

MDFormer: Transformer-Based Multimodal Fusion for Robust Chest Disease Diagnosis



Abstract
1. Introduction
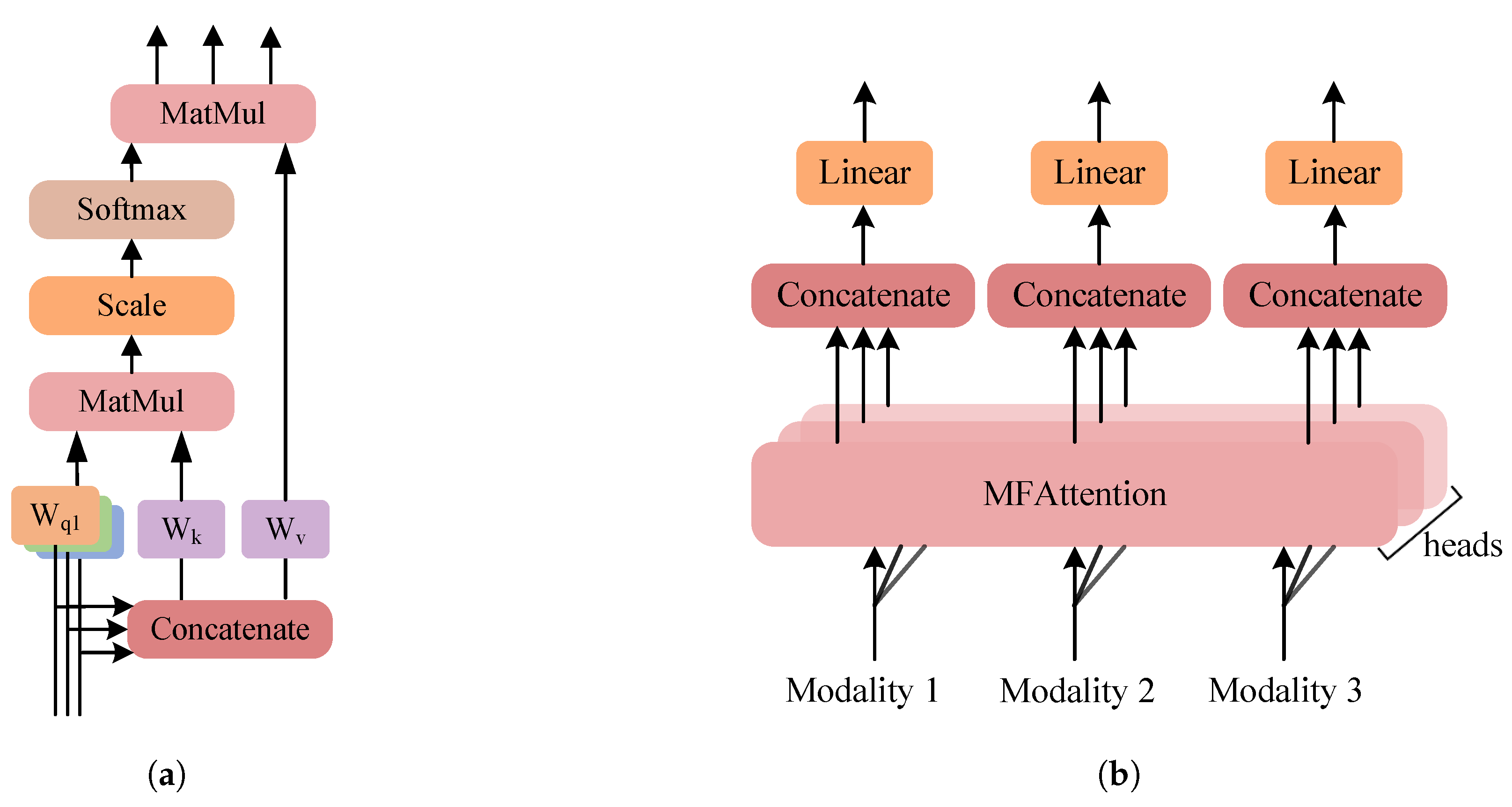
- We extend the self-attention mechanism to use different modalities as queries, simultaneously learning both intra-modality and inter-modality correlations. By combining group convolutions to extract local information, we design a lightweight fusion module MFTrans based on a multi-head attention mechanism. This approach effectively enhances fusion performance while maintaining low computational overhead.
- By integrating multimodal data such as time-series vital signs, chest X-ray images, and patient diagnostic reports, we propose a Transformer-based multimodal chest disease classification model, MDFormer. This model processes data from different modalities through modality-specific encoders, implements multimodal feature interaction and fusion in MFTrans, and ultimately achieves accurate chest disease diagnosis.
- This study combines modality masking and contrastive learning to propose a two-stage Mask-Enhanced Classification and Contrastive Learning training framework, MECCL. To further balance the optimization process of different task objectives in the two-stage training, we introduce a Sigmoid dynamic balance loss weight, enabling adaptive adjustment between loss terms. This framework allows the model to maintain effective diagnostic and classification performance even when some modality data are missing, thereby enhancing the model’s robustness and training stability.
