3.1. Overview Design
We propose ECHO, a kernel fuzzer that incorporates call stack-based crash deduplication to optimize the fuzzing process, enhancing both the quality of the input corpus and the overall code coverage. As depicted in
Figure 2, ECHO operates through a two-stage pipeline: Call Stack Deduplication and Corpus Refinement. These stages are strategically designed to complement each other, ensuring that redundant crashes are minimized, while allowing the fuzzer to focus on novel and deeper kernel code paths.
The first stage, Call Stack Deduplication, aims to reduce noise in the fuzzing process by grouping similar crash reports together based on call stack analysis. This deduplication process ensures that the fuzzer does not waste resources on revisiting already discovered bugs. Instead, it enables ECHO to refine its focus on new crash scenarios, enhancing the overall bug detection efficiency. By accurately distinguishing between distinct kernel faults, ECHO accelerates the identification of unique vulnerabilities, ensuring faster feedback and more productive fuzzing cycles.
In the second stage, Corpus Refinement, ECHO builds upon the deduplication results to continuously improve the seed corpus. Using feedback from previous fuzzing cycles, it refines the inputs by prioritizing those that trigger new code paths or provide unique crash information. This iterative process ensures that the fuzzer continues to explore deeper kernel logic and uncover bugs that might otherwise remain hidden. Together, these two stages form a complete workflow, wherein the fuzzer’s focus shifts from redundant crashes to new, complex vulnerabilities, ultimately increasing both the breadth and depth of kernel code coverage.
To better illustrate the modular structure of ECHO and its integration with existing fuzzing and monitoring infrastructure, we provide a component-level architecture diagram in
Figure 3. This figure complements the high-level workflow in
Figure 2 by detailing how the internal modules of ECHO interact with the underlying kernel fuzzing framework and runtime instrumentation components. As shown in
Figure 3, ECHO builds upon a Syzkaller-based fuzzing engine, where the input generation and execution environment are inherited from Syzkaller’s infrastructure. Test cases are executed in a QEMU-based virtual machine, with KCOV collecting coverage information and KASAN detecting memory violations. These runtime signals, along with crash logs, are passed to the deduplication module of ECHO, which normalizes the stack traces and clusters crash instances based on structural similarity. The resulting clusters, combined with coverage feedback, are used to guide the prioritization of future test inputs. This componentized design enables ECHO to introduce a lightweight and effective deduplication strategy, while remaining compatible with existing kernel fuzzing pipelines.
3.2. Call Stack Deduplication
The first phase of ECHO, Call Stack Deduplication, is designed to enhance the fuzzing process by reducing redundant crash reports, improving the seed corpus quality, and accelerating bug discovery. This phase focuses on generating high-quality system call inputs, executing them in a virtualized kernel environment, parsing resulting crashes, and performing call stack-based deduplication. The process works by distinguishing between unique crashes—which manifest distinct faulting conditions and root causes—and repeated symptoms, which are structurally similar to previously seen traces and likely stem from the same underlying defect, ensuring that the fuzzer focuses on new, unexploited code paths. There are two types of crashes, outlined as follows: (1) unique crashes, which represent new bugs with different causes, and (2) repeated crashes, which look similar to previous ones and usually come from the same bug. By filtering out repeated crashes, the system can better concentrate on discovering truly new problems in the kernel. The Call Stack Deduplication process can be divided into the following three main stages: Input Generation and System Execution, Crash Parsing, and Stack Deduplication.
- (1)
Input Generation and System Execution
In this phase, input syscalls are generated using a customized version of the Syzkaller syscall fuzzer. Our customized version enhances the default functionality by introducing state-aware syscall sequence generation, syscall replay features for debugging, and improved support for concurrent syscall injections via multi-threaded execution. The modified fuzzer also incorporates additional constraints to avoid known kernel hangs and to emphasize code regions uncovered in previous executions. This modified fuzzer creates system call sequences that include basic operations such as file descriptor manipulation, network interactions, memory management, and other typical kernel operations. The goal is to create syntactically valid, diverse, and comprehensive syscall sequences that cover a broad spectrum of kernel behaviors.
These generated inputs are executed in a virtualized kernel environment, leveraging QEMU/KVM [
26] to simulate kernel behavior. During execution, each syscall is monitored using instrumentation tools like KCOV and KASAN, which capture important runtime metadata such as code coverage, memory corruption, and crash occurrences. The KCOV tool is specifically used to gather kernel code coverage data by tracking which code paths are executed during fuzzing, while KASAN is used to detect memory errors such as buffer overflows and use-after-free vulnerabilities.
