
An Efficient Malware Detection Method Using a Hybrid ResNet-Transformer Network and IGOA-Based Wrapper Feature Selection


Abstract
1. Introduction
- Introduction of a novel deep neural network, HRT-Net, designed to simultaneously extract both local and global features from malware images, resulting in a comprehensive and enriched representation of complex patterns and previously unknown threats.
- Utilization of a Multi-Head Attention mechanism within the Transformer module to identify long-range dependencies, high-level patterns, and semantic relationships within malware data, which significantly enhances detection accuracy.
- Implementation of a wrapper-based feature selection method employing the Improved Grasshopper Optimization Algorithm (IGOA), capable of identifying relevant features while eliminating redundant ones, thereby reducing inter-feature redundancy and improving model efficiency.
- Introducing an efficient and novel dynamic optimization technique, defined as Improved Grasshopper Optimization Algorithm (IGOA), with dynamic mutation coefficient and dynamic inertia motion weights to decrease the risk of convergence into local optima for selecting optimal features in malware detection systems.
- Adoption of the Ensemble Learning classification algorithm to build a noise-resilient and stable model capable of accurately detecting various types of malware, ultimately enhancing the overall performance and robustness of the proposed approach.
2. Related Works
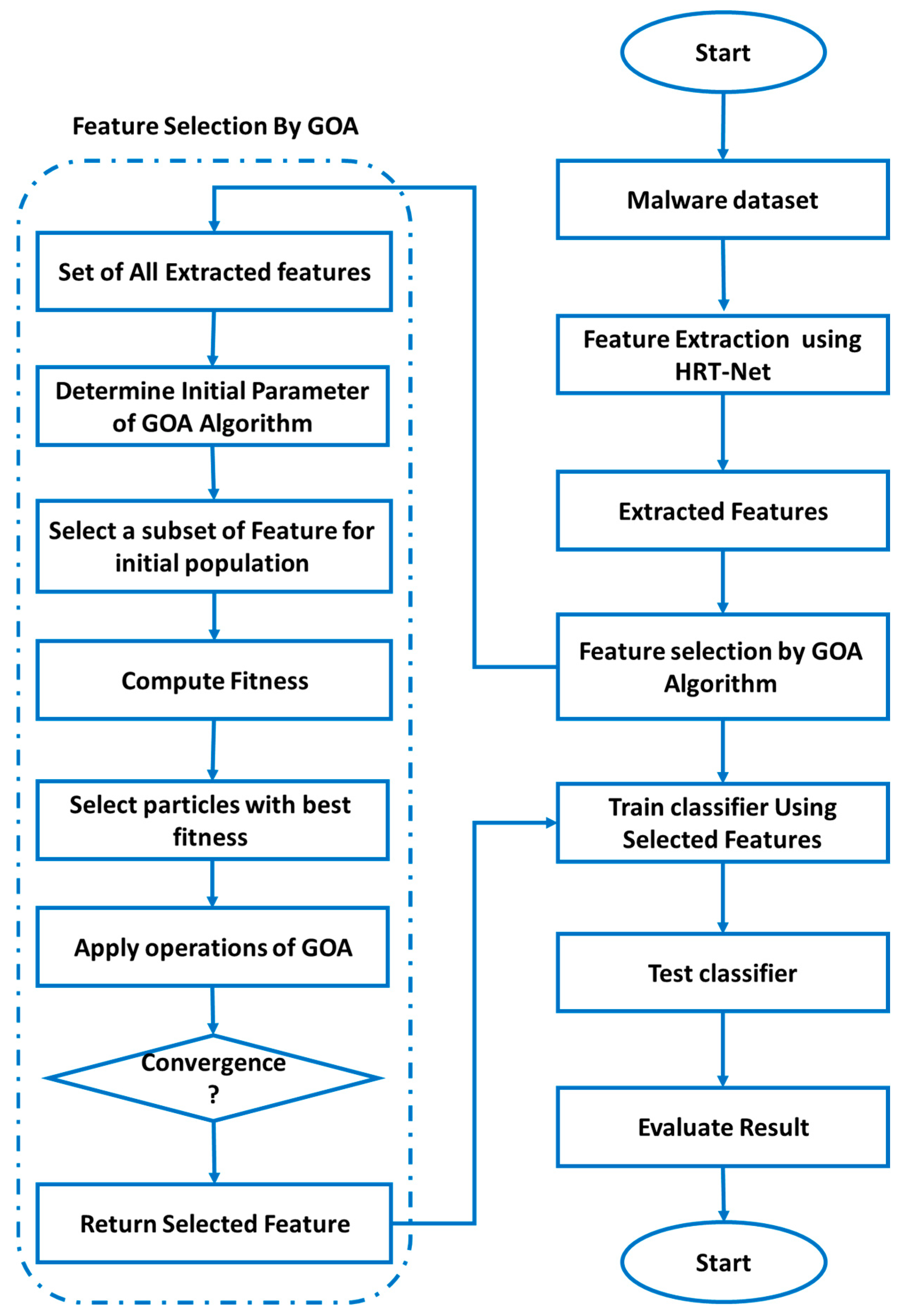
3. Materials and Methods
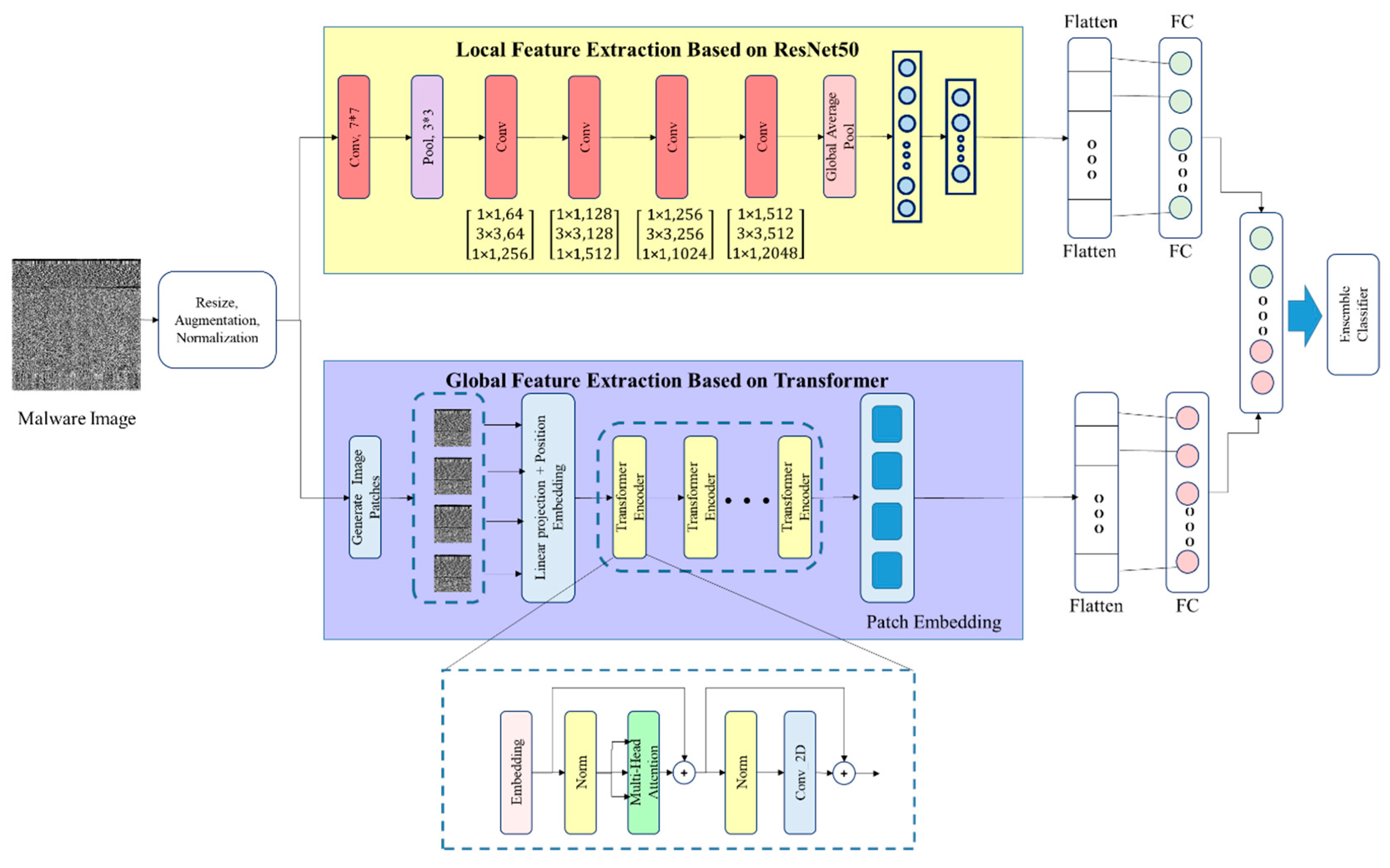
3.1. Feature Extraction Using Hybrid Resnet-Transformer Network (HRT-Net)
- Layer Normalization: Stabilizes and accelerates training by normalizing the input features.
- Multi-Head Self-Attention: Enables the model to learn dependencies between distant regions of the image. This mechanism uses query (Q), key (K), and value (V) matrices to compute attention scores, defined as follows:where is the dimensionality of the key vectors, and the softmax function normalizes the attention weights.
- Two-layer Feedforward Network (MLP): Enhances the model’s nonlinearity and capacity to learn higher-order feature interactions.
3.2. Selection of Optimal Features with the Improved Grasshopper Optimization Algorithm
- Step 1: Initialization of Parameters
- Step 2: Generation of Initial Population
- Step 3: Evaluation of the Fitness Function
- Step 4: Identification of the Best Discovered Solution
