All articles published by MDPI are made immediately available worldwide under an open access license. No special
permission is required to reuse all or part of the article published by MDPI, including figures and tables. For
articles published under an open access Creative Common CC BY license, any part of the article may be reused without
permission provided that the original article is clearly cited. For more information, please refer to
https://www.mdpi.com/openaccess.
Feature papers represent the most advanced research with significant potential for high impact in the field. A Feature
Paper should be a substantial original Article that involves several techniques or approaches, provides an outlook for
future research directions and describes possible research applications.
Feature papers are submitted upon individual invitation or recommendation by the scientific editors and must receive
positive feedback from the reviewers.
Editor’s Choice articles are based on recommendations by the scientific editors of MDPI journals from around the world.
Editors select a small number of articles recently published in the journal that they believe will be particularly
interesting to readers, or important in the respective research area. The aim is to provide a snapshot of some of the
most exciting work published in the various research areas of the journal.
Multi-dimensional classification (MDC), in which the training data are concurrently associated with numerous label variables across many dimensions, has garnered significant interest recently. Most of the current MDC methods are based on the framework of supervised learning, which induces a predictive model from a large amount of precisely labeled data. So, they are challenged to obtain satisfactory learning results in the situation where the training data are not annotated with precise labels but assigned with ambiguous labels. Besides, the current MDC algorithms only consider the scenario of centralized learning, where all training data are handled at a single node for the purpose of classifier induction. However, in some real applications, the training data are not consolidated at a single fusion center, but rather are dispersedly distributed among multiple nodes. In this study, we focus on the problem of decentralized classification involving partial multi-dimensional data that have partially accessible candidate labels, and develop a distributed method called dPL-MDC for learning with these partial labels. In this algorithm, we conduct one-vs.-one decomposition on the originally heterogeneous multi-dimensional output space, such that the problem of partial MDC can be transformed into the issue of distributed partial multi-label learning. Then, by using several shared anchor data to characterize the global distribution of label variables, we propose a novel distributed approach to learn the label confidence of the training data. Under the supervision of recovered credible labels, the classifier can be induced by exploiting the high-order label dependencies from a common low-dimensional subspace. Experiments performed on various datasets indicate that our proposed method is capable of achieving learning performance in distributed partial MDC.
The learning problems of traditional classification methods are usually formalized under the frameworks of binary classification [1,2,3,4] and multi-class classification [5], which learn the classifier under the supervision of a single label variable. In numerous real-world scenarios, the complex semantics of training data are conveyed through multiple heterogeneous label variables rather than a single variable. For example, in the e-commerce platforms, smartphones can be classified by brand dimension (with potential classes Apple, Huawei, Xiaomi, etc.), price dimension (with potential classes high grade, medium grade, and low grade), and color dimension (with potential classes white, black, blue, etc.). In recent years, a range of multi-dimensional classification (MDC) methods has been created to address this type of data and has been extensively utilized across numerous domains [6,7,8,9,10,11,12,13,14,15,16,17,18,19,20], such as text categorization [7], image processing [8], biomedical engineering [9], etc.
Generally speaking, there exist several primary categories of MDC methods. The simple and straightforward solution is to ignore the dependencies between multiple heterogeneous class spaces, and then decompose the problem of MDC into several independent problems of multi-class classification for classifier induction. Nevertheless, this strategy fails to consider label dependencies, potentially resulting in unsatisfactory learning performances. The key to building an effective MDC approach lies in making full use of label dependencies in an appropriate way. In recent years, several strategies for exploiting label dependencies have been developed, including grouping distinct combinations of class variables into new super-class variables [6], capturing the dependencies between a pair of labels [12], learning a directed cyclic graph for class spaces [17,18], utilizing classifier chaining to exploit the high-order label correlations [14,19,20], etc.
Nevertheless, there are generally two main limitations in the existing MDC methods. Firstly, most contemporary MDC algorithms rely on a supervised learning framework, which needs a lot of labeled data with correct information to ensure excellent learning results. However, since label acquisition is a costly and time-consuming process, such a requirement hardly holds in many real applications. Typically, only partially labeled data that are associated with a set of candidate labels composed of correct labels and noisy labels are accessible. Many experiments in previous studies [5], Refs. [21,22,23,24,25,26] have demonstrated that noisy labels give incorrect guidance, which negatively impacts the learning performance of algorithms. Therefore, the primary challenge in this paper is to eliminate the impact of noisy labels.
Additionally, the aforementioned MDC techniques exclusively focus on centralized processing, necessitating the aggregation of the entire training dataset to a single fusion node for processing. Nonetheless, in several practical applications, such as anomaly detection [27], industrial Internet of Things [28], and traffic control systems [29,30], the training data samples are usually distributed at different nodes and cannot be centralized into one node due to various reasons [27,28,29,30,31,32]. Therefore, how to make the algorithm adapt to the distributed network and perform distributed learning without the transmission of original data is the second major challenge to be addressed in this paper.
In this paper, we develop the distributed partial label learning algorithm for multi-dimensional classification (dPL-MDC) by jointly considering the influence of noisy labels and the distributed storage of training data. The primary contributions are delineated as follows:
1. By using the one-vs.-one decomposition method, we transform the original distributed partial MDC problem into a distributed partial multi-label learning problem, which facilitates the subsequent exploitation of label correlations and the disambiguation of partial labels.
2. By leveraging weakly supervised information from ambiguous labels and ensuring constant similarity between label and feature spaces based on several anchor data, a distributed label recovery method is devised to estimate the label confidence of training data.
3. By adaptively updating the label confidence and model parameter of the classifier, we learn a multi-dimensional classifier while eliminating the influence of noisy labels. During the procedure of classifier induction, to exploit the high-order dependencies among newly transformed classes for classifier induction, we alternately learn the model parameters and the globally common predictive structure in the low-dimensional subspace by employing a computationally inexpensive and energy-saving distributed estimation method.
4. Simulations performed on several real datasets indicate that our proposed approach surpasses the existing MDC techniques.
The subsequent sections of this work are organized as follows. Section 2 provides a concise overview of the frameworks related to dPL-MDC over a network. Subsequently, Section 3 elaborates on the technical specifics of the dPL-MDC algorithm. After that, Section 4 presents the experimental results of the proposed algorithm alongside the existing MDC approaches. This paper concludes in Section 5.
2. Related Works
As far as we know, no prior research has tackled the issue of distributed classification of multi-dimensional data with ambiguous labels. In this section, a brief introduction related to three popular frameworks of dPL-MDC is presented, including MDC, distributed learning, and PLL.
The framework of MDC is similar to that of the widely researched multi-label classification (MLC) and multi-class classification (MCC). When the number of potential classes in each dimensional class space is equivalent to 2, the issue of MDC is transformed into the issue of MLC. If the dimension of output space is restricted to 1, then the issue of MDC degenerates into the issue of MCC. For MDC, the intuitive solution is to directly decompose the problem of MDC into several problems of MCC based on the dimensions of output space, and independently solve these problems dimension by dimension. This straightforward technique completely disregards the label dependencies across several class spaces, perhaps resulting in poor classification results. Therefore, how to exploit the label dependencies efficiently and induce a unified predictive model for multiple heterogeneous class spaces is the key to designing the MDC methods.
In recent years, a series of label dependence exploitation methods have also been proposed. An easy and straightforward way to exploit label dependence is to convert the label space of MDC into several new class spaces and treat each distinctly combined class variable as a new class variable for model induction [6]. This method has a significant flaw; they are unable to train classifiers for categories that have not appeared in the training set, which greatly restricts their applicability. Another strategy is to construct a directed acyclic graph (DAG) to characterize the distribution of the classes, and then induce the MDC model using a multi-dimensional Bayesian network [17,18]. However, since constructing Bayesian networks requires substantial computations, the performance of these methods is constrained by high computational costs, especially when dealing with large-scale data. Additionally, the issue of MDC can also be solved by a chain of induced multi-class classifiers [14,19,20], where the output of the previous classifier can be regarded as the extra features of the subsequent classifier. Obviously, for these algorithms, obtaining a proper chaining order is a precondition for achieving good learning performance. The absence of prior knowledge makes it challenging to determine the optimal order. Recently, two novel MDC methods have been developed based on decomposed label encoding [12,15]. These two approaches employ a one-vs.-one decomposition strategy to formulate a sequence of binary classification tasks inside a multi-dimensional output space. Then, they use the manifold structure [15] or covariance regularization [12] to exploit the relationship between a pair of newly transformed labels for the induction of MDC classifier. Nonetheless, as stated in Section 1, the existing MDC methods have two limitations. First, they fail to extract effective information from partially labeled data annotated with noisy labels to train classification models. Second, they cannot directly handle data stored distributively across distributed networks. These two aspects thus constitute the two key issues to be addressed in this paper.
