD-specific branch network for each LoD level l:
where and denote the weights associated with the coarse and fine inferences at LoD level l, respectively, and and represent the corresponding cross-entropy loss functions. These weights represent the contributions of different LoD levels as well as the coarse and fine inferences. By adjusting them, it is possible to prioritize certain LoD levels to achieve higher accuracy or to adjust the trade-off between accuracy and computational cost. The weights across LoD levels can be determined based on the importance or frequency of inferences at each LoD level, while those for the coarse and fine inferences can be adjusted considering available computational resources.
The loss function for LCvT in (9) incorporates all the losses of both coarse and fine inference losses at every LoD level. This enables LCvT to be trained in an end-to-end manner across all LoD levels and inference modes. In other words, during its training, each sample can contribute simultaneously to learning for both coarse and fine inferences at all LoD levels. To ensure this, the confidence threshold should be set to avoid an early exit from occurring. This unified approach effectively trains LCvT to behave as if it is an integrated generalized model of independent models designed for different LoD levels. In addition, embedding structural prior knowledge into the model also facilitates efficient gradient flow to shallow layers, thereby enhancing training efficiency and overall performance [21]. With sufficient training on a large dataset, LCvT learns key features tailored to each LoD level’s objectives for LoD-aware DT synchronization, resulting in high inference accuracy across all levels.
4. LCvT in LoD-Aware DT Synchronization
4.1. LCvT Workflow for LoD-Aware DT Synchronization
We describe a workflow of LCvT in DT systems, i.e., how LCvT works effectively within the context of LoD-aware DT synchronization, assuming that each LCvT model is adequately trained for its corresponding LoD label tree within a target DT system. When a new physical object corresponding to the LoD label tree arrives, the DT system determines its required LoD level according to the object’s level of interest, depending on its location and velocity. Subsequently, a request for LoD-aware DT synchronization is initiated, whose payload includes the unique identification of the object, the input feature image captured via IoT sensors, the required LoD level, and so on.
To address the request, the LCvT model employs an LoD-aware classification of the object based on the payload. The LCvT model processes the input feature image by passing it through its backbone to extract a token map until it reaches the LoD-specific branch network for the required LoD level. The LoD-specific branch network then predicts the class for the required LoD level using the coarse classifier at the LoD-specific branch network. If the prediction is sufficiently confident, the LCvT model terminates the inference process. Otherwise, the LoD-specific branch network proceeds with further patch splitting and performs the fine inference. Once the inference process of the LCvT model is completed, the response to the LoD-aware DT synchronization request is then constructed, including the inference result for the target object in the required LoD level, and transferred to the DT system. Finally, the DT system performs the LoD-aware DT synchronization based on the response.
In the context of LoD-aware DT synchronization in real-world environments, the required LoD levels could be flexibly adjusted according to the purpose of DT-related tasks and the dynamic state of physical objects. To effectively address these dynamic changes in the required LoD level for each DT object, the structural properties of LCvT can be exploited. First, if the required LoD level is lowered for a DT object that has previously undergone LoD-aware DT synchronization, no additional computation is necessary since the class of the lower LoD level is obvious based on the LoD label tree. On the other hand, if a higher LoD level is required, it is possible to utilize the token map from the backbone network for the previous synchronization so as to perform the subsequent stages in the backbone network for the higher LoD level without having to perform from the beginning of the backbone network. To take advantage of this, the token maps from the backbone networks can be stored along with the identification of the corresponding DT for future reuse. This property of LCvT ensures efficient LoD-aware DT synchronization without unnecessary computation, which implies that the LCvT model structure provides significant time efficiency benefits by balancing high inference accuracy and minimal inference time across all LoD levels. Therefore, in real-world environments where the required LoD levels change dynamically, LCvT can be significantly effective compared to using independent models for each LoD level.
4.2. Practical Implications of LCvT in DT Systems
The proposed LCvT framework has practical implications for DT applications, especially in scenarios where real-time synchronization must adapt to varying LoDs. For example, in a vehicle DT system, cameras may continuously stream visual data under changing conditions. LCvT enables the DT to flexibly update either coarse-grained information (e.g., vehicle type) or fine-grained information (e.g., specific model) depending on task requirements and available resources. By leveraging LoD-specific branches, LCvT minimizes latency and computation without sacrificing accuracy, which is critical for timely DT synchronization.
