3. Motivation
The issue of class imbalance in IoT datasets leads to biased models that favor majority groups while struggling to identify underrepresented attacks. This challenge arises for various reasons, including the use of diverse devices and the heterogeneous nature of IoT environments, resource limitations, unbalanced real-world attack distributions, etc. Traditional IDSs fail to generalize a solution for these environments because they learn overrepresented classes of attacks and perform poorly for underrepresented ones. This problem should be addressed to ensure a secure and stable environment, preventing intrusion in vulnerable large-scale IoT networks. GAN-based augmentation can mitigate class imbalance, but existing methods generate data without feature relevance, resulting in noisy, low-quality samples. In addition, resampling methods do not learn attack behavior that reduces the robustness of models.
Identifying the most important features enhances both the generation process and the model’s performance. In our model, we use a novel feature-aware augmentation approach that uses GANs not only for data generation but also for feature selection. This approach ensures the production of meaningful synthetic data and prevents overfitting. Moreover, the GIR is introduced for dynamic and class-importance-aware augmentation that is more effective than traditional ones.
In this section, the details of the used datasets and the proposed GIR are provided to address the problem of class imbalance in IoT deployments.
3.1. Why FIGS?
The existing data augmentation techniques suffer from severe limitations:
Oversampling techniques such as SMOTE, ADASYN, etc., do not consider the feature importance and generate samples containing noise and irrelevant samples. Moreover, they do not learn the attack pattern effectively.
GAN-based data augmentation methods lack feature awareness, which results in generating low-quality data. Additionally, these models require high power, which is not suitable for resource-constrained IoT environments.
Although some models combine GANs with resampling methods, they still fail to find the most important features, making them computationally expensive and not practical for IoT deployment.
FIGS is proposed to solve the above problems:
Performs feature-aware augmentation by selecting the critical attack features for synthetic sample generation.
Using targeted GAN-based data generation, it produces high-quality synthetic data.
Improve the resampling method by FISMOTE and prevent noisy data.
Using the new GIR metric, FIGS can dynamically adapt augmentation strategies and be more effective than traditional models.
The enhancements provided by FIGS are summarized in
Table 2.
3.2. Datasets
We conducted a comprehensive investigation of many datasets to choose the best for our work. Based on our research, some datasets were frequently used in the papers that addressed the class imbalance problem, and we provide details of these datasets in
Table 3.
The CICIoMT2024 dataset [
24] is a realistic benchmark for evaluating the security of Internet of Medical Things (IoMT) devices in healthcare environments. It consists of 9 million records, including 18 various attacks against a testbed of 40 IoMT devices (25 real and 15 simulated), considering common protocols in healthcare devices such as MQTT, WiFi, and Bluetooth. The attacks are categorized into five major categories: DDoS, DoS, Recon, MQTT, and Spoofing. This dataset uses real and simulated IoMT devices as attackers and victims and provides a robust platform for developing and testing IDS. By doing so, CICIoMT2024 fills the critical gaps in earlier datasets to reflect the dynamic and heterogeneous nature of IoMT environments.
To investigate the performance of this dataset, several ML and DL algorithms, such as Logistic Regression (LR), Random Forest (RF), Adaptive Boosting classifier (AdaBoost), and Deep Neural Networks (DNN), have been evaluated. Like other datasets, CICIoMT2024 presents the class imbalance challenge across its attack categories. Although this dataset includes a diverse range of attack classes, some of them, such as DDoS floods, dominate the dataset, and some others, such as ARPSpoofing, are significantly underrepresented.
We are the first to investigate the CICIoMT2024 dataset to examine the class imbalance problem. In fact, the CICIoMT2024 dataset was chosen for evaluating the FIGS because of its comprehensive nature for IoMT environments. IoMT environments are parts of IoT environments and overlap with them in terms of security challenges and resource constraint problems. This dataset has a broad range of attack types that make it suitable for investigating conditions in IoT environments. In contrast, the CICIoT2022 dataset reflects IoT profiling and is limited in scope in terms of attack diversity and distribution. The dataset does not provide a necessary range of attacks and malicious traffic required to evaluate an IDS, and instead targets profiling and behavioral analysis rather than attack assessment. The CICIoT2023 dataset introduces a larger number of attacks, but its attack distribution is more balanced compared to CICIoMT2024. Using CICIoMT2024 ensures that the proposed model is evaluated in realistic scenarios and increases its reliability for real-world IoT deployments. The class distribution and category distribution of the CICIoMT2024 dataset are shown in
Figure 1 and
Figure 2.
The CICIDS2017 dataset is widely recognized as a comprehensive and highly valuable dataset for IDS. One of its key strengths is the inclusion of various kinds of modern attack simulations. These are DoS/DDoS, Patator, Heartbleed, infiltration, web attacks, etc. This variety makes CICIDS2017 a robust dataset for training and testing, especially for the ML models that seek to identify different forms of intrusions. Because of the diverse attack types in CICIDS2017, this dataset is a good option that can perform well in real-world scenarios.
