Abstract
Existing databases supporting Online Transaction Processing (OLTP) workloads based on non-volatile memory (NVM) almost all use Multi-Version Concurrency Control (MVCC) protocol to ensure data consistency. MVCC allows multiple transactions to execute concurrently without lock conflicts, reducing the wait time between read and write operations, and thereby significantly increasing the throughput of NVM OLTP engines. However, it requires garbage collection (GC) to clean up the obsolete tuple versions to prevent storage overflow, which consumes additional system resources. Furthermore, existing GC approaches in NVM OLTP engines are inefficient because they are based on methods designed for dynamic random access memory (DRAM) OLTP engines, without considering the significant differences in read/write bandwidth and cache line size between NVM and DRAM. These approaches either involve excessive random NVM access (traversing tuple versions) or lead to too many additional NVM write operations, both of which degrade the performance and durability of NVM. In this paper, we propose TB-Collect, a high-performance GC approach specifically designed for NVM OLTP engines. On the one hand, TB-Collect separates tuple headers and contents, storing data in an append-only manner, which greatly reduces NVM writes. On the other hand, TB-Collect performs GC at the block level, eliminating the need to traverse tuple versions and improving the utilization of reclaimed space. We have implemented TB-Collect on DBx1000 and MySQL. Experimental results show that TB-Collect achieves 1.15 to 1.58 times the throughput of existing methods when running TPCC and YCSB workloads.
1. Introduction
Non-volatile memory (NVM) is an emerging memory technology that combines DRAM-like read and write bandwidth with byte-addressability and data persistence after power loss [1]. These features make NVM an ideal storage medium for building high-performance Online Transaction Processing (OLTP) engines. Specifically, NVM can replace DRAM as the primary storage for data execution due to its high bandwidth and fine-grained access, while also providing persistent storage without requiring logging and checkpointing mechanisms typical of DRAM OLTP engines [2,3,4,5].
Current research on OLTP engines built on NVM includes NV-Logging [6], FOEDUS [7], WBL [8], Zen [9,10], Hyrise-NV [11], and Falcon [12], among which Zen and Falcon can process millions of transactions per second while ensuring data consistency after system crashes. Existing studies on NVM OLTP engines mainly focus on NVM index structures [13,14,15] and recovery mechanisms [16,17,18]. There are currently no garbage collection approaches specifically designed for NVM OLTP engines. Instead, existing GC approaches used in NVM OLTP engines are adaptations of three prior approaches, including timely version chain pruning, background scanning, and partition clearing [19,20,21]. Due to differences in hardware characteristics and performance between NVM and DRAM, directly applying GC approaches from DRAM OLTP engines leads to a series of challenges.
Table 1 shows the issues caused by existing garbage collection schemes in NVM OLTP engines. The first is the low reclamation rate caused by traversing the version chain. GC approaches such as timely version chain pruning and background scanning typically collect obsolete versions by traversing the version chain, which relies on the byte-addressability of DRAM. However, this approach has been shown to be highly inefficient because the large number of random accesses to DRAM significantly impacts system performance [21]. Although NVM also features byte-addressability, its read bandwidth is lower than that of DRAM [22,23,24,25]. Therefore, using the same approach to traverse the version chain for collecting obsolete versions in NVM results in even lower efficiency. Second, long version chains affect system access efficiency. To address the frequent random DRAM accesses during the GC collection phase, the partition clearing approach collects obsolete versions on a partition basis. However, this approach requires configuring partitions as relatively large DRAM regions, causing the version chains within each partition to continuously grow, which directly impacts the efficiency of accessing old versions. The third issue is the additional overhead of version chain consolidation. To address the version chain consolidation issue [21], the partition clearing approach builds a hash index for tuple versions within each partition. This process generates a large number of random small write operations [9,12]. On NVM, the cost of these small writes is significantly higher than on DRAM because the minimum write granularity of NVM is 256 bytes, compared to 64 bytes for DRAM, leading to write amplification on NVM. Additionally, NVM has lower write bandwidth and higher write latency than DRAM [22,23,24,25], making the large volume of small write operations a performance bottleneck.

Table 1.
Challenges of existing GC approaches in NVM OLTP engines and the TB-Collect solution.
To more intuitively understand the impact of GC on system performance, we designed a set of experiments to test the performance of the three approaches on DRAM and NVM OLTP engines (using the same platform as in the experimental section, with one using DRAM storage and the other using NVM storage). We used the TPCC workload with 100 warehouses and 40 concurrent threads (the number of logical cores on the machine). We set NoGC, which never performs garbage collection, as the baseline. The experimental results are shown in Figure 1, where the x-axis represents different systems and the y-axis represents the performance ratio compared to NoGC. Partition clearing (PC) achieves 88% of NoGC’s performance in the DRAM OLTP engine, while timely version chain pruning (TVCP) and background scanning (BS) achieves 79% and 83%, respectively. However, in NVM OLTP engines, their performance is only 56% to 68% of the NoGC’s.
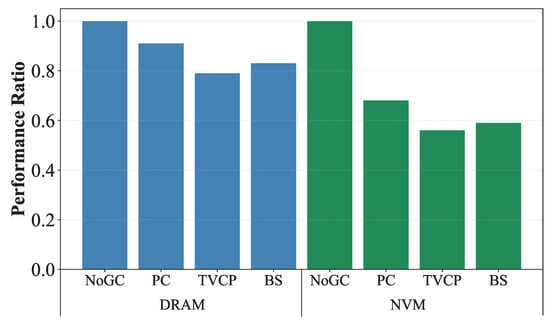
Figure 1.
Impact of garbage collection in NVM or DRAM OLTP engines.
In this paper, we propose a high-efficiency GC approach for NVM OLTP engines, called TB-Collect. It separates tuple headers from tuple contents to reduce writes to NVM. Instead of traversing version chains, TB-Collect reclaims obsolete versions in parallel at the block level using local threads. It also adopts a delayed version reclamation strategy to address the chain consolidation issue caused by long transactions. This design minimizes write amplification and significantly reduces garbage collection overhead and associated costs. Additionally, TB-Collect deploys an epoch mechanism to locklessly obtain the global minimum transaction, reducing contention among threads.
The contributions of this paper are as follows:
- We analyze and experiment with existing GC approaches in DRAM and NVM OLTP engines, discovering that those GC approaches are not well suited for NVM OLTP engines, and summarize the design directions for GC in NVM OLTP engines.
- We propose a garbage collection approach for NVM OLTP engines, TB-Collect, which does not require version chain traversal during reclamation, solves the problem of version chain merging caused by long transactions at a minimal cost, and significantly reduces writes to NVM.
- We implement TB-Collect on DBx1000 [26] and MySQL [27,28], including the GC algorithm and NVM storage, and we evaluate the performance in a real NVM hardware environment and five simulated NVM configurations. Experimental results show that TB-Collect improves transactional throughput by up to 1.58× compared to the existing methods.
2. Background and Motivation
In this section, we introduce the role of garbage collection in the MVCC OLTP engines, followed by an introduction to the various types of version storage in the NVM OLTP engine. We then present and discuss existing GC approaches and subsequently introduce our insights and challenges.
2.1. MVCC in NVM OLTP Engine
The NVM OLTP engine is an Online Transaction Processing database engine based on non-volatile memory. NVM features byte-addressability and data persistence across power failures, making it a bridge between DRAM and persist storage. The advantages of using NVM to build an OLTP engine are evident. In ideal scenarios, an NVM OLTP engine can achieve higher throughput and much faster recovery speeds compared to a DRAM OLTP engine. Additionally, its capacity limit can reach up to 6 TB [1,24]. However, current NVM still has some performance gaps compared to DRAM, including the following: (1) NVM has an IO size of 256 B, while DRAM has only 64 B, (2) NVM’s bandwidth is only one-third to one-half of DRAM’s bandwidth, and (3) NVM’s read performance is better than its write performance [1,9,12,22,23,24].
Multi-Version Concurrency Control (MVCC) is the mainstream concurrency control mechanism in the NVM OLTP engine, and most of NVM OLTP engines adopt this protocol. MVCC manages data by creating new versions for each write operation (insert or update), allowing read operations to proceed without waiting for write operations to complete, thereby improving system concurrency and performance while reducing lock contention [29,30]. Additionally, by leveraging the persistence of old versions in NVM, the system can achieve fast recovery when restarting [17,31,32,33,34]. However, using the MVCC protocol generates a large number of obsolete versions. If these invalid versions are not garbage collected, they will reduce space utilization and eventually lead to storage overflow. Garbage collection is more important in the NVM OLTP engine due to NVM’s persistence characteristics. Obsolete versions persist even after system reboot, becoming permanently unusable fragments if not cleared. A good garbage collection approach needs to efficiently reclaim garbage versions while minimizing the impact on the system. Leveraging the characteristics of version storage to design effective algorithms is key to improving garbage collection.
2.2. Version Storage
Before discussing GC approaches, we must understand how tuple versions are stored. In the MVCC DRAM OLTP engine, there are three types of version storage. The first is delta storage, the second is time-travel storage, and the third is append-only storage.
Delta storage separates the latest versions and old versions, storing them in main storage and version storage, respectively. When a tuple is modified, it is first copied and written to version storage, followed by an in-place update in the main storage [35,36,37]. Time-travel storage is similar to delta storage in that the latest versions and old versions are stored in main storage and version storage, respectively. The difference is that in version storage, old versions are arranged in an append-only manner, thus having a chronological order [38,39,40].
Both of these methods are not NVM write-friendly. We discuss this in two scenarios. The first scenario is where both main storage and version storage are placed in NVM. In this case, in-place updates in main storage lead to write amplification in NVM, and writing old versions to version storage increases the NVM write burden. The second scenario is placing main storage in NVM and version storage in DRAM. In this case, in-place updates in main storage still result in write amplification. Additionally, if old versions are stored in DRAM, any data in DRAM will be lost in the event of a power failure, rendering the NVM’s power-failure resilience useless for recovery purposes.
Only Falcon [12], among various NVM OLTP engines, adopts delta storage. It stores old versions in DRAM and uses the CPU’s persistent cache [41] for replaying logs during recovery. However, the multi-version storage in Falcon is merely a supplementary solution in its research. In large-scale data scenarios, storing the larger-sized old versions in DRAM and the smaller-sized latest versions in NVM clearly contradicts the design principles of an NVM OLTP engine.
Append-only storage stores both the latest versions and old versions in the same table heap. Whether it is an update or an insert, the system will append a new version at the end of the heap. This means that both updates and new inserts require only write-once, which is very beneficial for NVM, especially during batch updates, as it allows for sequential NVM writes. However, many current GC approaches do not fully adhere to the append-only principle. When recording obsolete versions, old versions still need to be marked, and these small write operations directly lead to write amplification in NVM. The details of GC are discussed in the following sections.
2.3. Garbage Collection Approaches
In a modern MVCC OLTP engine, garbage collection is an essential component. It not only cleans up obsolete versions, improving storage utilization and preventing storage overflow, but also avoids the performance degradation caused by accessing long version chains. However, GC itself consumes system resources. If too many resources are allocated, it can negatively impact the overall system performance. Conversely, if too few resources are allocated, GC may fail to promptly remove obsolete versions, leading to increased storage usage and eventual overflow. In this subsection, we discuss common GC approaches for MVCC OLTP engines for both DRAM and NVM.
