
Optimized FPGA Architecture for CNN-Driven Subsurface Geotechnical Defect Detection


Abstract
1. Introduction
- (1)
- We design a heterogeneous parallel architecture with dedicated DSP arrays optimized for the distinct operational characteristics of the 1 × 1 and 3 × 3 kernels in YOLOv5n, reducing resource redundancy caused by uniform parallelization.
- (2)
- We have improved the mainstream bit-partitioning strategy for DSP resources. We optimized the timing and reduced LUT resource consumption while ensuring unchanged DSP resource consumption and computational efficiency.
- (3)
- In dataflow design, we employ a row-buffered streaming architecture to form a multi-row data pool for sliding window operations, increasing the utilization of on-chip block RAM (BRAM) and reducing redundant data reloading.
2. Algorithmic Foundation
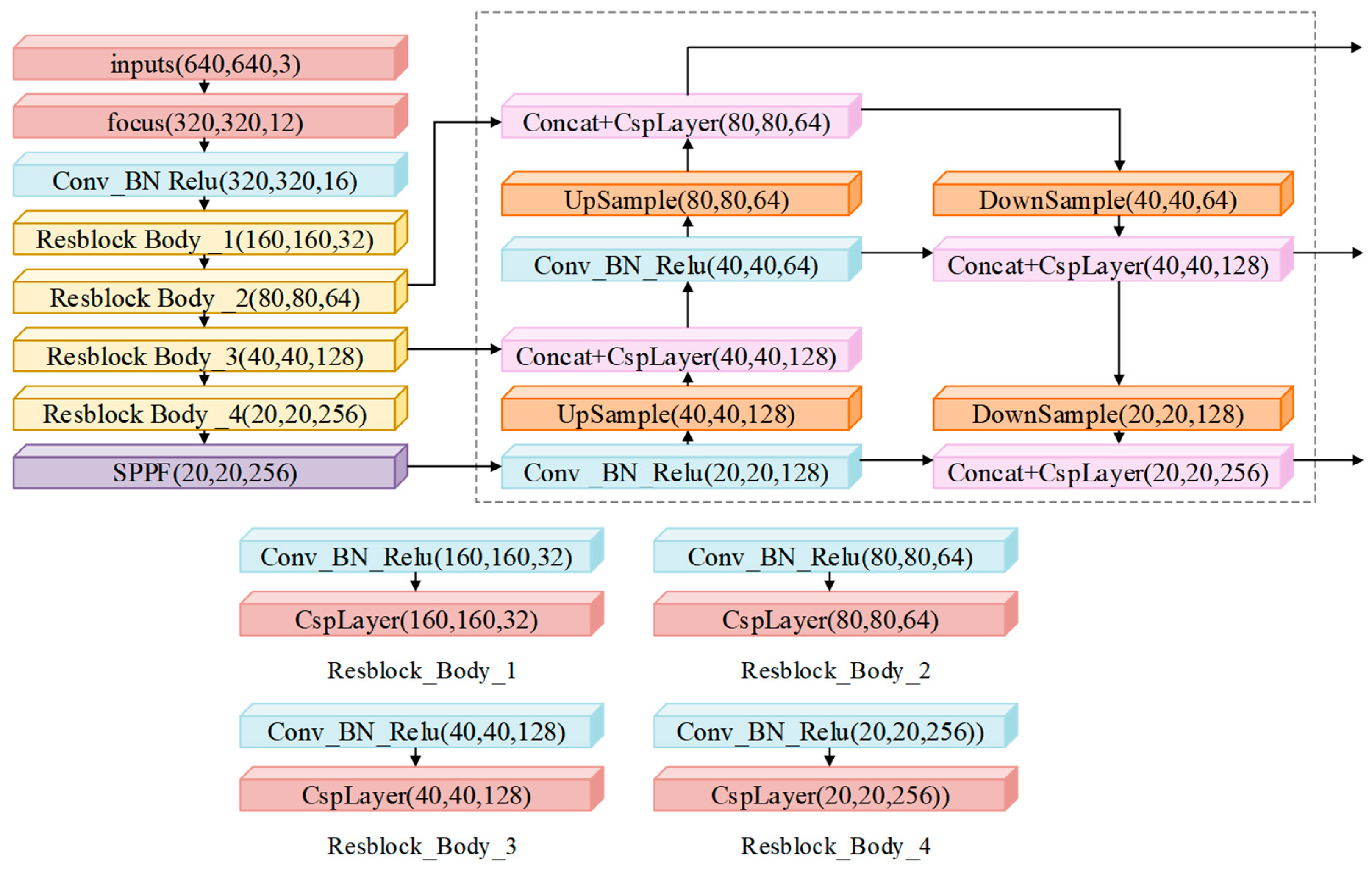
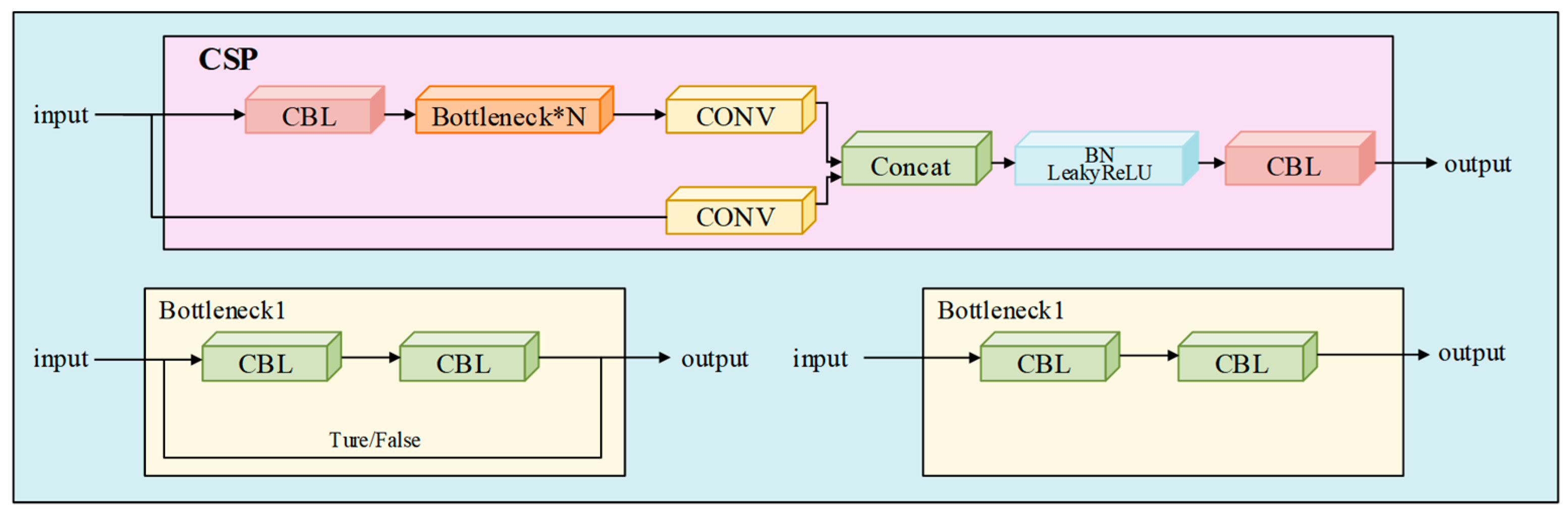
2.1. Architecture and Operational Principles of YOLOv5n
2.2. The 8-Bit Quantization Strategy
3. Accelerator Architecture
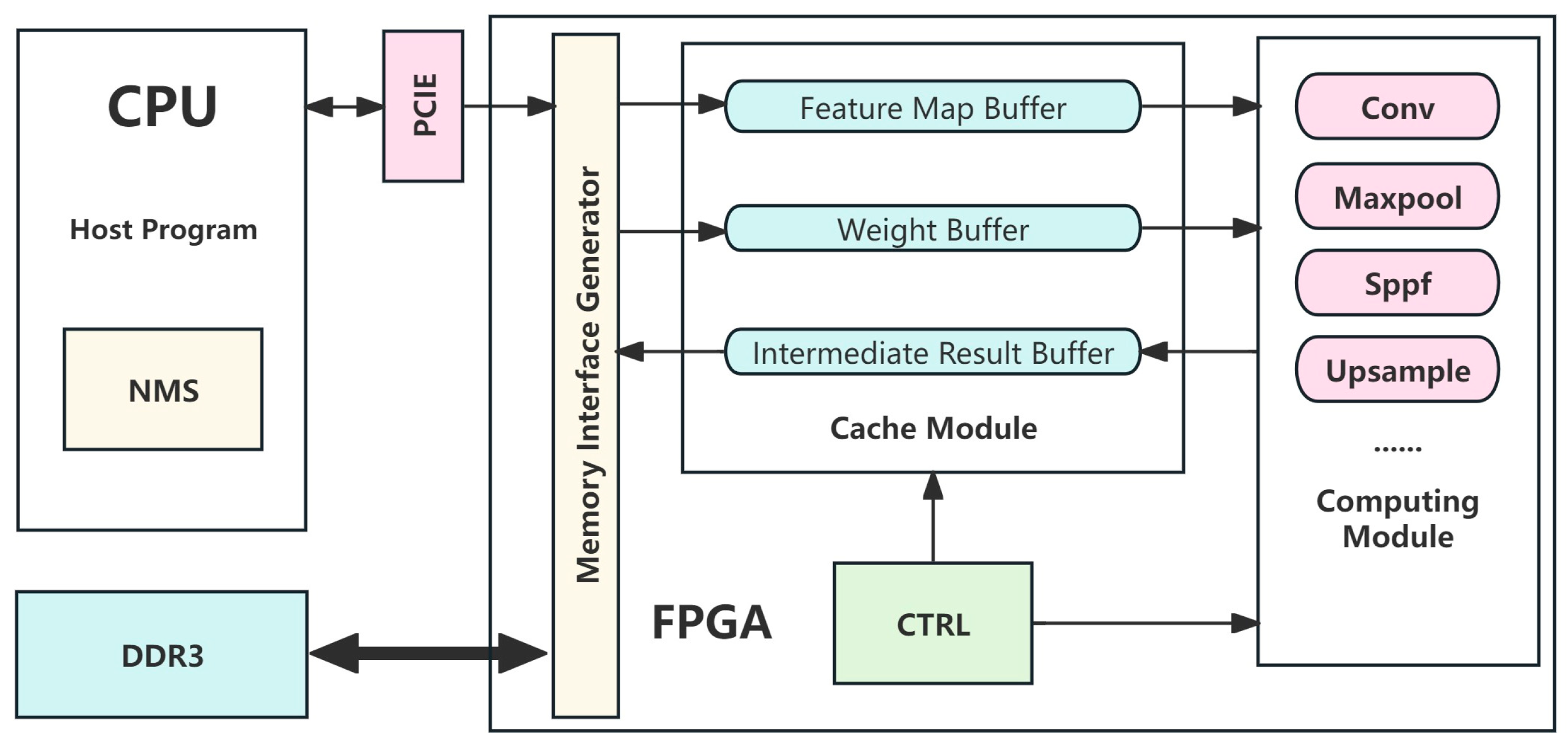
3.1. Overall Hardware Architecture
3.2. Dataflow Buffer Design
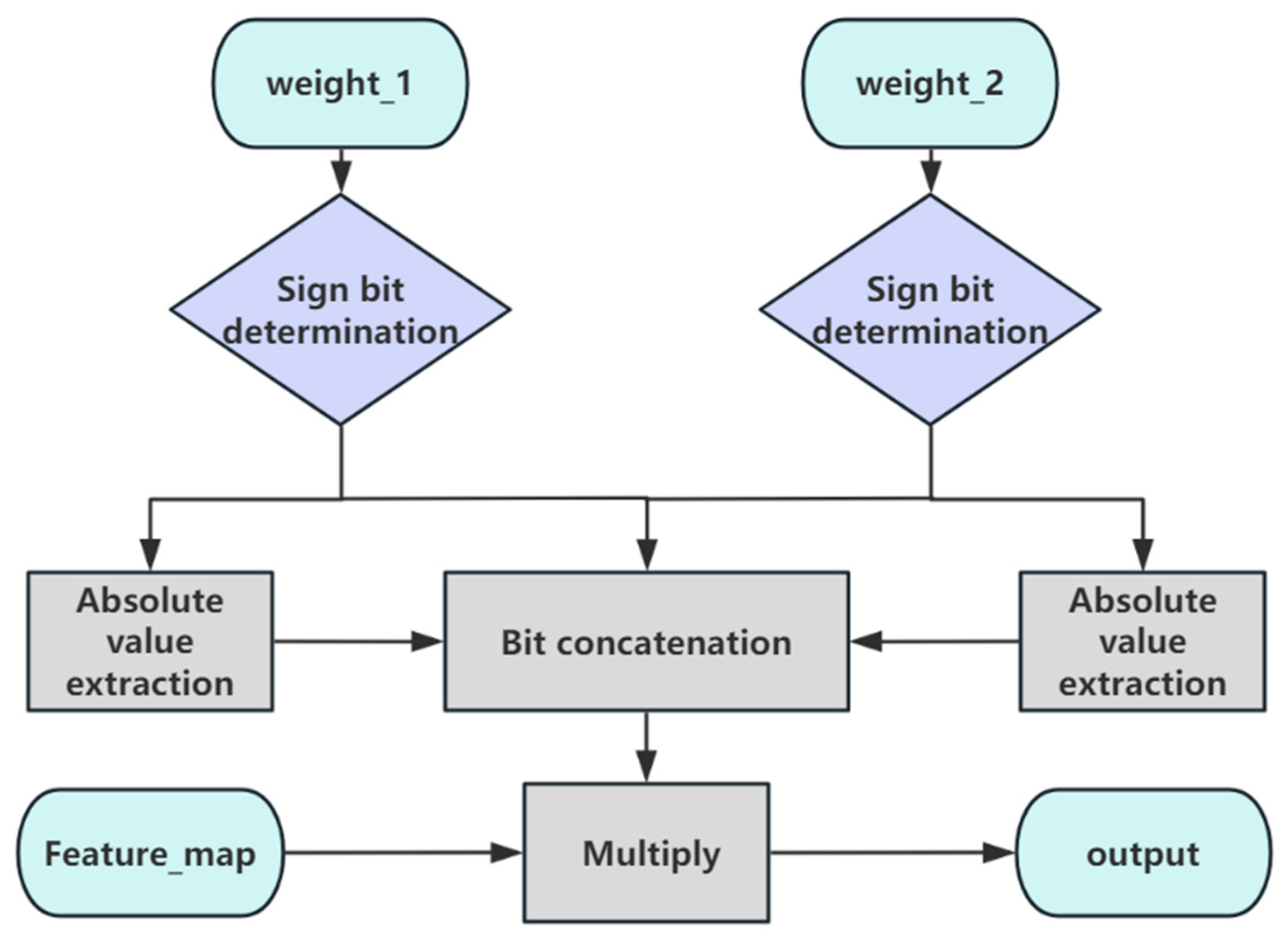
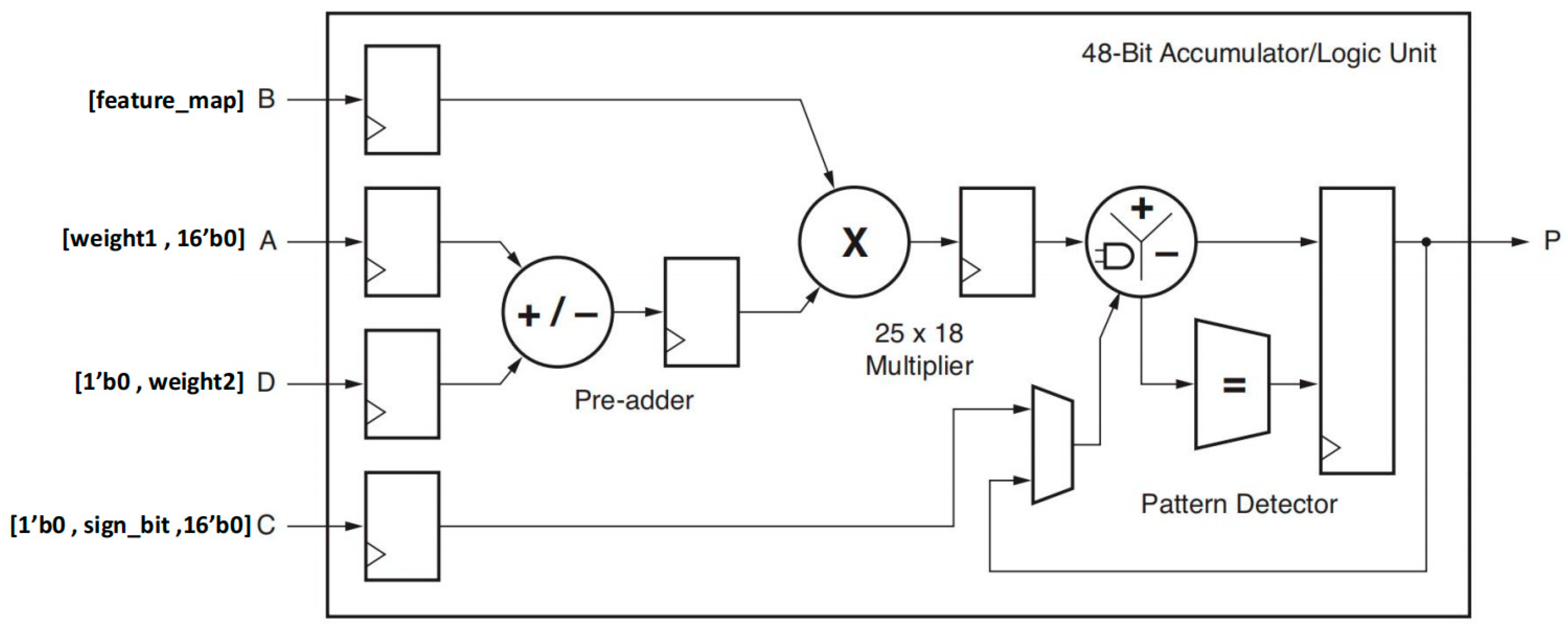
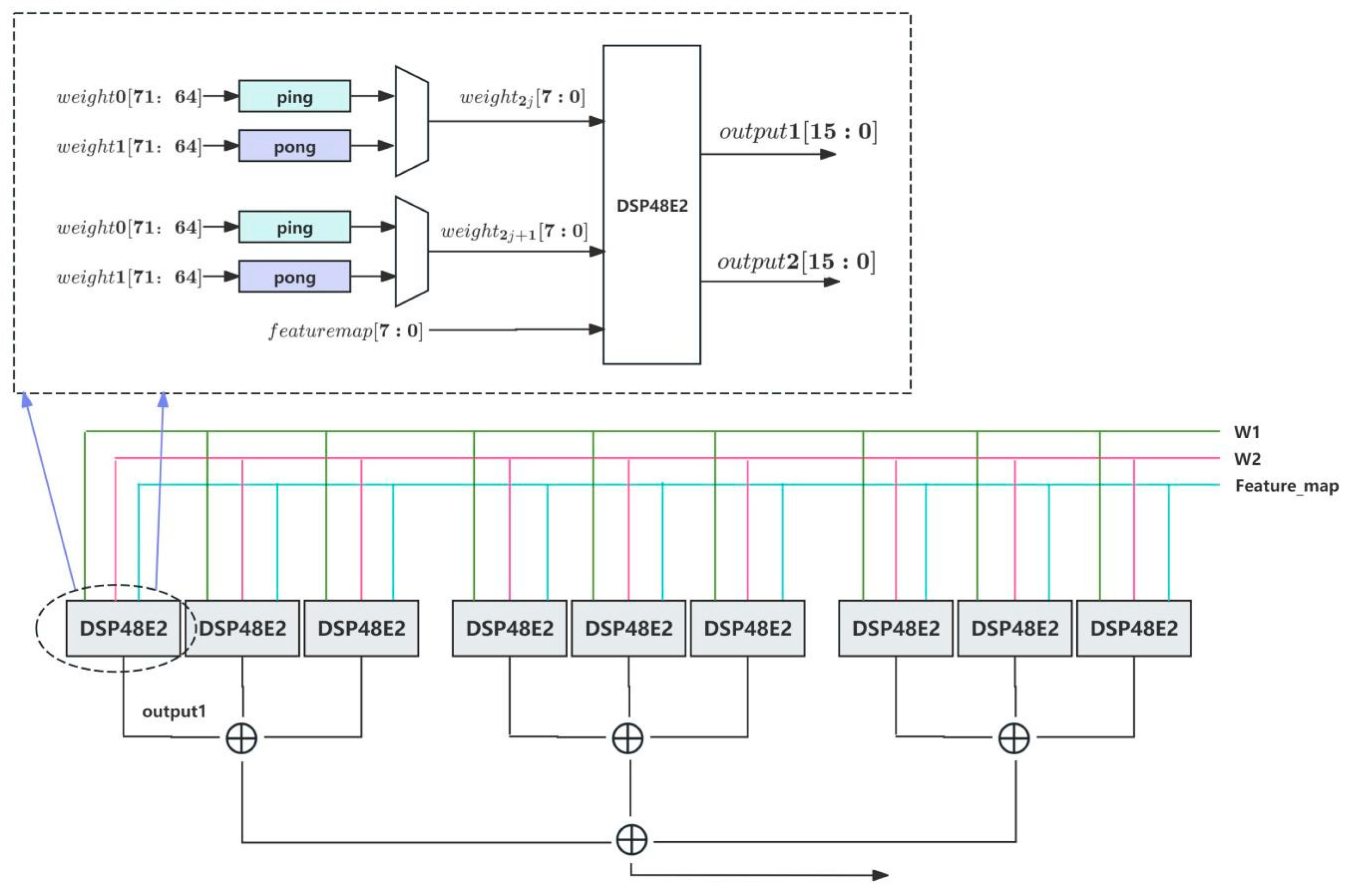
3.3. High Bit-Width Partitioning Strategy for DSPs
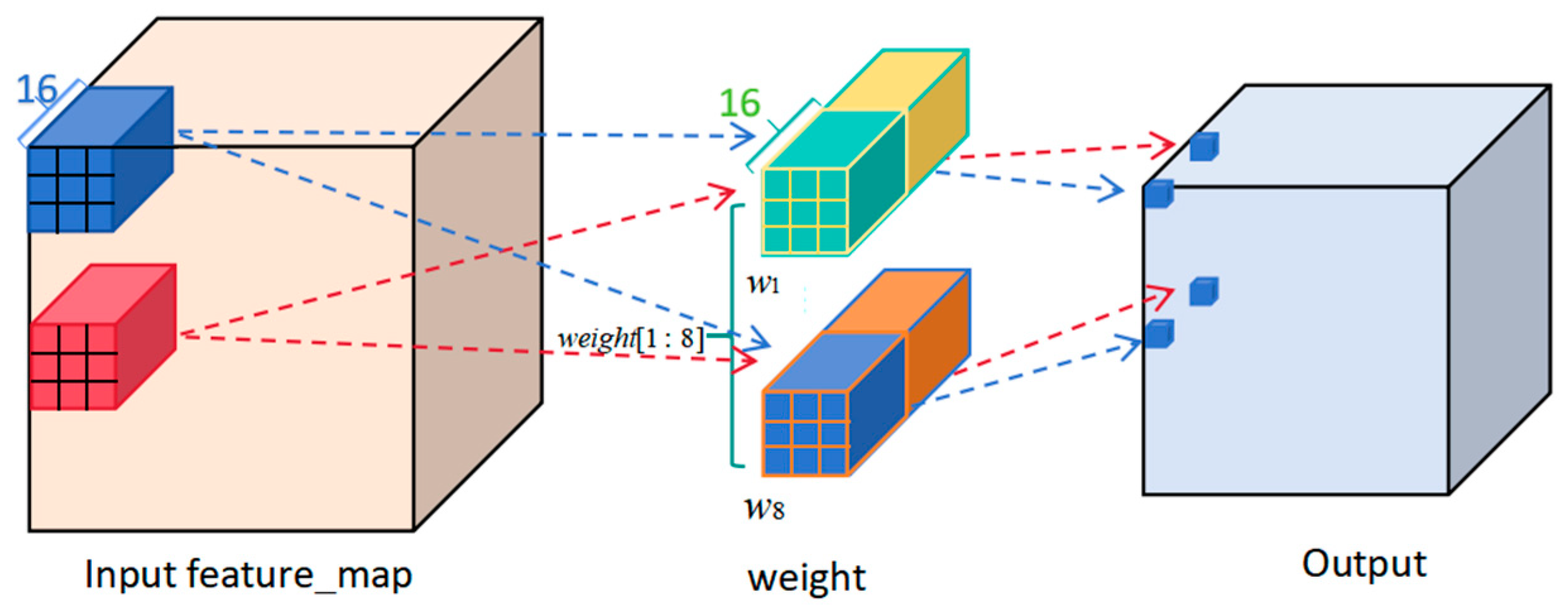
3.4. Convolutional Layer Hybrid-Acceleration Strategy
3.5. Convolutional Layer PE Design
4. Experiment Results
4.1. Experimental Environments
4.2. Dataset
4.2.1. VOC Dataset
4.2.2. Subsurface Geotechnical Defect-Detection Dataset
4.2.3. Printed Circuit Board (PCB) Defect Dataset
4.3. Training and Inference Results
4.4. Analysis and Comparison