Another important implication is system reliability. In practice, DT systems often require mechanisms to address uncertainty in predictions. LCvT’s hierarchical design inherently supports fallback strategies. When fine-grained classification confidence is low, the system can either rely on coarse-grained classification (i.e., predictions at a lower LoD level) to maintain DT consistency or re-trigger inference with additional sensor input. This contributes to robust synchronization between physical and virtual entities.
The LCvT architecture is applicable to broader domains beyond vehicular DTs, such as industrial IoT, smart cities, and edge computing environments. For example, smart city surveillance systems may operate at a lower LoD to track general pedestrian flow under normal conditions but switch to a higher LoD when accidents or anomalies are detected, enabling them to identify specific situations. Similarly, in manufacturing quality inspection, a coarse LoD can be employed for rapid defect detection during mass production, while a fine LoD is applied only when anomalies arise, to enable precise analysis. In these contexts, LoD-awareness enables resource-efficient monitoring and adaptive synchronization in DT systems, ensuring that DTs remain both responsive and scalable. Overall, LCvT demonstrates that the careful integration of LCvT components can directly improve the operational effectiveness of DT systems.
5. Experimental Results
In this section, we provide experimental results to evaluate the performance of the proposed LCvT architecture on the LoD-aware classification problem.
5.1. Experimental Setup
We conduct experiments using two datasets with a hierarchy, the comprehensive cars dataset (CompCars dataset) and the ImageNet dataset, which are suitable for LoD-aware classification. In our experiments, we consider the LoD-aware classification problem with two distinct levels associated with each dataset’s characteristics. We map each dataset’s broad level to LoD 1, representing less specific information, and the fine level to LoD 2 for more detailed information about the objects.
The CompCars dataset consists of car images captured from multiple angles, organized hierarchically from a broad to detailed level. At the broad level, the dataset includes 75 car manufacturers, while the detailed level encompasses 431 specific car models [29]. Figure 3 illustrates an example of an LoD label tree used for car DT synchronization, based on the CompCars dataset. Similarly, the hierarchical structure of the ImageNet dataset supports both supercategory and category-level classification [30]. This dataset provides 664 supercategories at the broad level and supports more detailed classification across 1000 categories within those groups. To effectively train our LCvT model, we utilize 36,334 images for training and 10,442 images for validation from the CompCars dataset. Additionally, for the ImageNet dataset, we use 560,000 images for training and 140,000 images for testing. All images are resized to pixels and utilized as an RGB image with three channels.
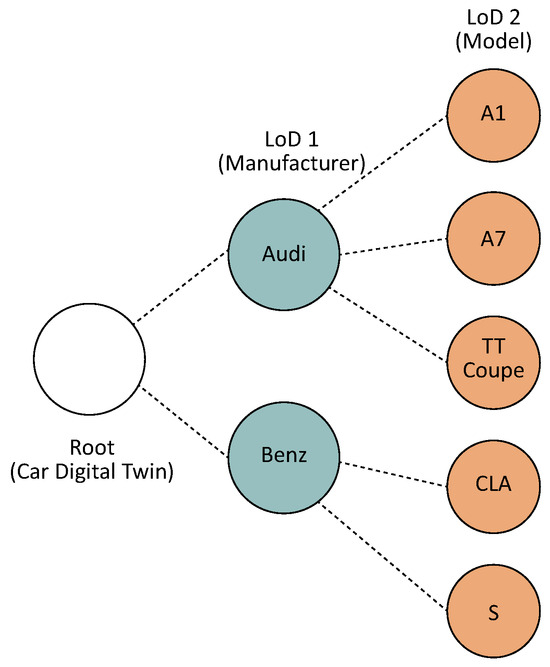
Figure 3.
The illustrative example of the LoD label tree for LoD-aware car DT synchronization in the experiments with the CompCars dataset.