2. Related Works
2.1. Deep Learning-Based Chest Disease Diagnosis
2.2. Medical Multimodal Disease Diagnosis
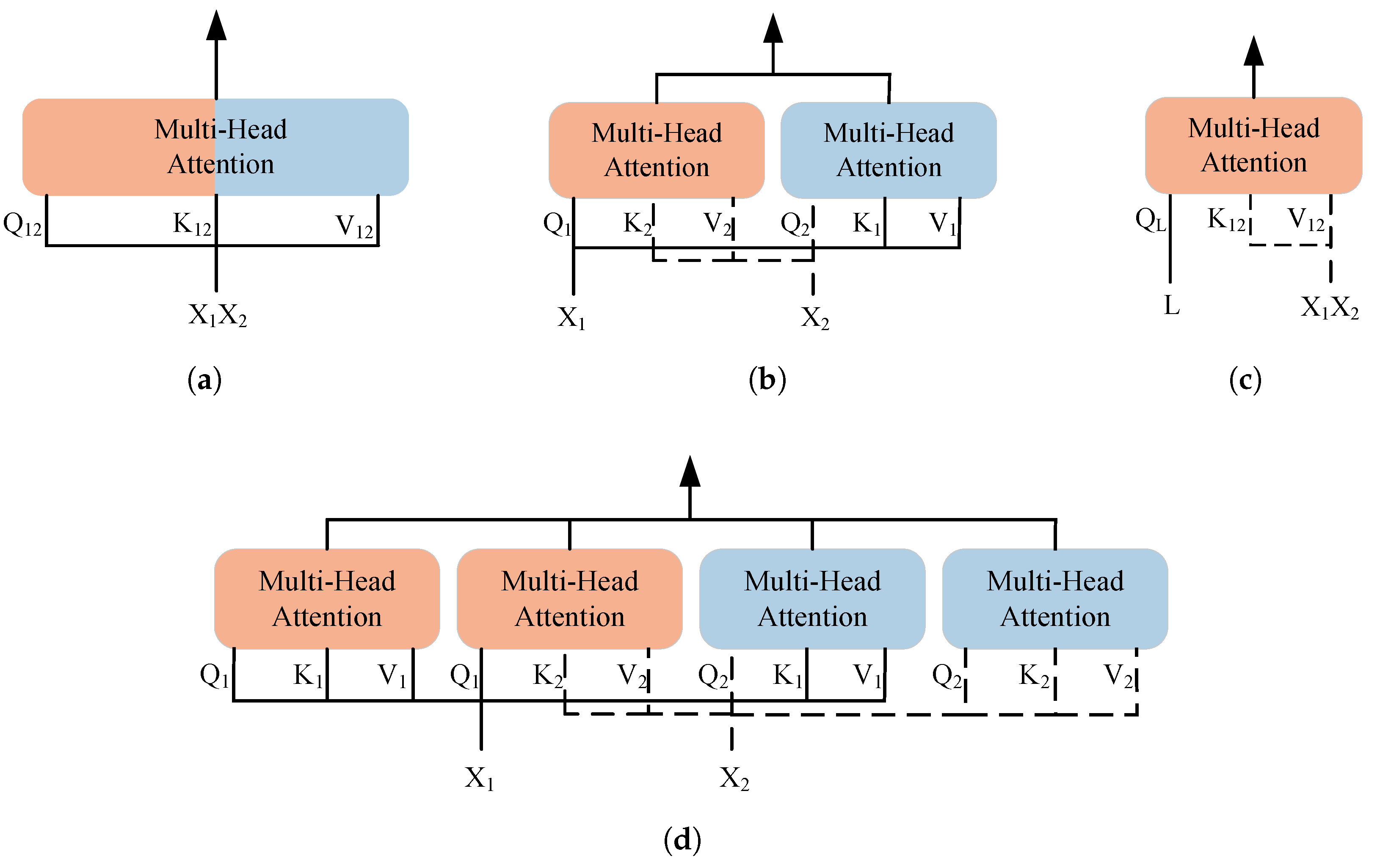
2.3. Transformer-Based Multimodal Data Fusion Methods
3. Data and Methodology
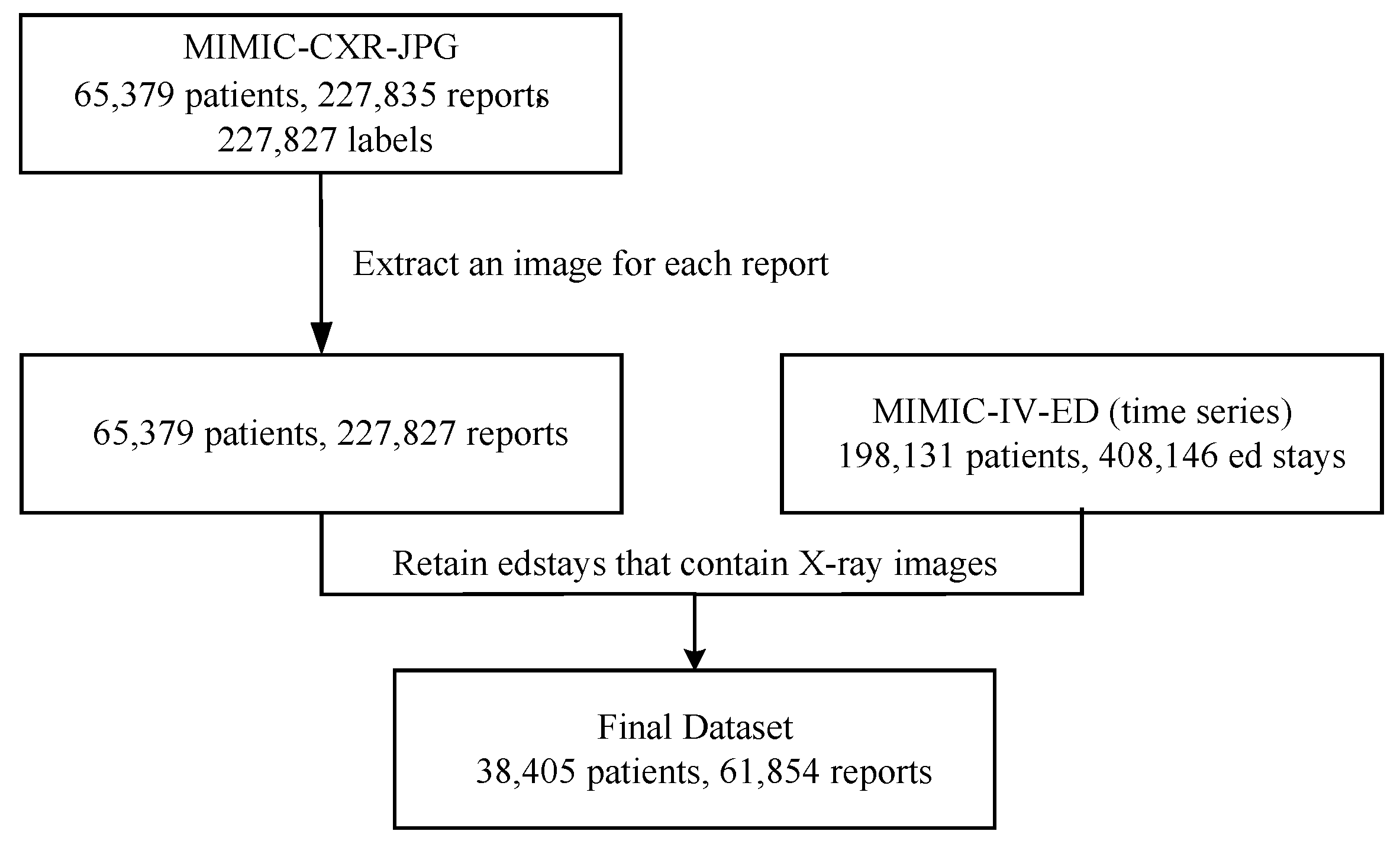
3.1. Dataset Construction
3.2. Data Preprocessing
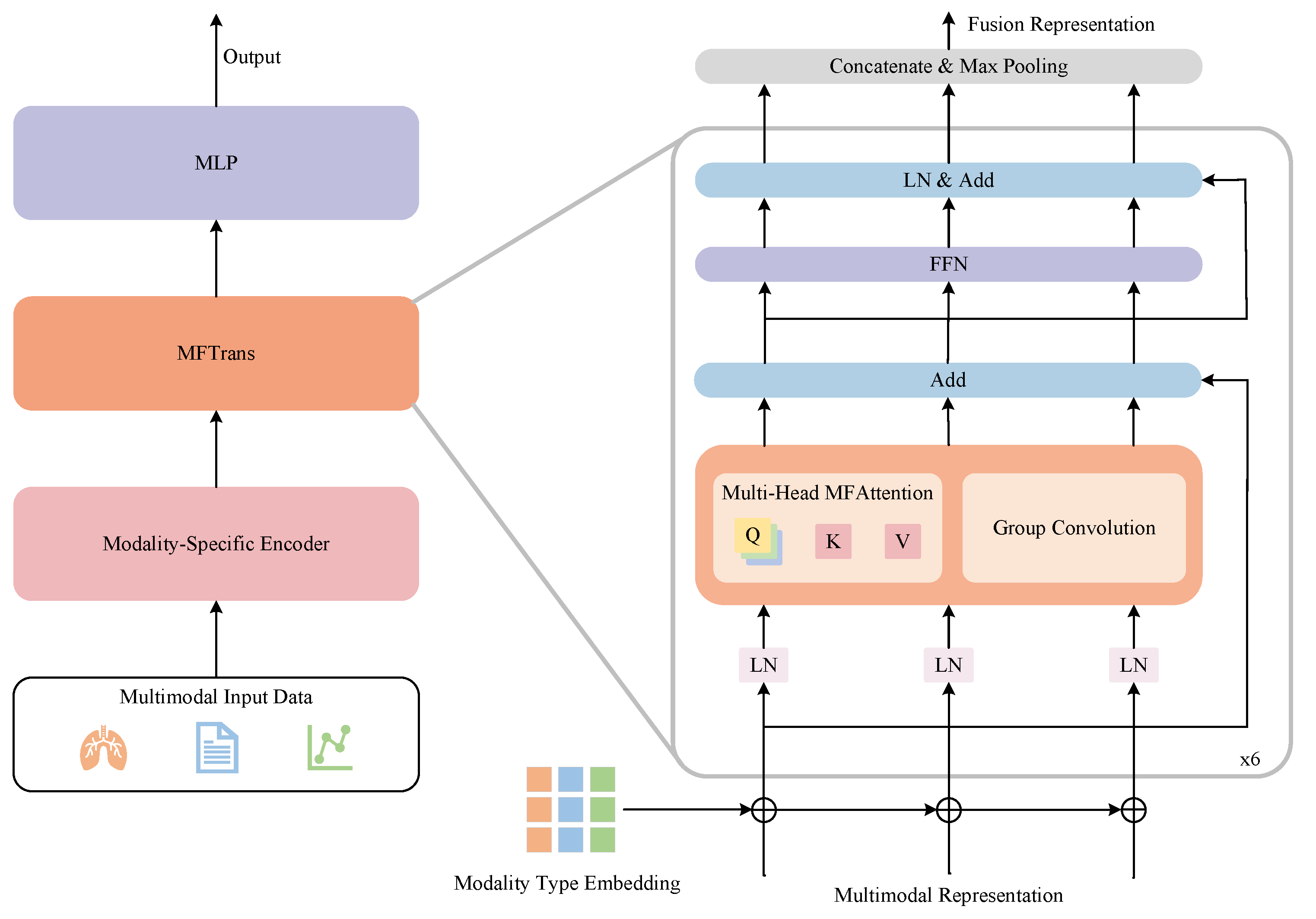
3.3. Multimodal Chest Disease Diagnosis Model