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | convolutional neural network |
| DSP | Digital Signal Processor |
| mAP | mean average precision |
| GPR | ground-penetrating radar |
| CLB | configurable logic block |
| BRAM | block RAM |
| MAC | Multiply Accumulate |
| SPP | Spatial Pyramid Pooling |
| SPPF | Spatial Pyramid Pooling Fast |
| AXI_DMA | AXI Direct Memory Access |
| NMS | non-maximum suppression |
| HDL | Verilog hardware description language |
| RTL | Register Transfer Level |
| PE | Processing Element |
References
- Li, B.; Chu, X.; Lin, F.; Wu, F.; Jin, S.; Zhang, K. A highly efficient tunnel lining crack detection model based on Mini-Unet. Sci. Rep. 2024, 14, 28234. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Z.; Zhang, J.; Gong, C. Hybrid semantic segmentation for tunnel lining cracks based on Swin Transformer and convolutional neural network. Comput.-Aided Civ. Infrastruct. Eng. 2023, 38, 2491–2510. [Google Scholar] [CrossRef]
- Fu, Y.; Liu, Y.; Chen, G. Stability analysis of rock slopes based on CSMR and convolutional neural networks. J. Nat. Disasters 2023, 32, 114–121. [Google Scholar]
- Lin, M.; Chen, X.; Chen, G.; Zhao, Z.; Bassir, D. Stability prediction of multi-material complex slopes based on self-attention convolutional neural networks. Stoch. Environ. Res. Risk Assess. 2024, 1–17. [Google Scholar] [CrossRef]
- Guo, W.; Zhang, X.; Zhang, D.; Chen, Z.; Zhou, B.; Huang, D.; Li, Q. Detection and classification of pipe defects based on pipe-extended feature pyramid network. Autom. Constr. 2022, 141, 104399. [Google Scholar] [CrossRef]
- Ghodhbani, R.; Saidani, T.; Zayeni, H. Deploying deep learning networks based advanced techniques for image processing on FPGA platform. Neural Comput. Appl. 2023, 35, 18949–18969. [Google Scholar] [CrossRef]
