
Comparative Analysis of Feature Selection Methods in Clustering-Based Detection Methods


Abstract
1. Introduction
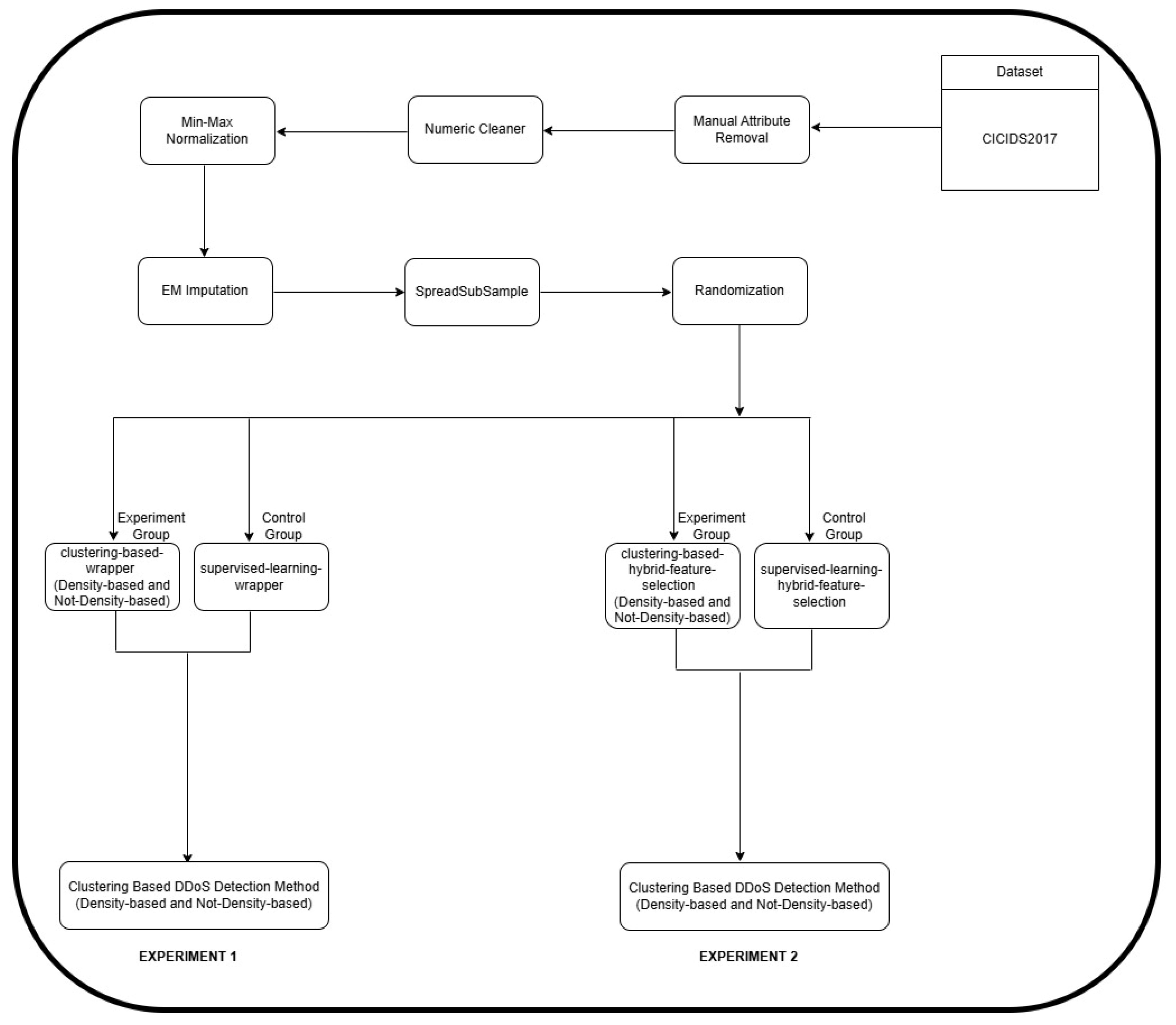
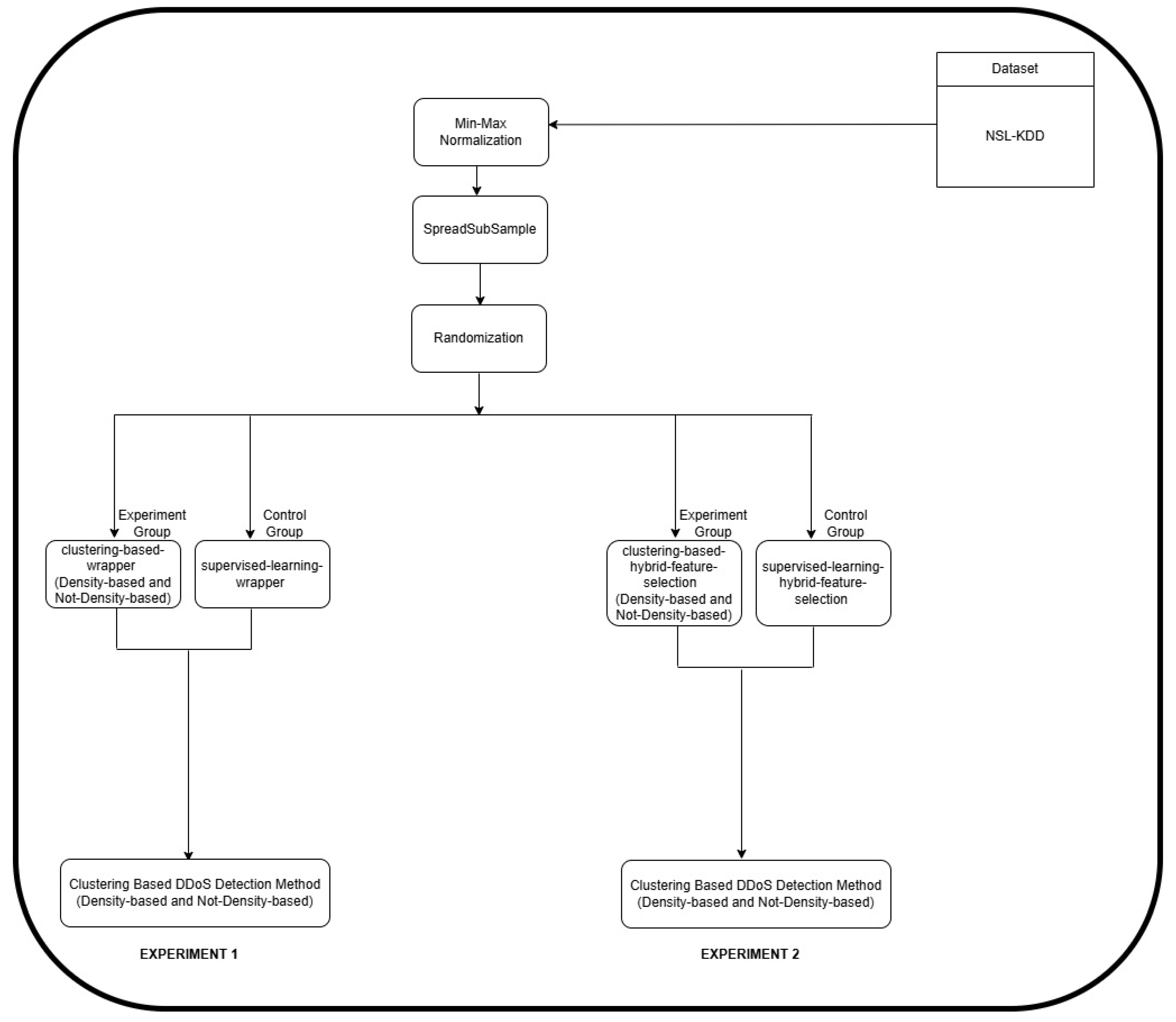
2. Materials and Methods
3. Literature Review
3.1. Concerns Surrounding DDoS Attacks
3.2. Application of Clustering Algorithms in DDoS Attack Detection
4. Data Analysis and Experimentation
4.1. Statistical Analysis Using One-Way ANOVA Considering the CICIDS2017 Dataset
4.2. Statistical Analysis Using One-Way ANOVA Considering NSL-KDD Dataset
4.3. Comparison Analysis Based on Descriptive Statistics Using CICIDS2017 Dataset
4.4. Comparison Analysis Based on Descriptive Statistics Using NSL-KDD Dataset
5. Discussion
Analysis of Mechanism Effectiveness
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Independent Variables Table

{kind=link}
{kind=link}
| Independent Variables | Procedures |
|---|---|
| Clustering Based DDoS Detection Method | Not-Density-Clustering of EM Not-Density-Clustering of SimpleKMeans MakeDensityBasedClusterer(EM) MakeDensityBasedClusterer(SimpleKMeans) |
| Clustering-Based-Wrapper Method | WrapperSubsetEval(Not-Density-Based-Clustering) WrapperSubsetEval(Density-Based-Clustering) |
| Supervised-Learning-Wrapper Method | WrapperSubsetEval(J48) WrapperSubsetEval(DecisionTable) WrapperSubsetEval(NaïveBayes) |
| Clustering-Based-Hybrid-Feature-Selection Method | InformationGainAttributeEval + WrapperSubsetEval(Not-Density-Based-Clustering) ChiSquaredAttributeEval + WrapperSubsetEval(Not-Density-Based-Clustering) InformationGainAttributeEval + WrapperSubsetEval(Density-Based-Clustering) ChiSquaredAttributeEval + WrapperSubsetEval(Density-Based-Clustering) |
| Supervised-Learning-Hybrid-Feature-Selection Method | InformationGainAttributeEval + WrapperSubsetEval(J48) InformationGainAttributeEval + WrapperSubsetEval(DecisionTable) InformationGainAttributeEval + WrapperSubsetEval(NaïveBayes) ChiSquaredAttributeEval + WrapperSubsetEval(J48) ChiSquaredAttributeEval + WrapperSubsetEval(DecisionTable) ChiSquaredAttributeEval + WrapperSubsetEval(NaïveBayes) |
Appendix B. Experimental Results Using CICIDS2017 Dataset
| Applied Clustering-Based Feature Selection | Applied Clustering Methods in DDoS Attack Detection | False Positive Rates |
|---|---|---|
| Not-Density-Clustering-based-Wrapper method using EM | Not-Density-based Clustering using EM | 0.002 |
| Not-Density-Clustering-based-Wrapper method using EM | Density-based Clustering using EM | 0.027 |
| Not-Density-Clustering-based-Wrapper method using EM | Not-Density-based Clustering using SimpleKMeans | 0.216 |
| Not-Density-Clustering-based-Wrapper method using EM | Density-based Clustering using SimpleKMeans | 0.282 |
| Not-Density-Clustering-based-Wrapper method using SimpleKMeans | Not-Density-based Clustering using EM | 0.086 |
| Not-Density-Clustering-based-Wrapper method using SimpleKMeans | Density-based Clustering using EM | 0.121 |
| Not-Density-Clustering-based-Wrapper method using SimpleKMeans | Not-Density-based Clustering using SimpleKMeans | 0.005 |
| Not-Density-Clustering-based-Wrapper method using SimpleKMeans | Density-based Clustering using SimpleKMeans | 0.083 |
| Density-Clustering-based-Wrapper method using EM | Not-Density-based Clustering using EM | 0.004 |
| Density-Clustering-based-Wrapper method using EM | Density-based Clustering using EM | 0.008 |
| Density-Clustering-based-Wrapper method using EM | Not-Density-based Clustering using SimpleKMeans | 0.299 |
| Density-Clustering-based-Wrapper method using EM | Density-based Clustering using SimpleKMeans | 0.332 |
| Density-Clustering-based-Wrapper method using SimpleKMeans | Not-Density-based Clustering using EM | 0.636 |
| Density-Clustering-based-Wrapper method using SimpleKMeans | Density-based Clustering using EM | 0.636 |
| Density-Clustering-based-Wrapper method using SimpleKMeans | Not-Density-based Clustering using SimpleKMeans | 0.000 |
| Density-Clustering-based-Wrapper method using SimpleKMeans | Density-based Clustering using SimpleKMeans | 0.011 |
| Applied Clustering-Based Hybrid Feature Selection | Applied Clustering Methods in DDoS Attack Detection | False Positive Rates |
|---|---|---|
| Not-Density-Clustering-based-Hybrid method using ChiSquared and EM | Not-Density-based Clustering using EM | 0.002 |
| Not-Density-Clustering-based-Hybrid method using ChiSquared and EM | Density-based Clustering using EM | 0.027 |
| Not-Density-Clustering-based-Hybrid method using ChiSquared and EM | Not-Density-based Clustering using SimpleKMeans | 0.216 |
| Not-Density-Clustering-based-Hybrid method using ChiSquared and EM | Density-based Clustering using SimpleKMeans | 0.282 |
| Not-Density-Clustering-based-Hybrid method using ChiSquared and SimpleKMeans | Not-Density-based Clustering using EM | 0.006 |
| Not-Density-Clustering-based-Hybrid method using ChiSquared and SimpleKMeans | Density-based Clustering using EM | 0.003 |
