
Vehicle Detection in Videos Leveraging Multi-Scale Feature and Memory Information

Abstract
1. Introduction
- We analyze and design a multi-scale feature fusion method to improve the adaptability of the static detector to the vehicle scale. The method considers the characteristics of each feature scale and the complexity of temporal operations.
- We propose a parallel memory network for feature enhancement. It establishes a framework for simultaneously aggregating multi-scale features.
- We verify the proposed video vehicle detection network on the UA-DETRAC and ImageNet VID dataset, obtaining satisfactory detection accuracy.
2. Related Works
2.1. Vehicle Detection in Images
2.2. Vehicle Detection in Videos
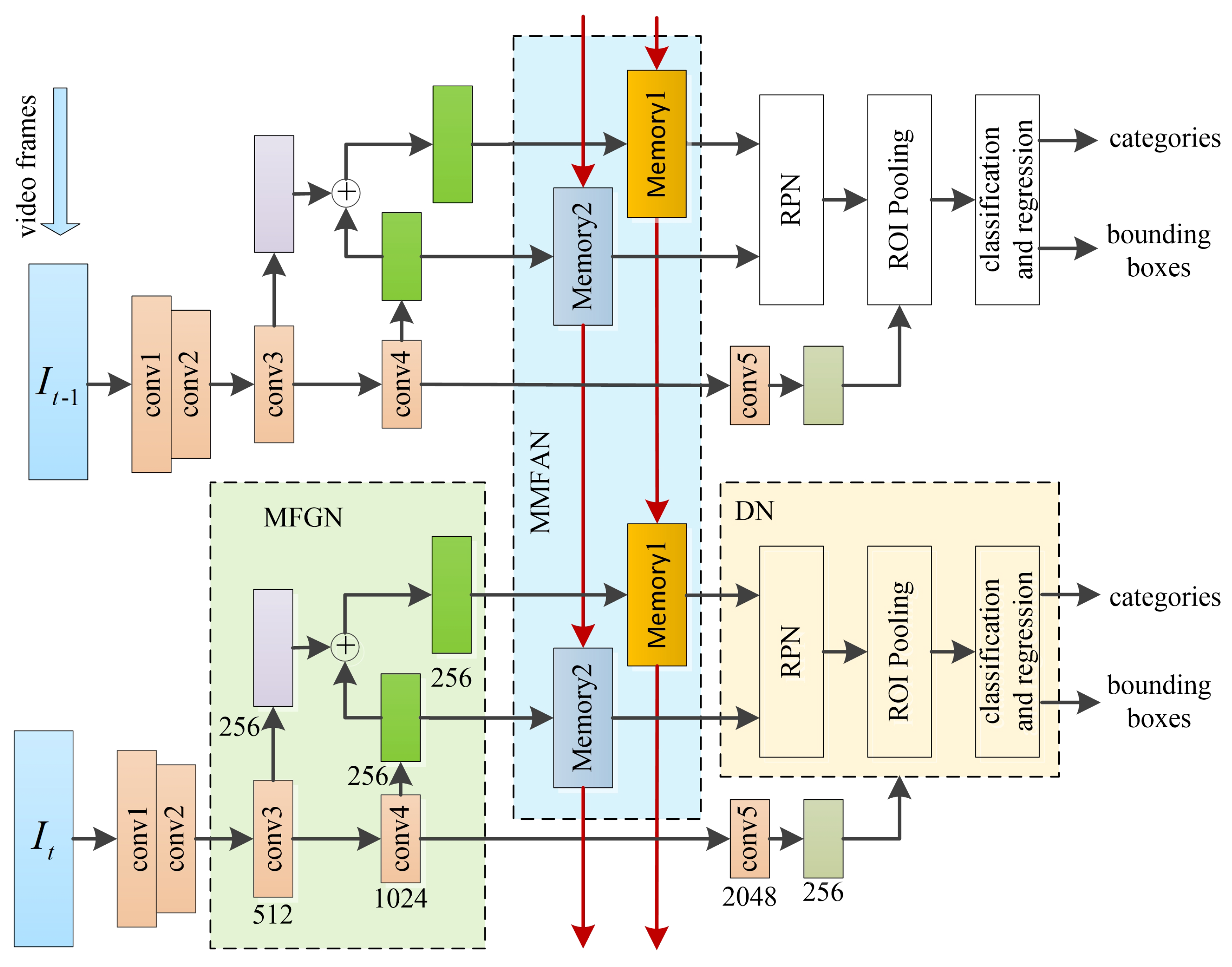
3. Method
3.1. Multi-Scale Feature Generation Network
3.2. Memory-Based Multi-Scale Feature Aggregation Network
4. Experiments
4.1. Experimental Settings
4.1.1. Datasets
4.1.2. Evaluation Metrics
4.1.3. Implementation Details
4.2. Ablation Study
4.2.1. Analysis of Multi-Scale Feature Strategies
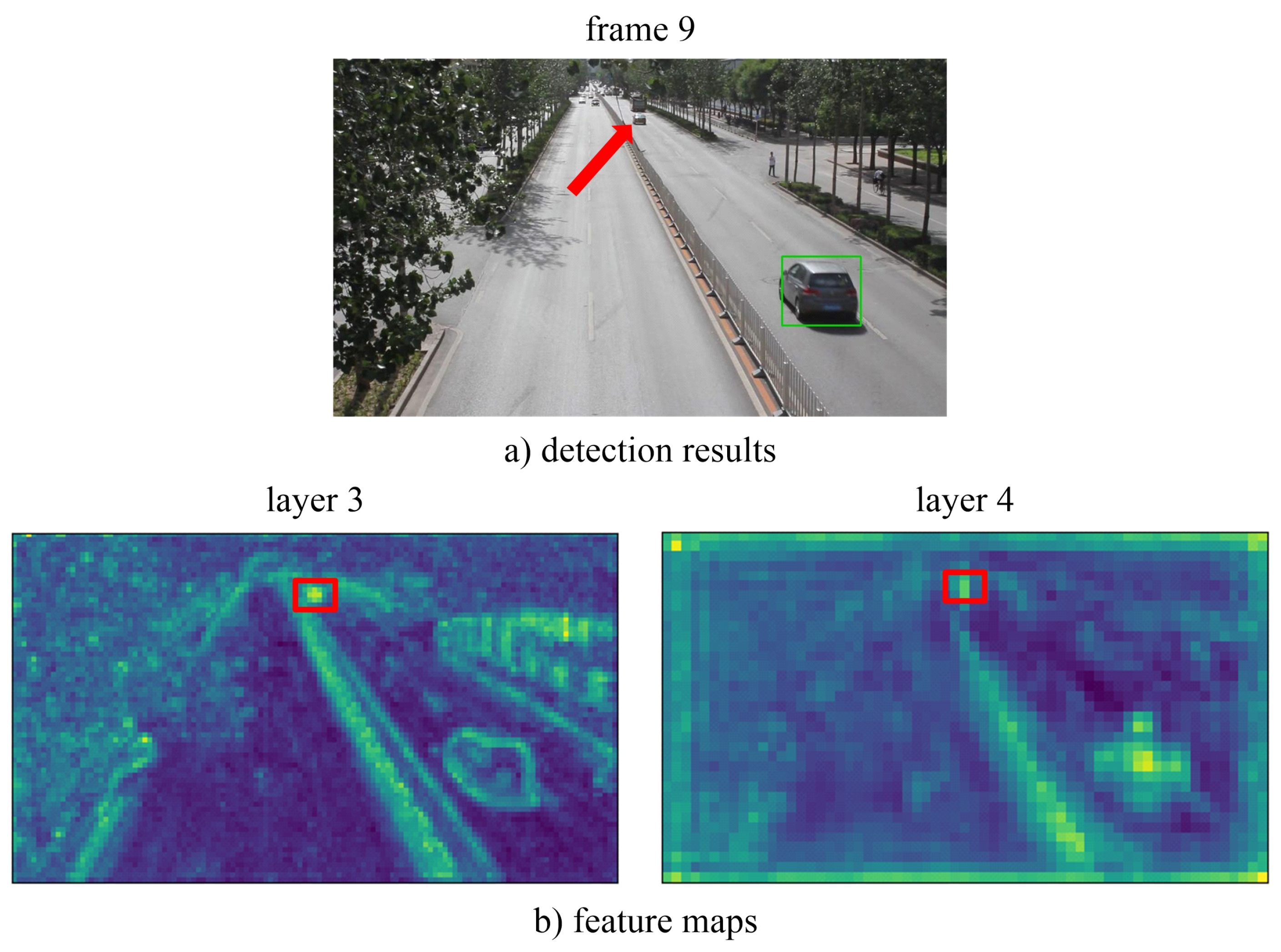
4.2.2. Module Analysis
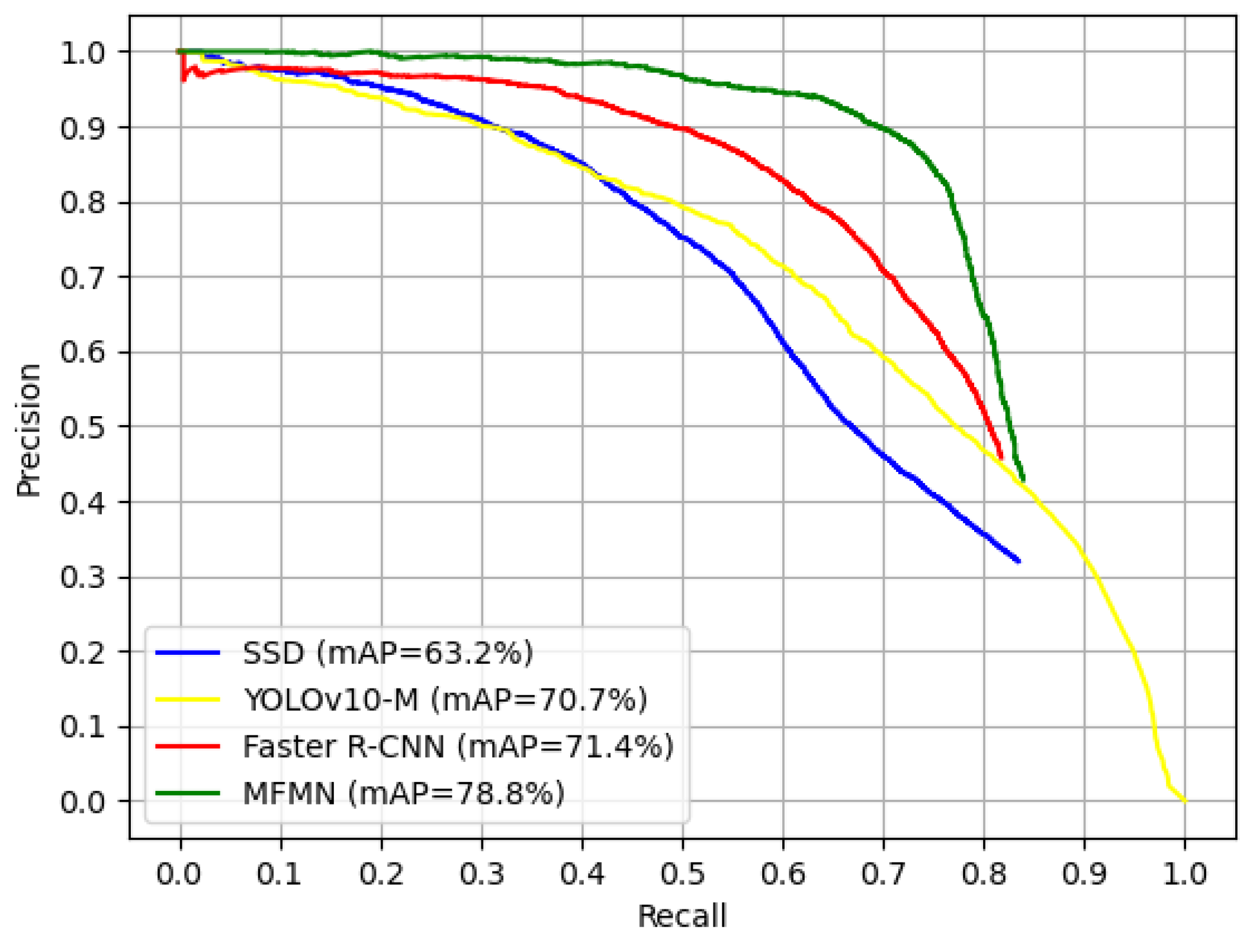
4.3. Comparison with State-of-the-Art Methods
4.3.1. Results on the UA-DETRAC Dataset
4.3.2. Results on the ImageNet VID Dataset
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, J.; Wang, F.; Wang, K.; Lin, W.; Xu, X.; Chen, C. Data-Driven Intelligent Transportation Systems: A Survey. IEEE Trans. Intell. Transport. Syst. 2011, 12, 1624–1639. [Google Scholar] [CrossRef]
- Zhang, F.; Li, C.; Wang, K.; Yang, F. Vehicle Detection in Urban Traffic Surveillance Images Based on Convolutional Neural Networks with Feature Concatenation. Sensors 2019, 19, 594. [Google Scholar] [CrossRef]
- Zhang, W.; Gao, X.; Wang, K.; Yang, C.; Jiang, F.; Chen, Z. A object detection and tracking method for security in intelligence of unmanned surface vehicles. J. Ambient Intell. Humaniz. Comput. 2020, 13, 1279–1291. [Google Scholar] [CrossRef]
