1. Introduction
License plate detection technology plays a crucial role in intelligent transportation, parking management, and road safety by enabling the automatic recognition of vehicle license plate information. This technology facilitates real-time traffic monitoring and management, improving both efficiency and security. With the widespread adoption of surveillance equipment and advancements in image quality, achieving accurate and efficient license plate detection has become a key focus in enhancing modern traffic management systems [
1,
2].
Currently, license plate detection primarily relies on traditional image processing techniques and deep learning-based approaches.
Traditional image processing methods for license plate detection typically rely on features such as color, texture, and edges to achieve localization and identification. The process begins with image preprocessing techniques, including grayscaling, noise filtering, and histogram equalization, to enhance image quality and improve the recognizability of target features [
3]. Next, morphological operations such as dilation, erosion, and opening and closing operations are applied to emphasize the structural characteristics of the license plate region while suppressing interference from non-target areas [
4]. Feature extraction techniques, including color threshold segmentation, edge detection, and connected component analysis, are then used to identify potential license plate candidate regions [
5]. Finally, these candidate regions are verified based on geometric properties, scale, and texture to accurately determine the license plate’s location [
4]. However, variations in lighting conditions—such as strong light, shadows, backlighting, and nighttime illumination—significantly affect the color and luminance characteristics of license plates, leading to instability in color- and grayscale-based feature extraction methods. This reduces detection accuracy and makes it difficult to meet practical application requirements [
6]. Additionally, complex background interference presents a major challenge for traditional image-based license plate detection, as elements like billboards, road markings, and non-motorized vehicles may share similar colors or textures with license plates, increasing the risk of false detection [
7]. Further complications arise when license plates are partially obscured or deformed—whether due to dirt, stickers, or objects covering the plate, or perspective distortion caused by changes in camera angles [
6]. These factors significantly impact the effectiveness of shape- and edge-based detection methods, making it difficult for traditional approaches to achieve high reliability and accuracy in complex environments. As a result, they often fall short of meeting the stringent precision and robustness requirements of intelligent transportation and public safety applications.
To achieve accurate license plate detection in real-world applications and develop advanced techniques capable of adapting to complex environments, researchers are increasingly turning to deep learning-based approaches.
In deep learning-based methods, the dataset plays a crucial role in influencing detection accuracy. Therefore, researchers have implemented targeted enhancements to the license plate dataset, increasing its diversity and enriching the variety of scenarios to better support the model’s performance. Hsu et al. introduced the Application-Oriented License Plate (AOLP) benchmark dataset, designed to provide more challenging and diverse scenarios for model evaluation and optimization [
8]. The dataset is categorized into three application-driven scenarios: Access Control (AC), Traffic Law Enforcement (LE), and Road Patrol (RP). The AC scenario features relatively simple conditions, the LE scenario primarily focuses on capturing illegal vehicles, and the RP scenario includes randomly captured images with varying angles and distances, offering greater diversity. Covering a wide range of lighting conditions, weather variations, and viewing angles, the AOLP dataset effectively simulates complex real-world environments, enhancing the adaptability and robustness of license plate detection models. To further address the challenges of real-world license plate detection, Chowdhury et al. developed the Automated Multi-License Plate Recognition (AMLPR) dataset, which serves as a valuable resource for evaluating model performance in multi-license plate detection within congested street scenes [
9]. The AMLPR dataset comprises 1501 images, annotated with a total of 4986 license plate instances. It is divided into single-license-plate and multi-license-plate scenarios, with each image containing between one and five license plates. Unlike traditional datasets, AMLPR emphasizes the challenges of crowded street environments, incorporating complex backgrounds, vehicles positioned at various angles and distances, and external factors such as lighting variations and occlusions.
Meanwhile, other researchers have focused on refining deep learning modeling modules to further enhance detection accuracy. Chung et al. incorporated the SimAM attention mechanism into the ELAN and ELAN-H modules, creating the SimAM-ELAN and SimAM-ELAN-H modules. This enhancement improved feature extraction capability, mitigating issues like occlusion [
10]. However, the method still struggles with detecting small license plates with indistinct features. To mitigate the negative impact of motion blur on object recognition, Zhou et al. proposed a convolutional neural network-based visual target recognition method specifically designed for motion-blurred images. The approach was validated using synthesized samples for model training [
11]. However, its effectiveness remains limited under low-light conditions. To tackle the challenge of low-quality images, Yu et al. introduced an advanced detector, SrcLPD, which employs a dual-branch detection head and integrates the Corner Detection Module (CDM) with the Center-to-Corner Regression (CETCO) strategy. This combination leverages the strengths of both methods in various low-quality image scenarios, enhancing model robustness [
12]. However, the introduction of the dual-branch detection head and soft-coupling loss function increases model complexity, making it unsuitable for real-time applications.
To meet the real-time requirements of license plate detection, researchers have explored various lightweight networks, such as GhostNet [
13] and FasterNet [
14], to reduce computational costs and model parameters. GhostNet introduces the Ghost module, which generates additional feature maps through inexpensive operations, thereby minimizing redundant computation. Meanwhile, FasterNet enhances network structure optimization to improve inference speed. However, these methods face limitations in feature expressiveness, making it challenging to capture fine-grained details of license plates effectively. To address this issue, researchers have incorporated attention mechanisms and improved feature fusion strategies into lightweight networks to enhance detection accuracy. Zhang et al. proposed a lightweight license plate detection network integrating an attention mechanism, significantly boosting detection accuracy while maintaining model efficiency [
15]. However, its performance remains suboptimal when detecting dense small targets. Additionally, Chen et al. embedded the CBAM attention mechanism into a multi-scale feature extraction module and replaced the backbone network with FasterNet to balance accuracy and model efficiency [
16]. Nevertheless, CBAM applies global average pooling and max-pooling in two steps—channel and spatial attention—which substantially increases computational complexity and slows down inference speed.
To further reduce model parameters and computational cost, depthwise separable convolution is widely employed in object detection models such as MobileNet-SSD [
17] and EfficientDet [
18]. These models achieve significant parameter reduction by decomposing standard convolution into depthwise convolution and pointwise convolution. However, while this approach reduces computational complexity, it also weakens the model’s feature representation, leading to a decline in detection accuracy. To address this issue, MobileNetv2 introduces an inverted residual structure and a linear bottleneck layer, enhancing feature representation while maintaining a lightweight design [
19]. ShuffleNet improves information flow between channels by incorporating pointwise convolutional grouping and channel rearrangement mechanisms, thereby boosting model performance [
20]. Additionally, MixConv integrates depthwise convolution branches of different kernel sizes to capture multi-scale features, improving accuracy without significantly increasing computational cost [
21]. While these enhancements effectively mitigate the performance degradation caused by depthwise separable convolution, there is still potential for further accuracy improvements, particularly in complex scenarios.
In summary, researchers have made significant efforts to improve detection accuracy and optimize model complexity by enhancing dataset diversity, refining network architectures, and promoting lightweight designs. However, these approaches still face key challenges. Balancing high detection accuracy with computational efficiency remains difficult, and models struggle to adapt to complex environmental conditions. Additionally, performance often degrades in scenarios involving dense, small-scale license plates, motion blur, occlusion, and long-distance imaging. Therefore, there is still a need for a detection approach that ensures both high precision and efficient deployment in real-world surveillance environments.
To address these issues, we propose a license plate detection method based on an improved YOLOv8n. By optimizing the network structure and loss function of YOLOv8n and incorporating a residual structure, our model effectively balances detection accuracy and real-time performance, particularly for small-scale license plates under varying lighting conditions. Additionally, it mitigates the challenges posed by feature inconspicuousness due to extreme weather and motion blur, thereby enhancing the model’s robustness and adaptability in complex scenarios.