| Not-Density-Clustering-based-Hybrid method using ChiSquared and SimpleKMeans | Not-Density-based Clustering using SimpleKMeans | 0.102 |
| Not-Density-Clustering-based-Hybrid method using ChiSquared and SimpleKMeans | Density-based Clustering using SimpleKMeans | 0.098 |
| Not-Density-Clustering-based-Hybrid method using Information Gain and EM | Not-Density-based Clustering using EM | 0.290 |
| Not-Density-Clustering-based-Hybrid method using Information Gain and EM | Density-based Clustering using EM | 0.290 |
| Not-Density-Clustering-based-Hybrid method using Information Gain and EM | Not-Density-based Clustering using SimpleKMeans | 0.267 |
| Not-Density-Clustering-based-Hybrid method using Information Gain and EM | Density-based Clustering using SimpleKMeans | 0.260 |
| Not-Density-Clustering-based-Hybrid method using Information Gain and SimpleKMeans | Not-Density-based Clustering using EM | 0.000 |
| Not-Density-Clustering-based-Hybrid method using Information Gain and SimpleKMeans | Density-based Clustering using EM | 0.000 |
| Not-Density-Clustering-based-Hybrid method using Information Gain and SimpleKMeans | Not-Density-based Clustering using SimpleKMeans | 0.006 |
| Not-Density-Clustering-based-Hybrid method using Information Gain and SimpleKMeans | Density-based Clustering using SimpleKMeans | 0.033 |
| Density-Clustering-based-Hybrid method using ChiSquared and EM | Not-Density-based Clustering using EM | 0.003 |
| Density-Clustering-based-Hybrid method using ChiSquared and EM | Density-based Clustering using EM | 0.008 |
| Density-Clustering-based-Hybrid method using ChiSquared and EM | Not-Density-based Clustering using SimpleKMeans | 0.309 |
| Density-Clustering-based-Hybrid method using ChiSquared and EM | Density-based Clustering using SimpleKMeans | 0.331 |
| Density-Clustering-based-Hybrid method using ChiSquared and SimpleKMeans | Not-Density-based Clustering using EM | 0.636 |
| Density-Clustering-based-Hybrid method using ChiSquared and SimpleKMeans | Density-based Clustering using EM | 0.636 |
| Density-Clustering-based-Hybrid method using ChiSquared and SimpleKMeans | Not-Density-based Clustering using SimpleKMeans | 0.000 |
| Density-Clustering-based-Hybrid method using ChiSquared and SimpleKMeans | Density-based Clustering using SimpleKMeans | 0.011 |
| Density-Clustering-based-Hybrid method using Information Gain and EM | Not-Density-based Clustering using EM | 0.000 |
| Density-Clustering-based-Hybrid method using Information Gain and EM | Density-based Clustering using EM | 0.009 |
| Density-Clustering-based-Hybrid method using Information Gain and EM | Not-Density-based Clustering using SimpleKMeans | 0.359 |
| Density-Clustering-based-Hybrid method using Information Gain and EM | Density-based Clustering using SimpleKMeans | 0.343 |
| Density-Clustering-based-Hybrid method using Information Gain and SimpleKMeans | Not-Density-based Clustering using EM | 0.626 |
| Density-Clustering-based-Hybrid method using Information Gain and SimpleKMeans | Density-based Clustering using EM | 0.625 |
| Density-Clustering-based-Hybrid method using Information Gain and SimpleKMeans | Not-Density-based Clustering using SimpleKMeans | 0.000 |
| Density-Clustering-based-Hybrid method using Information Gain and SimpleKMeans | Density-based Clustering using SimpleKMeans | 0.064 |
| Applied Clustering-Based Feature Selection | Applied Clustering Methods in DDoS Attack Detection | False Positive Rates |
|---|---|---|
| Supervised-Learning-Wrapper method using NaïveBayes | Not-Density-based Clustering using EM | 0.340 |
| Supervised-Learning-Wrapper method using NaïveBayes | Density-based Clustering using EM | 0.344 |
| Supervised-Learning-Wrapper method using NaïveBayes | Not-Density-based Clustering using SimpleKMeans | 0.200 |
| Supervised-Learning-Wrapper method using NaïveBayes | Density-based Clustering using SimpleKMeans | 0.209 |
| Supervised-Learning-Wrapper method using J48 | Not-Density-based Clustering using EM | 0.381 |
| Supervised-Learning-Wrapper method using J48 | Density-based Clustering using EM | 0.380 |
| Supervised-Learning-Wrapper method using J48 | Not-Density-based Clustering using SimpleKMeans | 0.511 |
| Supervised-Learning-Wrapper method using J48 | Density-based Clustering using SimpleKMeans | 0.490 |
| Supervised-Learning-Wrapper method using DecisionTable | Not-Density-based Clustering using EM | 0.356 |
| Supervised-Learning-Wrapper method using DecisionTable | Density-based Clustering using EM | 0.356 |
| Supervised-Learning-Wrapper method using DecisionTable | Not-Density-based Clustering using SimpleKMeans | 0.674 |
| Supervised-Learning-Wrapper method using DecisionTable | Density-based Clustering using SimpleKMeans | 0.638 |
| Applied Clustering-Based Hybrid Feature Selection | Applied Clustering Methods in DDoS Attack Detection | False Positive Rates |
|---|---|---|
