

Causality and “In-the-Wild” Video-Based Person Re-Identification: A Survey




Abstract
1. Introduction
- We provide a comprehensive taxonomy of causal methods in re-identification, covering structural modeling, interventional training, adversarial disentanglement, and counterfactual evaluation;
- We review state-of-the-art causal re-identification models (e.g., DIR-ReID, IS-GAN, UCT) and analyze their performance across real-world challenges such as clothing change, domain shift, and multi-modality;
- We propose a unified causal framework for reasoning about identity, confounders, and interventions in re-identification pipelines;
- We discuss emerging causal evaluation metrics, interpretability tools, and benchmark gaps that must be addressed for widespread adoption;
- We identify open problems and outline future research directions at the intersection of causality, efficiency, privacy, and fairness in real-world re-identification systems.
2. Fundamentals of Person Re-Identification
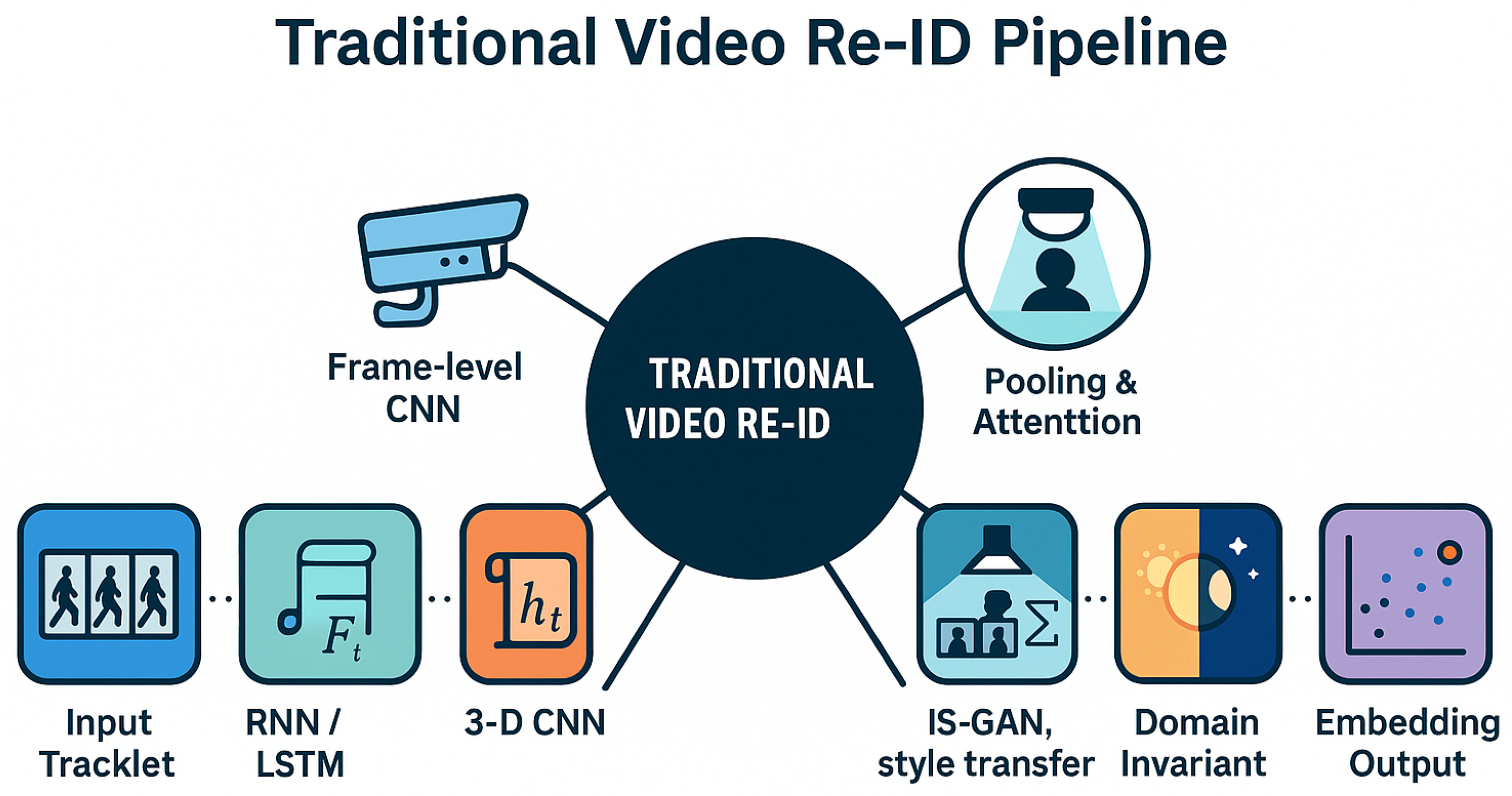
2.1. Overview of Video-Based Person Re-Identification
2.2. Challenges in Video-Based Re-Identification
2.3. Traditional Approaches and Their Limitations
- (1)
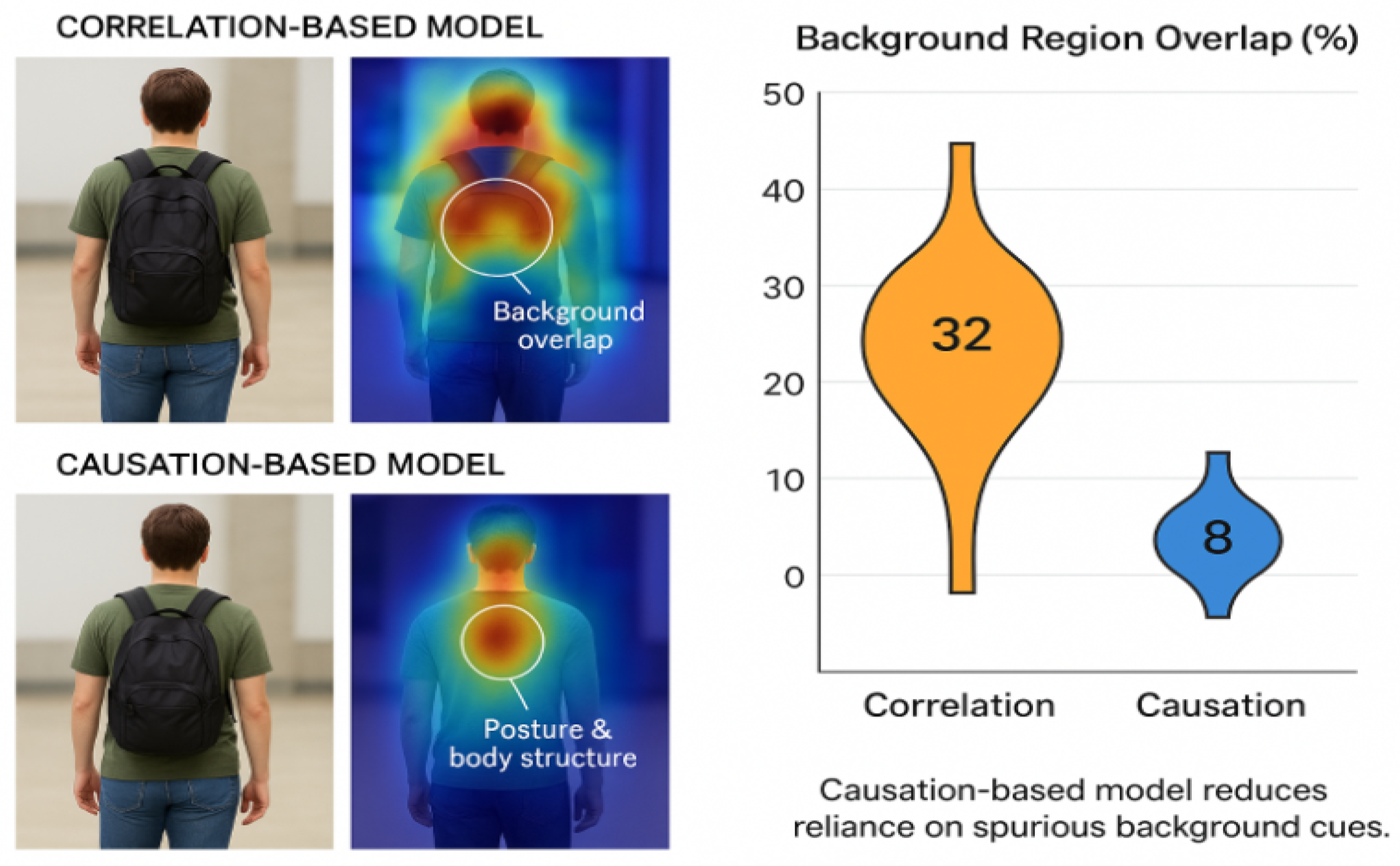
- Spurious Correlation Dependence: Traditional models conflate identity-specific features (gait, body structure) with confounding factors (clothing, background, lighting), causing performance degradation under domain shifts [4,6]. Causal alternative: Structural causal models (SCMs) explicitly separate identity factors from confounders through interventional training, ensuring robust identity representations [5,12].
