
Research on Road Damage Detection Algorithms for Intelligent Inspection Robots

 ,
,
Abstract
1. Introduction
- (a)
- To overcome the challenges of limited detection accuracy and suboptimal inference speed observed in current models operating in complex environments, this study incorporates a multi-scale convolutional attention mechanism, the SPPELAN module, and the WIOU loss function. These enhancements collectively improve the model’s feature representation, minimize information loss, and refine loss function optimization, thereby ensuring both accurate and real-time road surface detection.
- (b)
- Existing models exhibit reduced detection performance in challenging scenarios involving reflections and shadows, adversely impacting accuracy. In response, a multi-scale convolutional attention is integrated to strengthen the model’s capacity for key feature extraction, thereby improving its ability to handle complex real-world conditions and enhancing both detection robustness and accuracy.
2. Materials and Methods
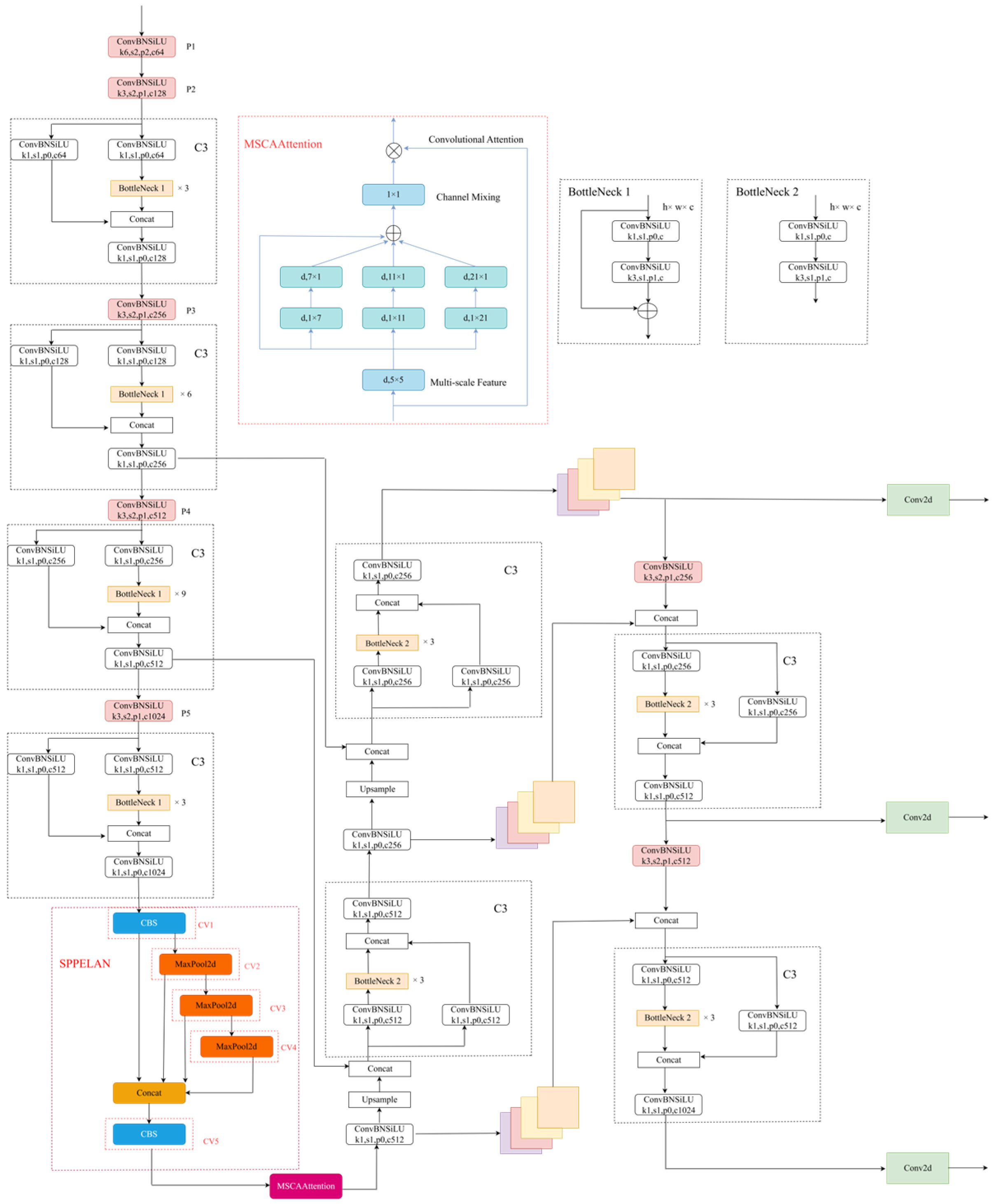
2.1. Design of Road Damage Detection Model
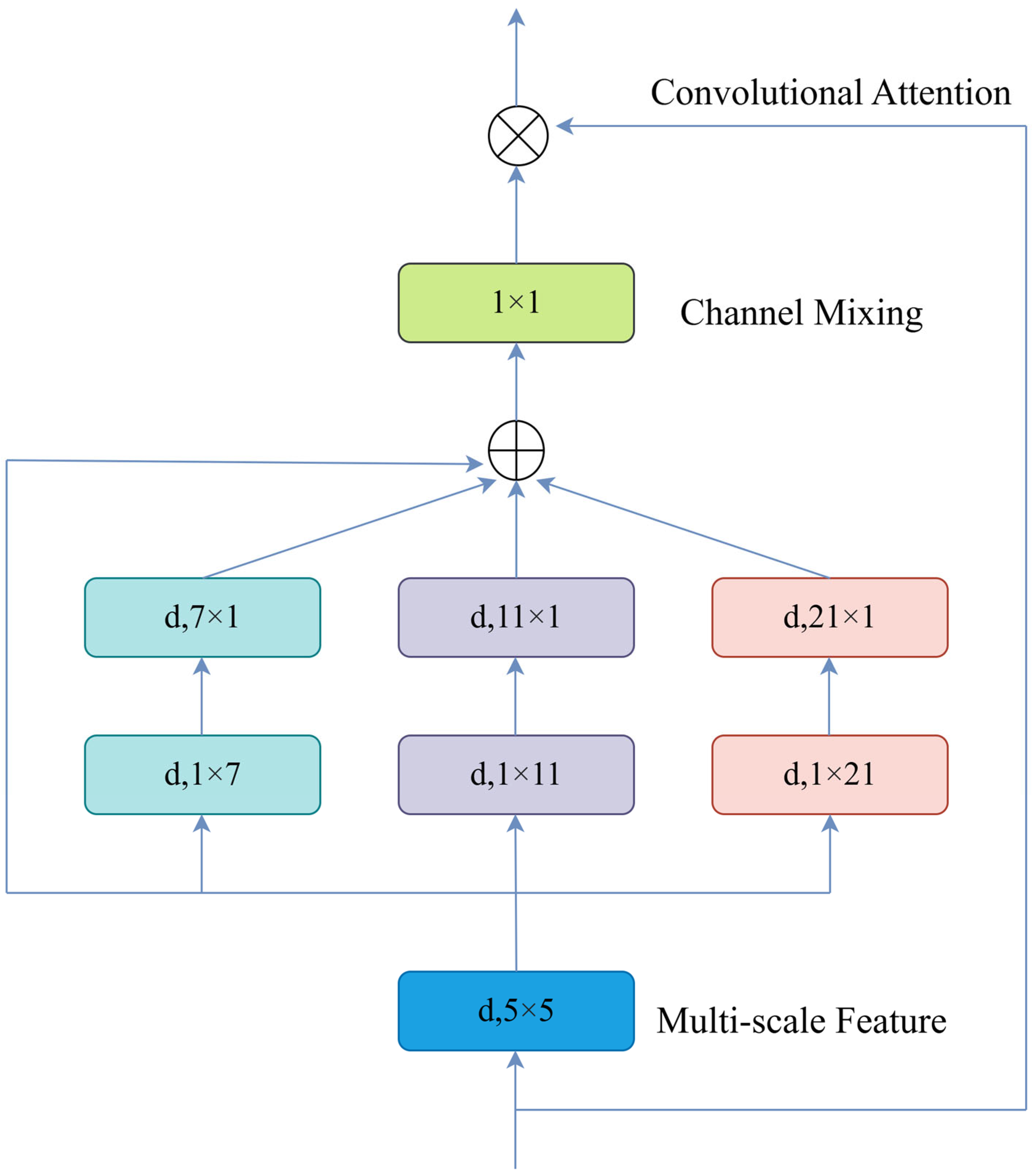
2.2. Multi-Scale Convolutional Attention Mechanism
2.3. Pyramid Pooling Structure
2.4. WIOU Loss Function
3. Experimental Method
3.1. Experimental Setup and Implementation
3.2. Evaluation Metrics
4. Results and Analysis
4.1. Experimental Results
4.2. Ablation Experiment
4.3. Comparative Experiment
4.4. Model Validation
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, Y. Constructing the intelligent expressway traffic monitoring system using the internet of things and inspection robot. J. Supercomput. 2024, 80, 8742–8766. [Google Scholar] [CrossRef]
- Wang, X.; Ma, X.; Li, Z. Research on SLAM and path planning method of inspection robot in complex scenarios. Electronics 2023, 12, 2178. [Google Scholar] [CrossRef]
- Zhang, C.; Nateghinia, E.; Miranda-Moreno, L.F.; Sun, L. Pavement distress detection using convolutional neural network (CNN): A case study in Montreal, Canada. Int. J. Transp. Sci. Technol. 2022, 11, 298–309. [Google Scholar] [CrossRef]
