Abstract
Human Action Recognition (HAR) is an important field that identifies human behavior through sensor data. Three-dimensional human skeleton data extracted from the Kinect depth sensor have emerged as a powerful alternative to mitigate the effects of lighting and occlusion of traditional 2D RGB or grayscale image-based HAR. Data augmentation is a key technique to enhance model generalization and robustness in deep learning while suppressing overfitting to training data. In this paper, we conduct a comprehensive study of various data augmentation techniques specific to skeletal data, which aim to improve the accuracy of deep learning models. These augmentation methods include spatial augmentation, which generates augmented samples from the original 3D skeleton sequence, and temporal augmentation, which is designed to capture subtle temporal changes in motion. The evaluation covers two publicly available datasets and a proprietary dataset and employs three neural network models. The results highlight the impact of temporal augmentation on model performance on the skeleton datasets, while exhibiting the nuanced impact of spatial augmentation. The findings underscore the importance of tailoring augmentation strategies to specific dataset characteristics and actions, providing novel perspectives for model selection in skeleton-based human action recognition tasks.
1. Introduction
Human action recognition (HAR) research is a multidisciplinary field in computer vision and machine learning, aiming to develop algorithms that automatically detect, analyze, and classify human actions from sensor data. It involves acquiring data through sensors such as cameras or depth sensors, capturing information like 2D or 3D skeletal joint positions, RGB images, or depth maps. HAR applications span fall detection in the elderly, anomaly behavior detection for safety enhancement, motion analysis in sports, healthcare, and ergonomics, and video surveillance system automation. Traditional 2D RGB or grayscale image-based HAR approaches face challenges like partial body occlusion where certain body parts are obscured from view, lighting interference causing variations in image quality due to changing illumination conditions, two-dimensional space limitations which restrict the understanding of three-dimensional actions, and feature extraction difficulties that hinder accuracy and effectiveness [1]. In addition to image-based approaches, HAR research also explores the utilization of alternative sensor data such as inertial measurement units, combined with diverse neural network models [2,3,4,5,6].
Recently, there has been a surge in interest surrounding 3D skeleton-based human action recognition, primarily due to the increased affordability of 3D skeleton data [7,8,9,10,11,12,13,14,15,16,17]. This methodology exploits the temporal dynamics of body postures and the spatial relationships among joints inherent in skeleton sequences, valued for its efficiency and stability, effectively overcoming limitations found in traditional image-based HAR. The acquisition of human skeleton information through Kinect’s depth sensor not only enhances accuracy but also mitigates challenges arising from illumination variations and occlusion issues. The evolution of machine learning techniques has revolutionized human action recognition by automating feature extraction, replacing manual methods like template matching. Convolutional Neural Networks (CNN), Long Short-Term Memory (LSTM) and Recurrent Neural Networks (RNN) find extensive application in human action recognition. Each technique presents unique strengths and weaknesses, contingent on the dataset characteristics and noise levels. Recent 3D skeleton-based HAR research has focused on enhancing performance by combining multiple network models [11], along with employing data augmentation [12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27].
Data augmentation involves introducing variations into the dataset, thereby expanding its size and diversity, and proving particularly valuable when dealing with limited dataset sizes [28,29]. It helps mitigate overfitting by exposing the network model to diverse samples, enhancing generalization by fostering the learning of invariant and discriminative features. It also helps address class imbalance and enhances transfer learning benefits. This practice is already established in the image recognition fields. For example, AlexNet [30] used cropping, mirroring, and color augmentation, and Residual Networks (ResNet) [31] used scaling, cropping, and color augmentation. Similar to image data augmentation, 3D skeleton data augmentation involves random transformations, such as rotation, scaling, shearing, jittering, permutation, speeding up or slowing down the action sequences, and time warping. Drawing on past research, we categorize data augmentation techniques for skeleton-based human action recognition into spatial and temporal augmentations, as well as generative models.
Spatial augmentation techniques involve various geometric transformations such as translation, rotation, scaling, shearing, projection, and multiple transformations applied to 3D skeleton data. These techniques aim to enhance the diversity of training samples by simulating different scenarios and positions. For instance, Gaussian noise is added to joint coordinates to generate estimation or annotation errors, while cropping selects specific joints for training, and translation mimics movement in various positions. Rotation, scaling, and shearing imitate different body directions, sizes, and shapes. Projection transforms the skeleton sequence into a 2D projection, allowing the model to focus on specific planes. Temporal augmentation strategies include Gaussian blur, time reversing, time interpolation, time shifting, and time warping. These techniques aim to reduce details and noise, smooth motion trajectories, increase or decrease sequence length, and resample sequence. Generative models like encoder–decoder networks, Generative Adversarial Networks (GANs), diffusion models, and contrastive learning contribute to synthesizing realistic skeletal sequences, enriching training data for improved model robustness and generalization.
It has been established that data augmentation techniques significantly improve the performance of skeleton-based action recognition models. However, the exploration of specific network models in combination with these augmentation techniques remains largely unexplored in the field of skeleton-based human action recognition. This knowledge gap impedes our understanding of how diverse network models behave when coupled with different augmentation strategies. Consequently, a crucial step towards filling this void involves conducting a controlled study to illuminate the variations in performance when specific neural network models are integrated with distinct augmentation strategies. To comprehensively address this gap, we propose a comparative evaluation that investigates various data augmentation techniques in conjunction with representative neural network models tailored for 3D skeleton data. The primary objective of this research is to gather and assess numerous data augmentation techniques for skeleton-based human action recognition using various datasets.
In this research, we dive deeper into data augmentation methods for skeleton-based action classification and evaluate augmentation methods on various datasets and neural network models. Then, we provide analysis, observations, and recommendations from the results. The contributions of this research are as follows:
- We systematically review skeleton-based data augmentation through a comprehensive categorization;
- We conduct a comparative assessment of skeleton-based data augmentation methods and demonstrate their impacts on various neural network models, such as Convolutional Neural Network (CNN), a Long Short-Term Memory network (LSTM), and a CNNLSTM combined model (CNNLSTM). The evaluated data augmentation methods encompass Gaussian noise, cropping, translation, rotation, scaling, shearing, projection, Gaussian blur, time reversing, time interpolation, time slicing, and time scaling. Each method is compared to no augmentation. Three datasets are employed for the evaluation: the publicly accessible Microsoft Research MSR Action 3D dataset [32], Nanyang Technological University NTURGB+D60 dataset [33], and our proprietary Exergame dataset [34];
- We discuss the characteristics of each skeleton-based data augmentation method, providing a comprehensive guide for the usage with different dataset types and different neural network models.
The rest of this paper is structured as follows: Section 2 offers a concise overview of previous research on data augmentation techniques using 3D skeleton data. Section 3 outlines the comparative evaluation methods and experimental designs. Section 4 scrutinizes the experimental results and engages in discussions, and Section 5 concludes the paper by summarizing the finding and proposing potential directions for future research.
2. Data Augmentation for Skeleton-Based Human Action Recognition
A taxonomy of the skeleton data augmentation methods is shown in Figure 1. Traditional image processing techniques like cropping, resizing, rotating, sharpening, adding noise, blur, color inversion, contrast adjustment, and segmentation are commonly utilized for augmenting image data [35]. However, the direct application of these techniques to 3D skeleton data faces limitations, as they primarily manipulate pixel values and may overlook the intrinsic nature of 3D skeleton data. Moreover, the irregular, sparse, and high-dimensional characteristics of 3D skeleton data make the directly application of traditional image techniques less effective in achieving the desired effects. Data augmentation techniques for 3D skeleton-based human action recognition aim to increase the diversity and quantity of training data by applying various transformations to the original dataset. In prior research, the data augmentation techniques primarily encompassed translation, rotation, scaling, shearing, jittering, permutation, speeding up or slowing down the action sequences, and time warping, as found in studies [12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27]. This section provides a brief summary of data augmentation strategies for 3D skeleton data to generate skeleton samples.
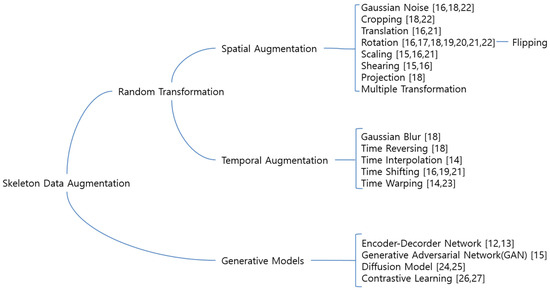
Figure 1.
Taxonomy of Skeleton Data Augmentation.
2.1. Spatial Augmentation
Gaussian noise is added to the joint coordinates of the initial 3D skeleton action sequence in order to simulate the noisy positions caused by estimation or annotation. It can improve the robustness of the network model. Cropping is a method of selecting specific skeleton joints from 3D skeleton data as training samples. For example, it is a method of training a model by selecting only joints of the upper body or selecting specific motion steps. Translation is a method of arbitrarily moving the position of 3D skeleton data, mimicking the fact that movement can occur in various positions. Through this, the model can be prevented from overfitting to the position of the human body. Rotation (including Flipping) is used to imitate various directions of the human body by arbitrarily rotating the position of the 3D skeleton data on a random axis (generally the central vertical axis of the human body). Through this, it can prevent the model overfitting for the direction of the human body.
Scaling is used to imitate various sizes of the human body, such as changes in height, weight, and body shape, by converting the size of 3D skeleton data. Shearing is used to shift each skeleton joint consistently in a predetermined direction, causing the 3D coordinates of body joints to take on a slanted shape with a random angle. Projection involves applying a projection transformation to all joint coordinates along a randomly selected plane (typically defined as X-, Y-, Z-) of the skeleton sequence. This process transforms the original skeleton sequence into a 2D projection sequence, allowing the model to focus on learning dominant action patterns from a specific plane. Multiple transformation is a method of applying multiple geometric transformations to 3D skeleton data. Figure 2 shows examples of random transformation-based spatial augmentation for skeleton data using the ‘high arm wave’ action of the MSR Action 3D dataset.
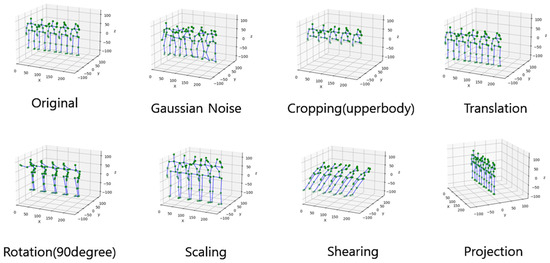
Figure 2.
Visualization of spatial augmentation for the original skeleton sequence: Gaussian Noise, Cropping, Translation, Rotation, Scaling, Shearing, and Projection.
In three-dimensional space, human skeleton coordinates can be augmented by rotation. Um et al. [6] compared the different data augmentation methods on the performance of a CNN model for Parkinson’s disease monitoring using wearable sensor data, and found that rotation improved accuracy, particularly in combination with other augmentation techniques. Chen et al. [16] suggested a CNN-based method for skeleton-based action recognition using relative features. These features represent human actions and are encoded into color images. Augmentation techniques such as random scaling, translation, rotation, and noise addition are applied to introduce variations.
Park et al. [17] proposed a sequence-wise augmentation technique involving random rotations (along the up-axis or the spine vector) into 3D skeleton data, aiming to simulate diverse viewing directions of human actions. The assessment involving Conv1D, LSTM, and Transformer models, demonstrated improvement of classification accuracy attributed to the data augmentations. Rao et al. [18] presented AS-CAL, an unsupervised method utilizing Contrastive Action Learning (CAL), for 3D skeleton-based action recognition. AS-CAL employs a momentum LSTM as the key encoder to learn more consistent action representations, and a queue-based dictionary to store the encoded keys for contrastive learning. The method incorporated diverse data augmentation strategies, including Gaussian noise, rotation, shear, joint mask (i.e., cropping), and channel mask (i.e., projection).
Xin et al. [19] evaluated the effects of spatial augmentation on 3D skeleton data for SVM, CNN, LSTM, and CNNLSTM models. The spatial augmentation involved rotating skeleton sequences around the y-axis at various angles. The results indicated an enhancement in accuracy for the recognition of human action based on skeletons. Wang et al.’s study [20] introduced Joint Trajectory Maps (JTMs), three 2D images representing spatio-temporal information of 3D skeleton sequences. Encoding joint trajectories and dynamics into color distribution, ConvNets learn discriminative features for human action recognition. It employed rotating the skeleton data along the polar and azimuthal angles to mimic multiple views and augment the training data for cross-view action recognition. This approach improved final recognition through multiplicative score fusion and achieved the state-of-the art results on four public benchmark datasets.
