

A Review on Federated Learning Architectures for Privacy-Preserving AI: Lightweight and Secure Cloud–Edge–End Collaboration
 , ,
, ,  and
and 
Abstract
1. Introduction
1.1. Background and Overview
- -
- Cloud: It possesses centralized ultra-large-scale computing and storage resources, suitable for the training of complex models and massive data analysis.
- -
- Edge: It has relatively limited but flexible deployment of computing nodes (e.g., base stations, roadside units, or micro data centers), which can provide low-latency services for applications with high real-time requirements [6].
- -
- End: Refers to terminal devices (e.g., various IoT sensors, wearable devices, and intelligent vehicles), which are truly close to the data source and have a large quantity. They can operate lightweight AI models or participate in collaborative training under various scenarios [7,8]. A large number of research studies and practical applications have shown that a “cloud–edge–end” architecture can balance the needs for the global analysis of massive data and local real-time processing. It is widely used in scenarios such as autonomous driving, video surveillance, intelligent manufacturing, smart healthcare, and AI-generated content that demand high bandwidth, low latency, and computational capabilities [9,10,11,12]. Simultaneously, the emergence of distributed data and layered heterogeneous networks continues to drive the iteration of security and privacy protection technologies [13,14]. Therefore, under such developmental trends, the cloud–edge–end collaborative model provides a new direction for future intelligent applications.
1.2. Motivation and Main Challenges
- Device Capability Constraints: The computation, storage, and energy consumption of edge nodes or terminal devices are generally limited, making it difficult to run large-scale models or maintain long-term deep operations [24]. Especially in IoT scenarios, sensors, wearable devices, and the like often have extremely limited resources, requiring algorithms to be lightweight or scalable while ensuring accuracy [25].
- Network Instability and Connectivity Issues: The number of edge devices connected in real time is vast, and their conditions are variable. Some devices or edge nodes may frequently go offline or experience communication delays or packet loss because of insufficient bandwidth [9]. This dynamism affects the convergence efficiency of FL and distributed training, which requires the development of adaptive collaboration strategies.
- Data Heterogeneity (i.e., Non-Independent and Identically Distributed, non-IID): Compared to traditional centralized training, data in the cloud–edge–end scenario often exhibits non-IID characteristics. Different edges or terminals exhibit significant differences in data categories, distribution, and quantity, which can easily lead to unstable model training or a decline in performance [19]. How to design robust federated optimization algorithms and adaptive aggregation strategies is crucial for the overall performance of the system.
1.3. Summary of Contributions
1.4. Review Structure
2. Research Methodology
2.1. Research Goal Formulation
- -
- RQ1: What are the state-of-the-art architectures for privacy-preserving FL in cloud–edge–end collaborative environments, and how are they categorized based on deployment patterns, coordination mechanisms, and communication structures?
- -
- RQ2: What are the major technical challenges and trustworthiness concerns—such as robustness, fairness, explainability, and security—in these architectures, and what methods have been proposed to address them?
- -
- RQ3: What future research directions and open opportunities exist for enabling lightweight, secure, and trustworthy FL under dynamic and resource-constrained cloud–edge–end conditions?
2.2. Systematic Literature Review Approach
- IEEE Xplore digital library (https://ieeexplore.ieee.org, accessed on 17 January 2025).
- Elsevier ScienceDirect (https://www.sciencedirect.com, accessed on 17 January 2025).
- Web of Science (https://webofscience.clarivate.cn, accessed on 17 January 2025).
- Requisites for inclusion:
- Technical Relevance
- -
- Studies proposing architectures, algorithms, or frameworks for privacy-preserving FL in cloud–edge–device collaboration (e.g., split learning and encrypted aggregation).
- -
- Works addressing resource constraints (e.g., computational efficiency, communication optimization) through lightweight model design, adaptive offloading, or dynamic resource allocation.
- -
- Research integrating trustworthy AI principles (robustness, fairness, and explainability) into FL workflows, particularly in distributed environments.
- Application Context
- -
- Papers validating solutions in key application domains or analogous scenarios requiring multimodal data fusion or real-time decision-making.
- Methodological Rigor
- -
- Empirical studies with quantitative evaluations (e.g., accuracy, latency, and privacy leakage metrics) and comparisons against baseline methods.
- -
- Theoretical analyses provide convergence guarantees, privacy bounds, or scalability proofs for the proposed algorithms.
- Publication Quality and Academic Influence
- -
- Studies published in reputable, peer-reviewed venues indexed by IEEE Xplore, ScienceDirect, and Web of Science, ensuring a baseline level of editorial and methodological rigor.
- -
- Preference was given to highly cited works within the domain of federated learning and cloud–edge–end collaboration, using the citation count as a secondary indicator of reliability and relevance.
- Temporal Scope
- -
- Publications from 2021 to 2025 (January).
However, the query terms yielded many irrelevant results, with some papers mentioning FL only briefly within unrelated contexts. Our exclusion criteria are listed below:
- Requisites for Exclusion:
- Initial Screening of Title
- -
- Further excluding the literature that does not contain keyword combinations relevant to the search.
- Scope Misalignment
- -
- Studies focused solely on centralized cloud computing or standalone edge/device architectures without cross-layer collaboration.
- -
- Works on FL in non-distributed environments (e.g., single-server/client setups) that lack explicit privacy-preserving mechanisms.
- Methodological Deficiencies
- -
- Conceptual papers without experimental validation or theoretical grounding.
- -
- Redundant studies replicating existing frameworks without novel contributions (e.g., incremental parameter tuning of FedAvg).
- Contextual Irrelevance
- -
- Applications unrelated to cloud–edge–end ecosystems.
- -
- Non-English publications or non-peer-reviewed technical reports.
3. Cloud–Edge–End Collaboration: Architecture, Challenges, and Privacy–Security Concerns
3.1. Multi-Layer Architecture and Function
3.1.1. Hierarchical Collaboration Concept
- Cloud Layer: Global Computation and Model Aggregation CenterThe cloud layer serves as a top-level hub, relying on powerful computing and storage capabilities to undertake global model training, parameter aggregation, and strategy scheduling tasks. Reference [27] proposed the FedAgg framework, which, through a recursive knowledge distillation protocol, achieves layer-by-layer model expansion from the edge to the cloud, enhancing generalization performance while satisfying privacy constraints. The SFETEC framework [28] further decomposes the model into “base–core” components, allowing the cloud to centrally optimize core model parameters, significantly reducing the cross-layer communication load. Moreover, by integrating local updates from multiple edge nodes (e.g., clustered federated architecture [29]), the cloud layer can effectively alleviate data heterogeneity issues, enhancing the robustness of the global model. Reference [30] introduced a layered FL system that employs a federated averaging strategy at the edge–cloud layer, optimizing user–edge allocation relationships to make the data distribution at the edge layer approach independent and identically distributed (IID), thereby improving the global model performance. Similarly, the CEE-FLA architecture [31] moves the traditional model aggregation task from the cloud to the edge layer, reducing the frequency of direct edge–cloud connections, while employing a K-Vehicle random scheduling strategy to mitigate the impact of edge–side heterogeneity on the convergence speed.
- Edge Layer: Real-time Collaboration and Resource Scheduling HubThe edge layer acts as an intermediate bridge between the cloud and edge, possessing both a low-latency response and regional coordination capabilities. It mainly performs data preprocessing, local model aggregation, and dynamic resource allocation. Reference [32] proposed the I-UDEC framework, which integrates the blockchain and AI to achieve the joint optimization of computation offloading and service caching in ultra-dense 5G networks, balancing real-time performance and security. The clustered federation mechanism [33] balances the communication efficiency between edge nodes and model convergence speed through a layered asynchronous aggregation strategy. The HybridFL protocol [34] adopts an “edge–cloud” two-level aggregation strategy: the edge layer introduces a “regional relaxation factor” through a probabilistic client selection mechanism to alleviate device dropout and performance fluctuation issues, whereas the cloud layer performs asynchronous global updates to shorten the duration of federation. The FED GS framework [35] further exploits the natural clustering properties of factory equipment, constructing homogeneous super-nodes through a gradient replacement algorithm, and deploying a composite step synchronization protocol at the edge layer to enhance robustness against non-IID data. The edge layer can also serve as an implementation carrier for incentive mechanisms. The evolutionary game model [36] optimizes the enthusiasm for edge node participation by dynamically adjusting the cluster reward strategies.
- End Layer: Privacy Protection and Lightweight ExecutionEnd devices, serving as data sources and lightweight computation units, focus on local model inference or fine-tuning and reduce the transmission of raw data or transmit encrypted data. The FedHome framework [37] generates a balanced dataset while protecting user privacy through a generative convolutional autoencoder (GCAE) at the edge side, alleviating the problem of non-IID data in medical monitoring scenarios; FedSens [38] further addresses the challenge of class imbalance in health monitoring, proposing a lightweight federated optimization algorithm that adapts to the resource constraints of edge devices. Moreover, the edge side can indirectly participate in global training through the edge layer. FedParking [39] proposed leveraging the idle computing power of parking terminals to perform federated tasks and coordinate model updates through edge servers, thereby achieving dual improvements in resource utilization and privacy protection. The FedVL framework [40] implements personalized federated learning (PFL) at the edge side, collaboratively training adaptive models in cloud–edge–end scenarios, and utilizing semi-supervised mechanisms to cope with dynamic environmental changes. The Blockchain Federated Learning (BFL) architecture [41] allows mobile devices to offload data to edge servers and achieves decentralized model aggregation through P2P blockchain communication, resisting poison attacks.
- -
- Computation Collaboration: The cloud layer and edge layer achieve dynamic adaptation of heterogeneous computing resources through model segmentation [28] or distillation [27]. Reference [41] proposed a joint optimization scheme based on deep reinforcement learning (DRL) to dynamically adjust the computation resource allocation and channel the bandwidth of mobile devices. The K-Vehicle scheduling strategy [31] reduced the negative impact of low-performance devices on model convergence by randomly selecting high-computation vehicles for training. Both the DQN-driven parameter pre-synchronization in [42] and the composite step synchronization protocol in [35] reflect the evolution trend from static resource allocation to dynamic adaptive allocation.
- -
- Communication Optimization: The edge layer reduces the pressure of direct end-to-cloud transmission by utilizing cluster aggregation [33], asynchronous updates [32], or privacy relaying [39]. The PSPFL framework [42] introduced parameter selection and pre-synchronization mechanisms at the edge–end layer. The clients only transmit partial key parameters, and the edge base station performs pre-aggregation before uploading to the cloud, significantly reducing the amount of data transmitted. Reference [30] optimized the user–edge allocation relationship, making the data distribution at the edge layer approach IID, thus reducing the number of rounds required for global aggregation. Meanwhile, reference [34] probabilistically selected clients, and [41] used blockchain P2P communication to optimize communication efficiency from device reliability and security perspectives, respectively.
- -
- Security Enhancement: The edge adopts local data retention strategies [37,38], the edge layer introduces anonymization and incentive mechanisms [36], and the cloud layer implements encrypted aggregation [27], constructing a multi-level defense system. The BFL framework [41] combines blockchain consensus mechanisms with FL. Through hash power allocation and data offloading decision optimization, the trustworthy verification of model sharing and rapid detection of poison attacks are achieved. The FED GS framework in [35] employs gradient permutation algorithms at the edge layer to avoid the risk of exposing sensitive industrial data during super-node construction. In contrast, reference [34] mitigated device unreliability through relaxation factors, whereas reference [40] isolated private data through personalized models, reflecting different security design emphases at various levels.
- -
- Highly Dynamic Scenarios: Reference [32] supported the rapid processing of vehicle perception data and model updates through an intelligent ultra-dense edge computing framework, combined with real-time resource allocation algorithms. The CEE-FLA architecture [31] uses edge servers as regional aggregation centers, designs random scheduling strategies considering the performance differences of vehicles, and supports the rapid processing of highly dynamic vehicle data. Reference [40] further realized personalized positioning in multiple scenarios through cloud–edge–end collaboration, addressing model drift issues caused by changes in the vehicle environment.
- -
- Strong Privacy Scenario: References [37,38] proposed generative data augmentation and class balancing strategies, respectively, to improve model accuracy while avoiding the sharing of original medical data. The FED GS framework [35] targeted the characteristics of factory equipment clusters, utilized gradient replacement algorithms to construct homogeneous super-nodes, and addressed dynamic stream data and non-IID through edge layer synchronization protocols, thereby adapting to high real-time, strong privacy industrial requirements.
- -
- Large-scale Node Scenarios: References [29,33] addressed the efficiency and stability issues of training caused by massive terminals through data clustering and cluster federation mechanisms. The BFL framework [41] achieved low-latency, anti-attack model training in edge computing scenarios through blockchain consensus mechanisms and joint optimization algorithms, addressing sensitive data sharing in smart cities.
3.1.2. Cloud–Edge–End Collaborative Architecture in Internet of Vehicles (IoV)
3.1.3. Cloud–Edge–End Collaborative Architecture in Smart City
3.1.4. Cloud–Edge–End Collaborative Architecture in Healthcare
3.2. Key Technical Challenges
3.2.1. Data Distribution and Heterogeneity
3.2.2. Communication Overhead and Latency Sensitivity
3.2.3. Resource and Computational Constraints
3.2.4. Scalability and System Reliability
3.3. Privacy and Security Threats
3.3.1. Data Leakage Risks
3.3.2. Poisoning Attacks and Adversarial Samples
3.3.3. Systemic Vulnerabilities
3.4. Potential Solutions
3.4.1. Encrypted and Anonymized Privacy-Preserving Protocols
3.4.2. Deep Integration of FL and Trustworthy AI
4. FL Meets Trusted AI
4.1. Foundations of FL
4.1.1. Overview of FL
4.1.2. Horizontal FL
- Privacy protection methods in HFLTo solve the problem of data security and confidentiality in the distributed data environment in pattern recognition, reference [94] proposed a classifier based on fuzzy rules. Reference [95] studied the reliability of participants, integrity, and credibility of messages in the medical IoT and proposed a privacy-preserving disease research system based on HFL. Reference [96] focused on the automatic detection of IoT devices and proposed a HFL scheme HFedDI, which is scalable and can improve the performance of device recognition in various scenarios. Reference [97] designed a novel FL architecture named EHFL, which protects data privacy by using single masking and group key encryption and significantly reduces the computation and communication overhead of clients.