- Step 5: Position Update of Grasshoppers
- Step 6: Update of Dynamic Inertia Weight
- Step 7: Application of Jumping Based on Dynamic Jump Probability Coefficient and Triangular Jump Strategy
- Step 8: Stopping Condition
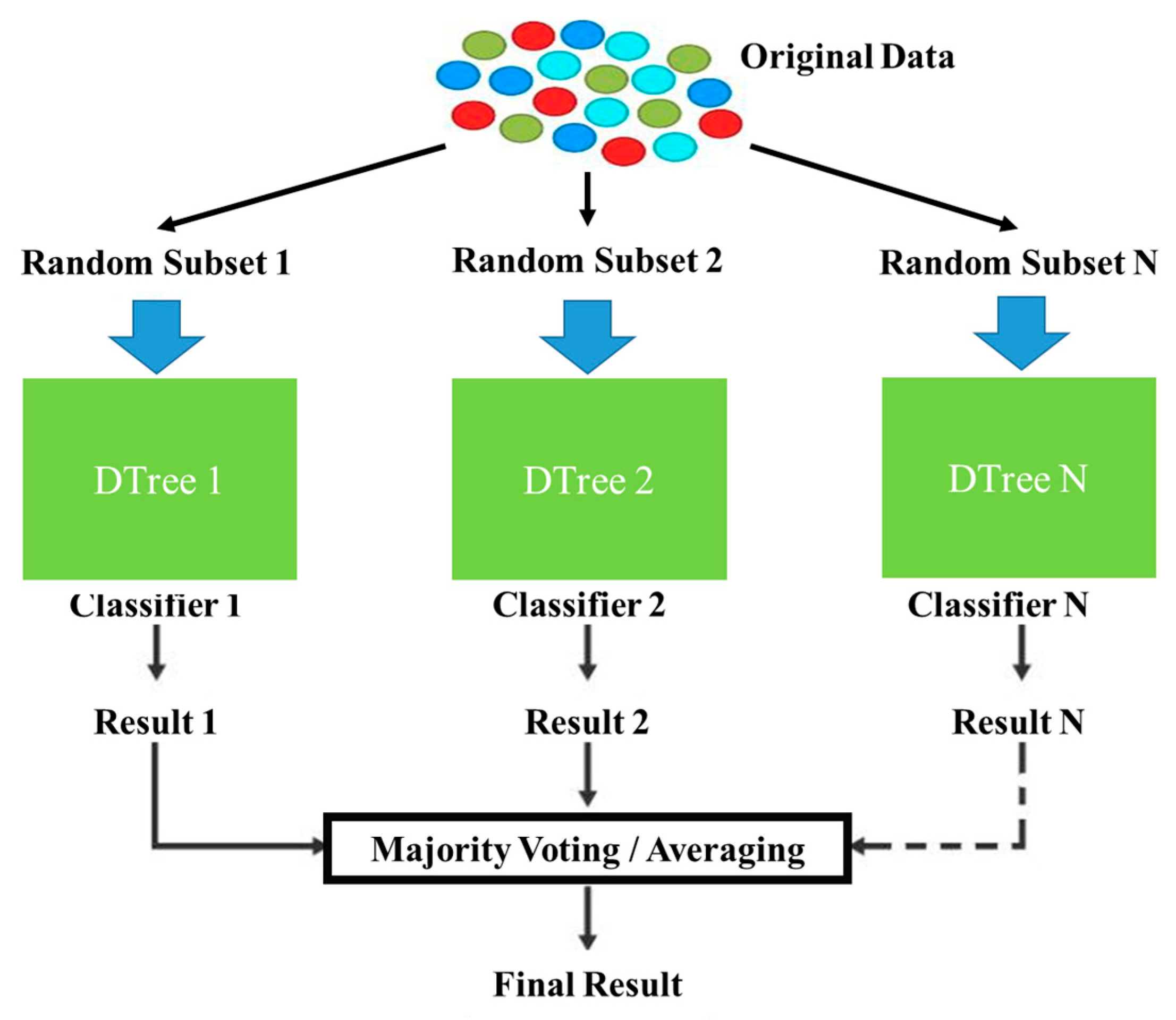
3.3. Classification Using Ensemble Learning Technique
3.4. Investigating the Feature Selection Process on Computational Complexity in the Classification Stage
4. Results
4.1. Database
4.2. Evaluation Metric
- True Positive (TP): Refers to the samples that are truly identified as positive.
- False Positive (FP): Indicates the samples that are falsely identified as positive.
- False Negative (FN): Represents the samples that are wrongly identified as negative.
- True Negative (TN): Refers to the samples that are correctly identified as negative.
4.3. Results Evaluation
4.3.1. Evaluation of Training Process for Ensemble Learning
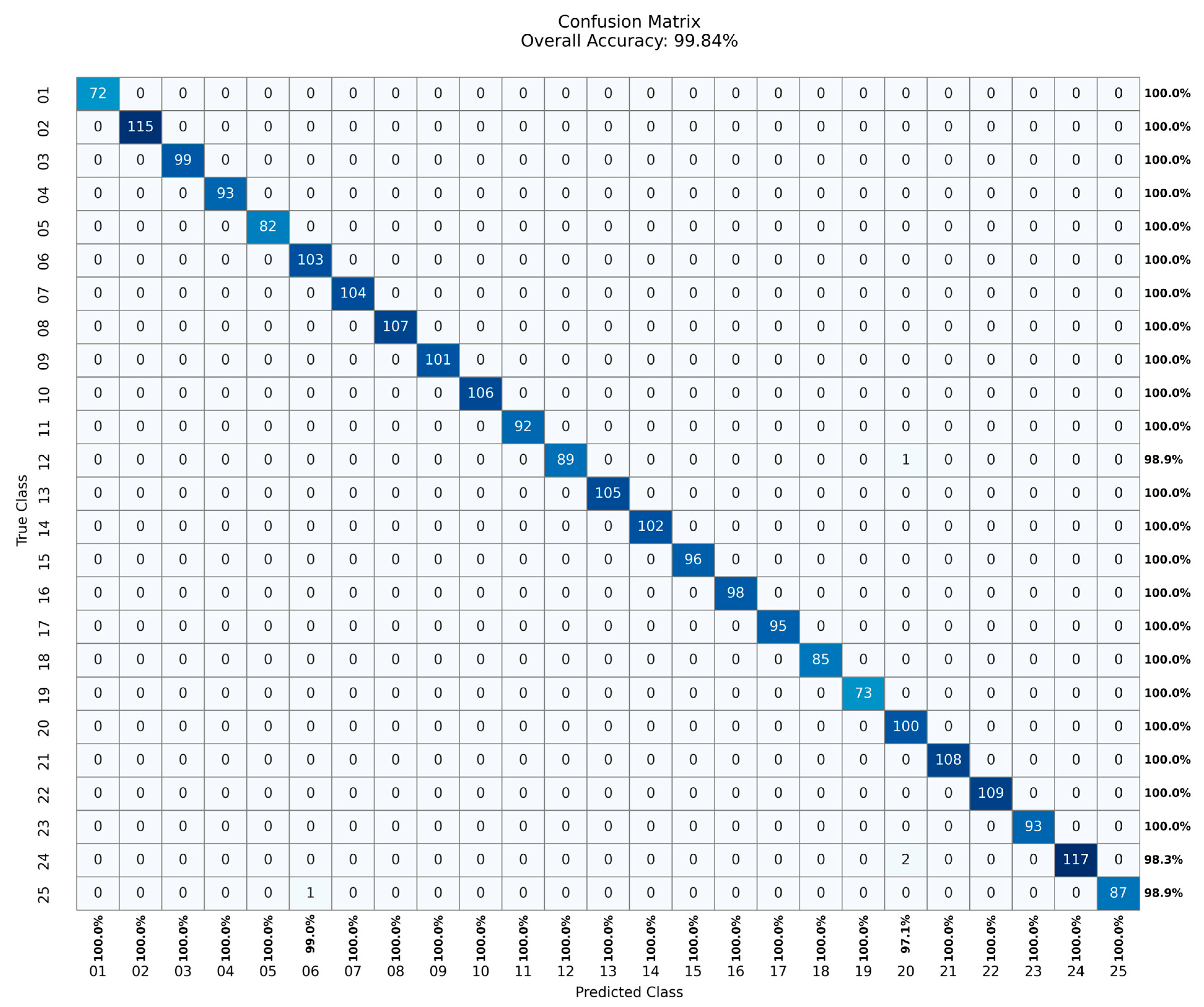
4.3.2. Evaluation of Test Process for Ensemble Learning
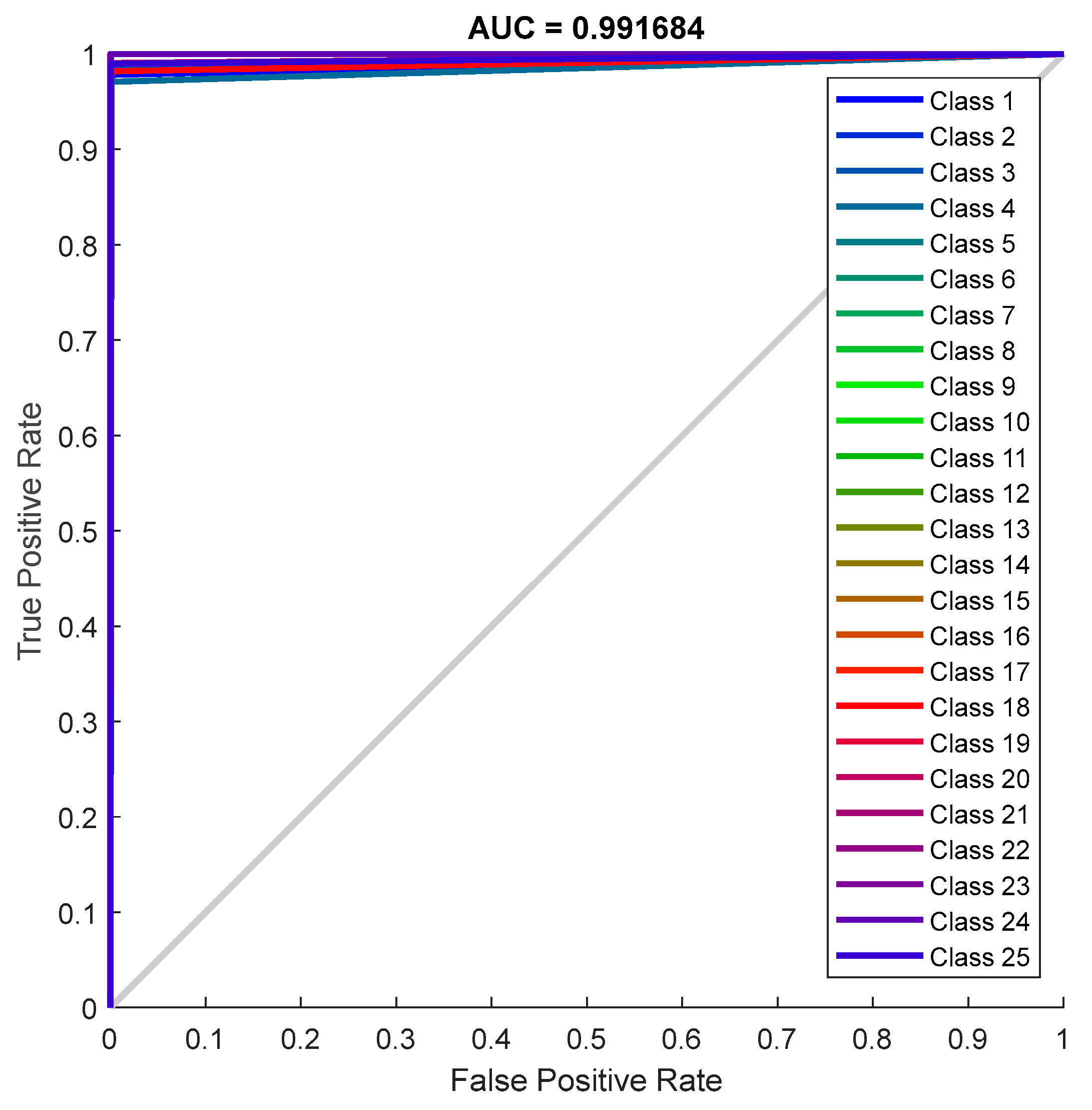
4.3.3. Receiver Operating Characteristic (ROC) Analysis
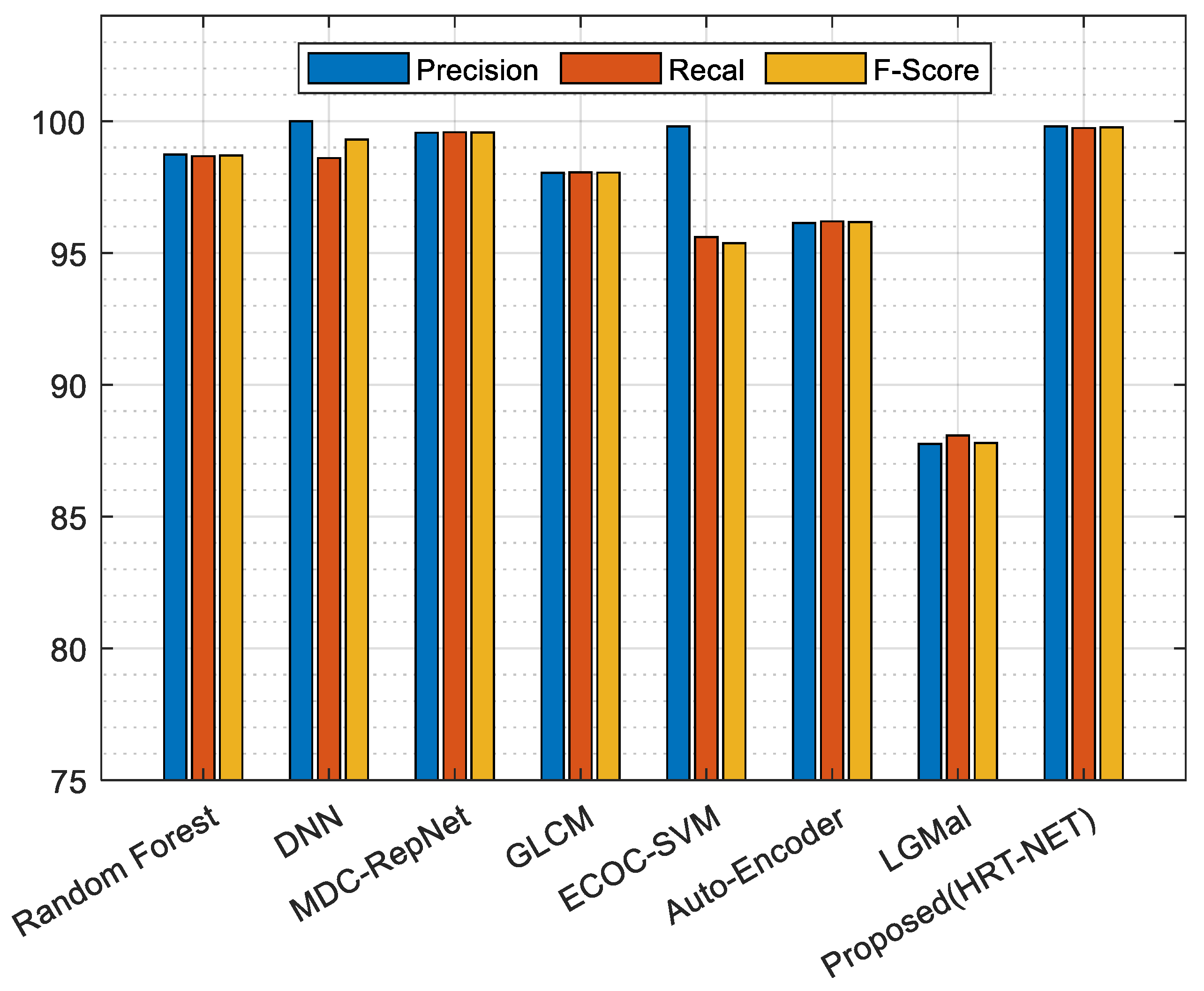
4.3.4. Results Comparison and Discussion
5. Conclusions
6. Future Work
- Firstly, recognizing that the current Ensemble Learning technique utilized is “quite time consuming,” a significant focus will be placed on optimizing the computational efficiency of the classification phase. This involves exploring more lightweight ensemble methodologies, investigating parallel processing techniques, or developing adaptive ensemble strategies that dynamically select models based on real-time constraints, thereby reducing detection latency without compromising accuracy.
- Secondly, while HRT-Net effectively extracts features from malware images for static analysis, a crucial next step is to extend its capabilities to dynamic analysis. This involves integrating behavioral features derived from API calls, system logs, or network traffic. A hybrid static-dynamic analysis approach could provide a more comprehensive understanding of malware behavior, significantly enhancing detection robustness against advanced obfuscation techniques and zero-day threats.
- Furthermore, we aim to rigorously evaluate the HRT-Net’s performance against significantly larger and more diverse real-world malware datasets, including those containing a higher volume of previously unseen (zero-day) and highly evasive samples. This will allow for a more robust assessment of its scalability and generalization capabilities in real-world cybersecurity scenarios.