Lee et al. [21] introduced innovative ensemble temporal sliding LSTM networks tailored for skeleton-based action recognition, with a focus on capturing diverse temporal dependencies inherent in human actions. The approach involves transforming input skeletons into a human cognitive coordinate system, ensuring resilience to scale, rotation, and translation. Bo et al. [22] presented an image classification-based approach for the skeleton-based video action recognition. They proposed a translation-scale invariant image mapping method called skeleton-images and a fine-tunable multi-scale deep convolutional neural network (CNN) architecture, leveraging pre-trained CNNs. They incorporated data augmentation strategies, including random rotation, Gaussian noise, and video crop, to enhance training set diversity, asserting that this improves the deep CNN classifier’s performance and prevents overfitting with limited annotated skeleton videos.
2.2. Temporal Augmentation
Figure 3 shows examples of random transformation-based temporal augmentation for skeleton data using the ‘high arm wave’ action of the MSR Action 3D dataset. As an augmentation strategy aimed at reducing the level of details and noise of image, Gaussian blur (Motion smoothing) can be implemented on the skeleton sequence, making motion trajectories smoother and better reflecting the overall movement trends of joints. This process serves to smooth out noisy joints and diminish the intricacies of the depicted actions. Excessive blur causes information loss, so the degree of blur must be adjusted appropriately. Time reversing is a method of playing the action sequence of 3D skeletal data in reverse order. This approach is motivated by the observation that the sequence’s order may not significantly affect human perception of actions, and the model will effectively glean essential action details, such as joint positions and angles, from sequences played in reverse. Time interpolation is a method of increasing the length of the sequence by interpolating additional frames into the original action sequence of 3D skeleton data. Time shifting (scaling) is a method of sampling the action sequences of 3D skeletal data by randomly changing the speed to fast or slow. Time warping is to allow irregular resampling of 3D skeletal data sequences to mimic changes in the speed of action.
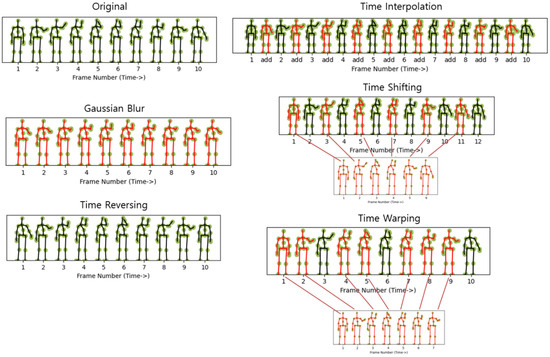
Figure 3.
Visualization of temporal augmentation for the original skeleton sequence: Gaussian Blur, Time Reversing, Time Interpolation, Time Shifting, and Time Warping.
In Chen et al. [16], temporal augmentation techniques like random time-shifting and skipping frames are also employed. These techniques enhance the diversity and robustness of the training data, improving the model’s generalization and ability to recognize actions under different conditions. Rao et al. [18] incorporated temporal data augmentation strategies, such as Gaussian blur and time reversing. Gaussian blur enables the model to learn dominant action patterns from a blurred sequence. Reversing encourages the model to learn crucial action details from a reverse sequence. Xin et al. [19] also introduced temporal data augmentation techniques to generate diverse and complex skeleton samples. Temporal data augmentation is obtained by varying the speed of the action sequence, generating samples that are faster or slower than the original speed. Temporal information is important for human action recognition, especially for actions that have similar spatial movement (e.g., walking and running).
In Lee et al. [21], salient motion features are extracted from temporal differences in skeletons. The temporal sliding LSTM framework employs multiple networks with varying time-step sizes, window sizes, and strides to model short-term, medium-term, and long-term temporal dynamics of actions. Finally, an ensemble deep learning strategy combines the outputs of these networks using an average ensemble method, yielding the ultimate action recognition result. Huynh et al. [14] proposed a CNN-based approach for 3D action recognition that involved extracting pose features from 3D skeleton data and encoding them into images. To enhance diversity, data augmentation techniques were applied to the encoded pose images. Temporal data augmentation was introduced to prevent overfitting and enhance generalization by generating manifold action images from a single skeleton sequence through the random addition or elimination of some skeleton frames. Vemulapalli et al. [23] used dynamic time warping (DTW), Fourier temporal pyramid, and linear SVM classifier for human action recognition using 3D skeletons and Lie group theory. The results demonstrate the superiority of this representation over existing methods on three action datasets.
2.3. Generative Models
In addition to spatial and temporal data augmentation techniques, various generative models play pivotal roles in skeleton-based human action recognition. The encoder–decoder network is a fundamental architecture designed to capture temporal dependencies and spatial relationships within skeletal sequences. It consists of an encoder that learns a condensed representation and a decoder that reconstructs the input or performs action recognition. Generative Adversarial Networks (GANs) contribute by generating synthetic skeletal sequences through a generator, which creates realistic samples, and a discriminator, which distinguishes between real and generated data, facilitating effective data augmentation. The diffusion model focuses on the temporal evolution of skeletal sequences by modeling the gradual transformation of information over time. Contrastive learning, on the other hand, utilizes positive and negative samples to train the model, aiding in self-supervised learning and enabling the network to distinguish between different instances of actions. These techniques collectively enrich the training data, improving the robustness and generalization capabilities of skeleton-based action recognition models.
Tu et al. [12] presented LSTM autoencoder network to improve skeleton-based human action recognition. The LSTM autoencoder is trained to encode and decode skeleton sequences, while spatial augmentation is accomplished through random transformations (scaling, translation, rotation, noise) in the latent space and temporal augmentation involves time-shifting and frame skipping. Meng et al. [13] proposed a data augmentation called a sample fusion network (SFN) based on LSTM autoencoder network and showed performance enhancement on skeleton-based human action recognition. Shen et al. [15] introduced the Imaginative Generative Adversarial Network (Im-GAN), a novel approach that combines GANs with automatic data augmentation to enhance dynamic skeleton-based hand gesture and human action recognition models. Im-GAN achieved fast training times and improved accuracy when compared to classical data augmentation techniques (such as scaling, shifting, interpolating, and adding noise) using CNN or LSTM models.
Ren et al. [24] proposed a novel method for generating 3D human motion from complex natural language sentences. They used Denoising Diffusion Probabilistic Model (DDPM), combining Gaussian noise removal and cross-modal linear transformers, and includes a text encoder and motion decoder. The proposed model exhibits the capability to synthesize diverse and natural motions guided by textual descriptions. The method achieves competitive results on the HumanML3D dataset, demonstrating better fidelity, diversity, and zero-shot capability compared to baseline methods. Tevet et al. [25] introduced Motion Diffusion Model (MDM), a diffusion-based generative model for human motion with proficiency in handling diverse inputs like text or action. Employing a transformer encoder and geometric losses, MDM efficiently predicts realistic and coherent motion, achieving top-tier results on benchmarks and showcasing editing capabilities with minimal training time.
Guo et al. [26] proposed AimCLR, a contrastive learning framework for self-supervised action recognition from skeleton sequences. AimCLR leverages extreme augmentations, an energy-based attention-guided drop module, dual distributional divergence minimization loss, and nearest neighbors mining to achieve state-of-the-art performance on benchmark datasets. The method demonstrates better generalization ability and robustness compared to existing approaches. Wang et al. [27] proposed Contrast-Reconstruction Representation Learning (CRRL), an unsupervised framework for skeleton-based action recognition. CRRL simultaneously captures pose and motion dynamics in skeletal data by combining contrast learning and reconstruction learning. By introducing additional velocity information and knowledge distillation strategy, we realized effective fusion between skeletal coordinate sequence and motion dynamics. The method outperforms existing approaches on benchmark datasets, demonstrating its effectiveness and superiority.
3. Comparative Evaluation
In this section, we describe the comparative assessment conducted employing various data augmentation methods. The objective of this evaluation is to empirically compare the impact of data augmentation across a spectrum of neural network models and datasets focused on recognizing human action based on skeletons.
3.1. Datasets
We used multiple public datasets and an additional custom human action sequences to evaluate the data augmentation methods. This includes MSR Action 3D dataset [32], NTURGB+D60 dataset [33], and Exergame dataset [34]. The MSR Action3D dataset [32] comprises 20 action sequences captured by a Kinect V1 device. These actions encompass a range of movements such as high arm wave, horizontal arm wave, hammer, hand catch, forward punch, high throw, draw x, draw tick, draw circle, hand clap, two-hand wave, sideboxing, bend, forward kick, side kick, jogging, tennis swing, tennis serve, golf swing, and pick up and throw. Each of these actions was executed by ten different subjects and recorded three times. The dataset maintains a frame rate of 15 frames per second and a resolution of 640 × 480, resulting in a total of 23,797 frames of depth maps across 402 action samples. Despite the dataset’s clean background, it poses a challenge due to the inherent similarity among many of the actions it encompasses.
The NTURGB+D60 dataset [33] is a comprehensive and widely utilized dataset designed for 3D human action recognition. The dataset is a substantial collection comprising 60 action classes and a total of 56,880 video samples. It encompasses a diverse range of actions, including waving, clapping, jumping, and more complex activities, facilitating algorithm evaluation at varying difficulty levels. Actions are performed in diverse scenarios, introducing environmental variations, and the dataset incorporates challenges like body-worn accessories and occlusions. The dataset includes RGB videos at 1920 × 1080 resolution, depth map sequences at 512 × 424 resolution, 3D skeleton data coordinates with 25 body joints, and 512 × 424 IR (Infrared) videos. These diverse data types were concurrently captured using the Kinect V2 device, spanning various categories such as daily behavior, interactive behavior, and medical symptoms.
The Exergame dataset [34], collected through the Kinect v2, features 25 skeletal joint nodes and focuses on four distinct actions: rest, walk, run, and tennis. With 30 diverse users, each performing every action twice, the dataset presents sequences with multiple repetitions for each action. Specifically, it records 3D skeleton joint data for exercise gameplays involving walking, running, and playing tennis. In these gameplays, each subject engaged in a 3-minute exercise session using Nintendo Switch’s ring fit adventure game, resulting in Kinect capturing 5,400 frames per action. To manage the repetitive nature of the exercise motions, consecutive sequences of 100 frames were extracted for each participant. Ensuring consistency, normalization was applied to the initial frame of all sequences. The skeleton joint data encompass 25 joints captured in 100 frames, highlighting the necessity for effective feature extraction in accurate action classification within this dataset.
3.2. Network Models
In order to evaluate the data augmentation methods, we chose three neural network models. This includes Convolutional Neural Network (CNN), Long Short-Term Memory (LSTM), and a fusion model that combines CNN and LSTM. These networks were chosen due to being state-of-the-art in skeleton-based human action recognition. CNNs excel in capturing spatial features, making them particularly suitable for tasks like image processing. LSTMs effectively model temporal dependencies and are well-suited for time-series data analysis. By leveraging the strengths of these techniques, researchers have achieved significant advancements in 3D skeleton-based human action recognition.
3.2.1. Convolutional Neural Network
Convolutional Neural Network (CNN) is a feedforward neural network model widely applied in image and speech processing. It effectively learns input data features by stacking multiple convolutional layers, pooling layers, and fully connected layers, enabling tasks like data classification, recognition, and regression. Over time, various CNN variants have emerged to enhance performance. ResNet, for instance, introduces residual connections, enabling the learning of deeper feature representations and improve model performance. Inception networks employ convolutional filters of different sizes and pooling operations within the same layer to extract varied-sized features. Xception networks enhance efficiency by combining convolutional operations with depth-separated convolutional operations. Sparse Convolutional Networks (SCNs) introduce sparse convolutional operations to reduce computation and number of parameters. Attention Mechanism CNNs (AMCNNs) incorporate attention mechanisms for emphasizing important feature regions, enhancing model performance and robustness.
The CNN model utilized in this study, based on the ResNet18 architecture, consists of four residual blocks with two convolutional layers, two batch normalization layers, and one skip connection. The skip connection mitigates gradient vanishing and explosion issues as network depth increases, preserving low-level features while learning higher-level features in subsequent layers. The model outputs a 20-dimensional vector, which undergoes processing using the softmax function. To facilitate training, the cross-entropy loss is employed, and the optimization is carried out using the adaptive moment estimation (Adam) algorithm to minimize this loss. In the final layer, the softmax function serves as an activation function, transforming the model’s raw output into a probability vector. This function ensures that each element x in the output is converted to a positive number, and normalized so that the sum of all elements equals 1. The cross-entropy loss is computed by multiplying and summing the logarithm of the true-value probabilities and the predicted-value probabilities across all samples, subsequently updating the weight parameters through the Adam’s algorithm.
