
Key Information Extraction for Crime Investigation by Hybrid Classification Model

Abstract
1. Introduction
2. Materials and Methods
2.1. Data Collection
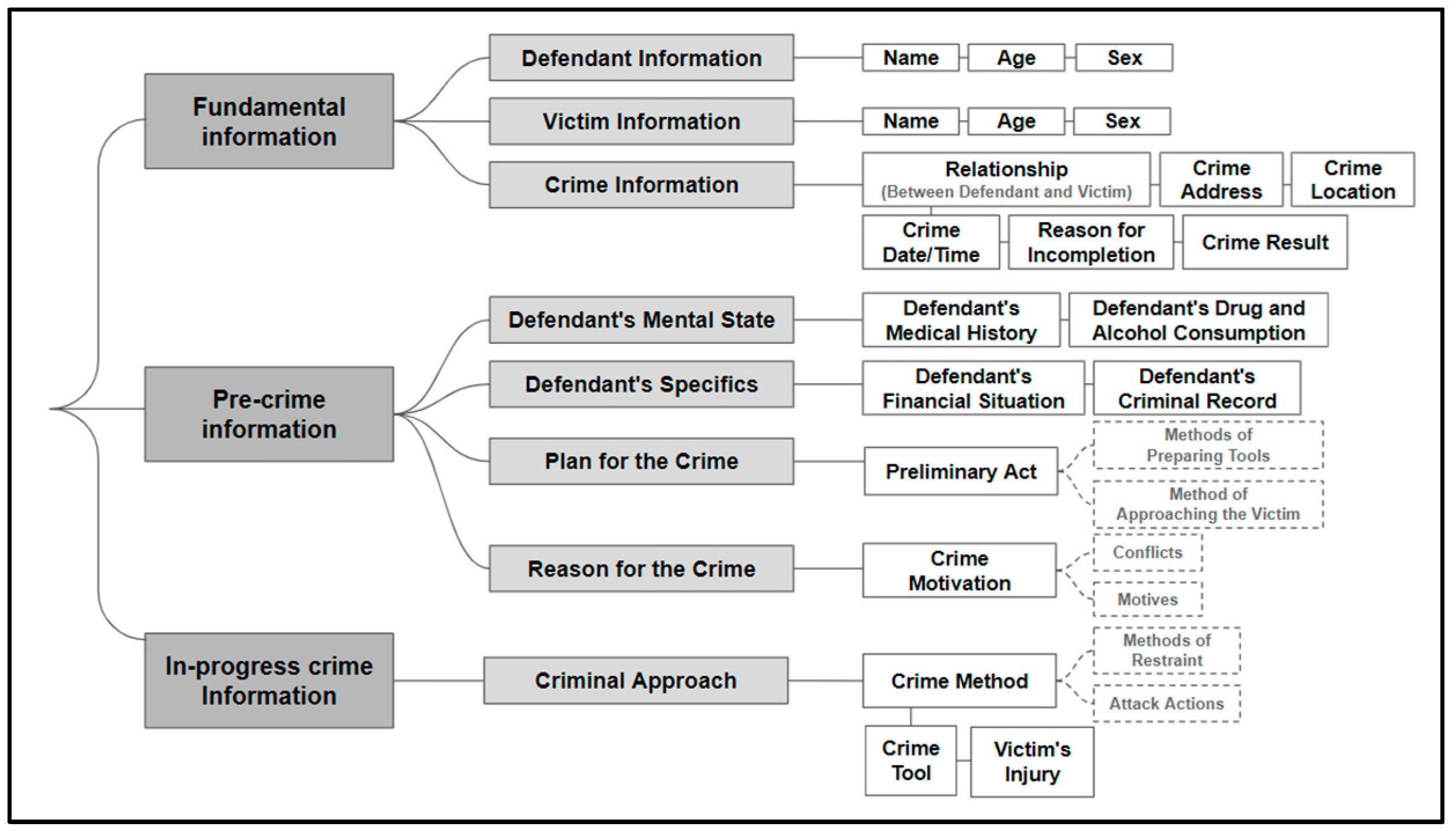
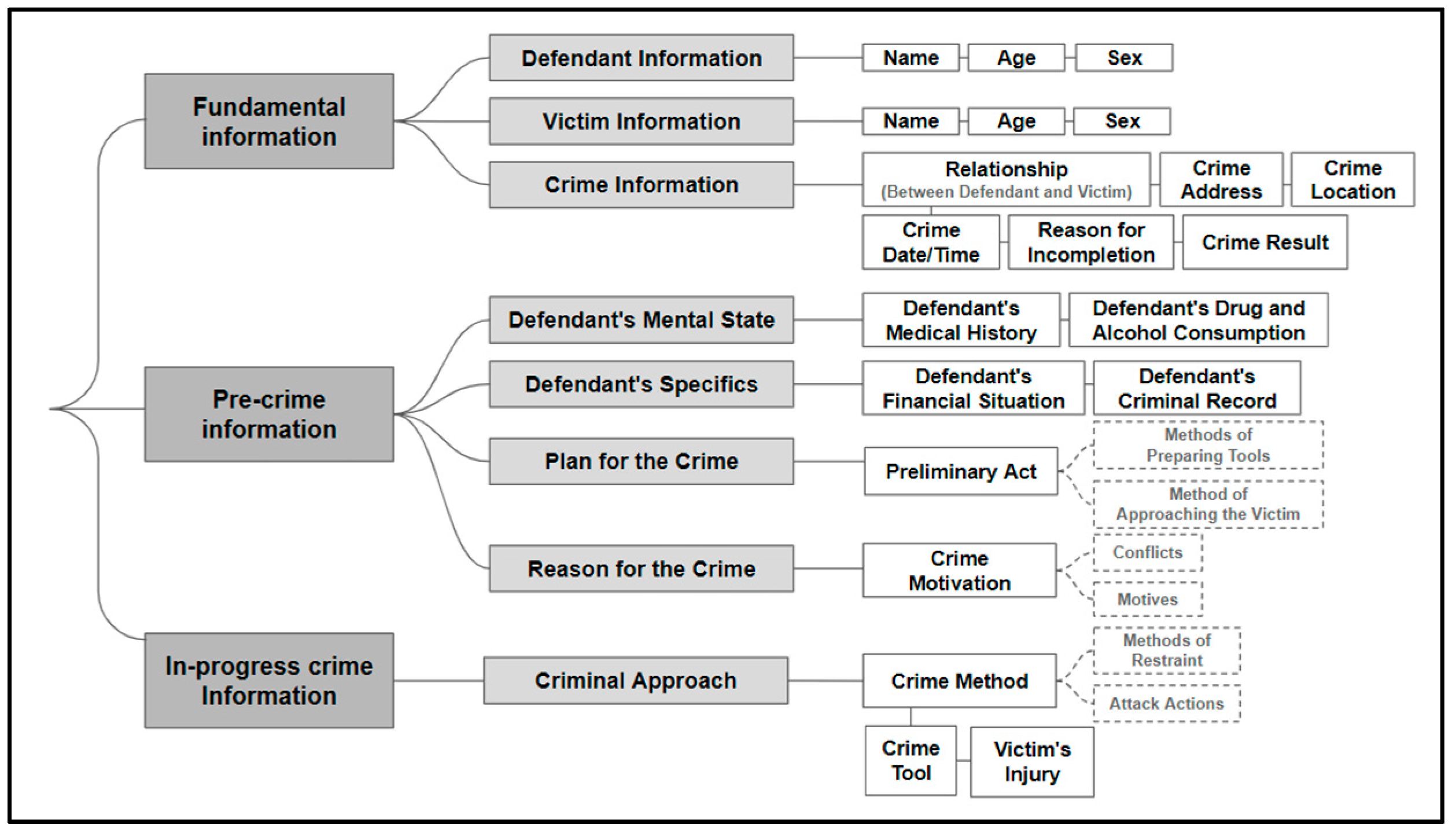
2.2. Definition of Key Information
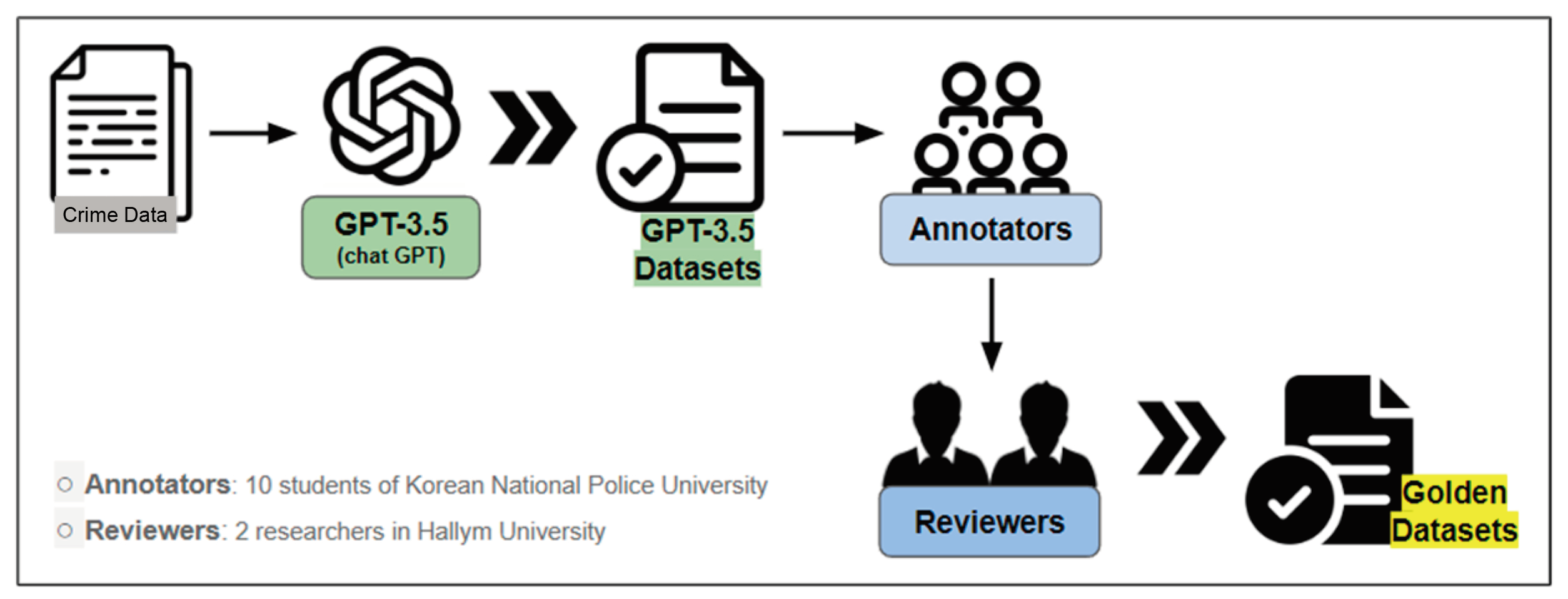
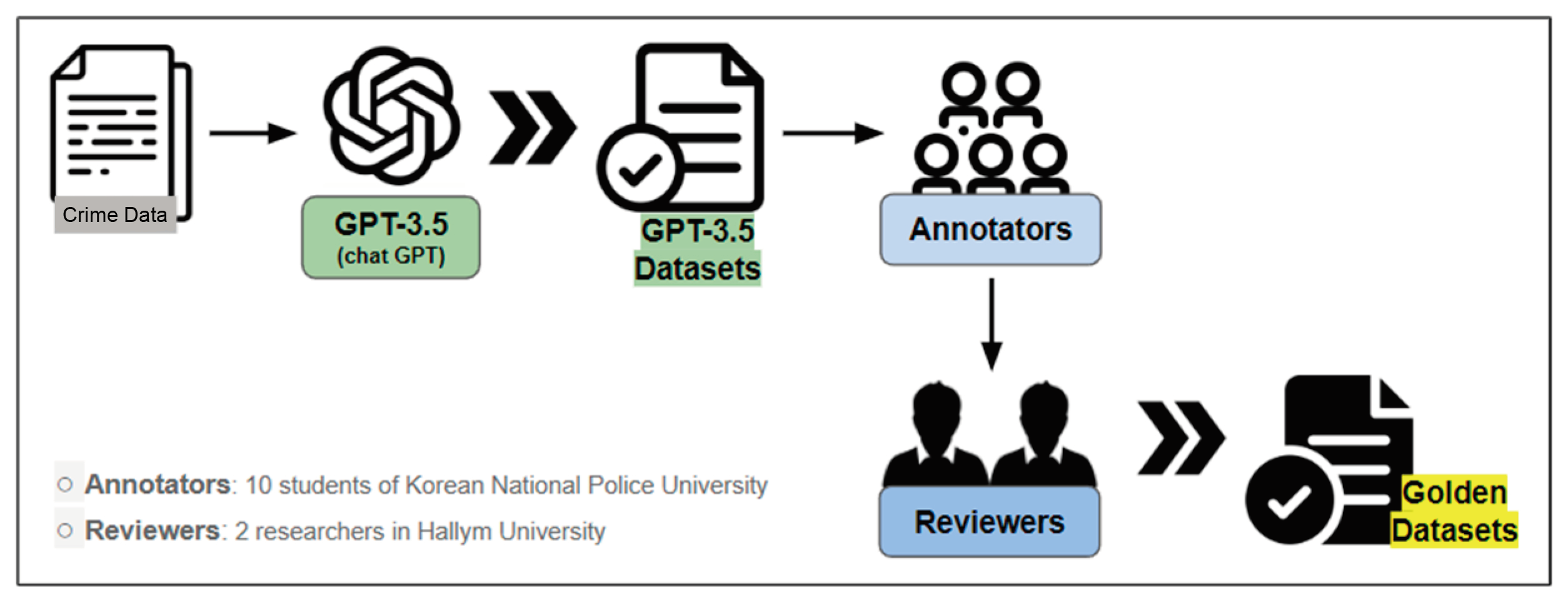
2.3. Dataset Building
2.3.1. Building Procedure
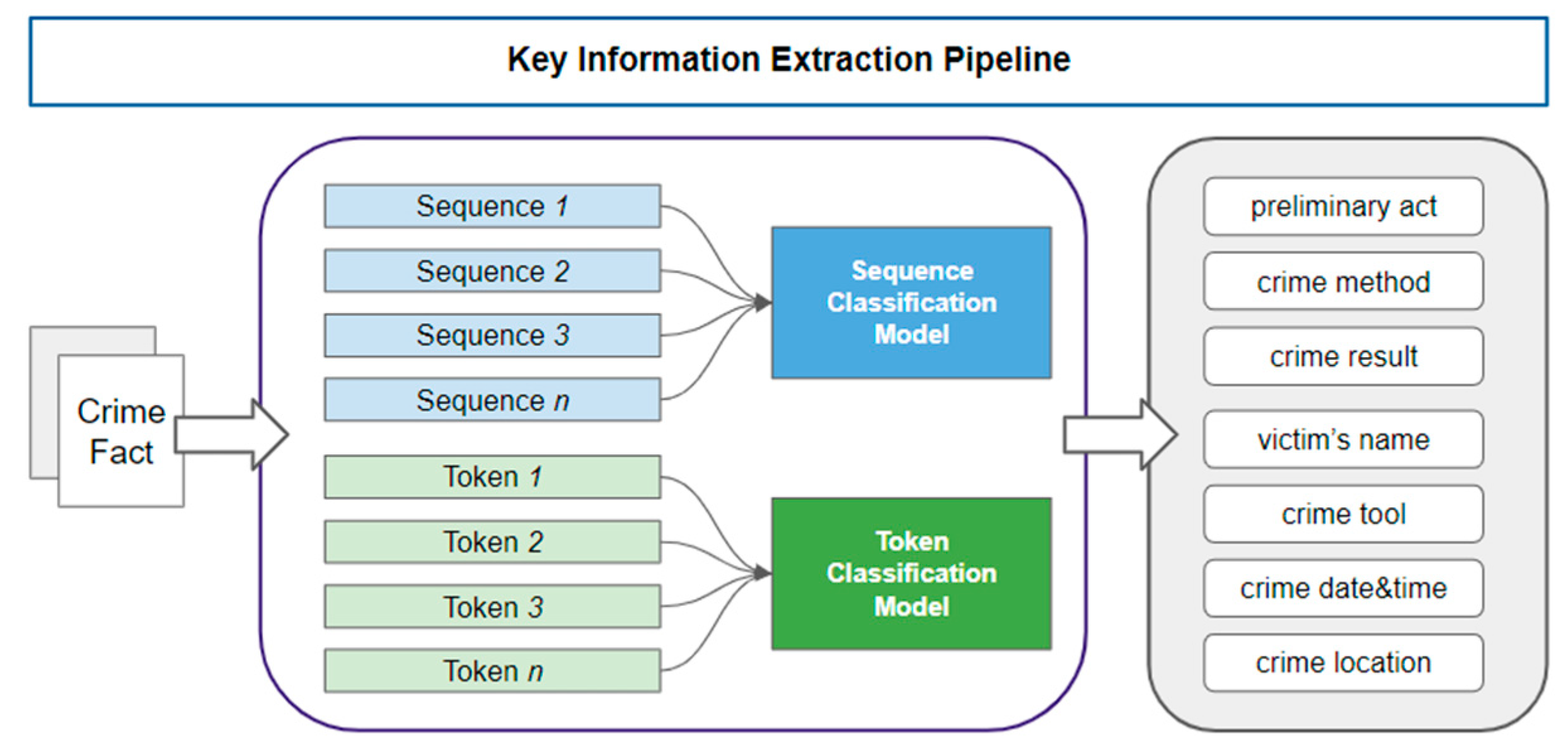
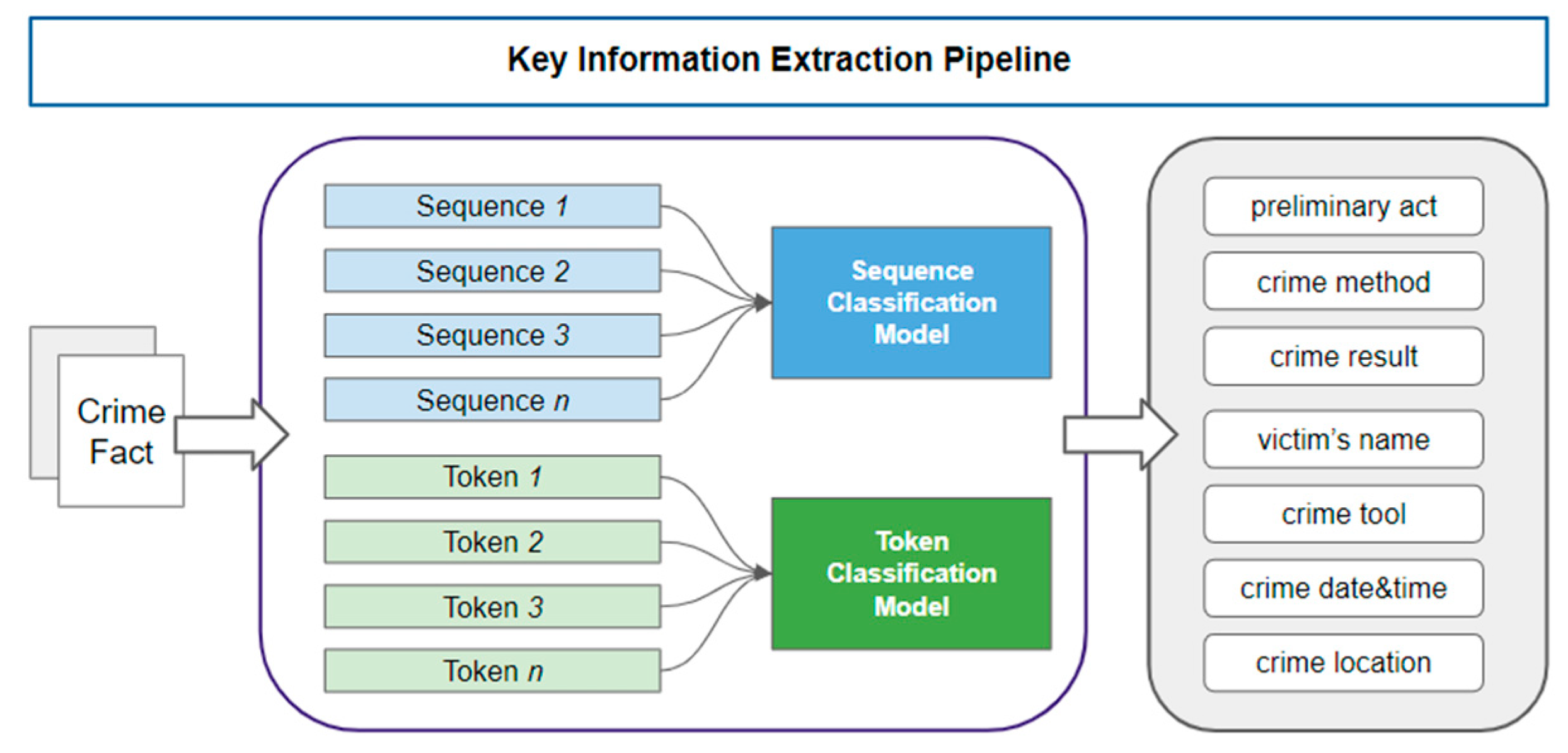
2.3.2. Token and Sequence Datasets
2.4. Model Design
3. Results
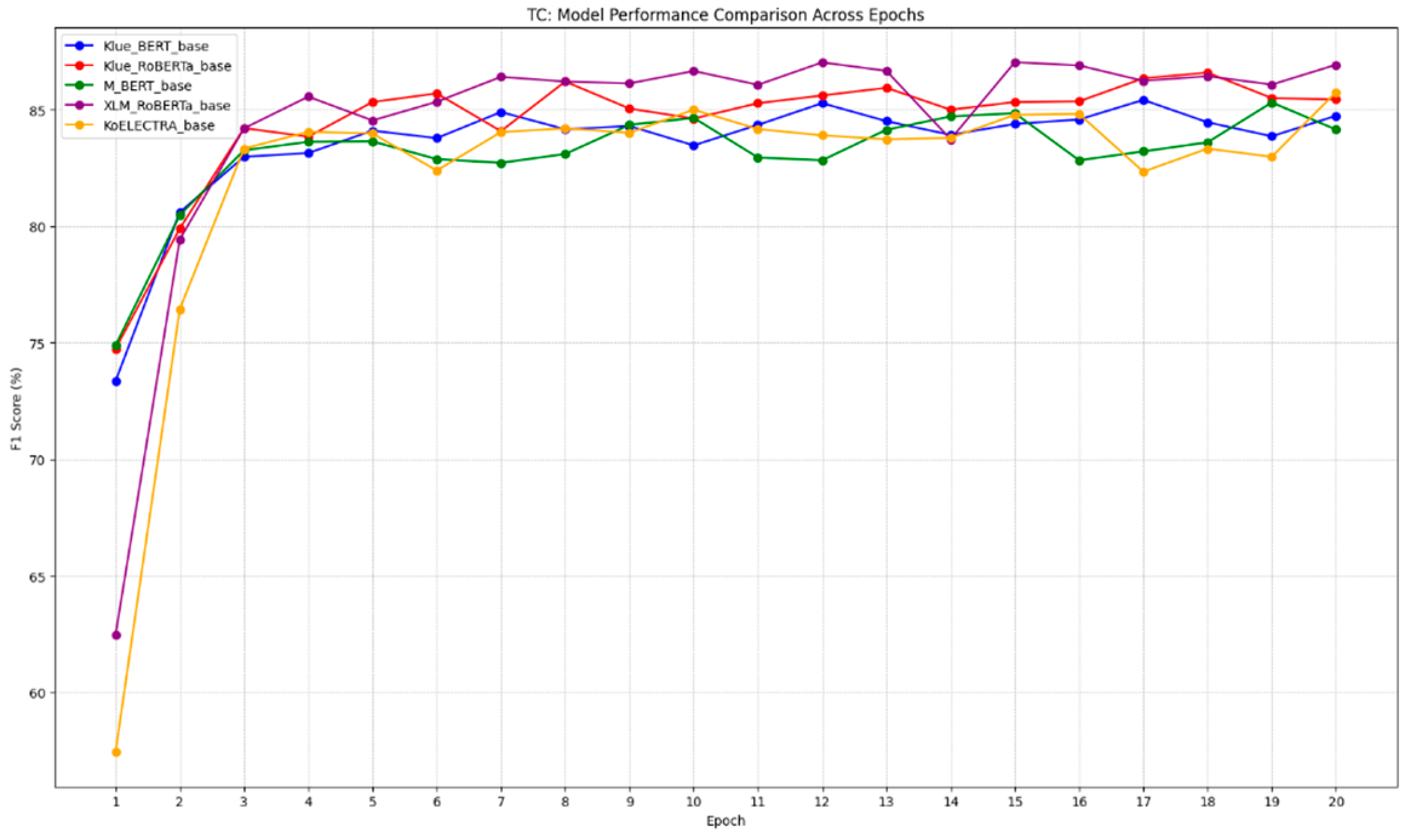
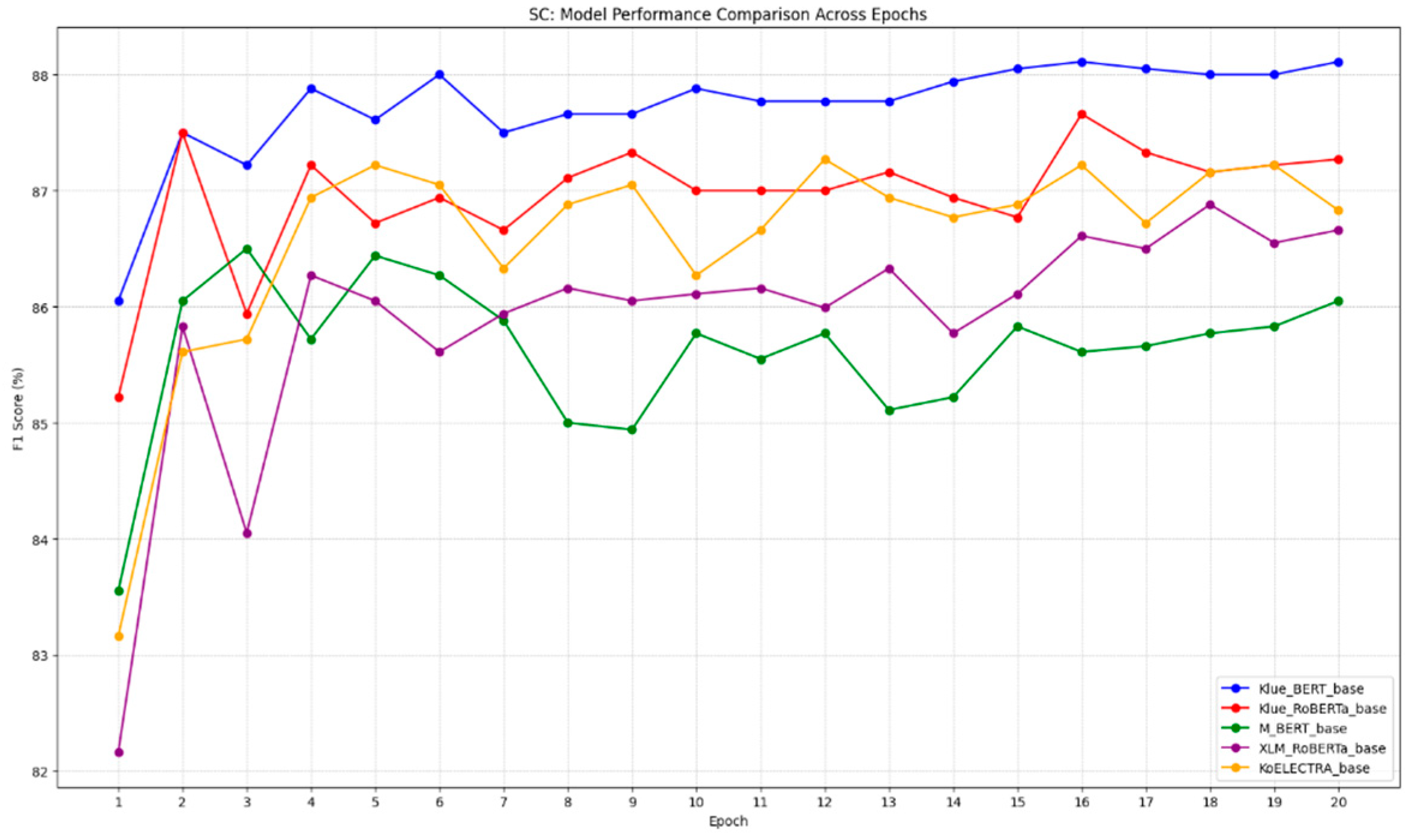
3.1. Experimental Results of Benchmark Models
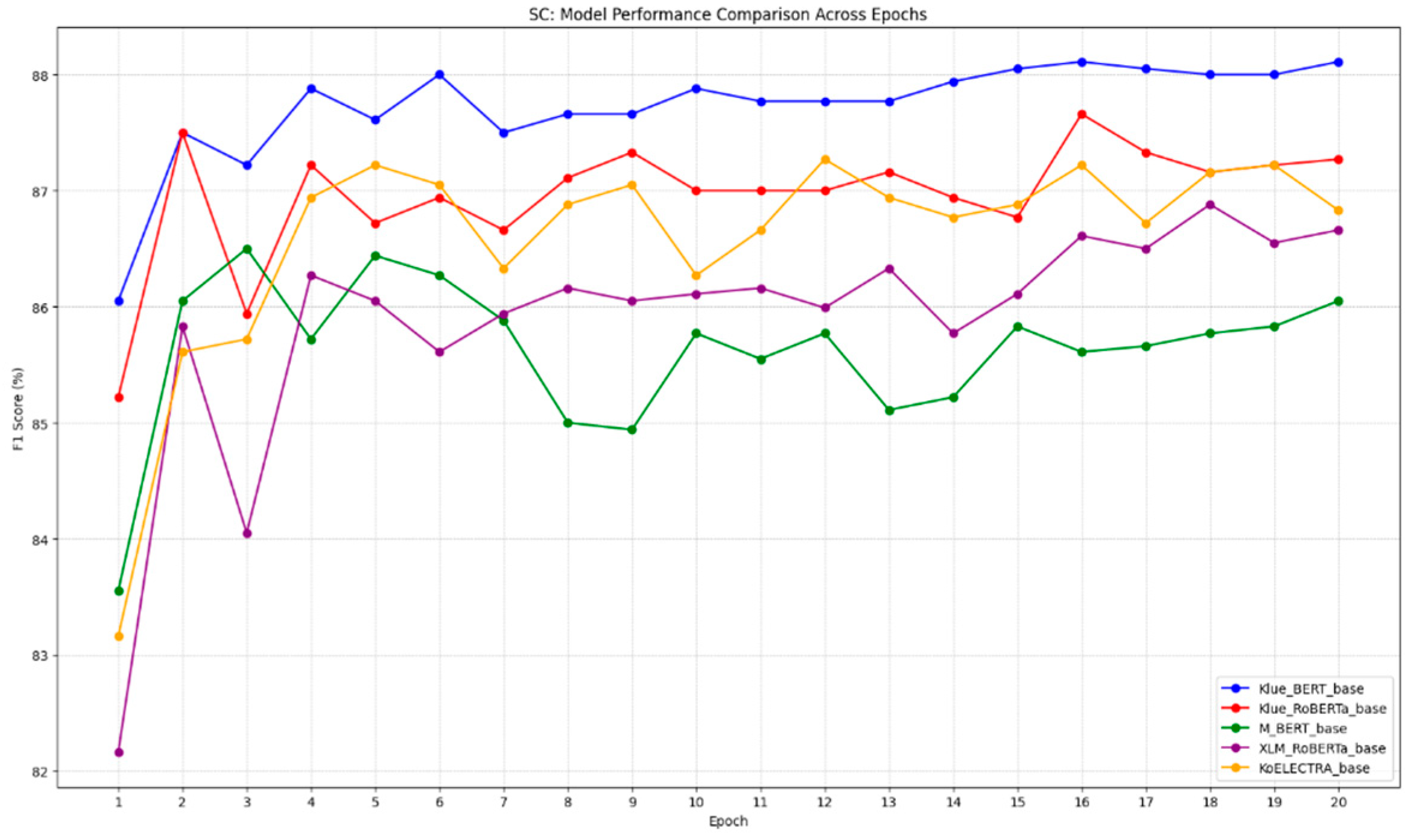
3.2. Performance Comparison of Models
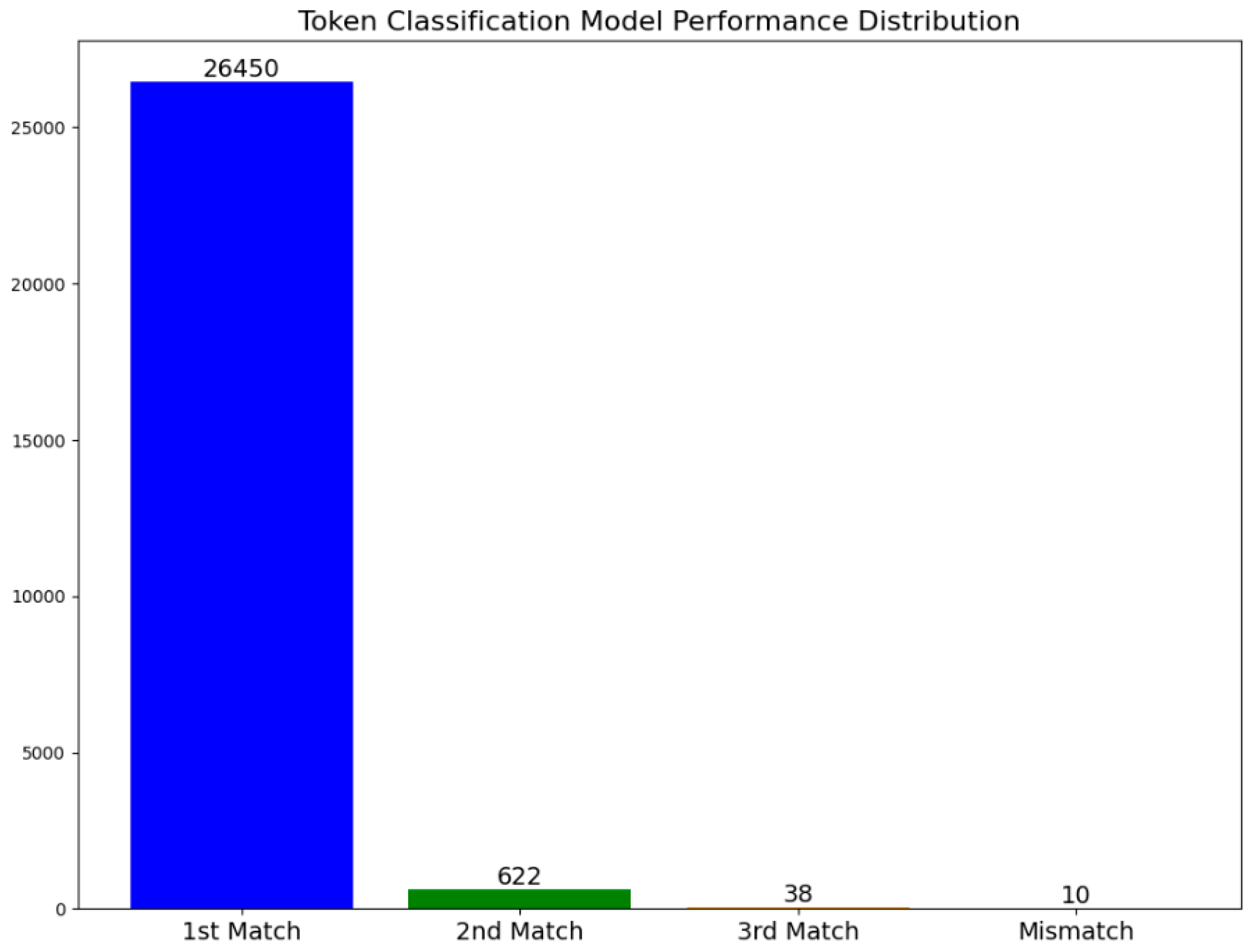
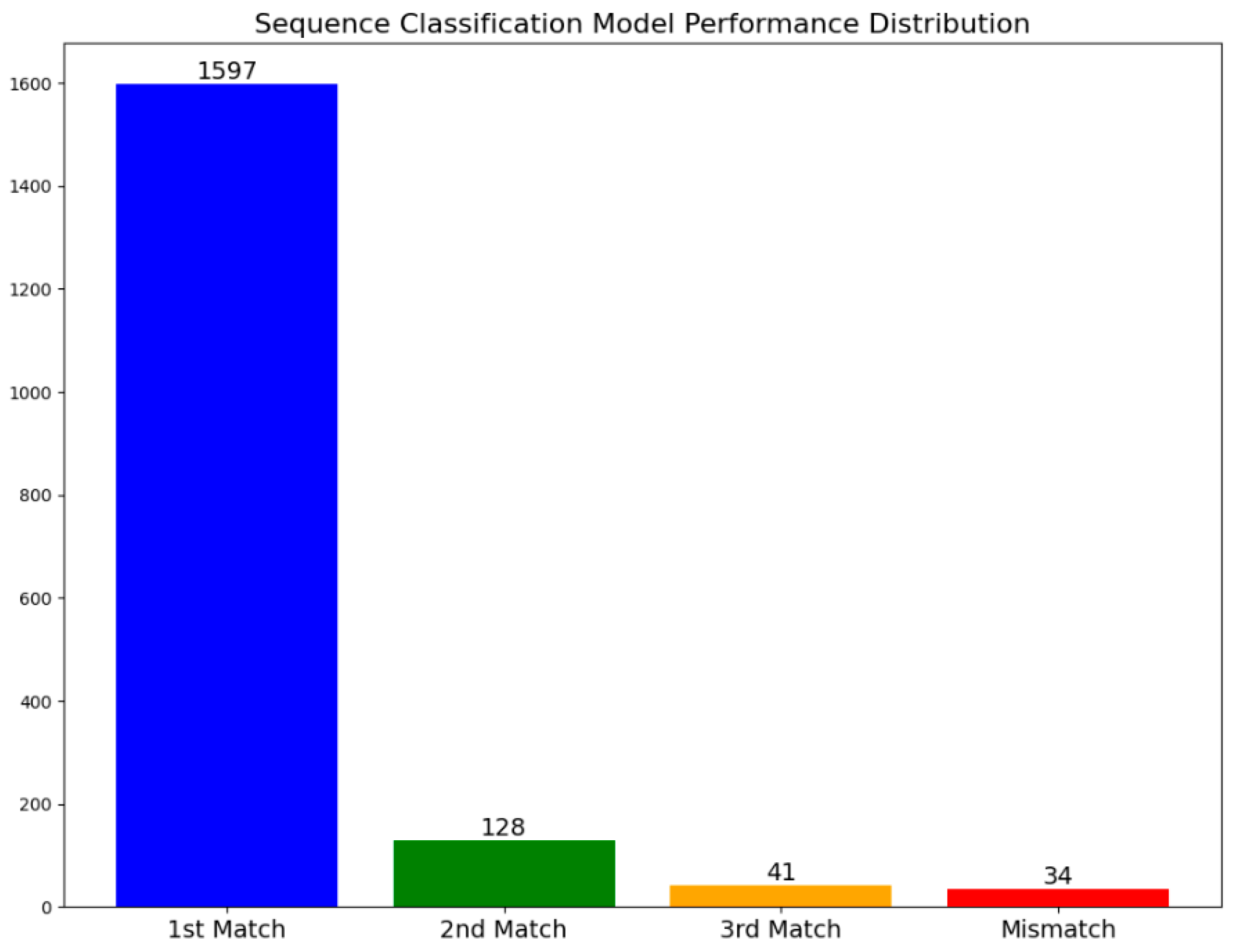