The architecture of the LCvT model incorporates the CvT model up to stage 1, followed by an LoD-specific branch network for LoD 1 named LoD 1 Branch, and then proceeds with the backbone up to stage 3 before executing another LoD-specific branch network for LoD 2 named LoD 2 Branch. To evaluate the effectiveness of our LCvT architecture, we compare it with different state-of-the-art models capable of hierarchical classification as follows.
- LCvT is our proposed model.
- LCvT-OC is a model that shares identical architecture of LCvT, but only executes coarse-grained inference in each LoD.
- CvT is a model that only executes identical backbone model used in LCvT with the inference for each LoD.
- CNN is a model that only executes traditional convolution-based feature extraction. This model shares a design philosophy with [21].
The architecture of all models is summarized in Table 1. For all models in the experimental results, we average the results from the multiple instances using different test samples.

Table 1.
The architecture of LCvT and baseline models.
To evaluate model performance, we build an experimental environment by using a Pytorch [31] library. In the environment, we use an Adam optimizer with a momentum of when training the models for both the CompCars and ImageNet datasets. For the CompCars dataset, we train the models for 200 epochs with a learning rate of , and for the ImageNet dataset, we train the models for 200 epochs with a learning rate of . We set the mini-batch size to 32 for all experiments. Notably, we use a loss function that sums the weighted loss for inferences at each LoD (i.e., , where is the cross-entropy loss for predicting the target class for l) for the LCvT-OC, CvT, and CNN models.
5.2. Performance Evaluation
We provide experimental results that demonstrate the outperforming performance of our proposed LCvT model compared to existing baseline models. To evaluate the LCvT model’s performance, we compare the top-1 inference accuracy. In addition, to show the performance in both coarse-grained and fine-grained inference, here we do not consider the early exit mechanism of the LCvT model.
5.2.1. Comparison with Baseline Models
We provide the accuracy of each model across different LoDs on datasets in Table 2. As shown in the table, LCvT consistently achieves the highest accuracy across all LoDs. Specifically, LCvT with the fine-grained inference achieves the accuracies of and for LoD 1 and LoD 2, respectively, on the Compcars dataset, while the best-performing accuracy among the baseline models reached only and . LCvT with the fine-grained inference also maintains superior performance on the ImageNet dataset, achieving and for each LoD, compared to the best-performing accuracy among the baseline models, which reached and . Furthermore, we can see that LCvT outperforms the baseline models even with the coarse-grained inference.
Table 2.
Top-1 inference accuracy of each model on datasets (in the results of LCvT, (C) and (F) denote the performances of coarse-grained inference and fine-grained inference, respectively).
In prior studies, CvT models have been shown to outperform CNNs in terms of inference accuracy in most cases [14]. However, the experimental results in the table indicate that LCvT-OC and CvT exhibit lower accuracy than CNN at LoD 2. This is primarily due to the more complex architecture of CvT models compared to traditional CNNs, which require additional training data or epochs to reach optimal accuracy. Nevertheless, LCvT, which employs CvT as its backbone, achieves the highest accuracy among all evaluated models. Notably, it demonstrates at least and higher accuracy at lower LoDs on the Compcars and ImageNet datasets, respectively. This clearly shows the effectiveness of the LoD-specific branch network in LCvT, which addresses the limitations of reduced feature extraction stages at lower LoDs. Specifically, LCvT performs more stages to extract features tailored to each LoD and employs a coarse-to-fine inference strategy combined with effective informative patch splitting. These mechanisms enable LCvT to achieve superior performance by efficiently detecting key features across varying LoDs.
From the results by LCvT and LCvT-OC, we can see that incorporating additional fine stages after the coarse stage, along with our training strategy, results in higher accuracy across all LoDs for both coarse-grained and fine-grained inference. Simultaneous training on both coarse and fine granularities provides significant advantages over training exclusively on coarse-grained inference. This approach enables our LCvT architecture to leverage rich hierarchical features and shared representations while detecting fine-grained details that enhance performance at both granularities. By integrating complementary information across granularities within its hierarchical structure, LCvT improves representation quality for both inferences. Overall, the experimental results demonstrate that LCvT achieves high inference accuracy across all LoDs and granularities, making it highly effective for LoD-aware DT synchronization.