The principal contributions of this research are as follows:
- (1)
We propose a multi-scale enhanced C2f structure to address the challenge of detecting low-resolution, small targets in complex backgrounds. The improved C2f module consists of two main components: a multi-scale convolutional branch and a detail detection branch. The multi-scale convolutional branch comprises three parallel convolutional paths with different depths, designed to extract license plate features across small, medium, and large receptive fields. The detail detection branch, composed of a 1 × 1 convolution and residual connections, focuses on capturing pixel-level fine details such as vehicle edges. This design significantly enhances the model’s ability to detect low-resolution, small license plates in complex scenes and also provides a structural reference for similar detection tasks in other challenging environments.
- (2)
We propose an improved SPPF (Spatial Pyramid Pooling Fast) structure for the detection of sparse feature targets. In this enhanced design, a 1 × 1 CBS (Convolution–Batch Normalization–SiLU) module is added after each max-pooling operation at all levels of the original SPPF structure. This addition enables the fusion of multi-channel spatial information across different receptive fields. By introducing the CBS module, independent weight learning for different feature channels is achieved, which enhances the nonlinear interactions between channels. As a result, the flow of information becomes smoother and more enriched, effectively strengthening sparse license plate features. This structure also serves as a reference for improving the detection of other types of sparse targets.
- (3)
We propose a lightweight detection head based on the YOLOv8n detector head structure, specifically designed for small targets with sparse features. In this design, the conventional convolution in the CBS module is replaced with depthwise separable convolution to reduce computational complexity. Additionally, Batch Normalization is replaced with Group Normalization to improve model stability and normalization effectiveness, particularly with small batch sizes. To compensate for the potential loss of fine-grained information caused by these modifications, a residual structure is introduced. The proposed detection head provides a structural reference for lightweight designs capable of effectively capturing detailed features.
- (4)
We propose an improved WIoUv2 loss function for detecting small, blurred targets with relatively fixed shapes. This enhanced version incorporates an aspect ratio penalty term from the CIoU loss into the original WIoUv2 formulation. While WIoUv2 improves the model’s focus on hard samples by dynamically adjusting gradient gains—thereby reducing the influence of easy samples—the added aspect ratio penalty further refines bounding box regression accuracy. This combination enhances the overall detection performance for small, fuzzy, and shape-consistent targets. The proposed loss function also provides a useful reference for designing loss functions aimed at similar detection tasks involving vague or shape-constrained objects.
2. Proposed Methods
2.1. YOLOv8n Algorithm Architecture
YOLOv8n is a lightweight variant of the YOLOv8 series, designed for resource-constrained devices and real-time applications. This version is highly optimized in terms of parameter count and computational complexity, enabling fast inference with minimal hardware resources while maintaining high detection accuracy. Compared with other YOLOv8 versions, YOLOv8n prioritizes network simplification and efficiency, making it particularly well suited for real-time small-target detection tasks, such as license plate recognition in surveillance scenarios. The network structure of YOLOv8n is illustrated in
Figure 1.
Figure 1 illustrates the network structure of YOLOv8n, which consists of three main components: the Backbone, Neck, and Head. In the figure, the three sets of multiplying numbers represent the width, height, and number of channels of the feature map, where the width and height are measured in pixels. The symbol k denotes the convolution kernel size, with k = 3 indicating a 3 × 3 pixel kernel. The symbol s represents the stride used in operations such as convolution, while p indicates the zero-padding size. Specifically, p = 1 means that a row of zero-padding pixels is added to each side of the image, whereas p = 0 signifies no padding.
In the Backbone section, YOLOv8n processes a 640 × 640 pixel, 3-channel input image through a series of ordered CBS and C2f modules, using a 3 × 3 convolution kernel with a stride of 2. This progressively downsamples the input image by a factor of 2 until a 20 × 20 pixel, 512-channel feature map is obtained. This process effectively suppresses minor disturbances in complex backgrounds while reducing computational costs. Such an approach is particularly crucial for mitigating interference in surveillance-based license plate detection, where environmental elements like traffic signals, roads, and trees can affect recognition accuracy.
The C2f module in the Backbone of YOLOv8n enhances multi-scale feature fusion through feature segmentation and multi-layer Bottleneck stacking. When detecting small license plates in surveillance scenarios, the C2f module improves feature diversity by recombining feature branches, thereby enhancing fine-grained feature representation along license plate edges. At the end of the Backbone, the SPPF module is introduced to efficiently retain and fuse key features across different scales using multi-scale pooling. This enhances target detection in complex backgrounds by preserving critical license plate features while filtering out background noise.
However, since multiple downsampling operations in the Backbone reduce its ability to capture local details, small license plate boundaries may not be sufficiently extracted. To address this, the Neck of YOLOv8n integrates a Path Aggregation Network (PANet), which combines the top-down feature propagation of the Feature Pyramid Network (FPN) with the bottom-up feature enhancement of PAN. This structure further optimizes multi-scale feature fusion, which is crucial for license plate detection in surveillance scenarios where plates often appear small, blurry, and obscured by complex backgrounds. The Neck module improves small-target perception by progressively fusing small, medium, and large feature layers from the Backbone output. Distant license plates typically suffer from low resolution and sparse information, but the Neck compensates for this by passing global features from higher layers to lower layers through top-down feature propagation. Meanwhile, the bottom-up path reinforces low-level detail contributions to high-level semantic features. This dual-path enhancement strategy enables the model to effectively detect license plates despite challenges such as dense traffic flow, lighting variations, and motion blur. Ultimately, this approach not only boosts detection performance for distant and blurry license plates but also significantly enhances model robustness, ensuring stable accuracy in surveillance scenarios.
In the Head section, the YOLOv8n detection head processes multi-scale features (P3, P4, and P5) separately, applying feature transformations before using independent classification and regression heads to generate detection results directly. Additionally, YOLOv8n adopts an anchor-free design, eliminating the complex prior box generation and matching process required in traditional anchor-based methods. Instead, it predicts the target’s centroid position and bounding box attributes directly.
The anchor-free design significantly simplifies network training and reduces reliance on hyperparameters. For small license plate detection in surveillance scenarios, this approach avoids performance degradation caused by the improper distribution of prior anchors. In particular, when license plates vary greatly in size or have irregular spatial distributions, the anchor-free method enhances both detection accuracy and efficiency by directly predicting the center point of each target.
Overall, YOLOv8n achieves stable detection accuracy and efficiency in license plate recognition due to its strong ability to capture fine details, remove complex background noise, and optimize the detection process. However, there is still room for improvement, particularly in handling ultra-small license plates in surveillance scenarios and adapting to extreme lighting conditions, such as overly bright or low-light environments.
2.2. Improved C2f Module
As shown in
Figure 1, the Split module in the C2f module of YOLOv8n divides the input feature map into two parts along the channel dimension. One part serves as a detail layer and is directly passed to the later Concat layer, while the other undergoes processing in the Bottleneck for feature fusion. However, the details fed directly into the Concat layer from the Split module contain only half of the feature channel information. For small license plates with sparse features in surveillance scenarios or low-resolution conditions, this limitation can lead to insufficient feature representation of license plate details.
Additionally, the Bottleneck in the C2f module of YOLOv8n primarily relies on two stacked 3 × 3 CBS convolutional modules for feature extraction. In license plate detection, where the receptive field is relatively small, capturing the global structure of larger license plates after imaging becomes challenging. While increasing the number of Bottleneck layers could enhance the receptive field, it would also introduce excessive computational overhead, negatively impacting real-time performance.