2.3.1. Timely Version Chain Pruning
Currently, systems using this approach include Hekaton [2], Hyper [35], and Steam [19]. Among them, Steam has refined this approach. They design a garbage collection mechanism called Steam for the DRAM OLTP engine, utilizing transaction commits as the GC trigger. Initially, it traverses the local recycle queue, and for each old version in the queue, if it meets the recycling conditions (it can no longer be accessed by any active transaction), it is marked as obsolete and placed into the reuse list of the corresponding table. If the transaction contains version chain updates, and the old version meets the recycling conditions, it is immediately marked as obsolete and placed into the reuse list of the corresponding table. If the updated version does not meet the recycling conditions (it might still be accessed by other active transactions), it is placed into the local recycle queue. N2DB [42], an NVM OLTP engine, adopts this approach for garbage collection. The point of this approach is that all GC operations are completed within transactions, without using additional background threads, resulting in more stable latency for systems using this approach. Moreover, timely reclamation of obsolete versions minimizes the length of version chains, making it friendly for workloads with many long transactions, and mixed OLAP and OLTP workloads.
However, this approach has several shortcomings. First, it relies on traversing the version chain, and such random access operations can significantly impact system throughput. Second, it does not actually release storage space but instead manages obsolete versions by placing them into the reuse list. When reinserting tuples, elements in this list can cause significant contention, leading to performance degradation. Third, the fewer the operations in a transaction, the more frequent the GC, which increases the impact on the system. Since NVM’s random read/write performance is not as good as DRAM’s, the shortcomings of this approach are magnified in an NVM OLTP engine.
2.3.2. Background Scanning
Currently, systems using this approach include Peloton [20] and SAP HANA [38,43]. This approach divides GC into two phases. In the collecting phase, using the transaction ID, old versions that meet the recycling conditions are placed into the local recycle queue. In the cleaning phase, a background thread periodically scans the local recycle queue for obsolete versions and reclaims them, maintaining the reclaimed space using a reuse list. The point of this approach is that the space cleaning phase is periodically completed by a background thread, eliminating the need to traverse the garbage collection queue upon every transaction commit. This increases the efficiency of GC while also reducing the operations required for transaction processing. State-of-the-art NVM OLTP engines, including Zen [9] and Falcon [12], adopt this GC approach.
However, this approach has several shortcomings. Similar to the timely version chain pruning, background scanning also relies on traversing the version chain, although it shifts this task from transaction commit time to periodic background execution. Additionally, the reuse list also suffers from significant contention. Moreover, the background GC thread consumes system resources, leading to unstable throughput and higher latency during garbage collection. Due to the presence of many random read/write operations, this approach is also unsuitable for NVM OLTP engines.
2.3.3. Partition Clearing
The previously introduced GC approaches reclaim space at the tuple version granularity, resulting in numerous random accesses that significantly impact system performance. Reference [21] proposes a partition-based approach for garbage collection, called OneShotGC. As shown in Figure 2, OneShotGC employs delta storage, dividing DRAM into several partitions and storing old versions generated over a period within a specific partition. When all old versions in a partition become obsolete, the entire partition is released at once. The key feature of this approach is that it releases by partition instead of by tuple, completely avoiding the performance impact of traversing version chains during GC process. However, OneShotGC relies on delta or time-travel storage. To release a large contiguous DRAM at one time, it requires the latest versions and old versions to be stored in different table heaps.
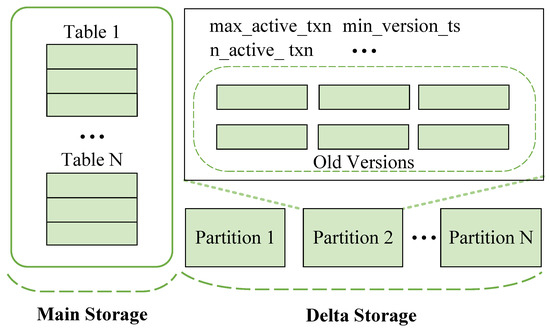
Figure 2.
Storage of OneShotGC.
However, when a tuple version may be accessed by a long-running transaction, the entire partition containing the previous version of that tuple cannot be released; otherwise, it would result in the loss of the version chain. In order to perform chain consolidation and access earlier tuple versions, OneShotGC uses a hashmap to build a version index for old versions in the partition. When intermediate versions are missing, the version index is used for access. While this approach might be feasible in DRAM OLTP engines, constructing and accessing the hash index involves numerous small writes, which can severely degrade the performance of NVM OLTP engines. Furthermore, OneShotGC must be bound to delta or time-travel storage. The separate storage of the latest and old versions is inherently less efficient for NVM reads and writes.
2.4. Challenge
Currently, the GC approaches used in the NVM OLTP engine are based on the three approaches mentioned earlier, but they do not effectively leverage NVM characteristics for design and optimization. We have decided to develop a specialized garbage collection mechanism for the NVM OLTP engine. We choose coarse-grained obsolete version collection to avoid extensive traversal of version chains and adopt an append-only storage mode to reduce NVM writes. The main challenges are twofold:
Firstly, the version chain traversal-based approach is impractical, while partition-based approaches require binding to delta or time-travel storage. Designing a mechanism that avoids version chain traversal and aligns storage layout with NVM GC mechanisms is a significant challenge. Secondly, OneShotGC uses hash indexes to perform chain consolidation. However, implementing this approach in the NVM OLTP engine increases NVM IO overhead, slowing down the entire system. Designing a mechanism to address this problem is also a challenge.
3. Related Work
3.1. Garbage Collection in Drive-Based Databases
GCaR [44] proposes a GC-aware replacement policy that prioritizes caching data blocks from flash chips undergoing GC, reducing contention between user I/O requests and GC-induced I/O requests, and improving overall storage performance. Harmonia [45] addresses SSD performance issues caused by GC conflicts with I/O requests, especially in RAID arrays with uncoordinated GC processes. It introduces a Global Garbage Collection (GGC) mechanism and an SSD-aware RAID controller to synchronize GC cycles, improving response times and reducing variability for bursty and write-heavy workloads. Reference [46] proposes a semi-preemptive GC scheme for NAND flash memory that pauses GC processes to handle pending I/O requests and pipelines GC operations with these requests, enhancing response times and reducing response time variance for write-heavy workloads. GC-ARM [47] introduces a scheme with a write buffer and an FTL (Flash Translation Layer) component to enhance SSD performance by improving GC efficiency and reducing address translation overhead. It also optimizes RAM space allocation based on workload randomness. Reference [48] presents a new GC approach combining Advanced Garbage Collection (AGC) and Delayed Garbage Collection (DGC), where AGC defers GC operations to idle times and DGC manages remaining collections, leading to significant reductions in GC overhead and more stable SSD performance. TTFLASH [49] reduces tail latencies caused by GC in SSDs using plane-blocking GC, rotating GC, GC-tolerant read, and GC-tolerant flush approaches, along with advanced technologies like powerful controllers and capacitor-backed RAM, and intra-plane copyback operations. CDA-GC [50] introduces a cache data management strategy that minimizes unnecessary data migration during SSD garbage collection, enhancing device performance and efficiency in data-intensive applications.
3.2. OLTP Engines for NVM
Besides the previously mentioned WBL [8] and Zen [9], there have been several OLTP engines based on NVM proposed before this. NV-Logging [6] adopts an append-only data page storage model on disk and stores indexes on disk as well. It maintains a page-granularity cache in DRAM. A logical log buffer is maintained in NVM, and background threads periodically replay the logs to persist record versions to disk. FOEDUS [7] stores tuple versions in snapshot pages on NVM and employs a page cache mechanism in DRAM. It maintains indexes in DRAM and executes transactions. Redo logs generated by transactions are periodically handled by background threads, and new snapshots are generated in NVM through a MapReduce-like computation process [51]. Hyrise [11] uses an append-only approach to write record versions into NVM and runs the index directly on NVM. It implements a series of optimizations for NVM-based indexing, including multi-version storage and support for parallel reads and writes. Falcon [12] is optimized for eADR-enabled NVM [41], leveraging persistent cache capabilities to perform in-place data updates on eADR-supported NVM. Redo logs are recorded in the persistent cache to reduce NVM writes, and the index is stored in NVM for fast recovery. For transaction processing, Falcon stores version information in DRAM to support Multi-Version Concurrency Control.
4. TB-Collect Design
In this section, we first present the layout of TB-Collect version storage and the internal architecture of its GC (Section 4.1 and Section 4.2). Then, we describe the GC process of TB-Collect (Section 4.3), long transaction processing, and chain consolidation (Section 4.4). Finally, we introduce TB-Collect’s GC approach after failure recovery (Section 4.5).
4.1. Tile-Block Append-Only Storage
Figure 3 illustrates the logical organization of tuple versions and the physical organization of data in DRAM and NVM in TB-Collect. Each table contains several tuples, each tuple containing several versions, which are connected by pointers in a new-to-old manner. Each tuple version consists of two parts: the tuple_header in DRAM and the tuple_content in NVM. Each tuple_content includes content data and a 64-bit txn_id representing the transaction generating the tuple_content. Every 1920 tuple_contents form a block. Each block maintains an update_map, a bitmap with a length of 240 bytes (1920 bits), aligned to the write size of NVM, where each bit corresponds to the position of a tuple_content in the block, and the value indicates whether the tuple version is obsolete. Additionally, there are 8-byte fields for max_txnid and min_txnid; the former indicates the transaction ID of the most recent update to a tuple version in the block, while the latter indicates the transaction ID when the tuple version was first inserted into the block.
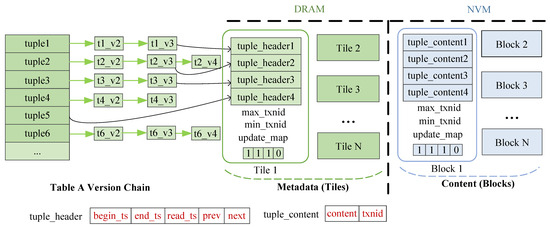
Figure 3.
Version storage of TB-Collect.
Due to the update_map, max_txnid, and min_txnid having a combined size of exactly 256 B, which meets the minimum write unit of NVM, updating these values can be achieved in a single NVM write. The tuple_header is the metadata for each tuple version, including begin_ts, end_ts, and read_ts for concurrency control, next pointing to the next version of the tuple, and prev pointing to the previous tuple version. Every 1920 tuple_headers form a tile. The Table_Mapping maintains the relationships between tiles and blocks. Each tuple version contains a logical address (tile_id/block_id, offset) that can be used to locate the physical position of each tuple version in DRAM or NVM. The storage of TB-Collect fully adheres to the append-only principle. Once tuple versions are written, they are not modified until they are cleaned up.
The tuple_headers in the tile are used for transaction processing, including the tuple’s start and end timestamps and version chain pointers. After a system crash recovery, the transaction IDs are reset to their initial values, and only one snapshot version remains. Therefore, the content in the tuple_headers does not need to be persisted and can be stored in DRAM. On the other hand, the tuple_contents in the block record the version data, which must be persisted to ensure database durability and are therefore stored in NVM. This separation between tile and block storage significantly reduces the NVM write amplification caused by small writes to the tuple_headers [9] and supports subsequent version chain consolidation strategies, making it much more efficient compared to similar strategies (see Section 4.4).
4.2. Internal Structure of GC
TB-Collect uses MVTO (Multi-Version Timestamp Ordering, an MVCC approach) as the concurrency control protocol. After a period of running time, a large number of obsolete versions will accumulate, which are mainly written by update and delete operations. As described earlier, a tuple version is stored in both a tile and a block. When it becomes obsolete, the corresponding locations in DRAM and NVM should be cleaned. Our cleaning granularity is at the tile/block level, meaning that when all or most data in a tile/block becomes obsolete, the entire tile and block are cleaned (For the impact of long transactions on garbage collection, see Section 4.4). When the system crashes and recovers, all tuples are the latest versions, and the tuple_header in the tile is initialized, so there is no need to clean the data in the tile, but rather the data in the block.
