Abstract
Extensive research has been carried out on reinforcement learning methods. The core idea of reinforcement learning is to learn methods by means of trial and error, and it has been successfully applied to robotics, autonomous driving, gaming, healthcare, resource management, and other fields. However, when building reinforcement learning solutions at the edge, not only are there the challenges of data-hungry and insufficient computational resources but also there is the difficulty of a single reinforcement learning method to meet the requirements of the model in terms of efficiency, generalization, robustness, and so on. These solutions rely on expert knowledge for the design of edge-side integrated reinforcement learning methods, and they lack high-level system architecture design to support their wider generalization and application. Therefore, in this paper, instead of surveying reinforcement learning systems, we survey the most commonly used options for each part of the architecture from the point of view of integrated application. We present the characteristics of traditional reinforcement learning in several aspects and design a corresponding integration framework based on them. In this process, we show a complete primer on the design of reinforcement learning architectures while also demonstrating the flexibility of the various parts of the architecture to be adapted to the characteristics of different edge tasks. Overall, reinforcement learning has become an important tool in intelligent decision making, but it still faces many challenges in the practical application in edge computing. The aim of this paper is to provide researchers and practitioners with a new, integrated perspective to better understand and apply reinforcement learning in edge decision-making tasks.
1. Introduction
Reinforcement learning [1,2,3] is a learning method inspired by behaviorist psychology that attempts to maintain a balance between exploration and exploitation, focusing on online learning. The point of difference with other machine learning methods is that in reinforcement learning, no data need to be given in advance; the learning information is obtained by receiving rewards or feedback from the environment for the actions, which enables the updating of the model parameters. As a class of framework methods, it has a certain degree of versatility; it can be widely integrated in such areas as cybernetics [4], game theory [5], information theory [6], operations research [7], simulation optimization [8], multiagent systems [9], collective intelligence [10], statistics [11], and other fields of results; and it is very suitable for complex intelligent decision-making problems. Compared to centralized intelligent decision making, the approach of syncing the computation and decision-making processes in reinforcement learning at the edge has additional advantages. On the one hand, intelligent decision making at the edge can be closer to the data source and end users, which reduces the delay of data transmission, lowers the network cost of information transmission, and improves the guarantee of privacy and data security. On the other hand, because the edge device can generate decisions independently, it avoids the risk of system collapse caused by the failure of the central server or other nodes; improves the reliability and robustness of the system; and is able to partially take offline decision-making tasks. In recent years, more and more researchers have moved their attention to the problem of intelligent decision making at the edge, and it has been successful in many fields, such as the Internet of Things [12], intelligent transportation [13], and industry [14].
However, in the current practice of intelligent decision making at the edge based on reinforcement learning, it is usually just a simple choice to use the existing reinforcement learning methods according to their respective decision characteristics; for example, some algorithms are suitable for solving continuous space or continuous action problems [15,16], some other algorithms have a very good training effect for few-shot learning problems [17,18], and so on. However, intelligent decision making at the edge often requires consideration of several aspects of characterization, limited by its own configuration conditions and task types. These unique characteristics as well as the diversity and complexity of the requirements lead to a higher degree of difficulty in solving [19] and limit the generalizability of solutions across these problems. Compared with intelligent decision problems, such as the game of gaming in data centers, it is difficult to meet the needs of the actual application at the edge by using a single type of reinforcement learning method for strategy training in intelligent decision problems, which reveals the problems of nonconvergence of the training and the inefficiency and low accuracy of the training model [20,21]. In some cases, the demand for certain specific types of decision-making tasks can be satisfied, but the shortcomings of other elements still restrict its application in actual decision making at the edge. For example, can the limited storage capacity and computing power at the edge support the collection and utilization of training data required for reinforcement learning [22]? In terms of efficiency, the limited computational resources of edge devices may lead to a decrease in training efficiency, and reinforcement learning algorithms at the edge are more sensitive to real-time requirements and need to make decisions in real or near-real time. Therefore, algorithms must operate efficiently under limited resources to ensure responsiveness and real-time performance [23]. In terms of generalization, in edge environments, due to the limited data volume, algorithms may struggle to generalize sufficiently and may exhibit poorer performance in new environments and tasks [24]. Additionally, factors such as data security and privacy may also need to be considered when running reinforcement learning algorithms at the edge [25].
The solution to the above problems cannot simply rely on the optimization and upgrading of individual intelligence. Therefore, this paper tries to find other paths that can solve these challenges. Considering that since a single reinforcement learning method at the edge always has shortcomings in one way or another, is it possible to better cope with these problems if multiple types of reinforcement learning methods are integrated together? As a matter of fact, the integration of multiple methods in the same domain has been explored in other fields of AI, and some classical integration frameworks have been formed, such as the integration of random forests into multiple decision trees [26], bootstrapping, bagging, boosting, and other machine learning combination algorithms [27]. However, in the field of reinforcement learning, there is no systematic theory to support this. Most research on intelligent decisions based on reinforcement learning still focuses on a single technique or family of techniques. Although these techniques have a common form of knowledge representation, they can only be applied to solve individual isolated problems, and it is difficult to meet the realistic requirements and challenges of adaptive adaptation generalization for complex scenarios at the edge. In addition, the integration of these methods in artificial intelligence heavily relies on analyzing expert knowledge of the target task. As a result, these methods often lack sufficient generalization and flexibility, making them inapplicable to other tasks. Therefore, this paper aims to provide a general integration design framework and solution for edge intelligence decision making based on reinforcement learning.
To this end, this paper first analyzes the current problems and challenges in the direct application of reinforcement learning to intelligent decision in edge computing. Subsequently, based on the definition and analysis of the design ideas of the integration framework and the collation of the focuses of current researchers in related studies, it is observed that current reinforcement learning-based strategy training methods primarily concentrate on five key aspects: architectural methods, pattern types, optimization directions, characterization methods, and training strategies. Meanwhile, by analyzing the inherent nested relationships among these methods, the decision-making characteristics of different reinforcement learning approaches are summarized. Finally, by integrating the technical characteristics and decision-making features of reinforcement learning, as well as the general requirements for intelligent decision, a corresponding integration framework for reinforcement learning is designed. The key issues to be solved in each link of the integration framework are analyzed to better meet the requirements of key capabilities. We aim to provide a clear and practical guide through the format of a survey, assisting beginners and those new to engineering design in better understanding and utilizing reinforcement learning methods. Our goal is to facilitate the integration and development of reinforcement learning techniques in the field of engineering, fostering a deeper connection between engineering practices and reinforcement learning technology.
It is worth noting that this paper is not intended to comprehensively analyze all reinforcement learning methods but rather to organize the vast research outcomes and system architectures of reinforcement learning from an engineering perspective, understanding the choices of technical routes in different modules and their impacts. This aims to assist relevant researchers and practitioners in realizing the trade-offs across various aspects and carefully selecting the most practical options. In this paper, we design a general integrated framework consisting of five main modules and examine the most representative algorithms in each module. This framework is expected to provide more direct assistance for the design of solutions in edge intelligent environments, thereby guiding researchers in developing reinforcement learning solutions tailored to specific research problems. The contributions of this paper are summarized as follows:
- This paper presents a generic integrated framework for designing edge reinforcement learning methods. It decomposes the solution design for intelligent decision-making problems into five steps, enhancing the robustness of the framework in different edge environments by integrating different reinforcement learning methods in each layer. Additionally, it can provide a general guidance framework for researchers in related fields through process-oriented solution design.
- This paper surveys the existing research studies related to the five layers of the integration framework, respectively, including architectural schemes, pattern types, optimization directions, characterization methods, and training strategies. The current mainstream research directions and representative achievements of each layer are summarized, and the emphases of different mainstream methods are analyzed. This provides a fundamental technical solution for various layers of integration frameworks. At the same time, it also provides a theoretical foundation for designing and optimizing edge intelligence decision making.
- This paper demonstrates the working principle of the proposed framework through a design exercise as a case study. In the design process, this paper provides a detailed introduction to the workflow of the integration framework, including how to properly map the decision problem requirements to reinforcement learning components and how to select suitable methods for different components. Furthermore, we further illustrate the practicality and flexibility of the integration framework by using AlphaGo as a real-world example.
- The architecture proposed in this paper integrates existing reinforcement learning systems and frameworks at a higher level, going beyond the limitations of existing surveys that are restricted to a particular area of research in reinforcement learning. Instead, it adopts an integrated perspective, focusing on the deployment and design of reinforcement learning methods in real-world applications. This paper aims to create a more accessible tool for researchers and practitioners to reference and apply. It also provides them with a new perspective and approach for engaging in related research and work.
After analyzing the basic requirements of reinforcement learning framework design from an integrated perspective and giving a high-level framework design idea in Section 2, we introduce the five key parts of the framework design species, architectural scheme, pattern type, optimization direction, characterization method, and training strategy in Section 3, Section 4, Section 5, Section 6 and Section 7, respectively, to provide a systematic overview of the reinforcement learning system. In order to demonstrate the applicability of the integrated framework, we selected representative research achievements in various typical application scenarios of reinforcement learning in Section 8, and we describe their solutions using the integrated framework. Additionally, this section provides an example of generating a reinforcement learning solution to showcase the flexibility and workflow of our framework. Subsequently, in Section 9, several noteworthy issues are discussed. Finally, in Section 10, we summarize the work presented in this paper. The terminology and symbols used in this paper are summarized in Table 1.

Table 1.
Explanation of formula terms.
2. Framework Design from Integrated Perspective
Most of the mature edge intelligent decision-making solutions focus on designing, optimizing, and adapting to a single problem (e.g., automated car driving [28] and some board games [29]); rely heavily on expert knowledge; and are still limited to a single technology or family of technologies. Despite the common knowledge representation of these technologies, the solution-building process still lacks systematic design guidance and can only analyze each isolated problem separately, making it difficult to provide generalized solutions for edge intelligent decision making. It is increasingly recognized that the effective implementation of intelligent decision making requires both the fusion of multiple forms of experience, rules, and knowledge data and the ability to combine multiple technological means of learning, planning, and reasoning. These combined capabilities are necessary for interactive systems (cyber or physical) that need to operate in uncertain environments and communicate with the subjects who need to make decisions [30]. Therefore, this section designs a framework for reinforcement learning in edge computing through an integrated perspective by characterizing reinforcement learning methods. The design ideas and characterization will be explored in detail in the following sections.
2.1. Related Work
Reinforcement learning, as a branch highly regarded in the field of artificial intelligence, has attracted considerable attention and investment from researchers in recent years. Surveys dedicated to reinforcement learning have shown a thriving trend, encompassing a comprehensive range of topics from fundamental theories to practical applications. In terms of fundamental theories, researchers have conducted extensive studies based on various types of reinforcement learning methods. To address the challenges of difficulty in data acquisition and insufficient training efficiency, Narvekar et al. designed a curriculum learning framework for reinforcement learning [31]. Gronauer et al. focused on investigating training schemes for multiple agents in reinforcement learning, considering behavioral patterns in cooperative, competitive, and mixed scenarios [32]. Pateria et al. discussed the autonomous task decomposition in reinforcement learning, outlining challenges in hierarchical methods, policy generation, and other aspects from a hierarchical reinforcement learning perspective [33]. Samasmi et al. discussed potential research directions in deep reinforcement learning from a distributed perspective [34]. Ramirez et al. started from the principle of reinforcement learning and discussed methods and challenges in utilizing expert knowledge to enhance the performance of model-free reinforcement learning [35]. In contrast, Moerland et al. provided a comprehensive overview and introduction to model-based reinforcement learning methods [36]. These studies focused on how to adjust reinforcement learning methods to generate more powerful models. In practical applications, Moerland et al. focused on the emotional aspects of reinforcement learning in robotics, investigating the emotional theories and backgrounds of reinforcement learning agents [37]. Chen et al. approached the topic from the perspective of daily life, exploring the application of reinforcement learning methods in recommendation systems and discussing the key issues and challenges currently faced [38]. Meanwhile, Luong et al. emphasized addressing communication issues, surveying the current state of research in dynamic network access, task offloading, and related areas [39]. Haydari et al. summarized the work of reinforcement learning methods in the field of traffic control [40]. Elallid et al. investigated the current state of deep reinforcement learning in autonomous driving technology [41]. Similar types of work have also emerged in healthcare [42], gaming [43], the Internet of Things (IoT) [44], and security [45]. These studies focused on conducting a systematic investigation of the application of reinforcement learning methods in different domains. However, these surveys concentrated on the microlevel of the reinforcement learning field, specifically discussing the strengths and weaknesses of different reinforcement learning methods within specific domains or task scenarios.
At a macrolevel, some researchers have made achievements, such as Stapelberg et al., who discussed existing benchmark tasks in reinforcement learning to provide an overview for beginners or researchers with different task requirements [46]. Aslanides et al. attempted to organize existing results of general reinforcement learning methods [47]. Arulkumaran et al. reviewed deep reinforcement learning methods based on value and policy and highlighted the advantages of deep neural networks in the reinforcement learning process [48]. Sigaud et al. conducted an extensive survey on policy search problems under continuous actions, analyzing the main factors limiting sample efficiency in reinforcement learning [49]. Recht et al. introduced the representation, terminology, and typical experimental cases in reinforcement learning, attempting to make contributions to generality [16]. The aforementioned works either focus on specific types of problems or provide simple introductions from a macroperspective, lacking a systematic analysis of the inherent connections between different key techniques. Such a situation can only provide beginners or relevant researchers with an introductory perspective, but it still lacks a comprehensive understanding of the relationships and integration methods among different technical systems, and it is not able to provide systematic and effective guidance for rapidly constructing reinforcement learning solutions in real-world tasks. For a newly emerging reinforcement learning task, researchers still need to explore and generate a solution from numerous methods, lacking a structured framework to provide appropriate solution approaches. Therefore, this paper aims to provide researchers with more in-depth and comprehensive references and guidance to help them better understand the complexity of the reinforcement learning field and conduct further research.
2.2. Framework Design Ideas
For researchers, although there are currently methods to develop the capabilities of reinforcement learning in individual tasks, there is still a lack of understanding and experience in how to construct intelligent systems that integrate these functionalities, relying on expert knowledge for discussions on research problems [50,51]. A key open question is what the best overall organizational method for multiagent systems is: homogeneous nonmodular systems [52]; fixed, static modular systems [53]; dynamically reconfigurable modular systems over time [54]; or other types of systems. In addition to the organizational methods, there are challenges in the transformation and coexistence of alternative knowledge representation approaches, such as symbolic, statistical, neural, and distributed representations [55], because the different representation techniques vary in their expressiveness, computational efficiency, and interpretability. Therefore, in practical applications, it is necessary to select the appropriate knowledge representation method according to the specific problem and scenario. Furthermore, the optimal way to design the workflow for integrated systems is still subject to discussion, i.e., how AI systems manage the sequencing of tasks and parallel processes between components. Both top-down, goal-driven and bottom-up, data-driven control strategies may be suitable for different problem scenarios. Although there are expected interdependencies among the components, rich information exchange and coordination are still necessary between them.
To address these issues, we specify the basic requirements for framework design under the integration perspective presented in this section. The purpose of this paper on framework design under the integration perspective is to provide a formal language to specify the organization of an integrated system, similar to the early work performed when building a computer system. The core of the research in this section is to provide a framework for analyzing, comparing, classifying, and synthesizing integration methods that support abstraction and formalization and that can provide a generic foundation for subsequent formal and empirical analyses.