3.3.1. Overview
3.3.2. Modality-Specific Encoders
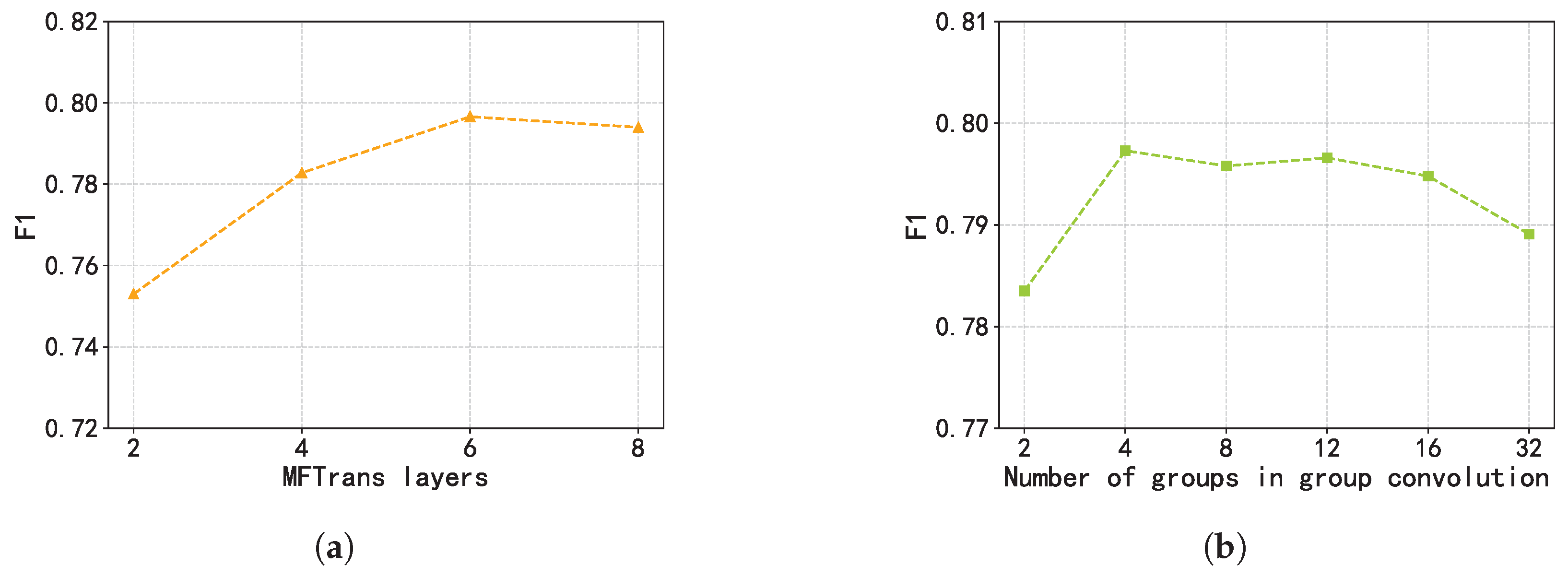
3.3.3. MFTrans
3.3.4. Classification Head
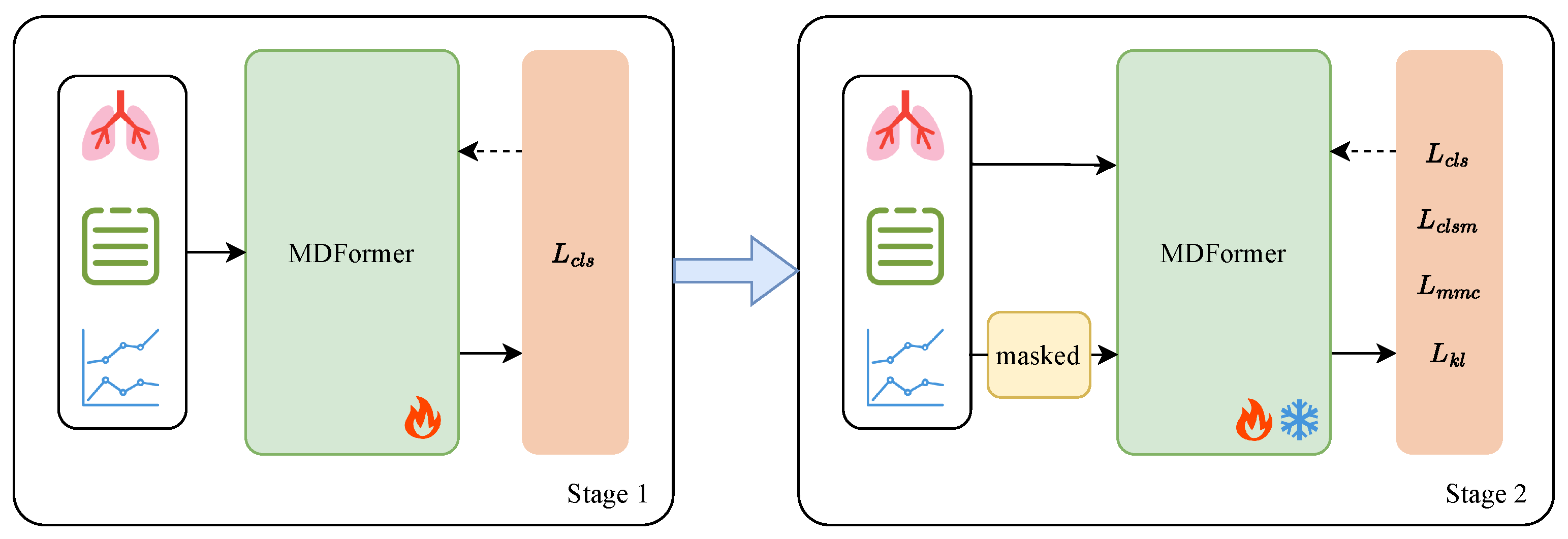
3.4. Two-Stage Training Framework
3.4.1. Overview
3.4.2. Modality Masked Classification
3.4.3. Modality Masked Contrastive Learning
3.4.4. Dynamic Balancing of Loss Weights
4. Results and Discussion
