1. Introduction
Medical image segmentation, serving as the core technology for computer-aided diagnosis systems, plays a pivotal role in clinical applications, including tumor localization [
1] and skin lesion analysis [
2]. Prior to automated solutions, manual segmentation proved both labor-intensive and clinically unreliable. The past decade has witnessed transformative advances in this domain, driven by escalating demands for surgical navigation and diagnostic assistance systems [
3,
4,
5]. A seminal breakthrough emerged in 2015 with Ronneberger et al.’s U-Net architecture [
6], which surpassed Fully Convolutional Networks (FCNs) [
7] through its encoder–decoder structure with skip connections. This design effectively integrates multi-scale contextual information, establishing U-Net as the paradigm for medical segmentation. Subsequent innovations like U-Net++ [
8], UNext [
9], and 3D U-Net [
10] have refined encoder–decoder configurations to enhance accuracy and robustness. Nevertheless, inherent limitations persist: CNN-based models rely on downsampling to manage computational load, inevitably sacrificing spatial detail. This fundamental trade-off underscores the critical need for richer global context and finer spatial features to support advanced semantic reasoning.
In 2017, Vaswani et al. [
11] introduced the Transformer architecture, which revolutionized natural language processing (NLP) through its capacity for modeling long-range dependencies and global context [
12,
13]. However, its adoption in computer vision remained limited until Dosovitskiy et al. [
14] pioneered the Vision Transformer (ViT), successfully adapting this paradigm to visual tasks. This breakthrough catalyzed a new era in semantic segmentation, with hybrid architectures like TransUNet [
15] and TransFuse [
16] enhancing global feature processing through U-Net integration. Despite these advances, a fundamental limitation persists: the Transformer’s self-attention mechanism incurs quadratic computational complexity relative to image resolution. This scaling behavior severely compromises inference efficiency when processing high-resolution medical images, raising critical research questions about achieving effective long-range dependency modeling without prohibitive computational overhead.
In 2024, Gu et al. [
17] proposed the Mamba model, offering a novel approach to balance modeling capability and computational efficiency in deep learning. Departing from Transformer’s attention mechanism, Mamba achieves input-dependent sequence modeling through structured state space equations (S4), a selective scanning mechanism, and hardware-aware algorithms. This architecture maintains linear computational complexity while enabling effective long-range dependency modeling. Subsequent visual adaptations—Vision Mamba [
18] with its ViM module and VMamba [
19] with the VSS module—successfully translated this framework to computer vision. These innovations position Mamba as a competitive alternative to CNN and Transformer architectures in U-Net optimization efforts.
Current deep learning approaches for skin lesion segmentation fundamentally struggle to reconcile diagnostic precision with clinical adaptability. The canonical UNet framework relies on standard convolutions that inherently blur fine edge textures, producing oversmoothed contours and false-positive artifacts that distort true lesion morphology. Attention-enhanced variants like Attention-UNet compound this limitation by prioritizing global contexts while neglecting micro-lesions and intricate margins, where diagnostic oversight carries direct clinical consequences. Even DeepLabv3+’s atrous convolutions, designed to expand receptive fields, inadvertently dilute locally critical features; this proves particularly detrimental for diagnostically decisive attributes like border microtopography and minute papulation, where feature aggregation attenuates essential information.
Our architectural response strategically counters these failure mechanisms through synergistic integration: The CPME module circumvents computational bottlenecks by fusing state-space modeling with channel prior attention, achieving linear-complexity global context capture impossible for either quadratic-cost Transformers or globally deficient CNNs. Complementarily, the MLSM module fortifies local semantics via multi-scale convolutional branches that hierarchically preserve high-frequency edge signatures and mid-frequency micro-lesion patterns during training, directly addressing pathological feature erosion. Meanwhile, the MAB module’s axially factorized depthwise convolutions maintain orientation-sensitive feature representation while eliminating parameter bloat, thus adapting to morphological complexity beyond conventional operators. This tripartite co-design establishes an emergent capability: clinically viable precision-adaptability alignment previously unattainable in lesion segmentation.
The following are the main contributions of our research:
- (1)
This paper proposes a lightweight model, VML-UNet, and further explores the potential of the lightweight Mamba model for skin lesion applications. It achieves a trade-off between the Mamba model’s efficiency and accuracy, providing a valuable solution for Mamba to become a mainstream lightweight model in the future.
- (2)
This paper proposes a visual state space module based on channel prior convolutional attention. This module integrates channel prior convolutional attention and VSS modules, dynamically allocating attention weights through multi-scale depth-separable convolutional modules and retaining channel priors. This combination can help the network better capture important features and improve its ability to represent features.
- (3)
We designed an MLSM module based on a multi-scale convolutional neural network to compensate for the model’s lack of perception of local feature information. Convolution operations at three different scales and the introduction of an auxiliary loss function enhance the perception of local semantic information. In addition, MLSM is only designed in the training phase, which can reduce the inference burden and thus ensure the model’s operation efficiency.