- Kumari, N.; Ruf, V.; Mukhametov, S.; Schmidt, A.; Kuhn, J.; Küchemann, S. Mobile eye-tracking data analysis using object detection via YOLO v4. Sensors 2021, 21, 7668. [Google Scholar] [CrossRef]
- Ma, J.; Zhou, Y.; Zhou, Z.; Zhang, Y.; He, L. Toward smart ocean monitoring: Real-time detection of marine litter using YOLOv12 in support of pollution mitigation. Mar. Pollut. Bull. 2025, 217, 118136. [Google Scholar] [CrossRef]
- Tu, C.; Yi, A.; Yao, T.; He, W. High-precision garbage detection algorithm of lightweight yolov5n. Comput. Eng. Appl. 2023, 59, 187–195. [Google Scholar]
- Feng, Y.; Zhao, X.; Tian, R.; Liang, C.; Liu, J.; Fan, X. Research on an Intelligent Seed-Sorting Method and Sorter Based on Machine Vision and Lightweight YOLOv5n. Agronomy 2024, 14, 1953. [Google Scholar] [CrossRef]
- Chen, Z.; Lin, Y.; Xu, J.; Lu, K.; Huang, Z. A fused score computation approach to reflect the overlap between the predicted box and the ground truth in pedestrian detection. IET Image Process. 2024, 18, 4287–4296. [Google Scholar] [CrossRef]
- Zhang, Y.; Guo, Z.; Wu, J.; Tian, Y.; Tang, H.; Guo, X. Real-time vehicle detection based on improved yolo v5. Sustainability 2022, 14, 12274. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Guo, Z.; Gao, Y.; Hu, H.; Gong, D.; Liu, K.; Wu, X. Research on Acceleration of Convolutional Neural Network Algorithm Based on Hybrid Architecture. J. Comput. Eng. Appl. 2022, 58, 88–94. [Google Scholar]
- Zhang, D.; Wang, A.; Mo, R.; Wang, D. End-to-end acceleration of the YOLO object detection framework on FPGA-only devices. Neural. Comput. Appl. 2024, 36, 1067–1089. [Google Scholar] [CrossRef]