The entire internal structure of the GC is shown in Figure 4. The global epoch manager maintains a global timer that increments by 1 every 40 ms. Each thread obtains the current epoch from the global epoch manager when starting a new transaction, referred to as the local_epoch. The local_epoch_min represents the minimum value of all current local_epochs, and no txn_id will be earlier than the time represented by local_epoch_min. Each thread manages a gc_pending_queue and a local_gc_queue, with the former holding the logical addresses of tiles/blocks that will become obsolete and the latter holding the logical addresses of obsolete tiles/blocks. The local_gc_queue_frozen contains logical addresses of tiles/blocks ready for collection.
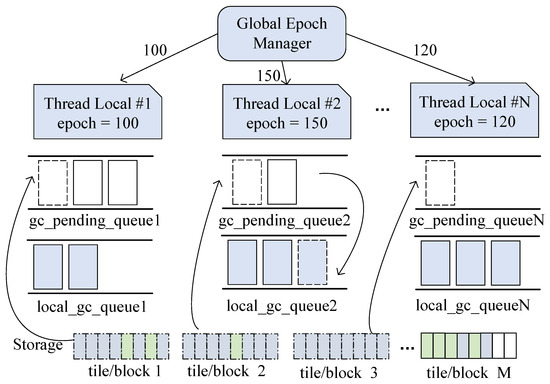
Figure 4.
GC structure of TB-Collect.
The epoch mechanism significantly reduces contention on the last Commit ID. Traditional methods require threads to frequently access and update the last Commit ID, leading to performance bottlenecks in high-concurrency scenarios [2,52,53,54]. The epoch mechanism, however, manages time through a global timer, eliminating the need for frequent synchronization of transaction states. Threads only need to read the current epoch at the start of a transaction, and subsequent operations use the local maintained time information, avoiding contention between threads. Additionally, the logical timestamp ordering of the epoch mechanism simplifies the conditions for garbage collection and improves the execution efficiency of concurrent transactions, especially in multi-core systems, where hardware advantages can be fully utilized.
4.3. Garbage Collection Processing
In MVTO, each tuple version has a lifecycle. The begin_ts represents the time it is created, and the end_ts represents the time it is deleted or when its next version is created. When the end_ts is infinite, it indicates that the tuple version is the latest version. If an active transaction (uncommitted) has a txn_id greater than a tuple version’s end_ts or less than its begin_ts, then that tuple version is invisible to the transaction. When a tuple version is invisible to all active transactions, it becomes obsolete and can be reclaimed by garbage collection. In TB-Collect, we perform reclamation at the tile/block level. When the proportion of obsolete tuple versions in a tile/block exceeds a certain threshold, the tile/block is considered obsolete and can be reclaimed. Based on multiple experiments, we set to 90%. In the GC process, each thread adds the logical addresses of obsolete tiles/blocks into its own local_gc_queue. Once the queue reaches its capacity, the thread triggers the reclamation process to clean the corresponding data regions. To balance reclamation frequency and memory overhead, we set the total capacity of all local_gc_queues to 15% of the current data volume, an empirically determined value. This quota is evenly divided among all threads, ensuring balanced GC workloads. Such a uniform per-thread setting simplifies implementation and maintains consistent GC behavior across threads.
Transaction Execution and Obsolete Block Collection. Figure 5 shows the obsolete block marking process during the execution of transaction Txn 200, as well as the reclamation process of obsolete blocks after the transaction is committed. This transaction consists of a simple update statement. First, when the transaction begins (step 1), it reads the tuple version from tile 1 and sets the end_ts in the tuple_header of the tuple version to the current txn_id, marking the time when the tuple version becomes an old version. Note that at this point, the old version is not yet obsolete, as the transaction may fail to commit and roll back. Next, the tuple version is marked as 1 in the update_map, and the max_txnid of the tile/block containing the tuple version is updated to the current txn_id (step 2). The max_txnid indicates the most recent modification time of the block. This process is NVM cache-aligned and requires only one NVM write. If the number of 1 in the update_map exceeds , meaning that old versions in the tile/block account for more than , the block becomes eligible for reclamation. However, the tile/block 1 cannot be immediately added to the local_gc_queue because the transaction is still executing, and the tile/block 1 is not yet obsolete. To address this, we designed a buffer queue called the gc_pending_queue, which is maintained and exclusively owned by each thread. The logical address of the tile/block is added to the gc_pending_queue. Meanwhile, the gc_pending_queue is scanned, and blocks that have become obsolete, i.e., those with block.max_txnid less than local_epoch_min, are dequeued and moved to the local_gc_queue (step 4). The local_gc_queue is also thread-bound to the corresponding transaction. A block in the local_gc_queue indicates that the number of obsolete tuple versions within it exceeds and is ready for cleanup and reclamation.
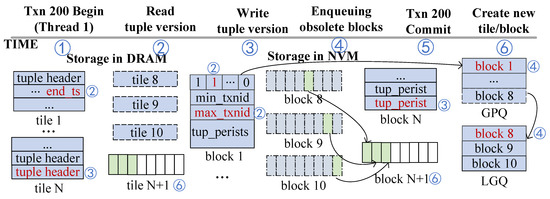
Figure 5.
GC process of TB-Collect.
Obsolete Block Cleanup and Reclamation. In this phase, after Txn 200 is committed, the transaction thread checks its maintained local_gc_queue. If the local_gc_queue is full, the thread enters GC mode. The address of the local_gc_queue is assigned to thread.local_gc_queue_frozen, and a new queue is created with its address assigned to local_gc_queue. Subsequently, for each block in local_gc_queue_frozen, the latest versions are quickly retrieved based on the offsets in the update_map (a value of 0 in the update_map indicates that the corresponding tuple version has never been modified) and are inserted into the new (block N + 1) (step 6). Finally, all DRAM and NVM spaces corresponding to the tiles/blocks in local_gc_queue_frozen are released.
Compared to traditional GC approaches, TB-Collect offers several irreplaceable advantages: Firstly, by using an append-only storage approach and reclaiming obsolete tuple versions at the tile/block level, TB-Collect minimizes NVM writes. This approach allows for the reclamation of obsolete tuple versions without traversing the version chain, thus avoiding a large amount of random DRAM access and the unlinking of version chain pointers and significantly speeding up the reclamation process. Secondly, there is no need for additional background threads to perform GC. Instead, GC tasks are distributed across each execution thread. Since our GC operates at the tile/block level and only starts when the local_gc_queue reaches a certain size, the GC frequency is not affected by changing transaction size. Thirdly, during reclamation, NVM space is directly released, effectively avoiding the extra overhead associated with managing and allocating fragmented space. Fourthly, the use of the epoch mechanism effectively reduces contention issues. Traditionally, obtaining each transaction’s txn_id and calculating the minimum txn_id would slow down the system’s operation due to the high transaction throughput (millions of transactions per second) constantly changing the minimum txn_id. By using the epoch mechanism, we significantly reduce the update frequency of local_epoch_min, thereby decreasing contention.
4.4. Long Transaction and Chain Consolidation
Although coarse-grained GC approaches (recycling blocks or partitions) have advantages such as not needing to traverse version chains or manage reclaimed space, there is an unavoidable issue. When long transactions occur in the system, recycling may inadvertently reclaim intermediate versions of some tuples, leading to version chain break. We call the process of resolving this issue “Chain Consolidation”. OneShotGC constructs a hash index for versions that cannot be accessed through the version chain. Although this approach effectively solves the problem, it is inefficient. TB-Collect leverages the features of tile/block storage separation and designs a delayed clean algorithm that achieves chain consolidation with almost no additional overhead. It also provides a GC solution for long transactions.
When long transactions occur in the system, following the approach in Section 4.3, which recycles only if max_txnid is less than local_epoch_min, will result in long periods without GC. Even though there are long-running uncommitted transactions in the system, some tiles/blocks can still be reclaimed. Figure 6 illustrates such a case. In local thread 2, the gc_pending_queue contains a tile/block with min_txnid = 55 and max_txnid = 150, while the current local_epoch_min = 50 and local_epoch_sec_min = 200. In this situation, since tile/block K will not be accessed by any active transaction, it should be added to the local_gc_queue for recycling. However, once tile/block K is reclaimed, a new issue arises. If an intermediate version of a tuple is in tile/block K, its version chain will be broken, causing the long transaction (in local thread 1) to be unable to access the older version of the tuple.
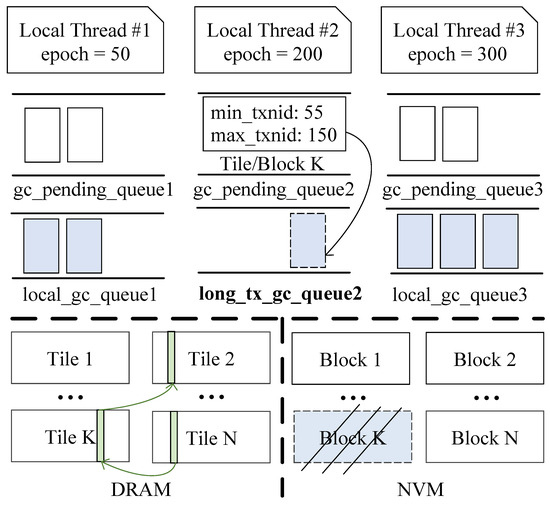
Figure 6.
One case for chain consolidation.
In TB-Collect, for TPCC data of 2000 warehouses (140 GB), the size of tiles is only 37 GB, while blocks are 148 GB. Assuming a workload with 20% long-running write transactions and 80% short write transactions, with uniform access distribution, approximately 20% of obsolete tuple versions are blocked by long transactions and cannot be reclaimed, approximately 7.4 GB of tiles in DRAM and 29.6 GB of blocks in NVM. The proportion of DRAM to be reclaimed is only one-fourth of NVM. However, the long-running transactions in TPCC are stock-level transactions, accounting for only 4% of all transactions, thus the size of tiles they affect is even smaller. Therefore, thanks to our design of separating tuple headers and tuple contents, when the conditions of the case in Figure 6 are met, we retain the header information in the tiles and only reclaim the blocks. We dequeue tile/block K from the gc_pending_queue2, which is blocked by long transactions, and place it into the long_tx_gc_queue2 of local thread 2. When the long_tx_gc_queue2 is full, we reclaim the blocks within it while retaining the tiles. This way, we avoid the complex operation of constructing a hash index for missing versions. By sacrificing a bit of DRAM space, we ensure smooth access to version chains, successfully reclaim space blocked by long transactions, and significantly improve the overall system efficiency.
The process of collecting obsolete tiles and blocks, as well as the technical principles for handling long transactions, is as follows. For a block K where the number of obsolete tuple versions reaches , it is handled based on three scenarios: First, if the ID of the smallest active transaction Txn Min is greater than the max_txnid of block K, then the block can be reclaimed. Second, if there exists an active transaction Txn L whose ID is smaller than the min_txnid of block K, and the IDs of all other active transactions are outside the range of min_txnid to max_txnid, then it indicates that Txn L is a long transaction. Moreover, none of the active transactions will access the data in block K. In this case, a part of the corresponding DRAM tile of the block can be retained to preserve the integrity of the version chain, and the block itself can be directly reclaimed. When the ID of Txn Min becomes smaller than the max_txnid of block K, the block can be reclaimed later. Third, if there exists an active transaction whose txnid falls within the range of min_txnid to max_txnid of block K, it indicates that the data in block K may still be accessed by active transactions, and thus block K will not be reclaimed.
The complete algorithm for obsolete tile and block collecting, as well as handling long transactions, is detailed in Algorithm 1. Initially, if the percentage of bits set to 1 in the update_map exceeds , the current block is placed in the local thread’s pre-recycling queue thread.gc_pending_queue (line 4). The algorithm then traverses thread.gc_pending_queue, and for each block, if the earliest active transaction is later than the most recent write transaction in the block (local_epoch_min is greater than block.max_txnid), the block is added to thread.local_gc_queue (line 9). If the earliest active transaction is earlier than the first write transaction in the block (local_epoch_min is less than block.min_txnid), further checks are performed: If the second earliest active transaction is later than the most recent write transaction in the block (local_epoch_sec_min is greater than block.max_txnid), it indicates the presence of a long transaction (the transaction corresponding to local_epoch_min). The block is then added to the long transaction recycling queue thread.long_tx_gc_queue, and the transaction is marked as a long transaction (lines 15, 16). If local_epoch_sec_min is less than block.min_txnid, the process iterates to the third smallest value, and so on. When a long transaction is identified, the block is placed in thread.long_tx_gc_queue, and the transaction is marked as a long transaction (lines 12 to 19).
