
Fast Inference End-to-End Speech Synthesis with Style Diffusion


Abstract
1. Introduction
- The stochastic duration predictor performs poorly, often assigning excessively short durations to critical phonemes, which leads to noticeable phoneme skipping in the synthesized audio.
- The relative positional encoding [5] used in the text encoder is computationally expensive and insufficient for modeling long-range dependencies, limiting the ability to capture natural prosody.
- The GAN [4]-based decoder employs multiple transposed convolution layers, which are computationally expensive and form the primary bottleneck during training and inference.
- The lack of explicit modeling of pitch information (e.g., fundamental frequency ) can lead to spectral artifacts and reduced synthesis quality.
- Externally supervised duration modeling is employed to avoid irregular phoneme durations. Additionally, a frame-level prior modeling strategy is introduced by learning frame-wise mean and variance, which enhances the model’s capacity to handle one-to-many mappings in acoustic modeling.
- Rotary Position Embedding (RoPE) [6] is incorporated into the text encoder to strengthen long-sequence modeling capabilities and improve efficiency.
- A diffusion-based Style Extractor is integrated to capture speaker style and expressive characteristics with high fidelity, significantly improving the expressiveness and controllability of synthesized speech.
- A novel decoder architecture, ConfoGAN, is designed to overcome the efficiency and modeling limitations of the original decoder. Built upon BigVGAN [7], ConfoGAN integrates the several following critical components.
2. Related Work
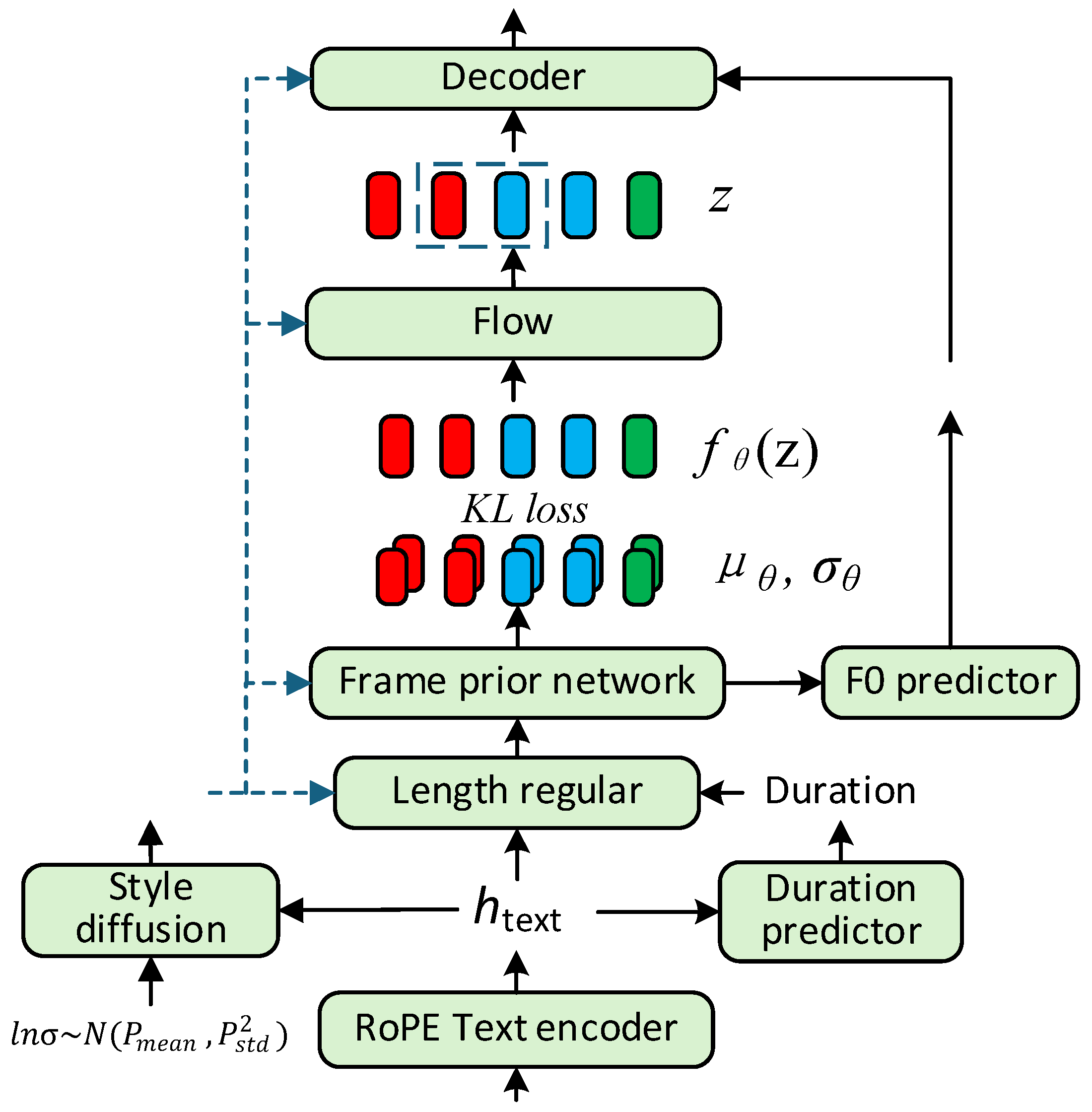
3. Materials and Methods
3.1. Prior Encoder
RoPE Text Encoder
3.2. Posterior Encoder
3.3. Decoder
- Artifact Generation. The use of transposed convolution during upsampling tends to introduce high-frequency noise and pitch-related artifacts, which significantly degrade the clarity and naturalness of the synthesized speech [33].
- Low Inference Efficiency. The complex convolutional architecture incurs substantial computational overhead. Experiments show that this module accounts for over 96% of the total inference time [34], becoming the primary bottleneck of the system.
- Limited Modeling Capability. Downsampling mechanisms such as average pooling and uniform sampling often lead to aliasing, making it difficult to accurately reconstruct the fundamental frequency () and its harmonic structure [35]. This issue is especially pronounced in speech with significant pitch variations [36,37].
- Inadequate Long-Term Dependency Modeling. Although GAN-based decoders are effective at generating fine-grained details, their reliance on convolutional structures with limited receptive fields hinders their ability to capture long-term patterns.