3. Methods
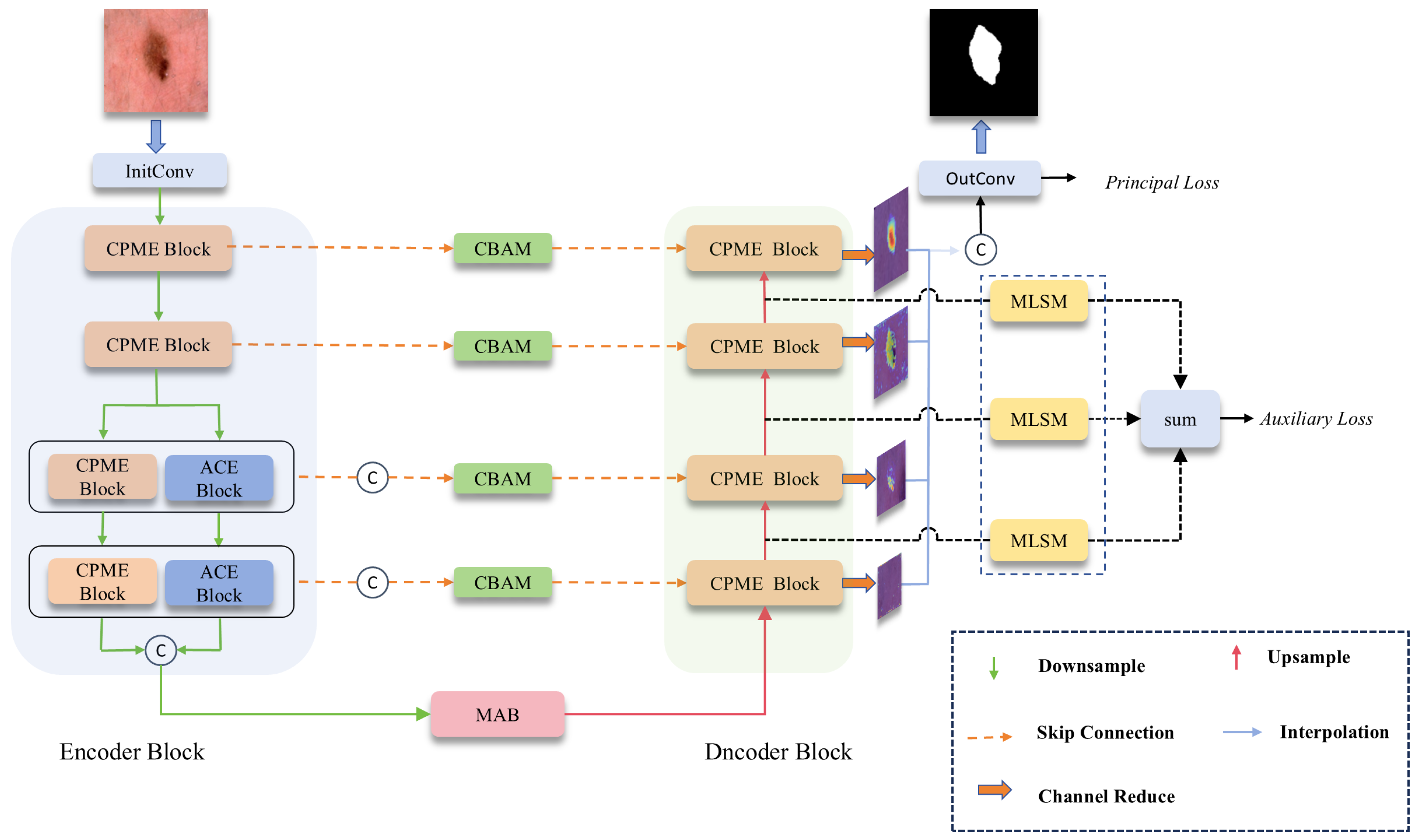
Figure 3 shows the proposed VML-UNet. The model adopts the structure of a U-shape network, which contains four basic substructures: encoder, decoder, bottleneck layer, and skip connection.
The input skin lesion image is initially adjusted to 16 channels after passing through a convolution layer. Subsequently, the generated feature map enters the encoder stage. Specifically, the feature map with a resolution will first pass through two CPMamba Enhancement blocks (CPME). After downsampling through the maximum pooling layer of these two encoding blocks, the spatial resolution of the feature map will be adjusted to and . The following two encoding layers will be divided into two parallel paths, effectively reducing the number of channels of the feature map by half. Then, it is processed by the CPME block of the main path and the axial convolution encoder (ACE block) of the auxiliary path. After the maximum pooling layers of these two CPME blocks and ACE blocks, the size of the feature map is adjusted to , respectively . Finally, the feature maps output by these two parallel paths are spliced on the channels to obtain a size of and are input into the MAB block of the bottleneck structure, which is then combined with the jump connection and passed through the decoding layer. Through the decoding layer of each layer, the number of channels of the output feature map is adjusted to 1 to obtain the reduced-map. Reduce all decoding layers map to perform channel splicing. These outputs are then passed through Final. The Conv layer performs processing to generate a predicted mask for the input image.