After a transaction commits, we perform the following three steps to clean obsolete tiles and blocks, as shown in Algorithm 2: (1) If the just-ended transaction is a long transaction, we scan the long_tx_gc_queue of all threads. For each block in the long_tx_gc_queue (lines 3, 4): If block.max_txnid is less than local_epoch_min, we add the block to thread.local_gc_queue (lines 6, 7). (2) If thread.long_tx_gc_queue is full, we reclaim the blocks within it, release the storage space in NVM, and retain the tile in DRAM (lines 8 to 11). (3) If thread.local_gc_queue is full, we assign its address to thread.local_gc_queue_frozen. Each block in local_gc_queue_frozen will undergo the following process (line 12): For each tile/block, quickly obtain the latest version based on the offset in block.update_map (unmodified version) and insert them into the new block N + 1. Finally, each tile/block’s logical address in local_gc_queue_frozen is traversed to locate the metadata in DRAM associated with the tile, including update_map and tile_header. These metadata are directly removed from DRAM, and any related data in the cache are invalidated to ensure that subsequent accesses do not reference the already-released DRAM space. Meanwhile, the block’s logical address is used to locate the corresponding physical address range (start_addr and size). This range is marked as available and added to the free block list in the NVM space manager (lines 16 to 24).
Owing to the separation of tile and block in TB-Collect, the version chain information, which occupies less space, can be fully stored in DRAM, while the tuple content in the block can be garbage collected without breaking the version chain. Compared to OneshotGC, our method has significant advantages. OneshotGC constructs a large hash index for each partition to query versions with broken version chains, which includes data from all tables. In contrast, TB-Collect does not require such a heavy operation; it only needs to directly reclaim the tuple content in NVM, and after long transactions end, it will reclaim the tuple header in DRAM. Additionally, due to the small size of blocks in TB-Collect, it avoids the issue in OneshotGC, where large regions (typically dozens of GB of partitions) must wait for long-running transactions to finish before garbage collection can proceed. This leads to more efficient garbage collection in TB-Collect.
| Algorithm 1: Collect obsolete block function. |
 |
| Algorithm 2: Clean obsolete block function. |
 |
4.5. GC After Recovery
When the system crashes, all ongoing operations will be terminated, including GC. Unlike DRAM-based OLTP engines, the NVM OLTP engine stores data in NVM, including data that are about to be or are currently being reclaimed. These data are not lost during a power failure and remain in NVM when the system restarts. Therefore, it is necessary to continue the GC work that was in progress before the crash during recovery.
In TB-Collect, since tiles are stored in DRAM, data are lost after a crash. Upon recovery, only the latest tuple version of all tuples in the tile will be retained. At this time, NVM may still contain obsolete blocks that have not been reclaimed. We use the status of each thread’s local_gc_queue_frozen to determine the state of reclamation before the crash, as shown in Algorithm 3. There are two main scenarios: (1) If local_gc_queue_frozen is empty, it indicates that the local thread has not yet executed GC, and the size of the local_gc_queue has not reached the threshold for reclamation. Therefore, there is no need to consider GC during system recovery (lines 4, 5). (2) If local_gc_queue_frozen is not empty, it indicates that the local thread was executing GC when the system crashed. In this case, we re-execute the GC during recovery, skipping the blocks that have already been cleaned (lines 6 to 13).
| Algorithm 3: GC after recovery function. |
 |
5. Evaluation
In this section, we evaluate the impact of GC on the entire system from dimensions such as concurrency scale, write ratio, transaction size, and write skewness (ZipF). We also conduct in-depth analysis on chain consolidation performance, efficiency of space reclamation, and average version chain length. Subsequently, we assess the performance of various GC approaches in a real commercial database system. The experiments are conducted using real NVM hardware as well as several simulated NVM configurations.
5.1. Experimental Setup
Infrastructures. Experiments are conducted on a server equipped with an Intel Xeon Gold 5218R CPU (Intel Corporation, Santa Clara, USA) with 20 physical cores @ 2.10 GHz and 27.5 MB LLC, and 256 GB DDR4 DRAM (Samsung Electronics, Suwon, South Korea), running Ubuntu 20.04.3 LTS. Each core supports two hardware threads, resulting in a total of 40 threads. The system includes 768 GB (128 × 6 GB) Intel Optane DC Persistent Memory NVDIMMs (Intel Corporation, Santa Clara, USA) [1]. Intel Optane PM supports two accessibility modes: Memory Mode and App Direct Mode. We choose App Direct Mode for easy mapping of DRAM and NVM into the same virtual address space. File systems are deployed in fs-dax mode on NVM, and libpmem from PMDK is used to establish mappings between NVM files and a process’s virtual memory. To ensure data persistence to NVM, clwb and sfence instructions are utilized. The entire codebase is developed in C/C++ and compiled using gcc 7.5.0.
To eliminate interference from modules such as transaction management and query processing and achieve the goal of controlling variables, we choose DBx1000 [26] as the runtime platform for the mentioned GC approaches. DBx1000 is a DRAM database prototype that uses a row-oriented format and includes methods of concurrency control, as well as integrating common benchmark suites. We implement the GC approaches and replace DRAM with NVM for storing content data, and we use MVCC for their concurrency control. Additionally, we import libpmem within PMDK to support NVM read and write. In order to further ensure the reliability of the experimental results, we perform each experiment more than 10 times. We discard the highest and lowest values, and use the average of the remaining data points.
Control Groups. The control groups for our experiment include NoGc, TB-Collect, OneShot, Steam, Zen, and N2DB, as shown in Table 2.
Table 2.
GC approaches used in various NVM OLTP engines.
NoGC: DBx1000 with NVM append-only storage, without garbage collection, used as a baseline.
Steam: A version of DBx1000 that implements Steam [19], adopting timely version chain pruning with append-only NVM storage.
OneShot: A version of DBx1000 that implements OneShotGC [21], adopting partition clearing with delta NVM storage.
Zen: A version of DBx1000 that implements Zen’s garbage collection approach [9], adopting background scanning with append-only NVM storage.
N2DB: A version of DBx1000 that implements N2DB’s garbage collection approach [42], adopting timely version chain pruning with append-only NVM storage.
TB-Collect: A version of DBx1000 that implements the garbage collection approach described in this paper.
Workloads. We utilize two benchmarks, YCSB [55] and TPCC [56], to evaluate our system.
YCSB (Yahoo! Cloud Serving Benchmark) is a commonly used key-value benchmark tool designed to assess the performance of database and storage systems under read and write workloads. It allows for a variety of workload characteristics through configurable parameters. These parameters include the number of requests in each transaction, the proportion of read, write, and read–modify–write (RMW) requests, and the skew factor that determines the distribution of requested keys in the ZipF distribution. In our experiments, the YCSB contains a single table and the size of every tuple version is 100 bytes with an 8-byte primary key.
TPCC (Transaction Processing Performance Council Benchmark C) is a benchmark for transaction processing performance. It is a database performance testing standard defined and maintained by the Transaction Processing Performance Council (TPC). TPCC is primarily used to simulate and evaluate the performance of database systems under high transaction loads with multiple users. It includes nine tables designed to emulate an online order processing application and involves five mixed transactions: Neworder (45%), Payment (43%), Ordstat (4%), Delivery (4%), and StockLevel (4%).
5.2. TPCC Experiments
Throughput. To evaluate the throughput of TB-Collect and other approaches in real transactional scenarios, we conduct tests using the TPCC workload. We set the TPCC data size to 500 warehouses. The experimental results are shown in Figure 7a, where the x-axis represents different engines, and the y-axis represents the throughput ratio of each engine to the baseline (where we consider the NoGC as the baseline). We observe that TB-Collect achieves approximately 91% of the baseline, making it the best performer among all systems with GC. Following TB-Collect, Zen achieves 75% of the baseline performance with GC enabled. The performances of N2DB and OneShotGC are relatively close, reaching 66% and 68% of the baseline, respectively. Steam shows the worst result, achieving only 63% of the baseline performance.
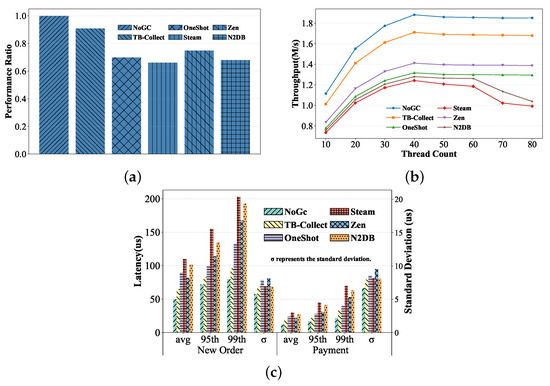
Figure 7.
TPCC performance. (a) Performance ratio on TPCC. (b) Scalability on TPCC. (c) Latency on TPCC.
Scalability. We also test the scalability of various GC approaches under the TPCC workload. The experimental results are shown in Figure 7b, where the x-axis represents the number of threads ranging from 10 to 80, and the y-axis represents the throughput of TPCC under each thread, measured in millions per second. As the number of concurrent threads increases, the throughput of all systems increases. When the number of concurrent threads exceeds the logical cores, the throughput of NoGC, TB-Collect, and OneShotGC no longer increases and remains stable. However, the performance of Steam, Zen, and N2DB starts to decline and then stabilizes, with Steam experiencing the worst drop, about 79% of its peak value.
Latency. As shown in Figure 7c, NoGC exhibits the best performance in system latency. TB-CollectC shows the second-best performance in terms of response time, with average latencies in the NewOrder and payment transactions approximately 1.3× and 1.6× those of NoGC, respectively. However, its response time is highly stable, with standard deviations of 6.85 us and 7.92 us, because it does not require scanning the version chain during garbage collection (GC), and the append-only write method is also NVM-friendly. Zen performs well in average latency but poorly in 99th percentile latency, with the maximum difference between the average and 99th percentiles reaching 2.4×. Zen also has the worst latency stability among all systems, with response time standard deviations of 8.13 us and 9.48 us, due to the frequent scanning of the version chain during GC, which increases transaction latency. Moreover, GC is completed by background threads. OneShotGC shows a small difference between the average and 99th percentiles, as it releases memory globally during GC. However, due to the high overhead of building hashmap indexes for the version chain, its average latency is higher than TB-Collect, with the average latency of the NewOrder transaction being about 1.26× that of TB-Collect. Steam and N2DB exhibit the worst response times in all systems, but their response times are very stable, with standard deviations similar to TB-Collect. Both Steam and N2DB need to frequently scan the version chain during GC; however, most of their GC work is accomplished by the transaction execution thread at the time of transaction commit. As a result, both systems have long response times but very small standard deviations.