- Li, L.; Sun, S.; Song, W.; Zhang, J.; Teng, Q. CrackYOLO: Rural pavement distress detection model with complex scenarios. Electronics 2024, 13, 312. [Google Scholar] [CrossRef]
- Ning, Z.; Wang, H.; Li, S.; Xu, Z. YOLOv7-RDD: A Lightweight Efficient Pavement Distress Detection Model. IEEE Trans. Intell. Transp. Syst. 2024, 25, 6994–7003. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, F.; Liu, W.; Huang, Y. Pavement distress detection using street view images captured via action camera. IEEE Trans. Intell. Transp. Syst. 2023, 25, 738–747. [Google Scholar] [CrossRef]
- Wu, P.; Wu, J.; Xie, L. Pavement distress detection based on improved feature fusion network. Measurement 2024, 236, 115119. [Google Scholar] [CrossRef]
- Zhang, T.; Wang, D.; Lu, Y. ECSNet: An accelerated real-time image segmentation CNN architecture for pavement crack detection. IEEE Trans. Intell. Transp. Syst. 2023, 24, 15105–15112. [Google Scholar] [CrossRef]
- Ibragimov, E.; Lee, H.J.; Lee, J.J.; Kim, N. Automated pavement distress detection using region based convolutional neural networks. Int. J. Pavement Eng. 2022, 23, 1981–1992. [Google Scholar] [CrossRef]
- Xu, H.; Chen, B.; Wang, J.; Chen, Z.; Qin, J. Elongated pavement distress detection method based on convolutional neural network. J. Comput. Appl. 2022, 42, 265–272. [Google Scholar]
- Hou, Y.; Dong, Y.; Zhang, Y.; Zhou, Z.; Tong, X.; Wu, Q.; Qian, Z.; Li, R. The application of a pavement distress detection method based on FS-Net. Sustainability 2022, 14, 2715. [Google Scholar] [CrossRef]
- Wang, Z.; Abbas, M.; Wang, L. An attention-based improved YOLOv8 method for pavement distress detection. In Proceedings of the Transportation Research Board Annual Meeting, Washington, DC, USA, 7–11 January 2024. [Google Scholar]
- Balci, F.; Yilmaz, S. Faster R-CNN structure for computer vision-based road pavement distress detection. J. Polytech. 2022, 26, 701–710. [Google Scholar] [CrossRef]