In terms of the design philosophy of a framework, an integrated framework should minimize complexity while meeting the corresponding design requirements. This requires considering how to correctly map the requirements to the components of reinforcement learning during the design process, as well as selecting an architecture that can accommodate these components. Modularizing the method modules within the integrated framework is a feasible solution [56]. By assembling various algorithms as modules into the framework, the efficiency and simplicity of the integrated reinforcement learning framework can be greatly improved. Furthermore, there exist integration relationships among some reinforcement learning methods [57], where certain algorithms can serve as submodules within other algorithms [58], providing a solid foundation for implementing the integrated framework. In summary, an integrated framework for reinforcement learning involves organically integrating multiple modules (different types of intelligent methods) into a versatile composite intelligent system. Different integration modules can be used for different task requirements. In the context of this paper’s application domain, the framework design must fully consider the key capability requirements for achieving intelligent decision making. This section aims to provide specific methods for optimizing the crucial steps of an innovative integration framework in order to better adapt to the demands of intelligent decision making.
2.3. Integrated Characteristic Analysis
To design a more reasonable integration method framework around reinforcement learning, it is important to understand the characteristics of reinforcement learning and interpret the underlying logic and integration relationships among them. In order to make the various parts of the framework self-consistent and integrated, our research has extensively reviewed the relevant literature and categorized these studies based on their different research focuses on reinforcement learning methods. From the application perspective of reinforcement learning, as Yang et al. [59] first divided the research scope into single-agent scenarios and multiagent scenarios in the exploration of reinforcement learning strategies; the integration framework also needs to set the research scope of the problem reasonably. After clarifying the research scope, the next issue to be addressed is data acquisition, which is the foundation of all machine learning methods. The most significant difference between reinforcement learning and other machine learning methods is that its training data need to be continuously generated through agent–environment interactions, as described in [35,36]. Then, these data are used to upgrade the current policy model. Ref. [60] briefly introduces the work in this field and tries to integrate several main methods. Additionally, choosing suitable representation methods is an important part of transforming these theories into implementations. Ref. [61] analyzes the characteristics of different types of artificial neural networks, while [62] investigates research on spiking neural networks that are more inclusive of time series. Finally, after determining the plans for all the above aspects, the integration framework needs to select an appropriate training strategy for reinforcement learning according to task requirements. This approach is similar to [63,64], which investigate different research areas in training strategies in the field of machine learning. Specifically, this paper categorizes the research from five aspects: architecture design, model types, optimization direction, representation methods, and training strategies:
- Architectural scheme: The architectural scheme aims to achieve the division of labor and collaboration between different methods and agents by decomposing and dividing complex tasks to accomplish a complex overall goal. One direction is to deconstruct the problem based on the scale of the task, e.g., a complex total problem is divided into several subproblems, and the optimal solution of each subproblem is combined to make the optimal solution of the total problem (realizing the idea of divide and conquer, which can significantly reduce the complexity of the problem) [33]. Another direction is to deconstruct the task based on the agents, e.g., to use multiple agents to cooperate to complete a task at the same time (multirobotic arms to assemble a car task, etc.). Common reinforcement learning methods that have been researched around architectural schemes include meta-reinforcement learning, hierarchical reinforcement learning, multi-intelligent reinforcement learning, etc. [32].
- Pattern type: Pattern type is used to describe the policy generation pattern adopted by reinforcement learning for a task environment. Different policy generation patterns have different complexities and learning efficiencies. The pattern type needs to be selected based on the complexity of the task and the cost of trial and error. The difference lies in the ability to construct a world model that resembles the real world based on the environment and state space for the task simulation beforehand. Common reinforcement learning methods that center on pattern types include model-based reinforcement learning algorithms, model-free reinforcement learning algorithms, and reinforcement learning algorithms that integrate model and model-free reinforcement learning algorithms.
- Optimization direction: The optimization direction starts from different concepts, condenses the formal features, and designs a more efficient strategy gradient updating method to accomplish the task. Policy gradient updating methods from different optimization directions have distinct characteristics, strengths, and weaknesses. Additionally, there are often multiple options for policy gradient updating methods within the same optimization direction, depending on the focus. Common optimization directions for reinforcement learning include value-based methods, policy-based methods, and fusion-based methods.
- Characterization method: The characterization method involves selecting encoders, policy mechanisms, neural networks, and hardware architectures with distinct features to develop targeted reinforcement learning algorithms tailored to specific application scenarios. Common reinforcement learning characterization methods include brain-inspired pulse neural networks, Bayesian analysis, deep neural networks, and so on.
- Training strategy: The training strategy is based on the perspective of the actual task, considering the characteristics of the edge and choosing a more reasonable and efficient training strategy to complete the training. Different training strategies have different applicable scenarios and characteristics and can cope with different types of challenges; for example, federated reinforcement learning can better protect the privacy of training data. Common reinforcement learning training strategies include centralized reinforcement learning, distributed reinforcement learning, and federated reinforcement learning.
After categorizing reinforcement learning in these five aspects, it is not difficult to find that there is a significant integration relationship among these five research directions (see Figure 1 for details). Although no study has yet synthesized reinforcement learning from an integration perspective and proposed a unified integration system, past research on different directions is not entirely disparate. The integration relationship between reinforcement learning provides the basis for the design of our integration framework in this paper.
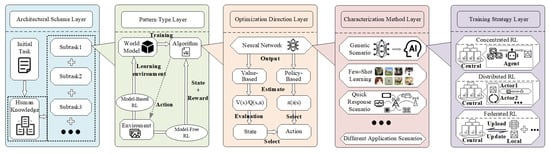
Figure 1.
Schematic diagram of integrated framework components.
The design of the integration framework should start with an architectural scheme to choose a suitable architecture to deconstruct and divide the complex task. Reinforcement learning methods centered on architecture are a direct match for this and can be used directly in the outermost architecture of the integration framework.
Second, the tasks of deconstruction can be viewed as a number of independent modules. For different modules, we can choose the pattern type to solve the problem according to the differences in the task environment. For example, for some environments, we need to build a world model first and then, based on the model, let the agent interact with it; or for environments that do not need to build a world model, we can let the agent learn directly in the environment through the model-free reinforcement learning method.
Then, after determining the pattern type, we choose the appropriate optimization direction for different algorithms to make the algorithms more robust and able to perform, such as optimizing the value function in the algorithm or optimizing the policy.
Then, at the bottom of the integration framework, facing different application scenarios, we can adopt different ways to deal with the input and output objects, i.e., selecting the characterization method to complete the input–output transformation.
Finally, after determining the characterization method, we choose the appropriate training strategy to fit the task at hand more closely and to improve the training efficiency while reducing the expenditure. For example, federated reinforcement learning is chosen for tasks with high privacy requirements.
It is worth noting that the integrated framework designed in this article is precisely based on the organic integration of these five different research directions in reinforcement learning, where the components are nested and complement each other. The process of selecting components in the integrated framework is itself an analysis of practical application problems. We hope that through this process, researchers or practitioners can quickly understand the mainstream research methods and characteristics of each component, reducing the reliance on expert knowledge. Additionally, the framework includes task decomposition at a macrolevel to strategy updates at a microlevel, taking into account the limitations of software algorithms and hardware devices. It is able to cover various requirements in real-world applications.
3. Architecture-Scheme Layer
Reinforcement learning methods that have been studied in an architectural scheme include meta-reinforcement learning [65], hierarchical reinforcement learning [33], and multiagent reinforcement learning [66]. In the design of the reinforcement learning integration framework, in order to ensure the normal operation, the architectural scheme layer should be designed around these three methods. This classification stems from a generalization after sorting out the different types of problems targeted by current reinforcement learning models. The family of techniques represented by meta-learning focuses on the generalization aspect of reinforcement learning, enabling trained agents to adapt to new environments or tasks. The system represented by hierarchical reinforcement learning, on the other hand, aims to address the complexity of reinforcement learning problems, attempting to make reinforcement learning algorithms effective in more complex scenarios. Multiagent reinforcement learning, as the name suggests, tackles the collaboration or competition among multiple agents in a shared environment, including adversarial games and cooperative scenarios. When designing an integrated framework for reinforcement learning methods, it is crucial to select appropriate architectural design principles as the foundation for subsequent work to ensure the smooth operation of the integrated framework.
3.1. Meta-Reinforcement Learning
Another term for meta-learning, learning to learn is the idea of “learning how to learn”, which, unlike general reinforcement learning, emphasizes the ability to learn to learn, knowing that learning a new task relies on past knowledge as well as experience [67]. Unlike traditional reinforcement learning methods, which generally train and learn for specific tasks, meta-learning aims to learn many tasks and then use these experiences to learn new tasks quickly in the future [68].
Meta-reinforcement learning is a research area that applies meta-learning to reinforcement learning [69]. The central concept is to leverage the acquired prior knowledge from learning a large number of reinforcement learning tasks, with the hope that AI can learn faster and more effectively when faced with new reinforcement learning tasks and adapt to the new environment accordingly [70].
For instance, if a person has an understanding of the world, they can quickly learn to recognize objects in a picture without having to start from scratch the way a neural network does, or if they have already learned to ride a bicycle, they can quickly pick up riding an electric bicycle (analogical learning—learning new things through similarities and experiences). In contrast, current AI systems excel at mastering specific skills but struggle when asked to perform simple but slightly different tasks [71]. Meta-reinforcement learning addresses this issue by designing models that can acquire diverse knowledge and skills based on past experience with only a small number of training samples (or even zero samples for initial training) [72]. The fine-tuning process can be represented as
where represents the fine-tuned model parameters. When the initial model is applied to a new task , the model parameters are updated through gradient descent ∇. denotes the step size of the model update.
The core of meta-learning is that AI owns core values so as to realize fast learning, i.e., so that AIs (agents) can form a core value network after learning various tasks and can utilize the existing core value network to accelerate its learning speed when facing new tasks in the future. Meta-reinforcement learning belongs to a branch of meta-learning, a technique for learning inductive bias. It consists roughly of two phases: one is the training phase (metatraining), which learns knowledge through the past Markov process (MDP); the second is the adaptation phase (meta-adaptation), which involves how to quickly change the network to adapt to a new task (task). Meta-reinforcement learning mainly tries to solve the problems of deep reinforcement learning (DRL) [73], such as the DRL algorithm’s low sample utilization; final performance of the DRL model being oftentimes unsatisfactory; the overfitting to the environment; and the existence of model instability.
The advantage of meta-reinforcement learning is that it can quickly learn a new task by building a core guidance network (and training several similar tasks at the same time) so that the agent can learn to face a new task by keeping the guidance network unchanged and building a new action network. The disadvantage of meta-reinforcement learning, however, is that the algorithm does not allow the intelligence to learn how to specify action decisions on its own, i.e., meta-reinforcement learning is unable to accomplish the type of tasks that require the intelligence to make decisions.
3.2. Hierarchical Reinforcement Learning
Hierarchical reinforcement learning is a popular research area in the field of reinforcement learning that addresses the challenge of sparse rewards [74]. The main focus of this area is to design hierarchical structures that can effectively capture complex and abstracted decision processes in an agent. The direct application of traditional reinforcement learning methods to real-world problems with sparse rewards can result in the nonconvergence or divergence of the algorithm due to the increasing complexity of the action space and state space. This issue arises from the need for the agent to learn from limited and sparse feedback. Just as when humans encounter a complex problem, they often decompose it into a number of easy-to-solve subproblems, and then once divided into subproblems, they work step by step to solve the subproblems, the idea of hierarchical reinforcement learning is derived from this. Simply put, hierarchical reinforcement learning methods use a hierarchical architecture to solve sparse problems (dividing the complete task into several subtasks to reduce task complexity) by increasing intrinsic motivation (e.g., intrinsic reward) [75,76].
Currently, hierarchical reinforcement learning can be broadly categorized into two approaches. One is a goal-conditioned algorithm [77,78]; its main step is to use a certain number of subgoals to train the agent toward these subgoals, and after the final training, the agent can complete the set total goal. The difficulty in this way is how to select suitable subgoals to assist the algorithm in reaching the final goal. The other type is based on multilevel control, which abstracts different levels of control, with the upper level controlling the lower level (generally divided into two levels; the upper level is called the metacontroller and the lower level is called the controller) [79,80]. These abstraction layers may be called different terms in different articles, such as the common option, skill, macroaction, etc. The metacontroller at the upper level gives a higher-level option and then passes the option to the lower-level controller layer, which takes an action based on the received option, and so on until the termination condition is reached.
The specific algorithms for goal-based hierarchical reinforcement learning include HIRO (hierarchical reinforcement learning with off-policy correction) [81], HER (hindsight experience replay) [82], etc. The specific algorithms for hierarchical reinforcement learning based on multilevel control include option critic [83], A2OC (asynchronous advantage option critic) [84], etc.
Hierarchical reinforcement learning can solve the problem of poor performance in scenarios with sparse rewards encountered by ordinary reinforcement learning (through the idea of hierarchical strategies at the upper and lower levels), and the idea of layering can also significantly reduce the “dimensional disaster” problem during training. However, hierarchical reinforcement learning is currently in the research stage, and hierarchical abstraction still requires a human to set goals to achieve good results, which means it has not yet reached the level of “intelligence”.
3.3. Multiagent Reinforcement Learning
Multiagent reinforcement learning refers to a type of algorithm where multiple agents interact with the environment and other agents simultaneously in the same environment [85]. It will construct a multiagent system (MAS) composed of multiple interactive agents in the same environment [86]. This system is commonly used to solve problems that are difficult to solve for independent agents and single-layer systems. The agents can be implemented by functions, methods, processes, algorithms, etc. Multiagent reinforcement learning has been widely applied in fields such as robot cooperation, human–machine chess, autonomous driving, distributed control resource management, collaborative decision support systems, autonomous combat systems, and data mining [87,88,89].
In multiagent reinforcement learning, each intelligence makes sequential decisions through a trial-and-error process of interacting with the environment, similar to the single-agent case. A major difference is that the agents need to interact with each other, so that the state of the environment and the reward function actually depend on the joint actions of all the agents. There is an intuitive notion: for one of the agents, the state actions, etc., of the other agents are also modeled as the environment is, and then the algorithms in the single-agent domain are trained and learn separately. Then the training of each agent is summarized into the system for analysis and learning.
A part of the algorithms of multiagent reinforcement learning is the solving of the cooperative/adversarial game problem, which can be categorized into four types according to the different requirements: (1) Complete competition between agents, i.e., one party’s gain is the other party’s loss, such as the predator and the prey or the two sides of the chess game. The general complete competition relationship is a zero-sum game or a negative-sum game (the two sides obtain the combined reward of 0 or less than 0). (2) Complete cooperation between agents, mainly for industrial robots or robotic arms to cooperate with each other to manufacture products or complete tasks. (3) Mixed relationship between agents (i.e., semicooperative and semicompetitive), such as in soccer robots, where the agents are on the same team and against the other team, which shows the two kinds of relationships; these are, respectively, cooperating with the intelligences for the cooperative and competitive relationships [32]. (4) Self-interest, where each agent only wants to maximize its own reward, regardless of others, such as in the automatic trading system of stocks and futures [90].
Compared with the shortcomings of single-agent reinforcement learning in some aspects, multiagent reinforcement learning can solve the problems of the algorithm being difficult to converge or the learning time being too long. At the same time, it can also complete cooperative or antagonistic game tasks that cannot be solved by single-agent reinforcement learning.
However, there are a number of problems with directly introducing a multi-intelligent system into the more successful algorithms of single-intelligent reinforcement learning, most notably the fact that the strategy of each intelligence changes as training progresses and is nonstationary from the point of view of any of the independent intelligences, which contradicts the static nature of the MDP. Similarly in the case of reinforcement learning, compared to a single intelligence, multi-intelligence reinforcement learning will have the following limitations: (1) Environmental uncertainty: while one intelligence is making a decision, all other intelligences are taking action while the state of the environment changes, and the joint action of all the intelligences and the associated instability result in the state of the environment and the state-space dimension rising. (2) Limitations in obtaining information: a single agent may only have local observation information, cannot obtain global information, and cannot know the observation information, action, and reward information of other agents. (3) Individual goal consistency: the goal consistency of each subject may not overlap. It may be the global optimal reward or the local optimal reward. In addition, high-dimensional state space and action space are usually involved in large-scale multiagent systems, which puts higher demands on the model representation ability and computational power in real scenarios. This may have certain scalability difficulties.
