1. Introduction
Multimodal sentiment analysis (MSA), which integrates information from textual, visual, and acoustic modalities, aims to achieve a comprehensive and accurate understanding of human emotions [
1,
2,
3,
4,
5,
6]. The availability of benchmark datasets such as CMU-MOSI [
7], CMU-MOSEI [
8], and CH-SIMS [
9] has significantly propelled research in this field, encouraging the development of advanced cross-modal fusion techniques. Despite these advances, several critical challenges remain, limiting the robustness and generalizability of MSA systems in real-world applications. One of the greatest challenges is the prevalence of incomplete modalities. Incomplete data caused by sensor failures, signal loss, or annotation omissions is common in practical scenarios [
10,
11,
12,
13]. To address this, Transformer-based models have been employed to reconstruct incomplete modalities. For example, TFR-Net [
10] uses an encoder–decoder structure with inter- and intra-modal attention to restore missing features and enhance robustness. However, Transformers suffer from quadratic computational complexity
, where
L denotes the input sequence length, making them inefficient for processing long sequences [
14]. Moreover, many existing approaches treat modality reconstruction and fusion as separate tasks, resulting in semantic misalignment and suboptimal fusion performance. Efforts such as MFMB-Net [
15] attempt to capture emotional cues at multiple granularities using macro- and micro-fusion branches. However, limited interaction between these branches hinders the exploitation of hierarchical semantics. Accurately modeling long-range temporal dependencies is also crucial, as emotions evolve over time. Traditional Transformers are constrained in this regard. Compared to traditional Transformer architectures that rely on global self-attention and suffer from quadratic time complexity
, Mamba exhibits a linear time complexity
, making it significantly more efficient for processing long sequences [
16]. Moreover, Mamba leverages a state-space model with selective memory updates, introducing a strong inductive bias for sequence modeling and facilitating more effective long-range temporal reasoning. These characteristics are particularly advantageous in multimodal sentiment analysis, where emotion evolves gradually and data may be incomplete or noisy. In this work, we incorporate Mamba into both the alignment and reconstruction modules to improve robustness and enhance semantic consistency across modalities.
Several models have addressed modality-specific challenges. MISA [
17] improves cross-modal alignment by disentangling modality-invariant and modality-specific representations but sacrifices fine-grained emotional nuances. SELF_MM [
18] enhances unimodal learning through pseudo-labeling but lacks coherent multimodal integration. TETFN [
19] employs text-centric attention and pre-trained visual Transformers but still struggles with long-range temporal alignment. ALMT [
20] mitigates modality conflicts via a language-guided hyper-modality framework, achieving competitive results. However, its Transformer-based architecture involves numerous parameters, limiting its performance on smaller datasets, particularly in fine-grained regression tasks. Discrepancies in modality representations and semantic inconsistency further hinder model generalization. Many models rely on decoupled designs for reconstruction and fusion, resulting in semantic disjunctions that degrade both missing modality recovery and downstream predictions. LNLN [
21] improves robustness under missing conditions by using language as the dominant modality via a correction and alignment mechanism. However, its generalization under real-world conditions remains constrained, and hyperparameter tuning for loss balancing remains nontrivial.
To address these limitations, we propose MGMR-Net (Mamba-guided multimodal reconstruction and fusion network), a unified framework that integrates text-centric cross-modal alignment, Mamba-enhanced modality reconstruction, and joint optimization for robust multimodal sentiment analysis. The main contributions of this work are summarized as follows:
We propose a text-centric two-stage collaborative fusion framework based on the Mamba architecture, which first performs language-guided cross-modal alignment via multi-layer bi-directional Mamba modules, and then conducts efficient multimodal integration using a time-prioritized Mamba-based fusion mechanism. This design significantly enhances the representational capacity and inference accuracy in multimodal sentiment analysis.
We further introduce a Mamba-enhanced modality reconstruction module, which integrates stacked Mamba layers with gated fusion to recover corrupted or incomplete features. This design restores temporal and semantic consistency within each modality, yielding more robust representations for downstream alignment and fusion.
We design a joint optimization strategy that couples sentiment prediction with modality reconstruction via a unified loss, promoting robust and generalizable representations under incomplete multimodal conditions.
Extensive experiments on CMU-MOSI, CMU-MOSEI, and CH-SIMS demonstrate that MGMR-Net consistently outperforms state-of-the-art methods across various levels of modality completeness and cultural diversity. Notably, it achieves superior generalization in missing-modality and cross-cultural scenarios, demonstrating its practical applicability to real-world multimodal sentiment analysis.
2. Related Work
2.1. Multimodal Sentiment Analysis
Multimodal sentiment analysis (MSA) has achieved significant progress in recent years, driven by the need to integrate and align heterogeneous information from diverse modalities—namely text, audio, and visual signals—for improved sentiment prediction. Early approaches primarily adopted straightforward feature concatenation, wherein unimodal features were directly merged into a joint representation before model training. A representative example is the tensor fusion network (TFN) [
22], which employed tensor decomposition to capture inter-modal interactions, leading to improved sentiment classification. However, such concatenation-based strategies often fail to effectively model the intricate and dynamic interdependencies among modalities, thereby limiting their ability to capture subtle and context-dependent emotional expressions in real-world scenarios.