3.4. Style Modeling
3.5. Final Loss
4. Experiments
4.1. Datasets
4.2. Model Setups

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | FPN | RoPE | F0 input | ConfoGAN | Style |
|---|---|---|---|---|---|
| VITS | × | × | × | × | × |
| FPN-VITS | √ | × | × | × | × |
| RoP-VITS | √ | √ | × | × | × |
| F0-VITS | √ | √ | √ | × | × |
| C-VITS | √ | √ | √ | √ | × |
| Q-VITS | √ | √ | √ | √ | √ |
5. Results
5.1. Evaluation
5.2. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kim, J.; Kong, J.; Son, J. Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech. In Proceedings of the International Conference on Machine Learning, PMLR, Beijing, China, 18–24 July 2021; pp. 5530–5540. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Rezende, D.; Mohamed, S. Variational inference with normalizing flows. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 1530–1538. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar] [CrossRef]
- Shaw, P.; Uszkoreit, J.; Vaswani, A. Self-attention with relative position representations. arXiv 2018, arXiv:1803.02155. [Google Scholar]
- Su, J.; Ahmed, M.; Lu, Y.; Pan, S.; Bo, W.; Liu, Y. Roformer: Enhanced transformer with rotary position embedding. Neurocomputing 2024, 568, 127063. [Google Scholar] [CrossRef]
- Lee, S.; Ping, W.; Ginsburg, B.; Catanzaro, B.; Yoon, S. Bigvgan: A universal neural vocoder with large-scale training. arXiv 2022, arXiv:2206.04658. [Google Scholar]
- Gulati, A.; Qin, J.; Chiu, C.C.; Parmar, N.; Zhang, Y.; Yu, J.; Han, W.; Wang, S.; Zhang, Z.; Wu, Y.; et al. Conformer: Convolution-augmented transformer for speech recognition. arXiv 2020, arXiv:2005.08100. [Google Scholar]
- Wang, X.; Takaki, S.; Yamagishi, J. Neural source-filter waveform models for statistical parametric speech synthesis. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 28, 402–415. [Google Scholar] [CrossRef]
- Kaneko, T.; Tanaka, K.; Kameoka, H.; Seki, S. iSTFTNet: Fast and lightweight mel-spectrogram vocoder incorporating inverse short-time Fourier transform. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 6207–6211. [Google Scholar]
- Nguyen, T.Q. Near-perfect-reconstruction pseudo-QMF banks. IEEE Trans. Signal Process. 1994, 42, 65–76. [Google Scholar] [CrossRef]
- Hunt, A.J.; Black, A.W. Unit selection in a concatenative speech synthesis system using a large speech database. In Proceedings of the 1996 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Atlanta, GA, USA, 9 May 1996; IEEE: Piscataway, NJ, USA, 1996; pp. 373–376. [Google Scholar]
- Black, A.W.; Taylor, P. Automatically clustering similar units for unit selection in speech synthesis. In Proceedings of the EUROSPEECH’97: 5th European Conference on Speech Communication and Technology, Rhodes, Greece, 22–25 September 1997. [Google Scholar]
- Zen, H.; Tokuda, K.; Black, A.W. Statistical parametric speech synthesis. Speech Commun. 2009, 51, 1039–1064. [Google Scholar] [CrossRef]