4.1. Experimental Setup
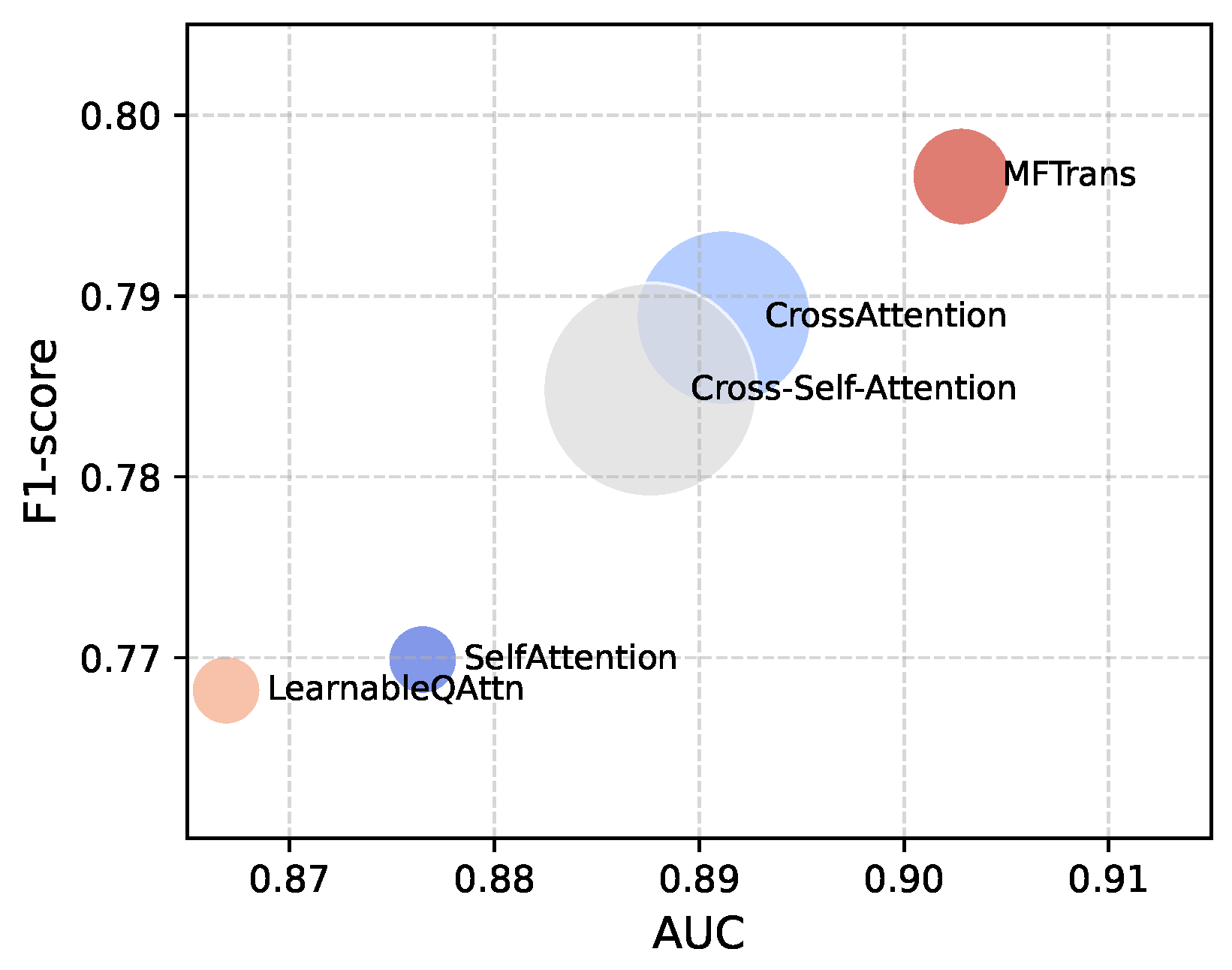
4.2. Comparative Experiment
4.3. Ablation Study
- w/o MFAttention: Removes the MFAttention, relying only on the self-attention mechanisms of individual modalities for information extraction in the fusion module.
- w/o Group Convolution: Removes the group convolution bypass.
- w/o MFTrans: Completely removes the MFTrans fusion module.