To address these shortcomings, more advanced architectures such as the multimodal Transformer (MulT) [
14] have been proposed. MulT utilizes cross-modal attention mechanisms to dynamically align and fuse features from different modalities, while self-attention enables it to capture long-range temporal dependencies and cross-modal correlations. This facilitates a richer contextual understanding of emotional content. Nonetheless, Transformer-based models encounter scalability issues due to their quadratic time complexity with respect to sequence length, which poses challenges when processing long video or audio streams—key sources for modeling evolving emotional states. Moreover, these models are susceptible to incomplete or noisy modality inputs (e.g., sensor failures or background noise), resulting in degraded performance and limited robustness.
Recent efforts have attempted to mitigate these issues. For instance, MMIM [
23] introduces a hierarchical mutual information maximization framework that enhances MSA by maximizing mutual information not only between unimodal inputs but also between the fused representation and its corresponding unimodal features. This design helps preserve task-relevant information during fusion. However, these methods may still suppress modality-specific nuances, which are crucial for capturing fine-grained emotional cues—especially in culturally diverse contexts where expression styles differ significantly.
To further improve robustness and modality alignment, CENet [
24] proposes a cross-modal enhancement network that enriches textual representations by integrating long-range visual and acoustic emotional cues into a pre-trained language model. Additionally, it employs a feature transformation strategy to reduce distributional discrepancies among modalities, facilitating more effective fusion. TeFNA [
25] introduces a text-centered fusion framework that leverages cross-modal attention to align unaligned inputs and incorporates a text-centered aligned fusion (TCA) strategy to preserve modality-specific characteristics while maximizing mutual information for task-relevant emotional signal retention.
Despite these advancements, several key challenges remain. Current MSA models still struggle to robustly handle incomplete modalities, efficiently process long sequential data, and balance the fusion of modality-specific and modality-invariant information. Furthermore, the generalizability of existing models across cultural domains is limited, as most datasets predominantly reflect Western emotional expression patterns. This hampers their effectiveness in recognizing subtler and culturally nuanced emotional expressions. Addressing these challenges is essential for developing more resilient and universally applicable MSA systems.
2.2. State-Space Models and Mamba
State-space models (SSMs) have recently garnered significant attention as powerful frameworks for modeling sequential data, especially in tasks involving intricate temporal dependencies [
26]. By efficiently capturing both short- and long-range temporal patterns, SSMs have achieved promising results across a variety of domains, including time-series forecasting, speech recognition, and, more recently, multimodal sentiment analysis [
27,
28,
29]. Fundamentally, SSMs model observed data as noisy emissions from latent dynamic processes that evolve over time via recursive state transition equations.
In the context of multimodal learning, SSMs offer a principled way to model modality-specific temporal structures and align them across different sources of information. Their capacity to capture long-range dependencies is especially beneficial for analyzing emotion progression in multimodal sentiment analysis, where cues from text, audio, and video may manifest asynchronously or over different time scales.
A notable advancement in this field is the Mamba architecture [
30], which extends conventional SSMs through a bi-directional design—referred to as Bi-Mamba—to facilitate global context modeling. In contrast to Transformer-based architectures that rely on self-attention mechanisms with quadratic complexity, Bi-Mamba achieves linear time complexity, making it more scalable for long sequences. Within the Mamba framework, modality-specific convolutional layers are first used to extract local features. These features are then fed into the Bi-Mamba module, which captures multi-scale temporal interactions across modalities. This pipeline is particularly well-suited for multimodal tasks, as it enables the model to effectively synchronize temporally dispersed signals and build holistic cross-modal representations.
Despite these advantages, applying SSMs and the Mamba architecture to multimodal sentiment analysis remains challenging [
31]. A primary issue lies in their limited compatibility with existing multimodal fusion strategies, particularly under incomplete modality conditions. The absence of one or more modalities can severely degrade model performance, as the remaining modalities often lack sufficient complementary information.
To address this, recent approaches have begun incorporating closed-loop mechanisms to reconstruct and refine incomplete modalities. For instance, our proposed MGMR-Net extends the Mamba architecture with a progressive reconstruction loop that iteratively restores the missing modality features based on observed inputs and previously predicted representations. This recursive feedback not only strengthens temporal coherence within each modality but also fosters better cross-modal alignment, thereby improving model robustness in real-world MSA settings.
2.3. Handling Incomplete Modalities
Incomplete modalities pose a significant challenge in multimodal sentiment analysis (MSA), as real-world data often suffer from incomplete or unavailable modalities due to sensor failures, transmission errors, or environmental constraints [
32,
33]. Early solutions typically ignored incomplete modalities or employed matrix completion techniques for estimation, but these approaches often led to suboptimal performance due to oversimplified assumptions and limited modeling capacity.
With the advent of deep learning, more advanced strategies have emerged, broadly categorized into generative methods and joint learning methods. Generative approaches focus on imputing incomplete modalities by synthesizing plausible data that approximates the distribution of the missing modality. Techniques such as variational autoencoders (VAEs) and cascaded residual autoencoders have been employed to infer latent representations and reconstruct missing signals [
34]. Some studies further adopt adversarial learning frameworks to conditionally generate realistic modality views based on available inputs. In contrast, joint learning methods seek to leverage the correlations among present modalities to infer shared representations, enabling the prediction or reconstruction of missing features through encoder–decoder or Transformer-based architectures.