4. Pattern-Type Layer
Reinforcement learning can be divided into model-free [91] and model-based [92] categories in terms of the type of model, the main differences being whether the current state is known or not, whether the action is shifted to the next state or not, and what the distribution of rewards is. When distribution is provided directly to the reinforcement learning method, these are called model-based algorithms (i.e., whether or not they rely on a learned model for exploration and exploitation, the algorithm first interacts with the real environment to fit a model and then predicts what it will see afterward and plans the path of action ahead of time based on it), and and the opposite are are called model-free algorithms. The classification criteria in this category are based on the classic article [1].
4.1. Model-Based Reinforcement Learning
Model-based reinforcement learning (MBRL) is a method of learning a model (environment model) by first obtaining data from the environment and then optimizing the policy based on the learned model [93]. The model is a simulation of the real world. In MBRL, one of the most central steps is the construction of an environment model, and the complete learning steps are summarized in Figure 2. First, a model is built from the experience of interacting with the real world. Second, the model is learned and updated with value functions and strategies, drawing on the methods used in MDP, TD, and other previous approaches. Subsequently, the learned value functions and strategies are used to interact with the real world, i.e., a course of action is planned in advance, and then the agent follows the course of action and explores the real environment to gain more experience (updating the value functions and strategies through the error values returned to update and make the environment model more accurate).
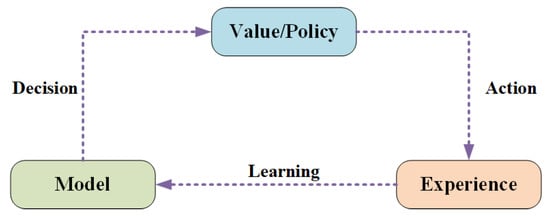
Figure 2.
Flow of the model-based reinforcement learning algorithm.
MBRL can be broadly categorized into two implementations. The first is the learn-the-model approach and the second is the given-the-model approach. The difference is that the given-the-model approach learns and trains based on an existing model, whereas the learn-the-model approach allows an agent to construct a world model of the environment by first exploring and developing it. Then the agent interacts with the constructed environment model (learning and training) and then iteratively updates the environment model to make the agent more sufficiently explore the real environment more accurately. A specific algorithm for the given-the-model approach is AlphaZero [94], and specific algorithms for learn the model are MBMF [95], MBVE [95], I2As [96], and so on.
The model-based algorithm has its own significant advantages: (1) based on supervised learning, it can effectively learn environmental models; (2) it is able to effectively learn using environmental models; (3) it reduces the impact of inaccurate value functions; (4) researchers can directly use the uncertainty of the environmental model to infer some previously unseen samples [97].
The model-based algorithm requires learning the environment function first and then constructing the value function, resulting in a higher time cost than the model-free algorithm. The biggest drawback of model-based learning is that it is difficult for agents to obtain a real model of the environment (i.e., there may be a significant error in the environment model compared to the real world).
Because there are two approximation errors in the algorithm, this can lead to the accumulation of errors and can affect the final performance. For example, there are errors from the differences between the real environment and the learned model, which may result in the expected performance of the intelligent agent in the real environment being far inferior to the excellent results in the model.
4.2. Model-Free Reinforcement Learning
Model-free reinforcement learning is the opposite of model-based; it completely does not rely on environmental models and can directly interact with the environment to gradually learn and explore. It is often difficult to obtain the state transitions, types of environmental states, and reward functions in real-life scenarios; therefore, if model-based reinforcement learning is still used, the error resulting from the difference between the learned model and the real environment will often be large, leading to an increasing accumulation of errors when the agent learns in the model and resulting in the model achieving far from the expected effect. Model-free algorithms are easier to implement and adjust because they interact with and learn directly from the environment [98].
In model-free learning, the agent cannot obtain complete information about the environment because it does not have a mode. It needs to interact with the environment to collect information about the trajectory data to update the policy and value function so that it can obtain more rewards in the future. Compared with model-based reinforcement learning, model-free algorithms are generally easier to implement and adjust because they take the approach of sampling the environment and then fitting and can update the policy and value function more quickly. Algorithmically specific, unlike Monte Carlo methods, the temporal-difference learning method guesses and continually updates the results of the guessed episodes after learning its own bootstrapping and incomplete episodes.
Model-free algorithms can be broadly classified into three categories: the unification of value iteration and strategy iteration, Monte Carlo methods, and temporal-difference learning, as follows: (1) Strategy iteration is actually used first to evaluate each strategy to obtain the value function, and then the greedy strategy is used to obtain the promotion of the strategy. The value iteration does not evaluate any but simply iterates over the value function to obtain the optimal value function and the corresponding optimal policy [99]. (2) The Monte Carlo method assumes that the value function of each state takes a value equal to the average of the returns of multiple episodes that must be executed in the termination state [100]. The value function of each state is the expectation of the payoff, and under the assumption of Monte Carlo reinforcement learning, the value function takes a value simplified from the expectation to the mean value. (3) Like Monte Carlo learning, temporal-difference learning from episode learning is the direct active experimentation with the environment to obtain the corresponding “experience” [101].
The advantage of model-free algorithms is that they are much easier to implement than model-based algorithms because they do not need to model the environment (the modeling process is prone to errors in modeling the real-world environment, which can affect the accuracy of the model); therefore, they are better than the model-based algorithms in terms of the generalizability of the problem. However, model-free algorithms also have shortcomings: the sampling efficiency of such algorithms is very low, a large number of samples is needed to learn the algorithm (high time cost), etc.
4.3. Reinforcement Learning Based on the Fusion of Model-Based and Model-Free Algorithms
Both model-based reinforcement learning methods and model-free reinforcement learning methods have their own characteristics; the advantage of model-based methods is that their generalization ability is relatively strong, while the sampling efficiency is high. The advantages of model-free methods are that they are universal, the algorithms are relatively simple, and they do not need to construct models, so they are suitable for solving problems that are difficult to model, and at the same time, they can guarantee that the optimal solution is obtained. However, both of them have their own limitations: for example, the sampling efficiency of model-free methods is low and their generalization ability is weak; model-based methods are not universal, they cannot model some problems, and their algorithmic errors are sometimes large. When encountering actual complex problems, modeled or model-less methods alone may not be able to completely solve the problem.
Therefore, the new idea is to combine model-based and model-free ideas to form an integrated architecture, that is, to fuse reinforcement learning based on model-based and model-free approaches, utilizing the advantages of both to solve complex problems. When an environment model is constructed, the agent can have two sources from which to obtain experience: one is actual experience (real experience) [35] and the other is simulated experience (simulated experience) [36]. It is expressed by the formula
where represents the state of the environment at the next moment, while real experience refers to the trajectory obtained by the agent interacting with the actual environment, and the state transition distribution and reward are obtained from feedback in the real environment. Simulated experiences rely on the environment model to generate trajectories based on state transition probabilities and reward functions.
The Dyna architecture was the first to combine real experiences that are not model-based with simulated experiences obtained from model-based sampling [102]. the algorithm learns from real experiences to obtain a model and then uses the real and simulated experiences jointly to learn while updating the value and policy functions. The flowchart of the Dyna architecture is shown in detail in Figure 3.
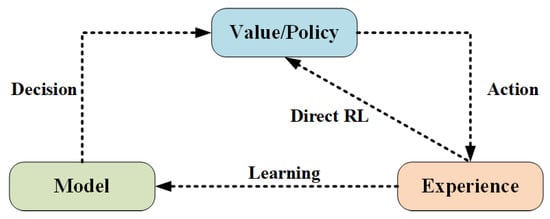
Figure 3.
The framework of Dyna.
The Dyna algorithmic framework is not a specific reinforcement learning algorithm but rather a series of a class of algorithmic frameworks, which differs from the flowchart of the modeled approach by the addition of a “direct RL” arrow. The Dyna algorithmic framework is used in combination with different model-free RLs to obtain specific fusion algorithms. If Q-learning based on value functions is used, then the Dyna-Q algorithm can be obtained [103]. In the Dyna framework, in each iteration, the environment is first interacted with and the value function and/or the policy function is updated. This is followed by n predictions of the model, again updating the value function, and the policy function. This allows for the experience of interacting with the environment and the predictions of the model to be utilized simultaneously.
The fusion algorithm integrates the advantages of both model-based and model-free algorithms, such as strong generalization ability, high sampling efficiency, and the ability to maintain a relatively fast training speed. This also makes it a popular type of algorithm in reinforcement learning, expanding a series of studies such as the Dyna-2 algorithm framework.
5. Optimization-Direction Layer
From the optimization direction, reinforcement learning can be classified into three main categories: algorithms based on value optimization [104], algorithms based on policy optimization [105], and algorithms combining value optimization and policy optimization [106]. Typical value-optimization algorithms are Q-learning and SARSA, and typical policy-optimization algorithms are TRPO (trust region policy optimization) and PPO (proximal policy optimization). The current research trend of algorithms combining value optimization and policy optimization is mainly based on the actor–critic (AC) method for improved optimization (the actor models the policy and the critic models the value function). These classifications stem from the classic textbooks in the field of reinforcement learning [107]. They represent two distinct approaches to thinking about and solving problems in reinforcement learning.
5.1. Optimization of Value-Based Reinforcement Learning
Specific examples of value-optimization-based algorithms are SARSA [108] and Q-learning [109]; these were introduced in the previous subsections. This type of reinforcement learning is based on the dynamic planning of the Q-table and introduces the notion of the Q-value, which represents the expectation of the value of the total reward and relies on the expectation of the currently required action to be evaluated. The core of the algorithm is to select a more optimal strategy for exploring and utilizing the environment in order to collect a more comprehensive model.
Value-based reinforcement learning (represented by Q-learning) actively separates the exploration and exploitation parts, taking randomized actions to sample the entire state space, making the exploration sufficient for the overall problem [109]. The idea of DP is then used to update the sampled state using the maximum value, and for complex problems, neural networks are often used for value function approximation.
The value-based optimization method has a high sampling rate, and the algorithm is easy to implement. However, the algorithm still has some limitations [110], including the following: (1) The maximum value function used for updating the value function has the challenge that it is difficult to find the same function for the corresponding operation in the continuous action, so it cannot solve these problems. (2) Due to the use of a completely random exploration strategy, it makes the computation of the value function very unstable. These problems have led researchers to constantly search for methods with better scene adaptation, such as the reinforcement learning methods based on policy optimization cited below.
5.2. Optimization of Policy-Based Reinforcement Learning
Due to the above reasons, reinforcement learning based on value optimization cannot be adapted to all scenarios, so the methods based on policy optimization (PO) are born [111]. Policy optimization reinforcement learning methods are usually divided by the determinism of the policy, where the deterministic policy approach will only choose a fixed action at each step and then enter the next state; furthermore, the policy of the stochastic policy approach is a probability distribution of an action (one out of several actions), and the agent will choose one according to the current state with a certain policy and then enter the next state.
Generally, for strategy optimization, the strategy gradient algorithm is used, which is implemented in two steps: (1) The gradient is derived based on the output of the strategy network. (2) The strategy network is updated using statistics on the total strategy distribution using the data generated by the interaction of the agents with the environment. Specific algorithms based on policy optimization include PPO [112], TRPO [113], etc. In particular, the PPO algorithm proposed by OpenAI has a very high degree of dissemination and is a commonly used method in industry today.
Since the policy-optimization approach uses a policy network for the reward expectation estimation of actions, no additional cache is needed to record redundant Q-values, and it can adapt to the stochastic nature of the environment. The disadvantage of policy optimization is that it may be undertrained when training stochastic policies.
5.3. Optimization of Combining Policy-Based and Value-Based Reinforcement Learning
Because both value optimization and policy optimization have their own drawbacks and limitations, using one of them alone may not always achieve good results, so some current research combines the two to form the actor–critic (AC) framework as shown in Figure 4. Most of the current research is based on the AC framework for improvement, and the experimental results are usually better than value optimization or strategy optimization alone. For example, the SAC (soft actor–critic) algorithm [114] is an improved algorithm based on the AC framework, which applies to continuous state space and continuous action space and is an off-policy algorithm developed for maximum entropy RL. SAC applies stochastic policy, which has some advantages over deterministic policy. Deterministic policy algorithms end the learning process after finding an optimal path, whereas maximum entropy stochastic policies need to explore all possible optimal paths.
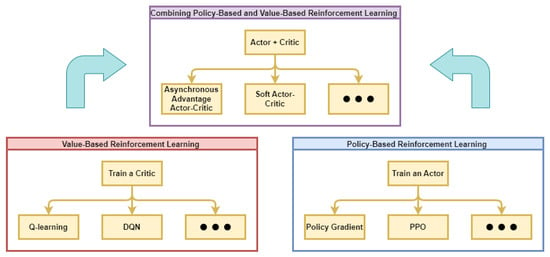
Figure 4.
Value-based and policy-based reinforcement learning.
The learning objective of ordinary DRL is to learn a strategy to maximize the return, i.e., to maximize the cumulative reward [48], which is expressed by the formula
Furthermore, the concept of maximum entropy is introduced in SAC (not only is the reward value required to be maximized but also the entropy is required); the larger the entropy, the larger the uncertainty of the system, that is, the probability of the action is made to be spread out as much as possible instead of being concentrated on one action. The core idea of maximum entropy is to explore more actions and trajectories, while the DDPG algorithm is trained to obtain a deterministic policy, i.e., a policy that considers only one optimal action for an agent [114]. The optimal policy formula for SAC is
where stands for return, stands for entropy, and is a temperature parameter used to control whether the optimization objective focuses more on reward or entropy, which has the advantage of encouraging exploration while also learning near-optimal actions. The purpose of combining the reward and maximum entropy is to explore more regions, so that the original strategy does not stick to the fully explored local optimum and give up the wider exploration space. At the same time, maximizing the return ensures that the overall exploration of the agent remains at a high level of exploration.
Overall, SAC has the following advantages: (1) The maximum entropy term provides SAC with a broader exploration tendency, which makes the exploration space of SAC more diversified and brings better generalizability and adaptability. (2) The off-policy strategy is used to improve the sample efficiency (the full off policy in DDPG is difficult to apply to high-dimensional tasks), while SAC combines the off policy and the stochastic actor. (3) The training speed is faster. The maximum entropy makes the exploration more uniform and ensures the stability of the training and the effectiveness of the exploration.
6. Characterization-Method Layer
In reinforcement learning, characterization methods refer to how information such as states, actions, and value functions is represented, enabling agents to learn effectively and make decisions. The representation of these methods in reinforcement learning encompasses various approaches, including those based on spiking neural networks, Gaussian processes, and deep neural networks. It is important to note that it does not encompass all types of representation methods; other types, such as neural decision trees, are also included. Furthermore, the three approaches mentioned in this paper are the three most widely used different options in many current studies after extensive surveys. Therefore, we present these three methods as fundamental choices in this layer.
6.1. Spiking Neural Network
Compared with traditional artificial neural networks, a spiking neural network [115,116] has a working mechanism closer to that of the neural networks of the human brain and is therefore more suitable for revealing the nature of intelligence. Not only can spiking neural networks be used to model the brain neural system, they can also be applied to solve problems in the field of AI. The spiking neural network has a more solid biological foundation, such as its nonlinear accumulation of membrane potential, pulse discharge after reaching the threshold, and cooling during the nondeserved period after the discharge, etc. These characteristics, while providing a more complex information processing capability to the spiking neural network, also bring challenges and difficulties for its training and optimization.
The traditional learning method based on loss back-propagation has been shown to optimize artificial neural networks [117]; however, it requires the entire network and neuron nodes to be differentiable everywhere. Therefore, the use of traditional loss back-propagation methods is not suitable for the optimization of spiking neural networks, and its principles are at odds with the learning laws of the biological brain. There is currently no general training method available for spiking neural networks. The state of the spiking neural networks is recognized as the third generation of neural networks after the second generation of artificial neural networks (ANNs) based on the existing MLP (multilayer perceptron) [118].