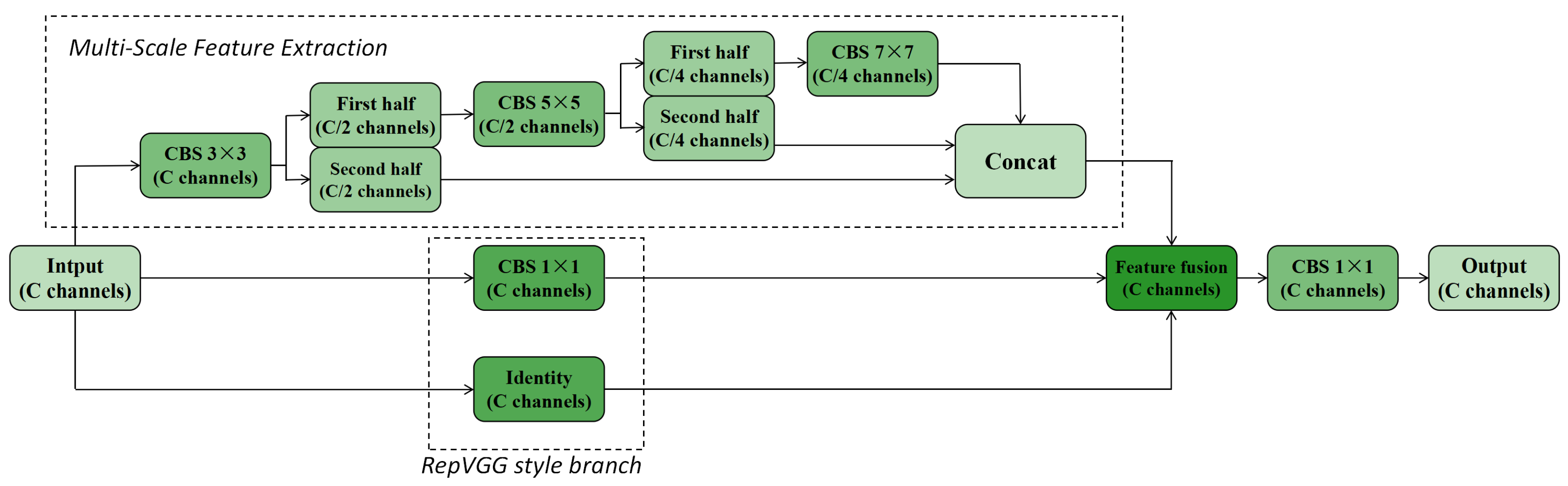
In summary, for license plate detection in surveillance scenarios, the Split module in YOLOv8n restricts the extraction of fine-grained license plate details, while the Bottleneck in the C2f module primarily extracts single-scale features, limiting its effectiveness in complex backgrounds and varying license plate sizes. This makes it difficult to distinguish targets from the background, increasing the risk of missed detections and false positives. To address these challenges, we propose an improved C2f module, as illustrated in
Figure 2, which enhances multi-scale feature extraction and fusion capabilities, providing a more effective alternative to the original C2f module.
The improved C2f module consists of two main parts, one of which is the multi-scale feature extraction branch. This branch is formed by the parallel connection of a 3 × 3 CBS convolutional branch, a 3 × 3 followed by a 5 × 5 CBS convolutional branch, and a 3 × 3 followed by a 5 × 5 followed by a 7 × 7 CBS convolutional branch. It is designed to capture license plate information across small, medium, and large fields of view. To reduce computational complexity and model parameters, this design incorporates lightweight strategies inspired by GhostNet and FasterNet, introducing the concept of partial convolution.
Specifically, the input feature map first undergoes a 3 × 3 CBS convolution, maintaining the number of channels as C. The resulting feature map is then split into two along the channel dimension, producing two feature maps with C/2 channels each. One of these feature maps is further processed by a 5 × 5 CBS convolution, maintaining a channel count of C/2. The output is again split into two along the channel dimension, yielding two feature maps with C/4 channels each. One of these feature maps undergoes a final 7 × 7 CBS convolution while retaining its C/4 channel count. Finally, the feature maps obtained from different branches—the C/2 feature map from the 3 × 3 CBS convolution, the C/4 feature map from the 3 × 3 followed by 5 × 5 convolution, and the C/4 feature map from the 3 × 3 followed by 5 × 5 followed by 7 × 7 convolution—are concatenated along the channel dimension, restoring the feature map to C channels.
Among these, the feature maps from the 3 × 3 CBS convolution (C/2 channels) primarily capture fine details at different scales, making them particularly effective for detecting small license plates in long-distance or low-resolution scenarios, where enhancing boundary regions is crucial. The feature maps from the 3 × 3 followed by 5 × 5 CBS convolution (C/4 channels) are better suited for capturing the overall texture of license plates across scales, especially medium-sized plates, benefiting from the larger receptive field. Lastly, the feature maps from the 3 × 3 followed by 5 × 5 followed by 7 × 7 CBS convolution (C/4 channels) strike a balance between local features such as edges and broader contextual information, further improving recognition performance across different scales. This multi-scale feature extraction strategy significantly enhances the model’s ability to recognize license plates of varying sizes in complex backgrounds.
Another component of the improved C2f module is the RepVGG-style branch, which adopts the branch structure of RepVGG and introduces a 1 × 1 convolution along with a residual connection, as illustrated in
Figure 2. This branch ensures that information across all channels is fully passed to the subsequent feature fusion layer, preventing the pixel-level detail loss that occurs in the original C2f module due to channel splitting. In surveillance scenarios involving long-distance imaging, low-resolution and small license plates often have sparse feature information, making them susceptible to being overwhelmed by background noise. The RepVGG-style branch addresses this challenge by preserving pixel-level features across all channels, thereby enhancing the representation of crucial elements such as license plate boundaries. This helps reduce instances of missed or incorrect detections. Additionally, the residual connections within this branch effectively mitigate the issue of gradient vanishing during deep network training, facilitating more efficient model optimization.
The RepVGG-style branch of the improved C2f module produces two outputs—one from the 1 × 1 convolution and another from the residual connection—both maintaining C output channels. These two C-channel feature maps, along with the C-channel feature map generated by the multi-scale feature extraction branch, are fused in the feature fusion layer. A final 1 × 1 convolution is then applied to produce the final C-channel output. This fusion operation integrates multi-scale feature representations with detailed spatial information, enhancing the module’s capacity to retain feature integrity while improving deep feature flow. Such a design is particularly critical for detecting small and low-resolution license plates, where maintaining both fine details and contextual robustness is essential.
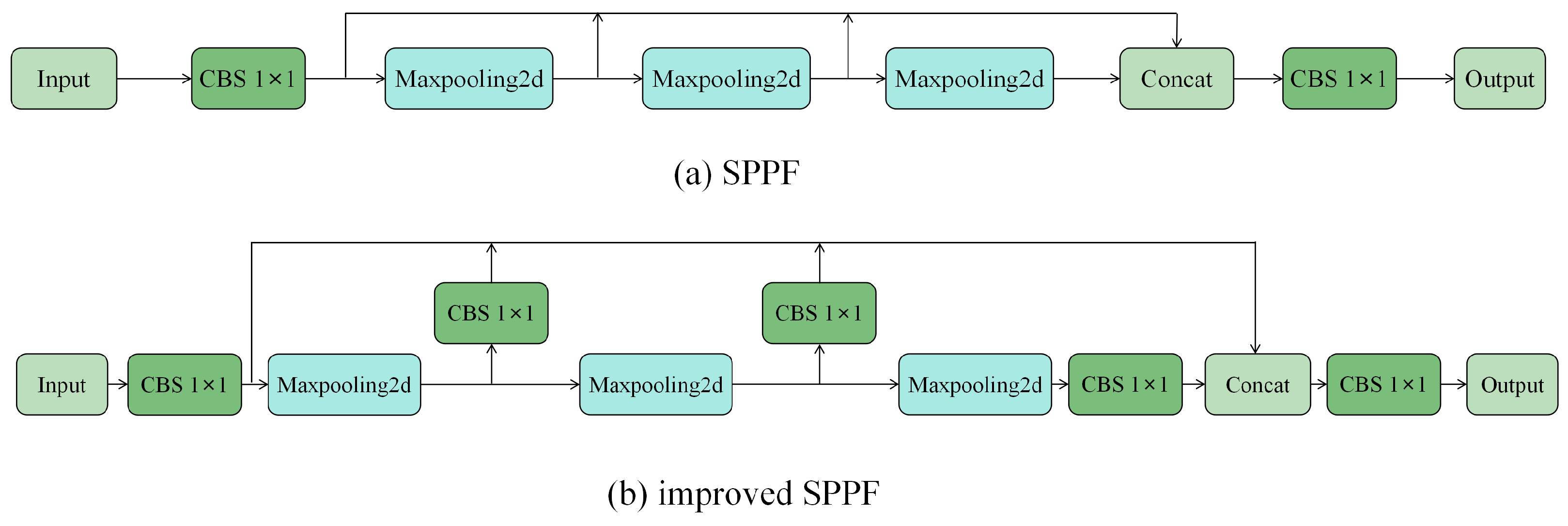
2.3. Improved SPPF Module
The SPPF module in YOLOv8n is located at the end of the Backbone, after a 32-fold downsampling of the image, and is commonly used for multi-scale feature aggregation, as illustrated in
Figure 3a. This module effectively enhances global information, particularly for features that exhibit distinct shape characteristics, such as the license plate. The max-pooling operation across different fields of view helps capture these features more effectively, making it well suited for license plate feature extraction. However, given that the license plate is a small target in comparison with various background elements (e.g., vehicles and trees) in surveillance scenarios, and considering that the license plate’s background and text colors are uniform, the features become sparse after 32-fold downsampling of the original image. To fully leverage the sparse features in the SPPF module, we propose an improvement to the original structure: adding a standard 1 × 1 convolutional module for fusing multi-channel spatial information, as shown in
Figure 3b.
