
MFF: A Multimodal Feature Fusion Approach for Encrypted Traffic Classification


Abstract
1. Introduction
- A multimodal encrypted traffic classification model named MFF is proposed, which integrates both temporal and statistical features. This model effectively addresses the feature loss problem caused by traffic truncation, thereby enhancing classification accuracy and generalization performance.
- A dual-path feature extraction and fusion mechanism is designed, where the ResNet18 architecture is enhanced with a Squeeze-and-Excitation (SE) attention mechanism for temporal feature extraction, and a deep autoencoder is employed to perform nonlinear dimensionality reduction on statistical features. By fusing these two types of features, the model achieves feature enhancement and improved overall performance.
- Extensive experiments on the ISCX VPN-nonVPN and USTC-TFC datasets across seven evaluation groups demonstrate the superiority of the proposed method. Furthermore, SHAP-based interpretability analysis is conducted to enhance the transparency and trustworthiness of the model.
2. Related Work
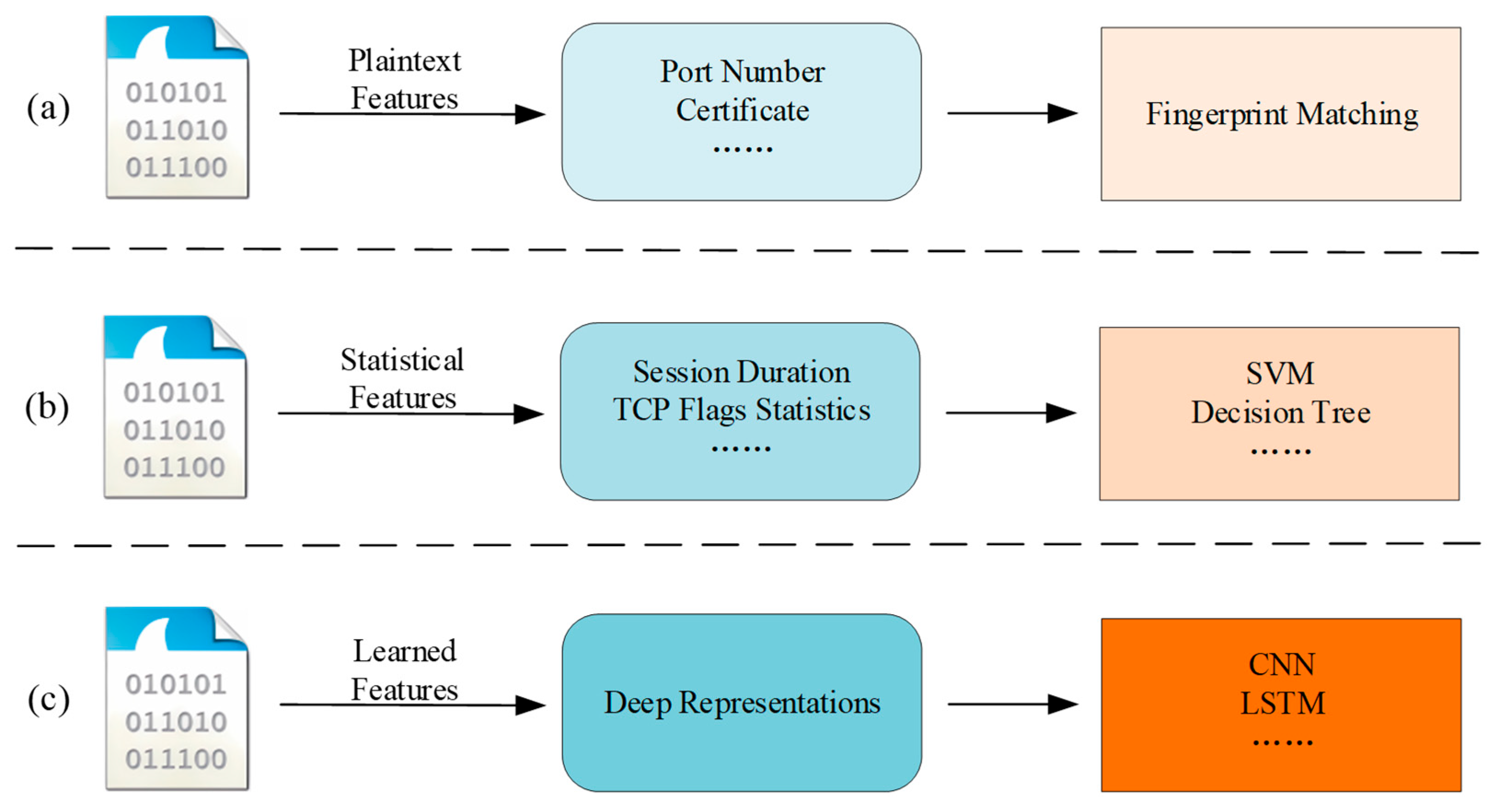
