
Enhancing Suburban Lane Detection Through Improved DeepLabV3+ Semantic Segmentation


Abstract
1. Introduction
- Similarity of background features: dynamic background elements such as building exterior walls with highly similar colors to the road surface, mountains or rock structures with similar texture features to the distance, and farmland crops with similar features to the road surface create significant semantic confusion with the road area in visual features, seriously distracting the model from the allocation of attention to the target lane.
- Blurring of geometric features: The degradation of fuzzy road boundaries, complex textured pavements, and lanes with various shapes makes it difficult for the feature extraction network to establish effective spatial context associations, resulting in a significant reduction in the reliability of the model’s environmental perception ability.
- An improved DeepLabV3+ lane-detection model is proposed. In the encoder, the traditional ASPP module is replaced with an innovative LC-DenseASPP module, and the DySample module is introduced in the decoder. Experimental results demonstrate that the proposed model exhibits excellent performance in both detection accuracy and real-time capability.
- Owing to the lack of publicly available datasets for suburban roads, we collected images of road scenes from suburban and rural areas in Liuzhou, Guangxi, and created a suburban road lane segmentation dataset named SubLane. These scenes were captured under clear weather conditions and primarily included roads with similar background features and roads with blurry geometric characteristics.
2. Related Work
2.1. Keypoint-Based Methods
2.2. Polynomial Regression-Based Methods
2.3. Detection-Based Methods
2.4. Segmentation-Based Methods
3. Dataset and Evaluation Criteria
3.1. SubLane Dataset
3.2. Evaluation Criteria
4. Design of Segmentation Module
4.1. Improved DeepLabV3+ Network Structure
4.2. Selection of Backbone Network MobileNetV2
4.3. LC-DenseASPP Network Structure
4.3.1. Dilated Convolution
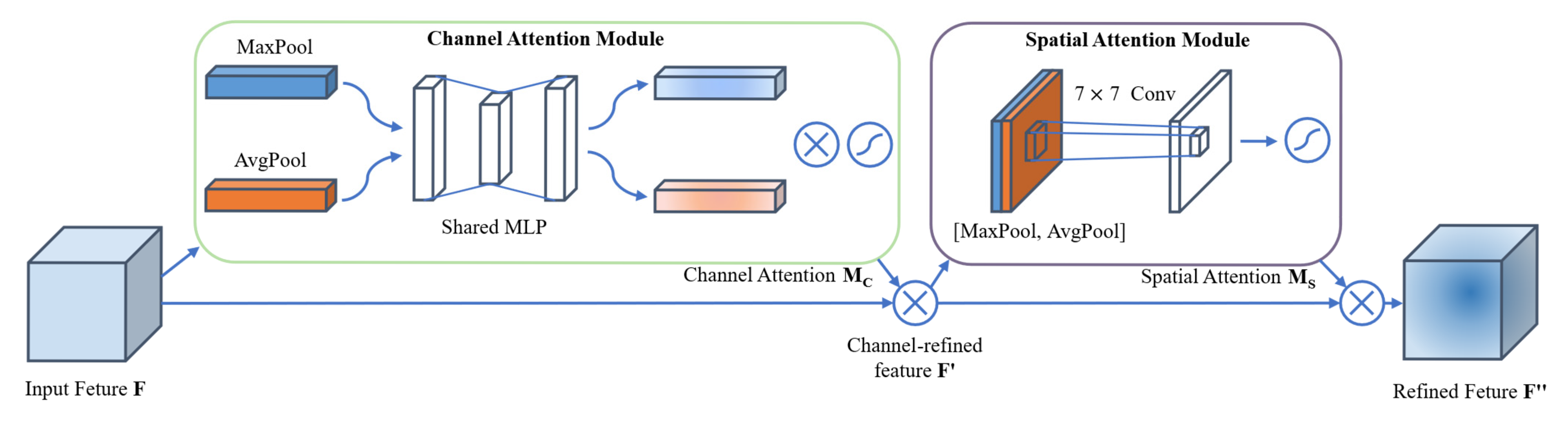
4.3.2. CBAM Module
4.3.3. LC-DenseASPP Module
4.4. DySample Network Structure
5. Experiment
5.1. Experiment Setup
5.2. Training and Results
5.3. Experiment and Analysis
- Real-time performance advantage: Our model achieves an inference speed of 128 FPS, which is more than twice that of SegFormer (59 FPS). This significant speedup is critical for practical autonomous driving applications, where real-time responsiveness (typically requiring ≥30 FPS) directly impacts vehicle safety and decision-making latency.