3.2.2. Long Short-Term Memory (LSTM)
Recurrent neural network (RNN) stands as a classical model tailored for processing sequence data. RNN showcases efficacy in capturing the temporal dependencies inherent in such data through the incorporation of a circular structure within the network. Fundamentally, RNN operates by considering the current-time input and the preceding-time state as inputs to the network, yielding the current-time output and state through a non-linear transformation (e.g., tanh or ReLU). This current-time state is subsequently fed as input to the network at the next time step. Various model structures can be employed in RNNs, with Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) emerging as the most common variants. LSTMs and GRUs introduce gate mechanisms to effectively manage lengthy sequence data and circumvent the vanishing gradient problem. An LSTM unit utilized in this study comprises three gates (an input gate, a forget gate, and an output gate) and a memory cell. These gates regulate information inflow and outflow, controlling memory and forgetting processes.
LSTMs realize information transfer within a single step through various gate functions. The function of each gate is determined by a linear combination of its weights and bias parameters and an activation function. In the Equation (1), defines the output of the Forget Gate. The function of this gate determines how much information from the previous memory cell state should be retained or forgotten. The σ(sigmoid) function constrains the output of the linear combination to be between 0 and 1. Let and represent the weight and bias parameters of the Forget Gate, respectively, is the hidden state of the previous time step, and is the input of the current time step.
In the Equation (2), is the output of the Input Gate, which determines how much of the current input information should be added to the state of the memory cell.
In the Equation (3), updates the state of the memory cell and is a key component of the LSTM. defines a candidate memory cell, where is the possible value of new information, which is generated with the current input and the previous hidden state. The tanh activation function ensures that the value ranges between −1 and 1. The Forget Gate determines how much old information to retain, and the Input Gate determines how much new information to add. stands for Hadamard multiplication, which is used to combine these two sources of information using an elementwise multiplication approach.
In the Equation (4), defines the output of Output Gate, which determines how much information from the internal memory cell state should be output.
In the Equation (5), is for the output of the hidden state, which combines the decision of the output gate with the current state of the memory cell. It can be used as an input to the next time step or be part of the final output sequence.
3.2.3. CNNLSTM Combination Model
Several investigations have demonstrated the enhanced processing capabilities of fusion models that integrate Convolutional Neural Networks (CNN) and Long Short-Term Memory (LSTM) in handling spatiotemporal data. In these amalgamated models, CNNs are conventionally employed to extract spatial features at each time step within a sequence, while LSTMs address temporal dependencies, generating sequential insights. Subsequently, these sequence-level features can be conveyed to fully connected layers for classification or other pertinent tasks.
The CNNLSTM model finds application across diverse domains, including video classification and action recognition. Ellis et al. [36] utilized the Euclidean distance between skeletal joints to extract spatial features. Muller et al. [37] employed Booleans features to represent the human body’s geometry. Xu et al. [38] analyzed features by computing the Euclidean distance between each skeletal joint, the distance between frame joints, and the cosine of the angle between joints. This method of feature extraction contributes to a reduction in input parameters and alleviates the computational load on the model. However, the independence of the extracted features often prevails, and the diversity of application scenarios necessitates distinct algorithms for feature extraction, resulting in compatibility challenges among models.
In this research, this fusion model used the structure of the ResNet and LSTM, respectively. The FC layer of the ResNet was removed, and the output sequence of Blk4 was used as the input of the LSTM. Also, we used the same training method as the previously mentioned CNN. Table 1 shows the overall structure of the CNNLSTM model. This model is an LSTM layer added to CNN where LSTM uses a single layer structure and has a hidden size of 256. The output size x of the model is related to the various types of training sets used.

Table 1.
The CNNLSTM Combination Model Network Structure.
3.3. Data Augmentation Methods
None denotes the original dataset with no augmentation and serves as the control experiment for comparison with data augmentation methods. The spatial and temporal data augmentation methods selected for the experiment were selected due to their compatibility with any skeleton-based action sequence dataset. We opted against methods requiring external training, such as the generative models. Before the introduction of data augmentation methods, normalization using average and standard deviation was carried out to standardize the 3D skeletal data captured, typically in the context of technology like Kinect. The goal is to make the skeletal data comparable across different subjects or actions, accounting for variations in physical size or movement styles. Each skeletal joint’s position at a specific frame is represented as where i denotes the joint index, and t denotes the frame. Normalization of each joint’s position is computed using the Equation (6):
where μi and σi are the average and standard deviation for the i -th coordinate (x, y, z) across all joints and frames.
In the Equation (7), D is the original skeletal data, i.e., a set of skeleton action sequence in the form of 3D coordinates with n frames, where is the frame at time t and n is the total number of frames in the sequence. is the coordinate of the i-th joint of the skeleton in frame where in Kinect v2. Each joint is designed as .
3.3.1. Spatial Augmentation
The Gaussian noise augmentation is used to simulate potential sensor errors and external environmental interference encountered during data collection. This method involves adding Gaussian noise to the original 3D human skeleton action sequence, enhancing the model’s noise immunity and overall robustness in real-world applications. Gaussian noise adheres to a normal distribution, , with parameters set to u = 0 and σ = 0.01, ensuring an appropriate noise level. This approach makes the noise effect discernible while preventing severe distortion of the original data. The original data, denoted as , possesses a certain dimensionality, and Gaussian noise with the same dimensionality is incorporated as . In this context, each element of N is independently sampled from .
Cropping is a data augmentation technique used to enhance the robustness of models by simulating real-world scenarios of occlusion or partial data loss during motion capture process. This method involves randomly removing certain joint points from the 3D skeletal data, mimicking situations where certain joints may be temporarily obscured or not captured. For each skeletal datum, a subset of joint nodes is randomly chosen, and these selected joint nodes are then set to zero, simulating the loss of specific joint data, creating a scenario where certain joints are temporarily obscured or missing. For example, Figure 2 shows cropping on the joint points of the lower half of the human body zeroed out. Di,t represents the original 3D skeletal joint data, where i represents the joint index, and t represents the frame. The subset of joints can be denoted as Sk, where k represents the randomly chosen joint indices. The cropping of the specified subset of joints from the original skeletal data is expressed using the Kronecker delta function δk, which is equal to 1 if k = i and 0 otherwise. . This equation sets the values of Dk,t to be equal to Di,t, only when i is one of the selected joint indices in Sk, and 0 otherwise.
Translation data augmentation aims to replicate alterations in human motion data across different spatial positions. By incorporating random movement transformations, this technique enhances the data’s diversity and boosts the model’s capacity to accommodate variations in location. A random shift value, denoted as Δ, is generated, with its range set as [−0.2, 0.2]. For each frame and joint in each sample, randomly generated movement values Δ are applied to the x-axis and z-axis directions (i.e., the ground) in the three-dimensional space (where the y-axis is the world up): .
Rotation in skeleton-based human action recognition involves systematically modifying the orientation of the 3D skeletal joint data to enhance the model’s ability to generalize across different viewing angles and orientations. This technique is applied to simulate variations in how human actions are captured from different perspectives. Similar to Park’s study [17], the coordinates (x, y, z) for each joint at every frame are rotated by the specified angles around the y-axis: . R is an element-wise rotation matrix by y-axis (i.e., the world up) for angle ranged in [5, 20] degrees. This alters the orientation of the entire skeletal structure. The rotation matrix around the y-axis is expressed as the Equation (8).
where represents the angle of rotation about the y-axis. When the column vector of each node is multiplied by the rotation matrix, this results in a new 3 × 1 column vector, which represents the coordinates of that spatial point after rotation.
Scaling involves systematically modifying the scale of the 3D skeletal joint data to improve the model’s ability to generalize across different body types and motion distances. This technique is applied to mimic variations in the spatial extent of human motion data. For each sample in the dataset, a random scaling factor ) is generated. This factor is selected from a predefined range, such as [0.8, 2.0]. The range ensures a variety of scaling factors to simulate both reduction and expansion of the skeletal data. For each joint at every frame, the coordinates of the raw 3D skeletal data are multiplied by the scaling factor which is defined as . This resizes the entire skeletal structure, effectively altering the spatial dimensions of the human pose data.
Shearing introduces nonlinear deformations to simulate variations that may arise during the execution of movements, i.e., the shape of 3D skeletal data will be slanted with a random angle. By applying the shearing transformation in three-dimensional space, it replicates changes in the shape of the skeletal data resulting from alterations in visual angles, body movements, and other factors. This process enhances the model’s ability to generalize across diverse perspectives and intricate motions. For each joint at every frame, the skeletal joint coordinates (x, y, z) are sheared by the shearing matrix, H: . The shearing matrix H is employed to distort the x and y axes of the data while preserving the z-axis. H is defined as the Equation (9).
Projection transforms the original skeleton sequence into a 2D projection sequence, allowing the model to extract dominant action patterns specifically from a particular plane. It is employed to replicate alterations in observational data arising from changes in perspective. Our approach in this context involves randomly selecting one axis (e.g., x-axis, y-axis, or a-axis) and applying a zero mask to all coordinates along the chosen axis for each joint in every frame of the skeletal sequence: . This emulates the impact of viewing skeletal motion data from various angles, enhancing the model’s adaptability to visual variations and fortifying its ability to handle diverse changes in perspective. Projection matrices for x-axis, y-axis, and z-axis are defined as the Equation (10).
3.3.2. Temporal Augmentation
Merely relying on body skeleton features in space is insufficient for describing human action. In the analysis and identification of 3D motion sequences in human skeletons, temporal data augmentation techniques become imperative. These methods hold a pivotal role in enhancing temporal comprehension by introducing a variety of time series transformations. For instance, distinguishing between activities like ‘walking’ and ‘running’, which share similar spatial movement information, proves challenging. The objective is to broaden the training dataset, enabling the model to grasp and acclimate to the intricate temporal characteristics inherent in motion sequences. We introduce a range of temporal augmentation methods crafted to emulate diversity and complexity. These approaches encompass fundamental time series transformations, such as Gaussian Blur, Time Reversing, Time Interpolation, Time Shifting, and Time Warping. The purpose behind employing these augmentation methods is to bolster the model’s resilience and enhance its adaptability to various patterns of change within time series data.
Gaussian Blur, a widely adopted image smoothing technique, aims to replicate the dynamic blur effect observed in sequences with motion, capturing nuanced temporal changes to modulate motion intensity and enhance the model’s robustness. Gaussian blur involves computing a weighted average of raw data values at each time point. The weights are determined by the Gaussian distribution function, facilitating the smoothing of data across both time and space. This enables the model to better comprehend and adapt to temporal variations. Specifically, for each time point t, Gaussian blur considers data from all previous time points τ (prior to t) and performs a weighted average using the Gaussian filter function weights denoted as M(t,τ). The Gaussian filter function’s shape ensures that points closer to time t exert a more substantial influence on the mean, while points farther from t gradually carry less weight.
In the context of the original skeletal data , Gaussian blur can be mathematically expressed as the Equation (11):
where t is within the range [0, j − 1]. The Gaussian blur value for sample s, time t, where the unit time of t corresponds to the relative time of each frame, frame j, skeleton point k, and Gaussian blur value in coordinate dimension c is expressed using the Gaussian filter function M(t,τ).
The Gaussian filter function M(t,τ) is defined as the Equation (12):
Here, σ represents the standard deviation, influencing the steepness of the weight distribution. We set the standard deviation to 1.0. The raw data value D(s,τ,k,c) pertains to the sample s, time t, skeleton point k, and coordinate dimension c.
Time Reversing is incorporated to make the model more aware of the temporal characteristics of motion and improve the overall robustness. By reversing the time axis of the skeletal action sequence, the model gains insight into different temporal patterns, fostering a more comprehensive understanding of spatiotemporal relationships within skeleton movements. The time-reversal operation generates a new motion sequence by flipping the order of frames in each sample. For the same original data , the transformed sequence, denoted as , is defined as the Equation (13):
Here, represents the reversed value for sample s, at time t, frame j, skeleton point k, and coordinate dimension c. The variable T signifies the total number of frames in each sample.