- Applications in HFLIn a smart grid, reference [98] proposed a dynamic security assessment method EFedDSA for a smart grid based on HFL and DP, which combines a Gaussian mechanism to protect the privacy of distributed dynamic security assessment (DSA) operation data. And in order to improve the operational safety and reliability of a distribution network, reference [99] proposed a new deep learning method to estimate the baseline load (CBL) of residential loads while applying HFL to local neural network training in residential units to protect the privacy of residential customers. Aimed at the data feature selection in the IoT, reference [100] proposed an unsupervised joint feature launch selection method, FSHFL, based on HFL, which can select a better federated feature set among participants in HFL to improve system performance. In addition, with respect to network dynamic programming technology, improving the operational safety and reliability of a distribution network, reference [101] used FL to model virtual network embedding (VNE) for the first time and proposed a VNE architecture, HFL-VNE, based on HFL, which can dynamically adjust and optimize the resource allocation of multi-domain physical networks.
4.1.3. Vertical FL
- Privacy protection methods in VFLReference [103] proposed an adaptive DP protocol for FL, AdaVFL. This protocol estimates the impact of organizations’ features on the global model and designs two weighting strategies to allocate the privacy budget adaptively for each organization, protecting its features heterogeneously. Reference [104] introduces a new protocol based on XGBoost called FEVERLESS, which utilizes information masking techniques and global differential privacy to prevent the leakage of private information during training. Reference [105] presents a new method for obtaining encrypted training datasets, termed NCLPSI, for privacy protection in VHL. Furthermore, reference [106] explores an efficient and privacy-preserving VFL framework based on the XGBlust algorithm, ELXGB. To address the slow convergence rate of VFL based on zero-order optimization when dealing with large modern models, a cascaded hybrid optimization method is proposed [107].
- Attack and defense strategies in VFLVFL faces several security threats, including backdoor attacks and label inference attacks. In VFL, the backdoor attack is a serious threat, where the attacker manipulates the model’s predictions by injecting specific triggers into the training dataset. Reference [108] proposed a novel and practical method (BadVFL), which enables the injection of backdoor triggers into the victim model without label information. Reference [109] explores the vulnerability of VFL in binary classification tasks and introduces a universal adversarial backdoor attack to poison VFL’s predictions. Reference [110] addressed the vulnerability of data protection during the VFL training phase and proposed a novel defense mechanism to obfuscate the association between bottom model changes and labels (i.e., features) during training. Also, for label inference attacks in VFL, where attackers speculate on other participants’ labels based on the trained model, leading to serious privacy leaks, reference [111] proposed a threshold filtering-based detection method and created six threat model categories based on adversary prior conditions.
- Model training efficiency in VFLIn order to improve the efficiency and performance of VFL, addressing the issues of synchronous computation and HE in VFL, reference [112] proposed an efficient asynchronous multi-party vertical federated learning method (AMVFL), significantly reducing the computational function cost and enhancing the accuracy of the model. Meanwhile, reference [113] analyzed the bottlenecks of VFL under HE and proposed a system that is resistant to procrastination and is computationally efficient for acceleration. Reference [114] introduces a novel communication-efficient VFL algorithm named FedONce, which only requires a single communication between parties, greatly improving the communication efficiency of VFL.
- Applications in VFLVFL provides convenience for cross-domain data collaboration, but it still faces challenges such as uneven data distribution, inconsistent features, and high communication costs. Due to the varied imaging guidelines of different hospitals, resulting in data with the same modality being difficult to meet the needs of practical applications, reference [115] proposed a Federated Consistent Regularization Constrained Feature Disentanglement (Fed-CRFD) framework for how to perform collaborative learning while maintaining privacy between multiple hospitals. This framework enhances MRI reconstruction by effectively utilizing overlapping samples (i.e., the same patient with different modalities in different hospitals) and solving the domain shift caused by different modalities. Another study focuses on wireless traffic prediction, emphasizing the issues of traditional centralized training methods in terms of data transmission, latency, and user privacy [116]. For this reason, reference [116] introduced a wireless traffic prediction framework based on partition learning and VFL. This framework enables multiple edge clients to collaboratively train high-quality prediction models by leveraging diverse traffic data while keeping the raw data confidential locally. Reference [117] conducted research on fine-grained data distribution in real-world FL applications. They proposed a VFL framework, HeteroVFL, to address the complexity of data distribution, and enhanced the privacy of HeteroVFL by adopting DP.
4.1.4. Federated Transfer Learning
- Knowledge transfer in FTLDue to the heterogeneity and distribution discrepancy of data, how to effectively transfer knowledge is a key problem. Reference [119] proposed the knowledge transfer method called PrivateKT, which transfers high-quality knowledge using actively selected small public data with privacy-preserving FL. Reference [120] defined FTL without labels in the source domain, conducted research on the road crack benchmark, and proposed a fedCrack model that obtains a pretrained encoder on the source domain without accessing the annotations. Reference [121] proposed a joint knowledge transfer (FedKT) method for the deficiencies of model learning caused by heterogeneous data distribution in the process of model collaborative training, which utilizes the advantages of fine-tuning and knowledge distillation to effectively extract general knowledge and specific knowledge from the early layers and output of the global model, respectively, so as to improve the learning performance of the local model. Reference [122] proposed federated fuzzy transfer learning (FdFTL) for class transformation, which can be trained across domains without data sharing. In order to overcome the data heterogeneity problem, reference [123] proposed a FedKT framework, which takes into account both diversity and consistency among clients and can serve as a general solution for knowledge extraction from distributed nodes. Reference [124] proposed a device selection method based on multi-objective optimization (MOO) and knowledge transfer (KT) for heterogeneous FL systems, so as to alleviate resource constraints while improving accuracy.
- Applications in FTLIn order to realize cross-domain fault diagnosis without data sharing, reference [125] proposed a fault diagnosis model based on Federated Transfer Learning. Reference [126] put forward a completely decentralized Federated Transfer Learning fault diagnosis method to solve the privacy and domain shift problems in deep learning. In response to the challenges of electricity load estimation caused by global population growth and the increasing demand for intelligent devices, reference [127] combines clustering analysis with joint transfer learning to construct a household-level prediction model. Reference [128] proposed a privacy protection framework for heating, ventilation, and air conditioning (HVAC) systems in buildings, which combines FL and transfer learning to evaluate the adjustment ability of HVAC systems. Reference [129] presents a collaborative learning framework for IDSs used in IoMT applications, which can achieve a detection accuracy of up to 95–99%.
4.2. Pillars of Trustworthy AI in Federated Context
4.2.1. Dimension Reconstruction of Trusted AI
- -
- Data Isolation: The privacy protection of traditional AI needs to be extended to collaborative training across clients, but data invisibility hinders global data quality verification and attack detection.
- -
- Participating Heterogeneity: Device heterogeneity and non-IID data across clients challenge traditional indicators (e.g., global fairness). In medical FL, the differences in data distribution between hospitals may mask biases against minority groups, while the low computing power of edge devices limits the deployment of complex robustness algorithms.
- Data TrustworthinessData trustworthiness ensures the authenticity, representativeness, and security of local data on the client side, preventing low-quality or malicious data from contaminating the global model and providing a reliable input for subsequent training. However, under data isolation, it is impossible to directly detect malicious samples (e.g., adversarial samples or poisoned data). In response to this, adversarial detection models are trained through federated collaboration, using local validation sets on the client side to identify abnormal data patterns. It is also possible to record statistical characteristics of data (e.g., mean and variance) based on the blockchain and exclude outlier clients through a consensus mechanism [130], achieving a consensus on data quality.
- Process TrustworthinessProcess trustworthiness focuses on two key goals: ensuring fairness and enabling traceability during the aggregation process. It prevents a few parties with dominant resources or data from monopolizing model evolution, thereby enhancing overall fairness. However, the participation of heterogeneous clients may lead to biases in contribution evaluations, such as clients with high data volumes dominating model updates. To address this, the Bayesian decision rules and evidence theory can be employed to quantify the uncertainty and performance of each client, providing a reliable strategy for client selection [131]. Additionally, malicious clients can be identified and suppressed through gradient similarity analysis or rule activation tracking [132].
- Outcome TrustworthinessOutcome trustworthiness ensures that global model decisions are transparent and consistent with domain knowledge, providing consistent decision explanations for cross-domain participants and supporting the implementation of models in high-trust scenarios such as clinical and industrial settings. However, data isolation leads to the inability of traditional explainable methods to generalize local explanations. To address this, it is important to extend Shapley values to federated scenarios [130], calculating global feature importance through encrypted gradient aggregation. At the same time, it is important to sparsify model parameters that are unrelated to decisions and retain causal association paths [133] to build a causally explainable framework.
4.2.2. The Foundation of the Trustworthiness Pillar
- Robustness
- Byzantine AttacksMalicious clients upload tampered gradients (e.g., gradient reversal and random noise) to disrupt the convergence of the global model. Although the Krum algorithm [137] can filter explicit abnormal gradients, it relies on statistical properties of gradients and is difficult to defend against covert poisoning attacks [137,138].
- Gradient PoisoningThe model is made to fail under certain trigger conditions by Backdoor Injection [138].
- Data/Device Unreliability
- Robust Aggregation Algorithm
- -
- Hierarchical Aggregation: Reference [33] proposed the resource-efficient FL with hierarchical aggregation (RFL-HA), which reduces communication overhead and limits the impact of malicious nodes through edge node clustering, but it may introduce the risk of a single point of failure within the cluster.
- -
- Dynamic Topology Optimization: The CoCo algorithm [141] adaptively constructs P2P topology and compresses model parameters, accelerating convergence under non-IID data (10 times speedup), but its consensus distance measure may fail in extremely heterogeneous scenarios.
- Privacy-Enhancing Defense
- -
- -
- Blockchain Auditing: Reference [143] leveraged decentralized ledgers to record contributions and detect tampering. In the smart home scenario, the blockchain traces model signatures of malicious clients while preventing poisoning attacks. However, its integration may also introduce latency from consensus protocols and additional storage/computation overhead, especially in edge-based federated deployments.
- Resource-Aware Defense
- -
- Adaptive Pruning: The FedMP framework [145] dynamically adjusts the pruning rate through a MAB to achieve efficient defense on resource-constrained devices, but its residual recovery synchronization (R2SP) mechanism is sensitive to non-IID data.
- -
- Edge-Assisted Computation: The EAFL scheme [144] offloads the computation tasks of stragglers to edge servers, reducing the window of poison attacks, but it is necessary to optimize the amount of offloaded data to balance efficiency and security.
- Adversarial Sample Detection RateThe RoFed method [140] filters the abnormal devices through the gradient direction angle to prevent the end devices trained with noisy data from participating in the parameter aggregation on the cloud device.
- Model Accuracy Fluctuation ThresholdThe FedSens framework [38] combines RL and an adaptive updating strategy in abnormal health detection (AHD), which makes the F1-score exhibit lower fluctuations to handle class imbalance data, ensuring performance stability across multiple iterations and different devices.
- Resource Efficiency Metrics
- Privacy–Robustness ParadoxPoisonGAN [146] attacks demonstrate that DP noise may weaken the model’s ability to detect poisoning attacks (the lower the privacy budget , the higher the backdoor success rate). Comparing chain-PPFL [142] and the PFLF framework [149], there is an inherent trade-off between LDP and model convergence speed (while PFLF reduces communication overhead through flexible participation mechanisms, it requires sacrificing some privacy strength).
- Fairness–Robustness ConflictThe FedSens framework [38] reveals that excessive emphasis on robustness (e.g., strict client selection) under the medical data imbalance scenario may exacerbate model bias.
- Adaptability to Dynamic Environments
- Fairness
- Client Selection Strategies
- -
- Dynamic Selection and Resource Awareness: In VEC, reference [151] proposed a greedy algorithm based on image quality, dynamically selecting high-contribution vehicles to participate in training, while jointly optimizing computational capability, transmission power, and model accuracy to minimize the overall system cost. Similarly, reference [155] allocates tasks in Multi-access Edge Computing (MEC) through matching game theory, reducing the uneven participation time of large-scale IoT devices caused by high mobility, thereby improving task allocation fairness while reducing latency.
- -
- Incentive Mechanism and Trustworthy Evaluation: The introduction of blockchain technology provides new ideas for fair participation. Reference [156] designs a two-layer blockchain architecture (LMUC and GMUC), which records the historical reputation of local model updates through D2D communication, and combines smart contracts to reward devices with high reputation, suppressing the influence of malicious nodes. The InFEDge framework proposed [157] further models the incentive mechanism as a multi-agent Stackelberg game, using contract theory to solve the problem of information asymmetry, ensuring that resource-constrained devices obtain reasonable compensation when contributing data. In addition, reference [164] proposed a reputation-based node selection algorithm (NSRA), which predicts device reputation in HFL, prioritizes the selection of devices with a high reputation to participate in training, and enhances the collaborative trust between devices through D2D communication, improving the model accuracy by 11.48% and 19.38% in MNIST and CIFAR-10 tasks, respectively.
- Loss Function Reconstruction and Heterogeneous Processing
- -
- Federated Fairness Loss Function: The Agnostic FL framework [161] alleviates group bias caused by data heterogeneity by introducing a fairness constraint term to minimize the upper bound of the worst client’s loss. This idea is further extended in the smart grid scenario. Reference [154] combined local data evaluation mechanisms, designed multi-objective optimization problems, and used DRL to dynamically adjust the weights of the loss function, incentivizing Energy Data Owners (EDOs) to share high-quality model updates.
- -
- Heterogeneous Client Adaptation: Addressing the heterogeneity of device resources and model architectures, reference [159] proposed an FTL framework, constructing multiple global models to adapt to clients with different resource levels. In the CIFAR-100 task, the training time for clients with abundant resources is significantly lower than that for constrained devices, and through grouped training and transfer learning, the overall convergence time is shortened. Similarly, reference [160] adopted DRL in air-space-ground integrated edge computing to adaptively adjust the task offloading strategy, balancing energy efficiency and computational fairness, ensuring the participation opportunities for low-power IoT devices in uncertain communication environments. Reference [153] focuses on the AI-driven healthcare sector, proposing a resource-adaptive framework for collaborative learning, which can dynamically adapt to varying computational capabilities to ensure fair participation.
- Performance Differences Across ClientsThe Fedsens framework [38] in the anomaly detection of medical data exhibits lower fluctuations when dealing with class-imbalanced data. The blockchained dual-asynchronous federated learning framework (BAFL-DT) [158] achieves global model aggregation through DT technology, statistically analyzing the standard deviation of accuracy across clients during asynchronous training, verifying its fairness advantages under non-IID data.
- Contribution Assessment and Incentive MechanismShapley values are widely used to quantify the contribution of clients, but their computational complexity limits their application in large-scale scenarios. Reference [165] models the incentive distribution in hierarchical FL through the Stackelberg game, derives the Nash equilibrium strategy, and proves that it can reduce participation costs while increasing model convergence speed in high dynamic edge cloud scenarios.