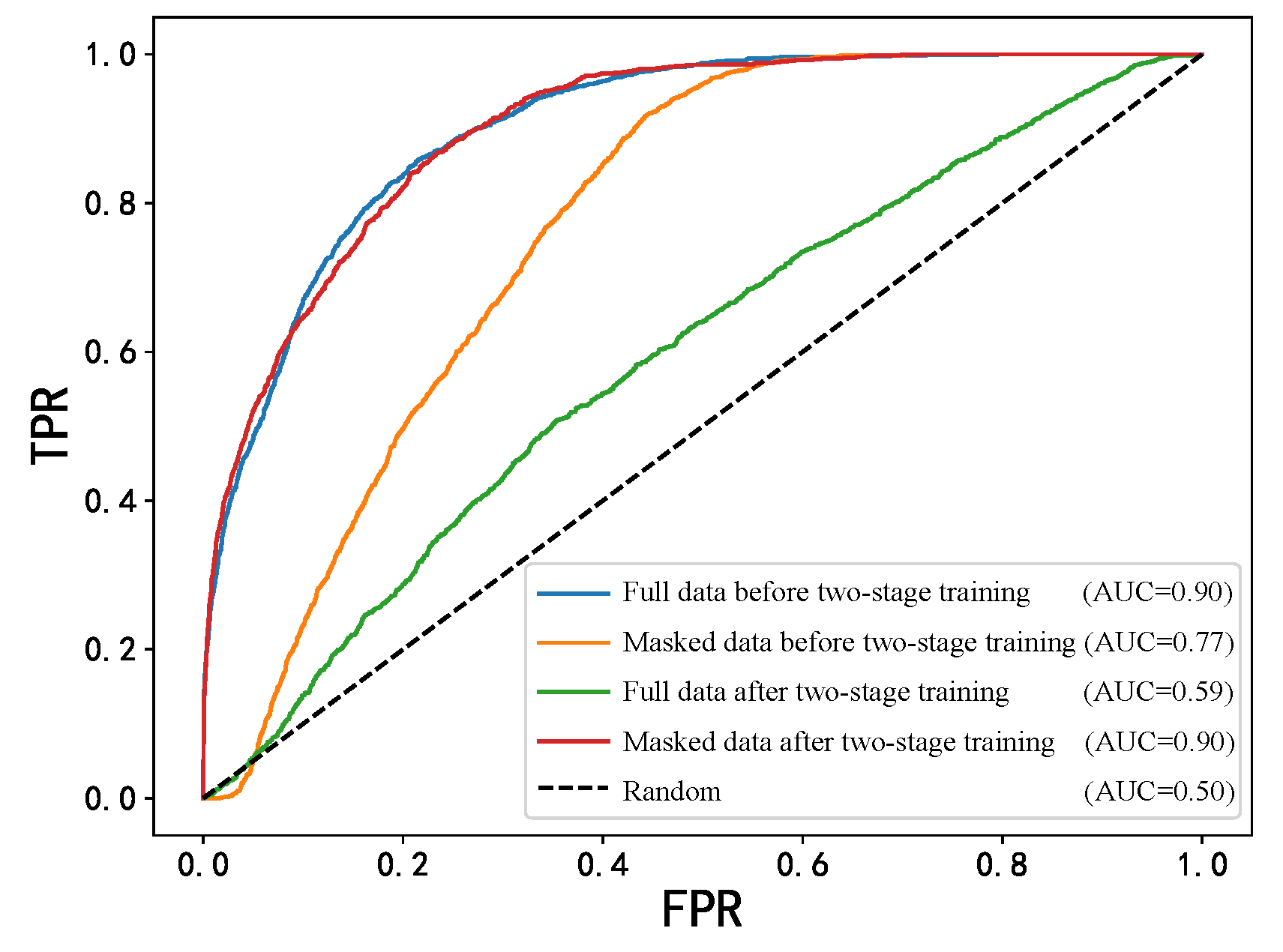
4.4. Two-Stage Training Experiment
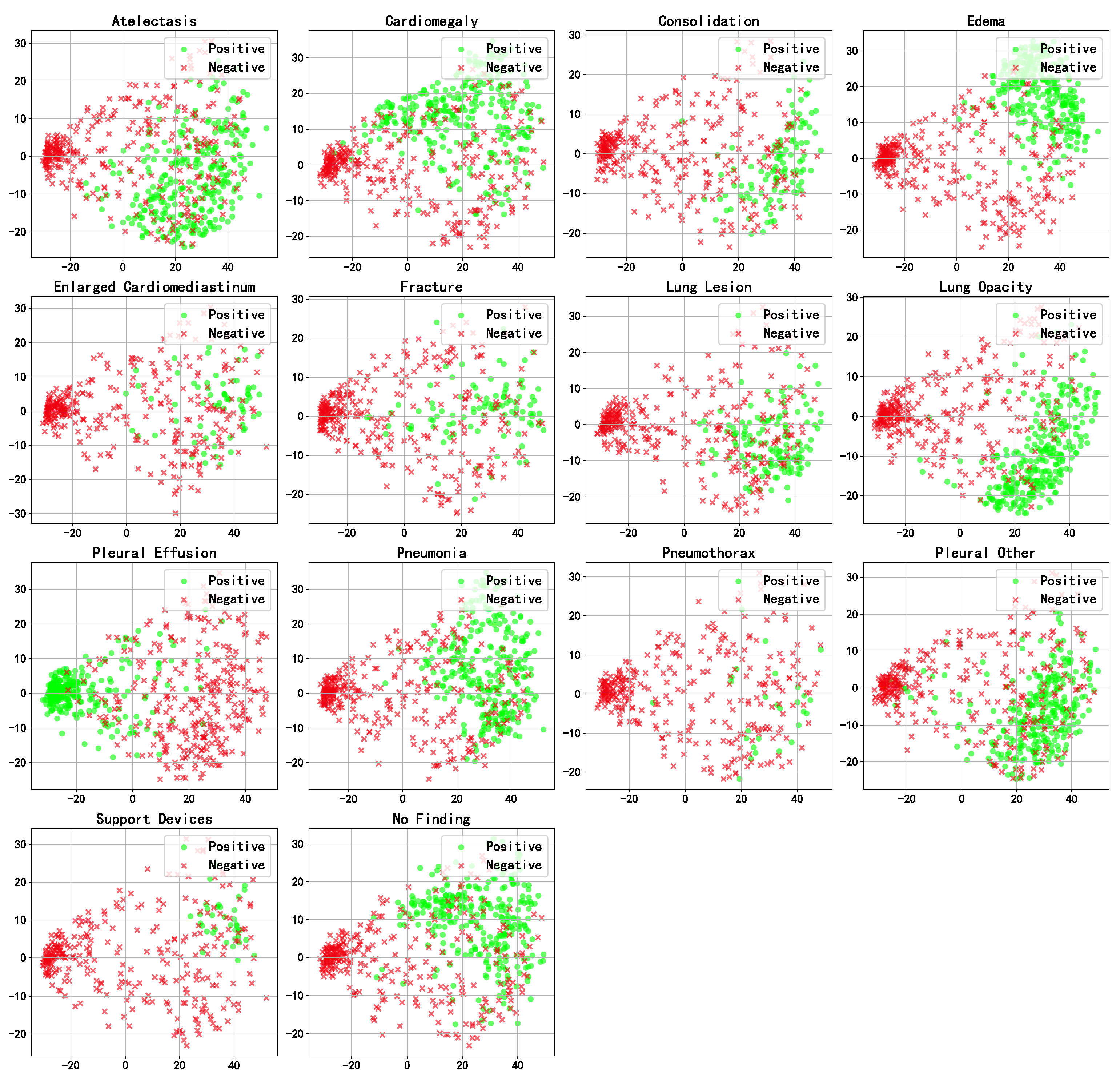
4.5. Visualization Analysis
5. Discussion
- Future work may consider integrating more data modalities, such as genomic data, pathology data, and laboratory test results, to build a more comprehensive multimodal fusion framework for more accurate diagnosis.