Time Interpolation has been introduced with the objective of enhancing the model’s temporal sensitivity by augmenting the density of the action sequence through the insertion of additional frames within consecutive time intervals. An interpolation factor is incorporated to regulate the quantity of newly inserted frames. Figure 3 illustrates a scenario with an interpolation factor of 2. Our approach for processing the original data D is implemented as the Equation (14):
Here, is expressed as the result of interpolation for sample s, at time t, frame j, skeleton point k, and coordinate dimension c. The variable t can be represented by the index of the interpolated frame, ranging from 0 to j × γ − 1.
Time Shifting involves a technique for processing raw motion sequential data S, which may have variable length, by sampling randomly spaced t frames from the action sequence, where . This guarantees the length of the new action sequence to be , which facilitates subsequent model training. The temporal data augmentation generates a new sequence using the Equation (15):
We used the mod operation, which guarantees that the index starts at the beginning when the number of frames to be cut exceeds the length n. A value of speed t that is too large can cause problems due to discontinuities in the feature data, so we set the value of t between 2 and 12.
Time warping introduces random time-scaling elements across various segments of the action sequence, enabling the model to discern variations in behavior over different time scales. This capability aids in detecting and understanding temporal changes in behavior. Time warping distorts the action within each time bin using distinct time-scale elements, enhancing the model’s robustness by simulating dynamic time-series variations observed in real-world action. To inject randomness into each time bin and augment the diversity of training data, we incorporated randomized time scaling factors. This addition contributes to the model’s improved adaptability to diverse temporal variations. For a given input data sequence D, and considering time warping for the s-th sample, the specific operations for mapping time frame j to a new time frame j’, and introducing a segmentation operation to generate a randomized time scaling factor t for each segment, followed by its application to all frames within that segment, is expressed as the Equation (16):
Here, signifies the warped data, and ⌊j + t⌋, where ‘j + t’ is an integer, represents the warping of the time frame. A new warp sequence is generated for each segment, and these segments are amalgamated to construct the overall time warp sequence. The specific implementation of segments involves generating new frames within each segment based on a time scaling factor t. These frames are then combined to ensure that the length of the constructed sequence aligns with a predetermined total number of frames.
3.4. Training
Based on the original data, we obtained 7 spatial transformation datasets: Gaussian noise, cropping, translation, rotation, scaling, shearing, and projection. In addition, we obtained 5 temporal transformation data: Gaussian blur, time reversing, time interpolation, time shifting, and time warping. We designed experimental conditions to analyze the advantages and disadvantages of each data augmentation method and its impact on convolutional neural network (CNN), long short-term memory network (LSTM), and convolutional long-short-term memory network (CNNLSTM) with different datasets. The implementation was based on PyTorch and was run on a system with Nvidia GeForce RTX 3080Ti, Ryzen 5 5600X 6-Core Processor 3.7 GHz, and 64 GB of RAM.
Figure 4 shows the training loss trends of three different models: CNN, LSTM, and CNNLSTM on the Exergame dataset. Analyses were performed without any data augmentation applied. To provide a more intuitive view of loss trends, loss values are normalized to a range of 0 to 100. As can be seen in the figure, the analysis results show that the CNN model exhibits faster fitting ability compared to LSTM and CNNLSTM when no data augmentation is applied. Additionally, CNNLSTM exhibits faster learning speed compared to LSTM.
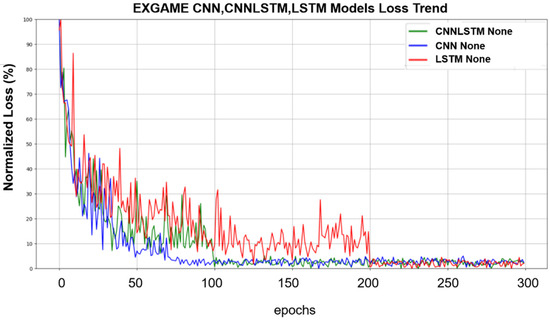
Figure 4.
Training loss trend for CNN, LSTM, CNNLSTM on the Exergame dataset with no augmentation.
Figure 5 shows the performance trend of the CNN model validating original data, spatially augmented data (rotation), and temporally augmented data (time interpolation) on the Exergame dataset. Whether raw data or spatially augmented and temporally augmented data are being processed, the epochs it takes for the model to reach the optimal learning state is roughly the same. However, by introducing time-augmented data, the model shows more stable performance in the later stages of training. This trend indicates that time augmentation techniques can improve the model’s adaptability and generalization ability to dynamic data. Therefore, it may be helpful to introduce time augmentation in the training process to achieve a balanced and robust learning curve.
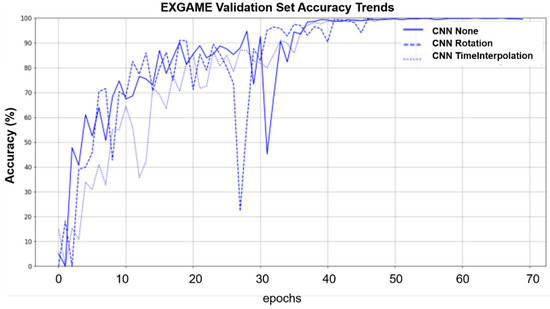
Figure 5.
Validation set accuracy trend for CNN on the Exergame dataset with none, rotation, and time interpolation.
4. Results and Discussions
The experimental design took into account two key characteristics of behavior: local spatial feature density and time dependence. For example, in the MSR Action 3D dataset, there are actions such as ‘draw x’, ‘draw tick’, and ‘draw circle’, which emphasize the importance of local spatial features as the model needs to learn the internal spatial variation of the action. On the other hand, ‘walk’ and ‘run’ actions in the Exergame dataset are mainly related to changes in the overall body posture and require the model to pay attention to the trend of temporal changes, which indicates the density of temporal features. In addition, the NTURGBD+D60 dataset contains 60 different actions, which provides an ideal platform to evaluate the ability of the model to recognize these two kinds of actions. This experiment focuses on analyzing the impact of different data augmentation techniques on model performance. In particular, we are interested in how these augmentation techniques optimize the model’s ability to capture local spatial detail and interpret temporal dynamics.
4.1. Principal Component Analysis (PCA)
Figure 6 shows the distribution of data according to different augmentation methods. We visualized the results of data dimensionality reduction using principal component analysis (PCA) generated by various augmentation methods in three datasets. It also shows the average Euclidean distance ratio between each augmentation method and the original data separately. Because each dataset has a different amount of new data generated by different augmentation methods, there are certain differences in the average value and distribution of the final generated data. In the MSR Action 3D dataset, the data generated by scaling has a large error in the average value compared to the original data. In the NTURGB+D 60 dataset, the data generated by time warping is the farthest away from the original data, and projection in the Exergame dataset generated the largest average distance difference. As shown in the experimental results in Section 4.2, it can be seen that the three network models have a very negative impact on the original dataset when using the scaling augmentation method on the MSR Action dataset. Similarly, we can see the experimental results in Section 4.3 that all three network models have a negative impact when time warping is used on the NTURGB+D 60 dataset.
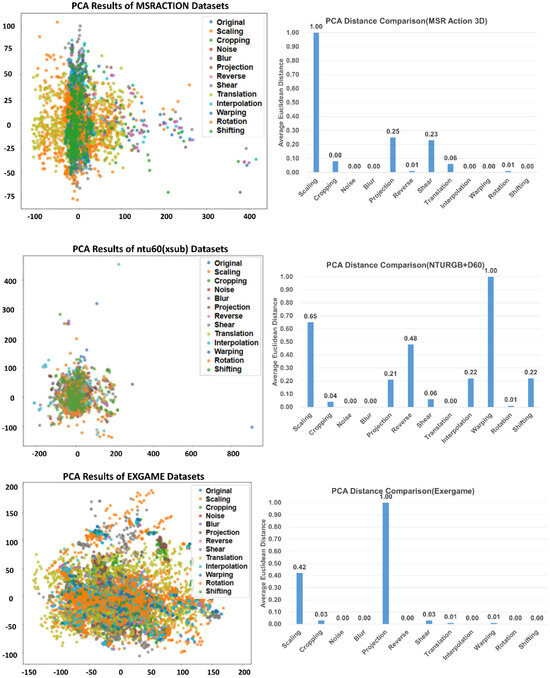
Figure 6.
PCA results (dotted graphs on the left) and PCA distance comparison (bar graphs on the right) for different augmentation methods in the MSR Action 3D dataset, NTURGB+D60 dataset, and Exergame dataset.
4.2. Spatial Augmentation
Table 2 shows the accuracy results obtained by performing various spatial data augmentation on the MSR Action 3D dataset, NTURGB+D60 dataset and Exergame dataset, using CNN, LSTM, and CNNLSTM models. In the Exergame original dataset, the CNN model had the highest performance at 91.30% and the LSTM model had the lowest performance at 87.96%. This is the same as the trend of the MSR Action 3D original dataset and the NTURGB+D 60 original dataset, indicating that the CNN model may have a stronger ability to process human action recognition and the performance of LSTM remained a slightly low as compared to CNN and CNNLSTM models. The result indicates that when the dataset contains a small number of clearly distinguishable actions including along with sufficient training data to cover a variety of situations, such as in the Exergame dataset, the model can achieve high performance without data augmentation. Additional data augmentation improved the network model performance on this dataset.
Table 2.
Accuracy of different spatial data augmentation methods by network models.
Figure 7 shows the comparative analysis of CNN, LSTM, CNNLSTM model performance differentials with various spatial augmentation techniques relative to baseline (none) on the MSR Action 3D dataset, NTURGB+D60 dataset, and Exergame dataset. It shows the how these spatial augmentation methods change the recognition rate compared to the original unprocessed data (none). Spatial data augmentation improved model performance in the NTURGB+D60 and Exergame datasets. On the other hand, unlike the NTURGB+D60 and Exergame datasets, the spatial augmentation methods on the MSR Action 3D dataset are not much effective. This is because there are too many local spatial features in this dataset, and adding more spatial features using spatial augmentation methods increases the learning difficulty of the model. Overall, among the spatial augmentation methods, noise showed positive results, improving recognition rates for all three models using diverse datasets. However, cropping, translation, rotation, scaling, shearing, and projection showed negative effects in network models in the MSR Action 3D dataset. In the NTURGB+D60 dataset, projection augmentation was the worst performance.

Figure 7.
Comparative analysis of model performance differentials with spatial augmentation relative to baseline (None).
For each action in the dataset, we performed a more granular analysis to study the impact of different spatial augmentation methods on single actions. For example, Figure 8 shows the confusion matrix with none and noise augmentation in the Exergame dataset. The models have high recognition rates for the ‘rest’ and ‘tennis’ actions without augmentation. With the Noise augmentation method, the recognition rates for both the ‘run’ and ‘walk’ actions are improved for all three models, especially for the ‘rest’ action, which reaches 100%. The ‘tennis’ action also has a high recognition rate of over 96%. The error rate was mainly due to the model incorrectly distinguishing between the ‘run’ and ‘walk’ actions. In addition, we analyzed the two actions ‘run’ and ‘walk’. When the augmentation method was not used, a value of 0.18 in the ‘run’ action of the CNN model means that 18% of all ‘run’ actions were incorrectly recognized as ‘walk’. The results show that the spatial augmentation method had a very positive augmentation effect on the two time-sensitive actions ‘run’ and ‘walk’ in the three models. Only in the LSTM model did some augmentation have a slight negative impact on the model. However, in both the CNN and CNNLSTM models, all actions show an improvement in the model’s ability to recognize the two actions.
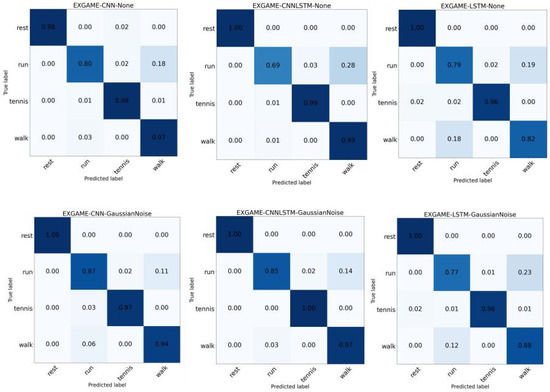
Figure 8.
Comparison of none and Gaussian Noise by CNN, LSTM, and CNNLSTM in the Exergame dataset.
