
Sketch Synthesis with Flowpath and VTF



Abstract
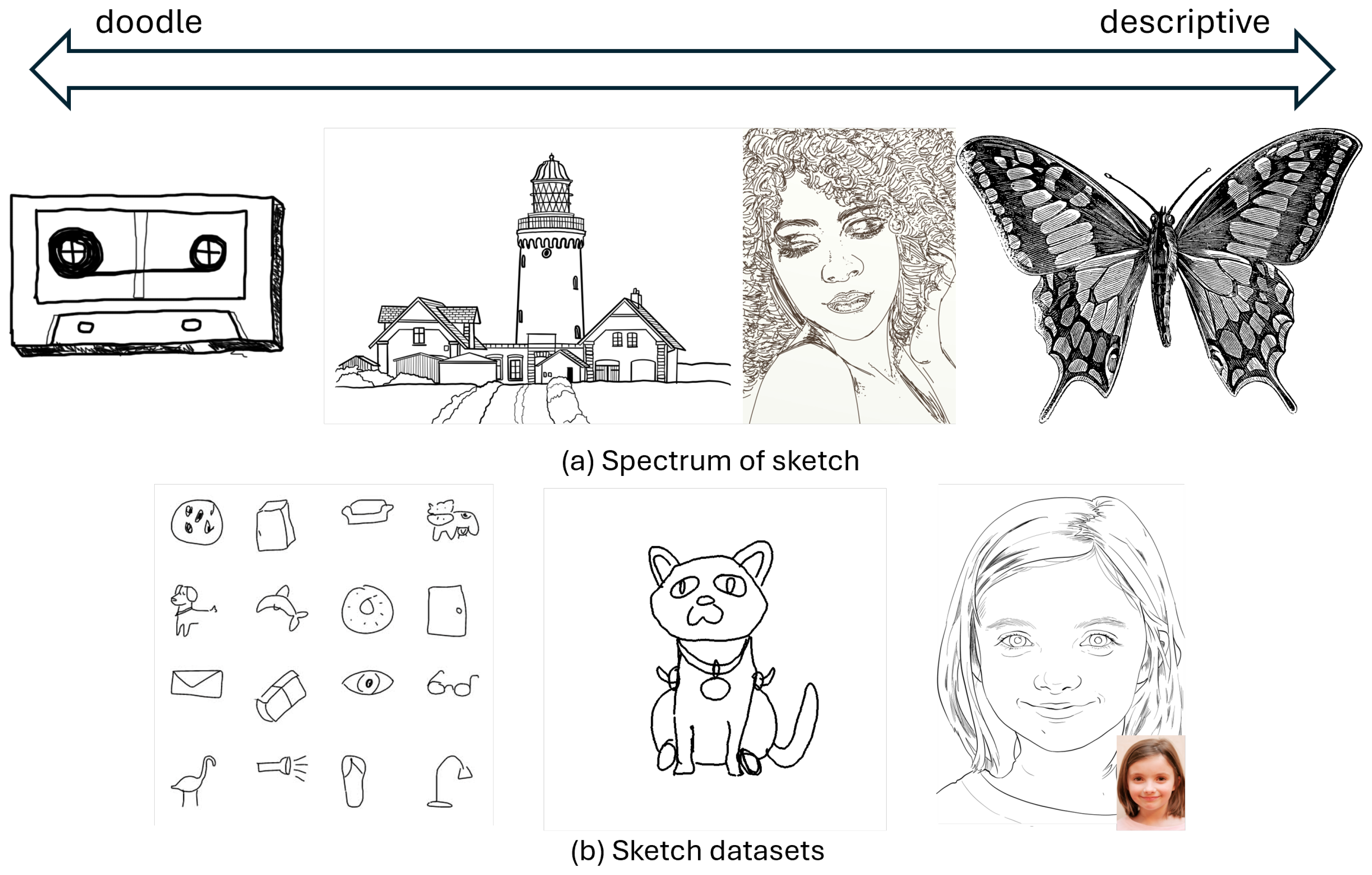
1. Introduction
2. Related Work
2.1. Raster Sketch Synthesis
2.2. Vector Sketch Synthesis
2.3. Sketch-Based Application
2.4. Dataset
3. Method
3.1. Overview
3.2. Edge Tangent Flow
3.3. Flowpath and VTF
| Algorithm 1 Algorithm for flowpath |
|
3.4. Noisy Sketch Generator
3.5. Noise Classifier
4. Implementation and Results
5. Comparison and Evaluation
5.1. Comparison
5.2. Quantitative Evaluation
5.3. Qualitative Evaluation
- Q1: Identity PreservationEvaluate how well the identity of the original image is maintained in the sketch image on a 10-point scale.A score of 10 indicates that the identity is well preserved, whereas a score of 1 suggests poor preservation.