As shown in the improved SPPF module in
Figure 3b, the input feature map is first processed by a 1 × 1 CBS convolution module, which performs feature fusion, batch normalization, and SiLU activation across all channels. This enhances the features and improves the network’s expressiveness and stability. The feature maps processed by the 1 × 1 CBS convolution module are then passed through three series-connected max-pooling layers, each using a 5 × 5 pooling kernel to capture the spatial features of the license plate at different scales. The outputs of each pooling layer are subsequently passed through a 1 × 1 CBS convolution module. The feature maps processed by the first 1 × 1 CBS convolution module are concatenated along the channel dimension and then fed into the next 1 × 1 standard convolution module. Compared with the original SPPF module, the addition of the 1 × 1 CBS convolution module after each max-pooling layer is specifically designed to enhance the nonlinear relationships between feature channels. By enabling independent weight learning for each channel, this modification facilitates smoother and richer information flow between the channels, which in turn helps to better capture the sparse features of the license plate and improves the accuracy of target recognition.
Importantly, the use of the 1 × 1 CBS module does not significantly increase computational overhead because 1 × 1 convolutions operate only across the channel dimension without expanding the spatial dimensions of the feature map. Experimental results show that the addition of the 1 × 1 convolutions increases the number of parameters by only 0.05M, accounting for just 1.6% of the total parameters. Thus, the proposed improvement achieves better feature utilization and target detectability with minimal computational cost.
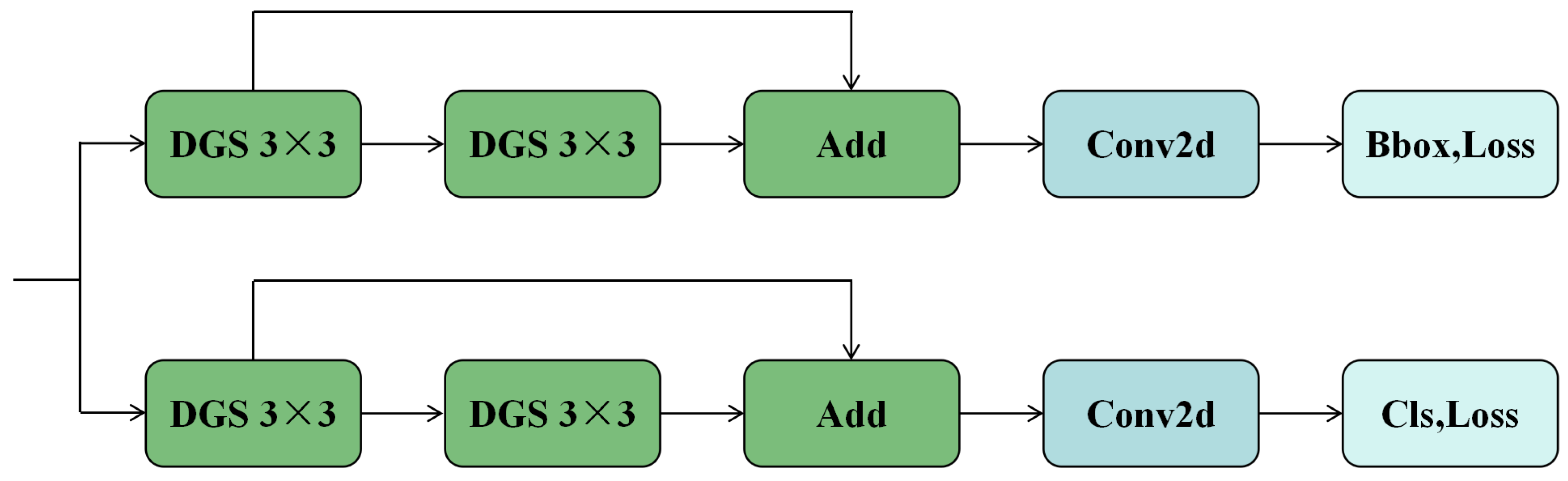
2.4. Improved Detection Head
As shown in
Figure 1, the feature extraction component of the detection head in YOLOv8n consists of two levels of CBS convolutional modules connected in series, followed by a convolutional layer. All convolution operations in the detection head use 3 × 3 kernels with a stride of 1. However, the detection head contains a large number of parameters, accounting for about one-fifth of the algorithm’s total computational load, which leads to inefficiencies in computation. To address this issue and better accommodate the small target characteristics and feature sparsity of the license plate, we propose an improved detection head structure, as illustrated in
Figure 4.
In the improved detection head, the conventional convolution used in the CBS convolution module is replaced with depth-separable convolution to reduce the number of parameters and enhance computational efficiency. To mitigate the potential loss of detail and further sparsification of the license plate features caused by the separable convolution, residual connections, as shown in
Figure 4, are introduced. These connections help enhance the network’s ability to capture fine-grained features.
Additionally, since the inputs P3, P4, and P5 to the detection head are features processed by the BatchNorm layers in the Backbone and Neck, they already reflect inter-sample statistics and variability in feature distributions across single-sample channels. Therefore, the BatchNorm in the CBS module of the detection head is replaced with GroupNorm.
The updated CBS module, with these modifications, is referred to as the Depthwise Separable Convolution, GroupNorm, SiLU module, or DGS for short.
DGS utilizes channel-wise grouping for normalization, which maintains feature distribution variability between channel groups while allowing for more efficient feature fusion within each group. This approach captures the consistency of feature distribution in adjacent areas of the license plate. The use of GroupNorm also improves training stability and reduces reliance on hardware resources [
22].
2.5. Improved Loss Function
2.5.1. WIoUv2 Loss Function
YOLOv8n uses CIoU as the default loss function, which has shown promise in optimizing box overlap, position matching, and shape consistency by incorporating centroid distance and aspect ratio penalty terms [
23]. However, the static loss calculation method of CIoU cannot dynamically adjust based on sample quality or training difficulty. As a result, the model tends to over-optimize easy samples while under-learning low-quality or difficult samples. This issue is particularly evident in license plate detection, where the targets are small and often suffer from low quality or difficulty due to factors like occlusion and adverse weather conditions. The static CIoU loss calculation negatively impacts the overall detection accuracy of the neural network. Moreover, when the predicted bounding box does not overlap with the ground truth (i.e., IoU is close to 0), the gradient of CIoU tends to vanish, leading to stagnant regression updates. This significantly slows down convergence, especially during the early stages of training, posing challenges to both model accuracy and training efficiency.