3.1. Multi-Scale Lightweight Axial Convolution Bottleneck (MAB)
Traditional convolutional bottlenecks exhibit fundamental limitations in modeling direction-sensitive structures like lesion edges due to their isotropic spatial response characteristics and parameter redundancy. These constraints impose prohibitive computational costs for capturing orientation-critical features. To address this dual challenge, we introduce the Multi-scale Axial Bottleneck (MAB) as shown in
Figure 4a. Its core innovation leverages three parallel axial depthwise separable convolutions (AxialDW) with kernel size n = 3, illustrated in
Figure 4b. This architecture implements strategic axis decomposition along orthogonal planes while incorporating depthwise channel factorization. Through synergistic optimization of directional sensitivity and parameter efficiency, MAB achieves O(N) computational complexity—exponentially superior to conventional approaches—while preserving vital orientation-aware feature representations. The AxialDW operation executes this through heat-diffusion-inspired directional processing:
where
X is the input feature,
Y is the output feature; DW, PW and BN represent depthwise convolution, pointwise convolution and normalization,
and
is the convolution kernel size.
and
represent the number of input and output channels of the feature map.
The multi-scale feature extraction module employs axially dilated depthwise convolutional layers (kernel size = 3) with dilation coefficients d = 1, 2, 3, as detailed in
Figure 4b. This configuration balances two critical design imperatives: First, after quadruple downsampling, feature map spatial dimensions reduce to 1/16th of the original inputs, where larger kernels would cause excessive feature overlap, making 3 × 3 kernels optimal for receptive field expansion while preserving resolution. Second, parallel branches with multi-rate dilation establish exponentially expanding equivalent receptive fields, systematically integrating contextual semantics across spatial granularities. This approach conceptually aligns with Atrous Spatial Pyramid Pooling (ASPP) principles [
37] through channel-concatenated cross-scale feature fusion. To further minimize learnable parameters, a pointwise convolution layer precedes the axial depthwise separable convolution mechanism, reducing channel dimensionality before feature processing.
3.2. CPMamba Enhancement Block (CPME)
Traditional visual state space (VSS) blocks, depicted in
Figure 5a, process inputs through sequential VSS, Layer Normalization (LN), and Multi-layer Perceptron (MLP) operations. This architecture fundamentally struggles with efficient modeling of cross-regional pathological features while exhibiting linear parameter growth relative to depth—severely limiting low-resource deployment.
3.2.1. Parallel Vision Mamba
Our CPME block innovates through the multi-branch architecture shown in
Figure 5b, centered on VSS-CPCA (channel prior convolutional attention) fusion. The first pathway employs 3 × 3 depthwise separable convolution for computationally efficient local feature extraction. Simultaneously, input features undergo channel-wise bisection into dual VSS processing streams, implementing Wu et al.’s parameter-optimized Mamba framework [
38] which preserves global reasoning capabilities at reduced computational cost. These parallel processed features then undergo channel concatenation to restore original dimensionality, followed by Instance Normalization and ReLU activation. This integrated design achieves breakthrough efficiency in complex medical image semantics modeling while maintaining stringent lightweight constraints, formally expressed as follows:
where IN represents the InstanceNorm operation.
represents splitting the output in half from the channel.
3.2.2. Channel Prior Convolutional Attention
In the second branch, the method proposed by CBAM is used to perform channel and spatial attention in sequence. First, a one-dimensional channel weight map is inferred from the input feature map
. Then, the channel attention values
are broadcast
along the spatial dimension by element-by-element multiplication with the input features to obtain refined features with channel attention
F. Subsequently, the spatial attention module (SA) is processed
to generate a spatial attention map
. Finally, the features are output by dynamically weighting the spatial dimensions of the feature map
. The whole process can be summarized as follows:
Average and maximum pooling operations are first used to aggregate spatial information in the feature map. This process generates two independent spatial context descriptors, which are then nonlinearly mapped through a multi-layer perceptron with shared weights. After element-by-element addition, a channel attention map is finally formed. In addition, to reduce the calculation parameters, a single hidden layer is used to form a shared MLP layer. The calculation of channel attention can be summarized as follows:
where
represents the sigmoid operation.
The obtained channel attention map is passed through a multi-scale depth-separable convolution to capture the spatial relationship between features, ensuring the preservation of the relationship between channels while reducing the computational complexity. Subsequently, the obtained output uses a strip convolution optimization structure to enhance the ability of the convolution operation to capture spatial relationships. Finally,
convolution with the same kernel size fuses the channel information. The calculation of spatial attention can be summarized as the following formula:
where DwConv represents depthwise convolution, and
refers to the 0 to
i branches inside the MSC block. Branch 0 preserves the original features to maintain the integrity of high-frequency details.