- (2)
- Lack of Invariance Guarantees: RNN-based temporal modeling and attention mechanisms fail to provide theoretical guarantees about feature invariance across environmental changes [18,19]. Causal alternative: Counterfactual reasoning enforces consistency constraints, ensuring that identity predictions remain stable under hypothetical attribute changes [10,14].
- (3)
- Limited Generalization Capability: Domain-invariant methods still rely on statistical correlations that can be easily confounded by spurious factors, reducing cross-domain robustness [5,16]. Causal alternative: Do-calculus and backdoor adjustment block confounding pathways, enabling reliable identity matching across dramatic environmental variations [1,20].
2.4. The Role of Visual Attributes in Video-Based Person Re-Identification
2.5. Attribute-Specific Evaluation Metrics for Video-Based Person Re-Identification
2.6. Common Datasets for Video-Based Person Re-Identification
3. Causal Foundations for Person Re-Identification
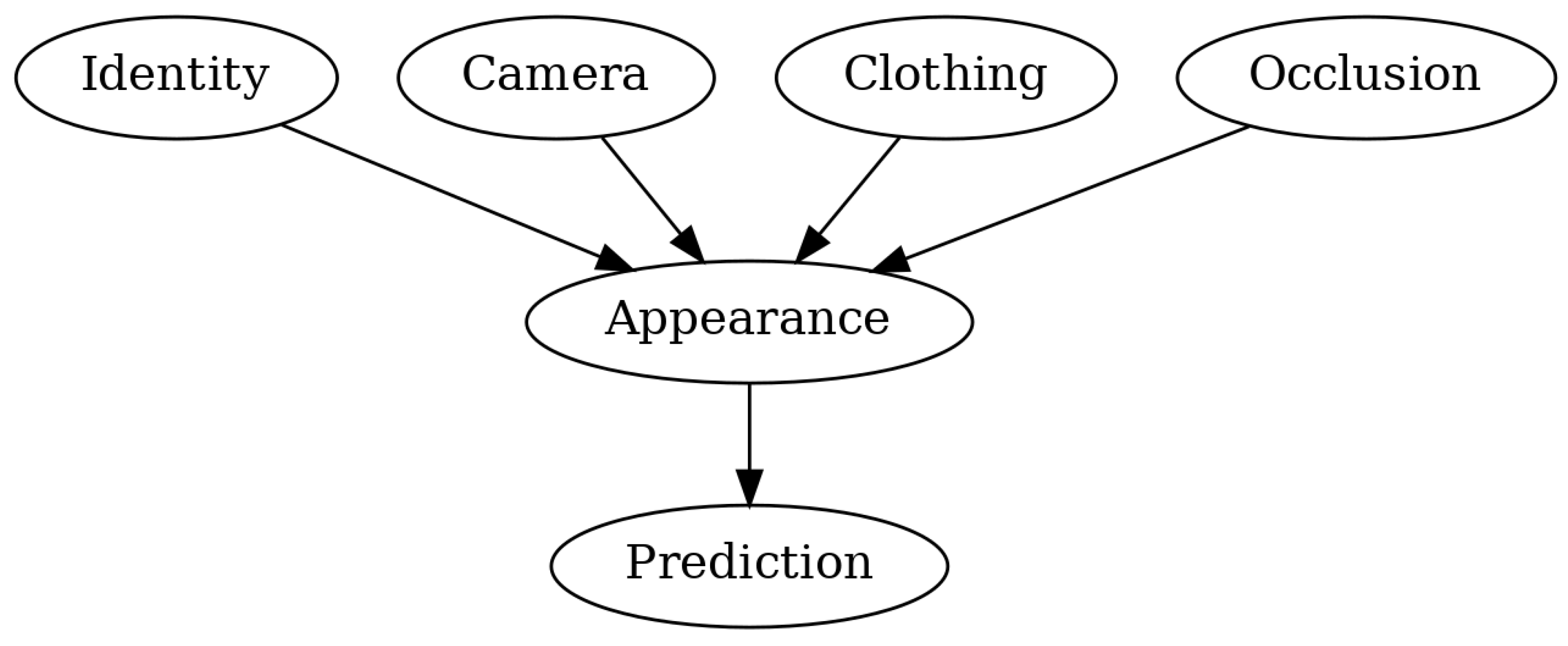
- Causal Inference: Unlike statistical correlation, which merely identifies patterns of association, causal inference aims to understand the underlying cause-and-effect relationships between variables [10,12]. In re-identification, this means distinguishing which visual features truly cause identity recognition (e.g., body structure) versus those that merely correlate with identity in specific contexts (e.g., clothing) [5].
- Structural Causal Models (SCMs): Mathematical frameworks that use directed graphs to explicitly represent causal relationships between variables [10,11]. In these graphs, nodes represent variables (such as identity, clothing, or background) and directed edges represent the causal influence of one variable on another [5,15].
3.1. Introduction to Causal Inference
3.2. Structural Causal Models (SCMs) and Counterfactual Reasoning
3.3. Key Causal Concepts in Re-Identification
3.4. An Intuitive Example of Causal Intervention in Re-Identification
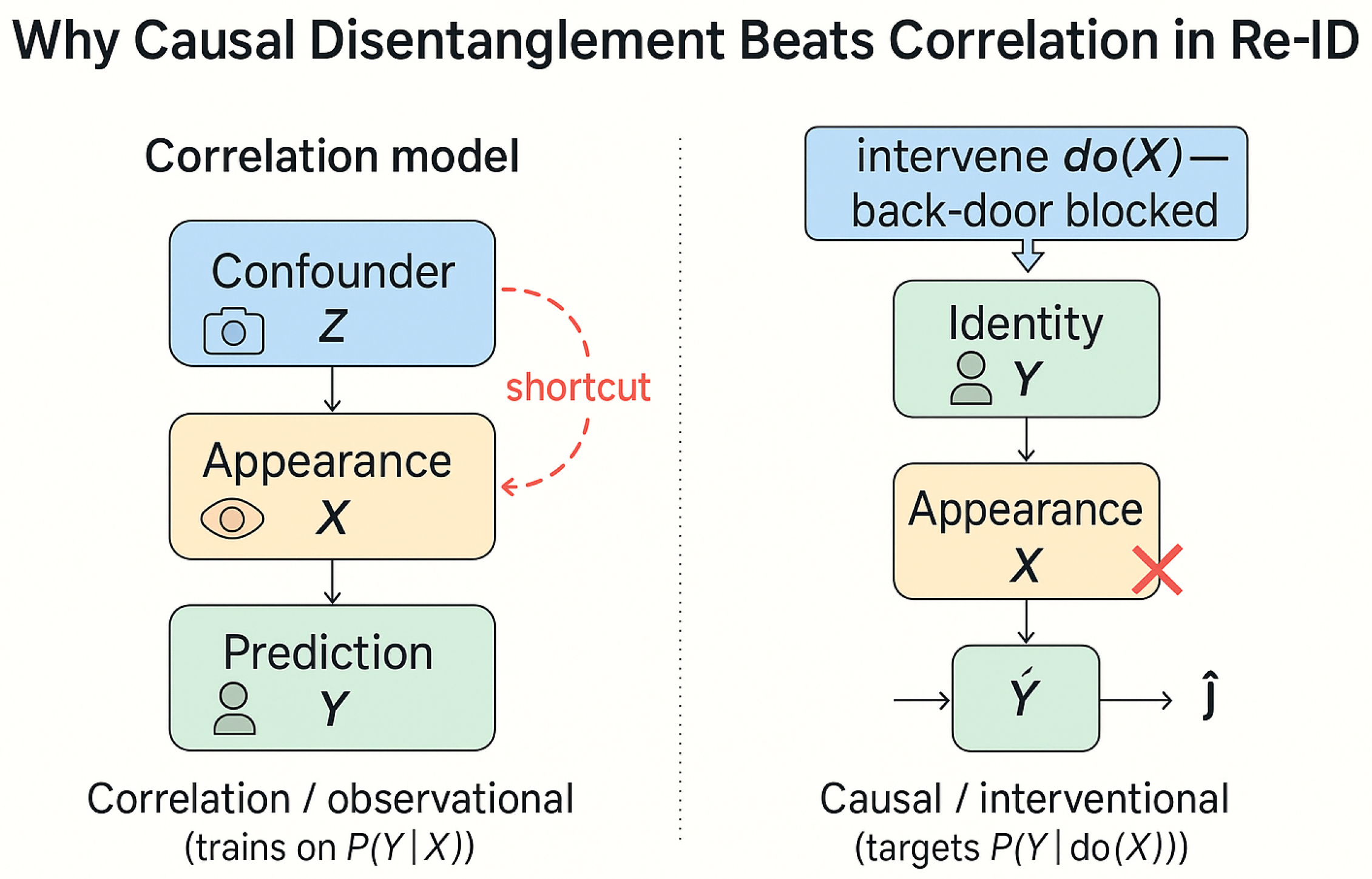
- Initial situation: A video-based person re-identification system is trained on a dataset where Person A is always wearing a red jacket and Person B always wears a blue jacket. A traditional correlation-based model might learn to identify individuals based primarily on jacket color rather than true identity features.