Distributed learning is another novel branch of machine learning frameworks, where the training data is distributed among several nodes interconnected by a network [3,5,31,32]. By utilizing consensus-based or diffusion-based strategies to perform information fusion among nodes, these distributed learning methods can achieve learning performance that is nearly as excellent as the corresponding centralized learning methods. Recently, several distributed learning methods have been proposed for MCC and MLC [5,31,32]. For example, in [31], two distributed information-theoretic semi-supervised MLC methods have been developed, which introduces a new decentralized regularization term to take advantage of the relationships between label variables across a network. In [32], a distributed subspace structure learning algorithm has been proposed to distributively exploit the similarity of model parameter vectors by exploiting a common predictive structure in depth. Lately, a novel distributed partial MCC method has been developed, where a high-precision multi-class classifier is trained from partial labeled data by collaboratively learning the label confidence and the data instance weights to disambiguate the ambiguous labels [5]. Compared with existing distributed classification algorithms, the problems addressed in this paper are more complex. Owing to the fact that the output space in multi-dimensional classification problems is composed of multiple heterogeneous class spaces, the output values of multi-dimensional classification models are not comparable. As a result, traditional label dependency exploitation strategies, such as label–pair correlation learning and subspace-based high-order correlation learning, cannot be directly applied in this context.
PLL has become a novel learning paradigm in machine learning recently, which learns the classifier from a series of candidate labels [5,21,22,23,24,25,26,33,34,35,36,37]. Most of the existing PLL methods are usually formalized based on the framework of MCC [21,22,26]. These PLL methods assign a proper label for each training data by correcting the ambiguous labels using disambiguation strategies [22,26] or employing the loss-based decoding method to decode the transformed binary classifier’s predictive outputs [21]. Lately, several novel PLL methods have been developed for MLC [33,34,35,36,37], which induce the predictive model by eliciting credible labels [33,34,37] or identifying noisy labels [35,36] from multiple candidate labels. Nevertheless, the majority of current PLL methods belong to centralized learning, which is impractical for distributed networks. So, developing a distributed PLL for MDC, where global classification can be performed across many nodes using dispersedly distributed partial multi-dimensional data, is the better option.
3. dPL-MDC Algorithm
This section formulates the issue of fully decentralized classification of partial multi-dimensional data and presents the technical specifics of the dPL-MDC algorithm.
3.1. Problem Formulation
An interconnected network consisting of J geographically dispersed nodes over a region is the subject of this paper. The total N partially multi-dimensional data are dispersedly distributed over J nodes. For the sake of generality, we use an undirected graph called to describe this network, where is the set of nodes and is the set of connections between them. For each node j, all the neighboring nodes and itself constitute the neighboring node set .
Let denote the input vector space, and let stand for the output space composed of a total of Q heterogeneous class spaces, where each class space contains possible classes. At each node j, there exist locally partial multi-dimensional data annotated with the candidate labels at observable class spaces , , where denotes the input vector of the features, and denotes the collected labels. A -dimensional vector is utilized to represent the collected label vector and denote the original candidate label vector. In the q-th dimensional label vector , the k-th element is assigned a value of 1 if the k-th label is included in the candidate label set, and -1 if it is excluded. Furthermore, a -dimensional diagonal matrix is designed, whose diagonal element equals 1 if the corresponding label is accessible and 0 otherwise. So, in the observed label vector , all the accessible labels are kept unchanged, and all the missing labels are set to zero.
Each node j is tasked with learning the globally optimum classifier using its local data and the discriminant information from neighboring nodes , ensuring that unseen data can be accurately classified into the appropriate categories.
3.2. Output Space Decomposition
For MDC, the main challenge is that the output space is composed of multiple heterogeneous class spaces, which makes the outputs of the predicted model across different class spaces not comparable with each other [12,15]. To tackle this problem, referring to the concept of decomposed label encoding strategy [12,15], we would like to conduct one-vs.-one decomposition on each dimensional class space of MDC, such that the problem of distributed partial MDC can be transformed into the problem of distributed homogeneous partial multi-label learning.
To be specific, for a label vector , supposing that the q-th class space composed of possible classes is observable, i.e., , we can transform a -dimensional label vector into a -dimensional ternary label vector via one-vs.-one decomposition, where with being the factorial of N. Furthermore, if the m-th class space can not be accessed, i.e., , then the newly transformed label vectors can be represented as a -dimensional vector consisting of all zero elements. Correspondingly, the originally collected label vector at total Q class spaces can be decomposed as a -dimensional vector , where denotes a -dimensional diagonal matrix with its diagonal element being 1 if the corresponding labels are accessible and 0 otherwise.
To clarify the process of one-vs.-one decomposition, two cases are presented as follows:
Case 1: For a collected data sample annotated with correct labels, supposing that the k-th class variable in the q-th dimensional label vector is the ground truth, each r-th element in the encoded ternary label vector equals
where the positive set for , and the negative set for , , or for .
Example 1.
Given four data with correct labels , supposing that the q-th dimensional original label vectors , , and for simplicity, the transformed ternary labels for these data samples can be obtained according to (1):
Case 2: For a collected partial multi-dimensional data sample annotated with several candidate labels, supposing that the candidate label set in the q-th dimensional class space consists of a total of m candidate labels (i.e., the ,…,-th class variables in are candidate labels), each r-th element in the ternary label vector equals
where the positive set . Furthermore, the corresponding negative set . The calculation of and is similar to those in case 1.
Example 2.
Given four data with candidate labels , supposing that the candidate labels in the q-th dimensional class space are composed of the correct label and an additional noisy label for simplicity, i.e., , , and , we have the transformed ternary labels as follows:
3.3. Label Recovery
In this study, it is imperative to devise an effective technique to mitigate the adverse effects of noisy labels and to recover the accurate labels from the candidate set.
Based on the underlying assumption in manifold learning that there exist similar structures in feature and label spaces [1], we would like to recover the correct labels by exploiting the similarity among the whole training data set. Nevertheless, because of the random distribution of training data across different nodes, the global distribution of data samples cannot be precisely characterized. To solve this problem, we randomly select or employ a decentralized vector quantization method [38] to select C global common anchor data as the representatives of the whole dataset. The research in [31] indicates that, given a sufficient amount of anchor data C, these quantized anchor data can cover all high-density regions. Furthermore, the similarity degree among the whole training dataset can be roughly measured by employing the quantized anchor data.
Following the analysis in Section 1, acquiring a significant quantity of precisely labeled anchor data samples necessitates extensive professional expertise. Consequently, we examine the typical scenario in which all anchor data samples are unlabeled. Now, the key to label recovery is to accurately estimate the labels of anchor data. To achieve this, a straightforward weighted voting method is used, which is given by
where represents the transformed label matrix of local training data, and represents the recovered label matrix of C anchor data. Furthermore, denotes the weighted parameter for measuring the similarity between C anchor data and training data at node j, in which each element can be calculated by the Gaussian kernel function. Furthermore, ∘ denotes the Hadamard product, and is the -dimensional matrix, which is computed by .
According to the basic setting in the considered network, only the label variable of anchor data in available class spaces (i.e., ) can be directly computed via (3). Moreover, owing to the existence of noisy labels, the predicted labels across various nodes for a specific class may be different. To address this issue, inspired by the concept of LMaFit presented in [39,40], we convert the problem of label recovery into the problem of decentralized matrix completion. To be specific, we factorize the label matrix of anchor data into two low-dimensional factorized matrices and ( denotes the rank of the matrix ), and then complete the matrix by adaptively updating the factorized matrices. The decentralized framework of label recovery can be formulated as follows:
The objective function (4) consists of three terms.
The first term is utilized to reduce the reconstruction error between the recovered labels of anchor data and training data in partially accessible class spaces. Here, denotes the initial estimation for matrix . The second term is targeted for imputing the missing entries in based on two factorized matrices A and .
The process of label recovery is composed of three main steps:
Initialization: A small loop indexed by is set. When , we calculate by (3) and set .
Update of : The local estimation of can be obtained by the linear combination of local estimations among one-hop neighboring nodes from its neighbors
where denotes learning rate, and denotes the cooperative coefficient, which is followed by the Metropolis cooperation rule [32].
Update of : The local estimation of can be obtained by the linear combination of local predictions from its neighbors , which is given by
Update of : Based on the current estimations and , we have the updated equation of recovered labels of anchor data
As for the update of elements in , there exist two different cases. The elements that cannot be locally estimated can be imputed using the product of two factorized matrices and . The elements that can be locally predicted by are derived from a weighted combination of the global estimation and the local estimation , utilizing a time-varying weighted coefficient . At the start, the global estimation is rough, since the information fusion among neighboring nodes is insufficient. A substantial value of is employed to provide low confidence to . After a sufficient number of iterations, more and more information shared by one node diffuses over the whole network, which makes the global estimation consistent with each other. So, a small value of is employed. Consequently, we define , with being a positive coefficient.
The primary processes of label recovery are summarized in Algorithm 1 for clarity.
end for Return the recovered label matrix of anchor points .
3.4. Classifier Induction
This subsection describes the induction of the classifier based on the label recovery.