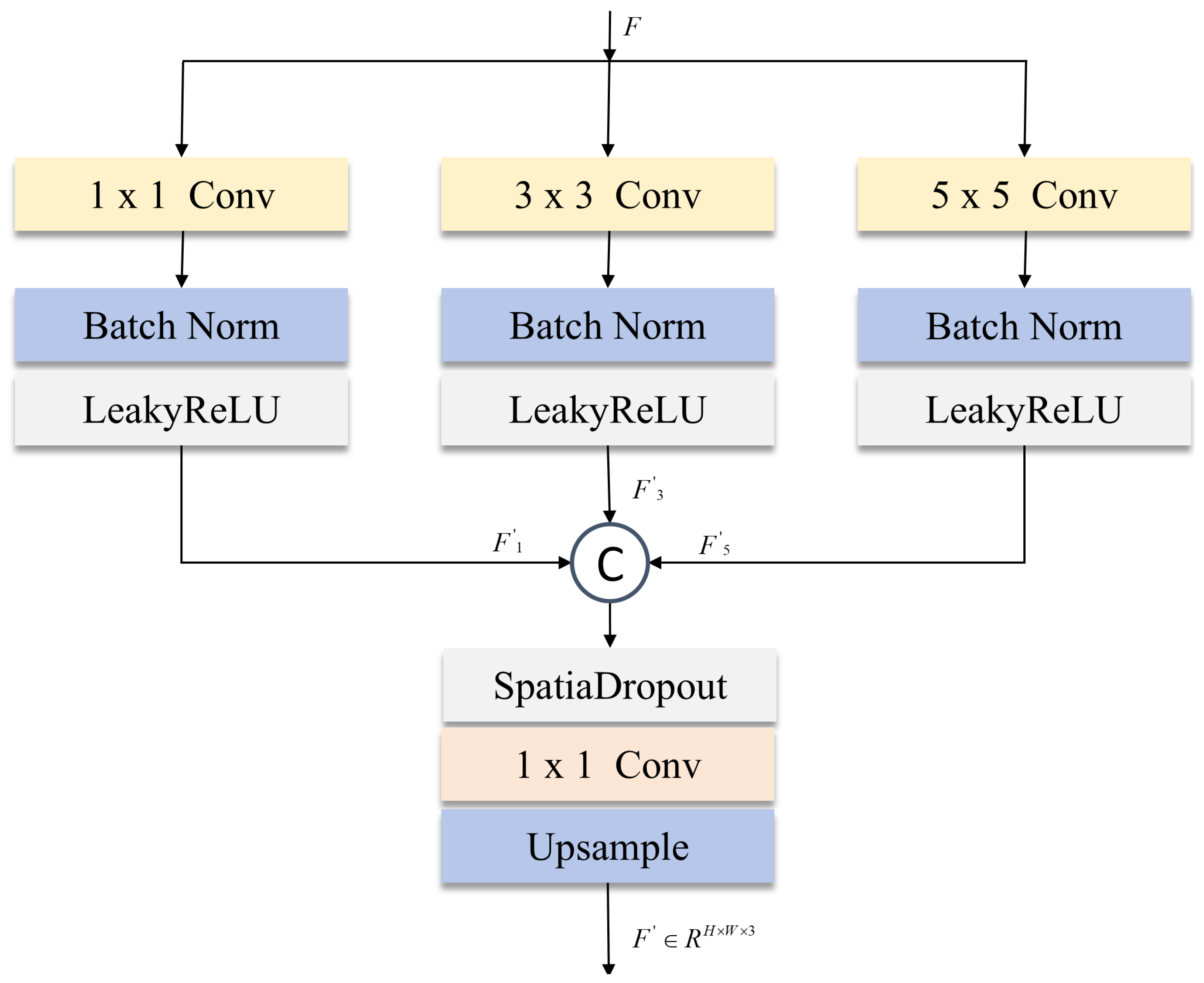
3.3. Multi-Scale Local Supervision Module (MLSM)
While the SS2D module in visual state space (VSS) architectures effectively captures long-range dependencies through receptive field expansion, its global attention mechanism suffers from local semantic dilution in skin lesion segmentation—particularly detrimental at lesion boundaries. Medical imaging’s inherent high-resolution demands precise spatial fidelity, yet deep feature extraction attenuates fine-grained information, compromising edge segmentation accuracy. Addressing this fundamental limitation, our multi-scale local supervision module (MLSM) introduced in
Figure 6 enables collaborative local–global optimization through heterogeneous multi-scale convolutions. This synergistic approach preserves critical boundary details while maintaining the SS2D’s global contextual strengths, resolving the spatial precision-efficiency trade-off endemic to medical image analysis.
We use three parallel convolution branches in MLSM:
convolution layer: extract high-frequency detail features (such as texture features at the edge of the lesion) through point-by-point convolution;
convolution layer: capture mid-frequency structural information and use symmetric padding to maintain the continuity of feature map boundaries;
convolution layer: model low-frequency global features and enhance spatial context perception through a large receptive field.
where BN is batch normalization, LeakyReLU is the activation function, and
represents the decoder’s output features at the corresponding stage.
