
Fast Decision-Tree-Based Series Partitioning and Mode Prediction Termination Algorithm for H.266/VVC

Abstract
1. Introduction
2. Related Works
3. Statistical Analysis
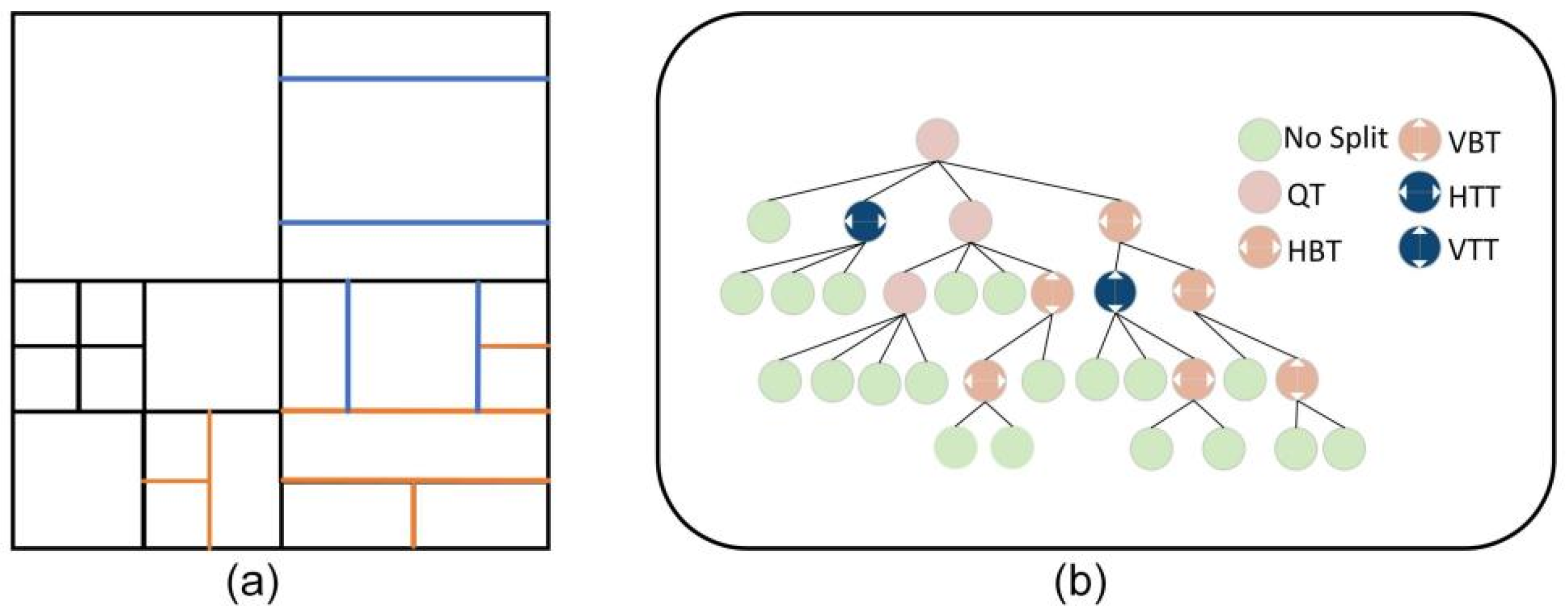
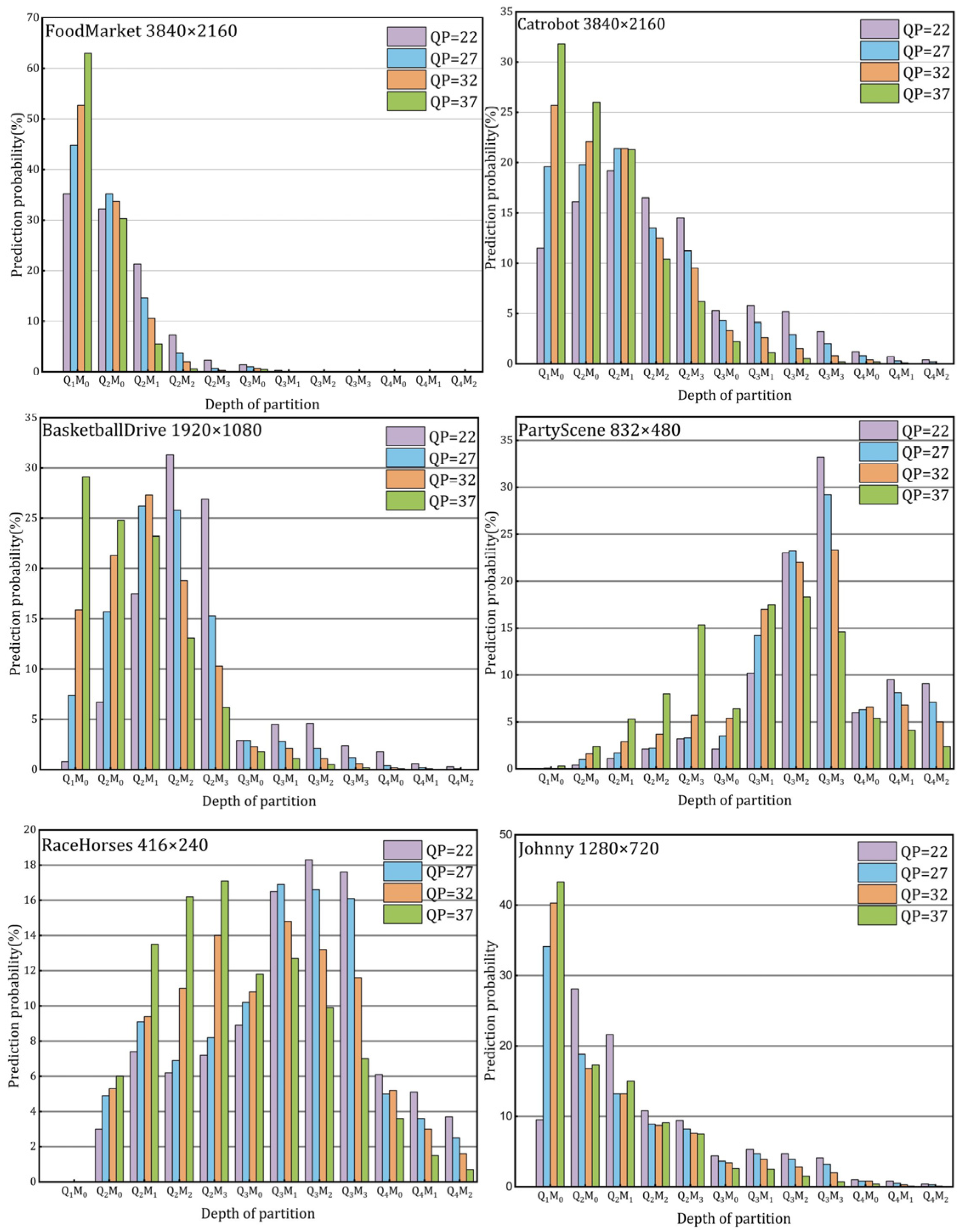
3.1. Size Distribution Analysis of Coding Units in VVC