- Zen, H.; Senior, A.; Schuster, M. Statistical parametric speech synthesis using deep neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 7962–7966. [Google Scholar]
- Davis, S.; Mermelstein, P. Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. IEEE Trans. Acoust. Speech Signal Process. 1980, 28, 357–366. [Google Scholar] [CrossRef]
- Saito, Y.; Takamichi, S.; Saruwatari, H. Statistical parametric speech synthesis incorporating generative adversarial networks. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 26, 84–96. [Google Scholar] [CrossRef]
- Wang, Y.; Skerry-Ryan, R.J.; Stanton, D.; Wu, Y.; Weiss, R.J.; Jaitly, N.; Yang, Z.; Xiao, Y.; Chen, Z.; Bengio, S.; et al. Tacotron: Towards end-to-end speech synthesis. arxiv 2017, arXiv:1703.10135. [Google Scholar]
- Shen, J.; Pang, R.; Weiss, R.J.; Schuster, M.; Jaitly, N.; Yang, Z. Natural tts synthesis by conditioning wavenet on mel spectrogram predictions. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Ren, Y.; Ruan, Y.; Tan, X.; Qin, T.; Zhao, S.; Zhao, Z.; Liu, T.-Y. Fastspeech: Fast, robust and controllable text to speech. Adv. Neural Inf. Process. Syst. 2019, 32, 3165–3174. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Łańcucki, A. Fastpitch: Parallel text-to-speech with pitch prediction. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 13 May 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 6588–6592. [Google Scholar]
- Ren, Y.; Hu, C.; Tan, X.; Qin, T.; Zhao, S.; Zhao, Z.; Liu, T.-Y. Fastspeech 2: Fast and high-quality end-to-end text to speech. arXiv 2020, arXiv:2006.04558. [Google Scholar]
- GLM, T.; Zeng, A.; Xu, B.; Wang, B.; Zhang, C.; Yin, D.; Zhang, D.; Rojas, D.; Feng, G.; Zhao, H.; et al. Chatglm: A family of large language models from glm-130b to glm-4 all tools. arXiv 2024, arXiv:2406.12793. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Mehta, S.; Tu, R.; Beskow, J.; Székely, É.; Henter, G.E. Matcha-TTS: A fast TTS architecture with conditional flow matching. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 11341–11345. [Google Scholar]
- Li, Y.A.; Han, C.; Raghavan, V.; Mischler, G.; Mesgarani, N. Styletts 2: Towards human-level text-to-speech through style diffusion and adversarial training with large speech language models. Adv. Neural Inf. Process. Syst. 2023, 36, 19594–19621. [Google Scholar]
- Li, Y.; Wang, Y.; Yang, X.; Im, S.K. Speech emotion recognition based on Graph-LSTM neural network. EURASIP J. Audio Speech Music Process. 2023, 2023, 40. [Google Scholar] [CrossRef]
- Sohn, K.; Lee, H.; Yan, X. Learning structured output representation using deep conditional generative models. Adv. Neural Inf. Process. Systems 2015, 2, 3483–3491. [Google Scholar]