- It could also validate the model’s generalization ability on a broader range of multimodal datasets and systematically evaluate its robustness under low-quality or non-standard input conditions.
- Additionally, self-supervised or semi-supervised learning methods can be adopted to train multimodal medical encoders with strong representation abilities, better adapting to the needs of downstream classification tasks.
- Such work can explore lightweight deployment techniques such as model quantization, pruning, and knowledge distillation to enable real-time, resource-efficient inference on edge devices, which is essential for mobile healthcare and remote diagnostic scenarios.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- World Health Organization. Global Health Estimates 2021, 2021. [In press]. Available online: https://www.who.int/data/global-health-estimates (accessed on 6 May 2025).
- Leslie, A.; Jones, A.; Goddard, P. The influence of clinical information on the reporting of CT by radiologists. Br. J. Radiol. 2000, 73, 1052–1055. [Google Scholar] [CrossRef] [PubMed]
- Cohen, M.D. Accuracy of information on imaging requisitions: Does it matter? J. Am. Coll. Radiol. 2007, 4, 617–621. [Google Scholar] [CrossRef] [PubMed]
- Boonn, W.W.; Langlotz, C.P. Radiologist use of and perceived need for patient data access. J. Digit. Imaging 2009, 22, 357–362. [Google Scholar] [CrossRef]
- Li, Y.; Wu, F.X.; Ngom, A. A review on machine learning principles for multi-view biological data integration. Brief. Bioinform. 2018, 19, 325–340. [Google Scholar] [CrossRef]
- Baltrušaitis, T.; Ahuja, C.; Morency, L.P. Multimodal machine learning: A survey and taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 423–443. [Google Scholar] [CrossRef]
- Asuntha, A.; Srinivasan, A. Deep learning for lung Cancer detection and classification. Multimed. Tools Appl. 2020, 79, 7731–7762. [Google Scholar] [CrossRef]
- Schroeder, J.D.; Bigolin Lanfredi, R.; Li, T.; Chan, J.; Vachet, C.; Paine III, R.; Srikumar, V.; Tasdizen, T. Prediction of obstructive lung disease from chest radiographs via deep learning trained on pulmonary function data. Int. J. Chronic Obstr. Pulm. Dis. 2020, 15, 3455–3466. [Google Scholar] [CrossRef]
- Pham, T.A.; Hoang, V.D. Chest X-ray image classification using transfer learning and hyperparameter customization for lung disease diagnosis. J. Inf. Telecommun. 2024, 8, 587–601. [Google Scholar] [CrossRef]
- Hussein, F.; Mughaid, A.; AlZu’bi, S.; El-Salhi, S.M.; Abuhaija, B.; Abualigah, L.; Gandomi, A.H. Hybrid clahe-cnn deep neural networks for classifying lung diseases from x-ray acquisitions. Electronics 2022, 11, 3075. [Google Scholar] [CrossRef]
- Mann, M.; Badoni, R.P.; Soni, H.; Al-Shehri, M.; Kaushik, A.C.; Wei, D.Q. Utilization of deep convolutional neural networks for accurate chest X-ray diagnosis and disease detection. Interdiscip. Sci. Comput. Life Sci. 2023, 15, 374–392. [Google Scholar] [CrossRef]
- Chandrashekar Uppin, G.G. Assessing the Efficacy of Transfer Learning in Chest X-ray Image Classification for Respiratory Disease Diagnosis: Focus on COVID-19. Lung Opacity, Viral Pneumonia 2024, 10, 11–20. [Google Scholar]
- Hayat, M.; Ahmad, N.; Nasir, A.; Tariq, Z.A. Hybrid Deep Learning EfficientNetV2 and Vision Transformer (EffNetV2-ViT) Model for Breast Cancer Histopathological Image Classification. IEEE Access 2024, 12, 184119–184131. [Google Scholar] [CrossRef]
- Tariq, Z.; Shah, S.K.; Lee, Y. Lung disease classification using deep convolutional neural network. In Proceedings of the 2019 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), San Diego, CA, USA, 18–21 November 2019; pp. 732–735. [Google Scholar]
- Pham, L.; Phan, H.; Palaniappan, R.; Mertins, A.; McLoughlin, I. CNN-MoE based framework for classification of respiratory anomalies and lung disease detection. IEEE J. Biomed. Health Inform. 2021, 25, 2938–2947. [Google Scholar] [CrossRef] [PubMed]
- Lal, K.N. A lung sound recognition model to diagnoses the respiratory diseases by using transfer learning. Multimed. Tools Appl. 2023, 82, 36615–36631. [Google Scholar] [CrossRef]
- Stahlschmidt, S.R.; Ulfenborg, B.; Synnergren, J. Multimodal deep learning for biomedical data fusion: A review. Brief. Bioinform. 2022, 23, bbab569. [Google Scholar] [CrossRef]
- Niu, S.; Ma, J.; Bai, L.; Wang, Z.; Guo, L.; Yang, X. EHR-KnowGen: Knowledge-enhanced multimodal learning for disease diagnosis generation. Inf. Fusion 2024, 102, 102069. [Google Scholar] [CrossRef]
- Glicksberg, B.S.; Timsina, P.; Patel, D.; Sawant, A.; Vaid, A.; Raut, G.; Charney, A.W.; Apakama, D.; Carr, B.G.; Freeman, R.; et al. Evaluating the accuracy of a state-of-the-art large language model for prediction of admissions from the emergency room. J. Am. Med. Inform. Assoc. 2024, 31, 1921–1928. [Google Scholar] [CrossRef]
- Bichindaritz, I.; Liu, G.; Bartlett, C. Integrative survival analysis of breast cancer with gene expression and DNA methylation data. Bioinformatics 2021, 37, 2601–2608. [Google Scholar] [CrossRef]
- Yan, R.; Zhang, F.; Rao, X.; Lv, Z.; Li, J.; Zhang, L.; Liang, S.; Li, Y.; Ren, F.; Zheng, C.; et al. Richer fusion network for breast cancer classification based on multimodal data. BMC Med. Inform. Decis. Mak. 2021, 21, 1–15. [Google Scholar] [CrossRef]