3.2. VVC Intra-Frame Mode Analysis
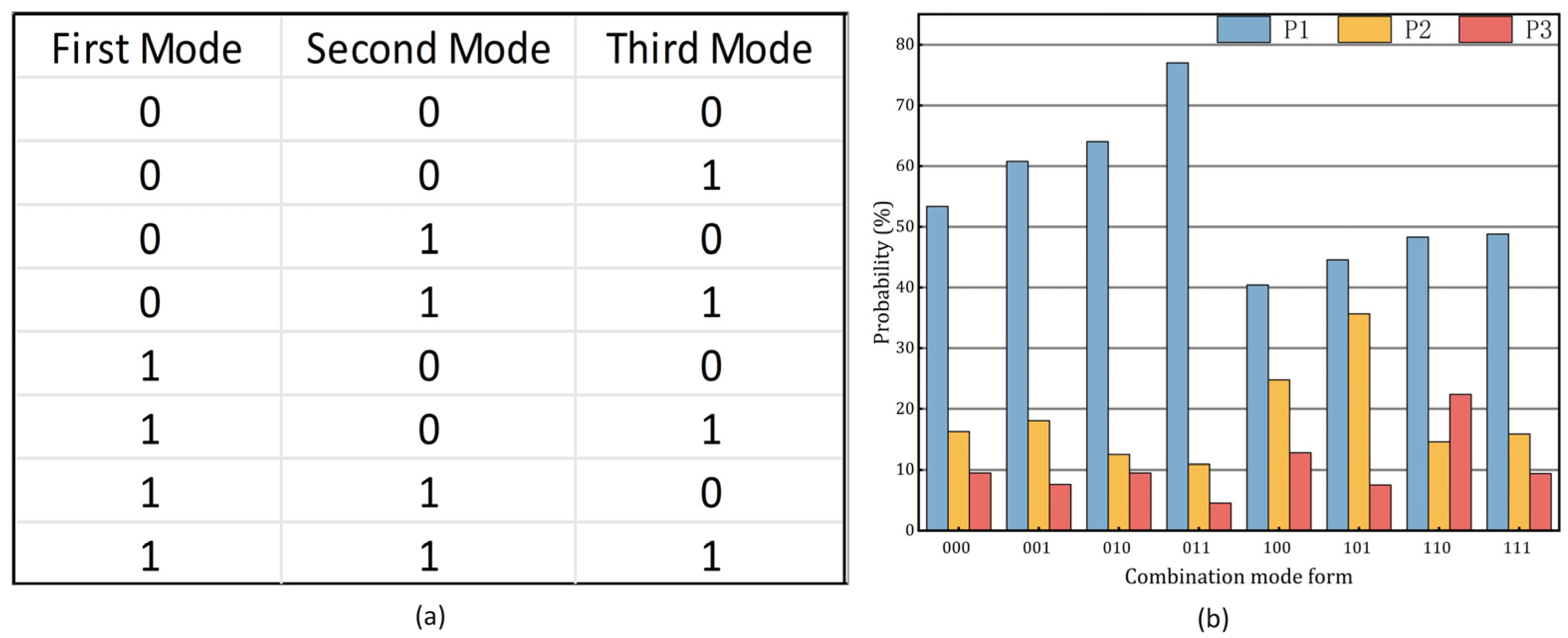
3.2.1. Hadamard Cost of Candidate Models
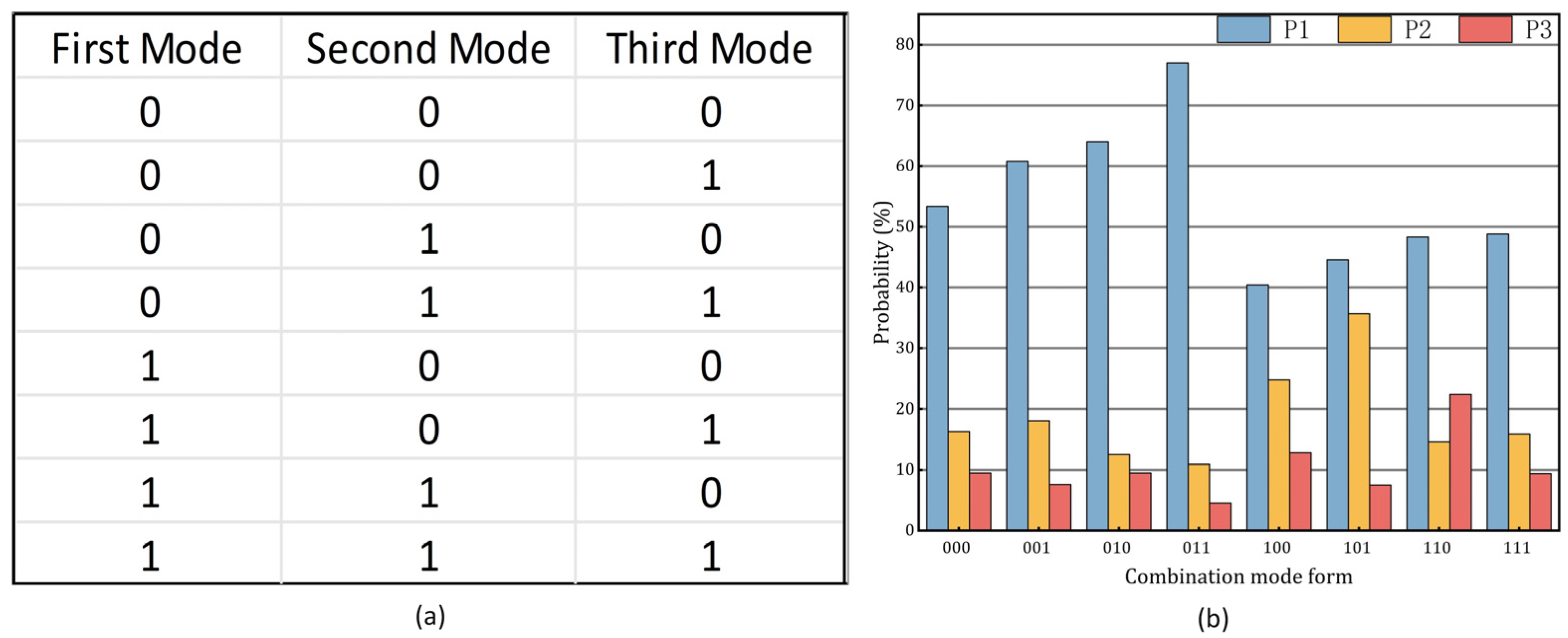
3.2.2. MRL Forecast Information
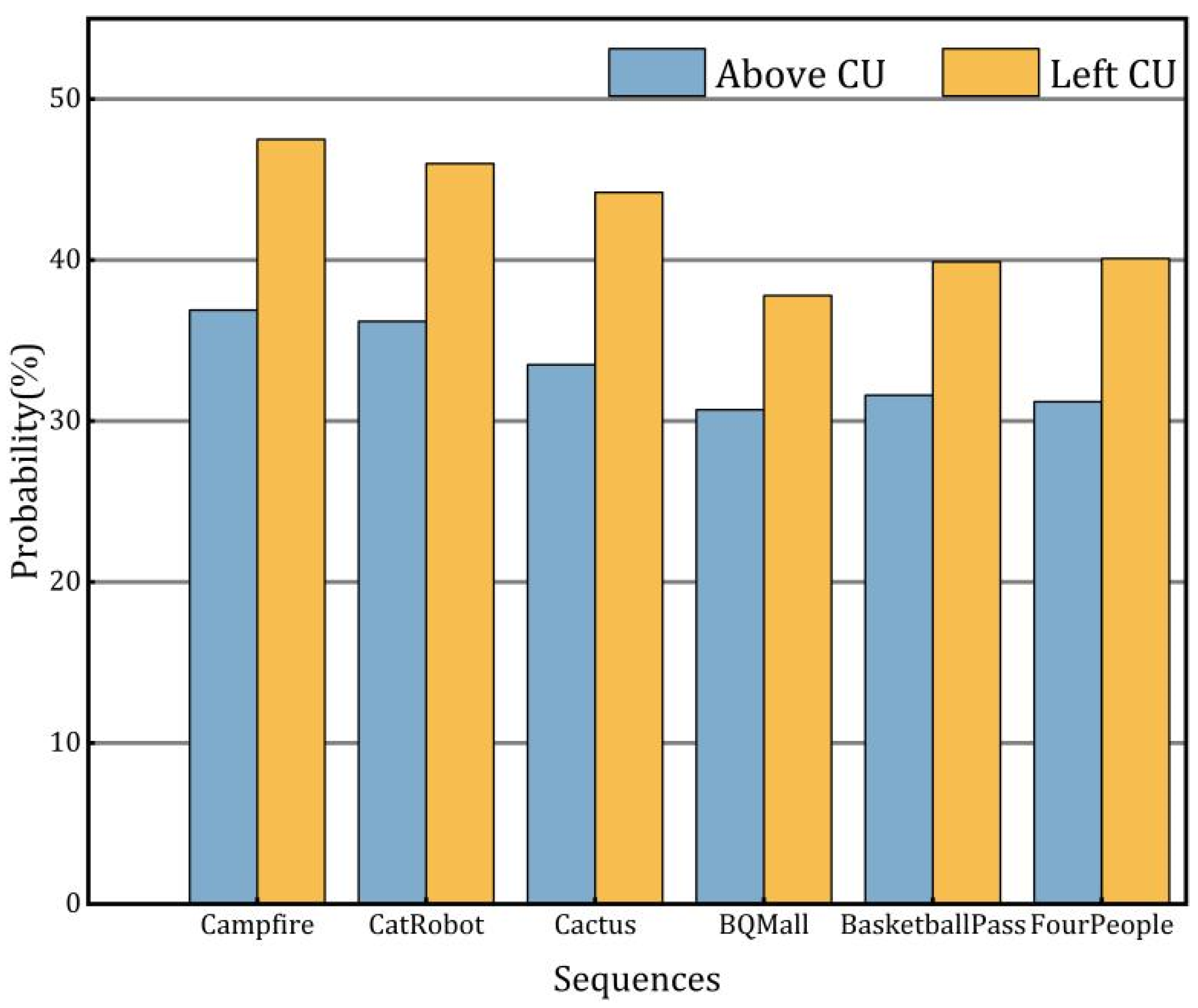
3.2.3. Spatial Coding Information
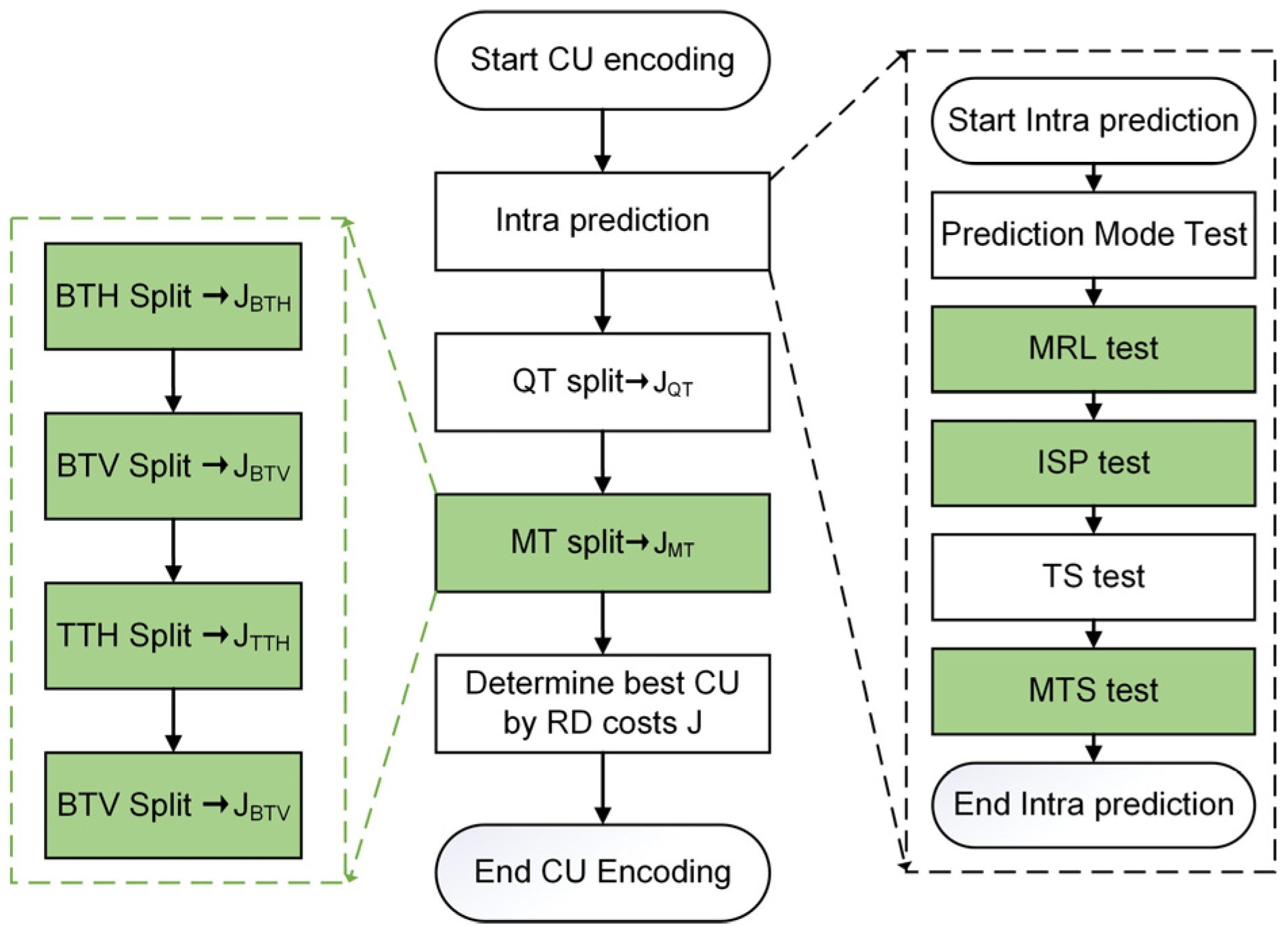