To address these limitations of CIoU, researchers introduced the WIoU series of loss functions [
24]. Among them, WIoUv2 tackles the issue of slow convergence in the later stages of training by incorporating a focusing mechanism. By dynamically adjusting the gradient gain, WIoUv2 enhances the model’s ability to focus on difficult samples while reducing the impact of easy samples on the loss function. The formula for WIoUv2 is defined as follows:
where
is the focusing coefficient and
is a hyperparameter used to adjust the value of the focusing coefficient. The
and
computation follows the same equation as shown in Equation (
2), where the * indicates that its value will be continuously updated based on each target detection during the training process.
Equation (
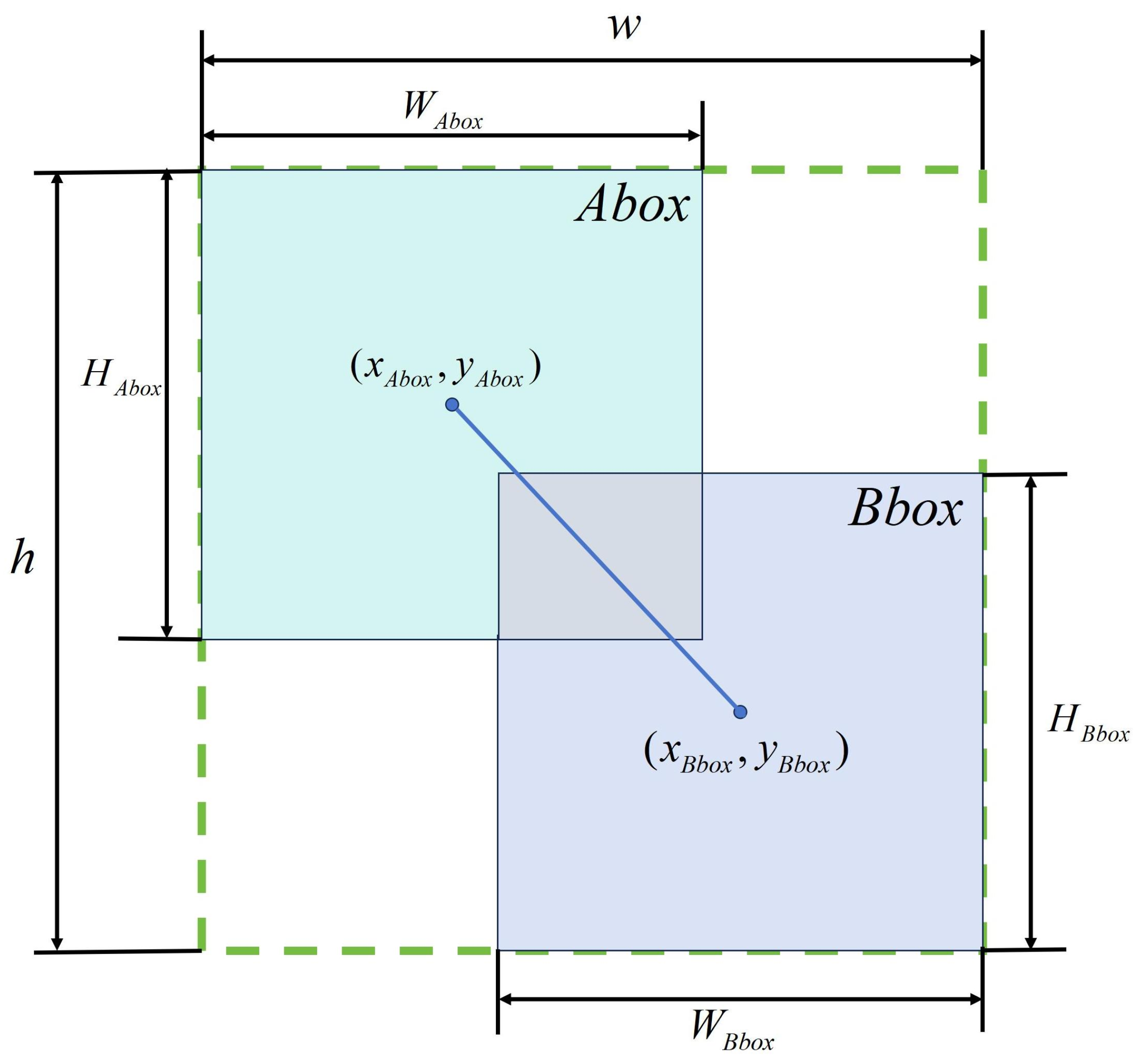
2) represents the complement of the intersection and the ratio of the predicted and target frames. As shown in
Figure 5, the
and
in Equation (
2) refer to the cyan-colored predicted frame in the upper-left corner and the blue-colored target frame in the lower-right corner, respectively.
In Equation (
1),
is the exponentially weighted moving average of
with momentum
m, used for dynamically updating the normalization factor to balance the gradient variations at different training stages [
24]. The parameter
m is given in Equation (
3).
where
t represents the epoch value and
n represents the batch size value.
By introducing , WIoUv2 can maintain a higher gradient gain in the later stages of training, addressing the issue of slower convergence speed in the later stages.
The second term,
, in Equation (
1) is defined as shown in Equation (
4).
where
is defined the same way as in Equation (
2), and
is defined as shown in Equation (
5).
where
and
represent the center coordinates of the predicted bounding box and the target bounding box, respectively, as shown in
Figure 5.
w and
h denote the width and height of the minimum enclosing box for the predicted and target bounding boxes, as illustrated by the green dashed box in
Figure 5.
The numerator part of Equation (
5) represents the squared Euclidean distance between the center points of the predicted bounding box and the target bounding box, reflecting the spatial positional differences between them. The denominator part normalizes this Euclidean distance by incorporating the squared width and height
of the minimum enclosing box of the predicted and target bounding boxes, thereby mitigating the impact of scale imbalance on weighting. The width and height parameters with the superscript * are excluded from gradient calculations to prevent gradient propagation from interfering with model training. Due to the attenuation characteristics of the exponential function shown in Equation (
5),
assigns lower weights to bounding boxes closer to the target and higher weights to those farther from the target. This enhances attention to occluded, small-scale, and multi-scale difficult targets, improving detection accuracy.
The application of and in WIoUv2 enables the model to better optimize difficult samples, thereby improving the overall performance of bounding box regression. It is particularly suitable for handling low-resolution, small targets, occluded license plates, and multi-scale challenging samples in license plate detection. Additionally, it facilitates more efficient convergence of the model during the later training stages, contributing to the overall enhancement of regression performance.
2.5.2. Improved WIoUv2 Loss Function
Since the aspect ratio of a license plate is typically fixed, we introduce an aspect ratio penalty term from CIoU into WIoUv2 to further enhance bounding box regression accuracy. This addition improves the detection of blurred license plates caused by motion, low-light conditions, and small license plates resulting from long-distance capture. CIoU effectively minimizes the deviation in the aspect ratio between the predicted and target bounding boxes by imposing shape constraints. By integrating CIoU with WIoUv2, the loss function is further optimized as:
where the parameter
is a weighting factor used to balance the dynamic distance weighting of
and the aspect ratio consistency term
. This helps reduce the impact of
on the detection accuracy of license plate images with aspect ratio deviations. Its definition is as follows:
where
represents the aspect ratio consistency between the predicted box and the target box. Its definition is as follows:
As shown in
Figure 5, in Equation (
8),
and
represent the width and height of the predicted box, while
and
represent the width and height of the target box.
3. Construction of Datasets
In deep learning model training, dataset diversity allows the model to learn a broader range of target features and scene variations, enhancing its adaptability and generalization in real-world applications. In license plate detection, the model must operate effectively across various real-world environments. Therefore, the dataset should encompass diverse conditions, including different lighting, weather variations, and occlusions, to improve model performance in complex scenarios.