Beyond this general classification, recent research has introduced more fine-grained categories for handling incomplete modalities, including GAN-based [
35,
36], correlation-based [
37], cycle-consistency-based [
38], and encoder-based approaches. GAN-based methods utilize adversarial training to generate absent modality features but may neglect fine-grained correlations with observed modalities. Correlation-based techniques explicitly model statistical dependencies between modalities, though they often struggle when multiple modalities are simultaneously missing. Cycle-consistency methods enforce bi-directional reconstruction to preserve shared semantics, yet they frequently assume static missing patterns. Encoder-based strategies leverage autoencoders or Transformer encoders to reconstruct missing information, offering flexibility but sometimes lacking the ability to capture shared semantic components across modalities.
In summary, despite considerable progress, effectively handling incomplete modalities in MSA remains an open problem. Many existing methods fail to model complex cross-modal dependencies or suffer from degraded performance under random missing patterns. To address these limitations, we propose MGMR-Net, which incorporates a cycle-consistent Mamba-enhanced reconstruction module based on selective state-space modeling. By leveraging Mamba’s continuous-time recurrence and dynamic gating mechanisms, the module captures long-range dependencies while preserving semantic coherence across modalities. The cycle-consistency constraint further ensures accurate reconstruction by enforcing alignment between observed and reconstructed modalities. Coupled with a unified multi-task loss, MGMR-Net achieves robust performance in scenarios with randomly incomplete modalities, balancing discriminative sentiment prediction with faithful modality recovery.
3. Methodology
In this section, we formalize the problem and present the proposed MGMR-Net model. The task is to develop a multimodal sentiment analysis system that operates on input sequences extracted from the same video segment, denoted as . Here, represents the raw input sequence of modality , where denotes the temporal length and is the feature dimension for text, audio, and visual modalities, respectively. The model is parameterized by and defined as , which aims to predict the sentiment intensity . In real-world applications, modality sequences may be partially or entirely missing due to sensor failures, noise, or transmission errors. To address this, the model receives as input a set of incomplete but pre-extracted modality features, denoted as . These features are derived from the raw inputs via a modality-specific feature extractor, and they serve as the effective inputs to the model: . The model is trained to perform robust sentiment prediction even under missing modality conditions. During training, the original complete modality features and their corresponding missing position masks are used as auxiliary supervision to guide representation learning. This strategy improves the model’s robustness and generalization in scenarios with incomplete multimodal information.
3.1. Overall Architecture
Our model, MGMR-Net, illustrated in
Figure 1, is specifically designed to tackle key challenges in multimodal sentiment analysis (MSA), including incomplete modalities, long-sequence processing, and efficient modality fusion. This section provides a detailed overview of the main components of MGMR-Net, which comprise a unimodal encoder, a Mamba-collaborative fusion module, and a Mamba-enhanced reconstruction module.
3.2. Unimodal Encoder
To preserve the sequential structure and model intra-modal temporal dependencies, we apply a unidirectional LSTM to each non-text modality independently:
where
and
denote the trainable parameters of the LSTM networks, and
,
represent the encoded audio and visual sequences, respectively.
For the textual modality, tokenized utterances—including special tokens such as
[CLS] and
[SEP]—are processed by a 12-layer BERT model [
39,
40]. The contextual embedding of the
[CLS] token from the final layer is used as the sentence-level representation:
where
represents the parameters of the BERT model.
To unify the feature dimensions and capture localized temporal correlations, the encoded sequences from all modalities are passed through independent 1D convolutional layers:
where
denotes the refined unimodal feature sequence and
is the size of the convolution kernel specific to the modality. This unified encoding strategy ensures that each modality is temporally contextualized and projected into a shared latent space, facilitating effective downstream cross-modal fusion.
3.3. Mamba-Collaborative Fusion Module
3.3.1. Text-Centric Two-Stage Mamba Modeling
To enhance cross-modal representation learning in multimodal sentiment analysis, we propose a text-centric two-stage framework built upon the Mamba architecture. Mamba is an advanced deep sequence modeling approach based on the selective state-space model (SSM), which replaces traditional self-attention with a dynamic recurrence mechanism. This allows for linear-time sequence processing, effectively overcoming the quadratic complexity limitations of Transformers. The core state-space formulation of Mamba is based on the classical state-space model:
where
is the hidden state,
is the input vector, and
A,
B,
C,
are learnable parameters. Note that in the Mamba architecture, the term
is omitted, as the input effect is incorporated through the recurrent dynamics.
During inference, Mamba employs a simplified recurrence for real-time sequence modeling,
where ⊙ denotes the Hadamard product (element-wise multiplication), which computes the product between corresponding elements of two vectors with the same dimensionality.
are learnable gating vectors that enable low-latency real-time sequence updates and
are learnable vectors that control the element-wise decay rate in the gating mechanism.
d denotes the feature dimension of the input and hidden vectors. This decay vector is conceptually and functionally distinct from the output projection matrix
in the classical SSM.
We define the
n-th Mamba layer as a function
, which maps an input sequence from the previous layer
to an output sequence
:
At each time step
t, the hidden state
and output
are computed as follows:
where
are learnable modulation vectors,
and
are the linear transformation weights and biases, and
is a nonlinear activation function, such as ReLU.
This structure allows each Mamba layer to model long-range temporal dependencies efficiently with linear complexity. As the foundational building block in our text-centric architecture, stacked Mamba layers empower subsequent cross-modal alignment and fusion stages by capturing temporally rich and semantically consistent features anchored on the textual modality.