Although traditional neural networks have achieved many good and excellent results in various tasks, their principles and computational processes are still far from the real human brain information process. The main differences can be summarized as follows: (1) Traditional neural network algorithms still use high-precision floating-point operations for arithmetic, which the human brain does not use. In the human sensing system and brain, information is transmitted, received, and processed in the form of action voltages, or electric spikes. (2) The training process of an ANN relies heavily on the back-propagation algorithm (gradient descent); however, in the real human brain’s learning process, scientists have not observed the human brain using gradient descent for learning. (3) ANNs usually require a large labeled dataset to drive the fitting of the network. This is quite different from the usual way of learning because the perception and learning process in many cases is unsupervised. Moreover, the human brain usually does not need such a large amount of repeated data to learn the same thing, and only a small amount of data is needed for training [115,119].
To summarize, to make neural networks closer to the human brain, the SNN was born, inspired by the way the biological brain processes information—in spikes. SNNs are not traditional neural network structures like CNNs and RNNs; SNN is a collective term for new neural network algorithms that are closer to the human brain and have better performance than CNNs and RNNs.
6.2. Gaussian Process
In recent years, Gaussian process regression [120,121] has become a widely used regression method. More precisely, the GP is a distribution of functions, which is a joint Gaussian distribution for any finite set of function values. It can be solved with an analytical solution and expressed in probabilistic form. The obtained mean and covariance are used for regression and uncertainty estimation, respectively. The advantage of GP regression is that overfitting can be avoided while still finding functions complex enough to describe any observed phenomenon, even in noisy or unstructured data.
In probability theory and statistics, a Gaussian process is a stochastic process in which observations appear in a continuous domain (e.g., time or space). In a Gaussian process, each point in a continuous input space is associated with a normally distributed random variable. Moreover, each finite set of these random variables has a multivariate normal distribution; in other words, any finite linear combination of them is normally distributed. The distribution of a Gaussian process is the joint distribution of all those (infinitely many) random variables, and because of that, it is the distribution of a function over a continuous domain (e.g., time or space). A Gaussian process is considered a machine learning algorithm that is learned in an inert manner using a measure of homogeneity between points as a kernel function in order to predict the value of an unknown point from the input training data.
Gaussian processes are often used in statistical modeling, and models using Gaussian processes can yield properties of Gaussian processes. For example, if a stochastic process is modeled as a Gaussian process, we can show that the distribution of various derivatives can be derived, such as the mean of the stochastic process over a range of counts or the error of the mean prediction using a small range of sample counts and sample values.
6.3. Deep Neural Network
Deep learning is a research direction in artificial intelligence, and the deep neural network [122,123] is a framework for deep learning; it is a type of neural network with at least one hidden layer. Similar to shallow neural networks, deep neural networks are able to provide modeling for complex nonlinear systems. However, the extra layers provide a higher level of abstraction for the model, thus increasing its capabilities. The properties of DNNs dictate that they are groundbreaking for speech recognition and image recognition and thus are often deployed in applications ranging from self-driving cars to cancer detection to complex games. In these areas, DNNs are able to outperform human accuracy.
The benefit of deep learning is that it replaces manual feature acquisition with unsupervised or semisupervised feature learning and efficient algorithms for hierarchical feature extraction, which improves the efficiency of feature extraction as well as reduces the time of acquisition. The goal of deep neural networks is to seek better representations and create better models to learn these representations from large-scale unlabeled data. Representations come from neuroscience and are loosely created to resemble information processing and understanding of communication patterns in the nervous system, such as neural coding, which attempts to define relationships between the responses of pulling neurons and between the electrical activity of neurons in the brain.
Based on deep neural networks, several new deep learning frameworks have been developed, such as convolutional neural networks [124], deep belief networks [125], and recursive neural networks [126], which have been applied to computer vision, speech recognition, natural language processing, audio recognition, and bioinformatics with excellent results.
7. Training-Strategy Layer
Reinforcement learning is categorized in terms of training strategies including different approaches such as centralized reinforcement learning, distributed reinforcement learning, and federated reinforcement learning. The intelligent decision-making problem at the edge needs to focus on selecting appropriate training strategies. When designing a program for an intelligent decision problem, the design of the content in this layer of the framework should be centered on these three methods according to the actual task state. This classification is based on [64]. With the advancement of computing devices, the training of reinforcement learning has gradually shifted from traditional centralized computation to distributed computation. Additionally, due to the increased consideration for data privacy and other factors this year, federated learning, as a new training method, has also received widespread attention.
7.1. Concentrated Reinforcement Learning
Concentrated reinforcement learning is one of the most traditional methods and has been skillfully used in both single-agent reinforcement learning and multiagent reinforcement learning scenarios. Single-agent reinforcement learning refers to the learning of an agent using standard reinforcement learning. It optimizes the decision of the agent by learning the value function or the policy function and is able to deal with complex situations such as continuous action space, high-dimensional state space, and so on. According to the characteristics and requirements of the problem, choosing a suitable centralized reinforcement learning method can improve the learning effect and decision quality of the agent. Common algorithms include Q-learning, DQNs (deep Q-networks) [127], policy gradient methods [128], proximal policy optimization, etc. Q-learning is a basic centralized reinforcement learning method to make optimal decisions by learning a value function. A DQN uses deep neural networks to approximate the Q-value function. It has made significant breakthroughs in complex environments such as images and videos. Policy gradient methods are a class of centralized reinforcement learning methods that directly optimize the policy function. These methods compute the gradient of the policy function by sampling trajectories and update the policy function according to the direction of the gradient. The representative algorithm PPO uses two policy networks, an old policy network for collecting experience and a new policy network for computing gradient updates. The update magnitude is adjusted by comparing the difference between the two strategies to achieve a more stable training process.
In the application of multiagent reinforcement learning, all agents in this training mode share the same global observation state, and decisions are made in a global manner. This means that there can be effective collaboration and communication between agents, but it also increases the complexity of training and decision making. Centralized reinforcement learning is suitable for tasks that require global information sharing and collaboration, such as multirobot systems or team gaming problems. For example, the neural network communication algorithm [129] is based on a deep neural network to model information exchange between agents in a multirobot system. Each agent decides its own actions through the observed state of the environment and partial information from other agents. This approach can be undertaken by connecting the observations of the agents to a common neural network that enables them to share and transfer information. A multiagent deep deterministic policy gradient [130] makes the actor network utilize the policies of the other agents as inputs to select an action, and at the same time, it receives its own observations and historical actions as inputs. The critic network estimates the joint value function of all agents. QMIX is a value function decomposition method for centralized reinforcement learning [131]. It estimates the local value function of each agent by using a hybrid network and synthesizes the global value function through a hybrid operation. The QMIX algorithm guarantees the monotonicity of the global value function, which promotes cooperative behavior.
However, in centralized reinforcement learning, it is often necessary to maintain a global state that contains all observation information. The global state can be a complete representation of the environment information or a combination of multiple agent observations and partial environment information. More importantly, the central controller is the core component of centralized reinforcement learning, which is responsible for processing the global state and making decisions. The central controller can be a neural network model that accepts the global state as input and outputs the actions of each agent; while this model is capable of generating better performing decision models for certain scenarios, the process still often requires a significant amount of time. Centralized reinforcement learning represents an inefficient way for the agent to interact with the environment, makes it difficult to generate a sufficient number of historical trajectories to update the policy model, and has a high demand on computational power that is difficult to meet at the edge. In addition, the use of old models is often not well adapted to new environments.
7.2. Distributed Reinforcement Learning
The common feature in various machine learning methods is that they all employ complex, large-scale learning models that rely on a large amount of training data. However, the training of these models is far from being satisfied by the edge, in terms of both computation and storage requirements. Therefore, distributed parallel computing has become a mainstream way to solve the large-scale network training problem. Distributed reinforcement learning can perform task allocation and collaborative decision making among multiple agents, thus improving performance and efficiency in large-scale, complex environments. Compared with the traditional centralized reinforcement learning, distributed reinforcement learning can learn and make decisions simultaneously on multiple computer clusters, which can effectively improve the efficiency of sample collection and the iteration rate of the model [132]. Meanwhile, since distributed reinforcement learning can gain experience from multiple agents at the same time, it can better cope with noise and uncertainty and improve the overall robustness. In addition, because of the way it utilizes information exchange and collaboration among multiple agents, the whole system has a higher learning ability and intelligence level. Therefore, distributed reinforcement learning can be easily extended to situations with more agents and more complex environments with better adaptability and flexibility.
Specifically, parallel ideas for distributed reinforcement learning mainly include four types: data parallelism [133], model parallelism [134], pipeline parallelism [135], and hybrid parallelism [136]. Data parallelism mainly targets large datasets and small model scenarios by pairwise slicing the dataset into several parts, which solves the problem that a single device’s memory is limited and cannot store all the data, but it cannot solve the memory overflow problem triggered by the large scale of the network model. Model parallelism for large dataset and large model scenarios, through the scheduling of a neural network cut, is used to solve the problem that a single device cannot store large-scale models, but the model cut and scheduling strategy is a constraint on the performance of training to improve the difficulty. Pipeline parallelism for deep learning training iterative characteristics, according to the neural network layer-by-layer dependency, overlaps the computation and communication processes to avoid the waiting blockage between the computation–communication and to achieve the efficient use of a multipipeline pipeline; this usually needs to be used in conjunction with data parallelism and model parallelism. Hybrid parallelism uses data parallelism, model parallelism, and pipeline parallelism at the same time, which is difficult to design. Distributed reinforcement learning architectures need to address typical problems in the distributed training process, including communication, consistency, memory management and scheduling, and their complex interactions, and different architectures exhibit different adaptations.
The DataFlow framework has the flexibility to support multiple parallelism modes at different granularities by describing the computational task as a directed acyclic data flow graph. In dataflow mode, distributed parallel training at different granularities can be realized by changing the structure of the flow graph, supporting multiple complex distributed parallel training modes, including data parallelism, model parallelism, and hybrid parallelism. Google’s TensorFlow [137], Facebook’s PyTorch [138], and Huawei’s MindSpore [139] are all typical distributed machine learning systems based on dataflow and are also the most commonly used distributed learning systems in research.
Furthermore, distributed deep reinforcement learning is more of a parallelization optimization of algorithms using existing distributed learning frameworks combined with reinforcement learning’s own characteristics. The training of reinforcement learning is mainly divided into two modules: one is the sample collection process, i.e., the agent interacts with the environment using the current policy model to generate training sample data; the other module is the training process, which uses the collected sample data to update the policy. Reinforcement learning training is a continuous repetition process of these two processes, where samples are first collected and then a gradient update is performed to generate a new policy, which is used to continue interacting with the environment. After the emergence of the classical algorithm for reinforcement learning, DQN, Gorila [140], a large-scale distributed framework for deep reinforcement learning, distributively accelerated the DQN algorithm and achieved some results. Subsequently, A3C with asynchronous updates and A2C with synchronous updates were introduced. D4PG [141] separates the actor for experience collection from the learner for policy learning, uses multiple parallel actors to collect data, and shares a large cache of experience data for the learner to learn from. The IMPALA approach, when the training scale is scaled up, can be considered, using multiple learners and multiple actors per GPU. Each learner receives samples only from its own actors for updating, the learners periodically exchange gradients and update the network parameters, and the actors periodically receive and update the neural network parameters from any of the learners. In 2019, Google proposed the SEED RL [142], which shifts the network inference to the learner side and utilizes a high degree of arithmetic concentration for inference sampling, data storage, and learning training. Overall, these research studies are based on optimizing the algorithmic structure, which can provide more robust and efficient decision model training.
7.3. Federated Reinforcement Learning
Federated reinforcement learning is a method that combines federated learning and reinforcement learning [25]. Federated learning is a distributed machine learning framework that allows multiple devices or users to train a global model together while protecting data privacy. Federated learning [143] was first proposed in 2016 and has been validated on different datasets for its effectiveness and safety. Since the initial introduction of the term federated learning, which focuses on mobile- and edge-device applications [144], federated learning serves as a machine learning framework in which multiple clients collaborate to solve a machine learning problem under the coordination of a central server or service provider. In traditional reinforcement learning, there is usually the problem of centralized data collection and training. However, in some cases, centralized training methods may not be feasible or appropriate due to the distributed nature of the data and privacy requirements [145]. Federated reinforcement learning is applied to such scenarios to address these issues. Each client’s raw data are stored locally and are not exchanged or transferred. Multiple agents or devices have their own local environment and data and perform reinforcement learning independently. Each agent or device uses the local data to update its own model parameters. These locally updated parameters are then aggregated into a global model for knowledge sharing and overall performance improvement. Importantly, federated reinforcement learning respects the data privacy of each agent or device during model updating. The workflow is shown in Figure 5.
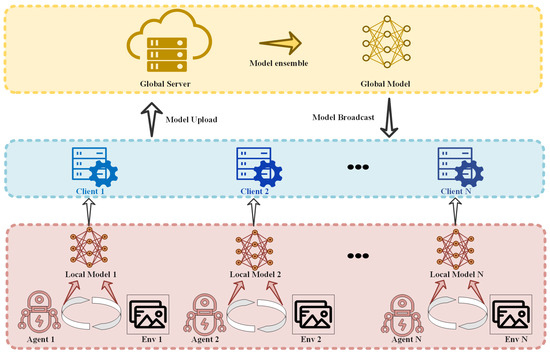
Figure 5.
Workflow of federated reinforcement learning.
Federated reinforcement learning uses federated learning as the base framework and trains neural networks through deep reinforcement learning. The aggregation center collects information about the neural networks of the agents and performs federated averaging [146]. Federated learning has a similar logical structure to data parallelization training in distributed reinforcement learning. In federated reinforcement learning, each party first downloads a basic shared model from the server, trains based on local data, and then uploads the updated model parameters to the server; the server integrates the parameters from each party into the global model. Then it is shared out again, and so on, until the global model converges or reaches the stopping condition. Like a federal system, each node in this training mode is independent of each other and enjoys the right to control the local data. The server cannot directly access the local data in each node but can only integrate and release the model at the parameter level. Compared with the distributed training method with parallel data, federated reinforcement learning is more adaptive to the nonindependent and homogeneously distributed data samples collected locally by each node, and it can cope with the imbalance of the data volume of each node in the distributed scenario, which is more suitable for the distribution of ultra-large-scale networks [147]. The aggregation process of federated reinforcement learning can be represented as follows:
where denotes the new global model after aggregation, and and denote the initial global and local models, respectively. and P represent the different model weights in the model update and model fusion.
Overall, federated reinforcement learning has the following features and benefits:
- 1.
- Data privacy protection: since federated reinforcement learning distributes data across local devices without centralized data collection, it is able to better protect the data privacy of individual users.
- 2.
- Distributed learning: multiple agents or devices learn independently and share global knowledge through parameter aggregation. This distributed learning can speed up learning and improve overall performance.
- 3.
- Cross-device collaboration: federated reinforcement learning enables cooperative learning between different devices to jointly optimize global models for better intelligent decisions.
Despite the advantages of federated reinforcement learning in providing data privacy protection and distributed learning, there are also challenges, such as dealing with heterogeneous data and coordinating the learning process. Therefore, federated reinforcement learning is still an active area of research with many ongoing research efforts to improve algorithms and solve problems in real-world applications.
8. Case Studies
Given that we have already provided various design choices for different parts of engineering design, we will use these choices to briefly describe the application of reinforcement learning methods in several representative frontier areas. At the end of this section, we will conduct a quick engineering design exercise using the integrated framework.
8.1. Swarm Robotics
Swarm robotics is a field of research and application that draws inspiration from collective behaviors in nature, particularly from social organisms such as ants, bees, and fish. The core idea in this field is to accomplish complex tasks through the collaborative work of a large number of simple individuals that interact locally through relatively simple rules, rather than relying on a central control unit. This approach offers advantages in terms of high scalability, robustness, and flexibility [148]. One of the recently published works [149] focuses on training a separate controller for each individual in a cluster to achieve coordination among them. Additionally, it aims to reduce the dependency of a large number of robots on a central server during the training process in order to adapt to communication constraints between robots and central servers in the real world.