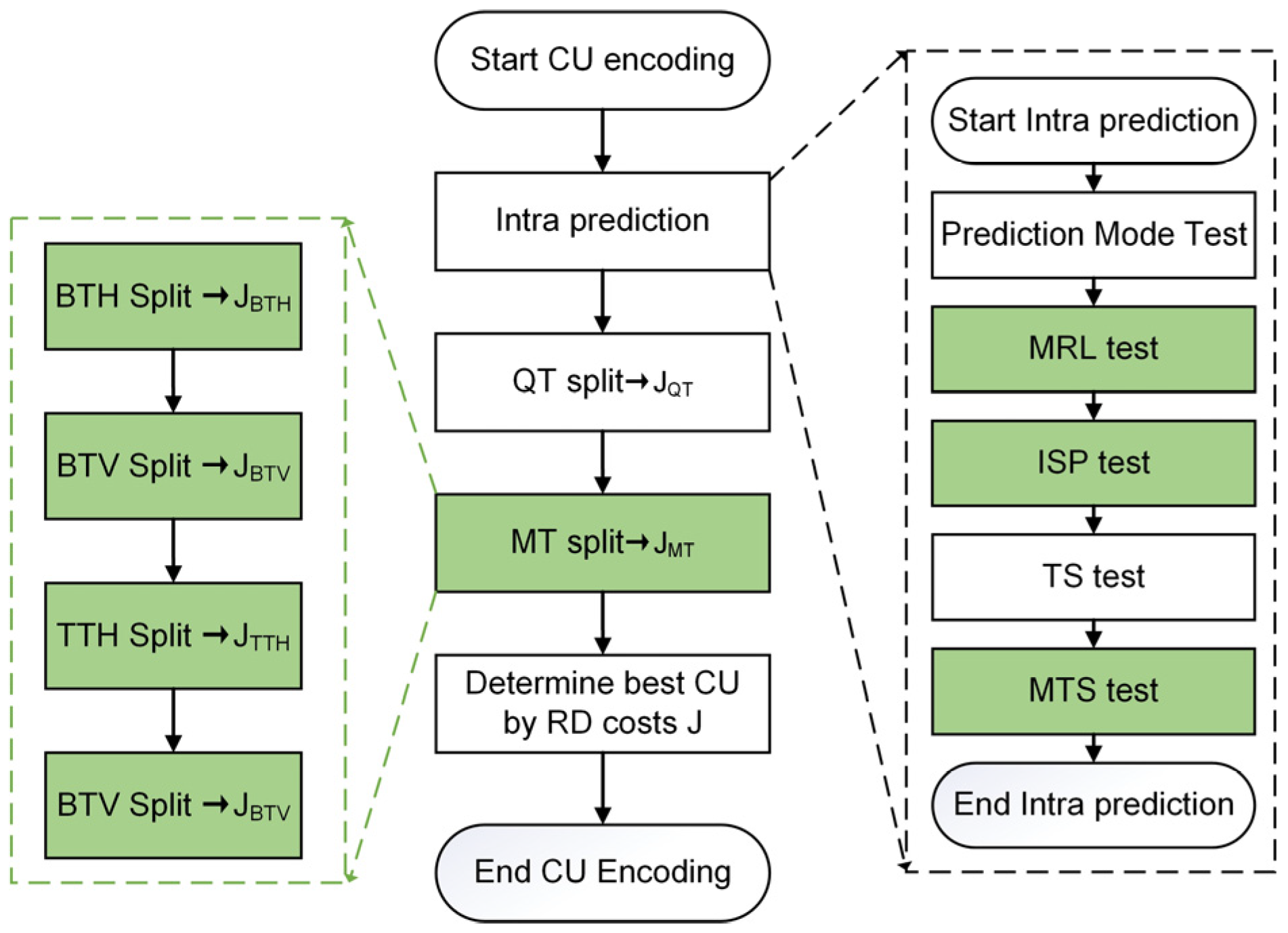
4. The Proposed Fast Intra-Coding Algorithm
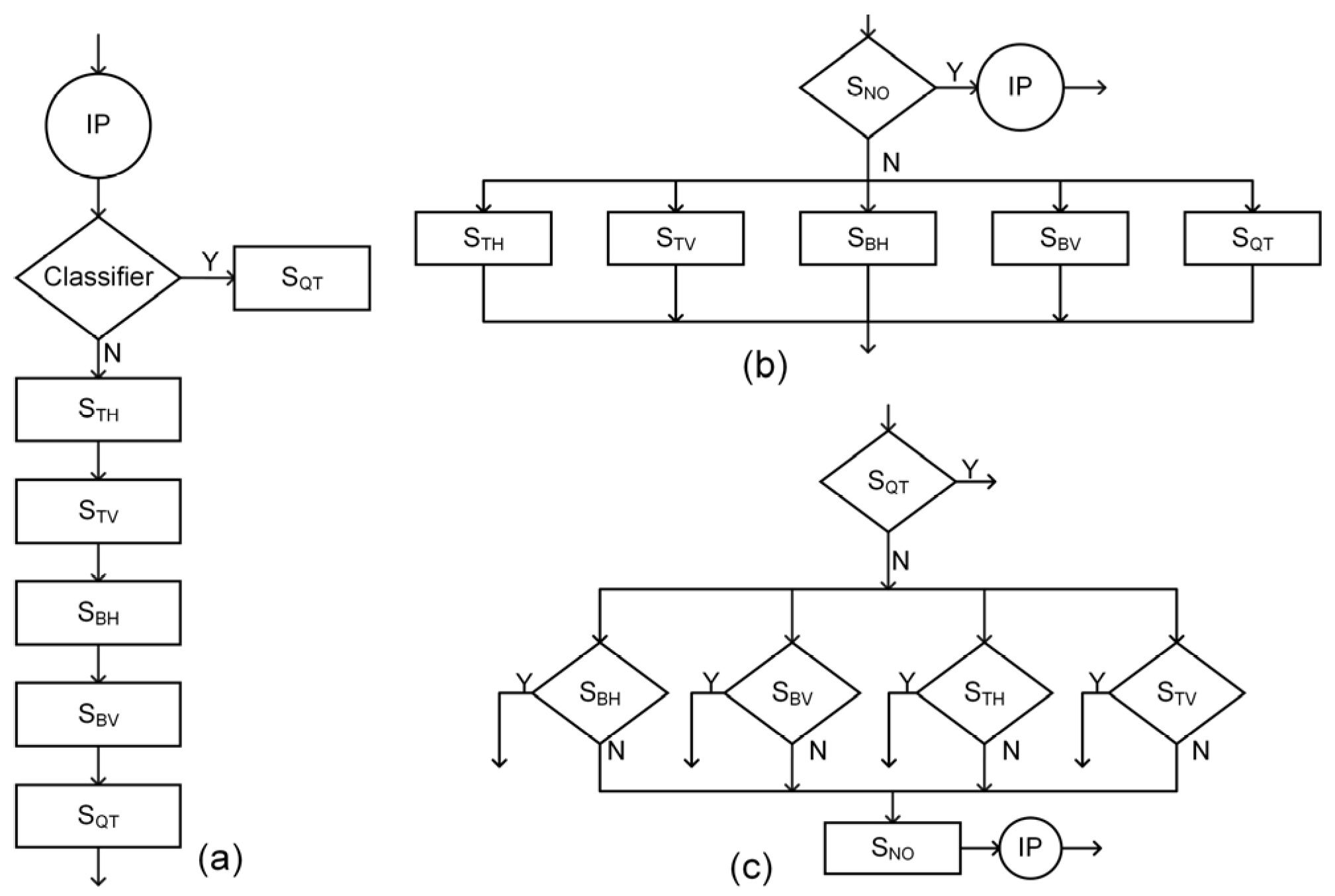
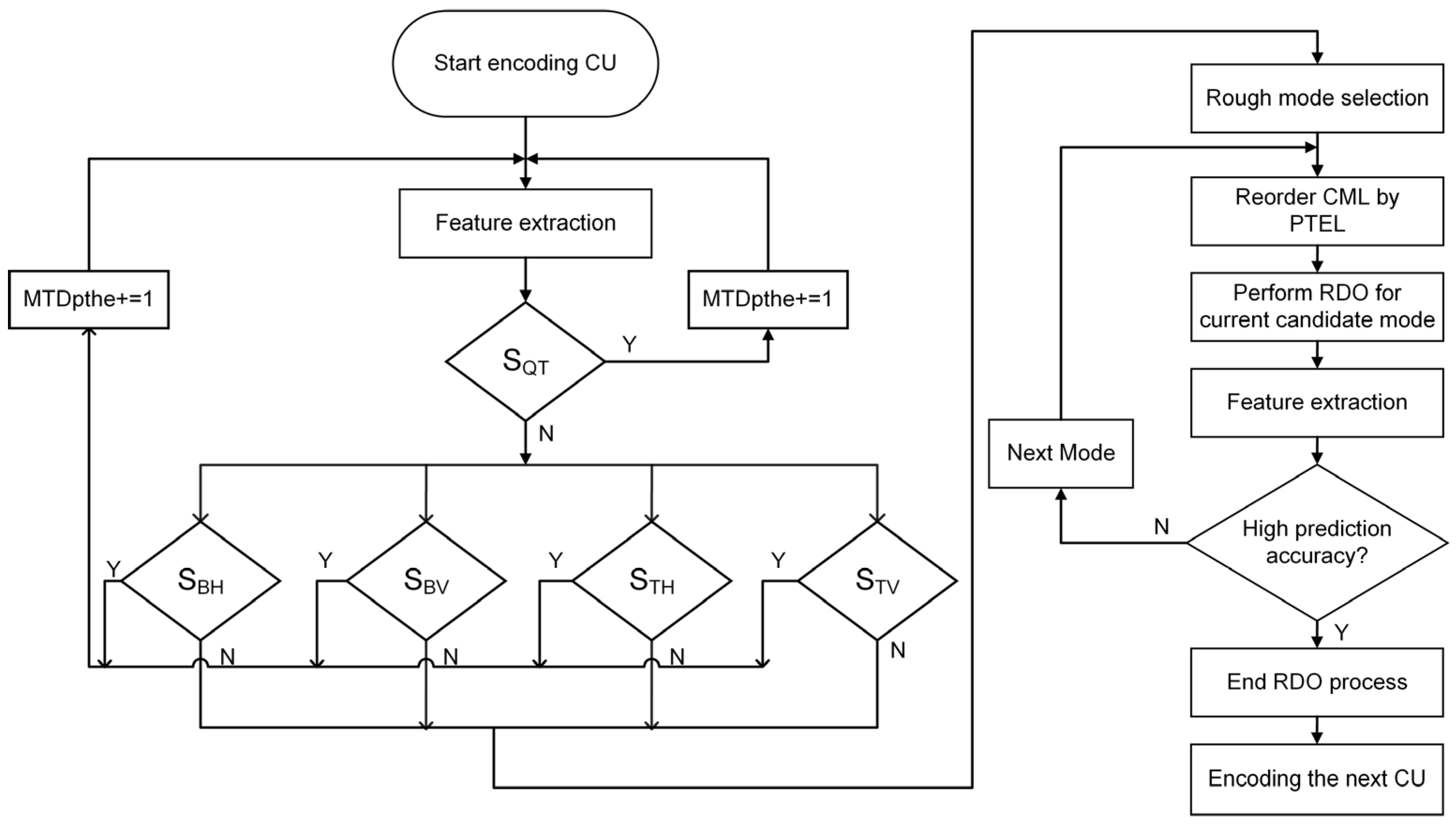
4.1. Decision-Tree-Based Series Partitioning Decision Algorithm
- (1)
- Texture information
- (2)
- Adjacent CU encoding information