5.2.2. Time Efficiency in Dynamic LoD Scenarios
To demonstrate the time efficiency of LCvT, we compare its inference time with that of CvT in real-world scenarios, where LoD requirements change dynamically, as described in Section 4. To model such dynamic LoD scenarios, we consider the transitions of LoD requirements from LoD 1 to LoD 2 and from LoD 2 to LoD 1. The total inference time for such transitions is calculated by summing the inference times for both the pre- and post-transition LoDs. In addition, when comparing the inference time, we do not consider the early exit mechanism in LCvT to ensure a fair comparison.
As shown in Table 3, LCvT consistently outperformed CvT in terms of time efficiency, achieving a significant time reduction of approximately 28 ms across both LoD transition scenarios. This time efficiency of LCvT can be attributed to its LoD-specific branch network architecture, which processes varying LoD requirements within a single model. In contrast, CvT requires independent models for each LoD, resulting in increased inference times. In CvT, handling higher LoD transition results in large execution times of ms and ms for lower LoD transition. On the other hand, in the case of LCvT, it significantly reduces computational overhead during LoD transitions. For example, when transitioning to a higher LoD, only an additional ms is required to execute backbone stages after stage 1 and the LoD 2 branch. In the scenario where transitioning to a lower LoD, the execution time is further reduced to ms for the LoD 1 branch, as LCvT can leverage precomputed backbone features.
Table 3.
Time consumption of each model in dynamic LoD scenarios (ms). Each total time consumption is the summation of execution time for each LoD (LoD 1 + LoD 2).
These results demonstrate that LCvT can significantly reduce redundant computations during LoD transitions, even though each LoD’s model execution times may be relatively higher than CvT’s due to the overhead of the additional stages of the LoD branch. Consequently, it is shown that the efficient transition between LoDs yields a notable time reduction of up to 28 ms, which has a substantial impact on the total time consumption of the DT synchronization. This time difference can serve a critical role in enhancing the efficiency of the DT synchronization process. Additionally, we note that activating the early exit mechanism in LCvT’s branch network can further optimize the inference process, potentially leading to even greater reductions in execution time and further enhancing time efficiency. Overall, our experimental results verify that our LCvT architecture outperforms the baseline models in terms of time efficiency in dynamic LoD scenarios, demonstrating its potential as a highly effective model for LoD-aware DT synchronization in real-world applications.
5.3. Interpretability and Qualitative Analysis
To further investigate the operation of LCvT, we provide a qualitative analysis of its internal decision-making process. While performance evaluations confirm the effectiveness of LCvT, understanding how it differentiates features across LoD stages provides additional insight into its behavior. In particular, visualizing the model’s attention patterns helps clarify the hierarchical inference strategy and illustrates how LCvT adapts its focus according to the target LoD.
The inference strategy of LCvT changes its attention regions across different LoD stages. To visualize this behavior, we applied Grad-CAM to the prediction outputs of the LoD1 and LoD2 branches to generate corresponding attention heatmaps. Figure 4 provides the attention heatmaps of LCvT at the inference step of each LoD branch using the CompCars dataset. Each heatmap shows where LCvT focuses during the inference process; red regions indicate the areas strongly focused.

Figure 4.
Attention heatmaps of LCvT at the inference step of each LoD branch.
The visualization results demonstrate that the LoD 1 heatmap in Figure 4a mainly highlights the vehicle body. In particular, it focuses on broad features, such as the vehicle’s silhouette and perimeter, for basic discrimination of the vehicle. This indicates that the LoD 1 branch relies on these broad features, which are more appropriate for predicting at a lower LoD level (i.e., the manufacturer). In contrast, the LoD 2 heatmap in Figure 4b focuses more strongly on fine and discriminative details, such as headlights and logos. This demonstrates that the LoD 2 branch makes more refined discriminations by utilizing these detailed features that are more effective for the higher LoD level classification (i.e., the model).