- Valadanzoj, Z.; Daryanavard, H.; Harifi, A. High-speed YOLOv4-tiny hardware accelerator for self-driving automotive. J. Supercomput. 2024, 80, 6699–6724. [Google Scholar] [CrossRef]
- Huang, H.; Liu, Z.; Chen, T.; Hu, X.; Zhang, Q.; Xiong, X. Design space exploration for yolo neural network accelerator. Electronics 2020, 9, 1921. [Google Scholar] [CrossRef]
- Shafiei, M.; Daryanavard, H.; Hatam, A. Scalable and custom-precision floating-point hardware convolution core for using in AI edge processors. J. Real-Time Image Process. 2023, 20, 94. [Google Scholar] [CrossRef]
- Yan, Z.; Zhang, B.; Wang, D. An FPGA-Based YOLOv5 Accelerator for Real-Time Industrial Vision Applications. Micromachines 2024, 15, 1164. [Google Scholar] [CrossRef]
- Kim, M.; Oh, K.; Cho, Y.; Seo, H.; Nguyen, X.T.; Lee, H.-J. A low-latency FPGA accelerator for YOLOv3-tiny with flexible layerwise map and dataflow. IEEE Trans. Circuits Syst. I Regul. Pap. 2023, 71, 1158–1171. [Google Scholar] [CrossRef]
- Guo, R.; Liu, H.; Xie, G.; Zhang, Y. Weld defect detection from imbalanced radiographic images based on contrast enhancement conditional generative adversarial network and transfer learning. IEEE Sens. J. 2021, 21, 10844–10853. [Google Scholar] [CrossRef]
- Dai, W.; Wang, Y.; Li, X.; Wang, Y. YOLO aluminum profile surface defect detection system for FPGA deployment. J. Electron. Meas. Instrum. 2023, 37, 160–167. [Google Scholar]
- Johnson, V.C.; Bali, J.; Chanchal, A.K.; Kumar, S.; Shukla, M.K. Performance Comparison of Machine Learning Classifiers for FPGA-Accelerated Surface Defect Detection. In Proceedings of the 2024 IEEE Conference on Engineering Informatics (ICEI), Melbourne, Australia, 20–28 November 2024. [Google Scholar]