The multi-scale features output by each branch are concatenated in the channel dimension and then passed through the SpatialDropout and
convolution compression layers. This design is inspired by the channel attention mechanism of SENet [
36] and improves feature robustness through spatial dimension regularization. Finally, the original input resolution is restored through bilinear interpolation upsampling. The MLSM process can be summarized as the following formula:
During model training, a multi-scale local supervision module (MLSM) is embedded in the second to fourth layers of the decoder to enhance the feature representation capabilities at different stages. The outputs of each layer are summed element by element to obtain the segmentation result, and an auxiliary loss function is constructed based on the result for model optimization.
3.4. Loss Function
In order to strengthen the learning of local details, this paper designs two loss functions: the main loss function and the auxiliary loss function. The main loss function solves the class imbalance problem between lesions and backgrounds in medical images
by combining Dice loss and Tversky loss. Among them, Tversky loss adjusts parameters
,
, to adapt to the blurred edges of skin lesions. The auxiliary loss function
is constructed by MLSM, which is introduced at the output of the second to fourth levels of the decoder. Tversky loss is used to constrain the features of each level independently, and the weight coefficient decays exponentially to achieve optimization from coarse-grained to fine-grained. The final total loss function is defined as L:
where
represents the predicted label of the pixel, and
represents the true label of each pixel. The
is set to 0.4.
4. Experiment
4.1. Dataset
The ISIC2017, ISIC2018, and PH2 datasets represent established public benchmarks in skin lesion segmentation, selected for their synergistic alignment with critical research objectives. These datasets collectively address urgent clinical needs through comprehensive coverage of high-mortality malignancies such as melanoma. Precise segmentation of such lesions directly enables early diagnostic interventions, fulfilling our core aim of enhancing clinical efficiency. Methodologically, their complementary design ensures rigorous evaluation: ISIC2017 and ISIC2018 provide substantial scale for robust model training, while PH2’s constrained sample size validates adaptive capability across operational scenarios. Crucially, all datasets incorporate expert-validated lesion annotations that guarantee gold-standard reliability, establishing a foundational basis for model development and comparative analysis.
During preprocessing, all images were standardized to 256 × 256 resolution. This decision balances computational efficiency with diagnostic integrity, specifically preserving critical edge textures essential for accurate segmentation while supporting lightweight architectural goals. Uniform resolution also eliminates input size variability as a potential confounding factor, ensuring experimental fairness in cross-model comparisons.
4.1.1. ISIC2017
This dataset contains 2000 images of skin lesions covering three clinically critical lesion types: melanoma, melanocytic nevus, and seborrheic keratosis. The format is a 24-bit deep RGB three-channel JPG and PNG mixed format, with original resolutions ranging from to . An accurate binary segmentation mask accompanies each image. We randomly selected 1800 images as the training set of the model and 200 images as the test set of the model.
4.1.2. ISIC2018
This dataset contains 2594 skin images covering common skin lesions such as melanoma, nevus, and seborrheic keratosis. The format is a 24-bit RGB three-channel PNG format with a uniform resolution of pixels. All images contain manually annotated binary segmentation masks. Similar to the ISIC2017 dataset, we randomly selected 2334 images as the training set of the model and 260 images as the test set of the model.
4.1.3. PH2
This dataset contains 200 dermoscopic images covering three clinically critical lesion types: benign nevus, atypical nevus, and melanoma. The images are stored in PNG format with 8-bit RGB depth, and the original resolution ranges from to pixels. They are all in 24-bit RGB three-channel PNG format. All images contain manually annotated binary segmentation masks. We randomly selected 170 images as the training set of the model and 30 images as the test set of the model.
4.2. Implementation Setup
This experiment is built on the PyTorch 2.3.0 framework, using the AdamW optimizer and performing end-to-end training on the ISIC2017, ISIC2018, and PH2 datasets. The initial learning rate is set to , and dynamically adjusted the learning rate is based on the Dice coefficient of the training set: if the optimal performance is not achieved for five consecutive training cycles, the learning rate is reduced to half of the current value, and the minimum learning rate threshold is ; the experiment was run on an Ubuntu 20.10 server equipped with an NVIDIA GeForce RTX 4070Ti GPU, the batch size was fixed to 16, the total number of training cycles was 300, and all tasks were completed in a single-card environment to control variables.
4.3. Evaluation Index
We used two main metrics in semantic segmentation to evaluate the model’s performance: Dice Similarity Coefficient (DSC) and Intersection over Union (IOU). These metrics help determine the similarity overlap between the predicted mask and the ground truth label, demonstrating the model’s effectiveness. The calculation formula is as follows:
where TP (True Positive) represents the number of correctly classified lesion pixels, FP (False Positive) represents the number of pixels in normal tissue that are misclassified as lesions, and FN (False Negative) represents the number of pixels that are missed in the lesion area.
5. Results and Discussion
5.1. Comparative Performance Analysis with State-of-the-Art Models
To verify the effectiveness of the VML-UNet model, this work selected seven representative medical segmentation models as baseline comparisons, including classic architectures (U-Net [
6]), attention mechanism variants (Attention U-Net [
39], DCSAU-Net [
40]), lightweight designs (UNext [
9], ULite [
41]), and cutting-edge state-space models (VM-UNet [
31], MambaU-Lite [
32]). All comparison models were reproduced based on the author’s open-source code and trained under a unified experimental configuration to eliminate experimental variable interference. The performance evaluation was performed on the ISIC2017, ISIC2018, and PH
2 datasets.