We also examine misclassified samples at both LoD stages in order to further illustrate the behavior of LCvT in failure cases. Figure 5 provides the attention heatmaps of misclassified samples generated from the LoD 1 and LoD 2 branches. These examples demonstrate insight into how the model’s focus deviates from discriminative regions, leading to incorrect predictions. By contrasting the attention distributions at different LoD levels, we can better understand the error patterns that arise in different LoD levels.
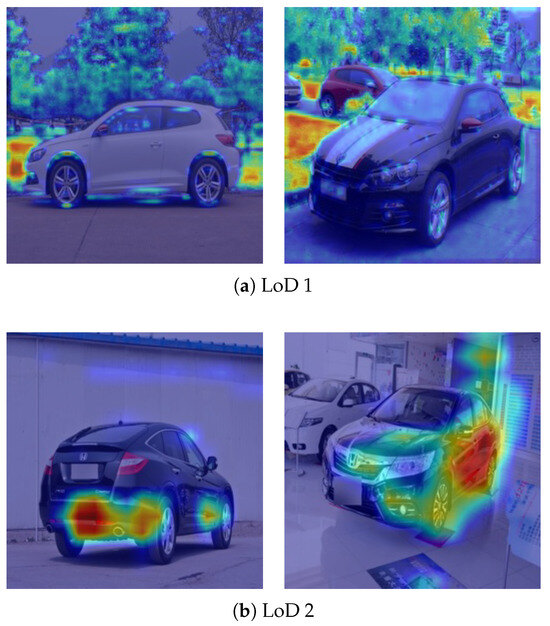
Figure 5.
Attention heatmaps of LCvT with misclassified samples at the inference step of each LoD branch.
In Figure 5a, the attention heatmaps are allocated not to the vehicle’s overall silhouette, but to background structures lacking discriminative features. In other words, the model relies on background artifacts rather than the global shapes to predict at a lower LoD level, which is inappropriate. This results in an incorrect decision. Similarly, in Figure 5b, the model focuses on broad side surfaces or reflections, which are misplaced or incomplete details, rather than on fine and discriminative details. This behavior indicates that the model fails to capture the fine-grained details required for predicting at a higher LoD level. Consequently, distinct vehicle models become conflated.
These qualitative results complement the quantitative assessments by demonstrating how LCvT progressively differentiates its feature concentration according to the required LoD. The attention visualizations confirm that the model relies on broad global patterns for coarse distinctions at low LoD levels and shifts toward localized detailed regions for fine-grained distinctions at high LoD levels. This behavior validates the effectiveness of LCvT’s hierarchical design and provides the interpretability that supports its applicability.
6. Conclusions
In this paper, we proposed an LCvT architecture to effectively perform LoD-aware DT synchronization involving hierarchical classification. LCvT detects key features tailored to each LoD using the corresponding branch network and extracts collective features across all LoDs through a backbone. In the experiments, we demonstrated that LCvT consistently outperforms other baseline models in terms of inference accuracy across all LoDs. LCvT is also more computationally efficient than using an independent model for each LoD, since it can reuse previously computed features through its backbone network and performs only the additional inferences needed for the required LoD within a single model. As a result, our proposed LCvT architecture is sufficiently applicable to LoD-aware DT synchronization in a more time- and cost-efficient manner by effectively leveraging this hierarchical structure.
In future research, several promising directions can extend and deepen this work. From an application perspective, LCvT can be deployed in DT/IoT-enabled smart factories, edge devices, and smart city infrastructures, where efficient LoD-aware synchronization directly translates into managerial and operational benefits. Future studies may also explore broader implications such as integrating LCvT into multi-modal digital twins that combine visual, sensor, and textual sources, thereby enhancing adaptability across diverse industrial domains. Methodologically, constructing dedicated industrial datasets tailored for evaluating LoD-awareness would provide a stronger empirical foundation and address potential limitations related to data bias and model scalability. Moreover, integrating efficiency techniques, such as token pruning and attention sparsification, can further optimize inference efficiency. These future research directions could extend the applicability of LCvT and improve its robustness and impact in real-world DT synchronization scenarios.