This is a reinforcement learning-based edge decision problem in a multiagent scenario, where robots need to obtain the optimal collective action of the entire group through individual decisions. Following the considerations of various factors and constraints in the work [149], we attempt to construct a solution according to the workflow of the integrated framework. Based on the five layers of the integrated framework, at the architecture layer, swarm robots focus more on collaboration with each other. Agents often need to make decisions independently based on local information and achieve better decision-making effects at the system level through coordination. Therefore, at this level, multiagent reinforcement learning methods are a better choice. At the pattern-type layer, model-free methods do not require explicit modeling of the environment but learn strategies directly based on interaction experiences with the environment. They are suitable for complex, difficult-to-model environments, possess stronger generalization capabilities, and do not rely on prior knowledge of the environment. In the optimization-direction layer, optimizing the movement of robot clusters needs effective strategy optimization in a continuous action space. Therefore, the deep deterministic policy gradient (DDPG), which combines value-based and policy-based reinforcement learning, was selected here. At the characterization-method layer, a critic neural network and an actor neural network are used to generate policies. The critic network is a two-layer fully connected network, while the actor network consists of three fully connected layers. The action space is set as two continuous values, representing velocity and rotation angle. The observation space consists of data from 24 sensors. In the training-strategy layer, considering the challenge of maintaining high-quality communication with a central server in real-world environments, the architecture of federated reinforcement learning is integrated into the training strategy.
It is worth noting that this is not the sole solution in swarm robotics but rather a balance based on the considerations of the problem and core focal elements in [149]. The above analysis, based on the integrated framework of this paper, analyzes and adapts the swarm robotics problem using five layers and provides recommended algorithms for each layer, demonstrating how the framework proposed in this paper can address edge decision problems in the field of swarm robotics.
8.2. Automatic Driving
The field of autonomous driving is an interdisciplinary field combining artificial intelligence and automotive engineering, where the application of reinforcement learning is undoubtedly a topic of great interest [150]. While reinforcement learning, especially deep reinforcement learning, provides strong support for decision making and control in autonomous driving systems, a key issue limiting the development of autonomous driving lies in its safety. One of the root causes of this issue is the difficulty in validating the performance of autonomous vehicles in dangerous situations. This is because training autonomous driving systems often involves high-dimensional data, and critical safety-related information may be overshadowed by numerous regular data points (also known as the curse of rarity). Moreover, facing both the “curse of rarity” and the “curse of dimensionality”, a single reinforcement learning approach struggles to achieve satisfactory model performance. A study [151] attempted to address this challenge at this level using an integrated reinforcement learning approach.
From the perspective of the integrated framework, the considerations made in [151] for implementing dense deep reinforcement learning (D2RL) can be explained and summarized from five different aspects. At the architecture-scheme layer, this complex problem is mainly constrained by training samples, with considerations excluding generalization and multiagent scenarios. Therefore, a traditional deep reinforcement learning architecture was chosen, which can be seen as single-layer hierarchical reinforcement learning. The architecture scheme is determined. Next, the training of autonomous driving problems involves a large amount of high-dimensional data and extremely complex scenarios including various road conditions, traffic rules, pedestrian behavior, and actions of other vehicles. These factors lead to high uncertainty in the environment, making it difficult to establish an accurate model to describe the entire driving process. In this layer, a model-free reinforcement learning strategy is employed. In terms of the optimization-direction layer, D2RL uses the PPO algorithm, which combines value-based and policy-based reinforcement learning, while training a policy network and a value network to cooperate. The choice at the characterization-method layer is the core of this work, constructing a three-layer fully connected network, with each layer containing 256 neurons. In contrast to traditional DRL, an additional filtering of training data is added here, where a substantial amount of low-quality sample data is discarded by D2RL at this layer, allowing for the maximization of rewards during the training process. Finally, in the training-policy layer, this study utilized a highly configured high-performance computing cluster for centralized training, equipped with 500 CPU cores and 3500 GB of memory.
It is worth noting that here we only used the integrated framework to describe the reinforcement learning part of the aforementioned work to demonstrate the applicability of the framework. This does not represent all the contributions and highlights of the above-mentioned work. From the above analysis, it can be observed that the integrated framework is able to align with the main ideas behind the design of reinforcement learning methods in this study. It comprehensively covers considerations regarding algorithmic details in optimization direction, characterization methods, and training strategies. Therefore, the analysis of each module in the integrated framework can be regarded as a decomposition of the entire reinforcement learning decision problem, thereby providing reasonable solutions for each component. This is one of the reasons why the integrated framework can adapt to this study.
8.3. Healthcare
The healthcare field is another representative application of reinforcement learning, which shows great potential and prospects. Healthcare is an information-intensive and complex domain. The addition of reinforcement learning has brought new ways of thinking and technical means to the medical community. It can assist in improving the intelligence level of medical decision making, enhancing patients’ diagnostic and treatment experience, and promoting the personalized and precise development of healthcare services [152]. In traditional medical practice, doctors’ diagnoses and treatment decisions often rely on experience and clinical guidelines. The introduction of reinforcement learning allows machines to autonomously learn from data, continuously optimize medical decisions, and provide more effective diagnosis and treatment plans personalized to patients, thereby improving the quality and efficiency of healthcare services. One of the early works that combined reinforcement learning with the healthcare field is presented in the work [153]. It attempted to train a typical symptom checker using reinforcement learning to infer diseases more accurately for patients.
Due to the time in which work [153] was conducted, reinforcement learning methods had not yet undergone significant development. Therefore, the algorithm used in the work is not complex; it is a traditional reinforcement learning method that can be easily described by using our framework. From the perspective of the architectural-scheme layer, the complexity of this problem is not high, and it does not consider other aspects of reinforcement learning. Hence, a classic reinforcement learning architecture was employed in the study. At the layer of pattern type, the symptom checker needs to continuously interact with patients through question-and-answer exchanges to collect evidence of disease types, hence utilizing model-free reinforcement learning methods for training. In terms of optimization direction, the model needs to determine which disease type is most likely based on interactions with the patient and provide the next relevant question. Value-based reinforcement learning methods are well suited for this scenario. At the layer of characterization methods, each model consists of a four-layer fully connected network. The state of symptoms is represented by a one-hot encoding of a triple. The patient’s input is defined as true or false. Regarding training strategies, given the relatively simple nature of the problem, a traditional centralized training approach is sufficient to meet the requirements.
It is worth noting that the above-mentioned approach represents one of the early applications of reinforcement learning in the healthcare system. With the development of algorithms and computing capabilities, the application of reinforcement learning in the healthcare sector is increasingly expanding, incorporating more factors to be considered in the design of solutions. These considerations can also be reflected in the integrated framework proposed in this paper. For instance, the study [154] evolved beyond a mere disease inference question-and-answer system to employ a specialized robot for assisting in disease treatment. This presents a significantly complex issue that demands high levels of accuracy. Thus, the study uses PPO algorithms that can be more adaptable to complex scenarios at the optimization-direction layer, i.e., both base-optimization and policy-optimization methods are used to ensure the reliability of the actions. Furthermore, with the increasing value of data in recent years, concerns about user data, especially patient data privacy, have attracted attention. For instance, ref. [155] considers data privacy in smart healthcare work and uses a federated reinforcement learning architecture for data security risk reduction and knowledge sharing at the training-strategy layer. This indicates that even when experiencing algorithmic updates at different stages of research or different considerations at certain levels, the design of reinforcement learning solutions through an integrated framework does not require starting from scratch. Instead, it retains the main ideas from existing similar works and only adjusts the choices in certain components to adapt to new decision problems. This not only demonstrates the flexibility and generality of the integrated framework but also shows its ability to provide efficient guidance for reinforcement learning in engineering design.
8.4. Design Exercise
Now, to demonstrate how to use the integrated framework to design a reinforcement learning solution for a specific problem, let us consider designing an intelligent decision-making model similar to a home energy management system (HEMS) for a nonterrestrial network (NTN) composed of multiple UAVs. UAVs act as network relays and need to provide network services to ground devices under the coverage area. UAVs typically have a limited communication range and are difficult to support during long cruises. Additionally, the network requirements and spatial distribution of ground devices are variable, requiring a decision-making model to plan the UAVs’ paths and make communication decisions while ensuring data freshness and information processing reliability. This is a typical edge intelligence decision problem based on reinforcement learning. We will use our integrated framework to conduct a quick exercise in designing a reinforcement learning solution. It is important to note that this is not the only correct solution.
Specifically, the first part of this subsection demonstrates how to perform adaptive analysis based on an evolutionary perspective using the reinforcement learning framework when facing an edge intelligence decision task. Following the five levels of the integrated characteristics of reinforcement learning, which include architectural schemes, pattern types, optimization directions, representation methods, and training strategies, we can dynamically select appropriate methods within each level to construct an integrated framework for reinforcement learning. This targeted approach provides integrated solutions. Building upon this, the second part of this subsection provides a diagram of the final layers of the solution, detailing the working principles of each layer in this case study. Additionally, it summarizes the superiority of this framework in the practical application process.
8.4.1. Suitability Analysis
In this section, based on the integrated framework, we discuss the solutions to the above problem from the five layers of design.
The reinforcement learning architectural-scheme layer include meta-reinforcement learning, hierarchical reinforcement learning, and multiagent reinforcement learning. In practical application scenarios, although meta-reinforcement learning can effectively ensure that agents can quickly complete policy training under new tasks based on past experience, the ground coverage area that NTN needs to cover usually has significant irreproducibility, and actions usually need to be generated quickly, without preplanning. These challenges prevent meta-reinforcement learning’s advantages from being fully exploited. In multiagent reinforcement learning, one agent makes decisions while other agents take actions. These changes in the environment state are associated with the actions of each drone. The strong dynamics of real-time decisions lead to the instability of the state and the high dimensionality of the state space dimension. They will lead to higher requirements for network model expression ability and hardware arithmetic power in real scenarios. So the method will encounter greater challenges in convergence and scalability in practical use. Considering the adaptability of various methods to real-time decision-making environments, hierarchical reinforcement learning is an effective method to support the real-time decision making of the current layer of intelligence, which can design the regional coverage problem as subproblems of overall planning, trajectory setting, and resource allocation. So this case proposes to use hierarchical reinforcement learning as the basis for creating the architecture of the program layer in the integration framework.
The reinforcement learning pattern-type layer includes model-based reinforcement learning, model-free reinforcement learning, and the fusion of model-based and model-free reinforcement learning. Model-based reinforcement learning methods are more effective when training with small samples, while model-free reinforcement learning methods outperform model-based algorithms and are more likely to achieve good results in unknown environments, but they require a longer training time. The fusion of model-based and model-free reinforcement learning combines the advantages of both sides, i.e., it is able to train small samples of data with significant effects and the training time is not too long, while ensuring good performance. However, the theoretical research in this direction is still less than that of the conventional methods, and it lacks the necessary integration methods. Considering that the amount of real data in real-time decision scenarios is usually very small, although the model-based approach alone may be more favorable to achieve the training, the variability of the environment may also make the trained models perform poorly in the new environment; on the contrary, if the model-free approach is used alone, although the adaptability to the new environment is better, the training time is too long, the amount of real data is small, and the model-free algorithms may not be able to achieve good performance in the training process. The unfitting phenomenon of algorithms during the training process may lead to poor results in the final training. Reinforcement learning methods with model-based and model-free fusion combine the advantages and are well adapted to real environments. Therefore, this paper proposes to use the reinforcement learning approach with fusion version as the basis of the pattern-type layer of the integration framework.
The theory of the optimization-direction layer of reinforcement learning includes reinforcement learning based on value optimization, reinforcement learning based on strategy optimization, and reinforcement learning that combines value optimization and strategy optimization. By decomposing problems based on NTN, we can assign different reinforcement learning methods to different levels of problems. The upper level, which handles overall planning, addresses user trend changes and can utilize value-based optimization in reinforcement learning. The lower level, focused on individual drone control strategies, benefits from using a combined value-based and policy-based optimization approach, which aligns more finely with the research problem.
Reinforcement learning characterization methods mainly include a series of methods from neural networks, spiking neural networks, Bayesian networks, and traditional machine learning. Current reinforcement learning methods are mainly based on deep neural networks, which have already achieved good results, as described in the previous section, so deep neural networks are one of the basic methods in the characterization-method layer of the integrated framework of this research. In addition, the Gaussian process is easy to analyze and suitable for small-sample problems.The unique advantage of GP regression avoids overfitting while guaranteeing that complex functions sufficiently describing the observed phenomena can be found even in noisy or unstructured data. Spiking neural networks, as a new type of neural network algorithm that is closer to the human brain, have better low-power and low-latency performance than CNNs and RNNs and are widely recognized as a new generation of characterization methods that will be important for future intelligence. However, in this problem, the deep neural network, which is the most mature technology, can be used to try to achieve excellent results.
The reinforcement learning training-strategy layer includes centralized reinforcement learning, distributed reinforcement learning, and federated reinforcement learning. Due to the diversity of actual tasks and the uniqueness of each training strategy, it is usually necessary to select an appropriate training strategy based on the characteristics of different tasks and different hardware conditions. Furthermore, centralized reinforcement learning, as a traditional reinforcement learning method, has been extensively studied but requires powerful resources, which are not supported by UAVs. Considering the communication cost between UAVs and the privacy of data, federated reinforcement learning is a better choice. FRL is currently a popular research field and has received widespread attention due to its unique data privacy protection. It can also integrate the characteristics of both federated learning and reinforcement learning, reduce communication costs, and protect data security by transmitting only the model while using local data for training. Therefore, this field can provide effective solutions for data privacy and model sharing problems in edge environments.
8.4.2. Schematic Design
After clarifying the basic elements of the integration framework, the design of the specific reinforcement learning integration scheme is gradually taking shape. Based on the framework, we integrate five aspects: the architectural scheme (using hierarchical reinforcement learning), pattern type (Dyna-Q algorithm with model-based and model-free fusion), optimization direction (choosing from strategy optimization, value optimization, or both according to demand), training strategy (centralized training, distributed training, and federated learning according to demand), and characterization method (choosing from a spiking neural network, Gaussian process, and deep neural network according to demand), thus presenting a complete reinforcement learning solution for real-time decision tasks.
As shown in Figure 6, the proposed integration framework in this paper adopts a hierarchical reinforcement learning approach in the architecture layer: a multilayer structure (Layer1,... LayerN), in which Layer1 is the topmost control layer, which is used to receive external input data (from the environment provided by the infrastructure). The top control layer receives the data and then generates a goal according to the policy model, which is labeled as g1, and passes it to the lower layer, which then generates a subgoal according to its own policy model, labeled as sg1, and then passes it to the lower layer. The lowest level LayerN generates an action based on the received subgoals and marks it as A1 as the return result.
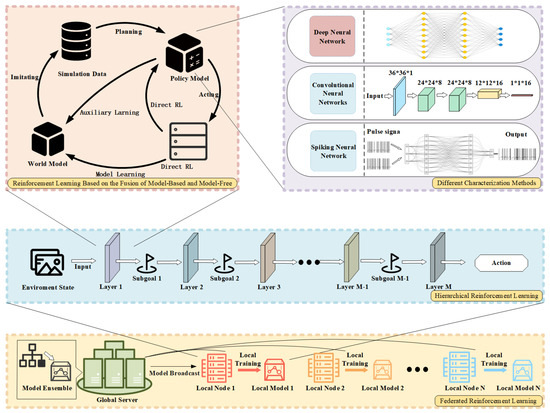
Figure 6.
Framework diagram of reinforcement learning scheme for NTN intelligent decision. At the Characterization Method layer, the Deep Neural Network is selected.
