
An Efficient Multi-Scale Attention Feature Fusion Network for 4K Video Frame Interpolation

Abstract
1. Introduction
- We propose a novel VFI framework based on multi-scale attention feature fusion network for 4K VFI tasks.
- We propose the UHD4K120FPS dataset, a high-quality 4K video dataset at 120 fps, containing diverse texture information and large motion, which can be used for 4K VFI tasks.
- Our method effectively captures the long-range pixel dependence and self-similarity in 4K frames, while reducing the computational cost of attention through simple mapping. It performs well on the UHD4K120FPS dataset and multiple benchmarks.
2. Related Work
2.1. Flow-Based
2.2. Kernel-Based
3. UHD4K120FPS Dataset
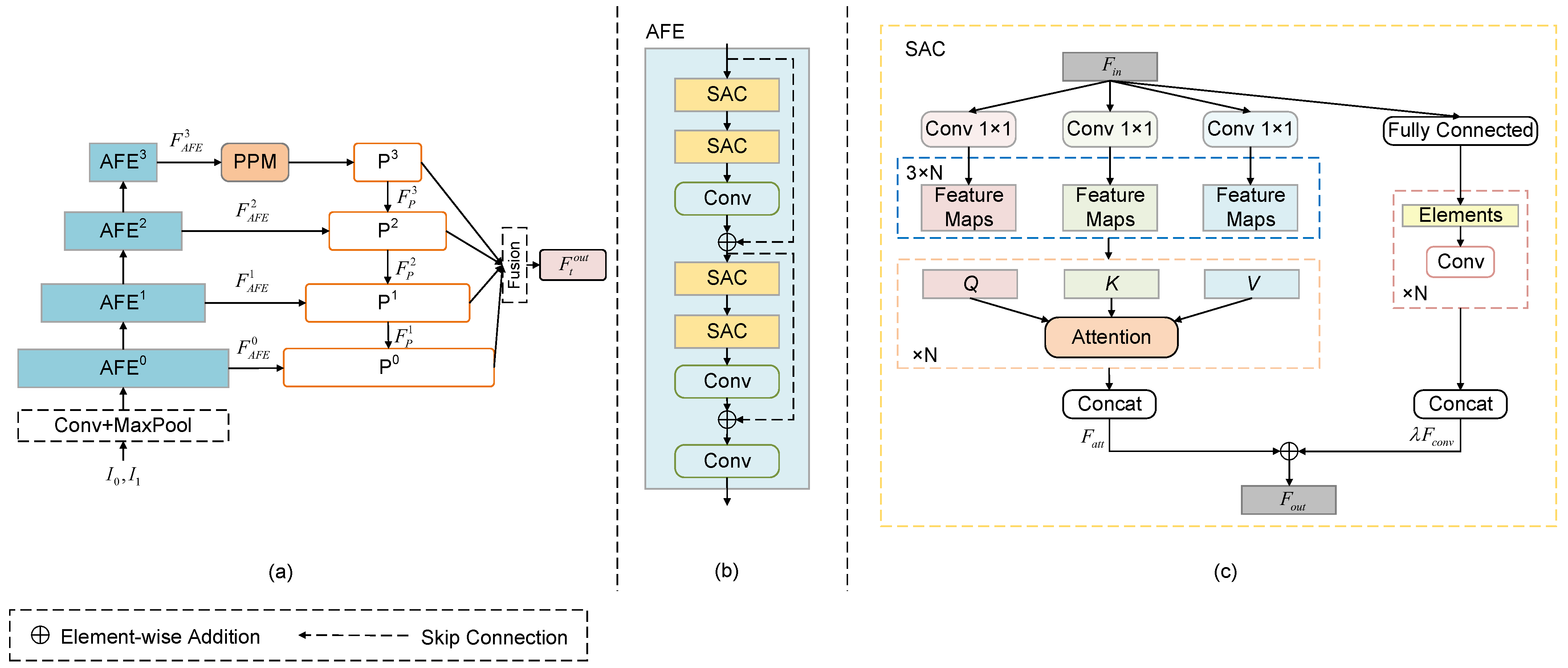
4. Proposed Method