Noise adds random Gaussian noise to the data and mimics the natural tremor that can occur during the course of a movement. The improvement in recognition rate is most likely due to the model’s enhanced ability to recognize subtle changes due to the added noise, which is especially evident when processing movements with subtle differences in movement details. Adding noise seems to help the model better capture these subtle differences in kinematic features, thus improving the model’s recognition ability in these categories. Cropping augments the model by cutting out some key points in the data, and the cropping method shows a clear improvement except for the CNN model with the MSR Action 3D dataset. However, while cropping augmentation can help the model to pay attention to some key information, further optimization is needed when dealing with specific motion recognition to achieve higher recognition accuracy.
Translation augments the data by mimicking the movement of a person’s body to a different location. The result shows a clear improvement in effectiveness on the NTURGB+D60 and Exergame datasets. It suggests that the translation augmentation can effectively enhance the model’s sensitivity to changes in the spatial location of actions, or differences in the temporal dimension, thereby strengthening its discriminative ability when recognizing different actions. Rotating the skeleton alters its angle, enabling the model to observer behavior from different perspectives. The results reveal a distinct enhancement in effectiveness on the NTURGB+D60 and Exergame datasets. In contrast, on the MSR Action 3D dataset, PCA generated through scaling displays a substantial disparity in the average value compared to the original data. The results also show a clear negative impact on the original dataset when applying the scaling augmentation method to the MSR Action 3D dataset, especially observed in the performance of the three network models.
Shearing introduces nonlinear deformations to mimic potential variations occurring during the execution of movements. Specifically, it involves tilting the shape of 3D skeletal data at a random angle. The projection method projects three-dimensional motion onto a two-dimensional plane, increasing the diversity of the data. Shearing and projection augmentation methods performed poorly for most models on the MSR Action 3D and NTURGB+D60 datasets.
4.3. Temporal Augmentation
Table 3 shows the accuracy results obtained by performing various temporal data augmentation on the MSR Action 3D dataset, NTURGB+D60 dataset, and Exergame dataset, using CNN, LSTM, and CNNLSTM models. Figure 9 shows the comparative analysis of CNN, LSTM, CNNLSTM model performance differentials with various spatial augmentation techniques relative to baseline (none) on the MSR Action 3D dataset, NTURGB+D60 dataset, and Exergame dataset. For the Exergame dataset, we can see that temporal data augmentation improves model performance. For the MSR Action 3D dataset, where the spatial augmentation technique performed poorly, we can also see that the temporal data augmentation technique improved the model performance. On the other hand, for the NTURGB+D60 dataset, temporal data augmentation is only effective for blur and time shifting, and we see a significant drop in model performance for reversing, time interpolation, and warping.
Table 3.
Accuracy of different temporal data augmentation methods by network models.

Figure 9.
Comparative analysis of model performance differentials with temporal augmentation relative to baseline (none).
Figure 10 shows the difference between the results of none and time interpolation augmentation methods on the Exergame dataset. It is shown that all the different augmentation methods showed a positive association compared to none, except for the negative effect when time interpolation was used by the LSTM model. In other words, in most cases, using the augmentation methods improved the recognition performance of the model. By comparing these two confusion matrices, we found that the time interpolation augmentation method increased the recognition accuracy of the ‘walk’ motion, but at the same time increased the false recognition rate of the ‘tennis’ motion. Visual analysis of the motions revealed that the ‘tennis’ actions were predominantly in a ‘rest’ state before they were performed and had a large overlap with the ‘rest’ action. These observations suggest that although the interpolation method theoretically enhances the detail of the temporal dimension by increasing the number of frames, it may also cause dilution or deformation of the original motion characteristics.
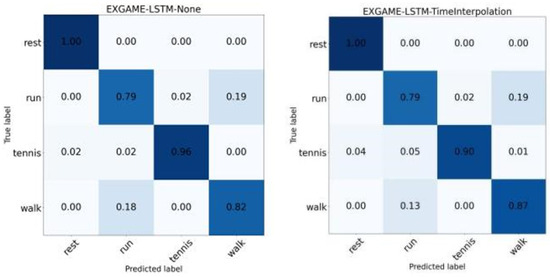
Figure 10.
Confusion matrix for none and time interpolation by LSTM in the Exergame dataset.
The NTURGB+D60 dataset contains 60 different types of actions, many of which have complex spatial behavior and strong time dependence. We classified these actions and performed analysis on some characteristic behaviors. We divided them into three types: actions strongly related to time, actions with local spatial features, and actions with global spatial characteristics. Followings are the types of actions we selected. Actions strongly related to time are A8 sit down, A9 stand up, A14 put on jacket, A15 take off jacket, A16 put on a shoe, A17 take off a shoe, A18 put on glasses, A19 take off glasses, A20 put on a hat/cap, and A21 take off a hat/cap. Actions with local spatial features are A3 brushing teeth, A4 brushing hair, A37 wiping face, A44 touching head (headache), A45 touching chest (stomachache/heartache), and A46 touching back (back pain). Actions with global spatial characteristics are A26 jumping on one foot, A27 jumping up, A42 stumbling, A43 falling, A59 moving towards each other, and A60 moving away from each other. We found the best and worst time augmentation methods in NTURGB+D 60. According to Table 3 and Figure 8, the best temporal augmentation method is blur with CNNLSTM, and the worst is time warping with CNNLSTM.
Blur seems help the model ignore unimportant details and focuses on the main features of the action, which may be the reason for the accuracy improvement, such as in the NTURGB+D60 and Exergame datasets. However, for actions where detail recognition is important, blur destroyed important features, resulting in no accuracy improvement for network models. By reversing temporal sequence, the model performance can be improved, especially for actions which movement pattern is symmetrical over time, such as in the MSR Action 3D and Exergame datasets. On the other hand, for actions that are strongly related to time, such as A8, A9, A14, A15, A16, A17, A18, A19, A20, and A21 in the NTURGB+D60 dataset (these actions are exactly opposite action sequences), time reversing can disrupt the movement pattern, which can reduce recognition accuracy.
Time interpolation, which smooths out the motion by adding intermediate frames to the original action sequence, helps the model better understand the continuity of the motion. Interpolation has a positive impact on the recognition of certain actions. However, for actions that rely on fast and abrupt changes in motion, interpolation can introduce unrealistic motion states and cause the model to learn incorrect temporal characteristics. Time Shifting, which speeds up the sequence of actions along the time axis, can increase the robustness of action recognition by providing the model with changes in actions at different times. Time warping, which distorts the sequence of actions through a nonlinear time transformation, can help the model learn more complex motion changes. Time warping can have a positive impact on simple actions, such as in the MSR Action 3D and Exergame datasets. However, for complex actions, such as in the NTURGB+D60 dataset, warping can lead to distortion of important features, reducing accuracy.
5. Conclusions and Future Directions
Data augmentation is a widely adopted practice in the field of deep learning, especially in areas such as image and video processing. This method is extensively utilized to enrich the variety and amount of training data by applying diverse augmentations such as jittering, cropping, rotating, scaling, and time warping to existing datasets. Its primary goal is to enhance the generalization, robustness, and overall performance of model by exposing it to a wider variety of examples for training. In this study, we closely examined the impact of different spatial and temporal data augmentation methods on the performance of models such as CNN, LSTM, and CNNLSTM designed for skeleton-based human action recognition. The analysis was conducted on three different datasets—MSR Action 3D, NTURGB+D 60, and Exergame dataset—and focused on the interaction between local spatial feature density and time dependence in action sequences.
Unlike previous research on data augmentation that focuses on the overall effect of augmentation to improve model accuracy and generalization ability, our approach provides a detailed analysis of the impact of various spatial and temporal augmentation techniques on different training datasets and different neural network models. This intricate exploration aims to provide comprehensive insights into how distinct augmentation strategies uniquely affect neural network performance across different models and datasets, particularly in the context of skeleton-based human action recognition. Spatial augmentation showed some interesting trends, with Gaussian noise proving to be a consistently effective method across all three models. Other spatial augmentation methods showed more nuanced results, with some making positive contributions and others having a negative impact, especially on datasets with many local spatial features.
Temporal augmentation likewise played a crucial role in influencing recognition performance. Blur and time shifting prove to be effective in capturing subtle temporal variations in action sequences, which is crucial for accurate identification of complex or rapidly changing human action. Blur seemed to help improve performance on datasets like NTURGB+D60 and Exergame by disregarding unimportant details and focusing on essential features. Time warping, on the other hand, exhibited challenges, especially on datasets with complex actions. The nonlinear time transformation introduced by time warping was found to have a positive impact on simple actions, such as the MSR Action 3D and Exergame datasets, but distorted important features and reduced accuracy on complex actions, as observed on NTURGB+D60. We also found that the choice of temporal augmentation method should be carefully considered, as certain techniques, such as time reversing on the NTURGB+D 60 dataset, exhibited negative impacts on recognition rates.
This research provides novel perspectives and guidance on model selection and data augmentation strategies in the context of skeleton-based human action recognition tasks. The findings highlight the importance of selecting appropriate data augmentation strategies based on the specific characteristics of datasets and actions, providing a foundation for further refinements in the application of these techniques. As the field continues to evolve, understanding the intricacies of augmentation methodologies will undoubtedly contribute to the development of more robust and effective models in human action recognition tasks. While this study focused on data augmentation for skeleton-based HAR, these findings can provide insights into data augmentation strategies for analyzing other sensor data in deep learning.
In the future, we would like to perform comprehensive experiments involving a wider range of data augmentation methods applied to more neural network models, including the utilization of generative adversarial networks (GANs). Furthermore, it is crucial to explore the combination of data augmentation and neural network models, such as integrating spatial augmentation with CNN as one layer and temporal augmentation with LSTM as another layer, among other approaches.