We can express the output of the discriminant function for the k-th class variable in the q-th dimensional class space as a linear combination of kernel functions, under the assumption that the discriminant function is non-linear. This is represented by the following:
where denotes a kernel function, and denotes the weight coefficient.
By introducing the infinite-dimensional kernel feature map , we have
where the weight vector .
Nevertheless, it is evident from (11) that the weight vectors , which are composed of a succession of kernel feature maps, cannot be explicitly expressed or freely exchanged among neighbors, as the infinite-dimensional kernel feature map is unknown.
To resolve this issue, we project the training data into a feature space with a constrained number of dimensions, thereafter substituting the kernel feature map with the random feature map for the construction of model parameters. Consequently, the kernel function may be approximated as follows: [41,42]
It is noted that we take the Gaussian kernel function into account here. According to the theory in [41,42], we have
where is stochastically drawn from the distribution .
Based on this, we can explicitly express the weight vector as a D-dimensional vector, denoted as .
Moreover, in order to exploit the high-order dependencies among the total recovered label variables, we suppose that there exists a low-dimensional common predictive structure among all the label variables [43]. Consequently, the weight vector can be rewritten as
where and () denote the private weight vectors with respect to (w.r.t.) the k-th class variable in the q-th dimensional class space, and denotes the common predictive structure. Furthermore, to reduce the complexity of the predictive structure, we assume that there exists an orthogonality property, i.e., .
The global optimization problem can be formulated as follows by taking into account the aforementioned considerations:
In the above global optimization problem, the first term is utilized to extract the weakly supervised information from the transformed label variables. Furthermore, denotes the weight parameter, and denotes the k-th recovered label of the n-th training data in the q-th dimensional class space. The second term is targeted for seeking the optimal solution by minimizing the reconstruction error between the recovered labels of anchor data and training data in partly observable class spaces with weight parameter . The third term is the loss function with weight parameter , where stands for the output value of the discriminant function. The fourth term is the regularization term weighted by the parameter , which serves the purpose of reducing the complexity of components out of the subspace. The fifth term represents an additional regularization term with the weight parameter , utilized to enhance the generalization of the learned classifier.
To render the global optimization issue (13) suitable for the distributed network, we decentralize it by utilizing the local estimations to replace the global ones and adding two consensus constraints, which are given by
Two consensus constraints are incorporated into the optimization for forcing all the local estimations among different nodes to agree on the consensus value.
Optimized procedure of : Given fixed , we have the sub-optimized problem
By employing the steepest gradient descent (SGD) method, we have the update equation of as follows:
where denotes the step size, and the gradient
with the indicator variable if ; otherwise, .
Optimized procedure of : For fixed and , the sub-optimized problem reduces to
Referring to the update process of distributed learning [3,31], we have the updated equation of , which is composed of two parts (adaptive and cooperative steps):
where denotes the step size, and the gradient
Optimized procedure of : Incorporating the fixed and into the decentralized optimization problem (14), we have the update equation of
Optimized procedure of : Based on the updated , the optimization problem (14) can be reduced to
Based on the current consensus estimations , we can seek the optimal solution of sub-optimization (21) by employing eigenvalue decomposition (ED) of . Specifically, the rows of are determined by the eigenvectors w.r.t. the largest h eigenvalues of .
The ideal predictive model may be achieved by iteratively optimizing the four aforementioned sub-optimization issues until convergence. Subsequently, for an unseen instance , the outputs of the discriminant function may be derived from the trained classifier. Correspondingly, the predicted label vector in the transformed output space can be calculated by
where sign denotes the element-wise signed function. Now, the predicted label vector can be expressed as a -dimensional binary vector consisting of elements.
To obtain the -dimensional label vector in the original output space, a one-vs.-one decoding rule is applied to the -dimensional transformed label vector . To be specific, referring to (1), we count the elements in binary vector whose serial number belongs to sets and , where for , and for , , or for . Based on this, we utilize and to denote, respectively, the count number w.r.t. positive set and negative set , and then compute the value of the k-th class variable in the q-th dimensional original label vectors using the majority voting method, i.e.,
Similarly, the predicted label vector of unseen data in all the Q class spaces can be obtained.
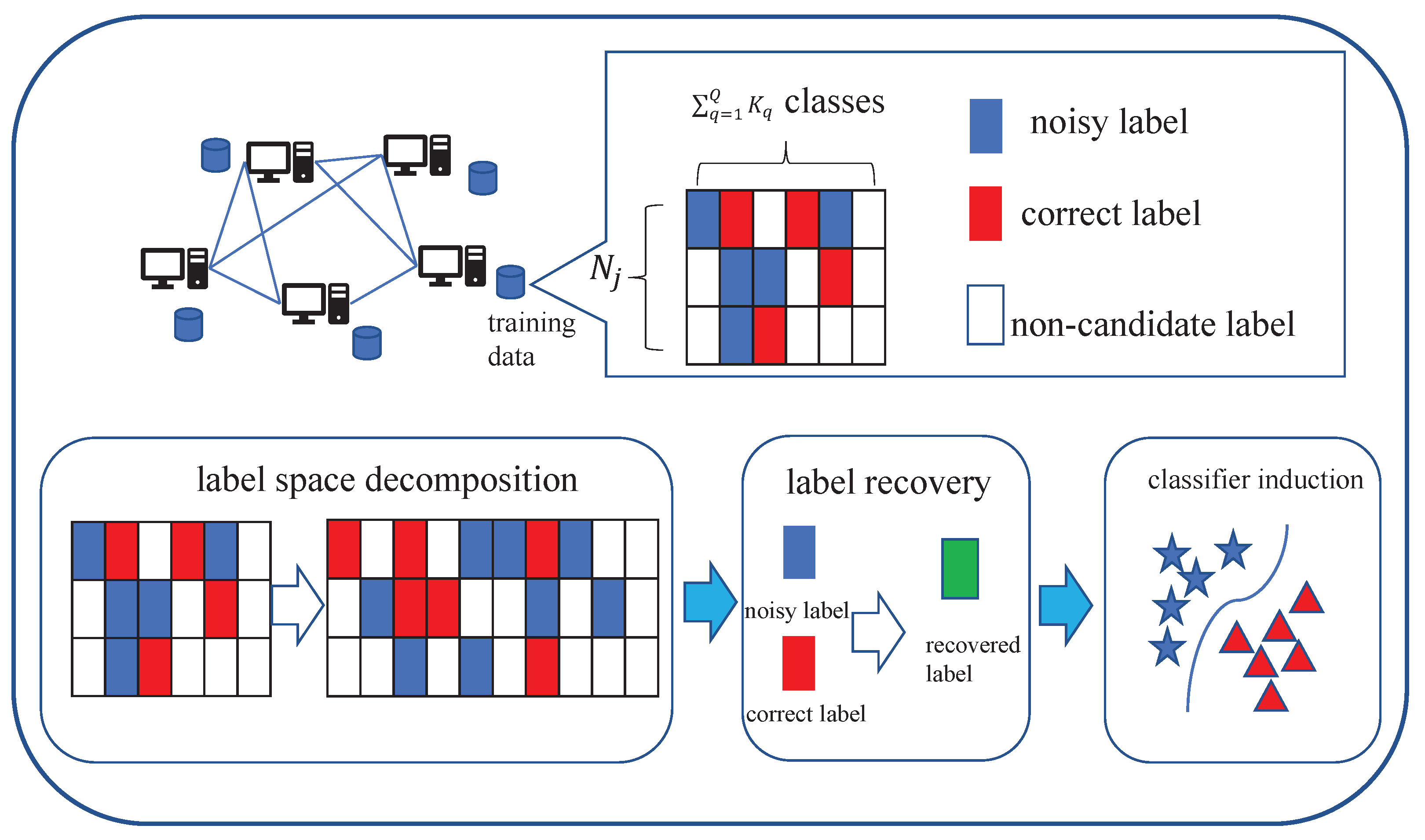
The flowchart of the proposed dPL-MDC algorithm is depicted in Figure 1, and the essential steps of the dPL-MDC algorithm are encapsulated in Algorithm 2.
Algorithm 2 dPL-MDC algorithm
Require:
Input training data . Initialize and .
1:
Obtain the transformed labels for training data via (1) or (2).
2:
Obtain the recovered label matrix of anchor points via Algorithm 1.
Return by applying one-vs.-one decoding rule over .
3.5. Performance Analysis
This subsection analyzes the performance of the proposed dPL-MDC algorithm.
Convergence Analysis: To carry out the following analysis, a frequently employed assumption is implemented.
Assumption 1.
The cooperative matrixΛ with its element in the distributed learning methods satisfies the following conditions:
(1) , .
(2) The spectrum norm of the matrix is no more than 1.
Theorem 1.
If Assumption 1 is valid, the estimations of the model parameters , , and at each node j will converge to their optimal values as t approaches , i.e., , and , where and denote their optimal values, respectively.