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kim, D.G. Status and Improvement Plans for Investigation Closure after the Adjustment of Investigative Powers; Occasional Research Report 21-AB-04; Korean Institute of Criminal Justice Policy: Seoul, Republic of Korea, 2022. [Google Scholar]
- Kang, J.G. Piling Investigations… One Year After the Adjustment of Investigative Powers ‘No One Was Satisfied’. Hankyoreh, 22 February 2022. [Google Scholar]
- Noh, Y.J. ‘Insufficient Follow-up Measures’ Adjustment of Prosecutorial and Police Investigative Powers, The Damage Is on the People? LIFEIN, 30 March 2023. [Google Scholar]
- Park, N.S. A Study on the Reconstruction of Criminal Facts and the Role of Hypothetical Reasoning (Abduction). Police Sci. Res. 2012, 12, 3–22. [Google Scholar] [CrossRef]
- Jung, W. Analysis of Increased Workload for the Economic Team Due to the Establishment of a Police Responsibility Investigation System; Responsibility Research Report 11-1332522-000117-01; Police University Security Policy Institute: Asan, Republic of Korea, 2021. [Google Scholar]
- Won, G.J. A Rational Crime Analysis and Fact-Acknowledgment Inference Visualization Model. Master’s Thesis, Hallym University Graduate School, Chooncheon, Republic of Korea, 2018. [Google Scholar]
- Ranaldi, L.; Pucci, G. Knowing Knowledge: Epistemological Study of Knowledge in Transformers. Appl. Sci. 2023, 13, 677. [Google Scholar] [CrossRef]
- Lee, S.J. The Future of Legal Services Depending on How to Utilize Artificial Intelligence AI. Legal Journal, 18 August 2022. [Google Scholar]
- Jung, C.Y. Policy Study for the Introduction and Acceptance of Artificial Intelligence Technology in Judicial Procedures and Judicial Services; [JPRI] Research Report 32-9741568-001430-01; Judicial Policy Research Institute: Seoul, Republic of Korea, 2021. [Google Scholar]