First, we compare the accuracy of VML-UNet with other classical models on the ISIC2017, ISIC2018, and PH2 datasets. All models are trained under the same conditions to ensure fairness; the results are shown in
Table 1.
For the ISIC2017 and ISIC2018 datasets, which contain diverse skin lesions such as melanoma, nevus, and others with significant variations in size, morphology, and anatomical distribution, VML-UNet achieves an average Dice Similarity Coefficient (DSC) of 0.9075 and Intersection over Union (IoU) of 0.8367. This performance can be attributed to the CPMamba module efficiently capturing the long-range spatial dependencies of complex lesion distributions. In addition, the MLSM module refines the boundaries of heterogeneous lesions, improving the DSC metric by approximately compared to CNN-based models such as UNet, UNext, and Attention UNet.
For the small PH2 dataset, characterized by high labeling accuracy and dense micro-lesions, VML-UNet achieves a DSC score of 0.9564 and an IoU of 0.9053. This high accuracy is attributed to two factors: (1) the fine-grained local supervision of the MLSM module accurately capturing the boundaries of micro-lesions, and (2) the effective suppression of background noise by the CPMamba module, facilitated by the low-noise imaging environment typical of PH2 images. Consequently, VML-UNet outperforms models such as VM-UNet and Attention UNet on this dataset. Its final performance also exceeds that of Mamba-based models like VM-UNet and MambaU-Lite, verifying the model’s robustness in small-data scenarios.
The visualization results in
Figure 7 further demonstrate that, even with common challenges like low-contrast lesion boundaries and complex backgrounds in the datasets, the model’s predicted masks exhibit significantly higher overlap with the ground truth contours. This is likely due to the CPMamba module effectively capturing global lesion features through its channel-space dynamic weight allocation mechanism.
Table 2 shows the efficiency and corresponding segmentation performance of our VML-UNet and several existing models on the ISIC2017 dataset. On the ISIC2017 dataset, VML-UNet achieves the current optimal segmentation accuracy with a Dice coefficient (DSC) of 0.9121 and an intersection over union (IoU) of 0.8452. Its computational complexity is only 1.24 GFLOPS, and the number of parameters is as low as 0.53 M. Although the UNext model exhibits higher computational efficiency as low as 0.57 GFLOPS, its DSC score and IoU are only 0.8775 and 0.8054, which are significantly lower than VML-UNet, indicating that traditional lightweight designs have difficulty in balancing accuracy and efficiency. Our VML-UNet achieves an excellent balance between segmentation accuracy and efficiency.
5.2. Robustness Evaluation of VML-UNet Under Complex Imaging Interference
To rigorously evaluate robustness in clinical deployment, we systematically augmented public skin lesion datasets to design specialised test datasets, generating 200 images for each interference scenario.
Figure 8 visually illustrates the three key real-world interference scenarios we simulated: For sensor noise simulation, we added
salt-and-pepper noise to ISIC2017 images to replicate CMOS sensor degradation during clinical imaging, with panel (a) clearly showing the contrast between the original image and the noisy version; For hair occlusion scenarios, we used naturally obscured lesion images professionally curated from the ISIC2017 and ISIC2018 datasets, where panel (b) displays the difference between images without occlusion and those with hair interference on either side; Low-light conditions were achieved by calibrated luminance reduction of ISIC2017 samples to mimic suboptimal dermoscopic illumination, an effect observable in the comparison between normal and low-light environment images in panel (c). Additionally, for high-resolution assessment, we preserved the native resolution of ISIC2017 images to fully retain diagnostic-grade details, facilitating evaluation of computational scaling performance. This comprehensive validation framework, closely aligned with the scenarios presented in
Figure 8, establishes an ecologically valid stress-testing system that covers various critical failure modes commonly encountered in real-world dermatological clinical practice.
VML-UNet achieves robust multi-scene adaptation with merely 0.53 M parameters and a 2.18 MB memory footprint. This extreme lightweight design demonstrates remarkable operational stability, evidenced in
Table 3 by two key observations: Under high-resolution inputs where pixel proliferation extends inference to 210 ms, the model maintains peak segmentation accuracy (DSC = 0.9260, IoU = 0.8630) through meticulous detail preservation. Meanwhile, in clinically challenging scenarios involving noise, low-light, or hair occlusion, inference efficiency stabilizes at 38–47 ms while exhibiting minimal performance variance, with maximum IoU deviation limited to
across all test conditions. Such deterministic behavior under environmental stressors confirms the architecture’s resilience for deployment in diverse clinical environments.
5.3. Ablation Studies
5.3.1. Effects of the Proposed Modules
To verify the effectiveness of the CPME, MAB, and MLSM modules in VML-UNet, this work conducts ablation experiments based on the Mamba-ULite architecture on the ISIC2017 dataset, as shown in
Table 4.