In terms of features, CICIDS2017 provides 80 features; some are related to low levels of network traffic, such as packet size and flags, and others are related to high-level features, including connection duration and source IP. This has made the dataset ideal for feature selection to ensure that only ideal features for intrusion detection are considered. The CICIDS2017 emulates real network traffic in a laboratory setting with both normal and attack traffic. This represents a real-world implementation since traffic flows with noise and anomalies must be processed in an IDS. On the other hand, other datasets, such as NSL-KDD, sometimes termed synthetic, cannot fully represent real traffic. Thus, for the IoT systems that may be connected with more extensive enterprise or cloud networks, such a realistic model of attacks makes CICIDS2017 an effective dataset for identifying network-based intrusions.
The size of CICIDS2017 is about 3 million records, which means that the dataset is not too small to train complex models, but also does not require significant computational resources. Finally, CICIDS2017 offers a meaningful starting point to test different ML/DL methods. RF, SVM, and DNN have been tested before on CICIDS2017; thus, it is a perfect platform for developing a practical IDS for various IoT applications. In this work, CICIDS2017 is used because it consists of real attack scenarios and non-malicious traffic, including brute force, DoS, DDoS, and infiltration. We divide this dataset into 8 main classes, including Benign, DoS, DDoS, PortScan, Patator, WebAttack, BoT, Infiltration, and Heartbleed. The class distribution of the CICIDS2017 dataset is shown in
Figure 3.
3.3. Generalized Imbalance Ratio (GIR)
One of the biggest problems in the IoT IDS is the impossibility of reaching a high detection rate for all categories without threatening the detection rate of other groups. Traditional imbalanced metrics often fail to capture the importance of different attack types in many IDS cases. To address this problem, we define a new metric called GIR, which integrates sample counts and domain-specific weighting factors to improve imbalance assessments and identify the datasets’ imbalance rate.
Why is a new imbalance metric (GIR) needed?
The common class imbalance metrics, such as the imbalance ratio (IR), measure dataset imbalance solely with a simple sample count. Therefore, these methods face two main drawbacks for IoT security applications. The first one is, they assume all traffic classes have the same priority, which leads to augmenting data regardless of real-world concerns. Secondly, existing oversampling approaches treat all minority classes the same, while some of them are more critical than others. Additionally, GAN-based augmentation models do not prioritize rare but critical attacks and generate traffic for less relevant attacks.
The GIR metric addresses this problem by a dynamic weighting procedure that specifically focuses on important attack categories. The GIR operates differently from standard IR because the GIR allocates increased generation emphasis on attack types that represent higher security risks, which supports real-world IDS effectiveness through enhanced synthetic traffic generation. For example, if two attack types have approximately similar sample counts, but one of them has more attack severity, GIR ensures that the high-risk one gets more priority for augmentation.
Overall, GIR helps enhance IDS performance by:
Prevents over-augmentation of non-critical attack classes.
- –
GIR dynamically prioritizes the data generation process to give more focus to critical attacks.
- –
Without GIR, all minority classes are treated equally, leading to unnecessary augmentation for non-critical attack categories.
Helps to balance the datasets without compromising the detection rate.
- –
Traditional augmenting methods balance the dataset blindly and are prone to introducing noise and irrelevant data.
- –
By optimizing the augmentation data, GIR helps to improve the recall rate without distorting the dataset.
Improves model generalization for real-world IoT security.
- –
Most IDSs are biased in favor of majority groups and fail to generalize the imbalanced nature of IoT environments.
- –
Using GIR helps the augmentation methods, such as FIGS, to adjust data generation strategies and provide more resilient samples for unseen attacks.
Some recent research, such as [
4,
7,
11,
12,
36,
37], used IR for calculating the imbalance rate of datasets, but it solely focuses on the number of instances per class. Although IR is useful for understanding underlying class imbalance, it does not account for situations where the importance of classes is not simply a function of their size. By introducing weights, GIR allows for more accurate measurement and management of class imbalances. On the other hand, in many real-world applications, not all classes are equally important, and GIR allows us to prioritize some classes. A summary of using IR in various studies is provided in
Table 4. One of the novelties of this paper is proposing a new metric for calculating class imbalance in imbalanced datasets, designed to quantify the degree of imbalance between classes in a dataset, especially when dealing with scenarios where the minority class is underrepresented. The formula for GIR is:
where:
- -
: the number of samples in the majority class.
- -
: the number of samples in the minority class.
- -
: the weight assigned to the majority class.
- -
: the weight assigned to the minority class.
Table 4.
Comparison of models for imbalance ratio.
Table 4.
Comparison of models for imbalance ratio.
| Ref. | Calculating Imbalance Ratio | Considering Weight for Minority Class | Considering IDS | Considering IoT |
|---|
| CTGAN-MOS [7] | √ | • | • | • |
| Fault Diagnosis [11] | √ | • | • | • |
| IGAN-IDS [12] | √ | • | √ | • |
| S2CGAN-IDS [4] | √ | • | √ | √ |
| Improved SMOTE [36] | √ | • | • | • |
| CIDH-ODLID [37] | √ | • | √ | √ |
| FIGS | √ | √ | √ | √ |
To calculate the GIR with weights, it is necessary to define the weights based on the importance of each class. We set:
equal to 1 in order not to give additional weight to the majority class.
is higher, to give more importance to minority classes.