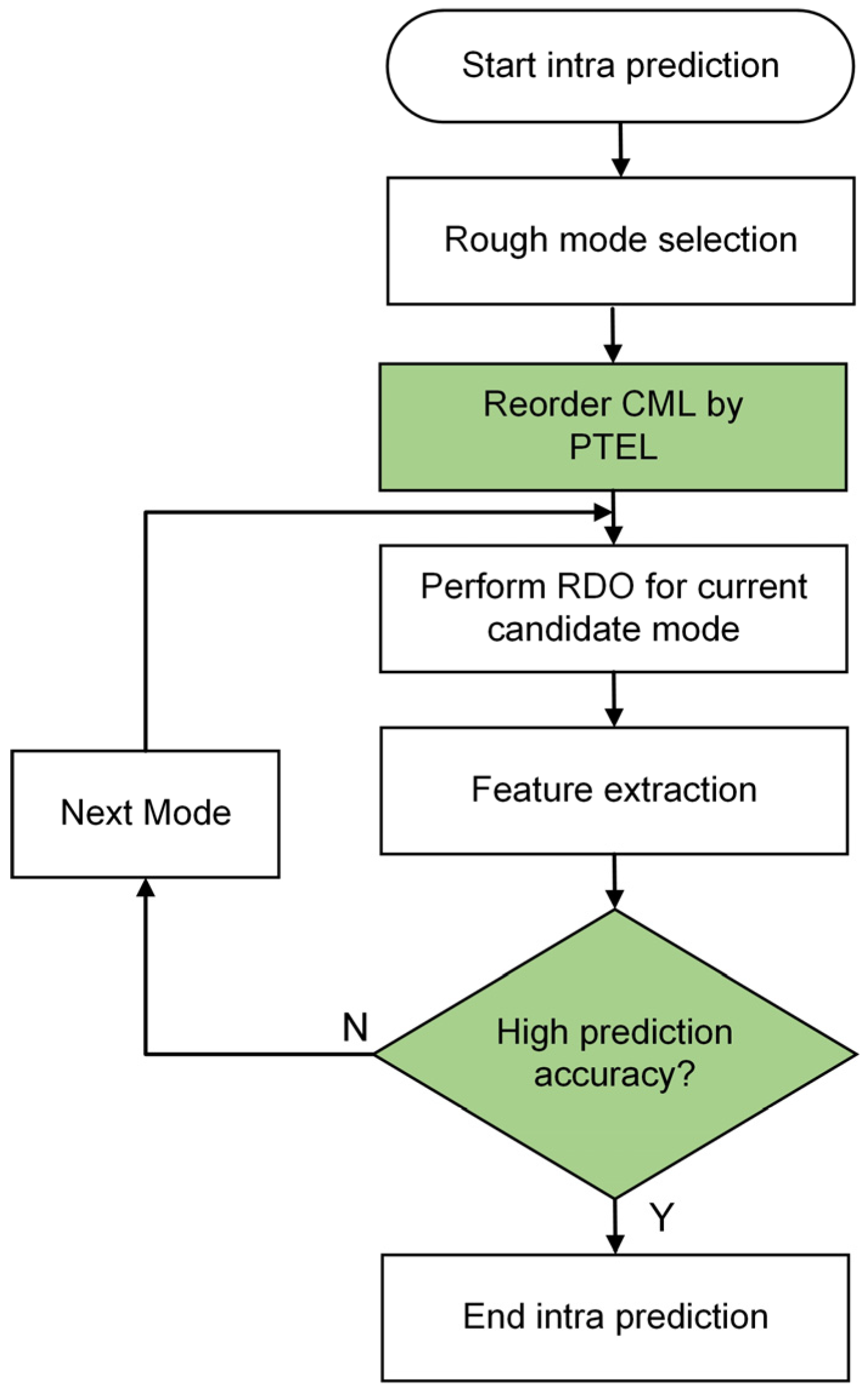
4.2. Mode prediction Termination Algorithm Based on Ensemble Learning
4.3. Overall Algorithm
5. Experimental Results
5.1. Analysis of the Proposed Algorithm
5.2. Comparison with Other Algorithms
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jonsson, P.; Carson, S.; Davies, S.; Lindberg, P.; Blennerud, G.; Fu, K.; Bezri, B.; Manssour, J.; Theng Khoo, S.; Burstedt, F.; et al. Ericsson Mobility Report. Stockholm, Sweden. 2021. Available online: https://www.ericsson.com/en/reports-and-papers/mobility-report/reports/november-2021 (accessed on 10 September 2023).