- Zhang, Y.; Cong, J.; Xue, H.; Xie, L.; Zhu, P.; Bi, M. Visinger: Variational inference with adversarial learning for end-to-end singing voice synthesis. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 7237–7241. [Google Scholar]
- McAuliffe, M.; Socolof, M.; Mihuc, S.; Wagner, M.; Sonderegger, M. Montreal forced aligner: Trainable text-speech alignment using kaldi. Interspeech 2017, 2017, 498–502. [Google Scholar]
- Kong, J.; Kim, J.; Bae, J. Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis. Adv. Neural Inf. Process. Syst. 2020, 33, 17022–17033. [Google Scholar]
- Pons, J.; Pascual, S.; Cengarle, G.; Serrà, J. Upsampling artifacts in neural audio synthesis. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 3005–3009. [Google Scholar]
- Kawamura, M.; Shirahata, Y.; Yamamoto, R.; Tachibana, K. Lightweight and high-fidelity end-to-end text-to-speech with multi-band generation and inverse short-time fourier transform. In Proceedings of the ICASSP 202—023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, Rhodes Island, Greece, 5 May 2023; pp. 1–5. [Google Scholar]
- Morrison, M.; Kumar, R.; Kumar, K.; Seetharaman, P.; Courville, A.; Bengio, Y. Chunked Autoregressive GANforConditional Waveform Synthesis. In Proceedings of the International Conference on Learning Representations, Virtually, 25–29 April 2022. [Google Scholar]
- Lorenzo-Trueba, J.; Drugman, T.; Latorre, J.; Merritt, T.; Pu trycz, B.; Barra-Chicote, R.; Moinet, A.; Aggarwal, V. Towards Achieving Robust Universal Neural Vocoding. In Proceedings of the Interspeech, Graz, Austria, 15–19 September 2019; pp. 181–185. [Google Scholar]
- Zaïdi, J.; Seuté, H.; van Niekerk, B.; Carbonneau, M.-A. Daft-Exprt: Cross-speaker prosody transfer on any text for expressive speech synthesis. arXiv 2021, arXiv:2108.02271. [Google Scholar]
- Ziyin, L.; Hartwig, T.; Ueda, M. Neural networks fail to learn periodic functions and how to fix it. Adv. Neural Inf. Process. Syst. 2020, 33, 1583–1594. [Google Scholar]
- Li, Y.A.; Han, C.; Jiang, X.; Mesgarani, N. HiFTNet: A fast high-quality neural vocoder with harmonic-plus-noise filter and inverse short time fourier transform. arXiv 2023, arXiv:2309.09493. [Google Scholar]
- Takida, Y.; Liao, W.H.; Uesaka, T.; Takahashi, S.; Mitsufuji, Y. Preventing posterior collapse induced by oversmoothing in gaussian vae. arXiv 2021, arXiv:2102.08663. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising Diffusion Probabilistic Models. Adv. Neural Inf. Process. Syst. (NeurIPS) 2020, 33, 6840–6851. [Google Scholar]
- Ito, K.; Johnson, L. The LJ Speech Dataset. 2017. Available online: https://keithito.com/LJ-Speech-Dataset/ (accessed on 14 May 2025).
- Databaker: Databaker Technology. Chinese Standard Female Voice Database. Available online: https://en.data-baker.com/datasets/freeDatasets/ (accessed on 14 May 2025).
- ITU-T Recommendation P.800; Subjective Testing Methods for Voice Quality Assessment. ITU-T: Geneva, Switzerland, 1996.