- Problem identification: When Person A appears wearing a blue jacket in a new camera view, the traditional model misidentifies them as Person B because it has learned a spurious correlation between jacket color and identity.
- Causal modeling: In a causal approach, we explicitly model the data generation process using a structural causal model (SCM) where identity (I) and clothing (C) both influence appearance (A): . This acknowledges that clothing is a separate factor from identity.
- Intervention: We perform a “do-operation” by artificially modifying the clothing variable while keeping identity constant: . In practice, this might involve
- Generating synthetic images of Person A wearing different colored jackets;
- Using image manipulation to swap clothing items between images;
- Applying data augmentation that specifically targets clothing attributes.
- Learning with intervention: The model is trained to produce the same identity prediction for both the original image and the transformed image with modified clothing. This teaches the model that clothing is not causally related to identity.
- Consistency enforcement: A special loss function penalizes the model when its identity predictions change due to clothing modifications: , where d is a distance function and is the identity prediction function.
- Result: After training with these interventions, when Person A appears in a blue jacket, and the model correctly identifies them as Person A because it has learned to focus on stable identity features like facial structure, body shape, and gait patterns rather than superficial clothing attributes.
4. Taxonomy of Causal Video-Based Person Re-Identification Methods
4.1. Generative Disentanglement Methods
4.2. Domain-Invariant Causal Modeling
4.3. Causal Transformer Architectures
4.4. Comparative Analysis and Research Directions
5. State-of-the-Art Methods
5.1. Transformer-Based Causal Reasoning for Video-Based Person Re-Identification
5.2. Explicit Causal Modeling Approaches for Video-Based Person Re-Identification
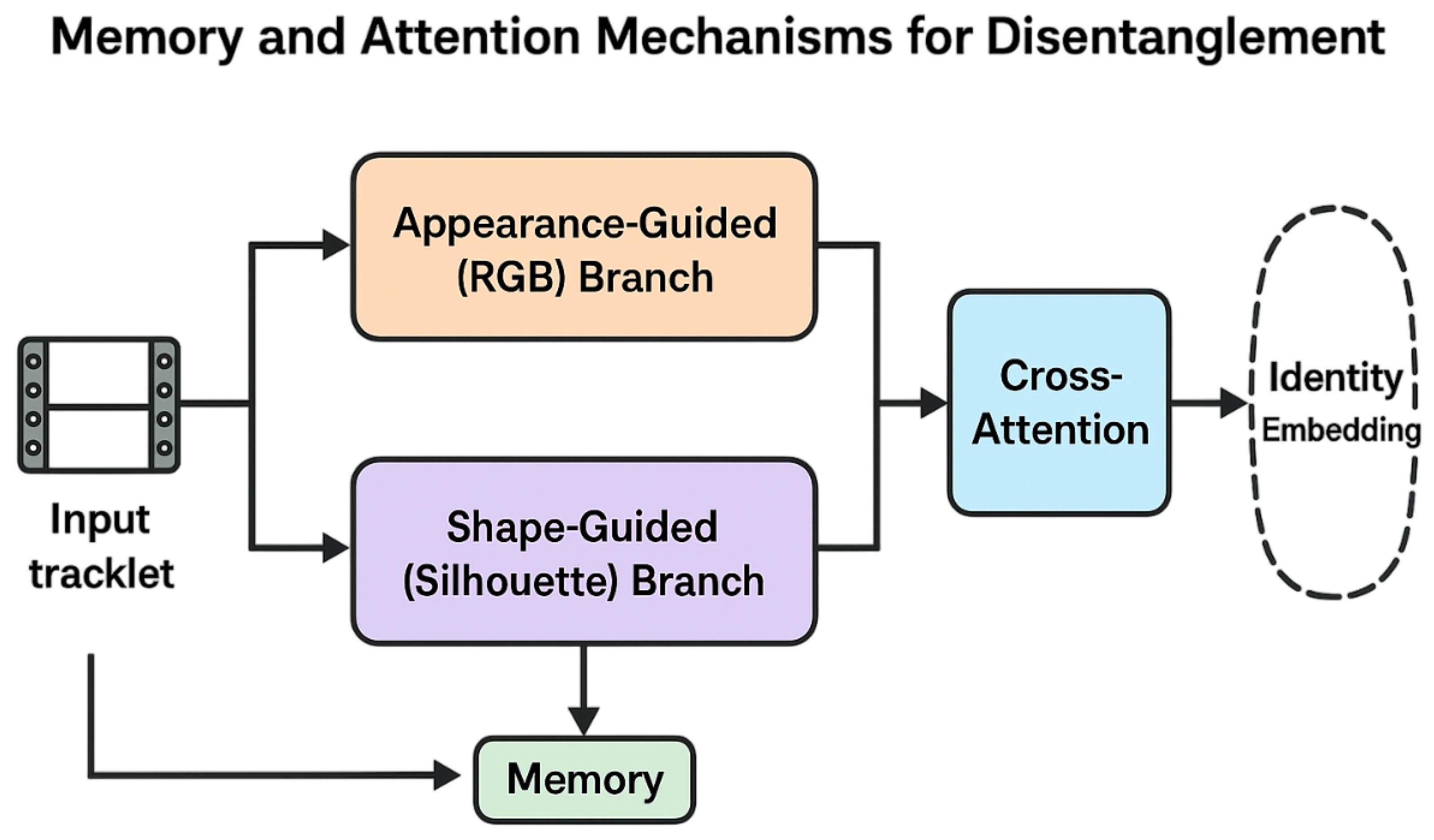
5.3. Memory and Attention Mechanisms for Causal Disentanglement
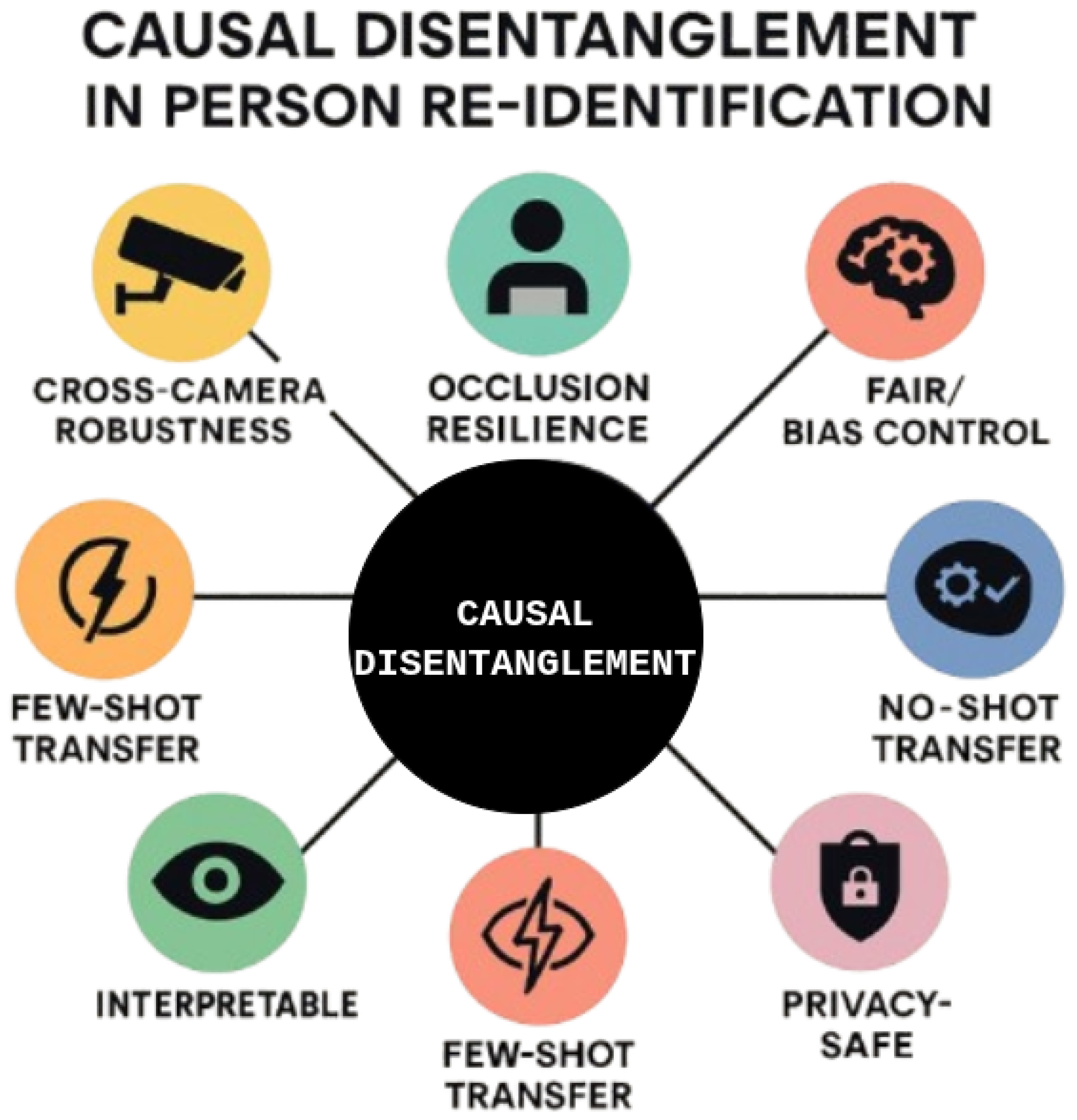
6. Causal Disentanglement in Video-Based Person Re-Identification
6.1. Causal Disentanglement Techniques
6.2. Applications of Causal Disentanglement
7. Discussion
8. Future Directions
9. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wu, L.; Wang, Y.; Gao, J.; Li, X. Where-and-When to Look: Deep Siamese Attention Networks for Video-based Person Re-identification. arXiv 2018, arXiv:1808.01911. [Google Scholar] [CrossRef]
- Geng, H.; Peng, J.; Yang, W.; Chen, D.; Lv, H.; Li, G.; Shao, Y. ReMamba: A hybrid CNN-Mamba aggregation network for visible-infrared person re-identification. Sci. Rep. 2024, 14, 29362. [Google Scholar] [CrossRef] [PubMed]
- Xu, S.; Cheng, Y.; Gu, K.; Yang, Y.; Chang, S.; Zhou, P. Jointly Attentive Spatial-Temporal Pooling Networks for Video-based Person Re-Identification. arXiv 2017, arXiv:1708.02286. [Google Scholar] [CrossRef]
- Geirhos, R.; Jacobsen, J.; Michaelis, C.; Zemel, R.; Brendel, W.; Bethge, M.; Wichmann, F. Shortcut learning in deep neural networks. Nat. Mach. Intell. 2020, 2, 665–673. [Google Scholar] [CrossRef]
- Zhang, Y.F.; Zhang, Z.; Li, D.; Jia, Z.; Wang, L.; Tan, T. Learning Domain Invariant Representations for Generalizable Person Re-Identification. arXiv 2021, arXiv:2103.15890. [Google Scholar] [CrossRef]
- Yang, Z.; Lin, M.; Zhong, X.; Wu, Y.; Wang, Z. Good is Bad: Causality Inspired Cloth-debiasing for Cloth-changing Person Re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; Technical Report. IEEE: Piscataway, NJ, USA, 2024. [Google Scholar] [CrossRef]
- Gu, X.; Chang, H.; Ma, B.; Zhang, H.; Chen, X. Appearance-preserving 3D convolution for video-based person re-identification. arXiv 2020, arXiv:2007.08434. [Google Scholar] [CrossRef]
- Liao, X.; He, L.; Yang, Z.; Zhang, C. Video-based Person Re-identification via 3D Convolutional Networks and Non-local Attention. arXiv 2018, arXiv:1807.05073. [Google Scholar] [CrossRef]
- Jin, X.; Lan, C.; Zeng, W.; Chen, Z.; Zhang, L. Style Normalization and Restitution for Generalizable Person Re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; Technical Report. IEEE: Piscataway, NJ, USA, 2020. [Google Scholar] [CrossRef]
- Pearl, J. Causality: Models, Reasoning, and Inference; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar] [CrossRef]
- Peters, J.; Janzing, D.; Schlkopf, B. Elements of Causal Inference: Foundations and Learning Algorithms; MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Schölkopf, B.; Locatello, F.; Bauer, S.; Ke, N.; Kalchbrenner, N.; Goyal, A.; Bengio, Y. Towards Causal Representation Learning. arXiv 2021, arXiv:2102.11107. [Google Scholar] [CrossRef]
- Ilse, M.; Tomczak, J.M.; Louizos, C.; Welling, M. DIVA: Domain invariant variational autoencoders. In Proceedings of the Third Conference on Medical Imaging with Deep Learning, PMLR, Montreal, QC, Canada, 6–8 July 2020. [Google Scholar] [CrossRef]
- Yuan, B.; Lu, J.; You, S.; Bao, B.K. Unbiased Feature Learning with Causal Intervention for Visible-Infrared Person Re-identification. Acm Trans. Multimed. Comput. Commun. Appl. 2024, 20, 1–20. [Google Scholar] [CrossRef]
- Bareinboim, E.; Correa, J.; Ibeling, D.; Icard, T. On Pearl’s Hierarchy and the Foundations of Causal Inference. In Probabilistic and Causal Inference: The Works of Judea Pearl; ACM: New York, NY, USA, 2022. [Google Scholar] [CrossRef]
- Eom, C.; Lee, G.; Lee, J.; Ham, B. Video-based Person Re-identification with Spatial and Temporal Memory Networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; Technical Report. IEEE: Piscataway, NJ, USA, 2021. [Google Scholar] [CrossRef]
- Li, S.; Bak, S.; Carr, P.; Wang, X. Diversity Regularized Spatiotemporal Attention for Video-based Person Re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar] [CrossRef]