4.1. Multi-Scale Pyramid Network
4.2. Self-Attention Conv Module
4.3. Context Extraction Module
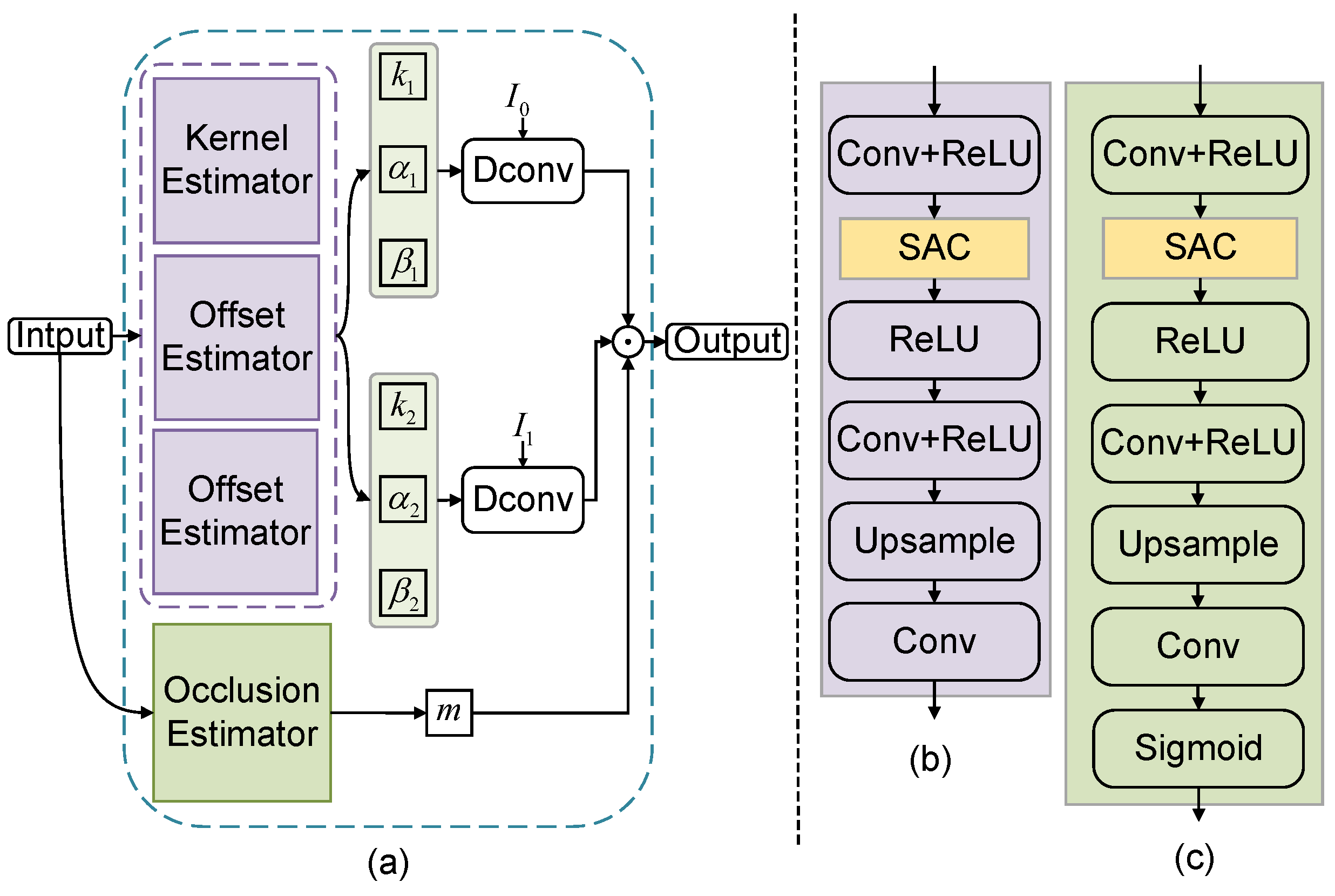
4.4. Deformable Convolutional Synthesis Module
5. Experiment
5.1. Datasets and Evaluation Metrics
5.1.1. Training Datasets
- 4K Training Datasets: A training sample is defined as a triplet consisting of two input frames and , and the middle frame . To investigate the impact of different frame rates on model training, we construct two sets of 4K training datasets from the dataset, based on different temporal distances (TDs). These are set as TD = 1 and TD = 2, respectively, and are denoted as and . Each training dataset comprises 51,840 triplets, with each sample measuring 128 × 128 in size. They are augmented with random flipping and time reversal.