The pattern-type layer of the integration framework is based on the fusion version in each layer. By constructing a model-based world model and a model-free experience pool, agents have two sources of experience: one is real experience and the other is simulated experience. Subsequently, a positive cross-fertilization between the two is achieved based on the necessary fusion and synergy. On this basis, in the specific process of world model construction and strategy model training, the appropriate optimization-direction layer, training-strategy layer, and characterization-method layer can be dynamically selected according to different scenarios.
It is worth noting that this is not the only correct solution for the multi-UAV composition of NTN, and the technical solution of the modules can be flexibly adjusted through modular design. For example, in a scenario where we have a communication system without cost considerations and all nodes can be trusted to share their own data, the federated learning method in the training scheme layer can be replaced by ordinary distributed reinforcement learning. Furthermore, if there are sufficient computational resources available, the training of this edge decision model can even consider using centralized training methods. Now, let us assume that the application scenario has changed, and the UAVs no longer need to dynamically form networks but instead need to hover in the air to provide network coverage for the ground as relay nodes. This problem has a similar task background and resource allocation to the previous path-planning problem but requires a different task analysis. The UAVs are no longer dynamic nodes but static base stations. The new edge tasks have lower problem complexity. Therefore, at the architecture-scheme layer, we can choose traditional reinforcement learning methods to train an intelligent agent similar to a commanding brain, or we can train a higher-level collaborative strategy based on multiagent reinforcement learning methods. Overall, compared to traditional engineering design methods, leveraging integrated frameworks to design solutions for edge intelligence decision-making problems has the following advantages:
- 1.
- It reduces the reliance on expert knowledge. The lack of expertise in both engineering design and artificial intelligence poses a significant challenge in generating solutions for edge decision-making problems. This integrated framework, by organizing various research directions in the field of reinforcement learning and mapping the steps of solution design to reinforcement learning from an engineering perspective, consists of five modules. It integrates problem analysis with solution design into a single process and provides fundamental choices in each module, along with a discussion of the trade-offs and the impact on the system for each option. This process significantly reduces the reliance on expert knowledge in the solution design process, moderately lowers the technical threshold required for related research, and indirectly enhances the efficiency of engineering design in edge intelligence decision-making problems.
- 2.
- It exhibits stronger generalization capabilities. In the current field of intelligent decision making, most technical approaches involve in-depth analysis of specific problems to design suitable solutions. These solutions often struggle to be transferred to other problems. It requires a repetition of the previous processes when facing new issues. However, the solutions generated by the integrated framework proposed in this paper, utilizing plug-and-play functional modules (especially at the layers of optimization direction, training strategy, and characterization method), can achieve flexible migration among various methods based on specific tasks. When encountering decision problems that are similar but not identical, it typically only requires adjustments to the technical methods of specific modules in existing solutions, rather than a complete redesign.
- 3.
- It exhibits a stronger integration advantage. Compared to single reinforcement learning, the integrated framework has better adaptability to dynamic and highly uncertain edge scenarios. By designing solutions through an integrated system and utilizing modular components that adapt to different levels and scales of scenarios, it effectively improves overall fault tolerance. For example, at the training-strategy layer, in response to the different hardware conditions of edge tasks, different training strategies can be configured to meet different computing power requirements, data distribution, and security and privacy needs. This can provide options that match the training strategy for intelligent decision-making tasks with different configurations. In addition, the collaborative effect between multiple modules is another manifestation of the integration advantage. For example, in the integration of the pattern-type layer, it is possible to achieve the fusion of knowledge-based world models and perception-based learning strategies, improving algorithm effectiveness while reducing reliance on training data. At the same time, at the training-strategy layer, knowledge sharing among multiple edge nodes can also be utilized to alleviate the problem of data-hungry in-edge scenarios, enhancing the decision-making capabilities of edge decision models in small samples.
- 4.
- Compared to current surveys of reinforcement learning, the integrated framework proposed in this paper is better suited to the characteristics of engineering design. On the one hand, the integrated framework focuses on the specific application of reinforcement learning methods in the engineering design process. From the macrolevel of architectural design to the microlevel of representation methods to th system level of training strategies, the framework integrates reinforcement learning techniques into each design phase to achieve design objectives and optimize system performance. On the other hand, the framework presented in this paper covers various types of reinforcement learning algorithms and techniques, including value-based methods, policy gradients, and more. Through a comprehensive introduction and comparative analysis of these methods, researchers can choose the most suitable method for their needs in practical design processes. Finally, through case studies, this paper demonstrates the practical application of reinforcement learning methods in various engineering fields. Leveraging these advantages, researchers can more efficiently apply reinforcement learning methods to solve actual design problems in engineering practice, accelerating the iteration and optimization process of the design workflow.
9. Discussion
In this section, we further discuss the framework of reinforcement learning with the following questions:
(1) What is the main purpose of designing an integration framework?When building reinforcement learning solutions at the edge, there are often more constraints to consider compared to single reinforcement learning-based intelligent decision making. This paper aims to analyze the specific requirements of edge decision generation and the characteristics of traditional reinforcement learning methods and design a comprehensive framework from an integrated perspective. The primary research objectives encompass two aspects: intelligent decision-making solutions and an edge intelligence research reference.
- In the intelligent decision-making solution aspect, the integrated framework proposed in this paper aims to generate suitable reinforcement learning solutions based on edge environments, thereby enhancing the efficiency and performance of edge intelligent decision-making tasks. In contrast, a single reinforcement learning approach is inadequate to address the challenges of edge decision-making tasks and struggles to provide a generalized solution. Section 1 elaborates on this issue, noting the lack of a systematic theoretical foundation in the field of reinforcement learning to support the integration of multiple reinforcement learning methods. This forms one of the key motivations for the present study.
- In the edge intelligence research reference aspect, we categorize the focus of reinforcement learning-based research into five areas: architectural scheme, pattern type, optimization direction, characterization method, and training strategy. They correspond to different modules in the reinforcement learning solution. Section 2 introduces the basic idea of the integrated framework design. Section 3, Section 4, Section 5, Section 6 and Section 7 present the details of each module and representative reinforcement learning algorithms, respectively. It is worth noting that our work is not to design algorithms in each module that outperform all existing methods but to introduce and summarize the characterization and representative algorithms in each part of the architecture, in the hope that our work can provide new perspectives and ideas for related researchers.
(2) Why does the framework consist of five parts? The integrated framework proposed in this paper comprises five modules: architectural scheme, pattern type, optimization direction, characterization method, and training strategy. As discussed in Section 2, these modules have distinct roles and are responsible for different tasks. When designing a reinforcement learning-based solution for an edge decision-making task, the selection of appropriate methods in each module assists and guides researchers in analyzing and solving the edge intelligent decision problem. The architectural-scheme layer establishes the structure and division of the complex task into multiple cooperative subtasks. The pattern-type layer describes the policy generation pattern employed by the reinforcement learning methods in each subtask. The optimization-direction layer selects the suitable policy-updating method based on this pattern. The characterization-method layer determines customized reinforcement learning methods, such as an encoder or neural network, according to the specific task. Finally, a suitable training strategy is chosen based on the task characteristics and the selected reinforcement learning method. These steps constitute a comprehensive process for generating a reinforcement learning problem solution.
It is worth noting that the five modules mentioned above are not rigidly concatenated together. Instead, they have been categorized and organized based on the current research content in the field of reinforcement learning, revealing a certain degree of correlation among them. This integration relationship serves as the basis for the research of the integration framework discussed in this paper.
(3) How does the framework perform when applied to high-dimensional game domains? To better demonstrate the workflow of designing the integration framework in this paper, we use AlphaGo [156] as a real-world example to discuss the role played by the framework. The game of Go is a typical complex decision problem with a very high task complexity, where the size of the board is and the combination of action sequences is approximately . Therefore, solving the game of Go using a single reinforcement learning method is extremely challenging. Similar to the design of the integrated framework proposed in this study, AlphaGo’s solving process also relies on the design of five modules to find solutions.
At the architectural-scheme layer, AlphaGo decomposes the decision-making process into two aspects: reinforcement learning and a Monte Carlo tree search. RL trains the policy and value networks to eliminate low-value actions and conduct simulated gameplay, while the Monte Carlo tree search is responsible for searching for the optimal decision based on reinforcement learning. In terms of the pattern-type layer, AlphaGo utilizes a model-free reinforcement learning approach. In AlphaGo, reinforcement learning is used to train the policy and value networks, which can directly learn from the state and actions of the board without requiring hard-coded game rules. In terms of the optimization-direction layer, AlphaGo employs a combined value- and policy-optimization reinforcement learning method. By training the policy network, AlphaGo learns the probability distribution to select the best action given a specific board position. The value network evaluates the quality of the current situation and guides the search process. Regarding the characterization-method layer, AlphaGo adopts deep reinforcement learning. The policy network is a 13-layer convolutional network, with each layer containing 19 × 19 filters to preserve the original board size. The value network consists of a 16-layer convolutional network, with the first 12 layers identical to the policy network. It is worth noting that the number of convolutional layers in AlphaGo can be flexibly adjusted depending on the specific implementation and training requirements. In terms of the training-strategy layer, AlphaGo performs centralized training supported by powerful computation. The entire training process is completed using a computation cluster. However, in edge scenarios where such computational resources may not be available, it is necessary to design corresponding training strategies based on practical situations to train the models.
10. Conclusions
Despite the large research literature on reinforcement learning, most of the studies investigate existing reinforcement learning algorithms while improving them and/or exploring other interesting problems, such as using reinforcement learning to target new types of scenarios, new types of networks, and different data privacy requirements. While this kind of work is very valuable and should be continued, there is still an opportunity to develop new architectures from an integrated perspective, contributing to improving existing designs for the state of the art. In this paper, we depart from the deployment of reinforcement learning in practical applications and design an integrated framework consisting of five main modules for edge intelligence decision problems. We summarize the current primary research results and technological characteristics within each module and integrate several major research directions at a higher level, analyzing their nested relationships. Compared to existing research, our framework comprehensively covers the research content in the field of reinforcement learning, clearly indicating the interrelations between different research topics. This framework can provide more direct and convenient assistance to researchers and practitioners in solving reinforcement learning application problems in practical settings, thereby aiding in selecting more suitable technical approaches to address real-world reinforcement learning problems. Then, we conduct a comprehensive analysis and validation of the applicability of the framework by integrating typical cases from multiple dimensions. Several representative achievements in real-world reinforcement learning application domains are selected as typical cases. We apply the integrated framework to edge reinforcement learning decision-making problems in different scenarios (real-world and simulation environments), domains, and stages and extend the cases to validate its effectiveness and generalizability. The results show that the integrated framework designed in this paper can provide solutions with different considerations for various application scenarios. This not only provides favorable support and evidence for its applicability and effectiveness but also indicates that it is a general guiding framework with generalization capabilities and versatility. Furthermore, we present a design exercise to showcase the workflow and advantages of the framework. Finally, the discussion supplements relevant core ideas and practical explanations. We hope this paper not only serves as a survey into existing design solutions and their characteristics but also provides a new perspective for researchers in deploying future reinforcement learning methods.