By analyzing these data, ECHO adjusts its input selection strategy in a feedback-driven manner. Specifically, inputs that trigger novel kernel behaviors, or cover previously unexplored code paths, are prioritized for further mutation. The feedback-driven generation mechanism ensures that the fuzzer evolves based on coverage and crash results, guiding the input mutation towards areas of the kernel that have not been sufficiently explored.
This phase incorporates a weighted mutation scheme, where higher priority is given to inputs that modify syscall parameters likely to trigger kernel vulnerabilities, based on previous crash data or known kernel weaknesses. The weighted mutation scheme uses heuristics such as previous crash patterns and call path analysis to ensure that the generated inputs evolve quickly and target high-value paths. This strategy ensures that the fuzzer efficiently evolves the input corpus, targeting high-value paths and accelerating the discovery of novel kernel bugs.
- (2)
Crash Parsing
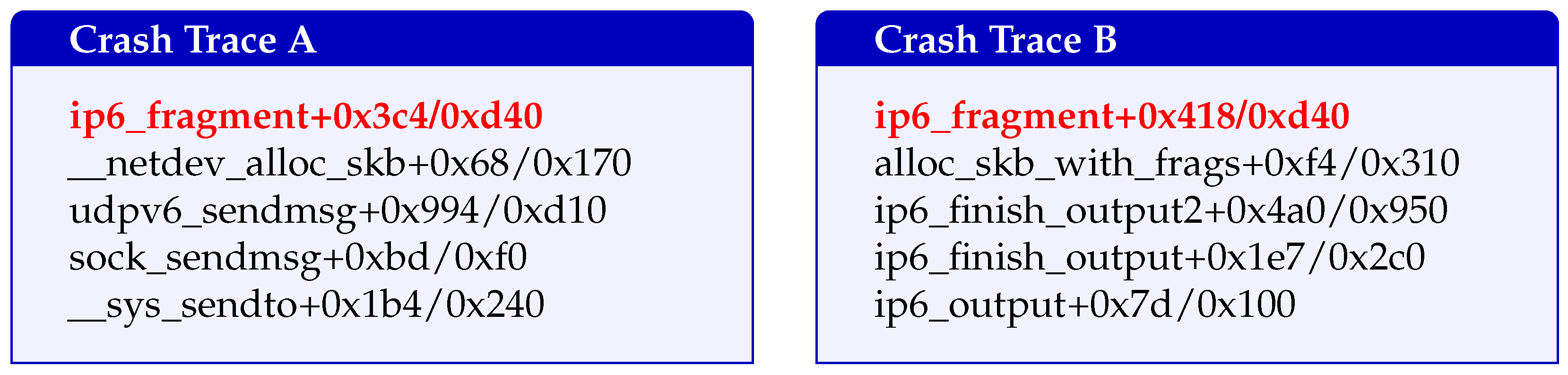
Crash logs are collected whenever a crash occurs during the fuzzing process. These logs typically contain a wealth of information, including the stack trace, faulting address, exception type (e.g., page fault and null dereference), register values, code context, and kernel tainted flags. However, not all parts of the crash log are relevant for effective deduplication. In this step, ECHO focuses on extracting the most pertinent crash information, particularly the stack trace, which is key to identifying whether a crash is new or already encountered.
The first step in crash parsing is the normalization of crash logs. Raw logs are processed to remove irrelevant details like timestamps, specific CPU registers, and minor fluctuations in the execution state, all of which are not crucial for identifying root causes. Once normalized, the crash logs are parsed to extract the stack trace, which contains a sequence of function calls leading to the crash. Stack trace normalization ensures that the comparison between different crash reports is consistent. This process removes irrelevant data such as address spaces or module-specific addresses, focusing instead on the function call sequences that are shared across different kernel versions or module variations. The key functions in the stack are normalized using kernel symbols from the /proc/kallsyms file or debug symbols (when available). This makes it possible to match function names consistently and detect commonalities across different crash logs.
In this process, ECHO also identifies the key variables in the stack trace that are most likely to correlate with crash causes, such as memory corruption, invalid pointer dereferencing, and others. To further ensure accuracy during stack normalization, ECHO incorporates specialized cleaning strategies for non-standard stack frames, including those generated by inline functions and interrupt contexts.
For inline functions, which are often expanded into their callers and thus not represented as separate frames in the raw stack trace, we identify such inlined symbols by cross-referencing kernel DWARF debug information (when available) or leveraging inlining hints extracted from symbol metadata. In the absence of precise debug symbols, heuristics are used based on known inlined function patterns (e.g., ‘kfree’, ‘netif_rx’) and typical stack trace truncation behaviors. Interrupt and exception handling frames (e.g., ‘__irq_svc’, ‘irq_exit_rcu’, ‘do_softirq’, ‘asm_common_interrupt’) introduce transient, non-deterministic entries that do not contribute directly to crash causality. To eliminate their impact, we maintain a noise frame list
and apply a filtering rule:
where
is the original raw stack trace, and
is the filtered version used in downstream comparison. This rule ensures that stack alignment remains robust against scheduling and hardware-induced noise.