- Benchmark Training Datasets: To more fairly validate the performance of our model, we also train it on Vimeo90K [9]. Its training set contains 51,312 triplets with a resolution of 448 × 256 for training. During training, we randomly crop 192 × 192 patches from the training samples and augment them through random horizontal and vertical flipping and time reversal.
5.1.2. Testing Datasets
- 4K Testing Datasets: serves as the 4K testing dataset. To correspond with the training set, is also divided into two testing datasets based on temporal distances (TD = 1 and TD = 2), denoted as and , respectively. Each testing set contains 12 triplets. Due to hardware limitations, we resize the and to one fourth (1920 × 1080) and one ninth (1280 × 720) of their original size, respectively, denoted as (1/4), (1/9), (1/4), and (1/9). When TD = 1, the frame rate increases from 120 fps to 240 fps, and when TD = 2, it increases from 60 fps to 120 fps.
- Vimeo90K: Vimeo90K [9] has been extensively evaluated in recent VFI methods. It contains 3782 triplets with a resolution of 448 × 256.
- UCF101: UCF101 [20] is a collection of videos featuring various human actions, consisting of 379 triplets with a resolution of 256 × 256.
- Middlebury: The resolution of samples in the Middlebury [21] dataset is approximately 640 × 480 pixels. It consists of two subsets, with the OTHER subset providing the ground-truth intermediate frames.
5.1.3. Evaluation Metrics
5.2. Implementation Details
- Network Achitecture: The MPNet comprises four levels of AFE, with a scale factor of 2 at each level and feature channels of 24, 48, 96, and 192. Each AFE contains four SACs, with each SAC possessing five attention heads and a 3 × 3 convolution kernel with stride of 1. The hyperparameter in SAC that controls the output strength of the convolution is set to 0.3.
- Training Details: Our model is trained end-to-end for 100 epochs by using the Adam optimiser [28], where the hyperparameters , , and of the optimiser are set to 0.98, 0.92, and 0.99, respectively. The batch size is 8. The initial learning rate is set to , reduced by a factor of 4 at the 50th, 75th, and 90th epochs. Training takes about four days with two NVIDIA TITAN XP GPUs (manufactured by NVIDIA Corporation, Santa Clara, CA, USA) with PyTorch 1.12.0.
5.3. Comparison to the Previous Methods
5.3.1. Quantitative Comparison
5.3.2. Qualitative Comparison
5.4. Ablation Study
5.4.1. Quantitative Comparison
- Effect of the SAC: SAC determines the range of pixel information captured by the model and its computational cost, so we conduct an ablation study on SAC to examine its impact. The experimental results are shown in Table 3, demonstrating that the model performs poorly when it lacks SAC. On , the model achieves the highest PSNR of 41.80 dB when the number of SAC is 4, and the overall performance is optimal when the number of SAC is 6. To balance model performance and computational cost, we set SAC to 4 in the experiments. Notably, the model with one SAC performs 1.92 dB less than the model without SAC. This result suggests that when only one SAC is used, it leads to worse model performance. It can also be shown that the fixed-size convolution kernel weakens its ability to learn long-range information correlation when the information captured by a single attention is passed to the convolutional layers.