Author Contributions
Methodology, C.X., S.K., Y.C. and K.S.P.; Software, C.X.; Formal analysis, C.X., S.K., Y.C. and K.S.P.; Writing—original draft, C.X., S.K., Y.C. and K.S.P.; Writing—review & editing, C.X., S.K., Y.C. and K.S.P. All the authors took part in the experimental design and the analysis of experiment results as well as the writing of this paper. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no extra funding.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Zhang, H.-B.; Zhang, Y.-X.; Zhong, B.; Lei, Q.; Yang, L.; Du, J.-X.; Chen, D.-S. A Comprehensive Survey of Vision-Based Human Action Recognition Methods. Sensors 2019, 19, 1005. [Google Scholar] [CrossRef] [PubMed]
- Sun, Z.; Ke, Q.; Rahmani, H.; Bennamoun, M.; Wang, G.; Liu, J. Human Action Recognition from Various Data Modalities: A Review. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 3200–3225. [Google Scholar] [CrossRef] [PubMed]
- Hammerla, N.Y. Shane Halloran and Thomas Plötz. 2016. Deep, convolutional, and recurrent models for human activity recognition using wearables. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 1533–1540. [Google Scholar]
- Cruciani, F.; Vafeiadis, A.; Nugent, C.; Cleland, I.; McCullagh, P.; Votis, K.; Giakoumis, D.; Tzovaras, D.; Chen, L.; Hamzaoui, R. Feature learning for Human Activity Recognition using Convolutional Neural Networks. CCF Trans. Pervasive Comput. Interact. 2020, 2, 18–32. [Google Scholar] [CrossRef]
- Kim, Y.-W.; Cho, W.-H.; Kim, K.-S.; Lee, S. Inertial-Measurement-Unit-Based Novel Human Activity Recognition Algorithm Using Conformer. Sensors 2022, 22, 3932. [Google Scholar] [CrossRef]
- Um, T.T.; Pfister, F.M.J.; Pichler, D.; Endo, S.; Lang, M.; Hirche, S.; Fietzek, U.; Kulić, D. Data augmentation of wearable sensor data for parkinson’s disease monitoring using convolutional neural networks. In Proceedings of the 19th ACM International Conference on Multimodal Interaction, Glasgow, UK, 13–17 November 2017; ACM: New York, NY, USA, 2017; pp. 216–220. [Google Scholar]
- Wang, P.; Li, W.; Gao, Z.; Zhang, J.; Tang, C.; Ogunbona, P.O. Action Recognition from Depth Maps Using Deep Convolutional Neural Networks. IEEE Trans. Human-Machine Syst. 2015, 46, 498–509. [Google Scholar] [CrossRef]
- Gao, X.; Li, K.; Zhang, Y.; Miao, Q.; Sheng, L.; Xie, J.; Xu, J. 3D Skeleton-Based Video Action Recognition by Graph Convolution Network. In Proceedings of the 2019 IEEE International Conference on Smart Internet of Things (SmartIoT), Tianjin, China, 9–11 August 2019; pp. 500–501. [Google Scholar]
- An, J.; Cheng, X.; Wang, Q.; Chen, H.; Li, J.; Li, S. Human action recognition based on Kinect. J. Phys. Conf. Ser. 2020, 1693, 012190. [Google Scholar] [CrossRef]
- Yadav, S.K.; Tiwari, K.; Pandey, H.M.; Akbar, S.A. Skeleton-based human activity recognition using ConvLSTM and guided feature learning. Soft Comput. 2021, 26, 877–890. [Google Scholar] [CrossRef]