Although existing license plate recognition datasets, such as the CCPD (Chinese City Parking Dataset) [
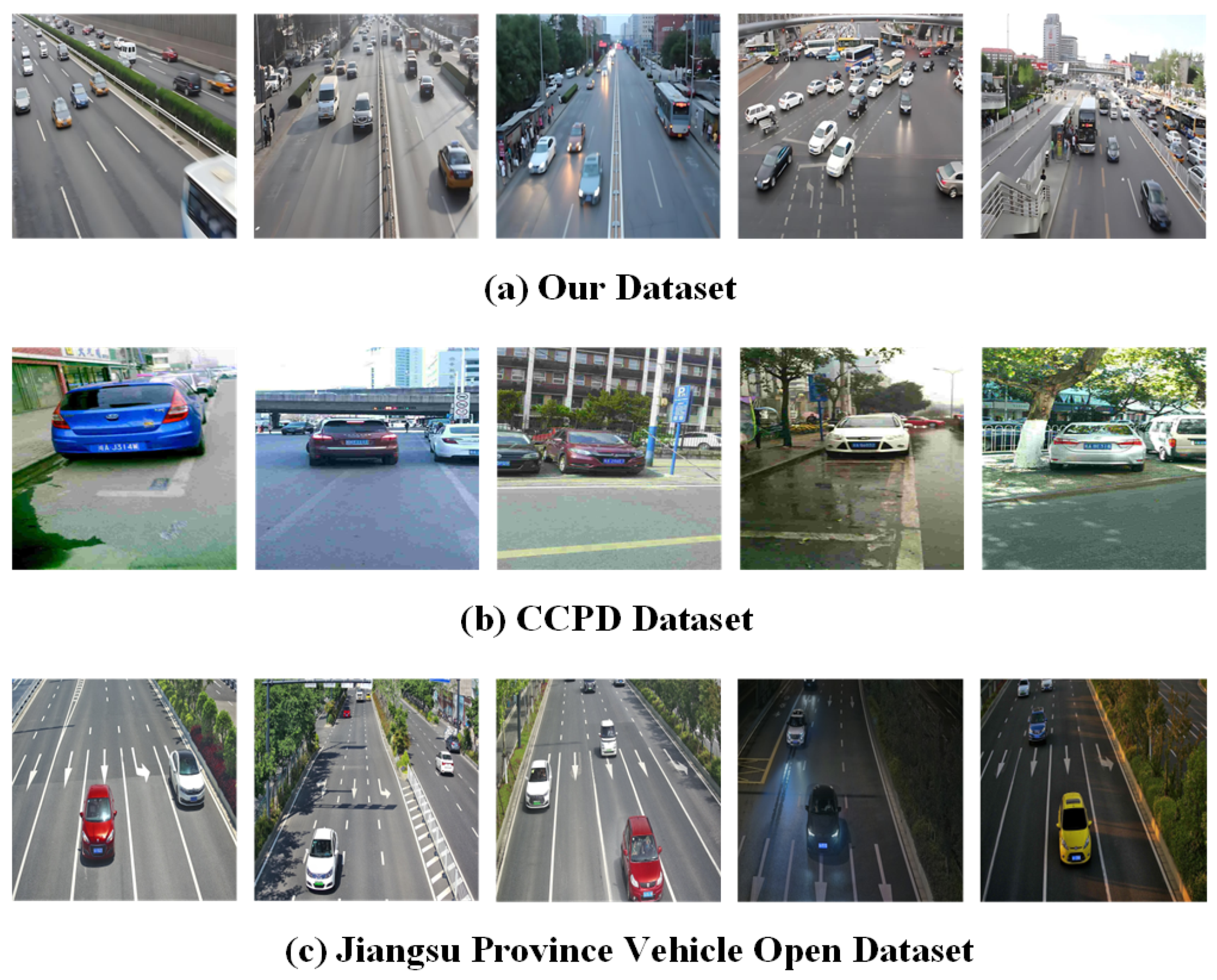
25], contain images captured under various weather conditions, they still present notable limitations. The images in the CCPD are typically taken from close range with high clarity, making them suitable for relatively controlled and static environments. Additionally, while the CCPD includes images featuring multiple license plates, these plates rarely occlude each other, and the spacing between them remains relatively wide. This fails to reflect the challenges posed by dense traffic scenarios, where overlapping or partial occlusions frequently occur. In real-world surveillance environments, cameras often capture license plates from greater distances, resulting in smaller and sometimes blurred images due to factors such as focal length, image quality, and motion. While existing datasets provide images under different weather conditions, they do not sufficiently address the reality of small, blurred license plate images commonly encountered in surveillance scenarios.
To bridge this gap, we selected images from the CCPD and UA-DETRAC datasets, supplemented them with additional manually collected and annotated images, and constructed a new dataset specifically tailored for license plate detection in surveillance scenarios. The sample distribution of this constructed dataset is presented in
Table 1.
According to
Table 1, our dataset exhibits a relatively balanced distribution across various real-world conditions. Notably, 19.7% of the images were captured at night (1135 samples), and 14.9% under rainy conditions (861 samples), both of which are typically more challenging for license plate detection algorithms. In terms of imaging angle, 24.8% of the images (1435 samples) feature lateral views of vehicles, which often present oblique or partially occluded license plates. Additionally, 60.7% of the samples (3509 images) involve distant targets, further increasing detection difficulty. These distributions collectively enhance the dataset’s realism and diversity, making it well suited for evaluating performance in complex surveillance scenarios.
Figure 6 presents representative example images from our constructed dataset.
As shown in
Figure 6, the dataset includes a variety of conditions in real-world surveillance scenarios.
Figure 6a,b depict scenes under different lighting conditions, with the former representing a daytime environment and the latter capturing a nighttime scene. These variations demonstrate the model’s ability to detect license plates under both optimal and challenging low-light conditions, where illumination can significantly impact detection accuracy. Additionally,
Figure 6c,d showcase images taken with sunny and rainy weather, further highlighting the model’s robustness in diverse weather conditions. These scenarios involve varying visibility due to glare, reflections, and rain, which are common challenges in real-world environments.
The dataset also includes images captured from various angles to reflect the different perspectives encountered in surveillance.
Figure 6e presents a frontal view, while
Figure 6f shows a lateral view captured in a dense traffic scenario. The latter is particularly challenging as vehicles are closely packed, often leading to occlusion or overlapping of license plates. This emphasizes the model’s ability to detect and differentiate multiple license plates in such high-density environments. Finally, the dataset spans a range of target distances, from close-up shots in
Figure 6g to distant views in
Figure 6h. This ensures that the model is capable of detecting license plates effectively across different distances, from nearby vehicles to those further away, making it adaptable to a variety of real-world surveillance settings.
To effectively highlight the superiority of our dataset, we conducted a comparative analysis with widely used existing datasets. The results of this comparison are presented in
Figure 7.
As shown in
Figure 7, our dataset exhibits greater diversity in vehicle types, license plate angles, and lighting conditions, making it particularly well suited for license plate recognition in complex environments.
To provide a more objective comparison between our dataset and others, we defined small license plate targets as those with a size smaller than 10 pixels, medium-sized targets as those ranging from 10 to 32 pixels, and large targets as those exceeding 32 pixels. Based on this classification, we statistically analyzed the number of targets and the proportion of small, medium, and large license plates in each image across the three datasets. Additionally, we calculated the average number of targets per image in each of the three datasets to better understand the overall density and complexity of the images. The statistical results are presented in
Table 2.
As shown in
Table 2, our dataset contains an average of 7.77 license plate targets per image, reflecting the complex backgrounds, high target density, and frequent occlusion scenarios typical of real-world surveillance environments. Additionally, the majority of the license plates are of medium and small sizes, accounting for 62.5% and 37.1% of the total, respectively. Compared with the CCPD and Jiangsu datasets, where large license plates dominate, our dataset presents a significantly higher proportion of small and densely distributed targets. This characteristic more accurately replicates the challenging conditions encountered in actual surveillance footage, providing a more rigorous and realistic benchmark for license plate detection systems.
4. Experiments
4.1. Datasets Processing
For data preprocessing, we resized all images to 640 × 640 pixels to ensure consistency in input dimensions, improving model stability and efficiency while reducing computational overhead. The dataset was split into 80% for training, 10% for validation, and 10% for testing, ensuring a balanced and representative distribution.