- Song, H.; Liang, H.; Li, H.; Dai, Z.; Yun, X. Vision-based vehicle detection and counting system using deep learning in highway scenes. Eur. Transp. Res. Review. 2019, 11, 51. [Google Scholar] [CrossRef]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Detect to track and track to detect. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Honolulu, HI, USA, 19–25 October 2017; pp. 2961–2969. [Google Scholar]
- He, K.M.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Honolulu, HI, USA, 19–25 October 2017; pp. 2961–2969. [Google Scholar]
- Wang, S.Y.; Group, A.; Lu, H.C.; Deng, Z.D. Fast Object Detection in Compressed Video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7104–7113. [Google Scholar]
- Zhu, X.Z.; Wang, Y.J.; Dai, J.F.; Yuan, L.; Wei, Y.C. Flow-guided feature aggregation for video object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Honolulu, HI, USA, 19–25 October 2017; pp. 408–417. [Google Scholar]
- Wang, S.Y.; Zhou, Y.C.; Yan, J.J.; Deng, Z.D. Fully motion-aware network for video object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 542–557. [Google Scholar]
- Chen, Y.H.; Cao, Y.; Hu, H.; Wang, L.W. Memory Enhanced Global-Local Aggregation for Video Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10337–10346. [Google Scholar]
- Shi, X.J.; Chen, Z.R.; Wang, H.; Wang, H.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, BC, Canada, 7–12 December 2015; pp. 802–810. [Google Scholar]
- Chen, X.Y.; Yu, J.Z.; Wu, Z.X. Temporally identity-aware SSD with attentional LSTM. IEEE Trans. Cybern. 2019, 50, 2674–2686. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J.; Berg, A. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 39, 91–99. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Bochkovskiy, A.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Dai, J.F.; Li, Y.; He, K.M.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1440–1448. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. Int. J. Comput. Vis. 2020, 128, 642–656. [Google Scholar] [CrossRef]