- Privacy–Fairness Trade-offReference [162] designed a privacy protection incentive mechanism in federated cloud–edge learning (PFCEL), quantifying the relationship between data leakage risk and model accuracy through a three-level Stackelberg game. Experiments show that this mechanism, while protecting the privacy of sensitive devices, enhances system utility, verifying the synergistic feasibility of privacy and fairness. The resource-adaptive framework [153] improves model accuracy, safeguards patient privacy, and promotes equitable access to trustworthy and efficient AI-driven healthcare solutions.
- The Persistence of Fairness ParadoxAlthough existing mechanisms (e.g., dynamic selection and incentive mechanisms) can alleviate participation imbalance to a certain extent, they cannot completely eliminate the bias caused by data heterogeneity. In smart grids, high-resource devices may still dominate model updates, leading to the neglect of the electricity consumption patterns of edge household users [154]. Therefore, in the FL paradigm, it is necessary to design methods that are more sensitive to resources [153].
- Limitations of Evaluation MetricsIn federated scenarios, the contribution of clients with high data volume may be overestimated, while the weight of low-resource but high-value data may be underestimated. Although incentive mechanisms can encourage client participation [165], they are constrained by their own computational resources and cannot join. Moreover, the blockchain trusted computing framework [163] can enhance the transparency of data interaction, but its public ledger may leak the device participation pattern, thus harming fairness.
- Adaptability to Dynamic EnvironmentsExisting methods (e.g., DRL offloading strategy [160]) largely rely on static network assumptions, making it difficult to cope with extreme dynamic scenarios (e.g., dramatic topology changes in drone swarms). Moreover, the delay in blockchain consensus [157,158] may intensify resource competition and reduce the enthusiasm of participation from devices with low computational power.
- Explainability
- Data Isolation and Explanation FragmentationClient-side data distribution (non-IID) leads to local explanations that cannot be generalized. Sensor data from different factories in the IIoT may vary significantly in features, and traditional feature importance analysis might overestimate the impact of local noise [169].
- Privacy–Explainability Trade-offEnhancing explainability requires exposing details of model decisions (e.g., feature contributions) but may leak sensitive data information. VFL is particularly sensitive in the medical field. Reference [170] points out that explaining the association of patient features across institutions may expose privacy, necessitating the design of fine-grained access controls.
- Dynamic Model HeterogeneityThe differences in client model architectures (e.g., resource-constrained devices using lightweight networks) make it difficult to unify explanation methods. When the CTFL framework [132] tracks rule activation patterns in heterogeneous models, the evaluation bias in contributions may occur due to differences in classification rules.
- Privacy-Preserving Explanation Enhancement
- -
- Encryption and Feature Selection: The IP2FL model [130] combines additive homomorphic encryption (AHE) to protect gradient privacy, while utilizing Shapley values to quantify feature contributions, achieving high-trust anomaly detection in Industrial Cyber-Physical Systems (ICPSs). This framework optimizes system performance through dual feature selection while ensuring interpretive transparency.
- -
- Adaptive Gradient Protection (AGP): Reference [168] designs a selective noise injection mechanism that only perturbs channel parameters with minimal impact on explainability. It preserves the importance of key features while defending against gradient leakage attacks. Experiments show that this method can balance privacy and explainability under both IID and non-IID data.
- Causal Learning and Blockchain Auditing
- -
- Causal Sparsification: Reference [133] adopts a heterogeneous perception causal learning method, sparsifying weights that contribute less to model decisions, reducing communication costs and enhancing traceability. In medical image segmentation, only connections strongly related to pathological features are retained, assisting doctors in understanding the model’s decision-making path.
- -
- Decentralized Data Quality Assessment: By integrating blockchain technology, the aggregation weights are dynamically adjusted to prioritize the integration of a high-quality data node explanation, enhancing the credibility of the global model [133].
- Multimodal and Rule-Driven Explanation
- -
- Multimodal Explanation Fusion: In [134], MRI, clinical, and psychological data are integrated into the prediction of Alzheimer’s disease, using Shapley values to explain the interaction of multimodal features. The global model AUC reaches 99.97%, and the contribution of key biomarkers (e.g., hippocampal atrophy) can be traced, assisting clinical decision-making.
- -
- Efficient Contribution Estimation: Reference [132] proposed a contribution evaluation framework based on rule activation, which tracks the client’s contribution to classification rules through a logistic neural network. It demonstrates significant accuracy and computational efficiency on four public classification datasets.
- Clinical Verification
- Industry TrustworthinessReference [169] proposed a trustworthy federation framework for IIoT scenarios, verifying through a case study the impact of explainability on security decision-making (e.g., real-time response to anomaly detection results).
- Contribution FairnessThe CTFL framework [132] evaluates the fairness of contribution allocation based on theoretical properties, such as symmetry and zero-element, and verifies the robustness through confrontation experiments.
- Privacy–Explainability ParadoxReference [170] points out that feature correlation explanation in vertical federations may leak cross-institutional user identities, necessitating the design of dynamic desensitization and access control strategies.
- Heterogeneous Rule ConflictCTFL [132] faces the problem of insufficient rule generalization under extreme non-IID scenarios and needs to combine meta-learning to optimize rule adaptability.
- Real-Time Constraints
5. Lightweight FL Framework for Resource-Constrained Edge–End Devices
5.1. Analysis of the Core Contradiction in Resource-Constrained FL
5.1.1. Privacy–Efficiency–Accuracy Dynamic Game

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Research Direction | References | Main Findings | Supporting Evidence | Research Significance |
|---|---|---|---|---|
| Combining Compressed Learning (CL) and FL | [176,178] | Integrating CL and FL, reducing computational and communication overheads, while preserving privacy. | Ref. [176]: computational overhead reduced by 66%, communication reduced by 99%, while accuracy still reaches 80%; Ref. [178]: using compressed sensing and DP, the feasibility of Raspberry Pi and Android devices is verified. | This resolves the contradiction between security and efficiency in resource-constrained IoT devices, promoting the practical application of edge computing and lightweight privacy protection. |
| Lightweight Models and Training Optimization | [171,179,180,181] | Reduction in local computing and communication burden through Sparse/Binary Neural Networks, model pruning, quantization, and other techniques. | Ref. [171]: the LDES algorithm reduces energy consumption by 56.21%; Ref. [180]: FedQNN compressed the model by more than 30 times, saving 90% of computational energy consumption; Ref. [181]: the GWEP method accelerates by 10.23 times. | It enhances the feasibility of edge devices participating in FL, reduces resource consumption, and expands the deployment scenarios of FL in low-performance terminals (e.g., IoT). |
| Blockchain-Enhanced Security in FL | [182,183,184,185] | Design of lightweight blockchain architectures (e.g., LiteChain and BEFL), combining digital signatures and consensus mechanisms to resist attacks. | Ref. [182]: proposed anti-counterfeiting signature algorithm; Ref. [183]: the LPBFL scheme reduces computational load through Paillier encryption and batch verification; Ref. [184]: LiteChain optimizes latency and storage. | It enhances the security of FL (resistance to poisoning and forgery attacks), meets industrial-grade privacy requirements, and supports dynamic user join/leave. |
| Dynamic Resource Allocation and Heterogeneous Device Adaptation | [175,186,187,188] | Based on device capabilities, dynamically adjusting the model pruning rate, participation frequency, or resource allocation to optimize latency and energy consumption. | Ref. [186]: the Client Eligibility-based Lightweight Protocol (CELP) reduces communication overhead by 81%; Ref. [187]: the DDSRA algorithm balances training delay and accuracy; Ref. [175]: FedMP is accelerated by 4.1 times. | To address the disparities in the resources of heterogeneous devices, enhance the robustness of FL in dynamic network environments, and achieve efficient collaborative training. |
| Optimization for non-IID Data | [177,189,190] | Mitigates the issue of skewed data distribution through methods such as model splitting, bidirectional distillation (Bi-distillation), and prototype constraints. | Ref. [177]: FedAnil+ improves model accuracy by 13–26%; Ref. [189]: Double RL optimizes client selection and aggregation frequency; Ref. [190]: FedCPG achieves an average accuracy of 95%. | It addresses the issue of data heterogeneity in real-world scenarios, enhancing the usability of FL in industrial inspections, high-speed mobile networks, and other complex environments. |
| Communication Efficiency Improvement Strategies | [171,174,191,192] | Combining sparsification, quantification, and optimal model selection strategies (e.g., FedLamp) to compress communication data volume. | Ref. [191]: the PROBE algorithm supports the training of large-scale devices under bandwidth constraints; Ref. [192]: FedLamp reduces traffic by 63% and time by 52%. | Significantly reduces communication costs of FL, adapts to bandwidth-limited edge networks, and supports large-scale device collaboration. |
| Privacy Protection Enhancement Mechanisms | [172,178,182,193] | Design lightweight cryptographic schemes (e.g., dual-server architecture and EC-ElGamal encryption) or DP to protect local data. | Ref. [193]: resists collusion attacks, with only a marginal increase in communication overhead; Ref. [172]: MEEC supports multi-key collaborative computation, reducing communication failure rates. | While ensuring high accuracy, it also achieves strict privacy protection, making it suitable for sensitive scenarios such as healthcare and the IoT. |
| Optimization for Industrial and IoT Applications | [173,174,190,194] | Tailored lightweight FL solutions for scenarios such as industrial equipment fault detection (FedCPG), coal mine video surveillance (Rep-ShuffleNet), and network intrusion detection (Lightweight-Fed-NIDS). | Ref. [173]: model size reduced by 90%, training speed increased by 3 times; Ref. [194]: after optimization, YOLOv8 achieved an APsmall of 86.7%; Ref. [190]: memory usage reduced by 82%. | Promoting the implementation of FL in fields such as industrial automation and cybersecurity, addressing multiple challenges of real-time requirements, resource constraints, and high-precision demands. |
5.1.2. Multi-Objective Optimization Dilemma Under Communication Constraints
5.1.3. Increased System Entropy Triggered by Privacy Protection Enhancement
5.2. Optimization Paradigm for FL with Resource Constraints
5.2.1. Dynamic Resource-Aware FL Architecture
5.2.2. Spatio-Temporal Decoupling Communication Optimization Mechanism
5.2.3. Privacy–Efficiency Collaborative Enhancement Technology
5.3. Evaluation Metrics and Benchmarking Considerations
- Model Accuracy and Convergence: Accuracy, precision, and recall are the most widely used performance indicators, with convergence speed and the number of rounds until convergence also frequently reported. For instance, the NSRA improved accuracy by 11.48% and 19.38% on MNIST and CIFAR-10 tasks, respectively [164].
- Communication Overhead: Assessed by total transmitted data, the number of communication rounds, or bandwidth occupancy. The CELP reported 81.01% communication reduction via aggregation pruning and sparsification [186].