- Bang, J.S.; Park, W.J.; Yoon, S.Y.; Sin, J.H.; Lee, Y.T. Trends of Intelligent Public Safety Service Technologies. Electron. Telecommun. Trends 2019, 34, 111–112. [Google Scholar] [CrossRef]
- Park, S.; Lee, Y.; Choi, A.; Ahn, J.M.J. The ‘Online Access to Judgment’ Service in Korea: A Study on Improving Judgment Data for the Development of Legal AI (Artificial Intelligence). J. Police Law 2021, 19, 3–36. [Google Scholar] [CrossRef]
- Hendrycks, D.; Burns, C.; Chen, A.; Ball, S. CUAD: An Expert-Annotated NLP Dataset for Legal Contract Review. arXiv 2021, arXiv:2103.06268. [Google Scholar]
- Chalkidis, I.; Androutsopoulos, I.; Michos, A. Extracting contract elements. In Proceedings of the 16th edition of the International Conference on Artificial Intelligence and Law, London, UK, 12–16 June 2017; ACM: London, UK, 2017; pp. 19–28. [Google Scholar] [CrossRef]
- Shaheen, Z.; Wohlgenannt, G.; Filtz, E. Large Scale Legal Text Classification Using Transformer Models. arXiv 2020, arXiv:2010.12871. [Google Scholar]
- Kim, H.D.; Hong, S.; Kim, D.H.; Kim, J.Y. Analysis on Voice Phishing using Artificial Intelligence Named Entity Recognition Model for Information Search. J. Police Sci. 2020, 20, 255–283. [Google Scholar] [CrossRef]
- Kim, H.-D.; Lim, H. A Named Entity Recognition Model in Criminal Investigation Domain using Pretrained Language Model. J. Korea Converg. Soc. 2022, 13, 13–20. [Google Scholar] [CrossRef]
- Korean Institute of Criminal Justice Policy Investigation Reform Team. Investigation Report Writing Technique. 2016. Available online: https://www.yes24.com/Product/Goods/117752063 (accessed on 20 August 2023).
- Lee, Y. A Study on Extracting Crime Information from Criminal Judgments Using Machine Reading Comprehension. Master’s Thesis, Hallym University Graduate School, Chooncheon, Republic of Korea, 2021. [Google Scholar]
- Park, Y.; Park, R.-S.; Won, G. A Plan for Building a Criminal Judgment Information Extraction Dataset—Focusing on the Use of GPT-3.5 Prompts. In Proceedings of the 2023 Korea Computer Congress, Jeju, Republic of Korea, 18–20 June 2023. [Google Scholar]
- Wang, S.; Liu, Y.; Xu, Y.; Zhu, C.; Zeng, M. Want to Reduce Labeling Cost? GPT-3 Can Help. arXiv 2021, arXiv:2108.13487. [Google Scholar]
- Gilardi, F.; Alizadeh, M.; Kubli, M. ChatGPT Outperforms Crowd-Workers for Text-Annotation Tasks. Proc. Natl. Acad. Sci. USA 2023, 120, e2305016120. [Google Scholar] [CrossRef] [PubMed]
- Choi, J.H.; Hickman, K.E.; Monahan, A.; Schwarcz, D.B. ChatGPT Goes to Law School. SSRN Electron. J. 2023. [Google Scholar] [CrossRef]
- Doccano: Open Source Annotation Tool. Available online: https://github.com/doccano/doccano (accessed on 8 April 2024).