- Roh, B.; Shin, J.W.; Shin, W.Y.; Kim, S. Sparse DETR: Efficient End-to-End Object Detection with Learnable Sparsity. arXiv 2021, arXiv:2111.14330v2. [Google Scholar]
- Zhu, X.Z.; Su, W.J.; Lu, L.W.; Li, B.; Wang, X.G.; Dai, J.F. Deformable DETR: Deformable Transformers for End-to-End Object Detection. arXiv 2021, arXiv:2010.04159v4. [Google Scholar]
- Duan, K.W.; Bai, S.; Xie, L.X.; Qi, H.G.; Huang, Q.M.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. arXiv 2019, arXiv:1904.08189v3. [Google Scholar]
- Dong, Z.W.; Li, G.X.; Liao, Y.; Wang, F.; Ren, P.J.; Qian, C. CentripetalNet: Pursuing High-Quality Keypoint Pairs for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 18–23 June 2020; pp. 10516–10525. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Jiao, L.; Zhang, R.; Liu, F.; Yang, S.; Hou, B.; Li, L.; Tang, X. New Generation Deep Learning for Video Object Detection: A Survey. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 3195–3215. [Google Scholar] [CrossRef] [PubMed]
- Han, W.; Khorrami, P.; Paine, T.L.; Ramachandran, P.; Babaeizadeh, M.; Shi, H.H.; Li, J.N.; Yan, S.C.; Huang, T.S. Seq-nms for video object detection. arXiv 2016, arXiv:1602.08465. [Google Scholar]
- Tang, P.; Wang, C.; Wang, X.; Liu, W.; Zeng, W.; Wang, J. Object detection in videos by short and long range object linking. arXiv 2018, arXiv:1801.09823. [Google Scholar]
- Liu, X.; Nejadasl, F.K.; van Gemert, J.C.; Booij, O.; Pintea, S.L. Objects Do Not Disappear: Video Object Detection by Single-Frame Object Location Anticipation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 1–13. [Google Scholar]
- Zhu, X.Z.; Xiong, Y.W.; Dai, J.F.; Yuan, L.; Wei, Y.C. Deep feature flow for video recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2349–2358. [Google Scholar]
