
Fast Intra-Prediction Mode Decision Algorithm for Versatile Video Coding Based on Gradient and Convolutional Neural Network


Abstract
1. Introduction
- A fast intra-normal mode selection algorithm based on gradient analysis is proposed. In this paper, the gradient of the current CU block is calculated using the Laplace operator, and the most likely prediction direction is determined based on the image gradient, thereby skipping less probable prediction modes.
- An early termination algorithm for intra-advanced modes based on CNN is proposed. Two efficient neural network models, MIP-NET and ISP-NET, are developed to assess whether to halt the prediction process for MIP and ISP modes prematurely. By leveraging the neural network’s intelligent decision-making capabilities, redundant mode prediction computations are minimized, thereby enhancing the efficiency of intra-prediction mode selection without compromising coding performance.
2. Related Works
2.1. Fast CU Partitioning Methods in VVC
2.2. Fast Mode Decision Methods in VVC
3. Preliminaries: Data Analaysis
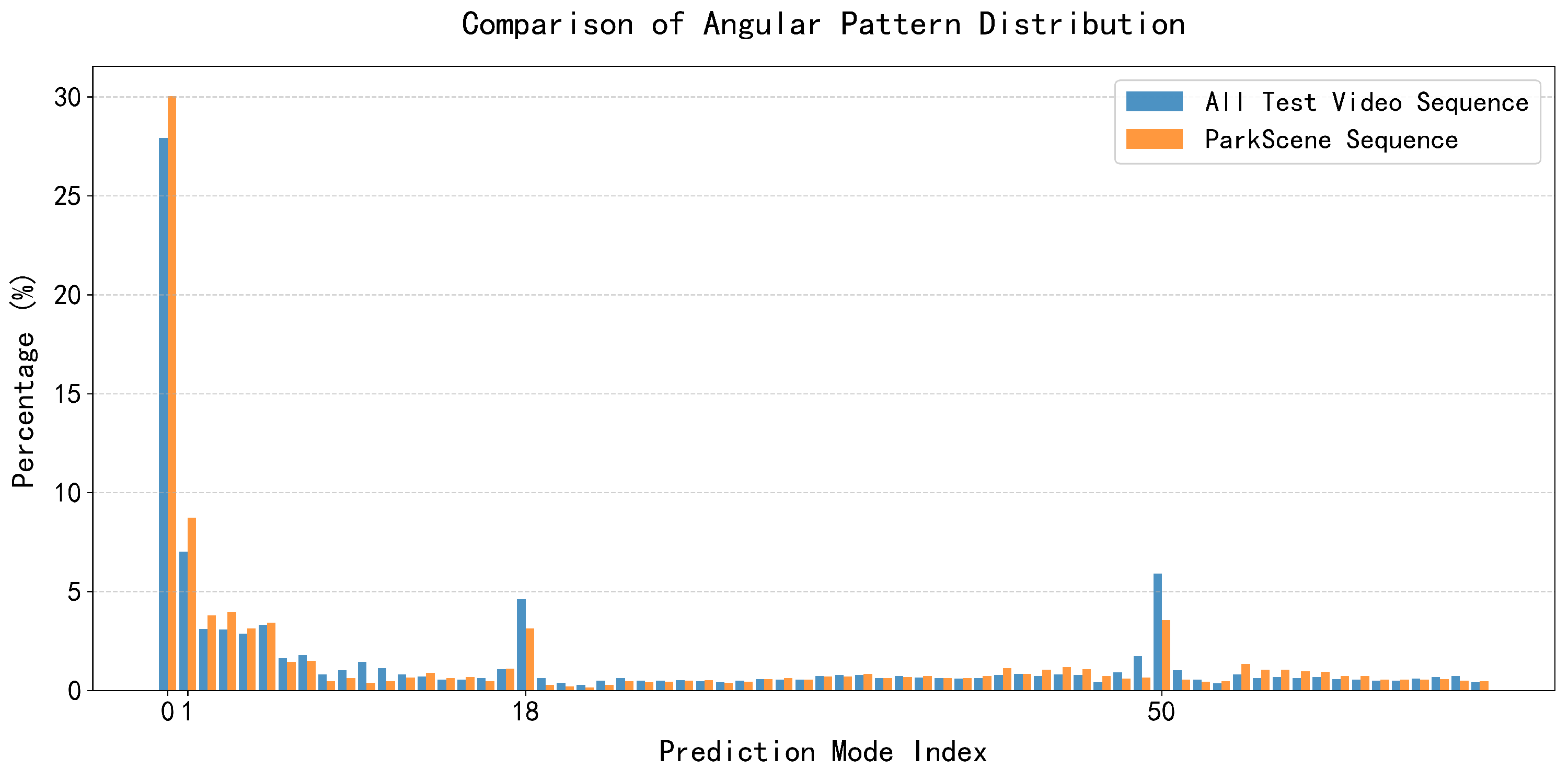
3.1. Modal Distribution Analysis of Angular Mode