6. Advanced Topics and Future Research Directions
6.1. Real-Time and Low-Latency FL
6.1.1. Online FL
6.1.2. Latency Optimization for Edge/End–Side Inference
6.2. Multimodal FL
6.2.1. Multi-Source Heterogeneous Data Fusion
6.2.2. Synchronization and Alignment Issue
6.3. Dynamic Resource Allocation and Adaptive Learning
6.3.1. Network and Node Dynamics
6.3.2. Adaptive FL Framework
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| FL | federated learning |
| PFL | personalized federated learning |
| BFL | Blockchain Federated Learning |
| VFL | Vertical Federated Learning |
| HFL | Horizontal Federated Learning |
| FTL | Federated Transfer Learning |
| BGFL | Blockchain-enhanced Grouped Federated Learning |
| KT | knowledge transfer |
| RL | reinforcement learning |
| DRL | deep reinforcement learning |
| RFL-HA | resource-efficient federated learning with hierarchical aggregation |
| AMVFL | asynchronous multi-party vertical federated learning |
| IID | independent and identically distributed |
| Non-IID | Non-Independent and Identically Distributed |
| IIoT | industrial Internet of Things |
| GCAE | generative convolutional autoencoder |
| HE | homomorphic encryption |
| AHE | additive homomorphic encryption |
| AGP | Adaptive Gradient Protection |
| ICPSs | Industrial Cyber-Physical Systems |
| AHD | abnormal health detection |
| DP | differential privacy |
| LDP | local differential privacy |
| UCB | Upper Confidence Bound |
| GAIN | Generative Adversarial Imputation Nets |
| GANs | Generative Adversarial Networks |
| VNE | virtual network embedding |
| DSA | dynamic security assessment |
| VEC | Vehicle Edge Computing |
| DAG | directed acyclic graph |
| HVAC | heating, ventilation, and air conditioning |
| FLR | Federated Logistic Regression |
| PSNR | peak signal-to-noise ratio |
| PCS | partial cosine similarity |
| IDSs | intrusion detection systems |
| DT | digital twin |
| DRAs | Data Reconstruction Attacks |
| MMFFC | Multimodal Multi-Feature Construction |
| AoU | Age of Update |
| CL | Compressed Learning |
| VRF | verifiable random function |
| CELP | Client Eligibility-based Lightweight Protocol |
References
- Letaief, K.B.; Chen, W.; Shi, Y.; Zhang, J.; Zhang, Y.J.A. The roadmap to 6G: AI empowered wireless networks. IEEE Commun. Mag. 2019, 57, 84–90. [Google Scholar] [CrossRef]
- Noor-A-Rahim, M.; Liu, Z.; Lee, H.; Khyam, M.O.; He, J.; Pesch, D.; Moessner, K.; Saad, W.; Poor, H.V. 6G for vehicle-to-everything (V2X) communications: Enabling technologies, challenges, and opportunities. Proc. IEEE 2022, 110, 712–734. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A.y. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, PMLR, Fort Lauderdale, FL, USA, 20–22 April 2017; Volume 54, pp. 1273–1282. [Google Scholar]
- Liu, S.; Liu, L.; Tang, J.; Yu, B.; Wang, Y.; Shi, W. Edge computing for autonomous driving: Opportunities and challenges. Proc. IEEE 2019, 107, 1697–1716. [Google Scholar] [CrossRef]
- Baktir, A.C.; Ozgovde, A.; Ersoy, C. How Can Edge Computing Benefit From Software-Defined Networking: A Survey, Use Cases, and Future Directions. IEEE Commun. Surv. Tutor. 2017, 19, 2359–2391. [Google Scholar] [CrossRef]
- Yuan, J.; Xiao, H.; Shen, Z.; Zhang, T.; Jin, J. ELECT: Energy-efficient intelligent edge–cloud collaboration for remote IoT services. Future Gener. Comput. Syst. 2023, 147, 179–194. [Google Scholar] [CrossRef]
- Zolanvari, M.; Teixeira, M.A.; Gupta, L.; Khan, K.M.; Jain, R. Machine Learning-Based Network Vulnerability Analysis of Industrial Internet of Things. IEEE Internet Things J. 2019, 6, 6822–6834. [Google Scholar] [CrossRef]
- Moustafa, N.; Keshky, M.; Debiez, E.; Janicke, H. Federated TON-IoT Windows Datasets for Evaluating AI-Based Security Applications. In Proceedings of the 2020 IEEE 19th International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Guangzhou, China, 29 December–1 January 2021; pp. 848–855. [Google Scholar] [CrossRef]
- Al-Ansi, A.; Al-Ansi, A.M.; Muthanna, A.; Elgendy, I.A.; Koucheryavy, A. Survey on Intelligence Edge Computing in 6G: Characteristics, Challenges, Potential Use Cases, and Market Drivers. Future Internet 2021, 13, 118. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, S.; Ren, X.; Zhao, P.; Zhao, C.; Yang, X. IndustEdge: A Time-Sensitive Networking Enabled Edge-Cloud Collaborative Intelligent Platform for Smart Industry. IEEE Trans. Ind. Inform. 2022, 18, 2386–2398. [Google Scholar] [CrossRef]
- Zhou, X.; Liang, W.; She, J.; Yan, Z.; Wang, K.I.K. Two-Layer Federated Learning with Heterogeneous Model Aggregation for 6G Supported Internet of Vehicles. IEEE Trans. Veh. Technol. 2021, 70, 5308–5317. [Google Scholar] [CrossRef]
- Liu, Z.; Du, H.; Hou, X.; Huang, L.; Hosseinalipour, S.; Niyato, D.; Letaief, K.B. Two-Timescale Model Caching and Resource Allocation for Edge-Enabled AI-Generated Content Services. arXiv 2024, arXiv:2411.01458. [Google Scholar]
- Duc, T.L.; Leiva, R.G.; Casari, P.; Östberg, P.O. Machine Learning Methods for Reliable Resource Provisioning in Edge-Cloud Computing: A Survey. ACM Comput. Surv. 2019, 52, 94. [Google Scholar] [CrossRef]
- Hard, A.; Partridge, K.; Mathews, R.; Augenstein, S. Jointly learning from decentralized (federated) and centralized data to mitigate distribution shift. In Proceedings of the Neurips Workshop on Distribution Shifts, on the NeurIPS Virtual Site, Virtual, 13 December 2021. [Google Scholar]
- Saad, W.; Bennis, M.; Chen, M. A Vision of 6G Wireless Systems: Applications, Trends, Technologies, and Open Research Problems. IEEE Netw. 2020, 34, 134–142. [Google Scholar] [CrossRef]
- Chang, Z.; Liu, S.; Xiong, X.; Cai, Z.; Tu, G. A Survey of Recent Advances in Edge-Computing-Powered Artificial Intelligence of Things. IEEE Internet Things J. 2021, 8, 13849–13875. [Google Scholar] [CrossRef]
- Yao, J.; Zhang, S.; Yao, Y.; Wang, F.; Ma, J.; Zhang, J.; Chu, Y.; Ji, L.; Jia, K.; Shen, T.; et al. Edge-Cloud Polarization and Collaboration: A Comprehensive Survey for AI. IEEE Trans. Knowl. Data Eng. 2023, 35, 6866–6886. [Google Scholar] [CrossRef]
- Ren, J.; Zhang, D.; He, S.; Zhang, Y.; Li, T. A Survey on End-Edge-Cloud Orchestrated Network Computing Paradigms: Transparent Computing, Mobile Edge Computing, Fog Computing, and Cloudlet. ACM Comput. Surv. 2019, 52, 125. [Google Scholar] [CrossRef]
- Xu, R.; Baracaldo, N.; Zhou, Y.; Anwar, A.; Kadhe, S.; Ludwig, H. DeTrust-FL: Privacy-Preserving Federated Learning in Decentralized Trust Setting. In Proceedings of the 2022 IEEE 15th International Conference on Cloud Computing (CLOUD), Barcelona, Spain, 10–16 July 2022; pp. 417–426. [Google Scholar] [CrossRef]
- Jiang, Q.; Xu, X.; He, Q.; Zhang, X.; Dai, F.; Qi, L.; Dou, W. Game Theory-Based Task Offloading and Resource Allocation for Vehicular Networks in Edge-Cloud Computing. In Proceedings of the 2021 IEEE International Conference on Web Services (ICWS), Chicago, IL, USA, 5–10 September 2021; pp. 341–346. [Google Scholar] [CrossRef]
- Sengupta, J.; Ruj, S.; Das Bit, S. A Comprehensive Survey on Attacks, Security Issues and Blockchain Solutions for IoT and IIoT. J. Netw. Comput. Appl. 2020, 149, 102481. [Google Scholar] [CrossRef]
- Tran, N.H.; Bao, W.; Zomaya, A.; Nguyen, M.N.H.; Hong, C.S. Federated Learning over Wireless Networks: Optimization Model Design and Analysis. In Proceedings of the IEEE INFOCOM 2019—IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; pp. 1387–1395. [Google Scholar] [CrossRef]
- Fu, Y.; Li, C.; Yu, F.R.; Luan, T.H.; Zhao, P. An Incentive Mechanism of Incorporating Supervision Game for Federated Learning in Autonomous Driving. IEEE Trans. Intell. Transp. Syst. 2023, 24, 14800–14812. [Google Scholar] [CrossRef]
- Zhou, Z.; Chen, X.; Li, E.; Zeng, L.; Luo, K.; Zhang, J. Edge Intelligence: Paving the Last Mile of Artificial Intelligence with Edge Computing. Proc. IEEE 2019, 107, 1738–1762. [Google Scholar] [CrossRef]
- Ananthanarayanan, G.; Bahl, P.; Bodík, P.; Chintalapudi, K.; Philipose, M.; Ravindranath, L.; Sinha, S. Real-Time Video Analytics: The Killer App for Edge Computing. Computer 2017, 50, 58–67. [Google Scholar] [CrossRef]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. BMJ 2021, 372, n71. [Google Scholar] [CrossRef]
- Wu, Z.; Sun, S.; Wang, Y.; Liu, M.; Gao, B.; Pan, Q.; He, T.; Jiang, X. Agglomerative Federated Learning: Empowering Larger Model Training via End-Edge-Cloud Collaboration. In Proceedings of the IEEE INFOCOM 2024—IEEE Conference on Computer Communications, Vancouver, BC, Canada, 20–23 May 2024; pp. 131–140. [Google Scholar] [CrossRef]
- Le, V.A.; Haga, J.; Tanimura, Y.; Nguyen, T.T. SFETEC: Split-FEderated Learning Scheme Optimized for Thing-Edge-Cloud Environment. In Proceedings of the 2024 IEEE 20th International Conference on e-Science (e-Science), Osaka, Japan, 16–20 September 2024; pp. 1–2. [Google Scholar] [CrossRef]
- Li, C.; Yang, H.; Sun, Z.; Yao, Q.; Zhang, J.; Yu, A.; Vasilakos, A.V.; Liu, S.; Li, Y. High-Precision Cluster Federated Learning for Smart Home: An Edge-Cloud Collaboration Approach. IEEE Access 2023, 11, 102157–102168. [Google Scholar] [CrossRef]
- Mhaisen, N.; Abdellatif, A.A.; Mohamed, A.; Erbad, A.; Guizani, M. Optimal User-Edge Assignment in Hierarchical Federated Learning Based on Statistical Properties and Network Topology Constraints. IEEE Trans. Netw. Sci. Eng. 2022, 9, 55–66. [Google Scholar] [CrossRef]
- Ren, X.; Wang, Y.; Zhang, J.; Han, Z. Research on Edge-Cloud Collaborative Data Sharing Method Based on Federated Learning in Internet of Vehicles. In Proceedings of the 2023 IEEE 29th International Conference on Parallel and Distributed Systems (ICPADS), Ocean Flower Island, China, 17–21 December 2023; pp. 1075–1080. [Google Scholar] [CrossRef]
- Yu, S.; Chen, X.; Zhou, Z.; Gong, X.; Wu, D. When Deep Reinforcement Learning Meets Federated Learning: Intelligent Multitimescale Resource Management for Multiaccess Edge Computing in 5G Ultradense Network. IEEE Internet Things J. 2021, 8, 2238–2251. [Google Scholar] [CrossRef]
- Wang, Z.; Xu, H.; Liu, J.; Huang, H.; Qiao, C.; Zhao, Y. Resource-Efficient Federated Learning with Hierarchical Aggregation in Edge Computing. In Proceedings of the IEEE INFOCOM 2021—IEEE Conference on Computer Communications, Vancouver, BC, Canada, 10–13 May 2021; pp. 1–10. [Google Scholar] [CrossRef]
- Wu, W.; He, L.; Lin, W.; Mao, R. Accelerating Federated Learning Over Reliability-Agnostic Clients in Mobile Edge Computing Systems. IEEE Trans. Parallel Distrib. Syst. 2021, 32, 1539–1551. [Google Scholar] [CrossRef]
- Li, Z.; He, Y.; Yu, H.; Kang, J.; Li, X.; Xu, Z.; Niyato, D. Data Heterogeneity-Robust Federated Learning via Group Client Selection in Industrial IoT. IEEE Internet Things J. 2022, 9, 17844–17857. [Google Scholar] [CrossRef]
- Lim, W.Y.B.; Ng, J.S.; Xiong, Z.; Jin, J.; Zhang, Y.; Niyato, D.; Leung, C.; Miao, C. Decentralized Edge Intelligence: A Dynamic Resource Allocation Framework for Hierarchical Federated Learning. IEEE Trans. Parallel Distrib. Syst. 2022, 33, 536–550. [Google Scholar] [CrossRef]
- Wu, Q.; Chen, X.; Zhou, Z.; Zhang, J. FedHome: Cloud-Edge Based Personalized Federated Learning for In-Home Health Monitoring. IEEE Trans. Mob. Comput. 2022, 21, 2818–2832. [Google Scholar] [CrossRef]
- Zhang, D.Y.; Kou, Z.; Wang, D. FedSens: A Federated Learning Approach for Smart Health Sensing with Class Imbalance in Resource Constrained Edge Computing. In Proceedings of the IEEE INFOCOM 2021—IEEE Conference on Computer Communications, Virtually, 10–13 May 2021; pp. 1–10. [Google Scholar] [CrossRef]