| Hybrid Feature Selection using ChiSquared and NaïveBayes | Not-Density-based Clustering using EM | 0.340 |
| Hybrid Feature Selection using ChiSquared and NaïveBayes | Density-based Clustering using EM | 0.344 |
| Hybrid Feature Selection using ChiSquared and NaïveBayes | Not-Density-based Clustering using SimpleKMeans | 0.200 |
| Hybrid Feature Selection using ChiSquared and NaïveBayes | Density-based Clustering using SimpleKMeans | 0.209 |
| Hybrid Feature Selection using Information Gain and NaïveBayes | Not-Density-based Clustering using EM | 0.001 |
| Hybrid Feature Selection using Information Gain and NaïveBayes | Density-based Clustering using EM | 0.001 |
| Hybrid Feature Selection using Information Gain and NaïveBayes | Not-Density-based Clustering using SimpleKMeans | 0.199 |
| Hybrid Feature Selection using Information Gain and NaïveBayes | Density-based Clustering using SimpleKMeans | 0.198 |
| Hybrid Feature Selection using ChiSquared and J48 | Not-Density-based Clustering using EM | 0.392 |
| Hybrid Feature Selection using ChiSquared and J48 | Density-based Clustering using EM | 0.391 |
| Hybrid Feature Selection using ChiSquared and J48 | Not-Density-based Clustering using SimpleKMeans | 0.373 |
| Hybrid Feature Selection using ChiSquared and J48 | Density-based Clustering using SimpleKMeans | 0.367 |
| Hybrid Feature Selection using Information Gain and J48 | Not-Density-based Clustering using EM | 0.326 |
| Hybrid Feature Selection using Information Gain and J48 | Density-based Clustering using EM | 0.326 |
| Hybrid Feature Selection using Information Gain and J48 | Not-Density-based Clustering using SimpleKMeans | 0.372 |
| Hybrid Feature Selection using Information Gain and J48 | Density-based Clustering using SimpleKMeans | 0.369 |
| Hybrid Feature Selection using ChiSquared and DecisionTable | Not-Density-based Clustering using EM | 0.362 |
| Hybrid Feature Selection using ChiSquared and DecisionTable | Density-based Clustering using EM | 0.362 |
| Hybrid Feature Selection using ChiSquared and DecisionTable | Not-Density-based Clustering using SimpleKMeans | 0.674 |
| Hybrid Feature Selection using ChiSquared and DecisionTable | Density-based Clustering using SimpleKMeans | 0.638 |
| Hybrid Feature Selection using InformationGain and DecisionTable | Not-Density-based Clustering using EM | 0.362 |
| Hybrid Feature Selection using InformationGain and DecisionTable | Density-based Clustering using EM | 0.362 |
| Hybrid Feature Selection using InformationGain and DecisionTable | Not-Density-based Clustering using SimpleKMeans | 0.674 |
| Hybrid Feature Selection using InformationGain and DecisionTable | Density-based Clustering using SimpleKMeans | 0.638 |
Appendix C. Experimental Results Using NSL-KDD Dataset
| Applied Clustering-Based Feature Selection | Applied Clustering Methods in DDoS Attack Detection | False Positive Rates |
|---|---|---|
| Not-Density-Clustering-based-Wrapper method using EM | Not-Density-based Clustering using EM | 0.017 |
| Not-Density-Clustering-based-Wrapper method using EM | Density-based Clustering using EM | 0.031 |
| Not-Density-Clustering-based-Wrapper method using EM | Not-Density-based Clustering using SimpleKMeans | 0.090 |
| Not-Density-Clustering-based-Wrapper method using EM | Density-based Clustering using SimpleKMeans | 0.093 |
| Not-Density-Clustering-based-Wrapper method using SimpleKMeans | Not-Density-based Clustering using EM | 0.045 |
| Not-Density-Clustering-based-Wrapper method using SimpleKMeans | Density-based Clustering using EM | 0.046 |
| Not-Density-Clustering-based-Wrapper method using SimpleKMeans | Not-Density-based Clustering using SimpleKMeans | 0.039 |
| Not-Density-Clustering-based-Wrapper method using SimpleKMeans | Density-based Clustering using SimpleKMeans | 0.042 |
| Density-Clustering-based-Wrapper method using EM | Not-Density-based Clustering using EM | 0.063 |
| Density-Clustering-based-Wrapper method using EM | Density-based Clustering using EM | 0.032 |
| Density-Clustering-based-Wrapper method using EM | Not-Density-based Clustering using SimpleKMeans | 0.045 |
| Density-Clustering-based-Wrapper method using EM | Density-based Clustering using SimpleKMeans | 0.053 |
| Density-Clustering-based-Wrapper method using SimpleKMeans | Not-Density-based Clustering using EM | 0.058 |
| Density-Clustering-based-Wrapper method using SimpleKMeans | Density-based Clustering using EM | 0.068 |
| Density-Clustering-based-Wrapper method using SimpleKMeans | Not-Density-based Clustering using SimpleKMeans | 0.003 |
| Density-Clustering-based-Wrapper method using SimpleKMeans | Density-based Clustering using SimpleKMeans | 0.033 |
| Applied Clustering-Based Hybrid Feature Selection | Applied Clustering Methods in DDoS Attack Detection | False Positive Rates |
|---|---|---|
| Not-Density-Clustering-based-Hybrid method using ChiSquared and EM | Not-Density-based Clustering using EM | 0.021 |