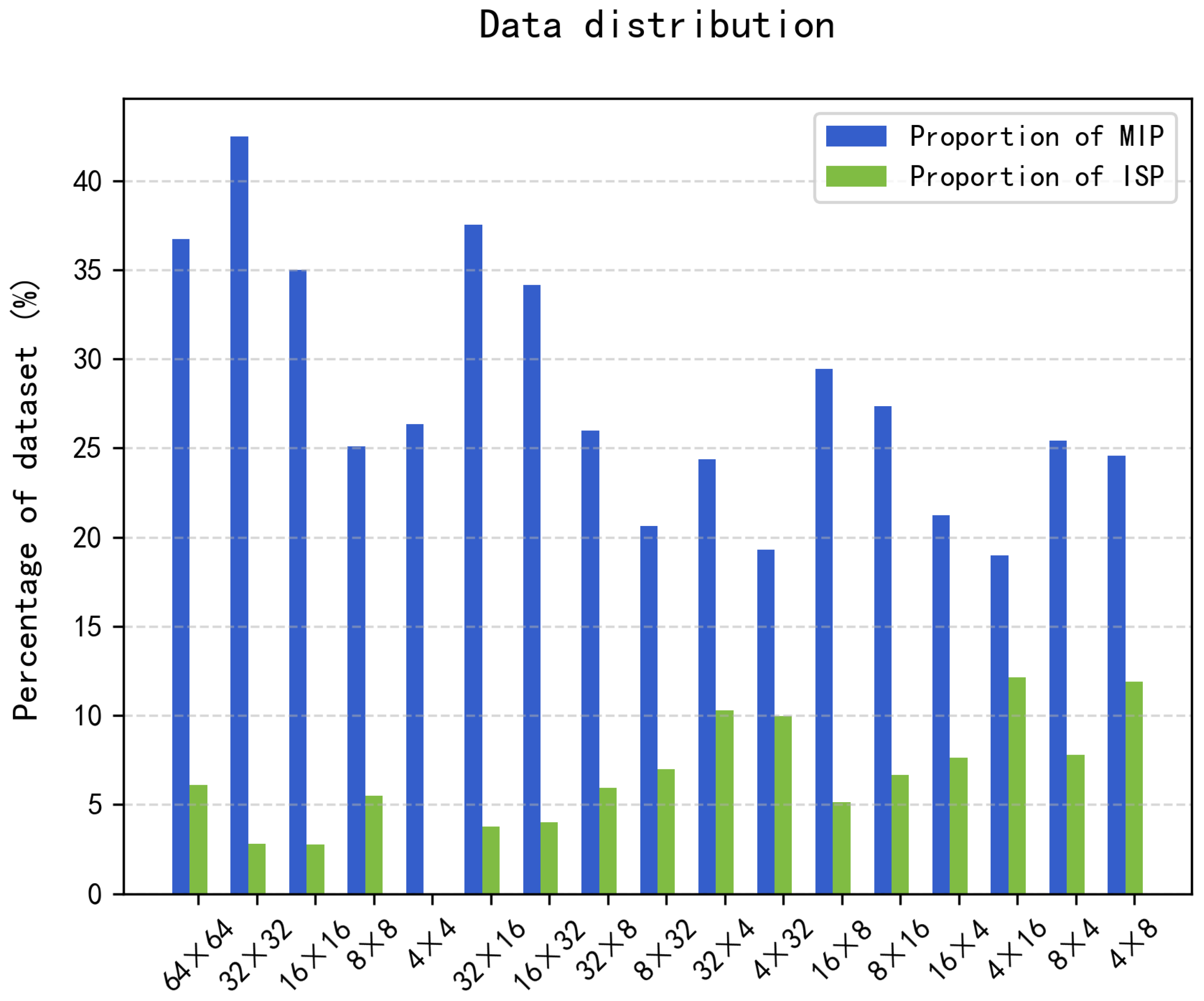
3.2. Analysis of MIP and ISP Mode Distribution
- Most angle modes, ISP, and MIP advanced modes are not often selected.
- The selection of both angle and advanced modes is highly correlated with image texture.
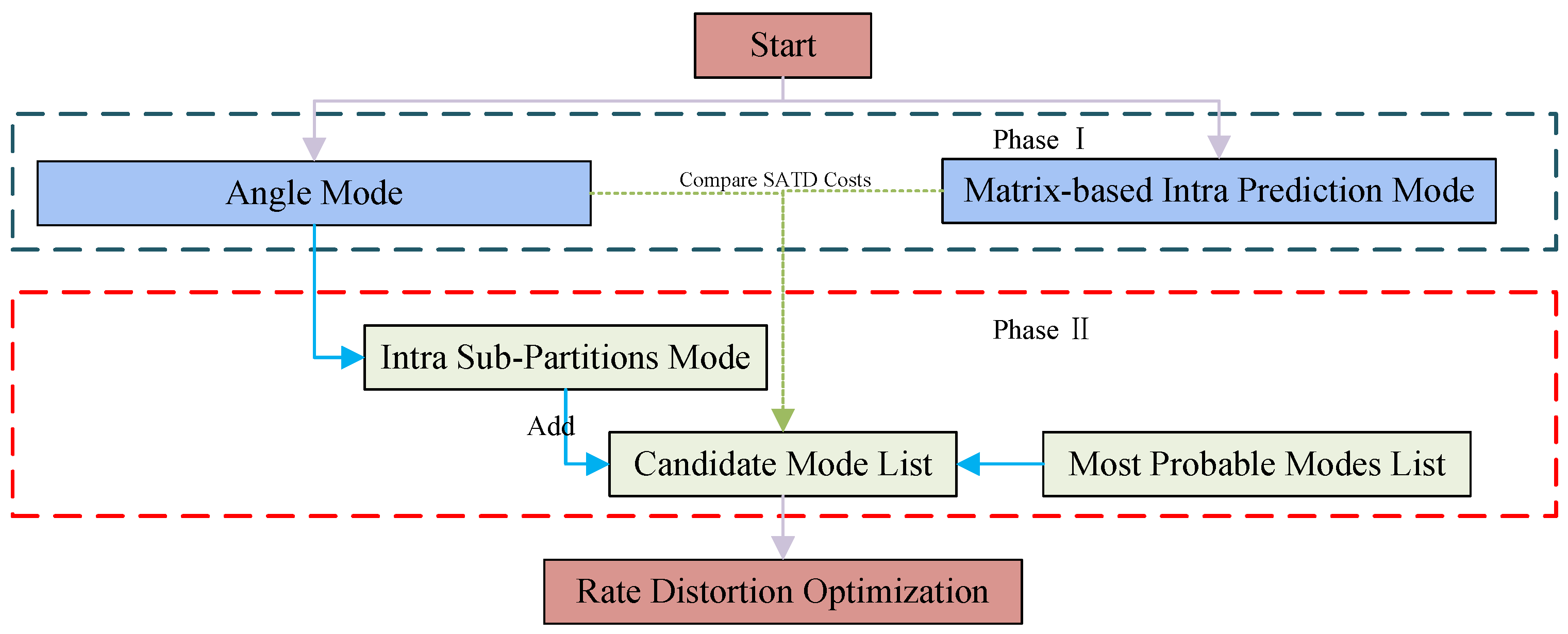
4. The Proposed Method
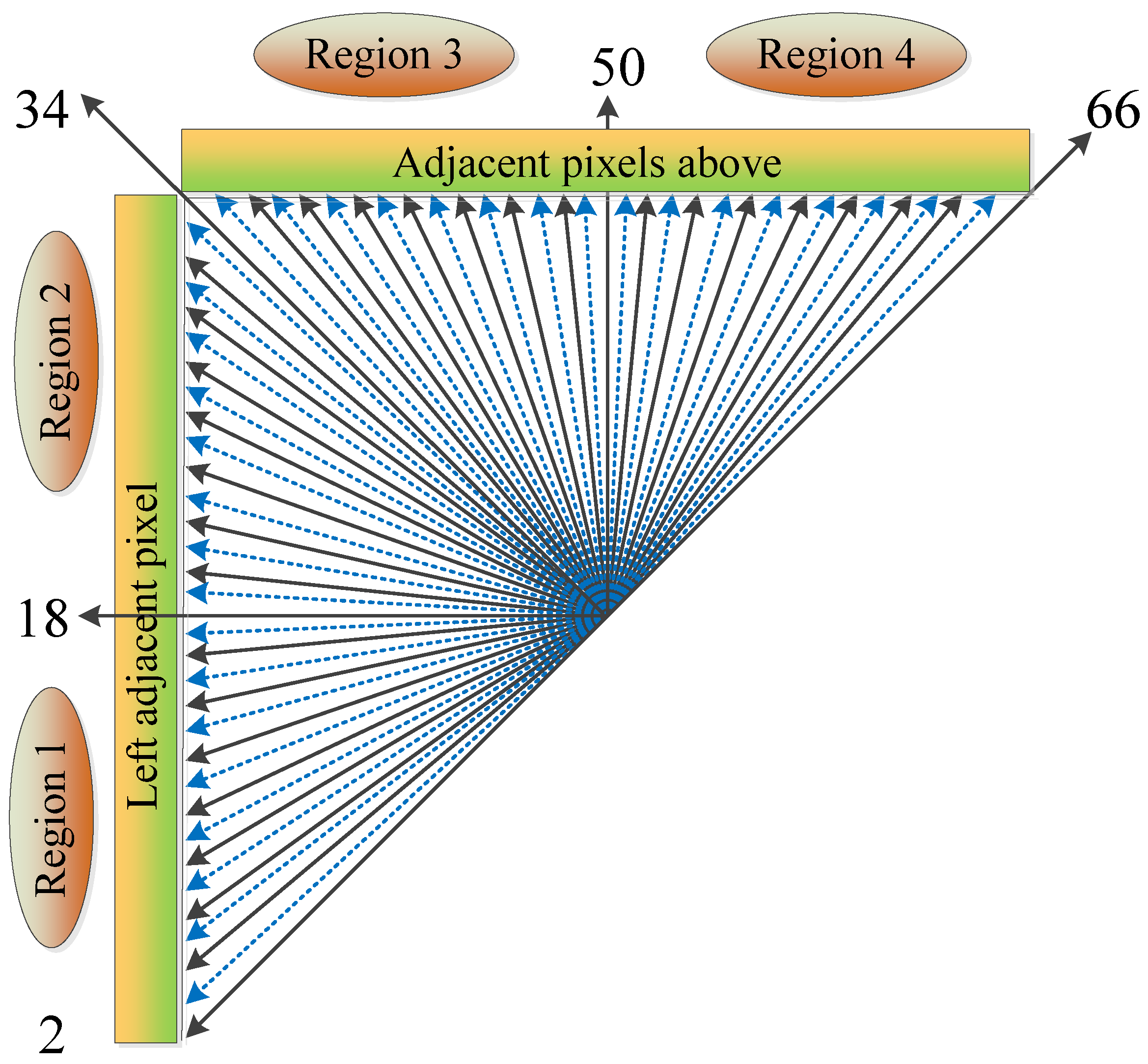
4.1. Intra-Angular Mode Prediction
- If condition is met, we further compare the gradient values of and . If condition is satisfied, Regions 2, 3, and 4 are skipped; otherwise, Regions 1, 3, and 4 are skipped.