- Gao, J.; Nevatia, R. Revisiting Temporal Modeling for Video-based Person ReID. arXiv 2018, arXiv:1805.02104. [Google Scholar] [CrossRef]
- Jia, M.; Cheng, X.; Lu, S.; Zhang, J. Learning Disentangled Representation Implicitly via Transformer for Occluded Person Re-Identification. arXiv 2021, arXiv:2107.02380. [Google Scholar] [CrossRef]
- Wang, X.; Li, Q.; Yu, D.; Cui, P.; Wang, Z.; Xu, G. Causal disentanglement for semantics-aware intent learning in recommendation. arXiv 2022, arXiv:2202.02576. [Google Scholar] [CrossRef]
- Subramaniam, A.; Nambiar, A.; Mittal, A. Co-segmentation inspired attention networks for video-based person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; Technical Report. IEEE: Piscataway, NJ, USA, 2019. [Google Scholar] [CrossRef]
- Tian, M.; Yi, S.; Li, H.; Li, S.; Zhang, X.; Shi, J.; Yan, J.; Wang, X. Eliminating Background-bias for Robust Person Re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; Technical Report. IEEE: Piscataway, NJ, USA, 2018. [Google Scholar] [CrossRef]
- Liu, X.; Yu, C.; Zhang, P.; Lu, H. Deeply-coupled convolution-transformer with spatial-temporal complementary learning for video-based person re-identification. arXiv 2023, arXiv:2304.14122. [Google Scholar] [CrossRef]
- Liao, S.; Hu, Y.; Zhu, X.; Li, S.Z. Person Re-Identification by Local Maximal Occurrence Representation and Metric Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 2197–2206. [Google Scholar] [CrossRef]
- Lin, J.; Zheng, L.; Zheng, Z.; Li, Y.; Wang, S.; Yang, Y.; Tian, Q. Improving Person Re-Identification by Attribute and Identity Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–25 July 2017; pp. 2839–2848. [Google Scholar] [CrossRef]
- Tang, C.; Wu, P.; Xu, T.; Song, Y.Z.; Lin, L.; Bai, X.; Liu, X.; Tian, Q. Improving Pedestrian Attribute Recognition With Weakly-Supervised Multi-Scale Attribute-Specific Localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4997–5006. [Google Scholar] [CrossRef]
- Zhang, Y.; Shen, L.; Zhang, Y.; Zheng, L.; Tian, Q. Person Re-Identification by Mid-Level Attribute and Part-Based Convolutional Neural Network. In Proceedings of the 35th International Conference on Machine Learning (ICML), Stockholm, Sweden, 10–15 July 2018; pp. 7232–7241. [Google Scholar] [CrossRef]
- Chao, H.; He, Y.; Zhang, J.; Feng, J.; Huang, J. GaitSet: Regard Gait as a Set for Cross-View Gait Recognition. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Honolulu, HI, USA, 27 January–1 February 2019; pp. 8126–8133. [Google Scholar] [CrossRef]
- Munaro, M.; Ghidoni, S.; Dizmen, D.T.; Menegatti, E. A Feature-Based Approach to People Re-Identification Using Skeleton Keypoints. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 423–430. [Google Scholar] [CrossRef]
- Matsukawa, T.; Okabe, T.; Suzuki, E.; Sato, Y. Hierarchical Gaussian Descriptor for Person Re-Identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1363–1372. [Google Scholar]
- Su, C.; Li, J.; Zhang, S.; Xing, J.; Gao, W.; Tian, Q. Pose-Driven Deep Convolutional Model for Person Re-Identification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3960–3969. [Google Scholar] [CrossRef]
- Zheng, L.; Shen, L.; Tian, Q.; Wang, S.; Wang, J. Scalable Person Re-identification: A Benchmark. In Proceedings of the IEEE International Conference on Computer Vision, Nashville, TN, USA, 11–15 June 2025; Technical Report. IEEE: Piscataway, NJ, USA, 2015. [Google Scholar] [CrossRef]
- Oliveira, H.; Machado, J.; Tavares, J. Re-identification in urban scenarios: A review of tools and methods. Appl. Sci. 2024, 11, 10809. [Google Scholar] [CrossRef]
- Khamis, S.; Kuo, C.H.; Singh, V.; Shet, V.; Davis, L. Joint Learning for Attribute-Consistent Person Re-Identification. In Computer Vision—ECCV 2014 Workshops: Zurich, Switzerland, 6–7 and 12 September 2014, Proceedings, Part III 132015; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar] [CrossRef]
- Hermans, A.; Beyer, L.; Leibe, B. In Defense of the Triplet Loss for Person Re-Identification. arXiv 2017, arXiv:1703.07737. [Google Scholar] [CrossRef]
- Yan, Y.; Ni, B.; Song, Z.; Ma, C.; Yan, Y.; Yang, X. Person Re-Identification via Recurrent Feature Aggregation. arXiv 2017, arXiv:1701.06351. [Google Scholar] [CrossRef]
- Li, J.; Wang, J.; Tian, Q.; Gao, W.; Zhang, S. Global-Local Temporal Representations For Video Person Re-Identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; Technical Report. IEEE: Piscataway, NJ, USA, 2019. [Google Scholar] [CrossRef]
- Chen, Z.; Li, A.; Jiang, S.; Wang, Y. Attribute-aware identity-hard triplet loss for video-based person re-identification. arXiv 2020, arXiv:2006.07597. [Google Scholar] [CrossRef]
- Chai, T.; Chen, Z.; Li, A.; Chen, J.; Mei, X.; Wang, Y. Video Person Re-identification using Attribute-enhanced Features. arXiv 2021, arXiv:2108.06946. [Google Scholar] [CrossRef]
- Xu, P.; Zhu, X. DeepChange: A long-term person re-identification benchmark with clothes change. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; Technical Report. IEEE: Piscataway, NJ, USA, 2024. [Google Scholar] [CrossRef]
- Li, X.; Lu, Y.; Liu, B.; Hou, Y.; Liu, Y.; Chu, Q.; Ouyang, W.; Yu, N. Clothes-invariant feature learning by causal intervention for clothes-changing person re-identification. arXiv 2023, arXiv:2305.06145. [Google Scholar] [CrossRef]
- Luiten, J.; Osep, A.; Dendorfer, P.; Torr, P.; Geiger, A.; Leal-Taixé, L.; Leibe, B. HOTA: A Higher Order Metric for Evaluating Multi-object Tracking. Int. J. Comput. Vis. 2021, 129, 548–578. [Google Scholar] [CrossRef]
- Suter, R.; Miladinović, D.; Schölkopf, B.; Bauer, S. Robustly Disentangled Causal Mechanisms: Validating Deep Representations for Interventional Robustness. In Proceedings of the 36th International Conference on Machine Learning, Long Breach, CA, USA, 9–15 June 2019; Technical Report. IEEE: Piscataway, NJ, USA, 2019. [Google Scholar] [CrossRef]