| Not-Density-Clustering-based-Hybrid method using ChiSquared and EM | Density-based Clustering using EM | 0.040 |
| Not-Density-Clustering-based-Hybrid method using ChiSquared and EM | Not-Density-based Clustering using SimpleKMeans | 0.011 |
| Not-Density-Clustering-based-Hybrid method using ChiSquared and EM | Density-based Clustering using SimpleKMeans | 0.028 |
| Not-Density-Clustering-based-Hybrid method using ChiSquared and SimpleKMeans | Not-Density-based Clustering using EM | 0.045 |
| Not-Density-Clustering-based-Hybrid method using ChiSquared and SimpleKMeans | Density-based Clustering using EM | 0.046 |
| Not-Density-Clustering-based-Hybrid method using ChiSquared and SimpleKMeans | Not-Density-based Clustering using SimpleKMeans | 0.039 |
| Not-Density-Clustering-based-Hybrid method using ChiSquared and SimpleKMeans | Density-based Clustering using SimpleKMeans | 0.042 |
| Not-Density-Clustering-based-Hybrid method using Information Gain and EM | Not-Density-based Clustering using EM | 0.059 |
| Not-Density-Clustering-based-Hybrid method using Information Gain and EM | Density-based Clustering using EM | 0.026 |
| Not-Density-Clustering-based-Hybrid method using Information Gain and EM | Not-Density-based Clustering using SimpleKMeans | 0.043 |
| Not-Density-Clustering-based-Hybrid method using Information Gain and EM | Density-based Clustering using SimpleKMeans | 0.046 |
| Not-Density-Clustering-based-Hybrid method using Information Gain and SimpleKMeans | Not-Density-based Clustering using EM | 0.068 |
| Not-Density-Clustering-based-Hybrid method using Information Gain and SimpleKMeans | Density-based Clustering using EM | 0.044 |
| Not-Density-Clustering-based-Hybrid method using Information Gain and SimpleKMeans | Not-Density-based Clustering using SimpleKMeans | 0.006 |
| Not-Density-Clustering-based-Hybrid method using Information Gain and SimpleKMeans | Density-based Clustering using SimpleKMeans | 0.040 |
| Density-Clustering-based-Hybrid method using ChiSquared and EM | Not-Density-based Clustering using EM | 0.063 |
| Density-Clustering-based-Hybrid method using ChiSquared and EM | Density-based Clustering using EM | 0.032 |
| Density-Clustering-based-Hybrid method using ChiSquared and EM | Not-Density-based Clustering using SimpleKMeans | 0.045 |
| Density-Clustering-based-Hybrid method using ChiSquared and EM | Density-based Clustering using SimpleKMeans | 0.053 |
| Density-Clustering-based-Hybrid method using ChiSquared and SimpleKMeans | Not-Density-based Clustering using EM | 0.058 |
| Density-Clustering-based-Hybrid method using ChiSquared and SimpleKMeans | Density-based Clustering using EM | 0.068 |
| Density-Clustering-based-Hybrid method using ChiSquared and SimpleKMeans | Not-Density-based Clustering using SimpleKMeans | 0.003 |
| Density-Clustering-based-Hybrid method using ChiSquared and SimpleKMeans | Density-based Clustering using SimpleKMeans | 0.033 |
| Density-Clustering-based-Hybrid method using Information Gain and EM | Not-Density-based Clustering using EM | 0.059 |
| Density-Clustering-based-Hybrid method using Information Gain and EM | Density-based Clustering using EM | 0.012 |
| Density-Clustering-based-Hybrid method using Information Gain and EM | Not-Density-based Clustering using SimpleKMeans | 0.006 |
| Density-Clustering-based-Hybrid method using Information Gain and EM | Density-based Clustering using SimpleKMeans | 0.016 |
| Density-Clustering-based-Hybrid method using Information Gain and SimpleKMeans | Not-Density-based Clustering using EM | 0.059 |
| Density-Clustering-based-Hybrid method using Information Gain and SimpleKMeans | Density-based Clustering using EM | 0.012 |
| Density-Clustering-based-Hybrid method using Information Gain and SimpleKMeans | Not-Density-based Clustering using SimpleKMeans | 0.006 |
| Density-Clustering-based-Hybrid method using Information Gain and SimpleKMeans | Density-based Clustering using SimpleKMeans | 0.016 |
| Applied Clustering-Based Feature Selection | Applied Clustering Methods in DDoS Attack Detection | False Positive Rates |
|---|---|---|
| Supervised-Learning-Wrapper method using NaïveBayes | Not-Density-based Clustering using EM | 0.237 |
| Supervised-Learning-Wrapper method using NaïveBayes | Density-based Clustering using EM | 0.255 |
| Supervised-Learning-Wrapper method using NaïveBayes | Not-Density-based Clustering using SimpleKMeans | 0.185 |
| Supervised-Learning-Wrapper method using NaïveBayes | Density-based Clustering using SimpleKMeans | 0.228 |
| Supervised-Learning-Wrapper method using J48 | Not-Density-based Clustering using EM | 0.091 |
| Supervised-Learning-Wrapper method using J48 | Density-based Clustering using EM | 0.091 |
| Supervised-Learning-Wrapper method using J48 | Not-Density-based Clustering using SimpleKMeans | 0.007 |
| Supervised-Learning-Wrapper method using J48 | Density-based Clustering using SimpleKMeans | 0.035 |