- Huang, X.; Li, P.; Yu, R.; Wu, Y.; Xie, K.; Xie, S. FedParking: A Federated Learning Based Parking Space Estimation With Parked Vehicle Assisted Edge Computing. IEEE Trans. Veh. Technol. 2021, 70, 9355–9368. [Google Scholar] [CrossRef]
- Ma, Q.; Zhang, Z.; Zhu, Z.; Zhao, Y. Cloud-Edge-End Collaboration Personalized Semi-supervised Federated Learning for Visual Localization. In Proceedings of the 2023 IEEE 29th International Conference on Parallel and Distributed Systems (ICPADS), Ocean Flower Island, China, 17–21 December 2023; pp. 2848–2849. [Google Scholar] [CrossRef]
- Nguyen, D.C.; Hosseinalipour, S.; Love, D.J.; Pathirana, P.N.; Brinton, C.G. Latency Optimization for Blockchain-Empowered Federated Learning in Multi-Server Edge Computing. IEEE J. Sel. Areas Commun. 2022, 40, 3373–3390. [Google Scholar] [CrossRef]
- Li, M.; Sun, P.; Zhou, H.; Zhao, L.; Liu, X.; Leung, V.C.M. Poster: Towards Accurate and Fast Federated Learning in End-Edge-Cloud Orchestrated Networks. In Proceedings of the 2023 IEEE 43rd International Conference on Distributed Computing Systems (ICDCS), Hong Kong, China, 18–21 July 2023; pp. 1–2. [Google Scholar] [CrossRef]
- Prathiba, S.B.; Raja, G.; Anbalagan, S.; Dev, K.; Gurumoorthy, S.; Sankaran, A.P. Federated Learning Empowered Computation Offloading and Resource Management in 6G-V2X. IEEE Trans. Netw. Sci. Eng. 2022, 9, 3234–3243. [Google Scholar] [CrossRef]
- Wu, Q.; Zhao, Y.; Fan, Q.; Fan, P.; Wang, J.; Zhang, C. Mobility-Aware Cooperative Caching in Vehicular Edge Computing Based on Asynchronous Federated and Deep Reinforcement Learning. IEEE J. Sel. Top. Signal Process. 2023, 17, 66–81. [Google Scholar] [CrossRef]
- Kong, X.; Gao, H.; Shen, G.; Duan, G.; Das, S.K. FedVCP: A Federated-Learning-Based Cooperative Positioning Scheme for Social Internet of Vehicles. IEEE Trans. Comput. Soc. Syst. 2022, 9, 197–206. [Google Scholar] [CrossRef]
- Zhang, X.; Tham, C.K.; Wang, W. Hierarchical Federated Learning with Edge Optimization in Constrained Networks. In Proceedings of the 2024 IEEE 99th Vehicular Technology Conference (VTC2024-Spring), Singapore, 24–27 June 2024; pp. 1–5. [Google Scholar] [CrossRef]
- Benhelal, M.S.; Jouaber, B.; Afifi, H.; Moungla, H. SiamFLTP: Siamese Networks Empowered Federated Learning for Trajectory Prediction. In Proceedings of the 2024 International Wireless Communications and Mobile Computing (IWCMC), Ayia Napa, Cyprus, 27–31 May 2024; pp. 1106–1111. [Google Scholar] [CrossRef]
- Li, X.; Cheng, L.; Sun, C.; Lam, K.Y.; Wang, X.; Li, F. Federated-Learning-Empowered Collaborative Data Sharing for Vehicular Edge Networks. IEEE Netw. 2021, 35, 116–124. [Google Scholar] [CrossRef]
- Yuan, X.; Chen, J.; Yang, J.; Zhang, N.; Yang, T.; Han, T.; Taherkordi, A. FedSTN: Graph Representation Driven Federated Learning for Edge Computing Enabled Urban Traffic Flow Prediction. IEEE Trans. Intell. Transp. Syst. 2023, 24, 8738–8748. [Google Scholar] [CrossRef]
- Liu, D.; Cui, E.; Shen, Y.; Ding, P.; Zhang, Z. Federated Learning Model Training Mechanism with Edge Cloud Collaboration for Services in Smart Cities. In Proceedings of the 2023 IEEE International Symposium on Broadband Multimedia Systems and Broadcasting (BMSB), Beijing, China, 14–16 June 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Du, Z.; Zhang, G.; Zhang, Y.; Wei, W.; Chu, Z. Online Fine-tuning Method for Power Grid Artificial Intelligence Model Based on Cloud-Edge Collaboration. In Proceedings of the 2023 3rd International Conference on Robotics, Automation and Intelligent Control (ICRAIC), Zhangjiajie, China, 24–26 November 2023; pp. 72–76. [Google Scholar] [CrossRef]
- Nguyen, D.C.; Ding, M.; Pathirana, P.N.; Seneviratne, A.; Zomaya, A.Y. Federated Learning for COVID-19 Detection with Generative Adversarial Networks in Edge Cloud Computing. IEEE Internet Things J. 2022, 9, 10257–10271. [Google Scholar] [CrossRef]
- Qayyum, A.; Ahmad, K.; Ahsan, M.A.; Al-Fuqaha, A.; Qadir, J. Collaborative Federated Learning for Healthcare: Multi-Modal COVID-19 Diagnosis at the Edge. IEEE Open J. Comput. Soc. 2022, 3, 172–184. [Google Scholar] [CrossRef]
- Hu, R.; Yang, R. Fedsemgan: A Semi-Supervised Federated Learning-Based Edge-Cloud Collaborative Framework for Medical Diagnosis Service. In Proceedings of the 2023 China Automation Congress (CAC), Chongqing, China, 17–19 November 2023; pp. 4051–4056. [Google Scholar] [CrossRef]
- Kang, S.; Ros, S.; Song, I.; Tam, P.; Math, S.; Kim, S. Real-Time Prediction Algorithm for Intelligent Edge Networks with Federated Learning-Based Modeling. Comput. Mater. Contin. 2023, 77, 1967–1983. [Google Scholar] [CrossRef]
- Daraghmi, Y.A.; Daraghmi, E.Y.; Daraghma, R.; Fouchal, H.; Ayaida, M. Edge–Fog–Cloud Computing Hierarchy for Improving Performance and Security of NB-IoT-Based Health Monitoring Systems. Sensors 2022, 22, 8646. [Google Scholar] [CrossRef]
- Yao, Z.; Zhao, C. FedTMI: Knowledge aided federated transfer learning for industrial missing data imputation. J. Process Control 2022, 117, 206–215. [Google Scholar] [CrossRef]
- Wei, Z.; Wang, J.; Zhao, Z.; Shi, K. Toward data efficient anomaly detection in heterogeneous edge–cloud environments using clustered federated learning. Future Gener. Comput. Syst. 2025, 164, 107559. [Google Scholar] [CrossRef]
- Zhang, S.; Wang, X.; Zeng, R.; Zeng, C.; Li, Y.; Huang, M. A personalized federated cloud-edge collaboration framework via cross-client knowledge distillation. Future Gener. Comput. Syst. 2025, 165, 107594. [Google Scholar] [CrossRef]
- Qin, T.; Cheng, G.; Wei, Y.; Yao, Z. Hier-SFL: Client-edge-cloud collaborative traffic classification framework based on hierarchical federated split learning. Future Gener. Comput. Syst. 2023, 149, 12–24. [Google Scholar] [CrossRef]
- Su, L.; Li, Z. Incentive-driven long-term optimization for hierarchical federated learning. Comput. Netw. 2023, 234, 109944. [Google Scholar] [CrossRef]
- Zhu, K.; Chen, W.; Jiao, L.; Wang, J.; Peng, Y.; Zhang, L. Online training data acquisition for federated learning in cloud–edge networks. Comput. Netw. 2023, 223, 109556. [Google Scholar] [CrossRef]
- Arouj, A.; Abdelmoniem, A.M. Towards Energy-Aware Federated Learning via Collaborative Computing Approach. Comput. Commun. 2024, 221, 131–141. [Google Scholar] [CrossRef]
- Li, D.; Lai, J.; Wang, R.; Li, X.; Vijayakumar, P.; Gupta, B.B.; Alhalabi, W. Ubiquitous intelligent federated learning privacy-preserving scheme under edge computing. Future Gener. Comput. Syst. 2023, 144, 205–218. [Google Scholar] [CrossRef]
- Savoia, M.; Prezioso, E.; Mele, V.; Piccialli, F. Eco-FL: Enhancing Federated Learning sustainability in edge computing through energy-efficient client selection. Comput. Commun. 2024, 225, 156–170. [Google Scholar] [CrossRef]
- Mazzocca, C.; Romandini, N.; Montanari, R.; Bellavista, P. Enabling Federated Learning at the Edge through the IOTA Tangle. Future Gener. Comput. Syst. 2024, 152, 17–29. [Google Scholar] [CrossRef]
- Parra-Ullauri, J.M.; Madhukumar, H.; Nicolaescu, A.C.; Zhang, X.; Bravalheri, A.; Hussain, R.; Vasilakos, X.; Nejabati, R.; Simeonidou, D. kubeFlower: A privacy-preserving framework for Kubernetes-based federated learning in cloud–edge environments. Future Gener. Comput. Syst. 2024, 157, 558–572. [Google Scholar] [CrossRef]
- Xu, J.; Lin, J.; Li, Y.; Xu, Z. MultiFed: A fast converging federated learning framework for services QoS prediction via cloud–edge collaboration mechanism. Knowl.-Based Syst. 2023, 268, 110463. [Google Scholar] [CrossRef]
- Xu, X.; Liu, W.; Zhang, Y.; Zhang, X.; Dou, W.; Qi, L.; Bhuiyan, M.Z.A. PSDF: Privacy-aware IoV Service Deployment with Federated Learning in Cloud-Edge Computing. ACM Trans. Intell. Syst. Technol. 2022, 13, 70. [Google Scholar] [CrossRef]
- Yang, J.; Zheng, J.; Zhang, Z.; Chen, Q.I.; Wong, D.S.; Li, Y. Security of federated learning for cloud-edge intelligence collaborative computing. Int. J. Intell. Syst. 2022, 37, 9290–9308. [Google Scholar] [CrossRef]
- Zhao, L.; Ni, S.; Wu, D.; Zhou, L. Cloud-Edge-Client Collaborative Learning in Digital Twin Empowered Mobile Networks. IEEE J. Sel. Areas Commun. 2023, 41, 3491–3503. [Google Scholar] [CrossRef]
- Shi, L.; Shu, J.; Zhang, W.; Liu, Y. HFL-DP: Hierarchical Federated Learning with Differential Privacy. In Proceedings of the 2021 IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 7–11 December 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Zhang, L.; Xu, J.; Sivaraman, A.; Deborah Lazarus, J.; Sharma, P.K.; Pandi, V. A Two-Stage Differential Privacy Scheme for Federated Learning Based on Edge Intelligence. IEEE J. Biomed. Health Inform. 2024, 28, 3349–3360. [Google Scholar] [CrossRef]
- Yang, J.; Zheng, J.; Baker, T.; Tang, S.; Tan, Y.a.; Zhang, Q. Clean-label poisoning attacks on federated learning for IoT. Expert Syst. 2023, 40, e13161. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, R.; Mo, X.; Li, Z.; Tang, T. Robust Hierarchical Federated Learning with Anomaly Detection in Cloud-Edge-End Cooperation Networks. Electronics 2023, 12, 112. [Google Scholar] [CrossRef]
- Aouedi, O.; Piamrat, K.; Muller, G.; Singh, K. Intrusion detection for Softwarized Networks with Semi-supervised Federated Learning. In Proceedings of the ICC 2022—IEEE International Conference on Communications, Seoul, Republic of Korea, 16–20 May 2022; pp. 5244–5249. [Google Scholar] [CrossRef]
- Huong, T.T.; Bac, T.P.; Long, D.M.; Thang, B.D.; Binh, N.T.; Luong, T.D.; Phuc, T.K. LocKedge: Low-Complexity Cyberattack Detection in IoT Edge Computing. IEEE Access 2021, 9, 29696–29710. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, S.; Zhao, Z.; Sun, M. Trustworthy Localization with EM-Based Federated Control Scheme for IIoTs. IEEE Trans. Ind. Inform. 2023, 19, 1069–1079. [Google Scholar] [CrossRef]
- Xia, F.; Chen, Y.; Huang, J. Privacy-preserving task offloading in mobile edge computing: A deep reinforcement learning approach. Softw. Pract. Exp. 2024, 54, 1774–1792. [Google Scholar] [CrossRef]
- Chen, X.; Xu, G.; Xu, X.; Jiang, H.; Tian, Z.; Ma, T. Multicenter Hierarchical Federated Learning with Fault-Tolerance Mechanisms for Resilient Edge Computing Networks. IEEE Trans. Neural Netw. Learn. Syst. 2025, 36, 47–61. [Google Scholar] [CrossRef]
- Math, S.; Tam, P.; Kim, S. Reliable Federated Learning Systems Based on Intelligent Resource Sharing Scheme for Big Data Internet of Things. IEEE Access 2021, 9, 108091–108100. [Google Scholar] [CrossRef]
- Truong, V.T.; Hoang, D.N.M.; Le, L.B. BFLMeta: Blockchain-Empowered Metaverse with Byzantine-Robust Federated Learning. In Proceedings of the GLOBECOM 2023—2023 IEEE Global Communications Conference, Kuala Lumpur, Malaysia, 4–8 December 2023; pp. 5537–5542. [Google Scholar] [CrossRef]
- Peng, G.; Shi, X.; Zhang, J.; Gao, L.; Tan, Y.; Xiang, N.; Wang, W. BGFL: A blockchain-enabled group federated learning at wireless industrial edges. J. Cloud Comput. 2024, 13, 148. [Google Scholar] [CrossRef]
- Wu, F.; Li, X.; Li, J.; Vijayakumar, P.; Gupta, B.B.; Arya, V. HSADR: A New Highly Secure Aggregation and Dropout-Resilient Federated Learning Scheme for Radio Access Networks with Edge Computing Systems. IEEE Trans. Green Commun. Netw. 2024, 8, 1141–1155. [Google Scholar] [CrossRef]