Theorem 1 may be demonstrated by adhering to the proof presented in [1,2,3]. Consequently, we do not provide the comprehensive proof herein.
Complexity Analysis: The complexity analysis of the suggested method is then reported. This section uses the amount of multiplication and addition operations at each node throughout each iteration to assess computational complexity. The detailed results are summarized in Table 1.
Each node j must send scalars to its one-hop neighbors at each iteration of the label recovery procedure. In addition, the quantity of scalars exchanged among neighboring nodes during the process of classifier induction is at each iteration t.
The analysis indicates that the complexity of the proposed algorithm is contingent upon the total number of potential classes , the rank , the amount of anchor points C, and the dimension D, with the value of being associated with . In actual classification situations, the total number of label classes is constrained, resulting in a modest value of . So, as long as the dimension D and the value C are adjusted to a reasonable level, the complexity of our suggested approach is practically manageable.
4. Experiments
This section conducts a series of experiments with real MDC datasets to evaluate the efficacy of the proposed method. In these experiments, we utilize MATLAB 2024a to conduct all experiments on an identical workstation featuring a 12th Gen Intel Core (2.10-GHz) CPU, 32 GB of RAM, (Intel Corporation, Santa Clara, CA, USA) and the Windows 11 operating system.
We should first present some related descriptions before conducting the experiments. This experiment examines a distributed network with 20 nodes and 38 edges, with all training data randomly allocated among these nodes. In our configuration, each MDC data sample is allocated a collection of candidate labels inside partially observed class spaces. To produce this type of data, we incorporate additional false positive labels into the candidate labels within the available class spaces while designating the labels in other inaccessible spaces as missing. To assess the influence of different quantities of noisy labels on the learning efficacy of the proposed method, the Average Number of Noisy Labels at each available class space (ANL) is defined. Furthermore, to examine the influence of varying quantities of accessible class spaces on learning performance, the amount of available class spaces at each node j, denoted as , is specified. Furthermore, to facilitate an easy comparison of the effectiveness of various comparison algorithms across several aspects, several widely utilized metrics in MDC, including Hamming loss, exact match, and sub-exact match, may be employed. For their detailed definition, please refer to [10,13].
4.1. Verification Experiment on Convergence of dPL-MDC Algorithm
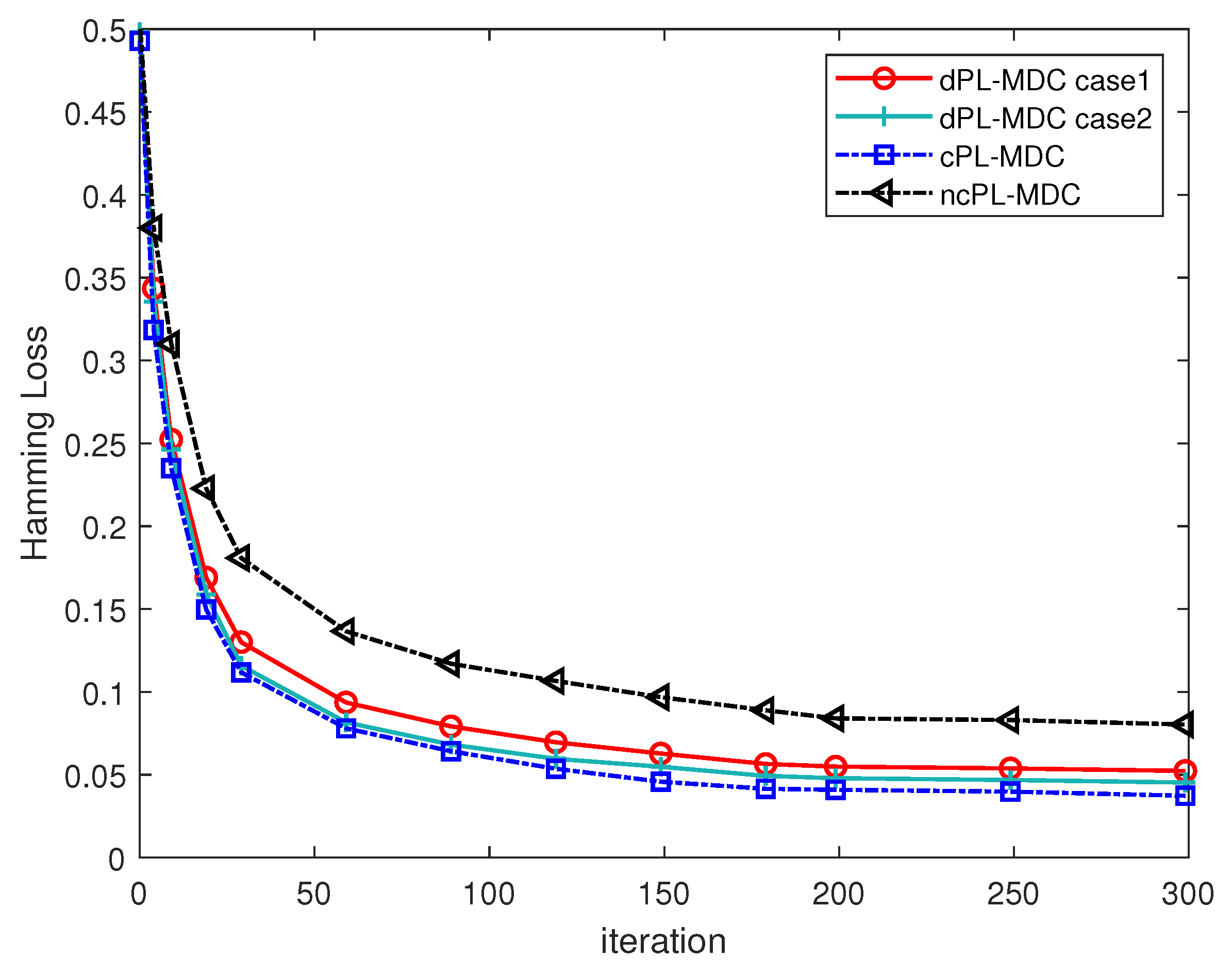
The learning performance of the dPL-MDC method is initially assessed utilizing the “Edm” dataset. In this experiment, we assign the values of the weight parameters , , , , , , the dimension , and the step sizes , respectively (available code: https://github.com/yujue-xuzhen/dpl-mdc access on 25 June 2025). Taking the Hamming loss as a representative for performance evaluation, and setting the values of and ANL = 0.2, we illustrate the learning curve of the proposed dPL-MDC method in Figure 2. To assess the efficacy of the suggested method with varying quantities of accessible class spaces, we additionally simulate the Hamming loss of the proposed dPL-MDC with . To differentiate the previous simulation with (denoted as dPL-MDC case 1), we call this simulation dPL-MDC case 2. Furthermore, we also simulate the Hamming loss of the centralized partial label learning for MDC (denoted by “cPL-MDC”, that is, one fusion center centrally processes all the training data), and the non-cooperative partial label learning for MDC (denoted by “ncPL-MDC”, that is, each node in the considered network independently trains classifiers without any information fusion) in Figure 2 for comparison. In fairness to these comparison algorithms, we set for cPL-MDC and ncPL-MDC, that is, all the training data are assigned with complete label information in all the considered class spaces.
Figure 2 demonstrates that all of the learning curves exhibit comparable tendencies in their evolution. In the initial period, all learning curves experience a rapid decline. All of the learning curves progressively converge and remain unaltered after approximately 150 iterations. These simulation results intuitively illustrate that the dPL-MDC method can obtain classification results that are virtually equivalent to those of the corresponding centralized learning method, and significantly outperform the corresponding non-cooperative method. Additionally, it can also be noticed that the learning performance of the dPL-MDC case 1 is slightly worse than that of the dPL-MDC case 2. Such a simulation result indicates that as the value of decreases, the number of available labels becomes smaller, which leads to a slight performance deterioration. Owing to the effectiveness of the dPL-MDC algorithm, the performance deterioration can be controlled in an acceptable region.
4.2. Investigation on Parameter Sensitivity of dPL-MDC Algorithm
The impacts of the varying values of weight coefficients , , , , and on the Hamming loss of the proposed algorithm are investigated in Figure 3. From Figure 3, it can be observed that all parameters have their applicable ranges. Once the parameters are less than the lower bound or greater than the upper bound of the applicable range, the algorithm performs poorly. Conversely, when parameters are selected within the applicable range, the algorithm can achieve superior performance. Consequently, we can ascertain that the appropriate selection of parameters is set as , , , and , respectively.