- If condition is met, we further compare the gradient values of and . If condition is satisfied, Regions 1, 2, and 3 are skipped; otherwise, Regions 1, 2, and 4 are skipped.
4.2. CNN Models for ISP and MIP
5. Experimental Results and Analyses
5.1. Experimental Configuration
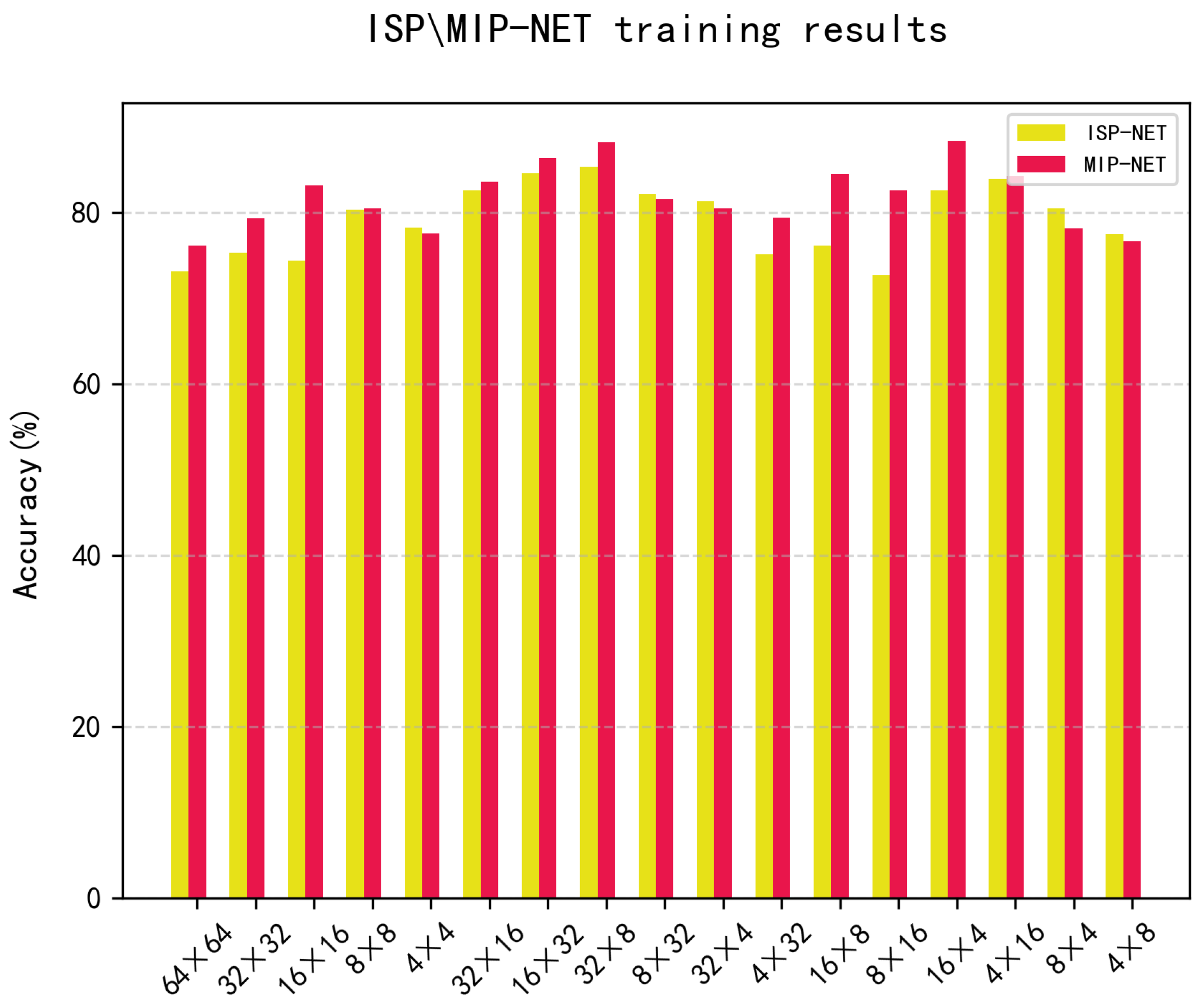
5.2. CNN Training
5.3. Ablation Experiments
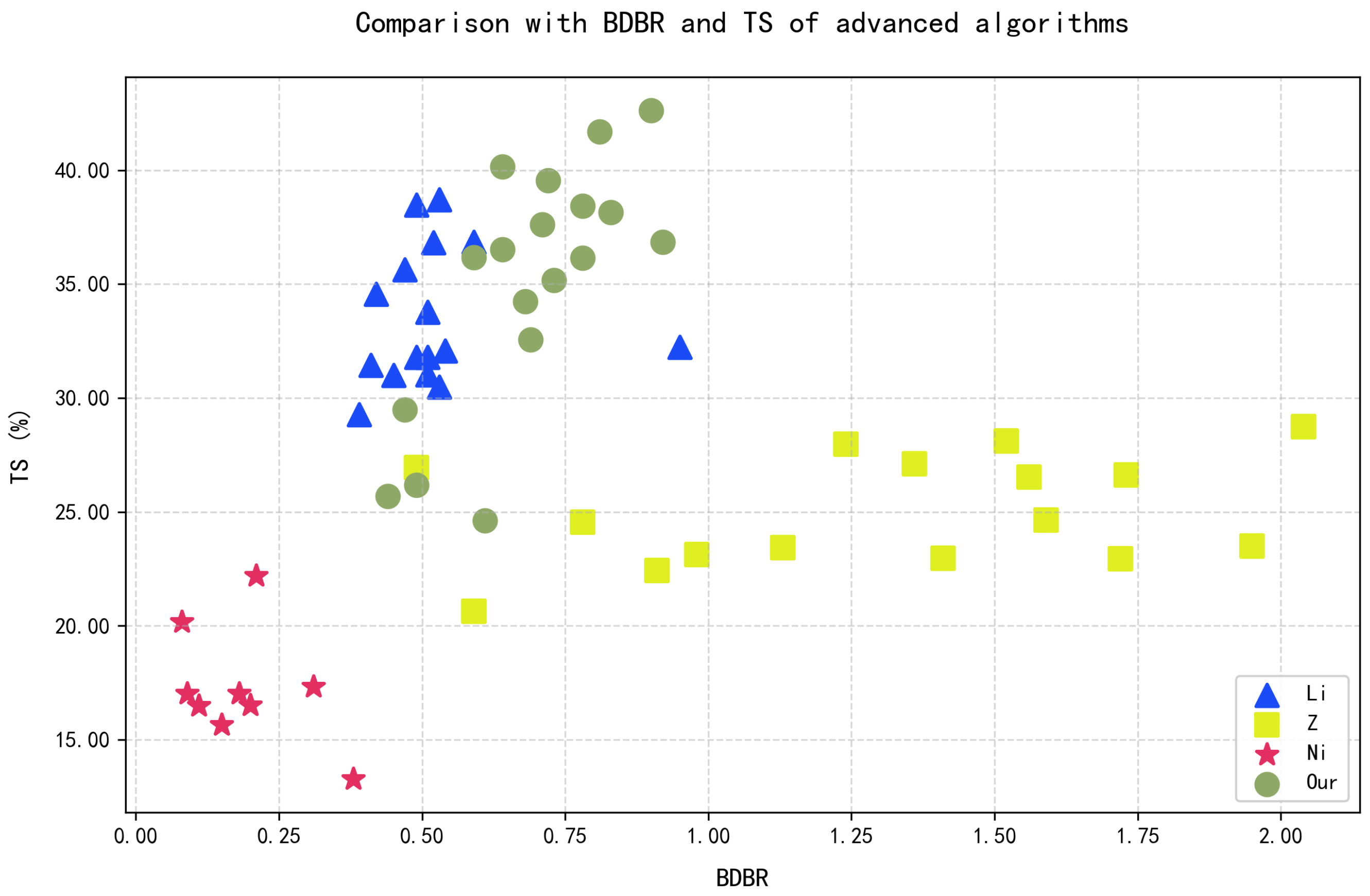
5.4. Comparison with State-of-the-Art Algorithms
5.5. Experimental Results and Fast Coding Discussion
- Feature extraction optimization: The current algorithm mainly depends on texture features. In the future, more coding context information (such as MPM reference list) can be combined to improve the accuracy of mode prediction;
- Extension of machine learning method: In addition to CNN, lightweight models such as decision tree and support vector machine (SVM) can be explored to adapt to the computing power constraints of mobile terminals;
- Multi link joint optimization: in addition to intra-mode decision-making, future work can further explore the acceleration strategies of coding unit (CU) division, loop filtering, and inter coding to achieve more comprehensive VVC complexity optimization.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bross, B.; Wang, Y.K.; Ye, Y. Overview of the Versatile Video Coding (VVC) Standard and Its Applications. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3736–3764. [Google Scholar] [CrossRef]
- Wang, M.; Zhang, J.; Huang, L.; Xiong, J. Machine Learning-Based Rate Distortion Modeling for VVC/H.266 Intra-Frame. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Filipe, J.N.; Tavora, L.M.; Faria, S.M.; Navarro, A.; Assuncao, P.A. Complexity Reduction Methods for Versatile Video Coding: A Comparative Review. Digit. Signal Process. 2025, 160, 105021. [Google Scholar] [CrossRef]
- Pfaff, J.; Filippov, A.; Liu, S.; Zhao, X.; Chen, J.; De-Luxan-Hernandez, S.; Wiegand, T.; Rufitskiy, V.; Ramasubramonian, A.K.; Van Der Auwera, G. Intra Prediction and Mode Coding in VVC. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3834–3847. [Google Scholar] [CrossRef]
- Tissier, A.; Mercat, A.; Amestoy, T.; Hamidouche, W.; Vanne, J.; Menard, D. Complexity Reduction Opportunities in the Future VVC Intra Encoder. In Proceedings of the 2019 IEEE 21st International Workshop on Multimedia Signal Processing (MMSP), Kuala Lumpur, Malaysia, 27–29 September 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Huo, J.; Sun, Y.; Wang, H. Unified Matrix Coding for NN Originated MIP in H.266/VVC. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 1635–1639. [Google Scholar] [CrossRef]
- De-Luxan-Hernandez, S.; George, V.; Ma, J.; Nguyen, T.; Schwarz, H.; Marpe, D.; Wiegand, T. An Intra Subpartition Coding Mode for VVC. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1203–1207. [Google Scholar] [CrossRef]