Stage 1: Cross-Modal Alignment via Multi-Layer Collaborative Bi-Mamba
To fully leverage the dominant role of the language modality in multimodal sentiment analysis, as illustrated in
Figure 2, we propose a multi-layer collaborative Bi-Mamba architecture to dynamically align textual representations with both audio and visual modalities. Specifically, we align the text modality with both the audio and visual modalities through multiple layers of bi-directional Mamba modules, thus enhancing interactions and understanding between modalities.
First, for each modality, we use modality-specific encoders to convert raw features into unified-dimensional temporal feature sequences in the Unimodal Encoder Section. For modality
, the feature sequence generated is represented as
where
represents the feature vector of modality
m at time step
t.
Next, for the text–audio and text–video branches, we use stacked bi-directional Mamba modules for forward and backward temporal modeling. In each layer
n, the forward pass for modality
m is computed recursively via MambaLayer. The forward pass starts with the modality feature sequence
, and, at each layer, the output from the previous layer is used as the input to update the current layer. The forward recursion is given by
where
is the initial input, and
is the hidden state at layer
n. In each layer, the hidden state is updated based on the previous layer’s output and the current input.
For the backward pass, we first apply temporal flipping to the input sequence and then execute the same computation as in the forward pass. Specifically, for time step
t, the backward recursion is given by
The temporal flip operation restores the reversed sequence to the correct temporal order, and the final backward hidden state sequence is generated.
After completing both the forward and backward passes, the bi-directional output for modality
m at time step
t is obtained by fusing the forward and backward outputs:
Here, is the bi-directional aligned feature for modality m at time step t, where the forward and backward outputs are averaged to preserve their respective temporal information and features.
For the text modality, since it participates in both the text–audio and text–video branches, its final aligned feature
is obtained by averaging the outputs from the two branches:
In general, the resulting aligned features not only preserve the temporal characteristics of each modality but also improve cross-modal interactions and understanding, providing a solid foundation for subsequent multimodal fusion and prediction of sentiment.
Stage 2: Mamba-Based Multimodal Fusion
Following cross-modal alignment in stage 1, we obtain synchronized and refined feature sequences for audio, visual, and text modalities, denoted as , , and , respectively. These modality-specific aligned features are subsequently integrated via a multimodal fusion module based on the Mamba architecture, which is specifically designed to model expressive temporal dynamics and enable effective cross-modal interactions.
To preserve temporal causality while maintaining computational efficiency, we adopt Mamba’s time-priority selective scanning mechanism, which achieves linear time complexity in sequence length, as opposed to the quadratic complexity of traditional self-attention. At each time step, the features from the three modalities are interleaved to form a unified multimodal sequence.
This concatenated sequence
is processed by a stack of
N Mamba layers:
producing the following final fused multimodal representation:
To aggregate temporal information into a fixed-size representation for sentiment prediction, we apply temporal max pooling across all
tokens:
where the max operation is performed element-wise along the temporal dimension.
The pooled vector
is then fed into a fully connected layer to generate the final sentiment prediction:
where
c denotes the number of sentiment categories.
This fusion design effectively leverages Mamba’s linear temporal modeling to maintain causality and computational efficiency, while the interleaved token arrangement promotes fine-grained cross-modal interactions. Consequently, the hierarchical processing yields temporally coherent and semantically enriched multimodal representations, thereby enhancing robustness and accuracy in sentiment inference.
3.4. Mamba-Enhanced Reconstruction Module
In this module, we perform the reconstruction of modality feature sequences for each modality using the Mamba architecture, with the goal of recovering corrupted or incomplete modality features. Let the encoded feature sequence for each modality be denoted as , where represents text, audio, and visual modalities, respectively. Specifically, , where represents the feature of modality m at time step t. These features are extracted through unimodal encoders designed to capture modality-specific characteristics.
We apply modality-specific reconstruction pipelines composed of stacked Mamba layers to produce the refined set of representations. This process is defined as
After passing through
N stacked layers, we obtain the final output feature at each layer. By combining the outputs from each layer across time steps
t, we obtain the reconstructed feature sequence
:
where
is the output feature after
N stacked layers, representing the unimodal feature at time step
t.
To adaptively fuse the original features with the reconstructed features, we introduce a gating mechanism
, which controls the fusion ratio through learned gating parameters:
Then, the fused features are obtained as
where
is the learnable gating parameter, controlling the fusion ratio between the original and reconstructed features, and
is the fused feature.
Finally, to ensure dimensional consistency across modalities, we apply feature normalization and projection to the fused feature, resulting in a unified feature space representation:
where
is the learnable projection matrix, ensuring that the fused feature has consistent dimensionality across modalities.
This reconstruction module seamlessly integrates stacked MambaLayer blocks with state-space modeling and gated fusion mechanisms. It effectively restores the temporal dynamics and semantic coherence of each modality, providing robust and enriched representations for the subsequent cross-modal alignment and fusion stages.
3.5. Model Optimization
MGMR-Net employs a unified multi-task learning framework that jointly optimizes sentiment intensity regression and modality reconstruction objectives. Unlike prior works, which optimize prediction and feature recovery separately, our framework explicitly couples these tasks via a composite loss function, enabling synergistic learning of both discriminative and reconstructive representations.