- Black, E.; Wang, Z.; Fredrikson, M.; Datta, A. Consistent counterfactuals for deep models. arXiv 2021, arXiv:2110.03109. [Google Scholar] [CrossRef]
- Qian, Y.; Barthelemy, J.; Karuppiah, E.; Perez, P. Identifying Re-identification Challenges: Past, Current and Future Trends. SN Comput. Sci. 2024, 5, 937. [Google Scholar] [CrossRef]
- Alkanat, T.; Bondarev, E.; De With, P. Enabling Open-Set Person Re-Identification for Real-World Scenarios. J. Image Graph. 2020, 8, 26–36. [Google Scholar] [CrossRef]
- Zheng, L.; Bie, Z.; Sun, Y.; Wang, J.; Su, C.; Wang, S.; Tian, Q. Mars: A video benchmark for large-scale person re-identification. In Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11-14 October 2016, Proceedings, Part VI 14; Springer: Cham, Switzerland, 2016. [Google Scholar] [CrossRef]
- Ristani, E.; Solera, F.; Zou, R.; Cucchiara, R.; Tomasi, C. Performance Measures and a Data Set for Multi-Target, Multi-Camera Tracking. arXiv 2016, arXiv:1609.01775. [Google Scholar] [CrossRef]
- Wu, A.; Zheng, W.S.; Yu, H.X.; Gong, S.; Lai, J. RGB-Infrared Cross-Modality Person Re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar] [CrossRef]
- Wu, J.; Huang, Y.; Gao, M.; Gao, Z.; Zhao, J.; Zhang, H.; Zhang, A. A two-stream hybrid convolution-transformer network architecture for clothing-change person re-identification. IEEE Trans. Multimed. 2023, 26, 5326–5339. [Google Scholar] [CrossRef]
- Li, Y.; Lian, G.; Zhang, W.; Ma, G.; Ren, J.; Yang, J. Heterogeneous feature-aware Transformer-CNN coupling network for person re-identification. PeerJ Comput. Sci. 2022, 8, e1098. [Google Scholar] [CrossRef]
- Zhao, S.; Gao, C.; Zhang, J.; Cheng, H.; Han, C.; Jiang, X.; Guo, X.; Zheng, W.S.; Sang, N.; Sun, X. Do Not Disturb Me: Person Re-identification Under the Interference of Other Pedestrians. arXiv 2020, arXiv:2008.06963. [Google Scholar] [CrossRef]
- Rao, Y.; Chen, G.; Lu, J.; Zhou, J. Counterfactual attention learning for fine-grained visual categorization and re-identification. arXiv 2021, arXiv:2108.08728. [Google Scholar] [CrossRef]
- Sun, Z.; Zhao, F. Counterfactual attention alignment for visible-infrared cross-modality person re-identification. Pattern Recognit. Lett. 2023, 168, 79–85. [Google Scholar] [CrossRef]
- Hirzer, M.; Beleznai, C.; Roth, P.; Bischof, H. Person Re-Identification by Descriptive and Discriminative Classification. In Image Analysis, Proceedings of the 17th Scandinavian Conference, SCIA 2011, Ystad, Sweden, 23–25 May 2011, Proceedings 17; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar] [CrossRef]
- Wang, T.; Gong, S.; Zhu, X.; Wang, S. LNCS 8692—Person Re-identification by Video Ranking. In Computer Vision—ECCV 2014 13th European Conference, Zurich, Switzerland, 6–12 September 2014, Proceedings, Part IV; Technical Report; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar] [CrossRef]
- Ye, M.; Shen, J.; Lin, G.; Xiang, T.; Shao, L.; Hoi, S. Deep learning for person re-identification: A survey and outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 2872–2893. [Google Scholar] [CrossRef]
- Cosar, S.; Bellotto, N. Human Re-Identification with a Robot Thermal Camera using Entropy-based Sampling. J. Intell. Robot. Syst. 2019, 98, 85–102. [Google Scholar] [CrossRef]
- Kumar, S.; Yaghoubi, E.; Das, A.; Harish, B.; Proença, H. The P-DESTRE: A Fully Annotated Dataset for Pedestrian Detection, Tracking, Re-Identification and Search from Aerial Devices. arXiv 2020, arXiv:2004.02782. [Google Scholar] [CrossRef]
- Yin, J.; Wu, A.; Zheng, W. Fine-Grained Person Re-identification. Int. J. Comput. Vis. 2020, 128, 1654–1672. [Google Scholar] [CrossRef]
- Siv, R.; Mancas, M.; Sreng, S.; Chhun, S.; Gosselin, B. People Tracking and Re-Identifying in Distributed Contexts: PoseTReID Framework and Dataset. In Proceedings of the 2020 12th International Conference on Information Technology and Electrical Engineering (ICITEE), Yogyakarta, Indonesia, 6–8 October 2020. [Google Scholar] [CrossRef]
- Wang, X.; Paul, S.; Raychaudhuri, D.; Liu, M.; Wang, Y.; Roy-Chowdhury, A. Learning Person Re-identification Models from Videos with Weak Supervision. arXiv 2020, arXiv:2007.10631. [Google Scholar] [CrossRef]
- Jia, X.; Zhu, C.; Li, M.; Tang, W.; Liu, S.; Zhou, W. LLVIP: A Visible-infrared Paired Dataset for Low-light Vision. arXiv 2021, arXiv:2108.10831. [Google Scholar] [CrossRef]
- Du, Y.; Lei, C.; Zhao, Z.; Dong, Y.; Su, F. Video-Based Visible-Infrared Person Re-Identification With Auxiliary Samples. IEEE Trans. Inf. Forensics Secur. 2024, 19, 1313–1325. [Google Scholar] [CrossRef]
- Zhao, Y.; Shen, X.; Jin, Z.; Lu, H.; Hua, X.S. Attribute-driven feature disentangling and temporal aggregation for video person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; Technical Report. IEEE: Piscataway, NJ, USA, 2020. [Google Scholar] [CrossRef]
- Xiang, S.; Fu, Y.; You, G.; Liu, T. Unsupervised Domain Adaptation Through Synthesis For Person Re-Identification. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020. [Google Scholar] [CrossRef]
- Zhang, S.; Luo, W.; Cheng, D.; Yang, Q.; Ran, L.; Xing, Y.; Zhang, Y. Cross-Platform Video Person ReID: A New Benchmark Dataset and Adaptation Approach. In Computer Vision—ECCV 2024 18th European Conference, Milan, Italy, 29 September–4 October 2024, Proceedings, Part XXVII; Springer: Berlin/Heidelberg, Germany, 2024. [Google Scholar] [CrossRef]
- Hambarde, K.A.; Mbongo, N.; MP, P.K.; Mekewad, S.; Fernandes, C.; Silahtaroğlu, G.; Nithya, A.; Wasnik, P.; Rashidunnabi, M.; Samale, P.; et al. DetReIDX: A stress-test dataset for real-world UAV-based person recognition. arXiv 2025, arXiv:2505.04793. [Google Scholar] [CrossRef]
- Nguyen, H.; Nguyen, K.; Pemasiri, A.; Liu, F.; Sridharan, S.; Fookes, C. AG-VPReID: A Challenging Large-Scale Benchmark for Aerial-Ground Video-based Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville TN, USA, 11–15 June 2025. [Google Scholar] [CrossRef]