- Chang, Y.J.; Jhu, H.J.; Jiang, H.Y. Multiple Reference Line Coding for Most Probable Modes in Intra Prediction. In Proceedings of the 2019 Data Compression Conference (DCC), Snowbird, UT, USA, 26–29 March 2019; p. 559. [Google Scholar] [CrossRef]
- Sun, T.; Wang, Y.; Huang, Z.; Sun, J. STRANet: Soft-Target and Restriction-Aware Neural Network for Efficient VVC Intra Coding. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 11993–12005. [Google Scholar] [CrossRef]
- Huang, Y.H.; Chen, J.J.; Tsai, Y.H. Speed Up H.266/QTMT Intra-Coding Based on Predictions of ResNet and Random Forest Classifier. In Proceedings of the 2021 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 10–12 January 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Chen, J.J.; Huang, Y.H.; Yu, H.Y.; Tsai, Y.H. A Fast H.266/QTMT Intra Coding Scheme Based on Predictions of Learned Models. J. Chin. Inst. Eng. 2024, 47, 703–718. [Google Scholar] [CrossRef]
- Li, T.; Xu, M.; Tang, R.; Chen, Y.; Xing, Q. DeepQTMT: A Deep Learning Approach for Fast QTMT-based CU Partition of Intra-mode VVC. IEEE Trans. Image Process. 2021, 30, 5377–5390. [Google Scholar] [CrossRef]
- Feng, A.; Liu, K.; Liu, D.; Li, L.; Wu, F. Partition Map Prediction for Fast Block Partitioning in VVC Intra-Frame Coding. IEEE Trans. Image Process. 2023, 32, 2237–2251. [Google Scholar] [CrossRef] [PubMed]
- Huang, Y.; Yu, J.; Wang, D.; Lu, X. Learning-Based Fast Splitting and Directional Mode Decision for VVC Intra Prediction. IEEE Trans. Broadcast. 2024, 70, 681–692. [Google Scholar] [CrossRef]
- Si, L.; Yan, A.; Zhang, Q. Fast CU Decision Method Based on Texture Characteristics and Decision Tree for Depth Map Intra-Coding. EURASIP J. Image Video Process. 2024, 2024, 34. [Google Scholar] [CrossRef]
- Li, Y.; He, Z.; Zhang, Q. Fast Decision-Tree-Based Series Partitioning and Mode Prediction Termination Algorithm for H.266/VVC. Electronics 2024, 13, 1250. [Google Scholar] [CrossRef]
- Wu, S.; Shi, J.; Chen, Z. HG-FCN: Hierarchical Grid Fully Convolutional Network for Fast VVC Intra Coding. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 5638–5649. [Google Scholar] [CrossRef]
- Chen, L.; Cheng, B.; Zhu, H.; Qin, H.; Deng, L.; Luo, L. Fast Versatile Video Coding (VVC) Intra Coding for Power-Constrained Applications. Electronics 2024, 13, 2150. [Google Scholar] [CrossRef]
- Park, S.H.; Kang, J.W. Context-Based Ternary Tree Decision Method in Versatile Video Coding for Fast Intra Coding. IEEE Access 2019, 7, 172597–172605. [Google Scholar] [CrossRef]
- Park, S.h.; Kang, J.W. Fast Multi-Type Tree Partitioning for Versatile Video Coding Using a Lightweight Neural Network. IEEE Trans. Multimed. 2021, 23, 4388–4399. [Google Scholar] [CrossRef]
- Zheng, W.; Yang, C.; An, P.; Huang, X.; Shen, L. Learning-Based CU Partition Prediction for Fast Panoramic Video Intra Coding. Expert Syst. Appl. 2024, 258, 125187. [Google Scholar] [CrossRef]