- Ding, Z.; Liu, C.; Li, D.; Yi, G. Deep-sea biological detection method based on lightweight YOLOv5n. Sensors 2023, 23, 8600. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Hu, X.; Xu, L.; Wang, W.; Ghannouchi, F.M. Low computational complexity digital predistortion based on convolutional neural network for wideband power amplifiers. IEEE Trans. Circuits Syst. II Express Briefs 2021, 69, 1702–1706. [Google Scholar] [CrossRef]
- Wei, S.X.; Yu, H.; Zhang, P. A farmed fish detection method based on a non-channel-downscaling attention mechanism and improved YOLOv5. Fish. Mod. 2023, 50, 72–78. [Google Scholar]
- Zhang, H.; Shao, F.; He, X.; Zhang, Z.; Cai, Y.; Bi, S. Research on object detection and recognition method for UAV aerial images based on improved YOLOv5. Drones 2023, 7, 402. [Google Scholar] [CrossRef]
- Chen, L.; Lou, P. Clipping-Based Post Training 8-Bit Quantization of Convolution Neural Networks for Object Detection. Appl. Sci. 2022, 12, 12405. [Google Scholar] [CrossRef]
- Wang, J.; Fang, S.; Wang, X.; Ma, J.; Wang, T.; Shan, Y. High-performance mixed-low-precision cnn inference accelerator on fpga. IEEE Micro 2021, 41, 31–38. [Google Scholar] [CrossRef]
- Everingham, M.; Eslami, S.A.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Zhang, M.; Li, L.; Wang, H.; Liu, Y.; Qin, H.; Zhao, W. Optimized compression for implementing convolutional neural networks on FPGA. Electronics 2019, 8, 295. [Google Scholar] [CrossRef]
- Tsai, T.H.; Tung, N.C.; Chen, C.Y. An FPGA-Based Reconfigurable Convolutional Neural Network Accelerator for Tiny YOLO-V3. Circuits Syst. Signal Process. 2025, 44, 3388–3409. [Google Scholar] [CrossRef]