Additionally, to avoid bias introduced by deeply nested frames that do not influence fault proximity, we define a weighted positional score for each function frame
as:
where
indicates the position from the top of the stack, and
is the indicator function filtering out noise frames. This score is later used during vector encoding to emphasize fault-proximal frames in deduplication. This refined crash data can now be used for accurate clustering in the subsequent deduplication phase.
- (3)
Stack Deduplication
Following crash parsing, we perform stack-based crash deduplication. Each crash is analyzed based on its kernel stack trace. The goal of this step is to group similar crashes into clusters, each representing a distinct bug, thus avoiding the redundancy caused by crashes triggered by similar kernel paths.
ECHO utilizes a stack trace comparison algorithm that combines Longest Common Subsequence (LCS) and Cosine Similarity. This hybrid approach ensures that both the sequence of function calls and their semantic similarities are taken into account. The traces are considered to have “high similarity” if their LCS score exceeds 0.7 (normalized to stack length) and Cosine Similarity of vectorized function encodings is above 0.8. Conversely, traces are classified as “sufficiently different” if either metric falls below 0.5. This method also incorporates an adaptive threshold, which adjusts the clustering tolerance based on the number of crashes and the size of the corpus.
The stack traces are first normalized and then encoded using a hybrid representation that combines function signatures, stack depth, and positional weighting. Specifically, each stack trace is mapped to a vector of symbolic tokens representing kernel functions, ordered by call depth. Functions appearing in higher positions (closer to the fault) are assigned greater weight, while known noise functions (e.g., schedule(), irq_exit()) are assigned negligible influence. This encoding ensures that the comparison is not affected by minor variations such as different memory addresses or non-essential kernel operations, focusing instead on the core behavior that led to the crash.
3.3. Corpus Refinement
The deduplication algorithm operates by comparing each new crash stack trace against previously stored ones. If a stack trace closely resembles one in the database (based on a pre-set threshold), the crash is added to the existing cluster. If the crash is sufficiently different, it is grouped into a new cluster. The method ensures that each distinct bug is represented by a unique cluster, minimizing false positives and ensuring that new kernel faults are captured efficiently.
Crash logs are grouped based on stack trace similarity as shown in Algorithm 1. Initially, each crash log’s stack trace is extracted and hashed to generate a unique identifier. This identifier is then used to check if a similar crash log already exists in the cluster map. If a match is found, the crash log is added to the corresponding cluster; otherwise, a new cluster is created. This process involves analyzing each crash log independently. The function ExtractStack(c) extracts the stack trace from each crash log, while the HashStack(S) function computes the hash of the stack trace. If the computed hash (h) already exists in the crash cluster map (), the crash log c is added to the existing group. If it does not exist, a new cluster is created for that particular stack trace. The result of this algorithm is a crash cluster map (), which organizes the crash logs into distinct groups based on stack trace similarity. By grouping similar crashes, this approach reduces the redundancy in the fuzzing process and ensures that the fuzzing efforts focus on unique and potentially more insightful crashes, rather than repeatedly testing similar scenarios.
The second stage of ECHO is Corpus Refinement, which focuses on optimizing the fuzzing input corpus based on the feedback and results from the first phase. This stage ensures that fuzzing efforts are directed toward novel kernel paths while eliminating redundant or ineffective seeds, ultimately improving the efficiency of the fuzzing process.