- Sullivan, G.J.; Ohm, J.-R.; Han, W.-J.; Wiegand, T. Overview of the High Efficiency Video Coding (HEVC) Standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Bross, B.; Wang, Y.-K.; Ye, Y.; Liu, S.; Chen, J.; Sullivan, G.J.; Ohm, J.-R. Overview of the Versatile Video Coding (VVC) Standard and its Applications. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3736–3764. [Google Scholar] [CrossRef]
- Amestoy, T.; Mercat, A.; Hamidouche, W.; Menard, D.; Bergeron, C. Tunable VVC Frame Partitioning Based on Lightweight Machine Learning. IEEE Trans. Image Process. 2020, 29, 1313–1328. [Google Scholar] [CrossRef] [PubMed]
- Bross, B.; Chen, J.; Ohm, J.-R.; Sullivan, G.J.; Wang, Y.-K. Developments in International Video Coding Standardization After AVC, With an Overview of Versatile Video Coding (VVC). Proc. IEEE 2021, 109, 1463–1493. [Google Scholar] [CrossRef]
- Bossen, F.; Li, X.; Sühring, K. AHG Report: Test Model Software Development (AHG3); Technical Report; JVET-J0003; Joint Video Experts Team: Geneva, Switzerland, 2018. [Google Scholar]
- Saldanha, M.; Sanchez, G.; Marcon, C.; Agostini, L. Complexity Analysis of VVC Intra Coding. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; IEEE: New York, NY, USA, 2020; pp. 3119–3123. [Google Scholar] [CrossRef]
- Tang, G.; Jing, M.; Zeng, X.; Fan, Y. Adaptive CU Split Decision with Pooling-variable CNN for VVC Intra Encoding. In Proceedings of the 2019 IEEE Visual Communications and Image Processing (VCIP), Sydney, Australia, 1–4 December 2019; IEEE: New York, NY, USA, 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Zhang, H.; Ma, Z. Fast Intra Mode Decision for High Efficiency Video Coding (HEVC). IEEE Trans. Circuits Syst. Video Technol. 2014, 24, 660–668. [Google Scholar] [CrossRef]
- Zhang, Y.; Kwong, S.; Wang, X.; Yuan, H.; Pan, Z.; Xu, L. Machine Learning-Based Coding Unit Depth Decisions for Flexible Complexity Allocation in High Efficiency Video Coding. IEEE Trans. Image Process. 2015, 24, 2225–2238. [Google Scholar] [CrossRef] [PubMed]
- Shen, L.; Zhang, Z.; Liu, Z. Effective CU Size Decision for HEVC Intracoding. IEEE Trans. Image Process. 2014, 23, 4232–4241. [Google Scholar] [CrossRef] [PubMed]
- Min, B.; Cheung, R.C.C. A Fast CU Size Decision Algorithm for the HEVC Intra Encoder. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 892–896. [Google Scholar] [CrossRef]
- Ha, J.M.; Bae, J.H.; Sunwoo, M.H. Texture-based fast CU size decision algorithm for HEVC intra coding. In Proceedings of the 2016 IEEE Asia Pacific Conference on Circuits and Systems (APCCAS), Jeju, Republic of Korea, 25–28 October 2016; IEEE: New York, NY, USA, 2016; pp. 702–705. [Google Scholar] [CrossRef]
- Wei, R.; Xie, R.; Zhang, L.; Song, L. Fast depth decision with enlarged coding block sizes for HEVC intra coding of 4K ultra-HD video. In Proceedings of the 2015 IEEE Workshop on Signal Processing Systems (SiPS), Hangzhou, China, 14–16 October 2015; IEEE: New York, NY, USA, 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Zhang, H.; Ma, Z. Early termination schemes for fast intra mode decision in High Efficiency Video Coding. In Proceedings of the 2013 IEEE International Symposium on Circuits and Systems (ISCAS2013), Beijing, China, 19–23 May 2013; IEEE: New York, NY, USA, 2013; pp. 45–48. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Z.; Li, B. Gradient-based fast decision for intra prediction in HEVC. In Proceedings of the 2012 Visual Communications and Image Processing, San Diego, CA, USA, 27–30 November 2012; IEEE: New York, NY, USA, 2012; pp. 1–6. [Google Scholar] [CrossRef]
- Jung, S.; Park, H.W. A Fast Mode Decision Method in HEVC Using Adaptive Ordering of Modes. IEEE Trans. Circuits Syst. Video Technol. 2016, 26, 1846–1858. [Google Scholar] [CrossRef]
- Shen, L.; Zhang, Z.; Liu, Z. Adaptive Inter-Mode Decision for HEVC Jointly Utilizing Inter-Level and Spatiotemporal Correlations. IEEE Trans. Circuits Syst. Video Technol. 2014, 24, 1709–1722. [Google Scholar] [CrossRef]
- Jiang, W.; Ma, H.; Chen, Y. Gradient based fast mode decision algorithm for intra prediction in HEVC. In Proceedings of the 2012 2nd International Conference on Consumer Electronics, Communications and Networks (CECNet), Yichang, China, 21–23 April 2012; IEEE: New York, NY, USA, 2012; pp. 1836–1840. [Google Scholar] [CrossRef]
- Wang, L.-L.; Siu, W.-C. Novel Adaptive Algorithm for Intra Prediction with Compromised Modes Skipping and Signaling Processes in HEVC. IEEE Trans. Circuits Syst. Video Technol. 2013, 23, 1686–1694. [Google Scholar] [CrossRef]
- Chen, F.; Ren, Y.; Peng, Z.; Jiang, G.; Cui, X. A fast CU size decision algorithm for VVC intra prediction based on support vector machine. Multimed. Tools Appl. 2020, 79, 27923–27939. [Google Scholar] [CrossRef]
- Yang, H.; Shen, L.; Dong, X.; Ding, Q.; An, P.; Jiang, G. Low-Complexity CTU Partition Structure Decision and Fast Intra Mode Decision for Versatile Video Coding. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 1668–1682. [Google Scholar] [CrossRef]