- Wang, J.; Chang, X.; Mišić, J.; Mišić, V.B.; Chen, Z.; Fan, J. PA-iMFL: Communication-Efficient Privacy Amplification Method Against Data Reconstruction Attack in Improved Multilayer Federated Learning. IEEE Internet Things J. 2024, 11, 17960–17974. [Google Scholar] [CrossRef]
- Ma, X.; He, X.; Wu, X.; Wen, C. Multi-level federated learning based on cloud-edge-client collaboration and outlier-tolerance for fault diagnosis. Meas. Sci. Technol. 2023, 34, 125148. [Google Scholar] [CrossRef]
- Mahanipour, A.; Khamfroush, H. Multimodal Multiple Federated Feature Construction Method for IoT Environments. In Proceedings of the GLOBECOM 2023—2023 IEEE Global Communications Conference, Kuala Lumpur, Malaysia, 4–8 December 2023; pp. 1890–1895. [Google Scholar] [CrossRef]
- Yang, Z.; Fu, S.; Bao, W.; Yuan, D.; Zomaya, A.Y. Hierarchical Federated Learning with Momentum Acceleration in Multi-Tier Networks. IEEE Trans. Parallel Distrib. Syst. 2023, 34, 2629–2641. [Google Scholar] [CrossRef]
- Luo, L.; Zhang, C.; Yu, H.; Sun, G.; Luo, S.; Dustdar, S. Communication-Efficient Federated Learning with Adaptive Aggregation for Heterogeneous Client-Edge-Cloud Network. IEEE Trans. Serv. Comput. 2024, 17, 3241–3255. [Google Scholar] [CrossRef]
- Ma, C.; Li, X.; Huang, B.; Li, G.; Li, F. Personalized client-edge-cloud hierarchical federated learning in mobile edge computing. J. Cloud Comput. 2024, 13, 161. [Google Scholar] [CrossRef]
- Liu, J.; Liu, X.; Wei, X.; Gao, H.; Wang, Y. Group Formation and Sampling in Group-Based Hierarchical Federated Learning. IEEE Trans. Cloud Comput. 2024, 12, 1433–1448. [Google Scholar] [CrossRef]
- Zheng, Z.; Hong, Y.; Xie, X.; Li, K.; Chen, Q. A multi-dimensional incentive mechanism based on age of update in hierarchical federated learning. Softw. Pract. Exp. 2025, 55, 383–406. [Google Scholar] [CrossRef]
- Liu, L.; Zhang, J.; Song, S.; Letaief, K.B. Client-Edge-Cloud Hierarchical Federated Learning. In Proceedings of the ICC 2020—2020 IEEE International Conference on Communications (ICC), Virtual, 7–11 June 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Hu, X.; Zhu, X.; Yang, L.; Pedrycz, W.; Li, Z. A Design of Fuzzy Rule-Based Classifier for Multiclass Classification and Its Realization in Horizontal Federated Learning. IEEE Trans. Fuzzy Syst. 2024, 32, 5098–5108. [Google Scholar] [CrossRef]
- Yang, Y.; He, D.; Wang, J.; Feng, Q.; Luo, M. EPDR: An Efficient and Privacy-Preserving Disease Research System with Horizontal Federated Learning in the Internet of Medical Things. Hum.-Centric Comput. Inf. Sci. 2024, 14, 7. [Google Scholar] [CrossRef]
- Sumitra; Shenoy, M.V. HFedDI: A novel privacy preserving horizontal federated learning based scheme for IoT device identification. J. Netw. Comput. Appl. 2023, 214, 103616. [Google Scholar] [CrossRef]
- Zhang, Z.; Li, Y.; Zhang, K. EHFL: Efficient Horizontal Federated Learning with Privacy Protection and Verifiable Aggregation. IEEE Internet Things J. 2024, 11, 36884–36894. [Google Scholar] [CrossRef]
- Ren, C.; Wang, T.; Yu, H.; Xu, Y.; Dong, Z.Y. EFedDSA: An Efficient Differential Privacy-Based Horizontal Federated Learning Approach for Smart Grid Dynamic Security Assessment. IEEE J. Emerg. Sel. Top. Circuits Syst. 2023, 13, 817–828. [Google Scholar] [CrossRef]
- Wang, R.; Qiu, H.; Gao, H.; Li, C.; Dong, Z.Y.; Liu, J. Adaptive Horizontal Federated Learning-Based Demand Response Baseline Load Estimation. IEEE Trans. Smart Grid 2024, 15, 1659–1669. [Google Scholar] [CrossRef]
- Zhang, X.; Mavromatis, A.; Vafeas, A.; Nejabati, R.; Simeonidou, D. Federated Feature Selection for Horizontal Federated Learning in IoT Networks. IEEE Internet Things J. 2023, 10, 10095–10112. [Google Scholar] [CrossRef]
- Zhang, P.; Chen, N.; Li, S.; Choo, K.K.R.; Jiang, C.; Wu, S. Multi-Domain Virtual Network Embedding Algorithm Based on Horizontal Federated Learning. IEEE Trans. Inf. Forensics Secur. 2023, 18, 3363–3375. [Google Scholar] [CrossRef]
- Cheng, K.; Fan, T.; Jin, Y.; Liu, Y.; Chen, T.; Papadopoulos, D.; Yang, Q. SecureBoost: A Lossless Federated Learning Framework. IEEE Intell. Syst. 2021, 36, 87–98. [Google Scholar] [CrossRef]
- Errounda, F.Z.; Liu, Y. Adaptive differential privacy in vertical federated learning for mobility forecasting. Future Gener. Comput. Syst. 2023, 149, 531–546. [Google Scholar] [CrossRef]
- Wang, R.; Ersoy, O.; Zhu, H.; Jin, Y.; Liang, K. FEVERLESS: Fast and Secure Vertical Federated Learning Based on XGBoost for Decentralized Labels. IEEE Trans. Big Data 2024, 10, 1001–1015. [Google Scholar] [CrossRef]
- Yang, Y.; Chen, X.; Pan, Y.; Shen, J.; Cao, Z.; Dong, X.; Li, X.; Sun, J.; Yang, G.; Deng, R. OpenVFL: A Vertical Federated Learning Framework with Stronger Privacy-Preserving. IEEE Trans. Inf. Forensics Secur. 2024, 19, 9670–9681. [Google Scholar] [CrossRef]
- Xu, W.; Zhu, H.; Zheng, Y.; Wang, F.; Zhao, J.; Liu, Z.; Li, H. ELXGB: An Efficient and Privacy-Preserving XGBoost for Vertical Federated Learning. IEEE Trans. Serv. Comput. 2024, 17, 878–892. [Google Scholar] [CrossRef]
- Wang, G.; Zhang, Q.; Li, X.; Wang, B.; Gu, B.; Ling, C.X. Secure and fast asynchronous Vertical Federated Learning via cascaded hybrid optimization. Mach. Learn. 2024, 113, 6413–6451. [Google Scholar] [CrossRef]
- Xuan, Y.; Chen, X.; Zhao, Z.; Tang, B.; Dong, Y. Practical and General Backdoor Attacks Against Vertical Federated Learning. In Proceedings of the Machine Learning and Knowledge Discovery in Databases: Research Track, Turin, Italy, 18–22 September 2023; pp. 402–417. [Google Scholar]
- Chen, P.; Du, X.; Lu, Z.; Chai, H. Universal adversarial backdoor attacks to fool vertical federated learning. Comput. Secur. 2024, 137, 103601. [Google Scholar] [CrossRef]
- Zhu, D.; Chen, J.; Zhou, X.; Shang, W.; Hassan, A.E.; Grossklags, J. Vulnerabilities of Data Protection in Vertical Federated Learning Training and Countermeasures. IEEE Trans. Inf. Forensics Secur. 2024, 19, 3674–3689. [Google Scholar] [CrossRef]
- Ding, L.; Bao, H.; Lv, Q.; Zhang, F.; Zhang, Z.; Han, J.; Ding, S. Threshold Filtering for Detecting Label Inference Attacks in Vertical Federated Learning. Electronics 2024, 13, 4376. [Google Scholar] [CrossRef]
- Shi, H.; Xu, Y.; Jiang, Y.; Yu, H.; Cui, L. Efficient Asynchronous Multi-Participant Vertical Federated Learning. IEEE Trans. Big Data 2024, 10, 940–952. [Google Scholar] [CrossRef]
- Cai, D.; Fan, T.; Kang, Y.; Fan, L.; Xu, M.; Wang, S.; Yang, Q. Accelerating Vertical Federated Learning. IEEE Trans. Big Data 2024, 10, 752–760. [Google Scholar] [CrossRef]
- Wu, Z.; Li, Q.; He, B. Practical Vertical Federated Learning with Unsupervised Representation Learning. IEEE Trans. Big Data 2024, 10, 864–878. [Google Scholar] [CrossRef]
- Yan, Y.; Wang, H.; Huang, Y.; He, N.; Zhu, L.; Xu, Y.; Li, Y.; Zheng, Y. Cross-Modal Vertical Federated Learning for MRI Reconstruction. IEEE J. Biomed. Health Inform. 2024, 28, 6384–6394. [Google Scholar] [CrossRef] [PubMed]
- Li, P.; Guo, C.; Xing, Y.; Shi, Y.; Feng, L.; Zhou, F. Core network traffic prediction based on vertical federated learning and split learning. Sci. Rep. 2024, 14, 4663. [Google Scholar] [CrossRef]
- Zhang, R.; Li, H.; Tian, L.; Hao, M.; Zhang, Y. Vertical Federated Learning Across Heterogeneous Regions for Industry 4.0. IEEE Trans. Ind. Inform. 2024, 20, 10145–10155. [Google Scholar] [CrossRef]
- Liu, Y.; Kang, Y.; Xing, C.; Chen, T.; Yang, Q. A Secure Federated Transfer Learning Framework. IEEE Intell. Syst. 2020, 35, 70–82. [Google Scholar] [CrossRef]
- Qi, T.; Wu, F.; Wu, C.; He, L.; Huang, Y.; Xie, X. Differentially private knowledge transfer for federated learning. Nat. Commun. 2023, 14, 3785. [Google Scholar] [CrossRef] [PubMed]
- Jin, X.; Bu, J.; Yu, Z.; Zhang, H.; Wang, Y. FedCrack: Federated Transfer Learning with Unsupervised Representation for Crack Detection. IEEE Trans. Intell. Transp. Syst. 2023, 24, 11171–11184. [Google Scholar] [CrossRef]
- Wang, Z.; Xiao, J.; Wang, L.; Yao, J. A novel federated learning approach with knowledge transfer for credit scoring. Decis. Support Syst. 2024, 177, 114084. [Google Scholar] [CrossRef]
- Li, K.; Lu, J.; Zuo, H.; Zhang, G. Federated Fuzzy Transfer Learning with Domain and Category Shifts. IEEE Trans. Fuzzy Syst. 2024, 32, 6708–6719. [Google Scholar] [CrossRef]
- Mao, W.; Yu, B.; Zhang, C.; Qin, A.; Xie, Y. FedKT: Federated learning with knowledge transfer for non-IID data. Pattern Recognit. 2025, 159, 111143. [Google Scholar] [CrossRef]
- Dang, Q.; Zhang, G.; Wang, L.; Yang, S.; Zhan, T. Hybrid IoT Device Selection with Knowledge Transfer for Federated Learning. IEEE Internet Things J. 2024, 11, 12216–12227. [Google Scholar] [CrossRef]
- Li, Z.; Li, Z.; Gu, F. Intelligent diagnosis method for machine faults based on federated transfer learning. Appl. Soft Comput. 2024, 163, 111922. [Google Scholar] [CrossRef]
- Xu, D.; Liu, Y.; Wen, G.; Jin, Y.; Chai, T.; Yang, T. DeFedTL: A Decentralized Federated Transfer Learning Method for Fault Diagnosis. IEEE Trans. Ind. Inform. 2025, 21, 1704–1713. [Google Scholar] [CrossRef]
- Singh, G.; Bedi, J. A federated and transfer learning based approach for households load forecasting. Knowl.-Based Syst. 2024, 299, 111967. [Google Scholar] [CrossRef]
- Wang, Z.; Yu, P.; Zhang, H. Privacy-Preserving Regulation Capacity Evaluation for HVAC Systems in Heterogeneous Buildings Based on Federated Learning and Transfer Learning. IEEE Trans. Smart Grid 2023, 14, 3535–3549. [Google Scholar] [CrossRef]
- Alharbi, A.A. Federated transfer learning for attack detection for Internet of Medical Things. Int. J. Inf. Secur. 2024, 23, 81–100. [Google Scholar] [CrossRef]
- Namakshenas, D.; Yazdinejad, A.; Dehghantanha, A.; Parizi, R.M.; Srivastava, G. IP2FL: Interpretation-Based Privacy-Preserving Federated Learning for Industrial Cyber-Physical Systems. IEEE Trans. Ind. Cyber-Phys. Syst. 2024, 2, 321–330. [Google Scholar] [CrossRef]
- Qin, Z.; Yang, L.; Wang, Q.; Han, Y.; Hu, Q. Reliable and Interpretable Personalized Federated Learning. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 20422–20431. [Google Scholar] [CrossRef]
- Wang, Y.; Li, K.; Luo, Y.; Li, G.; Guo, Y.; Wang, Z. Fast, Robust and Interpretable Participant Contribution Estimation for Federated Learning. In Proceedings of the 2024 IEEE 40th International Conference on Data Engineering (ICDE), Utrecht, The Netherlands, 13–16 May 2024; pp. 2298–2311. [Google Scholar] [CrossRef]
- Mu, J.; Kadoch, M.; Yuan, T.; Lv, W.; Liu, Q.; Li, B. Explainable Federated Medical Image Analysis Through Causal Learning and Blockchain. IEEE J. Biomed. Health Inform. 2024, 28, 3206–3218. [Google Scholar] [CrossRef]
- Jahan, S.; Saif Adib, M.R.; Huda, S.M.; Rahman, M.S.; Kaiser, M.S.; Sanwar Hosen, A.S.M.; Ghimire, D.; Park, M.J. Federated Explainable AI-Based Alzheimer’s Disease Prediction with Multimodal Data. IEEE Access 2025, 13, 43435–43454. [Google Scholar] [CrossRef]
- Huong, T.T.; Bac, T.P.; Ha, K.N.; Hoang, N.V.; Hoang, N.X.; Hung, N.T.; Tran, K.P. Federated Learning-Based Explainable Anomaly Detection for Industrial Control Systems. IEEE Access 2022, 10, 53854–53872. [Google Scholar] [CrossRef]
- Wu, W.; He, L.; Lin, W.; Mao, R.; Maple, C.; Jarvis, S. SAFA: A Semi-Asynchronous Protocol for Fast Federated Learning with Low Overhead. IEEE Trans. Comput. 2021, 70, 655–668. [Google Scholar] [CrossRef]
- Blanchard, P.; El Mhamdi, E.M.; Guerraoui, R.; Stainer, J. Machine learning with adversaries: Byzantine tolerant gradient descent. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, Red Hook, NY, USA, 4–9 December 2017; pp. 118–128. [Google Scholar]