Figure 9 demonstrates VML-UNet’s module-specific optimization effects. Replacing encoder Mamba blocks with the CPME module reduces parameters from 0.42 M to 0.33 M while increasing DSC to 0.9078 and IoU to 0.8386. This improvement confirms CPME’s efficacy in decoding complex lesion semantics through fused channel prior attention and Mamba optimization. Substituting the bottleneck’s standard block with the MAB decreases FLOPs from 1.25 G to 0.93 G with only
DSC reduction, validating its axial decomposition strategy for lightweight efficiency. Concurrently, incorporating the MLSM elevates DSC and IoU by
and
respectively, despite increasing parameters to 0.62 M. This module enhances small lesion segmentation robustness through multi-level semantic supervision, strengthening local–global feature associations without inference overhead. Supporting visual evidence is provided in
Figure 10. Collectively, CPME and MAB achieve accuracy-efficiency co-optimization via global–local feature fusion and axial convolution decomposition, while MLSM provides zero-cost feature discrimination enhancement. This synergistic approach enables dual improvement in segmentation accuracy and computational efficiency.
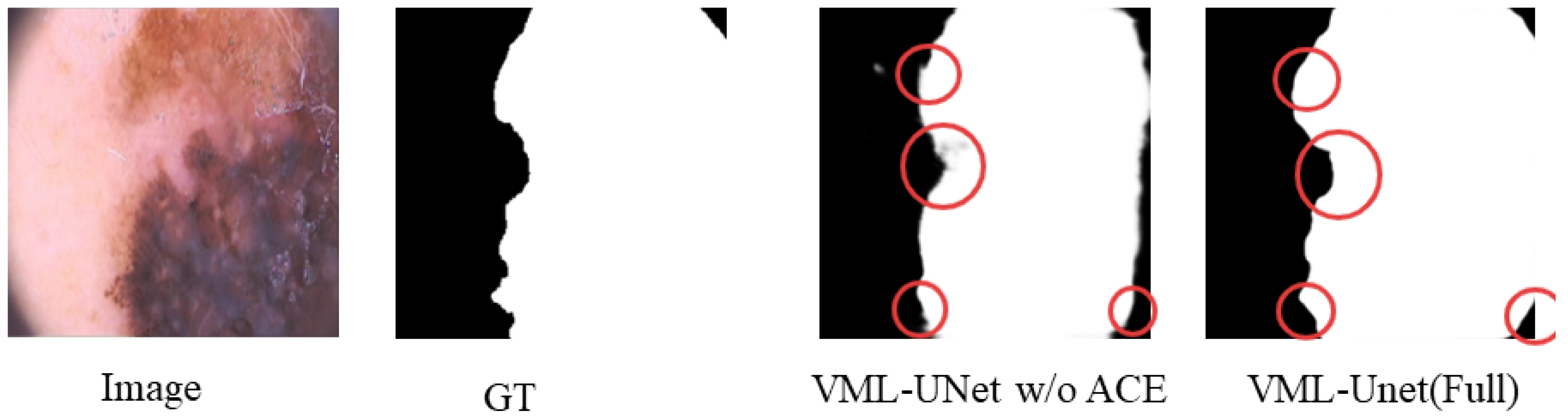
5.3.2. Effect of the Dual-Branch Structure
To validate the efficacy of the multi-path design, this study compares the performance of VML-UNet (Full), incorporating the ACE module, against its variant without this component (VML-UNet w/o ACE). Results, as shown in
Table 5, demonstrate that VML-UNet (Full) exhibits higher computational requirements with 1.24 G FLOPs, 0.53 M parameters, and 2.18 MB memory occupancy compared to VML-UNet w/o ACE. This increase stems from the additional computational steps and parameters introduced by the ACE module. Crucially, VML-UNet (Full) achieves significantly superior segmentation accuracy, attaining a DSC of 0.9078 and an IoU of 0.8386. These quantitative improvements are visually corroborated in
Figure 11, which presents a visualisation of segmentation results for VML-UNet with and without the ACE module. In the regions highlighted by circular annotations, the segmentation output of VML-UNet with the ACE module closely aligns with the ground truth, featuring stronger boundary continuity and more complete capture of fine-grained structures. These metrics and visual evidence collectively confirm that the multi-path architecture enhances skin lesion segmentation through the ACE module’s improved feature capture capability, while also establishing an optimal balance between efficiency and performance, particularly well-suited for high-precision segmentation tasks.
5.4. Discussion
The experimental results and visualization analysis of VML-UNet on three skin lesion datasets verified an effective balance between lightweight design and high accuracy. This balance can be analyzed in two aspects: model performance and core module contributions.
Regarding overall model performance, VML-UNet has only 0.53 M parameters, 2.18 MB memory occupation, and 1.24 GFLOPs computational complexity. This is significantly lower than the 44.3 M parameters of VM-UNet and the 65.52 G FLOPs of U-Net. Meanwhile, the DSC and IoU scores of VML-UNet are better than those of lightweight models, such as U-Lite and MambaU-Lite, across all three datasets. Especially on PH2, the model achieves a DSC score of 0.9564, attributed to its accurate capture of tiny lesions, verifying the synergy between lightweight design and segmentation accuracy.