| Supervised-Learning-Wrapper method using DecisionTable | Not-Density-based Clustering using EM | 0.142 |
| Supervised-Learning-Wrapper method using DecisionTable | Density-based Clustering using EM | 0.155 |
| Supervised-Learning-Wrapper method using DecisionTable | Not-Density-based Clustering using SimpleKMeans | 0.008 |
| Supervised-Learning-Wrapper method using DecisionTable | Density-based Clustering using SimpleKMeans | 0.106 |
| Applied Clustering-Based Hybrid Feature Selection | Applied Clustering Methods in DDoS Attack Detection | False Positive Rates |
|---|---|---|
| Hybrid Feature Selection using ChiSquared and NaïveBayes | Not-Density-based Clustering using EM | 0.237 |
| Hybrid Feature Selection using ChiSquared and NaïveBayes | Density-based Clustering using EM | 0.255 |
| Hybrid Feature Selection using ChiSquared and NaïveBayes | Not-Density-based Clustering using SimpleKMeans | 0.185 |
| Hybrid Feature Selection using ChiSquared and NaïveBayes | Density-based Clustering using SimpleKMeans | 0.228 |
| Hybrid Feature Selection using Information Gain and NaïveBayes | Not-Density-based Clustering using EM | 0.012 |
| Hybrid Feature Selection using Information Gain and NaïveBayes | Density-based Clustering using EM | 0.012 |
| Hybrid Feature Selection using Information Gain and NaïveBayes | Not-Density-based Clustering using SimpleKMeans | 0.170 |
| Hybrid Feature Selection using Information Gain and NaïveBayes | Density-based Clustering using SimpleKMeans | 0.172 |
| Hybrid Feature Selection using ChiSquared and J48 | Not-Density-based Clustering using EM | 0.095 |
| Hybrid Feature Selection using ChiSquared and J48 | Density-based Clustering using EM | 0.089 |
| Hybrid Feature Selection using ChiSquared and J48 | Not-Density-based Clustering using SimpleKMeans | 0.007 |
| Hybrid Feature Selection using ChiSquared and J48 | Density-based Clustering using SimpleKMeans | 0.036 |
| Hybrid Feature Selection using Information Gain and J48 | Not-Density-based Clustering using EM | 0.059 |
| Hybrid Feature Selection using Information Gain and J48 | Density-based Clustering using EM | 0.068 |
| Hybrid Feature Selection using Information Gain and J48 | Not-Density-based Clustering using SimpleKMeans | 0.007 |
| Hybrid Feature Selection using Information Gain and J48 | Density-based Clustering using SimpleKMeans | 0.044 |
| Hybrid Feature Selection using ChiSquared and DecisionTable | Not-Density-based Clustering using EM | 0.142 |
| Hybrid Feature Selection using ChiSquared and DecisionTable | Density-based Clustering using EM | 0.155 |
| Hybrid Feature Selection using ChiSquared and DecisionTable | Not-Density-based Clustering using SimpleKMeans | 0.008 |
| Hybrid Feature Selection using ChiSquared and DecisionTable | Density-based Clustering using SimpleKMeans | 0.106 |
| Hybrid Feature Selection using InformationGain and DecisionTable | Not-Density-based Clustering using EM | 0.068 |
| Hybrid Feature Selection using InformationGain and DecisionTable | Density-based Clustering using EM | 0.044 |
| Hybrid Feature Selection using InformationGain and DecisionTable | Not-Density-based Clustering using SimpleKMeans | 0.013 |
| Hybrid Feature Selection using InformationGain and DecisionTable | Density-based Clustering using SimpleKMeans | 0.036 |
Appendix D. Selected Features with Best Performance
| Applied Feature Selection Methods | Selected Features |
|---|---|
| Density-Clustering-based-Wrapper method using SimpleKMeans | Total Length of Fwd Packets Bwd Packet Length Std Flow IAT Std Fwd IAT Mean act_data_pkt_fwd |
| Not-Density-Clustering-based-Hybrid method using Information Gain and SimpleKMeans | Total Length of Fwd Packets Subflow Fwd Bytes Avg Bwd Segment Size Fwd IAT Mean Fwd IAT Std Bwd Packet Length Std |
| Density-Clustering-based-Hybrid method using ChiSquared and SimpleKMeans | Subflow Fwd Bytes Fwd IAT Mean act_data_pkt_fwd Bwd Packet Length Std Flow IAT Std |
| Density-Clustering-based-Hybrid method using Information Gain and EM | Total Length of Fwd Packets Subflow Fwd Bytes Avg Bwd Segment Size Destination Port Bwd Packet Length Max Avg Fwd Segment Size Fwd Packet Length Mean Init_Win_bytes_forward Fwd IAT Max Fwd IAT Mean Init_Win_bytes_backward Subflow Fwd Packets Total Fwd Packets Fwd IAT Std Packet Length Variance |
| Density-Clustering-based-Hybrid method using Information Gain and SimpleKMeans | Total Length of Fwd Packets act_data_pkt_fwd Bwd Packet Length Std |
| Applied Feature Selection Methods | Selected Features |
|---|---|
| Density-Clustering-based-Wrapper method using SimpleKMeans | duration service flag hot su_attempted num_shells count srv_serror_rate same_srv_rate dst_host_count dst_host_srv_count dst_host_diff_srv_rate dst_host_srv_rerror_rate |
| Density-Clustering-based-Hybrid method using ChiSquared and SimpleKMeans | service flag same_srv_rate dst_host_srv_count dst_host_diff_srv_rate count srv_serror_rate dst_host_count dst_host_srv_rerror_rate duration hot su_attempted num_shells |
