
Driver Abnormal Expression Detection Method Based on Improved Lightweight YOLOv5

Abstract
1. Introduction
- (1)
- First, in response to the current scarcity of publicly available datasets for facial expressions of pain and distress, we created our own dataset. This dataset primarily includes three categories of expressions that drivers commonly exhibit during driving: happiness, neutrality, and pain. In the driving context, expressions of happiness and pain can influence certain driving decisions, and in this paper, these two types of expressions are classified as abnormal driving expressions.
- (2)
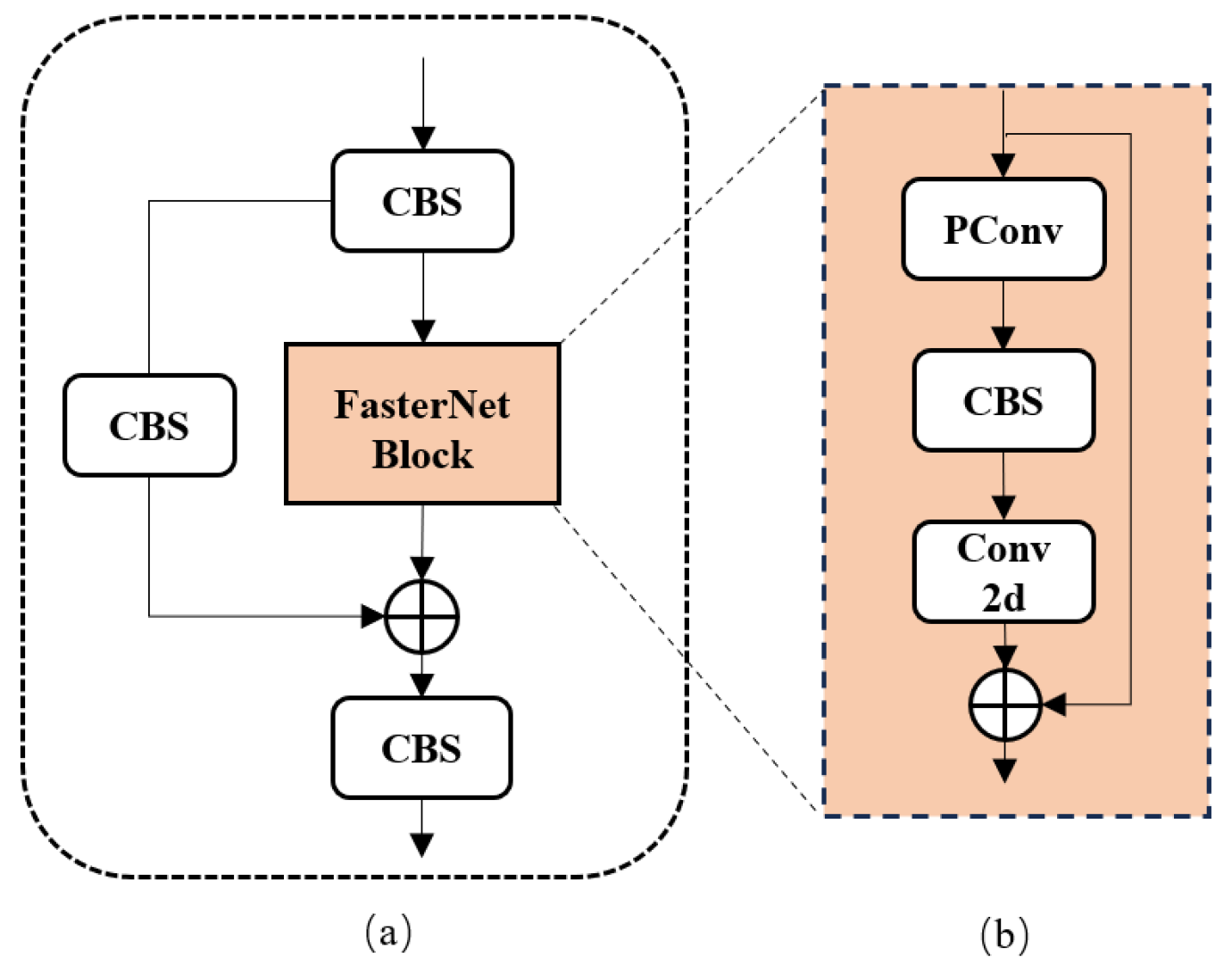
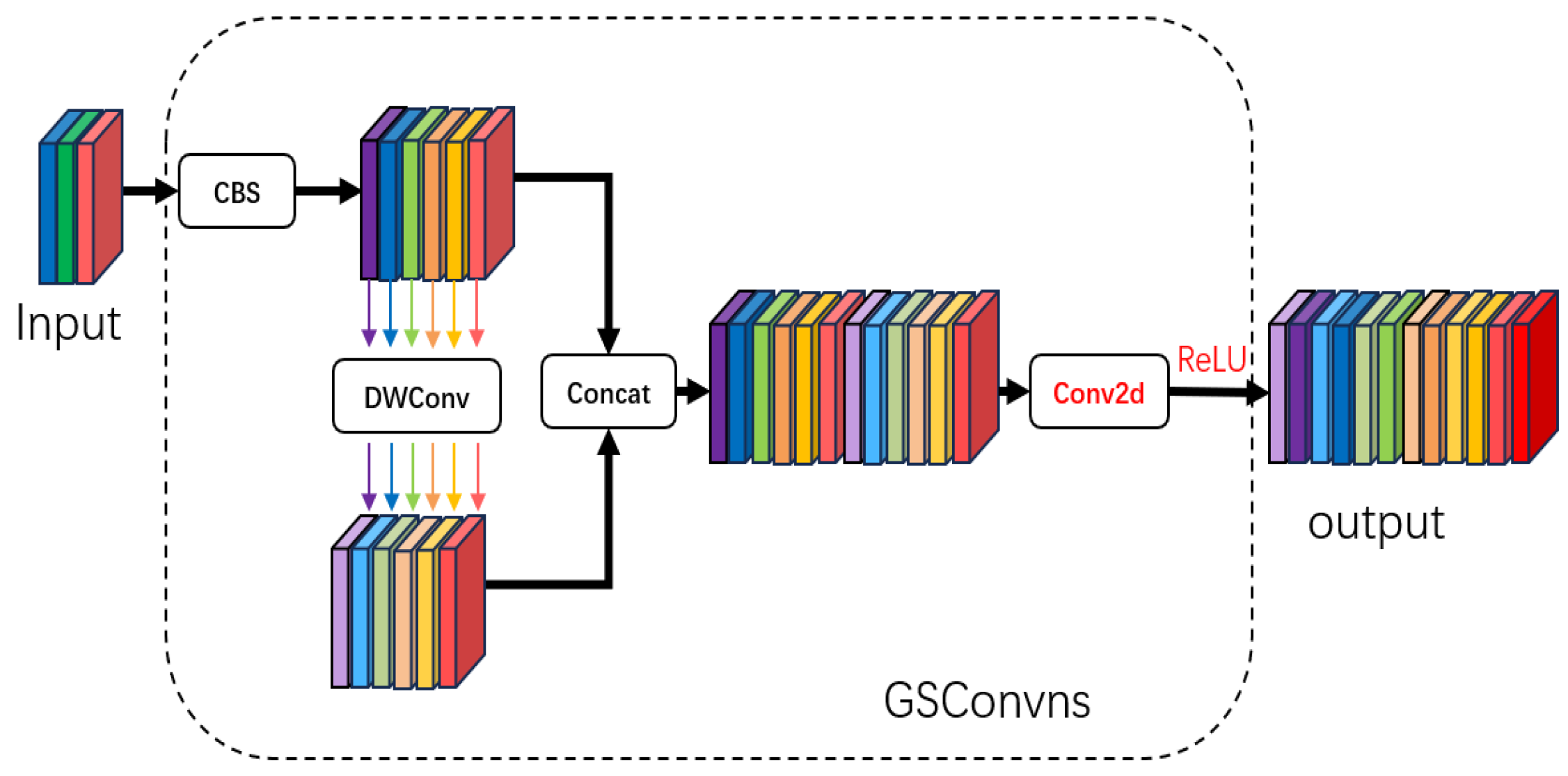
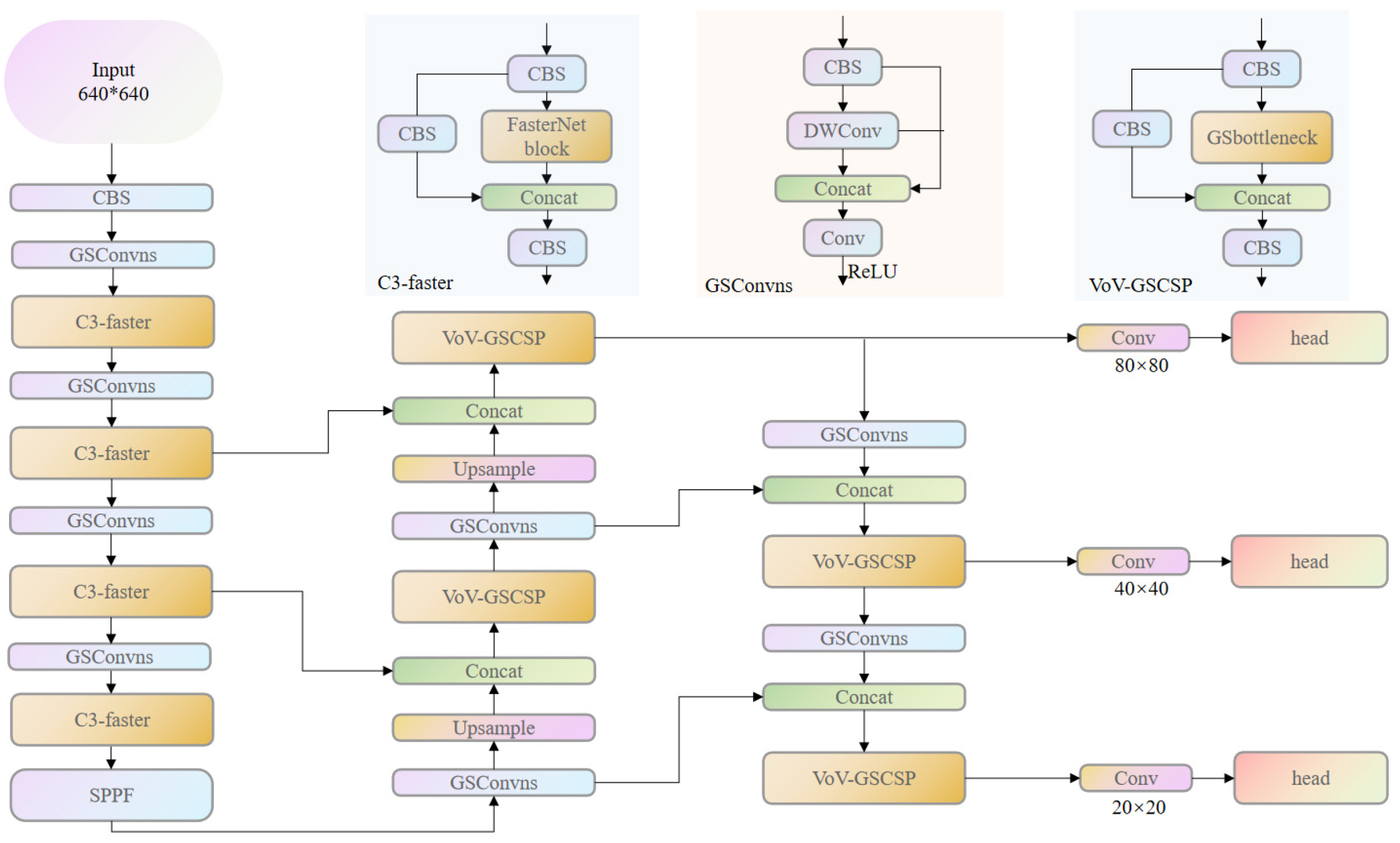
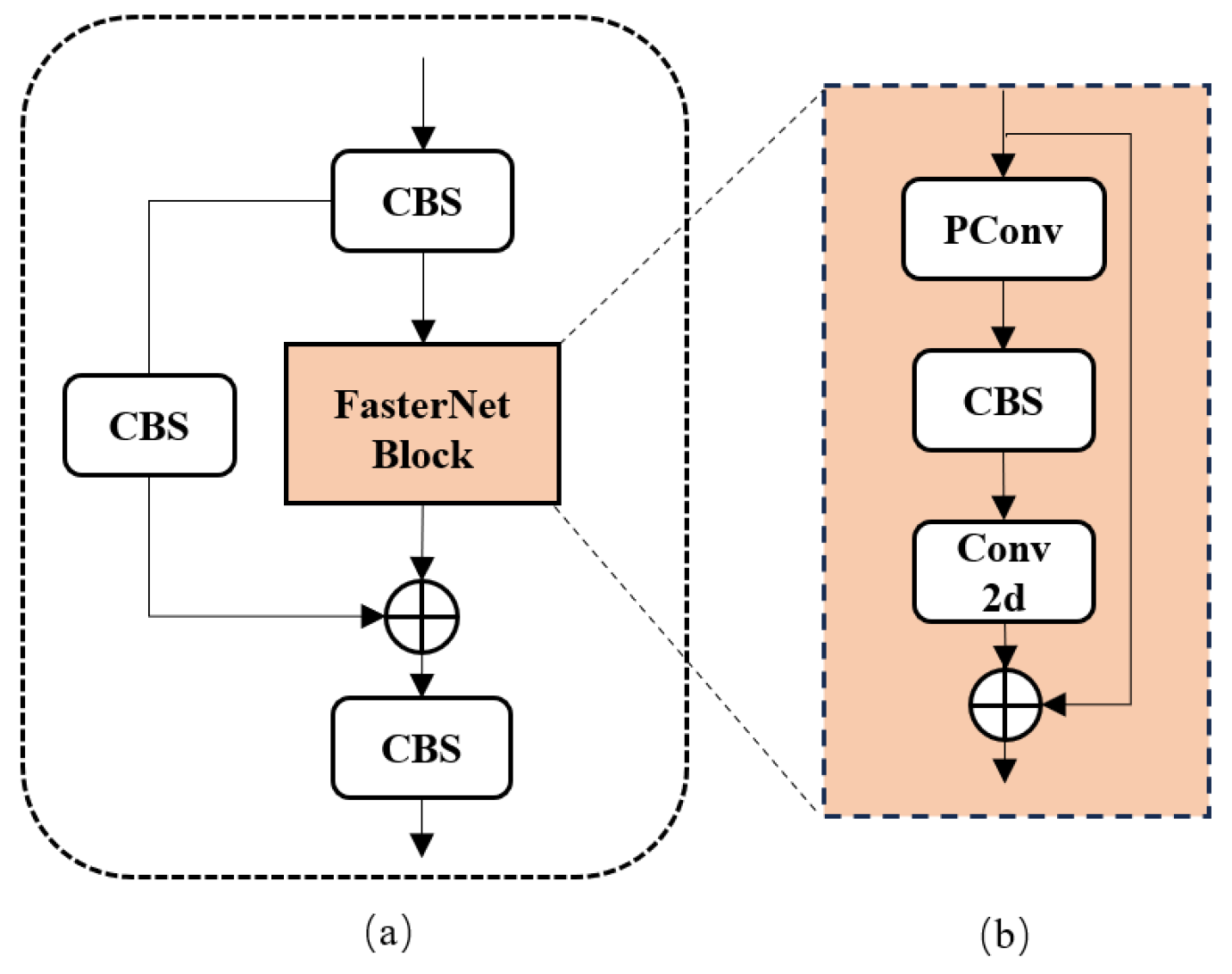
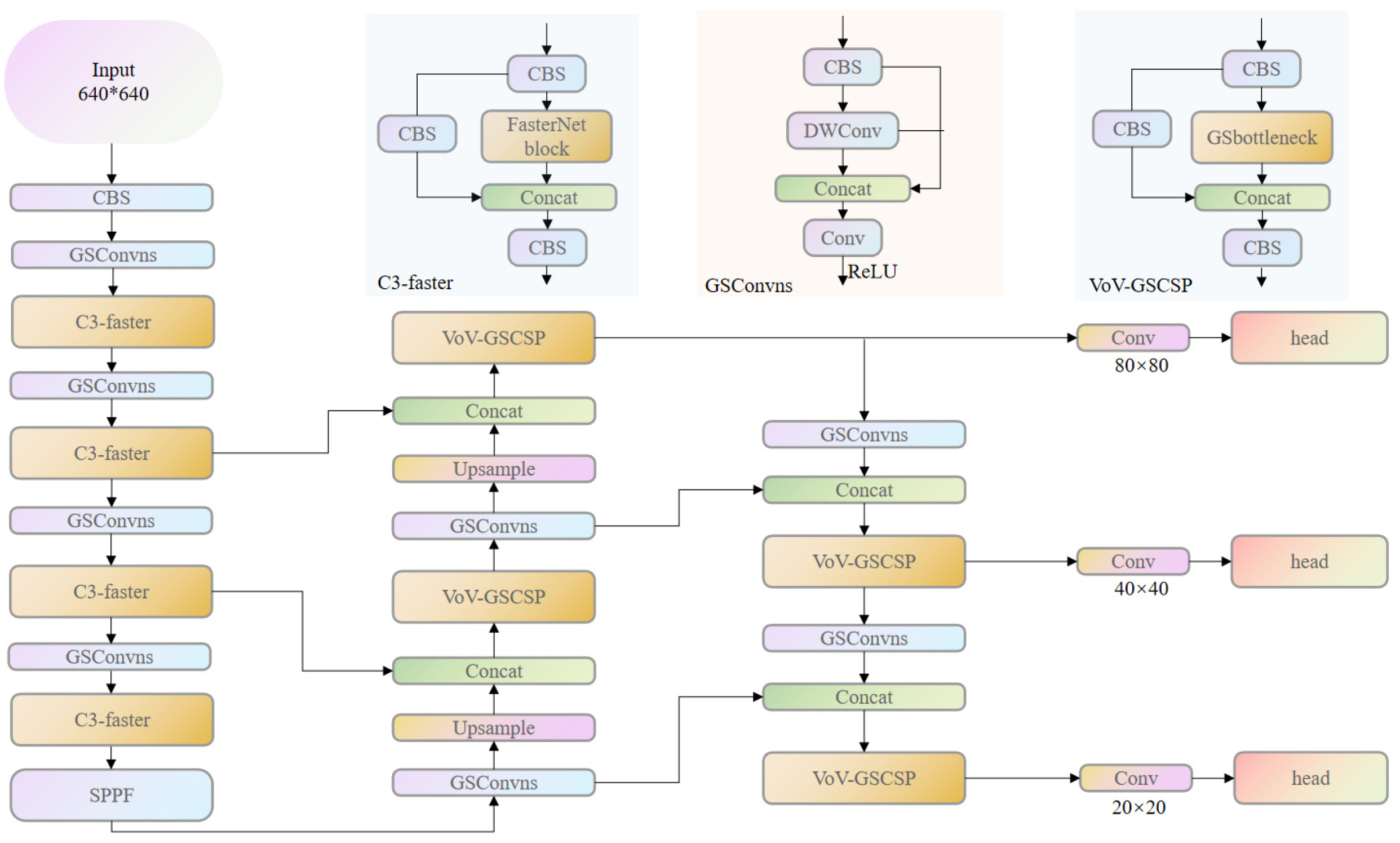
- Next, in the realm of model lightweighting enhancements, a lightweight design approach was implemented for the YOLOv5 backbone network. This involved substituting the C3 module in the backbone network with the C3-faster module and replacing certain convolutional modules in the YOLOv5 network with the refined GSConvns lightweight module. Additionally, lightweight processing was applied to the neck network using the VoV-GSCSP module. These modifications were aimed at reducing the overall model’s parameter count, computational load, and size while ensuring that the model maintains a high level of detection accuracy.