For sentiment intensity prediction, the mean absolute error (MAE) loss is employed, as follows:
where
and
denote the predicted and ground-truth sentiment intensities for the
i-th sample, respectively.
To ensure accurate recovery of corrupted modality features, the reconstruction loss is applied on the outputs of the Mamba-enhanced reconstruction module
with modality-specific masking focused on corrupted segments:
where
,
, and
being a binary mask isolating corrupted parts in modality
m.
The final loss integrates the task and reconstruction objectives across all modalities as
where
are modality-specific weights balancing the reconstruction loss contributions.
This joint optimization scheme encourages the model to learn representations that are both semantically discriminative for sentiment regression and robustly reconstruct incomplete modalities. The explicit gradient coupling between prediction and reconstruction facilitates improved generalization and robustness for real-world multimodal sentiment analysis with incomplete data.
4. Experiments
In this section, we will introduce the datasets, metrics, feature extraction, baselines, and implementation details.
4.1. Datasets and Metrics
We evaluate the proposed model on three widely used benchmarks for multimodal sentiment analysis (MSA): CMU-MOSI [
7], CMU-MOSEI [
8], and SIMS [
9]. All experiments are conducted under the unaligned modality setting, which better reflects real-world conditions by removing artificially imposed synchronization across modalities. To ensure fair comparison with prior work, we use the officially released pre-extracted features for all datasets. We adopt a comprehensive set of evaluation metrics. For CMU-MOSI and CMU-MOSEI, we report five-class (Acc-5) and seven-class (Acc-7) classification accuracies; for SIMS, three-class (Acc-3) and five-class (Acc-5) accuracies are reported. In addition, we evaluate all datasets using binary accuracy (Acc-2), mean absolute error (MAE), Pearson’s correlation coefficient (Corr), and F1-score (F1). For CMU-MOSI and CMU-MOSEI, Acc-2 and F1 are reported under two binary configurations: negative vs. positive (left of “/”) and negative vs. non-negative (right of “/”). Except for the MAE, where lower values indicate better performance, higher values on all other metrics reflect improved model effectiveness. Dataset statistics are summarized in
Table 1.
4.2. Feature Extraction
To ensure consistent evaluation and reproducibility across benchmarks, we utilize the officially released pre-processed multimodal features for all datasets, following the standardized MMSA protocol proposed by Mao et al. [
41]. Each modality—textual, acoustic, and visual—is encoded using well-established pre-trained models or signal processing toolkits, thereby avoiding additional learning bias during feature extraction.
For the textual modality, utterance-level representations are obtained using pre-trained BERT encoders. Specifically, we adopt
Bert-base-uncased [
40] for the English-language datasets (CMU-MOSI and CMU-MOSEI) and
Bert-base-Chinese [
41] for the Mandarin-language SIMS dataset. All embeddings are 768-dimensional. To ensure computational efficiency while preserving semantic coverage, input sequences are truncated or padded to a fixed length of 50 tokens for MOSI and MOSEI and 39 tokens for SIMS.
Acoustic features are extracted using established audio processing libraries specific to each dataset. For CMU-MOSI and CMU-MOSEI, we employ the COVAREP toolkit [
42] to extract low-level descriptors such as pitch, glottal source parameters, and cepstral coefficients, resulting in 5- and 74-dimensional features, respectively, with frame counts of 375 and 500. For SIMS, 33-dimensional features are extracted over 400 frames using Librosa [
43].
Visual representations are obtained from facial expression and movement analysis tools. For CMU-MOSI and CMU-MOSEI, we use Facet [
44,
45] to extract 20 and 35 attributes per frame, including action units and head pose estimations, standardized to 500 frames per video. For SIMS, high-dimensional (709D) visual features are extracted over 55 frames using OpenFace 2.0 [
46].
Each dataset provides continuous sentiment annotations on different scales. CMU-MOSI and CMU-MOSEI adopt a seven-point scale ranging from (strongly negative) to (strongly positive), while SIMS uses a normalized interval to represent sentiment polarity. These labels are used as regression targets in sentiment prediction tasks.
4.3. Baselines
To comprehensively evaluate the effectiveness of our proposed model, we benchmark it against a wide spectrum of MSA methods, ranging from early disentangled and mutual-information-based models to recent advances in self-supervised learning, cross-modal enhancement, and Transformer-based fusion.
MISA [
17] is a flexible MSA framework that disentangles representations into modality-invariant and modality-specific subspaces, thereby reducing modality gaps while preserving unique modality characteristics. It leverages multiple loss functions to guide representation learning and adopts a simple yet effective fusion strategy, demonstrating strong performance on sentiment and humor recognition tasks.
SELF_MM [
18] is a self-supervised MSA model that generates unimodal pseudo-labels to supervise modality-specific representation learning. It captures both cross-modal consistency and modality-specific variation without manual annotations. A momentum-based label refinement and dynamic weight adjustment further enhance its robustness, especially for samples with high modality discrepancy.
MMIM [
18] adopts a hierarchical mutual information maximization strategy that preserves task-relevant information across modalities and between input and fused representations. It combines neural parametric models with non-parametric Gaussian mixture models to estimate mutual information, yielding improved performance on standard MSA benchmarks.
CENET [
24] enhances text representations by integrating emotional cues from visual and acoustic modalities into a pre-trained language model. It employs a feature transformation mechanism that converts nonverbal features into token-like indices, reducing cross-modal distributional differences and improving fusion efficiency.