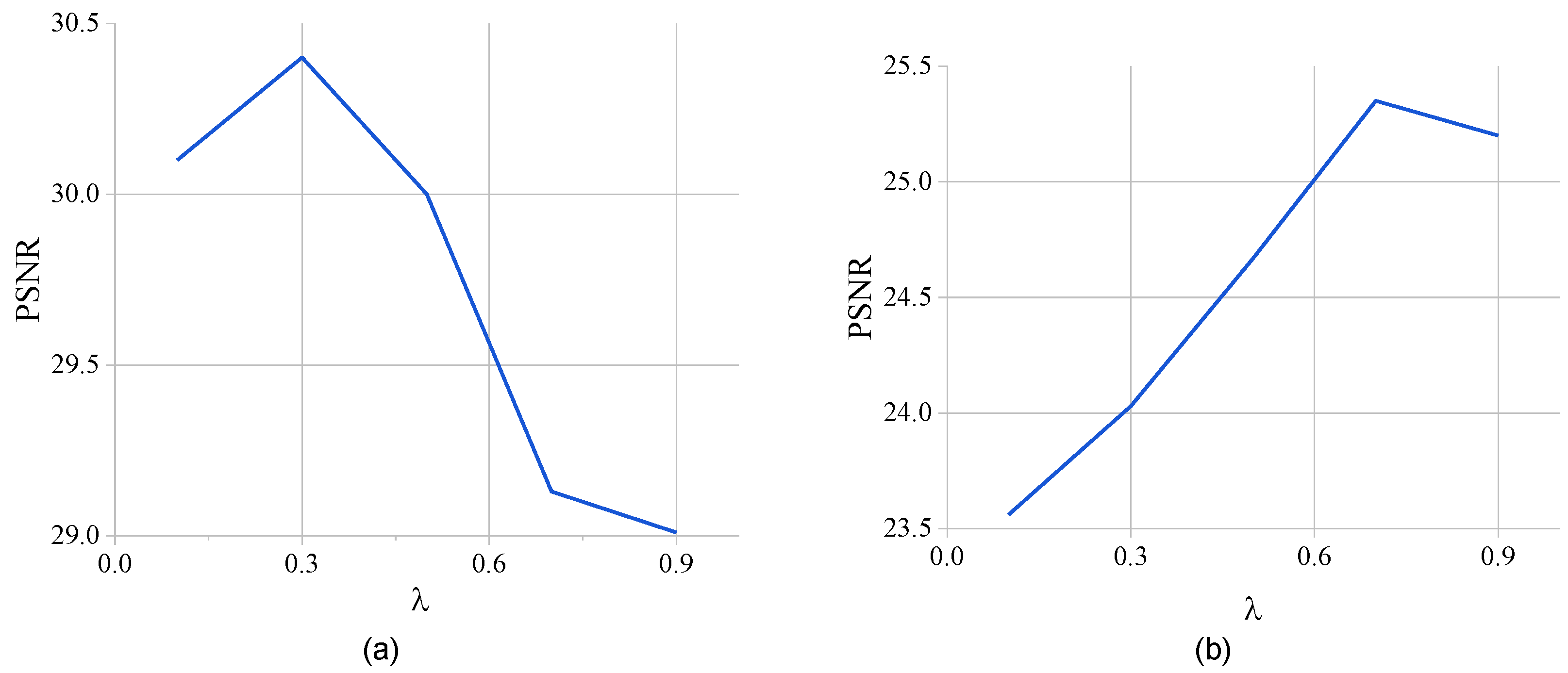
- Effect of the hyperparameter : To investigate the sensitivity of the hyperparameter to the strength of the convolutional output in SAC, we design two models with different numbers of layers, as shown in Figure 7. Figure 7 presents the complete model, and Figure 7b presents the model in the encoder of MPNet that contains only two AFE layers. Both models were trained and tested under the Vimeo90K [9] dataset with 30 epochs in total. The comparison shows that when there are fewer network layers, is larger and it is easier for convolution to extract features than attention. On the contrary, in more network layers, when the convolution output strength is larger, it will affect the ability of attention to extract features. And the larger the , the more pronounced this effect is. Finally, in order to balance the model performance, we set = 0.3. This result also motivates us to explore learnable hyperparameters in the future.