To reflect the critical impact of minority attack types in IoT security, we assign a higher importance weight to minority classes. Specifically, we set = 1 and = 2, assigning twice the priority to minority attack types, based on the assumption that failing to detect rare attacks can result in disproportionately higher security risks. These fixed weights allow the GIR to not only capture imbalance based on sample count but also incorporate a basic form of risk prioritization, which is particularly relevant in anomaly-based IDS contexts.
After the GIR calculation, we categorize classes based on percentiles of the GIR values. This is a flexible way of partitioning the classes depending on their relative standing in the distribution of the GIR values. We used a percentile classification that divides the classes into three groups:
Plentiful Class: The GIR in this group is less than 33%; thus, the classes in this group are fine and have sufficient data and little imbalance.
Limited Class: This class represents the minority class, the GIR is 34% to 66%. This category of classes requires data augmentation to help balance the ratios.
Sparse Class: The GIR in this category is greater than 67% and revealed that the imbalance is the worst. This data scarcity will lead to some serious issues in the generation and classification models.
This percentile-based categorization enables us to employ targeted augmentation strategies for the mentioned groups and make sure that the model handles various levels of class imbalance. This approach helps to improve the overall performance and robustness of the IDS, especially for minority classes. We calculated the GIR for all the classes in all datasets and categorized them into three categories. The details are provided in
Table 5 and
Table 6. For the CICIoMT2024, the categories of the data were also considered to have a comparison between our model and the baseline for 6-class classification. So, the GIR values are calculated for this kind of data, and the details are provided in
Table 7.
7. Evaluation and Results
In this section, we evaluate the performance of our method against other class balance algorithms and demonstrate its superiority in addressing class imbalance and detecting IoT security threats. We aim to highlight that our framework not only enhances performance but also reduces complexity and computational overhead. This comprehensive comparison demonstrates the advantages of our approach in effectively addressing the challenges in IoT environments.
To maintain the integrity of the evaluation without increasing performance, a strict 80–20 strategy was used, and the test set was isolated before any data augmentation. This ensures that no synthetic samples were present in the test set and eliminates the risk of data leakage. All performance metrics, including F1-score, precision, and MCC, were computed on this unseen test set to reflect generalization capability.
Table 9 shows each step and how operations are constrained to the training set only. The test set remains completely unseen until the final evaluation phase, with no augmentation or feature-importance extraction performed using test data. This guarantees that the reported performance metrics reflect true generalization capability without contamination.
The preprocessed datasets were randomly partitioned into training and test sets, with 8:2 ratio. To address the class imbalance issue, the FIGS framework was used to generate synthetic data exclusively for minority classes in the training datasets. This approach ensured that the original distribution and integrity of the test data remained untouched, thus allowing us to perform a fair and unbiased evaluation of our models. This decision ensures the prevention of data leakage and preserves the generalization capabilities of our models. By only balancing the training data and strictly isolating the test set, our evaluation results reflect the true effectiveness of the IDS models trained using FIGS.
Table 10 and
Table 11 present the sample distributions of CICIoMT2024 and CICIDS2017 before and after using FIGS.