- Glymour, C.; Zhang, K.; Spirtes, P. Review of causal discovery methods based on graphical models. Front. Genet. 2019, 10, 524. [Google Scholar] [CrossRef]
- Locatello, F.; Bauer, S.; Lucic, M.; Rätsch, G.; Gelly, S.; Schölkopf, B.; Bachem, O. Challenging common assumptions in the unsupervised learning of disentangled representations. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Technical Report. IEEE: Piscataway, NJ, USA, 2019. [Google Scholar] [CrossRef]
- Cui, Z.; Zhou, J.; Peng, Y.; Zhang, S.; Wang, Y. DCR-ReID: Deep component reconstruction for cloth-changing person re-identification. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 4415–4428. [Google Scholar] [CrossRef]
- Nguyen, V.; Mantini, P.; Shah, S. CrossViT-ReID: Cross-Attention Vision Transformer for Occluded Cloth-Changing Person Re-Identification. In Proceedings of the Asian Conference on Computer Vision (ACCV), Hanoi, Vietnam, 8–12 December 2024. [Google Scholar] [CrossRef]
- Liang, T.; Jin, Y.; Gao, Y.; Liu, W.; Feng, S.; Wang, T.; Li, Y. CMTR: Cross-modality transformer for visible-infrared person re-identification. IEEE Trans. Multimed. 2021, 25, 8432–8444. [Google Scholar] [CrossRef]
- Mishra, R.; Mondal, A.; Mathew, J. Nystromformer based cross-modality transformer for visible-infrared person re-identification. Sci. Rep. 2025, 15, 16224. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, P.; Gao, S.; Geng, X.; Lu, H.; Wang, D. Pyramid Spatial-Temporal Aggregation for Video-based Person Re-Identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; Technical Report. IEEE: Piscataway, NJ, USA, 2021. [Google Scholar] [CrossRef]
- Wu, P.; Wang, L.; Zhou, S.; Hua, G.; Sun, C. Temporal Correlation Vision Transformer for Video Person Re-Identification. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canasa, 20–27 February 2024; Technical Report. IEEE: Piscataway, NJ, USA, 2024. [Google Scholar] [CrossRef]
- Kasantikul, R.; Kusakunniran, W.; Wu, Q.; Wang, Z. Channel-shuffled transformers for cross-modality person re-identification in video. Sci. Rep. 2025, 15, 15009. [Google Scholar] [CrossRef] [PubMed]
- Kocaoglu, M.; Snyder, C.; Dimakis, A.G.; Vishwanath, S. CausalGAN: Learning causal implicit generative models with adversarial training. arXiv 2017, arXiv:1709.02023. [Google Scholar] [CrossRef]
- He, T.; Jin, X.; Shen, X.; Huang, J.; Chen, Z.; Hua, X.S. Dense interaction learning for video-based person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; Technical Report. IEEE: Piscataway, NJ, USA, 2023. [Google Scholar] [CrossRef]
- Chen, Y.; Yang, Y.; Liu, W.; Huang, Y.; Li, J. Pose-guided counterfactual inference for occluded person re-identification. Image Vis. Comput. 2022, 128, 104587. [Google Scholar] [CrossRef]
- Sun, J.; Li, Y.; Chen, L.; Chen, H.; Wang, M. Dualistic Disentangled Meta-Learning Model for Generalizable Person Re-Identification. IEEE Trans. Inf. Forensics Secur. 2024, 20, 1106–1118. [Google Scholar] [CrossRef]
- Kansal, K.; Wong, Y.; Kankanhalli, M. Privacy-Enhancing Person Re-Identification Framework—A Dual-Stage Approach. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; Technical Report. IEEE: Piscataway, NJ, USA, 2024. [Google Scholar] [CrossRef]
- Brkljač, B.; Brkljač, M. Person detection and re-identification in open-world settings of retail stores and public spaces. arXiv 2025, arXiv:2505.00772. [Google Scholar] [CrossRef]
- Fu, Y.; Wang, X.; Wei, Y.; Huang, T. STA: Spatial-Temporal Attention for Large-Scale Video-based Person Re-Identification. arXiv 2018, arXiv:1811.04129. [Google Scholar] [CrossRef]
- Liu, Y.; Yan, J.; Ouyang, W. Quality Aware Network for Set to Set Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; Technical Report. IEEE: Piscataway, NJ, USA, 2017. [Google Scholar] [CrossRef]
- Chen, D.; Doering, A.; Zhang, S.; Yang, J.; Gall, J.; Schiele, B. Keypoint Message Passing for Video-based Person Re-Identification. arXiv 2021, arXiv:2111.08279. [Google Scholar] [CrossRef]
- Alsehaim, A.; Breckon, T. VID-Trans-ReID: Enhanced Video Transformers for Person Re-identification. In Proceedings of the BMVC 2022: The 33rd British Machine Vision Conference, London, UK, 21–24 November 2024; Technical Report. Durham University: Durham, UK, 2022. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014. [Google Scholar] [CrossRef]
- Higgins, I.; Matthey, L.; Pal, A.; Burgess, C.; Glorot, X.; Botvinick, M.; Mohamed, S.; Lerchner, A. beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar] [CrossRef]
- Burgess, C.P.; Higgins, I.; Pal, A.; Matthey, L.; Watters, N.; Desjardins, G.; Lerchner, A. Understanding disentangling in beta-VAE. In Proceedings of the NIPS Workshop on Learning Disentangled Representations, Long Beach, CA, USA, 9 December 2017. [Google Scholar] [CrossRef]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-Adversarial Training of Neural Networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar] [CrossRef]
- Tzeng, E.; Hoffman, J.; Saenko, K.; Darrell, T. Adversarial Discriminative Domain Adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2021; pp. 7167–7176. [Google Scholar] [CrossRef]
- Zhang, Y.; Nie, S.; Liu, W.; Xu, X.; Zhang, D.; Shen, H.T. Sequence-to-Sequence Domain Adaptation Network for Robust Text Image Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2740–2749. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, L.; You, Y.; Zou, X.; Chen, V.; Li, S.; Huang, G.; Hariharan, B.; Weinberger, K. Resource Aware Person Re-identification across Multiple Resolutions. arXiv 2018, arXiv:1805.08805. [Google Scholar] [CrossRef]
- Shu, R.; Bui, H.H.; Narui, H.; Ermon, S. A DIRT-T Approach to Unsupervised Domain Adaptation. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Gabbay, A.; Hoshen, Y. Style Generator Inversion for Image Enhancement and Animation. arXiv 2019, arXiv:1906.11880. [Google Scholar] [CrossRef]