- Q2: Artifact SuppressionEvaluate the level of artifact suppression in the sketch image on a 10-point scale.A score of 10 signifies minimal artifacts, while a score of 1 indicates a high presence of artifacts.
- Q3: Line Drawing AppearanceEvaluate the extent to which the sketch resembles a line drawing on a 10-point scale.A score of 10 implies a strong resemblance to a line drawing, whereas a score of 1 suggests that the sketch appears more like a tonal sketch than a line drawing.
- Our method ranked third in terms of identity preservation and artifact suppression in the portrait category.
- Our method ranked second for identity preservation and artifact suppression among the tested approaches in the landscape and other categories. The commercial tool BeFunky outperformed our method in these aspects.
- Our method achieved the highest score across all categories in resembling line drawings. While BeFunky [65] demonstrated strong performance in various aspects, its generated sketches resemble tonal sketches rather than line drawings, making it less aligned with the objective of our study.
5.4. Ablation Study
5.5. Limitation
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sakamoto, D.; Honda, K.; Inami, M.; Igarashi, T. Sketch and run: A stroke-based interface for home robots. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Boston, MA, USA, 4–9 April 2009; pp. 197–200. [Google Scholar]
- Vinker, Y.; Pajouheshgar, E.; Bo, J.Y.; Bachmann, R.C.; Bermano, A.H.; Cohen-Or, D.; Zamir, A.; Shamir, A. Clipasso: Semantically-aware object sketching. ACM Trans. Graph. (TOG) 2022, 41, 86. [Google Scholar] [CrossRef]
- Vinker, Y.; Alaluf, Y.; Cohen-Or, D.; Shamir, A. Clipascene: Scene sketching with different types and levels of abstraction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 4146–4156. [Google Scholar]
- Singer, J.; Seeliger, K.; Kietzmann, T.; Hebart, M. From photos to sketches—How humans and deep neural networks process objects across different levels of visual abstraction. J. Vis. 2022, 22, 4. [Google Scholar] [CrossRef] [PubMed]
- Jongejan, J.; Rowley, H.; Kawashima, T.; Kim, J.; Fox-Gieg, N. A.I. Experiments: Quick, Draw! Available online: https://quickdraw.withgoogle.com/ (accessed on 14 July 2025).
- Yi, R.; Liu, Y.J.; Lai, Y.K.; Rosin, P.L. Apdrawinggan: Generating artistic portrait drawings from face photos with hierarchical gans. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 10743–10752. [Google Scholar]
- Xiao, C.; Su, W.; Liao, J.; Lian, Z.; Song, Y.Z.; Fu, H. DifferSketching: How Differently Do People Sketch 3D Objects? ACM Trans. Graph. 2022, 41, 264. [Google Scholar] [CrossRef]
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- Kang, H.; Lee, S.; Chui, C.K. Coherent line drawing. In Proceedings of the 5th International Symposium on Non-Photorealistic Animation and Rendering, San Diego, CA, USA, 4–5 August 2007; pp. 43–50. [Google Scholar]
- Kang, H.; Lee, S.; Chui, C.K. Flow-based image abstraction. IEEE Trans. Vis. Comput. Graph. 2008, 15, 62–76. [Google Scholar] [CrossRef] [PubMed]
- Ha, D.; Eck, D. A neural representation of sketch drawings. arXiv 2017, arXiv:1704.03477. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Xing, X.; Wang, C.; Zhou, H.; Zhang, J.; Yu, Q.; Xu, D. DiffSketcher: Text-Guided Vector Sketch Synthesis through Latent Diffusion Models. arXiv 2023, arXiv:2306.14685. [Google Scholar]