Compared with existing studies, the key innovations of VML-UNet are as follows: (1) It breaks through the local feature modeling limitations of traditional CNNs by utilizing the VSS block to achieve global dependency capture with linear computational complexity. (2) It employs the “training-specific” MLSM module to enhance local detail accuracy without increasing inference burden. (3) It incorporates the axial decomposition strategy of the MAB module to preserve orientation-sensitive features within the lightweight framework. This contrasts with models relying solely on single mechanisms, such as the MLP block in UNext or the pure SSM structure in VM-UNet.
VML-UNet’s particular success on PH2 can be explained by several factors: The dataset consists of 200 images characterized by high labeling accuracy, dense lesions, and low imaging interference, aligning well with VML-UNet’s design strengths. The MLSM module accurately captures details of dense, small lesions, while the attention mechanism of the CPMamba module effectively suppresses noise in PH2’s low-interference environment. The synergy between these modules enables superior performance on this dataset.
A significant limitation stems from dataset composition bias. The experimental datasets contain a disproportionately high percentage of light-skinned samples, leading to more robust feature learning for high-contrast lesions against light backgrounds. Conversely, the model’s capability to segment low-contrast lesions on dark or medium-skinned skin remains inadequately validated due to insufficient representation. This distributional bias risks reducing segmentation accuracy for dark-skinned lesions in clinical practice—a concern particularly amplified in small datasets like PH2. Compounding this issue, the textural complexity of darker skin may further interfere with lesion edge identification, while the scarcity of such samples fundamentally compromises model generalizability. Additionally, the PH2 dataset introduces specific constraints: its small sample size and limited coverage of rare lesions restrict rigorous validation of the model’s generalizability to these clinically important cases. Consequently, constructing large-scale datasets encompassing diverse skin tones and richer representations of rare lesions is imperative to rigorously assess clinical applicability and address these compounded limitations.
6. Limitation and Future Work
6.1. Limitation
Although VML-UNet demonstrates excellent accuracy and lightweight characteristics in skin lesion segmentation, it still exhibits the following limitations.
While VML-UNet’s FLOPs are significantly lower than U-Net and VM-UNet, its computational complexity remains higher than UNext. Further compression is needed to approach the efficiency required for ultra-lightweight deployment scenarios. Although the three experimental datasets (ISIC2017, ISIC2018, PH2) are representative, their coverage is limited. The PH2 dataset contains only 200 samples, and rare skin lesions are underrepresented across all datasets, restricting the model’s generalization in clinically complex scenarios. The datasets are predominantly composed of light-skinned samples, with insufficient representation of dark- and medium-skinned individuals. Consequently, the model’s performance in low-contrast scenarios (e.g., identifying pigmented lesions against dark skin backgrounds) is not fully validated, potentially limiting its clinical generalizability across diverse patient populations. Validation was confined to dermoscopic image datasets. The model’s adaptability to other imaging modalities or images acquired by different devices remains unevaluated, leaving its cross-modality and cross-device performance uncertain. The model’s performance was not stratified or validated based on lesion size during training or evaluation. Small lesions risk feature loss during downsampling, while large, irregularly shaped lesions may suffer from incomplete edge segmentation. VML-UNet’s robustness across varying lesion sizes requires dedicated assessment.
6.2. Future Work
To address these limitations, future work will focus on the following directions: Explore lightweight variants of the CPMamba module to further reduce FLOPs while maintaining accuracy, aiming to match or surpass the computational efficiency of UNext. Construct larger, more diverse, and hierarchically structured datasets. Prioritize validation across different skin tones and include a broader spectrum of rare lesions to improve clinical applicability and generalization. Incorporate domain adaptation techniques, such as adversarial training, to enhance the model’s generalization capability on cross-modal data. Collaborate with clinical institutions to evaluate real-time performance and diagnostic efficacy within actual clinical workflows, facilitating the transition from laboratory research to clinical application. Investigate the synergistic mechanisms between the CPMamba, MAB, and MLSM modules. Focus on reducing redundant computations through dynamic attention weight allocation. Explore lightweight fusion strategies with diffusion models to improve segmentation accuracy for lesions with fuzzy boundaries.
7. Conclusions
In this study, we proposed a lightweight network VML-UNet model for skin lesion segmentation to minimize the number of parameters, computational cost, and memory usage. We proposed the CPMamba block, which combines the advantages of Mamba and channel-spatial attention to effectively capture high-level and fine-grained features. To improve the local information learning ability of the model, we proposed a multi-scale local information supervision module MLSM that is only trained and introduced the MAB module with axial depthwise separable convolution as the core to ensure that the computational complexity is reduced while retaining the direction-sensitive features. Experiments on three skin lesion datasets verified the effectiveness of the proposed algorithm. The performance of our network is better than that of other methods, with IoUs reaching , , and , respectively.
While our model shows promising results on the skin lesion dataset, there is still a long way to go to make the Mamba model lightweight and efficient, and future work will aim to optimize the model efficiency further.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}