- Effect of the MPNet. MPNet and AFE are used to capture the long-range dependency of pixels and perform multi-scale feature extraction and fusion. To evaluate their impact on model performance, we replace MPNet with U-Net and AFE with multilayer convolution, both containing the same number of SACs. The experimental results in Table 4 demonstrate that Model 4 (complete model) exhibits the best performance on our dataset and two benchmark datasets. Specifically, on (1/4) and (1/9), Model 4 achieves PSNR over Model 3 (based on U-Net) by 0.06 dB and 0.3 dB, respectively. This highlights the importance of multi-scale information extraction and fusion for high-resolution videos. Additionally, comparing Model 4 with Model 2 reveals that the number of AFE layers significantly affects the ability of the model to learn multi-scale features.
- Effect of the CEModule. In Table 4, by comparing the results of Model 1 (without CEModule) and Model 4, we observe that the PSNR of (1/4) and (1/9) improves by 0.45 dB and 0.63 dB, respectively, while the LPIPS is reduced by 0.003 and 0.001, respectively. These findings indicate that the inclusion of CEModule significantly enhances the performance of the model. CEModule helps SAC learn contextual information and enhances the ability of the model to capture global information. Furthermore, these results further validate the effectiveness and adaptability of our model in high-resolution VFI tasks. Also, comparing the LPIPS of Model 4 and Model 1, although the change in their values is not obvious, in Figure 8, we can see a significant difference in the visualisation results (detail in Section 5.4.2).
5.4.2. Qualitative Comparison
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Niklaus, S.; Liu, F. Context-aware synthesis for video frame interpolation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1701–1710. [Google Scholar]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Space-time-aware multi-resolution video enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2859–2868. [Google Scholar]
- Wu, C.Y.; Singhal, N.; Krahenbuhl, P. Video compression through image interpolation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 416–431. [Google Scholar]
- Kalantari, N.K.; Wang, T.C.; Ramamoorthi, R. Learning-based view synthesis for light field cameras. ACM Trans. Graph. TOG 2016, 35, 193. [Google Scholar] [CrossRef]
- Sim, H.; Oh, J.; Kim, M. Xvfi: Extreme video frame interpolation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 14489–14498. [Google Scholar]
- Ahn, H.E.; Jeong, J.; Kim, J.W. A fast 4k video frame interpolation using a hybrid task-based convolutional neural network. Symmetry 2019, 11, 619. [Google Scholar] [CrossRef]
- Lee, H.; Kim, T.; Chung, T.Y.; Pak, D.; Ban, Y.; Lee, S. AdaCoF: Adaptive collaboration of flows for video frame interpolation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5315–5324. [Google Scholar]
- Ding, T.; Liang, L.; Zhu, Z.; Zharkov, I. Cdfi: Compression-driven network design for frame interpolation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8001–8011. [Google Scholar]