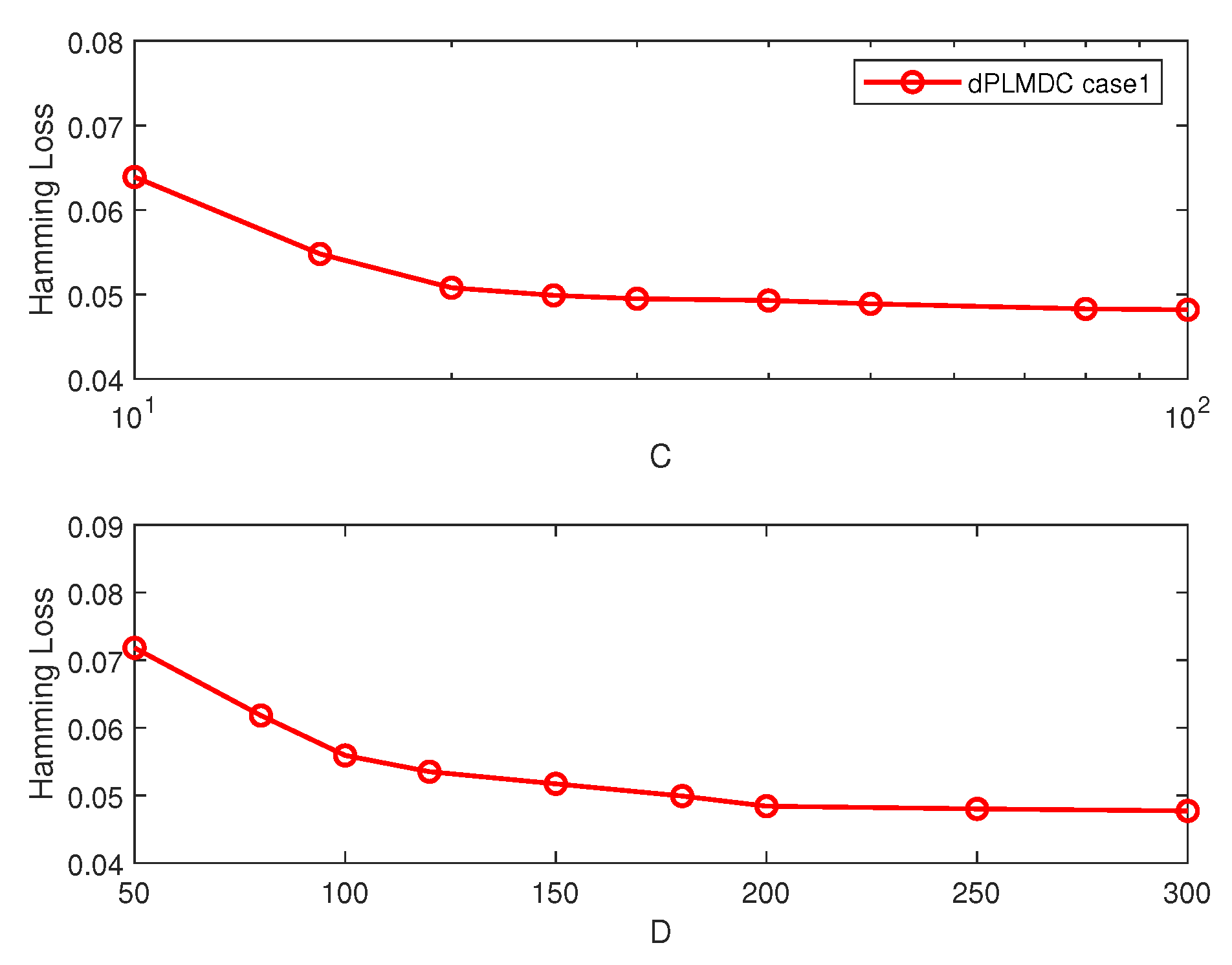
The learning performance of the proposed method is examined in relation to varying numbers of anchor points C and varied dimensions D on the “Edm” dataset. From the simulation results in the upper sub-figure of Figure 4, it can be observed that the classification performance of the algorithm gradually improves as the value of C increases. The analysis reveals that a deficient number of anchor points results in inadequate distribution to encompass all high-density areas. So, its ability to characterize the global data distribution is limited, which in turn affects the ability to eliminate noisy labels. Correspondingly, when the number of anchor points increases to more than 30, their ability to characterize data distribution significantly improves, thereby enhancing the capability to eliminate noisy labels. When the value of C exceeds 30, the performance improvement diminishes progressively. So, setting the number of anchor points C to 30 is suitable.
Moreover, the Hamming loss of the proposed methods gradually decreases as the value of D increases. When the dimension D is too small, the approximation error of the kernel function by random feature mapping is relatively large, thus affecting the performance of the classifier. As D increases, the random feature map yields a more precise approximation of the kernel feature map, hence enhancing classification performance. A larger dimension of the model parameter implies high computation and communication complexity. To achieve a balance between learning performance and computational complexity, we establish the value of D at 200.
4.3. Performance Comparison Among Multiple Contrast Algorithms
In order to further demonstrate the generality of the dPL-MDC algorithm, we conduct more simulations to evaluate its learning performance on a series of MDC datasets, including Edm [15], Song [12], WQani. [12], WQpla. [12], Jura [15], Flare [12] and Music-emo. [33]. The detailed profiles of the used datasets are summarized in Table 2. To examine the effect of different numbers of noisy labels on the learning efficacy of the proposed algorithm, we compare three evaluation metrics of the dPL-MDC algorithm with varying levels of ANL. Furthermore, to emphasize the superiority of our suggested algorithm, the performances of other prominent state-of-the-art algorithms are also evaluated. Given that the challenge of distributed classification of multi-dimensional data with ambiguous labels remains unresolved, we simulate a distributed partial single-dimensional classification method, namely, dS2PLL [31], and four centralized MDC methods, including ECC [19], ESC [6], M3MDC [13], and DLEM [15], for the purpose of comparison.
To be specific, dS2PLL independently induces a multi-class classifier for each dimensional output space by exploiting the useful information from candidate labels [31]. ECC trains the prediction model by training a sequence of multi-class classifiers inside each dimensional class space, where the output of the preceding classifier is considered as additional characteristics for the subsequent classifier [19]. ESC firstly groups the multi-dimensional class labels into a series of superclass labels, and learns the classifier based on these super-class label variables [6]. M3MDC maximizes the margins between each label pair, and exploits the label dependencies using a covariance regularization term [13]. DLEM initially decomposes the output space of MDC into an encoded label space, thereafter employing the manifold structure to leverage the relationship between pairs of encoded labels [15]. PLEM extracts intrinsic information within the encoded label space by maintaining consistency between attribute distributions and label distributions [16]. It is noted that the hyperparameters for these comparison methods are the same as those used in the referenced publication.
Furthermore, in order to comprehensively assess the efficacy of the dPL-MDC algorithm in dealing with a small amount of missing labels, we also compare the three evaluated metrics of the dPL-MDC algorithm with different values of . Similar to the last experiment, we use the dPL-MDC case 1 to denote the dPL-MDC with , and call the dPL-MDC with as dPL-MDC case 2 for simplicity. The classification performance of the cPL-MDC algorithm is evaluated as a benchmark.