- Finally, two additional critical directions for future work include assessing the HRT-Net’s resilience against adversarial attacks specifically designed to evade deep learning-based detectors and enhancing the interpretability and explainability of the model’s decisions, providing security analysts with actionable insights into the malicious characteristics identified by the system.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ferdous, J.; Islam, R.; Mahboubi, A.; Islam, M.Z. A Survey on ML Techniques for Multi-Platform Malware Detection: Securing PC, Mobile Devices, IoT, and Cloud Environments. Sensors 2025, 25, 1153. [Google Scholar] [CrossRef] [PubMed]
- Kumar, S.S.; Stephen, S.; Rumysia, M.S. Rootkit detection using deep learning: A comprehensive survey. In Proceedings of the 10th International Conference on Communication and Signal Processing (ICCSP), Melmaruvathur, India, 12–14 April 2024; IEEE: New York, NY, USA, 2024. [Google Scholar]
- Sharma, T.; Patni, K.; Li, Z.; Trajković, L. Deep echo state networks for detecting internet worm and ransomware attacks. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS), Monterey, CA, USA, 21–25 May 2023; IEEE: New York, NY, USA, 2023. [Google Scholar]
- Zhan, D.; Xu, K.; Liu, X.; Han, T.; Pan, Z.; Guo, S. Practical clean-label backdoor attack against static malware detection. Comput. Secur. 2025, 150, 104280. [Google Scholar] [CrossRef]
- Ahila, A.; Lakshmi, A.A.; Ragavendran, N.; Purushothaman, K.E.; Maheswari, G.U.; Saravanakumar, R. Advancements in Cybersecurity Using Deep Learning Techniques Attack Detection for Trojan Horses. In Proceedings of the International Conference on Electrical Electronics and Computing Technologies (ICEECT), Greater Noida, India, 29–31 August 2024; IEEE: New York, NY, USA, 2024; Volume 1. [Google Scholar]
- Almoqbil, A.H.N. Anomaly detection for early ransomware and spyware warning in nuclear power plant systems based on FusionGuard. Int. J. Inf. Secur. 2024, 23, 2377–2394. [Google Scholar] [CrossRef]
- Gautam, A.; Rahimi, N. Viability of machine learning in android scareware detection. Proceedings of 38th International Conference on Computers and Their Applications, Online, 20–22 March 2023; Volume 91, pp. 19–26. [Google Scholar]
- Velasco Mata, J. Botnet Activity Spotting with Artificial Intelligence: Efficient Bot Malware Detection and Social Bot Identification. Ph.D. Thesis, Universidad de León, León, Spain, 2023. [Google Scholar]