- Li, M.; Wang, Z.; Zhang, Q. Fast CU Size Decision and Intra-Prediction Mode Decision Method for H.266/VVC. EURASIP J. Image Video Process. 2024, 7, 16–52. [Google Scholar] [CrossRef]
- Ding, G.; Lin, X.; Wang, J.; Ding, D. Accelerating QTMT-based CU Partition and Intra Mode Decision for Versatile Video Coding. J. Vis. Commun. Image Represent. 2023, 94, 103832. [Google Scholar] [CrossRef]
- Ni, C.T.; Lin, S.H.; Chen, P.Y.; Chu, Y.T. High Efficiency Intra CU Partition and Mode Decision Method for VVC. IEEE Access 2022, 10, 77759–77771. [Google Scholar] [CrossRef]
- Li, W.; Fan, C. Intra-Mode Decision Based on Lagrange Optimization Regarding Chroma Coding. Appl. Sci. 2024, 14, 6480. [Google Scholar] [CrossRef]
- Yang, H.; Shen, L.; Dong, X.; Ding, Q.; An, P.; Jiang, G. Low-Complexity CTU Partition Structure Decision and Fast Intra Mode Decision for Versatile Video Coding. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 1668–1682. [Google Scholar] [CrossRef]
- Liu, Z.; Li, T.; Chen, Y.; Wei, K.; Xu, M.; Qi, H. Deep Multi-Task Learning Based Fast Intra-Mode Decision for Versatile Video Coding. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 6101–6116. [Google Scholar] [CrossRef]
- Dong, X.; Shen, L.; Yu, M.; Yang, H. Fast Intra Mode Decision Algorithm for Versatile Video Coding. IEEE Trans. Multimed. 2022, 24, 400–414. [Google Scholar] [CrossRef]
- Zouidi, N.; Belghith, F.; Kessentini, A.; Masmoudi, N. Fast Intra Prediction Decision Algorithm for the QTBT Structure. In Proceedings of the 2019 IEEE International Conference on Design & Test of Integrated Micro & Nano-Systems (DTS), Gammarth, Tunisia, 28 April–1 May 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Zouidi, N.; Kessentini, A.; Hamidouche, W.; Masmoudi, N.; Menard, D. Multitask Learning Based Intra-Mode Decision Framework for Versatile Video Coding. Electronics 2022, 11, 4001. [Google Scholar] [CrossRef]
- Finley, J.P. The Differential Virial Theorem with Gradient- and Laplacian-dependent Operator Formulas. Chem. Phys. Lett. 2017, 667, 244–246. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar] [CrossRef]
- Boyce, J.; Suehring, K.; Li, X. JVET-J1010: JVET Common Test Conditions and Software Reference Configurations. In Proceedings of the Joint Video Experts Team (JVET) of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29/WG 11 10th Meeting, San Diego, CA, USA, 10–20 April 2018; pp. 10–20. [Google Scholar]
- Agustsson, E.; Timofte, R. NTIRE 2017 Challenge on Single Image Super-Resolution: Dataset and Study. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1122–1131. [Google Scholar] [CrossRef]
- Gysel, P.; Pimentel, J.; Motamedi, M.; Ghiasi, S. Ristretto: A Framework for Empirical Study of Resource-Efficient Inference in Convolutional Neural Networks. IEEE Trans. Neural Networks Learn. Syst. 2018, 29, 5784–5789. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Solution | Angular Modes | Advanced Mode | BDBR (%) | TS (%) |