- Bertasius, G.; Torresani, L.; Shi, J. Object detection in video with spatiotemporal sampling networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 331–346. [Google Scholar]
- Han, L.; Yin, Z. Global Memory and Local Continuity for Video Object Detection. IEEE Trans. Multimed. 2023, 25, 3681–3693. [Google Scholar]
- Zhang, X.G.; Chou, C.H. Source-free Domain Adaptation for Video Object Detection Under Adverse Image Conditions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–18 June 2024; pp. 1–10. [Google Scholar]
- Kang, K.; Li, H.; Yan, J.; Zeng, X.; Yang, B.; Xiao, T.; Zhang, C.; Wang, Z.; Wang, R.; Wang, X. T-cnn: Tubelets with Convolutional Neural Networks for Object Detection from Videos. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 2896–2907. [Google Scholar] [CrossRef]
- Yao, C.H.; Fang, C.; Shen, S.; Wan, Y.Y.; Yang, M.S. Video Object Detection via Object-level Temporal Aggregation. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 160–177. [Google Scholar]
- Xu, Z.J.; Hrustic, E.; Vivet, D. CenterNet Heatmap Propagation for Real-time Video Object Detection. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 1–15. [Google Scholar]
- Zhu, X.Z.; Dai, J.F.; Yuan, L.; Wei, Y.C. Towards High Performance Video Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7210–7218. [Google Scholar]
- Hetang, C.; Qin, H.; Liu, S.; Yan, J. Impression Network for Video Object Detection. arXiv 2017, arXiv:1712.05896v1. [Google Scholar]
- Deng, J.J.; Pan, Y.W.; Yao, T.; Zhou, W.G.; Li, H.Q.; Mei, T. Relation Distillation Networks for Video Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7023–7032. [Google Scholar]
- Jiang, Z.K.; Liu, Y.; Yang, C.Y.; Liu, J.H.; Gao, P.; Zhang, Q.; Xiang, S.M.; Pan, C.H. Learning Where to Focus for Efficient Video Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Glasgow, UK, 23–28 August 2020; pp. 1–16. [Google Scholar]