To enhance the model’s adaptability to real-world conditions, we applied various data augmentation techniques. We introduced noise types like Gaussian and salt-and-pepper noise to simulate interference from surveillance systems. We also adjusted image brightness to replicate overexposed and underexposed scenarios, improving the model’s ability to handle extreme lighting variations. Additionally, we applied blurring techniques such as Gaussian and motion blur to mimic the effects of fast-moving vehicles or camera instability. These augmentations expanded the dataset to 5783 high-quality samples, increasing its diversity and robustness in complex surveillance environments.
4.2. Experiment Environment
The experimental setup runs on the Ubuntu 20.04 operating system with an AMD EPYC 7642 48-core processor and an NVIDIA RTX 3090 GPU with 24 GB of video memory. The system is equipped with 80 GB of hard disk space. The deep learning framework used is PyTorch 1.11.0, with CUDA 11.3.0 and Python 3.8. A detailed overview of the experimental environment is provided in
Table 3.
For the training setup, a learning rate decay strategy was implemented using the SGD optimizer. The training process consisted of 300 epochs, with an initial learning rate of 0.01 and a batch size of 64. The hyperparameter details are summarized in
Table 4. Additionally, eight worker threads were configured to accelerate data loading. The model’s initial weights were initialized using the YOLOv8n.pt file. Throughout training, we recorded the loss and accuracy for each epoch while also monitoring the learning rate decay. Upon completion of training, the final model weights were used to evaluate the test set, and the corresponding test results were generated.
4.3. Evaluation Metrics
This paper evaluates the accuracy of license plate detection using precision, recall, and mean average precision (mAP@0.5). Model size is determined by the number of parameters, while real-time processing capability is measured using FPS.
Precision refers to the proportion of correctly predicted positive samples among all predicted positives, while recall represents the proportion of correctly classified positive samples among all actual positive samples. The calculation methods for these metrics are provided in Equations (9) and (10).
where FP (False Positives) refers to the number of negative samples incorrectly classified as positive, while FN (False Negatives) represents the number of positive samples misclassified as negative.
AP measures the accuracy of a single class, with a higher AP indicating better model performance. The calculation formula for AP is provided in Equation (
11). mAP is the average of AP values across multiple classes and is used to evaluate the overall detection accuracy for multiple targets. Its calculation formula is given in Equation (
12).
where
r represents the recall value, and
denotes the corresponding precision at a given
r value.
mAP@0.5 refers to the mean average precision when the IoU threshold is set to 0.5. Additionally, mAP@0.5:0.95 describes the mean average precision calculated over IoU thresholds ranging from 0.5 to 0.95, with an interval of 0.05.
Parameters serve as a key metric for assessing the complexity of deep learning models, representing the total number of trainable weights and biases. A larger number of parameters generally enhances the model’s representational capability and computational demand but may also lead to increased training time and higher resource requirements.
FPS is a crucial indicator of real-time performance, representing the number of frames processed per second by the deep learning model. A higher FPS value signifies better real-time performance.
GFLOPs is a metric of a model’s computational complexity, indicating how many billion floating-point operations it performs per second during inference. A higher GFLOPs typically implies greater computational demands, which can affect inference speed and hardware efficiency, especially in resource-constrained environments.
4.4. Comparative Experiment
To comprehensively showcase the advantages of the improved model, we conducted comparative experiments using several classical models, including YOLOv5n, YOLOv6n, YOLOv9t, YOLOv10n, and Faster R-CNN. Additionally, our experiments also included transformer-based models like RT-DETR, as well as specific license plate detection methods proposed by other researchers. The results of these experiments are presented in
Table 5.
Based on the results in
Table 5, our model outperforms most others in detection accuracy. However, when compared with two-stage models like Faster R-CNN and transformer-based models like RT-DETR, our model has slightly lower mAP values. Despite this, it offers significant advantages in terms of parameters and FPS. Our model achieves 86 FPS, much higher than Faster R-CNN’s 27.4 FPS and RT-DETR’s 37.4 FPS, while maintaining a low parameter count of 2.1 M, compared with 43.2 M for Faster R-CNN and 32.0 M for RT-DETR. This makes our model more efficient for real-time detection, particularly in resource-constrained environments.
In contrast, compared with other YOLO versions, such as YOLOv5n, YOLOv6n, YOLOv9t, and YOLOv10n, our model offers superior accuracy while maintaining real-time performance. For example, while YOLOv5n achieves a higher FPS (152 FPS), its mAP@0.5 is 90.2%, which is lower than our model’s 94.4%. Thus, our improved YOLOv8n strikes an optimal balance between accuracy and processing speed, making it suitable for demanding detection tasks in real-time scenarios.
When compared with other research on specific license plate detection methods, which incorporate attention mechanisms or optimize detection heads and loss functions, our model demonstrates similar mAP performance. However, it holds a clear advantage in terms of parameters and FPS. With just 2.1 M parameters and a frame rate of 86 FPS, our model is more capable of performing real-time detection in surveillance scenarios, where efficiency is paramount.
To better illustrate the superiority of our improved network, we select several representative detection images for comparison, and the comparative results are presented in
Figure 8.
In the first comparison image, although Faster R-CNN demonstrates higher accuracy than our YOLOv8n overall, it exhibits noticeable shortcomings in detecting small, distant targets located in the upper-left corner of the image, failing to precisely capture blurry license plates and distant objects. Particularly in scenarios where license plates become indistinct and targets are small and far away, Faster R-CNN struggles to accurately localize these targets, resulting in significant missed detections. Conversely, our improved YOLOv8n maintains superior localization accuracy when addressing these fuzzy, distant, and small targets, significantly reducing missed and false detections.
In other images, as the angles of license plates and targets vary, our improved YOLOv8n consistently demonstrates strong robustness. While YOLOv5n, YOLOv6n, YOLOv9t, and YOLOv10n perform effectively in relatively simple scenarios, their detection accuracies sharply decline in more complex conditions involving substantial angular variations, particularly for side or tilted license plates, leading to inaccurate localization and false detections. For instance, in the fourth comparison image, YOLOv5n, YOLOv6n, and YOLOv9t fail to detect portions of the tilted license plate, resulting in missed detections. In contrast, our improved YOLOv8n benefits from optimized feature extraction and detection modules, ensuring more precise target localization in complex scenarios involving diverse angles and variable backgrounds. Additionally, the resulting detection boxes exhibit greater compactness and adaptability to angular variations, effectively capturing license plate targets at various angles with enhanced accuracy. Based on the overall comparison, our model is particularly well suited for detecting small-sized license plates, especially those with target pixels smaller than 10 pixels.
While our improved YOLOv8n demonstrates strong performance in a variety of scenarios, it is important to acknowledge areas where there is still room for improvement. Specifically, when compared with RT-DETR, a transformer-based model known for its robust handling of complex scenarios, our model faces challenges in certain situations.
In
Figure 9, our model performs well overall, but it struggles with severely tilted and very small license plates, leading to missed detections. In contrast, RT-DETR demonstrates more robustness in handling these scenarios, accurately detecting even the severely tilted and small license plates. This indicates a potential area for improvement in our model, particularly in enhancing its ability to handle such extreme cases where the angle or size of the license plate affects detection accuracy.
We also conducted experiments on license plate images captured under various conditions to evaluate the robustness and performance of the model across different scenarios. The detailed results are shown in
Table 6.
As shown in
Table 6, our model demonstrates strong detection performance in favorable conditions such as daytime, sunny, frontal, and close views, achieving high precision, recall, and mAP scores. However, the performance drops notably in the lateral condition, where the precision and recall decrease to 88.2% and 81.8%, respectively. This suggests that oblique angles pose a greater challenge for accurate detection, likely due to distortions and reduced visibility of the license plate.