Author Contributions
Conceptualization, J.-W.K. and H.-S.L.; methodology, J.-W.K.; software, M.-S.Y. and J.-W.K.; validation, M.-S.Y. and J.-W.K.; formal analysis, J.-W.K. and H.-S.L.; investigation, M.-S.Y. and J.-W.K.; resources, H.-S.L.; data curation, J.-W.K. and M.-S.Y.; writing—original draft preparation, J.-W.K.; writing—review and editing, M.-S.Y. and H.-S.L.; visualization, M.-S.Y. and J.-W.K.; supervision, H.-S.L.; project administration, H.-S.L.; funding acquisition, H.-S.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the Institute of Information & Communications Technology Planning & Evaluation (IITP) grant funded by the Korean government (Ministry of Science and ICT, MSIT) (No. RS-2022-II220545, Development of Intelligent digital twin object federation and data processing technology) and in part by the IITP-ITRC (Information Technology Research Center) grant funded by the Korean government (MSIT) (IITP-2025-RS-2021-II211816).
Data Availability Statement
The datasets used in this study, CompCars and ImageNet, are publicly available. The CompCars dataset is available at https://mmlab.ie.cuhk.edu.hk/datasets/comp_cars/ and the ImageNet dataset at https://www.image-net.org/ (accessed on 2 October 2025).
Conflicts of Interest
Author Ji-Wan Kim was employed by the company LIG Nex1. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as potential conflicts of interest.
References
- Grieves, M.; Vickers, J. Digital twin: Mitigating unpredictable, undesirable emergent behavior in complex systems. In Transdisciplinary Perspectives on Complex Systems: New Findings and Approaches; Springer: Cham, Switzerland, 2017; pp. 85–113. [Google Scholar]
- Wang, H.; Yang, Z.; Zhang, Q.; Sun, Q.; Lim, E. A digital twin platform integrating process parameter simulation solution for intelligent manufacturing. Electronics 2024, 13, 802. [Google Scholar] [CrossRef]
- Wu, Y.; Zhang, K.; Zhang, Y. Digital twin networks: A survey. IEEE Internet Things J. 2021, 8, 13789–13804. [Google Scholar] [CrossRef]
- Xu, H.; Wu, J.; Pan, Q.; Guan, X.; Guizani, M. A Survey on digital twin for industrial internet of things: Applications, technologies and tools. IEEE Commun. Surv. Tutor. 2023, 25, 2569–2598. [Google Scholar] [CrossRef]
- Zhang, J.; Tao, D. Empowering things with intelligence: A survey of the progress, challenges, and opportunities in artificial intelligence of things. IEEE Internet Things J. 2021, 8, 7789–7817. [Google Scholar] [CrossRef]
- Castaño, F.; Strzelczak, S.; Villalonga, A.; Haber, R.E.; Kossakowska, J. Sensor reliability in cyber-physical systems using internet-of-things data: A review and case study. Remote Sens. 2019, 11, 2252. [Google Scholar] [CrossRef]
- Al-Ali, A.R.; Gupta, R.; Zaman Batool, T.; Landolsi, T.; Aloul, F.; Al Nabulsi, A. Digital twin conceptual model within the context of internet of things. Future Internet 2020, 12, 163. [Google Scholar] [CrossRef]
- Fett, M.; Kraft, M.; Wilking, F.; Goetz, S.; Wartzack, S.; Kirchner, E. Medium-level architectures for digital twins: Bridging conceptual reference architectures to practical implementation in cloud, edge and cloud–edge deployments. Electronics 2024, 13, 1373. [Google Scholar] [CrossRef]
- Brooks, R.J.; Tobias, A.M. Choosing the best model: Level of detail, complexity, and model performance. Math. Comput. Model. 1996, 24, 1–14. [Google Scholar] [CrossRef]
- Abualdenien, J.; Borrmann, A. Levels of detail, development, definition, and information need: A critical literature review. J. Inf. Technol. Constr. 2022, 27, 363–392. [Google Scholar] [CrossRef]