- Shvets, M.; Liu, W.; Berg, A. Leveraging Long-Range Temporal Relationships Between Proposals for Video Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Wu, H.P.; Chen, Y.T.; Wang, N.Y.; Zhang, Z.X. Sequence Level Semantics Aggregation for Video Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9217–9225. [Google Scholar]
- Wang, H.; Tang, J.; Liu, X.D.; Guan, S.Y.; Xie, R.; Song, L. PTSEFormer: Progressive Temporal-Spatial Enhanced TransFormer Towards Video Object Detection. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2012; pp. 485–501. [Google Scholar]
- Zhou, Q.; Li, X.; He, L.; Yang, Y.; Cheng, G.; Tong, Y.; Ma, L.; Tao, D. TransVOD: End-to-End Video Object Detection with Spatial-Temporal Transformers. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 1–17. [Google Scholar] [CrossRef]
- Yuan, Y.; Liang, X.D.; Wang, X.L.; Yeung, D.Y.; Gupta, A. Temporal Dynamic Graph LSTM for Action-driven Video Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Honolulu, HI, USA, 19–25 October 2017; pp. 1801–1810. [Google Scholar]
- Liu, M.; Zhu, M.L. Mobile Video Object Detection with Temporally-Aware Feature Maps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 5686–5695. [Google Scholar]
- Liu, M.; Zhu, M.; White, M.; Li, Y.; Kalenichenko, D. Looking Fast and Slow: Memory-guided Mobile Video Object Detection. arXiv 2019, arXiv:1903.10172. [Google Scholar]
- Xiao, F.Y.; Lee, Y.J. Video Object Detection with an Aligned Spatial-temporal Memory. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 485–501. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Han, M.F.; Wang, Y.L.; Chang, X.J.; Qiao, Y. Mining Inter-Video Proposal Relations for Video Object Detection. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 1–16. [Google Scholar]