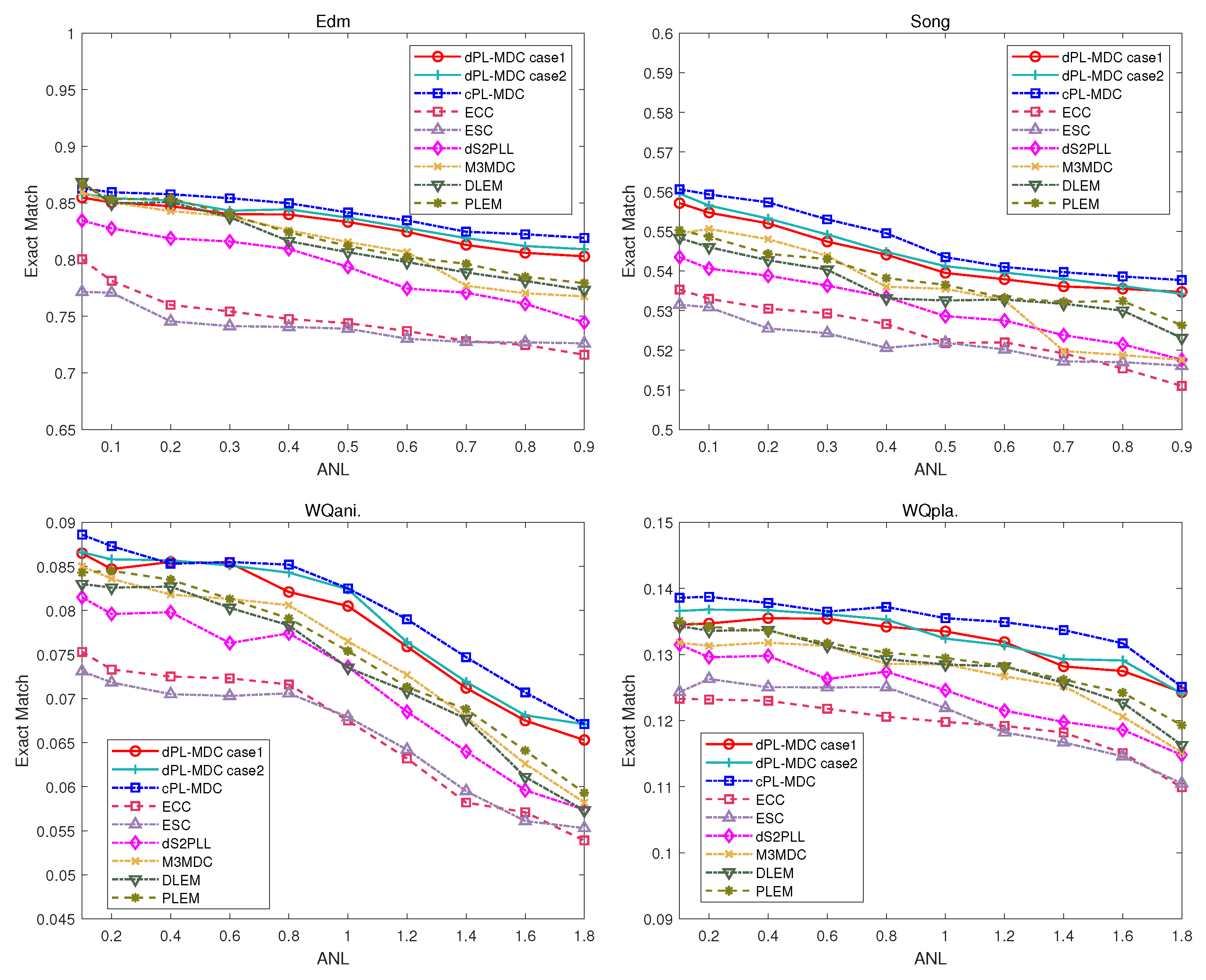
Initially, we evaluate the learning performance of several algorithms versus the ANL on the “Edm”, “Song”, “WQani”, and “WQpla” datasets, as illustrated in Figure 5, Figure 6 and Figure 7. It is noted that for the “Edm” and “Song” datasets, only one noisy label at most can be added into candidate label sets. Furthermore, for the “WQani.” and “WQpla.” datasets, the maximum number of noisy labels incorporated into the candidate label set is two. Therefore, in this experiment, the range of ANL is, respectively, set as [0.1, 0.9] for the “Edm” and “Song” datasets, and set as [0.1, 1.8] for the “WQani.” and “WQpla.” datasets. Analysis of the simulation results depicted in these figures reveals a clear trend; as the ANL grows, an increasing number of noisy labels are integrated into the training dataset. The efficacy of all comparison algorithms steadily declines due to the adverse impact of the noisy labels. Furthermore, our proposed dPL-MDC case 1, dPL-MDC case 2, and cPL-MDC algorithm achieve the best three performances among the comparison algorithms in all the metrics, indicating that our proposed algorithm has good generality in solving the MDC problem with a proportion of ambiguous labels. Furthermore, we can see that dPL-MDC case 2 shows better learning performance compared to dPL-MDC case 1. The simulation results demonstrate that more label information can enhance the learning performance of the proposed method to a certain degree.
1. We can see that the ECC and the ESC perform significantly worse than the other comparison algorithms. The possible reasons are analyzed as follows. During the training of ECC, the output from the preceding classifier is employed as an additional feature in the subsequent classifier. The accuracy of the former classifiers is influenced by the noisy labels, and then the prediction error also expands through the classifier chain propagation, which leads to unsatisfactory classification results. Furthermore, since ESC learns the classifier supervised by the superclasses, its learning performance heavily depends on the accuracy of the grouped superclasses. However, negatively affected by noisy labels, the grouped superclasses may be inaccurate, which seriously deteriorates the classification performance of ESC.
By comparing the learning performance of different comparison algorithms, we can observe the following phenomena.
2. The DLEM algorithm and M3MDC algorithm share similar training patterns, both employing the one-versus-one decomposition method to achieve problem transformation for multi-dimensional learning and leveraging correlations between label pairs to enhance model performance. Benefiting from the effectiveness of the label dependency exploitation strategy, the M3MDC and DLEM perform significantly better than the ESC and ECC. Nevertheless, due to the influence of noisy labels, the learning performances of M3MDC and DLEM are inferior to our proposed algorithm.
3. Furthermore, the dS2PLL initially clarifies the candidate labels by assessing label confidence, and subsequently trains the classifier under the supervision of reliable labels. So, it performs better than ESC and ECC. However, due to ignoring the potential label dependencies among multiple heterogeneous class spaces, the performance of dS2PLL is still inferior to the dPL-MDC algorithm.
4. Furthermore, the PLEM algorithm uses manifold structures to characterize the distributions of feature and label spaces, and explicitly leverages label correlation information for model training. Nevertheless, due to the adverse impact of noisy labels on the characterization of label distributions, the performance of the trained model is degraded. Overall, the PLEM algorithm does not perform as well as our proposed algorithm.
5. The proposed dPL-MDC algorithm demonstrates the best performance among all compared algorithms, and the possible reasons are as follows. When the parameters are set within appropriate ranges, the algorithm exhibits strong capabilities in eliminating noisy labels and exploiting label dependencies in heterogeneous class spaces. This enables the algorithm to significantly outperform other comparison algorithms when the value of ANL is equivalent to 0.8.
Additionally, we assess the efficacy of all comparison algorithms on the other datasets and obtain comparable results. The pertinent figures are not included in this section due to a page limitation. Instead, we present all the simulation results in terms of three evaluation metrics in Table 3, Table 4 and Table 5. By observing Table 3, Table 4 and Table 5, we can draw a similar conclusion as those made above.
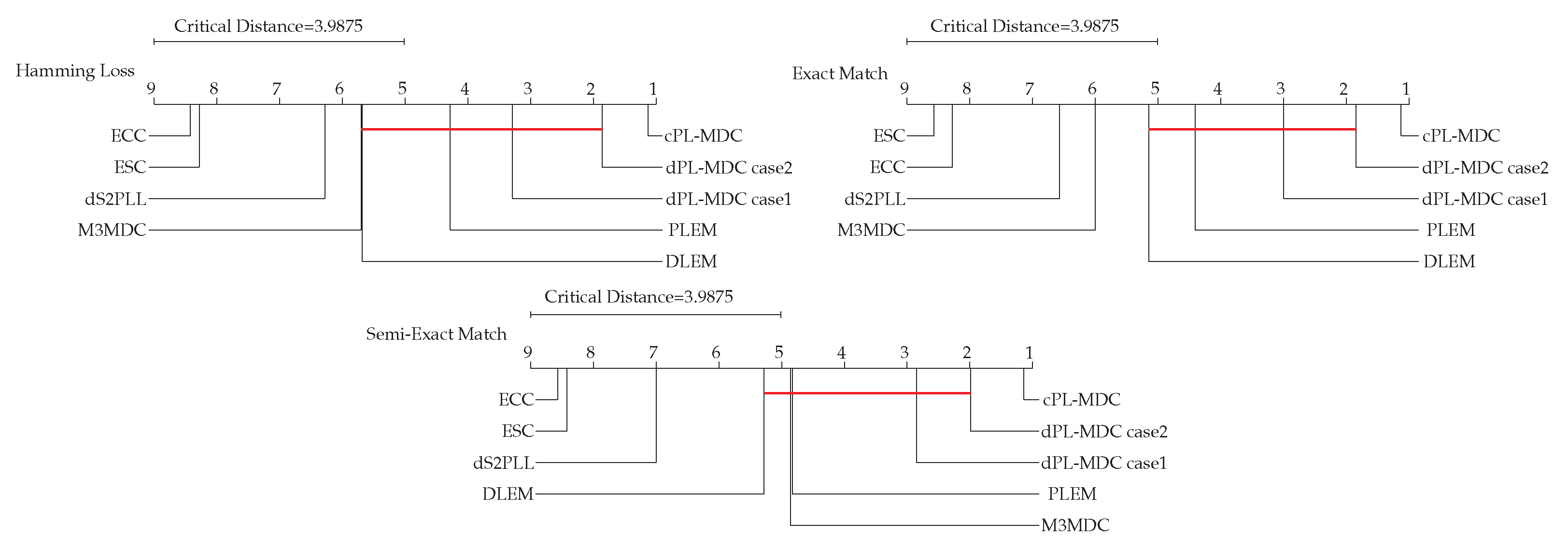
We rank all the comparison algorithms in Figure 8 in terms of three evaluation metrics to emphasize the advantages of the proposed algorithm from a macro perspective. Our proposed dPL-MDC case 1 and dPL-MDC case 2 algorithms are ranked lower than cPL-MDC. Furthermore, the rankings of the proposed dPL-MDC case 1 and dPL-MDC case 2 are significantly higher than the other comparison algorithms in each evaluation metric. This experimental result further corroborates the efficacy of the proposed method.