The CICIoMT2024 dataset is a new dataset, and FIGS is the first model to use this dataset to investigate the class imbalance problem. The effect of balancing the dataset using FIGS and generating synthetic data was investigated, and the performance results are presented in the figures and tables below. The first comparison is the binary classification for the baseline and after generating synthetic data for unbalanced classes.
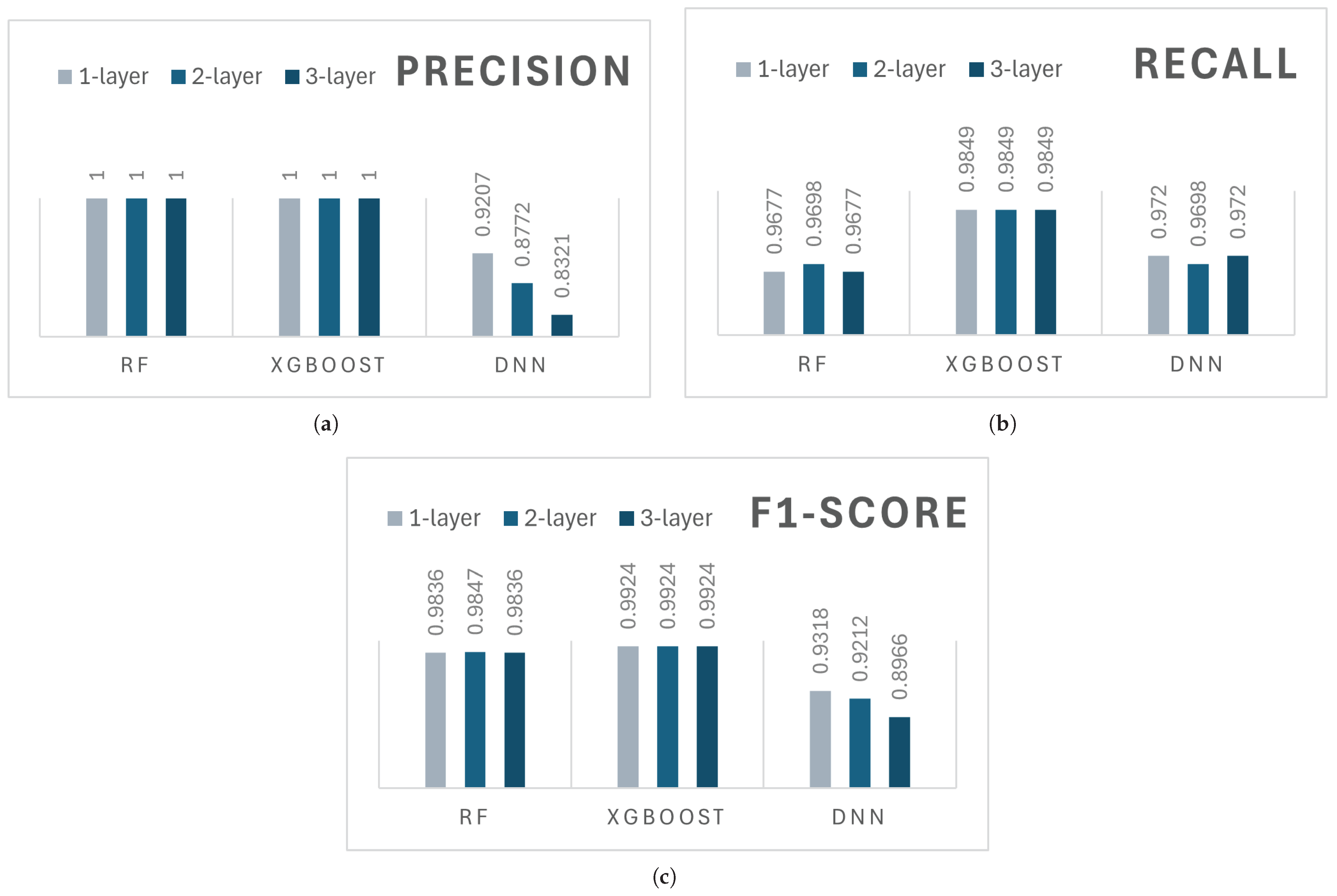
Table 12 shows the performance metrics for the comparison, and consistent improvement is observed across all metrics.
The results demonstrate that FIGS significantly enhances detection performance, especially for minority classes such as Recon-VulScan and Recon-Ping-Sweep. In the baseline setting, classifiers such as DNN and XGBoost exhibited a lower recall and F1-score due to limited training samples and unequal distribution between classes. For example, DNN has a recall of only 0.9231 for Ping-Sweep and a precision of 0.9608 for VulScan. After applying FIGS, all classifiers achieved perfect or near-perfect scores across all metrics, indicating the effectiveness of FIGS in improving the detection of underrepresented attack types.
Although RF generally performed well at baseline, FIGS significantly improved the robustness of DNN and XGBoost in all traffic categories. This enhancement is critical for IDSs deployed in unbalanced, real-world environments where minor attack classes may not be detected. The improvements observed suggest that FIGS effectively reduces model bias towards majority classes, enabling more reliable threat identification.
The high-performance metrics observed in this table, especially the F1-scores that are approaching 1.0, can be explained by the evaluation design that is based on binary classification tasks conducted per attack class. Under this configuration, each attack category is independently framed as a binary detection problem (attack and benign), rather than being evaluated under a multiclass configuration. This formulation inherently facilitates higher classification metrics, especially for well-separated classes such as TCP-IP DDoS and DoS variants, which exhibit distinct statistical patterns. When the FIGS were employed in generating synthetic samples for minority classes, there was great improvement in the generalizing capacity of the classifier on minority examples as well as a decrease in the number of FPs and FNs.
An MCC calculation is used to test the reliability and robustness of the proposed FIGS framework under binary classification. The performance evaluation of RF, XGBoost, and DNN models based on MCC measures presented in
Figure 10, where per-class results demonstrated comparative assessment with baseline MCC values without FIGS implementation.
The experimental results confirm FIGS as an effective performance enhancement method that excels at detecting minority classes that usually disappear in imbalanced scenarios. FIGS boosted the MCC evaluation scores to reach perfect correlation (MCC
) for certain attacks such as TCP-IP-DDoS-UDP, TCP-IP-DDoS-TCP, and Recon-VulScan, even though their baselines ranged between 0.86 and 0.98 across all three classifiers. FIGS improves classification performance and addresses class-majority bias by reflecting all confusion matrix elements (TP, TN, FP, FN), which makes it highly appropriate for imbalanced datasets [
47].
XGBoost delivered the most reliable performance by demonstrating minimal variance in attack detection, while DNN gained maximum advantages from FIGS, especially for Recon-Ping-Sweep and Recon-VulScan attacks. These results validate FIGS’ capability to enhance reliable classification outcomes under serious data imbalance situations typical of IoMT intrusion contexts.
To further support the MCC-based evaluation, the confusion matrices for all three classifiers under both baseline and FIGS conditions are analyzed. FIGS framework significantly reduces both false positives and false negatives according to
Figure 11 and
Figure 12.