References
- Zeinalpour, A.; McElroy, C.P. Comparing metaheuristic search techniques in addressing the effectiveness of clustering-based DDoS attack detection methods. Electronics 2024, 13, 899. [Google Scholar] [CrossRef]
- Najafimehr, M.; Zarifzadeh, S.; Mostafavi, S. DDoS attacks and machine-learning-based detection methods: A survey and taxonomy. Eng. Rep. 2023, 5, e12697. [Google Scholar] [CrossRef]
- Das, S.; Ashrafuzzaman, M.; Sheldon, F.T.; Shiva, S. Ensembling supervised and unsupervised machine learning algorithms for detecting distributed denial of service attacks. Algorithms 2024, 17, 99. [Google Scholar] [CrossRef]
- Riskhan, B.; Safuan, H.A.J.; Hussain, K.; Elnour, A.A.H.; Abdelmaboud, A.; Khan, F.; Kundi, M. An adaptive distributed denial of service attack prevention technique in a distributed environment. Sensors 2023, 23, 6574. [Google Scholar] [CrossRef]
- Prasad, A.; Chandra, S. VMFCVD: An optimized framework to combat volumetric ddos attacks using machine learning. Arab. J. Sci. Eng. 2022, 47, 9965–9983. [Google Scholar] [CrossRef]
- Xu, K.; Li, Z.; Liang, N.; Kong, F.; Lei, S.; Wang, S.; Paul, A.; Wu, Z. Research on Multi-Layer Defense against DDoS Attacks in Intelligent Distribution Networks. Electronics 2024, 13, 3583. [Google Scholar] [CrossRef]
- Ali, T.E.; Yung-Wey, C.; Manickam, S.; Yusoff, M.N.; Kok-Lim, A.Y.; Zoltan, A.D. A stacking ensemble model with enhanced feature selection for Distributed Denial-of-Service detection in software-defined networks. Eng. Technol. Appl. Sci. Res. 2025, 15, 19232–19245. [Google Scholar] [CrossRef]
- Zou, H. Clustering Algorithm and Its Application in Data Mining. Wirel. Pers. Commun. 2020, 110, 21–30. [Google Scholar] [CrossRef]
- Ahmed, S.; Khan, Z.A.; Mohsin, S.M.; Latif, S.; Aslam, S.; Mujlid, H.; Adil, M.; Najam, Z. Effective and efficient DDoS attack detection using deep learning algorithm, multi-layer perceptron. Future Internet 2023, 15, 76. [Google Scholar] [CrossRef]
- Belouch, M.; Elhadaj, S.; Idhammad, M. A hybrid filter-wrapper feature selection method for DDoS detection in cloud computing. Intell. Data Anal. 2018, 22, 1209–1226. [Google Scholar] [CrossRef]
- Kim, Y.E.; Kim, Y.S.; Kim, H. Effective feature selection methods to detect IoT DDoS attack in 5G core network. Sensors 2022, 22, 3819. [Google Scholar] [CrossRef] [PubMed]
- Zeinalpour, A. Addressing High False Positive Rates of DDoS Attack Detection Methods. Ph.D. Thesis, Walden University, Minneapolis, MN, USA, 2021. [Google Scholar]
- Bhattacharjee, P.; Mitra, P. A survey of density based clustering algorithms. Front. Comput. Sci. 2021, 15, 151308. [Google Scholar] [CrossRef]
- Hassan, A.I.; Reheem, E.A.E.; Guirguis, S.K. An entropy and machine learning based approach for DDoS attacks detection in software defned networks. Sci. Rep. 2024, 14, 18159. [Google Scholar] [CrossRef]
- Alrayes, F.S.; Zakariah, M.; Amin, S.U.; Khan, Z.I.; Helal, M. Intrusion detection in IoT systems using denoising autoencoder. IEEE Access 2024, 12, 122401–122425. [Google Scholar] [CrossRef]
- Ahn, B.; Abbas, E.; Park, J.A.; Choi, H.J. Increasing splicing site prediction by training gene set based on species. KSII Trans. Internet Inf. Syst. 2012, 6, 2784–2799. [Google Scholar] [CrossRef]
- Altalhan, M.; Algarni, A.; Alouane, M.T.H. Imbalanced data problem in machine learning: A review. IEEE Access 2025, 13, 13686–13699. [Google Scholar] [CrossRef]
- Aamir, M.; Zaidi, S.M.A. DDoS attack detection with feature engineering and machine learning: The framework and performance evaluation. Int. J. Inf. Secur. 2019, 18, 761–785. [Google Scholar] [CrossRef]
- Dasari, S.; Kaluri, R. An effective classification of DDoS attacks in a distributed network by adopting hierarchical machine learning and hyperparameters optimization techniques. IEEE Access 2024, 12, 10834–10845. [Google Scholar] [CrossRef]
- Revathi, M.; Ramalingam, V.V.; Amutha, B. A machine learning based detection and mitigation of the DDoS attack by using SDN controller framework. Wirel. Pers. Commun. Int. J. 2022, 127, 2417–2441. [Google Scholar] [CrossRef]
- Adedeji, K.B.; Abu-Mahfouz, A.M.; Kurien, A.M. DDoS attack and detection methods in internet-enabled networks: Concept, research perspectives, and challenges. J. Sens. Actuator Netw. 2023, 12, 51. [Google Scholar] [CrossRef]
- Keserwani, P.K.; Govil, M.C.; Pilli, E.S. An effective NIDS framework based on a comprehensive survey of feature optimization and classification techniques. Neural Comput. Appl. 2023, 35, 4993–5013. [Google Scholar] [CrossRef]
- Yoachimik, O.; Pacheco, J. 4.2 Tbps of Bad Packets and a Whole Lot More: Cloudflare’s Q3 DDoS Report; Cloudflare, Inc.: San Francisco, CA, USA, 2024; Available online: https://blog.cloudflare.com/ddos-threat-report-for-2024-q3 (accessed on 30 October 2024).