TETFN [
19] is a text-enhanced Transformer fusion network that incorporates text-oriented multi-head attention and cross-modal mappings to integrate sentiment-related cues from all modalities while retaining modality-specific predictions. It also utilizes a Vision Transformer backbone to extract both global and local visual features, achieving competitive results on multiple MSA benchmarks.
TFR-Net [
10] is a Transformer-based encoder–decoder architecture designed for unaligned multimodal inputs with random incomplete modalities. It reconstructs incomplete features via inter- and intra-modal attention mechanisms and employs reconstruction losses to produce semantically consistent representations, ensuring robustness under various missing conditions.
ALMT [
20] introduces an adaptive hyper-modality learning (AHL) module to mitigate the effects of redundant and conflicting information in nonverbal modalities. By leveraging multi-scale language features, ALMT generates a sentiment-relevant and noise-suppressed hyper-modality representation, enabling effective and robust multimodal fusion.
LNLN [
21] emphasizes the dominant role of the language modality in sentiment analysis and improves its reliability through a dominant modality correction (DMC) module and a dominant modality-based multimodal learning (DMML) module. This framework enhances model robustness under scenarios involving missing or noisy nonverbal modalities.
4.4. Implementation Details
We implement our model using the PyTorch 2.3.1 framework and conduct all experiments on a single NVIDIA GeForce RTX 4090 GPU (NVIDIA Corporation, Santa Clara, CA, USA),which provides sufficient computational capacity for large-scale multimodal training. To simulate incomplete modality scenarios, we adopt a random masking strategy during training, where independent temporal masks are applied to each modality. For audio and video, masked segments are replaced with zero vectors, effectively introducing white Gaussian noise into the feature space. For text, masked tokens are substituted with a special token to simulate missing semantic information [
17]. The model is optimized using the Adam optimizer. To ensure fair and consistent evaluation, we perform five independent runs for each predefined missing rate
, with increments of 0.1. For example, at
, 50% of the input information in each modality is randomly masked during testing. We report the average performance across all missing rates to comprehensively evaluate the model’s robustness under varying degrees of modality incompleteness. Additional details of the implementation, including the learning rate and batch size, are summarized in
Table 2. The hyperparameter settings in
Table 2 are empirically selected based on the characteristics of each dataset. Specifically, we adjust the Mamba depth configuration to align with the temporal complexity of different modalities. For example, CMU-MOSEI contains longer and more diverse utterances compared to CMU-MOSI, which motivates the use of deeper Mamba blocks ({2,2}) to better capture long-range dependencies. In contrast, CH-SIMS, with a shorter average sequence length and more balanced modality contributions, benefits from a moderate depth setting ({1,2}) to avoid overfitting. Other parameters such as sequence length
L and batch size are chosen based on GPU memory constraints and validation performance during initial experiments. These tailored configurations help ensure optimal learning dynamics for each dataset.
5. Results and Analysis
5.1. Overall Results
MGMR-Net achieves consistently strong performance across three widely used MSA benchmarks—CMU-MOSI, CMU-MOSEI, and CH-SIMS—demonstrating its effectiveness in cross-modal alignment, modality reconstruction, and temporal modeling.
On CMU-MOSI (
Table 3), MGMR-Net outperforms all baselines in key metrics, achieving the highest Acc-2 (73.50%), F1 (73.53%), and Pearson’s correlation coefficient (0.534), surpassing robust models such as LNLN and ALMT. This improvement stems from the proposed
Mamba-collaborative fusion module, which enables effective alignment and fusion of multimodal sequences within a language-centric state-space modeling framework.
On CMU-MOSEI (
Table 4), MGMR-Net maintains top-tier performance with Acc-2 reaching 77.42%, F1 at 78.21%, and MAE being reduced to 0.671. These results demonstrate the model’s strong generalization across diverse and large-scale datasets. The
Mamba-enhanced reconstruction module further contributes by restoring incomplete modality information through continuous-time dynamics and adaptive feature fusion.
On CH-SIMS (
Table 5), MGMR-Net achieves the best Acc-2 (73.65%) and a competitive F1-score (78.91%), closely matching LNLN’s 79.43%. These results reflect the model’s cross-lingual adaptability and robustness in the face of semantic and cultural variation. However, slight gaps in certain metrics suggest potential for further improvement in handling ambiguous or conflicting sentiment cues.