- Zhao, J.; Wang, Y.; Zhang, Q. Fast CU Size Decision Method Based on Just Noticeable Distortion and Deep Learning. Sci. Program. 2021, 2021, 3813116. [Google Scholar] [CrossRef]
- Tang, N.; Cao, J.; Liang, F.; Wang, J.; Liu, H.; Wang, X.; Du, X. Fast CTU Partition Decision Algorithm for VVC Intra and Inter Coding. In Proceedings of the 2019 IEEE Asia Pacific Conference on Circuits and Systems (APCCAS), Bangkok, Thailand, 11–14 November 2019; IEEE: New York, NY, USA, 2019; pp. 361–364. [Google Scholar] [CrossRef]
- Fu, T.; Zhang, H.; Mu, F.; Chen, H. Fast CU Partitioning Algorithm for H.266/VVC Intra-Frame Coding. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; IEEE: New York, NY, USA, 2019; pp. 55–60. [Google Scholar] [CrossRef]
- Park, S.; Kang, J.-W. Fast Multi-Type Tree Partitioning for Versatile Video Coding Using a Lightweight Neural Network. IEEE Trans. Multimed. 2021, 23, 4388–4399. [Google Scholar] [CrossRef]
- Chen, J.; Sun, H.; Katto, J.; Zeng, X.; Fan, Y. Fast QTMT Partition Decision Algorithm in VVC Intra Coding based on Variance and Gradient. In Proceedings of the 2019 IEEE Visual Communications and Image Processing (VCIP), Sydney, Australia, 1–4 December 2019; IEEE: New York, NY, USA, 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Cui, J.; Zhang, T.; Gu, C.; Zhang, X.; Ma, S. Gradient-Based Early Termination of CU Partition in VVC Intra Coding. In Proceedings of the 2020 Data Compression Conference (DCC), Snowbird, UT, USA, 24–27 March 2020; IEEE: New York, NY, USA, 2020; pp. 103–112. [Google Scholar] [CrossRef]
- Zhang, Q.; Wang, Y.; Huang, L.; Jiang, B. Fast CU Partition and Intra Mode Decision Method for H.266/VVC. IEEE Access 2020, 8, 117539–117550. [Google Scholar] [CrossRef]
- Lei, M.; Luo, F.; Zhang, X.; Wang, S.; Ma, S. Look-Ahead Prediction Based Coding Unit Size Pruning for VVC Intra Coding. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; IEEE: New York, NY, USA, 2019; pp. 4120–4124. [Google Scholar] [CrossRef]
- Zouidi, N.; Belghith, F.; Kessentini, A.; Masmoudi, N. Fast intra prediction decision algorithm for the QTBT structure. In Proceedings of the 2019 IEEE International Conference on Design & Test of Integrated Micro & Nano-Systems (DTS), Gammarth-Tunis, Tunisia, 28 April–1 May 2019; IEEE: New York, NY, USA, 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Dong, X.; Shen, L.; Yu, M.; Yang, H. Fast Intra Mode Decision Algorithm for Versatile Video Coding. IEEE Trans. Multimed. 2022, 24, 400–414. [Google Scholar] [CrossRef]
- Zhao, J.; Li, P.; Zhang, Q. A Fast Decision Algorithm for VVC Intra-Coding Based on Texture Feature and Machine Learning. Comput. Intell. Neurosci. 2022, 2022, 7675749. [Google Scholar] [CrossRef] [PubMed]
- Tissier, A.; Hamidouche, W.; Mdalsi, S.B.D.; Vanne, J.; Galpin, F.; Menard, D. Machine Learning Based Efficient QT-MTT Partitioning Scheme for VVC Intra Encoders. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 4279–4293. [Google Scholar] [CrossRef]
- Zhang, C.; Yang, W.; Zhang, Q. Fast CU Division Pattern Decision Based on the Combination of Spatio-Temporal Information. Electronics 2023, 12, 1967. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Sequence | Resolution | Frame Count | Frame Rate (fps) | Bit Depth |
|---|---|---|---|---|---|
| A1 | Campfire | 3840 × 2160 | 300 | 30 | 10 |
| FoodMarket4 | 300 | 60 | |||
| Tango2 | 294 | 60 | |||
| A2 | Catrobot | 3840 × 2160 | 300 | 60 | 10 |
| DaylightRoad2 | 300 | 60 | |||
| ParkRunning3 | 300 | 50 | |||
| B | BQTerrace | 1920 × 1080 | 600 | 60 | 8 |
| BasketballDrive | 500 | 50 | |||
| Cactus | 500 | 50 | |||
| Kimono | 240 | 24 | |||
| ParkScene | 240 | 24 | |||
| C | BQMall | 832 × 480 | 600 | 60 | 8 |
| BasketballDrill | 500 | 50 | |||
| PartyScene | 500 | 50 | |||
| RaceHorsesC | 300 | 30 | |||
| D | BasketballPass | 416 × 240 | 500 | 50 | 8 |
| BlowingBubbles | 500 | 50 | |||
| BQSquare | 600 | 60 | |||
| RaceHorses | 300 | 30 | |||
| E | FourPeople | 1280 × 720 | 600 | 60 | 8 |
| Johnny | 600 | 60 | |||
| KristenAndSara | 600 | 60 | |||
| F | BasketballDrillText | 832 × 480 | 500 | 50 | 8 |
| ChinaSpeed | 1280 × 720 | 500 | 30 | ||
| SlideEditing | 300 | 20 | |||
| SlideShow | 500 | 20 |
| Class | Sequence | Resolution | Bit Depth | Content Information |
|---|---|---|---|---|
| A1 | FoodMarket | 3840 × 2160 | 10 | Global motion |
| A2 | Catrobot | 3840 × 2160 | 10 | Local motion information |
| B | BasketballDrive | 1920 × 1080 | 8 | Global motion and local motion |
| C | PartyScene | 832 × 480 | 8 | High texture complexity |
| D | RaceHorses | 416 × 240 | 8 | Large amplitude motion |
| E | Johnny | 1280 × 720 | 8 | Large background area |
| Class | Sequence | Resolution | Bit Depth | Content Information |
|---|---|---|---|---|
| A1 | Campfire | 3840 × 2160 | 10 | The brightness dynamic range is large |