- (3)
- Finally, pruning and fine-tuning the improved network model further reduced its parameter count, computational load, and size. Through fine-tuning, any performance loss incurred during pruning was compensated for, enabling the model to maintain a high level of detection accuracy and meet the practical detection needs in driving environments.
2. Introduction to the YOLOv5 Algorithm
3. Related Improvements
3.1. Backbone Network Improvement
3.2. GSConv Module Improvement
3.3. Improvement of the Neck Network
3.4. Model Channel Pruning and Fine-Tuning
4. Experimental Results
4.1. Introduction to the Experimental Dataset
4.2. Experimental Environment
4.3. Evaluation Metrics
4.4. The Analysis of Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Luo, Y.; Wu, C.-M.; Zhang, Y. Facial expression recognition based on fusion feature of PCA and LBP with SVM. Opt.-Int. J. Light Electron. Opt. 2013, 124, 2767–2770. [Google Scholar] [CrossRef]
- Shan, C.; Gong, S.; McOwan, P.W. Facial expression recognition based on local binary patterns: A comprehensive study. Image Vis. Comput. 2009, 27, 803–816. [Google Scholar] [CrossRef]
- Kumar, P.; Happy, S.; Routray, A. A real-time robust facial expression recognition system using HOG features. In Proceedings of the 2016 International Conference on Computing, Analytics and Security Trends (CAST), Pune, India, 19–21 December 2016; pp. 289–293. [Google Scholar]
- Wang, X.; Jin, C.; Liu, W.; Hu, M.; Xu, L.; Ren, F. Feature fusion of HOG and WLD for facial expression recognition. In Proceedings of the 2013 IEEE/SICE International Symposium on System Integration, Kobe, Japan, 15–17 December 2013; pp. 227–232. [Google Scholar]
- Bartlett, M.S.; Littlewort, G.; Frank, M.; Lainscsek, C.; Fasel, I.; Movellan, J. Fully automatic facial action recognition in spontaneous behavior. In Proceedings of the 7th International Conference on Automatic Face and Gesture Recognition (FGR06), Southampton, UK, 10–12 April 2006; pp. 223–230. [Google Scholar]
- Anderson, K.; McOwan, P.W. A real-time automated system for the recognition of human facial expressions. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2006, 36, 96–105. [Google Scholar] [CrossRef] [PubMed]
- Pantic, M.; Patras, I. Dynamics of facial expression: Recognition of facial actions and their temporal segments from face profile image sequences. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2006, 36, 433–449. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Jin, K.; Zhou, D.; Kubota, N.; Ju, Z. Attention mechanism-based CNN for facial expression recognition. Neurocomputing 2020, 411, 340–350. [Google Scholar] [CrossRef]
- Shan, K.; Guo, J.; You, W.; Lu, D.; Bie, R. Automatic facial expression recognition based on a deep convolutional-neural-network structure. In Proceedings of the 2017 IEEE 15th International Conference on Software Engineering Research, Management and Applications (SERA), London, UK, 7–9 June 2017; pp. 123–128. [Google Scholar]
- Li, J.; Zhang, D.; Zhang, J.; Zhang, J.; Li, T.; Xia, Y.; Yan, Q.; Xun, L. Facial expression recognition with faster R-CNN. Procedia Comput. Sci. 2017, 107, 135–140. [Google Scholar] [CrossRef]