- Xu, S.; Zhou, Y.; Huang, Y.; Han, T. YOLOv4-tiny-based coal gangue image recognition and FPGA implementation. Micromachines 2022, 13, 1983. [Google Scholar] [CrossRef] [PubMed]
- Liu, M.; Luo, S.; Han, K.; Yuan, B.; DeMara, R.F.; Bai, Y. An efficient real-time object detection framework on resource-constricted hardware devices via software and hardware co-design. In Proceedings of the 2021 IEEE 32nd International Conference on Application-Specific Systems, Architectures and Processors (ASAP), Online, 7–9 July 2021; pp. 77–84. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Uniform Parallel Strategy | Hybrid Acceleration Strategy | |
|---|---|---|
| Theoretical DSP utilization | 1280 | 704 |
| 0.11 | 0.22 |
| 100 M | 200 M | 300 M | |||
|---|---|---|---|---|---|
| Layer | Time/ms | Layer | Time/ms | Layer | Time/ms |
| Focus | 2.801 | Focus | 2.506 | Focus | 1.944 |
| Conv1 | 3.736 | Conv1 | 2.817 | Conv1 | 2.537 |
| Resblock_Body1 | 10.474 | Resblock_Body1 | 8.024 | Resblock_Body1 | 7.906 |
| Resblock_Body2 | 10.036 | Resblock_Body2 | 6.784 | Resblock_Body2 | 5.863 |
| Resblock_Body3 | 11.648 | Resblock_Body3 | 7.186 | Resblock_Body3 | 5.96 |
| Resblock_Body4 | 8.414 | Resblock_Body4 | 4.813 | Resblock_Body4 | 3.731 |
| SPPF | 5.366 | SPPF | 3.716 | SPPF | 3.15 |
| Head | 33.413 | Head | 21.026 | Head | 17.399 |
| Total | 85.888 | Total | 56.872 | Total | 48.49 |
| Resource | Utilization | Available | Utilization |
|---|---|---|---|
| LUT | 125,956 | 277,400 | 45.41% |
| BRAM | 371 | 755 | 49.07% |
| DSP | 752 | 2020 | 37.23% |
| FF | 177,723 | 554,800 | 32.03% |
| Conv3 × 3 | Conv1 × 1 | Concat | SPPF | Bottleneck_Add | Focus | Upsample | |
|---|---|---|---|---|---|---|---|
| DSP | 576 | 128 | 16 | None | 32 | None | None |