- Sun, Z.; Kairouz, P.; Suresh, A.T.; McMahan, H.B. Can You Really Backdoor Federated Learning? arXiv 2019, arXiv:1911.07963. [Google Scholar] [CrossRef]
- Liu, Y.; Garg, S.; Nie, J.; Zhang, Y.; Xiong, Z.; Kang, J.; Hossain, M.S. Deep Anomaly Detection for Time-Series Data in Industrial IoT: A Communication-Efficient On-Device Federated Learning Approach. IEEE Internet Things J. 2021, 8, 6348–6358. [Google Scholar] [CrossRef]
- Qian, B.; Zhao, Y.; Tang, J.; Wang, Z.; Li, F.; Wang, J.; He, S.; Liu, J. Robust Federated Learning with Valid Gradient Direction for Cloud-Edge-End Collaboration in Smart Grids. In Proceedings of the 2024 International Conference on Energy and Electrical Engineering (EEE), Nanchang, China, 5–6 July 2024; pp. 1–5. [Google Scholar] [CrossRef]
- Wang, L.; Xu, Y.; Xu, H.; Chen, M.; Huang, L. Accelerating Decentralized Federated Learning in Heterogeneous Edge Computing. IEEE Trans. Mob. Comput. 2023, 22, 5001–5016. [Google Scholar] [CrossRef]
- Li, Y.; Zhou, Y.; Jolfaei, A.; Yu, D.; Xu, G.; Zheng, X. Privacy-Preserving Federated Learning Framework Based on Chained Secure Multiparty Computing. IEEE Internet Things J. 2021, 8, 6178–6186. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, J.; Jiang, L.; Tan, R.; Niyato, D.; Li, Z.; Lyu, L.; Liu, Y. Privacy-Preserving Blockchain-Based Federated Learning for IoT Devices. IEEE Internet Things J. 2021, 8, 1817–1829. [Google Scholar] [CrossRef]
- Ji, Z.; Chen, L.; Zhao, N.; Chen, Y.; Wei, G.; Yu, F.R. Computation Offloading for Edge-Assisted Federated Learning. IEEE Trans. Veh. Technol. 2021, 70, 9330–9344. [Google Scholar] [CrossRef]
- Jiang, Z.; Xu, Y.; Xu, H.; Wang, Z.; Qiao, C.; Zhao, Y. FedMP: Federated Learning through Adaptive Model Pruning in Heterogeneous Edge Computing. In Proceedings of the 2022 IEEE 38th International Conference on Data Engineering (ICDE), Virtual, 9–12 May 2022; pp. 767–779. [Google Scholar] [CrossRef]
- Zhang, J.; Chen, B.; Cheng, X.; Binh, H.T.T.; Yu, S. PoisonGAN: Generative Poisoning Attacks Against Federated Learning in Edge Computing Systems. IEEE Internet Things J. 2021, 8, 3310–3322. [Google Scholar] [CrossRef]
- Wang, T.; Liu, Y.; Zheng, X.; Dai, H.N.; Jia, W.; Xie, M. Edge-Based Communication Optimization for Distributed Federated Learning. IEEE Trans. Netw. Sci. Eng. 2022, 9, 2015–2024. [Google Scholar] [CrossRef]
- Liu, J.; Xu, H.; Wang, L.; Xu, Y.; Qian, C.; Huang, J.; Huang, H. Adaptive Asynchronous Federated Learning in Resource-Constrained Edge Computing. IEEE Trans. Mob. Comput. 2023, 22, 674–690. [Google Scholar] [CrossRef]
- Zhou, H.; Yang, G.; Dai, H.; Liu, G. PFLF: Privacy-Preserving Federated Learning Framework for Edge Computing. IEEE Trans. Inf. Forensics Secur. 2022, 17, 1905–1918. [Google Scholar] [CrossRef]
- Wang, Y.; Su, Z.; Zhang, N.; Benslimane, A. Learning in the Air: Secure Federated Learning for UAV-Assisted Crowdsensing. IEEE Trans. Netw. Sci. Eng. 2021, 8, 1055–1069. [Google Scholar] [CrossRef]
- Xiao, H.; Zhao, J.; Pei, Q.; Feng, J.; Liu, L.; Shi, W. Vehicle Selection and Resource Optimization for Federated Learning in Vehicular Edge Computing. IEEE Trans. Intell. Transp. Syst. 2022, 23, 11073–11087. [Google Scholar] [CrossRef]
- Shinde, S.S.; Bozorgchenani, A.; Tarchi, D.; Ni, Q. On the Design of Federated Learning in Latency and Energy Constrained Computation Offloading Operations in Vehicular Edge Computing Systems. IEEE Trans. Veh. Technol. 2022, 71, 2041–2057. [Google Scholar] [CrossRef]
- Zhang, F.; Zhai, D.; Bai, G.; Jiang, J.; Ye, Q.; Ji, X.; Liu, X. Towards fairness-aware and privacy-preserving enhanced collaborative learning for healthcare. Nat. Commun. 2025, 16, 2852. [Google Scholar] [CrossRef] [PubMed]
- Su, Z.; Wang, Y.; Luan, T.H.; Zhang, N.; Li, F.; Chen, T.; Cao, H. Secure and Efficient Federated Learning for Smart Grid with Edge-Cloud Collaboration. IEEE Trans. Ind. Inform. 2022, 18, 1333–1344. [Google Scholar] [CrossRef]
- Chen, D.; Hong, C.S.; Wang, L.; Zha, Y.; Zhang, Y.; Liu, X.; Han, Z. Matching-Theory-Based Low-Latency Scheme for Multitask Federated Learning in MEC Networks. IEEE Internet Things J. 2021, 8, 11415–11426. [Google Scholar] [CrossRef]
- Feng, L.; Yang, Z.; Guo, S.; Qiu, X.; Li, W.; Yu, P. Two-Layered Blockchain Architecture for Federated Learning Over the Mobile Edge Network. IEEE Netw. 2022, 36, 45–51. [Google Scholar] [CrossRef]
- Wang, X.; Zhao, Y.; Qiu, C.; Liu, Z.; Nie, J.; Leung, V.C.M. InFEDge: A Blockchain-Based Incentive Mechanism in Hierarchical Federated Learning for End-Edge-Cloud Communications. IEEE J. Sel. Areas Commun. 2022, 40, 3325–3342. [Google Scholar] [CrossRef]
- Qu, Y.; Yu, S.; Gao, L.; Sood, K.; Xiang, Y. Blockchained Dual-Asynchronous Federated Learning Services for Digital Twin Empowered Edge-Cloud Continuum. IEEE Trans. Serv. Comput. 2024, 17, 836–849. [Google Scholar] [CrossRef]
- Ahmed, K.M.; Imteaj, A.; Amini, M.H. Federated Deep Learning for Heterogeneous Edge Computing. In Proceedings of the 2021 20th IEEE International Conference on Machine Learning and Applications (ICMLA), Virtual, 13–16 December 2021; pp. 1146–1152. [Google Scholar] [CrossRef]
- Liu, Y.; Jiang, L.; Qi, Q.; Xie, S. Energy-Efficient Space–Air–Ground Integrated Edge Computing for Internet of Remote Things: A Federated DRL Approach. IEEE Internet Things J. 2023, 10, 4845–4856. [Google Scholar] [CrossRef]
- Mohri, M.; Sivek, G.; Suresh, A.T. Agnostic Federated Learning. In Proceedings of Machine Learning Research, Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Chaudhuri, K., Salakhutdinov, R., Eds.; PMLR: Cambridge, MA, USA, 2019; Volume 97, pp. 4615–4625. [Google Scholar]
- Liu, T.; Di, B.; An, P.; Song, L. Privacy-Preserving Incentive Mechanism Design for Federated Cloud-Edge Learning. IEEE Trans. Netw. Sci. Eng. 2021, 8, 2588–2600. [Google Scholar] [CrossRef]
- Xu, C.; Wu, Q. Research on Blockchain Privacy Computing Technology for End-edge-cloud Collaborative Architecture. In Proceedings of the 2023 4th Information Communication Technologies Conference (ICTC), Nanjing, China, 17–19 May 2023; pp. 316–320. [Google Scholar] [CrossRef]
- Xin, S.; Zhuo, L.; Xin, C. Node Selection Strategy Design Based on Reputation Mechanism for Hierarchical Federated Learning. In Proceedings of the 2022 18th International Conference on Mobility, Sensing and Networking (MSN), Guangzhou, China, 14–16 December 2022; pp. 718–722. [Google Scholar] [CrossRef]
- Zhao, Y.; Liu, Z.; Qiu, C.; Wang, X.; Yu, F.R.; Leung, V.C. An Incentive Mechanism for Big Data Trading in End-Edge-Cloud Hierarchical Federated Learning. In Proceedings of the 2021 IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 7–11 December 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16, New York, NY, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar] [CrossRef]
- Rozemberczki, B.; Watson, L.; Bayer, P.; Yang, H.T.; Kiss, O.; Nilsson, S.; Sarkar, R. The Shapley Value in Machine Learning. In Proceedings of the 31st International Joint Conference on Artificial Intelligence and the 25th European Conference on Artificial Intelligence, IJCAI-ECAI 2022, Vienna, Austria, 23–29 July 2022; pp. 5572–5579. [Google Scholar] [CrossRef]
- Li, Z.; Chen, H.; Ni, Z.; Gao, Y.; Lou, W. Towards Adaptive Privacy Protection for Interpretable Federated Learning. IEEE Trans. Mob. Comput. 2024, 23, 14471–14483. [Google Scholar] [CrossRef]
- Jagatheesaperumal, S.K.; Rahouti, M.; Alfatemi, A.; Ghani, N.; Quy, V.K.; Chehri, A. Enabling Trustworthy Federated Learning in Industrial IoT: Bridging the Gap Between Interpretability and Robustness. IEEE Internet Things Mag. 2024, 7, 38–44. [Google Scholar] [CrossRef]
- Sakib, S.K.; Das, A.B. Explainable Vertical Federated Learning for Healthcare: Ensuring Privacy and Optimal Accuracy. In Proceedings of the 2024 IEEE International Conference on Big Data (BigData), Washington, DC, USA, 15–18 December 2024; pp. 5068–5077. [Google Scholar] [CrossRef]
- Lei, L.; Yuan, Y.; Zhou, Y.; Yang, Y.; Luo, Y.; Pu, L.; Chatzinotas, S. Energy Optimization and Lightweight Design for Efficient Federated Learning in Wireless Edge Systems. IEEE Trans. Veh. Technol. 2024, 73, 13542–13557. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, L.; Ping, Y.; Atiquzzaman, M.; Mumtaz, S.; Zhang, Z.; Guizani, M.; Tian, Z. A Privacy-Preserving Federated Learning Framework with Lightweight and Fair in IoT. IEEE Trans. Netw. Serv. Manag. 2024, 21, 5843–5858. [Google Scholar] [CrossRef]
- Bouayad, A.; Alami, H.; Janati Idrissi, M.; Berrada, I. Lightweight Federated Learning for Efficient Network Intrusion Detection. IEEE Access 2024, 12, 172027–172045. [Google Scholar] [CrossRef]
- Du, J.; Qin, N.; Huang, D.; Jia, X.; Zhang, Y. Lightweight FL: A Low-Cost Federated Learning Framework for Mechanical Fault Diagnosis with Training Optimization and Model Pruning. IEEE Trans. Instrum. Meas. 2024, 73, 3504014. [Google Scholar] [CrossRef]
- Jiang, Z.; Xu, Y.; Xu, H.; Wang, Z.; Liu, J.; Chen, Q.; Qiao, C. Computation and Communication Efficient Federated Learning with Adaptive Model Pruning. IEEE Trans. Mob. Comput. 2024, 23, 2003–2021. [Google Scholar] [CrossRef]
- Gao, X.; Hou, L.; Chen, B.; Yao, X.; Suo, Z. Compressive-Learning-Based Federated Learning for Intelligent IoT with Cloud–Edge Collaboration. IEEE Internet Things J. 2025, 12, 2291–2294. [Google Scholar] [CrossRef]
- Fotohi, R.; Shams Aliee, F.; Farahani, B. A Lightweight and Secure Deep Learning Model for Privacy-Preserving Federated Learning in Intelligent Enterprises. IEEE Internet Things J. 2024, 11, 31988–31998. [Google Scholar] [CrossRef]
- Hidayat, M.A.; Nakamura, Y.; Arakawa, Y. Efficient and Secure: Privacy-Preserving Federated Learning for Resource-Constrained Devices. In Proceedings of the 2023 24th IEEE International Conference on Mobile Data Management (MDM), Singapore, 3–6 July 2023; pp. 184–187. [Google Scholar] [CrossRef]
- Yuan, P.; Huang, R.; Zhang, J.; Zhang, E.; Zhao, X. Accuracy Rate Maximization in Edge Federated Learning with Delay and Energy Constraints. IEEE Syst. J. 2023, 17, 2053–2064. [Google Scholar] [CrossRef]
- Ji, Y.; Chen, L. FedQNN: A Computation–Communication-Efficient Federated Learning Framework for IoT with Low-Bitwidth Neural Network Quantization. IEEE Internet Things J. 2023, 10, 2494–2507. [Google Scholar] [CrossRef]
- Prakash, P.; Ding, J.; Chen, R.; Qin, X.; Shu, M.; Cui, Q.; Guo, Y.; Pan, M. IoT Device Friendly and Communication-Efficient Federated Learning via Joint Model Pruning and Quantization. IEEE Internet Things J. 2022, 9, 13638–13650. [Google Scholar] [CrossRef]
- Sui, Z.; Sun, Y.; Zhu, J.; Chen, F. Comments on “Lightweight Privacy and Security Computing for Blockchained Federated Learning in IoT”. IEEE Internet Things J. 2024, 11, 15043–15046. [Google Scholar] [CrossRef]
- Fan, M.; Ji, K.; Zhang, Z.; Yu, H.; Sun, G. Lightweight Privacy and Security Computing for Blockchained Federated Learning in IoT. IEEE Internet Things J. 2023, 10, 16048–16060. [Google Scholar] [CrossRef]
- Chen, H.; Zhou, R.; Chan, Y.H.; Jiang, Z.; Chen, X.; Ngai, E.C.H. LiteChain: A Lightweight Blockchain for Verifiable and Scalable Federated Learning in Massive Edge Networks. IEEE Trans. Mob. Comput. 2025, 24, 1928–1944. [Google Scholar] [CrossRef]