- Luo, H.; Li, C.; Wu, M.; Cai, L. An enhanced lightweight network for road damage detection based on deep learning. Electronics 2023, 12, 2583. [Google Scholar] [CrossRef]
- Ren, M.; Zhang, X.; Chen, X.; Zhou, B.; Feng, Z. YOLOv5s-M: A deep learning network model for road pavement damage detection from urban street-view imagery. Int. J. Appl. Earth Obs. Geoinf. 2023, 120, 103335. [Google Scholar] [CrossRef]
- Lv, Z.; Cheng, C.; Lv, H. Automatic identification of pavement cracks in public roads using an optimized deep convolutional neural network model. Philos. Trans. R. Soc. A 2023, 381, 20220169. [Google Scholar] [CrossRef]
- Riid, A.; Lõuk, R.; Pihlak, R.; Tepljakov, A.; Vassiljeva, K. Pavement distress detection with deep learning using the orthoframes acquired by a mobile mapping system. Appl. Sci. 2019, 9, 4829. [Google Scholar] [CrossRef]
- Ho, M.C.; Lin, J.D.; Huang, C.F. Automatic image recognition of pavement distress for improving pavement inspection. GEOMATE J. 2020, 19, 242–249. [Google Scholar] [CrossRef]
- Dadashova, B.; Dobrovolny, C.S.; Tabesh, M. Detecting Pavement Distresses Using Crowdsourced Dashcam Camera Images; Technical Report; Safety through Disruption (Safe-D) University Transportation Center (UTC): College Station, TX, USA, 2021. [Google Scholar]
- Dong, H.; Song, K.; Wang, Y.; Yan, Y.; Jiang, P. Automatic inspection and evaluation system for pavement distress. IEEE Trans. Intell. Transp. Syst. 2021, 23, 12377–12387. [Google Scholar] [CrossRef]
- Ang, G.; Zhiwei, T.; Wei, M.; Yuepeng, S.; Longlong, R.; Yuliang, F.; Jianping, Q.; Lijia, X. Fruits hidden by green: An improved YOLOV8n for detection of young citrus in lush citrus trees. Front. Plant Sci. 2024, 15, 1375118. [Google Scholar] [CrossRef]
- Guo, M.H.; Lu, C.Z.; Hou, Q.; Liu, Z.; Cheng, M.M.; Hu, S.M. Segnext: Rethinking convolutional attention design for semantic segmentation. Adv. Neural Inf. Process. Syst. 2022, 35, 1140–1156. [Google Scholar]