- Bensaoud, A.; Kalita, J.; Bensaoud, M. A survey of malware detection using deep learning. Mach. Learn. Appl. 2024, 16, 100546. [Google Scholar] [CrossRef]
- Pang, S.; Wen, J.; Liang, S.; Huang, B. FICConvNet: A Privacy-Preserving Framework for Malware Detection Using CKKS Homomorphic Encryption. Electronics 2025, 14, 1982. [Google Scholar] [CrossRef]
- Silfiah, R.I.; Sulatri, K.; Ismail, Y. Legal Protection of Consumers with Online Transactions. J. Law Politic Humanit. 2024, 4, 2584–2595. [Google Scholar]
- Ighomereho, O.S.; Afolabi, T.S.; Oluwakoya, A.O. Impact of E-service quality on customer satisfaction: A study of internet banking for general and maritime services in Nigeria. J. Financ. Serv. Mark. 2023, 28, 488–501. [Google Scholar] [CrossRef]
- Laghari, A.A.; Jumani, A.K.; Laghari, R.A.; Li, H.; Karim, S.; Khan, A.A. Unmanned aerial vehicles advances in object detection and communication security review. Cogn. Robot. 2024, 4, 128–141. [Google Scholar] [CrossRef]
- Zhukabayeva, T.; Zholshiyeva, L.; Karabayev, N.; Khan, S.; Alnazzawi, N. Cybersecurity Solutions for Industrial Internet of Things–Edge Computing Integration: Challenges, Threats, and Future Directions. Sensors 2025, 25, 213. [Google Scholar] [CrossRef]
- Alhogail, A.; Alharbi, R.A. Effective ML-Based Android Malware Detection and Categorization. Electronics 2025, 14, 1486. [Google Scholar] [CrossRef]
- Lee, J.; Kim, J.; Jeong, H.; Lee, K. A Machine Learning-Based Ransomware Detection Method for Attackers’ Neutralization Techniques Using Format-Preserving Encryption. Sensors 2025, 25, 2406. [Google Scholar] [CrossRef]
- Tumuluru, P.; LRBurra MVVReddy SSudarsa, S.Y.; Reddy, A.L.A. APMWMM: Approach to Probe Malware on Windows Machine using Machine Learning. In Proceedings of the 2022 International Conference on Applied Artificial Intelligence and Computing (ICAAIC), Salem, India, 9–11 May 2022; pp. 614–619. [Google Scholar] [CrossRef]
- Duby, A.; Taylor, T.; Bloom, G.; Zhuang, Y. Detecting and Classifying Self-Deleting Windows Malware Using Prefetch Files. In Proceedings of the 2022 IEEE 12th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 26–29 January 2022; pp. 745–751. [Google Scholar] [CrossRef]
- Duby, A.; Taylor, T.; Bloom, G.; Zhuang, Y. Evaluating Feature Robustness for Windows Malware Family Classification. In Proceedings of the 2022 International Conference on Computer Communications and Networks (ICCCN), Honolulu, HI, USA, 25–27 July 2022; pp. 1–10. [Google Scholar] [CrossRef]