DNN started with moderate false positives (2738) and false negatives (42) before FIGS implementation made zero and 14 results, yielding a more reliable detection capability. The RF classifier achieves improved precision through FIGS because the framework succeeds in eliminating all false positive results. XGBoost shows the most reliable effectiveness since FIGS converted 20,157 false negatives to merely 12 instances, indicating robust recall without compromising its ability to identify correct patterns.
These improvements reflect FIGS’ ability to balance all components of the confusion matrix (TP, TN, FP, FN), which is particularly crucial in highly imbalanced IoT environments. The decrease of false negatives enhances the detection capacity of minority classes since they tend to produce incorrect classifications. Thus, confusion matrix analysis confirms that the proposed FIGS framework not only enhances overall classifier robustness but also ensures dependable detection across all traffic categories, even those traditionally underrepresented.
Since the results of the studies showed that the performance of this dataset for binary classifiers was close to optimal, in the subsequent studies, the performance of the dataset in multiclass classification was continued by considering the six existing categories. By examining the basic case in multiclass classification, it was found that the classifiers had a performance drop and were struggling with classes with few samples. After using the Figs model, a tremendous improvement in the results was observed. Additionally, we compared FIGS with DeepSMOTE [
48], a deep learning-based oversampling method designed that aims to mitigate class imbalance by interpolating latent representations of minority class samples. While DeepSMOTE achieved improvements over the baseline, its performance consistently fell short when compared to FIGS, as illustrated in
Figure 13. In this evaluation, for better comparison, we added LR and AdaBoost results.
Table 13 shows the numerical value for all micro, macro, and weighted metrics.
Based on the results that are shown in
Table 13, FIGS significantly enhanced the performance of all the classifiers compared to both the baseline and DeepSMOTE and achieved higher macro recall and macro F1-score. For example, the RF classifier has an increase in recall from 0.9379 in the baseline to 0.9449 with FIGS and F1-score from 0.9422 to 0.9525. Moreover, AdaBoost has a significant boost in recall from 0.7465 to 0.8545 and macro F1-score from 0.7748 to 0.8793. This pattern is consistent across DNN and LR as well, where DeepSMOTE offered marginal gains, but FIGS produced better performance boosts. These results validate the FIGS’s ability to outperform other oversampling methods like DeepSMOTE by generating higher-quality and more effective synthetic samples for minority classes.
The most significant enhancements are in classifiers with relatively lower baseline performance, such as LR and DNN. For LR, macro recall increased from 0.609 to 0.651, and macro F1-score from 0.6044 to 0.677. Indeed, LR had struggled with recall in the baseline, and FIGS provides critical improvements. Similarly, DNN, which had the lowest baseline recall at 0.7602, improved to 0.7695, and its F1-score increased from 0.7335 to 0.7742. FIGS also improved classifier accuracy; for instance, AdaBoost’s accuracy jumped from 0.7923 to 0.8368 with DeepSMOTE and to 0.9297 with FIGS. RF also saw a rise from 0.9938 to 0.9950 and then to 0.9978.
The evaluation results highlight the robustness of FIGS in enhancing classifiers’ performance under class imbalance, particularly when compared to DeepSMOTE. While DeepSMOTE provided incremental gains, especially in recall, it occasionally introduced instability or failed to improve precision and F1-scores. In contrast, FIGS consistently delivered superior and balanced performance across all metrics and classifiers. This suggests that FIGS not only improves general performance but also specifically targets and corrects deficiencies such as high false negatives in minority classes.
The performance metrics for all the categories are provided in
Table 14. The detection rate of the ARPSpoofing category improves notably, and the recall shows consistent growth among various classifiers. XGBoost improved its recall from 0.68 to 0.72. These results show that FIGS enhances the ability of most classifiers to identify even Sparse categories of data by generating meaningful synthetic samples for these categories and reducing false negatives.
Some other categories, like DDOS and MQTT, as plentiful categories, have strong performance even in the baseline. For example, both RF and XGBoost achieved perfect scores of 1.0 in precision, recall, and F1-score for DDoS in both baseline and augmented datasets. This consistency highlights that FIGS maintained a high performance for well-represented categories while improving the performance of underrepresented categories. The Recon category shows meaningful growth with the LR classifier, particularly with the recall metric that increases from 0.4 to 0.5, and the F1-score increases from 0.52 to 0.64. Indeed, FIGS addresses the challenges that LR has with an imbalanced dataset by providing more training opportunities for LR to recognize patterns in the Limited categories.
Another important highlight is how FIGS balances performance across all classes. While DeepSMOTE sometimes boosted recall, it occasionally harmed precision or introduced instability that is particularly visible in AdaBoost’s performance on the ARPSpoofing class, where DeepSMOTE’s precision dropped to 0.90 and recall to 0.20, leading to a weak F1-score of 0.33. On the other hand, FIGS produces a balanced output and ensures robustness without compromising specificity. This consistency comes from FIGS’s ability to create realistic and structurally similar synthetic samples rather than interpolated embeddings.