- Alfaro-Viquez, D.; Zamora-Hernandez, M.; Fernandez-Vega, M.; Garcia-Rodriguez, J.; Azorin-Lopez, J. A comprehensive review of AI-based digital twin applications in manufacturing: Integration across operator, product, and process dimensions. Electronics 2025, 14, 646. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. In Proceedings of the International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. CvT: Introducing convolutions to vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 22–31. [Google Scholar]
- Fukui, H.; Hirakawa, T.; Yamashita, T.; Fujiyoshi, H. Attention branch network: Learning of attention mechanism for visual explanation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 10705–10714. [Google Scholar]
- Teerapittayanon, S.; McDanel, B.; Kung, H. BranchyNet: Fast inference via early exiting from deep neural networks. In Proceedings of the International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 2464–2469. [Google Scholar]
- Cambazoglu, B.B.; Zaragoza, H.; Chapelle, O.; Chen, J.; Liao, C.; Zheng, Z.; Degenhardt, J. Early exit optimizations for additive machine learned ranking systems. In Proceedings of the ACM International Conference on Web Search and Data Mining (WSDM), New York, NY, USA, 3–6 February 2010; pp. 411–420. [Google Scholar]
- Matsubara, Y.; Levorato, M.; Restuccia, F. Split computing and early exiting for deep learning applications: Survey and research Challenges. ACM Comput. Surv. 2022, 55, 90. [Google Scholar] [CrossRef]
- Chen, M.; Lin, M.; Li, K.; Shen, Y.; Wu, Y.; Chao, F.; Ji, R. CF-ViT: A general coarse-to-fine method for vision transformer. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 7042–7052. [Google Scholar]
- Yan, Z.; Zhang, H.; Piramuthu, R.; Jagadeesh, V.; DeCoste, D.; Di, W.; Yu, Y. HD-CNN: Hierarchical deep convolutional neural networks for large scale visual recognition. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2740–2748. [Google Scholar]
- Zhu, X.; Bain, M. B-CNN: Branch convolutional neural network for hierarchical classification. arXiv 2017, arXiv:1709.09890. [Google Scholar] [CrossRef]
- Wang, Y.; Chung, S.H.; Khan, W.A.; Wang, T.; Xu, D.J. ALADA: A lite automatic data augmentation framework for industrial defect detection. Adv. Eng. Inform. 2023, 58, 102205. [Google Scholar] [CrossRef]
- Shi, Y.; Wei, P.; Feng, K.; Feng, D.C.; Beer, M. A survey on machine learning approaches for uncertainty quantification of engineering systems. Mach. Learn. Comput. Sci. Eng. 2025, 1, 11. [Google Scholar] [CrossRef]
- Khan, W.A.; Chung, S.H.; Wang, Y.; Eltoukhy, A.E.; Liu, S.Q. Intelligent early fault management using a continual deep learning information system for industrial operations. Ind. Manag. Data Syst. 2025; in press. [Google Scholar] [CrossRef]
- Kuts, V.; Modoni, G.; Terkaj, W.; Tähemaa, T.; Sacco, M.; Otto, T. Exploiting factory telemetry to support virtual reality simulation in robotics cell. In Proceedings of the International Conference on Augmented Reality, Virtual Reality, and Computer Graphics (AVR), Ugento, Italy, 12–15 June 2017; pp. 212–221. [Google Scholar]
- Zhang, J.; Cheng, J.; Chen, W.; Chen, K. Digital twins for construction sites: Concepts, LoD definition, and applications. J. Manag. Eng. 2022, 38, 04021094. [Google Scholar] [CrossRef]
- Rao, Y.; Zhao, W.; Liu, B.; Lu, J.; Zhou, J.; Hsieh, C.J. DynamicViT: Efficient vision transformers with dynamic token sparsification. Adv. Neural Inf. Process. Syst. 2021, 34, 13937–13949. [Google Scholar]
- Liang, Y.; Chongjian, G.; Tong, Z.; Song, Y.; Wang, J.; Xie, P. EViT: Expediting Vision Transformers via Token Reorganizations. In Proceedings of the International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- Yang, L.; Luo, P.; Loy, C.C.; Tang, X. A large-scale car dataset for fine-grained categorization and verification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015; pp. 3973–3981. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).