- Arbelaez, P.; Maire, M.; Fowlkes, C.; Malik, J. Contour detection and hierarchical image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 898–916. [Google Scholar] [CrossRef] [PubMed]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment anything. arXiv 2023, arXiv:2304.02643. [Google Scholar] [PubMed]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image style transfer using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2414–2423. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Su, H.; Niu, J.; Liu, X.; Li, Q.; Cui, J.; Wan, J. Mangagan: Unpaired photo-to-manga translation based on the methodology of manga drawing. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada (virtual), 2–9 February 2021; Volume 35, pp. 2611–2619. [Google Scholar]
- Kim, H.; Kim, J.; Yang, H. Portrait Sketch Generative Model for Misaligned Photo-to-Sketch Dataset. Mathematics 2023, 11, 3761. [Google Scholar] [CrossRef]
- Chan, C.; Durand, F.; Isola, P. Learning To Generate Line Drawings That Convey Geometry and Semantics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June June 2022; pp. 7915–7925. [Google Scholar]
- Cabral, B.; Leedem, L.C. Imaging vector fields using line integral convolution. In Proceedings of the Siggraph 1993, Anaheim, CA, USA, 2–6 August 1993; pp. 263–270. [Google Scholar]
- Winnemöller, H.; Kyprianidis, J.E.; Olsen, S.C. XDoG: An eXtended difference-of-Gaussians compendium including advanced image stylization. Comput. Graph. 2012, 36, 740–753. [Google Scholar] [CrossRef]
- Li, M.; Lin, Z.; Mech, R.; Yumer, E.; Ramanan, D. Photo-sketching: Inferring contour drawings from images. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1403–1412. [Google Scholar]
- Chen, Y.; Tu, S.; Yi, Y.; Xu, L. Sketch-pix2seq: A model to generate sketches of multiple categories. arXiv 2017, arXiv:1709.04121. [Google Scholar]
- Frans, K.; Soros, L.; Witkowski, O. Clipdraw: Exploring text-to-drawing synthesis through language-image encoders. Adv. Neural Inf. Process. Syst. 2022, 35, 5207–5218. [Google Scholar]
- Muhammad, U.R.; Yang, Y.; Song, Y.Z.; Xiang, T.; Hospedales, T.M. Learning deep sketch abstraction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8014–8023. [Google Scholar]
- Zhou, T.; Fang, C.; Wang, Z.; Yang, J.; Kim, B.; Chen, Z.; Brandt, J.; Terzopoulos, D. Learning to doodle with deep q networks and demonstrated strokes. In Proceedings of the British Machine Vision Conference, Newcastle upon Tyne, UK, 3–6 September 2018; Volume 1, p. 4. [Google Scholar]
- Jain, A.; Xie, A.; Abbeel, P. Vectorfusion: Text-to-svg by abstracting pixel-based diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 1911–1920. [Google Scholar]
- Bhunia, A.K.; Khan, S.; Cholakkal, H.; Anwer, R.M.; Khan, F.S.; Laaksonen, J.; Felsberg, M. Doodleformer: Creative sketch drawing with transformers. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 338–355. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Liu, M.Y.; Breuel, T.; Kautz, J. Unsupervised image-to-image translation networks. Adv. Neural Inf. Process. Syst. 2017, 30, 700–708. [Google Scholar]
- Huang, X.; Liu, M.Y.; Belongie, S.; Kautz, J. Multimodal unsupervised image-to-image translation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 10–13 September 2018; pp. 172–189. [Google Scholar]