4.4. Performance Comparative Analysis of Different Algorithms
Furthermore, to further measure the relative performance difference across all comparison methods, the Friedman test is employed [44]. According to its theory, we have the number of comparison algorithms and the number of data sets . Based on and , we can calculate the critical value w.r.t. each evaluation metric and the corresponding value of the Friedman statistic . The detailed statistical results are presented in Table 6. Obviously, the null hypothesis of no distinguishable performance difference across all the comparison algorithms is rejected for each evaluation metric, with a significant threshold of .
Finally, the Bonferroni–Dunn test is used to quantify the relative performance difference between a pair of comparison algorithms [44]. In this experiment, dPL-MDC case 2 is set as the controlled method. We calculate the value of the critical difference (CD) at a significance level , and depict the CD diagrams in Figure 8. In each sub-figure of Figure 8, the average rankings of all the comparison algorithms are depicted by black lines, and any comparison algorithm whose average rank is within one CD to that of the controlled method is connected using a red line. From Figure 8, the dPL-MDC instance 2 markedly surpasses the dS2PLL, ECC, and ESC across all evaluation metrics, proving the superiority of our proposed method.
5. Conclusions
This study has tackled the challenge of distributed classification of multi-dimensional data labeled with candidate labels inside partially accessible class spaces over a network, and developed the dPL-MDC algorithm. The proposed method has employed one-vs.-one decomposition on the original multi-dimensional output space, which converts the issue of partial multi-dimensional classification (MDC) into a series of problems related to distributed partial multi-label learning. Then, a distributed label recovery approach has been devised to assess the label confidence of the training data. Under the supervision of the recovered labels, by exploiting high-order label dependencies from a common predictive structure in the subspace, the classifier has been trained. A number of simulations using multiple MDC datasets have been conducted to validate the efficacy of the proposed approach. Existing experimental results show that as long as the parameters of the proposed algorithm are set within a reasonable range, it can significantly outperform existing comparison algorithms. Especially when the proportion of noisy labels is high, the performance advantage of our proposed algorithm becomes more significant.
Nonetheless, the proposed algorithm still has some limitations. For example, the proposed algorithm currently relies on manual selection of hyperparameters. Therefore, in the future, we would like to integrate swarm intelligence algorithms to assist in automatically setting the values of hyperparameters. Additionally, the proposed algorithm is currently more suitable for small-scale networks. In the future, developing a new information cooperation model between nodes to adapt to large-scale networks is also an interesting direction. Moreover, considering the excellent performance of deep learning in many fields, leveraging related deep learning technologies to achieve continual learning is also a potential research direction in the future.
Author Contributions
Conceptualization, Z.X.; Methodology, Z.X.; Software, S.C.; Validation, S.C.; Formal analysis, Z.X.; Investigation, S.C.; Resources, S.C.; Data curation, S.C.; Writing—original draft, Z.X.; Writing—review & editing, Z.X.; Supervision, Z.X.; Project administration, Z.X.; Funding acquisition, Z.X. All authors have read and agreed to the published version of the manuscript.
Funding
This work was partly supported by the National Natural Science Foundation of China (Grant No. 62201398).
Data Availability Statement
All data generated or analyzed during this study are included in this published article.
Conflicts of Interest
Author Sicong Chen was employed by the company Kasco Signal Co., Ltd. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
Liu, Y.; Xu, Z.; Li, C. Distributed online semi-supervised support vector machine. Inf. Sci.2018, 466, 236–257. [Google Scholar] [CrossRef]
Hua, J.; Li, C.; Shen, H. Distributed learning of predictive structures from multiple tasks over networks. IEEE Trans. Ind. Electron.2017, 5, 4246–4256. [Google Scholar] [CrossRef]
Read, J.; Bielza, C.; Larranaga, P. Multi-dimensional classification with super-classes. IEEE Trans. Knowl. Data Eng2014, 26, 1720–1733. [Google Scholar] [CrossRef]
Serafino, F.; Pio, G.; Ceci, M.; Malerba, D. Hierarchical multi-dimensional classification of web documents with multiwebclass. In Proceedings of the 18th International Conference on Discovery Science, Banff, AB, Canada, 4–6 October 2015; pp. 236–250. [Google Scholar]
Yang, M.; Deng, C.; Nie, F. Adaptive-weighting discriminative regression for multi-view classification. Pattern Recognit.2019, 88, 236–245. [Google Scholar] [CrossRef]
Borchani, H.; Bielza, C.; Toro, C.; Larranaga, P. Predicting human immunodeficiency virus inhibitors using multi-dimensional Bayesian network classifiers. Artif. Intell. Med.2013, 57, 219–229. [Google Scholar] [CrossRef]
Jia, B.-B.; Zhang, M.-L. Multi-dimensional classification via kNN feature augmentation. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 3975–3982. [Google Scholar]
Wang, H.; Chen, C.; Liu, W.; Chen, K.; Hu, T.; Chen, G. Incorporating label embedding and feature augmentation for multi-dimensional classification. In Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 6178–6185. [Google Scholar]
Jia, B.-B.; Zhang, M.-L. Maximum margin multi-dimensional classification. In Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 4312–4319. [Google Scholar]
Jia, B.-B.; Zhang, M.-L. Multi-dimensional classification via stacked dependency exploitation. Sci. China Inf. Sci.2020, 63, 222102. [Google Scholar] [CrossRef]
Zhu, M.; Liu, S.; Jiang, J. A hybrid method for learning multi-dimensional Bayesian network classifiers based on an optimization model. Appl. Intell.2016, 44, 123–148. [Google Scholar] [CrossRef]
Read, J.; Martino, L.; Luengo, D. Efficient monte carlo methods for multi-dimensional learning with classifier chains. Pattern Recogn.2014, 47, 1535–1546. [Google Scholar] [CrossRef]
Zaragoza, J.; Sucar, L.; Morales, E.; Bielza, C.; Larranaga, P. Bayesian chain classifiers for multidimensional classification. In Proceeding of the 22nd International Joint Conference on Artificial Intelligence (IJCAI), Barcelona, Spain, 12–16 July 2011; pp. 2192–2197. [Google Scholar]
Zhang, M.-L.; Yu, F.; Tang, C. Disambiguation-free partial label learning. IEEE Trans. Knowl. Data Eng.2017, 29, 2155–2167. [Google Scholar] [CrossRef]
Tang, C.; Zhang, M.-L. Confidence-rated discriminative partial label learning. In Proceeding of the 31st AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 2611–2617. [Google Scholar]
Feng, L.; Lv, J.; Han, B.; Xu, M.; Niu, G.; Geng, X.; An, B.; Sugiyama, M. Provably consistent partial-label learning. In Proceedings of the 33rd Neural Information Processing Systems (NeurIPS’20), Virtual Conference, 6–12 December 2020; pp. 10948–10960. [Google Scholar]
Lv, J.; Xu, M.; Feng, L.; Niu, G.; Geng, X.; Sugiyama, M. Progressive identification of true labels for partial-label learning. In Proceedings of the 37th International Conference on Machine Learning (PMLR), Virtual Conference, 13–18 July 2020; pp. 6500–6510. [Google Scholar]
Zhang, Q.; Zhu, Y.; Cordeiro, F.R.; Chen, Q. PSSCL: A progressive sample selection framework with contrastive loss designed for noisy labels. Pattern Recogn.2025, 161, 111284. [Google Scholar] [CrossRef]
Wang, W.; Zhang, M.-L. Semi-supervised partial label learning via confidence-rated margin maximization. In Proceedings of the 33rd Neural Information Processing Systems (NeurIPS’20), Virtual Conference, 6–12 December 2020; pp. 6982–6993. [Google Scholar]
Miao, X.; Liu, Y.; Zhao, H.; Li, C. Distributed online one-class support vector machine for anomaly detection over networks. IEEE Trans. Cybern.2019, 49, 1475–1488. [Google Scholar] [CrossRef]
Shen, X.; Liu, Y.; Zhang, Z. Performance-enhanced Federated Learning with Differential Privacy for Internet of Things. IEEE Int. Things J.2022, 9, 24079–24094. [Google Scholar] [CrossRef]
Shen, X.; Liu, Y. Privacy-preserving distributed estimation over multitask networks. IEEE Trans. Aerosp. Electron. Syst.2022, 58, 1953–1965. [Google Scholar] [CrossRef]
Chen, S.; Liu, Y. Robust distributed parameter estimation of nonlinear systems with missing data over networks. IEEE Trans. Aerosp. Electron. Syst.2020, 56, 2228–2244. [Google Scholar] [CrossRef]
Xu, Z.; Liu, Y.; Li, C. Distributed information theoretic semisupervised learning for multilabel classification. IEEE Trans. Cybern.2022, 52, 821–835. [Google Scholar] [CrossRef]
Xu, Z.; Zhai, Y.; Liu, Y. Distributed semi-supervised multi-label classification with quantized communication. In Proceedings of the 12th International Conference on Machine Learning and Computing, Shenzhen, China, 15–17 February 2020; pp. 57–62. [Google Scholar]
Fang, J.-P.; Zhang, M.-L. Partial multi-label learning via credible label elicitation. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 3518–3525. [Google Scholar]
Sun, L.; Feng, S.; Wang, T.; Lang, T.; Jin, Y. Partial multi-label learning by low-rank and sparse decomposition. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 5016–5023. [Google Scholar]
Yu, T.; Yu, G.; Wang, J.; Domeniconi, C.; Zhang, X. Partial multi-label learning using label compression. In Proceedings of the 2020 IEEE International Conference on Data Mining (ICDM), Sorrento, Italy, 17–20 November 2020; pp. 761–770. [Google Scholar]
Xie, M.-K.; Huang, S. Semi-supervised partial multi-label learning. In Proceedings of the 2020 IEEE International Conference on Data Mining (ICDM), Sorrento, Italy, 17–20 November 2020; pp. 691–700. [Google Scholar]
Li, C.; Luo, Y. Distributed vector quantization over sensor network. Int. J. Dis. Sens. Netw.2014, 10, 189619. [Google Scholar] [CrossRef]
Wen, Z.; Yin, W.; Zhang, Y. Solving a low-rank factorization model for matrix completion by a nonlinear successive over-relaxation algorithm. Math. Program. Comput.2012, 4, 333–361. [Google Scholar] [CrossRef]
Lin, A.Y.; Ling, Q. Decentralized and privacy-preserving low-rank matrix completion. J. Oper. Res. Soc. China2015, 3, 1–17. [Google Scholar] [CrossRef]
Rahimi., A.; Recht, B. Random features for large-scale kernel machines. In Proceedings of the 21st International Conference on Neural Information Processing Systems (NeurIPS’07), Vancouver, BC, Canada, 3–6 December 2007; pp. 1177–1184. [Google Scholar]
Sreekanth, V.; Vedaldi, A.; Zisserman, A.; Jawahar, C. Generalized RBF feature maps for efficient detection. In Proceedings of the 21st British Machine Vision Conference, Aberystwyth, UK, 31 August–3 September 2010; pp. 1–11. [Google Scholar]
Demsar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res.2006, 7, 1–30. [Google Scholar]
Figure 1.