5.3. YCSB Experiments
In this evaluation, we use the YCSB workload to evaluate the impact of the garbage collection module on different systems. To assess the performance of various garbage collection methods in several common scenarios more deeply, based on previous studies [19,21] and the analysis in this paper, we have set up four controllable variables: the proportion of write operations in transactions, the write skew ZipF [57], the number of concurrent threads, and the transaction size. First, as the proportion of write operations in a transaction increases, garbage collection is more likely to be triggered. By controlling the write proportion, we can evaluate the impact of the garbage collection module on the system under high load. Second, the higher the ZipF skew, the more concentrated the range of read and write operations will be. By controlling ZipF, we can evaluate the efficiency of garbage collection in reclaiming obsolete tuple versions for both hotspots and non-hotspots. Third, as the number of concurrent threads increases, the read and write pressure on the system also increases. By controlling the number of concurrent threads, we can evaluate the performance trend of each system under different levels of concurrency when garbage collection is enabled. Fourth, as the transaction size increases, the total number of operations executed per unit of time also increases, causing versions to expire faster, thereby increasing the frequency of garbage collection. By controlling the transaction size, we can indirectly evaluate the impact of garbage collection on the system. In the following experiments, we adopt the method of controlling variables, where only one dimension is varied while the others are kept constant to ensure the accuracy of the results.
Scalability and Write Proportion. We control the transaction size to be 20 to prevent Steam from performing GC too frequently and set the ZipF parameter () to 0 to ensure an evenly distributed access rate for each tuple. We vary the number of concurrent threads and obtain the throughput of each system. As illustrated in Figure 8, subplot (a) represents 50% read and write, while subplot (b) represents 100% write operations. Then, to further explore the performance of these GC approaches under mixed read–write workloads, we set the concurrent threads to 40, ZipF parameter () to 0, and transaction size to 20. We vary the write/read percentage and obtain the throughput ratios of each GC system compared to NoGC, as illustrated in Figure 8c.
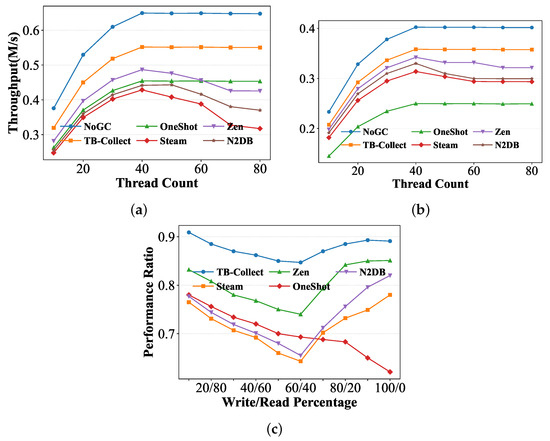
Figure 8.
YCSB performance with thread count and read–write percentages: (a) 50% writes, (b) 100% writes, (c) varying read–write percentages.
First, with a 50% read/write ratio, as the number of threads increases, the throughput of each system also increases, reaching its peak when the number of threads matches the logical cores. TB-Collect consistently performs best after NoGC, achieving approximately 85% of NoGC’s throughput. Notably, when the thread count exceeds the logical cores, Steam, Zen, and N2DB experience some performance degradation. This is because as the number of concurrent threads exceeds the logical core count, the surplus threads cannot be allocated sufficient resources and contend for CPU cache access. When cache contention is intense, cache hit rates drop, leading to increased NVM access latency. Steam, Zen, and N2DB GC frequently perform random NVM accesses during version chain traversal, so decreased cache efficiency directly impacts their performance. In contrast, OneShotGC and TB-Collect remain stable since they do not traverse the version chain during GC.
Second, with a 100% write ratio, all GC approaches perform similarly, achieving approximately 80% of NoGC’s throughput, except for OneShotGC. This is because when the write ratio is very high, the system bottleneck shifts from GC to NVM bandwidth, and different GC approaches have little impact on performance under high concurrency and high write scenarios. OneShotGC performs worst in this scenario because, unlike the append-only storage used by other systems, it uses the delta storage.
Third, to further validate the results in Figure 8b and explore the performance of these GC approaches under mixed read–write workloads, we design a set of experiments. While keeping other parameters unchanged, we control the total read–write percentage to 100%, starting with 10% writes and 90% reads, and reduce the read ratio by 10% while increasing the write ratio by 10% in each step, until reaching 100% writes. As shown in Figure 8c, we obtain the throughput ratios of each GC approach compared to NoGC. The experimental results show that as the write percentage increases in the workload, TB-Collect’s advantage over other systems becomes more apparent. When the transaction consists of 60% writes and 40% reads, TB-Collect’s advantage peaks, with throughput 10.2% to 20.3% higher than other systems. When the write percentage exceeds 80%, TB-Collect still maintains a performance advantage over other systems, but the performance of most systems, except for OneShot, gradually converges. This is because, in scenarios with a high write load, the bottleneck of each system gradually shifts to NVM writes, which limits the full potential of TB-Collect’s garbage collection advantages. On the other hand, OneShot’s performance degradation is more significant due to its use of Delta storage, which is detrimental to NVM writes.
Write Skew Rate. We set the transaction size to 20 to avoid Steam performing GC too frequently and set the thread count to 40 to ensure it does not exceed the logical cores. We vary the ZipF parameter . As shown in Figure 9, without GC, the larger the , the higher the throughput. This is because transactions read and write to a small portion of data, resulting in a high cache hit rate in the L3 cache. However, in some GC approaches, the larger the write skew, the greater the contention between GC and transactions for tuple versions, and the faster versions become obsolete, further increasing GC frequency. Consequently, the effect of throughput improvement on them is not significant.
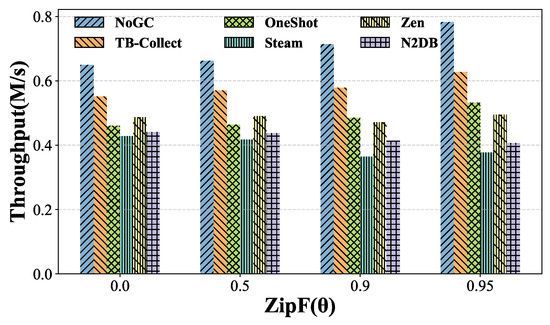
Figure 9.
YCSB performance with varying ZipF distribution.
Among all the GC approaches tested, TB-Collect consistently performs best. With 50% writes, its performance reaches 86% of NoGC at = 0.5 and 81% at = 0.9 in high contention mode, while Steam only achieves 63% and 51%, respectively. This is because Steam needs to traverse the version chain during GC, and higher GC frequency results in more frequent cache evictions, reducing cache hit rates during transactions. Notably, the increase in does not significantly negatively impact OneShotGC. On the contrary, its performance improves due to higher cache hit rates, maintaining around 70% of NoGC. However, its performance is limited to 70% of NoGC because it must be bound to a delta storage, which is not suitable for NVM.
Transaction Size. We set the number of threads to 40, ensuring that they do not exceed the logical cores. We set for zipF to 0 to exclude its interference and ensure uniform tuple access. The ratio of write/read transactions is 50%. We control the variation in transaction size (number of operations per transaction). Solid lines represent transaction throughput changes, scaled by the left y-axis, while dashed lines represent total operations changes, scaled by the right y-axis. As shown in Figure 10, as transaction size increases, undoubtedly, the throughput (transactions executed per second) of all systems decreases, while total operations initially increase and then decrease. On the one hand, increasing transaction size reduces concurrency control pressure, such as avoiding frequent creation and destruction of transaction contexts, reducing various judgments during transaction dispatch, and reducing thread scheduling, thus increasing total operations. On the other hand, as total operation count increases, versions expire faster, increasing GC frequency, while the impact of concurrency control gradually decreases, leading to a decrease in total operations.
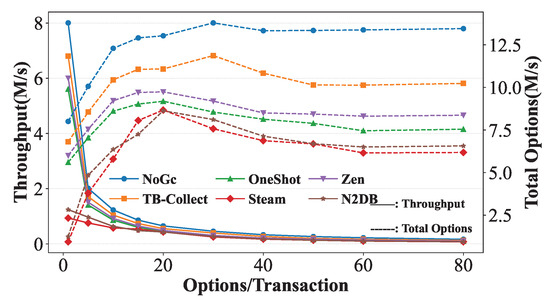
Figure 10.
YCSB performance with varying transaction sizes.
Among the GC approaches, TB-Collect performs the best, reaching 85% of NoGC’s throughput at an operation count of 20, with total operations declining most slowly after reaching peak values except for NoGC. It is worth noting that Steam and N2DB initially have low transaction throughput but show the most significant growth in total operations. This is because they perform GC upon transaction commit; smaller transaction sizes lead to more frequent GC. In contrast, TB-Collect, Zen, and OneShotGC perform GC checks upon transaction commit, initiating GC work only when obsolete tuple versions reach a threshold.
5.4. Chain Consolidation Performance
In this evaluation, we evaluate the performance of chain consolidation within various GC approaches, using YCSB as the benchmark. The GC approaches based on version chain scanning do not impose additional overhead when performing chain consolidation. We specifically compare the designs for chain consolidation in TB-Collect and OneShotGC. To achieve this, we implement the hash index of OneShotGC in TB-Collect, named TB-Collect-hash, which is used to access old versions. We set up two experimental scenarios:
Scenario 1: Set the ZipF parameter to 0.9, with all transactions having a size of 10, and a 50% write/read ratio. The ZipF distribution and concurrent threads ensure frequent GC, while the short transactions reduce the chance of chain consolidation.
Scenario 2: Set the ZipF parameter to 0.9, with 90% of transactions having a size of 10 and 10% of transactions having a size of 100, and a 50% write/read ratio. The ZipF distribution and concurrent threads ensure frequent GC, and the mixed load of long and short transactions increase the chance of chain consolidation.
By comparing the performance in these two scenarios, we can determine the efficiency of each GC approach in terms of chain consolidation. As shown in Figure 11, the solid line represents Scenario 1, and the dashed line represents Scenario 2. In the scenario with frequent GC but infrequent chain consolidation, as the number of threads increases, the performance of both TB-Collect and TB-Collect-hash increases and stabilizes, with their peak values reaching approximately 81% of NoGC. However, in the scenario with frequent GC and frequent chain consolidation, the performance of TB-Collect-hash is significantly lower than that of TB-Collect, achieving only 69% of NoGC at 40 threads, while TB-Collect reaches 79%.
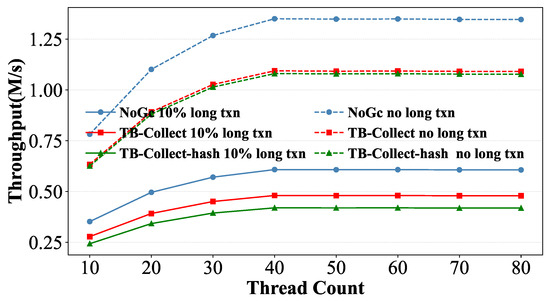
Figure 11.
Performance of Two Version Chain Consolidation Approaches.
In summary, under the same storage layout and GC approach, the overhead of constructing and maintaining hash indexes to access old versions is substantial. TB-Collect temporarily retains the version chain of long transactions in DRAM while immediately reclaiming the version content in NVM. This approach achieves the purpose of reclamation while avoiding unnecessary GC overhead.
5.5. Garbage Collection Performance
In this evaluation, we first use TPCC as our workload to better simulate real-world scenarios, testing the efficiency of space reclamation and performance changes over time. Then, we use YCSB with a 50% read and 50% update workload to conduct an in-depth evaluation of various GC approaches, focusing on the average tuple version chain length and the average number of accesses per tuple version after a period of operation.
Efficiency of Space Reclamation. Figure 12 shows the increase in NVM and DRAM storage for various GC approaches after running the TPCC workload for 10 min. To ensure fairness, we control each system’s throughput at 500 k transactions per second, with an initial warehouse size of 200 (14 GB). It can be observed that TB-Collect and Zen exhibit greater increases in DRAM usage, with the former storing tuple headers in DRAM and the latter actively caching portions of tables in DRAM. However, TB-Collect shows the smallest total increase in DRAM and NVM space compared to other GC approaches, ranging from 77% to 46%. This is due to two reasons: Firstly, TB-Collect recycles on a tile/block basis, completely releasing the occupied NVM and DRAM space, while Zen, Steam, and N2DB recycle on a tuple version basis, reusing released space without freeing it. Secondly, although OneShotGC also fully releases an NVM or DRAM area at once, it does so on a very large scale, typically waiting until the entire partition becomes obsolete before freeing space, thus unable to achieve timely reclamation.