2.1. Rule-Based Methods Leveraging Plaintext Features
2.2. Machine Learning Methods Based on Statistical Features
2.3. Deep Learning Methods Based on Self-Learned Features
3. Methodology
3.1. Datasets
3.2. Data Preprocessing
3.2.1. Session-Based Traffic Segmentation
3.2.2. Statistical Feature Extraction
3.2.3. Traffic Anonymization
3.2.4. Standardized Traffic Length
3.2.5. Visualization-Based Analysis of Preprocessed Data
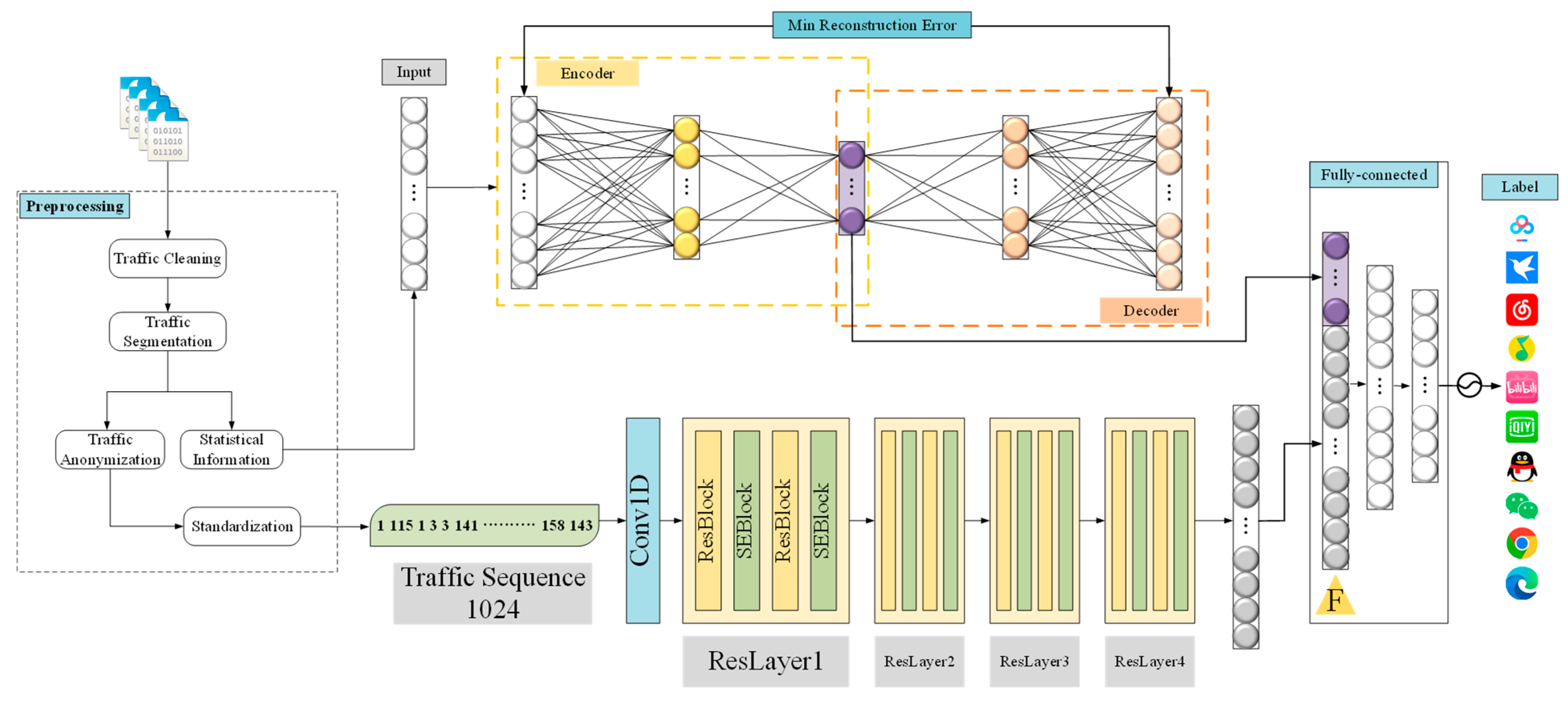
3.3. Architecture Design
3.3.1. Temporal Feature Extraction Branch Based on SE-ResNet18
3.3.2. Statistical Feature Extraction Branch Based on AE
3.3.3. Feature Fusion and Classification
4. Experiment and Analysis
4.1. Experimental Setup and Configuration
4.2. Experimental Settings
4.3. Evaluation Metrics
4.4. Experimental Results and Analysis
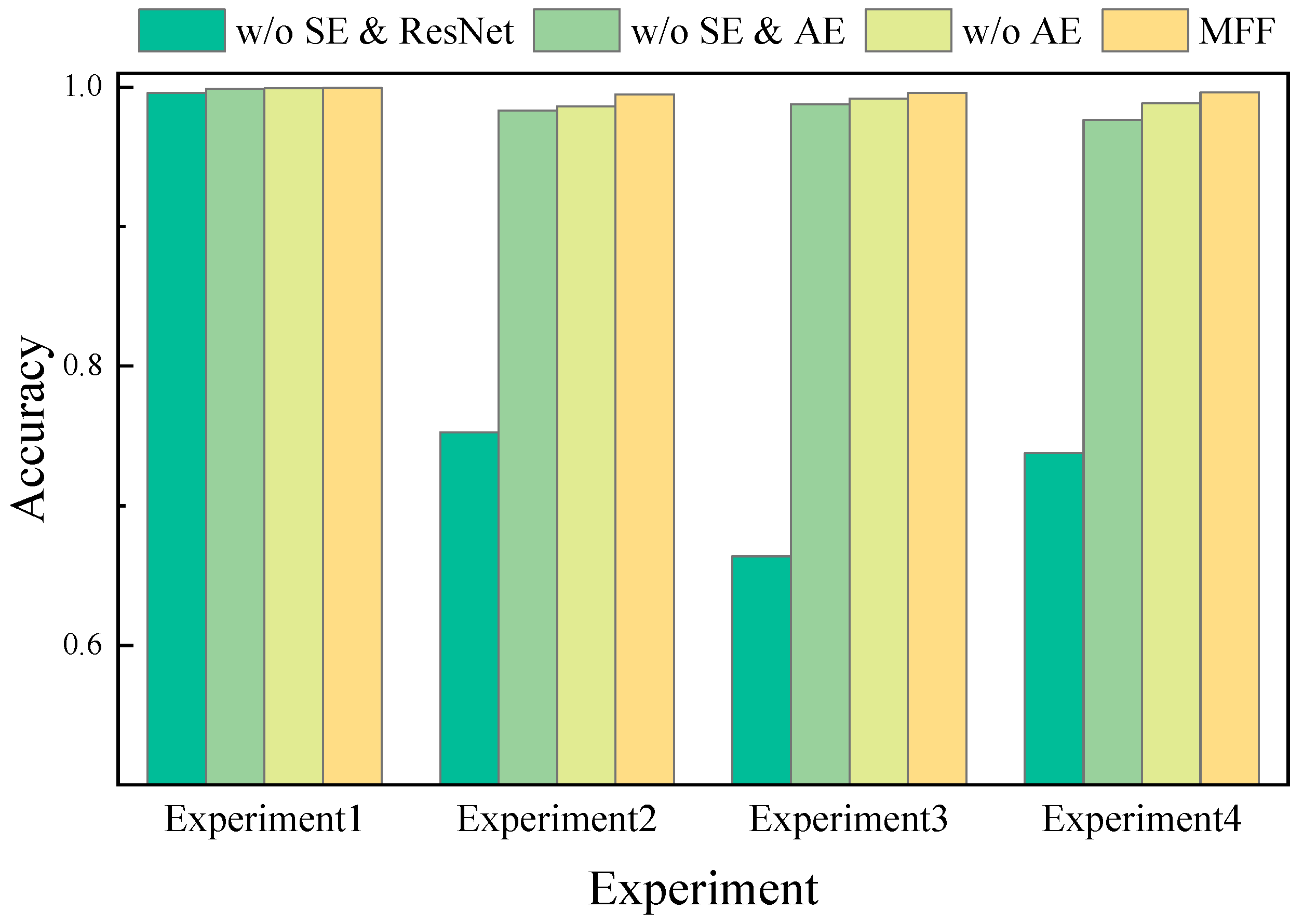
4.4.1. Ablation Study
- (1)
- w/o SE and ResNet: Statistical feature path only
- (2)
- w/o SE and AE: Basic temporal feature path only
- (3)
- w/o AE: Full temporal modeling without statistical features
- (4)
- Full MFF structure: Complete multimodal design with temporal and statistical features
4.4.2. Comparative Experiments and Result Analysis with Other Models
4.4.3. Interpretability Analysis
5. Conclusions and Future Work
- (1)
- Incorporate advanced temporal modeling techniques, such as transformer architectures or hybrid attention mechanisms, to better capture long-range dependencies in encrypted traffic;
- (2)
- Investigate the impact of varying input segment lengths (e.g., 512, 1024, 2048 bytes) on model performance to improve adaptability and generalization;
- (3)
- Explore model interpretability and lightweight design to improve deployability and efficiency, particularly in edge computing environments;
- (4)
- Extend support for emerging encryption protocols such as TLS 1.3 and QUIC by adapting the model architecture and expanding the dataset using automated traffic collection tools. These enhancements will further improve MFF’s practical relevance in real-world encrypted traffic analysis.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- HTTPS Encryption on the Web. Available online: https://transparencyreport.google.com/https/overview?hl=en (accessed on 2 January 2025).