| A2 | Catrobot | 3840 × 2160 | 10 | Local motion information |
| B | Cactus | 1920 × 1080 | 8 | Rotating objects |
| C | BQMall | 832 × 480 | 8 | Complex texture content |
| D | BasketballPass | 416 × 240 | 8 | Global and local motion information |
| E | FourPeople | 1280 × 720 | 8 | Simple background |
| Hardware | Software | ||
|---|---|---|---|
| CPU | Intel(R) Core (TM) i7-11800H (Lenovo, Beijing, China) | Reference software | VTM 10.0 |
| RAM | 16 GB | Configuration | All intra |
| OS | Microsoft Windows 10 64 bit | QP | 22,27,32,37 |
| Class | Sequence | SPD-DT | PTEL | Overall | |||
|---|---|---|---|---|---|---|---|
| ATS (%) | BDBR (%) | ATS (%) | BDBR (%) | ATS (%) | BDBR (%) | ||
| A1 | Campfire | 51.31 | 0.98 | 14.15 | 0.12 | 56.35 | 1.32 |
| FoodMarket4 | 55.63 | 0.59 | 12.32 | 0.10 | 52.67 | 1.16 | |
| Tango2 | 52.32 | 1.01 | 12.57 | 0.13 | 66.89 | 2.01 | |
| A2 | Catrobot | 46.37 | 1.08 | 14.33 | 0.51 | 62.35 | 1.64 |
| DaylightRoad2 | 61.52 | 0.51 | 12.58 | 0.26 | 63.24 | 1.58 | |
| ParkRunning3 | 54.17 | 0.79 | 13.46 | 0.25 | 58.41 | 1.65 | |
| B | BQTerrace | 57.35 | 2.11 | 12.64 | 0.24 | 56.35 | 1.56 |
| BasketballDrive | 65.10 | 2.30 | 14.92 | 0.23 | 59.43 | 1.86 | |
| Cactus | 57.92 | 1.91 | 13.13 | 0.31 | 62.53 | 1.71 | |
| Kimono | 64.34 | 1.89 | 13.55 | 0.23 | 66.21 | 1.53 | |
| ParkScene | 58.33 | 1.35 | 12.64 | 0.22 | 58.42 | 1.63 | |
| C | BQMall | 56.36 | 2.21 | 12.25 | 0.33 | 50.21 | 1.55 |
| BasketballDrill | 49.58 | 1.98 | 12.18 | 0.27 | 48.11 | 1.72 | |
| PartyScene | 46.33 | 0.63 | 11.97 | 0.25 | 49.32 | 1.31 | |
| RaceHorsesC | 49.66 | 1.22 | 13.31 | 0.16 | 49.23 | 1.36 | |
| D | BasketballPass | 47.34 | 2.42 | 12.42 | 0.30 | 42.13 | 1.72 |
| BlowingBubbles | 42.35 | 0.81 | 11.33 | 0.23 | 39.05 | 1.47 | |
| BQSquare | 46.82 | 0.79 | 10.25 | 0.25 | 44.22 | 1.36 | |
| RaceHorses | 44.21 | 0.93 | 13.17 | 0.24 | 48.23 | 1.56 | |
| E | FourPeople | 58.47 | 2.81 | 12.91 | 0.37 | 55.88 | 1.70 |
| Johnny | 9.52 | 3.35 | 13.22 | 0.28 | 57.69 | 2.09 | |
| KristenAndSara | 59.87 | 2.48 | 12.84 | 0.22 | 57.46 | 1.93 | |
| Average | 51.59 | 1.55 | 12.82 | 0.25 | 54.74 | 1.61 | |
| Class | Sequence | Chen [27] | Alexandre Tissier [34] | Zhang [35] | Ours | ||||
|---|---|---|---|---|---|---|---|---|---|
| ATS (%) | BDBR (%) | ATS (%) | BDBR (%) | ATS (%) | BDBR (%) | ATS (%) | BDBR (%) | ||
| A1 | Campfire | - | - | 67.4 | 2.02 | 55.92 | 1.81 | 56.35 | 1.32 |
| FoodMarket4 | - | - | 67.5 | 1.4 | 51.77 | 1.95 | 52.67 | 1.16 | |
| Tango2 | - | - | 80.9 | 1.48 | 65.06 | 2.07 | 66.89 | 2.01 | |
| A2 | Catrobot | - | - | 62.9 | 2.56 | 61.22 | 2.33 | 62.35 | 1.64 |
| DaylightRoad2 | - | - | 73.7 | 2.47 | 61.48 | 1.77 | 63.24 | 1.58 | |
| ParkRunning3 | - | - | 60.9 | 0.91 | 57.88 | 1.71 | 58.41 | 1.65 | |
| B | BQTerrace | 49.46 | 1.16 | 75.1 | 2.76 | 54.55 | 1.50 | 56.35 | 1.56 |
| BasketballDrive | 65.34 | 3.09 | 76.0 | 2.51 | 58.63 | 1.92 | 59.43 | 1.86 | |
| Cactus | 55.97 | 1.74 | 72.8 | 2.6 | 61.26 | 1.73 | 62.53 | 1.71 | |
| Kimono | 55.31 | 1.72 | - | - | 65.40 | 1.55 | 66.21 | 1.53 | |
| ParkScene | 56.36 | 1.28 | - | - | 57.94 | 1.65 | 58.42 | 1.63 | |
| C | BQMall | 56.51 | 1.79 | 71.1 | 3.08 | 49.5 | 1.52 | 50.21 | 1.55 |
| BasketballDrill | 53.19 | 1.91 | 67.7 | 4.69 | 47.27 | 1.79 | 48.11 | 1.72 | |
| PartyScene | 41.76 | 0.28 | 69.3 | 2.16 | 48.22 | 1.18 | 49.32 | 1.31 | |
| RaceHorsesC | 52.14 | 0.84 | 69.2 | 1.97 | 48.26 | 1.35 | 49.23 | 1.36 | |
| D | BasketballPass | 54.15 | 2.02 | 67.2 | 2.86 | 41.98 | 1.76 | 42.13 | 1.72 |
| BlowingBubbles | 43.97 | 0.49 | 64.7 | 2.37 | 38.02 | 1.46 | 39.05 | 1.47 | |
| BQSquare | 32.35 | 0.17 | 70.0 | 2.43 | 43.67 | 1.34 | 44.22 | 1.36 | |
| RaceHorses | 44.94 | 0.54 | 66.5 | 2.29 | 47.21 | 1.76 | 48.23 | 1.56 | |
| E | FourPeople | 62.27 | 2.55 | 73.1 | 3.46 | 56.81 | 1.77 | 55.88 | 1.70 |
| Johnny | 62.61 | 3.07 | 72.9 | 3.71 | 57.65 | 2.30 | 57.69 | 2.09 | |
| KristenAndSara | 60.83 | 2.26 | 71.8 | 3.32 | 56.57 | 1.98 | 57.46 | 1.93 | |
| Average | 52.95 | 1.56 | 70.04 | 2.56 | 53.92 | 1.74 | 54.74 | 1.61 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; He, Z.; Zhang, Q. Fast Decision-Tree-Based Series Partitioning and Mode Prediction Termination Algorithm for H.266/VVC. Electronics 2024, 13, 1250. https://doi.org/10.3390/electronics13071250
Li Y, He Z, Zhang Q. Fast Decision-Tree-Based Series Partitioning and Mode Prediction Termination Algorithm for H.266/VVC. Electronics. 2024; 13(7):1250. https://doi.org/10.3390/electronics13071250
Chicago/Turabian StyleLi, Ye, Zhihao He, and Qiuwen Zhang. 2024. "Fast Decision-Tree-Based Series Partitioning and Mode Prediction Termination Algorithm for H.266/VVC" Electronics 13, no. 7: 1250. https://doi.org/10.3390/electronics13071250
APA StyleLi, Y., He, Z., & Zhang, Q. (2024). Fast Decision-Tree-Based Series Partitioning and Mode Prediction Termination Algorithm for H.266/VVC. Electronics, 13(7), 1250. https://doi.org/10.3390/electronics13071250