- Lee, Y.C.; Cha, J.; Shim, I.; Park, W.Y.; Kang, S.W.; Lim, D.H.; Won, H.H. Multimodal deep learning of fundus abnormalities and traditional risk factors for cardiovascular risk prediction. NPJ Digit. Med. 2023, 6, 14. [Google Scholar] [CrossRef]
- Cui, C.; Liu, H.; Liu, Q.; Deng, R.; Asad, Z.; Wang, Y.; Zhao, S.; Yang, H.; Landman, B.A.; Huo, Y. Survival prediction of brain cancer with incomplete radiology, pathology, genomic, and demographic data. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Singapore, 18–22 September 2022; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2022; pp. 626–635. [Google Scholar]
- Liu, Z.; Wei, J.; Li, R.; Zhou, J. SFusion: Self-attention based n-to-one multimodal fusion block. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Singapore, 18–22 September 2022; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2023; pp. 159–169. [Google Scholar]
- Al-Tam, R.M.; Al-Hejri, A.M.; Alshamrani, S.S.; Al-antari, M.A.; Narangale, S.M. Multimodal breast cancer hybrid explainable computer-aided diagnosis using medical mammograms and ultrasound Images. Biocybern. Biomed. Eng. 2024, 44, 731–758. [Google Scholar] [CrossRef]
- Ramachandram, D.; Taylor, G.W. Deep multimodal learning: A survey on recent advances and trends. IEEE Signal Process. Mag. 2017, 34, 96–108. [Google Scholar] [CrossRef]
- Soto, J.T.; Weston Hughes, J.; Sanchez, P.A.; Perez, M.; Ouyang, D.; Ashley, E.A. Multimodal deep learning enhances diagnostic precision in left ventricular hypertrophy. Eur. Heart-J. Digit. Health 2022, 3, 380–389. [Google Scholar] [CrossRef]
- El-Ateif, S.; Idri, A. Eye diseases diagnosis using deep learning and multimodal medical eye imaging. Multimed. Tools Appl. 2024, 83, 30773–30818. [Google Scholar] [CrossRef]
- Liu, T.; Huang, J.; Liao, T.; Pu, R.; Liu, S.; Peng, Y. A hybrid deep learning model for predicting molecular subtypes of human breast cancer using multimodal data. Irbm 2022, 43, 62–74. [Google Scholar] [CrossRef]
- Saikia, M.J.; Kuanar, S.; Mahapatra, D.; Faghani, S. Multi-modal ensemble deep learning in head and neck cancer HPV sub-typing. Bioengineering 2023, 11, 13. [Google Scholar] [CrossRef]
- Reda, I.; Khalil, A.; Elmogy, M.; Abou El-Fetouh, A.; Shalaby, A.; Abou El-Ghar, M.; Elmaghraby, A.; Ghazal, M.; El-Baz, A. Deep learning role in early diagnosis of prostate cancer. Technol. Cancer Res. Treat. 2018, 17, 1533034618775530. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Nguyen, D.K.; Assran, M.; Jain, U.; Oswald, M.R.; Snoek, C.G.; Chen, X. An image is worth more than 16x16 patches: Exploring transformers on individual pixels. arXiv 2024, arXiv:2406.09415. [Google Scholar]
- Chen, Y.C.; Li, L.; Yu, L.; El Kholy, A.; Ahmed, F.; Gan, Z.; Cheng, Y.; Liu, J. Uniter: Universal image-text representation learning. In Proceedings of the European Conference on Computer Vision, Virtual, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 104–120. [Google Scholar]
- Kim, W.; Son, B.; Kim, I. Vilt: Vision-and-language transformer without convolution or region supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 5583–5594. [Google Scholar]
- Singh, A.; Hu, R.; Goswami, V.; Couairon, G.; Galuba, W.; Rohrbach, M.; Kiela, D. Flava: A foundational language and vision alignment model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 15638–15650. [Google Scholar]
- Wang, J.; Yang, Z.; Hu, X.; Li, L.; Lin, K.; Gan, Z.; Liu, Z.; Liu, C.; Wang, L. Git: A generative image-to-text transformer for vision and language. arXiv 2022, arXiv:2205.14100. [Google Scholar]
- Liu, S.; Wang, X.; Hou, Y.; Li, G.; Wang, H.; Xu, H.; Xiang, Y.; Tang, B. Multimodal data matters: Language model pre-training over structured and unstructured electronic health records. IEEE J. Biomed. Health Inform. 2022, 27, 504–514. [Google Scholar] [CrossRef] [PubMed]
- Tsai, Y.H.H.; Bai, S.; Liang, P.P.; Kolter, J.Z.; Morency, L.P.; Salakhutdinov, R. Multimodal transformer for unaligned multimodal language sequences. In Proceedings of the Conference Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Volume 2019, p. 6558. [Google Scholar]
- Zhou, H.Y.; Yu, Y.; Wang, C.; Zhang, S.; Gao, Y.; Pan, J.; Shao, J.; Lu, G.; Zhang, K.; Li, W. A transformer-based representation-learning model with unified processing of multimodal input for clinical diagnostics. Nat. Biomed. Eng. 2023, 7, 743–755. [Google Scholar] [CrossRef] [PubMed]
- Xu, T.; Chen, W.; Wang, P.; Wang, F.; Li, H.; Jin, R. Cdtrans: Cross-domain transformer for unsupervised domain adaptation. arXiv 2021, arXiv:2109.06165. [Google Scholar]
- Alayrac, J.B.; Donahue, J.; Luc, P.; Miech, A.; Barr, I.; Hasson, Y.; Lenc, K.; Mensch, A.; Millican, K.; Reynolds, M.; et al. Flamingo: A visual language model for few-shot learning. Adv. Neural Inf. Process. Syst. 2022, 35, 23716–23736. [Google Scholar]
- Moor, M.; Huang, Q.; Wu, S.; Yasunaga, M.; Dalmia, Y.; Leskovec, J.; Zakka, C.; Reis, E.P.; Rajpurkar, P. Med-flamingo: A multimodal medical few-shot learner. In Proceedings of the Machine Learning for Health (ML4H), New Orleans, LA, USA, 10 December 2023; pp. 353–367. [Google Scholar]