- Kim, J. U-gat-it: Unsupervised generative attentional networks with adaptive layer-instance normalization for image-to-image translation. arXiv 2019, arXiv:1907.10830. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Song, J.; Meng, C.; Ermon, S. Denoising diffusion implicit models. arXiv 2020, arXiv:2010.02502. [Google Scholar]
- Song, Y.; Sohl-Dickstein, J.; Kingma, D.P.; Kumar, A.; Ermon, S.; Poole, B. Score-based generative modeling through stochastic differential equations. arXiv 2020, arXiv:2011.13456. [Google Scholar]
- Kim, J.; Yang, H.; Min, K. DALS: Diffusion-Based Artistic Landscape Sketch. Mathematics 2024, 12, 238. [Google Scholar] [CrossRef]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 10684–10695. [Google Scholar]
- Zhang, L.; Rao, A.; Agrawala, M. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–13 October 2023; pp. 3836–3847. [Google Scholar]
- Song, J.; Pang, K.; Song, Y.Z.; Xiang, T.; Hospedales, T.M. Learning to sketch with shortcut cycle consistency. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 801–810. [Google Scholar]
- Huang, Z.; Heng, W.; Zhou, S. Learning to paint with model-based deep reinforcement learning. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Ma, X.; Zhou, Y.; Xu, X.; Sun, B.; Filev, V.; Orlov, N.; Fu, Y.; Shi, H. Towards layer-wise image vectorization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 16314–16323. [Google Scholar]
- Reddy, P.; Gharbi, M.; Lukac, M.; Mitra, N.J. Im2vec: Synthesizing vector graphics without vector supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual (Nashville, TN, USA), 19–25 June 2021; pp. 7342–7351. [Google Scholar]
- Liu, S.; Lin, T.; He, D.; Li, F.; Deng, R.; Li, X.; Ding, E.; Wang, H. Paint transformer: Feed forward neural painting with stroke prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 6598–6607. [Google Scholar]
- Li, T.M.; Lukáč, M.; Gharbi, M.; Ragan-Kelley, J. Differentiable vector graphics rasterization for editing and learning. ACM Trans. Graph. (TOG) 2020, 39, 1–15. [Google Scholar] [CrossRef]
- Bhunia, A.K.; Chowdhury, P.N.; Yang, Y.; Hospedales, T.; Xiang, T.; Song, Y.Z. Vectorization and Rasterization: Self-Supervised Learning for Sketch and Handwriting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Virtual (Nashville, TN, USA), 19–25 June 2021. [Google Scholar]
- Su, H.; Liu, X.; Niu, J.; Cui, J.; Wan, J.; Wu, X.; Wang, N. MARVEL: Raster Gray-level Manga Vectorization via Primitive-wise Deep Reinforcement Learning. IEEE Trans. Circuits Syst. Video Technol. 2023, 34, 2677–2693. [Google Scholar] [CrossRef]
- Wang, S.Y.; Bau, D.; Zhu, J.Y. Sketch your own gan. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual Conference with Main Sessions, Montreal, QC, Canada, 11–17 October 2021; pp. 14050–14060. [Google Scholar]
- Bashkirova, D.; Lezama, J.; Sohn, K.; Saenko, K.; Essa, I. Masksketch: Unpaired structure-guided masked image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 1879–1889. [Google Scholar]
- Koley, S.; Bhunia, A.K.; Sain, A.; Chowdhury, P.N.; Xiang, T.; Song, Y.Z. Picture that sketch: Photorealistic image generation from abstract sketches. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 6850–6861. [Google Scholar]