In deep learning model training, selecting an appropriate loss function is crucial, as different loss functions can significantly influence the model’s performance. Therefore, we conducted comparative experiments involving WIoU and other mainstream loss functions to identify the optimal choice. The experimental results are presented in
Table 7.
In the comparative experiments on loss functions, the improved WIoU demonstrates significant performance enhancements. Compared with traditional mainstream loss functions such as CIoU, DIoU, GIoU, EIoU, and SIoU, the improved WIoU achieves the highest precision (P) of 92.5% and recall (R) of 85.7%. Moreover, regarding mean average precision (mAP), the improved WIoU attains 93.5% on mAP@0.5 and 53.8% on mAP@0.5:0.95, surpassing all other methods, including the previously superior WIoUv2. These experimental results clearly demonstrate that the improved WIoU, by incorporating a penalty term for the aspect ratio, effectively enhances the model’s robustness in detecting targets across various scales. This advancement notably improves the detection accuracy of small targets in complex backgrounds and challenging surveillance perspectives, addressing the limitations of traditional IoU-based loss functions in terms of recall and generalization, thereby substantially elevating the model’s overall performance.
4.5. Ablation Experiment
Compared with the original YOLOv8n model, our improved model introduces enhancements in the C2f module, the SPPF module, the detection head, and the loss function. To comprehensively verify the effectiveness of these improvements, we designed six sets of ablation experiments as follows:
- (1)
The original YOLOv8n network.
- (2)
Scheme (1) combined with the improved C2f module.
- (3)
Scheme (1) combined with the improved SPPF module.
- (4)
Scheme (1) combined with the improved detection head module.
- (5)
Scheme (1) with the optimized loss function.
- (6)
Scheme (1) integrating all enhancements, including the improved C2f module, the improved SPPF module, the improved detection head module, and the optimized loss function.
The experimental environment remains consistent with the description provided in
Section 4.2, and the detailed experimental results are presented in
Table 8.
Compared with the baseline network, introducing the improved C2f module slightly increased mAP@0.5 from 90.9% to 91.1%, while reducing the parameter count from 3.1 M to 2.7 M, achieving a more lightweight model design. However, the FPS decreased from 151 to 112 due to the additional computational overhead from multi-scale feature fusion.
Incorporating the improved SPPF module resulted in a notable increase in mAP@0.5 from 90.9% to 91.5% and mAP@0.5:0.95 from 50.7% to 51.9%. The inclusion of a 1 × 1 convolution layer after each max-pooling layer enhanced multi-scale feature fusion, improving detection in complex backgrounds.
Adding the improved detection head module led to further accuracy improvements, with mAP@0.5 rising to 91.1%, while reducing the parameter count to 2.4 M. The use of depthwise separable convolutions and GroupNorm optimized the model’s efficiency and stability, particularly under small-batch training conditions.
The improved WIoU loss function boosted mAP@0.5 to 93.5% and mAP@0.5:0.95 to 53.8%, significantly enhancing boundary regression accuracy and model stability, especially for low-quality samples.
When all proposed modules were combined, the model showed substantial improvements across all metrics: mAP@0.5 increased to 94.4%, precision improved to 92.8%, and recall rose to 87.9%, with the parameter count reducing to 2.1 M. While FPS decreased to 86, it remained sufficient for real-time detection.
In summary, the ablation study highlights that integrating these improvements not only boosts accuracy but also optimizes computational efficiency, striking an effective balance between accuracy, real-time performance, and adaptability to complex scenarios.
To intuitively illustrate the contribution of each module, we selected several representative images for comparison, and the comparative results are presented in
Figure 10.
By testing four typical scenarios (
Figure 10A–D), the improved YOLOv8n demonstrates significant performance enhancements in license plate detection under complex backgrounds, long distances, occlusion, and low-light conditions.
In Scenario A, the baseline YOLOv8n struggles to detect small license plates in dense traffic, often leading to missed detections. Introducing the improved C2f module significantly improves small-target detection by enhancing feature fusion across scales. The improved SPPF module, with an added 1 × 1 convolution after max-pooling, strengthens global feature extraction and reduces background interference, making license plates more prominent. Furthermore, the improved detection head, incorporating depthwise separable convolution and residual connections, refines detection accuracy for small and blurred license plates. Optimizing the loss function enhances boundary regression, leading to more precise localization in complex backgrounds. As a result, the improved model effectively minimizes missed detections and delivers more accurate results.
In Scenario C, the baseline YOLOv8n struggles with long-distance, occluded, and multi-angle license plates, resulting in frequent missed detections—especially for distant and tilted targets. The improved C2f module greatly enhances detection under these conditions, while the improved SPPF module, with refined multi-scale pooling and 1 × 1 convolution, boosts small-target recognition. The enhanced detection head, incorporating depth-separable convolution and residual connections, improves recognition in complex backgrounds and at various angles. Meanwhile, the optimized loss function enhances boundary regression, further improving localization accuracy and robustness in challenging environments.
In Scenario D, where low-light conditions and strong reflections degrade performance, the baseline model performs poorly. The improved C2f module enhances detection under low-light conditions, while the improved SPPF module strengthens global information extraction, improving feature representation in complex lighting environments. The improved detection head, leveraging depth-separable convolution, boosts fine-grained feature extraction, ensuring stable performance despite drastic lighting variations. Additionally, the optimized loss function improves boundary accuracy, significantly reducing missed detections and enhancing detection precision in low-light conditions.
In summary, the progressive integration of these modules significantly enhances YOLOv8n’s performance in complex scenarios, particularly for multiple license plates, occlusions, challenging backgrounds, and low-light conditions. The optimized loss function further refines boundary regression accuracy and robustness, allowing YOLOv8n to maintain high real-time detection accuracy while adapting to diverse application scenarios. Ultimately, the improved model delivers more stable and reliable license plate detection results.
To further investigate the channel allocation strategy within the multi-scale feature extraction branch of our improved C2f module, we conducted an ablation study by evaluating different feature split ratios. Specifically, we examined how varying the number of channels allocated to the 5 × 5 and 7 × 7 convolutional layers impacts overall performance. The experimental results are presented in
Table 9.
As shown in
Table 9, the original channel split ratio of C/2 for the 5 × 5 convolution and C/4 for the 7 × 7 convolution achieves a better trade-off among detection accuracy, model size, and computational complexity. Although allocating more channels to the deeper convolutions (e.g., 3/4C or 4/5C to the 5 × 5 layer) slightly improves the mAP, it also leads to a significant increase in the number of parameters and GFLOPs. On the other hand, allocating fewer channels (e.g., 1/3C or 1/4C) results in reduced computational cost but at the expense of detection accuracy. Therefore, the default C/2 and C/4 configuration provides a well-balanced design, offering competitive performance while maintaining efficiency.
5. Conclusions
This paper proposes an improved license plate detection method based on the YOLOv8n network, targeting challenges such as complex backgrounds, varying target scales, and dense objects in surveillance scenarios. By redesigning the C2f module, enhancing the SPPF feature fusion, and introducing a lightweight detection head with depthwise separable convolution and GroupNorm, the model achieves better detection of small license plates and improved robustness in complex environments. In addition, the improved WIoU loss function replaces the original CIoU, further boosting bounding box regression accuracy, especially for low-quality samples.
Experimental results demonstrate that the improved model significantly enhances detection accuracy: mAP@0.5 increases from 90.9% in the baseline model to 94.4%, precision rises from 90.2% to 92.8%, and recall improves from 82.9% to 87.9%. Additionally, the inference speed reaches 86 FPS, meeting the requirements for real-time detection and showcasing the model’s efficiency and robustness in complex environments.
Although the improved model achieves a good balance between accuracy and real-time performance, there is still room for improvement. For instance, license plate detection in severely tilted license plate appearances and for very small targets remains a challenge. Future research will focus on optimizing the network structure to enhance adaptability in such scenarios and improve detection accuracy for small targets. Additionally, lightweight design will be a key area of future work, aimed at improving real-time inference efficiency on resource-constrained hardware platforms while maintaining efficient detection despite hardware limitations.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}