- Parameter efficiency: While SegFormer has 13.678 M parameters and our model has 10.416 M parameters, the key advantage lies in the balance between accuracy and computational complexity. For embedded systems in vehicles with limited hardware resources, our model’s lower parameter count and higher speed make it more deployable without significantly compromising accuracy (a difference of only 0.1% in mIoU).
- Scenario adaptability: SegFormer, as a transformer-based model, excels in general semantic segmentation but may not be specifically optimized for lane detection in suburban scenes. Our model’s improvements (LC-DenseASPP, CBAM, and DySample) are tailored to address suburban road challenges (e.g., blurred boundaries, dynamic backgrounds), which is reflected in its robust performance on lane-specific segmentation.
5.4. Study Limitations
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Waykole, S.; Shiwakoti, N.; Stasinopoulos, P. Review on Lane Detection and Tracking Algorithms of Advanced Driver Assistance System. Sustainability 2021, 13, 11417. [Google Scholar] [CrossRef]
- Mims, L.K.; Gangadharaiah, R.; Brooks, J.; Su, H.; Jia, Y.; Jacobs, J.; Mensch, S. What Makes Passengers Uncomfortable in Vehicles Today? An Exploratory Study of Current Factors that May Influence Acceptance of Future Autonomous Vehicles. In Proceedings of the WCX SAE World Congress Experience, Detroit, MI, USA, 18–20 April 2023. [Google Scholar]
- Chen, W.; Wang, W.; Wang, K.; Li, Z.; Li, H.; Liu, S. Lane departure warning systems and lane line detection methods based on image processing and semantic segmentation: A review. J. Traffic Transp. Eng. Engl. Ed. 2020, 7, 748–774. [Google Scholar] [CrossRef]
- Yao, S.; Guan, R.; Huang, X.; Li, Z.; Sha, X.; Yue, Y.; Lim, E.G.; Seo, H.; Man, K.L.; Zhu, X.; et al. Radar-Camera Fusion for Object Detection and Semantic Segmentation in Autonomous Driving: A Comprehensive Review. IEEE Trans. Intell. Veh. 2024, 9, 2094–2128. [Google Scholar] [CrossRef]
- Pavel, M.I.; Tan, S.Y.; Abdullah, A. Vision-Based Autonomous Vehicle Systems Based on Deep Learning: A Systematic Literature Review. Appl. Sci. 2022, 12, 6831. [Google Scholar] [CrossRef]
- Tang, J.; Li, S.; Liu, P. A review of lane detection methods based on deep learning. Pattern Recognit. 2021, 111, 107623. [Google Scholar] [CrossRef]
- Rasib, M.; Butt, M.A.; Riaz, F.; Sulaiman, A.; Akram, M. Pixel Level Segmentation Based Drivable Road Region Detection and Steering Angle Estimation Method for Autonomous Driving on Unstructured Roads. IEEE Access 2021, 9, 167855–167867. [Google Scholar] [CrossRef]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef]
- Dong, S.; Wang, P.; Abbas, K. A survey on deep learning and its applications. Comput. Sci. Rev. 2021, 40, 100379. [Google Scholar] [CrossRef]
- Zou, Q.; Jiang, H.; Dai, Q.; Yue, Y.; Chen, L.; Wang, Q. Robust Lane Detection from Continuous Driving Scenes Using Deep Neural Networks. IEEE Trans. Veh. Technol. 2020, 69, 41–54. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2018), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 6105–6114. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2018), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Cheng, Z.; Bai, F.; Xu, Y.; Zheng, G.; Pu, S.; Zhou, S. Focusing Attention: Towards Accurate Text Recognition in Natural Images. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Guo, M.-H.; Liu, Z.-N.; Mu, T.-J.; Hu, S.-M. Beyond Self-Attention: External Attention Using Two Linear Layers for Visual Tasks. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 5436–5447. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- An, S.; Liao, Q.; Lu, Z.; Xue, J.-H. Efficient Semantic Segmentation via Self-Attention and Self-Distillation. IEEE Trans. Intell. Transp. Syst. 2022, 23, 15256–15266. [Google Scholar] [CrossRef]