Author Contributions
Conceptualization, G.W. and D.Z.; methodology, G.W.; validation, G.W. and D.Z.; formal analysis, D.Z.; investigation, D.Z.; resources, W.B.; data curation, Z.M.; writing—original draft preparation, G.W.; writing—review and editing, D.Z.; supervision, J.C.; project administration, W.B.; funding acquisition, W.B. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported in part by the National Natural Science Foundation of China under Grants 62002369, 62102445, 62222121 and 62341110, in part by the Postgraduate Scientific Research Innovation Project of Hunan Province Grant XJCX2023069.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Wiering, M.A.; Otterlo, M.V. Reinforcement learning. Adapt. Optim. 2012, 12, 729. [Google Scholar]
- Zhou, T.; Lin, M. Deadline-aware deep-recurrent-q-network governor for smart energy saving. IEEE Trans. Netw. Sci. Eng. 2021, 9, 3886–3895. [Google Scholar] [CrossRef]
- Yang, Y.; Wang, J. An overview of multi-agent reinforcement learning from game theoretical perspective. arXiv 2020, arXiv:2011.00583. [Google Scholar]
- Still, S.; Precup, D. An information-theoretic approach to curiosity-driven reinforcement learning. Theory Biosci. 2012, 131, 139–148. [Google Scholar] [CrossRef]
- Mazyavkina, N.; Sviridov, S.; Ivanov, S.; Burnaev, E. Reinforcement learning for combinatorial optimization: A survey. Comput. Oper. Res. 2021, 134, 105400. [Google Scholar] [CrossRef]
- Bushaj, S.; Yin, X.; Beqiri, A.; Andrews, D.; Büyüktahtakın, İ.E. A simulation-deep reinforcement learning (sirl) approach for epidemic control optimization. Ann. Oper. 2023, 328, 245–277. [Google Scholar] [CrossRef]
- Gupta, J.K.; Egorov, M.; Kochenderfer, M. Cooperative multi-agent control using deep reinforcement learning. In Autonomous Agents and Multiagent Systems, Proceedings of the AAMAS 2017 Workshops, Best Papers, São Paulo, Brazil, 8–12 May 2017; Revised Selected Papers 16; Springer: Berlin/Heidelberg, Germany, 2017; pp. 66–83. [Google Scholar]
- Ha, D.; Tang, Y. Collective intelligence for deep learning: A survey of recent developments. Collect. Intell. 2022, 1, 26339137221114874. [Google Scholar] [CrossRef]
- Rowland, M.; Dadashi, R.; Kumar, S.; Munos, R.; Bellemare, M.G.; Dabney, W. Statistics and samples in distributional reinforcement learning. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 10–15 June 2019; pp. 5528–5536. [Google Scholar]
- Lyu, Y.; Liu, Z.; Fan, R.; Zhan, C.; Hu, H.; An, J. Optimal computation offloading in collaborative leo-iot enabled mec: A multi-agent deep reinforcement learning approach. IEEE Trans. Green Commun. Netw. 2022, 7, 996–1011. [Google Scholar] [CrossRef]
- Jarwan, A.; Ibnkahla, M. Edge-based federated deep reinforcement learning for iot traffic management. IEEE Internet Things J. 2022, 10, 3799–3813. [Google Scholar] [CrossRef]
- Zhang, P.; Gan, P.; Aujla, G.S.; Batth, R.S. Reinforcement learning for edge device selection using social attribute perception in industry 4.0. IEEE Internet Things J. 2021, 10, 2784–2792. [Google Scholar] [CrossRef]
- Tessler, C.; Efroni, Y.; Mannor, S. Action robust reinforcement learning and applications in continuous control. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 10–15 June 2019; pp. 6215–6224. [Google Scholar]
- Recht, B. A tour of reinforcement learning: The view from continuous control. Annu. Rev. Control. Robot. Auton. Syst. 2019, 2, 253–279. [Google Scholar] [CrossRef]
- Wang, Z.; Fu, Q.; Chen, J.; Wang, Y.; Lu, Y.; Wu, H. Reinforcement learning in few-shot scenarios: A survey. J. Grid Comput. 2023, 21, 30. [Google Scholar] [CrossRef]
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a few examples: A survey on few-shot learning. ACM Comput. Surv. (CSUR) 2020, 53, 1–34. [Google Scholar] [CrossRef]
- Ramstedt, S.; Pal, C. Real-time reinforcement learning. In Proceedings of the Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Guo, C.; Wang, X.; Zheng, Y.; Zhang, F. Real-time optimal energy management of microgrid with uncertainties based on deep reinforcement learning. Energy 2022, 238, 121873. [Google Scholar] [CrossRef]
- Wang, Z.-Z.; Zhang, K.; Chen, G.-D.; Zhang, J.-D.; Wang, W.-D.; Wang, H.-C.; Zhang, L.-M.; Yan, X.; Yao, J. Evolutionary-assisted reinforcement learning for reservoir real-time production optimization under uncertainty. Pet. Sci. 2023, 20, 261–276. [Google Scholar] [CrossRef]
- Surianarayanan, C.; Lawrence, J.J.; Chelliah, P.R.; Prakash, E.; Hewage, C. A survey on optimization techniques for edge artificial intelligence (ai). Sensors 2023, 23, 1279. [Google Scholar] [CrossRef]
- Kum, S.; Oh, S.; Yeom, J.; Moon, J. Optimization of edge resources for deep learning application with batch and model management. Sensors 2022, 22, 6717. [Google Scholar] [CrossRef]
- Ji, Z.; Qin, Z.; Tao, X. Meta federated reinforcement learning for distributed resource allocation. IEEE Trans. Wireless Commun. 2023. [Google Scholar] [CrossRef]
- Qi, J.; Zhou, Q.; Lei, L.; Zheng, K. Federated reinforcement learning: Techniques, applications, and open challenges. arXiv 2021, arXiv:2108.11887. [Google Scholar] [CrossRef]
- Ali, J.; Khan, R.; Ahmad, N.; Maqsood, I. Random forests and decision trees. Int. J. Comput. Sci. Issues (IJCSI) 2012, 9, 272. [Google Scholar]
- Das, B.; Rathore, P.; Roy, D.; Chakraborty, D.; Jatav, R.S.; Sethi, D.; Kumar, P. Comparison of bagging, boosting and stacking algorithms for surface soil moisture mapping using optical-thermal-microwave remote sensing synergies. Catena 2022, 217, 106485. [Google Scholar] [CrossRef]
- Sierra-Garcia, J.E.; Santos, M. Federated discrete reinforcement learning for automatic guided vehicle control. Future Gener. Comput. 2024, 150, 78–89. [Google Scholar] [CrossRef]
- Xu, C.; Ding, H.; Zhang, X.; Wang, C.; Yang, H. A data-efficient method of deep reinforcement learning for chinese chess. In Proceedings of the 2022 IEEE 22nd International Conference on Software Quality, Reliability, and Security Companion (QRS-C), Guangzhou, China, 5–9 December 2022; IEEE: Piscateville, NJ, USA, 2022; pp. 1–8. [Google Scholar]
- Zhao, X.; Hu, S.; Cho, J.-H.; Chen, F. Uncertainty-based decision making using deep reinforcement learning. In Proceedings of the 2019 22th International Conference on Information Fusion (FUSION), Ottawa, ON, Canada, 2–5 July 2019; IEEE: Piscateville, NJ, USA, 2019; pp. 1–8. [Google Scholar]
- Narvekar, S.; Peng, B.; Leonetti, M.; Sinapov, J.; Taylor, M.E.; Stone, P. Curriculum learning for reinforcement learning domains: A framework and survey. J. Mach. Learn. Res. 2020, 21, 7382–7431. [Google Scholar]
- Gronauer, S.; Diepold, K. Multi-agent deep reinforcement learning: A survey. Artif. Intell. Rev. 2022, 55, 895–943. [Google Scholar] [CrossRef]
- Pateria, S.; Subagdja, B.; Tan, A.-H.; Quek, C. Hierarchical reinforcement learning: A comprehensive survey. ACM Comput. Surv. (CSUR) 2021, 54, 1–35. [Google Scholar] [CrossRef]
- Samsami, M.R.; Alimadad, H. Distributed deep reinforcement learning: An overview. arXiv 2020, arXiv:2011.11012. [Google Scholar]
- Ramirez, J.; Yu, W.; Perrusquia, A. Model-free reinforcement learning from expert demonstrations: A survey. Artif. Intell. Rev. 2022, 55, 3213–3241. [Google Scholar] [CrossRef]
- Luo, F.-M.; Xu, T.; Lai, H.; Chen, X.-H.; Zhang, W.; Yu, Y. A survey on model-based reinforcement learning. arXiv 2022, arXiv:2206.09328. [Google Scholar] [CrossRef]
- Moerland, T.M.; Broekens, J.; Jonker, C.M. Emotion in reinforcement learning agents and robots: A survey. Mach. Learn. 2018, 107, 443–480. [Google Scholar] [CrossRef]
- Chen, X.; Yao, L.; McAuley, J.; Zhou, G.; Wang, X. Deep reinforcement learning in recommender systems: A survey and new perspectives. Knowl.-Based Syst. 2023, 264, 110335. [Google Scholar] [CrossRef]
- Luong, N.C.; Hoang, D.T.; Gong, S.; Niyato, D.; Wang, P.; Liang, Y.-C.; Kim, D.I. Applications of deep reinforcement learning in communications and networking: A survey. IEEE Commun. Surv. Tutor. 2019, 21, 3133–3174. [Google Scholar] [CrossRef]
- Haydari, A.; Yılmaz, Y. Deep reinforcement learning for intelligent transportation systems: A survey. IEEE Trans. Intell. Transp. Syst. 2020, 23, 11–32. [Google Scholar] [CrossRef]
- Elallid, B.B.; Benamar, N.; Hafid, A.S.; Rachidi, T.; Mrani, N. A comprehensive survey on the application of deep and reinforcement learning approaches in autonomous driving. J. King-Saud Univ.-Comput. Inf. Sci. 2022, 34, 7366–7390. [Google Scholar] [CrossRef]
- Yu, C.; Liu, J.; Nemati, S.; Yin, G. Reinforcement learning in healthcare: A survey. ACM Comput. Surv. (CSUR) 2021, 55, 1–36. [Google Scholar] [CrossRef]
- Osborne, P.; Nõmm, H.; Freitas, A. A survey of text games for reinforcement learning informed by natural language. Trans. Assoc. Comput. Linguist. 2022, 10, 873–887. [Google Scholar] [CrossRef]
- Gupta, S.; Singh, N. Toward intelligent resource management in dynamic fog computing-based internet of things environment with deep reinforcement learning: A survey. Int. J. Commun. Syst. 2023, 36, e5411. [Google Scholar] [CrossRef]
- Gasmi, R.; Hammoudi, S.; Lamri, M.; Harous, S. Recent reinforcement learning and blockchain based security solutions for internet of things: Survey. Wirel. Pers. Commun. 2023, 132, 1307–1345. [Google Scholar] [CrossRef]
- Stapelberg, B.; Malan, K.M. A survey of benchmarking frameworks for reinforcement learning. S. Afr. Comput. J. 2020, 32, 258–292. [Google Scholar]
- Aslanides, J.; Leike, J.; Hutter, M. Universal reinforcement learning algorithms: Survey and experiments. arXiv 2017, arXiv:1705.10557. [Google Scholar]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. A brief survey of deep reinforcement learning. arXiv 2017, arXiv:1708.05866. [Google Scholar] [CrossRef]
- Sigaud, O.; Stulp, F. Policy search in continuous action domains: An overview. Neural Netw. 2019, 113, 28–40. [Google Scholar] [CrossRef]
- Obert, J.; Trevizan, R.D.; Chavez, A. Efficient distributed energy resource voltage control using ensemble deep reinforcement learning. Int. J. Semant. Comput. 2023, 17, 293–308. [Google Scholar] [CrossRef]
- Yao, Y.; Xiao, L.; An, Z.; Zhang, W.; Luo, D. Sample efficient reinforcement learning via model-ensemble exploration and exploitation. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; IEEE: Piscateville, NJ, USA, 2021; pp. 4202–4208. [Google Scholar]
- Baltieri, M.; Buckley, C.L. Nonmodular architectures of cognitive systems based on active inference. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; IEEE: Piscateville, NJ, USA, 2019; pp. 1–8. [Google Scholar]
- Contreras, I.G. A Scalable Static Analysis Framework for Reliable Program Development Exploiting Incrementality and Modularity. Ph.D. Thesis, Universidad Politécnica de Madrid, Madrid, Spain, 2021. [Google Scholar]
- Thomas, C.; Mirzaei, E.; Wudka, B.; Siefke, L.; Sommer, V. Service-oriented reconfiguration in systems of systems assured by dynamic modular safety cases. In Proceedings of the European Dependable Computing Conference, Munich, Germany, 3–16 September 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 12–29. [Google Scholar]
- Yu, C.; Zheng, X.; Zhuo, H.H.; Wan, H.; Luo, W. Reinforcement learning with knowledge representation and reasoning: A brief survey. arXiv 2023, arXiv:2304.12090. [Google Scholar]
- Mendez, J.A.; van Seijen, H.; Eaton, E. Modular lifelong reinforcement learning via neural composition. arXiv 2022, arXiv:2207.00429. [Google Scholar]
- Lee, K.; Laskin, M.; Srinivas, A.; Abbeel, P. Sunrise: A simple unified framework for ensemble learning in deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, PMLR, Virtually, 18–24 July 2021; pp. 6131–6141. [Google Scholar]
- Liu, R.-Z.; Guo, H.; Ji, X.; Yu, Y.; Pang, Z.-J.; Xiao, Z.; Wu, Y.; Lu, T. Efficient reinforcement learning for starcraft by abstract forward models and transfer learning. IEEE Trans. Games 2021, 14, 294–307. [Google Scholar] [CrossRef]
- Yang, T.; Tang, H.; Bai, C.; Liu, J.; Hao, J.; Meng, Z.; Liu, P.; Wang, Z. Exploration in deep reinforcement learning: A comprehensive survey. arXiv 2021, arXiv:2109.06668. [Google Scholar]
- Nachum, O.; Norouzi, M.; Xu, K.; Schuurmans, D. Bridging the gap between value and policy based reinforcement learning. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Kadhim, Z.S.; Abdullah, H.S.; Ghathwan, K.I. Artificial neural network hyperparameters optimization: A survey. Int. J. Online Biomed. Eng. 2022, 18, 59–87. [Google Scholar] [CrossRef]
- Yi, Z.; Lian, J.; Liu, Q.; Zhu, H.; Liang, D.; Liu, J. Learning rules in spiking neural networks: A survey. Neurocomputing 2023, 531, 163–179. [Google Scholar] [CrossRef]
- Verbraeken, J.; Wolting, M.; Katzy, J.; Kloppenburg, J.; Verbelen, T.; Rellermeyer, J.S. A survey on distributed machine learning. ACM Comput. Surv. (CSUR) 2020, 53, 1–33. [Google Scholar] [CrossRef]
- Liu, J.; Huang, J.; Zhou, Y.; Li, X.; Ji, S.; Xiong, H.; Dou, D. From distributed machine learning to federated learning: A survey. Knowl. Inf. Syst. 2022, 64, 885–917. [Google Scholar] [CrossRef]
- Mitchell, E.; Rafailov, R.; Peng, X.B.; Levine, S.; Finn, C. Offline meta-reinforcement learning with advantage weighting. In Proceedings of the International Conference on Machine Learning, PMLR, Virtually, 18–24 July 2021; pp. 7780–7791. [Google Scholar]
- Zhang, K.; Yang, Z.; Başar, T. Multi-agent reinforcement learning: A selective overview of theories and algorithms. In Handbook of Reinforcement Learning and Control; Springer: Cham, Switzerland, 2021; pp. 321–384. [Google Scholar]
- Hospedales, T.; Antoniou, A.; Micaelli, P.; Storkey, A. Meta-learning in neural networks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 5149–5169. [Google Scholar] [CrossRef] [PubMed]
- Vanschoren, J. Meta-learning: A survey. arXiv 2018, arXiv:1810.03548. [Google Scholar]
- Gupta, A.; Mendonca, R.; Liu, Y.; Abbeel, P.; Levine, S. Meta-reinforcement learning of structured exploration strategies. Adv. Neural Inf. Process. Syst. 2018, 31, 5307–5316. [Google Scholar]
- Beck, J.; Vuorio, R.; Liu, E.Z.; Xiong, Z.; Zintgraf, L.; Finn, C.; Whiteson, S. A survey of meta-reinforcement learning. arXiv 2023, arXiv:2301.08028. [Google Scholar]
- Bing, Z.; Lerch, D.; Huang, K.; Knoll, A. Meta-reinforcement learning in non-stationary and dynamic environments. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3476–3491. [Google Scholar] [CrossRef] [PubMed]
- Yun, W.J.; Park, J.; Kim, J. Quantum multi-agent meta reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–8 February 2023; Volume 37, pp. 11087–11095. [Google Scholar]
- Tian, Y.; Zhao, X.; Huang, W. Meta-learning approaches for learning-to-learn in deep learning: A survey. Neurocomputing 2022, 494, 203–223. [Google Scholar] [CrossRef]
- Park, J.; Choi, J.; Nah, S.; Kim, D. Distributional and hierarchical reinforcement learning for physical systems with noisy state observations and exogenous perturbations. Eng. Appl. Artif. 2023, 123, 106465. [Google Scholar] [CrossRef]
- Barto, A.G.; Mahadevan, S. Recent advances in hierarchical reinforcement learning. Discret. Event Dyn. Syst. 2003, 13, 41–77. [Google Scholar] [CrossRef]
- Jendoubi, I.; Bouffard, F. Multi-agent hierarchical reinforcement learning for energy management. Appl. Energy 2023, 332, 120500. [Google Scholar] [CrossRef]
- Eppe, M.; Gumbsch, C.; Kerzel, M.; Nguyen, P.D.; Butz, M.V.; Wermter, S. Intelligent problem-solving as integrated hierarchical reinforcement learning. Nat. Mach. Intell. 2022, 4, 11–20. [Google Scholar] [CrossRef]
- Hu, X.; Zhang, R.; Tang, K.; Guo, J.; Yi, Q.; Chen, R.; Du, Z.; Li, L.; Guo, Q.; Chen, Y.; et al. Causality-driven hierarchical structure discovery for reinforcement learning. Adv. Neural Inf. Process. 2022, 35, 20064–20076. [Google Scholar]
- Feng, L.; Xie, Y.; Liu, B.; Wang, S. Multi-level credit assignment for cooperative multi-agent reinforcement learning. Appl. Sci. 2022, 12, 6938. [Google Scholar] [CrossRef]