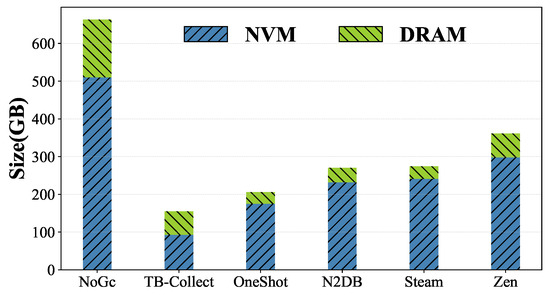
Figure 12.
Space size increase over 10 min.
Impact of Garbage Collection. We evaluate the impact of GC on the system while it is running. We control the system to run TPCC and record the throughput per second. As shown in Figure 13, with 40 concurrent threads and an initial warehouse count of 200, the x-axis represents time from 0 to 200 s, and the y-axis represents throughput. Before 150 s, the NoGC system, with the GC module turned off, exhibits the best stability and throughput. However, after 150 s, NoGC experiences a decrease in both performance and stability, while other systems with GC continue to maintain their previous performance. Over the entire process, NoGC has a throughput standard deviation of 0.035 M/s, which is worse than Steam and N2DB. This is because, in NoGC, the number of old versions increases, leading to a decrease in the efficiency of traversing long version chains.
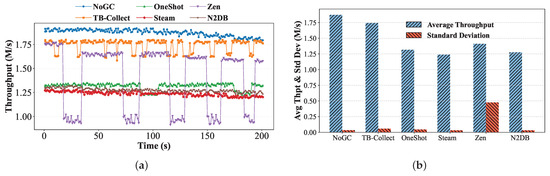
Figure 13.
System stability over time with various GC approaches. (a) Throughput over 200 s. (b) Throughput and standard deviation.
Steam has the worst throughput among all systems, with an average throughput of only 70.1% of TB-Collect. However, its stability is the best of all systems, with a throughput standard deviation of 0.032 M/s. This is because Steam does not have an additional GC thread; instead, the local thread performs GC checks and recovery during commit. N2DB’s design is similar to Steam’s, but with some optimizations in NVM writes, resulting in better performance than Steam. TB-Collect has the second-highest throughput, only trailing NoGC. It performs the best among all systems with GC enabled. Despite having less stability than Steam, N2DB, and OneShotGC, with a throughput standard deviation of 0.058 M/s, its average throughput is much higher, about 1.23× to 1.40× that of the other systems. Zen is the most unstable, as its GC is performed by a background thread. It is worth noting that over time, the throughput of Steam, N2DB, and Zen shows an overall decreasing trend. This is because they do not fully release the space of obsolete tuple versions but instead reuse this space. As the reused space accumulates, the competition for allocation increases, leading to a decline in throughput.
Version Chain Length and Access Frequency. We use YCSB with a workload of 50% reads and 50% updates, setting the ZipF parameter to 0 to ensure uniform data access. The initial dataset consists of 5 million tuples. Since the workload comprises only reads and updates, the number of tuples remains constant, but the number of versions increases over time. We observe the average version chain length and the average number of accesses per tuple across different systems over a given period. The average version chain length reflects the efficiency of GC in reclaiming space and influences the ease of accessing historical versions. A longer version chain indicates lower GC space reclamation efficiency and reduced read performance. The average number of accesses per tuple is calculated as the total number of accesses across all versions divided by the total number of tuples. This total access count includes regular read and write operations as well as accesses during GC. To ensure consistent read and write access patterns, we set the system throughput at a fixed value of 350,000 transactions per second (TPS) in the experiment. Thus, the average number of accesses per tuple determines GC efficiency: the more frequently versions are accessed, the lower the GC efficiency and the greater its impact on overall system performance [21].
The experimental results are shown in Figure 14. With 40 concurrent threads, the x-axis represents runtime (0 to 30 min), and the y-axis represents either the average version chain length or the average number of accesses per version. The average version chain lengths in Steam and N2DB are shorter than those in other systems, but their average access counts are significantly higher-up to 1.70× those of other systems. This is because both approaches reclaim old versions during transaction execution, achieving higher timeliness at the cost of frequent version chain traversal. OneshotGC exhibits the lowest average access count among all systems but has the longest average version chain length. This is due to its partition-based reclamation approach, where GC frequency is very low, requiring all versions in a partition to expire before reclamation starts, leading to excessively long version chains. In contrast, TB-Collect achieves a balanced performance, with an average version chain length only 51% of that in OneshotGC, and an average access count only 59% of that in Steam. This is attributed to TB-Collect’s block-based reclamation approach, which operates at a finer granularity than partition-based methods while avoiding frequent version chain traversals during GC.
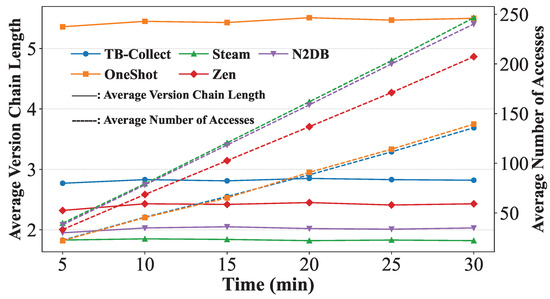
Figure 14.
Average version chain length and accesses over 30 min.
5.6. Garbage Collection in MySQL with Different NVM Configurations
In this evaluation, we will evaluate the performance of a real database system after applying garbage collection approaches. MySQL is a well-known open-source database system that has been widely adopted in commercial applications [27]. Its Customer Storage Engine feature allows users to easily implement custom storage engines [58]. Therefore, we implement an NVM-based storage engine in MySQL 8.4.2 [28], disable MySQL’s binlog [59], and remove external locks [60]. On this basis, we implement the GC approaches TB-Collect, TVCP, BS, and PC, naming them My_TB-Collect, My_TVCP, My_BS, and My_PC, respectively.
My_NoGC: MySQL with NVM append-only storage, without garbage collection, used as a baseline.
My_TB-Collect: A version of MySQL that implements the garbage collection approach described in this paper.
My_TVCP: A version of MySQL that implements the timely version chain pruning approach with append-only NVM storage.
My_BS: A version of MySQL that implements the background scanning approach with append-only NVM storage.
My_PC: A version of MySQL that implements the partition clearing approach with delta NVM storage.
NVM Simulation Configurations. In order to test the execution efficiency of GC approaches on different NVM hardware devices, we simulate several NVM configurations using Quartz [61]. Quartz is an NVM hardware simulation software that uses DRAM to simulate NVM read–write bandwidth, cache line size, latency, and other parameters. We set up the following five NVM hardware configurations, as shown in Table 3. The configurations range from low to high bandwidth, ultimately reaching the performance of DRAM. The mainstream commercial NVM currently available (and used in this paper) is Intel Optane DC Persistent Memory [1], which has 50% read and 30% write performance of DRAM, along with a cache line size of 256 B. With the continuous advancements in semiconductor technology, NVM hardware will continue to evolve. The purpose of our testing is to verify whether TB-Collect is suitable for the ever-evolving NVM devices. It is worth noting that in Quartz, as the NVM bandwidth is increased, the latency also changes accordingly. Therefore, our configuration does not include the NVM latency parameter.
Table 3.
Five NVM hardware configurations simulated by Quartz.
Experimental Environment. We use an Intel Xeon Gold 5218R CPU and 64 GB DDR4 DRAM device as the request node for the TPCC load, while the transaction processing node is equipped with the device described in Section 5.1. The two experimental devices are connected to a single switch and equipped with gigabit network cards. We use the TPCC benchmark, which simulates real-world e-commerce transactions, to evaluate the impact of GC on system performance and the recovery rate. The testing tool is BenchmarkSQL 5.0 [62]. In addition, we use TpmC (Transactions per Minute C), a unit commonly used in industrial testing, as the system throughput metric, which represents the number of new orders the system can process per minute while running TPCC. TpmC is primarily used to measure the performance of database systems under high load, particularly in commercial OLTP scenarios.
Scalability. In this experiment, we test the throughput of each system as the thread count varies using real NVM hardware (described in Section 5.1). As shown in Figure 15a, it can be observed that with the increase in the number of concurrent threads, My_TB-Collect consistently delivers the best throughput among all systems with GC enabled. Furthermore, at 40 threads, it reaches 88% of the My_NoGC throughput. When the thread count exceeds the number of logical CPU cores, the throughput of all systems decreases and eventually stabilizes. During the entire process, My_TB-Collect maintains a performance advantage, achieving throughput approximately 1.23–1.58× higher than other systems.
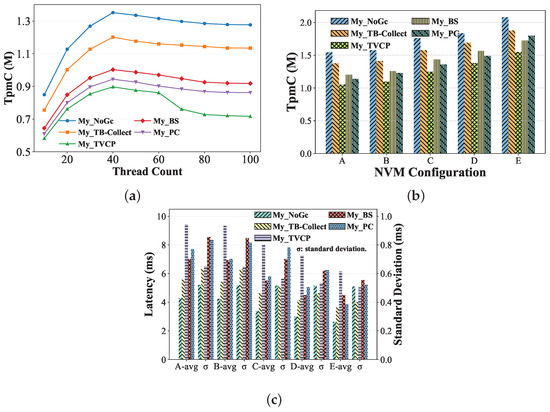
Figure 15.
TPCC performance in MySQL with GC implementation under different NVM hardware configurations. (a) Scalability on TPCC. (b) Throughput on TPCC. (c) Latency on TPCC.
Throughput. In this experiment, we set the number of threads to 40 and evaluate the system throughput with different NVM configurations. As shown in Figure 15b, we can see that when the NVM cache line size decreases from 256 B to 128 B, the changes in My_TB-Collect, My_TVCP, and My_BS are not significant, with only a 3%–5% increase. My_PC shows the largest improvement, about 10%, because as the NVM cache line size decreases, the number of write amplification operations also decreases. My_TB-Collect has the fewest write amplification operations among all systems, so the performance improvement is not very noticeable. On the other hand, My_PC, due to using in-place version storage, has the largest write amplification operations, resulting in the largest performance improvement. With the continuous increase in NVM read/write bandwidth, the performance of all systems also improves, and My_TB-Collect still performs the best among the systems. When the NVM read/write bandwidth is fully aligned with DRAM and the granularity is 64 B, which means NVM can match the performance of DRAM, we observe significant performance improvements in My_TVCP, My_BS, and My_PC; all of the GC approaches in these systems are designed for DRAM. Among them, My_PC shows the greatest improvement, with about 95% of My_TB-Collect’s performance. Nevertheless, My_TB-Collect still maintains a certain performance advantage. The reason is that My_TVCP and My_BS require traversing version chains during GC, which leads to performance degradation, while TB-Collect does not. Moreover, compared to My_PC, My_TB-Collect has a faster GC frequency, and its version chain length remains low (as shown in Figure 14), resulting in higher access efficiency for old versions compared to My_PC.
Latency. Figure 15c shows average latency of the systems under different NVM configuration hardware scenarios. In this experiment, we evaluate the response time of the new-order transaction, which has the highest proportion in TPCC, while controlling the number of threads to 40. With the increase in NVM hardware bandwidth, the response time of all systems decreases significantly. My_TB-Collect still maintains the lowest average latency. In terms of latency stability, except for My_TVCP, the other three systems show a significant improvement. This is because the TVCP approach performs version collection during each transaction execution. In contrast, the other three systems perform triggered collection after reaching a threshold, which requires executing a larger number of collection operations at once. As the bandwidth increases, the latency decreases more when executing large-scale collection tasks, resulting in improved stability.