- Chen, R.T.Q.; Li, X.; Grosse, R.B.; Duvenaud, D.K. Isolating Sources of Disentanglement in Variational Autoencoders. arXiv 2018. Available online: https://arxiv.org/abs/1802.04942 (accessed on 27 June 2025).
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein Generative Adversarial Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar] [CrossRef]
- Lee, H.Y.; Tseng, H.Y.; Huang, J.B.; Singh, M.; Yang, M.H. Diverse Image-to-Image Translation via Disentangled Representations. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar] [CrossRef]
- Huang, X.; Liu, M.Y.; Belongie, S.; Kautz, J. Multimodal Unsupervised Image-to-Image Translation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar] [CrossRef]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. DualGAN: Unsupervised Dual Learning for Image-to-Image Translation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar] [CrossRef]
- Yao, S.; Ardabili, B.; Pazho, A.; Noghre, G.; Neff, C.; Tabkhi, H. Real-World Community-in-the-Loop Smart Video Surveillance—A Case Study at a Community College. arXiv 2023, arXiv:2303.12934. [Google Scholar] [CrossRef]
- Gabdullin, N.; Raskovalov, A. Google Coral-based edge computing person reidentification using human parsing combined with analytical method. arXiv 2022, arXiv:2209.11024. [Google Scholar] [CrossRef]
- Ghiță, A.; Florea, A. Real-Time People Re-Identification and Tracking for Autonomous Platforms Using a Trajectory Prediction-Based Approach. Sensors 2022, 22, 5856. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute Type | Static/Dynamic | Typical Extraction Method (Key Reference) |
|---|---|---|
| Clothing Color | Static | Color histograms, Retinex–LOMO descriptor [24] |
| Clothing Category (shirt/pants) | Static | Part-based CNN multi-task attribute head (APR-Net) [25] |
| Accessories (bags, hats, and other accessories) | Static | Weakly-supervised multi-scale attribute localization [26], mid-level attribute CNN [27] |
| Gait/Silhouette | Dynamic | Set-level silhouette sequence model (GaitSet) [28] |
| Body Shape/Height | Static | 3-D skeleton key-point statistics [29] |
| Texture/Pattern | Static | Local Gaussian/SILTP texture blocks (HGD + LOMO) [24,30] |
| Gender/Age/Hair | Static | Multi-task mid-level attribute + identity CNN [27] |
| Pose/Motion State | Dynamic | Pose-driven deep convolutional model with RPN attention [31] |
| Carried Objects | Dynamic | Attribute-aware object detectors/semantic parts [26,27] |
| Metric | Measures | Used In/Reports | Advantages/Limitations |
|---|---|---|---|
| CMC/Rank-k Accuracy [35] | Probability of correct match within rank k (precision at k). | Almost all re-identification (image and video), e.g., MARS [47], DukeMTMC-VideoReID [48], SYSU [49]. | Standard precision metric; lacks recall information. |
| Rank-1 Accuracy [32] | Top-1 retrieval accuracy (). | Standard benchmark metric in most re-identification works [50,51]. | Single-number summary; no recall information. |
| Mean Average Precision (mAP) [37] | Overall retrieval quality (precision and recall averaged). | Used in re-identification benchmarks (Market-1501, MARS [47], etc.) | Comprehensive metric, but sensitive to outliers. |
| Attribute Consistency [38] | Semantic consistency across views. | Attribute-based re-identification works [34,39]. | Reveals stable cues, but depends on attribute annotation quality. |
| Attribute-Aware Accuracy [38] | Retrieval accuracy with attribute agreement. | Joint attribute/ID methods [22,39]. | Fine-grained measure, but rarely reported. |
| Occlusion Robustness [19] | Drop in performance under occlusion. | Occluded-Duke, Occluded-REID [52]. | Useful for real-world scenarios; needs labeled occlusions. |
| Clothing-Change Robustness [40] | Sensitivity to apparel changes. | Long-term re-identification (e.g., DeepChange [40]). | Reveals clothing cue reliance; needs paired outfits. |
| IDSR/IDF1 [42] | ID switch frequency. | Multi-camera tracking [42,48]. | Consistency metric; requires track-level GT. |
| Counterfactual Consistency [44] | Invariance to manipulated attributes. | Emerging causal re-identification metrics [6,53]. | Tests reliance on stable ID features; challenging to implement. |
| Causal Saliency Ranking [14] | Importance of features for ID matches. | Explainable re-identification studies [5,41]. | Reveals true causal drivers, but lacks numeric comparability. |
| Intervention-Based Score Shift [12] | Effect of controlled attribute interventions. | Causal evaluation studies [14,54]. | Quantifies sensitivity; requires well-defined interventions. |
| Dataset | Year | Modality | Identities | Sequences/Images | Cameras | Dataset Link |
|---|---|---|---|---|---|---|
| PRID2011 [55] | 2011 | RGB | 934 total (200 overlap) | 385 (camA) + 749 (camB) | 2 | Download |
| iLIDS-VID [56] | 2014 | RGB | 300 | 600 (300 × 2) | 2 | Download |
| MARS [47] | 2016 | RGB | 1261 | ≈20,000 tracklets (incl. 3248 distractors) | 6 | Download |
| SYSU-MM01 [49] | 2017 | RGB and Thermal | 491 | 287,628 RGB + 15,729 IR | 6 (4 RGB, 2 IR) | Download |
| RegDB [57] | 2017 | RGB and Thermal | 412 | 4120 (10 vis + 10 IR per ID) | 2 (1 vis, 1 IR) | Download |
| DukeMTMC-VideoReID [48] | 2018 | RGB | 1404 (702 train + 702 test) + 408 distractors | 4832 (2196 train + 2636 test) | 8 | Download |
| LS-VID [37] | 2019 | RGB | 3772 | 14,943 tracks (≈3M frames) | 15 (3 indoor, 12 outdoor) | Download |
| L-CAS RGB-D-T [58] | 2019 | RGB and Depth and Thermal | Not specified | ≈4000 (rosbags) | 3 (RGB, Depth, Thermal) | Download |
| P-DESTRE [59] | 2020 | RGB | 1581 | Over 40,000 frames | UAVs | Download |
| FGPR [60] | 2020 | RGB | 358 | 716 | 6 (2 per color group) | Download |
| PoseTrackReID [61] | 2020 | RGB | ≈5350 | ≈7725 tracks | Unknown | Download |
| RandPerson [62] | 2020 | Synthetic RGB | 8000 | 1,801,816 images | 19 (virtual cams) | Download |
| DeepChange [40] | 2022 | RGB | 1121 | 178,407 frames | 17 | Download |
| LLVIP [63] | 2022 | RGB and Thermal | ≈(15,488 pairs) | 30,976 images | 2 (1 RGB, 1 IR) | Download |