| BRAM | 92 | 63 | 16 | 20 | 12 | None | 8 |
| FF | 78,577 | 32,651 | 16,820 | 7565 | 17,261 | 1344 | 784 |
| LUT | 28,598 | 16,868 | 14,306 | 12,216 | 14,705 | 776 | 958 |
| Power/W | 0.977 | 1.105 | 1.053 | 0.157 | 1.314 | 0.063 | 0.014 |
| Layer | MAC/G | Time/ms | GOPS | Input_Channel | Output_Channel | Stride |
|---|---|---|---|---|---|---|
| Conv3 × 3_layer1 | 0.356 | 2.51 | 141.65 | 12 | 16 | 1 |
| Conv3 × 3_layer2 | 0.237 | 1.61 | 147.03 | 16 | 32 | 2 |
| Conv3 × 3_layer3 | 0.118 | 0.55 | 215.23 | 16 | 16 | 1 |
| Conv3 × 3_layer4 | 0.236 | 0.81 | 291.78 | 32 | 64 | 2 |
| Conv3 × 3_layer5 | 0.118 | 0.38 | 310.97 | 32 | 32 | 1 |
| Conv3 × 3_layer6 | 0.118 | 0.38 | 310.97 | 32 | 32 | 1 |
| Conv3 × 3_layer7 | 0.236 | 0.88 | 268.33 | 64 | 128 | 2 |
| Conv3 × 3_layer8 | 0.118 | 0.39 | 302.74 | 64 | 64 | 1 |
| Conv3 × 3_layer9 | 0.118 | 0.39 | 302.74 | 64 | 64 | 1 |
| Conv3 × 3_layer10 | 0.118 | 0.39 | 302.74 | 64 | 64 | 1 |
| Conv3 × 3_layer11 | 0.236 | 1.09 | 216.54 | 128 | 256 | 2 |
| Conv3 × 3_layer12 | 0.118 | 0.37 | 319.5 | 128 | 128 | 1 |
| Conv3 × 3_layer13 | 0.11807 | 0.38 | 310.7 | 64 | 64 | 1 |
| Conv3 × 3_layer14 | 0.11817 | 0.36 | 328.25 | 32 | 32 | 1 |
| Conv3 × 3_layer15 | 0.11807 | 0.45 | 262.37 | 64 | 64 | 2 |
| Conv3 × 3_layer16 | 0.11807 | 0.39 | 302.74 | 64 | 64 | 1 |
| Conv3 × 3_layer17 | 0.11801 | 0.56 | 210.74 | 128 | 128 | 2 |
| Conv3 × 3_layer18 | 0.11801 | 0.36 | 327.82 | 128 | 128 | 1 |
| [31] | [17] | [32] | [14] | [33] | [34] | This Work | |
|---|---|---|---|---|---|---|---|
| Platform | Zynq XCZU7EV | Xilinx ZC706 | Zynq XCZU7EV | Xilinx ZC709 | ZYNQ- 7020 | KCU116 | Zynq XC7Z100 |
| Network | AlexNet | Tiny YOLO-V2 | Tiny YOLO-V3 | Tiny YOLO-V3 | Tiny YOLO-V4 | YOLO- V5s | YOLO-V5n |