Efficiency of Space Reclamation. In this experiment, we set the number of threads to 40 and test the system’s NVM and DRAM space increase after running for 120 mina under different NVM configurations. To ensure fairness, we control each system’s throughput at 800 K transactions per minute, with an initial warehouse size of 200. As shown in Figure 16, the increase in NVM and DRAM space does not change with the increase in NVM bandwidth. This is because the space efficiency of GC depends on how the approach handles expired versions and the storage layout, which is independent of NVM bandwidth. Similar to the results in Figure 12, TB-Collect exhibits the best reclamation efficiency.

Figure 16.
Space size increase over 120 min with different NVM hardware configurations.
In conclusion, TB-Collect achieves the best GC efficiency under complex transaction processing workloads and is adaptable to real-world database system applications. As the NVM bandwidth and cache line size gradually approach and equal that of DRAM, the performance advantage of TB-Collect over other GC approaches diminishes, but it still maintains a certain level of superiority.
6. Discussion
6.1. Advantages of TB-Collect
TB-Collect demonstrates efficient garbage collection capabilities. Compared with GC approaches like Steam and N2DB, TB-Collect adopts a block-based version reclamation strategy that avoids frequent traversal of version chains, thereby exerting less impact on system performance. Furthermore, compared to OneShotGC, TB-Collect continuously maintains shorter version chains and avoids building additional hash index structures for old versions. This further reduces write amplification and extra overhead during reclamation, ensuring stable system read/write performance.
Under various workload patterns—such as mixed workloads with changing read/write ratios, data hotspot variations caused by different ZipF distribution parameters, and varying numbers of transactional operations—TB-Collect consistently maintains strong adaptability and efficient version reclamation. This indicates its robustness and general applicability in handling dynamic changes commonly seen in real-world business scenarios. Moreover, experimental results integrating TB-Collect into the real-world MySQL database show that it achieves optimal system performance under multiple thread configurations. This demonstrates that TB-Collect is not only effective within academic research frameworks but also validated for deployability and practical value in industrial-grade systems. These results further reinforce TB-Collect’s potential as a next-generation GC approach for NVM OLTP engines.
With advances in hardware technology, NVM performance is gradually approaching that of DRAM, which somewhat narrows TB-Collect’s performance advantages over other GC approaches. Nevertheless, due to its design that fully avoids costly memory operations, TB-Collect still maintains certain advantages in reclamation efficiency.
6.2. Limitations and Future Work
Although TB-Collect performs excellently in the current evaluation, there remain several directions worthy of further exploration. First, the reclamation mechanisms, including TB-Collect, OneShotGC, and Steam, currently adopt an on-demand triggering strategy based on events such as full reclamation queues, version expiration, or transaction commits. Such mechanisms may cause frequent GC triggers under high-concurrency write scenarios, leading to significant system overheads (e.g., CPU cycle consumption, decreased cache hit rates, and thread scheduling delays). Conversely, artificially reducing GC frequency might result in excessively long version chains, adversely affecting the efficiency of accessing old versions and wasting storage space. To address this issue, we plan to design a lightweight adaptive regulation mechanism that dynamically adjusts the GC frequency according to the runtime system load. Specifically, the system can periodically collect key metrics (such as average version chain length, system write pressure, current reclamation rate, etc.) and construct an adjustment model based on regression analysis or sliding thresholds: when rapid growth in version chains or reclamation lag is detected, the GC frequency is appropriately increased; when GC overhead is high or version chain changes are insignificant, the frequency is decreased to save resources. Additionally, this mechanism can incorporate machine learning methods to predict optimal reclamation windows based on historical load patterns, enabling finer-grained control [63,64,65].
Although TB-Collect’s delayed reclamation strategy effectively alleviates the version chain consolidation issue caused by long transactions, it inevitably introduces some space overhead. Moreover, the block-level reclamation approach lacks the timeliness of tuple-level reclamation, potentially resulting in slower space recovery. In the future, we plan to explore a hybrid-granularity reclamation strategy that dynamically combines block-level and tuple-level methods. This would allow finer-grained reclamation in scenarios requiring more timely cleanup, thereby improving space utilization while enhancing the system’s adaptability and flexibility.
Furthermore, we intend to conduct in-depth analysis of TB-Collect’s behavior under different types and intensities of transactional workloads to enhance its adaptability and robustness. We will also explore the feasibility of integrating TB-Collect with different NVM architectures and OLTP engines to improve its practicality and compatibility. Finally, as the NVM field continues to evolve, we will compare TB-Collect with emerging NVM-specific GC approaches to evaluate its long-term competitiveness and provide references and inspiration for future research.
7. Conclusions
In this paper, we propose TB-Collect, a block-based garbage collection approach tailored for OLTP engines on non-volatile memory. TB-Collect physically separates tuple headers from tuple contents to reduce write amplification on NVM. Instead of traversing version chains, it reclaims obsolete versions in parallel at the block level using local threads. To address the challenges posed by long transactions, TB-Collect adopts a delayed version reclamation strategy that mitigates the cost of version chain consolidation. Unlike traditional GC approaches inherited from DRAM-based designs, TB-Collect fully considers the architectural differences of NVM, steering clear of NVM-unfriendly behaviors such as deep version chain scans and old-version index reconstruction. Extensive experimental results on platforms such as DBx1000 and MySQL demonstrate that TB-Collect consistently outperforms state-of-the-art techniques across a wide range of metrics.
Despite its advantages, TB-Collect uses an on-demand GC approach, which may lead to frequent GC under high concurrency. These issues affect storage usage and system stability. As future work, we plan to introduce adaptive GC control based on statistical models and lightweight machine learning. To further improve TB-Collect’s robustness and adaptability, we also plan to explore a hybrid-granularity reclamation strategy that dynamically combines block-level and tuple-level methods, enabling more responsive cleanup in scenarios requiring timely space recovery. In addition, we will analyze its behavior under diverse workloads, explore integration with different NVM architectures and OLTP engines, and compare it with emerging GC techniques designed for NVM.
In summary, TB-Collect is an efficient garbage collection approach for NVM OLTP engines that achieves high-performance reclamation of obsolete versions. We believe this work provides a solid foundation for developing efficient and scalable NVM OLTP engines, and opens up new opportunities for future research in the era of non-volatile memory.
Author Contributions
Conceptualization, J.W., Q.Z. and X.G.; Methodology, J.W., Q.Z., Y.X. and X.G.; Software, J.W.; Validation, J.W. and Q.Z.; Formal analysis, J.W.; Investigation, J.W. and Y.X.; Resources, J.W.; Data curation, J.W.; Writing—original draft, J.W.; Writing—review & editing, J.W., Q.Z., Y.X. and X.G.; Visualization, J.W.; Supervision, X.G.; Project administration, J.W.; Funding acquisition, X.G. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China (61572194, 61672233).
Data Availability Statement
The data presented in this study are openly available in GitHub at https://github.com/w1397800/TB-Collect/tree/master (accessed on 29 July 2024).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Intel Optane DC Persistent Memory Architecture and Technology. Available online: https://www.intel.com/content/www/us/en/architecture-and-technology/optane-dc-persistent-memory.html (accessed on 15 March 2023).
- Diaconu, C.; Freedman, C.; Ismert, E.; Larson, P.; Mittal, P.; Stonecipher, R.; Verma, N.; Zwilling, M. Hekaton: SQL server’s memory-optimized OLTP engine. In Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data, New York, NY, USA, 22–27 June 2013; pp. 1243–1254. [Google Scholar]
- Stonebraker, M.; Weisberg, A. The VoltDB Main Memory DBMS. IEEE Data Eng. Bull. 2013, 36, 21–27. [Google Scholar]
- Faerber, F.; Kemper, A.; Larson, P.-Å.; Levandoski, J.; Neumann, T.; Pavlo, A. Main memory database systems. Found. Trends Databases 2017, 8, 1–130. [Google Scholar] [CrossRef]
- Larson, P.A.; Levandoski, J. Modern main-memory database systems. Proc. VLDB Endowment 2016, 9, 1609–1610. [Google Scholar] [CrossRef]
- Huang, J.; Schwan, K.; Qureshi, M.K. NVRAM-aware logging in transaction systems. Proc. VLDB Endow. 2014, 8, 389–400. [Google Scholar] [CrossRef]
- Kimura, H. FOEDUS: OLTP engine for a thousand cores and NVRAM. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, Melbournem, Australia, 31 May 2015–4 June 2015; pp. 691–706. [Google Scholar]
- Arulraj, J.; Perron, M.; Pavlo, A. Write-behind logging. Proc. VLDB Endow. 2016, 10, 337–348. [Google Scholar] [CrossRef]
- Liu, G.; Chen, L.; Chen, S. Zen: A high-throughput log-free OLTP engine for non-volatile main memory. Proc. VLDB Endow. 2021, 14, 835–848. [Google Scholar] [CrossRef]
- Liu, G.; Chen, L.; Chen, S. Zen+: A Robust NUMA-Aware OLTP Engine Optimized for Non-Volatile Main Memory. VLDB J. 2023, 32, 123–148. [Google Scholar] [CrossRef]
- Schwalb, D.; Kumar, G.B.K.; Dreseler, M.; Anusha, S.; Faust, M.; Hohl, A.; Berning, T.; Makkar, G.; Plattner, H.; Deshmukh, P. Hyrise-NV: Instant recovery for in-memory databases using non-volatile memory. In Proceedings of the Database Systems for Advanced Applications: 21st International Conference, DASFAA 2016, Dallas, TX, USA, 16–19 April 2016; pp. 267–282. [Google Scholar]
- Ji, Z.; Chen, K.; Wang, L.; Zhang, M.; Wu, Y. Falcon: Fast OLTP Engine for Persistent Cache and Non-Volatile Memory. In Proceedings of the 29th Symposium on Operating Systems Principles, Koblenz, Germany, 23–26 October 2023; pp. 531–544. [Google Scholar]
- Ma, S.; Chen, K.; Chen, S.; Liu, M.; Zhu, J.; Kang, H.; Wu, Y. ROART: Range-query optimized persistent ART. In Proceedings of the 19th USENIX Conference on File and Storage Technologies (FAST 21), Online, 23–25 February 2021; pp. 1–16. [Google Scholar]
- Zhang, B.; Zheng, S.; Qi, Z.; Huang, L. NBTree: A Lock-free PM-friendly Persistent B+-Tree for eADR-enabled PM Systems. Proc. VLDB Endow. 2022, 15, 1187–1200. [Google Scholar] [CrossRef]
- Chen, S.; Jin, Q. Persistent b+-trees in non-volatile main memory. Proc. VLDB Endow. 2015, 8, 786–797. [Google Scholar] [CrossRef]
- Wang, T.; Johnson, R. Scalable logging through emerging non-volatile memory. Proc. VLDB Endow. 2014, 7, 865–876. [Google Scholar] [CrossRef]
- Shin, S.; Tirukkovalluri, S.K.; Tuck, J.; Solihin, Y. Proteus: A flexible and fast software supported hardware logging approach for nvm. In Proceedings of the 50th Annual IEEE/ACM International Symposium on Microarchitecture, Cambridge, MA, USA, 14–18 October 2017; pp. 178–190. [Google Scholar]
- Zhang, M.; Hua, Y. Silo: Speculative Hardware Logging for Atomic Durability in Persistent Memory. In Proceedings of the 2023 IEEE International Symposium on High-Performance Computer Architecture (HPCA), Montreal, QC, Canada, 25 February–1 March 2023; pp. 651–663. [Google Scholar]
- Böttcher, J.; Leis, V.; Neumann, T.; Kemper, A. Scalable garbage collection for in-memory MVCC systems. Proc. VLDB Endow. 2019, 13, 128–141. [Google Scholar] [CrossRef]
- Peloton. Available online: https://pelotondb.io/ (accessed on 20 March 2025).