- Du, X.; Chen, H.; Yang, B.; Long, C.; Zhao, S. Hrl4ec: Hierarchical reinforcement learning for multi-mode epidemic control. Inf. Sci. 2023, 640, 119065. [Google Scholar] [CrossRef]
- Nachum, O.; Gu, S.S.; Lee, H.; Levine, S. Data-efficient hierarchical reinforcement learning. Adv. Neural Inf. Process. 2018, 31, 3307–3317. [Google Scholar]
- Andrychowicz, M.; Wolski, F.; Ray, A.; Schneider, J.; Fong, R.; Welinder, P.; McGrew, B.; Tobin, J.; Abbeel, O.P.; Zaremba, W. Hindsight experience replay. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Bacon, P.-L.; Harb, J.; Precup, D. The option-critic architecture. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Harb, J.; Bacon, P.-L.; Klissarov, M.; Precup, D. When waiting is not an option: Learning options with a deliberation cost. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Tan, M. Multi-agent reinforcement learning: Independent vs. cooperative agents. In Proceedings of the Tenth International Conference on Machine Learning, Amherst, MA, USA, 27–29 July 1993; pp. 330–337. [Google Scholar]
- Amirkhani, A.; Barshooi, A.H. Consensus in multi-agent systems: A review. Artif. Intell. Rev. 2022, 55, 3897–3935. [Google Scholar] [CrossRef]
- Yu, C.; Yang, X.; Gao, J.; Chen, J.; Li, Y.; Liu, J.; Xiang, Y.; Huang, R.; Yang, H.; Wu, Y.; et al. Asynchronous multi-agent reinforcement learning for efficient real-time multi-robot cooperative exploration. arXiv 2023, arXiv:2301.03398. [Google Scholar]
- Shalev-Shwartz, S.; Shammah, S.; Shashua, A. Safe, multi-agent, reinforcement learning for autonomous driving. arXiv 2016, arXiv:1610.03295. [Google Scholar]
- Charbonnier, F.; Morstyn, T.; McCulloch, M.D. Scalable multi-agent reinforcement learning for distributed control of residential energy flexibility. Appl. Energy 2022, 314, 118825. [Google Scholar] [CrossRef]
- Chung, S. Learning by competition of self-interested reinforcement learning agents. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 22 February–1 March 2022; Volume 36, pp. 6384–6393. [Google Scholar]
- Çalışır, S.; Pehlivanoğlu, M.K. Model-free reinforcement learning algorithms: A survey. In Proceedings of the 2019 27th Signal Processing and Communications Applications Conference (SIU), Sivas, Turkey, 24–26 April 2019; IEEE: Piscateville, NJ, USA, 2019; pp. 1–4. [Google Scholar]
- Moerland, T.M.; Broekens, J.; Plaat, A.; Jonke, C.M. Model-based reinforcement learning: A survey. In Foundations and Trends® in Machine Learning; Now Publishers Inc.: Delft, The Netherlands, 2023; Volume 16, pp. 1–118. [Google Scholar]
- Lee, H.; Kim, K.; Kim, N.; Cha, S.W. Energy efficient speed planning of electric vehicles for car-following scenario using model-based reinforcement learning. Appl. Energy 2022, 313, 118460. [Google Scholar] [CrossRef]
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T.; et al. A general reinforcement learning algorithm that masters chess, shogi, and go through self-play. Science 2018, 362, 1140–1144. [Google Scholar] [CrossRef] [PubMed]
- Wang, D.; Shen, Y.; Wan, J.; Sha, Q.; Li, G.; Chen, G.; He, B. Sliding mode heading control for auv based on continuous hybrid model-free and model-based reinforcement learning. Appl. Ocean. Res. 2022, 118, 102960. [Google Scholar] [CrossRef]
- Racanière, S.; Weber, T.; Reichert, D.; Buesing, L.; Guez, A.; Rezende, D.J.; Puigdomènech Badia, A.; Vinyals, O.; Heess, N.; Li, Y.; et al. Imagination-augmented agents for deep reinforcement learning. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Atkeson, C.G.; Santamaria, J.C. A comparison of direct and model-based reinforcement learning. In Proceedings of the International Conference on Robotics and Automation, Albuquerque, NM, USA, 20–25 April 1997; IEEE: Piscateville, NJ, USA, 1997; Volume 4, pp. 3557–3564. [Google Scholar]
- Degris, T.; Pilarski, P.M.; Sutton, R.S. Model-free reinforcement learning with continuous action in practice. In Proceedings of the 2012 American Control Conference (ACC), Montreal, QC, Canada, 27–29 June 2012; IEEE: Piscateville, NJ, USA, 2012; pp. 2177–2182. [Google Scholar]
- Lu, T.; Schuurmans, D.; Boutilier, C. Non-delusional q-learning and value-iteration. In Proceedings of the 32st International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; Volume 31. [Google Scholar]
- Wang, Y.; Velasquez, A.; Atia, G.K.; Prater-Bennette, A.; Zou, S. Model-free robust average-reward reinforcement learning. In Proceedings of the International Conference on Machine Learning, PMLR, Honolulu, HI, USA, 23–29 July 2023; pp. 36431–36469. [Google Scholar]
- Li, S.E. Model-free indirect rl: Temporal difference. In Reinforcement Learning for Sequential Decision and Optimal Control; Springer: Berlin/Heidelberg, Germany, 2023; pp. 67–87. [Google Scholar]
- Miller, W.T.; Sutton, R.S.; Werbos, P.J. First Results with Dyna, an Integrated Architecture for Learning, Planning and Reacting; The MIT Press: Cambridge, MA, USA, 1995. [Google Scholar]
- Zou, L.; Xia, L.; Du, P.; Zhang, Z.; Bai, T.; Liu, W.; Nie, J.-Y.; Yin, D. Pseudo dyna-q: A reinforcement learning framework for interactive recommendation. In Proceedings of the 13th International Conference on Web Search and Data Mining, Houston, TX, USA, 6–9 February 2020; pp. 816–824. [Google Scholar]
- Fan, J.; Wang, Z.; Xie, Y.; Yang, Z. A theoretical analysis of deep q-learning. In Proceedings of the Learning for Dynamics and Control, PMLR, Online, 11–12 June 2020; pp. 486–489. [Google Scholar]
- Degris, T.; White, M.; Sutton, R.S. Off-policy actor-critic. arXiv 2012, arXiv:1205.4839. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Hartikainen, K.; Tucker, G.; Ha, S.; Tan, J.; Kumar, V.; Zhu, H.; Gupta, A.; Abbeel, P.; et al. Soft actor-critic algorithms and applications. arXiv 2018, arXiv:1812.05905. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement learning: An introduction. Robotica 1999, 17, 229–235. [Google Scholar] [CrossRef]
- Zhao, Z.; Xun, J.; Wen, X.; Chen, J. Safe reinforcement learning for single train trajectory optimization via shield sarsa. IEEE Trans. Intell. Transp. Syst. 2022, 24, 412–428. [Google Scholar] [CrossRef]
- Lyu, J.; Ma, X.; Li, X.; Lu, Z. Mildly conservative q-learning for offline reinforcement learning. Adv. Neural Inf. Process. 2022, 35, 1711–1724. [Google Scholar]
- Kormushev, P.; Calinon, S.; Caldwell, D.G. Reinforcement learning in robotics: Applications and real-world challenges. Robotics 2013, 2, 122–148. [Google Scholar] [CrossRef]
- Hu, B.; Zhang, K.; Li, N.; Mesbahi, M.; Fazel, M.; Başar, T. Toward a theoretical foundation of policy optimization for learning control policies. Annu. Rev. Control. Robot. Auton. 2023, 6, 123–158. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust region policy optimization. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 1889–1897. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Proceedings of the International conference on machine learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 1861–1870. [Google Scholar]
- Ghosh-Dastidar, S.; Adeli, H. Spiking neural networks. Int. J. Neural Syst. 2009, 19, 295–308. [Google Scholar] [CrossRef] [PubMed]
- Tavanaei, A.; Ghodrati, M.; Kheradpisheh, S.R.; Masquelier, T.; Maida, A. Deep learning in spiking neural networks. Neural Netw. 2019, 111, 47–63. [Google Scholar] [CrossRef]
- Zhang, S.; Chen, H.; Sun, X.; Li, Y.; Xu, G. Unsupervised graph poisoning attack via contrastive loss back-propagation. In Proceedings of the ACM Web Conference 2022, Lyon, France, 25–29 April 2022; pp. 1322–1330. [Google Scholar]
- Riedmiller, M.; Lernen, A. Multi Layer Perceptron; Machine Learning Lab Special Lecture, University of Freiburg: Freiburg im Breisgau, Germany, 2014; pp. 7–24. [Google Scholar]
- Zou, J.; Han, Y.; So, S.-S. Overview of artificial neural networks. In Artificial Neural Networks: Methods and Applications; Humana Press: Totowa, NJ, USA, 2009; pp. 14–22. [Google Scholar]
- Jones, A.; Townes, F.W.; Li, D.; Engelhardt, B.E. Alignment of spatial genomics data using deep gaussian processes. Nat. Methods 2023, 20, 1379–1387. [Google Scholar] [CrossRef]
- Aigrain, S.; Foreman-Mackey, D. Gaussian process regression for astronomical time series. Annu. Rev. Astron. Astrophys. 2023, 61, 329–371. [Google Scholar] [CrossRef]
- Gawlikowski, J.; Tassi, C.R.N.; Ali, M.; Lee, J.; Humt, M.; Feng, J.; Kruspe, A.; Triebel, R.; Jung, P.; Roscher, R.; et al. A survey of uncertainty in deep neural networks. Artif. Intell. Rev. 2023, 56, 1513–1589. [Google Scholar] [CrossRef]
- Xiao, A.; Huang, J.; Guan, D.; Zhang, X.; Lu, S.; Shao, L. Unsupervised point cloud representation learning with deep neural networks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 11321–11339. [Google Scholar] [CrossRef]
- Li, X.; Zhong, J.; Kamruzzaman, M. Complicated robot activity recognition by quality-aware deep reinforcement learning. Future Gener. Syst. 2021, 117, 480–485. [Google Scholar] [CrossRef]
- Sangeetha, J.; Jayasankar, T. Emotion speech recognition based on adaptive fractional deep belief network and reinforcement learning. In Cognitive Informatics and Soft Computing: Proceeding of CISC 2017; Springer: Berlin/Heidelberg, Germany, 2019; pp. 165–174. [Google Scholar]
- Tan, J.; Liu, H.; Li, Y.; Yin, S.; Yu, C. A new ensemble spatio-temporal pm2. 5 prediction method based on graph attention recursive networks and reinforcement learning. Chaos Solitons Fractals 2022, 162, 112405. [Google Scholar] [CrossRef]
- Hafiz, A. A survey of deep q-networks used for reinforcement learning: State of the art. In Proceedings of the Intelligent Communication Technologies and Virtual Mobile Networks: Proceedings of ICICV 2022, Tirunelveli, India, 10–11 February 2022; pp. 393–402. [Google Scholar]
- Wang, Y.; Zou, S. Policy gradient method for robust reinforcement learning. In Proceedings of the International Conference on Machine Learning, PMLR, Baltimore, ML, USA, 17–23 July 2022; pp. 23484–23526. [Google Scholar]
- Shamir, O.; Srebro, N.; Zhang, T. Communication-efficient distributed optimization using an approximate newton-type method. In Proceedings of the International Conference on Machine Learning, PMLR, Beijing, China, 21–26 June 2014; pp. 1000–1008. [Google Scholar]
- Samende, C.; Cao, J.; Fan, Z. Multi-agent deep deterministic policy gradient algorithm for peer-to-peer energy trading considering distribution network constraints. Appl. Energy 2022, 317, 119–123. [Google Scholar] [CrossRef]
- Rashid, T.; Samvelyan, M.; Witt, C.S.D.; Farquhar, G.; Foerster, J.; Whiteson, S. Monotonic value function factorisation for deep multi-agent reinforcement learning. J. Mach. Learn. Res. 2020, 21, 7234–7284. [Google Scholar]
- Liang, E.; Liaw, R.; Nishihara, R.; Moritz, P.; Fox, R.; Goldberg, K.; Gonzalez, J.; Jordan, M.; Stoica, I. Rllib: Abstractions for distributed reinforcement learning. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 3053–3062. [Google Scholar]
- Chen, T.; Giannakis, G.; Sun, T.; Yin, W. Lag: Lazily aggregated gradient for communication-efficient distributed learning. In Proceedings of the 32st International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; Volume 31. [Google Scholar]
- Zhang, W.; Feng, Y.; Meng, F.; You, D.; Liu, Q. Bridging the gap between training and inference for neural machine translation. arXiv 2019, arXiv:1906.02448. [Google Scholar]
- Narayanan, D.; Harlap, A.; Phanishayee, A.; Seshadri, V.; Devanur, N.R.; Ganger, G.R.; Gibbons, P.B.; Zaharia, M. Pipedream: Generalized pipeline parallelism for dnn training. In Proceedings of the 27th ACM Symposium on Operating Systems Principles, Huntsville, ON, Canada, 27–30 October 2019; pp. 1–15. [Google Scholar]
- Chen, T.; Li, M.; Li, Y.; Lin, M.; Wang, N.; Wang, M.; Xiao, T.; Xu, B.; Zhang, C.; Zhang, Z. Mxnet: A flexible and efficient machine learning library for heterogeneous distributed systems. arXiv 2015, arXiv:1512.01274. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. “{TensorFlow}: A system for {Large-Scale} machine learning. In Proceedings of the 12th USENIX symposium on operating systems design and implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Co, L.H.T. Huawei mindspore ai development framework. In Artificial Intelligence Technology; Springer: Berlin/Heidelberg, Germany, 2022; pp. 137–162. [Google Scholar]
- Nair, A.; Srinivasan, P.; Blackwell, S.; Alcicek, C.; Fearon, R.; Maria, A.D.; Panneershelvam, V.; Suleyman, M.; Beattie, C.; Petersen, S.; et al. Massively parallel methods for deep reinforcement learning. arXiv 2015, arXiv:1507.04296. [Google Scholar]
- Barth-Maron, G.; Hoffman, M.W.; Budden, D.; Dabney, W.; Horgan, D.; Tb, D.; Muldal, A.; Heess, N.; Lillicrap, T. Distributed distributional deterministic policy gradients. arXiv 2018, arXiv:1804.08617. [Google Scholar]
- Espeholt, L.; Marinier, R.; Stanczyk, P.; Wang, K.; Michalski, M. Seed rl: Scalable and efficient deep-rl with accelerated central inference. arXiv 2019, arXiv:1910.06591. [Google Scholar]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated learning: Challenges, methods, and future directions. IEEE Signal Process. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Wang, S.; Tuor, T.; Salonidis, T.; Leung, K.K.; Makaya, C.; He, T.; Chan, K. Adaptive federated learning in resource constrained edge computing systems. IEEE J. Sel. Areas Commun. 2019, 37, 1205–1221. [Google Scholar] [CrossRef]
- Li, Y.; Wang, R.; Li, Y.; Zhang, M.; Long, C. Wind power forecasting considering data privacy protection: A federated deep reinforcement learning approach. Appl. Energy 2023, 329, 120291. [Google Scholar] [CrossRef]
- Nguyen, N.H.; Nguyen, P.L.; Nguyen, T.D.; Nguyen, T.T.; Nguyen, D.L.; Nguyen, T.H.; Pham, H.H.; Truong, T.N. Feddrl: Deep reinforcement learning-based adaptive aggregation for non-iid data in federated learning. In Proceedings of the 51st International Conference on Parallel Processing, Bordeaux, France, 29 August–1 September 2022; pp. 1–11. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. Acm Trans. Intell. Syst. Technol. (TIST) 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Brambilla, M.; Ferrante, E.; Birattari, M.; Dorigo, M. Swarm robotics: A review from the swarm engineering perspective. Swarm Intell. 2013, 7, 1–41. [Google Scholar] [CrossRef]
- Na, S.; Rouček, T.; Ulrich, J.; Pikman, J.; Krajník, T.; Lennox, B.; Arvin, F. Federated reinforcement learning for collective navigation of robotic swarms. IEEE Trans. Cogn. Dev. Syst. 2023, 15, 2122–2131. [Google Scholar] [CrossRef]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Sallab, A.A.A.; Yogamani, S.; Pérez, P. Deep reinforcement learning for autonomous driving: A survey. IEEE Trans. Intell. Transp. Syst. 2021, 23, 4909–4926. [Google Scholar] [CrossRef]
- Feng, S.; Sun, H.; Yan, X.; Zhu, H.; Zou, Z.; Shen, S.; Liu, H.X. Dense reinforcement learning for safety validation of autonomous vehicles. Nature 2023, 615, 620–627. [Google Scholar] [CrossRef] [PubMed]
- Gottesman, O.; Johansson, F.; Komorowski, M.; Faisal, A.; Sontag, D.; Doshi-Velez, F.; Celi, L.A. Guidelines for reinforcement learning in healthcare. Nat. Med. 2019, 25, 16–18. [Google Scholar] [CrossRef]
- Tang, K.-F.; Kao, H.-C.; Chou, C.-N.; Chang, E.Y. Inquire and diagnose: Neural symptom checking ensemble using deep reinforcement learning. In Proceedings of the 29th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Gao, H.; Xiao, X.; Qiu, L.; Meng, M.Q.-H.; King, N.K.K.; Ren, H. Remote-center-of-motion recommendation toward brain needle intervention using deep reinforcement learning. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; IEEE: Piscateville, NJ, USA, 2021; pp. 8295–8301. [Google Scholar]
- Ahmed, S.; Groenli, T.-M.; Lakhan, A.; Chen, Y.; Liang, G. A reinforcement federated learning based strategy for urinary disease dataset processing. Comput. Biol. Med. 2023, 163, 107210. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Driessche, G.V.D.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).