- Yu, Q.; Liu, F.; Song, Y.Z.; Xiang, T.; Hospedales, T.M.; Loy, C.C. Sketch me that shoe. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 799–807. [Google Scholar]
- Sangkloy, P.; Jitkrittum, W.; Yang, D.; Hays, J. A sketch is worth a thousand words: Image retrieval with text and sketch. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 251–267. [Google Scholar]
- Sain, A.; Bhunia, A.K.; Chowdhury, P.N.; Koley, S.; Xiang, T.; Song, Y.Z. Clip for all things zero-shot sketch-based image retrieval, fine-grained or not. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 2765–2775. [Google Scholar]
- Chaudhuri, A.; Bhunia, A.K.; Song, Y.Z.; Dutta, A. Data-free sketch-based image retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 12084–12093. [Google Scholar]
- Wang, A.; Ren, M.; Zemel, R. Sketchembednet: Learning novel concepts by imitating drawings. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual (Honolulu, HI, USA), 18–24 July 2021; pp. 10870–10881. [Google Scholar]
- Zou, C.; Yu, Q.; Du, R.; Mo, H.; Song, Y.Z.; Xiang, T.; Gao, C.; Chen, B.; Zhang, H. SketchyScene: Richly-Annotated Scene Sketches. In Proceedings of the ECCV, Munich, Germany, 8–14 September 2018; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 438–454. [Google Scholar] [CrossRef]
- Gao, C.; Liu, Q.; Xu, Q.; Wang, L.; Liu, J.; Zou, C. Sketchycoco: Image generation from freehand scene sketches. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5174–5183. [Google Scholar]
- Chowdhury, P.N.; Sain, A.; Bhunia, A.K.; Xiang, T.; Gryaditskaya, Y.; Song, Y.Z. Fs-coco: Towards understanding of freehand sketches of common objects in context. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 253–270. [Google Scholar]
- Wang, Z.; Qiu, S.; Feng, N.; Rushmeier, H.; McMillan, L.; Dorsey, J. Tracing Versus Freehand for Evaluating Computer-Generated Drawings. ACM Trans. Graph. 2021, 40, 52. [Google Scholar] [CrossRef]
- Yun, K.; Seo, K.; Seo, C.W.; Yoon, S.; Kim, S.; Ji, S.; Ashtari, A.; Noh, J. Stylized Face Sketch Extraction via Generative Prior with Limited Data. Comput. Graph. Forum 2024, 43, e15045. [Google Scholar] [CrossRef]
- Shugrina, M.; Liang, Z.; Kar, A.; Li, J.; Singh, A.; Singh, K.; Fidler, S. Creative Flow+ Dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June June 2019. [Google Scholar]
- Danbooru2021: A Large-Scale Crowdsourced and Tagged Anime Illustration Dataset. Available online: https://gwern.net/danbooru2021 (accessed on 14 July 2025).
- Ashtari, A.; Seo, C.W.; Kang, C.; Cha, S.; Noh, J. Reference Based Sketch Extraction via Attention Mechanism. ACM Trans. Graph. 2022, 41, 207. [Google Scholar] [CrossRef]
- Seo, C.W.; Ashtari, A.; Noh, J. Semi-supervised Reference-based Sketch Extraction using a Contrastive Learning Framework. ACM Trans. Graph. 2023, 42, 56. [Google Scholar] [CrossRef]
- BeFunky Photo Editor. Available online: https://www.befunky.com (accessed on 14 July 2025).
- Fotor. Photo to Sketch: Free Image to Sketch Converter. Available online: https://www.fotor.com/ (accessed on 14 July 2025).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Line-Drawing Sketch | Tonal Sketch | ||||||
|---|---|---|---|---|---|---|---|
| Ours | Li 2019 | Ashtari 2022 | Seo 2023 | BeFunky | Fotor | ||
| [23] | [63] | [64] | [65] | [66] | |||
| PSNR ↑ | 35.5045 | 35.4907 | 34.6952 | 35.4999 | 35.4729 | 33.0367 | |
| Portrait | FID ↓ | 282.7476 | 423.2384 | 359.2274 | 213.9626 | 171.6401 | 219.4862 |