- Wen, L.; Du, D.; Cai, Z.; Lei, Z.; Chang, M.C.; Qi, H.; Lim, J.; Yang, M.H.; Lyu, S. UADETRAC: A New Benchmark and Protocol for Multi-Object Detection and Tracking. arXiv 2015, arXiv:1511.04136. [Google Scholar]
- Sun, S.J.; Akhtar, N.; Song, X.Y.; Mian, A.; Shah, M. Simultaneous detection and tracking with motion modelling for multiple object tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 1–24. [Google Scholar]
- Kang, K.; Li, H.S.; Xiao, T.; Ouyang, W.; Yan, J.J.; Liu, X.; Wang, X.G. Object Detection in Videos with Tubelet Proposal Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 727–735. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.Q.; Sermanet, P.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sun, G.; Hua, Y.; Hu, G.; Robertson, N. Efficient One-stage Video Object Detection by Exploiting Temporal Consistency. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. arXiv 2019, arXiv:1904.01355. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Layer | Downsampling Multiple | Enhanced? | Anchor Scale | Aspect Ratio |
|---|---|---|---|---|
| conv3 | 8 | ✓ | (, , ) | 0.5, 1, 2 |
| conv4 | 16 | (, , ) | 0.5, 1, 2 |
| Faster R-CNN | MMFAN | Strategy I | Strategy II | Features | Anchors | Precision (%) | Recall (%) |
|---|---|---|---|---|---|---|---|
| ✓ | ✓ | conv4 | 20,736 | 74.8 | 80.6 | ||
| ✓ | ✓ | ✓ | {conv3, conv4} | 103,680 | 77.6 | 87.4 | |
| ✓ | ✓ | ✓ | {conv2–conv6} | 147,312 | 79.8 | 89.9 |
| Methods | Faster R-CNN | MFGN | MMFAN | mAP (%) | (%) | (%) | (%) | Runtime (fps) |
|---|---|---|---|---|---|---|---|---|
| (a) | ✓ | 71.1 | 79.2 | 68.9 | 51.3 | 5.6 | ||
| (b) | ✓ | ✓ | 5.3 | |||||
| (c) | ✓ | ✓ | 4.9 | |||||
| (d) | ✓ | ✓ | ✓ | 4.2 |
| Methods | AP(%) | |||
|---|---|---|---|---|
| Bicycle | Bus | Car | Motorcycle | |
| (a) | 69.9 | 78.6 | 56.0 | 79.9 |
| (b) | 73.4 | 78.8 | 65.9 | 80.4 |
| (c) | 74.6 | 81.3 | 64.4 | 81.2 |
| (d) | 77.9 | 83.8 | 67.7 | 81.7 |
| Sences | Precision (%) | Recall (%) | mAP (%) |
|---|---|---|---|