The percentile improvements achieved through the FIGS model across all classifiers are gathered in
Table 15. The key performance metrics for this table are accuracy, macro precision, macro recall, and macro F1-score, and the most significant improvements are highlighted. Based on the findings, AdaBoost exhibited the most significant improvements in accuracy (17.34%), macro recall (14.47%), and macro F1-score (13.49%). These significant enhancements result from several reasons. The first reason for this improvement is related to the inherent nature of AdaBoost, which creates a set of weak learners by assigning higher weights to misclassified examples in each iteration. This approach works well for standard datasets, but it suffers from performance degradation on imbalanced datasets because minority classes are less important due to their scarcity, leading to their neglect. By generating synthetic data, FIGS balances the class distributions, helping AdaBoost receive a variety of examples and focus equally on minority and majority classes during training, leading to a significant improvement in recall and a significant reduction in false negatives.
The second reason pertains to the nature of reweighting. FIGS provides a uniform distribution of examples from all classes and ensures that the reweighting process is not dominated by the majority class, thus improving AdaBoost’s performance. In addition, AdaBoost relies on weak learners, and these learners are exposed to noisy data. FIGS generates high-quality synthetic data that is closely similar to real minority class samples without introducing noise. Finally, the FIGS process directly targets false negative reduction, which is important for improving recall. Since AdaBoost emphasizes misclassifications during the iterative process, the additional minority class samples provided by FIGS allow AdaBoost to correct false negatives.
A critical challenge in most classifiers is addressing false negatives. XGBoost showed notable improvements in macro recall (15.57%) and macro F1-score (8.48%), indicating that FIGS can address this critical challenge. The increase in recall suggests an improved ability to correctly classify minority classes, a vital improvement for highly imbalanced datasets.
XGBoost is a gradient-boosting algorithm, and its performance is highly sensitive to the quality and distribution of the training data. FIGS provides a balanced training dataset by generating realistic synthetic samples for minority classes. This improved data distribution helps XGBoost to identify underrepresented classes more effectively, increases recall, and reduces false negatives. Moreover, XGBoost assigns higher weights to errors and misclassifications in subsequent boosting iterations. This enhances XGBoost’s ability to correct false negatives and leads to significant recall improvement.
The other classifiers, including DNN, RF, and LR, also showed improvements in their metrics, demonstrating the applicability of FIGS. DNN achieved a 9.19% increase in precision, signifying enhanced classification reliability. LR showed a balanced improvement across all metrics but has a special enhancement in the F1-score with 12.01%, highlighting FIGS’ role in bolstering performance. These results underscore the effectiveness of FIGS in improving classifier performance among a wide range of models and metrics. It also indicates that FIGS is successful in fulfilling its target of reducing false negatives and detecting minor but critical attacks.
To validate the performance improvements of FIGS, we employed McNemar’s test, a non-parametric statistical test, to assess the difference in classification based on the identical test sets. Unlike accuracy-based comparisons, the McNemar test specifically examines the pairs of mismatched points in which only one of the models has correctly classified or not. Thus, McNemar’s test offers a robust assessment of whether observed performance differences are statistically significant. This test was applied to compare FIGS with the baselines and DeepSMOTE on five classifiers.
The McNemar’s test results are summarized in
Table 16 and show that FIGS achieved statistically significant improvements over both comparators (
p < 0.05 for all tests). Specifically, the number of test samples correctly classified only by FIGS (b10) is significantly higher than those correctly classified by the baseline or DeepSMOTE (b01). While traditional performance metrics quantify these improvements in
Table 15, McNemar’s test confirms that these observed differences are not accidental but represent statistically robust enhancements. These findings provide strong statistical evidence that supports the efficacy of FIGS in enhancing classifier sensitivity to underrepresented attacks, therefore addressing a critical limitation in imbalanced intrusion-detection systems.
To substantiate the lightweight nature of the proposed FIGS framework, we conducted a comparative evaluation against S2CGAN (a recent lightweight IDS that integrates GANs with resampling). Our evaluation focuses on two key aspects: detection performance and computational efficiency under varying data load conditions using the CICIoMT2024 dataset.
Figure 14a shows the training efficiency; FIGS achieves significantly lower training time compared to S2CGAN across all load settings. At full load, FIGS trains under 600 s, while S2CGAN exceeds 1100 s. This performance gain is attributed to FIGS’s targeted augmentation mechanism that generated synthetic samples just for minority classes and only on important features identified by sensitivity analysis. In addition, FIGAN uses a shallow architecture of hidden layers that reduces training overhead.
Meanwhile,
Figure 14b presents the average recall achieved by FIGS and S2CGAN as the data set load increases. The recall metric was selected because of its relevance in intrusion detection, where minimizing false negatives and detecting actual attacks are important. FIGS consistently outperforms S2CGAN and obtains a 9.8% improvement in detection accuracy in comparison with S2CGAN. This demonstrates the robustness and high detection capability of FIGS, especially under high-volume, class-imbalanced intrusion scenarios common in IoT networks.
It is important to mention that the generation component in FIGS is used solely during training. During deployment, the model operates as a conventional classifier (e.g., XGBoost or RF), making inference latencies at the ms level that are compatible with real-time constraints in IoT environments. These findings show that FIGS offers a trade-off between accuracy and efficiency. Despite the integration of generative models, its selective design ensures reduced computational cost, rapid training, and real-time inference performance, making it practical for intrusion detection in resource-constrained IoT settings.