- Xue, T.; Chen, B.; Wu, J.; Wei, D.; Freeman, W. Video enhancement with task-oriented flow. Int. J. Comput. Vis. 2018, 127, 1106–1125. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Liu, Z.; Yeh, R.A.; Tang, X.; Liu, Y.; Agarwala, A. Video frame synthesis using deep voxel flow. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4463–4471. [Google Scholar]
- Huang, Z.; Zhang, T.; Heng, W.; Shi, B.; Zhou, S. Real-time intermediate flow estimation for video frame interpolation. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022; pp. 624–642. [Google Scholar]
- Jiang, H.; Sun, D.; Jampani, V.; Yang, M.H.; Learned-Miller, E.; Kautz, J. Super slomo: High quality estimation of multiple intermediate frames for video interpolation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9000–9008. [Google Scholar]
- Bao, W.; Lai, W.S.; Ma, C.; Zhang, X.; Gao, Z.; Yang, M.H. Depth-aware video frame interpolation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3703–3712. [Google Scholar]
- Kong, L.; Jiang, B.; Luo, D.; Chu, W.; Huang, X.; Tai, Y.; Wang, C.; Yang, J. Ifrnet: Intermediate feature refine network for efficient frame interpolation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1969–1978. [Google Scholar]
- Niklaus, S.; Liu, F. Sepconv: Separable convolution for fast video interpolation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 261–270. [Google Scholar]
- Niklaus, S.; Mai, L.; Liu, F. Video frame interpolation via adaptive convolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2270–2279. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable convnets v2: More deformable, better results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9308–9316. [Google Scholar]
- Cheng, X.; Chen, Z. Multiple video frame interpolation via enhanced deformable separable convolution. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 7029–7045. [Google Scholar] [CrossRef] [PubMed]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Baker, S.; Scharstein, D.; Lewis, J.; Roth, S.; Black, M.J.; Szeliski, R. A database and evaluation methodology for optical flow. Int. J. Comput. Vis. 2007, 92, 1–31. [Google Scholar] [CrossRef]
- Kim, S.Y.; Oh, J.; Kim, M. Fisr: Deep joint frame interpolation and super-resolution with a multi-scale temporal loss. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11278–11286. [Google Scholar]
- Zhao, S.; Zhao, L.; Zhang, Z.; Zhou, E.; Metaxas, D. Global matching with overlapping attention for optical flow estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17592–17601. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Pan, X.; Ge, C.; Lu, R.; Song, S.; Chen, G.; Huang, Z.; Huang, G. On the integration of self-attention and convolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 815–825. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Xie, X.; Zhou, P.; Li, H.; Lin, Z.; Yan, S. Adan: Adaptive Nesterov Momentum Algorithm for Faster Optimizing Deep Models. arXiv 2022, arXiv:2208.06677. [Google Scholar]
- Reda, F.; Kontkanen, J.; Tabellion, E.; Sun, D.; Pantofaru, C.; Curless, B. Film: Frame interpolation for large motion. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 250–266. [Google Scholar]