|---|---|---|---|---|
| [22] | Pixel value deviation | x | 0.72 | 39.86 |
| [26] | Gradient descent | x | 0.54 | 25.51 |
| [24] | Sobel operator | x | 0.19 | 17.30 |
| [27] | Convolutional neural network | Convolutional neural network | 1.56 | 30.12 |
| [16] | Ensemble learning | Ensemble learning | 0.25 | 12.82 |
| [30] | Multi-task learning | Multi-task learning | 1.77 | 21.69 |
| Proposed | Laplace operator | Convolutional neural network | 0.69 | 35.04 |
| VTM version | 10.0 |
| Video sequence | Tango2, FoodMarket4, CatRobot1, ParkRunning3, MarketPlace, RitualDance, Cactus, BasketballDrive, RaceHorses, BQMall, BasketballDrill, FourPeople, Johnny, BasketballDrillText, SlideEditing |
| Frames | 80 |
| QP | {22, 27, 32, 37} |
| Angle Mode | ISP Mode | MIP Mode |
|---|---|---|
| 70% | 5% | 25% |
| CU Size W × h | Layer 1 Channel | Residual I | Residual II | Residual III | Residual IV | F1 | F2 |
|---|---|---|---|---|---|---|---|
| 64 × 64 | 32 | P | P- | P | P- | 256 | 64 |
| 32 × 32 | 32 | P | P | P | P- | 128 | 64 |
| 16 × 16 | 16 | P | P | P | P | 128 | 64 |
| 32 × 16 | 16 | H | P | P | 128 | 64 | |
| 16 × 32 | 16 | V | P | P | 128 | 64 | |
| 32 × 8 | 16 | H | H | 128 | 64 | ||
| 8 × 32 | 16 | V | V | 128 | 64 | ||
| 32 × 4 | 16 | H | H | 128 | 64 | ||
| 4 × 32 | 16 | V | V | 128 | 64 | ||
| 16 × 8 | 8 | H | P | 96 | 48 | ||
| 8 × 16 | 8 | V | P | 96 | 48 | ||
| 16 × 4 | 8 | H | 96 | 48 | |||
| 4 × 16 | 8 | V | 96 | 48 | |||
| 8 × 8 | 8 | P | 64 | 32 | |||
| 8 × 4 | 4 | P | 64 | 32 | |||
| 4 × 8 | 4 | P | 64 | 32 | |||
| 4 × 4 | 4 | P | 64 | 32 |
| Class | Test Sequence | 1 | 2 | Proposed | |||
|---|---|---|---|---|---|---|---|
| BDBR (%) | TS (%) | BDBR (%) | TS (%) | BDBR (%) | TS (%) | ||
| Tango2 | 0.76 | 23.56 | 0.28 | 12.7 | 0.92 | 36.84 | |
| A1 | FoodMarket4 | 0.62 | 29.27 | 0.32 | 13.1 | 0.90 | 42.62 |
| Campfire | 0.75 | 31.75 | 0.36 | 11.5 | 0.83 | 38.15 | |
| DaylightRoad2 | 0.59 | 26.81 | 0.26 | 11.2 | 0.68 | 34.24 | |
| A2 | ParkRunning3 | 0.61 | 33.32 | 0.28 | 10.9 | 0.64 | 40.15 |
| CatRobot | 0.56 | 27.89 | 0.30 | 11.4 | 0.78 | 38.42 | |
| Kimono | 0.60 | 25.96 | 0.25 | 10.5 | 0.59 | 36.18 | |
| B | Cactus | 0.62 | 29.05 | 0.16 | 10.7 | 0.71 | 37.61 |
| BQTerrace | 0.52 | 26.57 | 0.23 | 11.0 | 0.73 | 35.18 | |
| BasketballDrill | 0.37 | 23.56 | 0.22 | 8.7 | 0.47 | 29.48 | |
| C | PartyScene | 0.42 | 29.42 | 0.25 | 10.6 | 0.64 | 36.52 |
| RaceHorsesC | 0.51 | 30.25 | 0.24 | 9.5 | 0.69 | 32.55 | |
| BasketballPass | 0.46 | 21.57 | 0.17 | 6.3 | 0.49 | 26.17 | |
| D | BlowingBubble | 0.32 | 24.92 | 0.20 | 7.5 | 0.44 | 25.69 |
| RaceHorses | 0.48 | 20.23 | 0.13 | 5.7 | 0.61 | 24.62 | |
| FourPeople | 0.59 | 31.28 | 0.31 | 12.3 | 0.78 | 36.14 | |