To validate the effectiveness of FIGS, we conduct extensive experiments on the CICIDS2017 dataset, comparing our method against three main categories of class imbalance handling techniques used in IDS research, including data generating, data resampling, and hybrid-generating models. The methods used for comparison of the CICIDS2017 dataset are as follows:
The detailed findings are recorded in
Table 17. This table gives a detailed overview of the results obtained from evaluating five state-of-the-art algorithms with a DNN classifier and our model with RF, XGBoost, and DNN classifiers separately. Moreover,
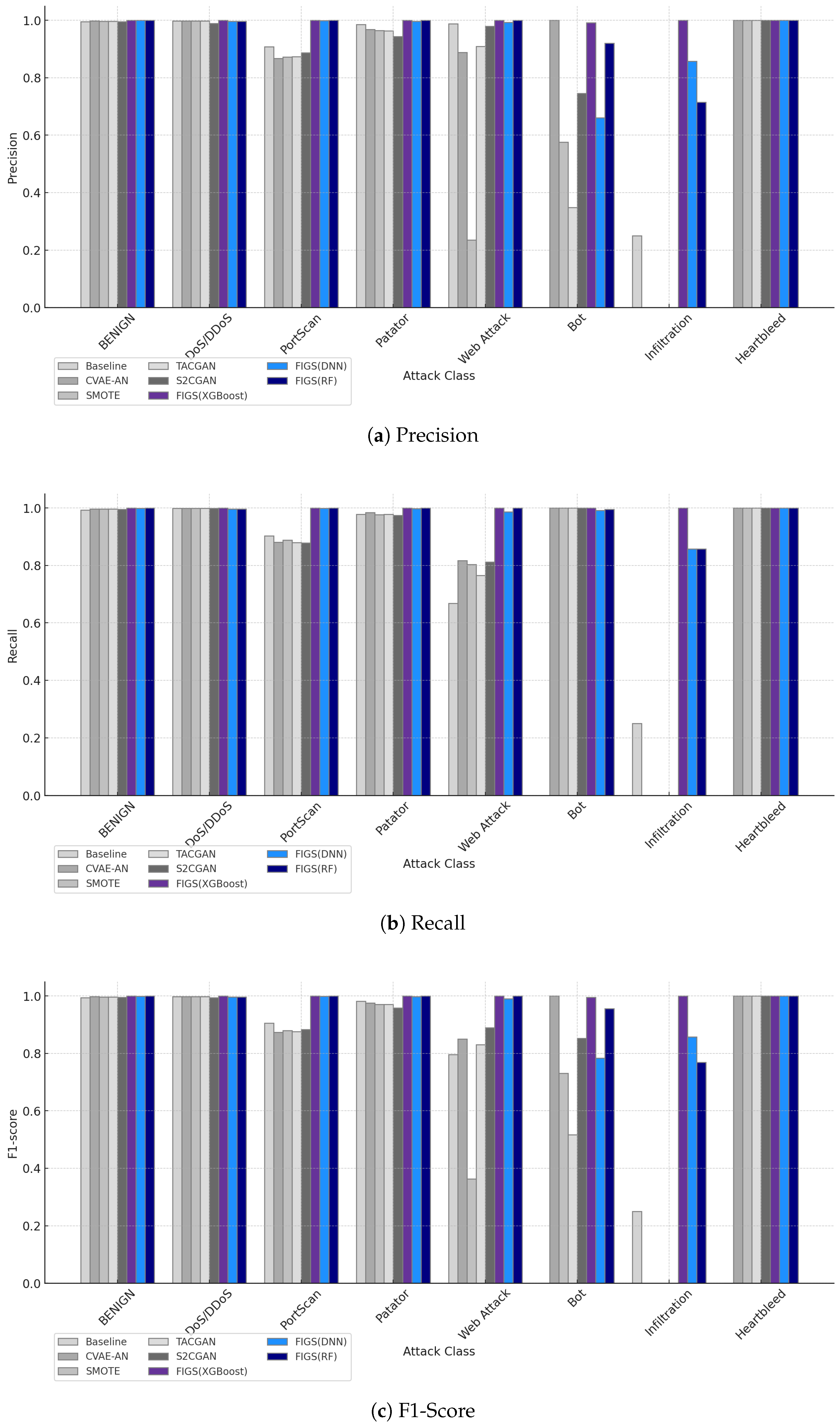
Figure 15 depicts the precision, recall, and F1-score in different classes.
The results clearly show that FIGS consistently outperforms or matches the best existing methods, especially in detecting minority attack classes while maintaining strong performance in Plentiful categories. For Plentiful groups that have sufficient data, such as DoS/DDoS, FIGS performs similarly to other models. As depicted in
Figure 15, FIGS, similar to other methods, reaches nearly perfect precision (1.00). This confirms that our model, as well as some state-of-the-art methods, manages attack classes where data imbalance is not a concern. In addition, unlike some other models such as SMOTE and CVAE-GAN, FIGS maintains sturdy performance in these Plentiful categories without introducing unnecessary complexity and extra computation overhead.