- Qiu, Z.; Huang, Z.; Mo, D.; Tian, X. GSE-YOLO: A Lightweight and High-Precision Model for Identifying the Ripeness of Pitaya (Dragon Fruit) Based on the YOLOv8n Improvement. Horticulturae 2024, 10, 852. [Google Scholar] [CrossRef]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding box regression loss with dynamic focusing mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Qian, L.; Qian, W.; Tian, D.; Zhu, Y.; Zhao, H.; Yao, Y. MSCA-UNet: Multi-scale convolutional attention UNet for automatic cell counting using density regression. IEEE Access 2023, 11, 85990–86001. [Google Scholar] [CrossRef]
- Yu, C.C.; Chen, Y.D.; Cheng, H.Y.; Jiang, C.L. Semantic Segmentation of Satellite Images for Landslide Detection Using Foreground-Aware and Multi-Scale Convolutional Attention Mechanism. Sensors 2024, 24, 6539. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Xue, Z.; Lin, H.; Wang, F. A small target forest fire detection model based on YOLOv5 improvement. Forests 2022, 13, 1332. [Google Scholar] [CrossRef]
- Saydirasulovich, S.N.; Mukhiddinov, M.; Djuraev, O.; Abdusalomov, A.; Cho, Y.I. An improved wildfire smoke detection based on YOLOv8 and UAV images. Sensors 2023, 23, 8374. [Google Scholar] [CrossRef]
- Arya, D.; Maeda, H.; Ghosh, S.K.; Toshniwal, D.; Sekimoto, Y. RDD2020: An annotated image dataset for automatic road damage detection using deep learning. Data Brief 2021, 36, 107133. [Google Scholar] [CrossRef]
- Maeda, H.; Kashiyama, T.; Sekimoto, Y.; Seto, T.; Omata, H. Generative adversarial network for road damage detection. Comput.-Aided Civ. Infrastruct. Eng. 2021, 36, 47–60. [Google Scholar] [CrossRef]
- Ang, G.; Han, R.; Yuepeng, S.; Longlong, R.; Yue, Z.; Xiang, H. Construction and verification of machine vision algorithm model based on apple leaf disease images. Front. Plant Sci. 2023, 14, 1246065. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Damage | Longitudinal Cracks | Transverse Cracks | Alligator Cracks | Potholes |
|---|---|---|---|---|
| number | 17,356 | 13,746 | 20,596 | 18,152 |
| percentage (%) | 24.85% | 19.68% | 29.49% | 25.98% |
| Fold | Precision | Recall | mAP@0.5 | F1 | FPS |