- Hu, K.; Xu, K.; Xia, Q.; Li, M.; Song, Z.; Song, L.; Sun, N. An overview: Attention mechanisms in multi-agent reinforcement learning. Neurocomputing 2024, 598, 128015. [Google Scholar] [CrossRef]
- Guo, M.-H.; Xu, T.-X.; Liu, J.-J.; Liu, Z.-N.; Jiang, P.-T.; Mu, T.-J.; Zhang, S.-H.; Martin, R.R.; Cheng, M.-M.; Hu, S.-M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Brauwers, G.; Frasincar, F. A General Survey on Attention Mechanisms in Deep Learning. IEEE Trans. Knowl. Data Eng. 2023, 35, 3279–3298. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. In Advances in Neural Information Processing Systems, Proceedings of the NeurIPS 2024, Vancouver, BC, Canada, 10–15 December 2024; Curran Associates Inc.: Nice, France, 2021; pp. 12077–12090. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3523–3542. [Google Scholar] [CrossRef] [PubMed]
- Guo, Y.; Liu, Y.; Georgiou, T.; Lew, M.S. A review of semantic segmentation using deep neural networks. Int. J. Multimed. Inf. Retr. 2018, 7, 87–93. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar] [CrossRef]
- Liu, W.; Lu, H.; Fu, H.; Cao, Z. Learning to Upsample by Learning to Sample. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023. [Google Scholar]
- Ko, Y.; Lee, Y.; Azam, S.; Munir, F.; Jeon, M.; Pedrycz, W. Key Points Estimation and Point Instance Segmentation Approach for Lane Detection. IEEE Trans. Intell. Transp. Syst. 2022, 23, 8949–8958. [Google Scholar] [CrossRef]
- Zhou, J.; Cui, G.; Hu, S.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. AI Open 2020, 1, 57–81. [Google Scholar] [CrossRef]
- Tabelini, L.; Berriel, R.; Paixao, T.M.; Badue, C.; De Souza, A.F.; Oliveira-Santos, T. Keep Your Eyes on the Lane: Real-Time Attention-Guided Lane Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Qin, Z.; Wang, H.; Li, X. Ultra Fast Structure-Aware Deep Lane Detection. In Computer Vision—ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 276–291. [Google Scholar]
- Tabelini, L.; Berriel, R.; Paixão, T.M.; Badue, C.; De Souza, A.F.; Oliveira-Santos, T. PolyLaneNet: Lane Estimation via Deep Polynomial Regression. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 6150–6156. [Google Scholar]
- Li, Q.; Yu, X.; Chen, J.; He, B.-G.; Wang, W.; Rawat, D.B.; Lyu, Z. PGA-Net: Polynomial Global Attention Network with Mean Curvature Loss for Lane Detection. IEEE Trans. Intell. Transp. Syst. 2024, 25, 417–429. [Google Scholar] [CrossRef]
- Yang, C.; Tian, Z.; You, X.; Jia, K.; Liu, T.; Pan, Z.; John, V. Polylanenet++: Enhancing the polynomial regression lane detection based on spatio-temporal fusion. Signal Image Video Process. 2024, 18, 3021–3030. [Google Scholar] [CrossRef]
- Wang, B.; Wang, Z.; Zhang, Y. Polynomial Regression Network for Variable-Number Lane Detection. In Computer Vision—ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 719–734. [Google Scholar]
- Li, X.; Li, J.; Hu, X.; Yang, J. Line-CNN: End-to-End Traffic Line Detection with Line Proposal Unit. IEEE Trans. Intell. Transp. Syst. 2020, 21, 248–258. [Google Scholar] [CrossRef]
- Liu, L.; Chen, X.; Zhu, S.; Tan, P. CondLaneNet: A Top-To-Down Lane Detection Framework Based on Conditional Convolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Dong, L.; Zhang, H.; Ma, J.; Xu, X.; Yang, Y.; Wu, Q.M.J. CLRNet: A Cross Locality Relation Network for Crowd Counting in Videos. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 6408–6422. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Ren, W.; Qiu, Q. LaneNet: Real-Time Lane Detection Networks for Autonomous Driving. arXiv 2018, arXiv:1807.01726. [Google Scholar] [CrossRef]
- Pan, X.; Shi, J.; Luo, P.; Wang, X.; Tang, X. Spatial as Deep: Spatial CNN for Traffic Scene Understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar] [CrossRef]