- Park, S.; Moon, J.; Kim, S.; Cho, W.I.; Han, J.; Park, J.; Song, C.; Kim, J.; Song, Y.; Oh, T.; et al. KLUE: Korean Language Understanding Evaluation. arXiv 2021, arXiv:2105.09680. [Google Scholar]
- Lee, J.; Lim, T.; Lee, H.; Jo, B.; Kim, Y.; Yoon, H.; Han, S.C. K-MHaS: A Multi-label Hate Speech Detection Dataset in Korean Online News Comment. arXiv 2023, arXiv:2208.10684. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| <Task Description> I want you to extract information from crime-related text in Korean based on the key information I give you. <Key Information> 1. motive of crime 2. injury of victim … If you can’t find matching information, don’t infer anything and simply add “없음 (None)”. |
| <Task Description> I want you to extract information from crime-related text in Korean based on the key information and an example I give you. <Key Information and Example> 1. motive of crime—e.g., “decided”, 2. injury of victim—e.g., “multiple lacerations, etc.” … <Conditions> If you can’t find matching information, don’t infer anything and simply add “없음 (None)”. ✔Tag must be in English and extracted information must be in Korean. ✔It is VERY important that you extract the information word by word. ✔NEVER summarize, rephrase or translate the given text. Tag the following text: |
| <Task Description> I want you to extract information from crime-related text in Korean based on the key information and examples I give you. <Key Information and Examples> 1. motive of crime—e.g., “enraged by the thought that the victim was ignoring him/her”, “decided to commit murder, fueled by anger when the victim got mad and refused to listen to him/her”, etc. 2. injury of victim—e.g., “multiple lacerations, etc.”, “asphyxiation due to neck compression”, “severe head injury” … <Conditions> If you can’t find matching information, don’t infer anything and simply add “None”. ✔Tag must be in English and extracted information must be in Korean. ✔It is VERY important that you extract the information word by word. ✔NEVER summarize, rephrase or translate the given text. Tag the following text: |
| ROUGE-L | Simple | One-Shot | Few-Shots |
|---|---|---|---|
| Recall | 54.59% | 54.85% | 61.85% |
| Precision | 57.11% | 71.66% | 78.01% |
| F1 score | 50.35% | 57.48% | 68.97% |
| Annotation without GPT | Annotation with GPT | ||
|---|---|---|---|
| Time | Total 375 h (time for case × total number of cases) ⇒ 15 min × 1500 cases = 22,500 min (375 h) | Total 181.25 h (1st annotation time + 2nd annotation time) ⇒ 375 min + 10,500 min = 10,875 min | |
| 1st Annotation Time (time for case × total number of cases) ⇒ 0.25 min × 1500 cases = 375 min | 2nd Annotation Time (time for case × total number of cases) ⇒ 7 min × 1500 cases = 10,500 min | ||
| Cost | Total KRW 3,697,500 (minimum wage × annotation time) ⇒ KRW 9860 × 375 h | Total KRW 1,866,025 (GPT-3.5 Fee + Annotator Minimum Wage Cost) ⇒ KRW 78,900 + KRW 1,787,125 | |
| GPT-3.5 Fee (cost for case × total number of cases) ⇒ KRW 52.60 (USD 0.04) × 1500 cases = KRW 78,900 | Annotator Wage Cost (minimum wage × annotation time) ⇒ KRW 9860 × 181.25 h = KRW 1,787,125 | ||
| Token (8) | ⦁ Victim Name; ⦁ Victim Age; ⦁ Victim Sex; ⦁ Relationship (Between Defendant and Victim); ⦁ Crime Tool; ⦁ Crime Address; ⦁ Crime Place; ⦁ Crime Date/Time. |
| Sequence (10) | ⦁ Defendant’s Medical History; ⦁ Defendant’s Financial Situation; ⦁ Defendant’s Criminal Record; ⦁ Defendant’s Drug and Alcohol Consumption; ⦁ Preliminary Act; ⦁ Crime Method; ⦁ Crime Motivation; ⦁ Crime Result; ⦁ Reason for Incompletion; ⦁ Victim’s Injury. |
| Tokens | Tags |
|---|---|
| “Crime Details: On 31 March 2017, around 8:00 p.m., at ‘E Bar’ located on the underground first floor of Building D in Gangnam-gu, Seoul, the defendant, along with four colleagues including the victim F G (37 years old), was attending the defendant’s farewell party. While intoxicated, the defendant got into an argument with the victim F outside the bar, grabbing each other by the collar. When the victim G, who is F’s younger brother, tried to intervene and stop the altercation, the defendant, in a fit of rage, decided to stab the victims whom he had premeditated to kill. Subsequently, at approximately 11:48 p.m. on 31 March 2017, in front of ‘E Bar’ on the street, the defendant took out a recreational knife from the back pocket of his pants and stabbed the victim G’s abdomen and left side of the neck four times each, and then stabbed the left side of the victim F’s waist four times with the same knife as he tried to intervene. However, due to the intervention of other colleagues who restrained the defendant and immediately called emergency services (119), the victims were promptly transported to the hospital, preventing fatalities, and the crime remained attempted.” | O O O O O O O crime_addr_B crime_addr_I crime_addr_I crime_addr_I crime_addr_I O O O v_name_B v_name_I v_name_I O v_age_B O O a_v_relation_B a_v_relation_I O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O crime_datetime_B crime_datetime_I crime_datetime_I crime_location_B crime_ location_I crime_ location_I crime_ location_I O O O O attack_tool_B attack_tool_I attack_tool_I attack_tool_I attack_tool_I attack_tool_I O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O |