- Ficco, M. Malware Analysis by Combining Multiple Detectors and Observation Windows. IEEE Trans. Comput. 2022, 71, 1276–1290. [Google Scholar] [CrossRef]
- Namita; Prachi; Sharma, P. Windows Malware Detection using Machine Learning and TF-IDF Enriched API Calls Information. In Proceedings of the 2022 Second International Conference on Computer Science, Engineering and Applications (ICCSEA), Gunupur, India, 8 September 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Nawshin, F.; Gad, R.; Unal, D.; Al-Ali, A.K.; Suganthan, P.N. Malware detection for mobile computing using secure and privacy-preserving machine learning approaches: A comprehensive survey. Comput. Electr. Eng. 2024, 117, 109233. [Google Scholar] [CrossRef]
- Uysal, D.T.; Yoo, P.D.; Taha, K. Data-Driven Malware Detection for 6G Networks: A Survey From the Perspective of Continuous Learning and Explainability via Visualisation. IEEE Open J. Veh. Technol. 2023, 4, 61–71. [Google Scholar] [CrossRef]
- Gopinath, M.; Sethuraman, S.C. A comprehensive survey on deep learning based malware detection techniques. Comput. Sci. Rev. 2023, 47, 100529. [Google Scholar]
- Gaurav, A.; Gupta, B.B.; Panigrahi, P.K. A Comprehensive Survey on Machine Learning Approaches for Malware Detection in IoT-Based Enterprise Information System. Enterp. Inf. Syst. 2022, 17, 1–25. [Google Scholar] [CrossRef]
- Yadav, P.; Menon, N.; Ravi, V.; Vishvanathan, S.; Pham, T.D. EfficientNet Convolutional Neural Networks-Based Android Malware Detection. Comput. Secur. 2022, 115, 102622. [Google Scholar] [CrossRef]
- Rey, V.; Sánchez, P.M.S.; Celdrán, A.H.; Bovet, G. Federated Learning for Malware Detection in IoT Devices. Comput. Netw. 2022, 204, 108693. [Google Scholar] [CrossRef]
- Cai, H. Assessing and Improving Malware Detection Sustainability through App Evolution Studies. ACM Trans. Softw. Eng. Methodol. 2020, 29, 1–28. [Google Scholar] [CrossRef]
- Xu, K.; Li, Y.; Deng, R.; Chen, K.; Xu, J. DroidEvolver: Self-Evolving Android Malware Detection System. In Proceedings of the IEEE European Symposium on Security and Privacy (EuroS&P), Vienna, Austria, 8–12 June 2019; pp. 47–62. [Google Scholar]
- Gibert, D.; Mateu, C.; Planes, J. A Hierarchical Convolutional Neural Network for Malware Classification. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Sharma, A.; Malacaria, P.; Khouzani, M.H.R. Malware Detection Using 1-Dimensional Convolutional Neural Networks. In Proceedings of the 2019 IEEE European Symposium on Security and Privacy Workshops (EuroS&PW), Stockholm, Sweden, 17–19 June 2019; pp. 247–256. [Google Scholar] [CrossRef]