- Kubichek, R. Mel-cepstral distance measure for objective speech quality assessment. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Victoria, BC, Canada, 19–21 May 1993; pp. 149–152. [Google Scholar]
- Sundermann, D.; Jaitly, N. Real-time voice conversion with recurrent neural networks. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 5450–5454. [Google Scholar]






| Model | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| VITS | 45 | 1 | 1 | 1 | 2 | - | - | - | - |
| FPN-VITS | 45 | 1 | 1 | 1 | 2 | - | - | - | - |
| RoP-VITS | 45 | 1 | 1 | 1 | 2 | - | - | - | - |
| F0-VITS | 45 | 1 | 1 | 1 | 2 | 1 | - | - | - |
| C-VITS | 45 | 1 | 1 | 1 | 2 | 1 | 1 | - | - |
| Q-VITS | 45 | 1 | 1 | 1 | 2 | 1 | 1 | 1 | 1 |
| Model | MOS ± CI | MCD | logF0 RMSE | RTF |
|---|---|---|---|---|
| Ground truth | 4.32 | - | - | - |
| VITS | 3.89 | 6.89 | 0.2889 | 0.223 |
| FPN-VITS | 3.91 | 6.88 | 0.2362 | 0.221 |
| RoP-VITS | 3.93 | 6.73 | 0.2274 | 0.216 |
| F0-VITS | 4.02 | 6.71 | 0.2203 | 0.276 |
| C-VITS | 4.08 | 6.62 | 0.2194 | 0.063 |
| Q-VITS | 4.12 | 6.36 | 0.2142 | 0.072 |
| Model | MOS ± CI | MCD | logF0 RMSE | RTF |
|---|---|---|---|---|
| Ground truth | 4.33 | - | - | - |
| VITS | 3.73 | 8.15 | 0.2803 | 0.228 |
| FPN-VITS | 3.77 | 8.07 | 0.2367 | 0.217 |
| RoP-VITS | 3.82 | 7.85 | 0.2342 | 0.211 |
| F0-VITS | 3.89 | 7.66 | 0.2309 | 0.222 |
| C-VITS | 4.01 | 7.59 | 0.2282 | 0.061 |
| Q-VITS | 4.09 | 7.48 | 0.2221 | 0.070 |
| Model | Inference Params | GFLOPs |
|---|---|---|
| VITS | 28.26 M | 59.14 |
| FPN-VITS | 24.82 M | 53.74 |
| RoP-VITS | 19.51 M | 49.69 |
| F0-VITS | 21.24 M | 51.34 |
| C-VITS | 23.93 M | 13.43 |
| Q-VITS | 28.89 M | 15.14 |
| Model | Baseline | MOS | MCD | RTF |
|---|---|---|---|---|
| Tacotron 2 | Tacotron | 3.77 | 7.17 | 0.33 |
| Transformer TTS | Transformer | 3.74 | 7.43 | 0.826 |
| FastSpeech | Transformer TTS | 3.96 | 6.96 | 0.048 |
| FastSpeech 2 | FastSpeech | 4.11 | 6.83 | 0.021 |
| FastPitch | FastSpeech | 4.06 | 6.87 | 0.029 |
| Q-VITS | VITS | 4.12 | 6.36 | 0.072 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, H.; Song, J.; Jiang, Y. Fast Inference End-to-End Speech Synthesis with Style Diffusion. Electronics 2025, 14, 2829. https://doi.org/10.3390/electronics14142829
Sun H, Song J, Jiang Y. Fast Inference End-to-End Speech Synthesis with Style Diffusion. Electronics. 2025; 14(14):2829. https://doi.org/10.3390/electronics14142829
Chicago/Turabian StyleSun, Hui, Jiye Song, and Yi Jiang. 2025. "Fast Inference End-to-End Speech Synthesis with Style Diffusion" Electronics 14, no. 14: 2829. https://doi.org/10.3390/electronics14142829
APA StyleSun, H., Song, J., & Jiang, Y. (2025). Fast Inference End-to-End Speech Synthesis with Style Diffusion. Electronics, 14(14), 2829. https://doi.org/10.3390/electronics14142829