- Alduailij, M.; Khan, Q.W.; Tahir, M.; Sardaraz, M.; Alduailij, M.; Malik, F. Machine-learning-based DDoS attack detection using mutual information and random forest feature importance method. Symmetry 2022, 14, 1095. [Google Scholar] [CrossRef]
- Abdullayeva, F.J. Distributed denial of service attack detection in E-government cloud via data clustering. Array 2022, 15, 100229. [Google Scholar] [CrossRef]
- Zong, Y.; Huang, G. Application of artificial fish swarm optimization semi-supervised kernel fuzzy clustering algorithm in network intrusion. J. Intell. Fuzzy Syst. 2020, 39, 1619–1626. [Google Scholar] [CrossRef]
- Panda, M.; Patra, M.R. Some clustering algorithms to enhance the performance of the network intrusion detection system. J. Theor. Appl. Inf. Technol. 2008, 26, 795–801. [Google Scholar]
- Kriegel, H.P.; Kröger, P.; Sander, J.; Zimek, A. Density-based clustering. WIREs Data Min. Knowl. Discov. 2011, 1, 231–240. [Google Scholar] [CrossRef]
- Mondragón, J.C.M.; Lara, E.R.; Eleuterio, R.A.; Gutirrez, E.E.G.; López, F.D.R. Density-based clustering to deal with highly imbalanced data in multi-class problems. Mathematics 2023, 11, 4008. [Google Scholar] [CrossRef]
- Koo, J.; Hwang, S. A unified defect pattern analysis of wafer maps using density-based clustering. IEEE Access 2021, 9, 78873–78882. [Google Scholar] [CrossRef]
- Zeinalpour, A.; Ahmed, H.A. Addressing the effectiveness of DDoS-attack detection methods based on the clustering method using an ensemble method. Electronics 2022, 11, 2736. [Google Scholar] [CrossRef]
- Shakil, M.; Fuad Yousif Mohammed, A.; Arul, R.; Bashir, A.K.; Choi, J.K. A novel dynamic framework to detect DDoS in SDN using metaheuristic clustering. Trans. Emerg. Telecommun. Technol. 2019, 33, e3622. [Google Scholar] [CrossRef]
- Bhaya, W.; Manaa, M.E. A proactive DDoS attack detection approach using data mining cluster analysis. J. Next Gener. Inf. Technol. 2014, 5, 36–47. [Google Scholar]
- Bhaya, W.; Manaa, M. DDoS attack detection approach using an efficient cluster analysis in large data scale. In Proceedings of the IEEE 2017 Annual Conference on New Trends in Information & Communications Technology Applications, Baghdad, Iraq, 7–9 March 2017; pp. 168–173. [Google Scholar]
- Qin, X.; Xu, T.; Wang, C. DDoS attack detection using flow entropy and clustering technique. In Proceedings of the IEEE 2015 11th International Conference on Computational Intelligence and Security, Shenzhen, China, 19–20 December 2015; pp. 412–415. [Google Scholar]
- Al-mamory, S.O.; Algelal, Z.M. A modified DBSCAN clustering algorithm for proactive detection of DDoS attacks. In Proceedings of the IEEE 2017 Annual Conference on New Trends in Information & Communications Technology Applications, Baghdad, Iraq, 7–9 March 2017; pp. 304–309. [Google Scholar]
- Ateş, Ç.; Özdel, S.; Anarım, E. Clustering based DDoS attack detection using the relationship between packet headers. In Proceedings of the IEEE 2019 Innovations in Intelligent Systems and Applications Conference, Izmir, Turkey, 31 October–2 November 2019; pp. 1–6. [Google Scholar]
- Gu, Y.; Li, K.; Guo, Z.; Wang, Y. Semi-supervised K-means DDoS detection method using hybrid feature selection algorithm. IEEE Access 2019, 7, 64351–64365. [Google Scholar] [CrossRef]
- Mansoor, A.; Anbar, M.; Bahashwan, A.A.; Alabsi, B.A.; Rihan, S.D.A. Deep Learning-Based Approach for Detecting DDoS Attack on Software-Defined Networking Controller. Systems 2023, 11, 296. [Google Scholar] [CrossRef]
- Elejla, O.E.; Anbar, M.; Hamouda, S.; Faisal, S.; Bahashwan, A.A.; Hasbullah, I.H. Deep-Learning-Based Approach to Detect ICMPv6 Flooding DDoS Attacks on IPv6 Networks. Appl. Sci. 2022, 12, 6150. [Google Scholar] [CrossRef]
- Wu, P.; Guo, H.; Moustafa, N. Pelican: A Deep Residual Network for Network Intrusion Detection. In Proceedings of the Annual IEEE/IFIP International Conference on Dependable Systems and Networks Workshops (DSN-W), Valencia, Spain, 29 June–2 July 2020; pp. 55–62. [Google Scholar]
- Das, S.; Venugopal, D.; Shiva, S.; Sheldon, F.T. Empirical Evaluation of the Ensemble Framework for Feature Selection in DDoS Attack. In Proceedings of the IEEE International Conference on Edge Computing and Scalable Cloud (EdgeCom), New York, NY, USA, 1–3 August 2020; pp. 56–61. [Google Scholar]
- Feng, Y.; Li, J.; Sisodia, D.; Reiher, P. On Explainable and Adaptable Detection of Distributed Denial-of-Service Traffic. IEEE Trans. Dependable Secur. Comput. 2023, 21, 2211–2226. [Google Scholar] [CrossRef]
- Bhattacharya, S.; Selvakumar, S. Multi-measure multi-weight ranking approach for the identification of the network features for the detection of DoS and Probe attacks. Comput. J. 2016, 59, 923–943. [Google Scholar] [CrossRef]
- Bhattacharya, S.; Selvakumar, S. LAWRA: A layered wrapper feature selection approach for network attack detection. Secur. Commun. Netw. 2015, 8, 3459–3468. [Google Scholar] [CrossRef]
- Bouzoubaa, K.; Taher, Y.; Nsiri, B. Predicting DOS-DDOS attacks: Review and evaluation study of feature selection methods based on wrapper process. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 132–145. [Google Scholar] [CrossRef]
- Bouzoubaa, K.; Taher, Y.; Nsiri, B. Dos attack forecasting: A comparative study on wrapper feature selection. In Proceedings of the IEEE 2020 International Conference on Intelligent Systems and Computer Vision, Fez, Morocco, 9–11 June 2020; pp. 1–7. [Google Scholar]
- Polat, H.; Polat, O.; Cetin, A. Detecting DDoS Attacks in Software-Defined Networks Through Feature Selection Methods and Machine Learning Models. Sustainability 2020, 12, 1035. [Google Scholar] [CrossRef]
- Budiman, A.; Hamidi, E.A.Z.; Ahdan, S.; Negara, R.M. Wrapper-Based Feature Selection to Improve The Accuracy of Intrusion Detection System (IDS). In Proceedings of the IEEE 2024 10th International Conference on Wireless and Telematics, Batam, Indonesia, 4–5 July 2024; pp. 1–5. [Google Scholar]