In Limited-level attack categories, such as Web Attack and Bot, FIGS demonstrates clear superiority, and for the Patator class, other models also have good results, but FIGS reaches better results near 1.00. The experimental results underscore the exceptional performance of FIGS in the BoT class of attack, while other models encounter challenges. Although some methods, such as TACGAN and CVAE-AN, show high Precision, they fall short in recall and F1-score. This reveals their inability to adequately detect true positive instances of the BoT class, leading to unreliable performance in real-world applications. In contrast, our model achieves a perfect score across all the metrics, demonstrating its robustness and reliability in identifying the BoT class. This improvement is crucial, as it demonstrates FIGS’s ability to generalize better and reduce false negatives in Limited attack detection. While methods like SMOTE and CVAE-GAN show moderate gains in these categories, FIGS stands out by delivering more consistent and reliable results.
As highlighted in
Table 17, other models struggle with Bot attacks, but FIGS, especially with XGBoost and RF classifiers, outperform in all the evaluation metrics. Although some models, such as TACGAN, achieve good precision, they fail in the recall and show bad results, which leads to their low F-score. Our model improves all metrics, indicating our model’s balancing performance and robustness. By investigating the results, we find that other models may avoid false positives but fail to capture enough true positives. This demonstrates that FIGS is the most reliable model for detecting BoT attacks.
The other advantages of FIGS are evident in the Sparse-level attack categories, such as Infiltration and Heartbleed. These attack types, characterized by extremely rare data, are challenging for most algorithms. In the Infiltration category, FIGS achieves near-perfect recall and F1-score (1.00), where baseline methods and even advanced techniques like TACGAN fail to perform adequately. This highlights FIGS’s unique capability to generate meaningful synthetic data in environments with severe data scarcity, a critical feature in IDS.
The good performance of the FIGS model in the Heartbleed class is due to the model’s effective use of advanced resampling techniques. Traditional models often struggle with Sparse classes. However, FIGS overcomes this problem by combining feature-importance-based selection with artificial data generation methods. This approach tries to make the synthetic samples for the Heartbleed class match the real data. The validation process confirmed that FIGS’s strong performance in Heartbleed was not just a fluke. For this reason, our model improves the reliability of the results even for highly unbalanced classes.
FIGS has one major advantage compared to other methods: it outperforms the Limited and Sparse categories and is on par with the Plentiful categories. Finding critical features and combining data augmentation enables FIGS to overcome the flaws of the oversampling techniques, such as SMOTE, which may introduce noise and redundancy.
The MCC analysis of the CICIDS2017 dataset confirms a comprehensive view of classifier reliability across different attack situations. As illustrated in
Figure 16, the FIGS model maintains superior MCC values for all attack types in comparison with the baseline model. Significantly, notable improvements are observed in previously underperforming classes, such as Bot and Infiltration. For instance, the baseline MCC for Bot detection was approximately 0.61, proving poor performance because of class imbalance, while FIGS increased this metric to over 0.80 by DNN and close to 0.99 using XGBoost. These results demonstrate that FIGS significantly improves the classification capability for the different attack types. Similarly, infiltration improved from baseline values below 0.86 to values above 0.92 with FIGS-enabled classifiers.
FIGS proves effective for fighting bias caused by class imbalance because it strengthens recognition of real positives while preserving accurate false positive identification. Moreover, similar performance among the RF, XGBoost, and DNN under FIGS highlights the framework’s generalizability across learning methods. These findings underscore the value of MCC as a stability-aware evaluation metric in imbalanced network intrusion-detection contexts.
FIGS proves to be stable and accurate among all the data imbalance levels and offers better computational efficiency. It not only outperforms the previous methods but also detects the minority attacks clearly, making it a possible solution for real-world IDS where data imbalance is an issue.
7.1. FIGS Complexity
Computational efficiency for FIGS is evaluated to validate its effectiveness compared to conventional data augmentation methods. FIGS achieves optimization of augmentation through its feature-importance selection process, while traditional IDS models analyze the entire feature space. FIGS’ operational complexity across all stages is provided in the following.
7.1.1. Feature-Importance Calculation (Sensitivity Analysis)
Each feature is perturbed and evaluated through the discriminator D.
Since only a subset of features is used, F is a small and constant value, and the complexity in this stage is
7.1.2. FIGAN Complexity
GAN training involves updating the Generator (G) and the Discriminator (D) iteratively.
The number of epochs, batch size, number of selected important features, and number of layers in the discriminator and generator are all finite values and constant, so the final complexity for this step is .
7.1.3. FISMOTE Complexity
The number of nearest neighbors is constant, and is typically much smaller than N. In the worst case, if all minority samples are augmented, can be at most proportional to N. Therefore, the complexity in this stage is .
7.1.4. Final Complexity Expression for FIGS
Summing all dominant terms:
Thus, FIGS has an overall complexity of , indicating that it scales linearly with the dataset size. This confirms FIGS as a computationally efficient framework, as linear time complexity is ideal for handling large-scale IoT datasets. By leveraging feature-aware augmentation strategies, FIGS optimizes data generation while maintaining minimal computational overhead. These efficiency gains make FIGS highly suitable for real-time IoT security applications where computational resources are limited.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}