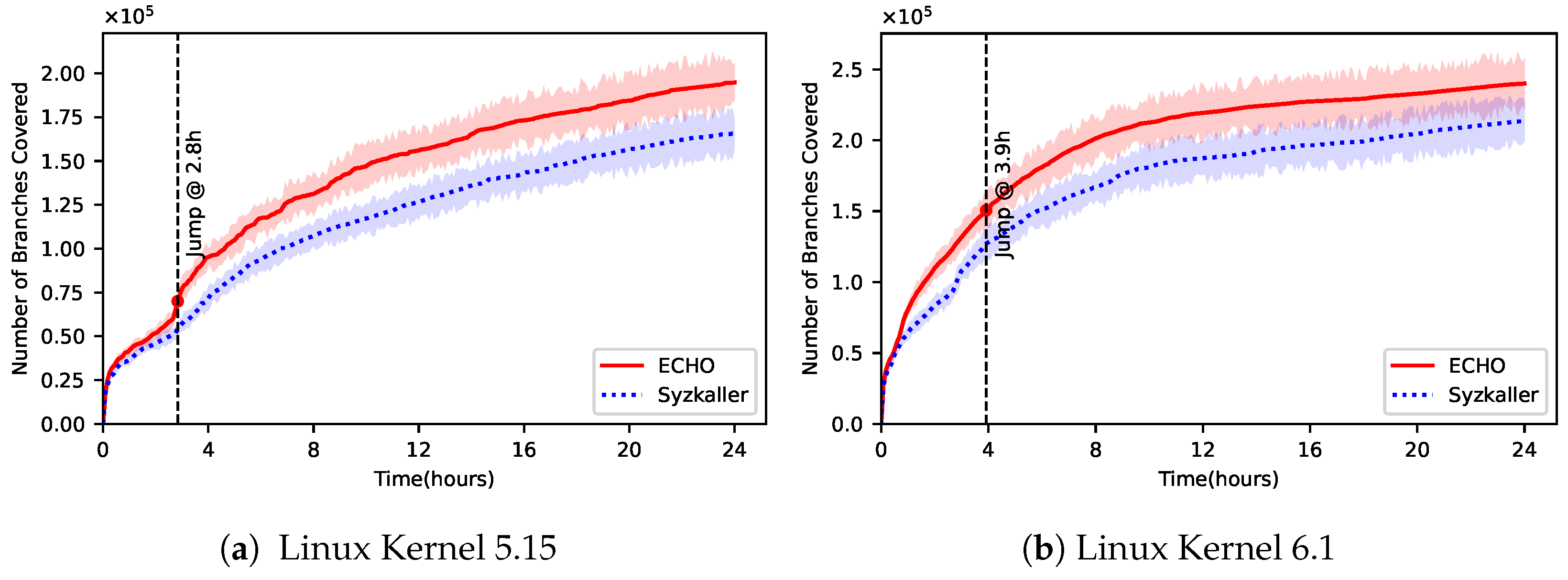
After each fuzzing cycle, the system evaluates the effectiveness of the generated inputs by comparing newly triggered code paths with previously covered ones. To track coverage, ECHO uses KCOV, which provides detailed coverage data in bitmap format, recording executed basic blocks and functions during kernel execution. A key characteristic of this phase is its ability to focus on previously unexplored kernel paths. If a seed triggers new coverage, it is prioritized for further mutation. Conversely, seeds that do not trigger new paths are deprioritized, ensuring that computational resources are spent on areas of the kernel that have not been explored yet.
| Algorithm 1: Adaptive stack clustering algorithm |
![Electronics 14 02914 i001]() |
In addition to coverage, the fuzzing loop incorporates a feedback mechanism that adjusts seed mutation based on previously observed kernel behaviors. Seeds with a higher likelihood of uncovering novel kernel states, as determined by coverage feedback and crash clustering results, are given a higher priority in the mutation queue. This feedback loop helps in maintaining a diverse and effective corpus, ensuring the fuzzer consistently explores deeper and more complex kernel logic.
3.4. Deduplication-Aware Feedback
To improve the quality of generated test inputs, ECHO refines the seed corpus using deduplication-aware feedback. This mechanism identifies and deprioritizes inputs that repeatedly trigger the same crash behavior, enabling the fuzzer to explore new and meaningful execution paths in the kernel.
The deduplication component is based on the call stack grouping results generated during the Call Stack Deduplication phase described in
Section 3.2. These results cluster crash reports that share structurally similar stack traces. A seed is considered novel only if it triggers a crash group that has not previously been seen.
Each seed s is scored using a linear combination of branch coverage improvement and crash group novelty: . Here, is the number of new edges covered, g is the crash group label returned by the deduplication module, is the set of previously encountered groups, and is the indicator function.
The corpus refinement process in ECHO is detailed in Algorithm 2. For each seed , the algorithm collects branch coverage from its execution. It computes , the number of new branches covered compared to the global map . Simultaneously, the deduplication engine assigns a crash group g to the seed based on its stack trace similarity. If g is not in the previously seen crash group set , the crash is considered novel.
The score combines coverage gain and crash novelty using a weighted formula. The tunable parameter controls the balance between coverage and novelty. Higher-scoring seeds are retained for mutation.
This design helps ECHO maintain a focused fuzzing effort: avoiding inputs that repeat known behaviors and favoring those that either discover new code regions or lead to semantically distinct crashes.
| Algorithm 2: Corpus Refinement with coverage and deduplication feedback |
![Electronics 14 02914 i002]() |












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}