|---|---|---|---|---|---|
| 1 | 0.976 | 0.966 | 0.989 | 0.971 | 263.157 |
| 2 | 0.978 | 0.970 | 0.989 | 0.974 | 270.270 |
| 3 | 0.977 | 0.970 | 0.990 | 0.973 | 270.270 |
| 4 | 0.977 | 0.970 | 0.991 | 0.973 | 270.270 |
| 5 | 0.978 | 0.970 | 0.989 | 0.974 | 270.270 |
| Average | 0.977 | 0.970 | 0.990 | 0.973 | 268.847 |
| Methods | Precision | Recall | mAP@0.5 | FPS | F1 |
|---|---|---|---|---|---|
| YOLOv5s | 0.958 | 0.956 | 0.984 | 238.095 | 0.957 |
| YOLOv5s-MSCA | 0.969 | 0.959 | 0.986 | 227.273 | 0.964 |
| Δ | 0.011 | 0.003 | 0.002 | −10.822 | 0.007 |
| YOLOv5s-MSCA-SPPELAN | 0.977 | 0.968 | 0.990 | 263.158 | 0.972 |
| Δ | 0.008 | 0.009 | 0.004 | 35.885 | 0.008 |
| YOLOv5s-MSCA-SPPELAN-WIOU | 0.975 | 0.970 | 0.990 | 263.158 | 0.973 |
| Δ | −0.002 | 0.002 | 0 | 0 | 0.001 |
| Methods | Precision | Recall | mAP@0.5 | FPS | F1 |
|---|---|---|---|---|---|
| YOLOv5 | 0.958 | 0.956 | 0.984 | 238.095 | 0.960 |
| YOLOv7 | 0.882 | 0.862 | 0.927 | 147.060 | 0.870 |
| YOLOv9 | 0.951 | 0.916 | 0.968 | 41.840 | 0.930 |
| Ours | 0.975 | 0.970 | 0.990 | 263.158 | 0.973 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, H.; Zhao, F.; Yang, D.; Cheng, H.; Zhang, J.; Song, S. Research on Road Damage Detection Algorithms for Intelligent Inspection Robots. Electronics 2025, 14, 2762. https://doi.org/10.3390/electronics14142762
Tian H, Zhao F, Yang D, Cheng H, Zhang J, Song S. Research on Road Damage Detection Algorithms for Intelligent Inspection Robots. Electronics. 2025; 14(14):2762. https://doi.org/10.3390/electronics14142762
Chicago/Turabian StyleTian, Hongsai, Feng Zhao, Dongqing Yang, Haitao Cheng, Jiahao Zhang, and Shuangshuang Song. 2025. "Research on Road Damage Detection Algorithms for Intelligent Inspection Robots" Electronics 14, no. 14: 2762. https://doi.org/10.3390/electronics14142762
APA StyleTian, H., Zhao, F., Yang, D., Cheng, H., Zhang, J., & Song, S. (2025). Research on Road Damage Detection Algorithms for Intelligent Inspection Robots. Electronics, 14(14), 2762. https://doi.org/10.3390/electronics14142762