- Shi, Z.; Cao, L.; Han, Y.; Liu, H.; Jiang, F.; Ren, Y. Research on Recognition of Motion Behaviors of Copepods. IEEE Access 2020, 8, 141224–141233. [Google Scholar] [CrossRef]
- Tu, J.; Liu, H.; Meng, F.; Liu, M.; Ding, R. Spatial-Temporal Data Augmentation Based on LSTM Autoencoder Network for Skeleton-Based Human Action Recognition. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 3478–3482. [Google Scholar]
- Meng, F.; Liu, H.; Liang, Y.; Tu, J.; Liu, M. Sample Fusion Network: An End-to-End Data Augmentation Network for Skeleton-Based Human Action Recognition. IEEE Trans. Image Process. 2019, 28, 5281–5295. [Google Scholar] [CrossRef]
- Huynh-The, T.; Hua, C.-H.; Kim, D.-S. Encoding Pose Features to Images with Data Augmentation for 3-D Action Recognition. IEEE Trans. Ind. Inform. 2019, 16, 3100–3111. [Google Scholar] [CrossRef]
- Shen, J.; Dudley, J.; Kristensson, P.O. The Imaginative Generative Adversarial Network: Automatic Data Augmentation for Dynamic Skeleton-Based Hand Gesture and Human Action Recognition. In Proceedings of the 2021 16th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2021), Jodhpur, India, 15–18 December 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Chen, J.; Yang, W.; Liu, C.; Yao, L. A Data Augmentation Method for Skeleton-Based Action Recognition with Relative Features. Appl. Sci. 2021, 11, 11481. [Google Scholar] [CrossRef]
- Park, J.; Kim, C.; Kim, S.-C. Enhancing Robustness of Viewpoint Changes in 3D Skeleton-Based Human Action Recognition. Mathematics 2023, 11, 3280. [Google Scholar] [CrossRef]
- Rao, H.; Xu, S.; Hu, X.; Cheng, J.; Hu, B. Augmented Skeleton Based Contrastive Action Learning with Momentum LSTM for Unsupervised Action Recognition. Inf. Sci. 2021, 569, 90–109. [Google Scholar] [CrossRef]
- Xin, C.; Kim, S.; Park, K.S. A Comparison of Machine Learning Models with Data Augmentation Techniques for Skeleton-based Human Action Recognition. In Proceedings of the 14th ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics, Houston, TX, USA, 3–6 September 2023; Article No.: 19. pp. 1–6. [Google Scholar] [CrossRef]
- Wang, P.; Li, W.; Li, C.; Hou, Y. Action recognition based on joint trajectory maps with convolutional neural networks. Knowl.-Based Syst. 2018, 158, 43–53. [Google Scholar] [CrossRef]
- Lee, I.; Kim, D.; Kang, S.; Lee, S. Ensemble Deep Learning for Skeleton-Based Action Recognition Using Temporal Sliding LSTM Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE, 2017; pp. 1012–1020. [Google Scholar]
- Li, B.; Dai, Y.; Cheng, X.; Chen, H.; Lin, Y.; He, M. Skeleton based action recognition using translation-scale invariant image mapping and multi-scale deep CNN. In Proceedings of the 2017 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Hong Kong, 10–14 July 2017; pp. 601–604. [Google Scholar]
- Vemulapalli, R.; Arrate, F.; Chellappa, R. Human Action Recognition by Representing 3D Skeletons as Points in a Lie Group. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 588–595. [Google Scholar]