- Raza, A.; Chrysogelos, P.; Anadiotis, A.C.; Ailamaki, A. One-shot garbage collection for in-memory OLTP through temporality-aware version storage. Proc. ACM Manag. Data 2023, 1, 1–25. [Google Scholar] [CrossRef]
- Condit, J.; Nightingale, E.B.; Frost, C.; Ipek, E.; Lee, B.; Burger, D.; Coetzee, D. Better I/O Through Byte-Addressable, Persistent Memory. In Proceedings of the ACM SIGOPS 22nd symposium on Operating Systems Principles, Big Sky, MT, USA, 11–14 October 2009. [Google Scholar]
- Jacob, B.; Wang, D.; Ng, S. Memory Systems: Cache, DRAM, Disk; Morgan Kaufmann: Burlington, MA, USA, 2010. [Google Scholar]
- Akram, S. Exploiting Intel Optane Persistent Memory for Full Text Search. In Proceedings of the 2021 ACM SIGPLAN International Symposium on Memory Management, Online, 22 June 2021; pp. 80–93. [Google Scholar]
- Le Gallo, M.; Sebastian, A. An overview of phase-change memory device physics. J. Phys. D Appl. Phys. 2020, 53, 213002. [Google Scholar] [CrossRef]
- Yu, X.; Bezerra, G.; Pavlo, A.; Devadas, S.; Stonebraker, M. Staring into the abyss: An evaluation of concurrency control with one thousand cores. Proc. VLDB Endow. 2014, 8, 209–220. [Google Scholar] [CrossRef]
- Botros, S.; Tinley, J. High Performance MySQL; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2021. [Google Scholar]
- MySQL 8.4 Reference Manual. Available online: https://dev.mysql.com/doc/refman/8.4/en/ (accessed on 15 October 2024).
- Neumann, T.; Mühlbauer, T.; Kemper, A. Fast serializable multi-version concurrency control for main-memory database systems. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, Melbourne, Australia, 31 May–4 June 2015; pp. 677–689. [Google Scholar]
- Freitag, M.; Kemper, A.; Neumann, T. Memory-Optimized Multi-Version Concurrency Control for Disk-Based Database Systems. Proc. VLDB Endow. 2022, 15, 2797–2810. [Google Scholar] [CrossRef]
- Izraelevitz, J.; Kelly, T.; Kolli, A. Failure-atomic persistent memory updates via JUSTDO logging. ACM SIGARCH Comput. Archit. News 2016, 44, 427–442. [Google Scholar] [CrossRef]
- Agrawal, R.; Jagadish, H.V. Recovery algorithms for database machines with non-volatile main memory. In International Workshop on Database Machines; Springer: Berlin/Heidelberg, Germany, 1989; pp. 269–285. [Google Scholar]
- Oukid, I.; Booss, D.; Lehner, W.; Bumbulis, P.; Willhalm, T. SOFORT: A hybrid SCM-DRAM storage engine for fast data recovery. In Proceedings of the 10th International Workshop on Data Management on New Hardware, Seattle, WA, USA, 18–23 June 2014; pp. 1–7. [Google Scholar]
- An, M.; Park, J.; Wang, T.; Nam, B.; Lee, S.W. NV-SQL: Boosting OLTP Performance with Non-Volatile DIMMs. Proc. VLDB Endow. 2023, 16, 1453–1465. [Google Scholar] [CrossRef]
- Funke, F.; Kemper, A.; Mühlbauer, T.; Neumann, T.; Leis, V. Hyper beyond software: Exploiting modern hardware for main-memory database systems. Datenbank-Spektrum 2014, 14, 173–181. [Google Scholar] [CrossRef]
- Kemper, A.; Neumann, T. HyPer: A hybrid OLTP&OLAP main memory database system based on virtual memory snapshots. In Proceedings of the 2011 IEEE 27th International Conference on Data Engineering, Hannover, Germany, 11–16 April 2011; pp. 195–206. [Google Scholar]
- Lyu, Z.; Zhang, H.H.; Xiong, G.; Guo, G.; Wang, H.; Chen, J.; Praveen, A.; Yang, Y.; Gao, X.; Wang, A.; et al. Greenplum: A hybrid database for transactional and analytical workloads. In Proceedings of the 2021 International Conference on Management of Data, Shaanxi, China, 20–25 June 2021; pp. 2530–2542. [Google Scholar]
- Lee, J.; Shin, H.; Park, C.G.; Ko, S.; Noh, J.; Chuh, Y.; Stephan, W.; Han, W.S. Hybrid garbage collection for multi-version concurrency control in SAP HANA. In Proceedings of the 2016 International Conference on Management of Data, San Francisco, CA, USA, 26 June–1 July 2016; pp. 1307–1318. [Google Scholar]
- Ahn, M.; Willhalm, T.; May, N.; Lee, D.; Desai, S.M.; Booss, D.; Kim, J.; Singh, N.; Ritter, D.; Rebholz, O. An Examination of CXL Memory Use Cases for In-Memory Database Management Systems using SAP HANA. Proc. VLDB Endow. 2024, 17, 3827–3840. [Google Scholar] [CrossRef]
- Julakanti, S.R.; Sattiraju, N.S.K.; Julakanti, R. Transforming Data in SAP HANA: From Raw Data to Actionable Insights. NeuroQuantology 2022, 19, 854–861. [Google Scholar]
- Intel Corporation. eADR: New Opportunities for Persistent Memory Applications. 2021. Available online: https://www.intel.com/content/www/us/en/developer/articles/technical/eadr-new-opportunities-for-persistentmemory-applications.html (accessed on 20 December 2023).
- Cai, S.; Chen, K.; Liu, M.; Liu, X.; Wu, Y.; Zheng, W. Garbage collection and data recovery for N2DB. Tsinghua Sci. Technol. 2021, 27, 630–641. [Google Scholar] [CrossRef]
- Färber, F.; Cha, S.K.; Primsch, J.; Bornhövd, C.; Sigg, S.; Lehner, W. SAP HANA database: Data management for modern business applications. ACM Sigmod Rec. 2012, 40, 45–51. [Google Scholar] [CrossRef]
- Wu, S.; Lin, Y.; Mao, B.; Jiang, H. GCaR: Garbage collection aware cache management with improved performance for flash-based SSDs. In Proceedings of the 2016 International Conference on Supercomputing, Istanbul, Turkey, 1–3 June 2016; pp. 1–12. [Google Scholar]
- Kim, Y.; Oral, S.; Shipman, G.M.; Lee, J.; Dillow, D.A.; Wang, F. Harmonia: A globally coordinated garbage collector for arrays of solid-state drives. In Proceedings of the 2011 IEEE 27th Symposium on Mass Storage Systems and Technologies (MSST), Denver, CO, USA, 23–27 May 2011; pp. 1–12. [Google Scholar]
- Lee, J.; Kim, Y.; Shipman, G.M.; Oral, S.; Wang, F.; Kim, J. A semi-preemptive garbage collector for solid state drives. In Proceedings of the (IEEE ISPASS) IEEE International Symposium on Performance Analysis of Systems and Software, Austin, TX, USA, 10–12 April 2011; pp. 12–21. [Google Scholar]
- Hu, J.; Jiang, H.; Tian, L.; Xu, L. GC-ARM: Garbage collection-aware RAM management for flash based solid state drives. In Proceedings of the 2012 IEEE Seventh International Conference on Networking, Architecture, and Storage, Xiamen, China, 28–30 June 2012; pp. 134–143. [Google Scholar]
- Jung, M.; Prabhakar, R.; Kandemir, M.T. Taking garbage collection overheads off the critical path in SSDs. In Proceedings of the Middleware 2012: ACM/IFIP/USENIX 13th International Middleware Conference, Montreal, QC, Canada, 3–7 December 2012; pp. 164–186. [Google Scholar]
- Yan, S.; Li, H.; Hao, M.; Tong, M.H.; Sundararaman, S.; Chien, A.A.; Gunawi, H.S. Tiny-tail flash: Near-perfect elimination of garbage collection tail latencies in NAND SSDs. ACM Trans. Storage (TOS) 2017, 13, 22. [Google Scholar] [CrossRef]
- Wang, K.; Tan, H.; He, Z.; Li, J.; Li, K. CDA-GC: An effective cache data allocation for garbage collection in flash-based solid-state drives. Integration 2025, 102, 102359. [Google Scholar] [CrossRef]
- Hedayati, S.; Maleki, N.; Olsson, T.; Ahlgren, F.; Seyednezhad, M.; Berahmand, K. MapReduce scheduling algorithms in Hadoop: A systematic study. J. Cloud Comput. 2023, 12, 143. [Google Scholar] [CrossRef]
- Bernstein, P.A.; Hadzilacos, V.; Goodman, N. Concurrency Control and Recovery in Database Systems; Addison-Wesley: Reading, MA, USA, 1987; Volume 370. [Google Scholar]
- Lomet, D.; Fekete, A.; Wang, R.; Ward, P. Multi-version Concurrency via Timestamp Range Conflict Management. In Proceedings of the 2012 IEEE 28th International Conference on Data Engineering (ICDE), Arlington, VA, USA, 1–5 April 2012; pp. 714–725. [Google Scholar]
- Guo, Z.; Wu, K.; Yan, C.; Yu, X. Releasing locks as early as you can: Reducing contention of hotspots by violating two-phase locking. In Proceedings of the 2021 International Conference on Management of Data, Shaanxi, China, 20–25 June 2021; pp. 658–670. [Google Scholar]
- Cooper, B.F.; Silberstein, A.; Tam, E.; Ramakrishnan, R.; Sears, R. Benchmarking cloud serving systems with YCSB. In Proceedings of the 1st ACM Symposium on Cloud Computing, Indianapolis, IN, USA, 10–11 June 2010; pp. 143–154. [Google Scholar]
- TPC Benchmark C. Available online: http://www.tpc.org/tpcc/ (accessed on 10 May 2023).
- Yang, Y.; Zhu, J. Write skew and zipf distribution: Evidence and implications. ACM Trans. Storage (TOS) 2016, 12, 1–19. [Google Scholar] [CrossRef]
- MySQL. MySQL Internals: Writing a Custom Storage Engine; Technical report; Oracle Corporation: Austin, TX, USA, 2024. [Google Scholar]
- The Binary Log. Available online: https://dev.mysql.com/doc/refman/8.4/en/binary-log.html (accessed on 15 October 2024).
- External Locking. Available online: https://dev.mysql.com/doc/refman/8.4/en/external-locking.html (accessed on 15 October 2024).
- Volos, H.; Magalhaes, G.; Cherkasova, L.; Li, J. Quartz: A lightweight performance emulator for persistent memory software. In Proceedings of the 16th Annual Middleware Conference, Vancouver, BC, Canada, 7–11 December 2015; pp. 37–49. [Google Scholar]
- BenchmarkSQL. Available online: https://github.com/pingcap/benchmarksql (accessed on 8 July 2023).
- Haas, P.J.; Ilyas, I.F.; Lohman, G.M.; Markl, V. Discovering and exploiting statistical properties for query optimization in relational databases: A survey. Stat. Anal. Data Mining ASA Data Sci. J. 2009, 1, 223–250. [Google Scholar] [CrossRef]
- Valavala, M.; Alhamdani, W. Automatic database index tuning using machine learning. In Proceedings of the 2021 6th International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 20–22 January 2021; pp. 523–530. [Google Scholar]
- Cook, J.E.; Klauser, A.W.; Wolf, A.L.; Zorn, B.G. Semi-automatic, self-adaptive control of garbage collection rates in object databases. In Proceedings of the 1996 ACM SIGMOD International Conference on Management of Data, Montreal, QC, Canada, 4–6 June 1996; pp. 377–388. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).