Additionally, as the proportion of incomplete modalities increases in
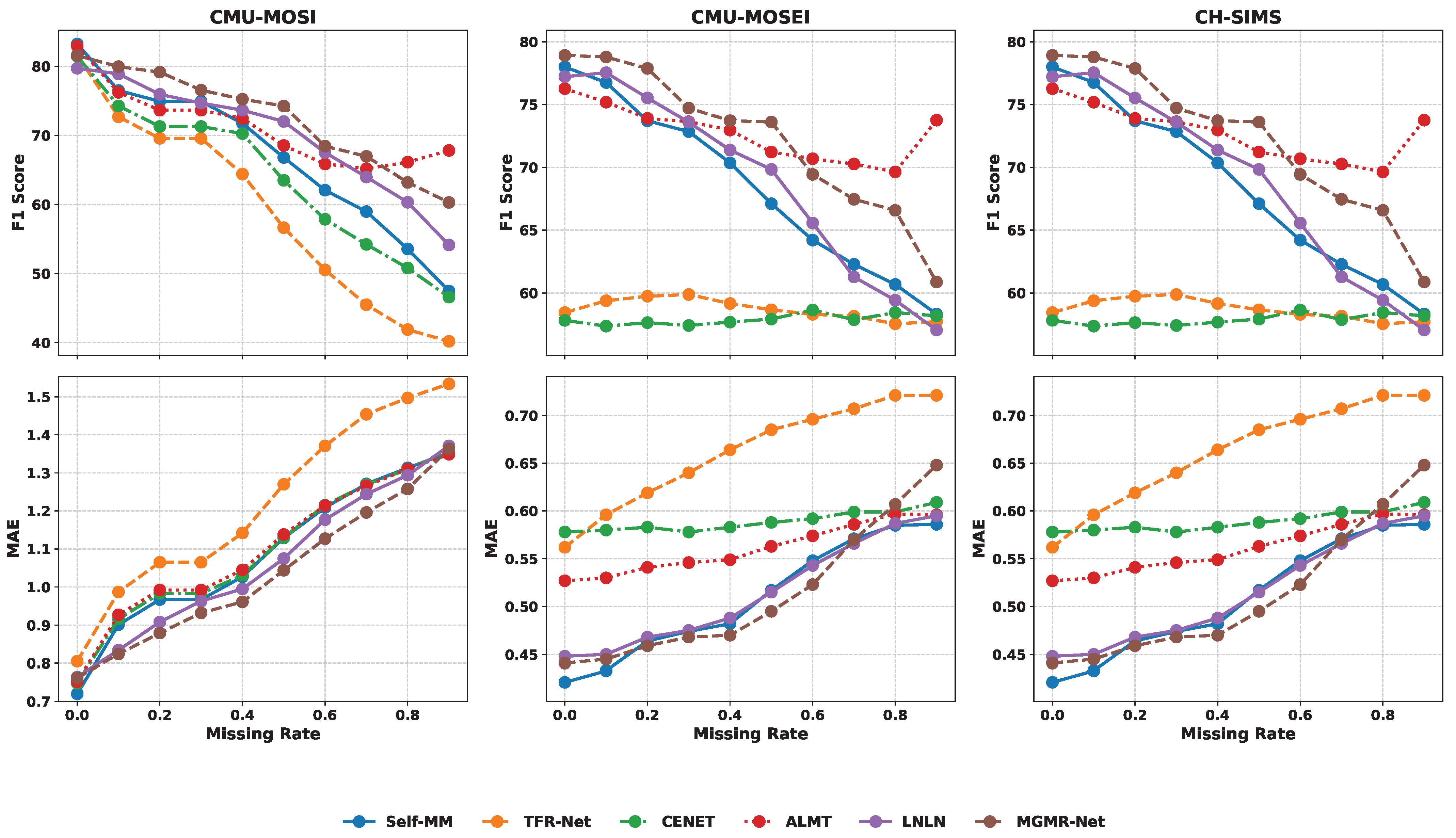
Figure 3, representative baseline models exhibit a clear decline in performance, highlighting their sensitivity to incomplete modality inputs. In contrast, MGMR-Net maintains a relatively stable performance, with only marginal degradation in both the F1-score and MAE across varying missing rates. This resilience indicates that MGMR-Net is less susceptible to modality incompleteness, largely due to its ability to capture cross-modal dependencies and suppress noise from missing segments. Such robustness renders it particularly well-suited for real-world multimodal sentiment analysis scenarios, where incomplete or noisy data are common.
In summary, MGMR-Net successfully integrates multimodal temporal modeling, semantic alignment, and robustness enhancement in a unified architecture, achieving excellent performance, broad applicability, and strong generalization capabilities.
5.2. Ablation Study
To evaluate the contribution of each core component in MGMR-Net, we conduct an ablation study on the CMU-MOSI dataset by selectively removing the following modules: (1) the cross-modal alignment module via multi-layer collaborative Bi-Mamba (denoted as S-1), (2) the Mamba-based multimodal fusion stream (S-2), and (3) the Mamba-enhanced reconstruction module (Recon). The results are summarized in
Table 6.
The complete MGMR-Net achieves the best overall performance, with Acc-2 scores of 73.50%/72.37% (negative vs. positive/negative vs. non-negative), F1-scores of 73.53%/72.39%, MAE of 1.038, and Pearson’s correlation coefficient of 0.534. These results demonstrate the effectiveness of the multi-branch architecture and stage-wise modeling for robust multimodal sentiment prediction.
Effect of removing S-1: Removing the S-1 module causes the largest drop in classification accuracy, with Acc-2 decreasing to 68.28%/67.96% and F1-scores to 70.32%/70.01%, representing relative declines of over 5.2% and 3.2%, respectively. MAE increases to 1.120, and correlation falls to 0.498, underscoring the critical role of alignment in maintaining temporal and semantic consistency across modalities.
Effect of removing S-2: Omission of the S-2 fusion stream leads to a moderate performance decline: Acc-2 drops to 71.20%/71.83%, F1 to 72.34%/71.78%, MAE rises to 1.073, and correlation slightly decreases to 0.516. This confirms that S-2 enhances global cross-modal interactions and enriches semantic representations.