| ClonedPerson [20] | 2022 | Synthetic RGB | 5621 | 887,766 images | 24 (virtual cams) | Download |
| BUPTCampus [64] | 2023 | RGB & Thermal | 3080 | (RGB-IR tracklets) | 2 (1 RGB, 1 IR) | Download |
| MSA-BUPT [65] | 2024 | RGB | 684 | 2665 | 9 (6 indoor, 3 outdoor) | Download |
| GPR+ [66] | 2024 | Synthetic RGB | 808 | 475,104 bounding boxes | Unknown | Download |
| G2A-VReID [67] | 2024 | RGB | 2788 | 185,907 images | Ground surveillance and UAVs | Download |
| DetReIDX [68] | 2025 | RGB | 509 | 13 million+ annotations | 7 university campuses (3 continents) | Download |
| AG-VPReID [69] | 2025 | RGB | 6632 | 32,321 tracklets | Drones (15–120 m altitude), CCTV, wearable cameras | Download |
| Challenge Category | Description | Example Methods | Causal Factors Addressed | Notable Outcomes |
|---|---|---|---|---|
| Visual Appearance Variations | Variations in viewpoint, pose, occlusions, motion blur, and lighting complicate feature extraction. | FIDN [23], SDL [62], DRL-Net [19] | Spatio-temporal noise, spectrum differences, occlusions | Improved accuracy, better occlusion tolerance, RGB-IR robustness. |
| Tracking and Sequence Issues | Identity drift and fragmentation from tracking errors can split a single trajectory into multiple IDs. | DIR-ReID [5], DCR-ReID [72], IS-GAN [16] | Domain shifts, clothing changes, background noise | Better domain generalization, clothing-change robustness, stable tracking. |
| Domain and Deployment | Performance drops due to cross-camera variation, environmental changes, and demographic diversity. | DIR-ReID [5], IS-GAN [16] | Camera bias, pose variations, background shifts | Superior cross-domain performance, robust deployment. |
| Data and Annotation Scarcity | High annotation costs and limited labeled data reduce training effectiveness. | DRL-Net [19], IS-GAN [16], DCR-ReID [72] | Occlusions, spectrum noise, missing labels | High accuracy with limited data, efficient learning, realistic augmentation. |
| Clothing and Appearance Changes | Long-term re-identification fails when individuals change outfits, accessories, or hairstyles. | IS-GAN [16], DeepChange [40], CrossViT-ReID [73] | Clothing bias, accessory dependence, temporal appearance drift | Robust to clothing changes, improved long-term tracking, identity-focused features. |
| Cross-Modal Challenges | Matching across different modalities (RGB-IR, RGB-Depth) introduces spectral and structural differences. | CMTR [74], UCT [14], NiCTRAM [75] | Modality gaps, spectral variations, sensor differences | Effective cross-modal matching, reduced modality bias, unified representations. |
| Temporal Consistency | Maintaining identity consistency across long video sequences with varying quality and conditions. | STMN [16], PSTA [76], TCViT [77] | Temporal noise, frame quality variations, motion blur | Improved temporal modeling, consistent identity features, robust sequence analysis. |
| Scale and Computational Efficiency | Real-time processing requirements conflict with complex model architectures needed for accuracy. | DCCT [23], HCSTNet [78], Lightweight Transformers | Computational constraints, memory limitations, inference speed | Efficient architectures, reduced parameters, real-time performance. |
| Fairness and Bias | Models exhibit performance disparities across demographic groups, raising ethical concerns. | Fairness-aware ReID, Bias-corrected training, Demographic-balanced datasets | Demographic bias, dataset imbalance, algorithmic fairness | Reduced bias, equitable performance, fair representations across groups. |
| Privacy and Security | Re-identification systems raise privacy concerns and potential misuse in surveillance applications. | Privacy-preserving ReID, Federated learning, Differential privacy | Identity exposure, surveillance misuse, data protection | Enhanced privacy protection, secure matching, anonymized features. |
| Model | Year | Architecture | Attention | Memory | Dataset(s) |
|---|---|---|---|---|---|
| STMN [16] | 2021 | CNN (ResNet) + RNN + Memory | Spatial and temporal attention (with memory lookup) | Yes | MARS, DukeV, LS-VID |
| DenseIL [80] | 2021 | Hybrid (CNN + Transformer decoder) | Dense multi-scale attention (“DenseAttn”) | No | MARS, DukeV, iLIDS-VID |
| PSTA [76] | 2021 | CNN (hierarchical pooling) | Pyramid spatial–temporal attention (SRA + TRA) | No | MARS, DukeV, iLIDS, PRID |
| DCCT [23] | 2023 | Hybrid (CNN + ViT) | Complementary content attention; gated temporal att. | No | MARS, DukeV, iLIDS-VID |
| CMTR [74] | 2023 | Transformer (ViT) | Modality embeddings + multi-head self-attention | No | SYSU-MM01 (VI), RegDB |
| CrossViT-ReID [73] | 2024 | Transformer (ViT branches) | Cross-attention between appearance/shape | No | DeepChange |
| NiCTRAM [75] | 2025 | Hybrid (CNN + Nystromformer) | Cross-attention and 2nd-order attn. for feature fusion | No | SYSU-MM01 (VI) |
| HCSTNet [78] | 2025 | Hybrid (ResNet + Transformer) | Channel-shuffled temporal transformer | No | SYSU-MM01 (VI) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rashidunnabi, M.; Hambarde, K.; Proença, H. Causality and “In-the-Wild” Video-Based Person Re-Identification: A Survey. Electronics 2025, 14, 2669. https://doi.org/10.3390/electronics14132669
Rashidunnabi M, Hambarde K, Proença H. Causality and “In-the-Wild” Video-Based Person Re-Identification: A Survey. Electronics. 2025; 14(13):2669. https://doi.org/10.3390/electronics14132669
Chicago/Turabian StyleRashidunnabi, Md, Kailash Hambarde, and Hugo Proença. 2025. "Causality and “In-the-Wild” Video-Based Person Re-Identification: A Survey" Electronics 14, no. 13: 2669. https://doi.org/10.3390/electronics14132669
APA StyleRashidunnabi, M., Hambarde, K., & Proença, H. (2025). Causality and “In-the-Wild” Video-Based Person Re-Identification: A Survey. Electronics, 14(13), 2669. https://doi.org/10.3390/electronics14132669