- Van Gansbeke, W.; De Brabandere, B.; Neven, D.; Proesmans, M.; Van Gool, L. End-to-end Lane Detection through Differentiable Least-Squares Fitting. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Chang, D.; Chirakkal, V.; Goswami, S.; Hasan, M.; Jung, T.; Kang, J.; Kee, S.-C.; Lee, D.; Singh, A.P. Multi-lane Detection Using Instance Segmentation and Attentive Voting. In Proceedings of the 2019 19th International Conference on Control, Automation and Systems (ICCAS), Jeju, Republic of Korea, 15–18 October 2019; pp. 1538–1542. [Google Scholar]
- Li, J. Lane Detection with Deep Learning: Methods and Datasets. Inf. Technol. Control 2023, 52, 297–308. [Google Scholar] [CrossRef]
- Everingham, M.; Eslami, S.M.A.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Yang, M.; Yu, K.; Zhang, C.; Li, Z.; Yang, K. DenseASPP for Semantic Segmentation in Street Scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Input | Operator | s | r | n | Output |
|---|---|---|---|---|---|---|
| Convolution | 320 × 320 × 3 | Conv2D 3 × 3 | 2 | - | 1 | 320 × 320 × 16 |
| Bottleneck 1 | 320 × 320 × 16 | Inverted Residual Block | 1 | Yes | 2 | 160 × 160 × 24 |
| Bottleneck 2 | 160 × 160 × 24 | 2 | No | 3 | 80 × 80 × 32 | |
| Bottleneck 3 | 80 × 80 × 32 | 1 | Yes | 4 | 40 × 40 × 64 | |
| Bottleneck 4 | 40 × 40 × 64 | 1 | Yes | 3 | 40 × 40 × 96 | |
| Bottleneck 5 | 40 × 40 × 96 | 2 | No | 3 | 20 × 20 × 160 | |
| Bottleneck 6 | 20 × 20 × 160 | 1 | Yes | 1 | 20 × 20 × 320 | |
| Convolution | 10 × 10 × 1024 | Conv2D 1 × 1 | 1 | - | 1 | 10 × 10 × 1280 |
| Keys | Values |
|---|---|
| Input shape | 320 × 320 |
| Initial epoch | 0 |
| Freeze epoch | 50 |
| Unfreeze epoch | 100 |
| Initial learning rate | 7 × 10−3 |
| Minimum learning rate | 7 × 10−5 |
| Optimizer type | SGD |
| Momentum | 0.9 |
| Weight decay | 1 × 10−4 |
| Learning rate decay strategy | cos |
| Method | IoU/% | mIoU/% | FPS/s | Params/M | |
|---|---|---|---|---|---|
| Background | Road | ||||
| Baseline | 95.24 | 94.96 | 95.10 | 158 | 11.782 |
| +DenseASPP | 95.52 | 95.31 | 95.41 | 157 | 10.332 |
| +DenseASPP&CBAM | 95.52 | 95.35 | 95.44 | 123 | 10.330 |
| +DenseASPP&CBAM&DySample | 95.56 | 95.39 | 95.48 | 128 | 10.416 |
| Method | Backbone | Classes | Recall/% | Precision/% | F1/% | mPA/% | Accuracy/% | Params/M | FPS |
|---|---|---|---|---|---|---|---|---|---|
| U-Net | VGG | Background | 97.81 | 96.26 | 96.90 | 96.88 | 96.91 | 24.891 | 37 |
| Road | 95.96 | 97.63 | |||||||
| PSP-Net | ResNet50 | Background | 97.45 | 95.68 | 96.41 | 96.38 | 96.42 | 46.739 | 50 |
| Road | 95.31 | 97.23 | |||||||
| HR-Net | HRNet-W18 | Background | 97.32 | 96.87 | 96.98 | 96.99 | 97.00 | 29.538 | 11 |
| Road | 96.65 | 97.13 | |||||||
| SegFormer | EfficientNet-B0 | Background | 97.74 | 98.02 | 97.81 | 97.82 | 97.82 | 13.678 | 59 |
| Road | 97.90 | 97.60 | |||||||
| DeepLabV3+ | MobileNetV2 | Background | 97.04 | 97.24 | 97.05 | 97.05 | 97.05 | 5.813 | 62 |
| Road | 97.06 | 96.86 | |||||||
| Ours | MobileNetV2 | Background | 96.62 | 98.87 | 97.70 | 97.72 | 97.69 | 10.416 | 128 |
| Road | 98.83 | 96.48 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, S.; Yang, B.; Wang, Z.; Zhang, Y.; Li, H.; Gao, H.; Xu, H. Enhancing Suburban Lane Detection Through Improved DeepLabV3+ Semantic Segmentation. Electronics 2025, 14, 2865. https://doi.org/10.3390/electronics14142865
Cui S, Yang B, Wang Z, Zhang Y, Li H, Gao H, Xu H. Enhancing Suburban Lane Detection Through Improved DeepLabV3+ Semantic Segmentation. Electronics. 2025; 14(14):2865. https://doi.org/10.3390/electronics14142865
Chicago/Turabian StyleCui, Shuwan, Bo Yang, Zhifu Wang, Yi Zhang, Hao Li, Hui Gao, and Haijun Xu. 2025. "Enhancing Suburban Lane Detection Through Improved DeepLabV3+ Semantic Segmentation" Electronics 14, no. 14: 2865. https://doi.org/10.3390/electronics14142865
APA StyleCui, S., Yang, B., Wang, Z., Zhang, Y., Li, H., Gao, H., & Xu, H. (2025). Enhancing Suburban Lane Detection Through Improved DeepLabV3+ Semantic Segmentation. Electronics, 14(14), 2865. https://doi.org/10.3390/electronics14142865