| Operation Frequency | 300 MHz | 100 MHz | 166 MHz | 200 MHz | None | None | 300 M |
| Arithmetic Precision | 8 | 16–32 | 16 | 16 | 16 | TT | 8 |
| BRAM | 198.5 | 301 | 254 | 624 | 96 | 220 | 370 |
| DSP | 696 | 784 | 46 | 514 | 216 | 1321 | 752 |
| LUT | 101,953 | 182,086 | 117,696 | 176,130 | 41,953 | 182,000 | 216,725 |
| FF | 127,577 | 132,869 | 117,157 | 140,012 | 47,652 | 123,098 | 224,544 |
| Throughput (GOPs) | 14.11 | 41.99 | 42.5 | 120 | 9.24 | 42.6 | 157.04 |
| Power (W) | 17.67 | 7.5 | 4.96 | 7.36 | 2.86 | 15.3 | 9.4 |
| Energy Efficiency (GOPs/W) | 0.8 | 5.6 | 8.57 | 16 | 3.23 | 2.8 | 16.7 |
| GPU | FPGA | |
|---|---|---|
| Device model | NVIDIA RTX 3090 | Xilinx Zynq7z100 |
| Throughput (GOPs) | 1075 | 157 |
| Power (W) | 170 | 9.4 |
| Energy Efficiency (GOPs/W) | 6.32 | 16.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Che, L.; Li, S.; Wang, Z.; Lai, W. Optimized FPGA Architecture for CNN-Driven Subsurface Geotechnical Defect Detection. Electronics 2025, 14, 2585. https://doi.org/10.3390/electronics14132585
Li X, Che L, Li S, Wang Z, Lai W. Optimized FPGA Architecture for CNN-Driven Subsurface Geotechnical Defect Detection. Electronics. 2025; 14(13):2585. https://doi.org/10.3390/electronics14132585
Chicago/Turabian StyleLi, Xiangyu, Linjian Che, Shunjiong Li, Zidong Wang, and Wugang Lai. 2025. "Optimized FPGA Architecture for CNN-Driven Subsurface Geotechnical Defect Detection" Electronics 14, no. 13: 2585. https://doi.org/10.3390/electronics14132585
APA StyleLi, X., Che, L., Li, S., Wang, Z., & Lai, W. (2025). Optimized FPGA Architecture for CNN-Driven Subsurface Geotechnical Defect Detection. Electronics, 14(13), 2585. https://doi.org/10.3390/electronics14132585