- Li, J.; Li, D.; Savarese, S.; Hoi, S. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In Proceedings of the International conference on machine learning, Honolulu, HI, USA, 23–29 July 2023; pp. 19730–19742. [Google Scholar]
- Bai, J.; Bai, S.; Yang, S.; Wang, S.; Tan, S.; Wang, P.; Lin, J.; Zhou, C.; Zhou, J. Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond. arXiv 2023, arXiv:2308.12966. [Google Scholar] [CrossRef]
- Johnson, A.E.; Pollard, T.J.; Greenbaum, N.R.; Lungren, M.P.; Deng, C.y.; Peng, Y.; Lu, Z.; Mark, R.G.; Berkowitz, S.J.; Horng, S. MIMIC-CXR-JPG, a large publicly available database of labeled chest radiographs. arXiv 2019, arXiv:1901.07042. [Google Scholar]
- Johnson, A.; Bulgarelli, L.; Pollard, T.; Celi, L.A.; Mark, R.; Horng, S. MIMIC-IV-ED (Version 2.2); PhysioNet: Boston, MA, USA, 2023. [Google Scholar] [CrossRef]
- Boecking, B.; Usuyama, N.; Bannur, S.; Castro, D.C.; Schwaighofer, A.; Hyland, S.; Wetscherek, M.; Naumann, T.; Nori, A.; Alvarez-Valle, J.; et al. Making the most of text semantics to improve biomedical vision–language processing. In Proceedings of the European conference on computer vision, Tel Aviv, Israel, 23–27 October; Springer: Cham, Switzerland, 2022; pp. 1–21. [Google Scholar]
- Zhang, T.; Zhang, Y.; Cao, W.; Bian, J.; Yi, X.; Zheng, S.; Li, J. Less is more: Fast multivariate time series forecasting with light sampling-oriented mlp structures. arXiv 2022, arXiv:2207.01186. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, US, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Yasunaga, M.; Leskovec, J.; Liang, P. Linkbert: Pretraining language models with document links. arXiv 2022, arXiv:2203.15827. [Google Scholar]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 11106–11115. [Google Scholar]
- Hayat, N.; Geras, K.J.; Shamout, F.E. MedFuse: Multi-modal fusion with clinical time-series data and chest X-ray images. In Proceedings of the Machine Learning for Healthcare Conference, Virtual, 28 November 2022; pp. 479–503. [Google Scholar]
- Li, J.; Selvaraju, R.; Gotmare, A.; Joty, S.; Xiong, C.; Hoi, S.C.H. Align before fuse: Vision and language representation learning with momentum distillation. Adv. Neural Inf. Process. Syst. 2021, 34, 9694–9705. [Google Scholar]
- Wang, Z.; Wu, Z.; Agarwal, D.; Sun, J. Medclip: Contrastive learning from unpaired medical images and text. In Proceedings of the Conference on Empirical Methods in Natural Language Processing. Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; Volume 2022, p. 3876. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Modalities | Model | Precision | Recall | F1 | AUC | Params | Inference Time | ||
|---|---|---|---|---|---|---|---|---|---|
| I | T | TS | |||||||
| ✓ | Densenet121 | 0.6012 | 0.5956 | 0.5984 | 0.7162 | 8M | 23.75 ms | ||
| ✓ | BioLinkBert | 0.7166 | 0.6863 | 0.7011 | 0.8164 | 108M | 40.84 ms | ||
| ✓ | Informer | 0.5397 | 0.5271 | 0.5333 | 0.6793 | 27M | 23.63 ms | ||
| ✓ | ✓ | MedFuse | 0.6627 | 0.6494 | 0.6560 | 0.7647 | 23M | 31.71 ms | |
| ✓ | ✓ | ALBEF | 0.7699 | 0.7776 | 0.7737 | 0.8890 | 209M | 26.11 ms | |
| ✓ | ✓ | MedCLIP | 0.7556 | 0.7169 | 0.7357 | 0.8585 | 137M | 29.70 ms | |
| ✓ | ✓ | ✓ | ConcatenateFusion | 0.7688 | 0.7231 | 0.7437 | 0.8689 | 138M | 23.89 ms |
| ✓ | ✓ | ✓ | MedFusionPlus | 0.7601 | 0.7488 | 0.7632 | 0.8731 | 132M | 24.60 ms |
| ✓ | ✓ | ✓ | MDFormer | 0.8043 | 0.7891 | 0.7966 | 0.9028 | 173M | 26.63 ms |
| Fusion Method | Precision | Recall | F1 | AUC | Params |
|---|---|---|---|---|---|
| SelfAttention | 0.7703 | 0.7696 | 0.7699 | 0.8756 | 18M |
| CrossAttention | 0.7905 | 0.7872 | 0.7888 | 0.8912 | 114M |
| Cross-Self-Attention | 0.7923 | 0.7774 | 0.7848 | 0.8876 | 170M |
| LearnableQAttn | 0.7744 | 0.7619 | 0.7682 | 0.8669 | 18M |
| MFTrans | 0.8043 | 0.7891 | 0.7966 | 0.9028 | 36M |
| Model | Precision | Recall | F1 | AUC |
|---|---|---|---|---|
| w/o MFAttention | 0.7712 | 0.7613 | 0.7662 | 0.8786 |
| w/o Group Convolution | 0.7904 | 0.7702 | 0.7821 | 0.8931 |
| w/o MFTrans | 0.7688 | 0.7231 | 0.7437 | 0.8539 |
| MDFormer | 0.8043 | 0.7891 | 0.7966 | 0.9028 |
| Model | Dataset | Precision | Recall | F1 | AUC |
|---|---|---|---|---|---|
| one-stage model | original test set | 0.8043 | 0.7891 | 0.7966 | 0.9028 |
| masked test set | 0.4566 | 0.4271 | 0.4441 | 0.5943 | |
| two-stage model | original test set | 0.8006 | 0.7842 | 0.7923 | 0.9024 |
| masked test set | 0.6770 | 0.6505 | 0.6675 | 0.7702 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Pan, F.; Song, H.; Cao, S.; Li, C.; Li, T. MDFormer: Transformer-Based Multimodal Fusion for Robust Chest Disease Diagnosis. Electronics 2025, 14, 1926. https://doi.org/10.3390/electronics14101926
Liu X, Pan F, Song H, Cao S, Li C, Li T. MDFormer: Transformer-Based Multimodal Fusion for Robust Chest Disease Diagnosis. Electronics. 2025; 14(10):1926. https://doi.org/10.3390/electronics14101926
Chicago/Turabian StyleLiu, Xinlong, Fei Pan, Hainan Song, Siyi Cao, Chunping Li, and Tanshi Li. 2025. "MDFormer: Transformer-Based Multimodal Fusion for Robust Chest Disease Diagnosis" Electronics 14, no. 10: 1926. https://doi.org/10.3390/electronics14101926
APA StyleLiu, X., Pan, F., Song, H., Cao, S., Li, C., & Li, T. (2025). MDFormer: Transformer-Based Multimodal Fusion for Robust Chest Disease Diagnosis. Electronics, 14(10), 1926. https://doi.org/10.3390/electronics14101926