- Dong, W.; Yu, J.; Lin, X.; Gou, G.; Xiong, G. Deep learning and pre-training technology for encrypted traffic classification: A comprehensive review. Neurocomputing 2024, 617, 128444. [Google Scholar] [CrossRef]
- Feng, Y.; Li, J.; Mirkovic, J.; Wu, C.; Wang, C.; Ren, H.; Xu, J.; Liu, Y. Unmasking the Internet: A Survey of Fine-Grained Network Traffic Analysis. IEEE Commun. Surv. Tutor. 2025. early access. [Google Scholar] [CrossRef]
- Wang, Z.; Yang, Y.; Wang, Y. A survey of encrypted traffic classification: Datasets, representation, approaches and future thinking. In Proceedings of the 2024 IEEE/ACIS 24th International Conference on Computer and Information Science (ICIS), Shanghai, China, 20–22 September 2024; pp. 113–120. [Google Scholar]
- Fernandes, S.; Antonello, R.; Lacerda, T.; Santos, A.; Sadok, D.; Westholm, T. Slimming down deep packet inspection systems. In Proceedings of the IEEE INFOCOM Workshops 2009, Rio de Janeiro, Brazil, 19–25 April 2009; pp. 1–6. [Google Scholar]
- Wang, X.; Jiang, J.; Tang, Y.; Liu, B.; Wang, X. StriD2FA: Scalable Regular Expression Matching for Deep Packet Inspection. In Proceedings of the 2011 IEEE International Conference on Communications (ICC), Kyoto, Japan, 5–9 June 2011; pp. 1–5. [Google Scholar]
- Alwhbi, I.A.; Zou, C.C.; Alharbi, R.N. Encrypted network traffic analysis and classification utilizing machine learning. Sensors 2024, 24, 3509. [Google Scholar] [CrossRef] [PubMed]
- Draper-Gil, G.; Lashkari, A.H.; Mamun, M.S.I.; Ghorbani, A.A. Characterization of encrypted and vpn traffic using time-related. In Proceedings of the 2nd International Conference on Information Systems Security and Privacy (ICISSP), Rome, Italy, 19–21 February 2016; pp. 407–414. [Google Scholar]
- Wang, W.; Zhu, M.; Wang, J.; Zeng, X.; Yang, Z. End-to-end encrypted traffic classification with one-dimensional convolution neural networks. In Proceedings of the 2017 IEEE International Conference on Intelligence and Security Informatics (ISI), Beijing, China, 22–24 July 2017; pp. 43–48. [Google Scholar]
- Alotaibi, F.M. Network Intrusion Detection Model Using Fused Machine Learning Technique. Comput. Mater. Contin. 2023, 75, 2479–2490. [Google Scholar]
- Meng, X.; Lin, C.; Wang, Y.; Zhang, Y. Netgpt: Generative pretrained transformer for network traffic. arXiv 2023, arXiv:2304.09513. [Google Scholar]
- Wang, W.; Zhu, M.; Zeng, X.; Ye, X.; Sheng, Y. Malware traffic classification using convolutional neural network for representation learning. In Proceedings of the 2017 International Conference on Information Networking (ICOIN), Da Nang, Vietnam, 11–13 January 2017; pp. 712–717. [Google Scholar]
- Van Ede, T.; Bortolameotti, R.; Continella, A.; Ren, J.; Dubois, D.J.; Lindorfer, M.; Choffnes, D.; van Steen, M.; Peter, A. Flowprint: Semi-supervised mobile-app fingerprinting on encrypted network traffic. In Proceedings of the Network and Distributed System Security Symposium (NDSS), San Diego, CA, USA, 23–26 February 2020; Volume 27. [Google Scholar]
- Hayes, J.; Danezis, G. k-fingerprinting: A robust scalable website fingerprinting technique. In Proceedings of the 25th USENIX Security Symposium (USENIX Security 16), Vancouver, BC, Canada, 16–18 August 2017; pp. 1187–1203. [Google Scholar]
- Lu, B.; Luktarhan, N.; Ding, C.; Zhang, W. ICLSTM: Encrypted traffic service identification based on inception-LSTM neural network. Symmetry 2021, 13, 1080. [Google Scholar] [CrossRef]