- Ren, Z.; Pan, Z.; Zhou, X.; Kang, L. Diffusion Motion: Generate Text-Guided 3D Human Motion by Diffusion Model. In Proceedings of the ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Tevet, G.; Raab, S.; Gordon, B.; Shafir, Y.; Cohen-Or, D.; Bermano, A.H. Human motion diffusion model. arXiv Preprint 2022, arXiv:2209.14916. [Google Scholar]
- Guo, T.; Liu, H.; Chen, Z.; Liu, M.; Wang, T.; Ding, R. Contrastive Learning from Extremely Augmented Skeleton Sequences for Self-Supervised Action Recognition. Proc. AAAI Conf. Artif. Intell. 2022, 36, 762–770. [Google Scholar] [CrossRef]
- Wang, P.; Wen, J.; Si, C.; Qian, Y.; Wang, L. Contrast-Reconstruction Representation Learning for Self-Supervised Skeleton-Based Action Recognition. IEEE Trans. Image Process. 2022, 31, 6224–6238. [Google Scholar] [CrossRef]
- Iwana, B.K.; Uchida, S. An empirical survey of data augmentation for time series classification with neural networks. PLoS ONE 2021, 16, e0254841. [Google Scholar] [CrossRef] [PubMed]
- Bakhshayesh, P.R.; Ejtehadi, M.; Taheri, A.; Behzadipour, S. The Effects of Data Augmentation Methods on the Performance of Human Activity Recognition. In Proceedings of the 8th Iranian Conference on Signal Processing and Intelligent Systems (ICSPIS), Behshahr, Iran, 28–29 December 2022; pp. 1–6. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Li, W.; Zhang, Z.; Liu, Z. Action Recognition Based on A Bag of 3D Points. In Proceedings of the IEEE International Workshop on CVPR for Human Communicative Behavior Analysis (in conjunction with CVPR2010), San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. NTU RGB+D: A Large Scale Dataset for 3D Human Activity Analysis. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1010–1019. [Google Scholar]
- Kim, D.; Kim, W.; Park, K.S. Effects of Exercise Type and Gameplay Mode on Physical Activity in Exergame. Electronics 2022, 11, 3086. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Ellis, C.; Masood, S.Z.; Tappen, M.F.; LaViola, J.J., Jr.; Sukthankar, R. Exploring the Trade-off between Accuracy and Observational Latency in Action Recognition. Int. J. Comput. Vis. 2013, 101, 420–436. [Google Scholar] [CrossRef]
- Muller, M.; Order, T.; Clausen, M. Efficient content-based retrieval of motion capture data. ACM Trans-Actions Graph. 2005, 24, 677–685. [Google Scholar] [CrossRef]
- Xu, S.; Gao, S.; Zhang, M.; Zhu, L. Research on Class Individual Action Recognition Based on 3D Skeleton Data. Comput. Eng. 2022, 50, 8. [Google Scholar]
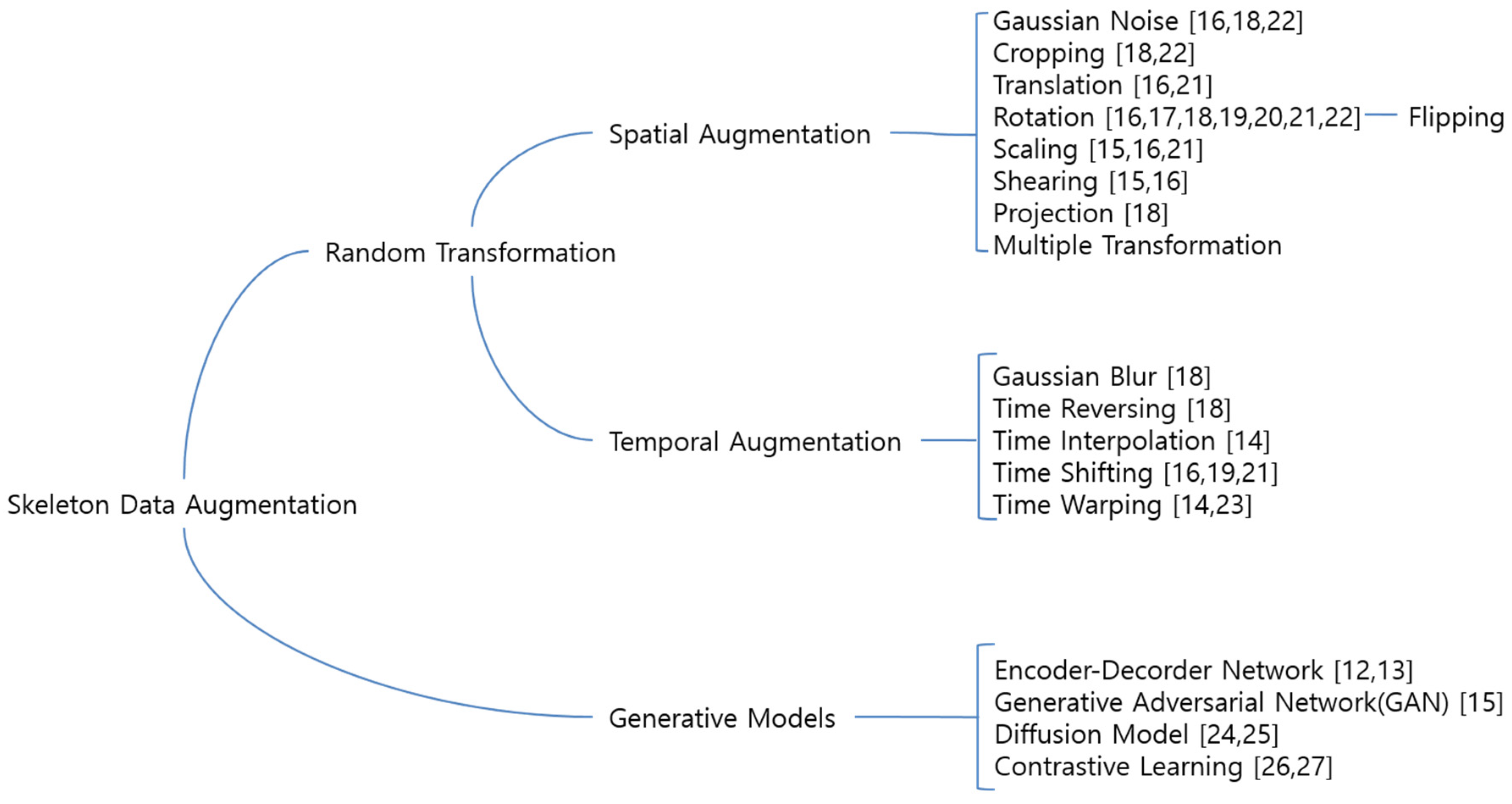
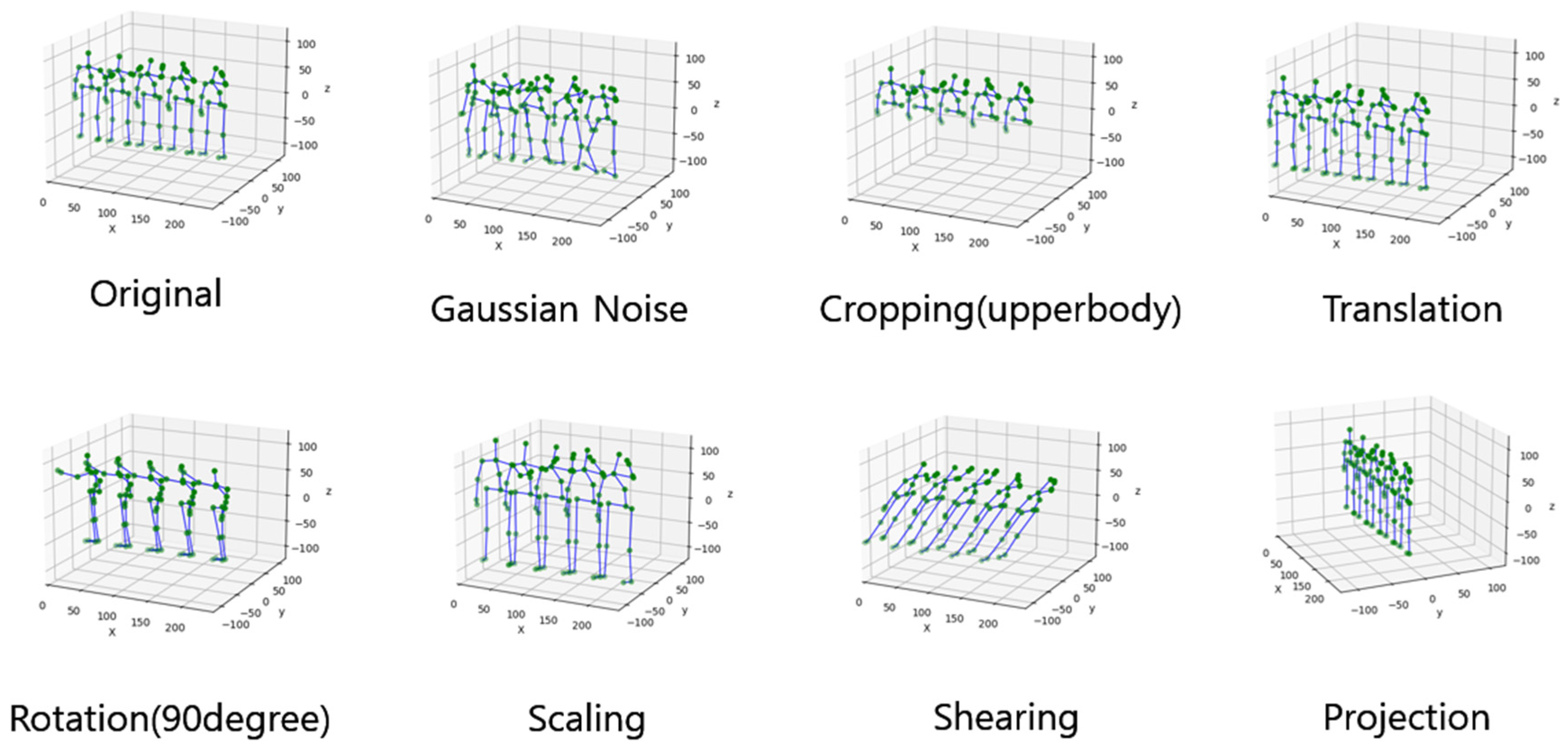
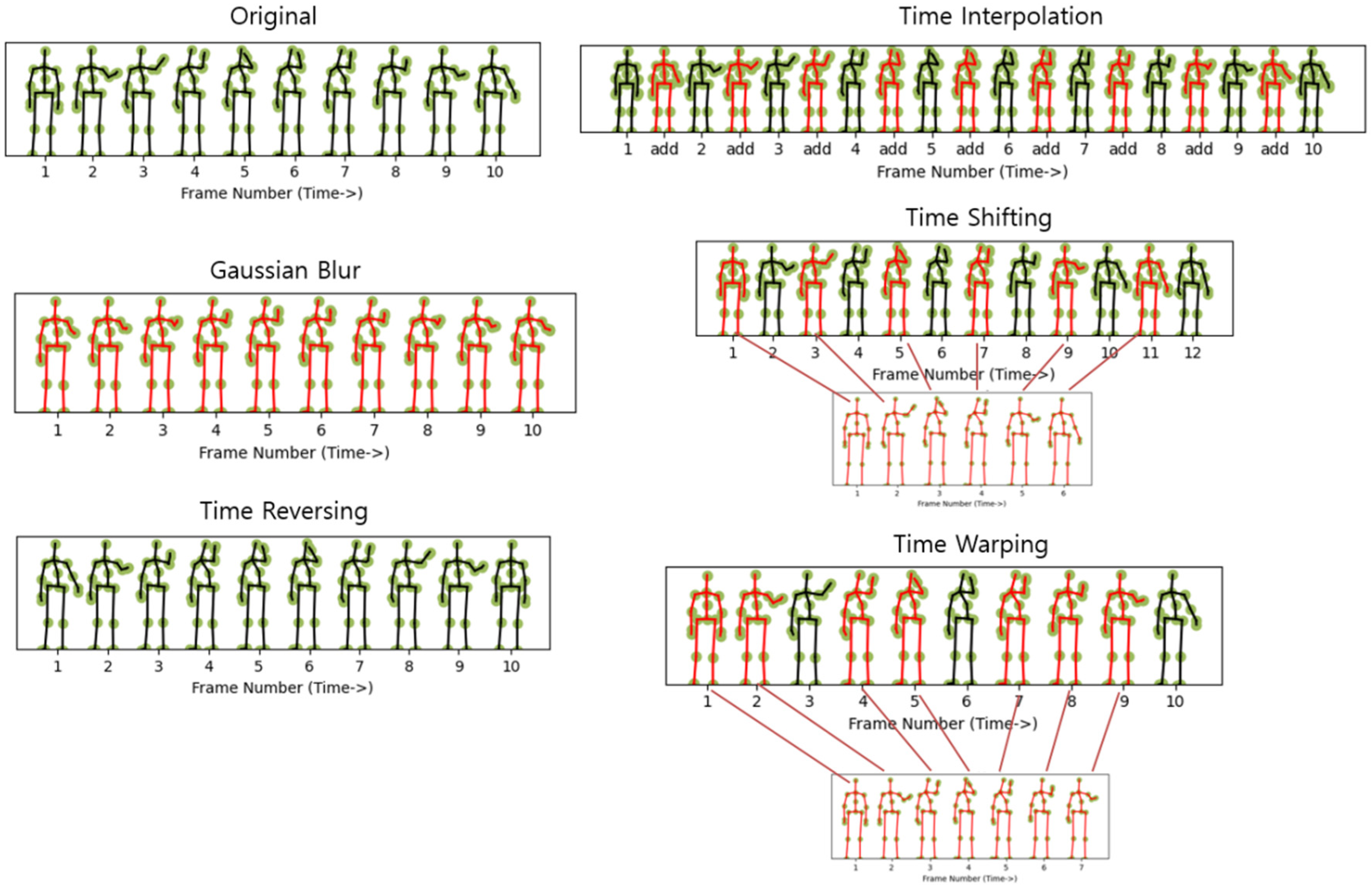
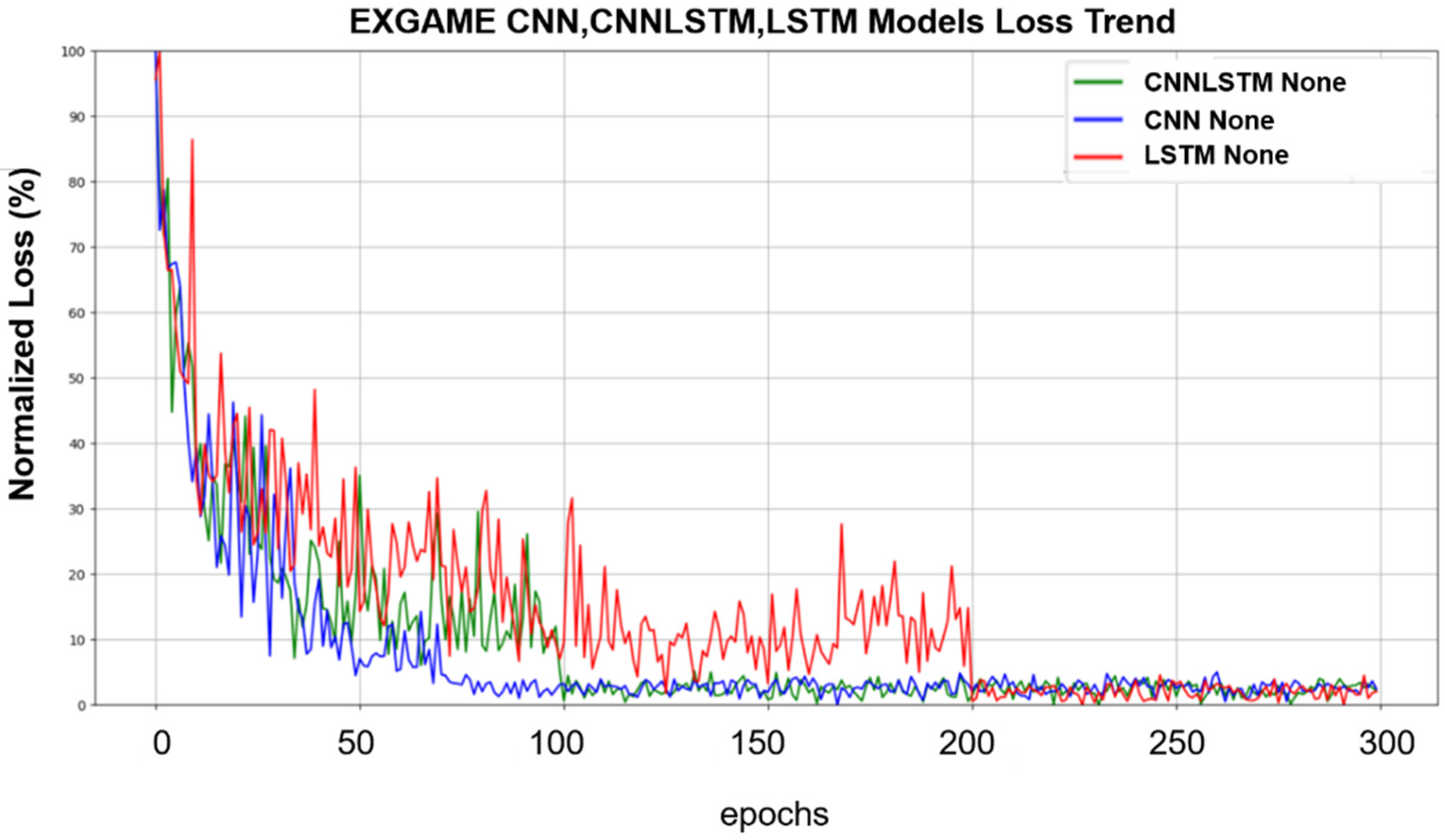
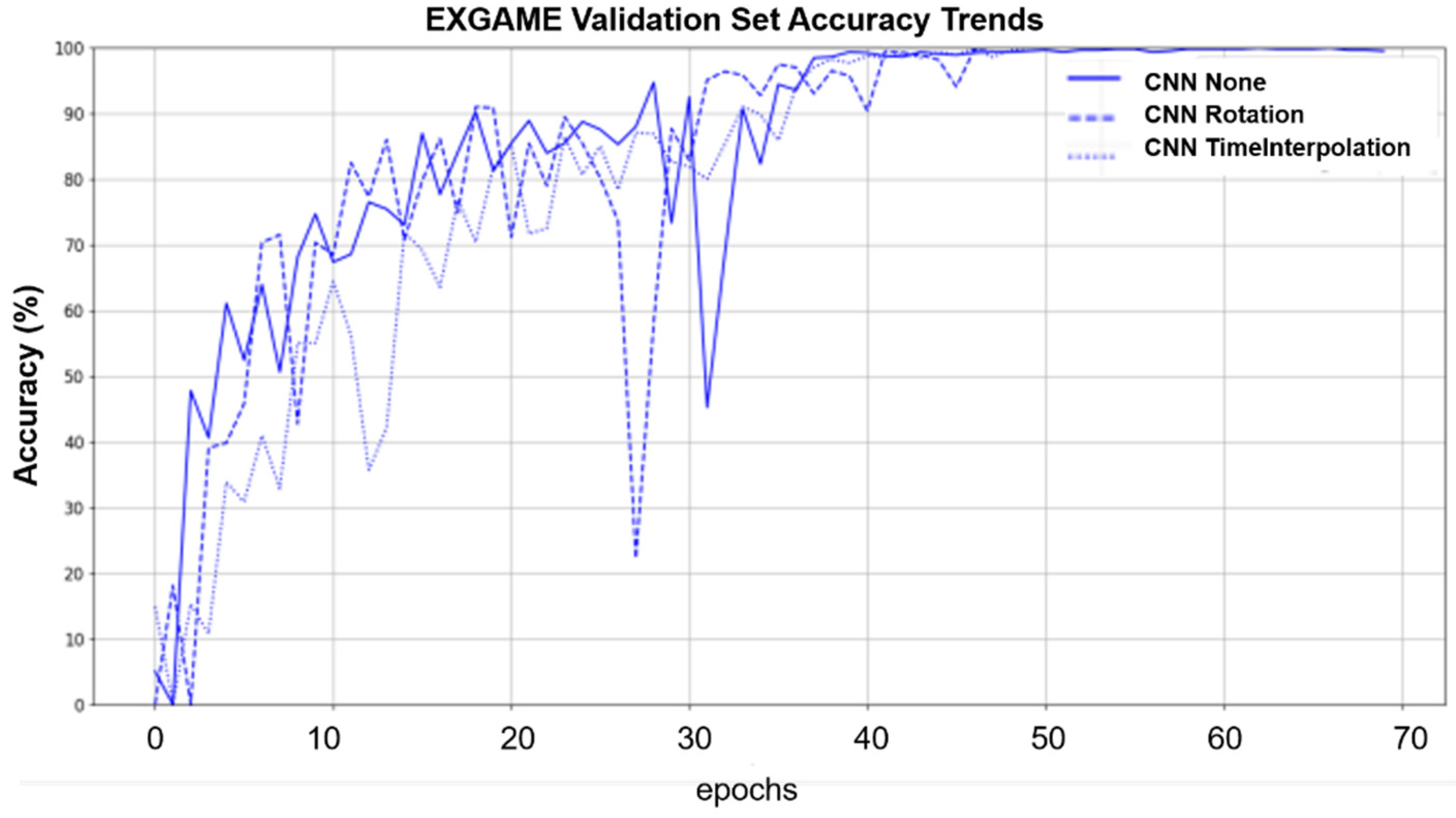
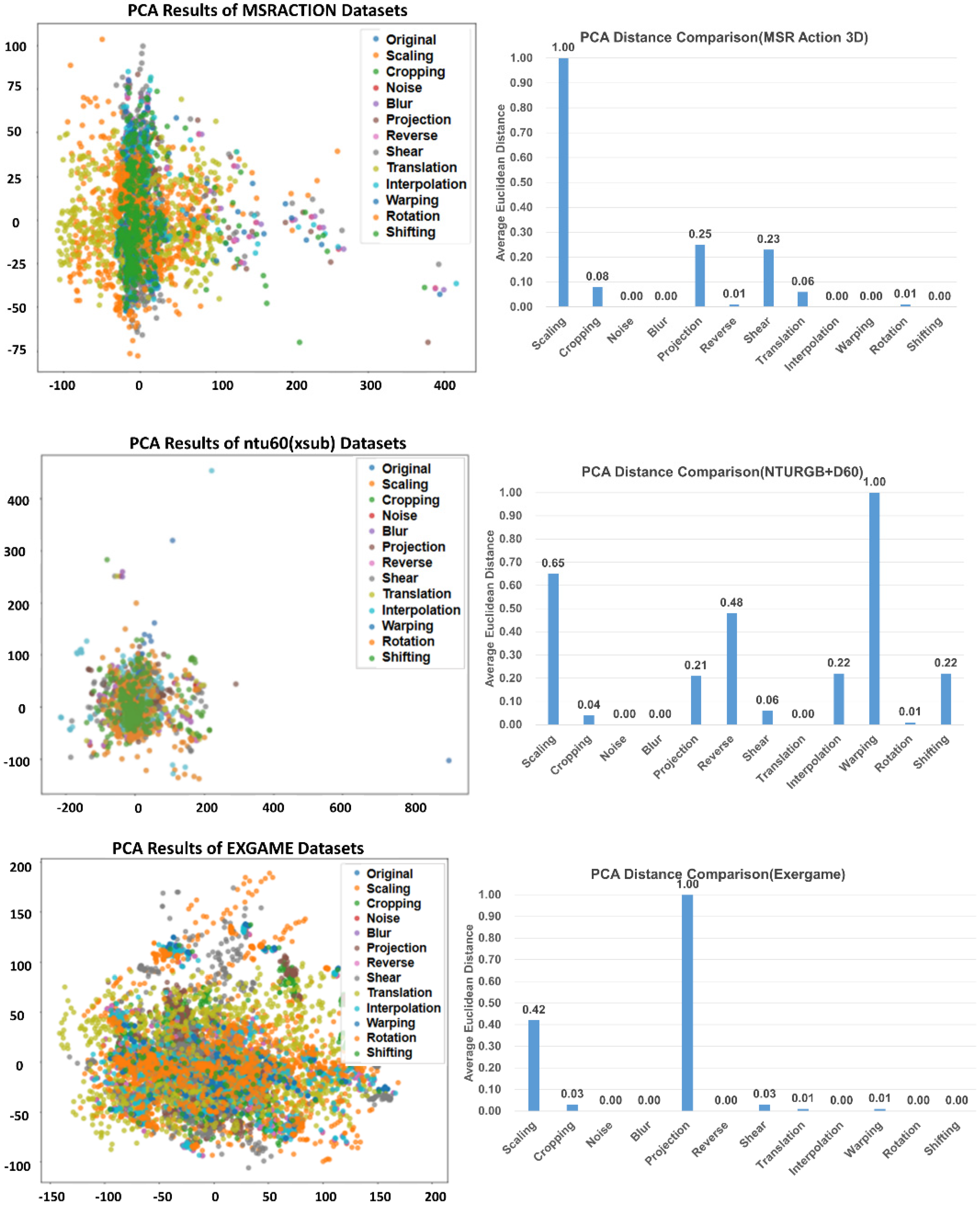

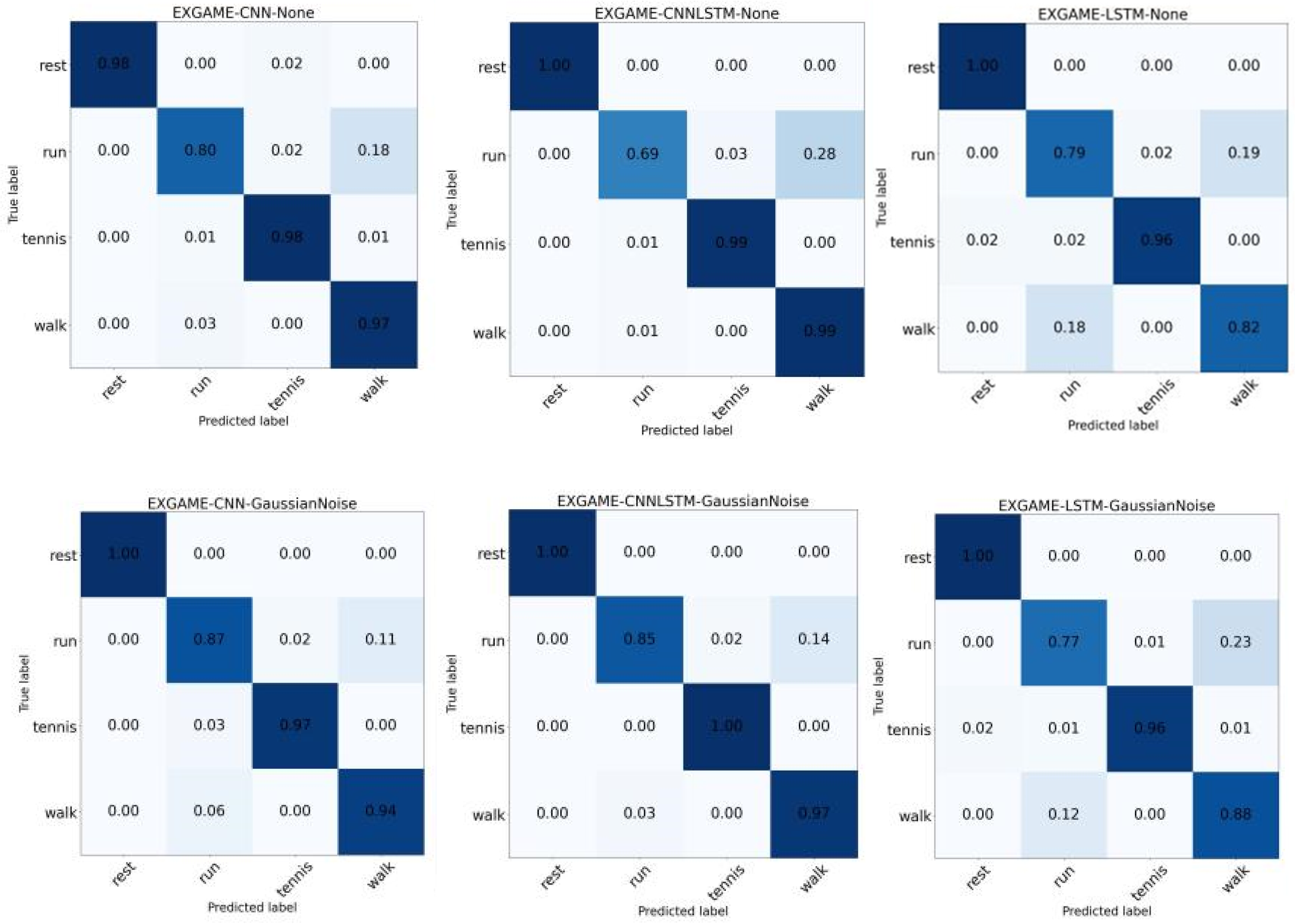

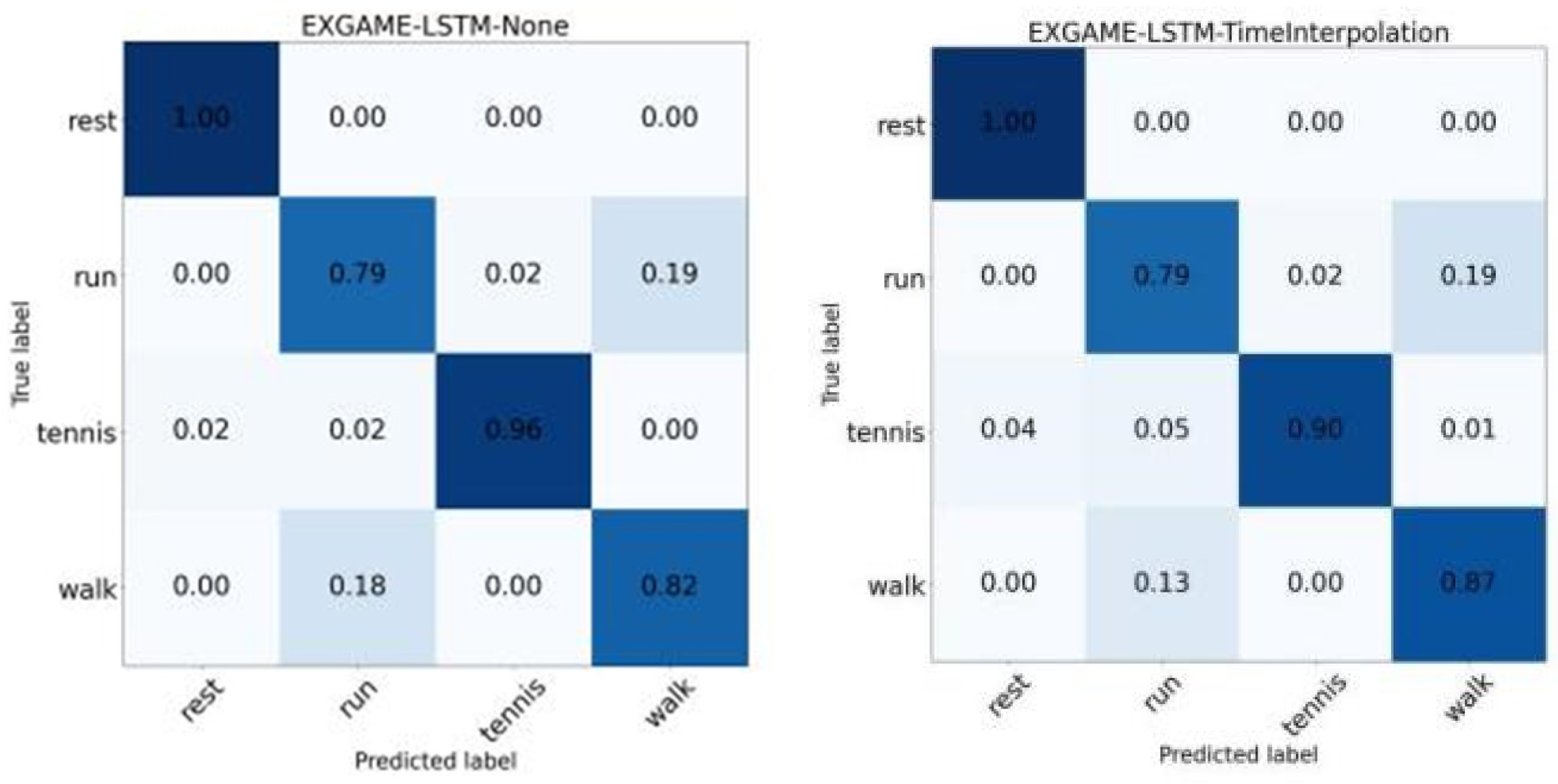
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).