- Saha, S.; Priyoti, A.T.; Sharma, A.; Haque, A. Towards an optimized ensemble feature selection for DDoS detection using both supervised and unsupervised method. Sensors 2022, 22, 9144. [Google Scholar] [CrossRef]
- Miniak-Górecka, A.; Podlaski, K.; Gwizdałła, T. Using k-means clustering in python with periodic boundary conditions. Symmetry 2022, 14, 1237. [Google Scholar] [CrossRef]
- Yang, M.S.; Lai, C.Y.; Lin, C.Y. A robust EM clustering algorithm for Gaussian mixture models. Pattern Recognit. 2012, 45, 3950–3961. [Google Scholar] [CrossRef]
- Ellis, T.J.; Levy, Y. Towards a guide for novice researchers on research methodology: Review and proposed methods. J. Issues Inf. Sci. Inf. Technol. 2009, 6, 323–337. [Google Scholar]
- Sarker, I.H. Machine Learning for intelligent data analysis and automation in cybersecurity: Current and future prospects. Ann. Data Sci. 2023, 10, 1473–1498. [Google Scholar] [CrossRef]
- Chiba, Z.; Abghour, N.; Moussaid, K.; El omri, A.; Rida, M. Intelligent approach to build a Deep Neural Network based IDS for cloud environment using combination of machine learning algorithms. Comput. Secur. 2019, 86, 291–317. [Google Scholar] [CrossRef]
- Haskasa, E.; Kalemi, E.; Koci, L.; Shpk, C.C. The influence that WEKA workbench has in processing information. In Proceedings of the ISCIM, Langkawi, Malaysia, 7–9 April 2013; pp. 27–37. [Google Scholar]
- Green, S.B.; Salkind, N.J. Using SPSS for Windows and Macintosh: Analyzing and Understanding the Data, 8th ed.; Pearson: Upper Saddle River, NJ, USA, 2017; p. 131. [Google Scholar]
- Arango-López, J.; Isaza, G.; Ramirez, F.; Duque, N.; Montes, J. Cloud-based deep learning architecture for DDoS cyber attack prediction. Expert Syst. 2025, 42, e13552. [Google Scholar] [CrossRef]
- Najar, A.A.; Naik, S.M. DDoS attack detection using MLP and Random Forest algorithms. Int. J. Inf. Tecnol. 2022, 14, 2317–2327. [Google Scholar] [CrossRef]
- Kaliyaperumal, P.; Periyasamy, S.; Thirumalaisamy, M.; Balusamy, B.; Benedetto, F. A novel hybrid unsupervised learning approach for enhanced cybersecurity in the IoT. Future Internet 2024, 16, 253. [Google Scholar] [CrossRef]
- Emadi, H.S.; Mazinani, S.M. A Novel Anomaly Detection Algorithm Using DBSCAN and SVM in Wireless Sensor Networks. Wirel. Pers. Commun. 2018, 98, 2025–2035. [Google Scholar] [CrossRef]
| Source | Type III Sum of Squares | df | Mean Square | F | Sig. | Partial Eta Squared |
|---|---|---|---|---|---|---|
| Corrected Model | 0.378 a | 1 | 0.378 | 10.547 | 0.003 | 0.289 |
| Intercept | 2.294 | 1 | 2.294 | 63.969 | <0.001 | 0.711 |
| Method | 0.378 | 1 | 0.378 | 10.547 | 0.003 | 0.289 |
| Error | 0.932 | 26 | 0.036 | |||
| Total | 3.388 | 28 | ||||
| Corrected Total | 1.310 | 27 |
| Source | Type III Sum of Squares | df | Mean Square | F | Sig. | Partial Eta Squared |
|---|---|---|---|---|---|---|
| Corrected Model | 0.400 a | 1 | 0.400 | 10.043 | 0.003 | 0.157 |
| Intercept | 3.939 | 1 | 3.939 | 98.897 | <0.001 | 0.647 |
| Method | 0.400 | 1 | 0.400 | 10.043 | 0.003 | 0.157 |
| Error | 2.151 | 54 | 0.040 | |||
| Total | 6.213 | 56 | ||||
| Corrected Total | 2.550 | 55 |
| Source | Type III Sum of Squares | df | Mean Square | F | Sig. | Partial Eta Squared |
|---|---|---|---|---|---|---|
| Corrected Model | 0.045 a | 1 | 0.045 | 12.768 | 0.001 | 0.329 |
| Intercept | 0.212 | 1 | 0.212 | 60.141 | <0.001 | 0.698 |
| Method | 0.045 | 1 | 0.045 | 12.768 | 0.001 | 0.329 |
| Error | 0.092 | 26 | 0.004 | |||
| Total | 0.325 | 28 | ||||
| Corrected Total | 0.136 | 27 |
| Source | Type III Sum of Squares | df | Mean Square | F | Sig. | Partial Eta Squared |
|---|---|---|---|---|---|---|
| Corrected Model | 0.046 a | 1 | 0.046 | 15.511 | <0.001 | 0.223 |
| Intercept | 0.230 | 1 | 0.230 | 77.572 | <0.001 | 0.590 |
| Method | 0.046 | 1 | 0.046 | 15.511 | <0.001 | 0.223 |
| Error | 0.160 | 54 | 0.003 | |||
| Total | 0.412 | 56 | ||||
| Corrected Total | 0.206 | 55 |
| Method | Mean | Std. Deviation | N |
|---|---|---|---|
| Clustering-based Wrapper | 0.17175 | 0.214897 | 16 |
| Supervised Wrapper | 0.40658 | 0.147547 | 12 |
| Total | 0.27239 | 0.220297 | 28 |
| Method | Mean | Std. Deviation | N |
|---|---|---|---|
| Clustering-based hybrid feature selection | 0.18256 | 0.215233 | 32 |
| Supervised learning hybrid feature selection | 0.35333 | 0.176245 | 24 |
| Total | 0.25575 | 0.215342 | 56 |
| Method | Mean | Std. Deviation | N |
|---|---|---|---|
| Clustering-based wrapper | 0.04738 | 0.023703 | 16 |
| Supervised wrapper | 0.12833 | 0.086914 | 12 |
| Total | 0.08207 | 0.071094 | 28 |
| Method | Mean | Std. Deviation | N |
|---|---|---|---|
| Clustering-based hybrid feature selection | 0.03578 | 0.020054 | 32 |
| Supervised learning hybrid feature selection | 0.09367 | 0.080083 | 24 |
| Total | 0.06059 | 0.061189 | 56 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeinalpour, A.; McElroy, C.P. Comparative Analysis of Feature Selection Methods in Clustering-Based Detection Methods. Electronics 2025, 14, 2119. https://doi.org/10.3390/electronics14112119
Zeinalpour A, McElroy CP. Comparative Analysis of Feature Selection Methods in Clustering-Based Detection Methods. Electronics. 2025; 14(11):2119. https://doi.org/10.3390/electronics14112119
Chicago/Turabian StyleZeinalpour, Alireza, and Charles P. McElroy. 2025. "Comparative Analysis of Feature Selection Methods in Clustering-Based Detection Methods" Electronics 14, no. 11: 2119. https://doi.org/10.3390/electronics14112119
APA StyleZeinalpour, A., & McElroy, C. P. (2025). Comparative Analysis of Feature Selection Methods in Clustering-Based Detection Methods. Electronics, 14(11), 2119. https://doi.org/10.3390/electronics14112119