- De Lucia, M.J.; Cotton, C. Detection of encrypted malicious network traffic using machine learning. In Proceedings of the MILCOM 2019-2019 IEEE Military Communications Conference (MILCOM), Norfolk, VA, USA, 12–14 November 2019; pp. 1–6. [Google Scholar]
- Taylor, V.F.; Spolaor, R.; Conti, M.; Martinovic, I. Robust smartphone app identification via encrypted network traffic analysis. IEEE Trans. Inf. Forensics Secur. 2017, 13, 63–78. [Google Scholar] [CrossRef]
- Cao, J.; Fang, Z.; Qu, G.; Sun, H.; Zhang, D. An accurate traffic classification model based on support vector machines. Int. J. Netw. Manag. 2017, 27, e1962. [Google Scholar] [CrossRef]
- Dusi, M.; Este, A.; Gringoli, F.; Salgarelli, L. Using GMM and SVM-based techniques for the classification of SSH-encrypted traffic. In Proceedings of the 2009 IEEE International Conference on Communications, Dresden, Germany, 14–18 June 2009; pp. 1–6. [Google Scholar]
- Shen, M.; Ye, K.; Liu, X.; Zhu, L.; Kang, J.; Yu, S.; Li, Q.; Xu, K. Machine learning-powered encrypted network traffic analysis: A comprehensive survey. IEEE Commun. Surv. Tutor. 2022, 25, 791–824. [Google Scholar] [CrossRef]
- Lotfollahi, M.; Jafari Siavoshani, M.; Shirali Hossein Zade, R.; Saberian, M. Deep packet: A novel approach for encrypted traffic classification using deep learning. Soft Comput. 2020, 24, 1999–2012. [Google Scholar] [CrossRef]
- Lin, K.; Xu, X.; Gao, H. TSCRNN: A novel classification scheme of encrypted traffic based on flow spatiotemporal features for efficient management of IIoT. Comput. Netw. 2021, 190, 107974. [Google Scholar] [CrossRef]
- Lin, X.; Xiong, G.; Gou, G.; Li, Z.; Shi, J.; Yu, J. Et-bert: A contextualized datagram representation with pre-training transformers for encrypted traffic classification. In Proceedings of the ACM Web Conference 2022, Lyon, France, 25–29 April 2022; pp. 633–642. [Google Scholar]
- Zhang, H.; Yu, L.; Xiao, X.; Li, Q.; Mercaldo, F.; Luo, X.; Liu, Q. Tfe-gnn: A temporal fusion encoder using graph neural networks for fine-grained encrypted traffic classification. In Proceedings of the ACM Web Conference 2023, Austin, TX, USA, 30 April–4 May 2023; pp. 2066–2075. [Google Scholar]
- Zhao, J.; Jing, X.; Yan, Z.; Pedrycz, W. Network traffic classification for data fusion: A survey. Inf. Fusion 2021, 72, 22–47. [Google Scholar] [CrossRef]
- Azab, A.; Khasawneh, M.; Alrabaee, S.; Choo, K.K.R.; Sarsour, M. Network traffic classification: Techniques, datasets, and challenges. Digit. Commun. Netw. 2024, 10, 676–692. [Google Scholar] [CrossRef]
- Sharma, A.; Lashkari, A.H. A survey on encrypted network traffic: A comprehensive survey of identification/classification techniques, challenges, and future directions. Comput. Netw. 2024, 257, 110984. [Google Scholar] [CrossRef]
- Wei, N.; Yin, L.; Zhou, X.; Ruan, C.; Wei, Y.; Luo, X.; Chang, Y.; Li, Z. A feature enhancement-based model for the malicious traffic detection with small-scale imbalanced dataset. Inf. Sci. 2023, 647, 119512. [Google Scholar] [CrossRef]
- Miao, G.; Wu, G.; Zhang, Z.; Tong, Y.; Lu, B. Boosting Encrypted Traffic Classification Using Feature-Enhanced Recurrent Neural Network with Angle Constraint. IEEE Trans. Big Data 2024. preprints. [Google Scholar] [CrossRef]
- Huang, H.; Zhang, X.; Lu, Y.; Li, Z.; Zhou, S. BSTFNet: An Encrypted Malicious Traffic Classification Method Integrating Global Semantic and Spatiotemporal Features. Comput. Mater. Contin. 2024, 78, 3929–3951. [Google Scholar] [CrossRef]
- Maonan, W.; Kangfeng, Z.; Ning, X.; Yanqing, Y.; Xiujuan, W. CENTIME: A direct comprehensive traffic features extraction for encrypted traffic classification. In Proceedings of the 2021 IEEE 6th International Conference on Computer and Communication Systems (ICCCS), Chengdu, China, 23–26 April 2021; pp. 490–498. [Google Scholar]