- Shiva Darshan, S.L.; Jaidhar, C.D. Windows Malware Detector Using Convolutional Neural Network Based on Visualization Images. IEEE Trans. Emerg. Top. Comput. 2019, 9, 1057–1069. [Google Scholar] [CrossRef]
- Shaukat, K.; Luo, S.; Varadharajan, V. A Novel Deep Learning-Based Approach for Malware Detection. Eng. Appl. Artif. Intell. 2023, 122, 106030. [Google Scholar] [CrossRef]
- Aslan, O.; Yilmaz, A.A. A New Malware Classification Framework Based on Deep Learning Algorithms. IEEE Access 2021, 9, 87936–87951. [Google Scholar] [CrossRef]
- Maniriho, P.; Mahmood, A.N.; Chowdhury, M.J.M. API-MalDetect: Automated Malware Detection Framework for Windows Based on API Calls and Deep Learning Techniques. J. Netw. Comput. Appl. 2023, 218, 103704. [Google Scholar] [CrossRef]
- Chai, Y.; Qiu, J.; Su, S.; Zhu, C.; Yin, L.; Tian, Z. LGMal: A Joint Framework Based on Local and Global Features for Malware Detection. In Proceedings of the International Wireless Communications and Mobile Computing Conference (IWCMC), Limassol, Cyprus, 15–19 June 2020; pp. 463–468. [Google Scholar] [CrossRef]
- Peng, J.; Kang, S.; Ning, Z.; Deng, H.; Shen, J.; Xu, Y.; Zhang, J.; Zhao, W.; Li, X.; Gong, W.; et al. Residual Convolutional Neural Network for Predicting Response of Transarterial Chemoembolization in Hepatocellular Carcinoma from CT Imaging. Eur. Radiol. 2020, 30, 413–424. [Google Scholar] [CrossRef] [PubMed]
- Obaid, Z.H.; Mirzaei, B.; Darroudi, A. An Efficient Automatic Modulation Recognition Using Time–Frequency Information Based on Hybrid Deep Learning and Bagging Approach. Knowl. Inf. Syst. 2024, 66, 2607–2624. [Google Scholar] [CrossRef]
- Malimg Malware Dataset. Available online: https://www.kaggle.com/datasets/manmandes/malimg (accessed on 1 May 2025).
- Verma, V.; Muttoo, S.K.; Singh, V.B. Multiclass Malware Classification via First- and Second-Order Texture Statistics. Comput. Secur. 2020, 97, 101895. [Google Scholar] [CrossRef]
- Atitallah, S.B.; Driss, M.; Almomani, I. A Novel Detection and Multi-Classification Approach for IoT-Malware Using Random Forest Voting of Fine-Tuning Convolutional Neural Networks. Sensors 2022, 22, 4302. [Google Scholar] [CrossRef]
- Shaukat, K.; Luo, S.; Varadharajan, V. A Novel Machine Learning Approach for Detecting First-Time-Appeared Malware. Eng. Appl. Artif. Intell. 2024, 131, 107801. [Google Scholar] [CrossRef]