| Key Information | Entity Name | Training | Valid | Test |
|---|---|---|---|---|
| Victim’s Name | v_name_B, v_name_I | 2413 | 314 | 298 |
| Victim’s Sex | v_sex_B, v_sex_I | 533 | 79 | 71 |
| Victim’s Age | v_age_B, v_age_I | 1188 | 152 | 149 |
| Relationship | a_v_relation_B, a_v_relation_I | 1337 | 184 | 187 |
| Crime Date/Time | crime_datetime_B, crime_datetime_I | 4988 | 613 | 602 |
| Crime Location (Place) | crime_place_B, crime_place_I | 2792 | 350 | 325 |
| Crime Address | crime_addr_B, crime_addr_I | 4291 | 543 | 519 |
| Crime Tool | attack_tool_B, attack_tool_I | 5535 | 846 | 800 |
| None | O | 191,611 | 25,016 | 24,169 |
| Sum | - | 214,688 | 28,097 | 27,120 |
| [ { “sequence”: “Wearing a prepared dagger (total length 22 cm, blade length 12 cm) concealed in the vest pocket, I entered the restaurant counter.”, “label”: “prep_act” }, { “sequence”: “Asking the victim, ‘Where’s the restroom, are you the manager?’ When the victim didn’t respond immediately, feeling displeased with the attitude,”, “label”: “motive” }, { “sequence”: “immediately pulled out the dagger and swung it towards the victim’s face.”, “label”: “crime_method” }, { “sequence”: “Then stabbed the victim’s abdomen and slashed the victim’s hands and neck as the victim defended.”, “label”: “crime_method” }, { “sequence”: “Attempted to kill the victim, but the victim resisted by grappling with the defendant and struggling, preventing the intention from being fulfilled.”, “label”: “reason_incmpl” }, { “sequence”: “The attempt failed.”, “label”: “crime_result” } ] |
| Patterns | Examples |
|---|---|
| Verb +, | “let’s”, “however”, “while doing”, “but” |
| Josa +, | “as”, “by means of” |
| Adjective +, | “while”, “in fact”, “despite”, “since” |
| Verb + Noun +, | “after doing”, “only after”, ”on the other hand” |
| Josa + Noun +, | “in the state of” |
| Adjective + Noun +, | “on the other hand”, “during”, “in the midst of” |
| Verb + Adjective +, | “after doing”, “while”, “after” |
| Key Information | Train | Valid | Test |
|---|---|---|---|
| a_eco_bg | 87 | 11 | 11 |
| a_crim_rec | 130 | 16 | 16 |
| a_mental_con | 378 | 48 | 47 |
| a_med_rec | 299 | 37 | 38 |
| motive | 3925 | 490 | 491 |
| prep_act | 693 | 86 | 87 |
| crime_method | 2231 | 279 | 279 |
| reason_incmpl | 747 | 94 | 93 |
| crime_result | 1347 | 168 | 169 |
| v_injury | 861 | 108 | 107 |
| nan | 3701 | 463 | 462 |
| Sum | 14,999 | 1800 | 1800 |
| Model | Token Base | Token Ours | Sequence Base | Sequence Ours |
|---|---|---|---|---|
| K-BERT | 40.98 | 84.74 | 35.61 | 88.11 |
| M-BERT | 38.17 | 84.15 | 33.2 | 86.05 |
| M-RoBERTa | 32.58 | 86.93 | 31.56 | 86.66 |
| KoELECTRA | 44.3 | 85.75 | 45.21 | 86.83 |
| K-RoBERTa | 43.52 | 85.44 | 32.51 | 87.27 |
| Key Information | F1 Score |
|---|---|
| Victim’s Name | 99.98 |
| Victim’s Age | 98.6 |
| Victim’s Name | 98.12 |
| Relationship | 75.04 |
| Crime Address | 81.24 |
| Crime Location | 70.06 |
| Crime Date/Time | 85.36 |
| Crime Result | 92.08 |
| Reason for Incompletion | 86.17 |
| Defendant’s Medical History | 91.55 |
| Defendant’s Financial Situation | 78.11 |
| Defendant’s Criminal Record | 95.68 |
| Defendant’s Drug and Alcohol Consumption | 94.16 |
| Preliminary Act | 83.08 |
| Crime Method | 92.04 |
| Crime Motivation | 88.11 |
| Crime Tool | 88.01 |
| Victim’s Injury | 91.38 |
| Avg. | 87.75 |
| Type | Criteria | Frequency (Tok) | Frequency (Seq) |
|---|---|---|---|
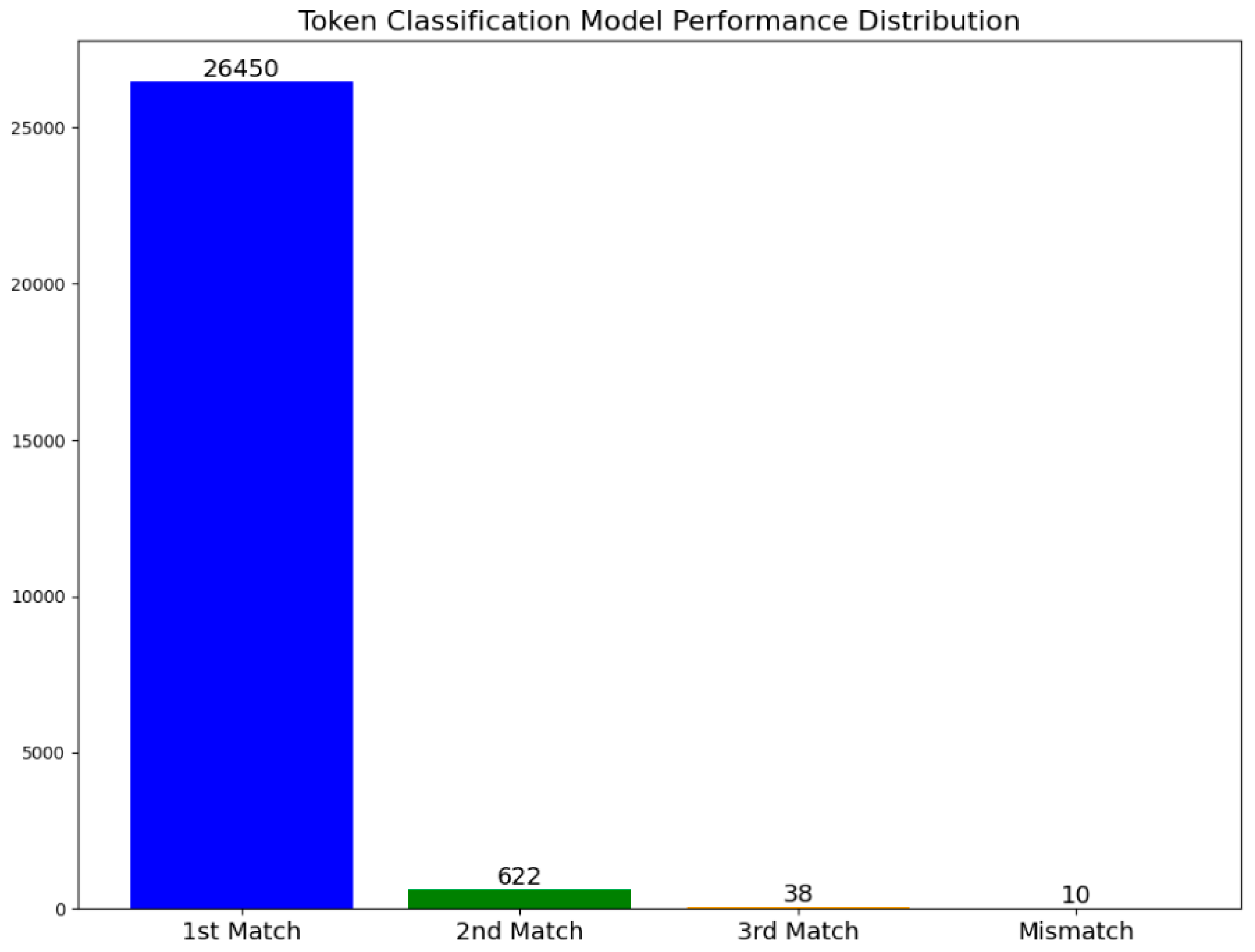
| Type 1 | When the target is key information but the predicted value is not key information | 6 | 19 |
| Type 2 | When the target is not key information but the predicted value is key information | 3 | 12 |
| Type 3 | When both the target and the predicted value are key information but are not identical | 0 | 3 |
| Idx | Token | Predicted | Target | Type |
|---|---|---|---|---|
| 1 | after birth | O | v_age | Type 1 |
| 2 | one month | O | v_age | Type 1 |
| Idx | Sequence | Predicted | Target | Type |
|---|---|---|---|---|
| 1 | Keeping the tip of the knife facing downwards After grabbing the kitchen knife | etc. | crime_method | Type 1 |
| 2 | After retrieving the knife from the belt | etc. | crime_method | Type 1 |
| 3 | Due to the mental stress caused by debt obligations and living in hiding Wondering what I should do next. Should I even consider going to prison? | a_eco_bg | motive | Type 3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, Y.; Park, R.S.; Kim, H. Key Information Extraction for Crime Investigation by Hybrid Classification Model. Electronics 2024, 13, 1525. https://doi.org/10.3390/electronics13081525
Park Y, Park RS, Kim H. Key Information Extraction for Crime Investigation by Hybrid Classification Model. Electronics. 2024; 13(8):1525. https://doi.org/10.3390/electronics13081525
Chicago/Turabian StylePark, Yerin, Ro Seop Park, and Hansoo Kim. 2024. "Key Information Extraction for Crime Investigation by Hybrid Classification Model" Electronics 13, no. 8: 1525. https://doi.org/10.3390/electronics13081525
APA StylePark, Y., Park, R. S., & Kim, H. (2024). Key Information Extraction for Crime Investigation by Hybrid Classification Model. Electronics, 13(8), 1525. https://doi.org/10.3390/electronics13081525