| E | Johnny | 0.62 | 27.41 | 0.34 | 11.3 | 0.81 | 41.68 |
| KristenAndSara | 0.56 | 28.46 | 0.34 | 12.3 | 0.72 | 39.54 | |
| Average | 0.55 | 27.27 | 0.26 | 10.39 | 0.69 | 35.04 | |
| Class | Test Sequence | Li [22] | Z [30] | Ni [24] | Proposed | ||||
|---|---|---|---|---|---|---|---|---|---|
| BDBR (%) | TS (%) | BDBR (%) | TS (%) | BDBR (%) | TS (%) | BDBR (%) | TS (%) | ||
| Tango2 | 0.49 | 31.79 | 0.98 | 23.13 | – | – | 0.92 | 36.84 | |
| A1 | FoodMarket4 | 0.47 | 35.64 | 0.91 | 22.43 | 0.09 | 17.04 | 0.90 | 42.62 |
| Campfire | 0.49 | 38.47 | 0.78 | 24.54 | – | – | 0.83 | 38.15 | |
| DaylightRoad2 | 0.51 | 33.78 | 1.59 | 24.64 | – | – | 0.68 | 34.24 | |
| A2 | ParkRunning3 | 0.52 | 36.82 | 0.59 | 20.63 | – | – | 0.64 | 40.15 |
| CatRobot | 0.54 | 32.08 | 1.13 | 23.43 | 0.21 | 22.21 | 0.78 | 38.42 | |
| Kimono | 0.59 | 36.85 | – | – | 0.08 | 20.18 | 0.59 | 36.18 | |
| B | Cactus | – | – | 1.36 | 27.11 | 0.15 | 15.66 | 0.71 | 37.61 |
| BQTerrace | 0.45 | 30.99 | 0.49 | 26.94 | – | – | 0.73 | 35.18 | |
| BasketballDrill | 0.39 | 29.27 | 1.52 | 28.12 | – | – | 0.47 | 29.48 | |
| C | PartyScene | 0.53 | 38.71 | 1.24 | 27.97 | 0.18 | 17.03 | 0.64 | 36.52 |
| RaceHorsesC | 0.51 | 31.79 | 2.04 | 28.74 | 0.11 | 16.50 | 0.69 | 32.55 | |
| BasketballPass | – | – | 1.41 | 22.96 | 0.38 | 13.28 | 0.49 | 26.17 | |
| D | BlowingBubbles | 0.41 | 31.45 | 1.56 | 26.53 | – | – | 0.44 | 25.69 |
| RaceHorses | 0.51 | 31.02 | 2.04 | 28.74 | – | – | 0.61 | 24.62 | |
| FourPeople | 0.53 | 30.49 | 1.73 | 23.63 | 0.20 | 16.52 | 0.78 | 36.14 | |
| E | Johnny | 0.42 | 34.56 | 1.72 | 22.95 | 0.31 | 17.34 | 0.81 | 41.68 |
| KristenAndSara | 0.95 | 32.24 | 1.95 | 23.50 | – | – | 0.72 | 39.54 | |
| Average | 0.51 | 33.51 | 1.77 | 21.69 | 0.19 | 17.30 | 0.69 | 35.04 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, N.; Wang, Z.; Zhang, Q.; He, L.; Zhang, W. Fast Intra-Prediction Mode Decision Algorithm for Versatile Video Coding Based on Gradient and Convolutional Neural Network. Electronics 2025, 14, 2031. https://doi.org/10.3390/electronics14102031
Li N, Wang Z, Zhang Q, He L, Zhang W. Fast Intra-Prediction Mode Decision Algorithm for Versatile Video Coding Based on Gradient and Convolutional Neural Network. Electronics. 2025; 14(10):2031. https://doi.org/10.3390/electronics14102031
Chicago/Turabian StyleLi, Nana, Zhenyi Wang, Qiuwen Zhang, Lei He, and Weizheng Zhang. 2025. "Fast Intra-Prediction Mode Decision Algorithm for Versatile Video Coding Based on Gradient and Convolutional Neural Network" Electronics 14, no. 10: 2031. https://doi.org/10.3390/electronics14102031
APA StyleLi, N., Wang, Z., Zhang, Q., He, L., & Zhang, W. (2025). Fast Intra-Prediction Mode Decision Algorithm for Versatile Video Coding Based on Gradient and Convolutional Neural Network. Electronics, 14(10), 2031. https://doi.org/10.3390/electronics14102031