- Shi, Z.; Luktarhan, N.; Song, Y.; Tian, G. BFCN: A novel classification method of encrypted traffic based on BERT and CNN. Electronics 2023, 12, 516. [Google Scholar] [CrossRef]
- Wang, M.; Zheng, K.; Luo, D.; Yang, Y.; Wang, X. An encrypted traffic classification framework based on convolutional neural networks and stacked autoencoders. In Proceedings of the 2020 IEEE 6th International Conference on Computer and Communications (ICCC), Chengdu, China, 11–14 December 2020; pp. 634–641. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Jin, X.; Xie, Y.; Wei, X.S.; Zhao, B.R.; Chen, Z.M.; Tan, X. Delving deep into spatial pooling for squeeze-and-excitation networks. Pattern Recognit. 2022, 121, 108159. [Google Scholar] [CrossRef]
- He, H.Y.; Yang, Z.G.; Chen, X.N. PERT: Payload encoding representation from transformer for encrypted traffic classification. In Proceedings of the 2020 ITU Kaleidoscope: Industry-Driven Digital Transformation (ITU K), Ha Noi, Vietnam, 7–11 December 2020; pp. 1–8. [Google Scholar]
- Zhu, S.; Xu, X.; Gao, H.; Xiao, F. CMTSNN: A deep learning model for multiclassification of abnormal and encrypted traffic of internet of things. IEEE Internet Things J. 2023, 10, 11773–11791. [Google Scholar] [CrossRef]
- Huoh, T.L.; Luo, Y.; Li, P.; Zhang, T. Flow-based encrypted network traffic classification with graph neural networks. IEEE Trans. Netw. Serv. Manag. 2022, 20, 1224–1237. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, X.; Qu, B.; Zhao, F. ATVITSC: A novel encrypted traffic classification method based on deep learning. IEEE Trans. Inf. Forensics Secur. 2024, 19, 9374–9389. [Google Scholar] [CrossRef]
- Wang, T.; Xie, X.; Wang, W.; Wang, C.; Zhao, Y.; Cui, Y. Netmamba: Efficient network traffic classification via pre-training unidirectional mamba. In Proceedings of the 2024 IEEE 32nd International Conference on Network Protocols (ICNP), Charleroi, Belgium, 28–31 October 2024; pp. 1–11. [Google Scholar]
- Liu, T.; Ma, X.; Liu, L.; Liu, X.; Zhao, Y.; Hu, N.; Ghafoor, K.Z. LAMBERT: Leveraging Attention Mechanisms to Improve the BERT Fine-Tuning Model for Encrypted Traffic Classification. Mathematics 2024, 12, 1624. [Google Scholar] [CrossRef]
- Mosca, E.; Szigeti, F.; Tragianni, S.; Gallagher, D.; Groh, G. SHAP-based explanation methods: A review for NLP interpretability. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; pp. 4593–4603. [Google Scholar]
- Shanmugam, V.; Razavi-Far, R.; Hallaji, E. Addressing Class Imbalance in Intrusion Detection: A Comprehensive Evaluation of Machine Learning Approaches. Electronics 2024, 14, 69. [Google Scholar] [CrossRef]
- Mosaiyebzadeh, F.; Pouriyeh, S.; Han, M.; Liu, L.; Xie, Y.; Zhao, L.; Batista, D.M. Privacy-Preserving Federated Learning-Based Intrusion Detection System for IoHT Devices. Electronics 2024, 14, 67. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Method | Advantages | Limitations |
|---|---|---|---|
| [13] | FlowPrint | Identifies applications without prior knowledge of features | Susceptible to interference from third-party shared traffic |
| [14] | k-Fingerprinting | Fast training and inference | Vulnerable to feature tampering |
| [17] | AppScanner | High degree of automation | Model stability affected by version updates |
| [18] | SVM | Optimizes classification parameters, reducing computational complexity | Sensitive to data scaling and feature dimensionality |