- Li, S.; Wang, J.; Song, Y.; Wang, S.; Wang, Y. A Lightweight Model for Malicious Code Classification Based on Structural Reparameterisation and Large Convolutional Kernels. Int. J. Comput. Intell. Syst. 2024, 17, 30. [Google Scholar] [CrossRef]
- Wong, W.; Juwono, F.H.; Apriono, C. Vision-Based Malware Detection: A Transfer Learning Approach Using Optimal ECOC-SVM Configuration. IEEE Access 2021, 9, 159262–159270. [Google Scholar] [CrossRef]
- Xing, X.; Jin, X.; Elahi, H.; Jiang, H.; Wang, G. A Malware Detection Approach Using Autoencoder in Deep Learning. IEEE Access 2022, 10, 25696–25706. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Class | Family | # | Class | Family |
|---|---|---|---|---|---|
| 1 | Worm | Allaple L | 14 | Trojan | Alueron.gen!J |
| 2 | Worm | Allaple A | 15 | Trojan | Malex.gen!J |
| 3 | Worm | Yuner A | 16 | PWS | Lolyda AT |
| 4 | PWS | Lolyda AA 1 | 17 | Dialer | Adialer.C |
| 5 | PWS | Lolyda AA 2 | 18 | TDownloader | Wintrim BX |
| 6 | PWS | Lolyda AA 3 | 19 | Dialer | Dialplatform B |
| 7 | Trojan | C2Lop.P | 20 | TDownloader | Dontovo A |
| 8 | Trojan | C2Lop.gen!g | 21 | TDownloader | Obfuscator.AD |
| 9 | Dialer | Instantaccess | 22 | Backdoor | Agent. FYI |
| 10 | TDownloader | Swizzot.gen!I | 23 | Worm AutoIT | Autorun K |
| 11 | TDownloader | Swizzor.gen!E | 24 | Backdoor | Rbot!gen |
| 12 | Worm | VB.AT | 25 | Trojan | Skintrim N |
| 13 | Rogue | Fakerean |
| Methods | Precision | Recall | F1-Score |
|---|---|---|---|
| GLCM [40] | 98.04 | 98.06 | 98.05 |
| Random Forest [41] | 98.74 | 98.67 | 98.70 |
| DNN [42] | 100 | 98.60 | 99.30 |
| MDC-RepNet [43] | 99.56 | 99.58 | 99.57 |
| ECOC –SVM [44] | 99.80 | 95.6 | 95.37 |
| Auto Encoder [45] | 96.14 | 96.20 | 96.17 |
| LGMal [36] | 87.76 | 88.08 | 87.79 |
| Proposed (HRT-Net-IGOA-Ensemble Learning) | 99.80 | 99.74 | 99.77 |
| Authors | Methods | Accuracy |
|---|---|---|
| Verma, et al. [40] | GLCM | 98.58 |
| Atitallah et al. [41] | Random Forest | 98.68 |
| Shaukat et al. [42] | DNN | 99.30 |
| Li, Sicong et al. [43] | MDC-RepNet | 99.57 |
| Wong, W. et al. [44] | ECOC-SVM | 95.01 |
| XIAOFEI XING et al. [45] | Auto Encoder | 96.22 |
| Yuhan Chai et al. [36] | LGMal | 88.78 |
| - | Proposed (HRT-Net-IGOA-Ensemble Learning) | 99.85 |
| Classes | GLCM | RF | DNN | MDC-RepNet | ECOC-SVM | Auto Encoder | LGMal | Proposed |
|---|---|---|---|---|---|---|---|---|
| C1 | 100 | 97.8 | 100 | 99.28 | 91.68 | 93.7 | 100 | 100 |
| C2 | 97.63 | 97.8 | 100 | 99.28 | 91.68 | 100 | 81.3 | 100 |