- Peleg, T.; Szekely, P.; Sabo, D.; Sendik, O. Im-net for high resolution video frame interpolation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2393–2402. [Google Scholar]
- Niklaus, S.; Liu, F. Softmax splatting for video frame interpolation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5437–5446. [Google Scholar]
- Park, J.; Ko, K.; Lee, C.; Kim, C.S. Bmbc: Bilateral motion estimation with bilateral cost volume for video interpolation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 109–125. [Google Scholar]
- Choi, M.; Kim, H.; Han, B.; Xu, N.; Lee, K.M. Channel attention is all you need for video frame interpolation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 10663–10671. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Training Dataset | UCF101 | Middlebury | ||||
|---|---|---|---|---|---|---|---|
| AdaCoF [7] | 40.73/0.954/0.017 | 39.70/0.940/0.023 | 34.81/0.909/0.042 | 33.36/0.887/0.051 | 34.52/0.944/0.018 | 33.36/0.936/0.020 | |
| Com_AdaCoF [8] | 34.04/0.899/0.037 | 33.88/0.884/0.044 | 30.18/0.830/0.050 | 29.83/0.814/0.059 | 33.30/0.935/0.021 | 30.93/0.889/0.031 | |
| CDFI [8] | 39.67/0.946/0.022 | 38.21/0.925/0.030 | 32.20/0.872/0.050 | 31.67/0.857/0.061 | 34.28/0.942/0.020 | 32.19/0.911/0.033 | |
| RIFE-Large [12] | 42.13/0.963/0.019 | 40.36/0.956/0.022 | 36.16/0.947/0.032 | 35.69/0.907/0.045 | 34.81/0.949/0.018 | 34.29/0.949/0.018 | |
| XVFI [5] | 42.35/0.964/0.018 | 41.10/0.959/0.021 | 36.19/0.953/0.031 | 35.73/0.908/0.040 | 34.95/0.950/0.016 | 34.36/0.949/0.017 | |
| FILM- [29] | 42.37/0.967/- | 42.74/0.966/- | 36.82/0.934/- | 37.85/0.928/- | 34.40/0.946/- | 34.66/0.950/- | |
| Ours | 42.47/0.965/0.017 | 41.31/0.959/0.020 | 36.30/0.955/0.031 | 35.87/0.909/0.043 | 34.75/0.947/0.017 | 34.63/0.950/0.017 | |
| AdaCoF [7] | 40.05/0.949/0.018 | 38.66/0.934/0.026 | 35.78/0.917/0.034 | 35.00/0.897/0.044 | 34.08/0.938/0.020 | 31.40/0.897/0.029 | |
| Com_AdaCoF [8] | 39.24/0.945/0.020 | 38.50/0.931/0.026 | 35.70/0.914/0.034 | 34.71/0.891/0.043 | 33.10/0.932/0.023 | 30.46/0.875/0.034 | |
| CDFI [8] | 40.58/0.955/0.020 | 39.37/0.942/0.027 | 35.54/0.922/0.036 | 35.15/0.902/0.047 | 33.87/0.943/0.019 | 32.31/0.923/0.029 | |
| RIFE-Large [12] | 41.57/0.959/0.019 | 40.51/0.953/0.024 | 37.69/0.949/0.032 | 36.63/0.914/0.044 | 34.85/0.950/0.019 | 33.88/0.941/0.025 | |
| XVFI [5] | 41.69/0.961/0.018 | 40.60/0.954/0.023 | 37.73/0.951/0.031 | 36.74/0.916/0.042 | 34.99/0.951/0.017 | 33.90/0.942/0.023 | |
| FILM- [29] | 42.19/0.967/- | 41.67/0.964/- | 38.27/0.940/- | 37.76/0.932/- | 34.12/0.944/- | 34.26/0.945/- | |
| Ours | 41.80/0.962/0.019 | 40.82/0.956/0.022 | 37.80/0.952/0.030 | 36.92/0.917/0.042 | 34.83/0.948/0.017 | 34.04/0.943/0.021 | |
| Methods | Training Dataset | #Params | Vimeo90K | UCF101 | Middlebury |
|---|---|---|---|---|---|
| † [16] | proprietary | 21.6 M | 33.80/0.956/0.027 | 34.79/0.947/0.029 | 35.73/0.959/0.017 |
| † [16] | proprietary | 21.6 M | 33.45/0.951/0.019 | 34.69/0.945/0.024 | 35.03/0.954/0.013 |
| † [1] | proprietary | - | 34.39/0.961/0.024 | 34.62/0.949/0.031 | 36.93/0.964/0.016 |
| † [1] | proprietary | - | 33.76/0.955/0.017 | 34.01/0.941/0.024 | 35.95/0.959/0.013 |