- Jin, R.; Hu, J.; Min, G.; Mills, J. Lightweight Blockchain-Empowered Secure and Efficient Federated Edge Learning. IEEE Trans. Comput. 2023, 72, 3314–3325. [Google Scholar] [CrossRef]
- Asad, M.; Otoum, S.; Shaukat, S. Clients Eligibility-Based Lightweight Protocol in Federated Learning: An IDS Use Case. IEEE Trans. Netw. Serv. Manag. 2024, 21, 3759–3774. [Google Scholar] [CrossRef]
- Deng, X.; Li, J.; Ma, C.; Wei, K.; Shi, L.; Ding, M.; Chen, W. Low-Latency Federated Learning with DNN Partition in Distributed Industrial IoT Networks. IEEE J. Sel. Areas Commun. 2023, 41, 755–775. [Google Scholar] [CrossRef]
- Mughal, F.R.; He, J.; Das, B.; Dharejo, F.A.; Zhu, N.; Khan, S.B.; Alzahrani, S. Adaptive federated learning for resource-constrained IoT devices through edge intelligence and multi-edge clustering. Sci. Rep. 2024, 14, 28746. [Google Scholar] [CrossRef]
- Zhou, X.; Zheng, X.; Cui, X.; Shi, J.; Liang, W.; Yan, Z.; Yang, L.T.; Shimizu, S.; Wang, K.I.K. Digital Twin Enhanced Federated Reinforcement Learning with Lightweight Knowledge Distillation in Mobile Networks. IEEE J. Sel. Areas Commun. 2023, 41, 3191–3211. [Google Scholar] [CrossRef]
- Li, H.; Wang, X.; Cao, P.; Li, Y.; Yi, B.; Huang, M. FedCPG: A class prototype guided personalized lightweight federated learning framework for cross-factory fault detection. Comput. Ind. 2025, 164, 104180. [Google Scholar] [CrossRef]
- Tao, Y.; Chen, S.; Zhang, C.; Wang, D.; Yu, D.; Cheng, X.; Dressler, F. Private Over-the-Air Federated Learning at Band-Limited Edge. IEEE Trans. Mob. Comput. 2024, 23, 12444–12460. [Google Scholar] [CrossRef]
- Xu, Y.; Liao, Y.; Xu, H.; Ma, Z.; Wang, L.; Liu, J. Adaptive Control of Local Updating and Model Compression for Efficient Federated Learning. IEEE Trans. Mob. Comput. 2023, 22, 5675–5689. [Google Scholar] [CrossRef]
- Zhong, L.; Wang, L.; Zhang, L.; Domingo-Ferrer, J.; Xu, L.; Wu, C.; Zhang, R. Dual-Server-Based Lightweight Privacy-Preserving Federated Learning. IEEE Trans. Netw. Serv. Manag. 2024, 21, 4787–4800. [Google Scholar] [CrossRef]
- Wu, J.; Zheng, R.; Jiang, J.; Tian, Z.; Chen, W.; Wang, Z.; Yu, F.R.; Leung, V.C.M. A Lightweight Small Object Detection Method Based on Multilayer Coordination Federated Intelligence for Coal Mine IoVT. IEEE Internet Things J. 2024, 11, 20072–20087. [Google Scholar] [CrossRef]
- Zhang, Z.; Wu, L.; Ma, C.; Li, J.; Wang, J.; Wang, Q.; Yu, S. LSFL: A Lightweight and Secure Federated Learning Scheme for Edge Computing. IEEE Trans. Inf. Forensics Secur. 2023, 18, 365–379. [Google Scholar] [CrossRef]
- Li, Y.; Yao, R.; Qin, D.; Wang, Y. Lightweight Federated Learning for On-Device Non-Intrusive Load Monitoring. IEEE Trans. Smart Grid 2025, 16, 1950–1961. [Google Scholar] [CrossRef]
- Lyu, B.; Yuan, H.; Lu, L.; Zhang, Y. Resource-Constrained Neural Architecture Search on Edge Devices. IEEE Trans. Netw. Sci. Eng. 2022, 9, 134–142. [Google Scholar] [CrossRef]
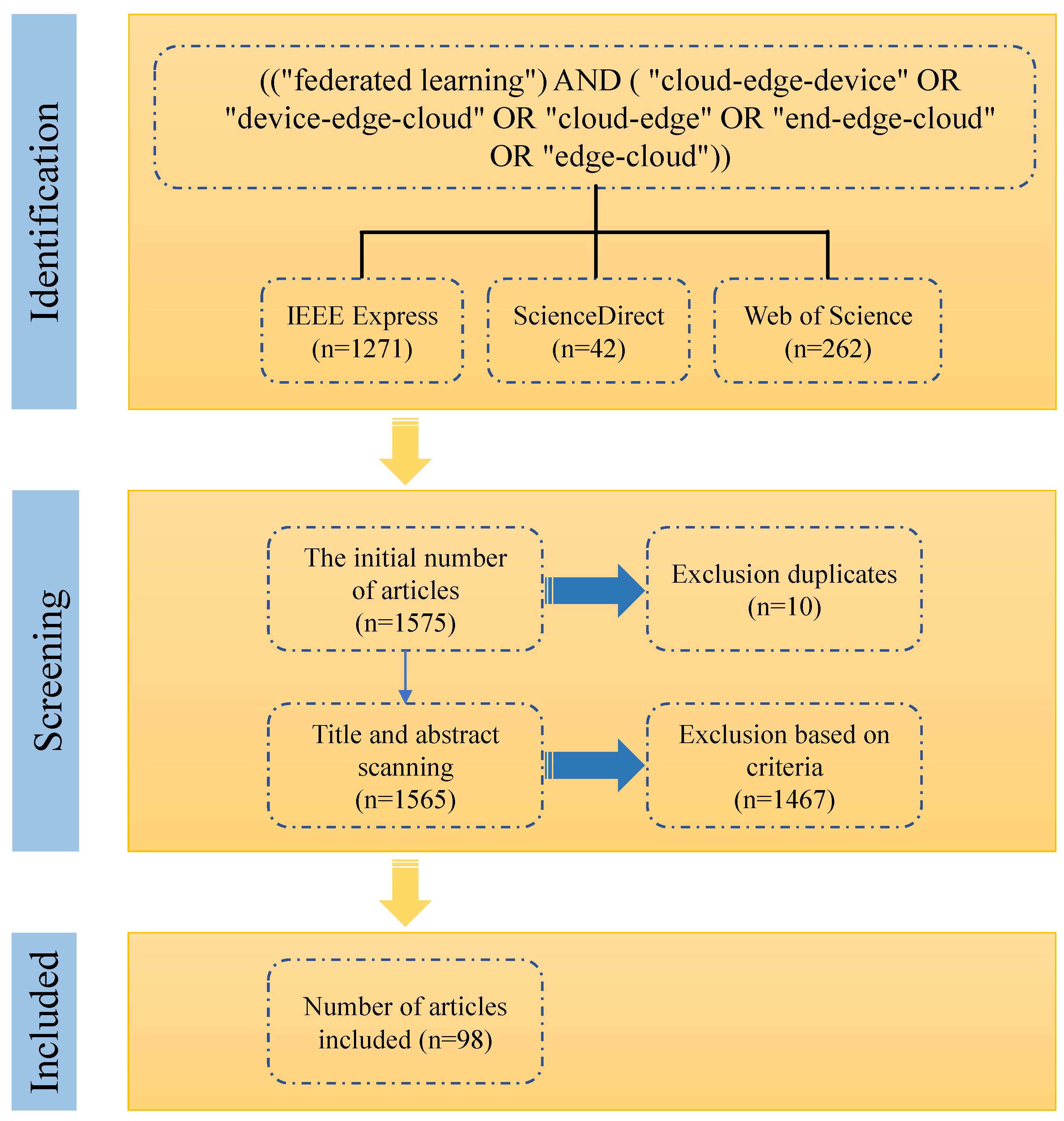

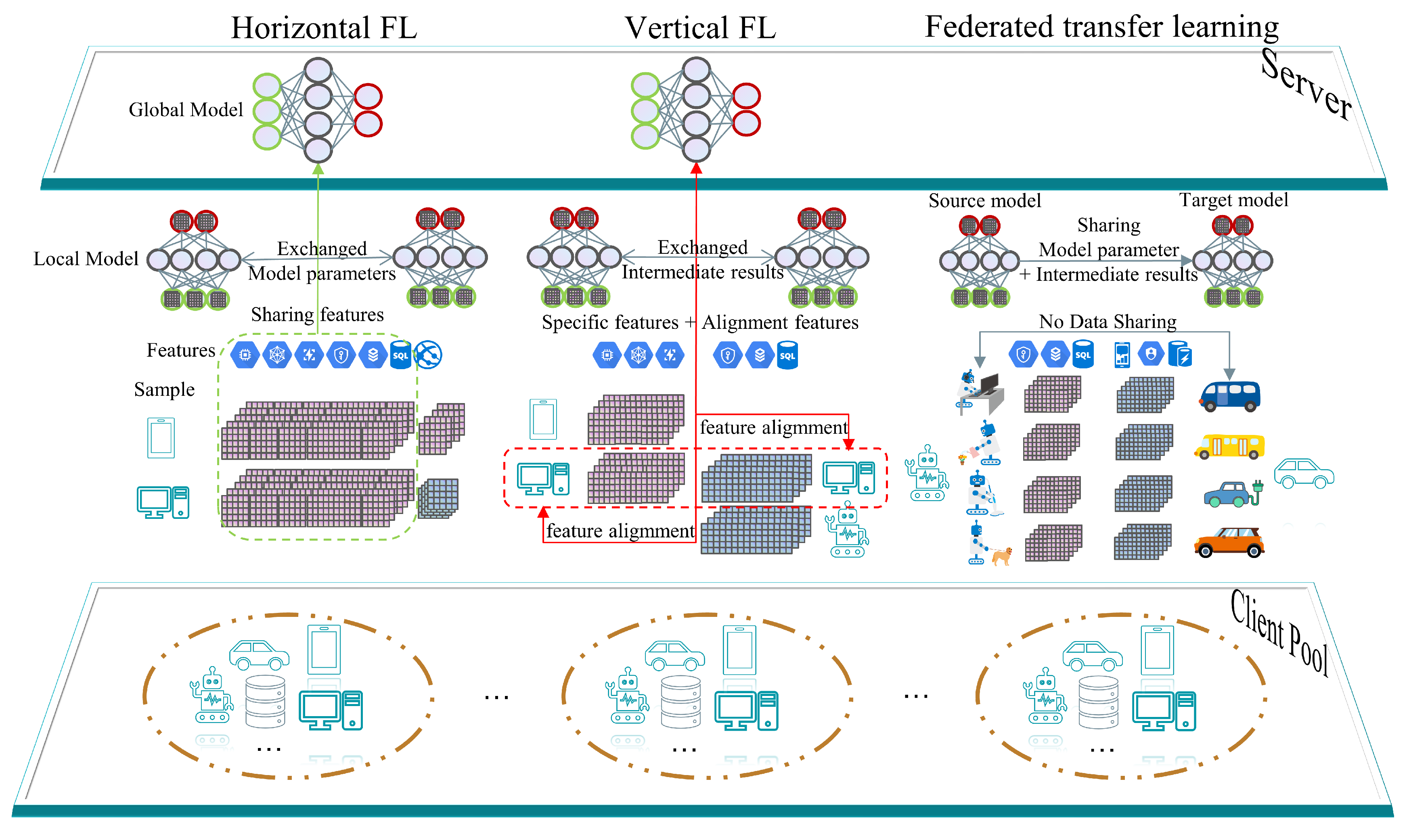
| FL Type | Objective/Formulation | Key Variables | Privacy Mechanism |
|---|---|---|---|
| HFL | Global loss minimization:
Global model update: | Local losses , model | Only model parameters shared |
| VFL | Split gain:
(Equation (4)) Leaf weight: (Equation (5)) | Gradients , | Encrypted statistics, no label sharing |
| FTL | Joint loss:
Prediction loss: | Cross-party embeddings, , , | Feature alignment, secure approximation |
| Research Direction | References | Main Findings | Research Significance |
|---|---|---|---|
| Robust Aggregation and Dynamic Topology Optimization | [33,141] | Ref. [33]: hierarchical aggregation clusters edge nodes to reduce communication overhead and limit the impact of malicious nodes; Ref. [141]: the CoCo algorithm adaptively constructs P2P topology, and the consensus distance measurement accelerates convergence (10 times speed improvement). | It optimizes communication efficiency and anti-attack capabilities of a decentralized architecture, suitable for the IIoT and dynamic network environments. |
| Byzantine Attack Defense Algorithm | [137] | Ref. [137]: the Krum algorithm filters explicit anomalies through gradient statistics, and is the first provably Byzantine-robust aggregation rule. | It provides theoretical guarantees for open federation scenarios and resists explicit attacks such as gradient inversion and noise injection. |
| Privacy Enhancement and Blockchain Auditing | [142,143] | Ref. [142]: the chain-PPFL framework combines chain-style secure multi-party computation with DP (); Ref. [143]: the blockchain records model signatures, tracing malicious client poisoning behavior. | While protecting gradient privacy, it enhances model traceability, supporting trustworthy collaboration in smart home and energy scenarios. |
| Resource-Aware Defense Mechanism | [144,145] | Ref. [144]: the EAFL scheme offloads computation from slow devices to the edge, reducing the poisoning window; Ref. [145]: the FedMP framework dynamically prunes to adapt to heterogeneous device resources, achieving an acceleration of 4.1 times. | It alleviates the contradiction between defense feasibility under resource constraints, balancing the efficiency and security of edge computing. |
| Attack Detection and Anomaly Filtering | [138,140] | Ref. [138]: Standardized DP and norm truncation resist backdoor attacks; Ref. [140]: the RoFed method filters noisy devices through the angle of the gradient direction. | It enhances the model’s robustness against covert poisoning attacks and data noise, ensuring reliable decisions in medical and power scenarios. |
| Research Direction | References | Main Findings | Research Significance |
|---|---|---|---|
| Dynamic Resource Allocation and Client Selection | [151,152,155] | Ref. [151]: dynamically selects high-contribution vehicles based on image quality, jointly optimizing computation, transmission, and model accuracy; Ref. [155]: matching the game allocation task, reducing the participation imbalance of high-mobility devices. | Enhancing the fairness of participation in Vehicle Edge Computing (VEC) and IoT scenarios, optimizing the resource utilization rate and model performance. |
| Blockchain-Driven Trustworthy Incentive Mechanism | [156,157,158] | Ref. [156]: the two-layer blockchain records the reputation, and the smart contract rewards high contribution devices; Ref. [158]: the InFEDge framework combines multi-agent game theory with contract theory to solve the problem of information asymmetry. | It enhances the fairness and transparency of device participation, suppresses malicious nodes, and supports credible collaboration in edge computing scenarios. |
| Heterogeneous Client Adaptation and Migration Learning | [153,159,160] | Ref. [159]: FTL constructs multiple global models to adapt to clients with different resource levels; Ref. [160]: DRL adaptively adjusts the integrated air-space-ground task offloading strategy. | This alleviates the participation bias caused by resource heterogeneity, ensuring fair opportunities for low-power devices in dynamic environments. |
| Federal Fairness Loss Function Design | [154,161] | Ref. [154]: multi-objective optimization and dynamic adjustment of loss weights with DRL, incentivizing high-quality model sharing; Ref. [161]: agnostic FL minimizes the upper bound of the worst client loss. | It addresses group bias caused by non-IID data, enhancing model generalization in medical and energy scenarios. |
| Privacy–Fairness Collaborative Optimization | [162,163] | Ref. [162]: PFCEL quantifies the trade-off between leakage risk and model accuracy through the Stackelberg game; Ref. [163]: the blockchain trusted computing framework realizes data are “usable but invisible”. | While protecting the privacy of sensitive data, it ensures the fairness of participation, promoting compliant AI applications in the fields of smart grids and healthcare. |
| Research Direction | References | Main Findings | Research Significance |
|---|---|---|---|
| Explanation Enhancement under Privacy Protection | [130,168] | Ref. [130]: combining AHE with Shapley values to quantify feature contributions, achieving privacy protection and explainability in industrial control systems; Ref. [168]: AGP selectively perturbs low-impact channel parameters, balancing privacy with explainability. | While protecting data privacy, it provides trustworthy model explanations, meeting the compliance and decision-making transparency requirements in industrial and medical scenarios. |
| Causal Learning and Blockchain Integration | [133] | Heterogeneous perception causal learning sparsifies non-causal weights, reducing communication overhead and enhancing decision traceability; the blockchain dynamically evaluates data quality and optimizes aggregation weights. | This enhances the interpretability and credibility of models in scenarios such as medical image analysis, supporting the transparency of clinical decision-making. |
| Multimodal and Rule-Driven Explanation | [134,170] | Ref. [134]: multimodal data (MRI and clinical indicators) combined with Shapley explanation, achieving a global AUC of 99.97%; Ref. [170]: designing a fine-grained privacy–interpretability trade-off framework in VFL. | This addresses the issue of the fragmented explanation of crossmodal data, promoting trustworthy AI applications in multi-institutional collaboration in medical diagnosis. |
| Efficient Contribution Assessment Mechanism | [132] | Rule-based Activation Contribution Assessment (CTFL): single training inference completes contribution allocation; logical neural networks and binarization techniques ensure efficiency and privacy. | They motivate high-quality data providers to participate in FL, address the bias issue in heterogeneous model contributions assessment, and enhance collaboration fairness. |
| Trustworthy Verification Framework | [135,169] | Ref. [169]: an IIoT trustworthy federation framework with case validation of the impact of explainability on security decision-making; Ref. [135]: real-time edge anomaly detection (FedeX) combined with XAI explanation, which occupies only 14% of memory. | Enhances the credibility and real-time response capability of industrial control systems, supporting transparent deployment in resource-constrained scenarios. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhan, S.; Huang, L.; Luo, G.; Zheng, S.; Gao, Z.; Chao, H.-C. A Review on Federated Learning Architectures for Privacy-Preserving AI: Lightweight and Secure Cloud–Edge–End Collaboration. Electronics 2025, 14, 2512. https://doi.org/10.3390/electronics14132512
Zhan S, Huang L, Luo G, Zheng S, Gao Z, Chao H-C. A Review on Federated Learning Architectures for Privacy-Preserving AI: Lightweight and Secure Cloud–Edge–End Collaboration. Electronics. 2025; 14(13):2512. https://doi.org/10.3390/electronics14132512
Chicago/Turabian StyleZhan, Shanhao, Lianfen Huang, Gaoyu Luo, Shaolong Zheng, Zhibin Gao, and Han-Chieh Chao. 2025. "A Review on Federated Learning Architectures for Privacy-Preserving AI: Lightweight and Secure Cloud–Edge–End Collaboration" Electronics 14, no. 13: 2512. https://doi.org/10.3390/electronics14132512
APA StyleZhan, S., Huang, L., Luo, G., Zheng, S., Gao, Z., & Chao, H.-C. (2025). A Review on Federated Learning Architectures for Privacy-Preserving AI: Lightweight and Secure Cloud–Edge–End Collaboration. Electronics, 14(13), 2512. https://doi.org/10.3390/electronics14132512