Diagram of the proposed dPL-MDC algorithm.
Figure 1.
Diagram of the proposed dPL-MDC algorithm.
Figure 2.
The learning curves of different algorithms on “Edm” dataset.
Figure 2.
The learning curves of different algorithms on “Edm” dataset.
Figure 3.
Hamming loss of dPL-MDC under varying values of parameters , , , , and on “Edm” dataset.
Figure 3.
Hamming loss of dPL-MDC under varying values of parameters , , , , and on “Edm” dataset.
Figure 4.
Hamming loss of dPL-MDC under varying numbers of anchor points C and dimensions of random feature map D on “Edm” dataset.
Figure 4.
Hamming loss of dPL-MDC under varying numbers of anchor points C and dimensions of random feature map D on “Edm” dataset.
Figure 5.
Hamming loss of different comparison algorithms versus the ANL on “Edm”, “Song”, “WQani.” and “WQpla.” datasets.
Figure 5.
Hamming loss of different comparison algorithms versus the ANL on “Edm”, “Song”, “WQani.” and “WQpla.” datasets.
Figure 6.
Exact match of different comparison algorithms versus the ANL on “Edm”, “Song”, “WQani.” and “WQpla.” datasets.
Figure 6.
Exact match of different comparison algorithms versus the ANL on “Edm”, “Song”, “WQani.” and “WQpla.” datasets.
Figure 7.
Semi-exact match of different comparison algorithms versus the ANL on “Edm”, “Song”, “WQani.” and “WQpla.” datasets.
Figure 7.
Semi-exact match of different comparison algorithms versus the ANL on “Edm”, “Song”, “WQani.” and “WQpla.” datasets.
Figure 8.
Comparison of dPL-MDC case 2 (the control algorithms) in contrast to other comparing algorithms using the Bonferroni–Dunn test.
Figure 8.
Comparison of dPL-MDC case 2 (the control algorithms) in contrast to other comparing algorithms using the Bonferroni–Dunn test.
Table 1.
Computational complexity of the proposed dS2PMDL algorithm.
Table 1.
Computational complexity of the proposed dS2PMDL algorithm.
Variables
Multiplication Operations
Addition Operations
Table 2.
Detailed profiles of used datasets.
Table 2.
Detailed profiles of used datasets.
Dataset
♯ Training Exam.
♯ Testing Exam.
♯ Feature
♯ Lab./Dim.
Edm
1230
310
2
3, 3
Song
3140
785
3
3, 3, 3
WQpla.
4240
1060
7
4, 4, 4, 4, 4, 4, 4
WQani.
4240
1060
7
4, 4, 4, 4, 4, 4, 4
Jura
2870
720
2
4, 5
Flare
2580
650
3
3, 4, 2
Music-emo.
5466
1367
11
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2
Table 3.
Hamming loss of different algorithms versus ANL on MDC datasets.
Table 3.
Hamming loss of different algorithms versus ANL on MDC datasets.
Hamming Loss
Dataset
Edm
Song
WQani.
WQpla.
Jura
Flare
Music-Emo.
ANL
0.8
0.8
0.8
0.8
0.8
0.8
0.481
dPL-MDC case 1
0.0590
0.1289
0.1728
0.1458
0.0587
0.0526
0.2521
dPL-MDC case 2
0.0576
0.1286
0.1719
0.1441
0.0570
0.0515
0.2504
cPL-MDC
0.0568
0.1273
0.1708
0.1430
0.0552
0.0519
0.2472
dS2PLL
0.0785
0.1434
0.1774
0.1507
0.0702
0.0536
0.2913
M3MDC
0.0735
0.1356
0.1745
0.1484
0.0735
0.0540
0.2924
DLEM
0.0713
0.1320
0.1757
0.1455
0.0707
0.0558
0.2933
ECC
0.1057
0.1402
0.1836
0.1621
0.0787
0.0621
0.3101
ESC
0.0956
0.1398
0.1870
0.1627
0.0775
0.0605
0.3175
PLEM
0.0685
0.1304
0.1744
0.1446
0.0685
0.0543
0.2872
Table 4.
Exact match of different algorithms versus ANL on MDC datasets.
Table 4.
Exact match of different algorithms versus ANL on MDC datasets.
Exact Match
Dataset
Edm
Song
WQani.
WQpla.
Jura
Flare
Music-Emo.
ANL
0.8
0.8
0.8
0.8
0.8
0.8
0.481
dPL-MDC case 1
0.8091
0.5355
0.0821
0.1342
0.7611
0.8227
0.2552
dPL-MDC case 2
0.8102
0.5364
0.0843
0.1354
0.7646
0.8245
0.2564
cPL-MDC
0.8224
0.5387
0.0854
0.1370
0.7706
0.8236
0.2577
dS2PLL
0.7612
0.5215
0.0774
0.1274
0.7055
0.8182
0.2087
M3MDC
0.7703
0.5188
0.0806
0.1285
0.7305
0.8140
0.2047
DLEM
0.7812
0.5300
0.0784
0.1278
0.7412
0.8201
0.2052
ECC
0.7247
0.5155
0.0716
0.1126
0.7070
0.7850
0.1880
ESC
0.7273
0.5170
0.0707
0.1171
0.7005
0.7826
0.1872
PLEM
0.7850
0.5324
0.0787
0.1303
0.7342
0.8198
0.2126
Table 5.
Semi-exact match of different algorithms versus ANL on MDC datasets.
Table 5.
Semi-exact match of different algorithms versus ANL on MDC datasets.
Semi-Exact Match
Dataset
Edm
Song
WQani.
WQpla.
Jura
Flare
Music-Emo.
ANL
0.8
0.8
0.8
0.8
0.8
0.8
0.481
dPL-MDC case 1
0.9895
0.9285
0.2842
0.3562
0.9702
0.9524
0.3756
dPL-MDC case 2
0.9897
0.9301
0.2856
0.3572
0.9689
0.9552
0.3779
cPL-MDC
0.9896
0.9315
0.2869
0.3590
0.9736
0.9566
0.3785
dS2PLL
0.9825
0.9165
0.2724
0.3465
0.9585
0.9368
0.3465
M3MDC
0.9867
0.9207
0.2806
0.3506
0.9608
0.9482
0.3551
DLEM
0.9858
0.9188
0.2773
0.3513
0.9598
0.9501
0.3568
ECC
0.9763
0.9005
0.2556
0.3360
0.9410
0.9257
0.3401
ESC
0.9755
0.9050
0.2568
0.3401
0.9487
0.9242
0.3385
PLEM
0.9842
0.9195
0.2794
0.3503
0.9625
0.9517
0.3593
Table 6.
Summary of the Friedman statistics and the critical value in teams of Hamming loss, exact match and semi-exact match.
Table 6.
Summary of the Friedman statistics and the critical value in teams of Hamming loss, exact match and semi-exact match.
Metric
Critical Value ()
Hamming loss
44.000
Exact match
49.814
2.14
Semi-exact match
61.605
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}