| † [31] | Vimeo90K (256 × 256) | - | 36.10/0.970/0.021 | 35.39/0.952/0.033 | 38.42/0.971/0.016 |
| † [31] | Vimeo90K (256 × 256) | - | 35.48/0.964/0.013 | 35.10/0.948/0.022 | 37.55/0.965/0.008 |
| † [14] | Vimeo90K (256 × 256) | 24.02 M | 34.70/0.964/0.022 | 35.00/0.950/0.028 | 36.70/0.965/0.017 |
| BMBC [32] | Vimeo90K (448 × 256) | 11.0 M | 35.06/0.964/0.015 | 35.16/0.950/0.019 | 36.79/0.965/0.015 |
| CAIN [33] | Vimeo90K (448 × 256) | 42.8 M | 34.65/0.959/0.020 | 34.98/0.950/0.021 | 35.11/0.951/0.019 |
| CDFI [8] | Vimeo90K (448 × 256) | 4.98 M | 35.17/0.964/0.010 | 35.21/0.950/0.015 | 37.14/0.966/0.007 |
| AdaCoF [7] | Vimeo90K (448 × 256) | 22.93 M | 34.56/0.959/0.018 | 35.16/0.950/0.019 | 36.09/0.962/0.017 |
| EDSC- [19] | Vimeo90K (448 × 256) | 8.9 M | 34.86/0.962/0.016 | 35.17/0.950/0.019 | 36.76/0.966/0.014 |
| EDSC- [19] | Vimeo90K (448 × 256) | 8.9 M | 34.57/0.958/0.010 | 35.04/0.948/0.015 | 36.48/0.963/0.007 |
| ‡ [12] | Vimeo90K (224 × 224) | 9.8 M | 35.62/0.978/ - | 35.28/0.969/ - | - |
| ‡ [15] | Vimeo90K (224 × 224) | 19.7 M | 36.20/0.980/ - | 35.42/0.969/ - | - |
| FILM- [29] | Vimeo90K (256 × 256) | - | 35.87/0.968/ - | 35.16/0.949/ - | 37.57/0.966/ - |
| XVFI [5] | Vimeo90K (256 × 256) | 5.5 M | 35.07/0.968/ - | 35.18/0.951/ - | - |
| Ours | Vimeo90K (192 × 192) | 5.8 M | 36.23/0.971/0.008 | 34.29/0.945/0.016 | 35.30/0.958/0.009 |
| Number of SAC | Training Dataset | ||
|---|---|---|---|
| 0 | 37.86/0.930/0.028 | 34.44/0.898/0.048 | |
| 1 | 35.94/0.917/0.029 | 31.55/0.847/0.053 | |
| 2 | 41.47/0.964/0.017 | 37.63/0.931/0.033 | |
| 4 | 41.80/0.962/0.019 | 37.80/0.952/0.030 | |
| 6 | 41.75/0.963/0.018 | 38.02/0.934/0.033 | |
| Backbone | SAC | CEModule | Number | UCF101 | Middlebury | |||
|---|---|---|---|---|---|---|---|---|
| of AEF | 1/4 | 1/9 | ||||||
| Model 1 | MPNet | ✓ | ✗ | 4 | 37.35/0.925/0.033 | 36.29/0.905/0.043 | 34.37/0.942/0.019 | 32.81/0.928/0.023 |
| Model 2 | MPNet | ✓ | ✓ | 3 | 37.53/0.929/0.035 | 36.53/0.912/0.044 | 34.40/0.945/0.018 | 33.06/0.929/0.026 |
| Model 3 | U-Net | ✓ | ✓ | – | 37.74/0.930/0.034 | 36.62/0.909/0.043 | 34.53/0.945/0.018 | 32.88/0.918/0.025 |
| Model 4 | MPNet | ✓ | ✓ | 4 | 37.80/0.952/0.030 | 36.92/0.917/0.042 | 34.83/0.948/0.017 | 34.04/0.943/0.021 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ning, X.; Li, Y.; Feng, Z.; Liu, J.; Ding, Y. An Efficient Multi-Scale Attention Feature Fusion Network for 4K Video Frame Interpolation. Electronics 2024, 13, 1037. https://doi.org/10.3390/electronics13061037
Ning X, Li Y, Feng Z, Liu J, Ding Y. An Efficient Multi-Scale Attention Feature Fusion Network for 4K Video Frame Interpolation. Electronics. 2024; 13(6):1037. https://doi.org/10.3390/electronics13061037
Chicago/Turabian StyleNing, Xin, Yuhang Li, Ziwei Feng, Jinhua Liu, and Youdong Ding. 2024. "An Efficient Multi-Scale Attention Feature Fusion Network for 4K Video Frame Interpolation" Electronics 13, no. 6: 1037. https://doi.org/10.3390/electronics13061037
APA StyleNing, X., Li, Y., Feng, Z., Liu, J., & Ding, Y. (2024). An Efficient Multi-Scale Attention Feature Fusion Network for 4K Video Frame Interpolation. Electronics, 13(6), 1037. https://doi.org/10.3390/electronics13061037