| [21] | CNN | Integrates feature extraction and classification | Relatively low accuracy |
| [21] | CNN + SAE | Automatic feature extraction | High dependency on specific datasets |
| [15] | Inception-LSTM | Effectively handles class imbalance | Complex parameter tuning, prone to overfitting |
| [22] | CNN + RNN | Efficient processing of encrypted traffic volumes | Complexity in handling long flows |
| [23] | ET-BERT | Strong representation capability | Requires significant computational resources for training/inference |
| [24] | TFE-GNN | High accuracy | High model complexity and computational cost |
| Type | Traffic Name |
|---|---|
| Regular encrypted traffic | Chat, Email, File Transfer, P2P, Streaming, VoIP |
| VPN encrypted traffic | VPN-Chat, VPN-Email, VPN-File Transfer, VPN-P2P, VPN-Streaming, VPN-VoIP |
| Type | Traffic Name |
|---|---|
| Benign | BitTorrent, Facetime, FTP Gmail, MySQL, Outlook, Skype, SMB, Weibo, WorldOfWarcraft, |
| Malware | Cridex, Geodo, Htbot, Miuref, Neris, Nsis-ay, Shifu, Tinba, Virut, Zeus |
| No. | Feature Description | No. | Feature Description |
|---|---|---|---|
| 1 | Avg. TCP SYN flag count per session | 27 | Burst duration |
| 2 | Avg. TCP URG flag count | 28 | Avg. burst interval |
| 3 | Avg. TCP FIN flag count | 29 | Byte transmission rate (B/s) |
| 4 | Avg. TCP ACK flag count | 30 | Burst packet count |
| 5 | Avg. TCP PSH flag count | 31 | Uplink/downlink byte count |
| 6 | Avg. TCP RST flag count | 32 | Uplink/downlink packet count |
| 7 | Proportion of DNS packets in session | 33 | Packet inter-arrival entropy |
| 8 | Proportion of TCP packets in session | 34 | Packet length entropy |
| 9 | Proportion of UDP packets in session | 35 | Packet inter-arrival peak |
| 10 | Proportion of ICMP packets in session | 36 | Packet interval entropy |
| 11 | Session duration (s) | 37 | TLS JA3 fingerprint entropy |
| 12 | Mean time gap between adjacent packets | 38 | Packet length peak |
| 13 | Min. time gap between adjacent packets | 39 | Packet length variance |
| 14 | Max. time gap between adjacent packets | 40 | Median packet interval |
| 15 | Std. deviation of inter-packet intervals | 41 | Median packet length |
| 16 | Avg. packet length | 42 | 25th percentile of packet length |
| 17 | Min. packet length | 43 | 75th percentile of packet length |
| 18 | Max. packet length | 44 | Proportion of small packets (<32 B) |
| 19 | Std. deviation of packet length | 45 | Packet rate (pkt/s) |
| 20 | Proportion of small packets (<32 B) in session | 46 | TCP duplicate packet ratio |
| 21 | Avg. TCP payload size | 47 | TLS record count |
| 22 | Max. TCP payload size | 48 | Avg. TLS record length |
| 23 | Min. TCP payload size | 49 | Avg. TCP window size |
| 24 | Std. deviation of TCP payload size | 50 | Std. deviation of TCP window size |
| 25 | DNS-to-TCP packet ratio | 51 | Empty packet count |
| 26 | Total number of packets in session | 52 | Number of out-of-order TCP packets |
| Module | Layer | Operation | Input | Filter | Output |
|---|---|---|---|---|---|
| SE-ResNet18 | Conv-1 | Conv1d | 1 × 1024 | 1 × 9 | 32 × 1024 |
| ResLayer-1 | ResBlock + SE | 32 × 1024 | 1 × 3 | 32 × 1024 | |
| ResLayer-2 | ResBlock + SE | 32 × 1024 | 1 × 3 | 64 × 512 | |
| ResLayer-3 | ResBlock + SE | 64 × 512 | 1 × 3 | 128 × 256 | |
| ResLayer-4 | ResBlock + SE | 128 × 256 | 1 × 3 | 256 × 128 | |
| Avg Pooling | Avg Pooling | 256 × 128 | - | 256 × 1 | |
| Flatten | Flatten | 256 × 1 | - | 256 | |
| AE | AutoEncoder-1 | fully connected + ReLU | 52 | - | 40 |
| AutoEncoder-2 | fully connected | 40 | - | 26 | |