| C3 | 97.63 | 100 | 100 | 99.28 | 91.68 | 100 | 100 | 100 |
| C4 | 97.63 | 100 | 98.83 | 99.28 | 91.68 | 93.7 | 100 | 100 |
| C5 | 97.63 | 97.8 | 98.83 | 100 | 91.68 | 93.7 | 81.3 | 100 |
| C6 | 97.63 | 100 | 100 | 99.28 | 100 | 100 | 100 | 100 |
| C7 | 100 | 97.8 | 98.83 | 99.28 | 91.68 | 100 | 81.3 | 100 |
| C8 | 97.63 | 97.8 | 100 | 99.28 | 91.68 | 93.7 | 81.3 | 100 |
| C9 | 100 | 100 | 98.83 | 100 | 100 | 93.7 | 100 | 100 |
| C10 | 100 | 100 | 98.83 | 99.28 | 100 | 100 | 81.3 | 100 |
| C11 | 100 | 97.8 | 98.83 | 100 | 91.68 | 93.7 | 100 | 100 |
| C12 | 97.63 | 97.8 | 98.83 | 100 | 100 | 93.7 | 81.3 | 98.9 |
| C13 | 97.63 | 97.8 | 98.83 | 100 | 91.68 | 93.7 | 81.3 | 100 |
| C14 | 97.63 | 100 | 98.83 | 99.28 | 100 | 93.7 | 81.3 | 100 |
| C15 | 100 | 100 | 98.83 | 99.28 | 100 | 93.7 | 81.3 | 100 |
| C16 | 97.63 | 97.8 | 100 | 99.28 | 91.68 | 93.7 | 100 | 100 |
| C17 | 97.63 | 97.8 | 98.83 | 100 | 91.68 | 100 | 81.3 | 100 |
| C18 | 100 | 97.8 | 98.83 | 100 | 91.68 | 100 | 81.3 | 100 |
| C19 | 100 | 97.8 | 98.83 | 99.28 | 100 | 93.7 | 100 | 100 |
| C20 | 97.63 | 100 | 98.83 | 100 | 91.68 | 93.7 | 81.3 | 100 |
| C21 | 97.63 | 97.8 | 100 | 100 | 91.68 | 100 | 100 | 100 |
| C22 | 97.63 | 100 | 100 | 100 | 91.68 | 93.7 | 100 | 100 |
| C23 | 100 | 97.8 | 98.83 | 99.28 | 100 | 100 | 81.3 | 100 |
| C24 | 97.63 | 97.8 | 100 | 99.28 | 100 | 93.7 | 81.3 | 98.3 |
| C25 | 100 | 100 | 100 | 99.28 | 100 | 100 | 81.3 | 98.9 |
| Av. | 98.58 | 98.68 | 99.30 | 99.57 | 95.01 | 96.22 | 88.78 | 99.85 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hafeth, A.A.; Abdullahi, A.I. An Efficient Malware Detection Method Using a Hybrid ResNet-Transformer Network and IGOA-Based Wrapper Feature Selection. Electronics 2025, 14, 2741. https://doi.org/10.3390/electronics14132741
Hafeth AA, Abdullahi AI. An Efficient Malware Detection Method Using a Hybrid ResNet-Transformer Network and IGOA-Based Wrapper Feature Selection. Electronics. 2025; 14(13):2741. https://doi.org/10.3390/electronics14132741
Chicago/Turabian StyleHafeth, Ali Abbas, and Abdu Ibrahim Abdullahi. 2025. "An Efficient Malware Detection Method Using a Hybrid ResNet-Transformer Network and IGOA-Based Wrapper Feature Selection" Electronics 14, no. 13: 2741. https://doi.org/10.3390/electronics14132741
APA StyleHafeth, A. A., & Abdullahi, A. I. (2025). An Efficient Malware Detection Method Using a Hybrid ResNet-Transformer Network and IGOA-Based Wrapper Feature Selection. Electronics, 14(13), 2741. https://doi.org/10.3390/electronics14132741