| (Figure 10) | CLIPscore ↑ | 0.8947 | 0.7632 | 0.8031 | 0.8844 | 0.9108 | 0.8661 |
| LPIPS ↓ | 0.2369 | 0.4086 | 0.3343 | 0.2827 | 0.3497 | 0.4789 | |
| PSNR ↑ | 33.2470 | 33.2460 | 32.9502 | 33.2134 | 33.2495 | 31.7239 | |
| Landscape | FID ↓ | 288.9014 | 571.9037 | 353.7223 | 362.5313 | 155.8621 | 312.4798 |
| (Figure 11) | CLIPscore ↑ | 0.9078 | 0.7304 | 0.8234 | 0.8524 | 0.9296 | 0.9015 |
| LPIPS ↓ | 0.3574 | 0.5399 | 0.4274 | 0.3776 | 0.3703 | 0.5723 | |
| PSNR ↑ | 39.7271 | 39.6895 | 37.3449 | 39.6778 | 39.6720 | 37.3697 | |
| Other | FID ↓ | 193.7292 | 398.5725 | 364.4751 | 215.5324 | 165.0447 | 207.1792 |
| (Figure 12) | CLIPscore ↑ | 0.9540 | 0.8664 | 0.7609 | 0.8837 | 0.8915 | 0.8472 |
| LPIPS ↓ | 0.1489 | 0.2450 | 0.4571 | 0.2591 | 0.2925 | 0.2941 | |
| Line-Drawing Sketch | Tonal Sketch | ||||||
|---|---|---|---|---|---|---|---|
| Ours | Li 2019 | Ashtari 2022 | Seo 2023 | BeFunky | Fotor | ||
| [23] | [63] | [64] | [65] | [66] | |||
| Portrait | Q1 ↑ | 7.67 | 1.33 | 3.67 | 9.00 | 8.00 | 6.33 |
| (Figure 10) | Q2 ↑ | 7.33 | 6.67 | 4.00 | 9.67 | 9.67 | 1.67 |
| Q3 ↑ | 9.67 | 6.67 | 4.67 | 9.33 | 5.00 | 4.00 | |
| Landscape | Q1 ↑ | 9.25 | 3.50 | 2.00 | 3.75 | 10.00 | 8.00 |
| (Figure 11) | Q2 ↑ | 8.25 | 5.00 | 2.75 | 4.75 | 9.50 | 7.25 |
| Q3 ↑ | 9.25 | 9.00 | 3.75 | 8.25 | 6.25 | 4.75 | |
| Other | Q1 ↑ | 9.00 | 5.25 | 1.75 | 6.75 | 9.50 | 7.50 |
| (Figure 12) | Q2 ↑ | 9.25 | 9.00 | 2.25 | 6.50 | 9.50 | 7.00 |
| Q3 ↑ | 9.50 | 9.25 | 1.50 | 5.50 | 4.75 | 4.50 | |
| Q1 ↑ | 8.64 | 3.36 | 2.47 | 6.50 | 9.17 | 7.28 | |
| Average | Q2 ↑ | 8.28 | 6.89 | 3.00 | 6.97 | 9.58 | 5.31 |
| Q3 ↑ | 9.47 | 8.31 | 3.31 | 7.69 | 5.33 | 4.42 | |
| Ours & Seo2023 [64] | Ours & BeFunky [65] | ||||
|---|---|---|---|---|---|
| p-Value | Valid | p-Value | Valid | ||
| Portrait | Q1 ↑ | 0.253 | invalid | 0.631 | invalid |
| (Figure 10) | Q2 ↑ | 0691 | invalid | 0.073 | invalid |
| Q3 ↑ | 0.667 | invalid | 0.019 | valid | |
| Landscape | Q1 ↑ | 0.003 | valid | 0.058 | invalid |
| (Figure 11) | Q2 ↑ | 0.012 | valid | 0.079 | invalid |
| Q3 ↑ | 0.092 | invalid | 0.011 | valid | |
| Other | Q1 ↑ | 0.003 | valid | 0.495 | invalid |
| (Figure 12) | Q2 ↑ | 0.048 | valid | 0.638 | invalid |
| Q3 ↑ | 0.034 | valid | 0.049 | valid | |
| Noisy Sketch | Ours | Ours | Ours | |
|---|---|---|---|---|
| (Thresholding) | (Image-Only) | (VTF-Only) | (Image + VTF) | |
| Figure 13b | Figure 13c | Figure 13d | Figure 13e | |
| PSNR ↑ | 36.7781 | 36.7299 | 36.7793 | 36.8004 |
| FID ↓ | 197.6035 | 398.3203 | 91.6925 | 55.8984 |
| CLIPscore ↑ | 0.9672 | 0.8791 | 0.9592 | 0.9732 |
| LPIPS ↓ | 0.1796 | 0.3586 | 0.2063 | 0.0651 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.; Yang, H.; Min, K. Sketch Synthesis with Flowpath and VTF. Electronics 2025, 14, 2861. https://doi.org/10.3390/electronics14142861
Kim J, Yang H, Min K. Sketch Synthesis with Flowpath and VTF. Electronics. 2025; 14(14):2861. https://doi.org/10.3390/electronics14142861
Chicago/Turabian StyleKim, Junho, Heekyung Yang, and Kyumgha Min. 2025. "Sketch Synthesis with Flowpath and VTF" Electronics 14, no. 14: 2861. https://doi.org/10.3390/electronics14142861
APA StyleKim, J., Yang, H., & Min, K. (2025). Sketch Synthesis with Flowpath and VTF. Electronics, 14(14), 2861. https://doi.org/10.3390/electronics14142861