- Febrian, R.; Halim, B.M.; Christina, M.; Ramdhan, D.; Chowanda, A. Facial expression recognition using bidirectional LSTM-CNN. Procedia Comput. Sci. 2023, 216, 39–47. [Google Scholar] [CrossRef]
- Wang, S.; Cheng, Z.; Deng, X.; Chang, L.; Duan, F.; Lu, K. Leveraging 3D blendshape for facial expression recognition using CNN. Sci. China Inf. Sci. 2020, 63, 120114. [Google Scholar] [CrossRef]
- Li, J.; Li, M. Research on facial expression recognition based on improved multi-scale convolutional neural networks. J. Chongqing Univ. Posts Telecommun. 2022, 34, 201–207. [Google Scholar]
- Qiao, G.; Hou, S.; Liu, Y. Facial expression recognition algorithm based on combination of improved convolutional neural network and support vector machine. J. Comput. Appl. 2022, 42, 1253–1259. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Chen, J.; Kao, S.-h.; He, H.; Zhuo, W.; Wen, S.; Lee, C.-H.; Chan, S.-H.G. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Li, H.; Li, J.; Wei, H.; Liu, Z.; Zhan, Z.; Ren, Q. Slim-neck by GSConv: A better design paradigm of detector architectures for autonomous vehicles. arXiv 2022, arXiv:2206.02424. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning efficient convolutional networks through network slimming. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2736–2744. [Google Scholar]
- Fernandes-Magalhaes, R.; Carpio, A.; Ferrera, D.; Van Ryckeghem, D.; Peláez, I.; Barjola, P.; De Lahoz, M.E.; Martín-Buro, M.C.; Hinojosa, J.A.; Van Damme, S. Pain E-motion Faces Database (PEMF): Pain-related micro-clips for emotion research. Behav. Res. Methods 2023, 55, 3831–3844. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Parameters/M | FLOPs/G | mAP@0.5/% | Size/MB |
|---|---|---|---|---|
| YOLOv5s | 6.7 | 15.8 | 85.7 | 13.7 |
| YOLOV7-tiny | 5.9 | 13.9 | 82.3 | 11.7 |
| Mobilenetv3 | 5.5 | 2.8 | 83.1 | 17.9 |
| Shufflenetv2 | 3.5 | 2.5 | 82.6 | 9.83 |
| Improved YOLOv5 | 2.1 | 5.1 | 84.5 | 4.6 |
| C3-Faster | GSConvns | VoV-GSCSP | Prune | Parameters/M | FLOPs/G | mAP@0.5/% | Size/MB |
|---|---|---|---|---|---|---|---|
| - | - | - | - | 6.7 | 15.8 | 85.7 | 13.7 |
| √ | - | - | - | 6.3 | 13.8 | 84.5 | 12.4 |
| - | √ | - | - | 6.2 | 12.4 | 82.0 | 12.2 |
| - | - | √ | - | 7.7 | 15.8 | 86.0 | 15.2 |
| - | √ | √ | - | 6.3 | 14.5 | 85.3 | 12.4 |
| √ | √ | √ | - | 5.5 | 10.4 | 84.9 | 10.7 |
| √ | √ | √ | √ | 2.1 | 5.1 | 84.5 | 4.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, K.; Wang, Z.; Guo, F.; Li, F. Driver Abnormal Expression Detection Method Based on Improved Lightweight YOLOv5. Electronics 2024, 13, 1138. https://doi.org/10.3390/electronics13061138
Yao K, Wang Z, Guo F, Li F. Driver Abnormal Expression Detection Method Based on Improved Lightweight YOLOv5. Electronics. 2024; 13(6):1138. https://doi.org/10.3390/electronics13061138
Chicago/Turabian StyleYao, Keming, Zhongzhou Wang, Fuao Guo, and Feng Li. 2024. "Driver Abnormal Expression Detection Method Based on Improved Lightweight YOLOv5" Electronics 13, no. 6: 1138. https://doi.org/10.3390/electronics13061138
APA StyleYao, K., Wang, Z., Guo, F., & Li, F. (2024). Driver Abnormal Expression Detection Method Based on Improved Lightweight YOLOv5. Electronics, 13(6), 1138. https://doi.org/10.3390/electronics13061138