| AutoEncoder-3 | fully connected + ReLU | 26 | - | 40 | |
| AutoEncoder-4 | fully connected | 40 | - | 52 | |
| Classification | Fully connected-1 | fully connected + ReLU | 256 + 26 | - | 100 |
| Fully connected-2 | fully connected + Softmax | 100 | - | num classes |
| Category | Parameter |
|---|---|
| System | Windows 11 Professional |
| CPU | AMD Ryzen 7 7735H 3.20 GHz |
| Memory | 32 GB |
| Graphics Card Python Version | NVIDIA GeForce RTX 4060 Laptop (8 GB) 3.7.16 |
| Deep Learning Backend | PyTorch 1.11.0 |
| Cuda Version | 11.3 |
| Experiment | Dataset | Description | Classes |
|---|---|---|---|
| 1 | ISCX VPN-nonVPN | Classification based on encapsulation type | 2 |
| 2 | Non-VPN encrypted service classification | 6 | |
| 3 | VPN encrypted service classification | 6 | |
| 4 | Combined encrypted service classification | 12 | |
| 5 | USTC-TFC | Classification of benign and malicious traffic | 2 |
| 6 | Fine-grained benign traffic classification | 10 | |
| 7 | Malware family classification | 20 |
| Model | AE | SE | ResNet | Acc (Exp 1) | Acc (Exp 2) | Acc (Exp 3) | Acc (Exp 4) |
|---|---|---|---|---|---|---|---|
| w/o SE and ResNet | ✓ | × | × | 0.9956 | 0.7525 | 0.6639 | 0.7376 |
| w/o SE and AE | × | × | ✓ | 0.9989 | 0.9831 | 0.9877 | 0.9765 |
| w/o AE | × | ✓ | ✓ | 0.9991 | 0.9862 | 0.9918 | 0.9883 |
| MFF | ✓ | ✓ | ✓ | 0.9993 | 0.9946 | 0.9959 | 0.9961 |
| Method | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| AppScanner [17] | 0.7182 | 0.7339 | 0.7225 | 0.7197 |
| FlowPrint [13] | 0.7962 | 0.8042 | 0.7812 | 0.7820 |
| DeepPacket [21] | 0.9329 | 0.9377 | 0.9306 | 0.9321 |
| PERT [37] | 0.9352 | 0.9400 | 0.9349 | 0.9368 |
| ET-BERT [23] | 0.9890 | 0.9891 | 0. 9890 | 0. 9890 |
| ICLSTM [15] | 0.981 | 0.98 | 0.98 | 0.981 |
| TFE-GNN [24] | 0.9591 | 0.9526 | 0.9593 | 0.9536 |
| ATVITSC [40] | 0.9789 | 0.9789 | 0.9788 | 0.9789 |
| NetMamba [41] | 0.9899 | 0.9899 | 0.9899 | 0.9899 |
| LAMBERT [42] | 0.9915 | 0.9917 | 0.9915 | 0.9915 |
| MFF | 0.9961 | 0.9961 | 0.9961 | 0.9961 |
| Method | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| AppScanner [17] | 0.8954 | 0.8984 | 0.8968 | 0.8892 |
| FlowPrint [13] | 0.8146 | 0.6434 | 0.7002 | 0.6573 |
| Deeppacket [21] | 0.9640 | 0.9650 | 0.9631 | 0.9641 |
| PERT [37] | 0.9909 | 0.9911 | 0.9910 | 0.9911 |
| ET-BERT [23] | 0.9929 | 0.9930 | 0.9930 | 0.9930 |
| LAMBERT [42] | 0.9930 | 0.9931 | 0.9930 | 0.9930 |
| CMTSNN [38] | 0.9876 | 0.9884 | 0.9881 | 0.9855 |
| Flow-GNN [39] | 0.9970 | 0.9959 | 0.9961 | 0.9974 |
| ATVITAC [40] | 0.9966 | 0.9967 | 0.9967 | 0.9966 |
| NetMamba [41] | 0.9990 | 0.9991 | 0.9990 | 0.9990 |
| MFF | 0.9999 | 0.9999 | 0.9999 | 0.9999 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, H.; Zhou, Y.; Jiang, F.; Zhou, X.; Jiang, Q. MFF: A Multimodal Feature Fusion Approach for Encrypted Traffic Classification. Electronics 2025, 14, 2584. https://doi.org/10.3390/electronics14132584
Huang H, Zhou Y, Jiang F, Zhou X, Jiang Q. MFF: A Multimodal Feature Fusion Approach for Encrypted Traffic Classification. Electronics. 2025; 14(13):2584. https://doi.org/10.3390/electronics14132584
Chicago/Turabian StyleHuang, Hong, Yinghang Zhou, Feng Jiang, Xiaolin Zhou, and Qingping Jiang. 2025. "MFF: A Multimodal Feature Fusion Approach for Encrypted Traffic Classification" Electronics 14, no. 13: 2584. https://doi.org/10.3390/electronics14132584
APA StyleHuang, H., Zhou, Y., Jiang, F., Zhou, X., & Jiang, Q. (2025). MFF: A Multimodal Feature Fusion Approach for Encrypted Traffic Classification. Electronics, 14(13), 2584. https://doi.org/10.3390/electronics14132584