| night | 73.7 | 77.1 | 75.2 |
| rainy | 70.9 | 78.4 | 74.1 |
| Methods | Compoments | mAP (%) | |||
|---|---|---|---|---|---|
| Feature Network | Static Detector | Multi-Scale Feature | LSTM | ||
| Faster R-CNN [14] | ResNet-101 [24] | Faster R-CNN | 73.4 | ||
| Mask R-CNN [6] | ResNet-101 | Mask R-CNN | ✓ | 77.2 | |
| STMN [47] | ResNet-101 | Fast R-CNN [17] | ✓ | 71.4 | |
| TPN [52] | GooLeNet [53] | Fast R-CNN | ✓ | 68.4 | |
| LSTM-SSD [45] | Mobilenet [54] | SSD [13] | ✓ | 54.4 | |
| MMNet [7] | ResNet-101 | R-FCN [52] | ✓ | ✓ | 76.4 |
| Faster R-CNN + MFGN | ResNet-101 | Faster R-CNN | ✓ | 76.5 | |
| Faster R-CNN + MMFAN | ResNet-101 | Faster R-CNN | ✓ | 77.6 | |
| MFMN | ResNet-101 | Faster R-CNN | ✓ | ✓ | 79.3 |
| Methods | Feature Network | Static Detector | mAP (%) | mAP(%) of Static Detector |
|---|---|---|---|---|
| CHP [35] | ResNet-101 [24] | CenterNet [21] | 76.7 | 73.6 |
| TransVOD [43] | ResNet-101 | Deformable DETR | 82.0 | 78.3 |
| YOLOX-M + LPN [55] | DarkNet-53 | YOLOX-M [56] | 75.1 | 69.4 |
| FCOS + LPN [55] | ResNet-101 | FCOS [57] | 79.8 | 73.3 |
| MFMN | ResNet-101 | Faster R-CNN [14] | 79.3 | 73.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Y.; Lu, S. Vehicle Detection in Videos Leveraging Multi-Scale Feature and Memory Information. Electronics 2025, 14, 2009. https://doi.org/10.3390/electronics14102009
Yang Y, Lu S. Vehicle Detection in Videos Leveraging Multi-Scale Feature and Memory Information. Electronics. 2025; 14(10):2009. https://doi.org/10.3390/electronics14102009
Chicago/Turabian StyleYang, Yanni, and Shengnan Lu. 2025. "Vehicle Detection in Videos Leveraging Multi-Scale Feature and Memory Information" Electronics 14, no. 10: 2009. https://doi.org/10.3390/electronics14102009
APA StyleYang, Y., & Lu, S. (2025). Vehicle Detection in Videos Leveraging Multi-Scale Feature and Memory Information. Electronics, 14(10), 2009. https://doi.org/10.3390/electronics14102009