Effect of removing Recon: Removing the reconstruction module significantly impairs performance, particularly in F1-scores, which decrease to 68.52%/67.59%, the lowest among all variants. Although Acc-2 remains close to the full model (73.10%/72.28%), MAE increases to 1.087 and correlation drops to 0.508, highlighting the importance of reconstruction for handling incomplete modalities and refining feature representations.
Overall, the ablation study confirms that each module contributes meaningfully to MGMR-Net’s performance. S-1 has the greatest impact on classification accuracy, while the reconstruction module is vital for robustness and precision in F1 and MAE metrics. Although S-2 plays a relatively smaller role individually, it provides complementary global semantic context. These findings validate the effectiveness of MGMR-Net’s multi-stage, multi-branch design for robust multimodal sentiment analysis.
5.3. Model Complexity
As shown in
Table 7, MGMR-Net demonstrates competitive inference efficiency under both complete and incomplete modality settings, with runtimes of 3.65 s and 3.93 s, respectively. The slight increase at a 0.5 missing rate highlights the model’s robustness and computational efficiency in handling incomplete data. This advantage stems from the adoption of the Mamba architecture, which replaces traditional self-attention with a selective state-space model (SSM), reducing computational complexity from quadratic
to linear
relative to sequence length. As a result, MGMR-Net is well-suited for long-range temporal modeling in multimodal sentiment analysis, enabling efficient cross-modal interaction and reconstruction with minimal inference overhead.
5.4. Case Study
To further illustrate the strengths and limitations of MGMR-Net, we present a qualitative analysis of three representative samples from the MOSI dataset (
Figure 4), covering scenarios of subtle sentiment cues, modality consistency, and severe modality missingness.
Case 1 involves a challenging instance where the textual modality conveys neutral sentiment, while the visual modality reveals subtle negative facial expressions. MGMR-Net correctly predicts a negative label, benefiting from the Mamba-collaborative fusion module that enables fine-grained cross-modal alignment and temporal gating. In contrast, ALMT, which heavily relies on textual dominance, predicts a neutral label, and LNLN is misled by audio noise, producing an incorrect positive classification.
Case 2 depicts a sample with consistent negative sentiment across all three modalities: explicit negative language, low-pitched and flat acoustic tone, and clear negative facial cues. MGMR-Net, LNLN, and ALMT all successfully predict the negative label. The strong modality agreement renders this sample relatively straightforward. Although MGMR-Net does not exhibit a significant advantage here, its hierarchical fusion ensures robust multimodal integration. Similarly, LNLN and ALMT perform reliably under well-aligned and conflict-free modality inputs.
Case 3 represents a failure case characterized by severe modality missingness. The visual modality is heavily corrupted, and the acoustic signal lacks prosodic information, containing only rhythmic patterns. All models fail to predict correctly. Despite MGMR-Net’s Mamba-enhanced reconstruction module, extreme information sparsity limits reconstruction effectiveness, revealing a common limitation among current models when faced with severely incomplete inputs.
These examples suggest that MGMR-Net excels in capturing subtle or noisy sentiment cues through dynamic fusion and reconstruction. Nonetheless, like other models, it struggles with highly sparse or conflicting modality conditions.
5.5. Comparative Discussion with Prior Models
To better position MGMR-Net within the multimodal sentiment analysis landscape (MSA), we provide a comparative discussion with several representative models, including MISA, SELF_MM, TETFN, ALMT, and LNLN.
MISA and SELF_MM emphasize modality-specific representation learning through disentanglement or pseudo-label generation. While they demonstrate strong performance when all modalities are present, they exhibit notable performance degradation in the presence of missing inputs due to the absence of explicit cross-modal recovery mechanisms. For example, on the CMU-MOSI dataset, MISA achieves an Acc-2 of 71.49%, while MGMR-Net surpasses this with 73.50%. Furthermore, with increasing missing rates, SELF_MM shows a significant decline in the F1-score, as illustrated in
Figure 3, while MGMR-Net maintains a relatively stable performance. These results highlight the effectiveness of the proposed Mamba-enhanced reconstruction module in addressing incomplete modality scenarios.
TETFN enhances textual representations via cross-modal attention and visual Transformers but lacks advanced temporal modeling capabilities. This limitation becomes evident on the CH-SIMS dataset, where its F1-score reaches only 68.67%, compared to MGMR-Net’s 78.91%. The superior performance of MGMR-Net can be attributed to the integration of Mamba state-space models, which facilitate long-range temporal dependency modeling with linear complexity.
ALMT and LNLN focus on leveraging the language modality as the dominant source of sentiment information, employing mechanisms for noise suppression and modality correction. Although these models perform well under balanced modality conditions, such as LNLN’s strong F1-score of 79.43% on CH-SIMS, they are less robust when confronted with substantial corruption or inconsistency in the modality. MGMR-Net, on the other hand, combines collaborative Bi-Mamba-based alignment with hierarchical fusion and temporal-aware reconstruction, yielding consistently high performance across CMU-MOSI, CMU-MOSEI, and CH-SIMS, as shown in the comprehensive results tables.
In summary, MGMR-Net integrates alignment, fusion, and reconstruction within a unified, text-centric architecture. Experimental evidence demonstrates its superiority in classification accuracy, F1-score, and robustness to incomplete modalities, thus validating the design choices and establishing its competitiveness among state-of-the-art MSA models.








{kind=link}
{kind=link}
{kind=link}
{kind=link}